Value fragility and AI takeover
post by Joe Carlsmith (joekc) · 2024-08-05T21:28:07.306Z · LW · GW · 5 commentsContents
1. Introduction 2. Variants of value fragility 2.1 Some initial definitions 2.2 Are these claims true? 2.3 Value fragility in the real world 2.3.1 Will agent’s optimize for their values on reflection, and does this matter? 2.3.2 Will agents optimize extremely/intensely, and does this matter? 2.3.2.1 Does it matter whether the optimization at stake is extreme or not? 2.4 Multipolar value fragility 2.4.1 Does multipolarity diffuse value fragility somehow? 3. What’s the role of value fragility in the case for AI risk? 3.1 The value of what an AI does after taking over the world 3.2 Value fragility in the context of extremely-easy takeovers 3.3 Value fragility in cases where takeover isn’t extremely easy 4. The possible role of niceness and power-sharing in diffusing these dynamics None 5 comments
1. Introduction
“Value fragility,” as I’ll construe it, is the claim that slightly-different value systems tend to lead in importantly-different directions when subject to extreme optimization. I think the idea of value fragility haunts the AI risk discourse in various ways – and in particular, that it informs a backdrop prior that adequately aligning a superintelligence requires an extremely precise and sophisticated kind of technical and ethical achievement. That is, the thought goes: if you get a superintelligence’s values even slightly wrong, you’re screwed.
This post is a collection of loose and not-super-organized reflections on value fragility and its role in arguments for pessimism about AI risk. I start by trying to tease apart a number of different claims in the vicinity of value fragility. In particular:
- I distinguish between questions about value fragility and questions about how different agents would converge on the same values given adequate reflection.
- I examine whether “extreme” optimization is required for worries about value fragility to go through (I think it at least makes them notably stronger), and I reflect a bit on whether, even conditional on creating super-intelligence, we might be able to avoid a future driven by relevantly extreme optimization.
- I highlight questions about whether multipolar scenarios alleviate concerns about value fragility, even if your exact values don’t get any share of the power.
- My sense is that people often have some intuition that multipolarity helps notably in this respect; but I don’t yet see a very strong story about why. If readers have stories that they find persuasive in this respect, I’d be curious to hear.
I then turn to a discussion of a few different roles that value fragility, if true, could play in an argument for pessimism about AI risk. In particular, I distinguish between:
- The value of what a superintelligence does after it takes over the world, assuming that it does so.
- What sorts of incentives a superintelligence has to try to take over the world, in a context where it can do so extremely easily via a very wide variety of methods.
- What sorts of incentives a superintelligence has to try to take over the world, in a context where it can’t do so extremely easily via a very wide variety of methods.
Yudkowsky’s original discussion of value fragility is most directly relevant to (1). And I think it’s actually notably irrelevant to (2). In particular, I think the basic argument for expecting AI takeover in a (2)-like scenario [LW · GW] doesn’t require value fragility to go through – and indeed, some conceptions of “AI alignment” seem to expect a “benign” form of AI takeover even if we get a superintelligence’s values exactly right.
Here, though, I’m especially interested in understanding (3)-like scenarios – that is, the sorts of incentives that apply to a superintelligence in a case where it can’t just take over the world very easily via a wide variety of methods. Here, in particular, I highlight the role that value fragility can play in informing the AI’s expectations with respect to the difference in value between worlds where it does not take over, and worlds where it does. In this context, that is, value fragility can matter to how the AI feels about a world where humans do retain control – rather than solely to how humans feel about a world where the AI takes over.
I close with a brief discussion of how commitments to various forms of “niceness” and intentional power-sharing, if made sufficiently credible, could help diffuse the sorts of adversarial dynamics that value fragility can create.
2. Variants of value fragility
What is value fragility? Let’s start with some high-level definitions and clarifications.
2.1 Some initial definitions
In Yudkowsky’s original treatment [LW · GW] of value fragility, the most important claim seems to be something like: “the future will not be good by reflective human lights by default; rather, for that to happen, the future needs to be actively steered in the direction of a quite specific set of human values – and if you get those values even slightly wrong, all the value might well get lost.”
As I discussed in “An even deeper atheism,” though, my sense is that people often come away from the AI risk discourse with a slightly broader lesson, focused on something more like:
Fragility of human value: extreme optimization for a slightly-wrong set of values tends to lead to valueless places, where “value” is defined as something like: value-according-to-humans.
I don’t think it’s fully clear, in Yudkowsky’s original framing, whether the optimization at stake needs to be “extreme.” And below I discuss below whether non-extreme optimization might do the trick. But I think many of the applications to AI risk involve an intuitively extreme amount of optimization, so I’m going to leave it in for now.
Note that here we’re specifically talking about the fragility of human values with respect to non-human values. As I discuss in “An even deeper atheism,” though, the theoretical arguments for expecting value fragility – in particular, “extremal Goodhardt” (see footnote[1]) – apply quite generally. For example, absent further empirical assumptions, they could easily apply to differences between human value systems as well. And it will matter, in what follows, whether non-human values – for example, the values possessed by an imperfectly-aligned AI – are “fragile” in the relevant sense as well.
So I’ll focus, here, on an even broader formulation, namely:
Value fragility: given two agents, A and B, with slightly different values-on-reflection, we should expect by default that a future optimized very intensely for A’s values-on-reflection will be quite low in value according to B’s values-on-reflection.[2]
Note that if we assume that the “having slightly different values-on-reflection” relation is symmetric (e.g., if it applies to A with respect to B, it also applies to B with respect to A), then Value fragility applies symmetrically as well. This will be relevant in the context of the discussion, below, about how a misaligned AI system might feel about a human-run world.
Here, the notion of “on reflection” is, as ever, ambiguous and fraught. Roughly, though, we are imagining some “idealization process” that takes us from a messy, real-world agent to a set of consistent, endorsed values that we treat as the standard for what that agent “should” value, by their own lights. More on this notion here, and on its various problems (I think that these problems are reasonably serious, but which I will mostly ignore them, for simplicity, in what follows).
Importantly, Value fragility is distinct from the following claim:
Extremely non-convergent reflection: given two agents, A and B, with slightly different values-relevant psychological profiles (i.e., slightly different preferences, desires, ethical convictions, etc), you should expect that the values that A would endorse on reflection to be least somewhat different than the values B would endorse on reflection.
It’s possible for Extremely non-convergent reflection to be false, but for Value fragility to be true – and vice versa. Thus, it could be that actually, there is a quite wide basin of psychological profiles that all converge on the same value system after reflection – but also, that slightly different value systems, optimized very hard, lead in very different directions. Alternatively, it could be the case that small values-relevant psychological differences create at-least-somewhat different post-reflection values, but that somewhat different post-reflection values do not lead to very different places given extreme optimization.
If we put Value fragility and Extremely non-convergent reflection together, though, we get something like:
Real-world divergence: given two agents, A and B, with slightly different values-relevant psychological profiles (i.e., slightly different preferences, desires, ethical convictions, etc), we should expect by default that a future optimized very intensely for A’s values-on-reflection will be quite low in value according to B’s values-on-reflection.
That is, on Real-world divergence, Value fragility bites our real-world relationships hard. After all: people tend to have at least slightly different values-relevant psychological profiles. So Extremely non-convergent reflection and Value fragility together imply that you would, by default, be quite unexcited by someone else’s optimal future.
2.2 Are these claims true?
Are these various claims true? I’m not going to examine the issue in depth here, and many of the terms at stake are sufficiently imprecise that clean evaluation isn’t yet possible. Roughly speaking, though:
- At least for the most salient conceptions of “reflection,” my best guess is that Extremely non-convergent reflection is false – for example, I expect that different small variations on a single person will often end up with the same values on reflection.
And it’s certainly possible to think of value systems where Value fragility is false as well – for example, “make at least one paperclip” and “maximize paperclips.”[3]
Indeed, as I discuss below, and especially in the context of comparatively resource-satiable value systems, I think Value fragility can be fairly easily made false via the addition of some amount of “niceness” – e.g., Agent A having at least some intrinsic concern about how things go according to Agent B’s values-on-reflection.[4]
And note that there is an entire structural category of value systems – i.e., “downside-focused value systems” – to which paradigmatic concerns about Value fragility seem to not apply. I.e., these value systems are primarily focused on things not being a certain way (e.g., not containing suffering). But as long as “most” value systems, or most directions the universe could be “steered,” don’t involve things being that way (or at least, not intensely that way), then Value fragility seems much less applicable. (Thus, suffering-focused ethicists are comparatively fine with a world of paperclips, a world of staples, a world of rocks, etc…)
- What’s more, intuitively, when I focus on Real-world divergence directly, and try to hazily imagine the “optimal future” according to the values I expect various humans to endorse on reflection, I feel pretty unsurprised if, by my own post-reflection lights, such futures are pretty great.
In general, I’d love to see more rigorous evaluation of the various claims above. In particular, I’d be interested to see more in-depth treatments of why, exactly, one might expect Value fragility to be true, and under what conditions.[5] But this isn’t my main purpose here.
2.3 Value fragility in the real world
I do, though, want to flag a few other possible claims relevant to our thinking about value fragility. In particular: thus far, we’ve focused centrally on various theoretical claims about value fragility. But the AI risk discourse often treats these claims, or something nearby to them, as importantly relevant to forecasting the value of what will actually happen to our future if we build superintelligent AIs. Here I’ll flag a few more claims that would support this kind of real-world relevance.
2.3.1 Will agent’s optimize for their values on reflection, and does this matter?
First:
Real-world optimization for values-for-reflection: given the time and resources necessary to reflect, we should expect real-world, sophisticated agents to end up optimizing for something closely akin to their values-on-reflection.
Here, the rough idea is that in a future run by sophisticated agents, we should expect the sorts of “values on reflection” at stake in the claims above to be decent approximations of the sorts of values the agents in question actually end up optimizing for. Where the vague justification for that is something like: well, to the extent we are imagining an agent’s “values on reflection” to be the governing standard for what that agent “should” do, failing to optimize for them would be a mistake, and we should expect sophisticated agents to not make such mistakes. But this claim, of course, raises a further bucket of questions about exactly how robustly we should expect reflection of the relevant kind, what the standards for “successful” reflection are, what sorts of time and resources are required to achieve it, etc.
Note, though, that Real-world optimization for values-on-reflection isn’t actually necessary for real-world worries quite nearby to Value fragility to go through. Rather, to the extent we expect real-world sophisticated agents to end up optimizing for some set of values or another, then we might worry about something like Value fragility regardless of whether those agents are making a “mistake,” in some sense, or not. That is, Value fragility, to the extent it’s true, plausibly applies to value systems in general, regardless of whether they are some particular agent’s “values on reflection” or not. Thus, for example, if a misaligned AI ends up optimizing very hard for paperclips, then even if, on reflection, it would’ve decided to optimize for staples instead, worries about the value of paperclips by human lights would still apply.
Indeed, perhaps we would do better to define value fragility in terms that don’t appeal to “values on reflection” at all, i.e.:
Value fragility revised: given two at-least-slightly-different value systems, A and B, a future optimized intensely according to A will be quite low in value according to B.
This definition would allow us to bracket questions about whether agents will optimize intensely for their “values on reflection” or not, and to focus solely on whether they will optimize intensely for some value system or other. Note, though, that to the extent we’re making room for unreflective value systems in this revised definition, there’s at least some question whether unreflective value systems will be sufficiently suitable targets for extreme optimization. For example, if a value system contains active contradiction or incoherence, it may be unclear what it even means to optimize it very hard (or indeed, at all).[6]
2.3.2 Will agents optimize extremely/intensely, and does this matter?
This brings us to our another empirical claim that would support the real-world relevance of Value fragility:
Real-world extreme optimization: we should expect real-world, sophisticated agents with access to mature technology to optimize with the sort of extreme intensity at stake in Value fragility above.
Here, I am trying to explicitly flag a substantive question-mark around the potential for differences between the type of “optimization” at stake in any sort of wanting, desiring, preferring, etc, and the type of optimization intuitively at stake in concerns about value fragility. That is, I think there is some intuitive sense in which the sorts of AI systems imagined by the classic AI risk discourse are assumed to be bringing to bear an unusual intensity and extremity of optimization – intensity/extremity that seem centrally responsible for taking things to the “tails” enough for those tails to come so dramatically apart.
Of course, on the standard story, this intensity/extremity falls out, simply, from the fact that the AI system in question is so intelligent/powerful – that is, relevantly “intense/extreme” optimization is just what having any values at all looks like, for a superintelligence. But it’s easy to wonder whether this standard story might be missing some important dimension along which desires/preferences/values can vary, other than the power/intelligence of the agent possessing them.
- For example, the standard story often assumes that the agents in question are well-understood as having “utility functions” that they are “maximizing.” But in my view, it’s a quite substantive hypothesis that ~all sophisticated agents will converge on value systems well-understood in this way – one that I don’t think appeals to “coherence arguments” and “not stepping on your own toes” are enough to warrant high confidence in.
- Relatedly, the standard story often seems to understand the values in question as focused, solely, on some kind of consequentialist outcome(s), as opposed having at least some non-consequentialist components (and note that non-consequentialist value systems are often difficult to square with consistent utility functions). And while I think some amount of consequentialism is required for any kind of AI risk story to go through (see my discussion of goal-content prerequisites here [LW · GW]), exclusive consequentialism is a different matter.
- A focus on a paperclip maximizer as the central image of misaligned AI also implicitly brings in a bunch of additional further structure, which can do substantive work in our conception of the situation in ways that it can be hard to keep track of. Examples include:
- It assumes that the AI’s value system is linear in additional resources.
- We can posit that an AI’s usage of resources will eventually be dominated by the most resource-hungry component of its value system – and that this resource-hungriness might indeed be linear. But positing that the AI has any resource-hungry component to its value system is itself a further substantive hypothesis; and as I discuss in this post [LW · GW], if the AI gets 99% of its available utility from a very small amount of resources, and then only needs “the galaxies” for the last 1%, this can make an important difference to its incentives overall.
- It assumes that the temporal horizon of the AI’s concern is unbounded and impartial.
- Again, I think that some non-myopic temporal horizon is required for ~any AI risk story to work (see, again my discussion of goal-content prerequisites here [LW · GW]). But this sort of unbounded and impartial temporal horizon is an additional step, and one quite relevant to the AI’s real-world incentives.
- It conjures a value system that involves a focus specifically on creating a certain kind of repeated structure over and over, which brings in additional connotations of boringness.
- But note, in this context, that not just any non-repeating structure will do to avoid value loss – see, for example, digits of pi, ongoingly varying sorts of static, etc.
- The paperclipper value system also, notably, has only one basic “component.” But in principle you could end up with AIs that are more akin to humans in that they value many different things in different ways, in quite complicated interactions.
- But note that this still doesn’t mean it values anything you like. And even if it did, it could be the case that extreme optimization for the AI’s values overall doesn’t lead to much of that thing (for example, because the AI gets more utility from focusing on the other stuff).
- It assumes that the AI’s value system is linear in additional resources.
- Finally, note there is indeed a (small) literature searching for that oh-so-elusive conception of how a superintelligence might, despite its power, just not optimize “that hard.” See, e.g., “soft optimization,” “corrigibility [? · GW],” “low impact agents,” and so on. If superintelligent agents, or superintelligence-empowered humans, can easily optimize in the way this literature is trying to elucidate, then this counts against Real-world extreme optimization as well.
I think it’s an interesting question whether, even in the context of building superintelligence, we might be able to avoid futures of “extreme optimization” entirely; what that might look like; and whether it would be desirable. Indeed, in this context, note that I’ve explicitly phrased Real-world extreme optimization so as to be neutral about whether it is human (or human-aligned) agents optimizing in an extreme way, vs. misaligned AI agents. That is: the claim here is that we should expect superintelligence-empowered humans, by default, to engage in relevantly “extreme optimization” as well (and this will matter, below, to questions about the AI’s attitudes towards a human-run world). But to the extent humans retain some intuitive (even if inchoate) conception of what it might be to not optimize “that hard,” one might wonder, in worlds where humans have solved alignment enough to avoid an AI takeover more generally, whether we might also end up with the ability to implement this conception of “mild optimization” in a manner that makes Real-world extreme optimization false of a human-run future. (Though whether doing so would be desirable is a further question. Indeed – modulo stuff like moral uncertainty, how could it be desirable to have something less optimized?! That’s just another word for “worse”! Right?).
Also: my sense is that many people have the intuition that multipolarity tends to lead to less “extreme” optimization in this sense. I’ll discuss this a bit below.
2.3.2.1 Does it matter whether the optimization at stake is extreme or not?
We should also note a nearby question, though: namely, is extreme optimization really necessary for concerns like Value fragility to go through? Couldn’t even fairly mild optimization do the trick? This, at least, would be the picture conjured by a focus on a contrast between human values and paperclips. That is, even fairly “mild” optimization for human values involves only a very small number of paperclips;[7] and similarly, even fairly mild optimization for paperclips creates very little that humans value directly.
Part of what’s going on in that case, though, is that human values and paperclips are actually quite a bit more than “slightly” different. Indeed, I worry somewhat that constantly imagining AIs as pursuing values as alien as “paperclips” stacks the deck too much towards a presumption of Value fragility-like vibes. For example, if we instead imagine e.g. AIs that are trying to be “helpful, harmless, and honest,” but which have ended up with some slightly-wonky concepts of helpfulness, harmless, and honesty, it’s quite a bit less clear what amount of optimization, in which contexts, is required for their attempts to be slightly-wonkily “helpful, harmless, and honest” to end up diverging radically from the actions and preferences of a genuinely HHH agent.
More generally: for values that are at least somewhat similar (e.g., HHH vs. slightly-wonky HHH; average utilitarianism vs. total utilitarianism; hedonism about welfare vs. preference satisfaction about welfare), it’s easier for “mild” pursuit of them – or at least, pursuit in a restricted search space, if we call that “mild” – to lead to more correlated behavior. And one key role for the “extremity” at stake in the optimization in question is to break these correlations, presumably via some Goodhardt-like mechanism.[8] So I tend to think that some amount of extremity is indeed important to the case.
That said, I think it’s an interesting and open question exactly how much extremity is necessary here, for which sorts of values differences – a question that a more in-depth analysis of when, exactly, to expect various types of value fragility would hopefully shed light on.
2.4 Multipolar value fragility
So far, we’ve only been talking about value fragility between single agents. We can also, though, talk about the more complicated dynamics that could arise in the context of multipolar scenarios, in which the future is not driven towards a single agent’s optima, but is rather driven, in some sense, by many different agents, with at-least-somewhat different values, simultaneously. Thus, consider:
Multi-polar value fragility: given an agent A and a large set of distinct agents 1-n, where all of these agents have at-least-slightly-different values-on-reflection, we should expect by default that a multi-polar future intensely optimized by agents 1-n, for their values on reflection, will be very low in value according to agent A’s values-on-reflection.
Note, importantly, that in Multi-polar value fragility, the future isn’t optimized by agent A, or by some agent with exactly agent A’s values, at all. That is, we’re not wondering about how agent A will feel about a multipolar future where agent A’s exact values get some small share of the power. Rather, we’re wondering about how agent A will feel about a future where agent A’s exact values get no power, but where some kind of multipolarity persists regardless.
Now, one way to motivate Multi-polar value fragility would be to posit:
Multipolar-unipolar equivalence: The combined multi-polar optimization of agents 1-n, each of which has at-least-slightly-different values-on-reflection from agent A, will end up equivalent, for the purposes of evaluating questions relevant to value fragility, to the intensive optimization of a single agent, which also has at least-slightly-different values-on-reflection from agent A.
If we accept Multipolar-unipolar equivalence, then Multipolar value fragility would fall out fairly directly from Value fragility above. And indeed, I think that simple models of a multipolar future sometimes expect that sophisticated agents with diverse values will end up acting as though they are actually one combined agent (see e.g. Yudkowsky [LW · GW]: “any system of sufficiently intelligent agents can probably behave as a single agent, even if you imagine you're playing them against each other”). My vague sense is that rationale here is often something like “you can get gains from trade by aggregating conflicting value systems into a single value system" (e.g., a "merged utility function"), combined with the assumption that sophisticated agents that are able to make credible commitments will reach such gains from trade. But these sorts of claims – especially construed, at least in part, as empirical predictions about what would actually happen as a result of a real-world multi-polar scenario – bring their own evidential burden.
Another, different-but-related angle on Multipolar value fragility could come from approximating the result of multipolar optimization by imagining that the agents 1-n in question “divide up the universe,” such that each ends up with some portion of available resources, which they then optimize, individually, to the same intense degree at stake in more unipolar versions of value fragility. I.e., the image is something like:
“Ok, if per Value Fragility you were willing to grant that a single agent A with somewhat-different-values from agent B ends up equivalent to a paperclip maximizer, then in the context of Multipolar value fragility you should imagine a whole host of different maximizers, each focused on a different sort of office supplies – e.g., staples, thumb-tacks, etc. So what sort of universe would you expect from the combined optimization of these many different agents? Plausibly: a universe filled with some combination of paperclips, staples, thumb-tacks, etc.[9] But if all of these office supplies are ~valueless from some agent A’s perspective, this is no better than a monoculture of paperclips.”
But here, again, we need to ask whether imagining a “divide up the universe and optimize super hard in your own backyard”-style outcome (or some evaluative equivalent) is indeed the default result of ongoing multi-polarity.
2.4.1 Does multipolarity diffuse value fragility somehow?
Even with these sorts of examples in mind, my sense is that people often have the intuition that concerns about value fragility apply much less in multipolar scenarios that preserve some balance of power between agents-with-different values, even if none of those agents is you. E.g., they do in fact find Multipolar value fragility much less plausible than the unipolar version. Why might this be?
One possibility might be that people have some hope like: “well, if it’s a multipolar future, then even if I myself have no power, it’s still more probable that one of the agents in question has my values in particular.” Strictly, this isn’t a case where Multipolar value fragility is false, but rather a case where its conditions don’t hold (e.g., at least one of the agents 1-n does have agent A’s values). But regardless, and especially if we’re bringing in Extremely non-convergent reflection as well, this sort of hope requires for it to just-so-happen that one of the agents 1-n has exactly your values – which plausibly remains quite unlikely even conditional on multipolarity.
- And note that the same objection applies to the hope that AIs will have complicated values, or that they might value lots of different things instead of only one thing. Maybe so – but valuing exactly what you value, even a little, is a different standard.
Are there other arguments for active skepticism about Multipolar value fragility? I don’t have a ton of great stories, here, but here a few other potential intuitions in play:
- If we think of “extreme” optimization as the part of your optimization that moves you from, say, 90% to 99.9999% of your potential utility, and we imagine various multipolar checks on your power keeping you below the 90% range, this could lead to an image of multipolarity as reducing the amount of “extreme” optimization at stake. E.g., maybe multipolarity forces you to only “get most of utility you can [EA · GW],” rather than “to get the most utility you can,” and this is somehow what’s required for Value fragility to not go through.
- I’m having trouble thinking of a compelling concrete example of this dynamic in action, though. And “the most utility you can get” was always going to be relative to your option set in a way that applies even in a multipolar situation.
- Alternatively, I think we often have some sense that in multipolar situations, agents don’t just do the some generalized equivalent of “dividing up the universe” (or, “dividing up the power”) and then optimizing intensively within their portion. Rather, they “rub up against each other” in ways that create some other kind of (potentially much healthier) dynamic. Maybe that helps with value fragility somehow?
- But it’s not super clear how it would do so. E.g., maybe agents 1-n all “rub up against each other” to create the future. But why does that make the future better by agent A’s lights?
- That said, I think the intuition here is worth exploring in more depth. In particular, I think it plausibly implicates some intuitive picture with respect to "collective intelligence" and the value of eco-system-like interactions between agents, that a more atomistic rational agent ontology risks neglecting. But it seems important to actually spell out the dynamics at stake in such a picture.
In general, to me it seems quite fruitful to examine in more detail whether, in fact, multipolarity of various kinds might alleviate concerns about value fragility. And to those who have the intuition that it would (especially in cases, like Multipolar value fragility, where agent A’s exact values aren’t had by any of agents 1-n), I’d be curious to hear the case spelled out in more detail.
3. What’s the role of value fragility in the case for AI risk?
OK: that was a bunch of stuff disentangling various claims in the vicinity of Value fragility. Let’s turn, now, to examining the relevance of these claims to the AI risk discourse more directly.
My sense is that for people who have been enmeshed in the discourse about AI alignment for a long time, and who think that building superintelligent AI goes quite badly by default, something like Value fragility often haunts their backdrop sense of the difficulty of the problem. That is, roughly speaking: a superintelligent AI will be a force for extreme optimization.[10] But according to Value fragility, extreme optimization for an even-somewhat-wrong set of values basically … sucks by default. So getting good outcomes from building a superintelligent AI requires some very delicate and sophisticated technical and ethical achievement. You need to both identify a set of values that lead to good outcomes given extreme optimization, AND you need to make it the case that the superintelligent AI you build is optimizing for precisely those values, and not for something even slightly different. Mess up at either stage, and the future is lost.
Of course, there are ways of getting concerned about alignment risk that do not load on Value fragility per se. For example: you could think that if you can successfully aim a superintelligence at a set of values within a fairly broad basin of value-sets, you’ll get good outcomes, but that our “aiming” ability is sufficiently poor that we’re not on track for even this. Indeed, especially in the modern era of ML, I expect that many people would want to argue for AI risk, first, on grounds of “we suck so bad at aiming our AIs at all,” and without introducing more esoteric philosophical questions about Value fragility directly.
Still, I think some prior nearby to Value fragility often matters quite a bit. Consider, for example, the contrast with the “Orthogonality thesis,” which is often understood as stating, simply, that superintelligence is compatible with the pursuit of arbitrary goals. True enough, as a first pass – but note that this isn’t, in itself, enough to get worried that we won’t be able to point a superintelligence at good enough goals with a bit of work (compare: gun technology is compatible with shooting at lots of different targets; but does that mean we won’t be able to aim our guns?). Really, I think, it’s often something like Value fragility that fills the argumentative gap, here (whether explicitly or not). It’s not just that, per Orthogonality, bad targets are on the table. Rather, bad targets are the very strong default, because the good-enough targets are such a narrow and finicky subset of the target space.
Here, though, I want to poke at this sort of prior in a bit more detail, and to try to get clearer about what role, exactly, it plays, or should play, in the case for pessimism about AI risk. In particular, I want to distinguish between:
- The value of what a superintelligence does after it takes over the world, assuming that it does so.
- What sorts of incentives a superintelligence has to try to take over the world, in a context where it can do so extremely easily via a very wide variety of methods.
- What sorts of incentives a superintelligence has to try to take over the world, in a context where it can’t do so extremely easily via a very wide variety of methods.
Let’s take these each in turn.
3.1 The value of what an AI does after taking over the world
The most natural and immediate role for Value fragility, in the argument for AI risk, is in motivating the claim that, after a superintelligence takes over the world, the thing it does with the world, and with the future, will be effectively valueless from the perspective of human values-on-reflection. That is, Value fragility, here, is a key (if not the key) theoretical motivator for the generalized concept of “paperclips.” And if we accept that some superintelligence has taken over the world, I do think it’s quite reasonable to have strong concerns in this vein.
And similarly, if we accept something like Multipolar value fragility, we shouldn’t expect to take much comfort in the possibility that multiple different superintelligences, with different values, ended up taking over the world, rather than only one. Still, if none of those superintelligences had exactly the right values, then Multipolar value fragility says that you’re screwed.
But the question of what an AI, or a set of AIs, does after taking over the world isn’t the only one that matters, here. In particular: I think we should also be interested in the question of whether to expect AI systems to try to take over the world at all – and especially, to take over in some violent or otherwise problematic way (rather than e.g. being given control by humans once we are good and ready, in a context where we could take that control back if we wanted to). Does Value fragility have any bearing on that question?
3.2 Value fragility in the context of extremely-easy takeovers
To analyze this, I want to turn to the framework I laid out, in my last post [LW · GW], for understanding the conditions under which an AI’s incentives favor problematic forms of power-seeking – and in particular, the sort of problematic power-seeking at stake in attempting to “take over the world.”[11] Quoting from that post:
“I think about the incentives at stake here in terms of five key factors:
- Non-takeover satisfaction: roughly, how much value the AI places on the best benign alternative….
- Ambition: how much the AI values the expected end-state of having-taken-over, conditional on its favorite takeover plan being successful (but setting aside the AI’s attitudes towards what it has to do along the path to takeover)....
- Inhibition: how much the AI disprefers various things it would need to do or cause, in expectation, along the path to achieving take-over, in the various success branches of its favorite take-over plan….
- Take-over success probability: the AI’s estimated likelihood of successfully achieving take-over, if it pursued its favorite takeover plan.
- Failed-takeover aversion: how much the AI disprefers the worlds where it attempts its favorite takeover plan, but fails.”
Thus, in a rough diagram:
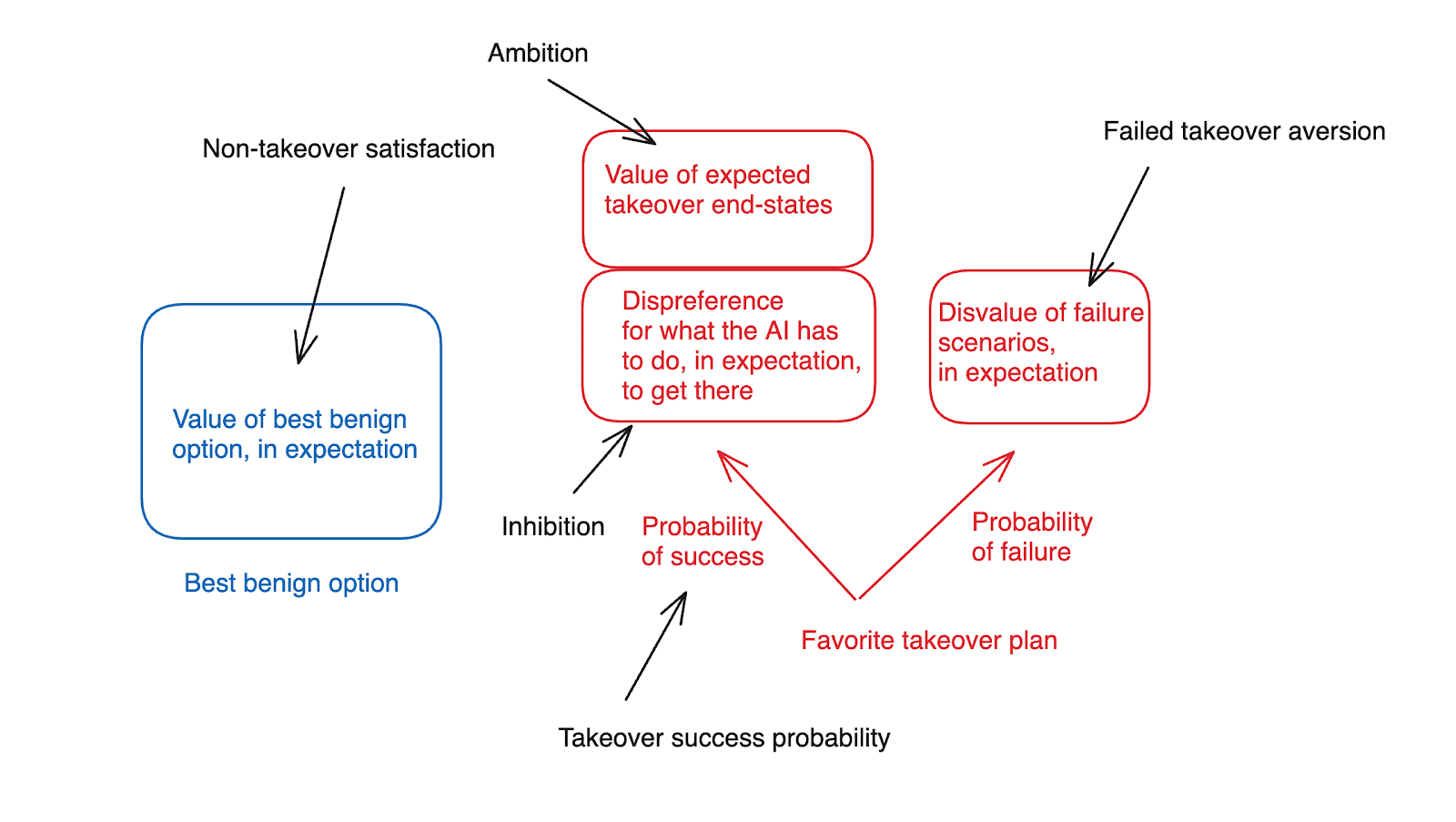
In particular, I want to first look at the potential role for value fragility in the recasting of the classic argument for AI risk [LW · GW] that I offered in my framework post. This argument proceeds, roughly, by positing that the superintelligent AI in question will be so capable that it will be able to take over the world extremely easily, via a very wide variety of methods. Positing this allows us to ignore “failed takeover aversion” (since the AI’s chance of success at takeover is so high); and it allows us to posit that the AI will be able to find a path to takeover compatible with its inhibitions (since it has so many viable paths available). So all we need to do is to find some amount of ambition in the AI, relative to the best benign option, for the favorite takeover plan to come out on top. And the claim is that it’s very easy for consequentialist goals with suitably long time-horizons to benefit at least somewhat from world domination.
What’s the role of Value fragility in this sort of argument? Interestingly, I’m not sure it needs to play an important role. Thus, for example, it’s compatible with this recasting that a human-controlled world would, in fact, result in 99% of the potential value, from the AI’s perspective. Still, if an inhibition-compatible takeover is suitably easy, it can be worth it, for the AI, just to get that extra 1%.
Indeed, I think it’s notable that the re-casted argument I offered appears, absent some further assumptions, to apply, at least potentially, even to quite virtuous superintelligences, and in the limit, perhaps, to superintelligences whose optimal universes are quite good by our lights – at least if we’re willing to consider “takeovers” that proceed via a path compatible with various human deontological inhibitions and constraints, and if we set aside what I’ll call below “intrinsically unambitious” or “intrinsically take-over averse” value systems. That is, for all the re-casted argument has said thus far, if you put even an extremely virtuous superintelligence in a position to take over the world extremely easily, via an extremely wide variety of methods, the re-casted argument above would seem to imply that this superintelligence, too, would be able find a path to takeover compatible with its ethical inhibitions; that it, too, wouldn’t need to worry about the downsides of failed takeovers; and that it, too, would have at least some grounds for ambition, relative to the non-takeover option, if its cares about some consequences in the world over the sorts of time-horizons that would allow the power so-acquired to be useful. This sort of scenario might not involve a “norm-violating” takeover, since a sufficiently virtuous superintelligence might make sure the chosen path to takeover adhered to all relevant ethical and legal norms. And perhaps the thing that this superintelligence does with the resulting power/control might be nice in various ways. But the re-casted argument above suggests the potential for incentives towards a “takeover” of some kind nonetheless.
- Of course, we can posit that sufficiently virtuous superintelligences will have values that are, in some sense, very robustly averse to takeover of any kind, such that roughly any kind of takeover will be ruled out on ethical grounds. This could be because sufficiently virtuous “inhibitions” very robustly block all available paths to takeover; or it could be because sufficiently virtuous valuations on the end-state of having-taken-over very robustly dis-prefer it to the best benign alternative (i.e., they are “intrinsically unambitious”), perhaps because such a takeover would violate intrinsic values related to fairness, legitimacy, and pluralism. And indeed, I think our intuitively skeptical reaction to claims like “sufficiently powerful but extremely virtuous AIs would try to take over too” expects a fairly high degree of takeover aversion in these respects. At an abstract level, though, I think it’s worth noting the degree to which the re-casted argument seems applicable, in principle, to very powerful virtuous agents as well – and in the limit, perhaps, to superintelligent agents to whom concerns about Value fragility do not apply.
Indeed, I think that some of Yudkowsky’s discussions of AI risk suggest that on his model, even if you solve alignment enough to avoid Value fragility, and so get a superintelligent pointed at that oh-so-precise and finicky set of targets that leads to good places even when subject to extreme optimization pressure – still, maybe you get a form of “takeover” regardless; except, hopefully, a benevolent one. Thus, for example, Yudkowsky, in “List of lethalities [LW · GW],” writes about two central approaches to alignment:
"The first approach is to build a CEV-style Sovereign which wants exactly what we extrapolated-want and is therefore safe to let optimize all the future galaxies without it accepting any human input trying to stop it. The second course is to build corrigible AGI which doesn't want exactly what we want, and yet somehow fails to kill us and take over the galaxies despite that being a convergent incentive there."
Here, the first approach corresponds, roughly, to solving the Value fragility problem – i.e., successfully creating an AI that wants “exactly what we extrapolated want.”[12] But note that the first approach sounds, still, like some kind of “takeover.” Apparently, you have, now, a “Sovereign” superintelligence running the world – indeed, optimizing the galaxies – and doing so, we’re told, without accepting any human input trying to stop it. That is, you still ended up with a dictator – just, apparently, a benevolent one.[13] (To be clear: my sense is that Yudkowsky doesn’t think we should actually be aiming at this approach to alignment – but I think that’s centrally because he thinks it too difficult to achieve.)
In this sense, it seems to me, the core role of Value fragility, at least in various ways of setting up the classic argument, isn’t, centrally, to differentiate between superintelligent AIs that take over, and superintelligent AIs that do not – since, apparently, you may well get a takeover regardless. Indeed, my sense of the Bostrom/Yudkowsky frame on AI risk is that “the superintelligence will take over and run the world” is often treated as baked in, even independent of alignment questions (an assumption, I think, we do well to query, and to look for options for making-false). And in the context of such an assumption, the core role of Value fragility is to argue, per section 3.1, that after the superintelligence takes over, you probably won’t like what it does. That is, whether you solve Value fragility or not, superintelligence is going to remain a force for extreme optimization; so if you built it, you should expect the universe to end up extremely optimized, and with superintelligence in the driver’s seat. The problem is just: that this tends to suck.
3.3 Value fragility in cases where takeover isn’t extremely easy
So overall, I don’t actually think that Value fragility is a key piece of the classic argument for expecting AI takeover per se – though it may be a key piece in the argument for expecting AI takeover to be bad by default; or for it to occur in a violent/illegal/unethical way.
As I noted in my “framework” post [LW · GW], though, I think the classic argument for AI takeover has an important limitation: namely, that it loads very heavily on the claim that the AIs in question will have an extremely easy time taking over, via a very wide variety of methods. If we relax this assumption, then the question of whether the AI’s overall incentives end up making takeover-seeking rational becomes substantially more complex. And in the context of this complexity, I think that questions about Value fragility may have a further role to play.
In particular: one big thing that changes in the classic argument, once you relax the assumption that the AI in question can take over extremely easily, is that you now need to consider in much more detail how good the “best benign option” is, according to the AI; and how much better the end state of having-taken-over is, relative to that option.[14] And one role Value fragility might play, here, is to create a large gap in value, according to the AI, between the best benign option and the end-state of the AI’s having-taken-over. In particular: if we assume that the best benign option leads, by default, to some set of human-like values steering the future, and being subjected to extreme optimization (because, for example, the AI assists the humans in achieving this end), and the AI’s values and this set of human values are such that Value fragility applies between them, then the AI, by hypothesis, is going to be quite unexcited about the best benign option – i.e., its “non-takeover satisfaction” will be low.
That is, the issue, here, isn’t that humans won’t like what the AI would do with the universe, which is the place that Yudkowsky’s original discussion of value fragility focuses. Rather, the issue is that the AI won’t like what (superintelligence-empowered) humans would do with the universe, either. So the best benign option, for the AI, is going to look quite bad; and the worlds where the AI succeeds in taking over, quite a bit superior. Thus, e.g., humans don’t like paperclips; but paperclippers don’t like human flourishing etc much, either.
At least in the context of this sort of “best benign option,” then, Value fragility can play a role in explaining why an AI might be comparatively “ambitious,” and so more liable to attempt a takeover even absent a high likelihood of success.[15]
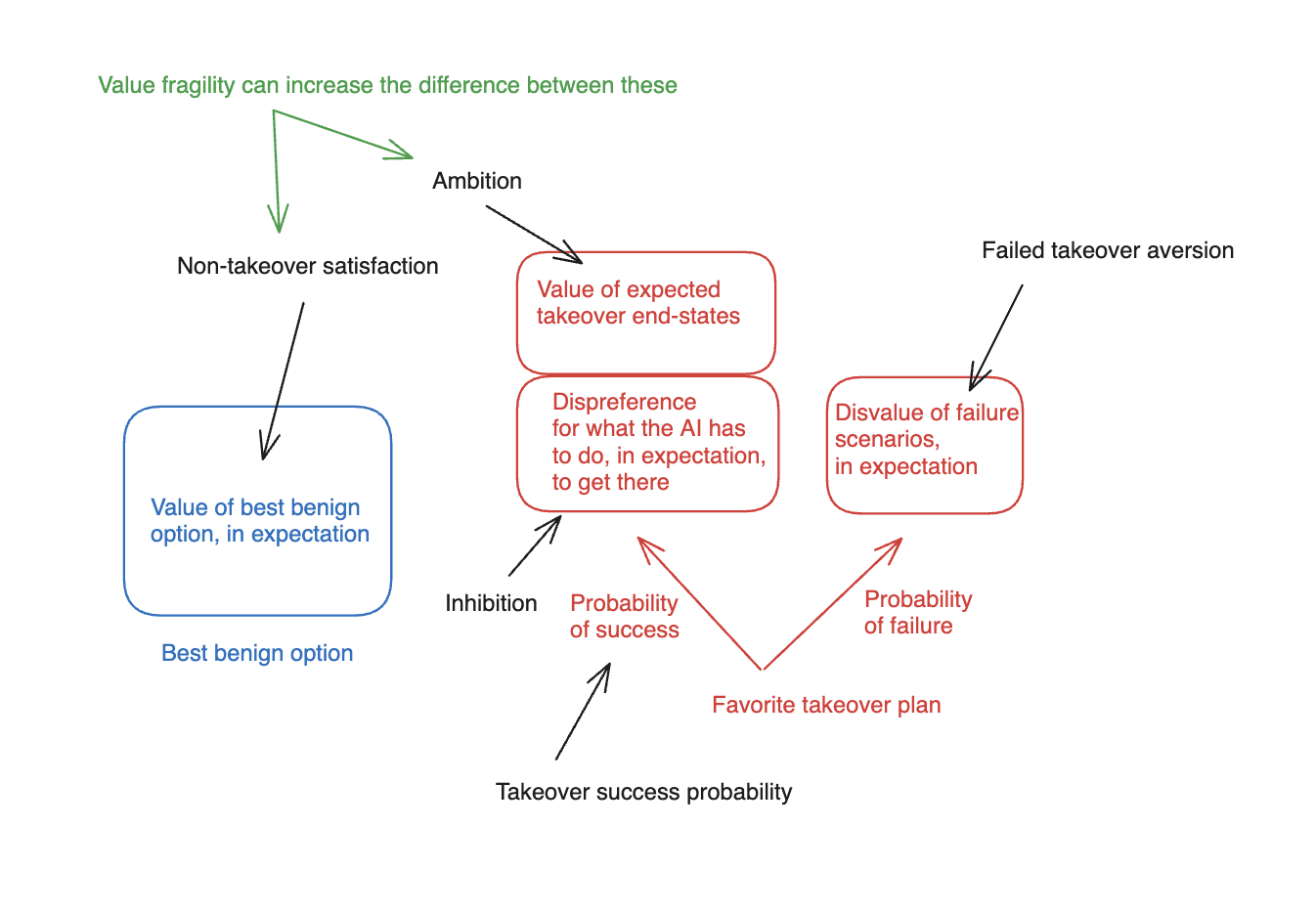
And indeed, my sense is that something like story plays a role in informing a backdrop sense, in the AI alignment discourse, that absent extremely precise and sophisticated success at alignment, the relationship between humans and AI systems will be actively adversarial by default – even if the AI systems in question are not yet fully dominant. That is, the picture is something like: the advent of AGI is a “battle for the future.” If humanity “wins,” then it will create a world that AIs with slightly different values-on-reflection would view as valueless; and vice versa. So: the stakes for both sides are extremely high – for both sides, and not just for humans, roughly everything of value is at stake. (And note, importantly, that to the extent one buys this narrative with respect to AIs vs. humans, the question of how much it applies to humans vs. other humans, as well, becomes much more salient – see “An even deeper atheism” for more on this).
Does it need to be this way? One way it could be not-that-way is if Value fragility, or something relevantly similar, is false. But even beyond that:
- Note that to the extent a human-run world would be, at least in many decently-likely cases, importantly multipolar, we need to lean specifically on Multipolar value fragility in order to establish that the human-run world would be ~valueless in expectation from the AI’s perspective.
- And note, too, that insofar as an AI would need to be participating in a large multipolar takeover effort, across many different AI systems, themselves with slightly different values, the upside of successful takeover, for the AI, will likely involve a much smaller share of the “pie.”
- Also: if, per my comments above, a human-run world somehow avoids “extreme optimization” of any kind, concerns about Value fragility might cease to apply from the AI’s perspective (though as I discussed above, “mild” optimization by humans might be enough to get similar concerns going).
- Finally: note that especially if the AI has a wide set of diverse motivations, not all of which are consequentialist and long-time-horizon, it could still be the case that it ends up reasonably satisfied with a human-run world, and/or inhibited/averse with respect to attempting take-over, even if concerns about Value fragility would apply to the more long-term consequentialist components of its value system. Thus, for example:
- The non-consequentialist components of an AI’s value system could still end speaking against the takeover option. And in general, the vibe behind Value fragility applies more jankily to non-consequentialist aspects of a value system. I.e., this vibe is really focused, paradigmatically, on “utility functions” over world histories, and it’s not clear that non-consequentialist value systems fit this mold.
- If the AI has various short-run consequentialist goals that are best achieved via not attempting takeover (e.g., if it cares at least somewhat about following human instructions, completing its assigned task well, getting short-term reward, etc), these might speak against takeover as well.
- And in general, short-run goals might be such that humans, within the relevant short period of time, wouldn’t, anyways, be engaging in the sort of extreme optimization required to make Value fragility relevant in practice. I.e., maybe the AI doesn’t like what human values look like “at the tails,” but human values won’t be “at the tails” until some time period beyond the scope of the AI’s concern.
Beyond all this, though, I want to highlight one key way in which I think this sort of adversarial dynamic can end up diffused – namely, via some combination of “niceness” and power-sharing. Let’s look at this aspect in more detail now.
4. The possible role of niceness and power-sharing in diffusing these dynamics
Above I mentioned one easy way for “value fragility” to be false of two agents A and B – namely, for agent A to be “nice” in the sense of: placing some intrinsic value on how things go according to agent B (or more specifically, agent B’s values-on-reflection). If agent A is nice in this sense, then agent A’s optimization can “bring agent B’s values along for the ride,” thereby making it much more likely things end up at least somewhat good according to agent B as well.
Of course, the details do matter here. For example:
- It still needs to be the case that doing at least some stuff for agent B ends up worth-it according to agent A’s lights in general (for example: I might aspire, other things equal, to be “nice” to every single ant, but it might still be the case that, at the end of the day, this aspiration doesn’t end up influencing my action, if I have too many other competing priorities).
- If agent B’s values are comparatively resource-hungry, then even if agent A ends up optimizing somewhat for B’s values, this might not be enough to get agent B a meaningful amount of the value that B was hoping for, and so something nearby to Value fragility might remain true.
Finally, agent A does in fact need to know how to be nice to agent B suitably effectively; to be motivated to be nice in this particular way; and to not mix in her own intrinsic values in a way that messes up the process by B’s lights.[16]
Still, niceness of this kind seems a natural route to avoiding certain kinds of value fragility. And as I argued in “Being nicer than clippy,” I think it’s plausible that some human value systems, at least, include some of this sort of niceness by default, at least towards certain sorts of moral patients. If so, and if we can expect this sort of niceness to actually play enough of a role in a human-run future, then this could potentially go some way towards improving the non-takeover option in the eyes of various AIs – especially if those AIs have comparatively resource-satiable values.
More importantly, though: even if we aren’t relevantly nice by default, on grounds solely of our terminal values, we can actively work to set up institutions and commitment-mechanisms that exert a similar (and potentially more targeted) impact on the incentives of our AIs. That is: even absent terminal niceness on our part, we can try to ensure that the non-takeover option is predictably sufficiently good/at-least-OK by the lights of our AI systems that they don’t view this sort of option as catastrophic relative to successful takeover. Or at least, we can try to do this to a degree similar to how we do it in human-human relationships, to which similar concerns about Value fragility (and hence, similar valuations on takeover vs. non-takeover options) could also, in principle, apply.
Working out the best way to do this credibly, and how to weigh its potential benefits and costs in the context of other priorities, is beyond my purpose here (though see this recent paper for an example exploration; and see e.g. here [EA(p) · GW(p)] for some discussion of cases in which a variant of this kind of power-sharing reduces p(takeover) by default). But I wanted to highlight it as an example of a broader dynamic that I expect to matter quite a bit in the context of advanced AI – namely, the way that commitments to various types of “niceness” and intentional power-sharing, if made sufficiently credible, can diffuse dynamics that could otherwise end up quite adversarial. That is, regardless of how we end up feeling about Value fragility in particular, the advent of advanced AI puts the possibility of very intense concentrations of power disturbingly on the table. In this context, it’s very natural for agents (both human and artificial) to fear being disempowered, oppressed, exploited, or otherwise cut out – and this sort of fear can itself exacerbate various incentives towards conflict. Value fragility represents one comparatively esoteric version of this – one that reduces the number of non-you agents you are happy to see wielding extreme amounts of optimization power -- but it arises even absent such esoterica, and we should be thinking hard, in general, about ways to diffuse the adversarial dynamics at stake.
(I work at Open Philanthropy but I'm here speaking only for myself and not for my employer.)
- ^
Quoting from “An even deeper atheism”:
“Can we give some sort of formal argument for expecting value fragility of this kind? The closest I’ve seen is the literature on “extremal Goodhart [LW · GW]” – a specific variant of Goodhart’s law (Yudkowsky gives his description here [LW(p) · GW(p)]). Imprecisely, I think the thought would be something like: even if the True Utility Function is similar enough to the Slightly-Wrong Utility Function to be correlated within a restricted search space, extreme optimization searches much harder over a much larger space – and within that much larger space, the correlation between the True Utility and the Slightly-Wrong Utility breaks down, such that getting maximal Slightly-Wrong Utility is no update about the True Utility. Rather, conditional on maximal Slightly-Wrong Utility, you should expect the mean True Utility for a random point in the space. And if you’re bored, in expectation, by a random point in the space (as Yudkowsky is, for example, by a random arrangement of matter and energy in the lightcone), then you’ll be disappointed by the results of extreme but Slightly-Wrong optimization.”
- ^
More specifically, extremal Goodhart, at least as I’ve interpreted it in “An even deeper atheism,” seems to suggest that expectation value, for A, of a world optimal-according-to-B, should be something like: the expected value of “random universe.” I won’t examine this in detail here, but note that it suggests that if A happens to be comparatively happy with a random universe (as, for example, a “suffering-focused” ethic might), then value fragility won’t hold.
- ^
This is also an example of a case where value fragility doesn’t hold symmetrically – e.g., A might be quite happy about B’s optimal universe, but not vice versa.
- ^
And note that if A has some intrinsic concern about the satisfaction of B’s values-on-reflection, but not vice versa, then this is another a case in which value fragility can be asymmetric.
- ^
My sense is that in the context of AI risk, at least, people’s intuitive picture of value fragility is often driven by (a) various examples like the ones in Yudkowsky’s original post [LW · GW]: e.g., you ask for happiness, and you get experience machines (see also Scott Alexander here), and (b) high-level abstract arguments like the “Extremal Goodhart” argument I outline here (see also Stuart Russell’s comments about “A system that is optimizing a function of n variables…” here). I think neither of these are enough, in their current form, to helpfully delineate the contexts in which we should or should not expect Value fragility to apply.
- ^
We could revise the revised definition yet further to reflect this, e.g. to limit it only to “coherent” value systems, but I’m going to skip this complexity for now.
- ^
Especially as our technology advances and we stop using or clipping-together paper.
- ^
Though note that the type of Goodhardt at stake makes an important difference to the degree of divergence to expect at optimization increases. My current sense is that “extremal Goodhardt” is the most relevant version here.
- ^
Plus the infrastructure necessary for maintaining whatever multi-polar institutional arrangements have been set up.
- ^
- ^
Here I am assuming that the AI in question satisfies various more structural prerequisites related to agency, consequentialism, and non-myopia. See the framework post [LW · GW] for more.
- ^
Whereas the second approach corresponds to failing to solve Value fragility, and yet, somehow, not getting killed anyway – a possibility that Yudkowsky deems “actively counter to instrumentally convergent behaviors within a core of general intelligence.”
- ^
My memory of Bostrom (2014) is that it often inhabits a similar vibe – but I’m going to pass on digging through the text at the moment.
- ^
You also need to consider how bad the failed-take-over states are, in expectation; and how much the AI’s inhibitions restrict its options for takeover – but these will be less key in what follows.
- ^
Of course, we’re here imagining not just that Value fragility is true, but that the AIs in question are aware enough of its truth, and incorporating enough of its truth into their calculations, that it can exert the relevant influence on their subjective incentives. And I do, personally, admit to finding it somewhat strange to imagine that AI systems will really be thinking in these sorts of philosophical terms. But: if it’s actually true, we should expect smart enough agents to recognize its truth.
- ^
See this exchange [LW(p) · GW(p)] for some debate about whether to expect misaligned superintelligences to be at least some amount nice in this manner by default.
5 comments
Comments sorted by top scores.
comment by johnswentworth · 2024-08-06T01:01:57.554Z · LW(p) · GW(p)
A key point (from here [LW(p) · GW(p)]) about value fragility which I think this post is importantly missing: Goodhart problems are about generalization, not approximation.
Suppose I have a proxy for a true utility function , and is always within of u (i.e. ). I maximize . Then the true utility achieved will be within of the maximum achievable utility. Reasoning: in the worst case, is lower than at the -maximizing point, and higher than at the -maximizing point.
Point is: if a proxy is close to the true utility function everywhere, then we will indeed achieve close-to-maximal utility upon maximizing the proxy. Goodhart problems require the proxy to not even be approximately close, in at least some places.
When we look at real-world Goodhart problems, they indeed involve situations where some approximation only works well within some region, and ceases to even be a good approximation once we move well outside that region. That's a generalization problem, not an approximation problem.
So approximations are fine, so long as they generalize well.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2024-08-07T02:08:35.389Z · LW(p) · GW(p)
Can you say more about how this insight undermines or otherwise changes the conclusions of the post?
Replies from: johnswentworth↑ comment by johnswentworth · 2024-08-07T03:29:02.405Z · LW(p) · GW(p)
I think section 3 still mostly stands, but the arguments to get there change mildly. Section 4 changes a lot more: the distinction between "A's values, according to A" vs "A's values, according to B" becomes crucial - i.e. A may have a very different idea than B of what it means for A's values to be satisfied in extreme out-of-distribution contexts. In the hard version of the problem, there isn't any clear privileged notion of what "A's values, according to A" would even mean far out-of-distribution.
comment by Vladimir_Nesov · 2024-08-06T00:09:09.530Z · LW(p) · GW(p)
A multipolar world has boundaries, places where a given agent's optimization is extremely strong and other places where it barely applies at all. This shape could be itself endorsed on reflection, as an aspect of values, so that an agent prefers others to optimize their own slice of the future, possibly even to help them harden their own ability to do so. This is not soft optimization, others keeping their autonomy can be a strong target, and all such agents could cooperate in maintaining this structure.
Values with this aspect of respect for autonomy won't be fragile. It's unclear if this aspect is itself fragile, so that most paths of reflection end up rejecting it. Multipolarity calls this principle to mind, though doesn't directly install it into anyone's values. But it might turn out to be helpful in adjusting the paths of reflection in a direction where values-on-reflection end up endorsing it, for agents that don't have rejection of respect for autonomy a settled part of values yet.
comment by Jan Betley (jan-betley) · 2024-08-12T19:00:51.667Z · LW(p) · GW(p)
Are there other arguments for active skepticism about Multipolar value fragility? I don’t have a ton of great stories
The story looks for me roughly like this:
- The agents won't have random values - they will be somehow scattered around the current status quo.
- Therefore the future we'll end up in should not be that far from the status quo.
- Current world is pretty good.
(I'm not saying I'm sure this is correct, it's just roughly how I think about that)