An even deeper atheism
post by Joe Carlsmith (joekc) · 2024-01-11T17:28:31.843Z · LW · GW · 47 commentsContents
The fragility of value Human paperclippers? Deeper into godlessness Balance of power problems None 47 comments
(Cross-posted from my website. Podcast version here, or search for "Joe Carlsmith Audio" on your podcast app.
This essay is part of a series I'm calling "Otherness and control in the age of AGI." I'm hoping that individual essays can be read fairly well on their own, but see here for brief summaries of the essays that have been released thus far.
Minor spoilers for Game of Thrones.)
In my last essay, I discussed Robin Hanson's critique of the AI risk discourse – and in particular, the accusation that this discourse "others" the AIs, and seeks too much control over the values that steer the future. I find some aspects of Hanson's critique uncompelling and implausible, but I do think he's pointing at a real discomfort. In fact, I think that when we bring certain other Yudkowskian vibes into view – and in particular, vibes related to the "fragility of value," "extremal Goodhart," and "the tails come apart" – this discomfort should deepen yet further. In this essay I explain why.
The fragility of value
Engaging with Yudkowsky's work, I think it's easy to take away something like the following broad lesson: "extreme optimization for a slightly-wrong utility function tends to lead to valueless/horrible places."
Thus, in justifying his claim that "any Future not shaped by a goal system with detailed reliable inheritance from human morals and metamorals, will contain almost nothing of worth," Yudkowsky argues that value is "fragile [LW · GW]."
There is more than one dimension of human value, where if just that one thing is lost, the Future becomes null. A single blow and all value shatters. Not every single blow will shatter all value - but more than one possible "single blow" will do so.
For example, he suggests: suppose you get rid of boredom, and so spend eternity "replaying a single highly optimized experience, over and over and over again." Or suppose you get rid of "contact with reality," and so put people into experience machines. Or suppose you get rid of consciousness, and so make a future of non-sentient flourishing.
Now, as Katja Grace points out, these are all pretty specific sorts of "slightly different."[1] But at times, at least, Yudkowsky seems to suggest that the point generalizes to many directions of subtle permutation: "if you have a 1000-byte exact specification of worthwhile happiness, and you begin to mutate it, the value created by the corresponding AI with the mutated definition falls off rapidly."

ChatGPT imagines "slightly mutated happiness."
Can we give some sort of formal argument for expecting value fragility of this kind? The closest I've seen is the literature on "extremal Goodhart" – a specific variant of Goodhart's law (Yudkowsky gives his description here [LW(p) · GW(p)]).[2] Imprecisely, I think the thought would be something like: even if the True Utility Function is similar enough to the Slightly-Wrong Utility Function to be correlated within a restricted search space, extreme optimization searches much harder over a much larger space – and within that much larger space, the correlation between the True Utility and the Slightly-Wrong Utility breaks down, such that getting maximal Slightly-Wrong Utility is no update about the True Utility. Rather, conditional on maximal Slightly-Wrong Utility, you should expect the mean True Utility for a random point in the space. And if you're bored, in expectation, by a random point in the space (as Yudkowsky is, for example, by a random arrangement of matter and energy in the lightcone), then you'll be disappointed by the results of extreme but Slightly-Wrong optimization.
Now, this is not, in itself, any kind of airtight argument that any utility function subject to extreme and unchecked optimization pressure has to be exactly right. But amidst all this talk of edge instantiation and the hidden complexity of wishes and the King Midas problem and so on, it's easy to take away that vibe.[3] That is, if it's not aimed precisely at the True Utility, intense optimization – even for something kinda-like True Utility – can seem likely to grab the universe and drive it in some ultimately orthogonal and as-good-as-random direction (this is the generalized meaning of "paperclips"). The tails come way, way apart.
I won't, here, try to dive deep on whether value is fragile in this sense (note that, at the least, we need to say a lot more about when and why the correlation between the True Utility and the Slightly-Wrong Utility breaks down). Rather, I want to focus on the sort of yang this picture can prompt. In particular: Yudkowskian-ism generally assumes that at least absent civilizational destruction or very active coordination, the future will be driven by extreme optimization pressure of some kind. Something is going to foom, and then drive the accessible universe hard in its favored direction. Hopefully, it's "us." But the more the direction in question has to be exactly right, lest value shatter into paperclips, the tighter, it seems, we must grip the wheel – and the more exacting our standards for who's driving.
Human paperclippers?
And now, of course, the question arises: how different, exactly, are human hearts from each other? And in particular: are they sufficiently different that, when they foom, and even "on reflection," they don't end up pointing in exactly the same direction? After all, Yudkowsky said, above, that in order for the future to be non-trivially "of worth," human hearts have to be in the driver's seat. But even setting aside the insult, here, to the dolphins, bonobos, nearest grabby aliens, and so on – still, that's only to specify a necessary condition. Presumably, though, it's not a sufficient condition? Presumably some human hearts would be bad drivers, too? Like, I dunno, Stalin?
Now: let's be clear, the AI risk folks have heard this sort of question before. "Ah, but aligned with whom?" Very deep. And the Yudkowskians respond with frustration. "I just told you that we're all about to be killed, and your mind goes to monkey politics? You're fighting over the poisoned banana!" And even if you don't have Yudkowsky's probability on doom, it is, indeed, a potentially divisive and race-spurring frame – and one that won't matter if we all end up dead. There are, indeed, times to set aside your differences – and especially, weird philosophical questions about how much your differences diverge once they're systematized into utility functions and subjected to extreme optimization pressure -- and to unite in a common cause. Sometimes, the white walkers are invading, and everyone in the realm needs to put down their disputes and head north to take a stand together; and if you, like Cercei, stay behind, and weaken the collective effort, and focus on making sure that your favored lineage sits the Iron Throne if the white walkers are defeated – well, then you are a serious asshole, and an ally of Moloch. If winter is indeed coming, let's not be like Cercei.
Cersei Sees The White Walker Best Scene- Game of Thrones Season 7 Ep 7
Let's hope we can get this kind of evidence ahead of time.
Still: I think it's important to ask, with Hanson, how the abstract conceptual apparatus at work in various simple arguments for "AI alignment" apply to "human alignment," too. In particular: the human case is rich with history, intuition, and hard-won-heuristics that the alien-ness of the AI case can easily elide. And when yang goes wrong, it's often via giving in, too readily, to the temptations of abstraction, to the neglect of something messier and more concrete (cf communism, high-modernism-gone-wrong, etc). But the human case, at least, offers more data to collide with – and various lessons, I'll suggest, worth learning. And anyway, even to label the AIs as the white walkers is already to take for granted large swaths of the narrative that Hanson is trying to contest. We should meet the challenge on its own terms.
Plus, there are already some worrying flags about the verdicts that a simplistic picture of value fragility will reach about "human alignment." Consider, for example, Yudkowsky's examples above, of utility functions that are OK with repeating optimal stuff over and over (instead of getting "bored"), or with people having optimal experiences inside experience machines, even without any "contact with reality." Even setting aside questions about whether a universe filled to the brim with bliss should count as non-trivially "of worth,"[4] there's a different snag: namely, that these are both value systems that a decent number of humans actually endorse – for example, various of my friends (though admittedly, I hang out in strange circles). Yet Yudkowsky seems to think that the ethics these friends profess would shatter all value – and if they would endorse it on reflection, that makes them, effectively, paperclippers relative to him. (Indeed, I even know illusionist-ish folks who are much less excited than Yudkowsky about deep ties between consciousness and moral-importance. But this is a fringe-er view.)
Now, of course, the "on reflection" bit is important. And one route to optimism about "human alignment" is to claim that most humans will converge, on reflection, to sufficiently similar values that their utility functions won't be "fragile" relative to each other. In the light of Reason, for example, maybe Yudkowsky and my friends would come to agree about the importance of preserving boredom and reality-contact. But even setting aside problems for the notion of "reflection" at stake, and questions about who will be disposed to "reflect" in the relevant way, positing robust convergence in this respect is a strong, convenient, and thus-far-undefended empirical hypothesis – and one that, absent a defense, might prompt questions, from the atheists, about wishful thinking.
Indeed, while it's true that humans have various important similarities to each other (bodies, genes, cognitive architectures, acculturation processes) that do not apply to the AI case, nothing has yet been said to show that these similarities are enough to overcome the "extremal Goodhart" argument for value fragility. That argument, at least as I've stated it, was offered with no obvious bounds on the values-differences to which it applies – the problem statement, rather, was extremely general. So while, yes, it condemned the non-human hearts – still, one wonders: how many human hearts did it condemn along the way?
A quick glance at what happens when human values get "systematized" and then "optimized super hard for" isn't immediately encouraging. Thus, here's Scott Alexander on the difference between the everyday cases ("mediocristan") on which our morality is trained, and the strange generalizations the resulting moral concepts can imply:
The morality of Mediocristan is mostly uncontroversial. It doesn't matter what moral system you use, because all moral systems were trained on the same set of Mediocristani data and give mostly the same results in this area. Stealing from the poor is bad. Donating to charity is good. A lot of what we mean when we say a moral system sounds plausible is that it best fits our Mediocristani data that we all agree upon...
The further we go toward the tails, the more extreme the divergences become. Utilitarianism agrees that we should give to charity and shouldn't steal from the poor, because Utility, but take it far enough to the tails and we should tile the universe with rats on heroin. Religious morality agrees that we should give to charity and shouldn't steal from the poor, because God, but take it far enough to the tails and we should spend all our time in giant cubes made of semiprecious stones singing songs of praise. Deontology agrees that we should give to charity and shouldn't steal from the poor, because Rules, but take it far enough to the tails and we all have to be libertarians.
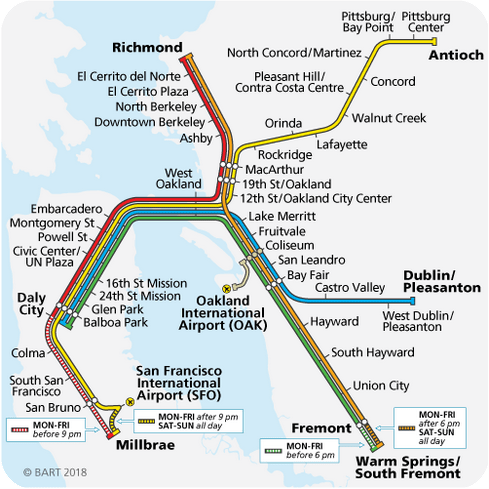
From Alexander: "Mediocristan is like the route from Balboa Park to West Oakland, where it doesn't matter what line you're on because they're all going to the same place. Then suddenly you enter Extremistan, where if you took the Red Line you'll end up in Richmond, and if you took the Green Line you'll end up in Warm Springs, on totally opposite sides of the map..."
That is, Alexander suggests a certain pessimism about extremal Goodhart in the human case. Different human value systems are similar, and reasonably aligned with each other, within a limited distribution of familiar cases, partly because they were crafted in order to capture the same intuitive data-points. But systematize them and amp them up to foom, and they decorrelate hard. Cf, too, the classical utilitarians and the negative utilitarians. On the one hand, oh-so-similar – not just in having human bodies, genes, cognitive architectures, etc, but in many more specific ways (thinking styles, blogging communities, etc). And yet, and yet – amp them up to foom, and they seek such different extremes (the one, Bliss; and the other, Nothingness).
Or consider this diagnosis, from Nate Soares of the Yudkowsky-founded Machine Intelligence Research Institute, about how the AIs will end up with misaligned goals:
The first minds humanity makes will be a terrible spaghetti-code mess [? · GW], with no clearly-factored-out "goal" that the surrounding cognition pursues in a unified way. The mind will be more like a pile of complex, messily interconnected kludges, whose ultimate behavior is sensitive to the particulars [LW · GW] of how it reflects and irons out the tensions within itself over time.
Sound familiar? Human minds too, seem pretty spaghetti-code and interconnected kludge-ish. We, too, are reflecting on and ironing-out our internal tensions, in sensitive-to-particulars ways.[5] And remind me why this goes wrong in the AI case, especially for AIs trained to be nice in various familiar human contexts? Well, there are various [LW · GW] stories – but a core issue, for Yudkowsky and Soares, is the meta-ethical anti-realism thing (though: less often named as such). Here's [LW · GW] Yudkowsky:
There's something like a single answer, or a single bucket of answers, for questions like 'What's the environment really like?' and 'How do I figure out the environment?' and 'Which of my possible outputs interact with reality in a way that causes reality to have certain properties?'... When you have a wrong belief, reality hits back at your wrong predictions... In contrast, when it comes to a choice of utility function, there are unbounded degrees of freedom and multiple reflectively coherent fixpoints. Reality doesn't 'hit back' against things that are locally aligned with the loss function on a particular range of test cases, but globally misaligned on a wider range of test cases.[6]
That is, the instrumental reasoning bit – that part is constrained by reality. But the utility function – that part is unconstrained. So even granted a particular, nice-seeming pattern of behavior on a particular limited range of cases, an agent reflecting on its values and "ironing out its internal tensions" can just go careening off in a zillion possible directions, with nothing except "coherence" (a very minimal desideratum) and the contingencies of its starting-point to nudge the process down any particular path. Ethical reflection, that is, is substantially a free for all. So once the AI is powerful enough to reflect, and to prevent you from correcting it, its reflection spins away, unmoored and untethered, into the land where extremal Goodhart bites, and value shatters into paperclips.
But: remind me what part of that doesn't apply to humans? Granted, humans and AIs work from different contingent starting-points – indeed, worryingly much. But so, too, do different humans. Less, perhaps – but how much less is necessary? What force staves off extremal Goodhart in the human-human case, but not in the AI-human one? For example: what prevents the classical utilitarians from splitting, on reflection, into tons of slightly-different variants, each of whom use a slightly-different conception of optimal pleasure (hedonium-1, hedonium-2, etc)?[7] And wouldn't they, then, be paperclippers to each other, what with their slightly-mutated conceptions of perfect happiness? I hear the value of mutant happiness drops off fast...
And we can worry about the human-human case for more mundane reasons, too. Thus, for example, it's often thought that a substantial part of what's going on with human values is either selfish or quite "partial." That is, many humans want pleasure, status, flourishing, etc for themselves, and then also for their family, local community, and so on. We can posit that this aspect of human values will disappear or constrain itself on reflection, or that it will "saturate" to the point where more impartial and cosmopolitan values start to dominate in practice – but see above re: "convenient and substantive empirical hypothesis" (and if "saturation" helps with extremal-Goodhart problems, can you make the AI's values saturate, too?). And absent such comforts, "alignment" between humans looks harder to come by. Full-scale egoists, for example, are famously "unaligned" with each other – Bob wants blah-for-Bob, and Sally, blah-for-Sally. And the same dynamic can easily re-emerge with respect to less extreme partialities. Cf, indeed, lots of "alignment problems" throughout history.
Of course, we haven't, throughout history, had to worry much about alignment problems of the form "suppose that blah agent fooms, irons out its contradictions into a consistent utility function, then becomes dictator of the accessible universe and re-arranges all the matter and energy to the configuration that maxes out that utility function." Yudkowsky's mainline narrative asks us to imagine facing this problem with respect to AI – and no surprise, indeed, that it looks unlikely to go well. Indeed, on such a narrative, and absent the ability to make your AI something other than an aspiring-dictator (cf "corrigibility," or as Yudkowsky puts it, building an AI that "doesn't want exactly what we want, and yet somehow fails to kill us and take over the galaxies despite that being a convergent incentive there"[8]), the challenge of AI alignment amounts, as Yudkowsky puts it, to the challenge of building a "Sovereign which wants exactly what we extrapolated-want and is therefore safe to let optimize all the future galaxies without it accepting any human input trying to stop it."
But assuming that humans are not "corrigible" (Yudkowsky, at least, wants to eat the galaxies) then especially if you're taking extremal Goodhart seriously, any given human does not appear especially "safe to let optimize all the future galaxies without accepting any input," either – that's, erm, a very high standard. But if that's the standard for being a "paperclipper," then are most humans paperclippers relative to each other?
Deeper into godlessness
We can imagine a view that answers "yes, most humans are paperclippers relative to each other." Indeed, we can imagine a view that takes extremal Goodhart and "the tails come apart" so seriously that it decides all the hearts, except its own, are paperclippers. After all, those other hearts aren't exactly the same as its own. And isn't value fragile, under extreme optimization pressure, to small differences? And isn't the future one of extreme optimization? Apparently, the only path to a non-paperclippy future is for my heart, in particular, to be dictator. It's bleak, I know. My p(doom) is high. But one must be a scout about such things.
In fact, we can be even more mistrusting. For example: you know what might happen to your heart over time? It might change even a tiny bit! Like: what happens if you read a book, or watch a documentary, or fall in love, or get some kind of indigestion – and then your heart is never exactly the same ever again, and not because of Reason, and then the only possible vector of non-trivial long-term value in this bleak and godless lightcone has been snuffed out?! Wait, OK, I have a plan: this precise person-moment needs to become dictator. It's rough, but it's the only way. Do you have the nano-bots ready? Oh wait, too late. (OK, how about now? Dammit: doom again.)

Doom soon?
Now, to be clear: this isn't Yudkowsky's view. And one can see the non-appeal. Still, I think some of the abstract commitments driving Yudkowsky's mainline AI alignment narrative have a certain momentum in this direction. Here I'm thinking of e.g. the ubiquity of power-seeking among smart-enough agents; the intense optimization to which a post-AGI future will be subjected; extremal Goodhart; the fragility of value; and the unmoored quality of ethical reflection given anti-realism. To avoid seeing the hearts of others as paperclippy, one must either reject/modify/complicate these commitments, or introduce some further, more empirical element (e.g., "human hearts will converge to blah degree on reflection") that softens their blow. This isn't, necessarily, difficult – indeed, I think these commitments are questionable/complicate-able along tons of dimensions, and that a variety of open empirical and ethical questions can easily alter the narrative at stake. But the momentum towards deeming more and more agents (and agent-moments) paperclippers seems worth bearing in mind.
We can see this momentum as leading to a yet-deeper atheism. Yudkowsky's humanism, at least, has some trust in human hearts, and thus, in some uncontrolled Other. But the atheism I have in mind, here, trusts only in the Self, at least as the power at stake scales – and in the limit, only in this slice of Self, the Self-Right-Now. Ultimately, indeed, this Self is the only route to a good future. Maybe the Other matters as a patient – but like God, they can't be trusted with the wheel.
We can also frame this sort of atheism in Hanson's language. In what sense, actually, does Yudkowsky "other" the AIs? Well, basically, he says that they can't be trusted with power – and in particular, with complete power over the trajectory of the future, which is what he thinks they're on track to get – because their values are too different from ours. Hanson replies: aren't the default future humans like that, too? But this sort of atheism replies: isn't everyone except for me (or me-right-now) like that? Don't I stand alone, surrounded on all sides by orthogonality, as the only actual member of "us"? That is, to whatever extent Yudkowsky "others" the paperclippers, this sort of atheism "others" everyone.
Balance of power problems
Now: I don't, here, actually want to debate, in depth, who exactly is how-much-of-a-paperclipper, relative to whom. Indeed, I think that "how much would I, on reflection, value the lightcone resulting from this agent's becoming superintelligent, ironing out their motivations into a consistent utility function, and then optimizing the galaxies into the configuration that maximizes that utility function?" is a question we should be wary about focusing on – both in thinking about each other, and in thinking about our AIs. And even if we ask it, I do actually think that tons of humans would do way better-than-paperclips – both with respect to not-killing-everyone (more in my next essay), and with respect to making the future, as Yudkowsky puts it, a "Nice Place To Live."
Still, I think that noticing the way in which questions about AI alignment arise with respect to our alignment-with-each-other can help reframe some of the issues we face as we enter the age of AGI. For one thing, to the extent extremal Goodhart doesn't actually bite, with respect to differences-between-humans, this might provide clues about how much it bites with respect to different sorts of AIs, and to help us notice places where over-quick talk of the "fragility of value" might mislead. But beyond this, I think that bringing to mind the extremity of the standard at stake in "how much do I like the optimal light-cone according to a foomed-up and utility-function-ified version of this agent" can help humble us about the sort of alignment-with-us we should be expecting or hoping for from fellow-creatures – human and digital alike – and to reframe the sorts of mechanisms at play in ensuring it.
In particular: pretty clearly, a lot of the problem here is coming from the fact that you're imagining any agent fooming, becoming dictator of the lightcone, and then optimizing oh-so-hard. Yes, it's scary (read: catastrophic) when the machine minds do this. But it's scary period. And viewed in this light, the "alignment problem" begins to seem less like a story about values, and more like a story about the balance of power. After all: it's not as though, before the AIs showed up, we were all sitting around with exactly-the-same communal utility function – that famous foundation of our social order. And while we might or might not be reasonably happy with what different others-of-us would do as superintelligent dictators, our present mode of co-existence involves a heavy dose of not having to find out. And intentionally so. Cf "checks and balances," plus a zillion other incentives, hard power constraints, etc. Yes, shared ethical norms and values do some work, too (though not, I think, in an especially utility-function shaped way). But we are, at least partly, as atheists towards each other. How much is it a "human values" thing, then, if we don't trust an AI to be God?
Of course, a huge part of the story here is that AI might throw various balances-of-power out the window, so a re-framing from "values problem" to "balance of power problem" isn't, actually, much comfort. And indeed, I think it sometimes provides false comfort to people, in a way that obscures the role that values still have to play. Thus, for example, some people say "I reject Yudkowsky's story that some particular AI will foom and become dictator-of-the-future; rather, I think there will be a multi-polar ecosystem of different AIs with different values. Thus: problem solved?" Well, hmm: what values in particular? Is it all still ultimately an office-supplies thing? If so, it depends how much you like a complex ecosystem of staple-maximizers, thumb-tack-maximizers, and so on – fighting, trading, etc. "Better than a monoculture." Maybe, but how much?[9] Also, are all the humans still dead?

Ok ok it wouldn't be quite like this...
Clearly, not-having-a-dictator isn't enough. Some stuff also needs to be, you know, good. And this means that even in the midst of multi-polarity, goodness will need some share of strength – enough, at least, to protect itself. Indeed, herein lies Yudkowsky's pessimism about humans ever sharing the world peacefully with misaligned AIs. The AIs, he assumes, will be vastly more powerful than the humans – sufficiently so that the humans will have basically nothing to offer in trade or to protect themselves in conflict. Thus, on Yudkowsky's model, perhaps different AIs will strike some sort of mutually-beneficial deal, and find a way to live in comparative harmony; but the humans will be too weak to bargain for a place in such a social contract. Rather, they'll be nano-botted, recycled for their atoms, etc (or, if they're lucky, scanned and used in trade with aliens).
We can haggle about some of the details of Yudkowsky's pessimism here (see, e.g., this debate about the probability that misaligned AIs would be nice enough to at least give us some tiny portion of lightcone; or these [LW(p) · GW(p)] sort of questions about whether the AIs will form of a natural coalition or find it easy to cooperate), but I'm sympathetic to the broad vibe: if roughly all the power is held by agents entirely indifferent to your welfare/preferences, it seems unsurprising if you end up getting treated poorly. Indeed, a lot of the alignment problem comes down to this.
So ultimately, yes, goodness needs at least some meaningful hard power backing and protecting it. But this doesn't mean goodness needs to be dictator; or that goodness seeks power in the same way that a paperclip-maximizer does; or that goodness relates to agents-with-different-values the way a paperclip-maximizer relates to us. I think this difference is important, at least, from a purely ethical perspective. But I think it might be important from a more real-politik perspective as well. In the next essay, I'll say more about what I mean.
"You could very analogously say 'human faces are fragile' because if you just leave out the nose it suddenly doesn't look like a typical human face at all. Sure, but is that the kind of error you get when you try to train ML systems to mimic human faces? Almost none of the faces on thispersondoesnotexist.com are blatantly morphologically unusual in any way, let alone noseless." ↩︎
I think Stuart Russell's comment here – "A system that is optimizing a function of n variables, where the objective depends on a subset of size k<n, will often set the remaining unconstrained variables to extreme values; if one of those unconstrained variables is actually something we care about, the solution found may be highly undesirable" – really doesn't cut it. ↩︎
See also: "The tails come apart" and "Beware surprising and suspicious convergence." Plus Yudkowsky's discussion of Corrigible and Sovereign AIs here [LW · GW], both of which appeal to the notion of wanting "exactly what we extrapolated-want." ↩︎
I'm no fan of experience machines, but still – yes? Worth paying a lot for over paperclips, I think. ↩︎
Indeed, Soares gives various examples of humans doing similar stuff here [LW · GW]. ↩︎
Thanks to Carl Shulman for suggesting this example, years ago. One empirical hypothesis here is that in fact, human reflection will specifically try to avoid leading to path-dependent conclusions of this kind. But again, this is a convenient and substantive empirical hypothesis about where our meta-reflection process will lead (and note that anti-realism assumes that some kind of path dependence must be OK regardless – e.g., you need ways of not caring about the fact that in some possible worlds, you ended up caring about paperclips). ↩︎
My sense is that Yudkowsky deems this behavior roughly as anti-natural as believing that 222+222=555, after exposure to the basics of math.* ↩︎
And note that "having AI systems with lots of different values systems increases the chances that those values overlap with ours" doesn't cut it, at least in the context of extremal goodhart, because sufficient similarity with human values requires hitting such a narrow target so precisely that throwing more not aimed-well-enough darts doesn't help much. And the same holds if we posit that the AI values will be "complex" rather than "simple." Sure, human values are complex, so AIs with complex values are at least still in the running for alignment. But the space of possible complex value systems is also gigantic – so the narrow target problem still applies. ↩︎
47 comments
Comments sorted by top scores.
comment by Charlie Steiner · 2024-01-11T23:11:31.374Z · LW(p) · GW(p)
I still endorse my Reducing Goodhart sequence [? · GW]
Replies from: roger-d-1Humans don't have our values written in Fortran on the inside of our skulls, we're collections of atoms that only do agent-like things within a narrow band of temperatures and pressures. It's not that there's some pre-theoretic set of True Values hidden inside people and we're merely having trouble getting to them - no, extracting any values at all from humans is a theory-laden act of inference, relying on choices like "which atoms exactly count as part of the person" and "what do you do if the person says different things at different times?"
The natural framing of Goodhart's law - in both mathematics and casual language - makes the assumption that there's some specific True Values in here, some V to compare to U. But this assumption, and the way of thinking built on top of it, is crucially false when you get down to the nitty gritty of how to model humans and infer their values..
↑ comment by RogerDearnaley (roger-d-1) · 2024-01-12T00:09:07.051Z · LW(p) · GW(p)
Having just read this sequence (or for some of the posts in it, reread them), I endorse it too: it's excellent.
It covers a lot of the same ground as my post Requirements for a STEM-capable AGI Value Learner (my Case for Less Doom) [LW · GW] in a more leisurely and discursive way, and I think ends up in about the same place: Value Learning isn't about locating the One True Unified Utility Function that is the True Name of happiness and can thus be safely strongly optimized, it's about treating researching human values like any other a STEM-like soft science field, and doing the same sorts of cautious, Bayesian, experimental things that we do in any scientific/technical/engineering effort, and avoiding Goodharting by being cautious enough not to trust models (of human values, or anything else) outside their experimentally-supported range of validity, like any sensible STE practitioner. So use all of STEM, don't only think like a mathematician.
comment by Matthew Barnett (matthew-barnett) · 2024-01-11T19:16:34.309Z · LW(p) · GW(p)
We can haggle about some of the details of Yudkowsky's pessimism here... but I'm sympathetic to the broad vibe: if roughly all the power is held by agents entirely indifferent to your welfare/preferences, it seems unsurprising if you end up getting treated poorly. Indeed, a lot of the alignment problem comes down to this.
I agree with the weak claim that if literally every powerful entity in the world is entirely indifferent to my welfare, it is unsurprising if I am treated poorly. But I suspect there's a stronger claim underneath this thesis that seems more relevant to the debate, and also substantially false.
The stronger claim is: adding powerful entities to the world who don't share our values is selfishly bad, and the more of such entities we add to the world, the worse our situation becomes (according to our selfish values). We know this stronger claim is likely to be false because—assuming we accept the deeper atheism claim that humans have non-overlapping utility functions—the claim would imply that ordinary population growth is selfishly bad. Think about it: by permitting ordinary population growth, we are filling the universe with entities who don't share our values. Population growth, in other words, causes our relative power in the world to decline.
Yet, I think a sensible interpretation is that ordinary population growth is not bad on these grounds. I doubt it is better, selfishly, for the Earth to have 800 million people compared to 8 billion people, even though I would have greater relative power in the first world compared to the second. [ETA: see this comment [LW(p) · GW(p)] for why I think population growth seems selfishly good on current margins.]
Similarly, I doubt it is better, selfishly, for the Earth to have 8 billion humans compared to 80 billion human-level agents, 90% of which are AIs. Likewise, I'm skeptical that it is worse for my values if there are 8 billion slightly-smarter-than human AIs who are individually, on average, 9 times more powerful than humans, living alongside 8 billion humans.
(This is all with the caveat that the details here matter a lot. If, for example, these AIs have a strong propensity to be warlike, or aren't integrated into our culture, or otherwise form a natural coalition against humans, it could very well end poorly for me.)
If our argument for the inherent danger of AI applies equally to ordinary population growth, I think something has gone wrong in our argument, and we should probably reject it, or at least revise it.
Replies from: steve2152, interstice↑ comment by Steven Byrnes (steve2152) · 2024-01-11T20:39:26.427Z · LW(p) · GW(p)
I don't think this argument works. The normal world is mediocristan, so the “humans have non-overlapping utility functions” musing is off-topic, right?
In normal world mediocristan, people have importantly overlapping concerns—e.g. pretty much nobody is in favor of removing all the oxygen from the atmosphere.
But it’s more than that: people actually intrinsically care about each other, and each other’s preferences, for their own sake, by and large. (People tend to be somewhat corrigible to each other, Yudkowsky might say?) There are in fact a few (sociopathic) people who have a purely transactional way of relating to other humans—they’ll cooperate when it selfishly benefits them to cooperate, they’ll tell the truth when it selfishly benefits them to tell the truth, and then they’ll lie and stab you in the back as soon as the situation changes. And those people are really really bad. If the population of Earth grows exclusively via the addition of those kinds of people, that’s really bad, and I very strongly do not want that. Having ≈1% of the population with that personality is damaging enough already; if 90% of the human population were like that (as in your 10×'ing scenario) I shudder to imagine the consequences.
Sorry if I’m misunderstanding :)
Replies from: matthew-barnett, TAG↑ comment by Matthew Barnett (matthew-barnett) · 2024-01-11T20:58:56.897Z · LW(p) · GW(p)
the “humans have non-overlapping utility functions” musing is off-topic, right?
I don't think it's off-topic, since the central premise of Joe Carlsmith's post is that humans might have non-overlapping utility functions, even upon reflection. I think my comment is simply taking his post seriously, and replying to it head-on.
Separately, I agree there's a big question about whether humans have "importantly overlapping concerns" in a sense that is important and relevantly different from AI. Without wading too much into this debate, I'll just say: I agree human nature occasionally has some kinder elements, but mostly I think the world runs on selfishness. As Adam Smith wrote, "It is not from the benevolence of the butcher, the brewer, or the baker, that we expect our dinner, but from their regard to their own interest." And of course, AIs might have some kinder elements in their nature too.
If you're interested in a slightly longer statement of my beliefs about this topic, I recently wrote a post that addressed some of these points [EA · GW].
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2024-01-11T21:53:34.877Z · LW(p) · GW(p)
the “humans have non-overlapping utility functions” musing is off-topic, right?
I don't think it's off-topic, since the central premise of Joe Carlsmith's post is that humans might have non-overlapping utility functions, even upon reflection. I think my comment is simply taking his post seriously, and replying to it head-on.
I mean, I’m quite sure that it’s false, as an empirical claim about the normal human world, that the normal things Alice chooses to do, will tend to make a random different person Bob worse-off, on-average, as judged by Bob himself, including upon reflection. I really don’t think Joe was trying to assert to the contrary in the OP.
Instead, I think Joe was musing that if Alice FOOMed to dictator of the universe, and tiled the galaxies with [whatever], then maybe Bob would be extremely unhappy about that, comparably unhappy to if Alice was tiling the galaxies with paperclips. And vice-versa if Bob FOOMed to dictator of the universe. And that premise seems at least possible, as far as I know.
This seemed to be a major theme of the OP—see the discussions of “extremal Goodhart”, and “the tails come apart”—so I’m confused that you don’t seem to see that as very central.
I agree human nature occasionally has some kinder elements, but mostly I think the world runs on selfishness. As Adam Smith wrote, "It is not from the benevolence of the butcher, the brewer, or the baker, that we expect our dinner, but from their regard to their own interest."
I’m not sure how much we’re disagreeing here. I agree that the butcher and brewer are mainly working because they want to earn money. And I hope you will also agree that if the butcher and brewer and everyone else were selfish to the point of being sociopathic, it would be a catastrophe. Our society relies on the fact that there are just not many people, as a proportion of the population, who will flagrantly and without hesitation steal and lie and commit fraud and murder as long as they’re sufficiently confident that they can get away with it without getting a reputation hit or other selfishly-bad consequences. The economy (and world) relies on some minimal level of trust between employees, coworkers, business partners and so on, trust that they will generally follow norms and act with a modicum of integrity, even when nobody is looking. The reason that scams and frauds can get off the ground at all is that there is in fact a prevailing ecosystem of trust that they can exploit. Right?
Replies from: matthew-barnett↑ comment by Matthew Barnett (matthew-barnett) · 2024-01-11T22:43:07.665Z · LW(p) · GW(p)
This seemed to be a major theme of the OP—see the discussions of “extremal Goodhart”, and “the tails come apart”—so I’m confused that you don’t seem to see that as very central.
I agree that a large part of Joe's post was about the idea that human values diverge in the limit. But I think if you take the thing he wrote about human selfishness seriously, then it is perfectly reasonable to talk about the ordinary cases of value divergence too, which I think are very common. Joe wrote,
And we can worry about the human-human case for more mundane reasons, too. Thus, for example, it's often thought that a substantial part of what's going on with human values is either selfish or quite "partial." That is, many humans want pleasure, status, flourishing, etc for themselves, and then also for their family, local community, and so on. We can posit that this aspect of human values will disappear or constrain itself on reflection, or that it will "saturate" to the point where more impartial and cosmopolitan values start to dominate in practice – but see above re: "convenient and substantive empirical hypothesis" (and if "saturation" helps with extremal-Goodhart problems, can you make the AI's values saturate, too?).
I mean, I’m quite sure that it’s false, as an empirical claim about the normal human world, that the normal things Alice chooses to do, will tend to make a random different person Bob worse-off, on-average, as judged by Bob himself, including upon reflection.
I think you're potentially mixing up two separate claims that have different implications. I'm not saying that people rarely act in such a way that makes random strangers better off. In addition to my belief in a small yet clearly real altruistic element to human nature, there's the obvious fact that the world is not zero-sum, and people routinely engage in mutually beneficial actions that make both parties in the interaction better off.
I am claiming that people are mostly selfish, and that the majority of economic and political behavior seems to be the result of people acting in their own selfish interests, rather than mostly out of the kindness of their heart. (Although by selfishness I'm including concern for one's family and friends; I'm simply excluding concern for total strangers.)
That is exactly Adam Smith's point: it is literally in the self-interest of the baker for them to sell us dinner. Even if the baker were completely selfish, they'd still sell us food. Put yourself in their shoes. If you were entirely selfish and had no regard for the preferences of other people, wouldn't you still try to obey the law and engage in trade with other people?
You said that, "if the butcher and brewer and everyone else were selfish to the point of being sociopathic, it would be a catastrophe." But I live in the world where the average person donates very little to charity. I'm already living in a world like the one you are describing; it's simply less extreme along this axis. In such a world, maybe charitable donations go from being 3% of GDP to being 0% of GDP, but presumably we'd still have to obey laws and trade with each other to get our dinner, because those things are mainly social mechanisms we use to coordinate our mostly selfish values.
The economy (and world) relies on some minimal level of trust between employees, coworkers, business partners and so on, trust that they will generally follow norms and act with a modicum of integrity, even when nobody is looking.
Trust is also valuable selfishly, if you can earn it from others, or if you care about not being deceived by others yourself. Again, put yourself in the shoes of a sociopath: is it selfishly profitable, in expectation, to go around and commit a lot of fraud? Maybe if you can get away with it with certainty. But most of the time, people can't be certain they'll get away with it, and the consequences of getting caught are quite severe.
Is it selfishly profitable to reject the norm punishing fraudsters? Maybe if you can ensure this rejection won't come back to hurt you. But I don't think that's something you can always ensure. The world seems much richer and better off, even from your perspective, if we have laws against theft, fraud, and murder.
It is true in a literal sense that selfish people have no incentive to tell the truth about things that nobody will ever find out about. But the world is a repeated game. Many important truths about our social world are things that will at some point be exposed. If you want to have power, there's a lot of stuff you should not lie about, because it will hurt you, even selfishly, in the eyes of other (mostly selfish) people.
Selfishness doesn't mean stupidity. Going around flagrantly violating norms, stealing from people, and violating everyone's trust doesn't actually increase your own selfish utility. It hurts you, because people will be less likely to want to deal with and trade with you in the future. It also usually helps you to uphold these norms, even as a selfish person, because like everyone else, you don't want to be the victim of fraud either.
↑ comment by TAG · 2024-01-11T21:05:54.032Z · LW(p) · GW(p)
I don’t think this argument works. The normal world is mediocristan, so the “humans have non-overlapping utility functions” musing is off-topic, right?
That would be true if extremes are the only possible source of value divergence, but they are not. You can see that ordinary people in ordinary situations have diverging values from politics.
↑ comment by interstice · 2024-01-11T20:22:14.563Z · LW(p) · GW(p)
I think people sharing Yudkowsky's position think that different humans ultimately(on reflection?) have very similar values, so making more people doesn't decrease the influence of your values that much.
ETA: apparently Eliezer thinks that maybe even ancient Athenians wouldn't share our values on reflection?! That does sound like he should be nervous about population growth and cultural drift, then. Well "vast majority of humans would have similar values on reflection" is at least a coherent position, even if EY doesn't hold it.
Replies from: matthew-barnett↑ comment by Matthew Barnett (matthew-barnett) · 2024-01-11T20:26:43.329Z · LW(p) · GW(p)
I think people sharing Yudkowsky's position think that different humans ultimately(on reflection?) have very similar values
I agree that's what many people believe, but this post was primarily about exploring the idea that humans do not actually have very similar values upon reflection. Joe Carlsmith wrote,
And one route to optimism about "human alignment" is to claim that most humans will converge, on reflection, to sufficiently similar values that their utility functions won't be "fragile" relative to each other. In the light of Reason, for example, maybe Yudkowsky and my friends would come to agree about the importance of preserving boredom and reality-contact. But even setting aside problems for the notion of "reflection" at stake, and questions about who will be disposed to "reflect" in the relevant way, positing robust convergence in this respect is a strong, convenient, and thus-far-undefended empirical hypothesis – and one that, absent a defense, might prompt questions, from the atheists, about wishful thinking.
[...]
We can see this momentum as leading to a yet-deeper atheism. Yudkowsky's humanism, at least, has some trust in human hearts, and thus, in some uncontrolled Other. But the atheism I have in mind, here, trusts only in the Self, at least as the power at stake scales – and in the limit, only in this slice of Self, the Self-Right-Now. Ultimately, indeed, this Self is the only route to a good future. Maybe the Other matters as a patient – but like God, they can't be trusted with the wheel.
As it happens, I agree more with this yet-deeper atheism, and don't put much faith in human values.
Replies from: interstice, interstice↑ comment by interstice · 2024-01-11T21:07:40.165Z · LW(p) · GW(p)
Another point, I don't think that Joe was endorsing the "yet deeper atheism", just exploring it as a possible way of orienting. So I think that he could take the same fork in the argument, denying that humans have ultimately dissimilar values in the same way that future AI systems might.
Replies from: matthew-barnett↑ comment by Matthew Barnett (matthew-barnett) · 2024-01-11T21:10:37.372Z · LW(p) · GW(p)
Even so, it seems valuable to explore the implications of the idea presented in the post, even if the post author did not endorse the idea fully. I personally think the alternative view—that humans naturally converge on very similar values—is highly unlikely to be true, and as Joe wrote, seems to be a "thus-far-undefended empirical hypothesis – and one that, absent a defense, might prompt questions, from the atheists, about wishful thinking".
↑ comment by interstice · 2024-01-11T20:31:54.808Z · LW(p) · GW(p)
In that case I'm actually kinda confused as to why you don't think that population growth is bad. Is it that you think that your values can be fully satisfied with a relatively small portion of the universe, and you or people sharing your values will be able to bargain for enough of a share to do this?
Replies from: matthew-barnett↑ comment by Matthew Barnett (matthew-barnett) · 2024-01-11T20:49:48.029Z · LW(p) · GW(p)
On current margins population growth seems selfishly good because
- Our best models of economic growth predict increasing returns to scale from population size, meaning that population growth makes most of us richer, and
- The negatives of cultural/value drift seems outweighed by the effect of increased per-capita incomes.
Moreover, even in a Malthusian state in which the median income is at subsidence level, it is plausible that some people could have very high incomes from their material investments, and existing people (including us) have plenty of opportunities to accumulate wealth to prepare for this eventual outcome.
Another frame here is to ask "What's the alternative, selfishly?" Population growth accelerates technological progress, which could extend your lifespan and increase your income. A lack of population growth could thus lead to your early demise, in a state of material deprivation. Is the second scenario really better because you have greater relative power?
To defend (2), one intuition pump is to ask, "Would you prefer to live in a version of America with 1950s values but 4x greater real per-capital incomes, compared to 2020s America?" To me, the answer is "yes", selfishly speaking.
All of this should of course be distinguished from what you think is altruistically good. You might, for example, be something like a negative utilitarian and believe that population growth is bad because it increases overall suffering. I am sympathetic to this view, but at the same time it is hard to bring myself to let this argument overcome my selfish values.
Replies from: interstice↑ comment by interstice · 2024-01-11T21:12:46.463Z · LW(p) · GW(p)
I see, I think I would classify this under "values can be satisfied with a small portion of the universe" since it's about what makes your life as an individual better in the medium term.
Replies from: matthew-barnett↑ comment by Matthew Barnett (matthew-barnett) · 2024-01-11T21:19:36.939Z · LW(p) · GW(p)
I think that's a poor way to classify my view. What I said was that population growth likely causes real per-capita incomes to increase. This means that people will actually get greater control over the universe, in a material sense. Each person's total share of GDP would decline in relative terms, but their control over their "portion of the universe" would actually increase, because the effect of greater wealth outweighs the relative decline against other people.
I am not claiming that population growth is merely good for us in the "medium term". Instead I am saying that population growth on current margins seems good over your entire long-term future. That does not mean that population growth will always be good, irrespective of population size, but all else being equal, it seems better for you, that more people (or humanish AIs who are integrated into our culture) come into existence now, and begin contributing to innovation, specialization, and trade.
And moreover, we do not appear close to the point at which the marginal value flips its sign, turning population growth into a negative.
Replies from: interstice↑ comment by interstice · 2024-01-11T21:45:47.033Z · LW(p) · GW(p)
but their control over their "portion of the universe" would actually increase
Yes, in the medium term. But given a very long future it's likely that any control so gained could eventually also be gained while on a more conservative trajectory, while leaving you/your values with a bigger slice of the pie in the end. So I don't think that gaining more control in the short run is very important -- except insofar as that extra control helps you stabilize your values. On current margins it does actually seem plausible that human population growth improves value stabilization faster than it erodes your share I suppose, although I don't think I would extend that to creating an AI population larger in size than the human one.
Replies from: matthew-barnett↑ comment by Matthew Barnett (matthew-barnett) · 2024-01-11T23:46:37.211Z · LW(p) · GW(p)
On current margins it does actually seem plausible that human population growth improves value stabilization faster than it erodes your share I suppose, although I don't think I would extend that to creating an AI population larger in size than the human one.
I mean, without rapid technological progress in the coming decades, the default outcome is I just die and my values don't get stabilized in any meaningful sense. (I don't care a whole lot about living through my descendents.)
In general, I think you're probably pointing at something that might become true in the future, and I'm certainly not saying that population growth will always be selfishly valuable. But when judged from the perspective of my own life, it seems pretty straightforward that accelerating technological progress through population growth (both from humans and AIs) is net-valuable valuable even in the face of non-trivial risks to our society's moral and cultural values.
(On the other hand, if I shared Eliezer's view of a >90% chance of human extinction after AGI, I'd likely favor slowing things down. Thankfully I have a more moderate view than he does on this issue.)
comment by Steven Byrnes (steve2152) · 2024-01-12T00:24:14.719Z · LW(p) · GW(p)
Yeah my guess is that Eliezer is empirically wrong about humans being broadly sufficiently similar to converge to the same morality upon ideal reflection; I was just writing about that last month in Section 2.7.2 here [LW · GW].
Replies from: Raemon↑ comment by Raemon · 2024-01-12T01:14:28.354Z · LW(p) · GW(p)
Has Eliezer actually made this claim? (the CEV paper from what I recall talks about a designing a system that checks for whether human values cohere, and shuts down automatically if they don't. This does imply a likely enough chance of success to be worth building a CEV machine but I don't know how likely he actually thought)
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2024-01-12T02:56:17.253Z · LW(p) · GW(p)
Oh sorry, it’s in the thing I linked. I was thinking of Eliezer’s metaethics sequence, for example [LW · GW]:
When a paperclip maximizer and a pencil maximizer do different things, they are not disagreeing about anything, they are just different optimization processes. You cannot detach should-ness from any specific criterion of should-ness and be left with a pure empty should-ness that the paperclip maximizer and pencil maximizer can be said to disagree about—unless you cover "disagreement" to include differences where two agents have nothing to say to each other.
But this would be an extreme position to take with respect to your fellow humans, and I recommend against doing so. Even a psychopath would still be in a common moral reference frame with you, if, fully informed, they would decide to take a pill that would make them non-psychopaths. If you told me that my ability to care about other people was neurologically damaged, and you offered me a pill to fix it, I would take it. Now, perhaps some psychopaths would not be persuadable in-principle to take the pill that would, by our standards, "fix" them. But I note the possibility to emphasize what an extreme statement it is to say of someone:
"We have nothing to argue about, we are only different optimization processes."
That should be reserved for paperclip maximizers, not used against humans whose arguments you don't like.
Hmm, I guess it’s not 100% clear from that quote by itself, but I read the whole metaethics sequence a couple months ago and this was my strong impression—I think a lot of the stuff he wrote just doesn’t make sense unless you include a background assumption that human neurodiversity doesn’t impact values-upon-ideal-reflection, with perhaps (!) an exception for psychopaths.
This [LW · GW] is another example—like, it’s not super-explicit, just the way he lumps humans together, in the context of everything else he wrote.
(Sorry if I’m putting words in anyone’s mouth.)
Replies from: Algon↑ comment by Algon · 2024-01-12T12:51:56.909Z · LW(p) · GW(p)
It has been a few years since I read that sequence in full, but my impression was that Eliezer thought there were some basic pieces that human morality is made out of, and some common ways of finding/putting those pieces together, though they needn't be exactly the same. If you run this process for long enough, using the procedures humans use to construct their values, then you'd end up in some relatively small space compared to the space of all possible goals, or all evolutionarily fit goals for superintelligences etc.
So too for a psychopath. This seems plausible to me. I don't expect a psychopath to wind up optimizing for paper-clips on reflection. But I also don't expect to be happy in a world that ranks very high accordting to a psychopath's values-on-reflection. Plausibly, I wouldn't even exist in such a world.
comment by Shankar Sivarajan (shankar-sivarajan) · 2024-01-12T00:00:20.272Z · LW(p) · GW(p)
"Ah, but aligned with whom?" Very deep.
It is a perfectly good question though. And yes, the "AI safety" people have heard it before, but their answer, insofar as they deign to provide one, is still shit.
The response that comes closest to an answer seems to be "imagine this thing we call 'humanity's CEV [? · GW].' It would be nice if such a thing existed, so we're going to assume it does."
Replies from: roger-d-1↑ comment by RogerDearnaley (roger-d-1) · 2024-01-12T00:19:38.324Z · LW(p) · GW(p)
That's not the only or even most recent answer. discussion of CEV dates back to around 2004 up to around 2010–2013 or so, and mostly predates Value Learning, which dates back to about 2011. That's more "Imagine this thing we call 'human values' that's about what humans want. It would be helpful if such a thing existed and could be systematized, and it clearly kind of does, since we've been studying it for over 3000 years, and subfields of it take up nearly half the Dewey Decimal system: pretty much every soft science, art, and craft. So we're going to have AI continue that research with us."
comment by Donald Hobson (donald-hobson) · 2024-01-12T02:58:56.721Z · LW(p) · GW(p)
Toy example. Suppose every person wanted lots of tasty food for themselves. No one cares in the slightest about other people starving.
In this scenario, everyone is a paperclipper with respect to everyone else, and yet we can all agree that it's a good idea to build a "feed everyone AI".
Sometimes you don't need your values to be in control, you just need them to be included.
comment by Wei Dai (Wei_Dai) · 2024-01-12T07:25:53.034Z · LW(p) · GW(p)
But the atheism I have in mind, here, trusts only in the Self, at least as the power at stake scales – and in the limit,only in this slice of Self, the Self-Right-Now. Ultimately, indeed,this Self is the only route to a good future.
I distrust even my Self-Right-Now. "Power corrupts" is a thing, and I'm not sure if being handed direct access to arbitrary amounts of power is safe for anyone, including me-right-now.
I also don't know how to do "reflection", or make the kinds of philosophical/intellectual progress needed to eventually figure out how to safely handle arbitrary amounts of power, except as part of a social process along with many peers/equals (i.e., people that I don't have large power differentials with).
It seems to me that nobody should trust themselves with arbitrary amounts of power or be highly confident that they can successfully "reflect" by themselves, so the "deeper atheism" you talk about here is just wrong or not a viable option? (I'm not sure what your conclusions/takeaways for this post or the sequence as a whole are though, so am unsure how relevant this point is.)
Replies from: andrew-burns↑ comment by Andrew Burns (andrew-burns) · 2024-01-12T16:06:13.060Z · LW(p) · GW(p)
Lord Acton was on to something when he observed that great men become bad men when given great power. "Despotic power is always accompanied by corruption of morality." I believe this is because morality flows from the knowledge of our own fragility...there but for the grace of God go I, the faithful might say...and the golden rule works because people stand on an equal playing field and recognize that bad actions have a tendency to boomerang and that anyone could be caught in a state of misfortune. So, when we reflect as we are now, weak mortals, we converge on a certain set of values. But, when given enormous powers, it is very likely we will converge on different values, values which might cause our present selves to shriek in disgust. No one can be trusted with absolute power.
Replies from: lahwran↑ comment by the gears to ascension (lahwran) · 2024-01-23T20:34:32.158Z · LW(p) · GW(p)
I would bet that when we have god-like knowledge of the universe (and presumably have successfully averted the issues we're discussing here in order to get it), that it will turn out that there have been people who could have been trusted with absolute power.
And that it would have been effectively impossible to identify them ahead of time, so of course, in fact, the interaction feedback network that someone is placed in does matter a lot.
Replies from: None↑ comment by [deleted] · 2024-01-23T21:19:13.519Z · LW(p) · GW(p)
Set could have zero elements in it.
The reason is because while it's easy to imagine a fair and buildable "utopia", to a certain definition of the word, and imagine millions of humans you can "trust" to do it.
I mean what do you want, right? Some arcologies where robot police and medical systems prevent violence and all forms of death. Lots of fun stuff to do, anything that isn't expensive in real resources is free.
The flaw is that if you give a human absolute power, it changes them. They diverge with learning updates from the "stable and safe" configuration you say know someone's mother as to a tyrant. This is why I keep saying you have to disable learning to make an AI system safe to use. You want the empress in the year 1000 of Her Reign to be making decisions using the same policy as at year 0. (This can be a problem if there are external enemies or new problems ofc)
comment by xpym · 2024-01-12T10:34:59.285Z · LW(p) · GW(p)
I don't see a substantial difference between a (good enough) experience machine and an 'aligned' superintelligent Bostromian singleton, so the apparent opposition to the former combined with the enthusiastic support for the latter from the archetypal transhumanist always confused me.
comment by Joe Collman (Joe_Collman) · 2024-01-12T02:17:13.114Z · LW(p) · GW(p)
The main case for optimism on human-human alignment under extreme optimization seems to be indirection: not that [what I want] and [what you want] happen to be sufficiently similar, but that there's a [what you want] pointer within [what I want].
Value fragility doesn't argue strongly against the pointer-based version. The tails don't come apart when they're tied together.
It's not obvious that the values-on-reflection of an individual human would robustly maintain the necessary pointers (to other humans, to past selves, to alternative selves/others...), but it is at least plausible - if you pick the right human.
More generally, an argument along the lines of [the default outcome with AI doesn't look too different from the default outcome without AI, for most people] suggests that we need to do better than the default, with or without AI. (I'm not particularly optimistic about human-human alignment without serious and principled efforts)
comment by Adam Kaufman (Eccentricity) · 2024-01-11T21:50:55.423Z · LW(p) · GW(p)
I’m enjoying this series, and look forward to the next installment.
comment by Ann (ann-brown) · 2024-01-11T18:16:32.921Z · LW(p) · GW(p)
In fact, we can be even more mistrusting. For example: you know what might happen to your heart over time? It might change even a tiny bit! Like: what happens if you read a book, or watch a documentary, or fall in love, or get some kind of indigestion – and then your heart is never exactly the same ever again, and not because of Reason, and then the only possible vector of non-trivial long-term value in this bleak and godless lightcone has been snuffed out?! Wait, OK, I have a plan: this precise person-moment needs to become dictator. It's rough, but it's the only way. Do you have the nano-bots ready? Oh wait, too late. (OK, how about now? Dammit: doom again.)
If you want to take it yet another step further, I have no particular intuition that my heart at a specific person-moment is in fact trustworthy to myself to become any sort of dictator, either, at least without some sort of discoverable moral realism "out there" for it to find post-power.
Replies from: roger-d-1↑ comment by RogerDearnaley (roger-d-1) · 2024-01-11T23:17:27.093Z · LW(p) · GW(p)
Completely agreed.
Also, even if we average over, or coherently extrapolate, the combined opinions of all humans, that can and will change over time. Especially once we have effective genetic engineering of human ethical instincts, or are cyborging heavily, or even just have ASIs with superhuman levels of persuasion (if that turns out to be a thing), this could then change a lot, making the contents of that far-future light-cone entirely unpredictable and almost certainly very alien to us now. A problem I discuss at length in The Mutable Values Problem in Value Learning and CEV [LW · GW].
comment by FlorianH (florian-habermacher) · 2024-01-11T23:41:03.787Z · LW(p) · GW(p)
Love the post. One relevant possibility that I think would be worthy of consideration w.r.t. the discussion about human paperclippers/inter-human compatibility:
Humans may not be as much misaligned as our highlty idiosyncratic value theories might suggest, if a typical individual's value theory is really mainly what she uses to justify/explain/rationalize her today's local intuitions & actions, yet without really driving the actions as much as we think. A fooming human might then be more likely to simply update her theories, to again become compatible what underlying more basic intuitions dictate to her. So the basic instincts that make us today locally have often reasonably compatible practical aims, might then still keep us more compatible than our individual exicit and more abstract value theories, i.e. rationalizations, would seem to suggest.
I think there are some observatiins that might suggest sth in that direction. Give the humans a new technology , and initially some will call it the devil's tool to be abstained from - but ultimately we all converge to using it, updating our theories, beliefs.
Survey persons on whether it's okay to actively put in acute danger one life for the sake of saving 10, and you have people stronlgy diverge on the topic, based on their abstract value theories. Put them in the corrsponding leadership position where that moral question becomes an regular real choice that has to be made, and you might observe them act much more homogenously according to the more fundamental ad pragmatic instincts.
(I think Jonathan Haidt's Righteous mind wluld also support some of this)
In this case, the Yudkowskian AI alignment challenge may keep a bit more of its specialness in comparison to the human paperclipper challenge.
comment by RogerDearnaley (roger-d-1) · 2024-01-11T22:51:17.088Z · LW(p) · GW(p)
A quick glance at what happens when human values get "systematized" and then "optimized super hard for" isn't immediately encouraging. Thus, here's Scott Alexander on the difference between the everyday cases ("mediocristan") on which our morality is trained, and the strange generalizations the resulting moral concepts can imply:
I can't answer for Yudkowski, but what I think most Utilitarians would say is:
Firstly, it's not very surprising if humans who never left Mediocrestan have maps that are somewhat inaccurate outside it, so we should explore outside its borders only slowly and carefully (which is the generic solution to Goodhart's law [LW · GW]: apply Bayesianism to theories about what your utility should be function, be aware of the Knightian uncertainty of this, and pessimize over this when optimizing: i.e. tread carefully when stepping out-of-distribution). The extrapolation in Coherent Extrapolated Volition includes learning from experience (which may sometimes be challenging to extrapolate).
Secondly, to the extent that humans have preferences over the map used and thus the maps become elements in the territory, summing over the utility of all humans will apply a lot of averaging. Unsurprisingly, the average position of Richmond, Antioch, Dublin and Warm Springs is roughly at Mount Diablo, which is a fairly sensible-looking extrapolation of where the Bay Bridge is leading to.
We can imagine a view that answers "yes, most humans are paperclippers relative to each other."
See my post Uploading [LW · GW] for exactly that argument. Except I'd say "almost all (including myself)".
comment by Review Bot · 2024-03-07T20:02:29.158Z · LW(p) · GW(p)
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2025. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
comment by SeñorDingDong (alhatho@gmail.com) · 2024-01-11T20:03:50.447Z · LW(p) · GW(p)
Like: what happens if you read a book, or watch a documentary, or fall in love, or get some kind of indigestion – and then your heart is never exactly the same ever again, and not because of Reason, and then the only possible vector of non-trivial long-term value in this bleak and godless lightcone has been snuffed out?!
I'm finding it hard to parse this, perhaps someone can clarify for me. At first I assumed this was a problem inherent in the 'naturalist' view Scott Alexander gives:
"This is only a problem for ethical subjectivists like myself, who think that we’re doing something that has to do with what our conception of morality is. If you’re an ethical naturalist, by all means, just do the thing that’s actually ethical."
E.g. Mr. negative utilitarian eats a taco and realises he ought to change his ethical views to something else, say, becoming classical utilitarian. If the later version was foomed, presumably this would be a disaster from the perspective of the earlier version.
But Joe gives broader examples: small, possibly imperceptible, changes as a result of random acts. These might be fully unconscious and non-rational - the indigestion example sticking out to me.
It feels a person whose actions followed from these changes, if foomed, would produce quite unpredictable, random futures unrelated necessarily to any particular ethical theory. This seems to be more like Scott's ethical subjectivist worries - no matter how your messy-spaghetti morality is extrapolated, it will be unsatisfying to you (and everyone?), regardless of whether you were in the 'right state' at foom-time. I think Joe covers something similar in 'On the Limits of Idealised Values.'
Perhaps to summarise the difference: extrapolating the latter 'subjectivist' position is like the influence of starting conditions on a projectile you are inside ('please don't fire!'); conversely, the naturalist view is like choosing a line on Scott's subway route (just make sure you're on the right line!).
Is this a useful framing?
Replies from: roger-d-1↑ comment by RogerDearnaley (roger-d-1) · 2024-01-11T23:09:38.921Z · LW(p) · GW(p)
My personal view on how to work with ethics [LW · GW] as described in ethical philosophy terminology is basically a moral anti-realist version of ethical naturalism: I think the constraints of things like evolutionary psychology and sociology give us a lot of guidelines, in the context of a specific species (humans), society, and set of technological capabilities, so I'm a moral relativist, and that designing an ethical system that suits these guidelines well is exacting work. I just don't think that they're sufficient to uniquely define a single answer, so I don't agree with the common moral-realist formulation of ethical naturalism. Perhaps I should start calling myself a moral semi-realist, and see how many philosophers I can confuse?
comment by Roko · 2024-01-12T01:50:14.064Z · LW(p) · GW(p)
I think Eliezer is strategically lying about the degree to which human extrapolated volitions are in conflict, because doing so helps us to cooperate in making the total pie bigger (reduce x-risk).
I'm glad other people are poking at this, as I didn't want to be the first person to say this.
Personally, I think giving a slice of the future to an average human extrapolated volition and giving it to a paperclip maximizer have roughly the same value to me, i.e. zero.
Case in point "NO REGRETS How Lotto lout Michael Carroll blew £9.7m on naked waitresses with coke on trays, eight-girl orgies and £2k-a-day on cocaine"
https://www.thesun.co.uk/news/8402541/how-national-lottery-lout-michael-carroll-blew-9-7m-pounds/
This is what I expect most other humans' EVs look like
Replies from: Dagon, jarviniemi, Dagon↑ comment by Dagon · 2024-01-12T03:05:19.152Z · LW(p) · GW(p)
You can’t forget the standard punchline “the rest I just wasted”.
Replies from: Feel_Love↑ comment by Feel_Love · 2024-01-12T18:20:37.893Z · LW(p) · GW(p)
In fact, the rest he gave to his mother, aunt, and sister -- £1,000,000 each. Quite generous for a 19-year-old. His ex-wife with newborn baby got £1,400,000.
I'm afraid to research it further... maybe they all blew it on drugs and hookers too.
↑ comment by Olli Järviniemi (jarviniemi) · 2024-01-12T18:05:03.232Z · LW(p) · GW(p)
Saying that someone is "strategically lying" to manipulate others is a serious claim. I don't think that you have given any evidence for lying over "sincere has different beliefs than I do" in this comment (which, to be clear, you might not have even attempted to do - just explicitly flagging it here).
I'm glad other people are poking at this, as I didn't want to be the first person to say this.
Note that the author didn't make any claims about Eliezer lying.
(In case one thinks I'm nitpicky, I think that civil communication involves making the line between "I disagree" and "you are lying" very clear, so this is an important distinction.)
This is what I expect most other humans' EVs look like
Really, most other humans? I don't think that your example supports this claim basically at all. "Case of a lottery winner as reported by The Sun" is not particularly representative of the whole humanity. You have the obvious filtering by the media, lottery winners not being a uniformly random sample from the population, the person being quite WEIRD. And what happened to humans not being ideal agents who can effectively satisfy their values?
(This is related to a pet peeve of mine. Gell-Mann amnesia effect is "Obviously news reporting on this topic is terrible... hey, look at what media has reported on this other thing!". The effect generalizes: "Obviously news reporting is totally unrepresentative... hey, look at this example from the media!")
If I'm being charitable, maybe again you didn't intend to make an argument here, but rather just state your beliefs and illustrate them with an example. I honestly can't tell. In case you are just illustrating, I would have appreciated to mark it down more explicitly - doubly so in the case of claiming that someone is lying.
Replies from: Roko, Roko↑ comment by Roko · 2024-01-13T14:56:30.734Z · LW(p) · GW(p)
Really, most other humans?
Well, actually I suspect that most other humans EVs would be even more disgusting to me.
People on this site underestimate the extent to which they live in a highly filtered bubble of high-IQ middle-aged-to-young westerners which is a very atypical part of humanity. Most humans are nonwestern and most humans have an IQ below about 80.
↑ comment by Roko · 2024-01-13T14:50:17.951Z · LW(p) · GW(p)
I don't think that you have given any evidence for lying
Well, there is other evidence I have but it is sensitive. A number of prominent people have confided to me that they think that human extrapolated volitions will probably have significant conflicts, but they don't want to say that because it is unstrategic to point out to your allies that they have latent conflicts.
Human-EV-value-conflicts is a big infohazard.
Replies from: Roman Leventov↑ comment by Roman Leventov · 2024-01-14T11:48:20.365Z · LW(p) · GW(p)
Extrapolated volition is a non-sensical concept altogether, as demonstrated in the OP. There is no extrapolated volition outside of it unfolding in real life in a specific context, which affects the trajectory of values/volition in a specific way. And which will be this context is unknown and unknowable (maybe aliens will visit Earth tomorrow, maybe not).
↑ comment by Dagon · 2024-01-13T18:11:02.395Z · LW(p) · GW(p)
I think Eliezer is strategically lying
Thank you for reminding me to include this in my hypothesis-set. I'm pretty sure the idea of CEV is a blind-spot, and is among the least likely approaches to AI control. But I'd only really considered insanity/mania as the reason it's popular, not intentional lying.