Paths and waystations in AI safety
post by Joe Carlsmith (joekc) · 2025-03-11T18:52:57.772Z · LW · GW · 1 commentsThis is a link post for https://joecarlsmith.substack.com/p/paths-and-waystations-in-ai-safety
Contents
1. Introduction 2. Goal states 3. Problem profile and civilizational competence 4. A toy model of AI safety 5. Sources of labor 6. Waystations on the path None 1 comment
(Audio version here (read by the author), or search for "Joe Carlsmith Audio" on your podcast app.
This is the third essay in a series that I’m calling “How do we solve the alignment problem?”. I’m hoping that the individual essays can be read fairly well on their own, but see this introduction for a summary of the essays that have been released thus far, and for a bit more about the series as a whole.)
1. Introduction
The first essay in this series defined the alignment problem; the second tried to clarify when this problem arises. In this essay, I want to lay out a high-level picture of how I think about getting from here either to a solution, or to some acceptable alternative. In particular:
- I distinguish between the underlying technical parameters relevant to the alignment problem (the “problem profile”) and our civilization’s capacity to respond adequately to a given version of the problem (our “competence profile”).
- I lay out a framework for thinking about what competence in this respect consists in – one that highlights the role for three key “security factors,” namely:
- Safety progress: our ability to develop new levels of AI capability safely;
- Risk evaluation: our ability to track and forecast the level of risk that a given sort of AI capability development involves; and
- Capability restraint: our ability to steer and restrain AI capability development when doing so is necessary for maintaining safety.
- I distinguish between a number of different possible sources of labor (e.g., both future AI labor, and possible improvements to the quality of future human labor as well) that could improve these security factors.
- And I discuss a variety of different intermediate milestones (e.g., global pause, automated alignment research, whole brain emulation, etc) that strategies in this respect could focus on.
This high-level picture sets up my next essay – “AI for AI safety” – which argues that we should try extremely hard to use future AI labor to improve the security factors I discuss; and the essay after that, which examines our prospects for safely automating AI alignment research in particular.
2. Goal states
Let’s start by recalling the goal states we’re aiming for.
In my first essay, I distinguished between two ways of not-failing on the alignment problem:
- Victory: avoiding loss of control scenarios while gaining access to the main benefits of superintelligent AI.
- Costly non-failure: avoiding loss of control scenarios, but giving up on access to some of the main benefits of superintelligent AI.
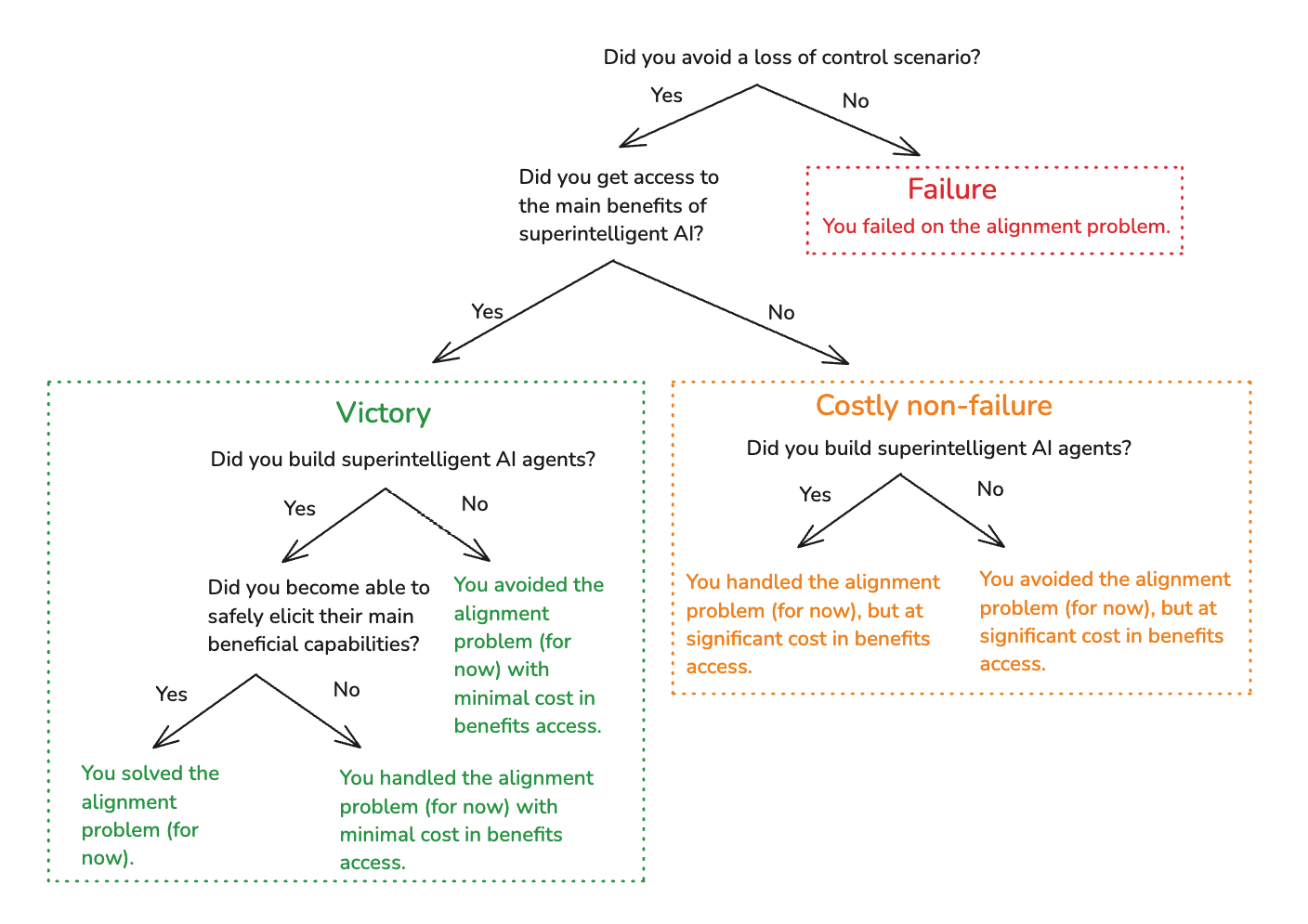
Victory is the ideal. But we should take costly non-failure if necessary.
3. Problem profile and civilizational competence
What does it take to reach either victory, or costly non-failure? I find it useful to decompose the challenge into two components:
- Problem profile: the settings of the underlying technical parameters relevant to the alignment problem.
- Competence profile: the range of problem profiles that our civilization would achieve victory or costly non-failure on.
Here the rough idea is: the problem profile is uncertain, but it’s not under our control. Rather, it’s set by Nature. Example aspects of the problem profile include: what sorts of training regimes lead to “scheming” by default; the competitiveness hit at stake in preserving human-legible reasoning in AI agents; what sorts of errors in a training signal lead to what sorts of misalignment; etc.
The competence profile, by contrast, is much more “up to us” – it’s about how our civilization responds to the problem profile we face. I’ll say more below about the factors I think matter most here.[1]
Our overall probability of failure vs. non-failure is determined by the way the problem profile and the competence profile combine – that is, by the probability that we face a given problem profile, multiplied by the probability that we avoid failure on this problem profile conditional on facing it, across all relevant possible problem profiles.
Problem profiles and competence profiles are high-dimensional. But for simplicity, I’ll sometimes talk about a rough spectrum of problem “hardness,” and a rough spectrum of civilizational “competence.”[2]
- That is, other things equal, harder problem profiles involve the sorts of key issues with motivation control and option control that I’ll discuss later in the series (e.g., issues with adversarial dynamics, opacity, oversight errors, etc) cropping up more consistently and robustly, in a wider range of AI systems, and in manner that requires more effort and resources to resolve.
- And more competent civilizations are the ones that avoid failure on such problem profiles nonetheless.
The basic goal of action on the alignment problem is to increase civilizational competence on the margin in the highest-expected-value ways. And note, importantly, that this is distinct from trying to ensure safety regardless of the problem profile. Indeed: robustness even to worst-case settings of all technical parameters may be quite difficult to achieve, and not the best target for marginal resources.
- Thus, for example, if you focus too much on making sure that your AI systems are “provably safe,” you may under-invest in more prosaic-but-tractable means of improving their safety.
- Or: if you focus too much on ensuring that we avoid loss of control even in scenarios where (a) an algorithmic breakthrough suddenly makes it possible for everyone to turn their old iPhones into a misaligned superintelligence and (b) the offense-defense balance is such that any such superintelligence can easily take over the whole world via a wide variety of methods, then you may end focusing centrally on highly coercive and centralized global governance regimes that come with a multitude of other downsides.
That said: I think it is disturbingly plausible that this problem is extremely hard. And I think it’s still well worth trying to improve our prospects in those worlds. Indeed, I am disturbed by how many approaches to the alignment problem seem to imply something like: “and if the problem is hard, then our plan is to die.” Let’s do better.
4. A toy model of AI safety
If we’re trying to improve civilizational competence in the highest-expected-value ways, then: what does civilizational competence consist in? That is: what sort of factors determine whether or not we succeed or fail on a given problem profile?
I’m going to focus on three main factors, which I’ll call “security factors.” These are:
Safety progress: our ability to develop new levels of AI capability safely.[3]
- Risk evaluation: our ability to track and forecast the level of risk that a given sort of AI capability development involves.
- Capability restraint: our ability to steer and restrain AI capability development when doing so is necessary for maintaining safety.
Why focus on these factors? Here’s a highly simplified toy model of AI safety, which will help explain why they stand out to me.[4]
We can think of the power of frontier AI systems (including both: what capabilities the AIs have, and what sorts of affordances they are given) along a single rough dimension of “AI capability.”[5] And we can think of any given AI developer as having what I’ll call a “capability frontier” (that is, the most powerful AI systems they have developed/deployed thus far), and a “safety range” (that is, the most powerful AI systems that they are able to develop/deploy safely).[6] Thus, in a diagram (and focusing for now on a single actor):[7]
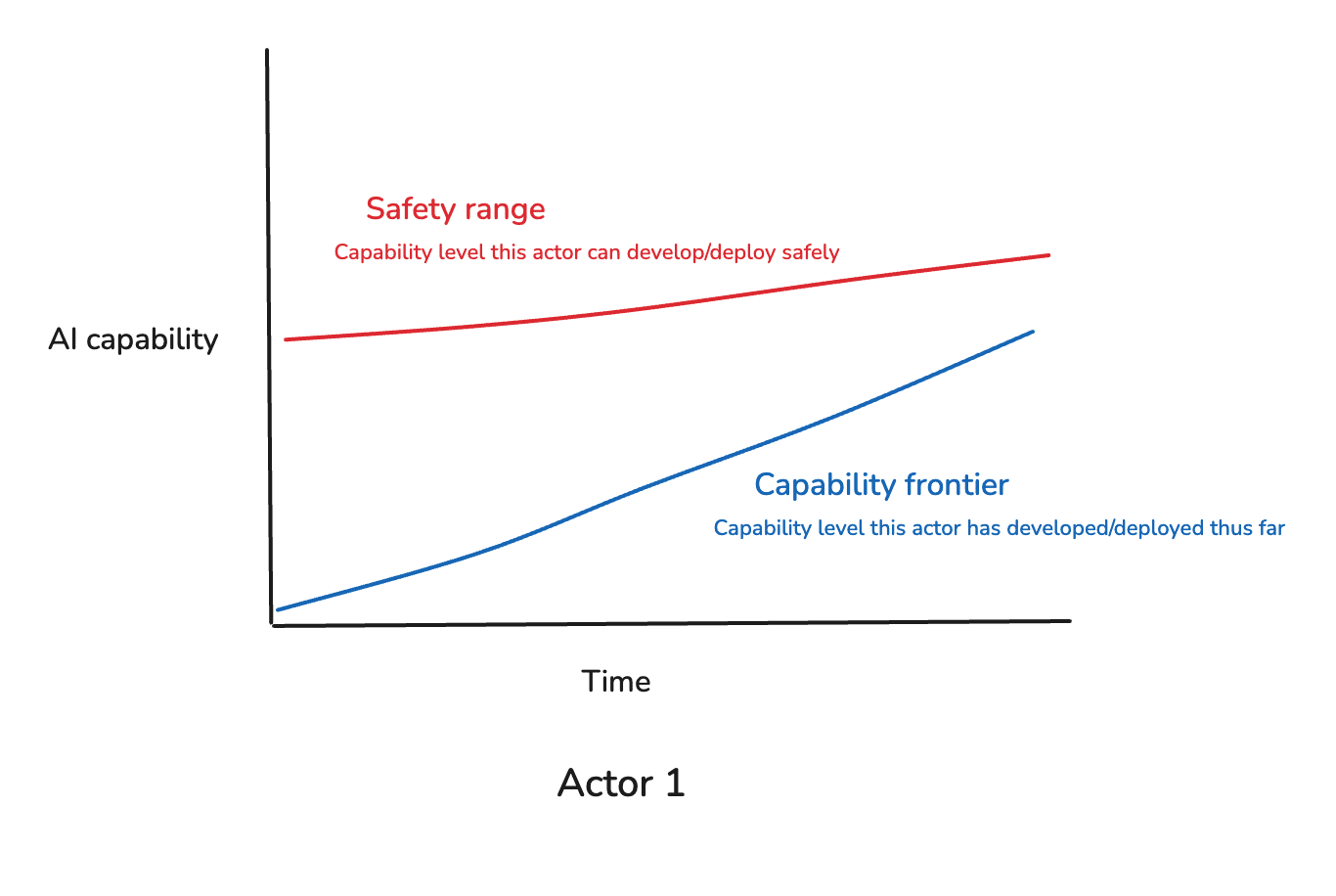
The main game, here, is to keep the capability frontier within the safety range. And in this context, the three main security factors above serve the following functions:
Safety progress expands the safety range, and makes it cheaper to develop a given level of AI capability safely.[8]
Paradigm examples include:
progress on controlling an AI’s motivations;
restricting AI options for rogue behavior (both via local intervention on its operating environment, and via “hardening” the world more broadly);
otherwise designing AI incentives to promote cooperative behavior.
- Risk evaluation tracks the safety range and the capability frontier, and it forecasts where a given form of AI development/deployment will put them.
- Paradigm examples include:
- evals for dangerous capabilities and motivations;
- forecasts about where a given sort of development/deployment will lead (e.g., via scaling laws, expert assessments, attempts to apply human and/or AI forecasting to relevant questions, etc);
general improvements to our scientific understanding of AI;[9]
structured safety cases and/or cost-benefit analyses that draw on this information.[10]
- Paradigm examples include:
- Capability restraint steers and pauses further development/deployment to keep it within the safety range.
- Paradigm examples include:
- caution on the part of individual actors;
- restrictions on the options for AI development available to a given actor (e.g., via limitations on compute, money, talent, etc);
- voluntary coordination aimed at safety (e.g., via mutual commitments, and credible means of verifying those commitments);
- enforcement of pro-safety norms and practices (e.g., by governments);
- other social incentives and attitudes relevant to decision-making around AI development/deployment (e.g. protests, boycotts, withdrawals of investment, public wariness of AI products, etc).
- Paradigm examples include:
And to develop superintelligence safely, you’d need to:
- Make enough safety progress to bring “superintelligence” within the safety range.
Do enough capability restraint (and accurate enough risk evaluation) to refrain from unsafe development in the meantime.[11]
Simple, right? It’s like how: to climb Mount Everest, keep going up, and don’t fall.
Thus, on the diagram:
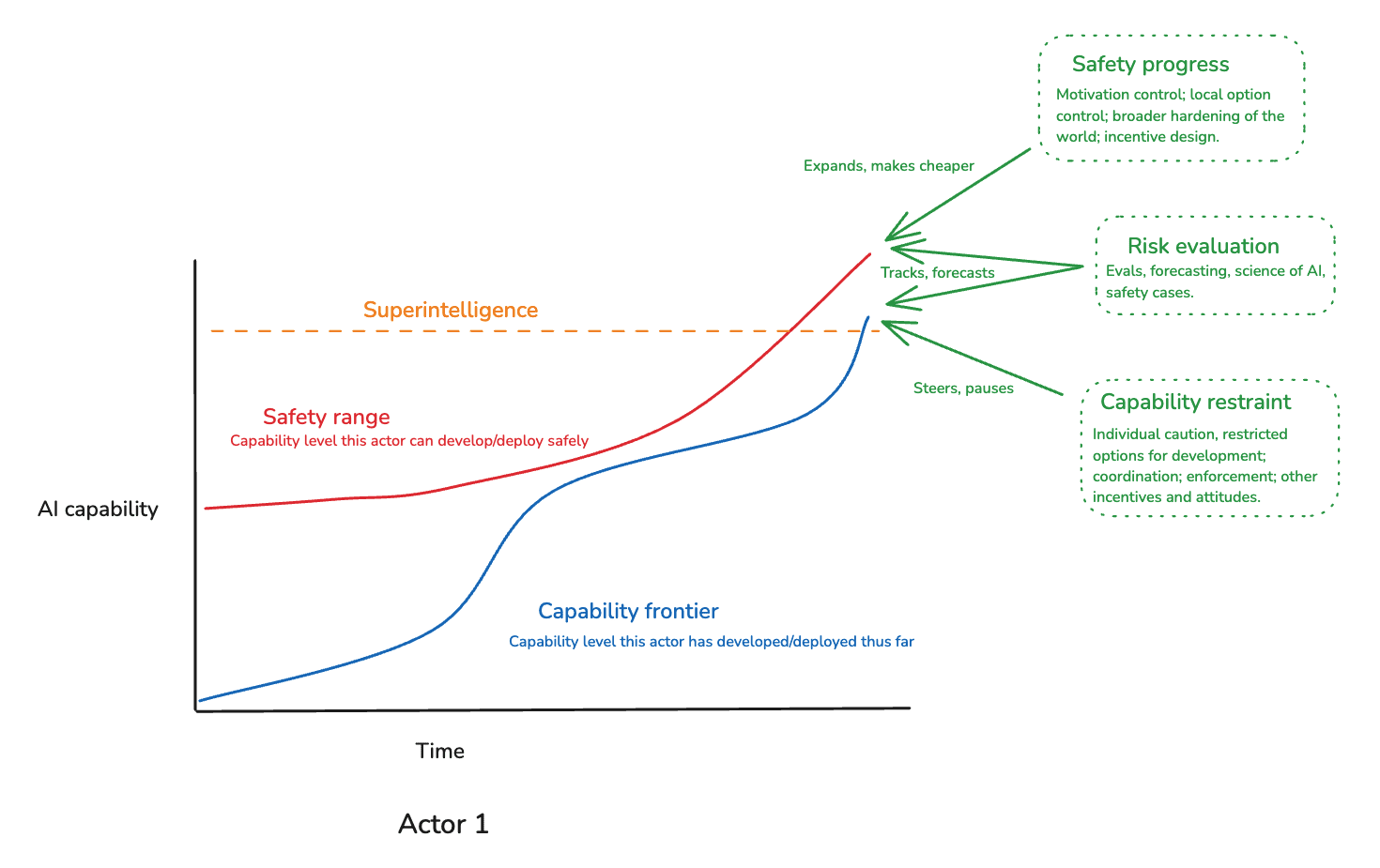
Here’s an analogy. Imagine an expedition into a dark cave. Parts of the cave are covered in toxic slime, which releases a cloud of poison gas if anything touches it. You can remove the slime using a certain kind of heat-lamp, which melts the slime away without releasing the gas. But the slime can be very difficult to see; and currently, you only have a fairly weak flashlight.
Here, loss of control is the slime. Safety progress is the heat-lamp. Risk evaluation is the flashlight. And capability restraint is your ability to not move forward until you’ve melted the slime away.[12]

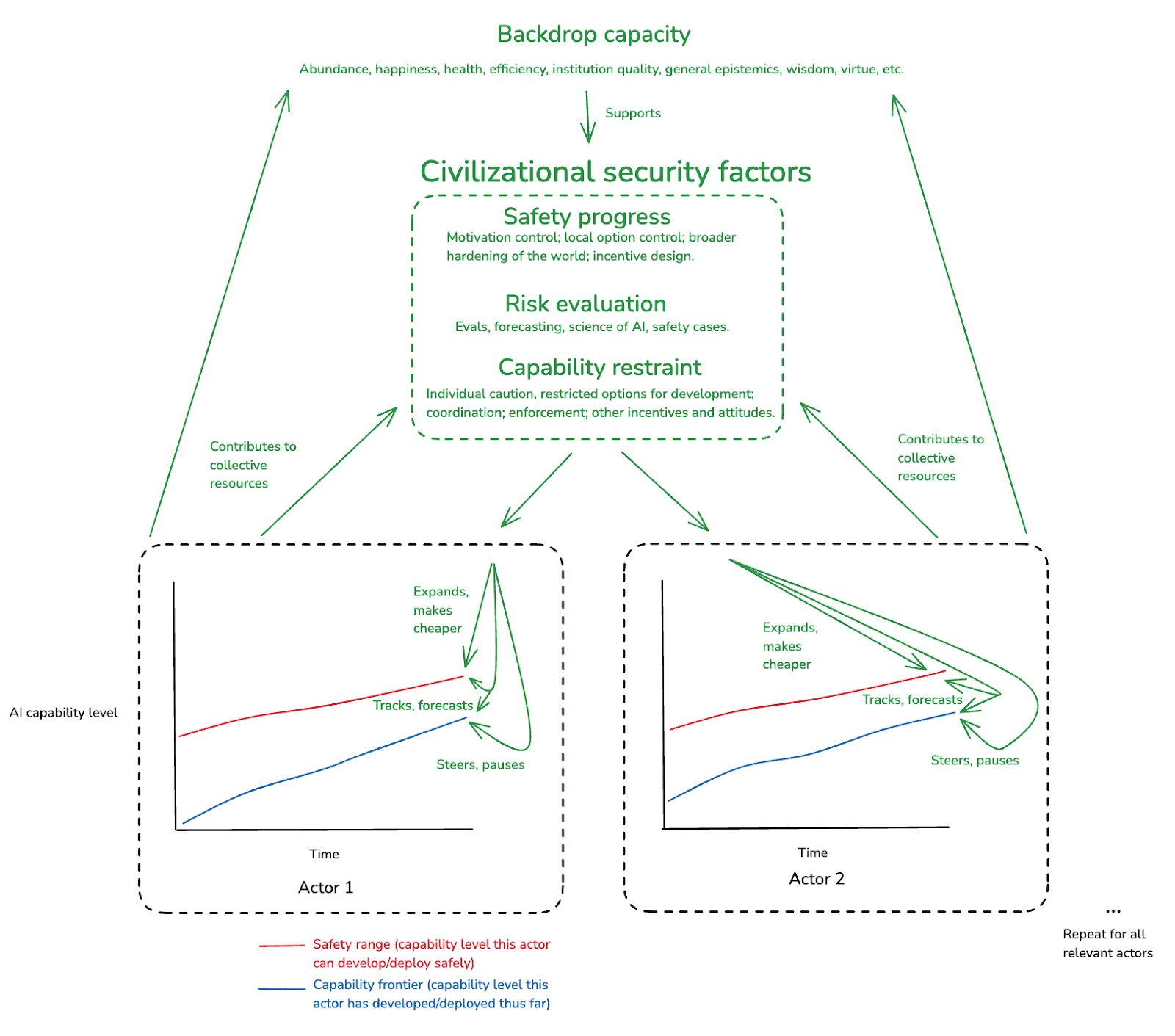
Now: so far I’ve only been talking about one actor. But AI safety, famously, implicates many actors at once – actors that can have different safety ranges and capability frontiers, and that can make different development/deployment decisions. This means that even if one actor is adequately cautious, and adequately good at risk evaluation, another might not be.[13] And each might worry about the other gaining power/market advantage in a manner that creates incentives for each to take greater risks. And of course, many of these dynamics only get worse as the number of actors increases.
That said, different actors do not just act in isolation. Rather, their safety progress, risk evaluation, and capability restraint are all influenced by various collective factors – e.g.
- by publicly available research on motivation control, option control, and incentive design, and by the degree to which the world in general has been hardened against rogue AI attack;
- by shared tools and practices for evals, safety cases, forecasting, and other aspects of risk evaluation;
- and by the norms, option-restrictions, coordination efforts, enforcement mechanisms, and other incentives that influence a given actor from the outside.
And each actor can themselves contribute to strengthening these collective factors – e.g., by sharing research and best practices, using AI labor for helpful-to-safety applications, participating in coordination and governance schemes, etc.
I’ll define our civilization’s safety progress, risk evaluation, and capability restraint as the factors (individual and collective) that ultimately determine the safety progress, risk evaluation, and capability restraint of each individual actor.
I’ll also throw in one final, catch-all factor, which I’ll call our “backdrop capacity.” By this I mean, roughly, the degree to which our civilization is strong, flourishing, and functional more generally. Paradigm aspects of this functionality include:
- Backdrop levels of abundance, economic growth, and technological progress.
- Baseline levels of health, education, and happiness in the population.
- The general quality of our discourse, epistemics, forecasting, and scientific understanding of the world (not just about AI in particular).
- The quality, efficiency and trustworthiness of our core institutions and processes (the government, the legal system, etc).
- The general availability of high quality cognitive labor and advice.
- How well we’re able to coordinate and to resolve conflict productively.
- Backdrop levels of various virtues like wisdom, prudence, creativity, integrity, compassion.
I include “backdrop capacity” because I think it influences the three main security factors above in myriad (albeit, sometimes indirect) ways. I also think that advanced AI might improve our backdrop capacity significantly (though: it could also degrade it in various ways as well). And as in the case of the three main security factors, actors developing/deploying AI can themselves contribute directly to these improvements.
Here’s a diagram of the dynamics I’ve discussed thus far (see footnote for a few of the complexities I’m leaving out[14]):
5. Sources of labor
I just laid out a toy model of what civilizational competence consists in – a model that focuses on the role of safety progress, risk evaluation, and capability restraint, along with our backdrop capacity more generally. Now I want to talk a little about the different sorts of labor – and especially: cognitive labor – that could improve our civilizational competence in this sense.[15]
We can divide sources of labor into two categories:
- Labor that is available now.
- Labor that might become available in the future.
The first category is relatively familiar. It includes, centrally:
- The labor of current biological humans.
The labor of present-day AI systems.[16]
The second category is more exotic. It includes, centrally:
- The labor of future, more advanced AI systems (both AI systems that satisfy the agency prerequisites, and those that do not).
- The possibility of what I’ll call “enhanced” human labor – that is, human labor of a significantly higher quality than what we have access to now.
- One possible form of “enhanced human labor” is sufficiently high-fidelity human whole brain emulation (WBE) or “uploading” – that is, replication in silico of the cognitively-relevant computational structure of the human brain, in a manner that preserves both human cognitive capabilities and human motivations.
The “preserving human motivations” aspect is important here, because it’s often thought that a key benefit of enhanced human labor is that it will be easier to suitably “align” than future AI labor, because human motivations are more aligned by default.[17]
- WBE is especially important because it captures some of the advantages of AI labor – i.e., brain emulations can be run very fast, copied in large quantities, etc.
There are also a variety of other possible routes to enhanced human labor – e.g. via biological interventions, or via more external tools (e.g., brain computer interfaces or “BCI”[18]).
These come on a spectrum of potency, difficulty, necessary time-lag, and so on.[19] To the extent they rely on biological human brains, though, they don’t share the advantages of WBE and AI labor re: speed, copying, etc.
As in the case of WBE, though, a key distinguishing feature of this labor is that it inherits human motivations by default.[20]
Obviously, in many cases, creating and drawing on these possible future forms of enhanced human labor would raise serious ethical and political questions – both about how the enhanced humans involved are being treated, and about the implications and consequences for everyone else.[21] But I’m not going to focus on these questions here.
- One possible form of “enhanced human labor” is sufficiently high-fidelity human whole brain emulation (WBE) or “uploading” – that is, replication in silico of the cognitively-relevant computational structure of the human brain, in a manner that preserves both human cognitive capabilities and human motivations.
Thus, in a diagram:
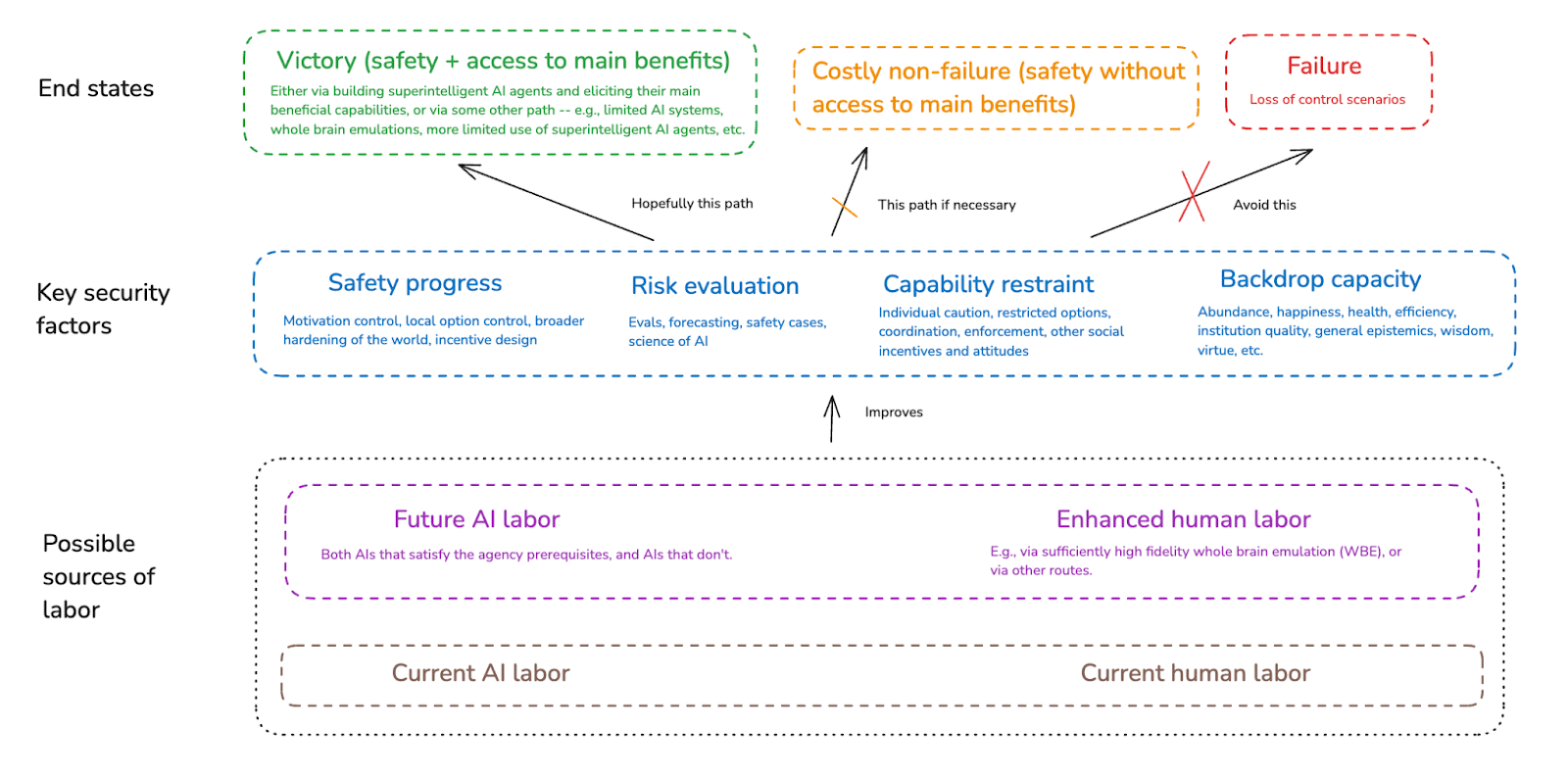
6. Waystations on the path
OK, I’ve now discussed the end states we’re shooting for, the security factors that can help us get there, and the sources of labor we can use to improve these security factors. I want to close this essay by discussing a few different intermediate “waystations” that strategies in this respect can focus on[22] – that is, milestones other than one of the end-states we’re aiming for, but which can function nevertheless as key goals for the purposes of current planning.[23]
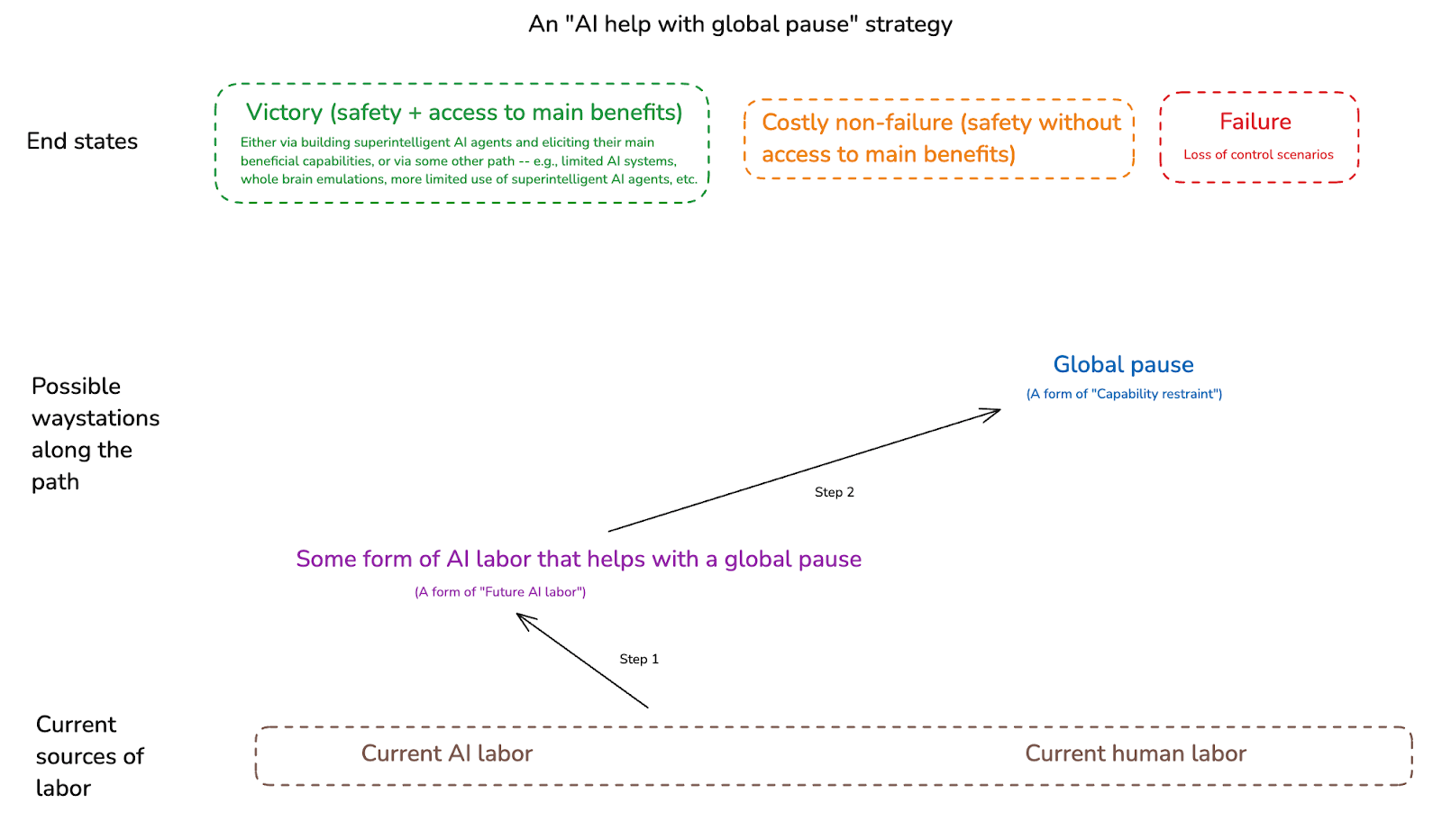
One example “waystation” that has already received some attention is some kind of global pause/halt on frontier AI development (we can think of this as a particular form of capability restraint).[24]
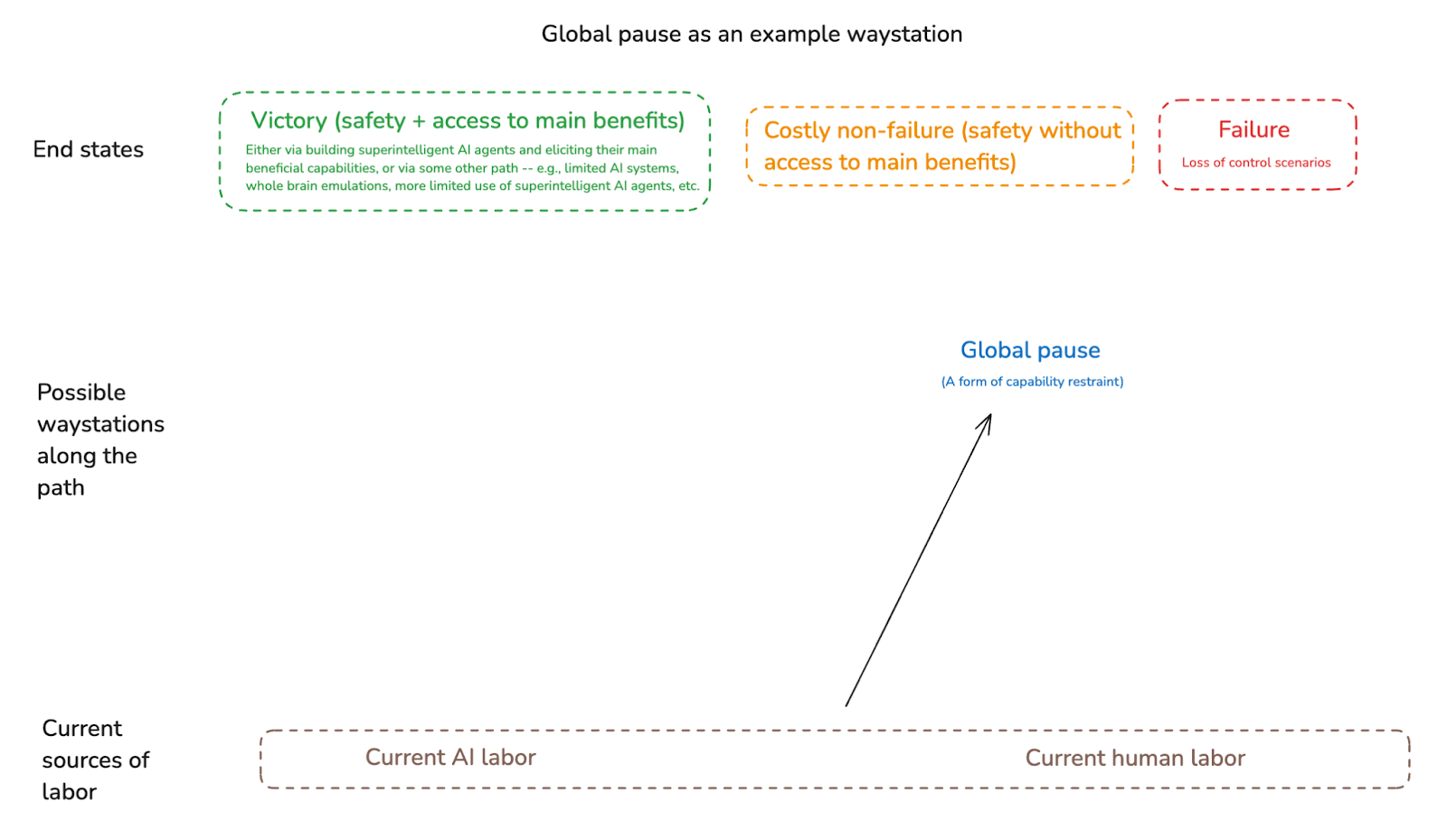
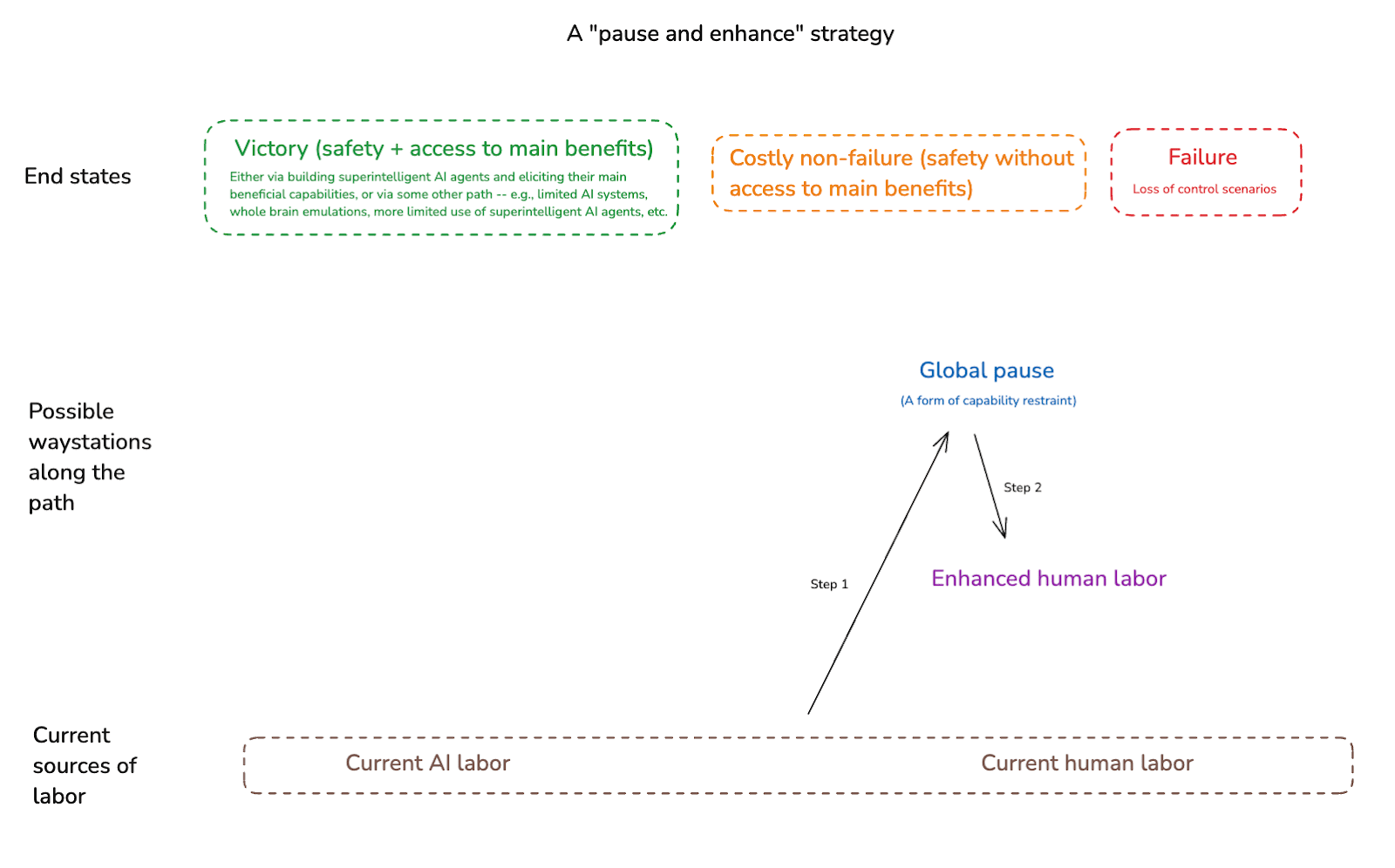
Another waystation would be something like: access to a given form of enhanced human labor. Indeed, my understanding is that the strategy favored by leadership at the Machine Intelligence Research Institute involves going to “Global pause” as a step 1, and then to “Enhanced human labor” as a step 2.[25] (And insofar as developing a given form of enhanced human labor – e.g., whole brain emulation – might take a long time, such a pause could well be necessary.)
A further possible waystation would be: safe access to the benefits of some kind of future AI labor, short of full-blown superintelligence. This sort of strategy can take a variety of different forms, but a paradigm example is a focus on “automated alignment researchers” that then help us significantly with aligning more advanced systems.[26]
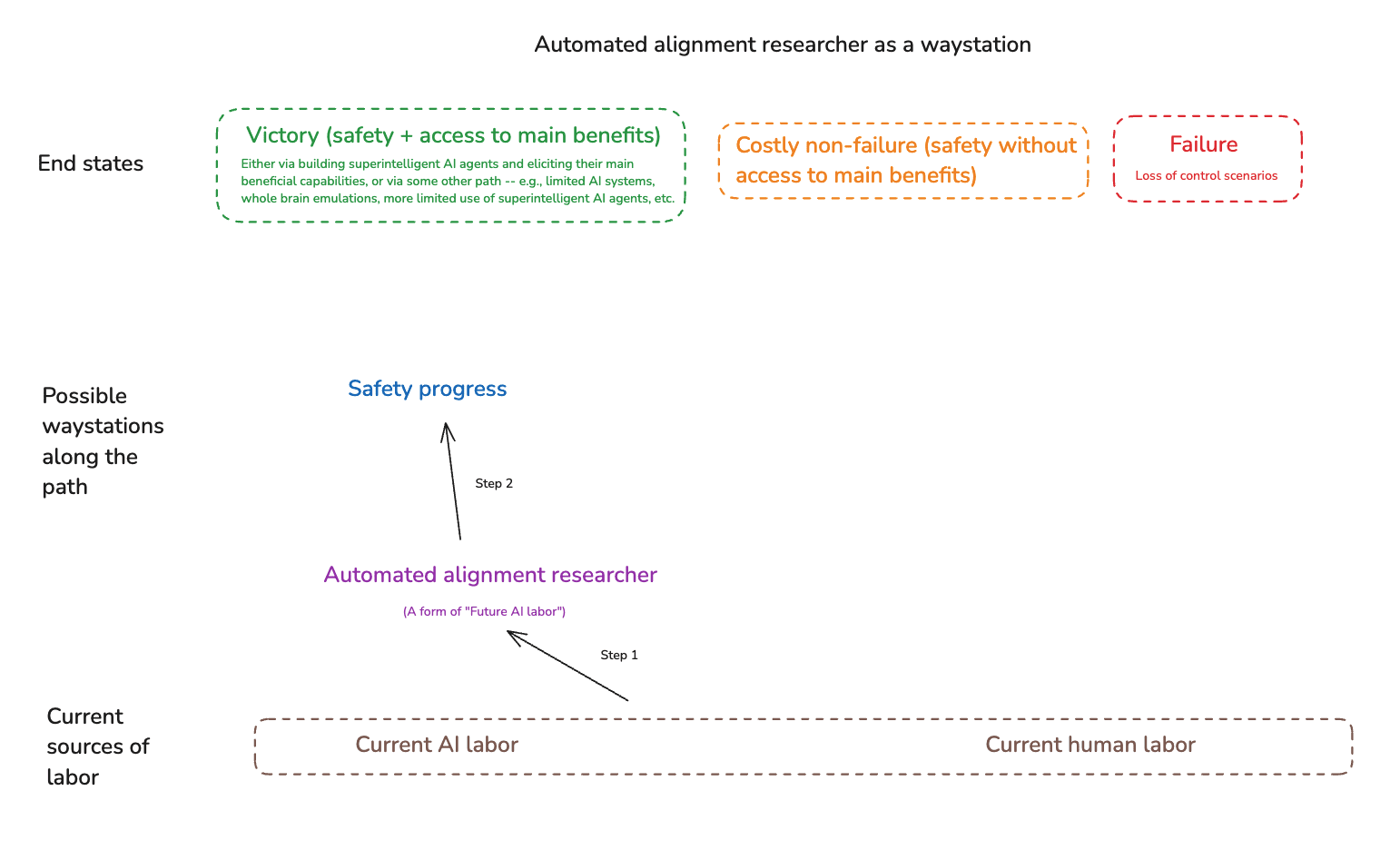
Note, though, that “automated alignment researcher” isn’t the only type of future AI labor one can focus on as a waystation. Rather, one could in principle focus on future AI labor that helps with some other application – for example, a narrow “scientist AI” that helps with access to some form of enhanced human labor like whole brain emulation.[27]
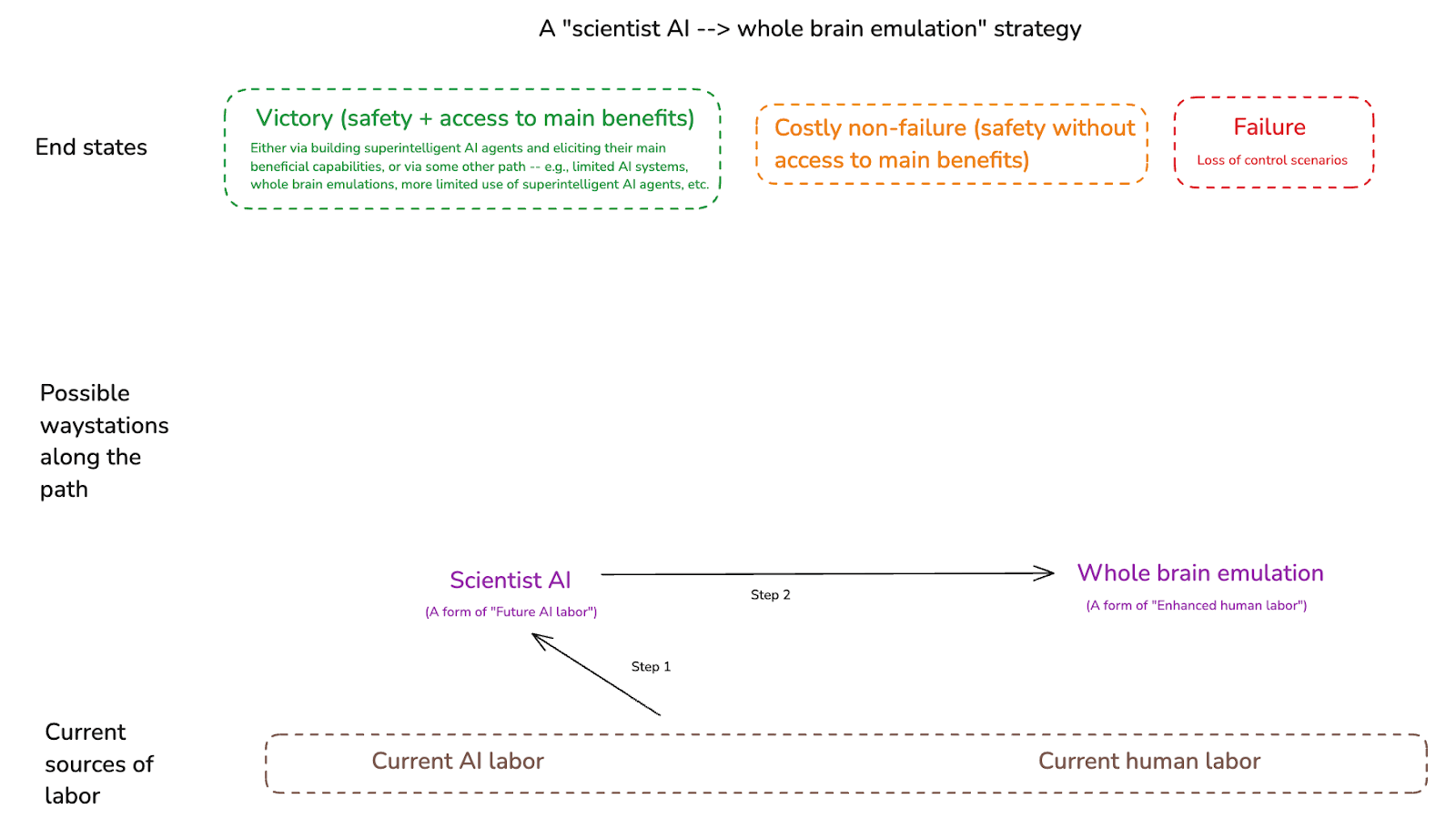
Another example would be: access to AI labor that helps significantly in making a global pause possible – for example, by significantly facilitating risk evaluation, coordination, negotiation, monitoring, enforcement, and so on.[28] (Though: note that to the extent that we are in principle in a position to institute a global pause on AI now, and the main bottleneck is political will rather than technological capacity, it’s not clear exactly how much AI labor on its own will help.[29])
And we can imagine a variety of other possible waystations as well. Examples include:
Some new ability to formally verify the safety properties of our AI systems.[30]
Some large amount of progress on interpretability/transparency, perhaps via some new paradigm of AI development.[31]
The formation and empowerment of some suitably safety-concerned global coalition.[32]
- A regime of “mutually-assured AI malfunction,” in which capability restraint is enforced by the threat (and/or actuality) of different actors sabotaging each other’s projects.
A global moratorium on particular kinds of AI development – e.g., autonomous general agents, as opposed to more tool-like AIs.[33]
Radical improvements to our ability to understand and forecast AI safety risks, perhaps via vastly better evals, scary demos, forecasting ability, etc.[34]
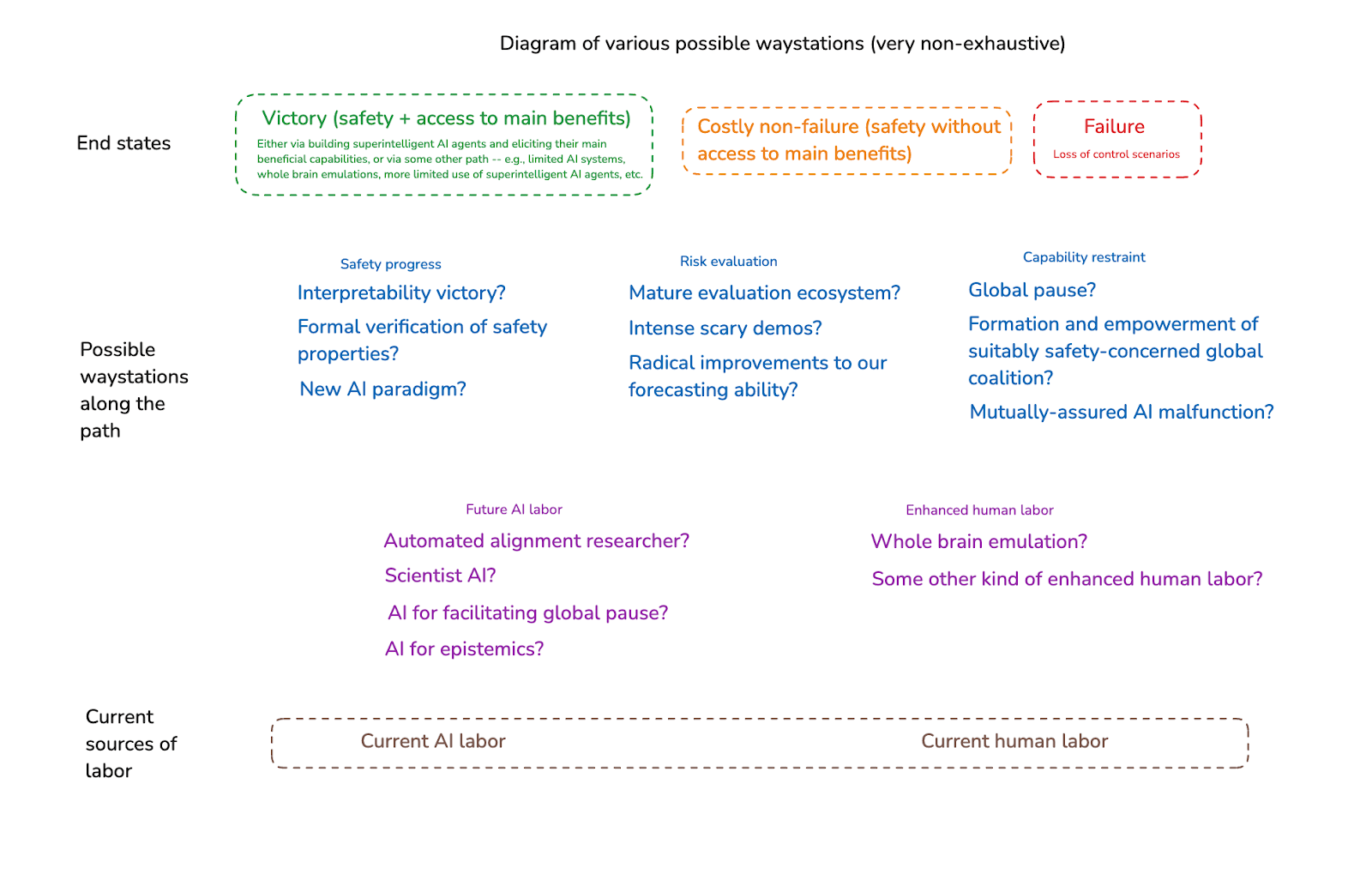
Of course, in all of these cases, there’s still a question of where, exactly, one goes from the relevant milestone. That is: if one succeeds in e.g. getting a global pause, or in creating a safe automated alignment researcher, or in developing whole brain emulation technology, one still needs to plot an overall path to victory (or to costly non-failure). Generally, though, a good waystation makes it clear why the path becomes much easier from there.
We also don’t need to focus on any one milestone in particular. Rather, we can work towards many at once. Indeed, in my next essay – “AI for AI safety” – I’ll defend the crucial importance of trying as hard as we can to use future AI labor, in particular, to strengthen our civilizational competence across the board. I’m especially interested, though, in “automated alignment researcher” as a milestone – and in the essay after next, I’ll analyze it in detail.
- ^
Though obviously, there are limits to the control that a given “we” can exert in this respect.
- ^
This simplification does have costs, though, in that strategies that work/don’t-work for one problem profile (for example: focusing a lot on interpretability) might be importantly different in their efficacy for some other problem profile.
- ^
I’m going to focus on safety from full-blown loss of control risk, but in principle this model extends both to lower-stakes forms of rogue behavior, and to safety from other risks that increase with greater AI capabilities.
- ^
I’ll also draw on it elsewhere in the series.
- ^
Obviously, AI capability is extremely multi-dimensional. But the model I’m using extends quite naturally to a multi-dimensional setting as well – the point is to avoid unsafe regions of capability space.
- ^
Deploying safely isn’t a binary, but I think the model works regardless of the safety standard you fix (via e.g. a given probability of failure).
- ^
Note that there’s a lot of room for debate about how to draw the lines on a diagram like this. E.g., if you think that the problem profile is easy, then you might put the red line quite high up – or perhaps, if you think that AI development is safe by default, you might not have a red line at all. And there’s a further question about how you think the red line has been changing over time. My particular version of the diagram isn’t meant to be making any claims about this – it’s just illustrative.
- ^
A more fine-grained model would distinguish between safety in the sense of avoiding loss-of-control, and elicitation in the sense I discussed here. But I’m going to skip over this for now.
- ^
Including: understanding relevant to which paradigms of AI development pose more or less risk.
- ^
This overlaps notably with safety progress. And no surprise: making systems safe and understanding when they’re safe vs. dangerous are closely tied.
- ^
And also: to steer towards safe approaches to superintelligence once available.
Alternatively: avoiding the alignment problem requires exerting enough capability restraint to not build superintelligent AI agents at all.
- ^
And/or: to steer around slime-y patches.
- ^
See e.g. Karnofsky (2022) [LW · GW] on “inaction risk.”
- ^
Complexities I’m leaving out (or not making super salient) include: the multi-dimensionality of both the capability frontier and the safety range; the distinction between safety and elicitation; the distinction between development and deployment; the fact that even once an actor “can” develop a given type of AI capability safely, they can still choose an unsafe mode of development regardless; differing probabilities of risk (as opposed to just a single safety range); differing severities of rogue behavior (as opposed to just a single threshold for loss of control); the potential interactions between the risks created by different actors; the specific standards at stake in being “able” to do something safely; etc.
- ^
Labor isn’t the only relevant input here. But because AI, and the technological advancement it unlocks, might make new and more powerful sorts of labor available, I think it’s an especially important input to track.
- ^
Maybe it sounds a bit strange to call this “labor,” but I think it’s roughly the right term, and it will be increasingly the right term as more advanced AI systems come online.
- ^
Indeed, it’s centrally because suitably high-fidelity human brain emulations inherit human motivations by default that I’m counting them as “enhanced human labor” rather than “future AI labor,” despite the fact that they run in silico. However, if a brain emulation process isn’t high enough fidelity to preserve human motivations/values, then I’m going to count it as “future AI labor” rather than enhanced human labor. And note that you also need the ems to suitably retain their human-like motivations over time (thanks to Jason Schukraft for discussion). And note, also, that depending on the problem profile, it may end up being easier to shape an AI’s motivations desirably than to create a human brain emulation with the right motivational profile, at least along many dimensions. In particular: the motivations of our AIs are shaped, by default, by much more active human effort. (Thanks to Owen Cotton-Barratt and Will MacAskill for discussion.)
- ^
Though: I doubt that just allowing direct brain control over external devices is an especially important intervention here, as I don’t think that “ability to affect external devices” is an especially key bottleneck to the quality of human cognitive labor at the moment.
- ^
And in some cases, the line between “enhanced human labor” and “normal human labor with some new tools” gets blurry.
- ^
And if it doesn’t do that (i.e., because a given form of intervention warps human values too much), it becomes much less useful.
I’ll also note some general open question about how far we should expect “this agent has human motivations” to go with respect to ensuring the sort of safety from AI takeover that we’re hoping for. That is: it’s sometimes thought that the central concern about the motivations of AI systems is that these motivations will be in some sense alien or non-human. And using enhanced human labor instead is supposed to provide comfort in this respect. But as I’ve discussed in other work (see here, and here [LW · GW]), the basic conceptual argument for expecting instrumentally convergent power-seeking, including takeover-seeking, applies with similar force to human-like motivations. And our degree of actual lived comfort with human motivations stems, I think, in central part from the option control that our civilization exerts with respect to individual agents, rather than from any kind of historical precedent where humans routinely refuse takeover options once such options are available and reasonably likely to lead to success. So to the extent that the agents at stake in “enhanced human labor” would end up having takeover options similar to those that we’re expecting advanced AI systems to have, I think we should not assume that enhanced human labor is safe.
Indeed, certain kinds of blueprints for AI motivations – in particular, blueprints that involve the AI systems functioning centrally as an instrument of someone else’s will, and being generally extremely docile/pliant/ready-to-be-shut-down-or-modified etc – seem like a relatively poor fit with human motivations. Or to put it another way, humans may (or may not) be reasonably “nice” by default; but they aren’t especially “corrigible.”
- ^
Indeed, as I discussed earlier in the series, I think that creating and using advanced AI labor raises these questions too.
- ^
These waystations generally fall under the umbrella either of one of the security factors I’ve discussed above, or of one of the possible sources of future labor.
- ^
Indeed, in some sense, my whole framing of the alignment problem is already focusing on a type of “waystation,” in that I’m not trying to plan all the way through to a good future in general – nor, even, to safe scaling up to arbitrary levels of superintelligence. That is, I’m treating something like “safe access to the benefits of some minimal form of full-blown superintelligence” as an end point past which my own planning, with respect to this problem, need not extend.
- ^
This is a waystation that has been advocated for by the Machine Intelligence Research Institute (MIRI), for example, and by Miotti et al in “A Narrow Path.”
- ^
From their January 2024 Strategy Update: “Nate and Eliezer both believe that humanity should not be attempting technical alignment at its current level of cognitive ability, and should instead pursue human cognitive enhancement (e.g., via uploading), and then having smarter (trans)humans figure out alignment.” And see also this podcast [LW · GW] with Yudkowsky, where he discusses this strategy in more detail.
- ^
This, for example, was the waystation that OpenAI’s old “superalignment” team was focusing on – see e.g. discussion here: “Our goal is to build a roughly human-level automated alignment researcher. We can then use vast amounts of compute to scale our efforts, and iteratively align superintelligence.” Something in the vicinity is suggested by Sam Bowman’s description of Anthropic’s theory of victory on AI as well (see especially section 2 on “TAI, or Making the AI do our homework”). And see also Clymer (2025) [LW · GW] for some more detailed discussion.
- ^
Indeed, in a sense, we can think of approaches that try to identify some “pivotal act” – i.e., an action that drastically improves the situation with respect to AI safety – that we use AI systems to perform as a generalized version of “Future AI labor” as a waystation. That is, first one gets access to some kind of pivotally useful AI system, and then one “saves the world” from there. See e.g. the strategy outlined in MIRI’s 2017 fundraiser update, and Yudkowsky’s discussion here [LW · GW] of “So far as I'm concerned, if you can get a powerful AGI that carries out some pivotal superhuman engineering task, with a less than fifty percent chance of killing more than one billion people, I'll take it.”
However: I have a number of problems with “pivotal acts” as a frame. For one thing: I think they often bring in an implicit assumption that the default outcome is doom (hence the need for the world to be “saved”) – an assumption I don’t take for granted. But more importantly: thinking in terms of discrete “pivotal acts” can mislead us about the nature and difficulty of the improvements to our civilizational security factors required in order for the world in question to get “saved.” In particular: those improvements can result from a very large assortment of individual actions by a very large number of different agents, no individual one of which needs to be pivotal. This is a point from Christiano (2022) [LW · GW]: “No particular act needs to be pivotal in order to greatly reduce the risk from unaligned AI, and the search for single pivotal acts leads to unrealistic stories of the future and unrealistic pictures of what AI labs should do.” See also Critch (2022) here [AF · GW].
- ^
Some versions of this get very scary very fast.
- ^
That said: better understanding of the risks, and better ability to identify, rationally-assess, and enforce mutually-acceptable agreements, seems like it could at least make a meaningful difference. Thanks to Nate Soares and Owen Cotton-Barratt for discussion here.
- ^
We might view the “Guaranteed safe AI” agenda, and related approaches, as focusing on waystations of this kind.
- ^
MIRI’s 2017 Fundraiser is suggestive of this kind of focal point; and see also Anthropic’s “Interpretability dreams” for some other discussion (though: not framed as a general strategy re: AI safety).
- ^
The “entente” strategy that Amodei discusses here might count as an instance of this.
- ^
See e.g. Aguirre’s “Keep the Future Human” for a tool-AI-focused proposal in this broad vein.
- ^
See Finnveden on “AI for epistemics [EA · GW]” for some relevant discussion – though this discussion isn’t framed specifically as an overall strategy.
1 comments
Comments sorted by top scores.
comment by Aprillion · 2025-03-13T11:15:46.511Z · LW(p) · GW(p)
toxic slime, which releases a cloud of poison gas if anything touches it
this reminds me of Oxygen Not Included (though I just learned the original reference is D&D), where Slime (which also releases toxic stuff) can be harversted to produce useful stuff in Algae Distiller
the metaphor runs differently, one of the useful stuff from Slime is Polluted Water, which is also produced by humans replicants in Lavatory ... and there is Water Sieve that will process Polluted Water into Water (and some plants want to be watered by the Polluted variant)
makes me wonder if there is any back-applicable insight - if AI slop is indistinguishable from corporate slop, can we use it to generate data to train spam filters to improve quality of search results and start valuing quality journalism again soon? (and maybe some cyborgs want to use AI assistants for useful work beyond buggy clones of open source tools)