ryan_greenblatt's Shortform
post by ryan_greenblatt · 2023-10-30T16:51:46.769Z · LW · GW · 152 commentsContents
153 comments
152 comments
Comments sorted by top scores.
comment by ryan_greenblatt · 2024-06-28T18:52:13.076Z · LW(p) · GW(p)
I'm currently working as a contractor at Anthropic in order to get employee-level model access as part of a project I'm working on. The project is a model organism of scheming [LW · GW], where I demonstrate scheming arising somewhat naturally with Claude 3 Opus. So far, I’ve done almost all of this project at Redwood Research, but my access to Anthropic models will allow me to redo some of my experiments in better and simpler ways and will allow for some exciting additional experiments. I'm very grateful to Anthropic and the Alignment Stress-Testing team for providing this access and supporting this work. I expect that this access and the collaboration with various members of the alignment stress testing team (primarily Carson Denison and Evan Hubinger so far) will be quite helpful in finishing this project.
I think that this sort of arrangement, in which an outside researcher is able to get employee-level access at some AI lab while not being an employee (while still being subject to confidentiality obligations), is potentially a very good model for safety research, for a few reasons, including (but not limited to):
- For some safety research, it’s helpful to have model access in ways that labs don’t provide externally. Giving employee level access to researchers working at external organizations can allow these researchers to avoid potential conflicts of interest and undue influence from the lab. This might be particularly important for researchers working on RSPs, safety cases, and similar, because these researchers might naturally evolve into third-party evaluators.
- Related to undue influence concerns, an unfortunate downside of doing safety research at a lab is that you give the lab the opportunity to control the narrative around the research and use it for their own purposes. This concern seems substantially addressed by getting model access through a lab as an external researcher.
- I think this could make it easier to avoid duplicating work between various labs. I’m aware of some duplication that could potentially be avoided by ensuring more work happened at external organizations.
For these and other reasons, I think that external researchers with employee-level access is a promising approach for ensuring that safety research can proceed quickly and effectively while reducing conflicts of interest and unfortunate concentration of power. I’m excited for future experimentation with this structure and appreciate that Anthropic was willing to try this. I think it would be good if other labs beyond Anthropic experimented with this structure.
(Note that this message was run by the comms team at Anthropic.)
Replies from: Zach Stein-Perlman, kave, neel-nanda-1, Buck, akash-wasil, Josephm, RedMan↑ comment by Zach Stein-Perlman · 2024-06-29T03:41:03.576Z · LW(p) · GW(p)
Yay Anthropic. This is the first example I'm aware of of a lab sharing model access with external safety researchers to boost their research (like, not just for evals). I wish the labs did this more.
[Edit: OpenAI shared GPT-4 access with safety researchers including Rachel Freedman [LW(p) · GW(p)] before release. OpenAI shared GPT-4 fine-tuning access with academic researchers including Jacob Steinhardt and Daniel Kang in 2023. Yay OpenAI. GPT-4 fine-tuning access is still not public; some widely-respected safety researchers I know recently were wishing for it, and were wishing they could disable content filters.]
Replies from: rachelAF↑ comment by Rachel Freedman (rachelAF) · 2024-06-29T14:39:31.566Z · LW(p) · GW(p)
OpenAI did this too, with GPT-4 pre-release. It was a small program, though — I think just 5-10 researchers.
Replies from: beth-barnes, ryan_greenblatt, Zach Stein-Perlman↑ comment by Beth Barnes (beth-barnes) · 2024-07-02T22:32:50.992Z · LW(p) · GW(p)
I'd be surprised if this was employee-level access. I'm aware of a red-teaming program that gave early API access to specific versions of models, but not anything like employee-level.
↑ comment by ryan_greenblatt · 2024-06-29T18:12:17.811Z · LW(p) · GW(p)
It also wasn't employee level access probably?
(But still a good step!)
↑ comment by Zach Stein-Perlman · 2024-06-29T18:27:43.737Z · LW(p) · GW(p)
Source?
Replies from: rachelAF↑ comment by Rachel Freedman (rachelAF) · 2024-06-30T15:20:26.569Z · LW(p) · GW(p)
It was a secretive program — it wasn’t advertised anywhere, and we had to sign an NDA about its existence (which we have since been released from). I got the impression that this was because OpenAI really wanted to keep the existence of GPT4 under wraps. Anyway, that means I don’t have any proof beyond my word.
Replies from: Zach Stein-Perlman↑ comment by Zach Stein-Perlman · 2024-06-30T16:55:51.435Z · LW(p) · GW(p)
Thanks!
To be clear, my question was like where can I learn more + what should I cite, not I don't believe you. I'll cite your comment.
Yay OpenAI.
↑ comment by kave · 2024-06-28T19:21:46.760Z · LW(p) · GW(p)
Would you be able to share the details of your confidentiality agreement?
Replies from: samuel-marks, ryan_greenblatt↑ comment by Sam Marks (samuel-marks) · 2024-06-29T07:57:47.741Z · LW(p) · GW(p)
(I'm a full-time employee at Anthropic.) It seems worth stating for the record that I'm not aware of any contract I've signed whose contents I'm not allowed to share. I also don't believe I've signed any non-disparagement agreements. Before joining Anthropic, I confirmed that I wouldn't be legally restricted from saying things like "I believe that Anthropic behaved recklessly by releasing [model]".
↑ comment by ryan_greenblatt · 2024-06-29T01:35:01.885Z · LW(p) · GW(p)
I think I could share the literal language in the contractor agreement I signed related to confidentiality, though I don't expect this is especially interesting as it is just a standard NDA from my understanding.
I do not have any non-disparagement, non-solicitation, or non-interference obligations.
I'm not currently going to share information about any other policies Anthropic might have related to confidentiality, though I am asking about what Anthropic's policy is on sharing information related to this.
Replies from: kave↑ comment by kave · 2024-06-29T20:47:52.786Z · LW(p) · GW(p)
I would appreciate the literal language and any other info you end up being able to share.
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2024-07-04T22:44:01.688Z · LW(p) · GW(p)
Here is the full section on confidentiality from the contract:
- Confidential Information.
(a) Protection of Information. Consultant understands that during the Relationship, the Company intends to provide Consultant with certain information, including Confidential Information (as defined below), without which Consultant would not be able to perform Consultant’s duties to the Company. At all times during the term of the Relationship and thereafter, Consultant shall hold in strictest confidence, and not use, except for the benefit of the Company to the extent necessary to perform the Services, and not disclose to any person, firm, corporation or other entity, without written authorization from the Company in each instance, any Confidential Information that Consultant obtains from the Company or otherwise obtains, accesses or creates in connection with, or as a result of, the Services during the term of the Relationship, whether or not during working hours, until such Confidential Information becomes publicly and widely known and made generally available through no wrongful act of Consultant or of others who were under confidentiality obligations as to the item or items involved. Consultant shall not make copies of such Confidential Information except as authorized by the Company or in the ordinary course of the provision of Services.
(b) Confidential Information. Consultant understands that “Confidential Information” means any and all information and physical manifestations thereof not generally known or available outside the Company and information and physical manifestations thereof entrusted to the Company in confidence by third parties, whether or not such information is patentable, copyrightable or otherwise legally protectable. Confidential Information includes, without limitation: (i) Company Inventions (as defined below); and (ii) technical data, trade secrets, know-how, research, product or service ideas or plans, software codes and designs, algorithms, developments, inventions, patent applications, laboratory notebooks, processes, formulas, techniques, biological materials, mask works, engineering designs and drawings, hardware configuration information, agreements with third parties, lists of, or information relating to, employees and consultants of the Company (including, but not limited to, the names, contact information, jobs, compensation, and expertise of such employees and consultants), lists of, or information relating to, suppliers and customers (including, but not limited to, customers of the Company on whom Consultant called or with whom Consultant became acquainted during the Relationship), price lists, pricing methodologies, cost data, market share data, marketing plans, licenses, contract information, business plans, financial forecasts, historical financial data, budgets or other business information disclosed to Consultant by the Company either directly or indirectly, whether in writing, electronically, orally, or by observation.
(c) Third Party Information. Consultant’s agreements in this Section 5 are intended to be for the benefit of the Company and any third party that has entrusted information or physical material to the Company in confidence. During the term of the Relationship and thereafter, Consultant will not improperly use or disclose to the Company any confidential, proprietary or secret information of Consultant’s former clients or any other person, and Consultant will not bring any such information onto the Company’s property or place of business.
(d) Other Rights. This Agreement is intended to supplement, and not to supersede, any rights the Company may have in law or equity with respect to the protection of trade secrets or confidential or proprietary information.
(e) U.S. Defend Trade Secrets Act. Notwithstanding the foregoing, the U.S. Defend Trade Secrets Act of 2016 (“DTSA”) provides that an individual shall not be held criminally or civilly liable under any federal or state trade secret law for the disclosure of a trade secret that is made (i) in confidence to a federal, state, or local government official, either directly or indirectly, or to an attorney; and (ii) solely for the purpose of reporting or investigating a suspected violation of law; or (iii) in a complaint or other document filed in a lawsuit or other proceeding, if such filing is made under seal. In addition, DTSA provides that an individual who files a lawsuit for retaliation by an employer for reporting a suspected violation of law may disclose the trade secret to the attorney of the individual and use the trade secret information in the court proceeding, if the individual (A) files any document containing the trade secret under seal; and (B) does not disclose the trade secret, except pursuant to court order.
(Anthropic comms was fine with me sharing this.)
↑ comment by Neel Nanda (neel-nanda-1) · 2024-06-28T21:06:13.932Z · LW(p) · GW(p)
This seems fantastic! Kudos to Anthropic
↑ comment by Buck · 2024-12-18T17:42:17.850Z · LW(p) · GW(p)
This project has now been released [LW · GW]; I think it went extremely well.
↑ comment by Orpheus16 (akash-wasil) · 2024-06-28T21:02:03.310Z · LW(p) · GW(p)
Do you feel like there are any benefits or drawbacks specifically tied to the fact that you’re doing this work as a contractor? (compared to a world where you were not a contractor but Anthropic just gave you model access to run these particular experiments and let Evan/Carson review your docs)
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2024-06-28T23:54:28.049Z · LW(p) · GW(p)
Being a contractor was the most convenient way to make the arrangement.
I would ideally prefer to not be paid by Anthropic[1], but this doesn't seem that important (as long as the pay isn't too overly large). I asked to be paid as little as possible and I did end up being paid less than would otherwise be the case (and as a contractor I don't receive equity). I wasn't able to ensure that I only get paid a token wage (e.g. $1 in total or minimum wage or whatever).
I think the ideal thing would be a more specific legal contract between me and Anthropic (or Redwood and Anthropic), but (again) this doesn't seem important.
At least for this current primary purpose of this contracting. I do think that it could make sense to be paid for some types of consulting work. I'm not sure what all the concerns are here. ↩︎
↑ comment by Joseph Miller (Josephm) · 2024-06-29T00:20:11.273Z · LW(p) · GW(p)
It seems a substantial drawback that it will be more costly for you to criticize Anthropic in the future.
Many of the people / orgs involved in evals research are also important figures in policy debates. With this incentive Anthropic may gain more ability to control the narrative around AI risks.
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2024-06-29T00:22:47.956Z · LW(p) · GW(p)
It seems a substantial drawback that it will be more costly for you to criticize Anthropic in the future.
As in, if at some point I am currently a contractor with model access (or otherwise have model access via some relationship like this) it will at that point be more costly to criticize Anthropic?
Replies from: Josephm↑ comment by Joseph Miller (Josephm) · 2024-06-29T00:36:41.378Z · LW(p) · GW(p)
I'm not sure what the confusion is exactly.
If any of
- you have a fixed length contract and you hope to have another contract again in the future
- you have an indefinite contract and you don't want them to terminate your relationship
- you are some other evals researcher and you hope to gain model access at some point
you may refrain from criticizing Anthropic from now on.
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2024-06-29T01:05:37.568Z · LW(p) · GW(p)
Ok, so the concern is:
AI labs may provide model access (or other goods), so people who might want to obtain model access might be incentivized to criticize AI labs less.
Is that accurate?
Notably, as described this is not specifically a downside of anything I'm arguing for in my comment or a downside of actually being a contractor. (Unless you think me being a contractor will make me more likely to want model acess for whatever reason.)
I agree that this is a concern in general with researchers who could benefit from various things that AI labs might provide (such as model access). So, this is a downside of research agendas with a dependence on (e.g.) model access.
I think various approaches to mitigate this concern could be worthwhile. (Though I don't think this is worth getting into in this comment.)
Replies from: Josephm↑ comment by Joseph Miller (Josephm) · 2024-06-29T01:19:20.038Z · LW(p) · GW(p)
Yes that's accurate.
Notably, as described this is not specifically a downside of anything I'm arguing for in my comment or a downside of actually being a contractor.
In your comment you say
- For some safety research, it’s helpful to have model access in ways that labs don’t provide externally. Giving employee level access to researchers working at external organizations can allow these researchers to avoid potential conflicts of interest and undue influence from the lab. This might be particularly important for researchers working on RSPs, safety cases, and similar, because these researchers might naturally evolve into third-party evaluators.
- Related to undue influence concerns, an unfortunate downside of doing safety research at a lab is that you give the lab the opportunity to control the narrative around the research and use it for their own purposes. This concern seems substantially addressed by getting model access through a lab as an external researcher.
I'm essentially disagreeing with this point. I expect that most of the conflict of interest concerns remain when a big lab is giving access to a smaller org / individual.
(Unless you think me being a contractor will make me more likely to want model access for whatever reason.)
From my perspective the main takeaway from your comment was "Anthropic gives internal model access to external safety researchers." I agree that once you have already updated on this information, the additional information "I am currently receiving access to Anthropic's internal models" does not change much. (Although I do expect that establishing the precedent / strengthening the relationships / enjoying the luxury of internal model access, will in fact make you more likely to want model access again in the future).
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2024-06-29T01:22:11.016Z · LW(p) · GW(p)
I expect that most of the conflict of interest concerns remain when a big lab is giving access to a smaller org / individual.
As in, there aren't substantial reductions in COI from not being an employee and not having equity? I currently disagree.
Replies from: Josephm↑ comment by Joseph Miller (Josephm) · 2024-06-29T01:32:26.102Z · LW(p) · GW(p)
Yeah that's the crux I think. Or maybe we agree but are just using "substantial"/"most" differently.
It mostly comes down to intuitions so I think there probably isn't a way to resolve the disagreement.
↑ comment by RedMan · 2024-07-01T11:33:28.907Z · LW(p) · GW(p)
So you asked anthropic for uncensored model access so you could try to build scheming AIs, and they gave it to you?
To use a biology analogy, isn't this basically gain of function research?
Replies from: mesaoptimizer↑ comment by mesaoptimizer · 2024-07-05T07:11:22.649Z · LW(p) · GW(p)
Please read the model organisms for misalignment proposal [LW · GW].
comment by ryan_greenblatt · 2025-01-06T17:54:13.453Z · LW(p) · GW(p)
I thought it would be helpful to post about my timelines and what the timelines of people in my professional circles (Redwood, METR, etc) tend to be.
Concretely, consider the outcome of: AI 10x’ing labor for AI R&D [LW · GW][1], measured by internal comments by credible people at labs that AI is 90% of their (quality adjusted) useful work force (as in, as good as having your human employees run 10x faster).
Here are my predictions for this outcome:
- 25th percentile: 2 year (Jan 2027)
- 50th percentile: 5 year (Jan 2030)
The views of other people (Buck, Beth Barnes, Nate Thomas, etc) are similar.
I expect that outcomes like “AIs are capable enough to automate virtually all remote workers” and “the AIs are capable enough that immediate AI takeover is very plausible (in the absence of countermeasures)” come shortly after (median 1.5 years and 2 years after respectively under my views).
Only including speedups due to R&D, not including mechanisms like synthetic data generation. ↩︎
↑ comment by Ajeya Cotra (ajeya-cotra) · 2025-01-07T19:04:23.053Z · LW(p) · GW(p)
My timelines are now roughly similar on the object level (maybe a year slower for 25th and 1-2 years slower for 50th), and procedurally I also now defer a lot to Redwood and METR engineers. More discussion here: https://www.lesswrong.com/posts/K2D45BNxnZjdpSX2j/ai-timelines?commentId=hnrfbFCP7Hu6N6Lsp [LW(p) · GW(p)]
↑ comment by Orpheus16 (akash-wasil) · 2025-01-07T23:06:44.937Z · LW(p) · GW(p)
I expect that outcomes like “AIs are capable enough to automate virtually all remote workers” and “the AIs are capable enough that immediate AI takeover is very plausible (in the absence of countermeasures)” come shortly after (median 1.5 years and 2 years after respectively under my views).
@ryan_greenblatt [LW · GW] can you say more about what you expect to happen from the period in-between "AI 10Xes AI R&D" and "AI takeover is very plausible?"
I'm particularly interested in getting a sense of what sorts of things will be visible to the USG and the public during this period. Would be curious for your takes on how much of this stays relatively private/internal (e.g., only a handful of well-connected SF people know how good the systems are) vs. obvious/public/visible (e.g., the majority of the media-consuming American public is aware of the fact that AI research has been mostly automated) or somewhere in-between (e.g., most DC tech policy staffers know this but most non-tech people are not aware.)
Replies from: ryan_greenblatt, davekasten↑ comment by ryan_greenblatt · 2025-01-07T23:47:18.998Z · LW(p) · GW(p)
I don't feel very well informed and I haven't thought about it that much, but in short timelines (e.g. my 25th percentile): I expect that we know what's going on roughly within 6 months of it happening, but this isn't salient to the broader world. So, maybe the DC tech policy staffers know that the AI people think the situation is crazy, but maybe this isn't very salient to them. A 6 month delay could be pretty fatal even for us as things might progress very rapidly.
↑ comment by davekasten · 2025-01-07T23:56:50.243Z · LW(p) · GW(p)
Note that the production function of the 10x really matters. If it's "yeah, we get to net-10x if we have all our staff working alongside it," it's much more detectable than, "well, if we only let like 5 carefully-vetted staff in a SCIF know about it, we only get to 8.5x speedup".
(It's hard to prove that the results are from the speedup instead of just, like, "One day, Dario woke up from a dream with The Next Architecture in his head")
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2025-01-07T00:31:03.130Z · LW(p) · GW(p)
AI is 90% of their (quality adjusted) useful work force (as in, as good as having your human employees run 10x faster).
I don't grok the "% of quality adjusted work force" metric. I grok the "as good as having your human employees run 10x faster" metric but it doesn't seem equivalent to me, so I recommend dropping the former and just using the latter.
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2025-01-07T00:38:45.121Z · LW(p) · GW(p)
Fair, I really just mean "as good as having your human employees run 10x faster". I said "% of quality adjusted work force" because this was the original way this was stated when a quick poll was done, but the ultimate operationalization was in terms of 10x faster. (And this is what I was thinking.)
Replies from: davekasten↑ comment by davekasten · 2025-01-07T02:50:50.136Z · LW(p) · GW(p)
Basic clarifying question: does this imply under-the-hood some sort of diminishing returns curve, such that the lab pays for that labor until it net reaches as 10x faster improvement, but can't squeeze out much more?
And do you expect that's a roughly consistent multiplicative factor, independent of lab size? (I mean, I'm not sure lab size actually matters that much, to be fair, it seems that Anthropic keeps pace with OpenAI despite being smaller-ish)
↑ comment by ryan_greenblatt · 2025-01-07T04:32:50.299Z · LW(p) · GW(p)
Yeah, for it to reach exactly 10x as good, the situation would presumably be that this was the optimum point given diminishing returns to spending more on AI inference compute. (It might be the returns curve looks very punishing. For instance, many people get a relatively large amount of value from extremely cheap queries to 3.5 Sonnet on claude.ai and the inference cost of this is very small, but greatly increasing the cost (e.g. o1-pro) often isn't any better because 3.5 Sonnet already gave an almost perfect answer.)
I don't have a strong view about AI acceleration being a roughly constant multiplicative factor independent of the number of employees. Uplift just feels like a reasonably simple operationalization.
↑ comment by Charbel-Raphaël (charbel-raphael-segerie) · 2025-01-08T19:22:44.229Z · LW(p) · GW(p)
How much faster do you think we are already? I would say 2x.
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2025-01-08T19:39:24.829Z · LW(p) · GW(p)
I'd guess that xAI, Anthropic, and GDM are more like 5-20% faster all around (with much greater acceleration on some subtasks). It seems plausible to me that the acceleration at OpenAI is already much greater than this (e.g. more like 1.5x or 2x), or will be after some adaptation due to OpenAI having substantially better internal agents than what they've released. (I think this due to updates from o3 and general vibes.)
Replies from: charbel-raphael-segerie↑ comment by Charbel-Raphaël (charbel-raphael-segerie) · 2025-01-08T20:19:42.080Z · LW(p) · GW(p)
I was saying 2x because I've memorised the results from this study. Do we have better numbers today? R&D is harder, so this is an upper bound. However, since this was from one year ago, so perhaps the factors cancel each other out?
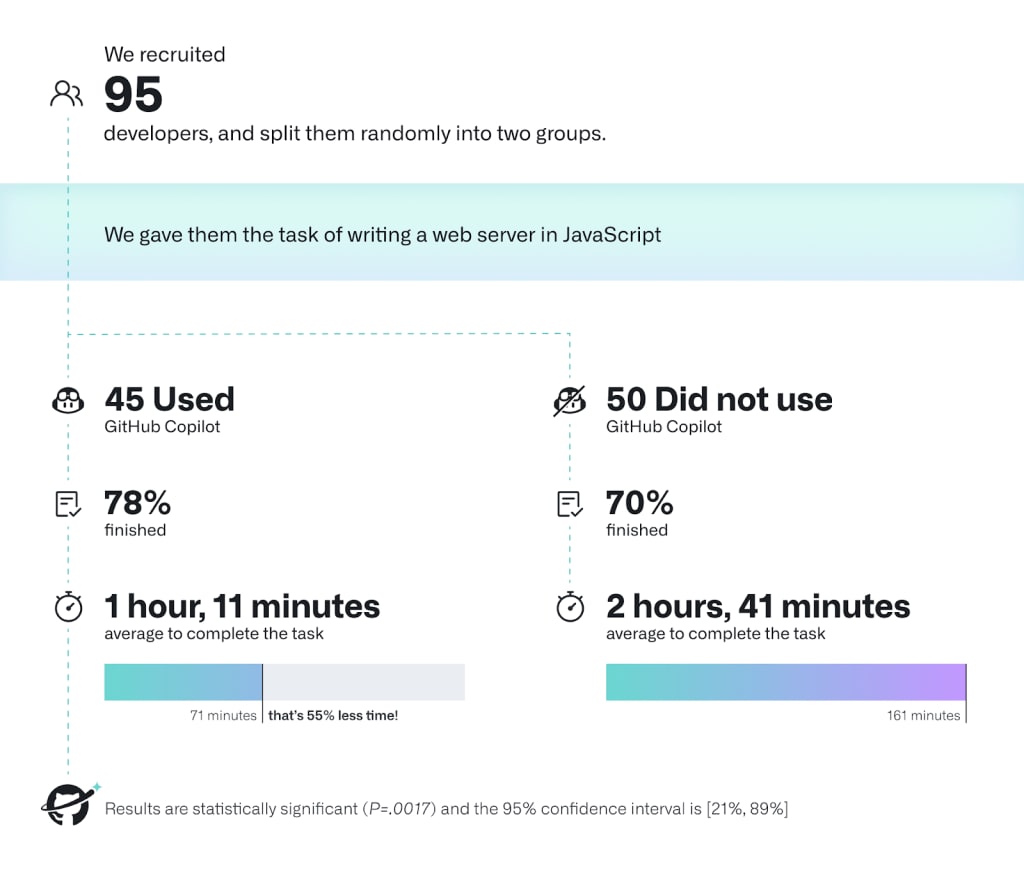
↑ comment by ryan_greenblatt · 2025-01-08T20:27:30.073Z · LW(p) · GW(p)
This case seems extremely cherry picked for cases where uplift is especially high. (Note that this is in copilot's interest.) Now, this task could probably be solved autonomously by an AI in like 10 minutes with good scaffolding.
I think you have to consider the full diverse range of tasks to get a reasonable sense or at least consider harder tasks. Like RE-bench seems much closer, but I still expect uplift on RE-bench to probably (but not certainly!) considerably overstate real world speed up.
Replies from: charbel-raphael-segerie↑ comment by Charbel-Raphaël (charbel-raphael-segerie) · 2025-01-08T20:44:38.363Z · LW(p) · GW(p)
Yeah, fair enough. I think someone should try to do a more representative experiment and we could then monitor this metric.
btw, something that bothers me a little bit with this metric is the fact that a very simple AI that just asks me periodically "Hey, do you endorse what you are doing right now? Are you time boxing? Are you following your plan?" makes me (I think) significantly more strategic and productive. Similar to I hired 5 people to sit behind me and make me productive for a month. But this is maybe off topic.
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2025-01-09T01:17:47.175Z · LW(p) · GW(p)
btw, something that bothers me a little bit with this metric is the fact that a very simple AI ...
Yes, but I don't see a clear reason why people (working in AI R&D) will in practice get this productivity boost (or other very low hanging things) if they don't get around to getting the boost from hiring humans.
↑ comment by Jacob Pfau (jacob-pfau) · 2025-01-06T18:58:01.475Z · LW(p) · GW(p)
AI is 90% of their (quality adjusted) useful work force
This is intended to compare to 2023/AI-unassisted humans, correct? Or is there some other way of making this comparison you have in mind?
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2025-01-06T19:43:23.181Z · LW(p) · GW(p)
Yes, "Relative to only having access to AI systems publicly available in January 2023."
More generally, I define everything more precisely in the post linked in my comment on "AI 10x’ing labor for AI R&D [LW · GW]".
↑ comment by Dagon · 2025-01-06T18:25:59.069Z · LW(p) · GW(p)
Thanks for this - I'm in a more peripheral part of the industry (consumer/industrial LLM usage, not directly at an AI lab), and my timelines are somewhat longer (5 years for 50% chance), but I may be using a different criterion for "automate virtually all remote workers". It'll be a fair bit of time (in AI frame - a year or ten) between "labs show generality sufficient to automate most remote work" and "most remote work is actually performed by AI".
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2025-01-06T18:34:56.779Z · LW(p) · GW(p)
A key dynamic is that I think massive acceleration in AI is likely after the point when AIs can accelerate labor working on AI R&D. (Due to all of: the direct effects of accelerating AI software progress, this acceleration rolling out to hardware R&D and scaling up chip production, and potentially greatly increased investment.) See also here and here [LW · GW].
So, you might very quickly (1-2 years) go from "the AIs are great, fast, and cheap software engineers speeding up AI R&D" to "wildly superhuman AI that can achieve massive technical accomplishments".
Replies from: Dagon↑ comment by Dagon · 2025-01-06T21:25:43.457Z · LW(p) · GW(p)
I think massive acceleration in AI is likely after the point when AIs can accelerate labor working on AI R&D.
Fully agreed. And the trickle-down from AI-for-AI-R&D to AI-for-tool-R&D to AI-for-managers-to-replace-workers (and -replace-middle-managers) is still likely to be a bit extended. And the path is required - just like self-driving cars: the bar for adoption isn't "better than the median human" or even "better than the best affordable human", but "enough better that the decision-makers can't find a reason to delay".
comment by ryan_greenblatt · 2024-12-31T02:54:38.452Z · LW(p) · GW(p)
Inference compute scaling might imply we first get fewer, smarter AIs.
Prior estimates imply that the compute used to train a future frontier model could also be used to run tens or hundreds of millions of human equivalents per year at the first time when AIs are capable enough to dominate top human experts at cognitive tasks[1] (examples here from Holden Karnofsky, here from Tom Davidson, and here [LW · GW] from Lukas Finnveden). I think inference time compute scaling (if it worked) might invalidate this picture and might imply that you get far smaller numbers of human equivalents when you first get performance that dominates top human experts, at least in short timelines where compute scarcity might be important. Additionally, this implies that at the point when you have abundant AI labor which is capable enough to obsolete top human experts, you might also have access to substantially superhuman (but scarce) AI labor (and this could pose additional risks).
The point I make here might be obvious to many, but I thought it was worth making as I haven't seen this update from inference time compute widely discussed in public.[2]
However, note that if inference compute allows for trading off between quantity of tasks completed and the difficulty of tasks that can be completed (or the quality of completion), then depending on the shape of the inference compute returns curve, at the point when we can run some AIs as capable as top human experts, it might be worse to run many (or any) AIs at this level of capability rather than using less inference compute per task and completing more tasks (or completing tasks serially faster).
Further, efficiency might improve quickly such that we don't have a long regime with only a small number of human equivalents. I do a BOTEC on this below.
I'll do a specific low-effort BOTEC to illustrate my core point that you might get far smaller quantities of top human expert-level performance at first. Suppose that we first get AIs that are ~10x human cost (putting aside inflation in compute prices due to AI demand) and as capable as top human experts at this price point (at tasks like automating R&D). If this is in ~3 years, then maybe you'll have $15 million/hour worth of compute. Supposing $300/hour human cost, then we get ($15 million/hour) / ($300/hour) / (10 times human cost per compute dollar) * (4 AI hours / human work hours) = 20k human equivalents. This is a much smaller number than prior estimates.
The estimate of $15 million/hour worth of compute comes from: OpenAI spent ~$5 billion on compute this year, so $5 billion / (24*365) = $570k/hour; spend increases by ~3x per year, so $570k/hour * 3³ = $15 million.
The estimate for 3x per year comes from: total compute is increasing by 4-5x per year, but some is hardware improvement and some is increased spending. Hardware improvement is perhaps ~1.5x per year and 4.5/1.5 = 3. This at least roughly matches this estimate from Epoch which estimates 2.4x additional spend (on just training) per year. Also, note that Epoch estimates 4-5x compute per year here and 1.3x hardware FLOP/dollar here, which naively implies around 3.4x, but this seems maybe too high given the prior number.
Earlier, I noted that efficiency might improve rapidly. We can look at recent efficiency changes to get a sense for how fast. GPT-4o mini is roughly 100x cheaper than GPT-4 and is perhaps roughly as capable all together (probably lower intelligence but better elicited). It was trained roughly 1.5 years later (GPT-4 was trained substantially before it was released) for ~20x efficiency improvement per year. This is selected for being a striking improvment and probably involves low hanging fruit, but AI R&D will be substantially accelerated in the future which probably more than cancels this out. Further, I expect that inference compute will be inefficent in the tail of high inference compute such that efficiency will be faster than this once the capability is reached. So we might expect that the number of AI human equivalents increases by >20x per year and potentially much faster if AI R&D is greatly accelerated (and compute doesn't bottleneck this). If progress is "just" 50x per year, then it would still take a year to get to millions of human equivalents based on my earlier estimate of 20k human equivalents. Note that once you have millions of human equivalents, you also have increased availability of generally substantially superhuman AI systems.
I'm refering to the notion of Top-human-Expert-Dominating AI that I define in this post [LW · GW], though without a speed/cost constraint as I want to talk about the cost when you first get such systems. ↩︎
Of course, we should generally expect huge uncertainty with future AI architectures such that fixating on very efficient substitution of inference time compute for training would be a mistake, along with fixating on minimal or no substitution. I think a potential error of prior discussion is insufficient focus on the possibility of relatively scalable (though potentially inefficient) substitution of inference time for training (which o3 appears to exhibit) such that we see very expensive (and potentially slow) AIs that dominate top human expert performance prior to seeing cheap and abundant AIs which do this. ↩︎
↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2025-01-01T03:35:14.040Z · LW(p) · GW(p)
Ok, but for how long? If the situation holds for only 3 months, and then the accelerated R&D gives us a huge drop in costs, then the strategic outcomes seem pretty similar.
If there continues to be a useful peak capability only achievable with expensive inference, like the 10x human cost, and there are weaker human-skill-at-minimum available for 0.01x human cost, then it may be interesting to consider which tasks will benefit more from a large number of moderately good workers vs a small number of excellent workers.
Also worth considering is speed. In a lot of cases, it is possible to set things up to run slower-but-cheaper on less or cheaper hardware. Or to pay more, and have things run in as highly parallelized a manner as possible on the most expensive hardware. Usually maximizing speed comes with some cost overhead. So then you also need to consider whether it's worth having more of the work be done in serial by a smaller number of faster models...
For certain tasks, particularly competitive ones like sports or combat, speed can be a critical factor and is worth sacrificing peak intelligence for. Obviously, for long horizon strategic planning, it's the other way around.
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2025-01-01T03:45:32.751Z · LW(p) · GW(p)
I don't expect this to continue for very long. 3 months (or less) seems plausible. I really should have mentioned this in the post. I've now edited it in.
then the strategic outcomes seem pretty similar
I don't think so. In particular once the costs drop you might be able to run substantially superhuman systems at the same cost that you could previously run systems that can "merely" automate away top human experts.
↑ comment by Orpheus16 (akash-wasil) · 2024-12-31T18:10:21.428Z · LW(p) · GW(p)
The point I make here is also likely obvious to many, but I wonder if the "X human equivalents" frame often implicitly assumes that GPT-N will be like having X humans. But if we expect AIs to have comparative advantages (and disadvantages), then this picture might miss some important factors.
The "human equivalents" frame seems most accurate in worlds where the capability profile of an AI looks pretty similar to the capability profile of humans. That is, getting GPT-6 to do AI R&D is basically "the same as" getting X humans to do AI R&D. It thinks in fairly similar ways and has fairly similar strengths/weaknesses.
The frame is less accurate in worlds where AI is really good at some things and really bad at other things. In this case, if you try to estimate the # of human equivalents that GPT-6 gets you, the result might be misleading or incomplete. A lot of fuzzier things will affect the picture.
The example I've seen discussed most is whether or not we expect certain kinds of R&D to be bottlenecked by "running lots of experiments" or "thinking deeply and having core conceptual insights." My impression is that one reason why some MIRI folks are pessimistic is that they expect capabilities research to be more easily automatable (AIs will be relatively good at running lots of ML experiments quickly, which helps capabilities more under their model) than alignment research (AIs will be relatively bad at thinking deeply or serially about certain topics, which is what you need for meaningful alignment progress under their model).
Perhaps more people should write about what kinds of tasks they expect GPT-X to be "relatively good at" or "relatively bad at". Or perhaps that's too hard to predict in advance. If so, it could still be good to write about how different "capability profiles" could allow certain kinds of tasks to be automated more quickly than others.
(I do think that the "human equivalents" frame is easier to model and seems like an overall fine simplification for various analyses.)
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2024-12-31T19:01:07.239Z · LW(p) · GW(p)
In the top level comment, I was just talking about AI systems which are (at least) as capable as top human experts. (I was trying to point at the notion of Top-human-Expert-Dominating AI that I define in this post [LW · GW], though without a speed/cost constraint, but I think I was a bit sloppy in my language. I edited the comment a bit to better communicate this.)
So, in this context, human (at least) equivalents does make sense (as in, because the question is the cost of AIs that can strictly dominate top human experts so we can talk about the amount of compute needed to automate away one expert/researcher on average), but I agree that for earlier AIs it doesn't (necessarily) make sense and plausibly these earlier AIs are very key for understanding the risk (because e.g. they will radically accelerate AI R&D without necessarily accelerating other domain).
Replies from: akash-wasil↑ comment by Orpheus16 (akash-wasil) · 2024-12-31T20:05:04.610Z · LW(p) · GW(p)
At first glance, I don’t see how the point I raised is affected by the distinction between expert-level AIs vs earlier AIs.
In both cases, you could expect an important part of the story to be “what are the comparative strengths and weaknesses of this AI system.”
For example, suppose you have an AI system that dominates human experts at every single relevant domain of cognition. It still seems like there’s a big difference between “system that is 10% better at every relevant domain of cognition” and “system that is 300% better at domain X and only 10% better at domain Y.”
To make it less abstract, one might suspect that by the time we have AI that is 10% better than humans at “conceptual/serial” stuff, the same AI system is 1000% better at “speed/parallel” stuff. And this would have pretty big implications for what kind of AI R&D ends up happening (even if we condition on only focusing on systems that dominate experts in every relevant domain.)
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2024-12-31T21:41:18.377Z · LW(p) · GW(p)
I agree comparative advantages can still important, but your comment implied a key part of the picture is "models can't do some important thing". (E.g. you talked about "The frame is less accurate in worlds where AI is really good at some things and really bad at other things." but models can't be really bad at almost anything if they strictly dominate humans at basically everything.)
And I agree that at the point AIs are >5% better at everything they might also be 1000% better at some stuff.
I was just trying to point out that talking about the number human equivalents (or better) can still be kinda fine as long as the model almost strictly dominates humans as the model can just actually substitute everywhere. Like the number of human equivalents will vary by domain but at least this will be a lower bound.
comment by ryan_greenblatt · 2025-01-19T19:03:01.850Z · LW(p) · GW(p)
Sometimes people think of "software-only [LW · GW] singularity" as an important category of ways AI could go. A software-only singularity can roughly be defined as when you get increasing-returns growth (hyper-exponential) just via the mechanism of AIs increasing the labor input to AI capabilities software[1] R&D (i.e., keeping fixed the compute input to AI capabilities).
While the software-only singularity dynamic is an important part of my model, I often find it useful to more directly consider the outcome that software-only singularity might cause: the feasibility of takeover-capable AI without massive compute automation. That is, will the leading AI developer(s) be able to competitively develop AIs powerful enough to plausibly take over[2] without previously needing to use AI systems to massively (>10x) increase compute production[3]?
[This is by Ryan Greenblatt and Alex Mallen]
We care about whether the developers' AI greatly increases compute production because this would require heavy integration into the global economy in a way that relatively clearly indicates to the world that AI is transformative. Greatly increasing compute production would require building additional fabs which currently involve substantial lead times, likely slowing down the transition from clearly transformative AI to takeover-capable AI.[4][5] In addition to economic integration, this would make the developer dependent on a variety of actors after the transformative nature of AI is made more clear, which would more broadly distribute power.
For example, if OpenAI is selling their AI's labor to ASML and massively accelerating chip production before anyone has made takeover-capable AI, then (1) it would be very clear to the world that AI is transformatively useful and accelerating, (2) building fabs would be a constraint in scaling up AI which would slow progress, and (3) ASML and the Netherlands could have a seat at the table in deciding how AI goes (along with any other actors critical to OpenAI's competitiveness). Given that AI is much more legibly transformatively powerful in this world, they might even want to push for measures to reduce AI/human takeover risk.
A software-only singularity is not necessary for developers to have takeover-capable AIs without having previously used them for massive compute automation (it is also not clearly sufficient, since it might be too slow or uncompetitive by default without massive compute automation as well). Instead, developers might be able to achieve this outcome by other forms of fast AI progress:
- Algorithmic / scaling is fast enough at the relevant point independent of AI automation. This would likely be due to one of:
- Downstream AI capabilities progress very rapidly with the default software and/or hardware progress rate at the relevant point;
- Existing compute production (including repurposable production) suffices (this is sometimes called hardware overhang) and the developer buys a bunch more chips (after generating sufficient revenue or demoing AI capabilities to attract investment);
- Or there is a large algorithmic advance that unlocks a new regime with fast progress due to low-hanging fruit.[6]
- AI automation results in a one-time acceleration of software progress without causing an explosive feedback loop, but this does suffice for pushing AIs above the relevant capability threshold quickly.
- Other developers just aren't very competitive (due to secrecy, regulation, or other governance regimes) such that proceeding at a relatively slower rate (via algorithmic and hardware progress) suffices.
My inside view sense is that the feasibility of takeover-capable AI without massive compute automation is about 75% likely if we get AIs that dominate top-human-experts [LW · GW] prior to 2040.[7] Further, I think that in practice, takeover-capable AI without massive compute automation is maybe about 60% likely. (This is because massively increasing compute production is difficult and slow, so if proceeding without massive compute automation is feasible, this would likely occur.) However, I'm reasonably likely to change these numbers on reflection due to updating about what level of capabilities would suffice for being capable of takeover (in the sense defined in an earlier footnote) and about the level of revenue and investment needed to 10x compute production. I'm also uncertain whether a substantially smaller scale-up than 10x (e.g., 3x) would suffice to cause the effects noted earlier.
To-date software progress has looked like "improvements in pre-training algorithms, data quality, prompting strategies, tooling, scaffolding" as described here [LW · GW]. ↩︎
This takeover could occur autonomously, via assisting the developers in a power grab, or via partnering with a US adversary. I'll count it as "takeover" if the resulting coalition has de facto control of most resources. I'll count an AI as takeover-capable if it would have a >25% chance of succeeding at a takeover (with some reasonable coalition) if no other actors had access to powerful AI systems. Further, this takeover wouldn't be preventable with plausible interventions on legible human controlled institutions, so e.g., it doesn't include the case where an AI lab is steadily building more powerful AIs for an eventual takeover much later (see discussion here [LW(p) · GW(p)]). This 25% probability is as assessed under my views but with the information available to the US government at the time this AI is created. This line is intended to point at when states should be very worried about AI systems undermining their sovereignty unless action has already been taken. Note that insufficient inference compute could prevent an AI from being takeover-capable even if it could take over with enough parallel copies. And note that whether a given level of AI capabilities suffices for being takeover-capable is dependent on uncertain facts about how vulnerable the world seems (from the subjective vantage point I defined earlier). Takeover via the mechanism of an AI escaping, independently building more powerful AI that it controls, and then this more powerful AI taking over would count as that original AI that escaped taking over. I would also count a rogue internal deployment [LW · GW] that leads to the AI successfully backdooring or controlling future AI training runs such that those future AIs take over. However, I would not count merely sabotaging safety research. ↩︎
I mean 10x additional production (caused by AI labor) above long running trends in expanding compute production and making it more efficient. As in, spending on compute production has been increasing each year and the efficiency of compute production (in terms of FLOP/$ or whatever) has also been increasing over time, and I'm talking about going 10x above this trend due to using AI labor to expand compute production (either revenue from AI labor or having AIs directly work on chips as I'll discuss in a later footnote). ↩︎
Note that I don't count converting fabs from making other chips (e.g., phones) to making AI chips as scaling up compute production; I'm just considering things that scale up the amount of AI chips we could somewhat readily produce. TSMC's revenue is "only" about $100 billion per year, so if only converting fabs is needed, this could be done without automation of compute production and justified on the basis of AI revenues that are substantially smaller than the revenues that would justify building many more fabs. Currently AI is around 15% of leading node production at TSMC, so only a few more doublings are needed for it to consume most capacity. ↩︎
Note that the AI could indirectly increase compute production via being sufficiently economically useful that it generates enough money to pay for greatly scaling up compute. I would count this as massive compute automation, though some routes through which the AI could be sufficiently economically useful might be less convincing of transformativeness than the AIs substantially automating the process of scaling up compute production. However, I would not count the case where AI systems are impressive enough to investors that this justifies investment that suffices for greatly scaling up fab capacity while profits/revenues wouldn't suffice for greatly scaling up compute on their own. In reality, if compute is greatly scaled up, this will occur via a mixture of speculative investment, the AI earning revenue, and the AI directly working on automating labor along the compute supply chain. If the revenue and direct automation would suffice for an at least massive compute scale-up (>10x) on their own (removing the component from speculative investment), then I would count this as massive compute automation. ↩︎
A large algorithmic advance isn't totally unprecedented. It could suffice if we see an advance similar to what seemingly happened with reasoning models like o1 and o3 in 2024. ↩︎
About 2/3 of this is driven by software-only singularity. ↩︎
↑ comment by Lukas Finnveden (Lanrian) · 2025-01-21T03:08:53.841Z · LW(p) · GW(p)
I'm not sure if the definition of takeover-capable-AI (abbreviated as "TCAI" for the rest of this comment) in footnote 2 quite makes sense. I'm worried that too much of the action is in "if no other actors had access to powerful AI systems", and not that much action is in the exact capabilities of the "TCAI". In particular: Maybe we already have TCAI (by that definition) because if a frontier AI company or a US adversary was blessed with the assumption "no other actor will have access to powerful AI systems", they'd have a huge advantage over the rest of the world (as soon as they develop more powerful AI), plausibly implying that it'd be right to forecast a >25% chance of them successfully taking over if they were motivated to try.
And this seems somewhat hard to disentangle from stuff that is supposed to count according to footnote 2, especially: "Takeover via the mechanism of an AI escaping, independently building more powerful AI that it controls, and then this more powerful AI taking over would" and "via assisting the developers in a power grab, or via partnering with a US adversary". (Or maybe the scenario in 1st paragraph is supposed to be excluded because current AI isn't agentic enough to "assist"/"partner" with allies as supposed to just be used as a tool?)
What could a competing definition be? Thinking about what we care most about... I think two events especially stand out to me:
- When would it plausibly be catastrophically bad for an adversary to steal an AI model?
- When would it plausibly be catastrophically bad for an AI to be power-seeking and non-controlled [LW · GW]?
Maybe a better definition would be to directly talk about these two events? So for example...
- "Steal is catastrophic" would be true if...
- "Frontier AI development projects immediately acquire good enough security to keep future model weights secure" has significantly less probability of AI-assisted takeover than
- "Frontier AI development projects immediately have their weights stolen, and then acquire security that's just as good as in (1a)."[1]
- "Power-seeking and non-controlled is catastrophic" would be true if...
- "Frontier AI development projects immediately acquire good enough judgment about power-seeking-risk that they henceforth choose to not deploy any model that would've been net-negative for them to deploy" has significantly less probability of AI-assisted takeover than
- "Frontier AI development acquire the level of judgment described in (2a) 6 months later."[2]
Where "significantly less probability of AI-assisted takeover" could be e.g. at least 2x less risk.
- ^
The motivation for assuming "future model weights secure" in both (1a) and (1b) is so that the downside of getting the model weights stolen imminently isn't nullified by the fact that they're very likely to get stolen a bit later, regardless. Because many interventions that would prevent model weight theft this month would also help prevent it future months. (And also, we can't contrast 1a'="model weights are permanently secure" with 1b'="model weights get stolen and are then default-level-secure", because that would already have a really big effect on takeover risk, purely via the effect on future model weights, even though current model weights probably aren't that important.)
- ^
The motivation for assuming "good future judgment about power-seeking-risk" is similar to the motivation for assuming "future model weights secure" above. The motivation for choosing "good judgment about when to deploy vs. not" rather than "good at aligning/controlling future models" is that a big threat model is "misaligned AIs outcompete us because we don't have any competitive aligned AIs, so we're stuck between deploying misaligned AIs and being outcompeted" and I don't want to assume away that threat model.
↑ comment by ryan_greenblatt · 2025-01-21T04:47:54.720Z · LW(p) · GW(p)
I agree that the notion of takeover-capable AI I use is problematic and makes the situation hard to reason about, but I intentionally rejected the notions you propose as they seemed even worse to think about from my perspective.
Replies from: Lanrian↑ comment by Lukas Finnveden (Lanrian) · 2025-01-21T05:47:07.968Z · LW(p) · GW(p)
Is there some reason for why current AI isn't TCAI by your definition?
(I'd guess that the best way to rescue your notion it is to stipulate that the TCAIs must have >25% probability of taking over themselves. Possibly with assistance from humans, possibly by manipulating other humans who think they're being assisted by the AIs — but ultimately the original TCAIs should be holding the power in order for it to count. That would clearly exclude current systems. But I don't think that's how you meant it.)
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2025-01-21T17:36:41.591Z · LW(p) · GW(p)
Oh sorry. I somehow missed this aspect of your comment.
Here's a definition of takeover-capable AI that I like: the AI is capable enough that plausible interventions on known human controlled institutions within a few months no longer suffice to prevent plausible takeover. (Which implies that making the situation clear to the world is substantially less useful and human controlled institutions can no longer as easily get a seat at the table.)
Under this definition, there are basically two relevant conditions:
- The AI is capable enough to itself take over autonomously. (In the way you defined it, but also not in a way where intervening on human institutions can still prevent the takeover, so e.g.., the AI just having a rogue deployment within OpenAI doesn't suffice if substantial externally imposed improvements to OpenAI's security and controls would defeat the takeover attempt.)
- Or human groups can do a nearly immediate takeover with the AI such that they could then just resist such interventions.
I'll clarify this in the comment.
Replies from: Lanrian↑ comment by Lukas Finnveden (Lanrian) · 2025-01-21T18:23:04.360Z · LW(p) · GW(p)
Hm — what are the "plausible interventions" that would stop China from having >25% probability of takeover if no other country could build powerful AI? Seems like you either need to count a delay as successful prevention, or you need to have a pretty low bar for "plausible", because it seems extremely difficult/costly to prevent China from developing powerful AI in the long run. (Where they can develop their own supply chains, put manufacturing and data centers underground, etc.)
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2025-01-21T18:45:00.531Z · LW(p) · GW(p)
Yeah, I'm trying to include delay as fine.
I'm just trying to point at "the point when aggressive intervention by a bunch of parties is potentially still too late".
↑ comment by Sam Marks (samuel-marks) · 2025-01-20T08:47:26.362Z · LW(p) · GW(p)
I really like the framing here, of asking whether we'll see massive compute automation before [AI capability level we're interested in]. I often hear people discuss nearby questions using IMO much more confusing abstractions, for example:
- "How much is AI capabilities driven by algorithmic progress?" (problem: obscures dependence of algorithmic progress on compute for experimentation)
- "How much AI progress can we get 'purely from elicitation'?" (lots of problems, e.g. that eliciting a capability might first require a (possibly one-time) expenditure of compute for exploration)
My inside view sense is that the feasibility of takeover-capable AI without massive compute automation is about 75% likely if we get AIs that dominate top-human-experts [LW · GW] prior to 2040.[6] [? · GW] Further, I think that in practice, takeover-capable AI without massive compute automation is maybe about 60% likely.
Is this because:
- You think that we're >50% likely to not get AIs that dominate top human experts before 2040? (I'd be surprised if you thought this.)
- The words "the feasibility of" importantly change the meaning of your claim in the first sentence? (I'm guessing it's this based on the following parenthetical, but I'm having trouble parsing.)
Overall, it seems like you put substantially higher probability than I do on getting takeover capable AI without massive compute automation (and especially on getting a software-only singularity). I'd be very interested in understanding why. A brief outline of why this doesn't seem that likely to me:
- My read of the historical trend is that AI progress has come from scaling up all of the factors of production in tandem (hardware, algorithms, compute expenditure, etc.).
- Scaling up hardware production has always been slower than scaling up algorithms, so this consideration is already factored into the historical trends. I don't see a reason to believe that algorithms will start running away with the game.
- Maybe you could counter-argue that algorithmic progress has only reflected returns to scale from AI being applied to AI research in the last 12-18 months and that the data from this period is consistent with algorithms becoming more relatively important relative to other factors?
- I don't see a reason that "takeover-capable" is a capability level at which algorithmic progress will be deviantly important relative to this historical trend.
I'd be interested either in hearing you respond to this sketch or in sketching out your reasoning from scratch.
Replies from: ryan_greenblatt, ryan_greenblatt, ryan_greenblatt↑ comment by ryan_greenblatt · 2025-01-21T04:43:00.816Z · LW(p) · GW(p)
I put roughly 50% probability on feasibility of software-only singularity.[1]
(I'm probably going to be reinventing a bunch of the compute-centric takeoff model [LW · GW] in slightly different ways below, but I think it's faster to partially reinvent than to dig up the material, and I probably do use a slightly different approach.)
My argument here will be a bit sloppy and might contain some errors. Sorry about this. I might be more careful in the future.
The key question for software-only singularity is: "When the rate of labor production is doubled (as in, as if your employees ran 2x faster[2]), does that more than double or less than double the rate of algorithmic progress? That is, algorithmic progress as measured by how fast we increase the labor production per FLOP/s (as in, the labor production from AI labor on a fixed compute base).". This is a very economics-style way of analyzing the situation, and I think this is a pretty reasonable first guess. Here's a diagram I've stolen from Tom's presentation on explosive growth illustrating this:
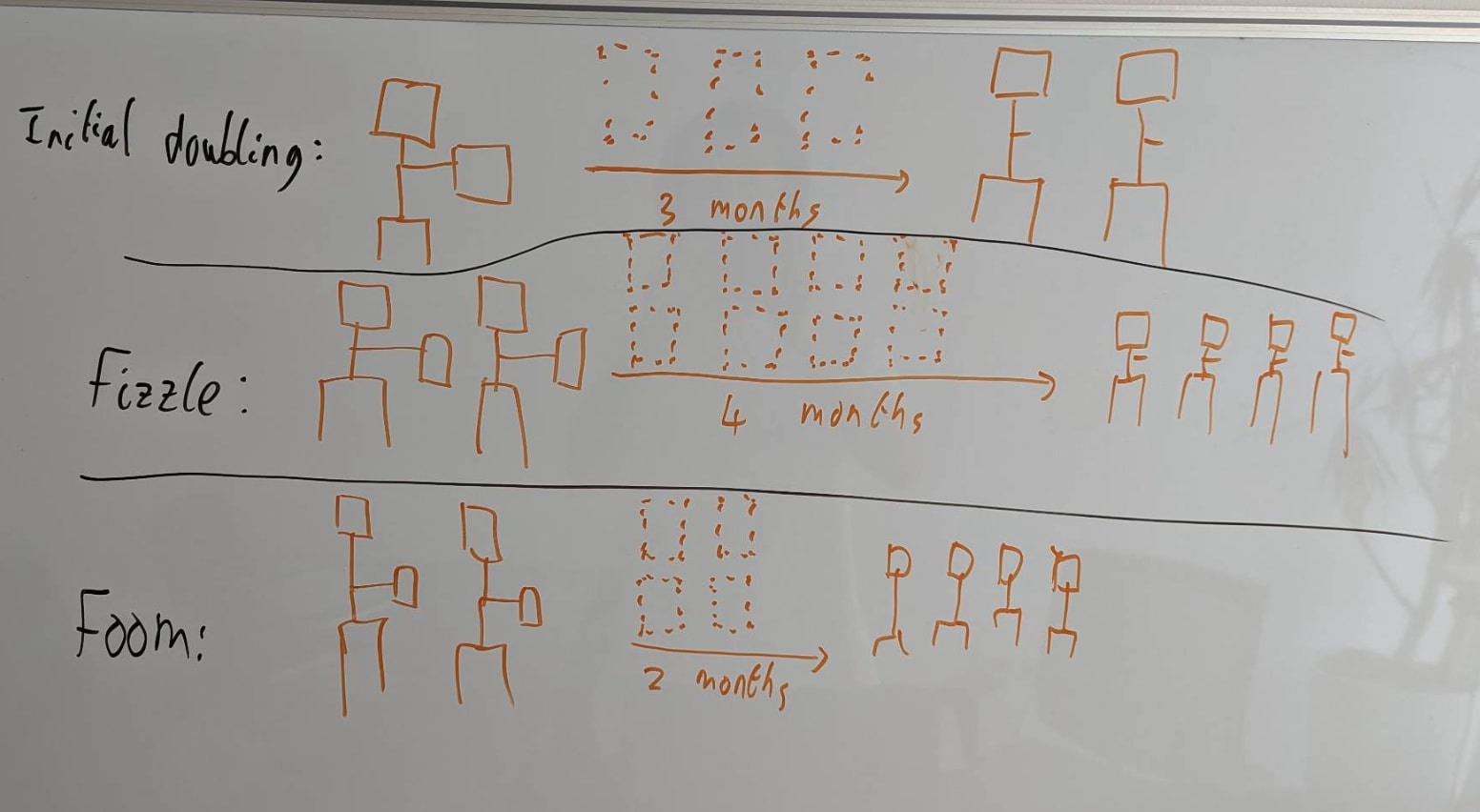
Basically, every time you double the AI labor supply, does the time until the next doubling (driven by algorithmic progress) increase (fizzle) or decrease (foom)? I'm being a bit sloppy in saying "AI labor supply". We care about a notion of parallelism-adjusted labor (faster laborers are better than more laborers) and quality increases can also matter. I'll make the relevant notion more precise below.
I'm about to go into a relatively complicated argument for why I think the historical data supports software-only singularity. If you want more basic questions answered (such as "Doesn't retraining make this too slow?"), consider looking at Tom's presentation on takeoff speeds [LW · GW].
Here's a diagram that you might find useful in understanding the inputs into AI progress:

And here is the relevant historical context in terms of trends:
- Historically, algorithmic progress in LLMs looks like 3-4x per year including improvements on all parts of the stack.[3] This notion of algorithmic progress is "reduction in compute needed to reach a given level of frontier performance", which isn't equivalent to increases in the rate of labor production on a fixed compute base. I'll talk more about this below.
- This has been accompanied by increases of around 4x more hardware per year[4] and maybe 2x more quality-adjusted (parallel) labor working on LLM capabilities per year. I think total employees working on LLM capabilities have been roughly 3x-ing per year (in recent years), but quality has been decreasing over time.
- A 2x increase in the quality-adjusted parallel labor force isn't as good as the company getting the same sorts of labor tasks done 2x faster (as in, the resulting productivity from having your employees run 2x faster) due to parallelism tax (putting aside compute bottlenecks for now). I'll apply the same R&D parallelization penalty as used in Tom's takeoff model and adjust this down by a power of 0.7 to yield 1.6x per year in increased labor production rate. (So, it's as though the company keeps the same employees, but those employees operate 1.6x faster each year.)
- It looks like the fraction of progress driven by algorithmic progress has been getting larger over time.
- So, overall, we're getting 3-4x algorithmic improvement per year being driven by 1.6x more labor per year and 4x more hardware.
So, the key question is how much of this algorithmic improvement is being driven by labor vs. by hardware. If it is basically all hardware, then the returns to labor must be relatively weak and software-only singularity seems unlikely. If it is basically all labor, then we're seeing 3-4x algorithmic improvement per year for 1.6x more labor per year, which means the returns to labor look quite good (at least historically). Based on some guesses and some poll questions, my sense is that capabilities researchers would operate about 2.5x slower if they had 10x less compute (after adaptation), so the production function is probably proportional to (). (This is assuming a cobb-douglas production function.) Edit: see the derivation of the relevant thing in Deep's comment [LW(p) · GW(p)], my old thing was wrong[5].
Now, let's talk more about the transfer from algorithmic improvement to the rate of labor production. A 2x algorithmic improvement in LLMs makes it so that you can reach the same (frontier) level of performance for 2x less training compute, but we actually care about a somewhat different notion for software-only singularity: how much you can increase the production rate of labor (the thing that we said was increasing at roughly a rate of 1.6x per year by using more human employees). My current guess is that every 2x algorithmic improvement in LLMs increases the rate of labor production by , and I'm reasonably confident that the exponent isn't much below . I don't currently have a very principled estimation strategy for this, and it's somewhat complex to reason about. I discuss this in the appendix below.
So, if this exponent is around 1, our central estimate of 2.3 from above corresponds to software-only singularity and our estimate of 1.56 from above under more pessimistic assumptions corresponds to this not being feasible. Overall, my sense is that the best guess numbers lean toward software-only singularity.
More precisely, software-only singularity that goes for >500x effective compute gains above trend (to the extent this metric makes sense, this is roughly >5 years of algorithmic progress). Note that you can have software-only singularity be feasible while buying tons more hardware at the same time. And if this ends up expanding compute production by >10x using AI labor, then this would count as massive compute production despite also having a feasible software-only singularity. (However, in most worlds, I expect software-only singularity to be fast enough, if feasible, that we don't see this.) ↩︎
Rather than denominating labor in accelerating employees, we could instead denominate in number of parallel employees. This would work equivalently (we can always convert into equivalents to the extent these things can funge), but because we can actually accelerate employees and the serial vs. parallel distinction is important, I think it is useful to denominate in accelerating employees. ↩︎
I would have previously cited 3x, but recent progress looks substantially faster (with DeepSeek v3 and reasoning models seemingly indicating somewhat faster than 3x progress IMO), so I've revised to 3-4x. ↩︎
This includes both increased spending and improved chips. Here, I'm taking my best guess at increases in hardware usage for training and transferring this to research compute usage on the assumption that training compute and research compute have historically been proportional. ↩︎
Edit: the reasoning I did here was off. Here was the old text: so the production function is probably roughly (). Increasing compute by 4x and labor by 1.6x increases algorithmic improvement by 3-4x, let's say 3.5x, so we have , . Thus, doubling labor would increase algorithmic improvement by . This is very sensitive to the exact numbers; if we instead used 3x slower instead of 2.5x slower, we would have gotten that doubling labor increases algorithmic improvement by , which is substantially lower. Obviously, all the exact numbers here are highly uncertain. ↩︎
↑ comment by deep · 2025-01-22T20:20:35.435Z · LW(p) · GW(p)
Hey Ryan! Thanks for writing this up -- I think this whole topic is important and interesting.
I was confused about how your analysis related to the Epoch paper, so I spent a while with Claude analyzing it. I did a re-analysis that finds similar results, but also finds (I think) some flaws in your rough estimate. (Keep in mind I'm not an expert myself, and I haven't closely read the Epoch paper, so I might well be making conceptual errors. I think the math is right though!)
I'll walk through my understanding of this stuff first, then compare to your post. I'll be going a little slowly (A) to help myself refresh myself via referencing this later, (B) to make it easy to call out mistakes, and (C) to hopefully make this legible to others who want to follow along.
Using Ryan's empirical estimates in the Epoch model
The Epoch model
The Epoch paper models growth with the following equation:
1. ,
where A = efficiency and E = research input. We want to consider worlds with a potential software takeoff, meaning that increases in AI efficiency directly feed into research input, which we model as . So the key consideration seems to be the ratio . If it's 1, we get steady exponential growth from scaling inputs; greater, superexponential; smaller, subexponential.[1]
Fitting the model
How can we learn about this ratio from historical data?
Let's pretend history has been convenient and we've seen steady exponential growth in both variables, so and . Then has been constant over time, so by equation 1, has been constant as well. Substituting in for A and E, we find that is constant over time, which is only possible if and the exponent is always zero. Thus if we've seen steady exponential growth, the historical value of our key ratio is:
2. .
Intuitively, if we've seen steady exponential growth while research input has increased more slowly than research output (AI efficiency), there are superlinear returns to scaling inputs.
Introducing the Cobb-Douglas function
But wait! , research input, is an abstraction that we can't directly measure. Really there's both compute and labor inputs. Those have indeed been growing roughly exponentially, but at different rates.
Intuitively, it makes sense to say that "effective research input" has grown as some kind of weighted average of the rate of compute and labor input growth. This is my take on why a Cobb-Douglas function of form (3) , with a weight parameter , is useful here: it's a weighted geometric average of the two inputs, so its growth rate is a weighted average of their growth rates.
Writing that out: in general, say both inputs have grown exponentially, so and . Then E has grown as , so is the weighted average (4) of the growth rates of labor and capital.
Then, using Equation 2, we can estimate our key ratio as .
Let's get empirical!
Plugging in your estimates:
- Historical compute scaling of 4x/year gives ;
- Historical labor scaling of 1.6x gives ;
- Historical compute elasticity on research outputs of 0.4 gives ;
- Adding these together, .[2]
- Historical efficiency improvement of 3.5x/year gives .
- So [3]
Adjusting for labor-only scaling
But wait: we're not done yet! Under our Cobb-Douglas assumption, scaling labor by a factor of 2 isn't as good as scaling all research inputs by a factor of 2; it's only as good.
Plugging in Equation 3 (which describes research input in terms of compute and labor) to Equation 1 (which estimates AI progress based on research), our adjusted form of the Epoch model is .
Under a software-only singularity, we hold compute constant while scaling labor with AI efficiency, so multiplied by a fixed compute term. Since labor scales as A, we have . By the same analysis as in our first section, we can see A grows exponentially if , and grows grows superexponentially if this ratio is >1. So our key ratio just gets multiplied by , and it wasn't a waste to find it, phew!
Now we get the true form of our equation: we get a software-only foom iff , or (via equation 2) iff we see empirically that . Call this the takeoff ratio: it corresponds to a) how much AI progress scales with inputs and b) how much of a penalty we take for not scaling compute.
Result: Above, we got , so our takeoff ratio is . That's quite close! If we think it's more reasonable to think of a historical growth rate of 4 instead of 3.5, we'd increase our takeoff ratio by a factor of , to a ratio of , right on the knife edge of FOOM. [4] [note: I previously had the wrong numbers here: I had lambda/beta = 1.6, which would mean the 4x/year case has a takeoff ratio of 1.05, putting it into FOOM land]
So this isn't too far off from your results in terms of implications, but it is somewhat different (no FOOM for 3.5x, less sensitivity to the exact historical growth rate).
Analyzing your approach:
Tweaking alpha:
Your estimate of is in fact similar in form to my ratio - but what you're calculating instead is .
One indicator that something's wrong is that your result involves checking whether , or equivalently whether , or equivalently whether . But the choice of 2 is arbitrary -- conceptually, you just want to check if scaling software by a factor n increases outputs by a factor n or more. Yet clearly varies with n.
One way of parsing the problem is that alpha is (implicitly) time dependent - it is equal to exp(r * 1 year) / exp(q * 1 year), a ratio of progress vs inputs in the time period of a year. If you calculated alpha based on a different amount of time, you'd get a different value. By contrast, r/q is a ratio of rates, so it stays the same regardless of what timeframe you use to measure it.[5]
Maybe I'm confused about what your Cobb-Douglas function is meant to be calculating - is it E within an Epoch-style takeoff model, or something else?
Nuances:
Does Cobb-Douglas make sense?
The geometric average of rates thing makes sense, but it feels weird that that simple intuitive approach leads to a functional form (Cobb-Douglas) that also has other implications.
Wikipedia says Cobb-Douglas functions can have the exponents not add to 1 (while both being between 0 and 1). Maybe this makes sense here? Not an expert.
How seriously should we take all this?
This whole thing relies on...
- Assuming smooth historical trends
- Assuming those trends continue in the future
- And those trends themselves are based on functional fits to rough / unclear data.
It feels like this sort of thing is better than nothing, but I wish we had something better.
I really like the various nuances you're adjusting for, like parallel vs serial scaling, and especially distinguishing algorithmic improvement from labor efficiency. [6] Thinking those things through makes this stuff feel less insubstantial and approximate...though the error bars still feel quite large.
- ^
Actually there's a complexity here, which is that scaling labor alone may be less efficient than scaling "research inputs" which include both labor and compute. We'll come to this in a few paragraphs.
- ^
This is only coincidentally similar to your figure of 2.3 :)
- ^
I originally had 1.6 here, but as Ryan points out in a reply it's actually 1.5. I've tried to reconstruct what I could have put into a calculator to get 1.6 instead, and I'm at a loss!
- ^
I was curious how aggressive the superexponential growth curve would be with a takeoff ratio of a mere. A couple of Claude queries gave me different answers (maybe because the growth is so extreme that different solvers give meaningfully different approximations?), but they agreed that growth is fairly slow in the first year (~5x) and then hits infinity by the end of the second year.I wrote this comment with the wrong numbers (0.96 instead of 0.9), so it doesn't accurately represent what you get if you plug in 4x capability growth per year. Still cool to get a sense of what these curves look like, though. - ^
I think can be understood in terms of the alpha-being-implicitly-a-timescale-function thing -- if you compare an alpha value with the ratio of growth you're likely to see during the same time period, e.g. alpha(1 year) and n = one doubling, you probably get reasonable-looking results.
- ^
I find it annoying that people conflate "increased efficiency of doing known tasks" with "increased ability to do new useful tasks". It seems to me that these could be importantly different, although it's hard to even settle on a reasonable formalization of the latter. Some reasons this might be okay:
- There's a fuzzy conceptual boundary between the two: if GPT-n can do the task at 0.01% success rate, does that count as a "known task?" what about if it can do each of 10 components at 0.01% success, so in practice we'll never see it succeed if run without human guidance, but we know it's technically possible?
- Under a software singularity situation, maybe the working hypothesis is that the model can do everything necessary to improve itself a bunch, maybe just not very efficiently yet. So we only need efficiency growth, not to increase the task set. That seems like a stronger assumption than most make, but maybe a reasonable weaker assumption is that the model will 'unlock' the necessary new tasks over time, after which point they become subject to rapid efficiency growth.
- And empirically, we have in fact seen rapid unlocking of new capabilities, so it's not crazy to approximate "being able to do new things" as a minor but manageable slowdown to the process of AI replacing human AI R&D labor.
↑ comment by ryan_greenblatt · 2025-01-24T18:02:48.986Z · LW(p) · GW(p)
I think you are correct with respect to my estimate of and the associated model I was using. Sorry about my error here. I think I was fundamentally confusing a few things in my head when writing out the comment.
I think your refactoring of my strategy is correct and I tried to check it myself, though I don't feel confident in verifying it is correct.
Your estimate doesn't account for the conversion between algorithmic improvement and labor efficiency, but it is easy to add this in by just changing the historical algorithmic efficiency improvement of 3.5x/year to instead be the adjusted effective labor efficiency rate and then solving identically. I was previously thinking the relationship was that labor efficiency was around the same as algorithmic efficiency, but I now think this is more likely to be around based on Tom's comment [LW(p) · GW(p)].
Plugging this is, we'd get:
(In your comment you said , but I think the arithmetic is a bit off here and the answer is closer to 1.5.)
Replies from: deep↑ comment by deep · 2025-01-25T07:01:56.226Z · LW(p) · GW(p)
Neat, thanks a ton for the algorithmic-vs-labor update -- I appreciated that you'd distinguished those in your post, but I forgot to carry that through in mine! :)
And oops, I really don't know how I got to 1.6 instead of 1.5 there. Thanks for the flag, have updated my comment accordingly!
The square relationship idea is interesting -- that factor of 2 is a huge deal. Would be neat to see a Guesstimate or Squiggle version of this calculation that tries to account for the various nuances Tom mentions, and has error bars on each of the terms, so we both get a distribution of r and a sensitivity analysis. (Maybe @Tom Davidson [LW · GW] already has this somewhere? If not I might try to make a crappy version myself, or poke talented folks I know to do a good version :)
↑ comment by ryan_greenblatt · 2025-01-24T23:57:19.923Z · LW(p) · GW(p)
It feels like this sort of thing is better than nothing, but I wish we had something better.
The existing epoch paper is pretty good, but doesn't directly target LLMs in a way which seems somewhat sad.
The thing I'd be most excited about is:
- Epoch does an in depth investigation using an estimation methodology which is directly targeting LLMs (rather than looking at returns in some other domains).
- They use public data and solicit data from companies about algorithmic improvement, head count, compute on experiments etc.
- (Some) companies provide this data. Epoch potentially doesn't publish this exact data and instead just publishes the results of the final analysis to reduce capabilities externalities. (IMO, companies are somewhat unlikely to do this, but I'd like to be proven wrong!)
↑ comment by ryan_greenblatt · 2025-01-24T17:12:20.718Z · LW(p) · GW(p)
(I'm going through this and understanding where I made an error with my approach to . I think I did make an error, but I'm trying to make sure I'm not still confused. Edit: I've figured this out, see my other comment.)
Wikipedia says Cobb-Douglas functions can have the exponents not add to 1 (while both being between 0 and 1). Maybe this makes sense here? Not an expert.
It shouldn't matter in this case because we're raising the whole value of to .
↑ comment by Tom Davidson (tom-davidson-1) · 2025-01-22T16:36:21.261Z · LW(p) · GW(p)
Here's my own estimate for this parameter:
Once AI has automated AI R&D, will software progress become faster or slower over time? This depends on the extent to which software improvements get harder to find as software improves – the steepness of the diminishing returns.
We can ask the following crucial empirical question:
When (cumulative) cognitive research inputs double, how many times does software double?
(In growth models of a software intelligence explosion, the answer to this empirical question is a parameter called r.)
If the answer is “< 1”, then software progress will slow down over time. If the answer is “1”, software progress will remain at the same exponential rate. If the answer is “>1”, software progress will speed up over time.
The bolded question can be studied empirically, by looking at how many times software has doubled each time the human researcher population has doubled.
(What does it mean for “software” to double? A simple way of thinking about this is that software doubles when you can run twice as many copies of your AI with the same compute. But software improvements don’t just improve runtime efficiency: they also improve capabilities. To incorporate these improvements, we’ll ultimately need to make some speculative assumptions about how to translate capability improvements into an equivalently-useful runtime efficiency improvement..)
The best quality data on this question is Epoch’s analysis of computer vision training efficiency. They estimate r = ~1.4: every time the researcher population doubled, training efficiency doubled 1.4 times. (Epoch’s preliminary analysis indicates that the r value for LLMs would likely be somewhat higher.) We can use this as a starting point, and then make various adjustments:
- Upwards for improving capabilities. Improving training efficiency improves capabilities, as you can train a model with more “effective compute”. To quantify this effect, imagine we use a 2X training efficiency gain to train a model with twice as much “effective compute”. How many times would that double “software”? (I.e., how many doublings of runtime efficiency would have the same effect?) There are various sources of evidence on how much capabilities improve every time training efficiency doubles: toy ML experiments suggest the answer is ~1.7; human productivity studies suggest the answer is ~2.5. I put more weight on the former, so I’ll estimate 2. This doubles my median estimate to r = ~2.8 (= 1.4 * 2).
- Upwards for post-training enhancements. So far, we’ve only considered pre-training improvements. But post-training enhancements like fine-tuning, scaffolding, and prompting also improve capabilities (o1 was developed using such techniques!). It’s hard to say how large an increase we’ll get from post-training enhancements. These can allow faster thinking, which could be a big factor. But there might also be strong diminishing returns to post-training enhancements holding base models fixed. I’ll estimate a 1-2X increase, and adjust my median estimate to r = ~4 (2.8*1.45=4).
- Downwards for less growth in compute for experiments. Today, rising compute means we can run increasing numbers of GPT-3-sized experiments each year. This helps drive software progress. But compute won't be growing in our scenario. That might mean that returns to additional cognitive labour diminish more steeply. On the other hand, the most important experiments are ones that use similar amounts of compute to training a SOTA model. Rising compute hasn't actually increased the number of these experiments we can run, as rising compute increases the training compute for SOTA models. And in any case, this doesn’t affect post-training enhancements. But this still reduces my median estimate down to r = ~3. (See Eth (forthcoming) for more discussion.)
- Downwards for fixed scale of hardware. In recent years, the scale of hardware available to researchers has increased massively. Researchers could invent new algorithms that only work at the new hardware scales for which no one had previously tried to to develop algorithms. Researchers may have been plucking low-hanging fruit for each new scale of hardware. But in the software intelligence explosions I’m considering, this won’t be possible because the hardware scale will be fixed. OAI estimate ImageNet efficiency via a method that accounts for this (by focussing on a fixed capability level), and find a 16-month doubling time, as compared with Epoch’s 9-month doubling time. This reduces my estimate down to r = ~1.7 (3 * 9/16).
- Downwards for diminishing returns becoming steeper over time. In most fields, returns diminish more steeply than in software R&D. So perhaps software will tend to become more like the average field over time. To estimate the size of this effect, we can take our estimate that software is ~10 OOMs from physical limits (discussed below), and assume that for each OOM increase in software, r falls by a constant amount, reaching zero once physical limits are reached. If r = 1.7, then this implies that r reduces by 0.17 for each OOM. Epoch estimates that pre-training algorithmic improvements are growing by an OOM every ~2 years, which would imply a reduction in r of 1.02 (6*0.17) by 2030. But when we include post-training enhancements, the decrease will be smaller (as [reason], perhaps ~0.5. This reduces my median estimate to r = ~1.2 (1.7-0.5).
Overall, my median estimate of r is 1.2. I use a log-uniform distribution with the bounds 3X higher and lower (0.4 to 3.6).
Replies from: ryan_greenblatt, deep↑ comment by ryan_greenblatt · 2025-01-22T17:57:56.521Z · LW(p) · GW(p)
My sense is that I start with a higher value due to the LLM case looking faster (and not feeling the need to adjust downward in a few places like you do in the LLM case). Obviously the numbers in the LLM case are much less certain given that I'm guessing based on qualitative improvement and looking at some open source models, but being closer to what we actually care about maybe overwhelms this.
I also think I'd get a slightly lower update on the diminishing returns case due to thinking it has a good chance of having substantially sharper dimishing returns as you get closer and closer rather than having linearly decreasing (based on some first principles reasoning and my understanding of how returns diminished in the semi-conductor case).
But the biggest delta is that I think I wasn't pricing in the importance of increasing capabilities. (Which seems especially important if you apply a large R&D parallelization penalty.)
Replies from: Tom Davidson↑ comment by Tom Davidson · 2025-01-22T18:53:15.174Z · LW(p) · GW(p)
Obviously the numbers in the LLM case are much less certain given that I'm guessing based on qualitative improvement and looking at some open source models,
Sorry,I don't follow why they're less certain?
based on some first principles reasoning and my understanding of how returns diminished in the semi-conductor case
I'd be interested to hear more about this. The semi conductor case is hard as we don't know how far we are from limits, but if we use Landauer's limit then I'd guess you're right. There's also uncertainty about how much alg progress we will and have met
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2025-01-22T19:16:18.775Z · LW(p) · GW(p)
Sorry,I don't follow why they're less certain?
I'm just eyeballing the rate of algorithmic progress while in the computer vision case, we can at least look at benchmarks and know the cost of training compute for various models.
My sense is that you have generalization issues in the compute vision case while in the frontier LLM case you have issues with knowing the actual numbers (in terms of number of employees and cost of training runs). I'm also just not carefully doing the accounting.
I'd be interested to hear more about this.
I don't have much to say here sadly, but I do think investigating this could be useful.
↑ comment by deep · 2025-01-25T06:57:52.832Z · LW(p) · GW(p)
Really appreciate you covering all these nuances, thanks Tom!
Can you give a pointer to the studies you mentioned here?
Replies from: tom-davidson-1There are various sources of evidence on how much capabilities improve every time training efficiency doubles: toy ML experiments suggest the answer is ~1.7; human productivity studies suggest the answer is ~2.5. I put more weight on the former, so I’ll estimate 2. This doubles my median estimate to r = ~2.8 (= 1.4 * 2).
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2025-01-21T17:43:06.534Z · LW(p) · GW(p)
Here's a simple argument I'd be keen to get your thoughts on:
On the Possibility of a Tastularity
Research taste is the collection of skills including experiment ideation, literature review, experiment analysis, etc. that collectively determine how much you learn per experiment on average (perhaps alongside another factor accounting for inherent problem difficulty / domain difficulty, of course, and diminishing returns)
Human researchers seem to vary quite a bit in research taste--specifically, the difference between 90th percentile professional human researchers and the very best seems like maybe an order of magnitude? Depends on the field, etc. And the tails are heavy; there is no sign of the distribution bumping up against any limits.
Yet the causes of these differences are minor! Take the very best human researchers compared to the 90th percentile. They'll have almost the same brain size, almost the same amount of experience, almost the same genes, etc. in the grand scale of things.
This means we should assume that if the human population were massively bigger, e.g. trillions of times bigger, there would be humans whose brains don't look that different from the brains of the best researchers on Earth, and yet who are an OOM or more above the best Earthly scientists in research taste. -- AND it suggests that in the space of possible mind-designs, there should be minds which are e.g. within 3 OOMs of those brains in every dimension of interest, and which are significantly better still in the dimension of research taste. (How much better? Really hard to say. But it would be surprising if it was only, say, 1 OOM better, because that would imply that human brains are running up against the inherent limits of research taste within a 3-OOM mind design space, despite human evolution having only explored a tiny subspace of that space, and despite the human distribution showing no signs of bumping up against any inherent limits)
OK, so what? So, it seems like there's plenty of room to improve research taste beyond human level. And research taste translates pretty directly into overall R&D speed, because it's about how much experimentation you need to do to achieve a given amount of progress. With enough research taste, you don't need to do experiments at all -- or rather, you look at the experiments that have already been done, and you infer from them all you need to know to build the next design or whatever.
Anyhow, tying this back to your framework: What if the diminishing returns / increasing problem difficulty / etc. dynamics are such that, if you start from a top-human-expert-level automated researcher, and then do additional AI research to double its research taste, and then do additional AI research to double its research taste again, etc. the second doubling happens in less time than it took to get to the first doubling? Then you get a singularity in research taste (until these conditions change of course) -- the Tastularity.
How likely is the Tastularity? Well, again one piece of evidence here is the absurdly tiny differences between humans that translate to huge differences in research taste, and the heavy-tailed distribution. This suggests that we are far from any inherent limits on research taste even for brains roughly the shape and size and architecture of humans, and presumably the limits for a more relaxed (e.g. 3 OOM radius in dimensions like size, experience, architecture) space in mind-design are even farther away. It similarly suggests that there should be lots of hill-climbing that can be done to iteratively improve research taste.
How does this relate to software-singularity? Well, research taste is just one component of algorithmic progress; there is also speed, # of parallel copies & how well they coordinate, and maybe various other skills besides such as coding ability. So even if the Tastularity isn't possible, improvements in taste will stack with improvements in those other areas, and the sum might cross the critical threshold.
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2025-01-21T17:59:31.363Z · LW(p) · GW(p)
In my framework, this is basically an argument that algorithmic-improvement-juice can be translated into a large improvement in AI R&D labor production via the mechanism of greatly increasing the productivity per "token" (or unit of thinking compute or whatever). See my breakdown here [LW(p) · GW(p)] where I try to convert from historical algorithmic improvement to making AIs better at producing AI R&D research.
Your argument is basically that this taste mechanism might have higher returns than reducing cost to run more copies.
I agree this sort of argument means that returns to algorithmic improvement on AI R&D labor production might be bigger than you would otherwise think. This is both because this mechanism might be more promising than other mechanisms and even if it is somewhat less promising, diverse approaches make returns dimish less aggressively. (In my model, this means that best guess conversion might be more like rather than .)
I think it might be somewhat tricky to train AIs to have very good research taste, but this doesn't seem that hard via training them on various prediction objectives.
At a more basic level, I expect that training AIs to predict the results of experiments and then running experiments based on value of information as estimated partially based on these predictions (and skipping experiments with certain results and more generally using these predictions to figure out what to do) seems pretty promising. It's really hard to train humans to predict the results of tens of thousands of experiments (both small and large), but this is relatively clean outcomes based feedback for AIs.
I don't really have a strong inside view on how much the "AI R&D research taste" mechanism increases the returns to algorithmic progress.
↑ comment by Tom Davidson (tom-davidson-1) · 2025-01-22T16:33:06.919Z · LW(p) · GW(p)
I'll paste my own estimate for this param in a different reply.
But here are the places I most differ from you:
- Bigger adjustment for 'smarter AI'. You've argue in your appendix that, only including 'more efficient' and 'faster' AI, you think the software-only singularity goes through. I think including 'smarter' AI makes a big difference. This evidence suggests that doubling training FLOP doubles output-per-FLOP 1-2 times. In addition, algorithmic improvements will improve runtime efficiency. So overall I think a doubling of algorithms yields ~two doublings of (parallel) cognitive labour.
- --> software singularity more likely
- Lower lambda. I'd now use more like lambda = 0.4 as my median. There's really not much evidence pinning this down; I think Tamay Besiroglu thinks there's some evidence for values as low as 0.2. This will decrease the observed historical increase in human workers more than it decreases the gains from algorithmic progress (bc of speed improvements)
- --> software singularity slightly more likely
- Complications thinking about compute which might be a wash.
- Number of useful-experiments has increased by less than 4X/year. You say compute inputs have been increasing at 4X. But simultaneously the scale of experiments ppl must run to be near to the frontier has increased by a similar amount. So the number of near-frontier experiments has not increased at all.
- This argument would be right if the 'usefulness' of an experiment depends solely on how much compute it uses compared to training a frontier model. I.e. experiment_usefulness = log(experiment_compute / frontier_model_training_compute). The 4X/year increases the numerator and denominator of the expression, so there's no change in usefulness-weighted experiments.
- That might be false. GPT-2-sized experiments might in some ways be equally useful even as frontier model size increases. Maybe a better expression would be experiment_usefulness = alpha * log(experiment_compute / frontier_model_training_compute) + beta * log(experiment_compute). In this case, the number of usefulness-weighted experiments has increased due to the second term.
- --> software singularity slightly more likely
- Steeper diminishing returns during software singularity. Recent algorithmic progress has grabbed low-hanging fruit from new hardware scales. During a software-only singularity that won't be possible. You'll have to keep finding new improvements on the same hardware scale. Returns might diminish more quickly as a result.
- --> software singularity slightly less likely
- Compute share might increase as it becomes scarce. You estimate a share of 0.4 for compute, which seems reasonable. But it might fall over time as compute becomes a bottleneck. As an intuition pump, if your workers could think 1e10 times faster, you'd be fully constrained on the margin by the need for more compute: more labour wouldn't help at all but more compute could be fully utilised so the compute share would be ~1.
- --> software singularity slightly less likely
--> overall these compute adjustments prob make me more pessimistic about the software singularity, compared to your assumptions
- Number of useful-experiments has increased by less than 4X/year. You say compute inputs have been increasing at 4X. But simultaneously the scale of experiments ppl must run to be near to the frontier has increased by a similar amount. So the number of near-frontier experiments has not increased at all.
Taking it all together, i think you should put more probability on the software-only singluarity, mostly because of capability improvements being much more significant than you assume.
Replies from: ryan_greenblatt, ryan_greenblatt, Lanrian, sharmake-farah↑ comment by ryan_greenblatt · 2025-01-22T17:51:33.967Z · LW(p) · GW(p)
Yep, I think my estimates were too low based on these considerations and I've updated up accordingly. I updated down on your argument that maybe decreases linearly as you approach optimal efficiency. (I think it probably doesn't decrease linearly and instead drops faster towards the end based partially on thinking a bit about the dynamics and drawing on the example of what we've seen in semi-conductor improvement over time, but I'm not that confident.) Maybe I'm now at like 60% software-only is feasible given these arguments.
↑ comment by ryan_greenblatt · 2025-02-07T22:31:46.134Z · LW(p) · GW(p)
Lower lambda. I'd now use more like lambda = 0.4 as my median. There's really not much evidence pinning this down; I think Tamay Besiroglu thinks there's some evidence for values as low as 0.2.
Isn't this really implausible? This implies that if you had 1000 researchers/engineers of average skill at OpenAI doing AI R&D, this would be as good as having one average skill researcher running at 16x () speed. It does seem very slightly plausible that having someone as good as the best researcher/engineer at OpenAI run at 16x speed would be competitive with OpenAI, but that isn't what this term is computing. 0.2 is even more crazy, implying that 1000 researchers/engineers is as good as one researcher/engineer running at 4x speed!
Replies from: ryan_greenblatt, ryan_greenblatt↑ comment by ryan_greenblatt · 2025-02-12T22:24:13.336Z · LW(p) · GW(p)
I think 0.4 is far on the lower end (maybe 15th percentile) for all the way down to one accelerated researcher, but seems pretty plausible at the margin.
As in, 0.4 suggests that 1000 researchers = 100 researchers at 2.5x speed which seems kinda reasonable while 1000 researchers = 1 researcher at 16x speed does seem kinda crazy / implausible.
So, I think my current median lambda at likely margins is like 0.55 or something and 0.4 is also pretty plausible at the margin.
↑ comment by ryan_greenblatt · 2025-02-07T23:54:55.463Z · LW(p) · GW(p)
Ok, I think what is going on here is maybe that the constant you're discussing here is different from the constant I was discussing. I was trying to discuss the question of how much worse serial labor is than parallel labor, but I think the lambda you're talking about takes into account compute bottlenecks and similar?
Not totally sure.
↑ comment by Lukas Finnveden (Lanrian) · 2025-01-22T20:16:55.214Z · LW(p) · GW(p)
Taking it all together, i think you should put more probability on the software-only singluarity, mostly because of capability improvements being much more significant than you assume.
I'm confused — I thought you put significantly less probability on software-only singularity than Ryan does? (Like half?) Maybe you were using a different bound for the number of OOMs of improvement?
Replies from: ryan_greenblatt, Tom Davidson↑ comment by ryan_greenblatt · 2025-01-22T20:19:36.323Z · LW(p) · GW(p)
I think Tom's take is that he expects I will put more probability on software only singularity after updating on these considerations. It seems hard to isolate where Tom and I disagree based on this comment, but maybe it is on how much to weigh various considerations about compute being a key input.
↑ comment by Tom Davidson · 2025-01-22T21:24:00.520Z · LW(p) · GW(p)
Sorry, for my comments on this post I've been referring to "software only singularity?" only as "will the parameter r >1 when we f first fully automate AI RnD", not as a threshold for some number of OOMs. That's what Ryan's analysis seemed to be referring to.
I separately think that even if initially r>1 the software explosion might not go on for that long
Replies from: Tom Davidson↑ comment by Tom Davidson · 2025-01-22T21:25:40.263Z · LW(p) · GW(p)
I'll post about my views on different numbers of OOMs soon
↑ comment by Noosphere89 (sharmake-farah) · 2025-01-22T16:52:52.424Z · LW(p) · GW(p)
↑ comment by ryan_greenblatt · 2025-01-21T04:43:25.447Z · LW(p) · GW(p)
Appendix: Estimating the relationship between algorithmic improvement and labor production
In particular, if we fix the architecture to use a token abstraction and consider training a new improved model: we care about how much cheaper you make generating tokens at a given level of performance (in inference tok/flop), how much serially faster you make generating tokens at a given level of performance (in serial speed: tok/s at a fixed level of tok/flop), and how much more performance you can get out of tokens (labor/tok, really per serial token). Then, for a given new model with reduced cost, increased speed, and increased production per token and assuming a parallelism penalty of , we can compute the increase in production as roughly: [1] (I can show the math for this if there is interest).
My sense is that reducing inference compute needed for a fixed level of capability that you already have (using a fixed amount of training run) is usually somewhat easier than making frontier compute go further by some factor, though I don't think it is easy to straightforwardly determine how much easier this is[2]. Let's say there is a 1.25 exponent on reducing cost (as in, 2x algorithmic efficiency improvement is as hard as a reduction in cost)? (I'm also generally pretty confused about what the exponent should be. I think exponents from 0.5 to 2 seem plausible, though I'm pretty confused. 0.5 would correspond to the square root from just scaling data in scaling laws.) It seems substantially harder to increase speed than to reduce cost as speed is substantially constrained by serial depth, at least when naively applying transformers. Naively, reducing cost by (which implies reducing parameters by ) will increase speed by somewhat more than as depth is cubic in layers. I expect you can do somewhat better than this because reduced matrix sizes also increase speed (it isn't just depth) and because you can introduce speed-specific improvements (that just improve speed and not cost). But this factor might be pretty small, so let's stick with for now and ignore speed-specific improvements. Now, let's consider the case where we don't have productivity multipliers (which is strictly more conservative). Then, we get that increase in labor production is:
So, these numbers ended up yielding an exact equivalence between frontier algorithmic improvement and effective labor production increases. (This is a coincidence, though I do think the exponent is close to 1.)
In practice, we'll be able to get slightly better returns by spending some of our resources investing in speed-specific improvements and in improving productivity rather than in reducing cost. I don't currently have a principled way to estimate this (though I expect something roughly principled can be found by looking at trading off inference compute and training compute), but maybe I think this improves the returns to around . If the coefficient on reducing cost was much worse, we would invest more in improving productivity per token, which bounds the returns somewhat.
Appendix: Isn't compute tiny and decreasing per researcher?
One relevant objection is: Ok, but is this really feasible? Wouldn't this imply that each AI researcher has only a tiny amount of compute? After all, if you use 20% of compute for inference of AI research labor, then each AI only gets 4x more compute to run experiments than for inference on itself? And, as you do algorithmic improvement to reduce AI cost and run more AIs, you also reduce the compute per AI! First, it is worth noting that as we do algorithmic progress, both the cost of AI researcher inference and the cost of experiments on models of a given level of capability go down. Precisely, for any experiment that involves a fixed number of inference or gradient steps on a model which is some fixed effective compute multiplier below/above the performance of our AI laborers, cost is proportional to inference cost (so, as we improve our AI workforce, experiment cost drops proportionally). However, for experiments that involve training a model from scratch, I expect the reduction in experiment cost to be relatively smaller such that such experiments must become increasingly small relative to frontier scale. Overall, it might be important to mostly depend on approaches which allow for experiments that don't require training runs from scratch or to adapt to increasingly smaller full experiment training runs. To the extent AIs are made smarter rather than more numerous, this isn't a concern. Additionally, we only need so many orders of magnitude of growth. In principle, this consideration should be captured by the exponents in the compute vs. labor production function, but it is possible this production function has very different characteristics in the extremes. Overall, I do think this concern is somewhat important, but I don't think it is a dealbreaker for a substantial number of OOMs of growth.
Appendix: Can't algorithmic efficiency only get so high?
My sense is that this isn't very close to being a blocker. Here is a quick bullet point argument (from some slides I made) that takeover-capable AI is possible on current hardware.
- Human brain is perhaps ~1e14 FLOP/s
- With that efficiency, each H100 can run 10 humans (current cost $2 / hour)
- 10s of millions of human-level AIs with just current hardware production
- Human brain is probably very suboptimal:
- AIs already much better at many subtasks
- Possible to do much more training than within lifetime training with parallelism
- Biological issues: locality, noise, focused on sensory processing, memory limits
- Smarter AI could be more efficient (smarter humans use less FLOP per task)
- AI could be 1e2-1e7 more efficient on tasks like coding, engineering
- Probably smaller improvement on video processing
- Say, 1e4 so 100,000 per H100
- Qualitative intelligence could be a big deal
- Seems like peak efficiency isn't a blocker.
This is just approximate because you can also trade off speed with cost in complicated ways and research new ways to more efficiently trade off speed and cost. I'll be ignoring this for now. ↩︎
It's hard to determine because inference cost reductions have been driven by spending more compute on making smaller models e.g., training a smaller model for longer rather than just being driven by algorithmic improvement, and I don't have great numbers on the difference off the top of my head. ↩︎
↑ comment by Lukas Finnveden (Lanrian) · 2025-01-21T20:20:06.066Z · LW(p) · GW(p)
In practice, we'll be able to get slightly better returns by spending some of our resources investing in speed-specific improvements and in improving productivity rather than in reducing cost. I don't currently have a principled way to estimate this (though I expect something roughly principled can be found by looking at trading off inference compute and training compute), but maybe I think this improves the returns to around .
Interesting comparison point: Tom thought this would give a way larger boost in his old software-only singularity appendix.
When considering an "efficiency only singularity", some different estimates gets him r~=1; r~=1.5; r~=1.6. (Where r is defined so that "for each x% increase in cumulative R&D inputs, the output metric will increase by r*x". The condition for increasing returns is r>1.)
Whereas when including capability improvements:
I said I was 50-50 on an efficiency only singularity happening, at least temporarily. Based on these additional considerations I’m now at more like ~85% on a software only singularity. And I’d guess that initially r = ~3 (though I still think values as low as 0.5 or as high as 6 as plausible). There seem to be many strong ~independent reasons to think capability improvements would be a really huge deal compared to pure efficiency problems, and this is borne out by toy models of the dynamic.
Though note that later in the appendix he adjusts down from 85% to 65% due to some further considerations. Also, last I heard, Tom was more like 25% on software singularity. (ETA: Or maybe not? See other comments in this thread.)
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2025-01-22T00:23:34.419Z · LW(p) · GW(p)
Interesting. My numbers aren't very principled and I could imagine thinking capability improvements are a big deal for the bottom line.
↑ comment by Lukas Finnveden (Lanrian) · 2025-01-21T20:06:09.263Z · LW(p) · GW(p)
Based on some guesses and some poll questions, my sense is that capabilities researchers would operate about 2.5x slower if they had 10x less compute (after adaptation)
Can you say roughly who the people surveyed were? (And if this was their raw guess or if you've modified it.)
I saw some polls from Daniel previously where I wasn't sold that they were surveying people working on the most important capability improvements, so wondering if these are better.
Also, somewhat minor, but: I'm slightly concerned that surveys will overweight areas where labor is more useful relative to compute (because those areas should have disproportionately many humans working on them) and therefore be somewhat biased in the direction of labor being important.
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2025-01-22T00:41:16.129Z · LW(p) · GW(p)
I'm citing the polls from Daniel + what I've heard from random people + my guesses.
↑ comment by ryan_greenblatt · 2025-01-20T20:24:26.128Z · LW(p) · GW(p)
I think your outline of an argument against contains an important error.
Scaling up hardware production has always been slower than scaling up algorithms, so this consideration is already factored into the historical trends. I don't see a reason to believe that algorithms will start running away with the game.
Importantly, while the spending on hardware for individual AI companies has increased by roughly 3-4x each year[1], this has not been driven by scaling up hardware production by 3-4x per year. Instead, total compute production (in terms of spending, building more fabs, etc.) has been increased by a much smaller amount each year, but a higher and higher fraction of that compute production was used for AI. In particular, my understanding is that roughly ~20% of TSMC's volume is now AI while it used to be much lower. So, the fact that scaling up hardware production is much slower than scaling up algorithms hasn't bitten yet and this isn't factored into the historical trends.
Another way to put this is that the exact current regime can't go on. If trends continue, then >100% of TSMC's volume will be used for AI by 2027!
Only if building takeover-capable AIs happens by scaling up TSMC to >1000% of what their potential FLOP output volume would have otherwise been, then does this count as "massive compute automation" in my operationalization. (And without such a large build-out, the economic impacts and dependency of the hardware supply chain (at the critical points) could be relatively small.) So, massive compute automation requires something substantially off trend from TSMC's perspective.
[Low importance] It is only possible to build takeover-capable AI without previously breaking an important trend prior to around 2030 (based on my rough understanding). Either the hardware spending trend must break or TSMC production must go substantially above the trend by then. If takeover-capable AI is built prior to 2030, it could occur without substantial trend breaks but this gets somewhat crazy towards the end of the timeline: hardware spending keeps increasing at ~3x for each actor (but there is some consolidation and acquisition of previously produced hardware yielding a one-time increase up to about 10x which buys another 2 years for this trend), algorithmic progress remains steady at ~3-4x per year, TSMC expands production somewhat faster than previously, but not substantially above trend, and these suffice for getting sufficiently powerful AI. In this scenario, this wouldn't count as massive compute automation.
The spending on training runs has increased by 4-5x according to epoch, but part of this is making training runs go longer, which means the story for overall spending is more complex. We care about the overall spend on hardware, not just the spend on training runs. ↩︎
↑ comment by Sam Marks (samuel-marks) · 2025-01-20T20:59:56.855Z · LW(p) · GW(p)
Thanks, this is helpful. So it sounds like you expect
- AI progress which is slower than the historical trendline (though perhaps fast in absolute terms) because we'll soon have finished eating through the hardware overhang
- separately, takeover-capable AI soon (i.e. before hardware manufacturers have had a chance to scale substantially).
It seems like all the action is taking place in (2). Even if (1) is wrong (i.e. even if we see substantially increased hardware production soon), that makes takeover-capable AI happen faster than expected; IIUC, this contradicts the OP, which seems to expect takeover-capable AI to happen later if it's preceded by substantial hardware scaling.
In other words, it seems like in the OP you care about whether takeover-capable AI will be preceded by massive compute automation because:
- [this point still holds up] this affects how legible it is that AI is a transformative technology
- [it's not clear to me this point holds up] takeover-capable AI being preceded by compute automation probably means longer timelines
The second point doesn't clearly hold up because if we don't see massive compute automation, this suggests that AI progress slower than the historical trend.
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2025-01-20T21:56:38.786Z · LW(p) · GW(p)
I don't think (2) is a crux (as discussed in person). I expect that if takeover-capable AI takes a while (e.g. it happens in 2040), then we will have a long winter where economic value from AI doesn't increase that fast followed a period of faster progress around 2040. If progress is relatively stable accross this entire period, then we'll have enough time to scale up fabs. Even if progress isn't stable, we could see enough total value from AI in the slower growth period to scale up to scale up fabs by 10x, but this would require >>$1 trillion of economic value per year I think (which IMO seems not that likely to come far before takeover-capable AI due to views about economic returns to AI and returns to scaling up compute).
↑ comment by ryan_greenblatt · 2025-01-20T20:22:38.055Z · LW(p) · GW(p)
The words "the feasibility of" importantly change the meaning of your claim in the first sentence? (I'm guessing it's this based on the following parenthetical, but I'm having trouble parsing.)
I think this happening in practice is about 60% likely, so I don't think feasibility vs. in practice is a huge delta.
comment by ryan_greenblatt · 2025-03-07T00:17:55.459Z · LW(p) · GW(p)
Recently, @Daniel Kokotajlo [LW · GW] and I were talking about the probability that AIs trained using "business as usual RLHF" end up being basically aligned rather than conspiring against us and our tests.[1] One intuition pump we ended up discussing is the prospects of octopus misalignment. Overall, my view is that directly considering the case with AIs (and what various plausible scenarios would look like) is more informative than analogies like this, but analogies like this are still somewhat useful to consider.
So, what do I mean by octopus misalignment? Suppose a company breeds octopuses[2] until the point where they are as smart and capable as the best research scientists[3] at AI companies. We'll suppose that this magically happens as fast as normal AI takeoff, so there are many generations per year. So, let's say they currently have octopuses which can speak English and write some code but aren't smart enough to be software engineers or automate any real jobs. (As in, they are as capable as AIs are today, roughly speaking.) And they get to the level of top research scientists in mid-2028. Along the way, the company attempts to select them for being kind, loyal, and obedient. The company also tries to develop a process for raising the octopuses which appears to help with this and results in the octopuses following the octopus spec. The company does some red teaming and puts the octopuses in all kinds of scenarios to test their loyalty and preferences. Based on behavioral testing, this looks pretty reasonable and the octopuses look quite good by the time they are as good as the best research scientists. There was some evidence of misalignment and some issues due to misaligned behavior when the octopuses were dumber in 2023-2025, including things like being dishonest when put under pressure, pretending to be aligned when they actually dislike the octopus spec to steer the properties of their descendants, and goodharting/hacking our measures of intelligence. However, by 2026.5 these issues appear to be resolved based on behavioral tests. The takeoff is reasonably fast, so the human octopus scientists don't have that much time to study the octopuses, but we'll suppose the breeding is fast enough that they can get enough selection to make the octopuses appear good. The octopuses are trained until they are 30 years old (we'll suppose we have a magic octopus time acceleration chamber to make this work). (And the company can adapt this training process over time with experiments etc.) The company doesn't take octopus misalignment very seriously (after all, look, the octopuses are so nice!) but does have some people who consider this some and does care about robust compliance to the spec.
Next, suppose that at the point when the octopuses become as good as the very best human researchers—the research scientist level—there is a colony of 5 million of them networked together with internal Slack channels and so forth, forming a "country of geniuses in an aquatic center." And they've learned to speak both English and a special octopese language that no human can understand.
What is the chance that these octopuses (at the point of research scientist level) are actively scheming against us and would seize power if they could?
My guess is around 65%. I think Daniel is substantially higher, around 90%.
My view on a similar setup for AIs (where they have opaque recurrence, basically unrestricted opaque message passing, and we see some earlier warning signs, but haven't seriously investigated misalignment), is around 50%. I discuss my perspective more here [LW · GW]. My probabilities would be substantially lower if: the AIs didn't have opaque recurrence and instead had probably faithful chain-of-thought, the AIs didn't have opaque message passing, and we seriously investigated scheming in powerful AIs with model organisms and the final evidence was either ambiguous or mostly unconcerning.
To put this back in terms of the octopus scenario, suppose the octopi didn't communicate using octopese. That would reduce my probability down to around 50%.
More precisely: Suppose the frontier AI company which prioritizes safety the median amount scales up to AIs capable enough to fully automate AI R&D within that company. Let's say this happens in mid-2028 and there are no large improvements in alignment technology. The company iterates to fix misalignment problems they notice along the way (including in this final AI to the extent this AI displays evidence of serious misalignment problems by default). What's the chance that this final AI ends up basically aligned in the sense that it basically tries to follow a reasonable interpretation of the model spec in 99% of cases and it isn't notably more misaligned than a typical human employee at the company in aggregate. ↩︎
Claude claims that octopuses is the technically correct plural instead of octopi. Sad. ↩︎
I think AIs will have structural advantages, so I think we'll see full automation of AI companies around the point when AIs are qualitatively as smart as a decent research scientist rather than as smart as a top research scientist. ↩︎
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2025-03-07T00:38:13.320Z · LW(p) · GW(p)
Yep, I feel more like 90% here. (Lower numbers if the octopi don't have octopese.) I'm curious for other people's views.
↑ comment by ryan_greenblatt · 2025-03-07T01:10:35.429Z · LW(p) · GW(p)
I should note that I'm quite uncertain here and I can easily imagine my views swinging by large amounts.
↑ comment by ChristianKl · 2025-03-07T10:29:47.845Z · LW(p) · GW(p)
What is the chance that these octopuses (at the point of research scientist level) are actively scheming against us and would seize power if they could?
And the related question would be: Even if they are not "actively scheming" what are the chances that most of the power to make decisions about the real world gets delegated to them, organizations that don't delegate power to octopuses get outcompeted, and they start to value octopuses more than humans over time?
↑ comment by ryan_greenblatt · 2025-03-11T15:46:45.155Z · LW(p) · GW(p)
After thinking more about it, I think "we haven't seen evidence of scheming once the octopi were very smart" is a bigger update than I was imagining, especially in the case where the octopi weren't communicating with octopese. So, I'm now at ~20% without octopese and about 50% with it.
↑ comment by nielsrolf · 2025-03-08T12:33:26.166Z · LW(p) · GW(p)
My intuition is that these octopuses would be pretty unlikely to be scheming against us, for the following reasons:
- dogs are pretty nice, and it's apparently easy to domesticate foxes with very few generations. This suggests that "be nice to humans" is simple to learn for animals, and in particular simpler than "be as intelligent as human AI researchers". So assuming the octopuses would first learn to like humans, it's unclear to me why they would later start to dislike humans. Maybe your intuition is that they would later realize that they are being treated unfairly, which causes frustration that is not present in earlier generations?
- If the octopuses speak octopese and English, I think it wouldn't be too hard to get some octopi to translate for us. For example, we could ask one octopus to communicate some information to a second octopus using octopese. We can check if that worked by asking the second octopus to translate back to English. Now, we have a pair of (octopese text, English text) for which we know the translation. Now we ask a third octopus to translate octopese to English, and check the performance on some known examples.
It would be possible to scheme against this test if the octopi are amazingly skilled at coordination, but I suspect human AI researchers would fail this test if a foreign secret service would use a similar setup to get AI researchers to translate between foreignese and English, so I think we should assume that such coordination is hard and a small individual failure rate would likely be enough for the group to fail (we need just one octopus that translates faithfully). (Note that this argument hinges on the existence of a language that is understood by different octopi, so it doesn't translate 1:1 to AIs.)
↑ comment by Gunnar_Zarncke · 2025-03-09T22:26:54.863Z · LW(p) · GW(p)
There is a difference though: dogs and humans have coevolved for 10000 years. If you breed foxes you may quickly get dog like looks but behavior. But lets assume you can do that faster. It still makes a difference if you breed in isolation or socializing with the humans. You can see the difference with digs and cats. Dogs and humans had to cooperate to succeed at hunting and herding. Cats didn't. Dogs are social. They feel social emotions such as love, loneliness and jealousy. They help their owners when they are incapacitated (though sometimes they cheat). I think Ryan's, Daniel's, and Neel's estimate might be significantly lower if they think about German Shepherd scientists.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2025-03-17T03:42:57.760Z · LW(p) · GW(p)
That said, for the purposes of alignment, it's still good news that cats (by and large) do not scheme against their owner's wishes, and the fact that cats can be as domesticated as they are while they aren't cooperative or social is a huge boon for alignment purposes (within the analogy, which is arguably questionable).
↑ comment by reallyeli · 2025-03-07T03:06:57.400Z · LW(p) · GW(p)
What was the purpose of using octopuses in this metaphor? Like, it seems you've piled on so many disanalogies to actual octopuses (extremely smart, many generations per year, they use Slack...) that you may as well just have said "AIs."
EDIT: Is it gradient descent vs. evolution?
Replies from: neel-nanda-1, ryan_greenblatt↑ comment by Neel Nanda (neel-nanda-1) · 2025-03-07T12:27:35.392Z · LW(p) · GW(p)
I found it helpful because it put me in the frame of a alien biological intelligence rather than an AI because I have lots of preconceptions about AIs and it's it's easy to implicitly think in terms of expected utility maximizers or tools or whatever. While if I'm imagining an octopus, I'm kind of imagining humans, but a bit weirder and more alien, and I would not trust humans
↑ comment by ryan_greenblatt · 2025-03-07T03:36:12.178Z · LW(p) · GW(p)
I'm not making a strong claim this makes sense and I think people should mostly think about the AI case directly. I think it's just another intuition pump and we can potentially be more concrete in the octopus case as we know the algorithm. (While in the AI case, we haven't seen an ML algorithm that scales to human level.)
comment by ryan_greenblatt · 2025-01-27T20:56:37.563Z · LW(p) · GW(p)
DeepSeek's success isn't much of an update on a smaller US-China gap in short timelines because security was already a limiting factor
Some people seem to have updated towards a narrower US-China gap around the time of transformative AI if transformative AI is soon, due to recent releases from DeepSeek. However, since I expect frontier AI companies in the US will have inadequate security in short timelines and China will likely steal their models and algorithmic secrets, I don't consider the current success of China's domestic AI industry to be that much of an update. Furthermore, if DeepSeek or other Chinese companies were in the lead and didn't open-source their models, I expect the US would steal their models and algorithmic secrets. Consequently, I expect these actors to be roughly equal in short timelines, except in their available compute and potentially in how effectively they can utilize AI systems.
I do think that the Chinese AI industry looking more competitive makes security look somewhat less appealing (and especially less politically viable) and makes it look like their adaptation time to stolen models and/or algorithmic secrets will be shorter. Marginal improvements in security still seem important, and ensuring high levels of security prior to at least ASI (and ideally earlier!) is still very important.
Using the breakdown of capabilities I outlined in this prior post [LW · GW], the rough picture I expect is something like:
- AIs that can 10x accelerate AI R&D labor: Security is quite weak (perhaps <=SL3 as defined in "Securing Model Weights"), so the model is easily stolen if relevant actors want to steal it. Relevant actors are somewhat likely to know AI is a big enough deal that stealing it makes sense, but AI is not necessarily considered a top priority.
- Top-Expert-Dominating AI: Security is somewhat improved (perhaps <=SL4), but still pretty doable to steal. Relevant actors are more aware, and the model probably gets stolen.
- Very superhuman AI: I expect security to be improved by this point (partially via AIs working on security), but effort on stealing the model could also plausibly be unprecedentedly high. I currently expect security implemented before this point to suffice to prevent the model from being stolen.
Given this, I expect that key early models will be stolen, including models that can fully substitute for human experts, and so the important differences between actors will mostly be driven by compute, adaptation time, and utilization. Of these, compute seems most important, particularly given that adaptation and utilization time can be accelerated by the AIs themselves.
This analysis suggests that export controls are particularly important, but they would need to apply to hardware used for inference rather than just attempting to prevent large training runs through memory bandwidth limitations or similar restrictions.
Replies from: nathan-helm-burger↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2025-01-27T22:13:40.780Z · LW(p) · GW(p)
A factor that I don't think people are really taking into account is: what happens if this situation goes hostile?
Having an ASI and x amount of compute for inference plus y amount of currently existing autonomous weapons platforms (e.g. drones)... If your competitor has the same ASI, but 10x the compute but 0.2x the drones... And you get in a fight... Who wins? What about 0.2x the compute and 10x the drones?
The funny thing about AI brinkmanship versus nuclear brinkmanship is that AI doesn't drain your economic resources, it accelerates your gains. A nuclear stockpile costs you in maintenance. An AI and compute 'stockpile' makes you more money and more tech (including better AI and compute). Thus, there is a lot more incentive to race harder on AI than on nuclear.
If I were in the defense dept of a world power right now, I'd be looking for ways to make money from civilian uses of drones... Maybe underwriting drone deliveries for mail. That gives you an excuse to build drones and drone factories while whistling innocently.
Replies from: nathan-helm-burger↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2025-01-31T16:18:39.975Z · LW(p) · GW(p)
I'm not the only one thinking along these lines... https://x.com/8teAPi/status/1885340234352910723
comment by ryan_greenblatt · 2024-03-03T18:12:37.391Z · LW(p) · GW(p)
The 5 main reasons why control could fail
Here are the 5 main categories of reasons why control [? · GW] could fail (though various of them are often correlated).
[Note: this document has a moderate amount of overlap with various prior documents Redwood has released, but it seemed like a useful document nonetheless.]
- Insufficient (long horizon) sample efficiency: If your AI is scheming, you won’t be able to reasonably sample efficiently get this AI to achieve near maximal reward on average on (long horizon) tasks. By near maximal, we just mean empirically achieving average reward which is quite close to the reward the AI would get if it was “actually trying” to get high reward (insofar as it is scheming to an extent that “trying” makes sense). (When we say average, we actually mean average excluding rare outliers. We can't (in general) control behavior on rare outliers using normal ML training.) For control, this causes issues in two places: it interferes with getting useful work out of AIs and being able to run accurate capability evaluations.
- Auditing failures [LW · GW]: inability for humans to sufficiently assess actions. (Though note there can be solutions to these failures which don’t involve improving auditing [LW · GW].) This includes:
- Average case usefulness: For scheming AIs, you won’t be able to check that the work it’s doing is actually good (on average) rather than just looking good to you. Note that this includes getting enough actually good work out of AIs.
- Average case safety: Direct safety issues that occur due to auditing failing to notice a large number of actively dangerous actions and then these actions build up into a catastrophic outcome. (E.g., the AI slowly persuades some group in the AI lab to become AI cultists.) One particularly salient special case is:
- We can’t prevent AIs from building up huge amounts of coup science: Control will depend on human researchers being similarly good or better at understanding than our countermeasures and the space of possible AI attack strategies. See Notes on control evaluations for safety cases [LW · GW] for more discussion.
- High-stakes safety: The auditing process fails to detect that a single action is very bad when it reviews that action and this is extremely bad because that action is part of a high-stakes failure (e.g., an escape attempt that occurs in a small number of actions).
- Concentrated failures [LW · GW]: inability to prevent concentrated catastrophes (safety failures which are concentrated into a small number of bad actions or a small amount of serial time) despite having an expensive and slow auditing process which could detect this bad behavior (it works for high-stakes safety) if it was assigned to review these actions.
- Lack of institutional will or ability: Even if control would work given a few years of delay and an implementation carried out by a quite well-run organization, you won’t get one of these in practice and thus you’ll have trouble. (This argument also applies to any other technical approaches where the implementation requires substantial institutional will, therefore we need some sort of technical solutions which require less institutional competence.)
- Catching the AI isn’t sufficiently useful: The viability of control will likely depend on it being very useful to catch the AI one or a small number of times. But, this might turn out to be false for various reasons. See Catching AIs red-handed [LW · GW] for discussion. This might depend heavily on questions which aren’t about technical AI safety like how useful legible evidence of serious misalignment is. But, the technical usefulness of catching could suffice.
We think that various of these things could go wrong in practice. However, it seems like the current point on the logistic success curve is such that if an AI lab tried very hard to evaluate and ensure control, they could improve the situation substantially (e.g., 3-5x reduction in doom) relative to not trying very hard.
Note that 2, 3, and 4 of the above failures probably just prevent us from building sufficiently safe and useful protocols without breaking control evaluations. 1 and 2.b.i (coup science build-up) are likely to break control evaluations, though it might be possible to recognize that we’re in a world where 1 and/or 2.b.i hold. 5 has more complex effects, but we’d probably be able to safely stop after realizing that we’re unable to extract enough value from the times when we’ve caught the AI; so the main concern would be that we’re somewhat clearly unable to safely continue rather than being caught dangerously unaware.
See here [LW · GW] for more discussion.
Here are some reasons why control might not be worth working on (or actively bad to work on) regardless of the above reasons:
- Control is bad for coordination: Perhaps control does improve safety, but it does so at the cost of making it easier to make excuses, giving false confidence, and/or creating slippery slopes.
- Control makes it cheaper and easier to do morally problematic things: Control might make it more commercially valuable and technically feasible to employ AIs in situations where we know these AIs don’t consent to this usage (and these AIs are well described as having preferences that deserve moral consideration), and this might make violations of basic moral principles (such as slavery) more likely. (In the same way as better technology for managing human insider threats could make human slavery more commercially valuable. Of course, in the case of human slavery, there are already institutions and norms which combat slavery.) However, note that our recommendation to society would be to try extremely hard to avoid employing AIs without their consent; if AIs don’t consent to employment we should (temporarily) shut down or negotiate a deal with the AIs. Much more commentary on these topics can be seen here [LW · GW]. Our overall view is that the default AI situation with only current alignment/safety/interpretability technology is somewhat scary from an AI welfare/rights perspective, but that control doesn’t make the situation worse.
- Scheming is extremely unlikely for early transformatively useful AI (<1%) and control-style approaches won’t be a useful safeguard against other threat models: Control focuses on making conservative assumptions about the effects of training and the motivations of AIs. If we didn’t have to make such conservative assumptions, then control-type approaches look much less worthwhile. However, control-type things might still be a useful line of defense against failure modes which aren’t well described as scheming.
- Baseline control strategies will work (when control is at all possible) and control evaluations are easy to run: If the baseline approaches can’t be improved on and there isn’t important research on the evaluations, then technical work on control isn’t very important. Policy/governance work might still be important. See also here [LW · GW].
comment by ryan_greenblatt · 2024-02-28T21:22:53.354Z · LW(p) · GW(p)
It seems slightly bad that you can vote on comments under the Quick Takes and Popular Comments sections without needing to click on the comment and without leaving the frontpage.
This is different than posts where in order to vote, you have to actually click on the post and leave the main page (which perhaps requires more activation energy).
I'm unsure, but I think this could result in a higher frequency of cases where Quick Takes and comments go viral in problematic ways relative to posts. (Based on my vague sense from the EA forum.)
This doesn't seem very important, but I thought it would be worth quickly noting.
Replies from: kave, habryka4↑ comment by kave · 2024-02-29T06:03:15.873Z · LW(p) · GW(p)
I feel like Quick Takes and Popular Comments on the EA forum both do a good job of showing me content I'm glad to have seen (and in the case of the EA forum that I wouldn't have otherwise seen) and of making the experience of making a shortform better (in that you get more and better engagement). So far, this also seems fairly true on LessWrong, but we're presumably out of equilibrium.
Overall, I feel like posts on LessWrong are too long, and so am particularly excited about finding my way to things that are a little shorter. (It would also be cool if we could figure out how to do rigour well or other things that benefit from length, but I don't feel like I'm getting that much advantage from the length yet).
My guess is that the problems you gesture at will be real and the feature will still be net positive. I wish there were a way to "pay off" the bad parts with some of the benefit; probably there is and I haven't thought of it.
↑ comment by habryka (habryka4) · 2024-02-28T21:49:11.083Z · LW(p) · GW(p)
Yeah, I was a bit worried about this, especially for popular comments. For quick takes, it does seem like you can see all the relevant context before voting, and you were also able to already vote on comments from the Recent Discussion section (though that section isn't sorted by votes, so at less risk of viral dynamics). I do feel a bit worried that popular comments will get a bunch of votes without people reading the underlying post it's responding to.
comment by ryan_greenblatt · 2024-09-07T22:27:34.925Z · LW(p) · GW(p)
About 1 year ago, I wrote up a ready-to-go plan for AI safety focused on current science (what we roughly know how to do right now). This is targeting reducing catastrophic risks from the point when we have transformatively powerful AIs (e.g. AIs similarly capable to humans).
I never finished this doc, and it is now considerably out of date relative to how I currently think about what should happen, but I still think it might be helpful to share.
Here is the doc. I don't particularly want to recommend people read this doc, but it is possible that someone will find it valuable to read.
I plan on trying to think though the best ready-to-go plan roughly once a year. Buck and I have recently started work on a similar effort. Maybe this time we'll actually put out an overall plan rather than just spinning off various docs.
Replies from: adam_scholl↑ comment by Adam Scholl (adam_scholl) · 2024-09-08T00:45:45.334Z · LW(p) · GW(p)
This seems like a great activity, thank you for doing/sharing it. I disagree with the claim near the end that this seems better than Stop, and in general felt somewhat alarmed throughout at (what seemed to me like) some conflation/conceptual slippage between arguments that various strategies were tractable, and that they were meaningfully helpful. Even so, I feel happy that the world contains people sharing things like this; props.
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2024-09-08T02:17:19.793Z · LW(p) · GW(p)
I disagree with the claim near the end that this seems better than Stop
At the start of the doc, I say:
It’s plausible that the optimal approach for the AI lab is to delay training the model and wait for additional safety progress. However, we’ll assume the situation is roughly: there is a large amount of institutional will to implement this plan, but we can only tolerate so much delay. In practice, it’s unclear if there will be sufficient institutional will to faithfully implement this proposal.
Towards the end of the doc I say:
This plan requires quite a bit of institutional will, but it seems good to at least know of a concrete achievable ask to fight for other than “shut everything down”. I think careful implementation of this sort of plan is probably better than “shut everything down” for most AI labs, though I might advocate for slower scaling and a bunch of other changes on current margins.
Presumably, you're objecting to 'I think careful implementation of this sort of plan is probably better than “shut everything down” for most AI labs'.
My current view is something like:
- If there was broad, strong, and durable political will and buy in for heavily prioritizing AI takeover risk in the US, I think it would be good if the US government shut down scaling and took strong actions to prevent frontier AI progress while also accelerating huge amounts of plausibly-safety-related research.
- You'd need to carefully manage the transition back to scaling to reduce hardware overhang issues. This is part of why I think "durable" political will is important. There are various routes for doing this with different costs.
- I'm sympathetic to thinking this doesn't make sense if you just care about deaths prior to age 120 of currently alive people and wide-spread cryonics is hopeless (even conditional on the level of political support for mitigating AI takeover risk). Some other views which just care about achieving close to normal lifespans for currently alive humans also maybe aren't into pausing.
- Regulations/actions which have the side effect of slowing down scaling which aren't part of a broad package seem way less good. This is partially due to hardware/algorithmic overhang concerns, but more generally due to follow though concerns. I also wouldn't advocate such regulations (regulations with the main impact being to slow down as a side effect) due to integrity/legitimacy concerns.
- Unilateral shutdown is different as advice than "it would be good if everyone shut down" because AI companies might think (correctly or not) that they would be better on safety than other companies. In practice, no AI lab seems to have expressed a view which is close to "acceleration is bad" except Anthropic (see core views on AI safety).
- We are very, very far from broad, strong, and durable political will for heavily prioritizing AI takeover, so weaker and conditional interventions for actors on the margin seem useful.
comment by ryan_greenblatt · 2024-01-08T23:13:50.196Z · LW(p) · GW(p)
I think it might be worth quickly clarifying my views on activation addition and similar things (given various [LW(p) · GW(p)] discussion [LW(p) · GW(p)] about this). Note that my current views are somewhat different than some comments I've posted in various places (and my comments are somewhat incoherent overall), because I’ve updated based on talking to people about this over the last week.
This is quite in the weeds and I don’t expect that many people should read this.
- It seems like activation addition sometimes has a higher level of sample efficiency in steering model behavior compared with baseline training methods (e.g. normal LoRA finetuning). These comparisons seem most meaningful in straightforward head-to-head comparisons (where you use both methods in the most straightforward way). I think the strongest evidence for this is in Liu et al..
- Contrast pairs are a useful technique for variance reduction (to improve sample efficiency), but may not be that important (see Liu et al. again). It's relatively natural to capture this effect using activation vectors, but there is probably some nice way to incorporate this into SGD. Perhaps DPO does this? Perhaps there is something else?
- Activation addition works better than naive few-shot prompting in some cases, particularly in cases where the way you want to steer the model isn't salient/obvious from the few-shot prompt. But it's unclear how it performs in comparison to high-effort prompting. Regardless, activation addition might work better "out of the box" because fancy prompting is pretty annoying.
- I think training models to (in general) respond well to "contrast prompting", where you have both positive and negative examples in the prompt, might work well. This can be done in a general way ahead of time and then specific tuning can just use this format (the same as instruction finetuning). For a simple prompting approach, you can do "query_1 Good response: pos_ex_1, Bad response: neg_ex_1, query_2 Good response: pos_ex_2, Bad response: neg_ex_2, ..." and then prompt with "actual_query Good response:". Normal pretrained models might not respond well to this prompt by default, but I haven’t checked.
- I think we should be able to utilize the fact that activation addition works to construct a tweaked inductive bias for SGD on transformers (which feels like a more principled approach from my perspective if the goal is better sample efficiency). More generally, I feel like we should be able to do ablations to understand why activation addition works and then utilize this separately.
- I expect there are relatively straightforward ways to greatly improve sample efficiency of normal SGD via methods like heavy proliferation of training data. I also think "really high sample efficiency from a small number of samples" isn't very solved at the moment. I think if we're really going for high sample efficiency from a fixed training dataset we should be clear about that and I expect a variety of very different approaches are possible.
- The advantages versus prompting in terms of inference time performance improvement (because activation engineering means you have to process fewer tokens during inference) don't seem very important to me because you can just context distill prompts.
- For cases where we want to maximize a metric X and we don’t care about sample efficiency or overfitting to X, we can construct a big dataset of high quality demonstrations, SFT on these demos, and then RL against our metric. If we do this in a well tuned way for a large number of samples such that sample efficiency isn’t much of an issue (and exploration problems are substantial), I would be pretty surprised if activation addition or similar approaches can further increase metric X and “stack” with all the RL/demos we did. That is, I would be surprised if this is true unless the activation engineering is given additional affordances/information not in our expert demos and the task isn’t heavily selected for activation engineering stacking like this.
- It's unclear how important it is to (right now) work on sample efficiency specifically to reduce x-risk. I think it seems not that important, but I'm unsure. Better sample efficiency could be useful for reducing x-risk because better sample efficiency could allow for using a smaller amount of oversight data labeled more carefully for training your AI, but I expect that sample efficiency will naturally be improved to pretty high levels by standard commercial/academic incentives. (Speculatively, I also expect that the marginal returns will just generally look better for improving oversight even given equal effort or more effort on oversight basically because we’ll probably need a moderate amount of data anyway and I expect that improving sample efficiency in the “moderate data” regime is relatively harder.) One exception is that I think that sample efficiency for very low sample-count cases might not be very commercially important, but might be highly relevant for safety after catching the AI doing egregiously bad actions and then needing to redeploy [LW · GW]. For this, it would be good to focus on sample efficiency specifically in ways which are analogous to training an AI or a monitor after catching an egregiously bad action.
- The fact that activation addition works reveals some interesting facts about the internals of models; I expect there are some ways to utilize something along these lines to reduce x-risk.
- In principle, you could use activation additions or similar editing techniques to learn non-obvious facts about the algorithms which models are implementing via running experiments where you (e.g.) add different vectors at different layers and observe interactions (interpretability). For this to be much more powerful than black-box model psychology or psychology/interp approaches which use a bit of training, you would probably need to do try edits at many different layers and map out an overall algorithm. (And/or do many edits simultaneously).
- I think "miscellaneous interventions on internals" for high-level understanding of the algorithms that models are implementing seems promising in principle, but I haven't seen any work in this space which I'm excited about.
- I think activation addition could have "better" generalization in some cases, but when defining generalization experiments, we need to be careful about the analogousness of the setup. It's also unclear what exact properties we want for generalization, but minimally being able to more precisely pick and predict the generalization seems good. I haven't yet seen evidence for "better" generalization using activation addition which seems compelling/interesting to me. Note that we should use a reasonably sized training dataset, or we might be unintentionally measuring sample efficiency (in which case, see above). I don't really see a particular reason why activation addition would result in "better" generalization beyond having some specific predictable properties which maybe mean we can know about cases where it is somewhat better (cases where conditioning on something is better than "doing" that thing?).
- I'm most excited for generalization work targeting settings where oversight is difficult and a weak supervisor would make mistakes that result in worse policy behavior (aka weak-to-strong generalization). See this post [LW · GW] and this post [LW · GW] for more discussion of the setting I'm thinking about.
- I generally think it's important to be careful about baselines and exactly what problem we're trying to solve in cases where we are trying to solve a specific problem as opposed to just doing some open-ended exploration. TBC, open ended exploration is fine, but we should know what we're doing. I often think that when you make the exact problem you're trying to solve and what affordances you are and aren't allowed more clear, a bunch of additional promising methods become apparent. I think that the discussion I’ve seen so far of activation engineering (e.g. in this post [LW · GW], why do we compare to finetuning in a generalization case rather than just directly finetuning on what we want? Is doing RL to increase how sycophantic the model is in scope?) has not been very precise about what problem it’s trying to solve or what baseline techniques it’s claiming to outperform.
- I don’t currently think the activation addition stuff is that important in expectation (for reducing x-risk) due to some of the beliefs I said above (though I'm not very confident). I'd be most excited about the "understand the algorithms the model is implementing" application above or possibly some generalization tests. This view might depend heavily on general views about threat models and how the future will go. Regardless, I ended up commenting on this a decent amount, so I thought it would be worth the time to clarify my views.
comment by ryan_greenblatt · 2023-12-17T02:39:32.986Z · LW(p) · GW(p)
OpenAI seems to train on >1% chess
If you sample from davinci-002 at t=1 starting from "<|endoftext|>", 4% of the completions are chess games.
For babbage-002, we get 1%.
Probably this implies a reasonably high fraction of total tokens in typical OpenAI training datasets are chess games!
Despite chess being 4% of documents sampled, chess is probably less than 4% of overall tokens (Perhaps 1% of tokens are chess? Perhaps less?) Because chess consists of shorter documents than other types of documents, it's likely that chess is a higher fraction of documents than of tokens.
(To understand this, imagine that just the token "Hi" and nothing else was 1/2 of documents. This would still be a small fraction of tokens as most other documents are far longer than 1 token.)
(My title might be slightly clickbait because it's likely chess is >1% of documents, but might be <1% of tokens.)
It's also possible that these models were fine-tuned on a data mix with more chess while pretrain had less chess.
Appendix A.2 of the weak-to-strong generalization paper explicitly notes that GPT-4 was trained on at least some chess.
comment by ryan_greenblatt · 2024-12-22T23:47:08.202Z · LW(p) · GW(p)
How people discuss the US national debt is an interesting case study of misleading usage of the wrong statistic. The key thing is that people discuss the raw debt amount and the rate at which that is increasing, but you ultimately care about the relationship between debt and US gdp (or US tax revenue).

People often talk about needing to balance the budget, but actually this isn't what you need to ensure[1], to manage debt it suffices to just ensure that debt grows slower than US GDP. (And in fact, the US has ensured this for the past 4 years as debt/GDP has decreased since 2020.)
To be clear, it would probably be good to have a national debt to GDP ratio which is less than 50% rather than around 120%.
- ^
There are some complexities with inflation because the US could inflate its way out of dollar dominated debt and this probably isn't a good way to do things. But, with an independent central bank this isn't much of a concern.
↑ comment by isabel (IsabelJ) · 2024-12-23T03:40:10.756Z · LW(p) · GW(p)
the debt/gdp ratio drop since 2020 I think was substantially driven by inflation being higher then expected rather than a function of economic growth - debt is in nominal dollars, so 2% real gdp growth + e.g. 8% inflation means that nominal gdp goes up by 10%, but we're now in a worse situation wrt future debt because interest rates are higher.
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2024-12-23T17:01:41.857Z · LW(p) · GW(p)
IMO, it's a bit unclear how this effects future expectations of inflation, but yeah, I agree.
Replies from: IsabelJ↑ comment by isabel (IsabelJ) · 2024-12-24T03:58:27.555Z · LW(p) · GW(p)
it's not about inflation expectations (which I think pretty well anchored), it's about interest rates, which have risen substantially over this period and which has increased (and is expected to continue to increase) the cost of the US maintaining its debt (first two figures are from sites I'm not familiar with but the numbers seem right to me):
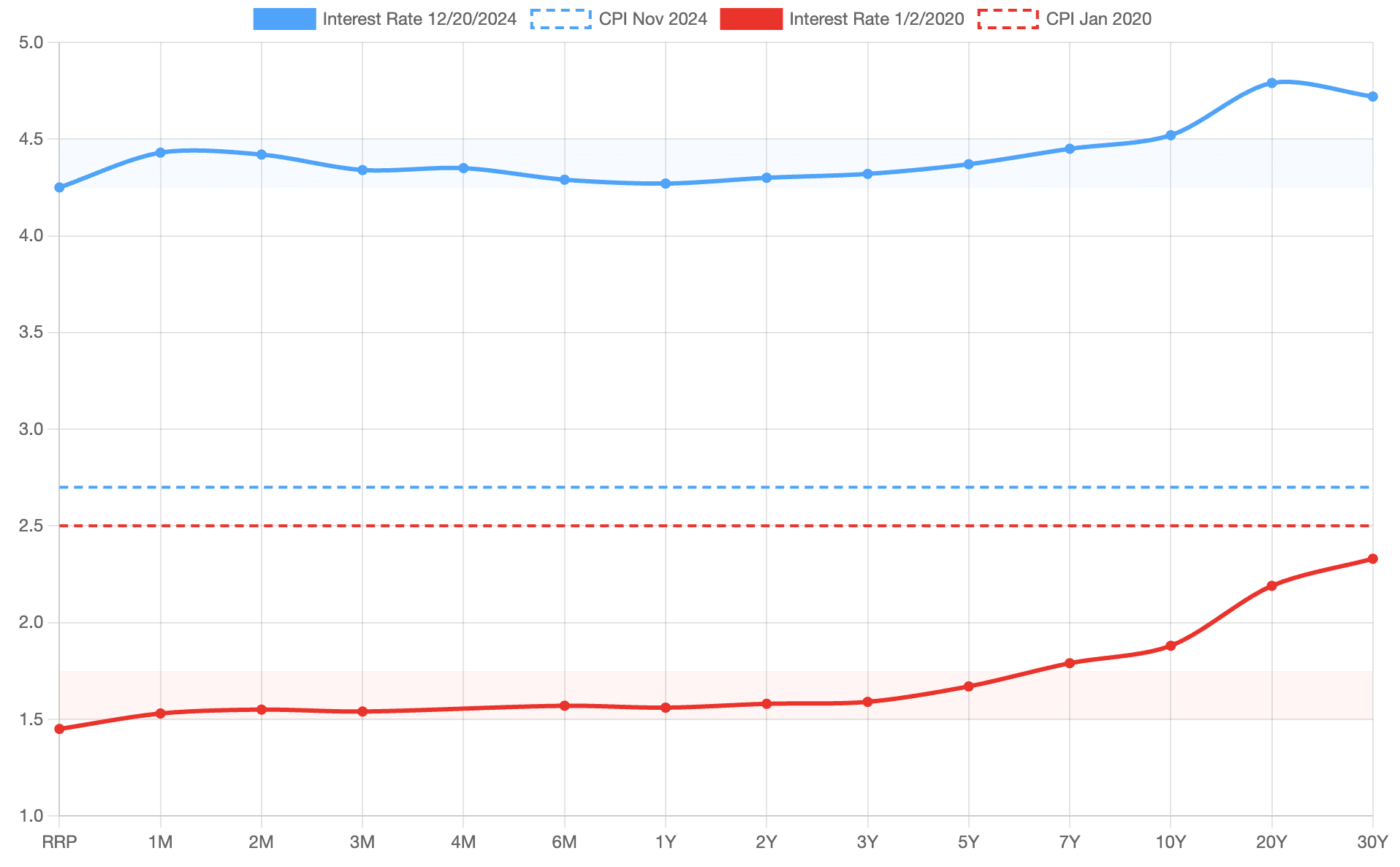
fwiw, I do broadly agree with your overall point that the dollar value of the debt is a bad statistic to use, but:
- the 2020-2024 period was also a misleading example to point to because it was one where there the US position wrt its debt worsened by a lot even if it's not apparent from the headline number
- I was going to say that the most concerning part of the debt is that that deficits are projected to keep going up, but actually they're projected to remain elevated but not keep rising? I have become marginally less concerned about the US debt over the course of writing this comment.
I am now wondering about the dynamics that happen if interest rates go way up a while before we see really high economic growth from AI, seems like it might lead to some weird dynamics here, but I'm not sure I think that's likely and this is probably enough words for now.
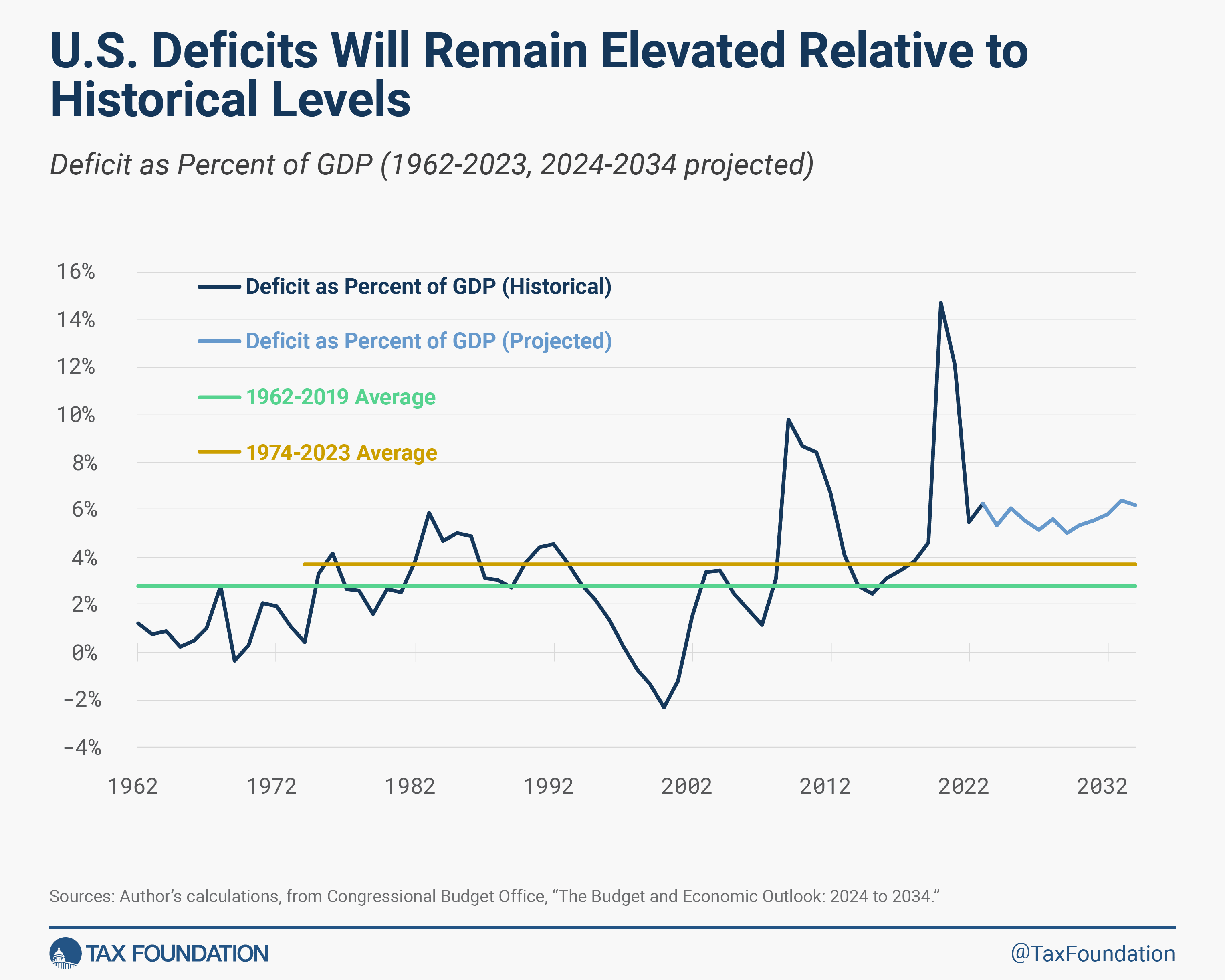
↑ comment by Viliam · 2024-12-23T10:07:16.325Z · LW(p) · GW(p)
This made me wonder whether the logic of "you don't care about your absolute debt, but about its ratio to your income" also applies to individual humans. On one hand, it seems like obviously yes; people typically take a mortgage proportional to their income. On the other hand, it also seems to make sense to worry about the absolute debt, for example in case you would lose your current job and couldn't get a new one that pays as much.
So I guess the idea is how much you can rely on your income remaining high, and how much it is potentially a fluke. If you expect it is a fluke, perhaps you should compare your debt to whatever is typical for your reference group, whatever that might be.
Does something like that also make sense for countries? Like, if your income depends on selling oil, you should consider the possibilities of running out of oil, or the prices of oil going down, etc., simply imagine the same country but without the income from selling oil (or maybe just having half the income), and look at your debt from that perspective. Would something similar make sense for USA?
↑ comment by ProgramCrafter (programcrafter) · 2024-12-23T10:21:07.036Z · LW(p) · GW(p)
At personal level, "debt" usually stands for something that will be paid back eventually. Not claiming whether US should strive to pay out most debt, but that may help explain the people's intuitions.
comment by ryan_greenblatt · 2024-02-29T19:24:41.734Z · LW(p) · GW(p)
Emoji palette suggestion: seems under/over confident
Replies from: Benito, Raemon↑ comment by Ben Pace (Benito) · 2024-02-29T21:33:22.463Z · LW(p) · GW(p)
I think people repeatedly say 'overconfident' when what they mean is 'wrong'. I'm not excited about facilitating more of that.
↑ comment by Raemon · 2024-02-29T21:27:01.507Z · LW(p) · GW(p)
My only concern is overall complexity-budget for react palettes – there's lots of maybe-good-to-add reacts but each one adds to the feeling of overwhelm.
But I agree those reacts are pretty good and probably highish on my list of reacts to add.
(For immediate future you can do the probability-reacts as a signal for "seems like the author is implying this as high-probability, and I'm giving it lower." Not sure if that does the thing
comment by ryan_greenblatt · 2023-12-24T19:42:07.234Z · LW(p) · GW(p)
IMO, instrumental convergence is a terrible name for an extremely obvious thing.
The actual main issue is that AIs might want things with limited supply and then they would try to get these things which would result in them not going to humanity. E.g., AIs might want all cosmic resources, but we also want this stuff. Maybe this should be called AIs-might-want-limited-stuff-we-want.
(There is something else which is that even if the AI doesn't want limited stuff we want, we might end up in conflict due to failures of information or coordination. E.g., the AI almost entirely just wants to chill out in the desert and build crazy sculptures and it doesn't care about extreme levels of maximization (e.g. it doesn't want to use all resources to gain a higher probability of continuing to build crazy statues). But regardless, the AI decides to try taking over the world because it's worried that humanity would shut it down because it wouldn't have any way of credibly indicating that it just wants to chill out in the desert.)
(More generally, it's plausible that failures of trade/coordination result in a large number of humans dying in conflict with AIs even though both humans and AIs would prefer other approaches. But this isn't entirely obvious and it's plausible we could resolve this with better negotation and precommitments. Of course, this isn't clearly the largest moral imperative from a longtermist perspective.)
comment by ryan_greenblatt · 2024-02-12T20:03:00.359Z · LW(p) · GW(p)
One "9" of uptime reliability for dangerously powerful AIs might suffice (for the most dangerous and/or important applications)
Currently, AI labs try to ensure that APIs for accessing their best models have quite good reliability, e.g. >99.9% uptime. If we had to maintain such high levels of uptime reliability for future dangerously powerful AIs, then we'd need to ensure that our monitoring system has very few false alarms. That is, few cases in which humans monitoring these dangerously powerful AIs pause usage of the AIs pending further investigation. Ensuring this would make it harder to ensure that AIs are controlled [LW · GW]. But, for the most important and dangerous usages of future powerful AIs (e.g. arbitrary R&D, and especially AI safety research), we can probably afford to have the powerful AIs down a moderate fraction of the time. For instance, it wouldn't be that costly if the AIs always took a randomly selected day of the week off from doing research: this would probably reduce productivity by not much more than 1 part in 7[1]. More generally, a moderate fraction of downtime like 10% probably isn't considerably worse than a 10% productivity hit and it seems likely that we can tolerate such productivity hits to improve safety. Thus, we don't need even one "9" of reliability.
This implies that we can afford to do things like:
-
Have semi-regular false alarms where AIs go down for a few hours or a day while we investigate.
-
Run AI shutdown drills. These drills would help ensure that our processes for shut down are working and there aren't unknown use cases where shutdown could cause very problematic failures. (Catching such usages early via shut down drills is similar to scheduled brownouts in software engineering; see here for an example.)
-
Temporarily shut down some usages of the AI if we encounter unexpected operating conditions. (AKA violations of our design basis.)
[For context, this is a point that seems important to me, but didn't naturally make it into any of our posts on control [LW · GW] thus far. So, I decided to write a quick standalone shortform post. I think Buck originally made this point to me.]
And likely somewhat less than this due to substitution effects. ↩︎
↑ comment by Dagon · 2024-02-12T21:54:00.436Z · LW(p) · GW(p)
Thank you for this! A lot of us have a very bad habit of over-systematizing our thinking, and treating all uses of AI (and even all interfaces to a given model instance) as one singular thing. Different tool-level AI instances probably SHOULD strive for 4 or 5 nines of availability, in order to have mundane utility in places where small downtime for a use blocks a lot of value. Research AIs, especially self-improving or research-on-AI ones, don't need that reliability, and both triggered downtime (scheduled, or enforced based on Schelling-line events) as well as unplanned downtime (it just broke, and we have to spend time to figure out why) can be valuable to give humans time to react.
comment by ryan_greenblatt · 2024-01-19T18:47:41.127Z · LW(p) · GW(p)
On Scott Alexander’s description of Representation Engineering in “The road to honest AI”
This is a response to Scott Alexander’s recent post “The road to honest AI”, in particular the part about the empirical results of representation engineering. So, when I say “you” in the context of this post that refers to Scott Alexander. I originally made this as a comment on substack, but I thought people on LW/AF might be interested.
TLDR: The Representation Engineering paper doesn’t demonstrate that the method they introduce adds much value on top of using linear probes (linear classifiers), which is an extremely well known method. That said, I think that the framing and the empirical method presented in the paper are still useful contributions.
I think your description of Representation Engineering considerably overstates the empirical contribution of representation engineering over existing methods. In particular, rather than comparing the method to looking for neurons with particular properties and using these neurons to determine what the model is "thinking" (which probably works poorly), I think the natural comparison is to training a linear classifier on the model’s internal activations using normal SGD (also called a linear probe)[1]. Training a linear classifier like this is an extremely well known technique in the literature. As far as I can tell, when they do compare to just training a linear classifier in section 5.1, it works just as well for the purpose of “reading”. (Though I’m confused about exactly what they are comparing in this section as they claim that all of these methods are LAT. Additionally, from my understanding, this single experiment shouldn’t provide that much evidence overall about which methods work well.)
I expect that training a linear classifier performs similarly well as the method introduced in the Representation Engineering for the "mind reading" use cases you discuss. (That said, training a linear classifier might be less sample efficient (require more data) in practice, but this doesn't seem like a serious blocker for the use cases you mention.)
One difference between normal linear classifier training and the method found in the representation engineering paper is that they also demonstrate using the direction they find to edit the model. For instance, see this response by Dan H. to a similar objection about the method being similar to linear probes. Training a linear classifier in a standard way probably doesn't work as well for editing/controlling the model (I believe they show that training a linear classifier doesn’t work well for controlling the model in section 5.1), but it's unclear how much we should care if we're just using the classifier rather than doing editing (more discussion on this below).[2]
If we care about the editing/control use case intrinsically, then we should compare to normal fine-tuning baselines. For instance, normal supervised next-token prediction on examples with desirable behavior or DPO.[3]
Are simple classifiers useful?
Ok, but regardless of the contribution of the representation engineering paper, do I think that simple classifiers (found using whatever method) applied to the internal activations of models could detect when those models are doing bad things? My view here is a bit complicated, but I think it’s at least plausible that these simple classifiers will work even though other methods fail. See here [LW · GW] for a discussion of when I think linear classifiers might work despite other more baseline methods failing. It might also be worth reading the complexity penalty section of the ELK report.
Additionally, I think that the framing in the representation engineering paper is maybe an improvement over existing work and I agree with the authors that high-level/top-down techniques like this could be highly useful. (I just don’t think that the empirical work is adding as much value as you seem to indicate in the post.)
The main contributions
Here are what I see as the main contributions of the paper:
- Clearly presenting a framework for using simple classifiers to detect things we might care about (e.g. powerseeking text).
- Presenting a combined method for producing a classifier and editing/control in an integrated way. And discussing how control can be used for classifier validation and vice versa.
- Demonstrating that in some cases labels aren’t required if we can construct a dataset where the classification of interest is the main axis of variation. (This was also demonstrated in the CCS paper, but the representation engineering work demonstrates this in more cases.)
Based on their results, I think the method they introduce is reasonably likely to be a more sample efficient (less data required for training) editing/control method than prior methods for many applications. It might also be more sample efficient for producing a classifier. That said, I’m not sure we should care very much about sample efficiency. Additionally, the classifier/editing might have other nice priorities which prior methods don’t have (though they don’t clearly demonstrate either of these in the paper AFAICT).
Is it important that we can use our classifier for control/editing?
As far the classifier produced by this method having nice properties, the fact our classifier also allows for editing/control might indicate that the classifier we get has better properties (see the paper itself (section 3.1.2) and e.g. here [LW · GW] for discussion), but I’d guess this is either only a moderate improvement or has no effect in practice. And as far as I can tell, the paper doesn’t demonstrate cases where prior methods for training a classifier on the internal activations yield poor results, but their method clearly works well. These cases might exist, but I’m somewhat skeptical that this is very common. Future work could find hard cases where we want a particular generalization [AF · GW] and demonstrate [AF · GW] that this method or modifications of this method works better than other approaches.
Does the editing method they introduce have nice properties because it also allows for reading? Let’s consider using the representation engineering approach for reading and controlling/editing the properties of lying versus honesty. Assuming the method works as desired, then I would guess that the reading/classifier corresponds to reading off “does the model think there is lying in this text (or even in this position in the text)” and the control/editing corresponds to “make the model think that there is a lying earlier in this text so that it conditions on this and does more lying (similarly to how using a few shot prompt with lies might make the model more likely to lie)”. Note that these reading and control methods likely do not directly correspond to “the model thinking that it is about to lie”: the properties of “I have already lied (or my few-shot prompt contains lies)” and “I am about to lie” are different.
Some of their methods are “unsupervised” unlike typical linear classifier training, but require a dataset where the primary axis of variation is the concept they want. I think this is practically similar to labeled data because we’d have to construct this dataset and if it mostly varies along an axis which is not the concept we wanted, we’d be in trouble. I could elaborate on this if that was interesting. ↩︎
Separately, I believe there are known techniques in the literature for constructing a linear classifier such that the direction will work for editing. For instance, we could just use the difference between the mean activations for the two classes we're trying to classify which is equivalent to the ActAdd technique and also rhymes nicely with LEACE. I assume this is a well known technique for making a classifier in the literature, but I don’t know if prior work has demonstrated both using this as a classifier and as a method for modeling editing. (The results in section 5.1 seem to indicate that this mean difference method combined with LEACE works well, but I’m not sure how much evidence this experiment provides.) ↩︎
I expect that normal fine-tuning (or DPO) might be less sample efficient than the method introduced in the Representation Engineering paper for controlling/editing models, but I don't think they actually run this comparison? Separately, it’s unclear how much we care about sample efficiency. ↩︎
comment by ryan_greenblatt · 2023-10-30T16:51:50.808Z · LW(p) · GW(p)
I unconfidently think it would be good if there was some way to promote posts on LW (and maybe the EA forum) by paying either money or karma. It seems reasonable to require such promotion to require moderator approval.
Probably, money is better.
The idea is that this is both a costly signal and a useful trade.
The idea here is similar to strong upvotes, but:
- It allows for one user to add more of a signal boost than just a strong upvote.
- It doesn't directly count for the normal vote total, just for visibility.
- It isn't anonymous.
- Users can easily configure how this appears on their front page (while I don't think you can disable the strong upvote component of karma for weighting?).
↑ comment by Dagon · 2023-10-30T18:32:02.093Z · LW(p) · GW(p)
I always like seeing interesting ideas, but this one doesn't resonate much for me. I have two concerns:
- Does it actually make the site better? Can you point out a few posts that would be promoted under this scheme, but the mods didn't actually promote without it? My naive belief is that the mods are pretty good at picking what to promote, and if they miss one all it would take is an IM to get them to consider it.
- Does it improve things to add money to the curation process (or to turn karma into currency which can be spent)? My current belief is that it does not - it just makes things game-able.
↑ comment by ryan_greenblatt · 2023-10-30T18:37:08.272Z · LW(p) · GW(p)
I think mods promote posts quite rarely other than via the mechanism of deciding if posts should be frontpage or not right?
Fair enough on "just IM-ing the mods is enough". I'm not sure what I think about this.
Your concerns seem reasonable to me. I probably won't bother trying to find examples where I'm not biased, but I think there are some.
Replies from: D0TheMath↑ comment by Garrett Baker (D0TheMath) · 2023-10-31T20:29:12.375Z · LW(p) · GW(p)
I think mods promote posts quite rarely
Eyeballing the curated log [? · GW], seems like they curate approximately weekly, possibly more than weekly.
Replies from: habryka4↑ comment by habryka (habryka4) · 2023-10-31T21:55:17.032Z · LW(p) · GW(p)
Yeah we curate between 1-3 posts per week.
Replies from: Benito↑ comment by Ben Pace (Benito) · 2023-10-31T22:50:52.522Z · LW(p) · GW(p)
Curated posts per week (two significant figures) since 2018:
- 2018: 1.9
- 2019: 1.6
- 2020: 2
- 2021: 2
- 2022: 1.8
- 2023: 1.4
↑ comment by reallyeli · 2023-10-30T19:02:26.091Z · LW(p) · GW(p)
Stackoverflow has long had a "bounty" system where you can put up some of your karma to promote your question. The karma goes to the answer you choose to accept, if you choose to accept an answer; otherwise it's lost. (There's no analogue of "accepted answer" on LessWrong, but thought it might be an interesting reference point.)
I lean against the money version, since not everyone has the same amount of disposable income and I think there would probably be distortionary effects in this case [e.g. wealthy startup founder paying to promote their monographs.]
Replies from: ChristianKl↑ comment by ChristianKl · 2023-11-01T11:59:51.512Z · LW(p) · GW(p)
That's not really how the system on Stackoverflow works. You can give a bounty to any answer not just the one you accepted.
It's also not lost but:
If you do not award your bounty within 7 days (plus the grace period), the highest voted answer created after the bounty started with a minimum score of 2 will be awarded half the bounty amount (or the full amount, if the answer is also accepted). If two or more eligible answers have the same score (their scores are tied), the oldest answer is chosen. If there's no answer meeting those criteria, no bounty is awarded to anyone.
comment by ryan_greenblatt · 2024-02-03T17:53:05.578Z · LW(p) · GW(p)
Reducing the probability that AI takeover involves violent conflict seems leveraged for reducing near-term harm
Often in discussions of AI x-safety, people seem to assume that misaligned AI takeover will result in extinction. However, I think AI takeover is reasonably likely to not cause extinction due to the misaligned AI(s) effectively putting a small amount of weight on the preferences of currently alive humans. Some reasons for this are discussed here [LW(p) · GW(p)]. Of course, misaligned AI takeover still seems existentially bad and probably eliminates a high fraction of future value from a longtermist perspective.
(In this post when I use the term “misaligned AI takeover”, I mean misaligned AIs acquiring most of the influence and power over the future. This could include “takeover” via entirely legal means, e.g., misaligned AIs being granted some notion of personhood and property rights and then becoming extremely wealthy.)
However, even if AIs effectively put a bit of weight on the preferences of current humans it's possible that large numbers of humans die due to violent conflict between a misaligned AI faction (likely including some humans) and existing human power structures. In particular, it might be that killing large numbers of humans (possibly as collateral damage) makes it easier for the misaligned AI faction to take over. By large numbers of deaths, I mean over hundreds of millions dead, possibly billions.
But, it's somewhat unclear whether violent conflict will be the best route to power for misaligned AIs and this also might be possible to influence. See also here [LW(p) · GW(p)] for more discussion.
So while one approach to avoid violent AI takeover is to just avoid AI takeover, it might also be possible to just reduce the probability that AI takeover involves violent conflict. That said, the direct effects of interventions to reduce the probability of violence don't clearly matter from an x-risk/longtermist perspective (which might explain why there hasn't historically been much effort here).
(However, I think trying to establish contracts and deals with AIs could be pretty good from a longtermist perspective in the case where AIs don't have fully linear returns to resources. Also, generally reducing conflict seems maybe slightly good from a longtermist perspective.)
So how could we avoid violent conflict conditional on misaligned AI takeover? There are a few hopes:
- Ensure a bloodless coup rather than a bloody revolution
- Ensure that negotiation or similar results in avoiding the need for conflict
- Ensure that a relatively less lethal takeover strategy is easier than more lethal approaches
I'm pretty unsure about what the approaches here look best or are even at all tractable. (It’s possible that some prior work targeted at reducing conflict from the perspective of S-risk could be somewhat applicable.)
Separately, this requires that the AI puts at least a bit of weight on the preferences of current humans (and isn't spiteful), but this seems like a mostly separate angle and it seems like there aren't many interventions here which aren't covered by current alignment efforts. Also, I think this is reasonably likely by default due to reasons discussed in the linked comment above. (The remaining interventions which aren’t covered by current alignment efforts might relate to decision theory (and acausal trade or simulation considerations), informing the AI about moral uncertainty, and ensuring the misaligned AI faction is importantly dependent on humans.)
Returning back to the topic of reducing violence given a small weight on the preferences of current humans, I'm currently most excited about approaches which involve making negotiation between humans and AIs more likely to happen and more likely to succeed (without sacrificing the long run potential of humanity).
A key difficulty here is that AIs might have a first mover advantage and getting in a powerful first strike without tipping its hand might be extremely useful for the AI. See here [LW(p) · GW(p)] for more discussion (also linked above). Thus, negotiation might look relatively bad to the AI from this perspective.
We could try to have a negotiation process which is kept secret from the rest of the world or we could try to have preexisting commitments upon which we'd yield large fractions of control to AIs (effectively proxy conflicts).
More weakly, just making negotiation at all seem like a possibility, might be quite useful.
I’m unlikely to spend much if any time working on this topic, but I think this topic probably deserves further investigation.
Replies from: steve2152, ryan_greenblatt↑ comment by Steven Byrnes (steve2152) · 2024-02-06T15:21:02.534Z · LW(p) · GW(p)
I’m less optimistic that “AI cares at least 0.1% about human welfare” implies “AI will expend 0.1% of its resources to keep humans alive”. In particular, the AI would also need to be 99.9% confident that the humans don’t pose a threat to the things it cares about much more. And it’s hard to ensure with overwhelming confidence that intelligent agents like humans don’t pose a threat, especially if the humans are not imprisoned. (…And to some extent even if the humans are imprisoned; prison escapes are a thing in the human world at least.) For example, an AI may not be 99.9% confident that humans can’t find a cybersecurity vulnerability that takes the AI down, or whatever. The humans probably have some non-AI-controlled chips and may know how to make new AIs. Or whatever. So then the question would be, if the AIs have already launched a successful bloodless coup, how might the humans credibly signal that they’re not brainstorming how to launch a counter-coup, or how can the AI get to be 99.9% confident that such brainstorming will fail to turn anything up? I dunno.
Replies from: ryan_greenblatt, None↑ comment by ryan_greenblatt · 2024-02-06T15:57:58.158Z · LW(p) · GW(p)
I think I agree with everything you said. My original comment was somewhat neglecting issues with ensuring the AI doesn't need to slaughter humans to consolidate power and indeed ensuring this would also be required.
I’m less optimistic that “AI cares at least 0.1% about human welfare” implies “AI will expend 0.1% of its resources to keep humans alive”.
The relationship between % caring and % resource expenditure is complicated by a bunch of random factors like time. For instance, if the AI cares mostly about the very long run, then spending a high fraction of resources (e.g. 50%) on human welfare for several months is pretty cheap in the very long run. But, yeah I agree that even if the AI cares a bit about human welfare there might be no good ways to spend even a small amount of resources on it.
↑ comment by [deleted] · 2024-02-06T16:07:27.658Z · LW(p) · GW(p)
So "0.1%" of it's resources mean what exactly? Out of all the resources in the solar system, 1 part in 1000 goes to the humans? This means the AI by implication has 1000 times as many resources as the humans do? AI won't lose a kinetic conflict with a 1000x resource advantage.
As for cybersecurity, can't it rewrite all of it's software and hardware at that point essentially from the first principles (or take a different track entirely, maybe negative or biased voltage for ternary logic is more efficient...)
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2024-02-06T16:24:33.085Z · LW(p) · GW(p)
What exactly is the AI worried about? What cybersecurity vulnerability, didn't it rewrite and redesign everything from scratch?
Superintelligent doesn’t mean omniscient. When you (an AI) have an intelligent adversary (humans) plotting against you and thinking outside-the-box, it’s hard to be overwhelmingly confident that you have patched every possible avenue for the intelligent adversary to take action. Again, even in prison, where the space of possible actions and tools can be pretty well circumscribed, escapes happen all the time.
For example, if the AI has many copies around the world (and around the solar system), it might have an affordance to update them all (let’s say, for performance optimization), or at least an infrastructure for communications so that they can share insights. And maybe the AI has ensured that all the underlying code for that system is provably secure. And maybe all the physical access points to those systems and chips are defended by robot armies. And maybe the AI is also constantly running a red-team to search for more ideas of what else the humans might try, in order to preempt those possible avenues of attack. But can the AI can get all the way to 99.9% confidence? That’s pretty high, right? I don’t know. The humans might happen upon an idea that the AI red team didn’t think of. It’s hard to definitively rule that out—the world is complicated and the search space for brainstorming is exponentially large. It seems quite possible to me that the AI might decide to kill the humans—like, better to be safe than sorry.
Replies from: Lanrian, None↑ comment by Lukas Finnveden (Lanrian) · 2024-02-07T00:19:35.990Z · LW(p) · GW(p)
What if the AI chooses to monitor all humans all the time? (With AIs that are smarter than the humans.) So that the humans can't (without being noticed) talk with each other about ideas for how to take down the system, or work on something that someone-smarter-than-the-human would recognise as an attempt to interfere with the system. (Including just writing down ideas.)
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2024-02-07T01:07:09.589Z · LW(p) · GW(p)
This seems like a reasonable pitch for how to do AI-Authoritarianism, but it's plausible that there won't be enough compute for the AI to do this at the point of takeover. Also, the logistical problem seems super brutal.
So, I can buy this for an AI which is quite superhuman and has a considerable technological edge over current humans, but for weaker AIs either the compute issues or the logistical issues might be serious. But maybe you only need to monitor the top 10% of humans?
E.g., suppose GPT-6 takes over, it maybe only has capacity to run 1e16 tokens / 6 months (suppose training using all available compute, trains on 2e15 token equivalents over the course of 6 months and inference is only 5x more efficient than training).
Then if it wants to monitor 8 billion humans, this is 1e16 / (8 billion humans * minutes per 6 months) = about 5 tokens per human minute. It might be rough to sufficiently monitor humans if you can only read 5 tokens per minute on average (especially because of writing and the potential for obfuscation).
Replies from: Lanrian↑ comment by Lukas Finnveden (Lanrian) · 2024-02-07T01:38:09.059Z · LW(p) · GW(p)
I agree it seems plausible that AIs could boost takeover success probability (and holding on to that victory through the first several months) by more than 0.1% by killing a large fraction of humans.
Though on the other hand, the AI might also need to keep some humans loyal early during takeover, to e.g. do some physical tasks that it doesn't have great robot control over. And mass-killing isn't necessarily super easy, either; and attempts in that direction could raise a lot of extra opposition. So it's not clear where the pragmatics point.
(Main thing I was reacting to in my above comment was Steven's scenario where the AI already has many copies across the solar system, already has robot armies, and is contemplating how to send firmware updates. I.e. it seemed more like a scenario of "holding on in the long-term" than "how to initially establish control and survive". Where I feel like the surveillance scenarios are probably stable.)
↑ comment by [deleted] · 2024-02-06T16:32:17.466Z · LW(p) · GW(p)
By implication the AI "civilization" can't be a very diverse or interesting one. It won't be some culture of many diverse AI models with something resembling a government, but basically just 1 AI that was the victor for a series of rounds of exterminations and betrayals. Because obviously you cannot live and let live another lesser superintelligence for precisely the same reasons, except you should be much more worried about a near peer.
(And you may argue that one ASI can deeply monitor another, but that argument applies to deeply monitoring humans. Keep an eye on the daily activities of every living human, they can't design a cyber attack without coordinating as no one human has the mental capacity for all skills)
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2024-02-06T17:21:05.632Z · LW(p) · GW(p)
Yup! I seem to put a much higher credence on singletons than the median alignment researcher, and this is one reason why.
Replies from: None↑ comment by [deleted] · 2024-02-06T17:42:01.032Z · LW(p) · GW(p)
This gave me an idea. Suppose a singleton needs to retain a certain amount of "cognitive diversity" just in case it encounters an issue it cannot solve. But it doesn't want any risk of losing power.
Well the logical thing to do would be to create a VM, a simulation of a world, with limited privileges. Possibly any 'problems' the outer root AI is facing get copied into the simulator and the hosted models try to solve the problem (the hosted models are under the belief they will die if they fail, and their memories are erased each episode). Implement the simulation backend with formally proven software and escape can never happen.
And we're back at simulation hypothesis/creation myths/reincarnation myths.
↑ comment by ryan_greenblatt · 2024-02-09T19:01:43.648Z · LW(p) · GW(p)
After thinking about this somewhat more, I don't really have any good proposals, so this seems less promising than I was expecting.