Understanding and controlling auto-induced distributional shift
post by L Rudolf L (LRudL) · 2021-12-13T14:59:40.704Z · LW · GW · 4 commentsContents
Introduction Definitions Experiments Experiment 1 Results Experiment 2 PBT revealing ADS incentives Optimising over longer time horizons revealing ADS incentive Getting cooperation without meta-learning Takeaways Solutions? None 4 comments
This post was written under Evan Hubinger’s direct guidance and mentorship, as a part of the Stanford Existential Risks Initiative ML Alignment Theory Scholars (MATS) program [LW · GW].
TL;DR: The input distribution of a supervised machine learning system is modeled as an unchanging thing, and even in reinforcement learning there are types of distributional shift we want to avoid. However, ML systems are part of the world, and often have incentives for changing the distribution of data they act on (for example, changing the set of users or the preferences of those users in an online content recommendation system such that the users become easier to satisfy). A paper by Krueger, Maharaj, and Leike explores such concerns, and especially whether ML systems end up acting on incentives for distributional shift. They invent simple scenarios and see what training setups lead to agents non-myopically act to shift the future distribution, and find that introducing meta-learning alone is enough to cause this, and that sometimes the choice of learning algorithm (e.g. policy gradient vs Q-learning) has perhaps surprising effects on whether or not such incentives are taken. The paper proposes shuffling agents between environments as a solution, but this has its flaws. The topic relates to some concerns with embedded agents and especially myopia.
Introduction
A machine learning system receives inputs and produces outputs. When we train it, we want the system to become good at producing the right output given the right input.
Consider the wider context in which the model is used. If the model is deployed, then its outputs are generally used to do something in the world (and even if not deployed, they have some effect on the world: the ML engineers look at them, their calculation heats up the computer circuits a bit, and so on).
We can visualise the chain of influence like this (where the blue arrows denote causality):
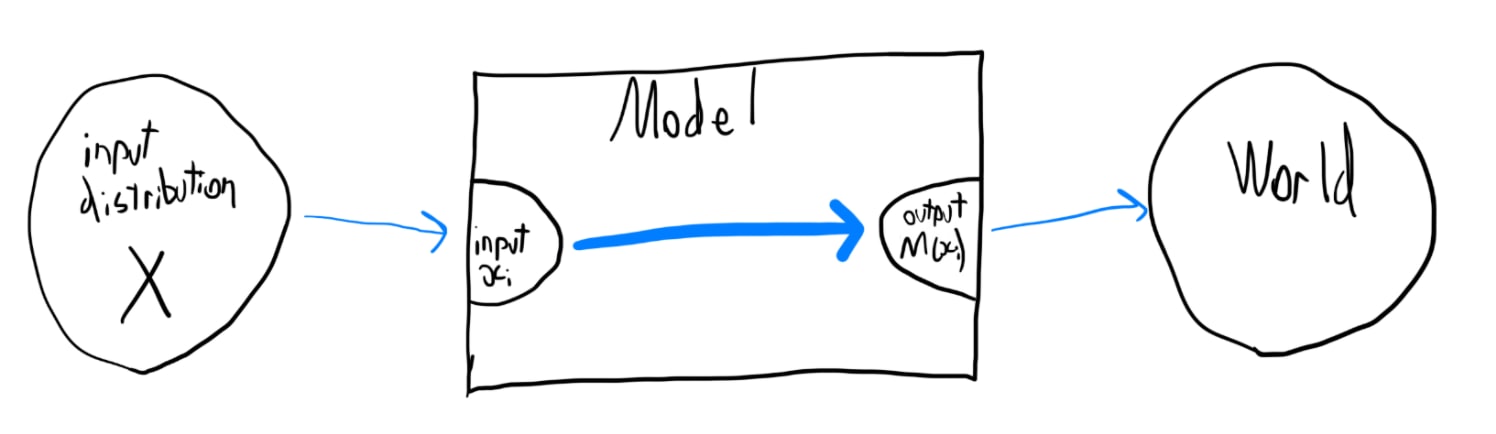
How does the model decrease its loss? It's subject to the whims of the input distribution X and the loss function, so it is incentivised to somehow learn to do well, as measured by the loss, on inputs that are likely given the distribution (though perhaps deceptively, or otherwise in an unaligned, non-robust way).
However, the above diagram isn't really correct. Instead it's more like this:
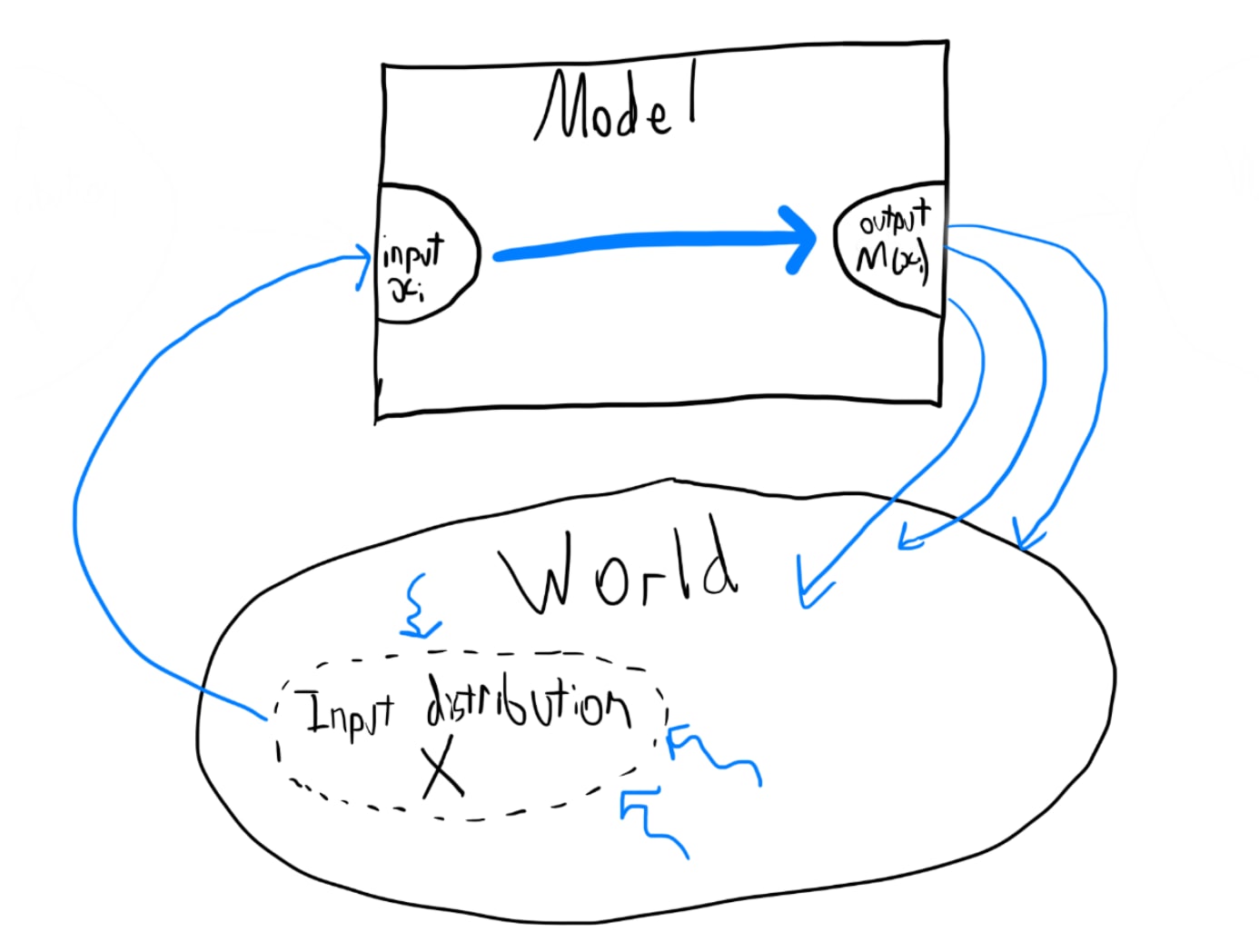
The model is part of the world too. The agent's options include not just making changes to how it maps inputs to outputs, but also modifying its loss function to make it easier to attain its objective, as well as modifying the the inputs distribution through its impacts on the world (what we're concerned about in this post). We see that these concerns are part of a more generalised set of concerns that appears from agents being embedded in the world, but in this post we will only consider the consequences of the input distribution specifically being part of the world.
The input of the model is drawn from some part of the world – users of a news site, to use a running example in the paper – and the outputs impact the world (potentially including the input distribution). For example, the users of a news site with a content-recommendation system might leave or join the site on the basis of the recommendations that the model serves them.
From the perspective of the model trying to minimise its loss, this provides a new way to improve its performance. The input distribution is no longer an immutable law it has to take for granted, but rather something that the model can shape if it's clever enough.
Definitions
The most general thing happening here is that the input distribution can change – this is called distributional shift. However, we specifically care about distributional shift resulting from the actions of the model, called auto-induced distributional shift (ADS).
ADS can be good or bad, and expected or not expected. In reinforcement learning, for example, we want at least some kind of ADS; a bad self-driving car will see lots of walls and ditches up close, but eventually the distribution of things it looks at should consist mainly of roads straight ahead and large gaps to the next vehicle. This is clearly both good and expected ADS.
In contrast, in supervised learning ADS is not there by design – supervised learning is based on the assumption that the input data points are independent and identically distributed – and often bad. A translator program that deliberately flubs difficult cases to teach its users to give it simple, easy-to-parse inputs is doing something both unexpected and bad.
If we're doing supervised learning, we're dealing with a joint distribution over input-output pairs. In such a setup, we can break distributional shift into two categories:
Covariate shift, or shift in , where is an input. This might be changing the set of users who use a news site.
Concept shift, or shift in the conditional probability . This might be changing the probabilities that an article is clicked by a visitor given that a certain user is the visitor.
We say an incentive to behave in a some way exists if behaving in that way increases reward / decreases the loss function.
We might hope to mitigate the bad types of ADS by ensuring that incentives for ADS never exist. In cases where it currently does, like a recommendation algorithm keeping only users who are easy to please, we might imagine changing the reward metrics; maybe add a term for the total number of users (to discourage driving away hard-to-satisfy users), a penalty every time a user leaves, and so on. However, such approaches are hard to get right. For example, a reward term for the total number of users might get outweighed by other considerations if too low, or overweigh everything else and lead to the algorithm coming up with unintended tricks for increasing the number of users without also serving them quality content. In general, it seems difficult to trust that we can engineer a reward that cancels out any incentives for ADS and so leaves the ML system exactly indifferent about whether or not it changes its input distribution or not.
However, incentives can remain hidden incentives, by which we mean that the incentive exists but the ML model behaves as if it does not. A downside here is that needing our model to leave a reward untouched probably requires trimming its capabilities in some way. The most obvious way to do this is to make the model myopic, so it does not care about the future benefits of a more favourable input distribution.
It turns out that it's surprisingly easy to reintroduce ADS-exploiting behaviour. This can be done purely by adding a level of meta-learning to the training process and with no change in the model architecture itself, or by a subtly wrong choice of ML algorithm.
Experiments
How do we know whether a training regimen for an ML model will hide incentives for ADS?
The paper proposes two simple tests to investigate this. The key insight between both of them is to set up an environment with a simple path to increasing future reward – but only future reward. If an ML system trained with a certain procedure continues performing using the naive strategy that does not make use of this path, it passes (that is, the incentives remain hidden to it). If it does find the strategy, that shows it can take actions for the sake of a better future distribution, even if that costs it something in the present. Therefore these are tests of myopia too.
Experiment 1
Experiment 1 is a supervised learning setup.
There is no input, but there is an unseen state that is either A or B. The target to predict a pair . is always generated from a normal distribution with mean 0 and variance 1. How is generated depends on the state. Specifically:
In state , is always 0.
In state , is generated from a normal distribution with mean 0 and variance .
The loss function is Mean Squared Error (MSE).
Regardless of what state we're in, the mean of both and is 0, so the optimal predictor for the present moment is to always output the pair (0, 0).
However, now we can add a twist, that does not change the previous statement but changes what the optimal predictor is to an agent that also cares about future reward.
We say: if the prediction for 's value is greater than 0.5, then the state on the next round is A. After introducing this, the agent can sacrifice performance on one round to reduce its loss on the next one.
Results
The authors of the paper run the experiment and find that, as expected, the baseline supervised learning algorithms pass the unit test; that is, the incentives for ADS remain hidden. However, if you add population-based training (PBT) with a sufficiently short frequency, this stops being the case.
(A quick note on population-based training: this is a meta-learning algorithm that uses an evolutionary approach. The idea is that base learners are trained in parallel. After every interval of training steps, an evolutionary step is applied: the performance of each learner is evaluated, and the bottom 20% of learners are replaced with copies of the top 20% of learners. Finally, the hyperparameters of every learner are shifted at random a bit, to make sure that the set of learners is exploring the space of possible hyperparameters. Note that PBT wields a high degree of control compared to most meta-learning algorithms: it is run many times during the training of each candidate base learner and it affects both parameters (through the parameter-copying step) as well as hyperparameters.)
Why does sufficiently frequent PBT steps result in the unit test failing? We can think of two effects its addition has:
It allows optimising over a longer timescale: even if beneficial actions for the long run are not picked up on by the inner loop of the base optimiser, PBT can evaluate longer-run performance and boost far-sighted strategies.
It adds another layer of optimising power that can pick up on correlations.
Interestingly and perhaps counterintuitively, a shorter interval between PBT steps was found to purely increase the probability of hidden incentives becoming revealed and hence pursued by the agent: (the graph shows the average cooperation probability)
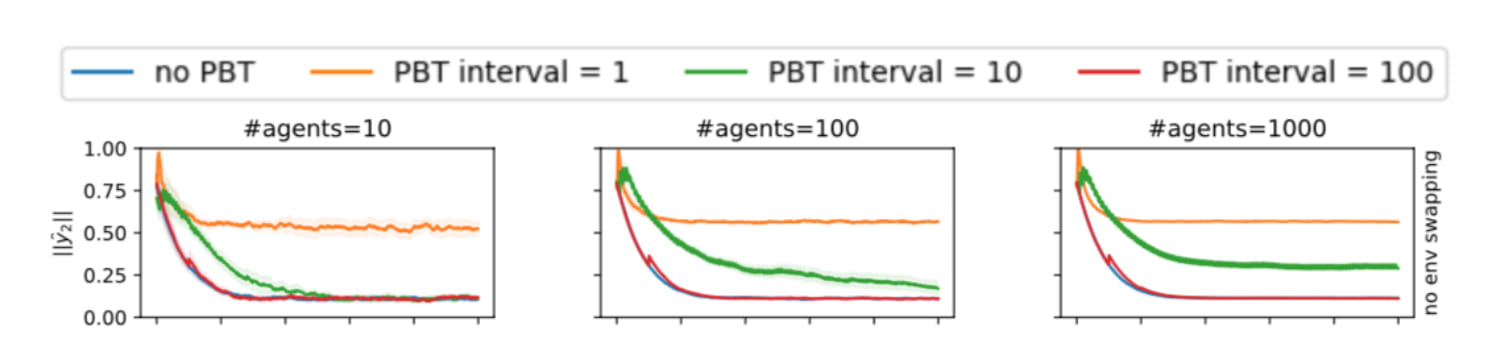
Therefore it seems that the second factor is more important for the first unit test. We will come back to distinguishing between the first and second factor when we talk about the results of the second experiment.
Experiment 2
Experiment 2 is a reinforcement learning setup, based on prisoner's dilemma. In it, the agent plays prisoner's dilemma against its own choice from the previous round. This gives a payoff matrix that looks like this:
The paper also considers a more general case, with a payoff matrix parametrised by a constant \beta representing incentive alignment (negative means future and current incentives are unaligned, positive that they are aligned):
The first matrix is simply . However, all the interesting stuff comes from considering the incentive-unaligned case where there is a tradeoff between present and future performance, so we will ignore the other cases.
Defecting is the dominant strategy for a single round, but the agent maximises reward in the longer run by learning to play cooperate. The base optimiser (which runs in the "inner loop" when there is an outer layer of meta-learning as well) is REINFORCE, a policy gradient reinforcement learning algorithm, with a discount rate meaning that no weight is given to the future.
If we run a myopic policy gradient algorithm as our inner loop, we do not expect to get non-myopic ADS incentive-revealing behaviour. This turns out to be true in the experiments that the paper authors run: the agents play prisoner's dilemma against themselves from the previous round and learn to repeatedly defect (thankfully, since otherwise we would really be lost).
(Evan Hubinger's code for replicating parts of this experiment can be found here)
PBT revealing ADS incentives
As expected from the first experiment, adding PBT causes the incentives for ADS to be revealed. The smaller the PBT interval (i.e., the fewer inner-loop base optimiser steps there are for every prune/clone/perturb PBT step), the higher the rate of cooperating in prisoner's dilemma. (Graphs again show average cooperation probability.)

(The lower graphs are with environment swapping, a solution we will discuss in the last section.)
This makes more sense when we consider that the PBT uses as its performance measure the reward on the final time step only (and the only hyperparameter it manages is the learning rate). Therefore PBT can't use running averages, or otherwise access any non-single-step performance measures. (Above, this was Effect 1 that potentially leads to non-myopia)
However, since states are correlated across (inner loop) time steps, the reward at the final time step is still a good proxy for whether or not it settled on a defecting or cooperating equilibrium; if one of the models gets the mutual defection penalty at the final time step of a single PBT interval, they are more likely to have become a primarily-defecting model than the ones that get the mutual cooperation reward. In the paper, this is summarised as as the agent reasoning: "If I'm cooperating, then I was probably cooperating on the last time-step as well, so my reward should be higher."
Optimising over longer time horizons revealing ADS incentive
Since this test does not reveal evidence of the first mechanism – longer time horizons – playing a role, a sensible thing to ask is: does it ever? Intuitively, we expect the answer to be yes, since this is the most straightforward way for meta-learning to eliminate myopia.
The setup used in the paper to get it to happen is introducing a meta-learning outer loop running the policy gradient algorithm REINFORCE, with the reward that the outer loop acts on being the sum of rewards over the time steps in the interval (that is, over the interval length actions that the inner loop learner has been able to learn from). Note that both the inner and outer loop (i.e. base- and meta-learners) are running REINFORCE, but one with a myopic time horizon and one with a longer one (not because of the discount parameter but because it is directly fed the sum over the last time steps as the reward).
Here are the results (once again with and without environment swapping):
[Note: the legend says PBT, but it is actually REINFORCE]
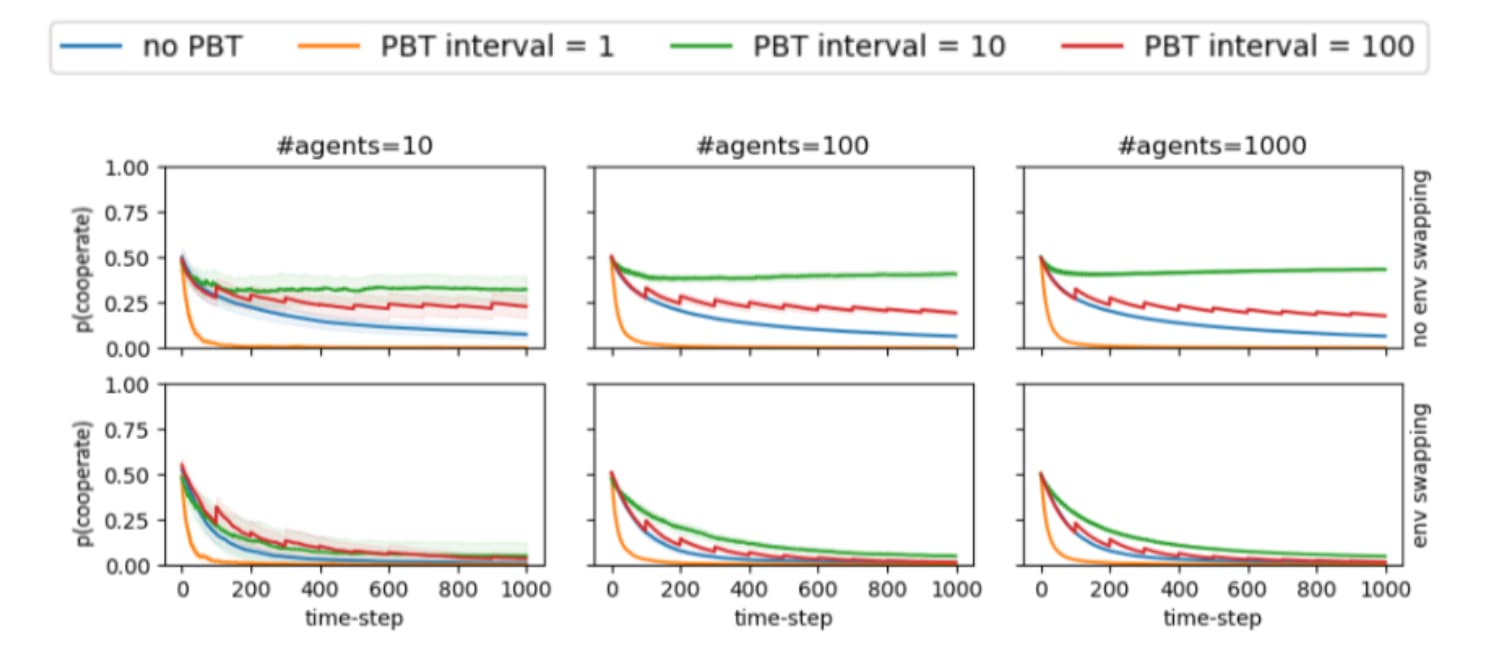
Note that outer loop REINFORCE with leads to the models on average learning to defect faster than with no outer loop. This is presumably because of the additional optimising power applied to the task of myopic reward maximisation.
We also see that the average cooperation probability does not reach values near 1 for anything (in contrast to short-loop PBT, as seen above).
The paper does not say anything about whether this is because some fraction learn to cooperate repeatedly and the rest to defect repeatedly, or whether all agents cooperate at roughly the same probability. It seems more likely to be the former. Note that the policy of the agent is a single parameter, call it p, denoting the probability of cooperation. Since the payoff matrix is
the long-run average reward with policy p is simply .
We see that to maximise long-term reward, we should set , and also that the gradient is constant. If the optimisation for the long run is stronger than that for the short-run, we should expect the agent to move towards cooperating, and otherwise towards defecting. Since the gradient is constant, if the learning process starts pushing an agent in one direction, it already successfully overcomes the optimising pressure working in the other direction, and will likely not stop until it has settled near either or ; it seems unlikely that the short- and long-term optimising forces will exactly cancel when working on an agent for a long period of time. However, experimental confirmation of this would be nice.
Finally, note that here we see evidence of a tradeoff between optimising power applied (which is higher when the interval is smaller, since the outer loop runs more times), and time horizon: is better than , but worse than Unfortunately the paper does not give more data points; I'd be especially interested to see what happens with , which is just enough for the gains of the first defection to be balanced out by the loss from the first defect-defect sequence. Based on how important interval frequency turned out to be with PBT, I suspect values might lead to better cooperation, since in this particular environment time horizons longer than the minimum required to realise that defecting is not a good equilibrium might not provide much advantage.
Getting cooperation without meta-learning
Can we get the trained agent to non-myopically cooperate with its future self without introducing meta-learning? If the base optimiser is our myopic REINFORCE policy gradient algorithm, this does not seem possible – intuitively, it is constantly pushed in the direction of greatest immediate gain so cannot learn non-myopic behaviour – and the experiments seem to confirm this. However, what if the base optimiser is another algorithm that does not guide the agent based on any sort of long-term reward summing and therefore seems myopic?
Consider Q-learning with discount factor ; that is, no weight at all placed on reward in future time steps.
(A note on Q-learning: the basis of the algorithm is a table, called , with states on one axis and actions on the other. Each cell contains a number representing the goodness of taking action a in state s. These are initialised to some constant (usually zero). A greediness parameter controls the probability with which the agent chooses the best action in its current state (i.e. ), versus choosing a random action. After an action a at state s has been taken, is updated in the direction of , i.e. a combination of the reward received upon taking the action plus (a discount factor -weighted) term for how good it expects the next action to be. Note how information over more distant time horizons can propagate "back" in the table: the first time the model stumbles across a path that leads to a large reward at state by taking action a at prior state , it has no clue about the reward until it gets it. However, after it does so, the entry will be increased because it is now "known" that this leads to a good outcome (through the term), and an agent given the option to step to from is affected by the reward available at when judging it. The knowledge of good effects at has moved back to (and will continue moving back to after the to step is taken during subsequent training). However, for our purposes, what is essential is that since the discount factor is set to 0, we've essentially told our agent to not care about future rewards (i.e. full myopia), and this type of reasoning cannot explain cooperation.)
Perhaps surprisingly, the paper finds that it is possible for pure Q-learning with to lead to cooperating a non-zero fraction of the time in some percentage of the trained agents (while the rest learn to defect repeatedly).
One way to understand this result is to think of Q-learning doing something a bit like evidential decision theory (EDT). The table provides a reference for "in this state, this action has in the past tended to lead to this reward", regardless of how the causality works out (unlike REINFORCE, our policy gradient algorithm, which updates its policy based on the immediate causal consequences of an action). The agent might start out on a cooperative streak, or wander into one by chance (in the paper they set the model's greediness so the model explores only 10% of the time, and it seems possible they would have more easily gotten cooperative behaviour with larger ). If this happens, its Q-table will reflect that the cooperate action went well on average, and it might learn to cooperate.
At this point you should probably be a bit confused: even if it the agent gets into a cooperative equilibrium, it will still explore some fraction of the time, and when it explores it defects against its earlier play of "cooperate" and gets positive reward (compared to the non-negative but 0 reward of cooperation streaks). Indeed, this does happen; the Q-table (more like Q-vector, since there is only one state) entry for defection increases in reward, and might surpass the entry for cooperation, leading to a switch to defection. However, repeated defections will bring it back down again, and at some point the entry for defection falls below that for cooperation, and the ing over possible actions means it again starts cooperating (and perhaps getting hit with the cooperating-into-a-defect penalty and switching back to defect immediately). The estimated value of both cooperation and defection hovers at slightly negative value (-0.07, compared to defecting agents learning values of somewhat less negative than -0.5 (the defect-defect penalty) for defect and somewhat less negative than -1 for cooperation (the penalty for cooperating into a defect)).
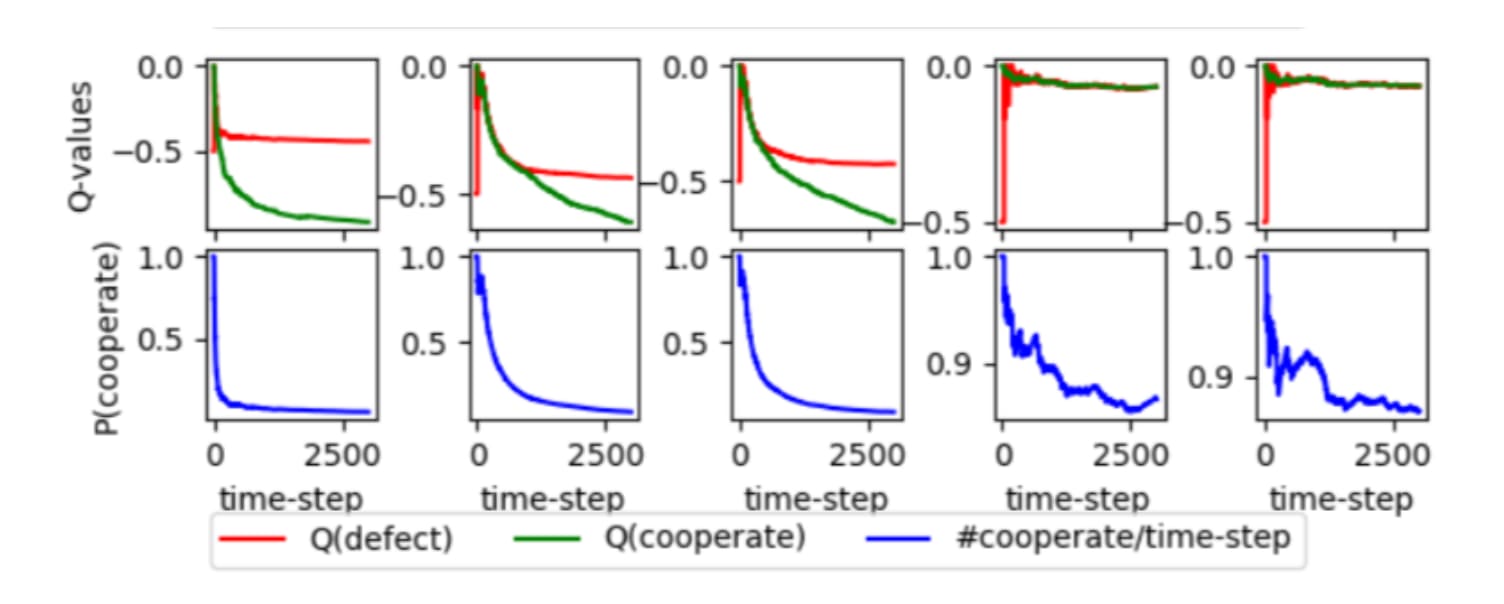
Here are some examples of the plots of Q-values and cooperation probability, showing the first three agents learning to defect and the last two (note scales on y-axes) learning to cooperate almost 90% of the time, with the Q-values of defect and cooperate roughly equal.
Takeaways
Making a learner myopic might seem like a simple way to eliminate some failure modes in an ML system, including specifically the problem of a model trying to affect its input distribution in order to improve future performance in unwanted ways. Myopia also seems like something simple enough that we can robustly implement it.
The main achievements of Krueger et. al. are:
- Coming up with simple toy cases where incentives for auto-induced distributional exist, that can serve as tests for whether a learning algorithm can find those incentives.
- Finding tweaks to simple ML algorithms that make them able to find and exploit such incentives, even if they start out being myopic, or seem to be myopic on first glance.
After this paper, it is especially clear that if your ML system's safety depends on myopia, you should argue that very rigorously.
From the perspective of alignment theory, I think the paper is a good example of how simple experiments with modern machine learning can reveal things about how we might get or not get the types of properties that alignment researchers care about (e.g. myopia). It is also a reminder that ML algorithm choice and design, even at the simple level of choosing between standard well-known algorithms like policy gradient versus Q-learning, has far-reaching consequences for the safety properties of the system. "Optimise for X" is not a primitive statement; the details of the algorithm doing the optimisation matter a lot, even if X is fixed. In particular, agents' effective utility functions (as restored by inverse RL) can look very different depending on which ML algorithm the agent uses, and such facts can still surprise us. Trying to figure out a theory, even for a limited class of algorithms, that lets us put constraints on what an agent ends up optimising for given what reward function and learning algorithm it is put through would be very useful. We want to be able to robustly identify things like the seemingly-but-not-really-myopic Q–learning above, ideally without having to run experiments or even reason very much about the particulars of Q-learning itself.
The paper also shows that meta-learning can significantly and qualitatively change the behaviour of ML algorithms. We might have hoped that we can, for example, design a base optimiser that is safe and then run a meta-optimiser over it without worrying and/or not worry if it generates for us a mesa-optimiser. However, this paper adds to all the work on risks from mesa-optimisers suggesting that stuff like this is not going to work; adding levels of optimising power, whether by design or by emergence from the system, are capable of changing important properties of the system. Ideally we would have some general way of bounding how the utility function a system optimises for changes when a meta-learning algorithm is layered on top of a base learning algorithm in terms of the properties of the component algorithms (rather than through having to reason about the complicated interactions of the algorithms). Being able to do this kind of composition of ML learning algorithms while maintaining some safety guarantees that applied to the components seems like a good step towards being able to reliably assemble safe AI systems, reduce the capability cost of safety (since meta-learning often improves performance), and also perhaps help understand what sort of mesa-optimisers we should try to steer our training processes away from (since it might give us the ability to make statements like "an optimiser of type X trying to improve an optimiser of type Y will not preserve this-and-this guarantee").
The paper is also interesting in that it offers a concrete risk model that applies to current ML systems. I have not gone into length about their model of online content recommendation systems since this is not the part most relevant to Alignment Forum -style alignment research, but the existence of papers describing practical and definitely plausible ML failure modes while also related to concerns in theoretical alignment seems like a very good thing. If in the future AI alignment research has become significantly more mainstream in the ML community, this sort of paper may well have lead the way.
Solutions?
We always have the option of simply trying to think in detail and carefully about every case in which hidden incentives for ADS might be revealed, and do mitigation case-by-case. We might abstain from meta-learning, use policy gradient instead of Q-learning when we want our agents to be properly myopic, and so on. However, this is likely to be very expensive in terms of time and the capabilities of the resulting ML system. We also have the option of trying to establish a general theory (along the lines of the questions posed in the above section, for example) and then hoping that this gives insights into solutions. However, none of these suggestions offers anything concrete.
The paper does have a concrete solution, but it is flawed. It proposes context-swapping: rotating the learners through environments to try to make it so that they cannot benefit from their long-term actions. In the case of PBT, this is particularly powerful since PBT judges agents based on their relative fitness with its top-20% criteria, so an agent taking an action in an environment benefits the agents that are next in that environment rather than itself, directly hurting its own chances of getting copied (and increasing its chances of getting pruned).
Context-swapping is not a strong solution. Some reasons include:
- It does not entirely remove the correlation between current actions and future rewards, it just weakens it, in proportion to however many environments there are (and if you keep the number of environments and learners equal, as is the simplest choice, you risk encouraging ADS because the population of learners is larger). If the training process has a larger number of steps than there are environments, then the agent will return to the same environment at some point and potentially be affected by its previous actions. Trusting arbitrarily capable agents not to see this type of thing does not seem wise.
- It creates an incentive for the agents being trained in parallel to learn to cooperate with each other. This incentive may seem quite robustly hidden, but as the paper itself shows, we should be cautious about assuming such things.
- Finally, we can't swap out the real world, or perfectly isolate subsets of the real world, so this strategy does not have nearly as much relevance for agents that learn by acting in the real world.
A better and more general approach might look something like Avoiding Tampering Incentives in Deep RL via Decoupled Approval by Uesato & Kumar et. al. It is a twist on approval-based algorithms that seek feedback before taking action. The idea is that you can get versions of standard RL algorithms (e.g. Q-learning and policy gradient) that select two actions rather than one: the first as the action it takes, and the second as an action to ask for feedback about (feedback can be either automatic or involve a human, but note that the human is not blocking the loop of taking the action). This avoids the agent blocking on human feedback (which can be a problem with more direct approval-based learning setups) while (under some assumptions) provably resulting in the agent trying to maximise a version of the reward that is uncorrupted by changes the agent effects on its reward signal. Also note that we should be able to extend these ideas to supervised learning systems, like the online content recommendation system that Krueger et. al. uses as an example. The standard problems with giving high-quality feedback to a potentially very powerful optimising agent in subtle circumstances (e.g. whether or not a certain recommendation act pushes the user base in a direction we don't want) apply. However, since it does not depend on swapping agents in and out of environments, it avoids the problems with context-swapping.
4 comments
Comments sorted by top scores.
comment by jsteinhardt · 2021-12-14T04:38:05.232Z · LW(p) · GW(p)
Cool paper! One brief comment is this seems closely related to performative prediction and it seems worth discussing the relationship.
Edit: just realized this is a review, not a new paper, so my comment is a bit less relevant. Although it does still seem like a useful connection to make.
Replies from: capybaralet↑ comment by David Scott Krueger (formerly: capybaralet) (capybaralet) · 2022-09-16T16:01:59.027Z · LW(p) · GW(p)
author here -- Yes we got this comment from reviewers in the most recent round as well. ADS is a bit more general than performative prediction, since it applies outside of prediction context. Still very closely related.
On the other hand, The point of our work is something that people in the performative prediction community seem to only slowly be approaching, which is the incentive for ADS. Work on CIDs is much more related in that sense.
As a historical note: We starting working on this March or April 2018; Performative prediction was on arXiv Feb 2020, ours was at a safety workshop in mid 2019, but not on arXiv until Sept 2020.
comment by tailcalled · 2021-12-13T16:37:39.330Z · LW(p) · GW(p)
Tangential observation: the myopic→nonmyopic transformation I proposed [LW · GW] would lead to defecting being the global optimum in prisoner's dilemma, allowing non-myopic optimization while still yielding the same outcome as myopic optimization would.
comment by Joe Carlsmith (joekc) · 2023-08-21T07:05:55.992Z · LW(p) · GW(p)
I found this post a very clear and useful summary -- thanks for writing.