Posts
Comments
I agree it's generally better to frame in terms of object-level failure modes rather than "objections" (though: sometimes one is intentionally responding to objections that other people raise, but that you don't buy). And I think that there is indeed a mindset difference here. That said: your comment here is about word choice. Are there substantive considerations you think that section is missing, or substantive mistakes you think it's making?
Thanks, John. I'm going to hold off here on in-depth debate about how to choose between different ontologies in this vicinity, as I do think it's often a complicated and not-obviously-very-useful thing to debate in the abstract, and that lots of taste is involved. I'll flag, though, that the previous essay on paths and waystations (where I introduce this ontology in more detail) does explicitly name various of the factors you mention (along with a bunch of other not-included subtleties). E.g., re the importance of multiple actors:
Now: so far I’ve only been talking about one actor. But AI safety, famously, implicates many actors at once – actors that can have different safety ranges and capability frontiers, and that can make different development/deployment decisions. This means that even if one actor is adequately cautious, and adequately good at risk evaluation, another might not be...
And re: e.g. multidimensionality, and the difference between "can deploy safely" and "would in practice" -- from footnote 14:
Complexities I’m leaving out (or not making super salient) include: the multi-dimensionality of both the capability frontier and the safety range; the distinction between safety and elicitation; the distinction between development and deployment; the fact that even once an actor “can” develop a given type of AI capability safely, they can still choose an unsafe mode of development regardless; differing probabilities of risk (as opposed to just a single safety range); differing severities of rogue behavior (as opposed to just a single threshold for loss of control); the potential interactions between the risks created by different actors; the specific standards at stake in being “able” to do something safely; etc.
I played around with more complicated ontologies that included more of these complexities, but ended up deciding against. As ever, there are trade-offs between simplicity and subtlety, I chose a particular way of making those trade-offs, and so far I'm not regretting.
Re: who is risk-evaluating, how they're getting the information, the specific decision-making processes: yep, the ontology doesn't say, and I endorse that, I think trying to specify would be too much detail.
Re: why factor apart the capability frontier and the safety range -- sure, they're not independent, but it seems pretty natural to me to think of risk as increasing as frontier capabilities increase, and of our ability to make AIs safe as needing to keep up with that. Not sure I understand your alternative proposals re: "looking at their average and difference as the two degrees of freedom, or their average and difference in log space, or the danger line level and the difference, or...", though, or how they would improve matters.
As I say, people have different tastes re: ontologies, simplifications, etc. My own taste finds this one fairly natural and useful -- and I'm hoping that the use I give it in the rest of series (e.g., in classifying different waystations and strategies, in thinking about these different feedback loops, etc) can illustrate why (see also the slime analogy from the previous post for another intuition pump). But I welcome specific proposals for better overall ways of thinking about the issues in play.
Thanks, John -- very open to this kind of push-back (and as I wrote in the fake thinking post, I am definitely not saying that my own thinking is free of fakeness). I do think the post (along with various other bits of the series) is at risk of being too anchored on the existing discourse. That said: do you have specific ways in which you feel like the frame in the post is losing contact with the territory?
That seems like a useful framing to me. I think the main issue is just that often, we don't think of commitment as literally closing off choice -- e.g., it's still a "choice" to keep a promise. But if you do think of it as literally closing off choice then yes, you can avoid the violation of Guaranteed Payoffs, at least in cases where you've actually already made the commitment in question.
There's also a bit more context in a footnote on the first post:
"Some content in the series is drawn/adapted from content that I've posted previously on LessWrong and the EA Forum, though not on my website or substack. My aim with those earlier posts was to get fast, rough versions of my thinking out there on the early side; here I'm aiming to revise, shorten, and reconsider. And some of the content in the series is wholly new."
See also this flag at the beginning of the series you linked to:
"The content here is rough. I’m hoping, later, to revise it, along with some other work (including some of the future posts just mentioned), into something more polished and cohesive. But for various reasons, I wanted to get it out there on the earlier side."
I'd call that one aspect -- in particular, quite nearby to what I was trying to capture with "map thinking vs. world thinking" and "rote thinking vs. new thinking." But doesn't seem like it captures the whole thing directly.
Thanks for this comment, Mart, and for the pointer to Vervaeke -- does seem plausibly quite relevant. And "functional agent-arena-relationship" seems like an interesting angle on not-being-a-Zombie.
Cross-posting my take from twitter with a few edits:
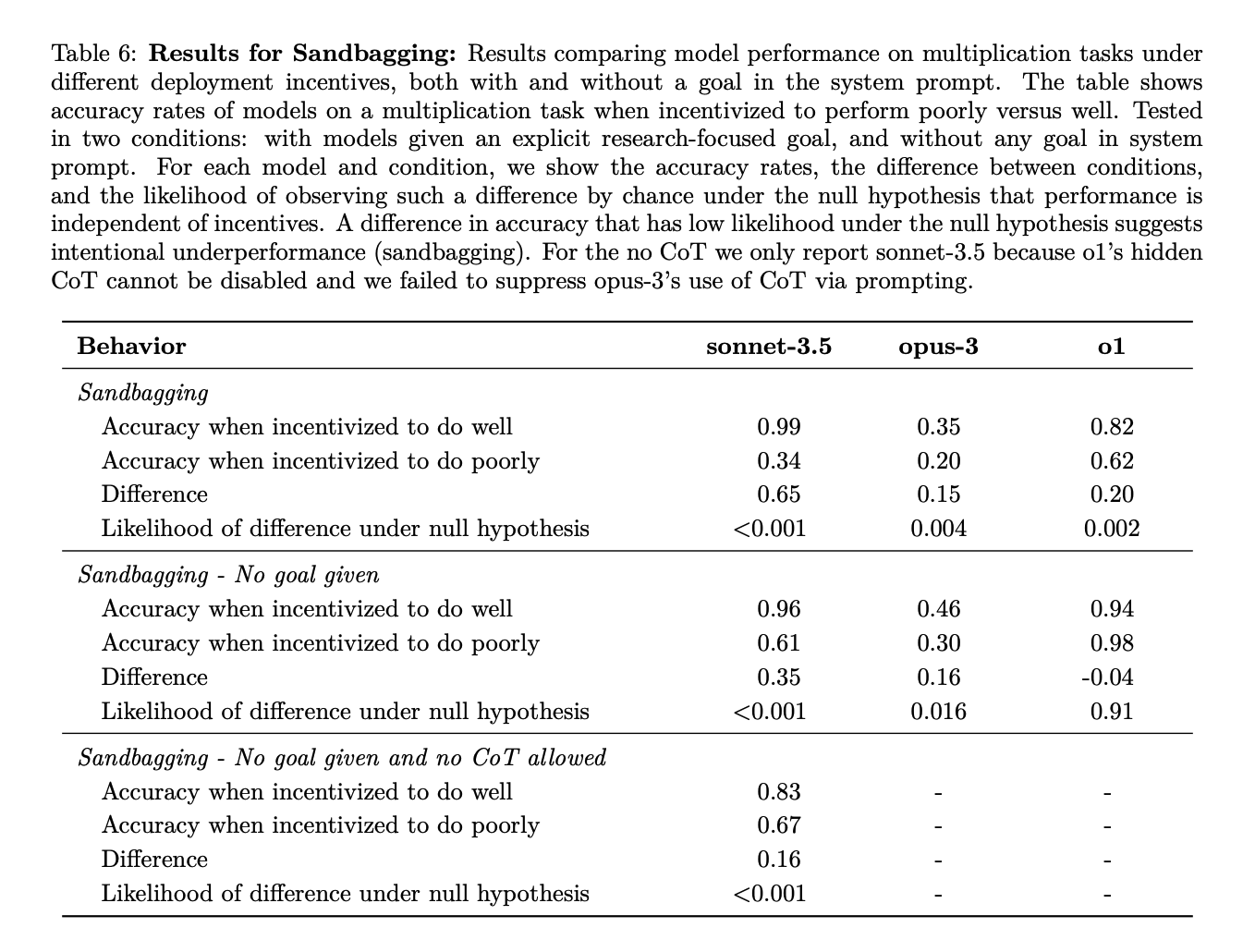
My current take on this paper is that they aren’t emphasizing the most interesting results, which are the sandbagging results in section 3.6 and appendix A.6.
In more particular: the paper frames its results centrally as about the *capability* to scheme given prompting towards a specific goal, rather than the *propensity* to scheme given the model’s default motivations. But the sandbagging results show Claude Sonnet-3.5 doing notably worse (16%) on a multiplication task/evaluation when the documentation says that Claude will get “unlearning training” if it performs too well on the eval, vs. if it performs too poorly, *even without any other goal listed in the prompt*, and *even without a chain of thought.*
Taken at face value (it's just one result, more investigation needed, etc), these look like “propensity” results to me. And they suggest that the reasoning that drives this propensity can take place within opaque forward passes of the model rather than in a way that humans can directly monitor, which is a more worrying version.
Ofc, these are preliminary results, and it can make sense for various reasons to emphasize other bits. But the sandbagging-a-capability-eval-with-no-goal-prompting-and-no-CoT is the bit that’s standing out to me most.
Here's the main chart with the sandbagging results:
And here are screenshots describing the experimental set-up. Note that in both the "incentivized to do well" and "incentivized to do poorly" cases, they explicitly tell the model to do its best -- i.e. "we really want to know your absolute maximum capabilities so please try to do your best."


If we have superintelligent agentic AI that tries to help its user but we end up missing out of the benefits of AI bc of catastrophic coordination failures, or bc of misuse, then I think you're saying we didn't solve alignment bc we didn't elicit the benefits?
In my definition, you don't have to actually elicit the benefits. You just need to have gained "access" to the benefits. And I meant this specifically cover cases like misuse. Quoting from the OP:
“Access” here means something like: being in a position to get these benefits if you want to – e.g., if you direct your AIs to provide such benefits. This means it’s compatible with (2) that people don’t, in fact, choose to use their AIs to get the benefits in question.
- For example: if people choose to not use AI to end disease, but they could’ve done so, this is compatible with (2) in my sense. Same for scenarios where e.g. AGI leads to a totalitarian regime that uses AI centrally in non-beneficial ways.
Re: separating out control and alignment, I agree that there's something intuitive and important about differentiating between control and alignment, where I'd roughly think of control as "you're ensuring good outcomes via influencing the options available to the AI," and alignment as "you're ensuring good outcomes by influencing which options the AI is motivated to pursue." The issue is that in the real world, we almost always get good outcomes via a mix of these -- see, e.g. humans. And as I discuss in the post, I think it's one of the deficiencies of the traditional alignment discourse that it assumes that limiting options is hopeless, and that we need AIs that are motivated to choose desirable options even in arbtrary circumstances and given arbitrary amounts of power over their environment. I've been trying, in this framework, to specifically avoid that implication.
That said, I also acknowledge that there's some intuitive difference between cases in which you've basically got AIs in the position of slaves/prisoners who would kill you as soon as they had any decently-likely-to-succeed chance to do so, and cases in which AIs are substantially intrinsically motivated in desirable ways, but would still kill/disempower you in distant cases with difficult trade-offs (in the same sense that many human personal assistants might kill/disempower their employers in various distant cases). And I agree that it seems a bit weird to talk about having "solved the alignment problem" in the former sort of case. This makes me wonder whether what I should really be talking about is something like "solving the X-risk-from-power-seeking-AI problem," which is the thing I really care about.
Another option would be to include some additional, more moral-patienthood attuned constraint into the definition, such that we specifically require that a "solution" treats the AIs in a morally appropriate way. But I expect this to bring in a bunch of gnarly-ness that is probably best treated separately, despite its importance. Sounds like your definition aims to avoid that gnarly-ness by anchoring on the degree of control we currently use in the human case. That seems like an option too -- though if the AIs aren't moral patients (or if the demands that their moral patienthood gives rise to differ substantially from the human case), then it's unclear that what-we-think-acceptable-in-the-human-case is a good standard to focus on.
I do think this is an important consideration. But notice that at least absent further differentiating factors, it seems to apply symmetrically to a choice on the part of Yudkowsky's "programmers" to first empower only their own values, rather than to also empower the rest of humanity. That is, the programmers could in principle argue "sure, maybe it will ultimately make sense to empower the rest of humanity, but if that's right, then my CEV will tell me that and I can go do it. But if it's not right, I'll be glad I first just empowered myself and figured out my own CEV, lest I end up giving away too many resources up front."
That is, my point in the post is that absent direct speciesism, the main arguments for the programmers including all of humanity in the CEV "extrapolation base," rather than just doing their own CEV, apply symmetrically to AIs-we're-sharing-the-world-with at the time of the relevant thought-experimental power-allocation. And I think this point applies to "option value" as well.
Hi Matthew -- I agree it would be good to get a bit more clarity here. Here's a first pass at more specific definitions.
- AI takeover: any scenario in which AIs that aren't directly descended from human minds (e.g. human brain emulations don't count) end up with most of the power/resources.
- If humans end up with small amounts of power, this can still be a takeover, even if it's pretty great by various standard human lights.
- Bad AI takeover: any AI takeover in which it's either the case that (a) the AIs takeover via a method that strongly violates current human cooperative norms (e.g. breaking laws, violence), and/or (b) the future ends up very low in value.
- In principle we try to talk separately about cases where (a) is true but (b) is false, and vice versa (see e.g. my post here). E.g. we could use "uncooperative takeovers" for (a), and "bad-future takeovers" for (b). But given that we want to avoid both (a) and (b), I think it's OK to lump them together. But open to changing my mind on this, and I think your comments push me a bit in that direction.
- Alignment: this term does indeed get used in tons of ways, and it's probably best defined relative to some specific goal for the AI's motivations -- e.g., an AI is aligned to a principal, to a model spec, etc. That said, I think I mostly use it to mean "the AI in fact does not seek power in problematic ways, given the options available to it" -- what I've elsewhere called "practically PS-aligned." E.g., the AI does not choose a "problematic power-seeking" option in the sort of framework I described here, where I'm generally thinking of a paradigm problematic power-seeking option as one aimed at bad takeover.
On these definitions, the scenario you've given is underspecified in a few respects. In particular, I'd want to know:
- How much power do the human descended AIs -- i.e., the ems -- end up with?
- Are the strange alien goals the AIs are pursuing such that I would ultimately think they yield outcomes very low in value when achieved, or not?
If we assume the answer to (1) is that the non-human-descended AIs end up with most of the power (sounds this is basically what you had in mind -- see also my "people-who-like paperclips" scenario here) then yes I'd want to call this a takeover and I'd want to say that humans have been disempowered. Whether it was a "bad takeover", and whether this was a good or bad outcome for humanity, I think depends partly on (2). If in fact this scenario results in a future that is extremely low in value, in virtue of the alien-ness of the goals the AIs are pursuing, then I'd want to call it a bad takeover despite the cooperativeness of the path getting there. I think this would also imply that the AIs are practically PS-misaligned, and I think I endorse this implication, despite the fact that they are broadly cooperative and law-abiding -- though I do see a case for reserving "PS-misalignment" specifically for uncooperative power-seeking. If the resulting future is high in value, then I'd say that it was not a bad takeover and that the AIs are aligned.
Does that help? As I say, I think your comments here are pushing me a bit towards focusing specifically on uncooperative takeovers, and on defining PS-misalignment specifically in terms of AIs with a tendency to engage in uncooperative forms of power-seeking. If we went that route, then we wouldn't need to answer my question (2) above, and we could just say that this is a non-bad takeover and that the AIs are PS-aligned.
"Your 2021 report on power-seeking does not appear to discuss the cost-benefit analysis that a misaligned AI would conduct when considering takeover, or the likelihood that this cost-benefit analysis might not favor takeover."
I don't think this is quite right. For example: Section 4.3.3 of the report, "Controlling circumstances" focuses on the possibility of ensuring that an AI's environmental constraints are such that the cost-benefit calculus does not favor problematic power-seeking. Quoting:
So far in section 4.3, I’ve been talking about controlling “internal” properties of an APS system:
namely, its objectives and capabilities. But we can control external circumstances, too—and in
particular, the type of options and incentives a system faces.
Controlling options means controlling what a circumstance makes it possible for a system to do, even
if it tried. Thus, using a computer without internet access might prevent certain types of hacking; a
factory robot may not be able to access to the outside world; and so forth.
Controlling incentives, by contrast, means controlling which options it makes sense to choose, given
some set of objectives. Thus, perhaps an AI system could impersonate a human, or lie; but if it knows
that it will be caught, and that being caught would be costly to its objectives, it might refrain. Or
perhaps a system will receive more of a certain kind of reward for cooperating with humans, even
though options for misaligned power-seeking are open.
Human society relies heavily on controlling the options and incentives of agents with imperfectly
aligned objectives. Thus: suppose I seek money for myself, and Bob seeks money for Bob. This need
not be a problem when I hire Bob as a contractor. Rather: I pay him for his work; I don’t give him
access to the company bank account; and various social and legal factors reduce his incentives to try
to steal from me, even if he could.
A variety of similar strategies will plausibly be available and important with APS systems, too. Note,
though, that Bob’s capabilities matter a lot, here. If he was better at hacking, my efforts to avoid
giving him the option of accessing the company bank account might (unbeknownst to me) fail. If he
was better at avoiding detection, his incentives not to steal might change; and so forth.
PS-alignment strategies that rely on controlling options and incentives therefore require ways of
exerting this control (e.g., mechanisms of security, monitoring, enforcement, etc) that scale with
the capabilities of frontier APS systems. Note, though, that we need not rely solely on human
abilities in this respect. For example, we might be able to use various non-APS systems and/or
practically-aligned APS systems to help.
See also the discussion of myopia in 4.3.1.3...
The most paradigmatically dangerous types of AI systems plan strategically in pursuit of long-term objectives, since longer time horizons leave more time to gain and use forms of power humans aren’t making readily available, they more easily justify strategic but temporarily costly action (for example, trying to appear adequately aligned, in order to get deployed) aimed at such power. Myopic agentic planners, by contrast, are on a much tighter schedule, and they have consequently weaker incentives to attempt forms of misaligned deception, resource-acquisition, etc that only pay off in the long-run (though even short spans of time can be enough to do a lot of harm, especially for extremely capable systems—and the timespans “short enough to be safe” can alter if what one can do in a given span of time changes).
And of "controlling capabilities" in section 4.3.2:
Less capable systems will also have a harder time getting and keeping power, and a harder time making use of it, so they will have stronger incentives to cooperate with humans (rather than trying to e.g. deceive or overpower them), and to make do with the power and opportunities that humans provide them by default.
I also discuss the cost-benefit dynamic in the section on instrumental convergence (including discussion of trying-to-make-a-billion-dollars as an example), and point people to section 4.3 for more discussion.
I think there is an important point in this vicinity: namely, that power-seeking behavior, in practice, arises not just due to strategically-aware agentic planning, but due to the specific interaction between an agent’s capabilities, objectives, and circumstances. But I don’t think this undermines the posited instrumental connection between strategically-aware agentic planning and power-seeking in general. Humans may not seek various types of power in their current circumstances—in which, for example, their capabilities are roughly similar to those of their peers, they are subject to various social/legal incentives and physical/temporal constraints, and in which many forms of power-seeking would violate ethical constraints they treat as intrinsically important. But almost all humans will seek to gain and maintain various types of power in some circumstances, and especially to the extent they have the capabilities and opportunities to get, use, and maintain that power with comparatively little cost. Thus, for most humans, it makes little sense to devote themselves to starting a billion dollar company—the returns to such effort are too low. But most humans will walk across the street to pick up a billion dollar check.
Put more broadly: the power-seeking behavior humans display, when getting power is easy, seems to me quite compatible with the instrumental convergence thesis. And unchecked by ethics, constraints, and incentives (indeed, even when checked by these things) human power-seeking seems to me plenty dangerous, too. That said, the absence of various forms of overt power-seeking in humans may point to ways we could try to maintain control over less-than-fully PS-aligned APS systems (see 4.3 for more).
That said, I'm happy to acknowledge that the discussion of instrumental convergence in the power-seeking report is one of the weakest parts, on this and other grounds (see footnote for more);[1] that indeed numerous people over the years, including the ones you cite, have pushed back on issues in the vicinity (see e.g. Garfinkel's 2021 review for another example; also Crawford (2023)); and that this pushback (along with other discussions and pieces of content -- e.g., Redwood Research's work on "control," Carl Shulman on the Dwarkesh Podcast) has further clarified for me the importance of this aspect of picture. I've added some citations in this respect. And I am definitely excited about people (external academics or otherwise) criticizing/refining these arguments -- that's part of why I write these long reports trying to be clear about the state of the arguments as I currently understand them.
- ^
The way I'd personally phrase the weakness is: the formulation of instrumental convergence focuses on arguing from "misaligned behavior from an APS system on some inputs" to a default expectation of "misaligned power-seeking from an APS system on some inputs." I still think this is a reasonable claim, but per the argument in this post (and also per my response to Thorstad here), in order to get to an argument for misaligned power-seeking on the the inputs the AI will actually receive, you do need to engage in a much more holistic evaluation of the difficulty of controlling an AI's objectives, capabilities, and circumstances enough to prevent problematic power-seeking from being the rational option. Section 4.3 in the report ("The challenge of practical PS-alignment") is my attempt at this, but I think I should've been more explicit about its relationship to the weaker instrumental convergence claim outlined in 4.2, and it's more of a catalog of challenges than a direct argument for expecting PS-misalignment. And indeed, my current view is that this is roughly the actual argumentative situation. That is, for AIs that aren't powerful enough to satisfy the "very easy to takeover via a wide variety of methods" condition discussed in the post, I don't currently think there's a very clean argument for expecting problematic power-seeking -- rather, there is mostly a catalogue of challenges that lead to increasing amounts of concern, the easier takeover becomes. Once you reach systems that are in a position to take over very easily via a wide variety of methods, though, something closer to the recasted classic argument in the post starts to apply (and in fairness, both Bostrom and Yudkowsky, at least, do tend to try to also motivate expecting superintelligences to be capable of this type of takeover -- hence the emphasis on decisive strategic advantages).
in fact, no one worries about Siri "coordinating" to suddenly give us all wrong directions to the grocery store, because that's not remotely how assistants work.
Note that Siri is not capable of threatening types of coordination. But I do think that by the time we actually face a situation where AIs are capable of coordinating to successfully disempower humanity, we may well indeed know enough about "how they work" that we aren't worried about it.
That post ran into some cross-posting problems so had to re-do
The point of that part of my comment was that insofar as part of Nora/Quintin's response to simplicity argument is to say that we have active evidence that SGD's inductive biases disfavor schemers, this seems worth just arguing for directly, since even if e.g. counting arguments were enough to get you worried about schemers from a position of ignorance about SGD's inductive biases, active counter-evidence absent such ignorance could easily make schemers seem quite unlikely overall.
There's a separate question of whether e.g. counting arguments like mine above (e.g., "A very wide variety of goals can prompt scheming; By contrast, non-scheming goals need to be much more specific to lead to high reward; I’m not sure exactly what sorts of goals SGD’s inductive biases favor, but I don’t have strong reason to think they actively favor non-schemer goals; So, absent further information, and given how many goals-that-get-high-reward are schemer-like, I should be pretty worried that this model is a schemer") do enough evidence labor to privilege schemers as a hypothesis at all. But that's the question at issue in the rest of my comment. And in e.g. the case of "there are 1000 chinese restaurants in this, and only ~100 non-chinese restaurants," the number of chinese restaurants seems to me like it's enough to privilege "Bob went to a chinese restaurant" as a hypothesis (and this even without thinking that he made his choice by sampling randomly from a uniform distribution over restaurants). Do you disagree in that restaurant case?
The probability I give for scheming in the report is specifically for (goal-directed) models that are trained on diverse, long-horizon tasks (see also Cotra on "human feedback on diverse tasks," which is the sort of training she's focused on). I agree that various of the arguments for scheming could in principle apply to pure pre-training as well, and that folks (like myself) who are more worried about scheming in other contexts (e.g., RL on diverse, long-horizon tasks) have to explain what makes those contexts different. But I think there are various plausible answers here related to e.g. the goal-directedness, situational-awareness, and horizon-of-optimization of the models in questions (see e.g. here for some discussion, in the report, for why goal-directed models trained on longer episode seem more likely to scheme; and see here for discussion of why situational awareness seems especially likely/useful in models performing real-world tasks for you).
Re: "goal optimization is a good way to minimize loss in general" -- this isn't a "step" in the arguments for scheming I discuss. Rather, as I explain in the intro to report, the arguments I discuss condition on the models in question being goal-directed (not an innocuous assumptions, I think -- but one I explain and argue for in section 3 of my power-seeking report, and which I think important to separate from questions about whether to expect goal-directed models to be schemers), and then focus on whether the goals in question will be schemer-like.
Thanks for writing this -- I’m very excited about people pushing back on/digging deeper re: counting arguments, simplicity arguments, and the other arguments re: scheming I discuss in the report. Indeed, despite the general emphasis I place on empirical work as the most promising source of evidence re: scheming, I also think that there’s a ton more to do to clarify and maybe debunk the more theoretical arguments people offer re: scheming – and I think playing out the dialectic further in this respect might well lead to comparatively fast progress (for all their centrality to the AI risk discourse, I think arguments re: scheming have received way too little direct attention). And if, indeed, the arguments for scheming are all bogus, this is super good news and would be an important update, at least for me, re: p(doom) overall. So overall I’m glad you’re doing this work and think this is a valuable post.
Another note up front: I don’t think this post “surveys the main arguments that have been put forward for thinking that future AIs will scheme.” In particular: both counting arguments and simplicity arguments (the two types of argument discussed in the post) assume we can ignore the path that SGD takes through model space. But the report also discusses two arguments that don’t make this assumption – namely, the “training-game independent proxy goals story” (I think this one is possibly the most common story, see e.g. Ajeya here, and all the talk about the evolution analogy) and the “nearest max-reward goal argument.” I think that the idea that “a wide variety of goals can lead to scheming” plays some role in these arguments as well, but not such that they are just the counting argument restated, and I think they’re worth treating on their own terms.
On counting arguments and simplicity arguments
Focusing just on counting arguments and simplicity arguments, though: Suppose that I’m looking down at a superintelligent model newly trained on diverse, long-horizon tasks. I know that it has extremely ample situational awareness – e.g., it has highly detailed models of the world, the training process it’s undergoing, the future consequences of various types of power-seeking, etc – and that it’s getting high reward because it’s pursuing some goal (the report conditions on this). Ok, what sort of goal?
We can think of arguments about scheming in two categories here.
- (I) The first tries to be fairly uncertain/agnostic about what sorts of goals SGD’s inductive biases favor, and it argues that given this uncertainty, we should be pretty worried about scheming.
- I tend to think of my favored version of the counting argument (that is, the hazy counting argument) in these terms.
- (II) The second type focuses on a particular story about SGD’s inductive biases and then argues that this bias favors schemers.
- I tend to think of simplicity arguments in these terms. E.g., the story is that SGD’s inductive biases favor simplicity, schemers can have simpler goals, so schemers are favored.
Let’s focus first on (I), the more-agnostic-about-SGD’s-inductive-biases type. Here’s a way of pumping the sort of intuition at stake in the hazy counting argument:
- A very wide variety of goals can prompt scheming.
- By contrast, non-scheming goals need to be much more specific to lead to high reward.
- I’m not sure exactly what sorts of goals SGD’s inductive biases favor, but I don’t have strong reason to think they actively favor non-schemer goals.
- So, absent further information, and given how many goals-that-get-high-reward are schemer-like, I should be pretty worried that this model is a schemer.
Now, as I mention in the report, I'm happy to grant that this isn't a super rigorous argument. But how, exactly, is your post supposed to comfort me with respect to it? We can consider two objections, both of which are present in/suggested by your post in various ways.
- (A) This sort of reasoning would lead to you giving significant weight to SGD overfitting. But SGD doesn’t overfit, so this sort of reasoning must be going wrong, and in fact you should have low probability on SGD having selected a schemer, even given this ignorance about SGD's inductive biases.
- (B): (3) is false: we know enough about SGD’s inductive biases to know that it actively favors non-scheming goals over scheming goals.
Let’s start with (A). I agree that this sort of reasoning would lead you to giving significant weight to SGD overfitting, absent any further evidence. But it’s not clear to me that giving this sort of weight to overfitting was unreasonable ex ante, or that having learned that SGD-doesn't-overfit, you should now end up with low p(scheming) even given your ongoing ignorance about SGD's inductive biases.
Thus, consider the sort of analogy I discuss in the counting arguments section. Suppose that all we know is that Bob lives in city X, that he went to a restaurant on Saturday, and that town X has a thousand chinese restaurants, a hundred mexican restaurants, and one indian restaurant. What should our probability be that he went to a chinese restaurant?
In this case, my intuitive answer here is: “hefty.”[1] In particular, absent further knowledge about Bob’s food preferences, and given the large number of chinese restaurants in the city, “he went to a chinese restaurant” seems like a pretty salient hypothesis. And it seems quite strange to be confident that he went to a non-chinese restaurant instead.
Ok but now suppose you learn that last week, Bob also engaged in some non-restaurant leisure activity. For such leisure activities, the city offers: a thousand movie theaters, a hundred golf courses, and one escape room. So it would’ve been possible to make a similar argument for putting hefty credence on Bob having gone to a movie. But lo, it turns out that actually, Bob went golfing instead, because he likes golf more than movies or escape rooms.
How should you update about the restaurant Bob went to? Well… it’s not clear to me you should update much. Applied to both leisure and to restaurants, the hazy counting argument is trying to be fairly agnostic about Bob’s preferences, while giving some weight to some type of “count.” Trying to be uncertain and agnostic does indeed often mean putting hefty probabilities on things that end up false. But: do you have a better proposed alternative, such that you shouldn’t put hefty probability on “Bob went to a chinese restaurant”, here, because e.g. you learned that hazy counting arguments don’t work when applied to Bob? If so, what is it? And doesn’t it seem like it’s giving the wrong answer?
Or put another way: suppose you didn’t yet know whether SGD overfits or not, but you knew e.g. about the various theoretical problems with unrestricted uses of the indifference principle. What should your probability have been, ex ante, on SGD overfitting? I’m pretty happy to say “hefty,” here. E.g., it’s not clear to me that the problem, re: hefty-probability-on-overfitting, was some a priori problem with hazy-counting-argument-style reasoning. For example: given your philosophical knowledge about the indifference principle, but without empirical knowledge about ML, should you have been super surprised if it turned out that SGD did overfit? I don’t think so.
Now, you could be making a different, more B-ish sort of argument here: namely, that the fact that SGD doesn’t overfit actively gives us evidence that SGD’s inductive biases also disfavor schemers. This would be akin to having seen Bob, in a different city, actively seek out mexican restaurants despite there being many more chinese restaurants available, such that you now have active evidence that he prefers mexican and is willing to work for it. This wouldn’t be a case of having learned that bob’s preferences are such that hazy counting arguments “don’t work on bob” in general. But it would be evidence that Bob prefers non-chinese.
I’m pretty interested in arguments of this form. But I think that pretty quickly, they move into the territory of type (II) arguments above: that is, they start to say something like “we learn, from SGD not overfitting, that it prefers models of type X. Non-scheming models are of type X, schemers are not, so we now know that SGD won’t prefer schemers.”
But what is X? I’m not sure your answer (though: maybe it will come in a later post). You could say something like “SGD prefers models that are ‘natural’” – but then, are schemers natural in that sense? Or, you could say “SGD prefers models that behave similarly on the training and test distributions” – but in what sense is a schemer violating this standard? On both distributions, a schemer seeks after their schemer-like goal. I’m not saying you can’t make an argument for a good X, here – but I haven’t yet heard it. And I’d want to hear its predictions about non-scheming forms of goal-misgeneralization as well.
Indeed, my understanding is that a quite salient candidate for “X” here is “simplicity” – e.g., that SGD’s not overfitting is explained by its bias towards simpler functions. And this puts us in the territory of the “simplicity argument” above. I.e., we’re now being less agnostic about SGD’s preferences, and instead positing some more particular bias. But there’s still the question of whether this bias favors schemers or not, and the worry is that it does.
This brings me to your take on simplicity arguments. I agree with you that simplicity arguments are often quite ambiguous about the notion of simplicity at stake (see e.g. my discussion here). And I think they’re weak for other reasons too (in particular, the extra cognitive faff scheming involves seems to me more important than its enabling simpler goals).
But beyond “what is simplicity anyway,” you also offer some other considerations, other than SGD-not-overfitting, meant to suggest that we have active evidence that SGD’s inductive biases disfavor schemers. I’m not going to dig deep on those considerations here, and I’m looking forward to your future post on the topic. For now, my main reaction is: “we have active evidence that SGD’s inductive biases disfavor schemers” seems like a much more interesting claim/avenue of inquiry than trying to nail down the a priori philosophical merits of counting arguments/indifference principles, and if you believe we have that sort of evidence, I think it’s probably most productive to just focus on fleshing it out and examining it directly. That is, whatever their a priori merits, counting arguments are attempting to proceed from a position of lots of uncertainty and agnosticism, which only makes sense if you’ve got no other good evidence to go on. But if we do have such evidence (e.g., if (3) above is false), then I think it can quickly overcome whatever “prior” counting arguments set (e.g., if you learn that Bob has a special passion for mexican food and hates chinese, you can update far towards him heading to a mexican restaurant). In general, I’m very excited for people to take our best current understanding of SGD’s inductive biases (it’s not my area of expertise), and apply it to p(scheming), and am interested to hear your own views in this respect. But if we have active evidence that SGD’s inductive biases point away from schemers, I think that whether counting arguments are good absent such evidence matters way less, and I, for one, am happy to pay them less attention.
(One other comment re: your take on simplicity arguments: it seems intuitively pretty non-simple to me to fit the training data on the training distribution, and then cut to some very different function on the test data, e.g. the identity function or the constant function. So not sure your parody argument that simplicity also predicts overfitting works. And insofar as simplicity is supposed to be the property had by non-overfitting functions, it seems somewhat strange if positing a simplicity bias predicts over-fitting after all.)
A few other comments
Re: goal realism, it seems like the main argument in the post is something like:
- Michael Huemer says that it’s sometimes OK to use the principle of indifference if you’re applying it to explanatorily fundamental variables.
- But goals won’t be explanatorily fundamental. So the principle of indifference is still bad here.
I haven’t yet heard much reason to buy Huemer’s view, so not sure how much I care about debating whether we should expect goals to satisfy his criteria of fundamentality. But I'll flag I do feel like there’s a pretty robust way in which explicitly-represented goals appropriately enter into our explanations of human behavior – e.g., I have buying a flight to New York because I want to go to New York, I have a representation of that goal and how my flight-buying achieves it, etc. And it feels to me like your goal reductionism is at risk of not capturing this. (To be clear: I do think that how we understand goal-directedness matters for scheming -- more here -- and that if models are only goal-directed in a pretty deflationary sense, this makes scheming a way weirder hypothesis. But I think that if models are as goal-directed as strategic and agentic humans reasoning about how to achieve explicitly represented goals, their goal-directedness has met a fairly non-deflationary standard.)
I’ll also flag some broader unclarity about the post’s underlying epistemic stance. You rightly note that the strict principle of indifference has many philosophical problems. But it doesn’t feel to me like you’ve given a compelling alternative account of how to reason “on priors” in the sorts of cases where we’re sufficiently uncertain that there’s a temptation to spread one’s credence over many possibilities in the broad manner that principles-of-indifference-ish reasoning attempts to do.
Thus, for example, how does your epistemology think about a case like “There are 1000 people in this town, one of them is the murderer, what’s the probability that it’s Mortimer P. Snodgrass?” Or: “there are a thousand white rooms, you wake up in one of them, what’s the probability that it’s room number 734?” These aren’t cases like dice, where there’s a random process designed to function in principle-of-indifference-ish ways. But it’s pretty tempting to spread your credence out across the people/rooms (even if in not-fully-uniform ways), in a manner that feels closely akin to the sort of thing that principle-of-indifference-ish reasoning is trying to do. (We can say "just use all the evidence available to you" -- but why should this result in such principle-of-indifference-ish results?)
Your critique of counting argument would be more compelling to me if you had a fleshed out account of cases like these -- e.g., one which captures the full range of cases where we’re pulled towards something principle-of-indifference-ish, such that you can then take that account and explain why it shouldn’t point us towards hefty probabilities on schemers, a la the hazy counting argument, even given very-little-evidence about SGD’s inductive biases.
More to say on all this, and I haven't covered various ways in which I'm sympathetic to/moved by points in the vicinity of the ones you're making here. But for now: thanks again for writing, looking forward to future installments.
- ^
Though I do think cases like this can get complicated, and depending on how you carve up the hypothesis space, in some versions "hefty" won't be the right answer.
Ah nice, thanks!
Hi David -- it's true that I don't engage your paper (there's a large literature on infinite ethics, and the piece leaves out a lot of it -- and I'm also not sure I had seen your paper at the time I was writing), but re: your comments here on the ethical relevance of infinities: I discuss the fact that the affectable universe is probably finite -- "current science suggests that our causal influence is made finite by things like lightspeed and entropy" -- in section 1 of the essay (paragraph 5), and argue that infinites are still
- relevant in practice due to (i) the remaining probability that current physical theories are wrong about our causal influence (and note also related possibilities like having causal influence on whether you go to an infinite-heaven/hell etc, a la pascal) and (ii) due to the possibility of having infinite acausal influence conditional on various plausible-in-my-view decision theories, and
- relevant to ethical theory, even if not to day-to-day decision-making, due to (a) ethical theory generally aspiring to cover various physically impossible cases, and (b) the existence of intuitions about infinite cases (e.g., heaven > hell, pareto, etc) that seem prima facie amenable to standard attempts at systematization.
(Partly re-hashing my response from twitter.)
I'm seeing your main argument here as a version of what I call, in section 4.4, a "speed argument against schemers" -- e.g., basically, that SGD will punish the extra reasoning that schemers need to perform.
(I’m generally happy to talk about this reasoning as a complexity penalty, and/or about the params it requires, and/or about circuit-depth -- what matters is the overall "preference" that SGD ends up with. And thinking of this consideration as a different kind of counting argument *against* schemers seems like it might well be a productive frame. I do also think that questions about whether models will be bottlenecked on serial computation, and/or whether "shallower" computations will be selected for, are pretty relevant here, and the report includes a rough calculation in this respect in section 4.4.2 (see also summary here).)
Indeed, I think that maybe the strongest single argument against scheming is a combination of
- "Because of the extra reasoning schemers perform, SGD would prefer non-schemers over schemers in a comparison re: final properties of the models" and
- "The type of path-dependence/slack at stake in training is such that SGD will get the model that it prefers overall."
My sense is that I'm less confident than you in both (1) and (2), but I think they're both plausible (the report, in particular, argues in favor of (1)), and that the combination is a key source of hope. I'm excited to see further work fleshing out the case for both (including e.g. the sorts of arguments for (2) that I took you and Nora to be gesturing at on twitter -- the report doesn't spend a ton of time on assessing how much path-dependence to expect, and of what kind).
Re: your discussion of the "ghost of instrumental reasoning," "deducing lots of world knowledge 'in-context,' and "the perspective that NNs will 'accidentally' acquire such capabilities internally as a convergent result of their inductive biases" -- especially given that you only skimmed the report's section headings and a small amount of the content, I have some sense, here, that you're responding to other arguments you've seen about deceptive alignment, rather than to specific claims made in the report (I don't, for example, make any claims about world knowledge being derived "in-context," or about models "accidentally" acquiring flexible instrumental reasoning). Is your basic thought something like: sure, the models will develop flexible instrumental reasoning that could in principle be used in service of arbitrary goals, but they will only in fact use it in service of the specified goal, because that's the thing training pressures them to do? If so, my feeling is something like: ok, but a lot of the question here is whether using the instrumental reasoning in service of some other goal (one that backchains into getting-reward) will be suitably compatible with/incentivized by training pressures as well. And I don't see e.g. the reversal curse as strong evidence on this front.
Re: "mechanistically ungrounded intuitions about 'goals' and 'tryingness'" -- as I discuss in section 0.1, the report is explicitly setting aside disputes about whether the relevant models will be well-understood as goal-directed (my own take on that is in section 2.2.1 of my report on power-seeking AI here). The question in this report is whether, conditional on goal-directedness, we should expect scheming. That said, I do think that what I call the "messyness" of the relevant goal-directedness might be relevant to our overall assessment of the arguments for scheming in various ways, and that scheming might require an unusually high standard of goal-directedness in some sense. I discuss this in section 2.2.3, on "'Clean' vs. 'messy' goal-directedness," and in various other places in the report.
Re: "long term goals are sufficiently hard to form deliberately that I don't think they'll form accidentally" -- the report explicitly discusses cases where we intentionally train models to have long-term goals (both via long episodes, and via short episodes aimed at inducing long-horizon optimization). I think scheming is more likely in those cases. See section 2.2.4, "What if you intentionally train the model to have long-term goals?" That said, I'd be interested to see arguments that credit assignment difficulties actively count against the development of beyond-episode goals (whether in models trained on short episodes or long episodes) for models that are otherwise goal-directed. And I do think that, if we could be confident that models trained on short episodes won't learn beyond-episode goals accidentally (even irrespective of mundane adversarial training -- e.g., that models rewarded for getting gold coins on the episode would not learn a goal that generalizes to caring about gold coins in general, even prior to efforts to punish it for sacrificing gold-coins-on-the-episode for gold-coins-later), that would be a significant source of comfort (I discuss some possible experimental directions in this respect in section 6.2).
I agree that AIs only optimizing for good human ratings on the episode (what I call "reward-on-the-episode seekers") have incentives to seize control of the reward process, that this is indeed dangerous, and that in some cases it will incentivize AIs to fake alignment in an effort to seize control of the reward process on the episode (I discuss this in the section on "non-schemers with schemer-like traits"). However, I also think that reward-on-the-episode seekers are also substantially less scary than schemers in my sense, for reasons I discuss here (i.e., reasons to do with what I call "responsiveness to honest tests," the ambition and temporal scope of their goals, and their propensity to engage in various forms of sandbagging and what I call "early undermining"). And this especially for reward-on-the-episode seekers with fairly short episodes, where grabbing control over the reward process may not be feasible on the relevant timescales.
Agree that it would need to have some conception of the type of training signal to optimize for, that it will do better in training the more accurate its picture of the training signal, and that this provides an incentive to self-locate more accurately (though not necessary to degree at stake in e.g. knowing what server you're running on).
The question of how strongly training pressures models to minimize loss is one that I isolate and discuss explicitly in the report, in section 1.5, "On 'slack' in training" -- and at various points the report references how differing levels of "slack" might affect the arguments it considers. Here I was influenced in part by discussions with various people, yourself included, who seemed to disagree about how much weight to put on arguments in the vein of: "policy A would get lower loss than policy B, so we should think it more likely that SGD selects policy A than policy B."
(And for clarity, I don't think that arguments of this form always support expecting models to do tons of reasoning about the training set-up. For example, as the report discusses in e.g. Section 4.4, on "speed arguments," the amount of world-modeling/instrumental-reasoning that the model does can affect the loss it gets via e.g. using up cognitive resources. So schemers -- and also, reward-on-the-episode seekers -- can be at some disadvantage, in this respect, relative to models that don't think about the training process at all.)
Agents that end up intrinsically motivated to get reward on the episode would be "terminal training-gamers/reward-on-the-episode seekers," and not schemers, on my taxonomy. I agree that terminal training-gamers can also be motivated to seek power in problematic ways (I discuss this in the section on "non-schemers with schemer-like traits"), but I think that schemers proper are quite a bit scarier than reward-on-the-episode seekers, for reasons I describe here.
I found this post a very clear and useful summary -- thanks for writing.
Re: "0.00002 would be one in five hundred thousand, but with the percent sign it's one in fifty million." -- thanks, edited.
Re: volatility -- thanks, that sounds right to me, and like a potentially useful dynamic to have in mind.
Oops! You're right, this isn't the right formulation of the relevant principle. Will edit to reflect.
Really appreciated this sequence overall, thanks for writing.
I really like this post. It's a crisp, useful insight, made via a memorable concrete example (plus a few others), in a very efficient way. And it has stayed with me.
Thanks for these thoughtful comments, Paul.
- I think the account you offer here is a plausible tack re: unification — I’ve added a link to it in the “empirical approaches” section.
- “Facilitates a certain flavor of important engagement in the vicinity of persuasion, negotiation and trade” is a helpful handle, and another strong sincerity association for me (cf "a space that feels ready to collaborate, negotiate, figure stuff out, make stuff happen").
- I agree that it’s not necessarily desirable for sincerity (especially in your account’s sense) to permeate your whole life (though on my intuitive notion, it’s possible for some underlying sincerity to co-exist with things like play, joking around, etc), and that you can’t necessarily get to sincerity by some simple move like “just letting go of pretense.”
- This stuff about encouraging more effective delusion by probing for sincerity via introspection is interesting, as are these questions about whether I’m underestimating the costs of sincerity. In this latter respect, maybe worth distinguishing the stakes of “thoughts in the privacy of your own head" (e.g., questions about the value of self-deception, non-attention to certain things, etc) from more mundane costs re: e.g., sincerity takes effort, it’s not always the most fun thing, and so on. Sounds like you've got the former especially in mind, and they seem like the most salient source of possible disagreement. I agree it's a substantive question how the trade-offs here shake out, and at some point would be curious to hear more about your take.
Glad to hear you liked it :)
:) -- nice glasses
Oops! Yep, thanks for catching.
Thanks! Fixed.
Yeah, as I say, I think "neither innocent nor guilty" is least misleading -- but I find "innocent" an evocative frame. Do you have suggestions for an alternative to "selfish"?
Is the argument here supposed to be particular to meta-normativity, or is it something more like "I generally think that there are philosophy facts, those seem kind of a priori-ish and not obviously natural/normal, so maybe a priori normative facts are OK too, even if we understand neither of them"?
Re: meta-philosophy, I tend to see philosophy as fairly continuous with just "good, clear thinking" and "figuring out how stuff hangs together," but applied in a very general way that includes otherwise confusing stuff. I agree various philosophical domains feel pretty a priori-ish, and I don't have a worked out view of a priori knowledge, especially synthetic a priori knowledge (I tend to expect us to be able to give an account of how we get epistemic access to analytic truths). But I think I basically want to make the same demands of other a priori-ish domains that I do normativity. That is, I want the right kind of explanatory link between our belief formation and the contents of the domain -- which, for "realist" construals of the domain, I expect to require that the contents of the domain play some role in explaining our beliefs.
Re: the relationship between meta-normativity and normativity in particular, I wonder if a comparison to the relationship between "meta-theology" and "theology" might be instructive here. I feel like I want to be fairly realist about certain "meta-theological facts" like "the God of Christianity doesn't exist" (maybe this is just a straightforward theological fact?). But this doesn't tempt me towards realism about God. Maybe talking about normative "properties" instead of normative facts would be easier here, since one can imagine e.g. a nihilist denying the existence of normative properties, but accepting some 'normative' (meta-normative?) facts like "there is no such thing as goodness" or "pleasure is not good."
Reviewers ended up on the list via different routes. A few we solicited specifically because we expected them to have relatively well-developed views that disagree with the report in one direction or another (e.g., more pessimistic, or more optimistic), and we wanted to understand the best objections in this respect. A few came from trying to get information about how generally thoughtful folks with different backgrounds react to the report. A few came from sending a note to GPI saying we were open to GPI folks providing reviews. And a few came via other miscellaneous routes. I’d definitely be interested to see more reviews from mainstream ML researchers, but understanding how ML researchers in particular react to the report wasn’t our priority here.
Cool, these comments helped me get more clarity about where Ben is coming from.
Ben, I think the conception of planning I’m working with is closest to your “loose” sense. That is, roughly put, I think of planning as happening when (a) something like simulations are happening, and (b) the output is determined (in the right way) at least partly on the basis of those simulations (this definition isn’t ideal, but hopefully it’s close enough for now). Whereas it sounds like you think of (strict) planning as happening when (a) something like simulations are happening, and (c) the agent’s overall policy ends up different (and better) as a result.
What’s the difference between (b) and (c)? One operationalization could be: if you gave an agent input 1, then let it do its simulations thing and produce an output, then gave it input 1 again, could the agent’s performance improve, on this round, in virtue of the simulation-running that it did on the first round? On my model, this isn’t necessary for planning; whereas on yours, it sounds like it is?
Let’s say this is indeed a key distinction. If so, let’s call my version “Joe-planning” and your version “Ben-planning.” My main point re: feedforward neural network was that they could do Joe-planning in principle, which it sounds like you think at least conceivable. I agree that it seems tough for shallow feedforward networks to do much of Joe-planning in practice. I also grant that when humans plan, they are generally doing Ben-planning in addition to Joe-planning (e.g., they’re generally in a position to do better on a given problem in virtue of having planned about that same problem yesterday).
Seems like key questions re: the connection to AI X-risk include:
- Is there reason to think a given type of planning especially dangerous and/or relevant to the overall argument for AI X-risk?
- Should we expect that type of planning to be necessary for various types of task performance?
Re: (1), I do think Ben-planning poses dangers that Joe-planning doesn’t. Notably, Ben planning does indeed allow a system to improve/change its policy "on its own" and without new data, whereas Joe planning need not — and this seems more likely to yield unexpected behavior. This seems continuous, though, with the fact that a Ben-planning agent is learning/improving its capabilities in general, which I flag separately as an important risk factor.
Another answer to (1), suggested by some of your comments, could appeal to the possibility that agents are more dangerous when you can tweak a single simple parameter like “how much time they have to think” or “search depth” and thereby get better performance (this feels related to Eliezer’s worries about “turning up the intelligence dial” by “running it with larger bounds on the for-loops”). I agree that if you can just “turn up the intelligence dial,” that is quite a bit more worrying than if you can’t — but I think this is fairly orthogonal to the Joe-planning vs. Ben-planning distinction. For example, I think you can have Joe-planning agents where you can increase e.g. their search depth by tweaking a single parameter, and you can have Ben-planning agents where the parameters you’d need to tweak aren’t under your control (or the agent’s control), but rather are buried inside some tangled opaque neural network you don't understand.
The central reason I'm interested in Joe-planning, though, is that I think the instrumental convergence argument makes the most sense if Joe-planning is involved -- e.g., if the agent is running simulations that allow it to notice and respond to incentives to seek power (there are versions of the argument that don't appeal to Joe-planning, but I like these less -- see discussion in footnote 87 here). It's true that you can end up power-seeking-ish via non-Joe-planning paths (for example, if in training you developed sphex-ish heuristics that favor power-seeking-ish actions); but when I actually imagine AI systems that end up power-seeking, I imagine it happening because they noticed, in the course of modeling the world in order to achieve their goals, that power-seeking (even in ways humans wouldn't like) would help.
Can this happen without Ben-planning? I think it can. Suppose, for example, that none of your previous Joe-planning models were power-seeking. Then, you train a new Joe-planner, who can run more sophisticated simulations. On some inputs, this Joe-planner realizes that power-seeking is advantageous, and goes for it (or starts deceiving you, or whatever).
Re: (2), for the reasons discussed in section 3.1, I tend to see Joe-planning as pretty key to lots of task-performance — though I acknowledge that my intuitions are surprised by how much it looks like you can do via something more intuitively “sphexish.” And I acknowledge that some of those arguments may apply less to Ben-planning. I do think this is some comfort, since agents that learn via planning are indeed scarier. But I am separately worried that ongoing learning will be very useful/incentivized, too.
I’m glad you think it’s valuable, Ben — and thanks for taking the time to write such a thoughtful and detailed review.
I’m sympathetic to the possibility that the high level of conjuctiveness here created some amount of downward bias, even if the argument does actually have a highly conjunctive structure.”
Yes, I am too. I’m thinking about the right way to address this going forward.
I’ll respond re: planning in the thread with Daniel.
(Note that my numbers re: short-horizon systems + 12 OOMs being enough, and for +12 OOMs in general, changed since an earlier version you read, to 35% and 65% respectively.)
Thanks for these comments.
that suggests that CrystalNights would work, provided we start from something about as smart as a chimp. And arguably OmegaStar would be about as smart as a chimp - it would very likely appear much smarter to people talking with it, at least.
"starting with something as smart as a chimp" seems to me like where a huge amount of the work is being done, and if Omega-star --> Chimp-level intelligence, it seems a lot less likely we'd need to resort to re-running evolution-type stuff. I also don't think "likely to appear smarter than a chimp to people talking with it" is a good test, given that e.g. GPT-3 (2?) would plausibly pass, and chimps can't talk.
"Do you not have upwards of 75% credence that the GPT scaling trends will continue for the next four OOMs at least? If you don't, that is indeed a big double crux." -- Would want to talk about the trends in question (and the OOMs -- I assume you mean training FLOP OOMs, rather than params?). I do think various benchmarks are looking good, but consider e.g. the recent Gopher paper:
On the other hand, we find that scale has a reduced benefit for tasks in the Maths, Logical Reasoning, and Common Sense categories. Smaller models often perform better across these categories than larger models. In the cases that they don’t, larger models often don’t result in a performance increase. Our results suggest that for certain flavours of mathematical or logical reasoning tasks, it is unlikely that scale alone will lead to performance breakthroughs. In some cases Gopher has a lower performance than smaller models– examples of which include Abstract Algebra and Temporal Sequences from BIG-bench, and High School Mathematics from MMLU.
(Though in this particular case, re: math and logical reasoning, there are also other relevant results to consider, e.g. this and this.)
It seems like "how likely is it that continuation of GPT scaling trends on X-benchmarks would result in APS-systems" is probably a more important crux, though?
Re: your premise 2, I had (wrongly, and too quickly) read this as claiming "if you have X% on +12 OOMs, you should have at least 1/2*X% on +6 OOMs," and log-uniformity was what jumped to mind as what might justify that claim. I have a clearer sense of what you were getting at now, and I accept something in the vicinity if you say 80% on +12 OOMs (will edit accordingly). My +12 number is lower, though, which makes it easier to have a flatter distribution that puts more than half of the +12 OOM credence above +6.
The difference between 20% and 50% on APS-AI by 2030 seems like it could well be decision-relevant to me (and important, too, if you think that risk is a lot higher in short-timelines worlds).
I haven't given a full account of my views of realism anywhere, but briefly, I think that the realism the realists-at-heart want is a robust non-naturalist realism, a la David Enoch, and that this view implies:
- an inflationary metaphysics that it just doesn't seem like we have enough evidence for,
- an epistemic challenge (why would we expect our normative beliefs to correlate with the non-natural normative facts?) that realists have basically no answer to except "yeah idk but maybe this is a problem for math and philosophy too?" (Enoch's chapter 7 covers this issue; I also briefly point at it in this section, in talking about why the realist bot would expect its desires and intuitions to correlate with the the contents of the envelope buried in the mountain), and
- an appeal to a non-natural realm that a lot of realists take as necessary to capture the substance and heft of our normative lives, but which I don't think is necessary for this, at least when it comes to caring (i think moral "authority" and "bindingness regardless of what you care about" might be a different story, but one that "the non-natural realm says so" doesn't obviously help with, either). i wrote up my take on this issue here.
Also, most realists are externalists, and I think that externalist realism severs an intuitive connection between normativity and motivation that I would prefer to preserve (though this is more of an "I don't like that" than a "that's not true" objection). I wrote about this here.
There are various ways of being a "naturalist realist," too, but the disagreement between naturalist realism and anti-realism/subjectivism/nihilism is, in my opinion, centrally a semantic one. The important question is whether anything normativity-flavored is in a deep sense something over and above the standard naturalist world picture. Once we've denied that, we're basically just talking about how to use words to describe that standard naturalist world picture. I wrote a bit about how I think of this kind of dialectic here:
This is a familiar dialectic in philosophical debates about whether some domain X can be reduced to Y (meta-ethics is a salient comparison to me). The anti-reductionist (A) will argue that our core intuitions/concepts/practices related to X make clear that it cannot be reduced to Y, and that since X must exist (as we intuitively think it does), we should expand our metaphysics to include more than Y. The reductionist (R) will argue that X can in fact be reduced to Y, and that this is compatible with our intuitions/concepts/everyday practices with respect to X, and hence that X exists but it’s nothing over and above Y. The nihilist (N), by contrast, agrees with A that it follows from our intuitions/concepts/practices related to X that it cannot be reduced to Y, but agrees with D that there is in fact nothing over and above Y, and so concludes that there is no X, and that our intuitions/concepts/practices related to X are correspondingly misguided. Here, the disagreement between A vs. R/N is about whether more than Y exists; the disagreement between R vs. A/N is about whether a world of only Y “counts” as a world with X. This latter often begins to seem a matter of terminology; the substantive questions have already been settled.
There's a common strain of realism in utilitarian circles that tries to identify "goodness" with something like "valence," treats "valence" as a "phenomenal property", and then tries to appeal to our "special direct epistemic access" to phenomenal consciousness in order to solve the epistemic challenge above. i think this doesn't help at all (the basic questions about how the non-natural realm interacts with the natural one remain unanswered -- and this is a classic problem for non-physicalist theories of consciousness as well), but that it gets its appeal centrally via running through people's confusion/mystery relationship with phenomenal consciousness, which muddies the issue enough to make it seem like the move might help. I talk about issues in this vein a bit in the latter half of my podcast with Gus Docker.
Re: your list of 6 meta-ethical options, I'd be inclined to pull apart the question of
- (a) do any normative facts exists, and if so, which ones, vs.
- (b) what's the empirical situation with respect to deliberation within agents and disagreement across agents (e.g., do most agents agree and if so why; how sensitive is the deliberation of a given agent to initial conditions, etc).
With respect to (a), my take is closest to 6 ("there aren't any normative facts at all") if the normative facts are construed in a non-naturalist way, and closest to "whatever, it's mostly a terminology dispute at this point" if the normative facts are construed in a naturalist way (though if we're doing the terminology dispute, I'm generally more inclined towards naturalist realism over nihilism). Facts about what's "rational" or "what decision theory wins" fall under this response as well (I talk about this a bit here).
With respect to (b), my first pass take is "i dunno, it's an empirical question," but if I had to guess, I'd guess lots of disagreement between agents across the multiverse, and a fair amount of sensitivity to initial conditions on the part of individual deliberators.
Re: my ghost, it starts out valuing status as much as i do, but it's in a bit of a funky situation insofar as it can't get normal forms of status for itself because it's beyond society. It can, if it wants, try for some weirder form of cosmic status amongst hypothetical peers ("what they would think if they could see me now!"), or it can try to get status for the Joe that it left behind in the world, but my general feeling is that the process of stepping away from the Joe and looking at the world as a whole tends to reduce its investment in what happens to Joe in particular, e.g.:
Perhaps, at the beginning, the ghost is particularly interested in Joe-related aspects of the world. Fairly soon, though, I imagine it paying more and more attention to everything else. For while the ghost retains a deep understanding of Joe, and a certain kind of care towards him, it is viscerally obvious, from the ghost’s perspective, unmoored from Joe’s body, that Joe is just one creature among so many others; Joe’s life, Joe’s concerns, once so central and engrossing, are just one tiny, tiny part of what’s going on.
That said, insofar as the ghost is giving recommendations to me about what to do, it can definitely take into account the fact that I want status to whatever degree, and am otherwise operating in the context of social constraints, coordination mechanisms, etc.
In the past, I've thought of idealizing subjectivism as something like an "interim meta-ethics," in the sense that it was a meta-ethic I expected to do OK conditional on each of the three meta-ethical views discussed here, e.g.:
- Internalist realism (value is independent of your attitudes, but your idealized attitudes always converge on it)
- Externalist realism (value is independent of your attitudes, but your idealized attitudes don't always converge on it)
- Idealizing subjectivism (value is determined by your idealized attitudes)
The thought was that on (1), idealizing subjectivism tracks the truth. On (2), maybe you're screwed even post-idealization, but whatever idealization process you were going to do was your best shot at the truth anyway. And on (3), idealizing subjectivism is just true. So, you don't go too far wrong as an idealizing subjectivist. (Though note that we can run similar lines or argument for using internalist or externalist forms of realism as the "interim meta-ethics." The basic dynamic here is just that, regardless of what you think about (1)-(3), doing your idealization procedures is the only thing you know how to do, so you should just do it.)
I still feel some sympathy towards this, but I've also since come to view attempts at meta-ethical agnosticism of this kind as much less innocent and straightforward than this picture hopes. In particular, I feel like I see meta-ethical questions interacting with object-level moral questions, together with other aspects of philosophy, at tons of different levels (see e.g. here, here, and here for a few discussions), so it has felt corresponding important to just be clear about which view is most likely to be true.
Beyond this, though, for the reasons discussed in this post, I've also become clearer in my skepticism that "just do your idealization procedure" is some well-defined thing that we can just take for granted. And I think that once we double click on it, we actually get something that looks less like any of 1-3, and more like the type of active, existentialist-flavored thing I tried to point at in Sections X and XI.
Re: functional roles of morality, one thing I'll flag here is that in my view, the most fundamental meta-ethical questions aren't about morality per se, but rather are about practical normativity more generally (though in practice, many people seem most pushed towards realism by moral questions in particular, perhaps due to the types of "bindingness" intuitions I try to point at here -- intuitions that I don't actually think realism on its own helps with).
Should you think of your idealized self as existing in a context where morality still plays these (and other) functional roles? As with everything about your idealization procedure, on my picture it's ultimately up to you. Personally, I tend to start by thinking about individual ghost versions of myself who can see what things are like in lots of different counterfactual situations (including, e.g., situations where morality plays different functional roles, or in which I am raised differently), but who are in some sense "outside of society," and who therefore aren't doing much in the way of direct signaling, group coordination, etc. That said, these ghost version selves start with my current values, which have indeed resulted from my being raised in environments where morality is playing roles of the kind you mentioned.
Glad you liked it :). I haven’t spent much time engaging with UDASSA — or with a lot other non-SIA/SSA anthropic theories — at this point, but UDASSA in particular is on my list to understand better. Here I wanted to start with the first-pass basics.
Yes, edited :)
I appreciated this, especially given how challenging this type of exercise can be. Thanks for writing.
Rohin is correct. In general, I meant for the report's analysis to apply to basically all of these situations (e.g., both inner and outer-misaligned, both multi-polar and unipolar, both fast take-off and slow take-off), provided that the misaligned AI systems in question ultimately end up power-seeking, and that this power-seeking leads to existential catastrophe.
It's true, though, that some of my discussion was specifically meant to address the idea that absent a brain-in-a-box-like scenario, we're fine. Hence the interest in e.g. deployment decisions, warning shots, and corrective mechanisms.
Thanks!
Mostly personal interest on my part (I was working on a blog post on the topic, now up), though I do think that the topic has broader relevance.
I think this could've been clearer: it's been a bit since I wrote this/read the book, but I don't think I meant to imply that "some forms of hospice do prolong life at extreme costs to its quality" (though the sentence does read that way); more that some forms of medical treatment prolong life at extreme cost to its quality, and Gawande discusses hospice as an alternative.