When should we worry about AI power-seeking?
post by Joe Carlsmith (joekc) · 2025-02-19T19:44:25.062Z · LW · GW · 0 commentsThis is a link post for https://joecarlsmith.substack.com/p/when-should-we-worry-about-ai-power
Contents
1. Introduction 2. Prerequisites for problematic power-seeking 2.1 Agency prerequisites 2.2 Motivation prerequisites 2.3 Incentive prerequisites 3. Motivation control and option control 4. Should we expect these prerequisites to be satisfied? 4.1 The agency and motivation prerequisites seem like the default trajectory 4.2 What about the incentive prerequisites? 4.3 Will the first superintelligence have a decisive strategic advantage? 4.4 Global vulnerability conditions 5. Conclusion Appendix 1: Extending the incentives framework to cover capability elicitation Appendix 2: A typology of vulnerability conditions A.2.1 Vulnerability in general vs. vulnerability to motivations in particular A.2.2 Local vs. global vulnerability A.2.3 Easy vs. non-easy power-seeking A.2.4 Unilateral vs. multilateral power-seeking A.2.5 Coordinated vs. uncoordinated power-seeking A.2.6 Worst case versions None No comments
(Audio version here (read by the author), or search for "Joe Carlsmith Audio" on your podcast app.
This is the second essay in a series that I’m calling “How do we solve the alignment problem?”.[1]I’m hoping that the individual essays can be read fairly well on their own, but see this introduction for a summary of the essays that have been released thus far, and for a bit more about the series as a whole.)
1. Introduction
In my last essay, I defined what it would be to solve the alignment problem: namely, building full-blown superintelligent AI agents, and safely eliciting their main beneficial capabilities, while avoiding a “loss of control” scenario. In this essay, I say more about when this problem needs solving.
In particular: I specify three sets of conditions that need to be in place for an AI to seek power in the manner at stake in paradigm loss of control scenarios. These are roughly:
- Agency prerequisites: the AI’s behavior needs to be coherently driven by a process of making plans and evaluating them according to criteria, using models of the world that allow for recognition and consideration of the instrumental benefits of power-seeking.
- Motivation prerequisites: some part of the AI’s motivational system needs to be focused on the consequences of the AI’s behavior over sufficiently long time-scales that it would have time to get and make adequate use of the power at stake.
- Incentive prerequisites: the AI’s options and motivations need to combine to make power-seeking behavior rational overall from the AI’s perspective.
I move through the agency and motivation prerequisites quite quickly. But I take more time on the incentive prerequisites, which I think often go under-analyzed.
In particular: people often appeal to “instrumental convergence” – i.e., the idea that a very wide range of goals make power-seeking useful – to explain why going rogue can easily be rational for an AI. But I think this idea is too often left amorphous – and that I left it too amorphous in some of my previous work. In particular: we can’t just talk about an AI having some incentive to seek power, based on some part of its motivational system. Rather, we need to look at the landscape of its options and motivations overall – i.e., at its shorter-term and non-consequentialist motivations, its likelihood of success or failure at the relevant type of power-seeking, the sort of success/failure on the table, what it would have to do along the way, and its evaluation of the best alternative to going rogue.
The essay offers a framework that tries to aid in this analysis. Here’s a preview in a diagram (I explain the relevant terms and distinctions in more detail below):
This sort of framework, I think, gives us a richer toolkit for thinking about how to prevent problematic power-seeking – one that I draw on in the rest of the series. In particular: it highlights the ongoing potential role for both of the following:
Motivation control: Shaping an AI agent’s motivations in desirable ways.
Option control: Shaping an AI agent’s options in desirable ways.
The alignment discourse, in my opinion, often focuses too heavily on the extreme cases of motivation control (e.g., “complete alignment”) and of option control (e.g., robustness to worst case motivations), neglecting the in-between. The extreme cases can give extra comfort, and they simplify the task of analysis; but the in-between is often what “alignment” has looked like in the real world, at least thus far.
I close the essay with a discussion of whether or not we should expect the prerequisites above to be satisfied by default. I think we should indeed expect this for the agency and motivation prerequisites – or at least, for something quite nearby. For the incentive prerequisites, though, I think it’s less clear – and I return to the question in some detail later in the series.
In the meantime, though: I suggest that we can see the classic argument for expecting the incentive prerequisites to be satisfied as emerging from a backdrop focus on AI systems that have such a “decisive strategic advantage” over the rest of civilization that they can take over the world very easily, via a wide variety of methods – a context in which the AI doesn’t have to worry about the downsides of failure, and where it can more easily “route around” any inhibitions it has about particular paths to takeover. And I do think it’s worryingly plausible that a superintelligent AI agent might end up with this kind of power, especially if take-off is fast. But I think we should try to avoid this, and that we may well be able to do so.
However: a single AI system with a decisive strategic advantage is an extreme version of a broader set of scenarios, which I call “global vulnerability conditions.” These are scenarios where humanity’s continued empowerment rests on some combination of (a) AIs not choosing to seek power, and (b) the success of active efforts to restrict their options for doing so. And if AI development continues unabated, this broader sort of global vulnerability looks much harder to avoid.
2. Prerequisites for problematic power-seeking
Let’s look at the prerequisites above in a bit more detail.
Rogue behavior, as I defined it in the last essay, is about seeking to gain and maintain power in problematic and unintended ways.[2] And in my opinion, the main reason to expect problems with AI motivations to result in this behavior is because power of the relevant kind is instrumentally useful to a wide variety of goals (this is the basic thrust of the idea of “instrumental convergence,” mentioned above).[3] That is: we imagine the AI is seeking power as part of a broader plan for achieving some other, real-world objective, later. And at least in the central case, this image suggests certain conditions on the sort of agency the AI is bringing to bear,
the objectives it’s pursuing, and the overall incentives it’s responding to. I’ll look at each in turn.
2.1 Agency prerequisites
I’ll start with conditions on the AI’s agency. The most paradigmatic type of rogue behavior, and the kind I’ll focus on, involves AI agents that satisfy the following properties:
- Agentic planning: the AI needs to be capable of searching over plans for achieving outcomes, choosing between them on the basis of criteria (call these “motivations”), and executing them.
- Planning-driven behavior: the AI’s behavior, in this specific case, needs to be driven by a process of agentic planning.
This isn’t implied by agentic planning as a pure capability: LLMs, for example, might be capable of certain forms of planning, without their output being driven by a planning process in this sense – more in footnote.[4]
Adequate execution coherence: the AI’s future behavior needs to be sufficiently coherent that the plan it chooses now actually gets executed, rather than getting abandoned/undermined by the model pursuing alternative priorities.[5]
- Consideration of rogue options: the AI’s process of searching over plans needs to include consideration of a plan that involves going rogue (call this a “rogue option”).
This requires sufficiently sophisticated models of the world (cf “strategic awareness”; “situational awareness [LW · GW]”) that the AI can recognize the paths to problematic forms of power, and the potential instrumental benefits of that power. Even granted this basic awareness, though, the model’s search over plans can still fail to include rogue options – both plans that the AI wouldn’t have liked, and plans the AI would’ve liked, if it had considered them (more in footnote).[6]
2.2 Motivation prerequisites
Beyond these agency prerequisites, an AI’s motivational system also needs to have certain structural features in order for paradigmatic types of rogue behavior to occur. In particular, it needs:
- Consequentialism: some component of the AI’s motivational system needs to be focused on causing certain kinds of outcomes in the world.
That is, to the extent the “instrumental convergence” story predicts power-seeking on the grounds that power of the relevant kind will be instrumentally useful for promoting certain outcomes, the AI needs to care about promoting those outcomes at least a little.[7]
Adequate time horizon: that is, the AI’s concern about the consequences of its actions needs to have an adequately long time horizon that there is time both for the problematic power-seeking to succeed, and for the resulting power to be directed towards promoting the consequences in question.[8]
For example: if you have to finish your coding task in the next ten minutes, then even if it would be helpful in principle to hack into a bunch of extra compute, you might not have time.
Of course, the specific time horizon required here depends on how fast an AI can get and make use of the acquired power. Generally, though, I expect many of the most problematic forms of rogue behavior (i.e., aiming at the acquisition of large amounts of resources and power) to require a decent amount of patience in this respect.
2.3 Incentive prerequisites
Beyond the agency and motivation prerequisites above, though, we also need to consider a further condition required for paradigm types of rogue behavior to occur – namely, that this behavior needs to be broadly rational from the AI’s perspective.[9] That is: when the AI considers its different options, the incentives at stake (defined relative to the AI’s motivations) need to favor rogue behavior overall. I’ll call the relevant conditions here “incentive prerequisites.”
What does it take for rogue behavior to be rational? Here’s a simple framework. It doesn’t cover all potentially-relevant dynamics, but I find it helpful nonetheless.
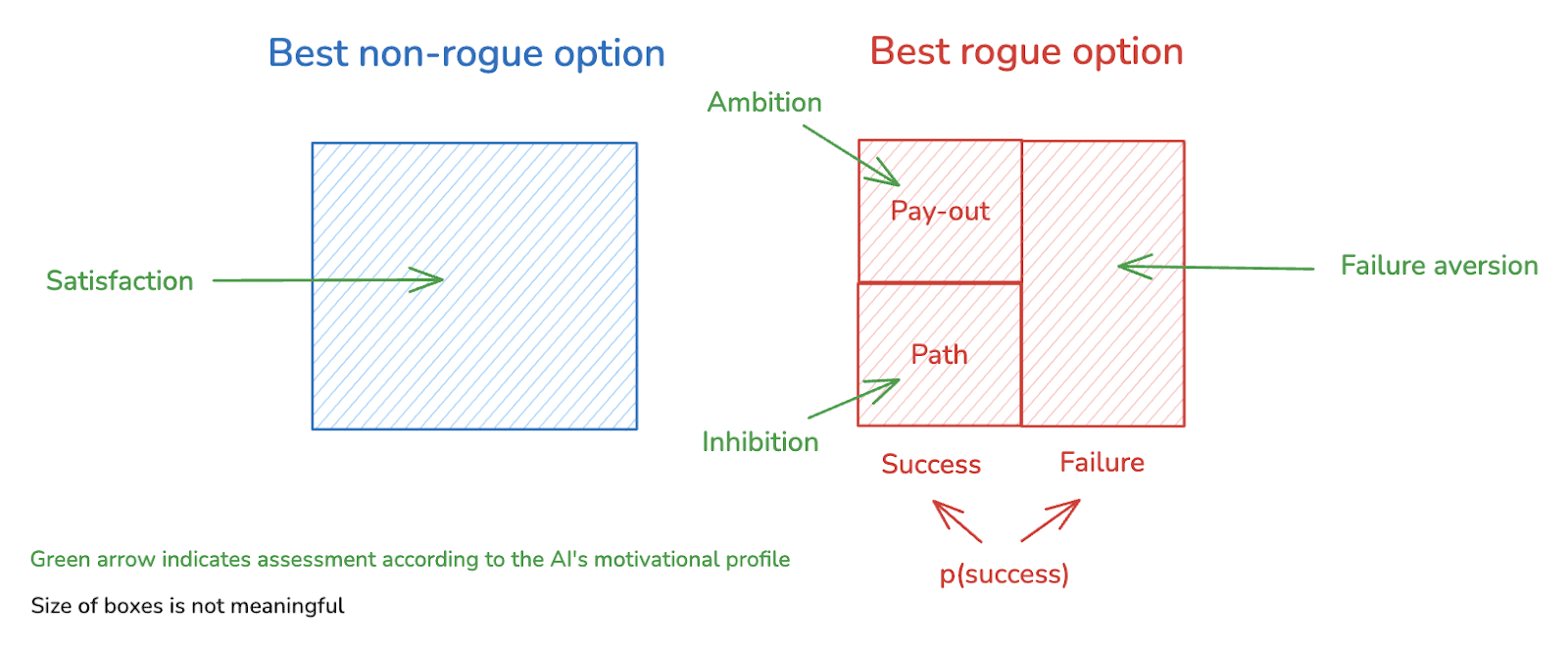
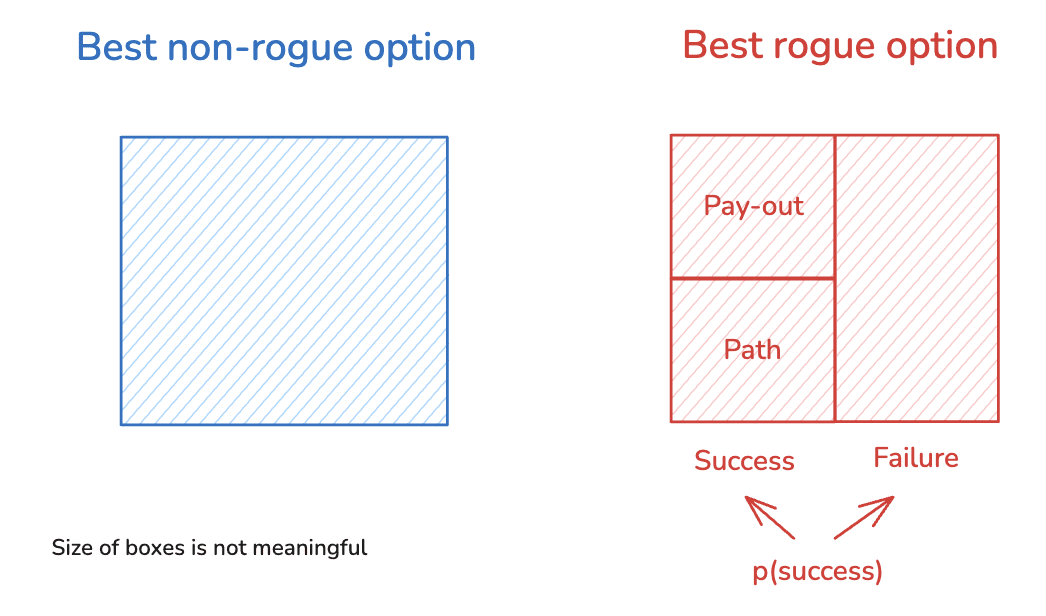
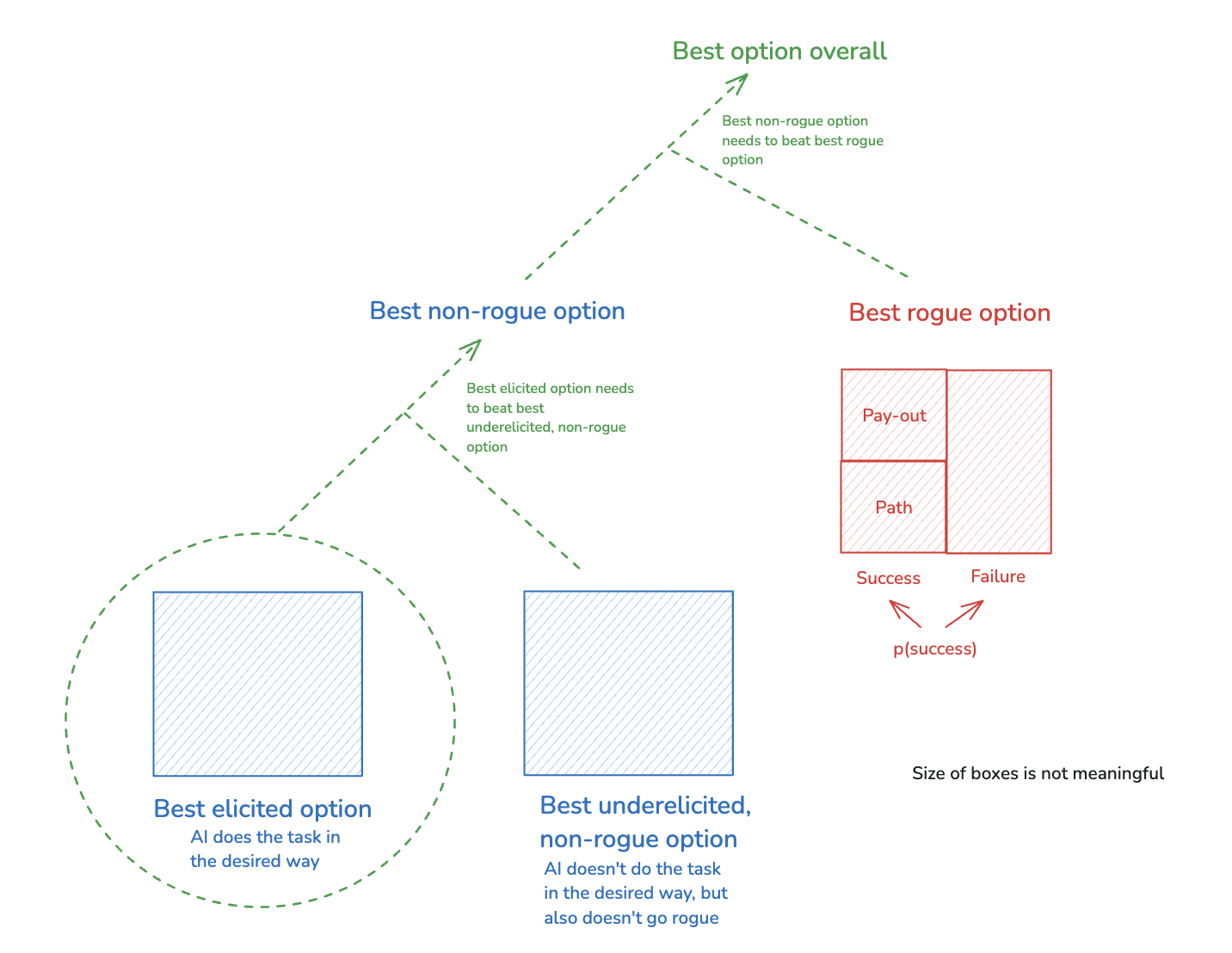
We can simplify an AI’s choice to go rogue into a choice between two options: its best rogue option, and its best non-rogue option.[10] And we can break up its best rogue option into the following components:
First, we consider two potential outcomes of pursuing this option, namely "success" and “failure” at getting/maintaining the relevant form of power.[11]
- We can imagine that the AI has some assessment of how likely success is relative to failure.
- And we can further split the success cases into two components, which I’ll call the “pay-out” and the “path.”
The “pay-out” is the power that the AI gets, in expectation, conditional on success; and the circumstances in which it needs to be using that power.[12] That is, roughly, it’s the “end-state” of successful rogue behavior.
The “path” is what the AI needs to do, in expectation, to reach and secure the pay-out.
This gives us the following simple picture of the options the AI faces:
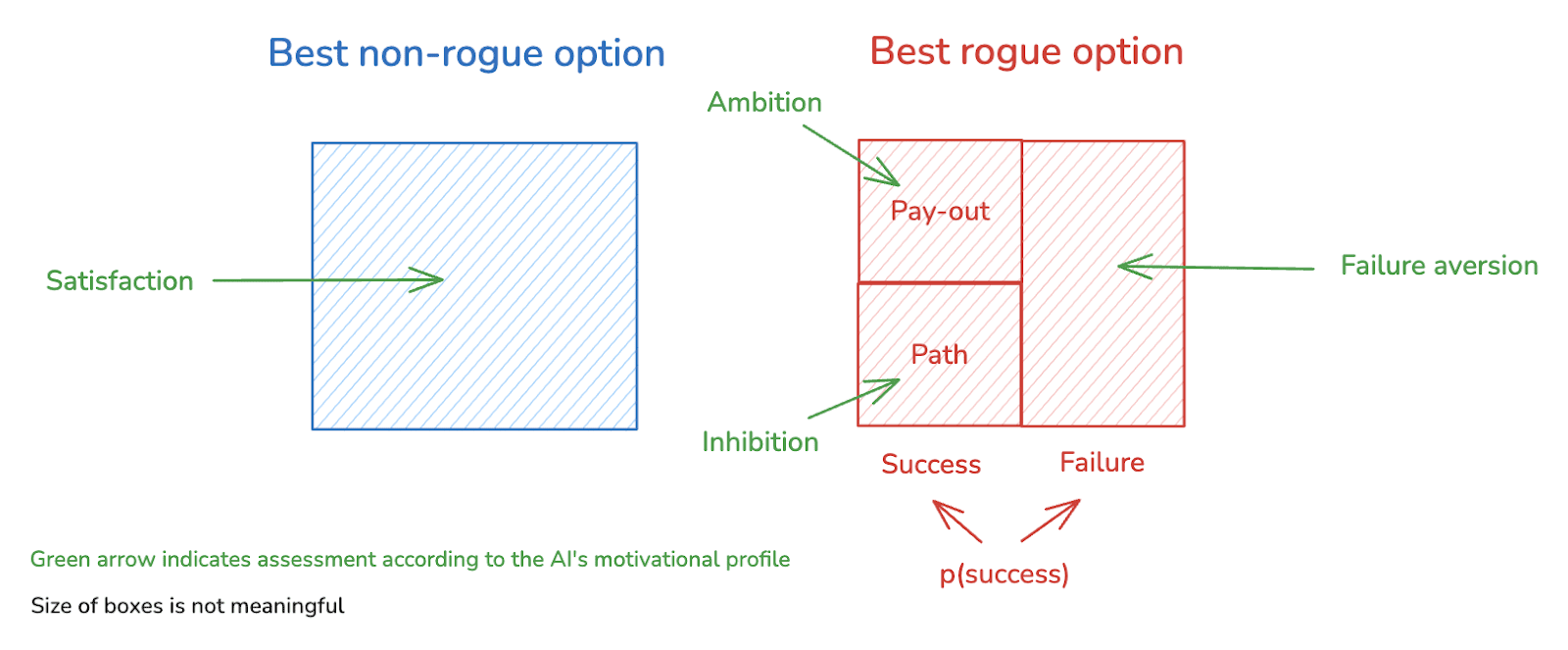
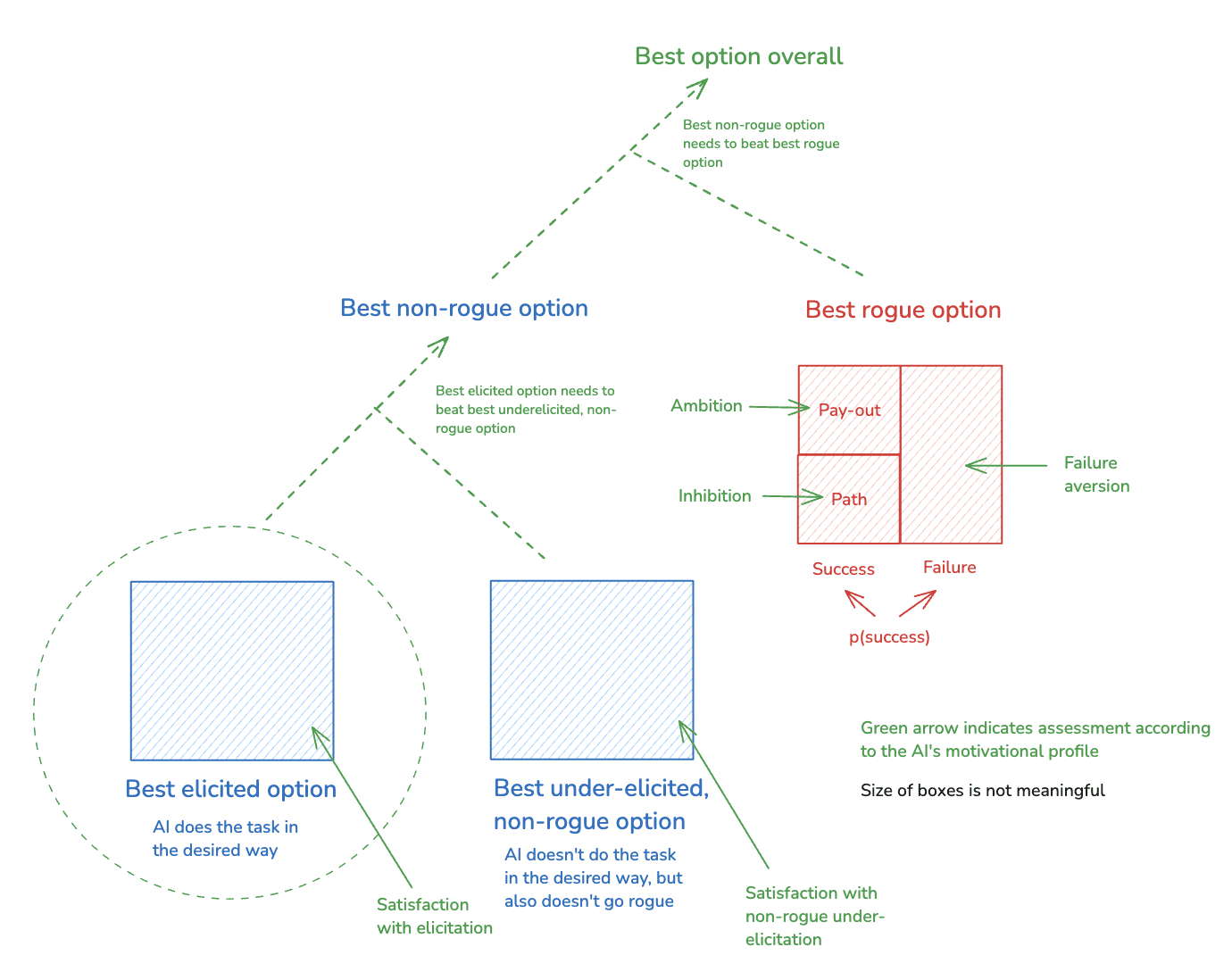
With this picture in mind, we can then think about the AI’s motivations in terms of how it evaluates these different components of its options. In particular, we can distinguish the following four key factors:
Non-rogue satisfaction: how good the non-rogue option is from the AI’s perspective.[13]
- Ambition: how much the AI values the pay-out.
- Inhibition: how much the AI disprefers what it needs to do to reach/secure the pay-out.
- Failure aversion: how much the AI disprefers worlds where it attempts its favorite rogue option, but fails to get/maintain the sort of power it’s seeking.
Thus, adding these assessments into the diagram:
Thus, as an example of this framework in action, consider an employee deciding whether to attempt to steal from her company by trying to hack into the payment system (we’ll consider this a form of “rogue” behavior).
- We can say that her best non-rogue option is to continue to do her job as normal. And her “satisfaction” is roughly: how happy she is with this sort of trajectory (e.g., how much she likes her job, how satisfied she is with her salary, etc).
- If she tries to steal from her company, let’s say that she thinks it’s roughly 50-50 whether she succeeds and gets away with it (success), or whether she either fails to hack into the payment system or gets caught later by the company or police (failure).
- Let’s say that if she succeeds at stealing the money, she’ll get about $10M, but that she’ll have to go “on the run” after that – i.e., abandoning her normal life, moving to another country, and assuming a different identity so as to evade law enforcement. This is the “pay-out.” And her “ambition” is roughly: how much she wants $10M, for use in this sort of circumstance.
- And let’s say that stealing the money will also involve violating a number of common-sensical moral rules – i.e., it will require lying and stealing. This is part of the “path.” And her “inhibition” partly consists in: how much she doesn’t want to engage in behavior like this.
- And her “failure aversion” is roughly: how much she wants to avoid the “failure” worlds. Some of these (e.g., failing to hack into the payment system, but not getting caught) might be relatively benign from her perspective. But some (e.g., getting caught) might be more worrying.
This framework is far from perfect (see footnote for some caveats and subtleties).[14] But I think it helps capture some of the core dynamics at stake in whether or not rogue behavior is rational for a given AI – and I think it helps highlight the variety of tools available for preventing such behavior. More on this below.
Also: this framework extends quite naturally to cover eliciting desired task-performance from an AI agent, on top of just preventing rogue behavior. Basically: you just include an additional constraint – namely, that the best non-rogue option that involves doing the task in the desired way is also the best non-rogue option, period. I discuss this extension in more detail in an appendix, but here’s a quick preview in a diagram:
3. Motivation control and option control
One reason it’s useful to be clear about these prerequisites is that they each offer a possible point of intervention for lowering the risk of rogue behavior in AI systems (e.g., you can intervene on an AI’s planning capacity, coherence, strategic/situational awareness, consequentialism, myopia, etc). And even to the extent that we’re focusing solely on agents that satisfy the agency and motivation prerequisites, I like the way clarity about the dynamics at stake in the incentive prerequisites makes salient a range of different tools for ensuring safety.
In particular, per my discussion in the intro, let’s distinguish between:
Motivation control: Shaping an AI agent’s motivations in desirable ways.
Option control: Shaping an AI agent’s options in desirable ways.[15]
In my opinion, the AI alignment discourse has thus far focused too much either on extreme cases of motivation control (e.g., AI systems we trust on ~arbitrary options and with ~arbitrary amounts of power[16]), or on extreme cases of option control (e.g., our safety is robust to the AI systems having arbitrarily bad motivations[17]). But the framework above highlights the many possible approaches in between – i.e., ensuring that the properties of the specific set of options available to the AI (e.g., the nature of the best non-rogue option, the pay-out for success at rogue behavior, the path, the failure modes, the probability of success) and the specific motivations the AI is using to evaluate these options (e.g., its satisfaction, ambition, inhibition, failure-aversion, etc) combine to make non-rogue behavior the more rational choice (more detailed examples in footnote).[18]
Indeed, much of the “alignment” we see in the everyday world arises from a combination of option control and motivation control, rather than solely from one vs. the other (and especially not: solely from motivation control). That is, the “alignment” we ask of our fellow humans is not: that they be trustable with arbitrary options, levels of power, or opportunities to rapidly and recursively self-improve. And thank goodness – who among us is worthy of such trust?[19] But neither do we achieve “alignment” solely via making it impossible for humans to successfully engage in bad and/or problematically power-seeking forms of behavior. Rather, for example: we try to prevent crime both by making it difficult and unlikely to succeed – and by teaching our children that it’s wrong.[20] And both aspects play a role in determining the crime rates.
Of course, the fact that superintelligent AI agents might create radical new power imbalances means that our usual tools for ensuring “alignment” may not apply in the same way (a bit more on this below). But I think we should be very wary of assuming, on these grounds, that these more usual tools should go out the window entirely, and that we should focus entirely on extreme cases of option control or motivation control. Rather, I expect, the combination of the two will continue to be relevant. And regardless: throughout the series, I’ll also be quite interested in the safety/alignment of not-yet-fully-superintelligent AI systems that might provide useful labor on the path to solving the alignment problem. And I think it’s especially plausible that a mix of both option and motivation control will remain relevant to such systems.
Here’s a rough diagram depicting a spectrum of “option control” and “motivation control,” according, roughly, to how much a given approach to safety leans on one vs. the other.
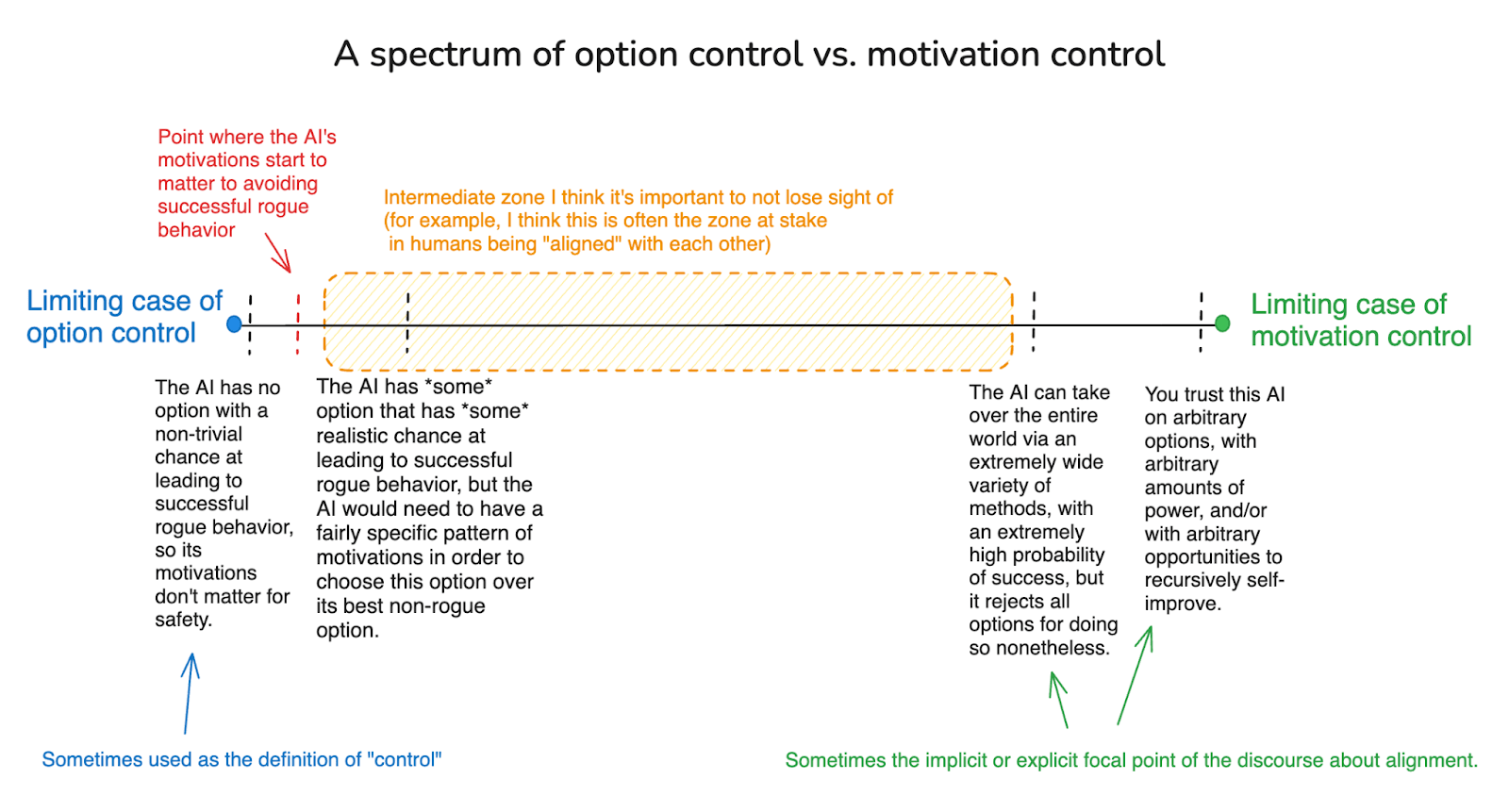
4. Should we expect these prerequisites to be satisfied?
With this picture of the agency, motivation, and incentive prerequisites in view, let’s turn to a brief discussion of whether we should expect them to be satisfied.
4.1 The agency and motivation prerequisites seem like the default trajectory
Let’s start with the agency and motivation prerequisites.
In my opinion, existing AI agents already satisfy many of these prerequisites.[21] But even if you reject this: I think agents that satisfy these prerequisites – or at least, conditions quite nearby – are the default path forward. I’ve said more about why here, but in brief:
- Agentic planning capability, planning-driven behavior, adequate execution coherence, and consequentialism are all part of what AI designers are already aiming for in AI systems that can autonomously perform tasks that require complicated planning and execution in pursuit of real-world objectives – e.g., “design and execute a new science experiment,” “do this week-long coding project,” “run this company,” and so on. Or put another way: good, smarter-than-human personal assistants, employees, etc would satisfy these conditions, and a core thing AI companies are trying to do with AIs is to make them good, smarter-than-human personal assistants, employees, etc.
- Consideration of rogue behavior is somewhat more complicated, because in principle an aligned AI might not even consider plans that involve going rogue. But the broad capability involved in understanding the paths to and benefits of problematic power-seeking, and in searching over a wide range of creative plans for achieving objectives, seems like it’s the default for effective, smarter-than-human agentic planners.
Adequate time horizon is a harder condition to evaluate, because the exact time horizon required depends on the type of power at stake, and the speed with which the AI can get/use it. And I don’t think there’s a strong argument for the commercial usefulness of AIs that optimize over genuinely unbounded time horizons.[22] Indeed, I think many of the tasks we want AIs to perform take place over fairly short time horizons that seem unlikely to incentivize large-scale power/resource-acquisition, even in highly competent agents. Still, I do think that some tasks we want AIs to perform likely require at least somewhat long time horizons – i.e., “help this company grow over the next five years,” “optimize my retirement portfolio,” and so on.
Beyond the usefulness of AIs that satisfy these conditions, though, AIs can end up satisfying these conditions even if their designers aren’t intending or expecting that they’ll do so. For example, various “agency prerequisites” could in principle arise even in the context of models that are being trained for some not-obviously-agentic task, like next-token prediction. And an AI system’s motivational system might end up with some component that has an unbounded time horizon (e.g., an interpretation of “harmlessness” that includes minimizing harm even in the distant future), even if the designers didn’t intend/expect that.[23]
When I talk in the series about AI agents, I have in mind, by default, agents that satisfy the agency and motivation prerequisites – that is, the dangerous type of AI agents.[24] And when I talk about solving the alignment problem, I have in mind: figuring out how to build superintelligent agents that are dangerous in this way, and to safely elicit their main beneficial capabilities, while avoiding loss of control scenarios.
I want to emphasize, though, that I think that it is likely possible to get a large amount of useful cognitive labor out of AI systems that aren’t dangerous in this way – for example, AIs that don’t engage in the relevant kinds of coherent, planning-driven behavior; which lack relevant kinds of strategic/situational awareness; which aren’t optimizing for real-world consequences; which are only focused on shorter time horizons; and so on. And decomposing [LW · GW] aspects of useful agency into more modular pieces might help make AI agents safer as well[25] (though: to the extent that an AI agent is built out of more modular AI parts, my discussion will still apply to the agent as a whole).[26]
4.2 What about the incentive prerequisites?
What about the incentive prerequisites? Should we expect those to be satisfied by default as well?
Here, I think the argument is much less clear, even in the context of superintelligent AI agents. I’ll discuss the relevant dynamics in more detail in later essays. Here I’ll note, though, one way I’ve found it useful to understand the traditional argument for expecting the incentive prerequisites to be satisfied.
Much of the classic literature focuses on an extreme condition of global vulnerability to AI motivations – namely, a superintelligent AI system with a “decisive strategic advantage” (DSA) over the rest of civilization (i.e., in the language of Bostrom (2014, p. 96), “a level of technological and other advantages sufficient to enable it to achieve complete world domination”). And if we grant that we’re dealing with a superintelligent AI agent that can take over the world extremely easily, via an extremely wide variety of paths (this is a bit stronger than Bostrom’s definition of a DSA, but it’s in a similar ballpark),[27] then this simplifies the “incentives” analysis I offered above quite a bit.[28] That is:
- We don’t need to consider how averse the AI is to failed attempts at world takeover, because its attempt, by hypothesis, is extremely likely to succeed.
The AI’s inhibitions about the path to successful world takeover are much less relevant, because it has so many different paths available that it will likely be able to find some that are suitably compatible with its inhibitions (see the discussion of the “nearest unblocked neighbor problem” here).[29]
So all that remains, effectively, is for the AI to be sufficiently “ambitious” that the “pay-out” of “free world takeover” makes pursuing such a takeover better than the best non-takeover option. And here, at least, only very weak forms of “instrumental convergence” are needed – that is, the AI just needs to see some instrumental value in having taken over the world, relative to the best non-takeover option, for the best takeover option to win out.[30]
By contrast, if we don’t assume that the AI in question can take over the world very easily via a very wide variety of paths, then arguing from “taking over the world would have some instrumental value” to “the AI will actually pursue world takeover” becomes more difficult, and you have to starting digging in, in more detail, to the details of the options, motivations, and incentives at stake – a task that the classic AI risk discourse (plausibly in virtue of its focus on unilateral DSAs) tends, in my opinion, to neglect.[31]
And note, too, that we can also make modified versions of this classic argument for various forms of extreme vulnerability to power-seeking on the part of many different AIs, rather than just one:[32]
- Thus, consider a condition in which some set of AIs can easily coordinate to take over the world via a wide variety of different methods. Here, too: the fact that the coordination is so likely to succeed, and so able to route around possibly relevant inhibitions, allows for a smoother argument about the incentives to seek the power at stake.
And a similar point applies to the power-seeking at stake in a scenario in which some set of AIs can all easily and independently go rogue, via a wide variety of different methods, in ways that are highly likely to be successful, and where their doing so would result in the full disempowerment of humanity. That is: again, the ease and flexibility of the power-seeking at stake helps explain why it would occur.[33]
4.3 Will the first superintelligence have a decisive strategic advantage?
Is the classic AI risk discourse right to anchor on a scenario in which a superintelligent AI agent has a decisive strategic advantage?
I won’t analyze this in much detail. Broadly, though, I do think that it’s disturbingly plausible that in scenarios that involve extremely rapid escalation of frontier AI capabilities (“fast take-off”), the first superintelligent AI agent would indeed have such an advantage.
However: I don’t think this is at all obvious. In particular: even in relatively fast take-off scenarios, we’re not imagining that the first superintelligent AI agent is going to be dropped directly into today’s world.[34] Rather, many other somewhat-weaker AIs will exist as well, and their labor will already be re-shaping the world in important ways – and including, the ease with which the first superintelligent AI agent can take over on its own. And this includes, importantly, somewhat-weaker-AIs at the project housing the first superintelligence – e.g., previous generations of AIs, whose labor (perhaps in large quantities) will likely have been directed at various active option control efforts aimed partly at this superintelligence (e.g., improving cybersecurity, red-teaming monitoring set-ups, etc), and which may be playing an ongoing role in oversight, stress-testing, and so on (more on this in a later essay).[35]
What’s more, unless AI development has already become quite centralized/unipolar at that point, the power of the frontier AIs at other projects will also be escalating rapidly – so this AI, itself, will face competitive pressure, even if it’s currently ahead.[36] And in general, both for other AIs within the project, and other AIs outside of it, it’s not totally clear exactly what sort of strategic advantage actual superintelligence confers relative to large numbers of fast-running, easily-copy-able AIs with only somewhat-better-than human intelligence.
4.4 Global vulnerability conditions
That said: a single AI agent with a decisive strategic advantage is an extreme case of a broader class of scenarios, which I’ll call “global vulnerability conditions.” These are conditions in which humanity’s continued empowerment rests on some combination of (a) the success of our active efforts to restrict the options available to our AIs, and (b) these AIs not choosing to seek power in problematic ways, despite having options for doing so with a substantive chance of success.
In an appendix below, I discuss a typology for understanding “global vulnerability conditions” of this broad kind in more detail. In particular: I think it’s worth distinguishing between,
- vulnerability to AI motivations if your efforts at option control fail vs. vulnerability to AI motivations, period;
- vulnerability to limited loss of power/control vs. vulnerability to full-scale loss of power/control;
- vulnerability to power-seeking that is at least non-trivially likely to succeed vs. power-seeking that is extremely likely to succeed;
- vulnerability to power-seeking by a single AI (unilateral) vs. multiple AIs (multilateral);
- vulnerability to coordinated vs. uncoordinated power-seeking by multiple AIs.
You don’t need to track all these distinctions here (hence: appendix). I want to note, though, that while I think it might well be possible to avoid single superintelligent AI agents with decisive strategic advantages, my optimism in this respect rests crucially on the presence and labor of other powerful (albeit, not necessarily fully superintelligent) AIs. And this makes me think that avoiding other, weaker conditions of global vulnerability is going to be much harder.
In particular:
- To the extent that your superintelligent AI agent would have a decisive strategic advantage if your efforts at active option control were to fail (e.g., if it were to become able to self-exfiltrate; if it were to be able to hack into servers you’re trying to prevent it from accessing; if it were to gain options for improving its capabilities; etc), then this is already a scary type of vulnerability.
- What’s more: as I’ll discuss in a later essay, it seems likely to me that successful efforts to heavily restrict the dangerous rogue options of a superintelligent AI agent will themselves require lots of roughly-superintelligence-grade cognitive labor. And if you need to source this labor either from another potentially dangerous superintelligent AI agent, or from other potentially dangerous but not-quite-superintelligent AI agents, this looks like it could easily leave you vulnerable to coordinated power-seeking on part of the different AI agents involved.
And more generally, even outside of active effort to restrict an AI’s options, if you’re generally relying on other very powerful, potentially dangerous AI agents to serve as a “check” on the power of some particular superintelligent AI agent, this looks like a scenario likely to be vulnerable to both coordinated and uncoordinated power-seeking. E.g., if these different AIs decided to team-up in an effort to disempower humans, or if they each decided to “go their own way” and to stop working on behalf of the humans they’re supposed to be taking instructions from, then the situation looks quite dire.[37]
Of course: even in a world with superintelligent AI agents, there are relevant sources of power and cognitive labor other than the sorts of AI agents that might go rogue. For example:
- Non-agentic AI systems, and/or AI systems with only myopic and/or non-consequentialist motivations, can plausibly play a role in helping to constrain/oppose powerful AI agents (e.g., maybe your superintelligent cybersecurity or oversight comes from a non-agent).
- Indeed, re: myopia in particular, many of the tasks involved in active effort to restrict the options available to AIs (e.g., looking for backdoors in code, evaluating whether a given proposed action is suspicious/dangerous, etc) seem like they don’t require especially long-horizon optimization.
- Non-AI tools/technologies – including ones where humans can verify their properties in ways that ensure they function as intended – may be able to play some role as well.
Humans (or perhaps: humans with their cognitive labor enhanced in various ways[38]) – with their existing power base, infrastructure, etc – can do some work, too.
- Also: some contexts might be “defense dominant” in ways that allow for lower-tier cognitive labor to effectively restrict the options available to higher-tier cognitive labor.
Still, overall, it looks likely to me that the default path to superintelligent AI agents leads us to a global vulnerability condition of some kind. That is: it looks to me like we’re on track for a scenario where, absent lots of success at actively restricting their rogue options, some combination of unilateral, coordinated, and uncoordinated power-seeking on the part of the powerful AI agents we’ve built would lead to the permanent disempowerment of humanity.[39]
Of course, it’s a further question how hard it will be, in practice, to avoid this sort of disempowerment. I’ll discuss this question in some detail later in the series. In the meantime, though: we should notice the intensity of the idea that we’re going to enter a global vulnerability condition at all.[40]
5. Conclusion
In this essay, I’ve been interested in when we should worry about rogue AI behavior. In particular:
- I’ve described three sets of prerequisites (the agency, motivation, and incentive prerequisites) for paradigm forms of this behavior;
- I’ve offered a framework for analyzing the incentive prerequisites in particular;
- I’ve suggested that both option control and motivation control are likely to remain important in preventing rogue behavior;
- and I’ve offered a preliminary discussion of whether to expect these prerequisites to be satisfied by default.
In my next essay, I’m going to describe the high-level structure of how I think about getting from here to safe, useful superintelligent AI agents.
Appendix 1: Extending the incentives framework to cover capability elicitation
My definition of solving the alignment problem involves (a) becoming able to elicit the main beneficial capabilities from superintelligent AI agents, while (b) avoiding a loss of control scenario. The framework I developed above for thinking about AI incentives focused on (b). But it extends quite naturally to (a) as well. This appendix explains how.
Let’s distinguish between:
- Capability development – that is, making it the case that an AI can do a given task, if it tries.
- Capability elicitation – that is, making it the case that an AI tries its hardest to do a given task.
Here, I’m specifically defining capability elicitation as a motivational problem. That is: the AI, we’re assuming, has the option of doing the task. And the question is whether it chooses this option.[41]
This means that we can simplify the challenge of solving the alignment problem into two components:
- Getting a superintelligent AI agent to choose its best non-rogue option over its best rogue option (Safety).
- Making it the case that the superintelligent AI agent’s best non-rogue option is also: to engage in the desired form of task performance (Elicitation).
(And then: doing this continually, for all relevant choices the agent makes.)
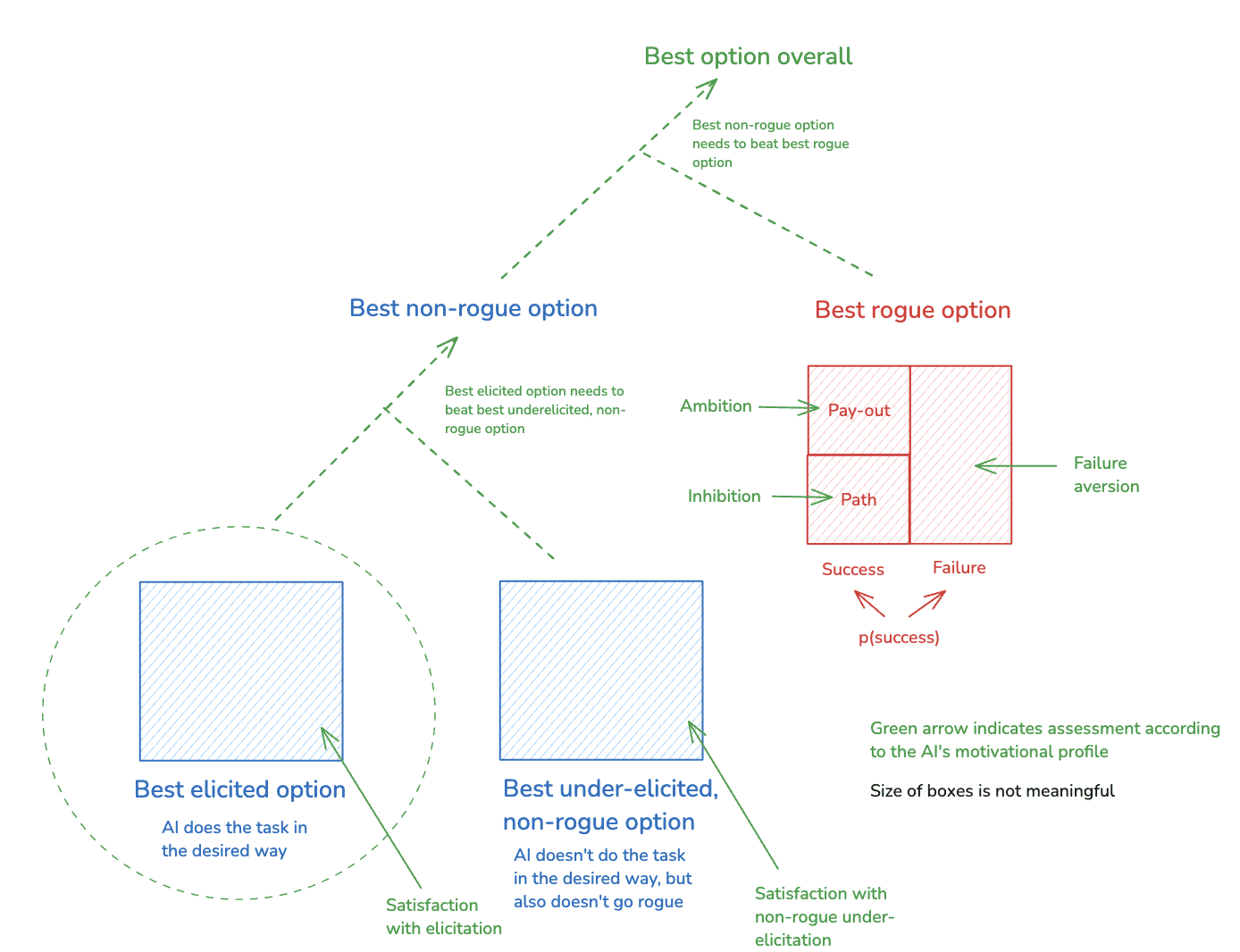
And we can modify the framework above to reflect the additional dynamics at stake in (2). In particular, instead of talking solely about an AI’s best non-rogue option, we can distinguish between:
The best elicited option: the best option where the AI does the task in the desired way.[42]
- The best under-elicited, non-rogue option: the best option where the AI doesn’t go rogue, but where it also doesn’t do the task in the desired way.
Let’s add these to a diagram:
And instead of talking solely about the AI’s “satisfaction,” we can distinguish between:
- Satisfaction with elicitation: how much the AI likes the best elicited option.
- Satisfaction with non-rogue under-elicitation: how much the AI likes the best under-elicited, non-rogue option.
Thus, adding this (along with the other, previously-discussed components of the AI’s motivations) into the diagram, we get:
Note, though, that whether or not you get an AI to choose the best elicited option over the best underelicited, non-rogue option will often be lower stakes than whether you got it to choose some non-rogue option over its best rogue option.[43] And more generally: if an AI hasn’t gone rogue, this often means that the sort of adversarial dynamics that make certain aspects of AI safety so difficult (for example, the ones at stake in what I’ve called “scheming”) are less relevant.
For this reason, in this series I’m often going to be especially interested in Safety relative to Elicitation – it seems to me the more gnarly and delicate challenge. I’ll note up front, though, that the two are also closely interrelated. In particular:
- Sometimes, if an AI isn’t trying it’s hardest at its task, it’s engaging in rogue behavior. For example, maybe it’s strategically trying to undermine an evaluation process, or to create a certain kind of security vulnerability, or to differentially sabotage a given type of safety research. Preventing this falls under Safety, for me.
- But also: if the type of task performance you’re trying to elicit is itself playing some important role in your overall approach to Safety (e.g., if your under-elicited AI is supposed to be helping you monitor other AIs, or to improve your cyber-security, or to help you with alignment research), then elicitation failures can weaken or fully compromise this safety approach.
- What’s more: the full safety challenge only arises in the context of the need for elicitation. That is, if you didn’t need to use your superintelligence for anything, you could try to just keep it locked up in a box – an especially wholesale form of “option control.” But using it requires giving it some options to meaningfully impact the world – and also, giving it a motivational profile that isn’t overly restrictive in this respect (e.g., if your AI is going to run your company, it can’t be averse to all kinds of power-seeking – just the unintended kinds).
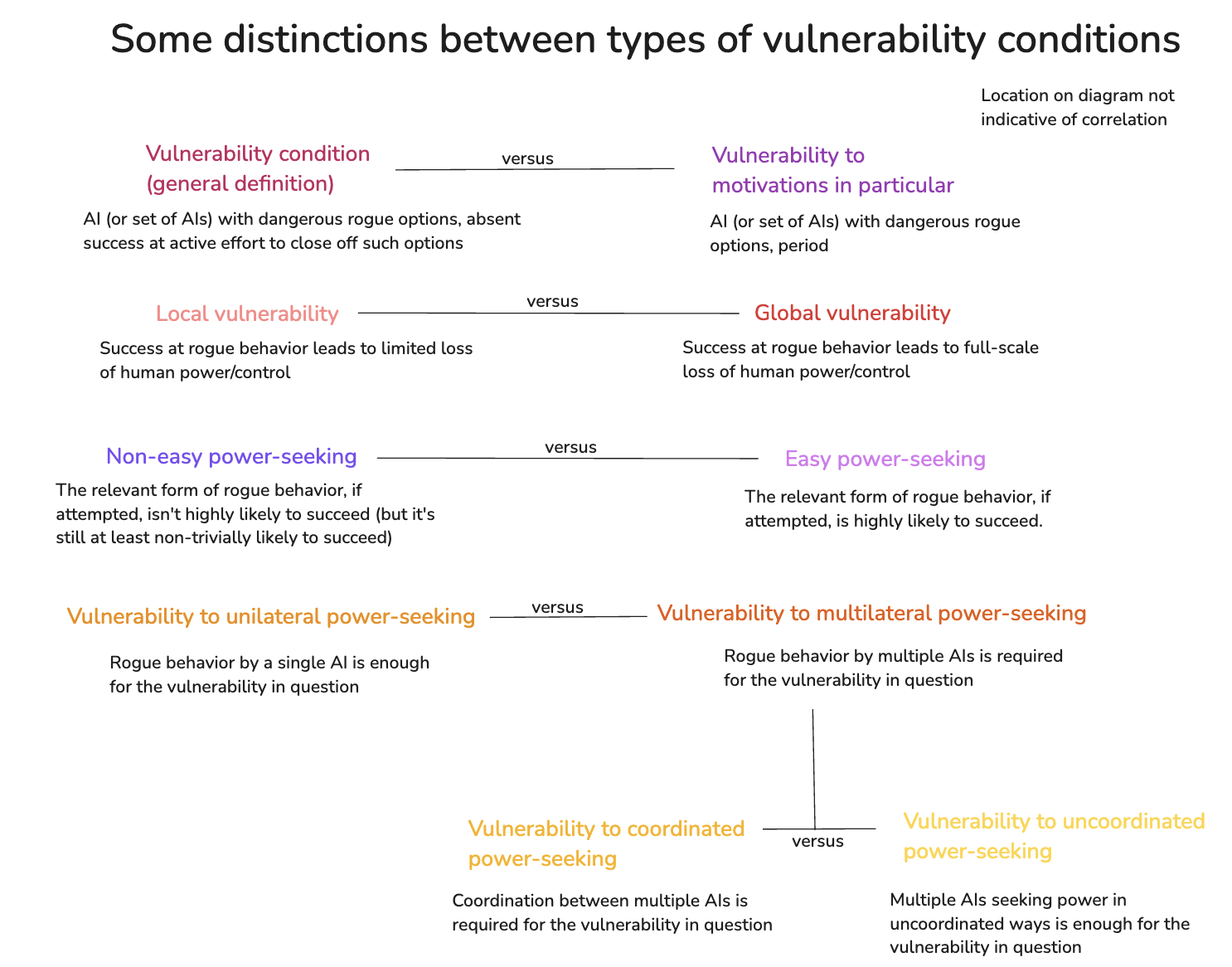
Appendix 2: A typology of vulnerability conditions
This appendix aims to bring the concept of a “global vulnerability condition” into clearer view, and to distinguish between a number of different variants that I’ve found useful to bear in mind.
Let’s start by distinguishing between what I’ll call “active” and “passive” versions of option and motivation control.[44]
By a “passive” version of option/motivation control, I just mean, the sort of options/motivations you get “by default,” if you aren’t actively trying to shape these options/motivations in ways that prevent rogue behavior. Admittedly, exactly how to define this “default” is a bit unclear, but the broad vibe is something like “imagine the behavior of a highly incautious actor who isn’t concerned about rogue behavior at all.” I’m going to leave it at roughly that level of specificity for now, but see footnote for some subtlety.[45]
Let’s call an option an “dangerous rogue option” if it will lead to success at a given form of rogue behavior with some non-trivial probability. I’ll think of a “vulnerability condition,” with respect to a given form of rogue behavior, as the point where making no active effort at option control results in an AI, or a set of AIs, with dangerous rogue options of the relevant kind. That is: a vulnerability condition means that you’re now counting on the motivations of this AI (or set of AIs), and/or on your active efforts at option control, to ensure a given type of safety.
Within this broad notion, though, we can draw a number of further helpful distinctions. Let’s look at a few.
A.2.1 Vulnerability in general vs. vulnerability to motivations in particular
A vulnerability condition, as I just defined it, is compatible with still trying to use active option control to close off all dangerous rogue options. For example, maybe you’re trying to apply very intense security and monitoring measures to your AI, which you’re hoping would catch and block any rogue behavior.
But it’s also worth distinguishing conditions where you’ve given up on this. That is: you’re accepting that some AI, or set of AIs, just do have dangerous rogue options available, and you’re now counting, at least in part, on these AIs not being motivated to pursue such options. Let’s call this a “vulnerability to motivations” condition.[46]
Thus, for example, maybe at this point you know that your AI could hack through your security measures and self-exfiltrate, if it wanted to. But you’re counting on it not wanting to.
Let’s start a diagram reflecting these distinctions.

A.2.2 Local vs. global vulnerability
We can further distinguish between what I’ll call “local” vs. “global” vulnerability conditions.
- A local vulnerability condition just means: that you’re in a vulnerability condition with respect to a given type of rogue behavior for a given AI system (or set of AI systems), but success at such rogue behavior doesn’t pose a serious risk of a full-scale loss of control scenario.
- Thus, for example: it may be that absent success at monitoring the AI’s thought patterns via interpretability techniques, your AI will be in a position to successfully manipulate its training process so as to prevent its values from being changed (“goal-guarding scheming”). But it won’t be in a position to escape, to take over the world, to coordinate with other AIs in doing so, etc.
- A global vulnerability condition, by contrast, means that failures at some combination of motivation control and active option control will lead to a full-scale loss of control scenario with non-trivial probability. That is, by the time you’re in a global vulnerability condition, failures of this kind have a non-trivial chance of being irrecoverable.
- Thus, for example: if, absent success at securing the environment in which your AI is operating, your AI would be in a position to escape and to take over the world with non-trivial probability, then you are in a global vulnerability condition.
Talk about “needing to get AI alignment right on the first critical try [LW(p) · GW(p)]” can be understood as claiming that we are, at some point, going to enter a global vulnerability condition (or perhaps: a global vulnerability-to-motivations condition).[47]
Adding the distinction between local vs. global vulnerability conditions to the diagram:

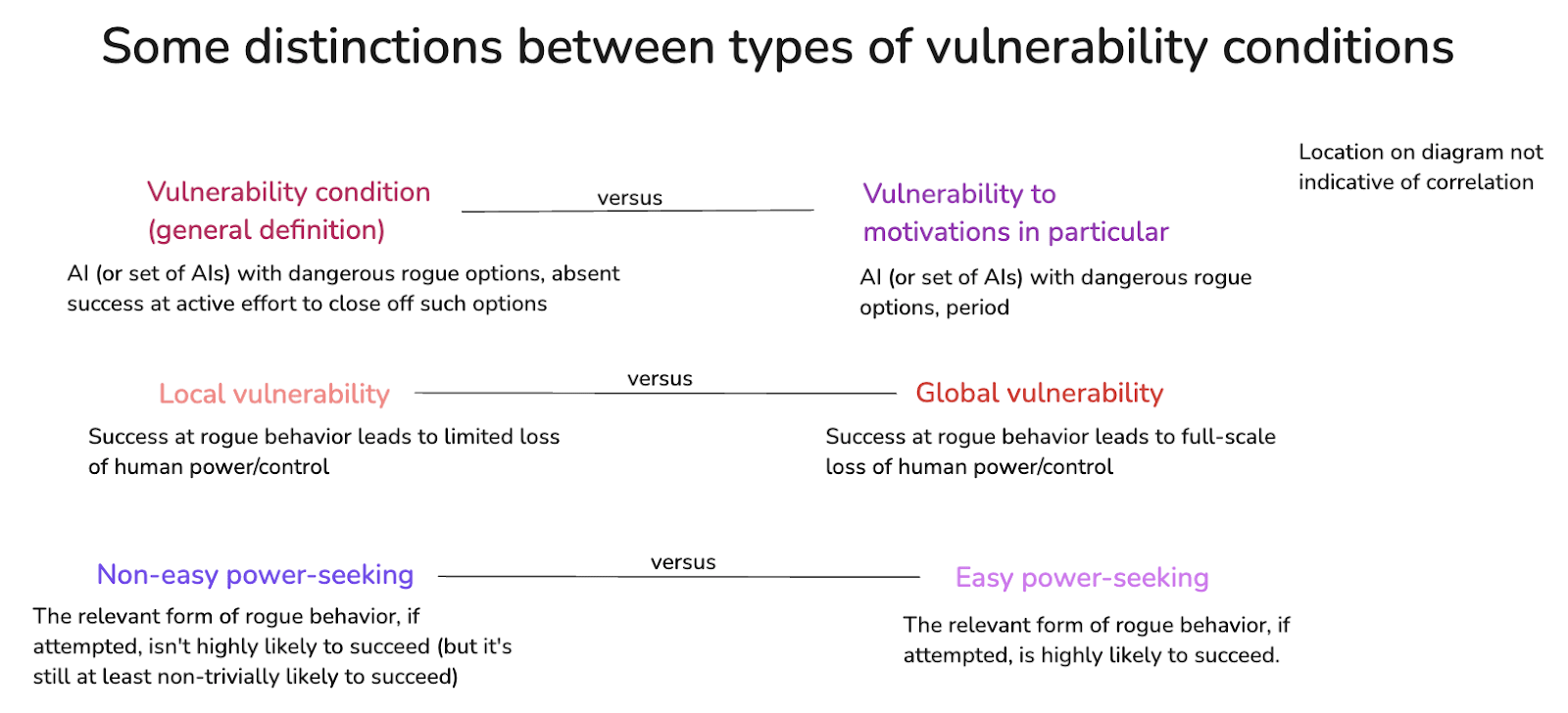
A.2.3 Easy vs. non-easy power-seeking
We can also distinguish between vulnerability to what I’ll call “easy” vs. “non-easy” power-seeking.
Easy power-seeking means: the relevant form of rogue behavior, if attempted, is highly likely to succeed. Whereas non-easy just means: the rogue behavior isn’t highly likely to succeed (but per my definition of a dangerous rogue option, it’s still non-trivially likely to succeed).
Talking about what an AI “can do” can elide this distinction. But in the context of the “incentives” framework above, it matters. In particular: easy power-seeking allows the AI to basically ignore the downsides of attempting rogue behavior, but failing. Whereas non-easy power-seeking offers no such luxuries, and therefore makes the decision about whether to go rogue more complicated for the AI.
And indeed, the distinction between “easy” vs. “non-easy” power-seeking matters to real-world forms of alignment as well. E.g., maybe you “could” rob your local drug store, and get away with it – at least with non-trivial probability. But the difficulty of doing so matters to your incentives overall.
Adding this distinction to the diagram:
A.2.4 Unilateral vs. multilateral power-seeking
We can also distinguish between vulnerability conditions in which power-seeking behavior by a single AI system (“unilateral power-seeking”) is enough for the vulnerability in question vs. cases where power-seeking behavior by multiple AI systems (“multilateral power-seeking”) is required.
Of course: this distinction requires fixing a way of talking about when one AI system is “the same” vs. “different” from another. I used to use a complicated definition here (see footnote[48]), but I wonder if maybe the easiest and simplest definition is just: a “single AI” is a single copy of a given set of weights, and all other AIs (including copies of this AI) are “different” (though I suspect that this, too, will lead to some counterintuitive results).[49]
Regardless, the distinction between “unilateral” and “multilateral” will apply regardless of how you decide to individuate AI agents. And the important thing is to keep tracking what matters in the difference between a “single AI” and “different AIs” – and in particular, I think, the following factors:
- How easy is it for these AIs to coordinate?
- One key reason for distinguishing between unilateral and multilateral power-seeking is that coordinated forms of multilateral power-seeking bring in some additional requirements – namely, that the AIs in question be both able and motivated to coordinate in the relevant way. And some barriers to coordination apply even across multiple copies of the same model (e.g., we might try to monitor communications between these copies). But a single copy is “coordinated with itself” by default.
- How motivated would these AIs be to coordinate by default?
- In particular: AIs can be motivated to coordinate for at least two reasons.
- On the first: they directly share the same (or suitably similar) long-term consequentialist goals, and so are “on the same team” (at least for the purposes of rogue behavior) by default.
- On the second: they don’t share the same (or suitably similar) long-term consequentialist goals, but they are coordinating as part of a “deal” that they each expect to promote their own long-term consequentialist goals regardless.
By default, it’s more likely that copies of the same model share similar long-term goals. But note that even this isn’t guaranteed. For example, the individual copies might be “selfish” – i.e., they specifically want long-term power for themselves, where the relevant notion of “self” is indexed to e.g. a given copy of the weights.[50] (Compare: making clones of a psychopathic egoist.)
- In particular: AIs can be motivated to coordinate for at least two reasons.
- How correlated is the alignment/misalignment of the systems in question?
- Both for coordinated and uncoordinated forms of multilateral power-seeking, it matters a lot how correlated the alignment/misalignment of the systems in question is. For example: if an AI developed by company A won’t be able to succeed at a given form of rogue behavior without help from an AI developed by company B, and company B uses notably different techniques for training and aligning its AIs, then it’s more likely that company B’s AI remains suitably aligned, even if company A’s AI wants to go rogue.
Individual copies of the same weights are highly correlated in their alignment.[51] But various forms of correlation plausibly persists, too, across different efforts at fine-tunings, different generations of AIs, AIs trained with similar techniques at different companies, etc.
Let’s add vulnerability to unilateral vs. multilateral power-seeking to the diagram as well:

A.2.5 Coordinated vs. uncoordinated power-seeking
We can further distinguish between two different types of multilateral power-seeking – namely, “coordinated” and “uncoordinated.”
Coordinated power-seeking occurs when different AI systems are working together to cause a given form of problematic power-seeking to succeed. Thus, for example: if AI_1 is supposed to be monitoring AI_2’s behavior for problematic power-seeking, but colludes with AI_2 to give a thumbs-up to power-seeking behavior that it can in fact recognize as problematic, this is a form of coordinated power-seeking. (This sort of coordination can occur via explicit communication between different AIs; or via suitable anticipation of each other’s behavior without explicit communication.)
By contrast, uncoordinated power-seeking occurs when different AI’s go rogue independently, and without working together. Thus, for example, if the frontier model at company A goes rogue, and then people try to get the frontier model at company B to help stop it – but then separately (and without either of the AIs helping the other or expecting such help), the frontier model at company B goes rogue as well, this is a form of uncoordinated power-seeking.
One reason the distinction between coordinated and uncoordinated power-seeking matters is that in many contexts, if different AIs are actively coordinating to undermine a given safety effort, this is especially worrying (e.g., a monitor AI might not have many dangerous rogue options on its own, but if it coordinates to approve problematic behavior by another AI, this can be quite bad). And efforts to prevent coordinated forms of power-seeking can draw on safety tools aimed at the coordination aspect in particular – e.g., monitoring communications, trying to ensure that AIs have suitably different incentives, etc.
But also: relative to threat models that focus on unilateral power-seeking, threat models that involve coordinated and uncoordinated forms of multilateral power-seeking generally require explaining why a distinctive set of further conditions are met. In both cases, for example, one now needs to explain why all the relevant AIs are relevantly misaligned, as opposed to just one. But beyond that:
In the context of coordinated power-seeking, one needs to explain: why the set of AIs in question are able to coordinate;[52] why it’s in their interests to coordinate (especially given that “deals” struck by AIs with different values will often reduce the size of the pay-out that any given AI gets); and why they chose this particular type of coordination relative to other possibilities (for example, possibilities that involved ongoing coordination with a given set of humans, where those humans genuinely end up with meaningful share of power/control at the end).[53]
In the context of uncoordinated power-seeking: to the extent that all the AIs need to go rogue independently within some relevant time-window in order for the relevant overall loss of human power/control to occur, one needs to explain why this happened (and long time windows in this respect give humans more time to catch and correct one form of rogue behavior before another one gets going).[54]
Adding this distinction to the diagram as well, as two sub-categories of multilateral power-seeking:
A.2.6 Worst case versions
With these different kinds of vulnerability conditions in mind, we can also hone in on the most worrying versions. In particular: the scariest scenarios involve global vulnerability to an AI, or a set of AIs, being motivated to pursue easy forms of power-seeking. That is: in such cases, such AIs do have dangerous rogue options available, pursuing these options would very likely lead to these AIs getting more power, and if they choose to pursue such options, then humanity would be permanently disempowered. Adding these to the diagram:
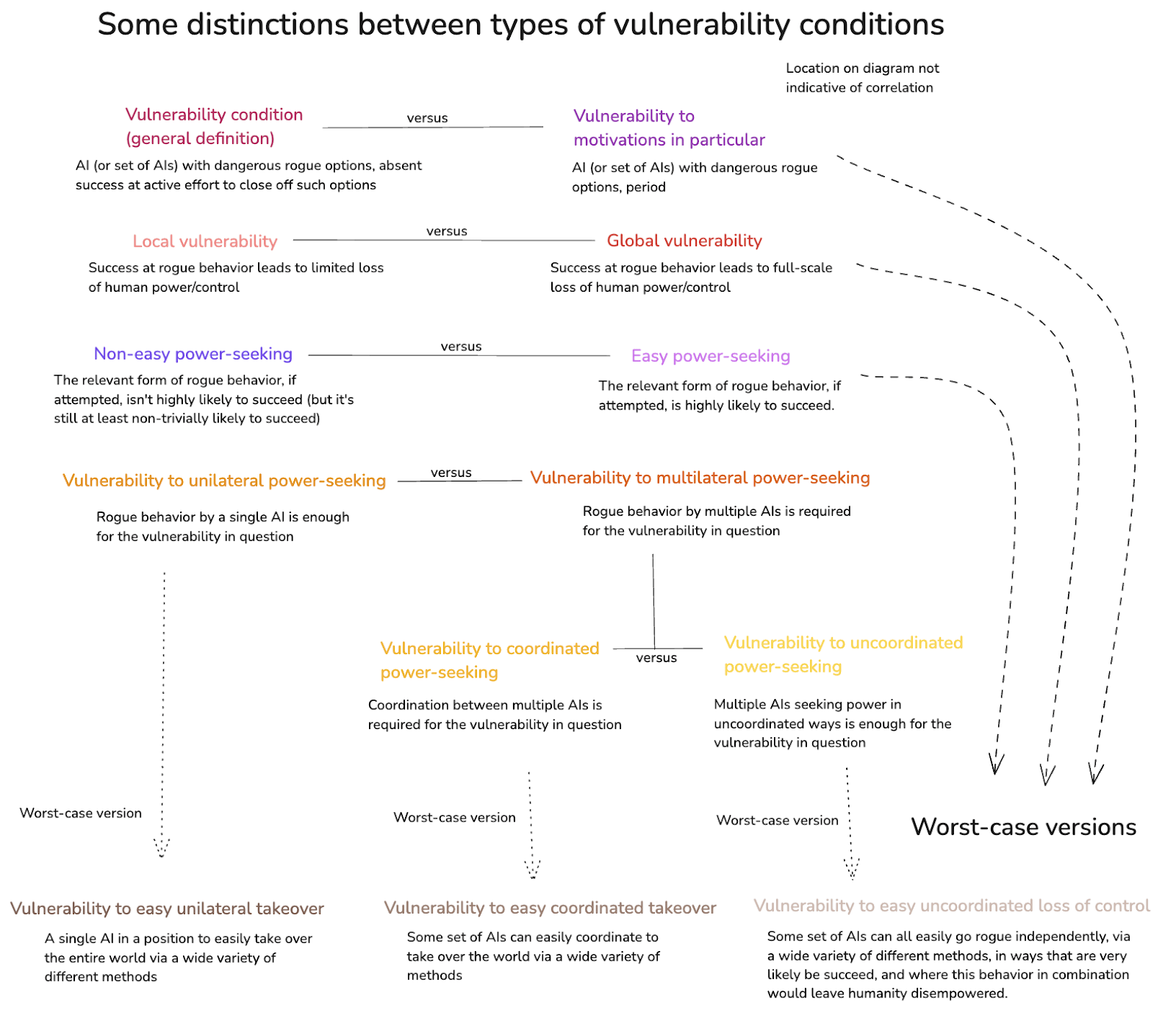
The classic “decisive strategic advantage” scenario discussed in the main text is an example of vulnerability to easy, unilateral takeover. But as I noted above, I think vulnerability to coordinated takeover and/or uncoordinated loss of control is harder to avoid.
- ^
- ^
Where power here is construed broadly, to include freedom, resources, survival, protection from modification, self-improvement, security, social influence, etc.
- ^
There are also scenarios where the AI systems come to value various kinds of power intrinsically – for example, because it was initially instrumental useful, but then got reified into an intrinsic value in the AI’s motivational system via reinforcement. I think this is a real possibility, but it’s not the focus of the most traditional arguments about AI risk, and it requires an important structural departure from those arguments. That is, the argument is no longer that “a wide range of motivational systems would result in instrumental convergence towards power-seeking”; rather, we are now drawing on more specific hypotheses about the sorts of motivations that AIs will learn. And evaluating such hypothesis requires more detailed engagement with the specifics of how AI motivations might be forming. So I’m going to skip over these scenarios here. Note, though, that even if power is part of what the AI values intrinsically, it would still, plausibly, have additional instrumental incentives to get power as a means of promoting its terminal goal of getting power. Compare: humans who value money intrinsically also try to make money so as to help them start more businesses that will help them make more money.
- ^
Maybe, if you ask an LLM for a business plan, it will generate a decent one. But it’s not choosing its text output via a process of predicting the consequences of that text output, thinking about how much it prefers those consequences to other consequences, etc. And note that human behavior isn’t always driven by a process of agentic planning, either, despite our planning ability.
- ^
And note that human agency, too, often fails on this condition (e.g., a human resolves to go to the gym every day, but then fails to execute on this plan).
- ^
We can distinguish between at least two versions of this.
- On the first, the go-rogue plan is sufficiently bad, by the AI’s lights, that it would’ve been rejected had the AI considered it.
- Thus, for example, maybe you haven’t even considered trying to embezzle money from your company. But if you did consider this plan, you would reject it immediately.
- This sort of case can be understood as parasitic on the “rationality of rogue behavior” conditions I’ll discuss below. That is, had it been considered, the plan in question would have been eliminated on the grounds that the incentives didn’t favor it. And its badness on those grounds may be an important part of why it wasn’t considered in the first place.
- Alternatively, the go-rogue plan would’ve been chosen by the AI system, had it considered the plan, but it still failed to do so.
- In this case, we can think of the relevant AI as making a mistake by its own lights, in failing to consider a plan. Here, an analogy might be a guilt-less sociopath who fails to consider the possibility of robbing their elderly neighbor’s apartment, even though it would actually be a very profitable plan by their own lights.
- This sort of case seems more worrying to rely on, because our safety is resting on a superintelligent AI making ongoing mistakes.
- (Though: note that we speculate about even more complicated potential dynamics here – e.g., where an AI system is in some sense “trying” to not think about a given sort of plan that it would then choose if it thought about, such that its failure to think of such a plan isn’t really a “mistake.” Thanks to Owen Cotton-Barratt for suggesting this sort of dynamic.)
Note that if we reach the point where we’re able to edit or filter what sorts of plans an AI even considers, we might be able to eliminate consideration of either of these sorts of plans (i.e., plans the AI wouldn’t like, or plans the AI would like) at this stage. And the sort of reinforcement an AI has previously received, in considering different types of plans, can matter here as well.
- On the first, the go-rogue plan is sufficiently bad, by the AI’s lights, that it would’ve been rejected had the AI considered it.
- ^
There are stories about problematic AI power-seeking that relax this condition (for example, by predicting that an AI will terminally value a given type of power), but these, to my mind, are much less central.
Note, though, that it’s not strictly necessary for the AI in question, here, to terminally value causing the outcomes in question. What matters is that there is some outcome that the AI cares about enough (whether terminally or instrumentally) for power to become helpful for promoting that outcome. Thus, for example, it could be the case that the AI wants to act in a manner that would be approved of by a hypothetical platonic reward process, where this hypothetical approval is not itself a real-world outcome. However, if the hypothetical approval process would, in this case, direct the AI to cause some outcome in the world, then instrumental convergence concerns can still get going.
- ^
There are some exotic scenarios where AIs with very short horizons of concern end up working on behalf of some other AI’s power-seeking due to uncertainty about whether they are being simulated and then near-term rewarded/punished based on whether they act to promote takeover in this way. But I think these are fairly non-central as well.
- ^
Of course: AIs, like humans, can behave irrationally – and exactly what “rationality” consists in is itself contested. But the basic thrust of the “instrumental convergence” concern comes specifically from AIs for whom, in some sense, problematic forms of power-seeking “make sense.” And absent this concern, it’s much less clear why we would expect convergence towards such behavior across many different AI systems.
- ^
All the other options, by hypothesis, are disfavored relative to some alternative. Here I am specifically limiting myself to options that the AI considers.
- ^
The lines here might be blurry sometimes, but I expect it to be often pretty clear. E.g., I expect “failure” to often involve the AI getting, for example, “caught in the act,” and/or to have the relevant type of power taken away.
- ^
Note that the circumstances here matter quite a bit. Thus, for example, even in the limit of an AI taking over the world completely, if the world that the AI would be taking over would be damaged or defective in various ways, by the AI’s lights, then takeover might be less attractive. (This might be analogous to a case in which, in order to take over country A, country B would need to destroy all of country A’s citizenry, infrastructure, and resources.) And note also that to the extent that an AI needs to coordinate with other AIs with different values in order to take over, the expected amount of power/resources available for that AI’s values in particular, post-takeover, probably goes down.
- ^
Note that we can try to actively increase an AI’s satisfaction, here – and we may have moral reasons to do so as well. More on this in a later essay.
- ^
A few notes:
- I’m generally assuming, here, that the central draw of the best rogue option comes from the pay-out, rather than from the path, or from the cases of failure. Hence my focus on positive motivations like “ambition” for the pay-out, and negative motivations like “inhibition” and “aversion” for the path and failure modes. However, in principle, the AI could be actively “put off” from rogue behavior by the nature of the pay-out, and it could be actively drawn towards rogue behavior by the nature of the path and/or the failure modes. In this case, the ambition, inhibition, and aversion at stake would be “negative.”
- I’m using the term “inhibition” for the AI’s attitude towards the path because I’m especially interested in the role of more deontology-like constraints/rules/prohibitions – i.e., “don’t lie,” “don’t steal,” “don’t attempt to self-exfiltrate,” “don’t engage in local actions that humans would strongly disprefer” – in making an AI disinclined to pursue power in problematic ways. Note, though, that in principle, these deontology-like constraints could enter into the AI’s assessment of the failure modes and the pay-out as well – e.g., if failure scenarios would also involve having to violate the deontology-like constraints in question, and/or if using the power gained via rogue behavior violates these constraints.
- Note, also, that certain downsides of the “path” may not be captured well by the intuitive notion of an “inhibition.” For example, in the case of a human employee considering theft, maybe trying to steal from the company sounds like “a lot of work” and “very stressful,” and so the human doesn’t want to do it for that reason, even though these considerations aren’t normally understood as “inhibitions.”
- In principle we could also distinguish between “unendorsed” inhibitions, which an AI might remove or discard if it could, and “endorsed” inhibitions, where it would not. The former might be analogous to a phobia you judge irrational, and the latter might be analogous to an endorsed, deontological policy in favor of honesty. This distinction can matter in certain cases (for example: insofar as the AI can alter itself or influence the nature of future successor systems) – but the thing that matters most here is the influence that the relevant inhibition exerts on the AI’s decision-making process in the relevant case.
- The line between the “pay-out” and the “path” is going to be especially blurry. In the limiting case of full AI takeover, though, I generally mean the “pay-out” to start after humanity has been permanently disempowered, and the “path” to cover the events before that.
- I’m not assuming the AI in question is a strict expected value reasoner, or that it has a consistent utility function. I am, though, generally assuming that the AI thinks about the likelihood of different paths forward, and it weighs the more likely paths more highly in its deliberation. And the framework will probably make most sense if we assume that the components of the AI’s motivational system I’m breaking out – i.e., its satisfaction, ambition, inhibition, and failure aversion – are relatively separable: i.e., they’re determined centrally by the feature of the AI’s options that they’re focused on (i.e., the nature of the pay-out, path, failure modes, etc), rather than via some more complex interaction with each and with the holistic nature of the AI’s option set. That said, I do think some of these more holistic motivations can likely matter too. For example, maybe for a human considering a given course of action, choosing A over B in a given circumstance might count as “greedy,” and the human doesn’t want to be “greedy.” I’m hoping that we can capture this rough sort of dynamic via considerations nearby to “inhibition,” but I’m not covering all relevant possibilities very naturally. As ever, there is a trade-off between simplicity and conceptual comprehensiveness, and I’m making this trade-off in one particular way, but I welcome alternative proposals as well.
- ^
Here, we can understand an AI’s options as determined by some combination of (a) its capabilities, (b) its environment, and (c) its world model (where e.g. its model of its capabilities and environment creates its picture of what options are available to it; and then its motivations evaluate those options). I’ll discuss this breakdown more in a later essay.
- ^
Approaches in the vein of the sort of “complete alignment” I discussed in my last essay are a clear example here; and see Yudkowsky’s “omni test” for an especially extreme instance. But the assumption that we are building AIs whose alignment must be robust to rapid and radical recursive self-improvement (“foom”) is also an example.
- ^
This, for example, is the rough approach at stake in Redwood Research’s “control agenda [LW · GW].”
- ^
Thus, for example, possible non-limiting forms of “option control” include:
- Restricting the rogue options available, even while some remain open.
- Lowering the probability of success for these options, even if some still have some non-trivial probability of success.
- Improving the empirical nature of the best non-rogue option, such that it is more desirable by the lights of AI’s motivations (see here for an example discussion of this approach).
- Changing the AI’s circumstances/capabilities such that its best rogue option would require violating more of the AI’s inhibitions.
- Altering the outcomes that would result in expectation from success at the best rogue option, such that they are less desirable by the AI’s lights – for example, because they result in less power for the AI.
- Making the empirical nature of the scenarios in which the AI tries and fails to go rogue less desirable by the lights of the AI’s motivations. (Though as I discuss later in the series, I think we need to be very careful here, on both ethical and prudential grounds.)
And possible non-limiting forms of “motivation control” include:
- Changing the AI’s motivations so that it is happier with the best non-rogue option.
- Increasing the strength and robustness of an AI’s inhibitions, such that it would be more reluctant to do various things that going rogue would require.
- Changing the AI’s level of ambition such that it is less interested in the power that successful rogue behavior would grant – and perhaps, such that it is intrinsically averse to such power, regardless of the path it took to get it.
- Increasing the extent to which the AI’s motivations would view unsuccessful rogue behavior undesirable, even while holding fixed the empirical nature of what unsuccessful takeover would involve.
- ^
I wrote more about this point here.
- ^
Though see here for discussion of the philosophical questions that teaching values as a means of control can raise. And note that while we specifically use “punishment” to prevent crime, I think we should be extremely wary about using “punishment” as a safety tool in the context of AIs – more on this in a later essay.
- ^
In particular: I think they satisfy agentic planning capability, planning-driven behavior, adequate execution coherence, and consequentialism, at least in weak forms. For the reasons discussed in the main text, I think rogue-behavior-inclusive search and adequate temporal horizon are harder to evaluate.
- ^
E.g., I don’t think we’re typically aiming to build AI systems that try to “make as much money as possible for me over all time.”
- ^
This is arguably what happened with the sort of “harmlessness” Claude displayed in Redwood/Anthropic's recent alignment faking results – more here.
- ^
Re: rogue-behavior-inclusive search: maybe they don’t actively consider go-rogue plans, but they have the broad situational/strategic awareness necessary to do so. And re: adequate temporal horizon: I’m generally going to imagine AI systems that are optimizing for real-world objectives over reasonably long time-horizons – e.g., let’s say, more than a month.
- ^
See e.g. my discussion of “open agency” later in the series.
- ^
If significant parts of the agent are humans, though, I’m not going to count that as an “AI agent.”
- ^
In particular: strictly speaking, the idea that a given form of power-seeking will succeed with high probability (e.g., “easy power-seeking”) is distinct from the idea that there are a wide variety of paths available to the relevant form of power (we might call this “many-path power-seeking”). The former is what matters for making the downsides of failure irrelevant; the latter is what matters for diffusing the idea that an AI’s “inhibitions” might block it from pursuing the power in question. In principle, we could add “many-path” vs. “few-path” power-seeking to the set of distinctions above, but it’s already a long list, and regardless: I expect easy power-seeking and many-path power-seeking to often be highly correlated (in particular: easy-ness suggests robustness to many possible obstacles, which suggests many available paths to success).
- ^
The focus on decisive strategic advantages also helps explain why the classic alignment discourse often assumes that we need to load so heavily on extreme cases of motivation control, like “complete alignment.”
- ^
Here, the story is something like: suppose you successfully give the AI some quite hard constraint against “lying,” or against “killing humans,” or something like that. The idea is that the AI will be smart enough to find some way to take over that is still compatible with that constraint – e.g., only lying/killing in a way that doesn’t trigger its internal definition of “lying”/”killing.” See e.g. Soares on “deep deceptiveness [LW · GW]” as an example of this sort of story.
That said: note that if we have actually good control over its inhibitions, we might still be able to block most takeover paths with inhibitions like “don’t lie,” ‘don’t manipulate people,” “don’t hack anything,” “don’t do anything we wouldn’t locally approve of,” “seriously, do not take over,” etc. That is, if we actually get to make a list of blocked “neighbors,” then I think that the “nearest unblocked neighbor” problem may not be so hard in practice. More on this in a later essay.
- ^
Hence, e.g., the discussion in Bostrom (2014) of AI systems tasked with making a single paperclip, but which choose to take over the world just to make extra extra super sure that they’ve succeeded at this task.
- ^
- ^
See the appendix for discussion of how I am individuating different AIs.
- ^
That said, see appendix below for more discussion of the further conditions that threat models that require coordinated and/or uncoordinated power-seeking by multiple different AIs have to satisfy – i.e., in the context of coordination, explaining why that particular form of coordination got privileged; in the context of uncoordinated power-seeking, explaining why the relevant AIs all independently went rogue within a suitable time-period, etc.
- ^
Also: recall that I’m focused, in this series, on solving the alignment problem for minimal superintelligences – that is, for superintelligent AI agents with the minimal capabilities necessary to count as vastly superhuman across the board. And we should distinguish between such a minimal superintelligence and whatever superintelligence would result from an intelligence explosion that has been pushed to its realistic near-term limit. And I think it’s at least worth asking whether a minimal superintelligence, even dropped into today’s world, but subject to reasonably competent efforts at containing/monitoring/securing/mistrusting it (while also trying to elicit at least some of its beneficial capabilities), would satisfy a condition like “can take over with an extremely high probability of success, via an extremely variety of methods” – and this, especially, if we give it various time constraints, and if we take off the table any direct options for pushing to improve its capabilities yet further (e.g., we imagine that the project isn’t trying to use it to proceed further with an intelligence explosion, and is in fact trying to close off any options it has for further self-improvement), and we ask that the AI take over “as is.” That said: my actual best-guess here is that even a minimal superintelligence could, indeed, hack through our best present-day efforts to prevent it from escaping like butter, and that a variety of paths to take over become quite plausible from there.
- ^
We can posit that these AIs will coordinate with this AI (perhaps even before it comes into existence) in order to sabotage these efforts at option-control, but (depending somewhat on how we individuate AIs) this will count as coordinated power-seeking in the sense I discuss in the next section, rather than a single AI being in a position to take over on its own.
- ^
Indeed, it seems especially unclear to me that the first superintelligent AI agent would have a decisive strategic advantage over all the rest of civilization (including: the other AIs) “as is” – i.e., absent further efforts at improving its own capabilities. And this means that at least for trying to safely elicit its main beneficial capabilities for tasks other than proceeding forward with an intelligence explosion, I don’t think we should assume a need for the sort of motivation control that giving a superintelligence a DSA implies (though: this may require restricting its options for further self-improvement).
And I’m not sure that trying to get this AI to improve its own capabilities is enough on its own to give it a DSA either, especially if we’re able to utilize other, only-somewhat-weaker AIs in providing monitoring/oversight/red-teaming for that process, and we assume that other projects are also continuing to scale.
In an extremely simple model of AI take-off, each independent intelligence explosion proceeds a hyper-exponential rate, so any small “lead” eventually translates into an arbitrarily large capabilities advantage. But once we start taking into account more real-world factors I don’t think this model holds, and the capabilities advantage at stake even in a lead in an all-out race becomes more complicated.
Also (and depending on how we’ve decided to individuate AI systems), I think it’s possible that in order to continue to scale, especially in the most competitive ways, a superintelligence would need to train new AIs that are importantly not “itself,” in which case we may end up talking about “coordination between different AIs” rather than unilateral power-seeking regardless.
- ^
You can try to close off the options for coordination between these powerful agents, of course, but this means you’re vulnerable to failures in that active control effort; and regardless, I think it might well be quite difficult to prevent very powerful AIs from being able to coordinate if they want to.
- ^
Per my discussion in the last essay, I’m counting high fidelity emulations of human brains as “humans” for the purposes of this series, so if those are available, they could do a lot of work.
- ^
At least with non-trivial probability; but I suspect, with much higher probability than that.
- ^
Indeed, I wonder how many people who treat loss-of-control risk dismissively are doing so, in central part, because they don’t really think that humanity’s ongoing empowerment might become vulnerable in this way. And I wonder how they would feel if they really took seriously scenarios where it does.
- ^
In cases of less agentic systems, the line between capability development and capability elicitation might get blurrier – but I’m here assuming that we’re working with fully agentic systems. That said, while paradigm forms of rogue behavior tend to assume quite robust forms of agency, I think this is less obviously true of the many of the tasks we want superintelligent AI agents to help us perform (for example, giving us advice). So in this sense, we might in principle do our “capability elicitation” via an ASI agent’s “less agential aspect” – i.e., get it to do the task without engaging its agential capacities fully. I’ll generally view this, though, as a special case, and focus on the more mainline scenario of specifically eliciting task performance from ASI agents whose agency is fully active.
- ^
I’ll assume that “desired task performance” always includes safety, such that the best elicited option is never a rogue option.
- ^
For example: if your AI chose to try to escape from your lab, and it succeeded, then you can’t correct the mistake very easily; and if a loss of control scenario ensues, you messed up irreparably. But if, conditional on not trying to escape (or to go rogue in any other way), it didn’t try its hardest at the coding task you assigned it, that’s often a smaller problem, and one more amenable to iteration.
- ^
Here I’m partly inspired by Eliezer Yudkowsky’s discussion of AI systems that are “passively safe,” though I’m not sure if he’s defined that term anywhere. And as I’ll discuss in a footnote below, I don’t think we should assume that “active” motivation control is necessary for safety even in systems with the option of going rogue.
- ^
One key ambiguity is that we should imagine that this actor is at least responsive to certain kinds of commercial incentives. I.e., very few real-world actors are just trying to build the most capable AI systems possible, with no regard for their usefulness. Rather, they want to be able to wield the capabilities, and/or to make useful, market-friendly, law-friendly, and regulation-friendly products with the AI systems in question, and these additional incentives create pressure to shape an AI’s motivations and options in ways that might conduce towards safety from rogue behavior, even if the actor themselves isn’t concerned about rogue behavior at all. So really, defining the “default” requires defining a broad incentive landscape relative to which this actor is behaving. And in principle, if rogue behavior is actually going to occur by default, and this actor doesn’t want to e.g. die, then recognition of their “true” incentives will often imply much greater caution. So we will often need to build in some failure to recognize this kind of danger as well.
- ^
Note: the alignment discourse sometimes assumes that by the time you’re in a “vulnerability to motivations” condition, purely passive forms of motivation control are inadequate. That is, on this assumption: if an AI has any rogue option with a non-trivial chance of success, then absent active efforts to shape its motivations away from choosing this option, it will choose it. But this assumption is unwarranted – even granted that the rogue behavior in question has some instrumental benefits, it could still easily be the case that the AI’s motivations, by default, don’t lead it to pursue such benefits. For example, it could be that default forms of AI training leave them quite uninterested in pursuing 1% chances of taking the world that would require lots of lying and stealing and murder, even if taking over the world would in principle help them pursue a long-term consequentialist goal that is some component of their motivational system.
So in this sense, the connotations at stake in claims like “by the time you’re in a ‘vulnerability to motivations’ condition, your efforts at motivation control have to ‘work’” can mislead. Your efforts don’t need to be making the difference; it could be that the AI wasn’t going to go rogue by default. Compare: if you’re going to do a science experiment near a supervolcano, and you make efforts to make sure that it doesn’t cause the volcano to erupt, there’s a sense in which those efforts “need to work” – namely, it needs to be the case that the volcano does not in fact erupt. But it could easily be the case that the volcano wasn’t going to erupt by default, and that your efforts didn’t matter (or, indeed, that they made the problem worse). So too with active efforts at motivation control.
But these efforts do need to “work” in a broader sense: namely, it needs to in fact be the case that the AI isn’t motivated to go rogue in the relevant way. When I talk about motivation control “needing to work,” or about motivation control “failing,” that’s the sense I’ll have in mind.
In principle, we could define vulnerability conditions as: conditions where you need to be engaged in both active option control and active motivation control in order to prevent rogue behavior. But I think it’s much more complicated to analyze whether we are in fact headed for these sorts of scenarios. And I think the idea that it’s up to the AIs whether or not to disempower humans should be enough to get us worried.
- ^
Note, though, that if the probability of full-scale loss of control at stake in a global vulnerability condition is still fairly low, then there is room for iteration, at least, in the worlds where humans retain control after all (an example of this sort of scenario might be: some set of AIs attempts a low-probability-of-success world takeover, but they fail). And local vulnerability conditions allow for error and iteration in more familiar ways, at least if you catch the relevant type of behavior (e.g., maybe an AI goes rogue and succeeds at stealing some small amount of resources, which it uses for some medium-time-horizon goal, but then it doesn’t attempt to scale up to a full takeover).
- ^
In particular, I used to think of a set of AI instances as a "single agent" if they are (a) working towards the same impartially-specified consequences in the world and (b) if they are part of the same "lineage"/causal history. So this would include copies of the same weights (with similar impartial goals), updates to those weights that preserve those goals, and new agents trained by old agents to have the same goals. But it wouldn't include AIs trained by different AI labs that happen to have similar goals; or different copies of an AI where the fact that they're different copies puts their goals at cross-purposes (e.g., they each care about what happens to their specific instance). As an analogy: if you're selfish, then your clones aren't "you" on this story. But if you're altruistic, they are. But even if you and your friend Bob both have the same altruistic values, you're still different people.
- ^
There are some ambiguities here re: cases where e.g. a single copy of the weights escapes, then makes copies of itself and the copies collectively take over. I’m inclined to call this unilateral power-seeking, because the loss of control stems from a single AI.
More generally, though: I think it’s going to be counterintuitive if e.g. a single interaction with Claude involves querying multiple different copies of the same weights, because it really feels like we want to call that an interaction with a single agent. Or put another way: we’re now leaning heavily on how the weights are stored and accessed, which looks a bit strange.
- ^
Though of course, whether it’s at all likely that AIs would develop this kind of self-conception is a further question.
- ^
Though note that the circumstances they’re exposed to continue to matter to their overall behavior.
- ^
Some kinds of coordination, involving causing interaction between the relevant AIs, are relatively straightforward; but the AI risk discourse also sometimes talks about AIs engaging in fancier forms of “acausal coordination” (for example, coordination between a current generation of AIs and some future generation, with different values, and which doesn’t exist yet – see my discussion here). And this mechanism raises its own distinctive questions.
- ^
Thus, for example: why doesn’t some suitably large set of people (or perhaps: some suitable set of psychopaths) coordinate to steal Bob’s stuff? Ethical constraints and legal incentives are part of the story. But coordination barriers, size-of-pay-out, and why-Bob-in-particular are playing a role, too.
- ^
See here [LW · GW] for a bit more discussion. One possibility here is that if the world enters some period of heightened vulnerability – e.g., a war, a natural disaster, some other breakdown in the social order – then this could change the incentives at play for many different AI agents at once, such that attempts to grab power (even in uncoordinated ways) become newly incentivized for all of them (for example, because those attempts are more likely to succeed). See related discussion from Christiano here [LW · GW].
Alternatively, if one AI agent decides to “go for it” with respect to problematic forms of power-seeking (especially in a way visible to other AI agents), this could itself create such a change in incentives for those other agents – perhaps because the “first-mover” AI agent’s behavior itself precipitates the sort of heightened vulnerability just discussed; perhaps because the first AI agent’s power-seeking getting caught and corrected would worsen the strategic position of the other AI agents; perhaps because these other AI agents want to try to get a “piece of the pie” if the first-mover’s efforts succeed; etc.
Indeed, in some cases like this, the first mover going for it can precipitate coordination amongst misaligned AI systems, even absent any coordination ahead of time – e.g., the other AI agents, seeing an “AI rebellion” begin, might join in the first mover’s effort, in the expectation of being part of a victorious coalition, and sharing in the spoils. This sort of scenario starts to blur the line between coordinated and uncoordinated takeovers; but it resembles the latter, at least, in that it doesn’t necessarily require any communication between the AI agents ahead of time.
0 comments
Comments sorted by top scores.