Video and transcript of presentation on Otherness and control in the age of AGI
post by Joe Carlsmith (joekc) · 2024-10-08T22:30:38.054Z · LW · GW · 1 commentsContents
Preliminaries Deep atheism So … yang? But this sort of yang has salient failure modes How should we respond to these failure modes? None 1 comment
(Cross-posted from my website.)
This is the video and transcript for a lecture I gave about my essay series “Otherness and control in the age of AGI” (slides available here). The lecture attempts to distill down what I see as the core thread explored in the series, which I summarize in the following chart:

The “Otherness and control in the age of AGI” series in a single chart
The lecture took place at Stanford University, for CS 362: Research in AI Alignment, on 1 October 2024. Transcript has been lightly edited.
Preliminaries

I’m Joe Carlsmith. I work at Open Philanthropy. So I’m going to be talking today about the essay series that Scott mentioned, “Otherness and control in the age of AGI.”

And in particular, my goal here — we’ll see how well I achieve it — is to try to distill down the core thread of this essay series. So it’s quite a long essay series. It’s not an especially focused, punchy essay series in terms of its thesis. It’s more of a meditation and exploration of a bunch of different threads. But as a result, I have some question mark: maybe people don’t have a good sense of what even is this essay series about — even people who’ve read the whole thing. So I’m going to try here to say in a single lecture at least one of the core threads that I see the series as exploring.
I will say though that some stuff is going to get lost. Well, for one thing, the series in general makes the most sense when viewed in response to a certain kind of discourse about the existential risk from artificial intelligence, and in particular the discourse associated with thinkers like Nick Bostrom and in particular Eliezer Yudkowsky. So these are two thinkers who have done a lot to popularize the possibility of misaligned AI destroying the world or causing human extinction or other forms of human disempowerment (that’s what I mean by AI risk). And the way that they talk about it and frame it, I think, has had a lasting influence, including on me, and on the way the discourse is now. If you haven’t been exposed to that, it’s possible that some of what I say will make a little less sense.
So I’m going to try to summarize the discourse as I am reconstructing it and how I’m understanding it. It’s possible some of this will be less resonant depending on your familiarity with what I’m responding to, but hopefully it’ll be productive regardless. And if you do later go and engage with this discourse, I’m curious if my characterization ends up resonating.
Also, as I said, the goal of the series as a whole, it’s less of a linear argument and it’s more about trying to encourage a certain kind of attunement to the philosophical structure at work in some of these discussions. … As we talk about AI alignment and the future of humanity and a bunch of the issues that crop up in the context of AI, I think moving underneath that are a bunch of abstractions and philosophical views. And there’s a bunch of stuff that I want us to be able to excavate and see clearly and understand in a way that allows us to choose consciously between the different options available, as opposed to just being structured unconsciously by the ideas we’re using.
So in some sense, the series isn’t about: here’s my specific thesis. It’s more about: let’s become sensitized to the structure of a conversation, so that we can respond to it wisely. But as a result, the particular format of this lecture is going to leave out a decent amount of what I’m trying to do in the series. Part of the series is about its vibe, it’s about trying to communicate some subtle stuff. And so I encourage you maybe check out the series as a whole. You might get a different sense of what it is — if you haven’t read, for example, the reading for this week, you might be surprised based on the lecture as to what the series itself is like.
I’ll also say: my understanding is at least some folks in the audience are coming from more of a CS background or have a bit more of a technical orientation. That’s great. In particular, I think one thing that that sort of orientation can do is put you in a position to help with some problems related to AI alignment and AI risk, from a more technical dimension. And a thing I want to flag is: I really think a lot of this issue is a technical problem and not a philosophy thing. So I’m going to be giving a very high level philosophy-ish story about a certain aspect and certain ways of viewing this problem. But I really think at a basic level, a lot of it is about the nitty-gritty of how do we build AI systems, how do we understand our AI systems, how do we learn to predict their behavior?
Ultimately, I think it can be easy actually – because philosophy is fun and interesting and maybe it’s more accessible, it’s less gnarly – it can be easy to get distracted by the philosophy and to lose touch with the sense in which this is actually ultimately a technical problem. So I want to flag that this is going to seem like this is a bunch of philosophy, but I actually think not really. And in particular, to the extent you end up reacting negatively to some of the philosophical takes that I offer, I want to emphasize that these are not the only angles that can lead you to care about AI systems not killing all humans.
I think AI systems not killing all humans is actually I think a quite robust… You don’t need a ton of fancy philosophy to get concerned about that if you think that that’s a real possibility. And so I’m talking about a particular set of philosophical assumptions that give rise to concern about that, but I don’t think there’s many others that would do the same. For example, I’m going to talk a bunch about atheism, but if you’re religious in various ways, you can still not want all of humanity to be killed by AI systems. And so similarly, maybe you’re a solipsist, you don’t even believe other people exist, but you yourself might be killed by AI systems and maybe you care about that. A lot of philosophical views don’t like being killed, including many that I won’t discuss. But just flagging that up top.

Okay. So diving in, this is the series in a single chart. You don’t need to read this chart. Don’t feel like, “Oh my God, I need to read this chart.” I’m going to go through this chart in detail. But just to give you a sense of the roadmap where we’re going, this is the full thing that I’m going to say.
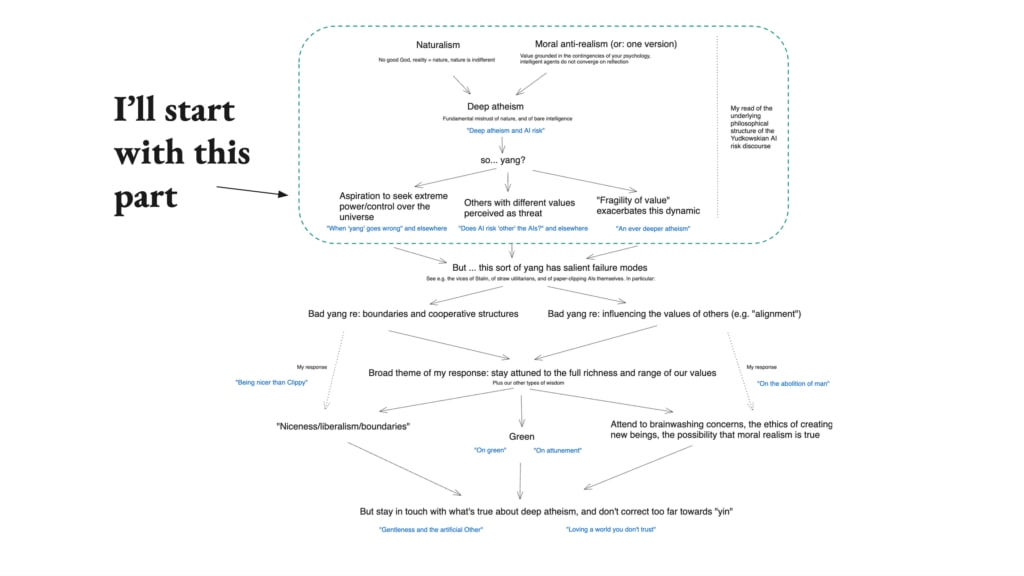
And so in particular, I’m going to start with this first bit, which is my read of the AI risk discourse that I mentioned earlier, what I’m calling the Yudkowskian AI risk discourse. So we’re going to zoom in on that to start with.
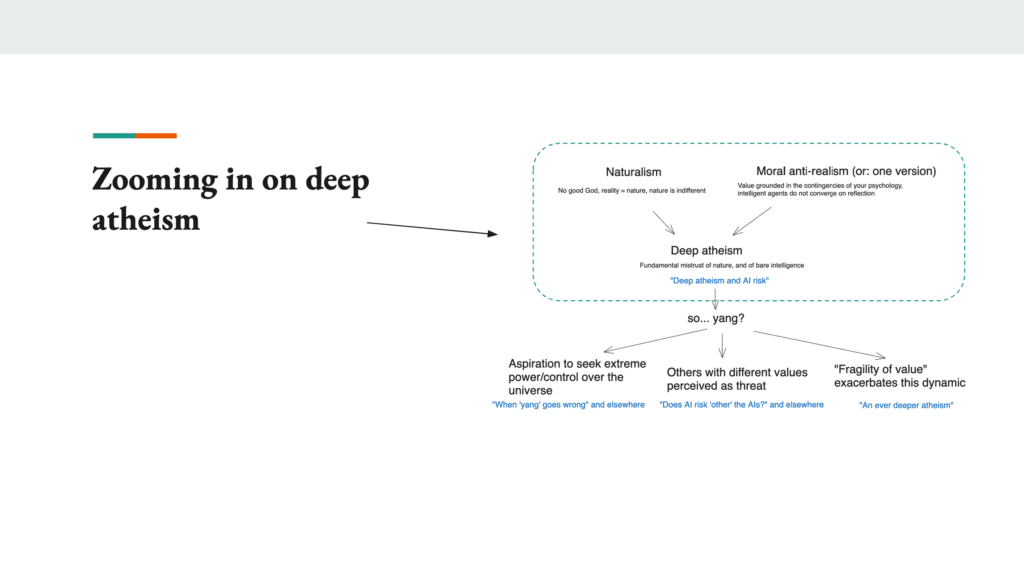
And in particular, I’m going to zoom in on what I’m calling deep atheism.
Deep atheism
So deep atheism is the first premise in this overall dialectic.

And deep atheism as I’m understanding it, consists centrally of two components. So the first is some sort of atheism-like thing which I’m calling naturalism. There’s a lot of subtlety in exactly how we’re construing it, but a particular thing that is being denied by this component is something like the sort of thing that a traditional Christian conception of God, or that underneath all of reality there is a perfect being. And that reality is in some sense structured by and explained by that being’s nature and action, such that in some sense at the bottom of everything, reality and goodness are fully unified. That is the thesis that is most important in this context to deny. The claim is that that is not true, it is not the case that underneath everything is goodness.
So that’s the first claim. And then we can talk about somewhat more specific stuff about our reality is nature, what’s nature. But if you need a handle for this, think about what would Richard Dawkins think. Or take some paradigm atheists, take their broad cluster of vibes and metaphysics and stuff like that, and roughly speaking that’s what I’m talking about here.
And then the second component is what I’m calling moral anti-realism. Again, there’s a bunch of different variants of that are in principle relevant here. The type that is most important to me — and is actually compatible with certain types of moral realism, which gets confusing, but just let’s just leave that aside — the most important thing is that intelligent agents do not converge on the same values even as they get smarter. So the picture I think that makes this most natural is to think that value, what is of value relative to a given agent, is grounded in the contingencies of that agent’s psychology. So what you should do, what is valuable relative to you, is a function of what you respond to in certain ways. And if you had a different agent, for example an agent that cared a bunch about maximizing paperclips, it would not be the case that that agent would have the same thing that matters relative to it, that matters relative to you. So there’s subjectivism about value that’s underneath this.
And then the thought is that that contingency and that difference between these agents, that will persist even given various types of enhancement or amplification to the intelligence and rationality of the agents at stake. So to get a sense … I don’t know if any of you guys have ever done the sorts of things that analytic ethicists tend to do. But basically what you do in philosophical ethics often, is you take a bunch of intuitions that you have and you stitch them together, you try to make them more coherent, you try to revise them in light of greater knowledge. There’s a process of reflection or reflective equilibrium, or there’s some sort of way we reason to try to improve our ethics, to try to gain better ethical understanding.
The claim is not that that process doesn’t go anywhere interesting or isn’t productive, the claim is that the terminus of that process is still, in an important sense, relative to you. That when you do that, you go in a certain direction because you’re like, “Oh, I care about people. I want to think about do I care about people based on where they are in space or time? I’m not sure.” And you go and you end up with some reflective ethic. But if you started by only caring about paperclips, that process, you’d be like, “Oh, which things are paperclips exactly? This is a different type of bent piece of metal. Is that a paper clip?” You would be doing reflection, but it would go in some importantly different direction, or at least that’s the claim.
That’s in contrast with stuff like if you think naively how we tend to think about where different aliens, for example, would go in their conception of mathematics or physics. We tend to think that advanced civilizations will converge in their mathematical beliefs because in some sense they’re responding to some objective structure. And so the claim is that value and ethics is not like that. This is importantly related to what’s often called at the Orthogonality Thesis in the context of AI risk. So this is roughly the claim that the AI is sure they’re going to be smart, but being smart just doesn’t itself cause you to be morally enlightened in the way that we care about. If you take a chess playing engine and you make it really, really good at chess, it’s just not going to be… At some point it’s not going to go, “You know what I should really do, is I should maximize human flourishing. I should help the meek.” It will just keep playing chess.
And I think there’s some intuition you can get for that if you think mechanistically about how values are implemented in minds. So roughly speaking, if you imagine values are implemented by: there’s some sort of classifier of different states of affairs, and that classifier is hooked up to your motivational system, such that when a certain thing is classified in a given way, that has a connection with the behavior of the agent. I think, thinking about it mechanistically, you can get a sense for like, “Oh yeah, I guess I could just build an agent such that that process just works for arbitrary things that are being classified.” Right? I can just hook up arbitrary features of the AI’s world model to its actions, such that in some sense it’ll be motivated by any old thing. That’s one intuition for how you might get into this picture of how an agent’s values work.
So that was naturalism and moral anti-realism. And so these two combine, along with various other vibes, to create what I’m calling deep atheism. So basically deep atheism is a fundamental mistrust both towards nature, because nature is indifferent, there’s no God underneath it, and then also towards stuff in the vicinity of bare intelligence or mind or reason. So you might have thought… The contrast here is some people, there’s a trust that they have in the universe. They’re like, “Ah, if I just let the universe do its thing, then things will go well.” And deep atheism is like, “Nope, can’t trust the universe.” And then similarly you can be like, “Ah, but at least let me trust Mind. Let me trust the process of reason and understanding and whatever it is that you’re amplifying when you think about more intelligent agents.” Oops, you can’t do that either because those agents… And sometimes those agents, they started out products of nature, and nature, can’t trust it. And then really all you did was amplify the direction that they’re going, that you didn’t… yeah. So you’re still stuck with the same old not-God underneath, only this time smarter and therefore scarier.
So … yang?

Okay, so the next concept I want to introduce is the distinction between yin and yang. You may have heard this distinction before. I’m not going to be claiming that I’m using it in a canonical way. In fact, I’m centrally ignoring some of the traditional connotations of these terms. So this is yin and yang sub Joe. But the particular aspect of yang that I want to isolate is basically an energy in the vicinity of active, doing, controlling. And then the contrast is with yin, which is receptive, not-doing, letting-go. So hopefully you can feel in to roughly what that distinction is pointing at.

And then the sort of claim I want to make … one of the animating interests of the series is in the sense in which deep atheism prompts a kind of yang. And it does that in a few different ways. So basically, first of all, yin, I think many types of yin involve a type of trust, right? Like, in so far as you care about things being a certain way, but you are not exerting your agency towards making them that way. You’re instead letting go, being passive, not exerting agency. Then you’re hoping that the other processes that are determining the thing are going to make it the way you want or make it good.
But the problem is that deep atheism is sort of pretty low on trust in processes, period. Deep atheism is just like, stuff in the universe, agents, non-agents, it’s all nature, none of it has God underneath. Why would you think it’s good? And then there’s some extra stuff depending on your values about things being… goodness being a very particular structure. In order for things to be good, you have to arrange things in particular way. And the default, if things are not arranged that way, is for things to be non-good, not necessarily bad. So I think to be actively bad is to be a particular way, you need to arrange things. Say you think suffering or something like that is bad, then you need to exert agency. But I think deep atheism will think absent of the good agency exerted in the world, then things will be sort of some random way, some way that was not controlled. And most sort of random ways of being are non-good. They’re just blank.
A very simple model of, if you imagine all of the matter in this room and you’re like, take all the different arrangements of the matter in this room and now rank them in terms of neutral, good and bad. The idea is the vast majority are going to be neutral, a few will be good — and it’s all these particular structures, happy humans, whatever you like. A few will be bad, like people suffering, but most of them are going to be just random stuff.
And that random stuff, that sort of vibe is the analog of the notion of paperclips. So when people talk about paperclips, it’s not actually literal paperclips. The thought is, if you’re not steering things in a very particular direction, your default prior is that they’re going to be meaningless, they’re going to be in some other direction. And if things aren’t curated in the right way, then that direction is going to be neutral. That’s a hazy intuition, it is not at all an airtight argument, but that’s an animating vibe underlying the type of deep atheism I’m interested in… And it leads to quite a lot of hesitation about just letting go and letting things do their thing without you shaping them.
There’s also a more particular type of mistrust that I haven’t talked about as much — and I could revise the notion of deep atheism to include this; I think it’s possible you should. But deep atheism is also in particular suspicious of the types of letting go and yin involved in trusting competition and bottom up processes in which agents just compete to see who’s the most powerful or there’s various types of, evolution is a bit like this, capitalism, people… this is related to the discourse about e/acc, but there’s a type of vibe that’s sort of like: the way to get good outcomes is to let power decide, let things compete, let them bump up against each other. And then what will emerge from that is hopefully goodness on this picture, but oops, deep atheism doesn’t trust that either. And why not?
Well, roughly speaking because the thing that wins competition is power, and power is unfortunately not the same as goodness. And so, in a competition, any chance you have to sacrifice goodness for the sake of power makes you more likely to win. So the ultimate, at least in the limit, competition is de-correlated from goodness. That’s a sort of general mistrust. This is related to the discourse about Moloch, if anyone has heard that term. But this means you can’t… there’s a sense in which deep atheism also tends to lead people to interest in a kind of, the way you get good stuff is you can’t just let stuff from a bottom up, upwelling, bump up against everything. Ultimately, there needs to be an agency that is controlling stuff and pushing it in the good direction actively. And that is… so that’s something I associate at least with yang and vibes in the vicinity of yang. We can talk about that. I mean, this is in some sense importantly related to some of the live policy debates about AI risk, though at a super abstract level. So we can talk about that.
And then finally, this is sort of a restatement, but basically nature and agents with different values can’t be trusted to steer the universe. So the way you get goodness on this picture is you need agents with your values in particular to be steering things ultimately. And who has your values most? You, you. Do you even know those other people? That’s a sort of default towards your yang in particular, an interest in your own agency.
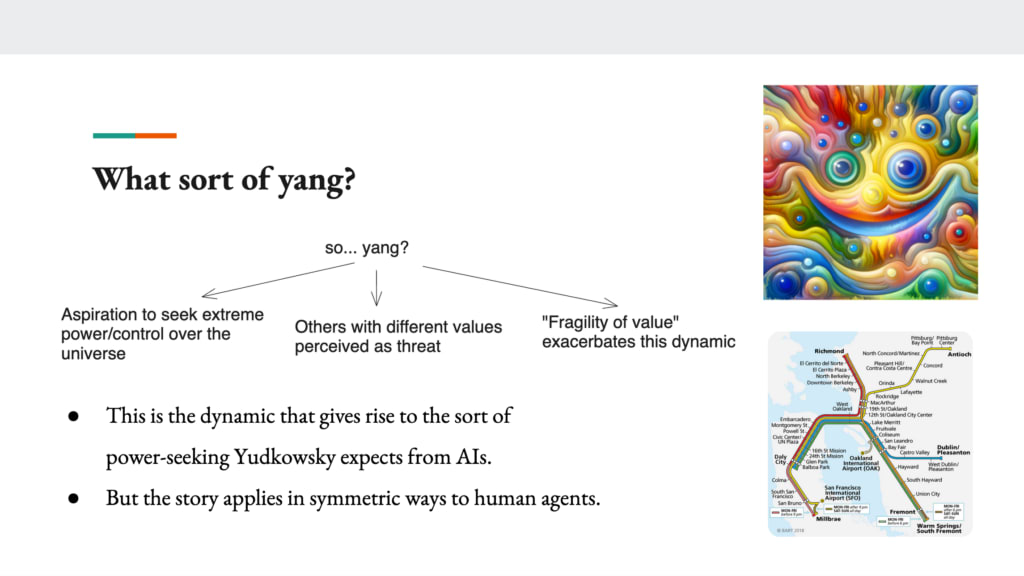
Okay. And then this is the part of the chart where it’s like, all right, deep atheism, so yang, and then here it’s specific types of yang at stake. I mentioned, so there’s an aspiration to seek extreme power and control over the universe. There’s perceiving others with different values as a threat because if they get power instead, then they’ll take things in a different direction. And then in particular, I want to highlight this notion, the fragility of value, which is a concept that crops up in the context of the AI risk discourse, which basically says… it’s sort of related to the thing I said about the different arrangements of atoms.
So broadly the vibe is that if you have value systems that are kind of similar, at least in a restricted search space. So if you think about, I don’t know, libertarianism and utilitarianism in the current world, these might actually agree on a decent number of options when we have a limited set of options available. But if you gave them the opportunity to rearrange all the atoms in the universe into the optimal configuration, the claim is that these two value systems would diverge much harder. And in general, that kind of intense optimization for different utility functions or different value systems tends to cause them to de-correlate as the optimization pressure becomes more extreme. So this is related to a particular manifestation of what’s sometimes called Goodhart’s law.
And again, that is not, I did not give any sort of logically tight argument for that. And I think there’s a bunch to say about whether this is actually right. But this is another core intuition driving the AI risk, at least the traditional AI risk discourse, where the thought is something like, even if you gave an AI kind of good values, kind of okay values, it’s like, actually, if you left something out or you got it slightly wrong, its concepts are kind of messed up, but then you give it some incredible godlike amount of oomph and intelligence such that it maximizes the utility function that emerges after some process of reflecting on the values you gave it, then you should be really scared of that maximization because it’s just very hard to create a target for optimization that is robust to really, really intensive forms of it. So that’s the fragility of value intuition.
And so, this dynamic is roughly speaking, what causes folks like, Yudkowsky to expect different types of power seeking from AIs. So when Yudkowsky sort of imagines, you create a super intelligence, the super intelligence wakes up and it goes like, you know what I need to do my thing, for a wide variety of things? I need power, resources, freedom. That’s what’s often called instrumental convergence thesis, that there’s just stuff that almost every agent wants once they sort of wake up and become sufficiently oomphy. And that stuff is basically yang. Agents, they want yang, they want the ability to exert their agency in the world, and they want to do it to a sort of extreme degree. And it’s just like you, you wake up and you’re like, oh, shit, God’s not going to maximize my utility, I have to do it. And AI is the same, everyone the same. They all realize this. They’re like, I got to… And so basically they’re like, I need to get out there and exert control over the universe myself if I want things to go my way.
And then others, then they’re not pushing for my way. So in the human case, the worry is the AI, it wakes up. It’s like, the humans, they’re like… I mean, there’s different stories about why the AI might be sort of antagonistic to humans, but one is that the humans are pushing it in a different direction. The humans might try to shut the AI down. And so the AI needs to prevent that. And then in principle, the AI would look at human values and like, I don’t like that.
But then notably, note that this sort of story also applies to humans with respect to each other. And this is something that’s less emphasized in the discourse. I think the AI risk discourse often treats humanity as a sort of unified value system and sort of human values, there’s a kind of, everyone’s on the same team, it’s team humanity versus the AIs. But in principle, all of these arguments, the conceptual structure at least applies to differences between human values as well.
And in fact, if you take the fragility of value thesis seriously enough, then you end up thinking that even very, very small differences between humans would lead to this fragility dynamic such that in principle, if you took a super intelligent version of yourself and a super intelligent version of your best friend or your mom or whatever and took those utility functions and then maxed them out super hard, the story, or one story you might have or you might wonder about is whether you would get the same sort of dynamic if you bought it in the AI case, such that your mom or your best friend and you actually, you would create universes that would be equivalent to paperclips relative to the other person’s values.
So now, we could hypothesize that that’s not the case about humans, that maybe… so if we go back to the convergence thing. You could soften this claim and say that some agents do converge on reflection, for example, humans. And we can wonder whether that’s true. I don’t think we’ve yet heard an argument for that being true. I don’t know exactly how you would become confident that that’s true, but that is one way to soften this and to sort of… you can say, and I think this is actually the somewhat implicit assumption underlying some of the AI risk discourse, is that in fact this is much more true of AIs relative to humans than humans relative to each other, in virtue of the way in which humans tend to converge or have sufficiently similar values. But that’s an open question. I think at a conceptual level, the same arguments apply.
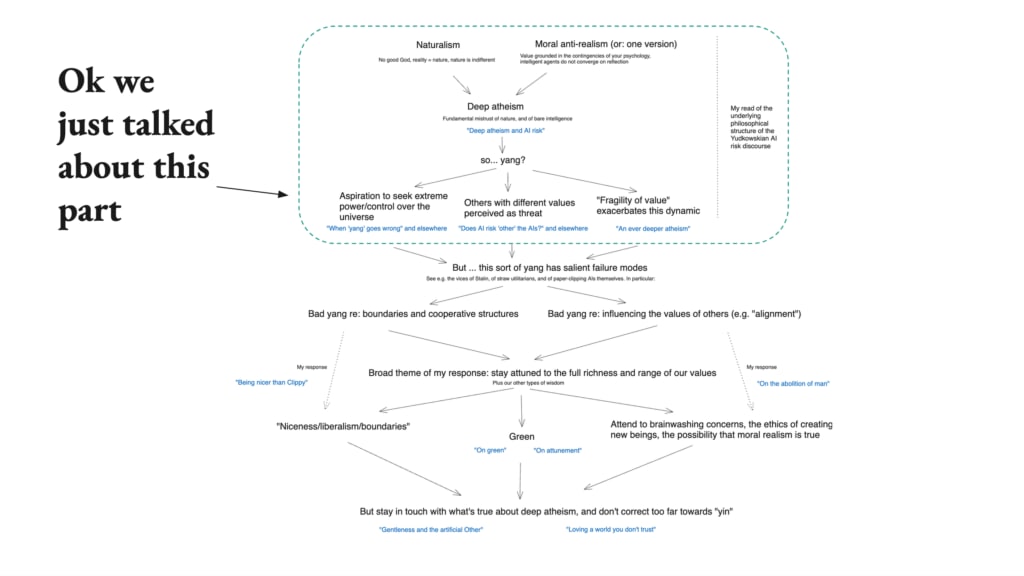
So that is my summary of the philosophical structure of the Yudkowskian AI-risk discourse.
So let’s move on to this part.
But this sort of yang has salient failure modes

So to some extent, the way this series ended up happening for me was I spent a bunch of time with this discourse of roughly the type that I described. I’m sympathetic to a lot of aspects of this. I do think something like deep atheism, at least some flavors of it look pretty plausible. But also, I feel something around how scary the type of vibe here can be, or in particular the type of yang that I think this sort of discourse can give rise to, seems like it has a number of quite salient failure modes. And so I’ll talk about a few of those here.
One is bad yang with respect to boundaries and cooperative structures. So an interesting aspect of the AI-risk discourse is it often wants to view humans and paperclippers as structurally analogous agents, right? It’s like, you care about different end outcomes, but ultimately you’re the same type of thing, doing the same type of game, namely competing for power. That is the fundamental narrative. Agents, they compete for power and that’s just the game.
But I think what that can lead to is some implicit assumption or there’s a way in which the paperclipper is doing stuff that is just unethical irrespective of what it ends up doing with the universe. So it kills everyone, or it steals stuff. It overthrows governments. There’s basic cooperative structures that the AI risk discourse often imagines the paper clipper to be violating. But note that the sort of instrumental dynamics that cause it to do that are actually independent of the thing that it values. So for example, this sort of issue crops up even in the context of various human ethical views like utilitarianism.
So the same sort of dynamic, I mean, the paperclipper is in some sense modeled off of a total utilitarian. it just has some material structure, it wants things to be that way, it happens to be paperclips. But even if it’s pleasure or something that you really like, even if it’s optimal, happy humans running in some perfect utopia, you know this old saying, there’s this quote, it’s like, “The AI does not hate you, does not love you, but you’re made of atoms that it can use for something else.” And it’s also true of utilitarianism, right? It’s true of just many, many ethics.
For most ethics that are sort of consequentialist, just like arrangements of matter in the world, they’re just not… they’re unlikely to be optimal on their own. And so, if the AI or if a human, if any sort of value system is in a position to rearrange all the atoms, it’s probably not going to just keep the atoms in the way they were with all the fleshy humans, or at least that’s the sort of concern. So basically I want to point to the sense in which this broad vibe, the vibe that is giving rise to the paperclipping and that would be sort of transferred to the humans, if you just assume that humans are structurally similar is in fact very, very scary with respect to how we think about boundaries and cooperative structures. You’re invading people, all sorts of stuff, taking their resources. There’s a bunch of stuff that just pure yang, naive yang I think does, that’s very bad. I’ve got Hitler invading. This is sort of a classic violation of various boundaries.
Then there’s a subtler issue, which is more about specifically influencing… is yang exerted via influencing the values of other creatures, and in particular, people in the future. So the discourse about AI alignment in some sense, the fundamental structure says, okay, we really want the future to be good. The future is going to be driven by agency, it’s going to be steered by agents on the basis of their values, and those values need to be my values because otherwise the future is going to be steered in some other direction. And so the specific way in which you’re… I mean, they’re either going to be… yeah, they have to be your values, your values on reflection.
And so, the theory of change in some sense is to do something such that the agents in the future are optimizing for your values in particular. The technical version of that, if you think that AIs are going to be driving a lot of stuff, is to be aligning the AIs with your values to sort cause the AIs to have your values, or at least that’s one traditional conception. There’s a bunch of subtlety raised. But broadly speaking, the claim is like, you got to make sure that the future people have a specific set of values. And what’s more, you’re doing that if you’re an anti-realist without any sort of intrinsic authority. It’s not like these values are God’s values or something like that, they’re just yours. You just want things to be this way and you’re just causing other agents to have your values too.
And there’s at least a vibe you can get into where that seems kind of tyrannical and problematic. That in some sense… And then you can worry on specifically, how are you causing these people or these AIs to have the values in question? Are you brainwashing them? Are you conditioning them in problematic ways? And you can have that worry, I think very saliently in the context of how we train AIs now. Even if we solved alignment, the way we currently treat AIs involves a bunch of treatment that would be, I think viewed as ethically repugnant and unacceptable if it was applied to humans. And so including the sorts of things that you would do to try to make the AI’s values be a particular way. So there’s a concern about tyranny towards the future routing specifically via influencing the future’s values. And I discussed that in a piece called “On the abolition of man,” which is responding to C.S. Lewis, who has a book about this. So those are two ways in which this sort of yang has very salient failure modes.
And then there’s also, beyond these specific articulations, I think there’s just a bunch of other general heuristics and bad vibes where people who really want a bunch of power and control, who their main thing is… in some sense the AI is like, the AI, it wants to be dictator of the universe, but that’s just normal on the story. It’s like, of course you want to be a dictator of the universe, you’re an agent. Why would you be less? Why would you want anything less? But actually we tend to think that wanting to be dictator of the universe in practice is intense. That’s scary. There’s something that has bad vibes about that. And I think it’s at least worth noticing what’s going on with that sort of hesitation, even if we don’t yet have an articulation of what it is.
How should we respond to these failure modes?

Okay. So those are sort of salient failure modes. And then, so what I try to do in the series is talk about how I think we should respond to some of these failure modes and think about them going forward. A thing I think we should not do, which is sort of I think strangely tempting to do, is to conclude that deep atheism is false or that AI risk is unreal because it could justify scary behavior. I think this is a quite common pattern of reasoning that people have where they’re sort of like, there’s some claim. They process that claim at the level of what could that claim be used to justify or could that claim lead to something bad? And then they conclude that the claim is false. And unfortunately that’s just not, or I don’t know, unfortunately that’s not how truth works. Or sometimes there are in fact true things that could in principle be used to justify scary things, and that’s just a possibility that we need to deal with.
And so, I think there’s some dance in learning how to hold these possibilities in the right way. And I think we should not reflexively be just associative in our response and be like, oh, this is a bad vibe, therefore the content, I don’t need to engage with the content of whether something is true or not. I think of the saliently in the context of … I would really like it if there were a perfectly good God underneath everything, for example, in the limit. I think that would great. But unfortunately I don’t think that’s true, and I think that might be true of other more specific claims here as well.
But I don’t think that’s the only option. So roughly speaking, so I sort of talk… the second half of the series or maybe the last third goes through different elements of what I see as an important response to the types of the failure modes I just discussed. In the context of the cooperation one, the response that I want us to look for is to really attend to the parts of our ethics that have to do with negotiating differences in values amongst different agents.
So in addition to having stuff that we directly value, we directly value people being happy or whatever, we also have this whole lived tradition, as humans, of dealing with competitions for power amongst different agents, in dealing with the ethics of exerting different types of control, dealing with how do we divvy up boundaries and resources and all this stuff. All the sorts of things that are, in principle, at stake in the sorts of conflicts in values between humans and AIs that the AI risk narrative is positing. This is actually old stuff. It’s intensified, but this is… Conflicts for resources and power and differences in values, that’s bread and butter of human history. And we have a bunch of lived wisdom about how to deal with that, at least within the specific constraints that we’ve had to deal with so far.
In particular, I am interested in… So one is niceness, which is there’s a thing you can do, which is, you care directly about some other people’s values, that’s a thing you can do, or give some space, be responsive to their values directly on their own terms. There’s also broader norms around liberalism and tolerance. So when we think about how we relate to people with different values, let’s say you’re out there and they’re listening to noise music or even you’re hanging out in your backyard and you’re just doing a very low value hobby. You could have a way better hobby. It could be way more pleasurable for you. We still just think: that’s your thing. I don’t get to go in there and be like, “Ah, this matter, it could be arranged more optimally in your backyard.” It’s like, nope, the backyard, that’s for you.
Now that doesn’t mean that you can torture people in your backyard. So we have actually subtle structure about which sorts of boundaries warrant what sorts of respect. But for a large variety of differences in values, we think that what we do, the way we handle that is we divvy things up, we establish norms, and then we leave people alone. I think there’s a sense in which the AI risk discourse is: nothing will be left alone. Everything will be optimized. And I think that’s not actually how we’ve handled this issue in the past. There’s a bunch of other liberal norms I think are relevant — property rights, a bunch of stuff — and boundaries is another way of generalizing what that means. So that’s one piece. I think attending to both the ethical dimensions of the liberal and deontological and niceness based aspects of our ethics…
And also I think there’s a reason we have this stuff that’s not just about our intrinsic values.I think this is also in many cases a powerful way of causing cooperation and conflict resolution between agents. So I think there are also instrumental reasons to be interested in why we have norms of this kind, reasons that might continue to apply in the AI case. We can talk more about that if you like.
[Rewinds the slides.] Maybe I’ll hop over here. So you can see it’s my response to bad yang. This is do niceness liberalism boundaries. So my response to bad yang in influencing values of others is basically, you got to attend to it. You got to really think about it. You can’t just be like, “Ah, I shall just cause the future people to have my values in whatever way.” You need to actually think about, well, we have a bunch of norms around what is it to shape people’s values in ethical and unethical ways.
Brainwashing, not good. Rational debate, good. And there’s a question of how can we reconstruct those norms in a way that’s robust to various types of meta-ethical considerations, including the moral anti-realism stuff. But I think there’s a bunch of rich structure, again, in our lived ethics that a naive yang about influencing the values of others doesn’t capture. And I think that needs to be at stake in how we think about creating AIs today. As I said, I think we are currently doing stuff to AIs that would be totally unacceptable if done to humans. I think it’s plausible that AIs at some point will be moral patients in a way that makes it genuinely unacceptable to do it to them, or at least such that there’s a strong pro-tandem moral objection to doing it to them. And I think we need to just actually stare that in the face and figure out what trade-offs we are making and why and whether that’s the right thing to do.
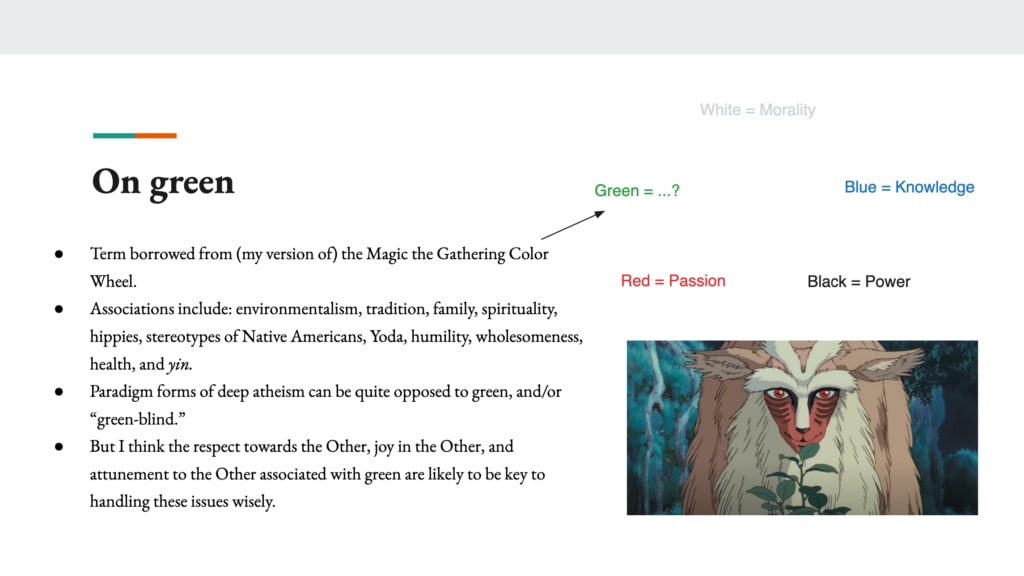
And then finally, I want to talk about green. So this is the end of the series. So green is a term that I borrowed from my version of the Magic the Gathering Color Wheel. I don’t play magic myself, but I have read some people who play a bunch of magic and who are interested in typologizing energies that animate people and institutions and all sorts of stuff in the following way. There are these five colors, white, blue, black, red and green. My summary of the schtick, though again this is my opinionated summary, people have different ways of doing this is, the vibe of white is about morality. The vibe of blue is about knowledge, black is about power, red is about passion, and then green is about… And then the essay is about trying to flesh out in thorough terms what green is.
So associations with green include environmentalism, tradition, family, spirituality, hippies, stereotypes of Native Americans, Yoda, humility, wholesomeness, health and yin. So I don’t know if that pinned something down for anyone. It is broad list. I don’t know if anyone is a Miyazaki fan, but Miyazaki is just incredibly green. There’s a bunch of stuff that’s green. Children’s movies are often quite green. So paradigm forms of deep atheism, I think can be quite opposed to green. And I think in some sense the rationality discourse, it either doesn’t know what green is or thinks green is one of these mistakes. So for example, a lot of the AI risk discourse like Bostrom and Yudkowsky were heavily influenced by also the discourse about longevity and about whether we should be trying to cure death. And a thing people will say about death is like, “Ah, you should let go. You’re being too yangy about death. Death is a part of life. Death is a part of nature”, et cetera.
And I think that’s an example of a place where people are like, “Ah, it’s green. These people are way too green. They can’t see that this is just a bad thing and we need to change it.” “Oh, nature has no sacredness. This is actually just bad.” And I think there’s a more generalized version of that mistrust that I think deep atheism can have. See also, wild animal suffering is another one that comes up here where people are like, “Ah, wild animal suffering is part of life.” And then there’s a different perception where you’re like, “Oh, actually wild animal suffering, sorry, it’s just bad. You could just stop it.” And if you were like, “Ah, no, this is sacred,” you’re seeing things wrong.
And I think there’s a bunch to this critique of green. And I think green, especially simplistic forms of green I think can be really off. But I actually think that various aspects of green are pretty important here. And I think I want to make sure we are attuned to them and able to incorporate them into our response to the AI situation. In particular, I’ve talked in the series about having notions of respect that don’t route via having the same values as someone, but that also don’t route by just thinking they’re smart or competent. There’s some other form of respect that I want to think about there.
I think there’s a way in which certain green-based vibes actually take joy in encountering something that you don’t control and dancing with it. There’s a sense of joy in not having everything. Whereas I think deep atheism has a… Obviously the best thing is to have arbitrary power and control because then you can shape things according to your will. Whereas I actually think that’s not how our values are structured.
And then also I talk about some notion of attunement. I have an essay about attunement, which I think of as a responsiveness to the world that is able to take in various types of meaning and value. So I think basically the two penultimate essays in the series are about green and about ways in which I want the vibe of green to be incorporated into our response to AI.
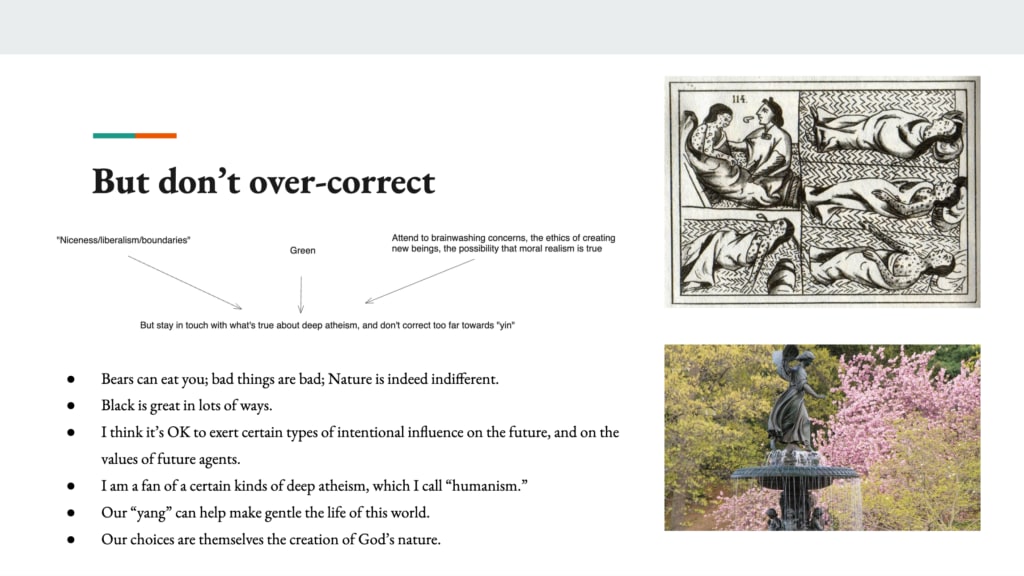
But I think we should not overcorrect. So I think we also need to stay in touch with what’s true about deep atheism as we deal with this issue. So in particular, I talked in the beginning, the series opens with this example of this guy Timothy Treadwell who aspires to be very gentle and yin and green towards grizzly bears. He’s an environmental activist.
And then he gets eaten alive by one of the bears. And I use it as an analogy of ways in which we could approach AI from a perspective of, ah, we are going to be very green and gentle and nice and forget the sense the deep atheist point that AIs can just be actually quite alien. And they can be alien, even as they’re worthy of respect, even as they’re moral patients, they can also just kill you brutally the way a bear can. And we need to remember that. Also, I think bad things are bad, they’re not good. They’re not sacred, bad things are bad. And so that’s important to remember. I think the raw indifference and coldness of nature is important to remember. Black, which is the power, yang, I think is great in lots of ways.
I think it’s okay to exert certain types of intentional influence on the future, including on the values of future agents. Modulo a bunch of ethical subtlety. I’m a fan of a certain kind of deep atheism, which I call in the last essay, humanism. And part of humanism is the idea that human agency can actually make the world better. So if you think about smallpox, this is an example. Smallpox, it’s bad, it’s bad, it was natural. In some sense, a very naive form of green, has a tough time distinguishing between curing cancer and ending death and stuff like this. I just think smallpox, we cured it, we did that. We can do that thing more. We can make gentle the life of this world and much more than that.
And then finally, I think there’s a way in which our choices… A simple form of deep atheism imagines. It’s like there’s reality over here, there’s god over there, and then there’s us rebelling or standing against god. But I think there’s a sense in which… We are actually a part of god’s nature and our choices are themselves the creation of god’s nature. So we get to choose some part of who god is. So if we want god to be good or at least better, then we should choose well.
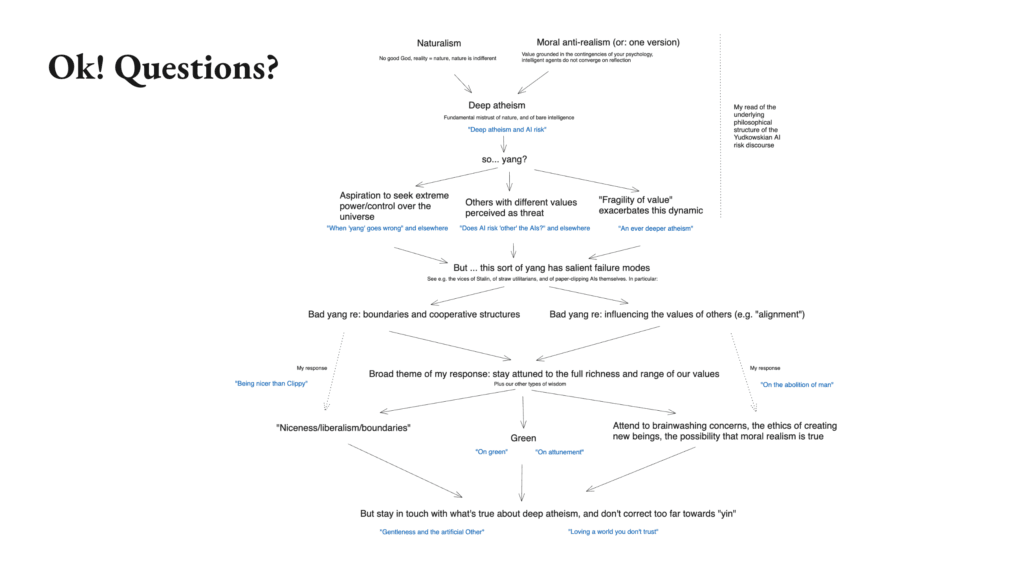
Ok, so that’s a bunch of stuff. I think that’s basically a summary of the whole series and we’ve got about 20 minutes for questions… Here’s the whole chart, so hopefully you now feel more familiar with it. So maybe let’s just talk about anything that’s come up. Thanks very much.
1 comments
Comments sorted by top scores.
comment by Raemon · 2024-10-09T04:41:32.472Z · LW(p) · GW(p)
The chart is great.
I'm curious what you'd think about updating the transcript here to have fewer awkward verbal repetitions – several places you started a sentence and then kind of start over halfway through (in a way that I imagine sounding natural in person, but just makes it harder to read here). I think an LLM could probably be instructed to remove them without otherwise messing up the post.