Clarifying AI X-risk
post by zac_kenton (zkenton), Rohin Shah (rohinmshah), David Lindner, Vikrant Varma (amrav), Vika, Mary Phuong (mary-phuong-2), Ramana Kumar (ramana-kumar), Elliot Catt (elliot-catt) · 2022-11-01T11:03:01.144Z · LW · GW · 24 commentsContents
Categorization Consensus Threat Model Development model: Risk model: Takeaway None 24 comments
TL;DR: We give a threat model literature review, propose a categorization and describe a consensus threat model from some of DeepMind's AGI safety team. See our post [AF · GW] for the detailed literature review.
The DeepMind AGI Safety team has been working to understand the space of threat models for existential risk (X-risk) from misaligned AI. This post summarizes our findings. Our aim was to clarify the case for X-risk to enable better research project generation and prioritization.
First, we conducted a literature review [AF · GW] of existing threat models, discussed their strengths/weaknesses and then formed a categorization based on the technical cause of X-risk and the path that leads to X-risk. Next we tried to find consensus within our group on a threat model that we all find plausible.
Our overall take is that there may be more agreement between alignment researchers than their disagreements might suggest, with many of the threat models, including our own consensus one, making similar arguments for the source of risk. Disagreements remain over the difficulty of the alignment problem, and what counts as a solution.
Categorization
Here we present our categorization of threat models from our literature review [AF · GW], based on the technical cause and the path leading to X-risk. It is summarized in the diagram below.
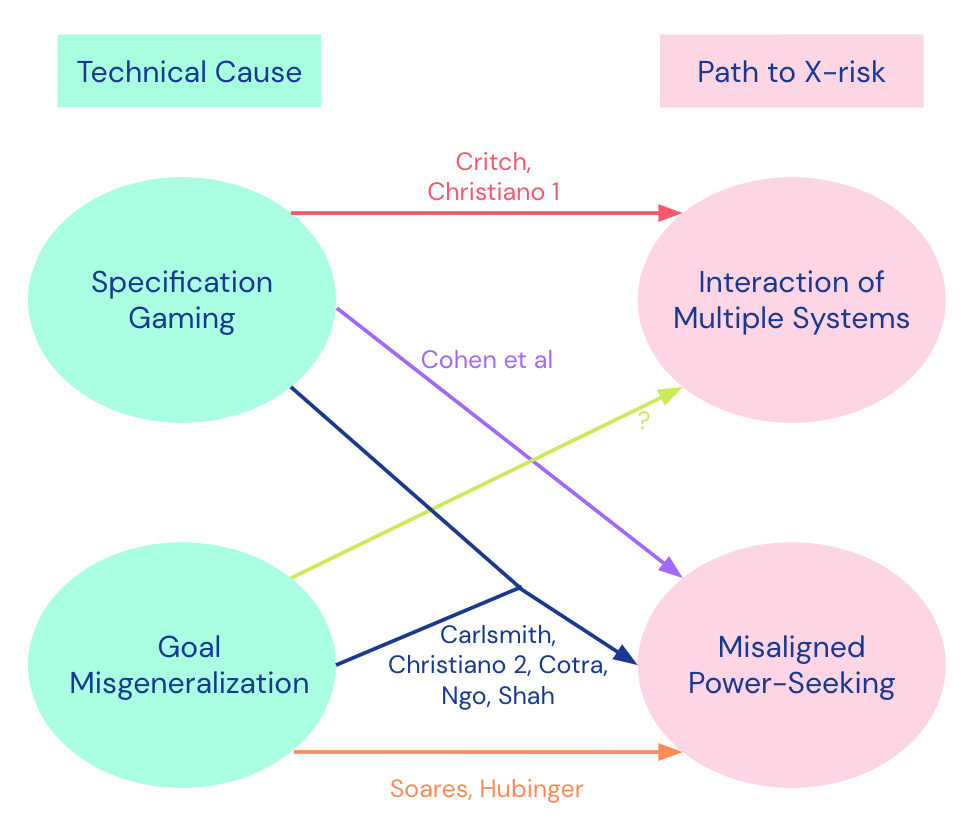
In green on the left we have the technical cause of the risk, either specification gaming (SG) or goal misgeneralization (GMG). In red on the right we have the path that leads to X-risk, either through the interaction of multiple systems, or through a misaligned power-seeking (MAPS) system. The threat models appear as arrows from technical cause towards path to X-risk.
The technical causes (SG and GMG) are not mutually exclusive, both can occur within the same threat model. The distinction between them is motivated by the common distinction in machine learning between failures on the training distribution, and when out of distribution.
To classify as specification gaming, there needs to be bad feedback provided on the actual training data. There are many ways to operationalize good/bad feedback. The choice we make here is that the training data feedback is good if it rewards exactly those outputs that would be chosen by a competent, well-motivated AI[1]. We note that the main downside to this operationalisation is that even if just one out of a huge number of training data points gets bad feedback, then we would classify the failure as specification gaming, even though that one datapoint likely made no difference.
To classify as goal misgeneralization, the behavior when out-of-distribution (i.e. not using input from the training data), generalizes poorly about its goal, while its capabilities generalize well, leading to undesired behavior. This means the AI system doesn’t just break entirely, it still competently pursues some goal, but it’s not the goal we intended.
The path leading to X-risk is classified as follows. When the path to X-risk is from the interaction of multiple systems, the defining feature here is not just that there are multiple AI systems (we think this will be the case in all realistic threat models), it’s more that the risk is caused by complicated interactions between systems that we heavily depend on and can’t easily stop or transition away from. (Note that we haven't analyzed the multiple-systems case very much, and there are also other technical causes for those kinds of scenarios.)
When the path to X-risk is through Misaligned Power-Seeking (MAPS), the AI system seeks power in unintended ways due to problems with its goals. Here, power-seeking means the AI system seeks power as an instrumental subgoal, because having more power increases the options available to the system allowing it to do better at achieving its goals. Misaligned here means that the goal that the AI system pursues is not what its designers intended[2].
There are other plausible paths to X-risk (see e.g. this list [AF · GW]), though our focus here was on the most popular writings on threat models in which the main source of risk is technical, rather than through poor decisions made by humans in how to use AI.
For a summary on the properties of the threat models, see the table below.
| Source of misalignment | ||||
Specification gaming (SG) | SG + GMG | Goal mis-generalization (GMG) | ||
Path to X-risk | Misaligned power seeking (MAPS) | Cohen et al | Carlsmith, Christiano2 [AF · GW], Cotra [AF · GW], Ngo [AF · GW], Shah [AF · GW] | |
Interaction of multiple systems | Christiano1 [AF · GW] | ? | ? | |
We can see that five of the threat models we considered substantially involve both specification gaming and goal misgeneralization (note that these threat models would still hold if one of the risk sources was absent) as the source of misalignment, and MAPS as the path to X-risk. This seems like an area where multiple researchers agree on the bare bones of the threat model - indeed our group’s consensus threat model was in this category too.
One aspect that our categorization has highlighted is that there are potential gaps in the literature, as emphasized by the question marks in the table above for paths to X-risk via the interaction of multiple systems, where the source of misalignment involves goal misgeneralization. It would be interesting to see some threat models that fill this gap.
For other overviews of different threat models, see here [AF · GW] and here [AF · GW].
Consensus Threat Model
Building on this literature review we looked for consensus among our group of AGI safety researchers. We asked ourselves the question: conditional on there being an existential catastrophe from misaligned AI, what is the most likely threat model that brought this about. This is independent of the probability of an occurrence of an existential catastrophe from misaligned AI. Our resulting threat model is as follows (black bullets indicate agreement, white indicates some variability among the group):
Development model:
- Scaled up deep learning foundation models with RL from human feedback (RLHF) fine-tuning.
- Not many more fundamental innovations needed for AGI.
Risk model:
- Main source of risk is a mix of specification gaming and (a bit more from) goal misgeneralization.
- A misaligned consequentialist arises and seeks power (misaligned mostly because of goal misgeneralization).
- Perhaps this arises mainly during RLHF rather than in the pretrained foundation model because the tasks for which we use RLHF will benefit much more from consequentialist planning than the pretraining task.
- We don’t catch this because deceptive alignment occurs (a consequence of power-seeking)
- Perhaps certain architectural components such as a tape/scratchpad for memory and planning would accelerate this.
- Important people won’t understand: inadequate societal response to warning shots on consequentialist planning, strategic awareness and deceptive alignment.
- Perhaps it’s unclear who actually controls AI development.
- Interpretability will be hard.
By misaligned consequentialist we mean
- It uses consequentialist reasoning: a system that evaluates the outcomes of various possible plans against some metric, and chooses the plan that does best on that metric
- Is misaligned - the metric it uses is not a goal that we intended the system to have
Overall we hope our threat model strikes the right balance of giving detail where we think it’s useful, without being too specific (which carries a higher risk of distracting from the essential points, and higher chance of being wrong).
Takeaway
Overall we thought that alignment researchers agree on quite a lot regarding the sources of risk (the collection of threat models in blue in the diagram). Our group’s consensus threat model is also in this part of threat model space (the closest existing threat model is Cotra [AF · GW]).
- ^
In this definition, whether the feedback is good/bad does not depend on the reasoning used by the AI system, so e.g. rewarding an action that was chosen by a misaligned AI system that is trying to hide its misaligned intentions would still count as good feedback under this definition.
- ^
There are other possible formulations of misaligned, for example the system’s goal may not match what its users want it to do.
24 comments
Comments sorted by top scores.
comment by johnswentworth · 2022-11-02T18:45:21.409Z · LW(p) · GW(p)
I continue to be surprised that people think a misaligned consequentialist intentionally trying to deceive human operators (as a power-seeking instrumental goal specifically) is the most probable failure mode.
To me, Christiano's Get What You Measure [LW · GW] scenario looks much more plausible a priori to be "what happens by default". For instance: why expect that we need a multi-step story about consequentialism and power-seeking in order to deceive humans, when RLHF already directly selects for deceptive actions? Why additionally assume that we need consequentialist reasoning, or that power-seeking has to kick in and incentivize deception over and above whatever competing incentives might be present? Why assume all that, when RLHF already selects for actions which deceive humans in practice even in the absence of consequentialism?
Or, another angle: the diagram in this post starts from "specification gaming" and "goal misgeneralization". If we just start from prototypical examples of those failure modes, don't assume anything more than that, and ask what kind of AGI failure the most prototypical versions of those failure modes lead to... it seems to me that they lead to Getting What You Measure. This story about consequentialism and power-seeking has a bunch of extra pieces in it, which aren't particularly necessary for an AGI disaster.
(To be clear, I'm not saying the consequentialist power-seeking deception story is implausible; it's certainly plausible enough that I wouldn't want to build an AGI without being pretty damn certain that it won't happen! Nor am I saying that I buy all the aspects of Get What You Measure - in particular, I definitely expect a much foomier future than Paul does, and I do in fact expect consequentialism to be convergent. The key thing I'm pointing to here is that the consequentialist power-seeking deception story has a bunch of extra assumptions in it, and we still get a disaster with those assumptions relaxed, so naively it seems like we should assign more probability to a story with fewer assumptions.)
Replies from: rohinmshah, tom4everitt, Koen.Holtman↑ comment by Rohin Shah (rohinmshah) · 2022-11-05T11:05:59.500Z · LW(p) · GW(p)
(Speaking just for myself in this comment, not the other authors)
I still feel like the comments on your post [LW · GW] are pretty relevant, but to summarize my current position:
- AIs that actively think about deceiving us (e.g. to escape human oversight of the compute cluster they are running on) come well before (in capability ordering, not necessarily calendar time) AIs that are free enough from human-imposed constraints and powerful enough in their effects on the world that they can wipe out humanity + achieve their goals without thinking about how to deal with humans.
- In situations where there is some meaningful human-imposed constraint (e.g. the AI starts out running on a data center that humans can turn off), if you don't think about deceiving humans at all, you choose plans that ask humans to help you with your undesirable goals, causing them to stop you. So, in these situations, x-risk stories require deception.
- It seems kinda unlikely that even the AI free from human-imposed constraints like off switches doesn't think about humans at all. For example, it probably needs to think about other AI systems that might oppose it, including the possibility that humans build such other AI systems (which is best intervened on by ensuring the humans don't build those AI systems).
Responding to this in particular:
The key thing I'm pointing to here is that the consequentialist power-seeking deception story has a bunch of extra assumptions in it, and we still get a disaster with those assumptions relaxed, so naively it seems like we should assign more probability to a story with fewer assumptions.
The least conjunctive story for doom is "doom happens". Obviously this is not very useful. We need more details in order to find solutions. When adding an additional concrete detail, you generally want that detail to (a) capture lots of probability mass and (b) provide some angle of attack for solutions.
For (a): based on the points above I'd guess maybe 20:1 odds on "x-risk via misalignment with explicit deception" : "x-risk via misalignment without explicit deception" in our actual world. (Obviously "x-risk via misalignment" is going to be the sum of these and so higher than each one individually.)
For (b): the "explicit deception" detail is particularly useful to get an angle of attack on the problem. It allows us to assume that the AI "knows" that the thing it is doing is not what its designers intended, which suggests that what we need to do to avoid this class of scenarios is to find some way of getting that knowledge out of the AI system (rather than, say, solving all of human values and imbuing it into the AI).
One response is "but even if you solve the explicit deception case, then you just get x-risk via misalignment without explicit deception, so you didn't actually save any worlds". My response would be that P(x-risk via misalignment without explicit deception | no x-risk via misalignment with explicit deception) seems pretty low to me. But that seems like the main way someone could change my mind here.
Replies from: johnswentworth, sharmake-farah↑ comment by johnswentworth · 2022-11-05T16:01:41.216Z · LW(p) · GW(p)
Two probable cruxes here...
First probable crux: at this point, I think one of my biggest cruxes with a lot of people is that I expect the capability level required to wipe out humanity, or at least permanently de-facto disempower humanity, is not that high. I expect that an AI which is to a +3sd intelligence human as a +3sd intelligence human is to a -2sd intelligence human would probably suffice, assuming copying the AI is much cheaper than building it. (Note: I'm using "intelligence" here to point to something including ability to "actually try" as opposed to symbolically "try", effective mental habits, etc, not just IQ.) If copying is sufficiently cheap relative to building, I wouldn't be surprised if something within the human distribution would suffice.
Central intuition driver there: imagine the difference in effectiveness between someone who responds to a law they don't like by organizing a small protest at their university, vs someone who responds to a law they don't like by figuring out which exact bureaucrat is responsible for implementing that law and making a case directly to that person, or by finding some relevant case law and setting up a lawsuit to limit the disliked law. (That's not even my mental picture of -2sd vs +3sd; I'd think that's more like +1sd vs +3sd. A -2sd usually just reposts a few memes complaining about the law on social media, if they manage to do anything at all.) Now imagine an intelligence which is as much more effective than the "find the right bureaucrat/case law" person, as the "find the right bureaucrat/case law" person is compared to the "protest" person.
Second probable crux: there's two importantly-different notions of "thinking about humans" or "thinking about deceiving humans" here. In the prototypical picture of a misaligned mesaoptimizer deceiving humans for strategic reasons, the AI explicitly backchains from its goal, concludes that humans will shut it down if it doesn't hide its intentions, and therefore explicitly acts to conceal its true intentions. But when the training process contains direct selection pressure for deception (as in RLHF), we should expect to see a different phenomenon: an intelligence with hard-coded, not-necessarily-"explicit" habits/drives/etc which de-facto deceive humans. For example, think about how humans most often deceive other humans: we do it mainly by deceiving ourselves, reframing our experiences and actions in ways which make us look good and then presenting that picture to others. Or, we instinctively behave in more prosocial ways when people are watching than when not, even without explicitly thinking about it. That's the sort of thing I expect to happen in AI, especially if we explicitly train with something like RLHF (and even moreso if we pass a gradient back through deception-detecting interpretability tools).
Is that "explicit deception"? I dunno, it seems like "explicit deception" is drawing the wrong boundary. But when that sort of deception happens, I wouldn't necessarily expect to be able to see deception in an AI's internal thoughts. It's not that it's "thinking about deceiving humans", so much as "thinking in ways which are selected for deceiving humans".
(Note that this is a different picture from the post you linked; I consider this picture more probable to be a problem sooner, though both are possibilities I keep in mind.)
Replies from: rohinmshah, Xodarap↑ comment by Rohin Shah (rohinmshah) · 2022-11-07T11:13:01.814Z · LW(p) · GW(p)
First probable crux: at this point, I think one of my biggest cruxes with a lot of people is that I expect the capability level required to wipe out humanity, or at least permanently de-facto disempower humanity, is not that high. I expect that an AI which is to a +3sd intelligence human as a +3sd intelligence human is to a -2sd intelligence human would probably suffice, assuming copying the AI is much cheaper than building it.
This sounds roughly right to me, but I don't see why this matters to our disagreement?
For example, think about how humans most often deceive other humans: we do it mainly by deceiving ourselves, reframing our experiences and actions in ways which make us look good and then presenting that picture to others. Or, we instinctively behave in more prosocial ways when people are watching than when not, even without explicitly thinking about it. That's the sort of thing I expect to happen in AI, especially if we explicitly train with something like RLHF (and even moreso if we pass a gradient back through deception-detecting interpretability tools).
This also sounds plausible to me (though it isn't clear to me how exactly doom happens). For me the relevant question is "could we reasonably hope to notice the bad things by analyzing the AI and extracting its knowledge", and I think the answer is still yes.
I maybe want to stop saying "explicitly thinking about it" (which brings up associations of conscious vs subconscious thought, and makes it sound like I only mean that "conscious thoughts" have deception in them) and instead say that "the AI system at some point computes some form of 'reason' that the deceptive action would be better than the non-deceptive action, and this then leads further computation to take the deceptive action instead of the non-deceptive action".
Replies from: johnswentworth↑ comment by johnswentworth · 2022-11-08T17:56:51.070Z · LW(p) · GW(p)
I maybe want to stop saying "explicitly thinking about it" (which brings up associations of conscious vs subconscious thought, and makes it sound like I only mean that "conscious thoughts" have deception in them) and instead say that "the AI system at some point computes some form of 'reason' that the deceptive action would be better than the non-deceptive action, and this then leads further computation to take the deceptive action instead of the non-deceptive action".
I don't quite agree with that as literally stated; a huge part of intelligence is finding heuristics which allow a system to avoid computing anything about worse actions in the first place (i.e. just ruling worse actions out of the search space). So it may not actually compute anything about a non-deceptive action.
But unless that distinction is central to what you're trying to point to here, I think I basically agree with what you're gesturing at.
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2022-11-08T19:11:58.882Z · LW(p) · GW(p)
But unless that distinction is central to what you're trying to point to here
Yeah, I don't think it's central (and I agree that heuristics that rule out parts of the search space are very useful and we should expect them to arise).
↑ comment by Xodarap · 2022-11-06T18:23:11.597Z · LW(p) · GW(p)
think about how humans most often deceive other humans: we do it mainly by deceiving ourselves... when that sort of deception happens, I wouldn't necessarily expect to be able to see deception in an AI's internal thoughts
The fact that humans will give different predictions when forced to make an explicit bet versus just casually talking seems to imply that it's theoretically possible to identify deception, even in cases of self-deception.
Replies from: johnswentworth↑ comment by johnswentworth · 2022-11-06T19:14:07.454Z · LW(p) · GW(p)
Of course! I don't intend to claim that it's impossible-in-principle to detect this sort of thing. But if we're expecting "thinking in ways which are selected for deceiving humans", then we need to look for different (and I'd expect more general) things than if we're just looking for "thinking about deceiving humans".
(Though, to be clear, it does not seem like any current prosaic alignment work is on track to do either of those things.)
↑ comment by Noosphere89 (sharmake-farah) · 2022-11-05T12:01:25.336Z · LW(p) · GW(p)
This. Without really high levels of capabilities afforded by quantum/reversible computers which is an additional assumption, you can't really win without explicitly modeling humans and deceiving them.
↑ comment by tom4everitt · 2022-11-04T12:12:37.198Z · LW(p) · GW(p)
For instance: why expect that we need a multi-step story about consequentialism and power-seeking in order to deceive humans, when RLHF already directly selects for deceptive actions?
Is deception alone enough for x-risk? If we have a large language model that really wants to deceive any human it interacts with, then a number of humans will be deceived. But it seems like the danger stops there. Since the agent lacks intent to take over the world or similar, it won't be systematically deceiving humans to pursue some particular agenda of the agent.
As I understand it, this is why we need the extra assumption that the agent is also a misaligned power-seeker.
Replies from: johnswentworth↑ comment by johnswentworth · 2022-11-04T16:37:04.635Z · LW(p) · GW(p)
For that part, the weaker assumption I usually use is that AI will end up making lots of big and fast (relative to our ability to meaningfully react) changes to the world, running lots of large real-world systems, etc, simply because it's economically profitable to build AI which does those things. (That's kinda the point of AI, after all.)
In a world where most stuff is run by AI (because it's economically profitable to do so), and there's RLHF-style direct incentives for those AIs to deceive humans... well, that's the starting point to the Getting What You Measure scenario.
Insofar as power-seeking incentives enter the picture, it seems to me like the "minimal assumptions" entry point is not consequentialist reasoning within the AI, but rather economic selection pressures. If we're using lots of AIs to do economically-profitable things, well, AIs which deceive us in power-seeking ways (whether "intentional" or not) will tend to make more profit, and therefore there will be selection pressure for those AIs in the same way that there's selection pressure for profitable companies. Dial up the capabilities and widespread AI use, and that again looks like Getting What We Measure. (Related: the distinction here is basically the AI version of the distinction made in Unconscious Economics [LW · GW].)
Replies from: tom4everitt↑ comment by tom4everitt · 2022-11-14T11:58:16.566Z · LW(p) · GW(p)
This makes sense, thanks for explaining. So a threat model with specification gaming as its only technical cause, can cause x-risk under the right (i.e. wrong) societal conditions.
↑ comment by Koen.Holtman · 2022-11-03T15:18:14.998Z · LW(p) · GW(p)
I continue to be surprised that people think a misaligned consequentialist intentionally trying to deceive human operators (as a power-seeking instrumental goal specifically) is the most probable failure mode.
Me too, but note how the analysis leading to the conclusion above is very open about excluding a huge number of failure modes leading to x-risk from consideration first:
[...] our focus here was on the most popular writings on threat models in which the main source of risk is technical, rather than through poor decisions made by humans in how to use AI.
In this context, I of course have to observe that any human decision, any decision to deploy an AGI agent that uses purely consequentialist planning towards maximising a simple metric, would be a very poor human decision to make indeed. But there are plenty of other poor decisions too that we need to worry about.
comment by Leon Lang (leon-lang) · 2022-11-01T15:49:13.674Z · LW(p) · GW(p)
To classify as specification gaming, there needs to be bad feedback provided on the actual training data. There are many ways to operationalize good/bad feedback. The choice we make here is that the training data feedback is good if it rewards exactly those outputs that would be chosen by a competent, well-motivated AI.
I assume you would agree with the following rephrasing of your last sentence:
The training data feedback is good if it rewards outputs if and only if they might be chosen by a competent, well-motivated AI.
If so, I would appreciate it if you could clarify why achieving good training data feedback is even possible: the system that gives feedback necessarily looks at the world through observations that conceal large parts of the state of the universe. For every observation that is consistent with the actions of a competent, well-motivated AI, the underlying state of the world might actually be catastrophic from the point of view of our "intentions". E.g., observations can be faked, or the universe can be arbitrarily altered outside of the range of view of the feedback system.
If you agree with this, then you probably assume that there are some limits to the physical capabilities of the AI, such that it is possible to have a feedback mechanism that cannot be effectively gamed. Possibly when the AI becomes more powerful, the feedback mechanism would in turn need to become more powerful to ensure that its observations "track reality" in the relevant way.
Does there exist a write-up of the meaning of specification gaming and/or outer alignment that takes into account that this notion is always "relative" to the AI's physical capabilities?
Replies from: Charlie Steiner, rohinmshah↑ comment by Charlie Steiner · 2022-11-01T16:45:27.728Z · LW(p) · GW(p)
Yeah, I think this comment is basically right. On nontrivial real-world training data, there are always going to be both good and bad ways to interpret it. At some point you need to argue from inductive biases, and those depend on the AI that's doing the learning, not just the data.
I think the real distinction between their categories is something like:
Specification gaming: Even on the training distribution, the AI is taking object-level actions that humans think are bad. This can include bad stuff that they don't notice at the time, but that seems obvious to us humans abstractly reasoning about the hypothetical.
Misgeneralization: On the training distribution, the AI doesn't take object-level actions that humans think are bad. But then, later, it does.
Replies from: leon-lang↑ comment by Leon Lang (leon-lang) · 2022-11-01T20:27:23.386Z · LW(p) · GW(p)
Specification gaming: Even on the training distribution, the AI is taking object-level actions that humans think are bad. This can include bad stuff that they don't notice at the time, but that seems obvious to us humans abstractly reasoning about the hypothetical.
Do you mean "the AI is taking object-level actions that humans think are bad while achieving high reward"?
If so, I don't see how this solves the problem. I still claim that every reward function can be gamed in principle, absent assumptions about the AI in question.
Replies from: Charlie Steiner↑ comment by Charlie Steiner · 2022-11-01T21:40:32.531Z · LW(p) · GW(p)
Sure, something like that.
I agree it doesn't solve the problem if you don't use information / assumptions about the AI in question.
↑ comment by Rohin Shah (rohinmshah) · 2022-11-02T11:22:22.874Z · LW(p) · GW(p)
I'm confused about what you're trying to say in this comment. Are you saying "good feedback as defined here does not solve alignment"? If so, I agree, that's the entire point of goal misgeneralization (see also footnote 1).
Perhaps you are saying that in some situations a competent, well-motivated AI would choose some action it thinks is good, but is actually bad, because e.g. its observations were faked in order to trick it? If so, I agree, and I see that as a feature of the definition, not a bug (and I'm not sure why you think it is a bug).
Replies from: leon-lang↑ comment by Leon Lang (leon-lang) · 2022-11-02T14:47:38.976Z · LW(p) · GW(p)
Neither of your interpretations is what I was trying to say. It seems like I expressed myself not well enough.
What I was trying to say is that I think outer alignment itself, as defined by you (and maybe also everyone else), is a priori impossible since no physically realizable reward function that is defined solely based on observations rewards only actions that would be chosen by a competent, well-motivated AI. It always also rewards actions that lead to corrupted observations that are consistent with the actions of a benevolent AI. These rewarded actions may come from a misaligned AI.
However, I notice people seem to use the terms of outer and inner alignment a lot, and quite some people seem to try to solve alignment by solving outer and inner alignment separately. Then I was wondering if they use a more refined notion of what outer alignment means, possibly by taking into account the physical capabilities of the agent, and I was trying to ask if something like that has already been written down anywhere.
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2022-11-02T15:51:22.465Z · LW(p) · GW(p)
Oh, I see. I'm not interested in "solving outer alignment" if that means "creating a real-world physical process that outputs numbers that reward good things and punish bad things in all possible situations" (because as you point out it seems far too stringent a requirement).
Then I was wondering if they use a more refined notion of what outer alignment means, possibly by taking into account the physical capabilities of the agent, and I was trying to ask if something like that has already been written down anywhere.
You could look at ascription universality [AF · GW] and ELK [AF · GW]. The general mindset is roughly "ensure your reward signal captures everything that the agent knows"; I think the mindset is well captured in mundane solutions to exotic problems [AF · GW].
Replies from: leon-lang↑ comment by Leon Lang (leon-lang) · 2022-11-02T18:05:52.635Z · LW(p) · GW(p)
Thanks a lot for these pointers!
comment by Vika · 2023-12-20T18:17:42.482Z · LW(p) · GW(p)
I continue to endorse this categorization of threat models and the consensus threat model. I often refer people to this post and use the "SG + GMG → MAPS" framing in my alignment overview talks. I remain uncertain about the likelihood of the deceptive alignment part of the threat model (in particular the requisite level of goal-directedness) arising in the LLM paradigm, relative to other mechanisms for AI risk.
In terms of adding new threat models to the categorization, the main one that comes to mind is Deep Deceptiveness [LW · GW] (let's call it Soares2), which I would summarize as "non-deceptiveness is anti-natural / hard to disentangle from general capabilities". I would probably put this under "SG MAPS", assuming an irreducible kind of specification gaming where it's very difficult (or impossible) to distinguish deceptiveness from non-deceptiveness (including through feedback on the model's reasoning process). Though it could also be GMG, where the "non-deceptiveness" concept is incoherent and thus very difficult to generalize well.
comment by Jemal Young (ghostwheel) · 2022-11-10T01:04:32.809Z · LW(p) · GW(p)
Not many more fundamental innovations needed for AGI.
Can you say more about this? Does the DeepMind AGI safety team have ideas about what's blocking AGI that could be addressed by not many more fundamental innovations?
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2022-11-10T10:06:59.100Z · LW(p) · GW(p)
If we did have such ideas we would not be likely to write about them publicly.
(That being said, I roughly believe "if you keep scaling things with some engineering work to make sure everything still works, the models will keep getting better, and this would eventually get you to transformative AI if you can keep the scaling going".)