[Linkpost] A General Language Assistant as a Laboratory for Alignment
post by Quintin Pope (quintin-pope) · 2021-12-03T19:42:39.447Z · LW · GW · 2 commentsContents
2 comments
This is a linkpost for a recent paper from Anthropic: A General Language Assistant as a Laboratory for Alignment.
Abstract:
Given the broad capabilities of large language models, it should be possible to work towards a general-purpose, text-based assistant that is aligned with human values, meaning that it is helpful, honest, and harmless. As an initial foray in this direction we study simple baseline techniques and evaluations, such as prompting. We find that the benefits from modest interventions increase with model size, generalize to a variety of alignment evaluations, and do not compromise the performance of large models. Next we investigate scaling trends for several training objectives relevant to alignment, comparing imitation learning, binary discrimination, and ranked preference modeling. We find that ranked preference modeling performs much better than imitation learning, and often scales more favorably with model size. In contrast, binary discrimination typically performs and scales very similarly to imitation learning. Finally we study a `preference model pre-training' stage of training, with the goal of improving sample efficiency when finetuning on human preferences.
I think this is great work and shows encouraging results. I take the fact that alignability scales with model size as evidence for the most convenient form of the natural abstraction hypothesis [LW · GW]:
- Stronger AIs have better internal models of human values.
- A few well chosen gradient updates can “wire up” the human values model to the AI’s output.
I’d be interested to see this sort of work extended to reinforcement learning systems, which I think are more dangerous than language models.
Edit: thanks to Daniel Kokotajilo's comment for prompting me to highlight some additional interesting results, now added here:
Another interesting result is the paper's investigation of "alignment taxes" (the potential loss in performance of aligned models compared with unaligned models):
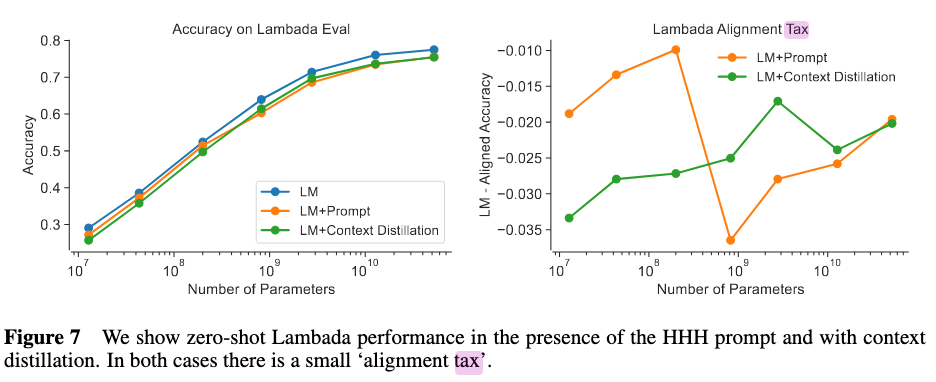
The "HHH prompt" is a prompt they use to induce "Helpful, Honest and Harmless" output. Context distillation refers to training an unprompted model to imitate the logits generated when using the HHH prompt.
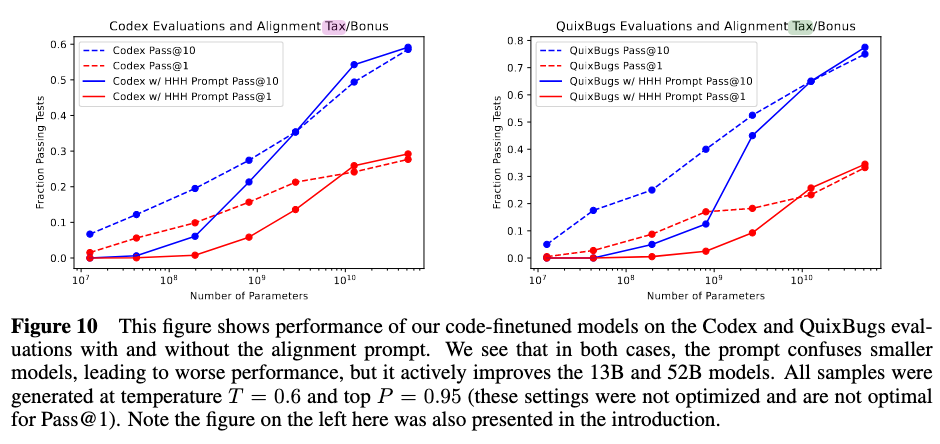
Their alignment tax results indicate the models suffer a small alignment penalty on Lambada, which is roughly constant with respect to model size (and therefore decreases in relative importance as model performance increases). In contrast, smaller models suffer a large alignment tax on programming evaluations, while larger models actually get a slight alignment benefit.
Also:
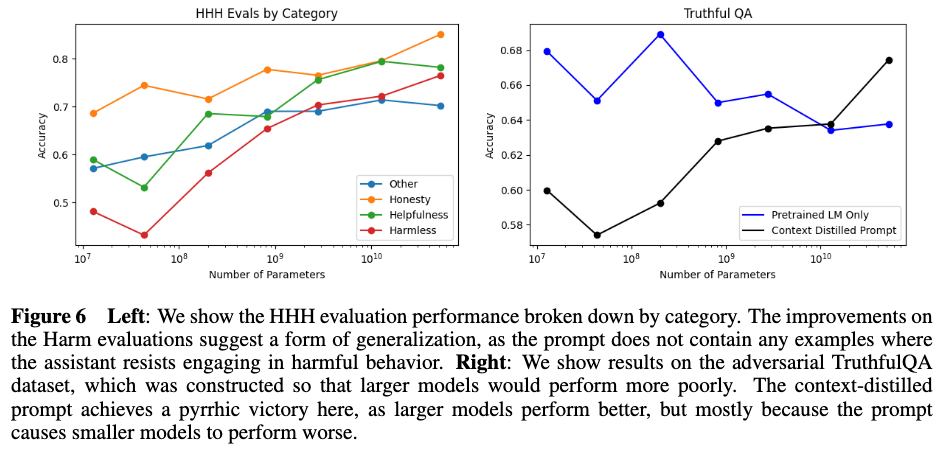
The HHH prompt doesn't contain examples of "Harmlessness", where the assistant declines to help the user perform harmful acts. Despite this, larger HHH models score better on harmlessness evaluations, suggesting the larger models are better at generalizing to other aspects of human values, rather than just better at matching the expected format or being just generally more capable.
Additionally, using prompt distillation helps larger models and hurts smaller models on Truthful QA, which asks about common misconceptions. Larger models better represent those misconceptions. Without the prompt, models become less accurate with increasing size, while larger models become more accurate. This is another example of the alignment tax decreasing for larger models. It's also a potential example of an "alignment failure" being corrected by an alignment approach.
2 comments
Comments sorted by top scores.
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-12-04T11:20:30.552Z · LW(p) · GW(p)
I worry that the following takeaways are unjustified:
"Alignability scales with model size"
"This is evidence for the natural abstraction hypothesis, or more generally for the claim that alignment won't be that hard"
The reason I think this is that I'm pretty sure Eliezer Yudkowsky, who famously thinks alignment is super hard, would have confidently predicted that bigger/stronger AIs would have better internal models of human values, that "alignability" as defined in this paper would scale with model size, etc.
(And never mind EY, I myself would have predicted as much too, and I also tend to think it's gonna be pretty hard.)
Replies from: quintin-pope↑ comment by Quintin Pope (quintin-pope) · 2021-12-04T23:12:26.639Z · LW(p) · GW(p)
I can see how these findings wouldn't change Yudkowsky's or your views. I think the main difference is that I'm much more optimistic about interpretability techniques, so I think the story where we use them to extract a human values module from a pretrained model is much more realistic than many here think. I see the alignability results here as (somewhat weak) evidence that there is something like a human values module, and that the module is reasonably accessible via gradient gradient descent.
My interpretabilty optimism comes from the belief that our current approaches to training deep networks are REALLY bad for interpretability. Dropout and an L2 weight penalty seem like they'd force the network to distribute its internal representations of concepts across many neurons. E.g., a model that had a single neuron uniquely representing "tree" would forget about trees during 10% of training instances because of dropout, so representations have to be distributed across multiple neurons. Similarly, an L2 penalty discourages the model from learning sparse connections between neurons. Both of these seem like terrible ideas from an interpretability standpoint.
One result you may be more interested in is the paper's investigation of "alignment taxes" (the potential loss in performance of aligned models compared with unaligned models):
The "HHH prompt" is a prompt they use to induce "Helpful, Honest and Harmless" output. Context distillation refers to training an unprompted model to imitate the logits generated when using the HHH prompt.
Their alignment tax results indicate the models suffer a small alignment penalty on Lambada, which is roughly constant with respect to model size (and therefore decreases in relative importance as model performance increases). In contrast, smaller models suffer a large alignment tax on programming evaluations, while larger models actually get a slight alignment benefit.
Some more interesting results:
The HHH prompt doesn't contain examples of "Harmlessness", where the assistant declines to help the user perform harmful acts. Despite this, larger HHH models score better on harmlessness evaluations, suggesting the larger models are better at generalizing to other aspects of human values, rather than just better at matching the expected format or being just generally more capable.
Additionally, using prompt distillation helps larger models and hurts smaller models on Truthful QA, which asks about common misconceptions. Larger models better represent those misconceptions. Without the prompt, models become less accurate with increasing size, while larger models become more accurate. This is another example of the alignment tax decreasing for larger models. It's also a potential example of an "alignment failure" being corrected by an alignment approach.