FAQ: What the heck is goal agnosticism?
post by porby · 2023-10-08T19:11:50.269Z · LW · GW · 38 commentsContents
Introductory Questions Q1: Why should anyone care about goal agnosticism? Q2: What do you mean by goal agnosticism? Q3: By "goal agnostic" do you mean that it's an optimizer that can have its goal swapped arbitrarily? Q4: Is this related to simulators? Q5: Is goal agnosticism binary? Q6: Can you give an example of a goal agnostic system? Q7: Um, is that the sales pitch? Q8: Would you care to give an example of a useful goal agnostic system? Questions Asked With A Furrowed Brow Q9: Wait, are you saying part of the value of goal agnostic systems is... when they're made very broad, any particular behavior is rare? Where's the usefulness come from? Q10: Aren't you just giving "goal agnosticism" the credit for predictors' capabilities? What's an example of something that's directly downstream of goal agnosticism alone? Q11: Assuming that you have a goal agnostic system, why don't you expect people to immediately shove it into an arbitrarily goal-oriented system so that it can achieve goals more effectively? Q12: Are you suggesting users just choose to use a goal agnostic system as a satisficer or quantilizer instead of a maximizer? Don't those have their own problems? Q13: How do you "choose not to use it as a strict optimizer?" Isn't that just assuming away problems in corrigibility? Q14: Could a goal agnostic system, in principle, be used to beat humans at chess? Q15: Wait, beating a human at chess implies some sort of goal that concerns the board state, doesn't it? Q16: ... Wh... why do you care about the fact that the underlying system is "goal agnostic," then? The endpoint is the same! Q17: That still doesn't seem to buy anything! Given the same magic hypercomputer, couldn't you get the goal agnostic ideal predictor to predict the same world-eating sequences as the world-eating chess AI? Q18: Hold on, suppose I train a predictor with a "goal agnostic architecture" on the input-output mappings from another goal agnostic predictor's outputs that have been conditioned for strong chess moves. Is my system still goal agnostic? Q19: This still seems like a meaningless distinction! Who cares if it doesn't have magic internally motivated tendencies if the external consequences are identical to a goal-oriented agent? Questions Involving Extremes Q20: Okay, but for avoiding extinction, we really don't care about the enormous number of random strings a goal agnostic autoregressive text generator could produce. We need useful (and probably scary) capability in a complex world. What work is goal agnosticism doing there? Q21: It sure sounds like you're about to take a dependency on "and as we scale capability into superintelligence, everything will remain hunky-dory so we can do the same thing to save the world," which I'm going to have additional questions about. Q22: As anticipated, I now have additional questions. For starters, what makes you think that a goal agnostic system won't snap into a more coherent goal-oriented shape when subjected to extreme optimization pressures? Q23: Even if we assume that's true, simulacra do not share the same property. Why do you think agents produced by the execution of goal agnostic systems will not cohere into a dangerous shape? Q24: Assuming that we have a strong goal agnostic predictor, why do you think that we can aim the extreme capability in a direction we want with sufficient precision? Q25: Suppose you train a predictor to perfectly predict what a specific human would do, for all conditions. Describing humans as "goal agnostic" would be dumb; do you think that the predictor would be goal agnostic? Q26: You could build a maximally conditional utility function to describe any agent's behavior without regard for external world states, including agents which have far simpler descriptions. Why do you think SGD would drive a neural network to learn values that fit that kind of utility function in a... Q27: You're describing why a predictor that learns the thing you think it would learn would meet your definition of goal agnostic, but why do you think it would learn that? Q28: If a predictor makes reflective predictions—predictions about things the predictor's predictions will influence—doesn't that give it degrees of freedom that are unconstrained? Q29: What if a subagent gains capability sufficient to take over predictive tasks for large chunks of the distribution while secretly working towards goals that it knows to hide because it's aware of the training context? Q30: Okay, even if a deceptive mesaoptimizer is unlikely, couldn't a predictor still express unconditional goals outside of the distribution constrained during training? Q31: Do you think that predictive loss automatically gives you robust and useful goal agnosticism? Q32: Suppose you've got a goal agnostic system, but someone asks it for a really good recipe. In an effort to give the best recipe, it outputs a script for the user to run that corresponds to a strong successor agent that doesn't have any of the same properties. What has goal agnosticism given you h... Q33: Isn't goal agnosticism pretty fragile? Aren't there strong pressures pushing anything tool-like towards more direct agency? Q34: Using a particular loss function does not guarantee that a neural network will learn internal values matching that loss; how do you rule out something like learning a desire to predict well along with the implied instrumental behavior? Q35: When you say predictive loss is "constraining," are you suggesting that goal agnosticism is limiting capability? A rock is pretty constrained too, but it won't help avoid catastrophe! Miscellaneous And Conclusory Questions Q36: Do you think the current forms of fine tuning, like RL(H/AI)F, maintain goal agnosticism? Q?37: I think that you overestimate the degree to which the training distribution covers necessary concepts like less "hard" optimization in a way that allows us to aim expressed preferences at them crisply, and that the likely error-relative-to-intent for accessible conditioning techniques is going... Q38: Suppose you've got a strong goal agnostic system design, but a bunch of competing or bad actors get access to it. How does goal agnosticism stop misuse? None 38 comments
Thanks to George Wang, Liron Shapira, Eliezer[1], and probably dozens of other people at Manifest and earlier conferences that I can't immediately recall the names of for listening to me attempt to explain this in different ways and for related chit chat.
I've gotten better at pitching these ideas over the last few conferences, but I think some of the explanations I've provided didn't land nearly as well as they could have. It's sometimes hard to come up with great explanations on the spot, so this FAQ/dialogue is an attempt to both communicate the ideas better and to prepare a bunch of explanatory contingencies.
The content and tone of these questions shouldn't be taken to represent any real person I talked to.[2]
This post is very roughly organized into four sections:
- A series of questions introducing what I mean by goal agnosticism, [LW · GW]
- Addressing general doubts about goal agnosticism and diving into what it is and isn't in more detail, [LW · GW]
- Addressing concerns about goal agnosticism as we reach extreme optimization pressures and capabilities, and [LW · GW]
- A conclusion of miscellaneous questions/notes and a discussion of objections that I currently lack nonfuzzy answers for. [LW · GW]
The questions and answers flow into each other, but it should be safe to jump around.
Introductory Questions
Q1: Why should anyone care about goal agnosticism?
Goal agnostic systems enable a promising path for incrementally extracting extreme capability from AI in a way that doesn't take a dependency on successfully pointing a strong optimizer towards human-compatible values on the first try. An intuitive form of corrigibility seems accessible.
I view goal agnostic systems as a more forgiving foundation from which we can easily build other agents. The capabilities of the system, particularly in predictive models as are used in LLMs, can directly help us aim those same capabilities. The problem is transformed into an iterative, bottom-up process, rather than a one shot top-down process.
If we can verify, maintain, and make productive use of goal agnostic systems, we have a decent shot at avoiding the convergent pitfalls implied by strong goal-directed optimizers.
As a bonus, there are some reasons to think that goal agnosticism and its productive use is an attractor in design space, at least for a notable subset of the tech tree.
Q2: What do you mean by goal agnosticism?
I have been using the phrase "goal agnostic" to describe any system where:
- A random sampling of its behavior has negligible[3] probability of being a dangerously capable optimizing process with incorrigible preferences over external world states.[4]
- The system cannot be described as having unconditional preferences about external world states. It is best described[5] by a VNM-coherent agent whose utility function [LW · GW] includes positive terms only for the conditional mapping of input to output.
This means the system has no default[6] incentive to act on the world; the system's "values" are most directly concerned with the system's output which the system has absolute control over.
A goal agnostic system will not exhibit internally[7] motivated instrumental behavior over external world states, because that instrumental behavior would be instrumental with respect to some goal that the system simply does not have.
I've previously referred to one such type of system as an "ideal predictor [LW · GW]," and also described them as having "minimal instrumentality [LW · GW]."
For reference, I frequently speak of "conditioning" a goal agnostic system in this post. That's because a subset of predictive models are the currently dominant architectural candidates for goal agnostic systems.
Q3: By "goal agnostic" do you mean that it's an optimizer that can have its goal swapped arbitrarily?
Nope![8]
The kind of goal agnostic system I'm talking about is not directly running an optimizer towards any goal that concerns external world states.
Q4: Is this related to simulators [LW · GW]?
Yes, closely!
Simulators can be examples of goal agnostic systems.[9] Inputs are mapped to outputs without preference for world states beyond the mapping process; the mapping is how simulation evolves.
Q5: Is goal agnosticism binary?
No; the requirement that a goal agnostic system can't be described as having unconditional preferences about external world states is binary, but:
- There are probably utility functions that unconditionally regard external world states which are still close enough to the goal agnostic ideal (or are simply aligned) such that they are still useful in similar ways.
- The definition requires that the probability of random behavior samples corresponding to world-concerned maximizers is "negligible," and negligible is not a single number.
- The definition as stated does not put a requirement on how "hard" it needs to be to specify a dangerous agent as a subset of the goal agnostic system's behavior. It just says that if you roll the dice in a fully blind way, the chances are extremely low. Systems will vary in how easy they make it to specify bad agents. I'd expect that you could build a system obeying the "goal agnostic" definition that would be extremely fragile and dangerous to use, but I do not foresee there being a reason to do so.[10]
Intuitively, an agent whose entire utility function is to unconditionally maximize squiggles is obviously not goal agnostic, and there are things between that and a simulator.
Q6: Can you give an example of a goal agnostic system?
Sure! Let's first start with a weak version that doesn't obey the "negligible probability" part of the definition.
Imagine you've got two systems: InertBot, and DevilBot. InertBot does nothing, while DevilBot tries to output sequences leading to maximally bad outcomes.
InertBot's utility function is simple. It doesn't care about anything out in the world; it does nothing. In isolation, it is goal agnostic in an uninteresting way.
DevilBot is far more complicated and is emphatically not goal agnostic in isolation. It has all kinds of preferences about world states that you would not like.
Now, combine these two bots into a single system with a switch on it. If it's flipped to the left, InertBot is active; to the right, DevilBot.[11]
Viewing the combined system as an agent, it has no unconditional preferences over external world states. It is technically goal agnostic by the weakened definition: turning it on does not necessarily imply that you've instantiated an agent with preferences about external world states.
Q7: Um, is that the sales pitch?
Not yet! This is a deliberate worst-ish case meant to motivate the stronger definition.
Goal agnostic systems are not intrinsically and necessarily safe. If you flip the switch to DevilBot, well, you've got DevilBot. It probably won't let you switch it back.
Q8: Would you care to give an example of a useful goal agnostic system?
Sure!
Instead of a switch that lets you choose between useless and terrible, consider large language models used in autoregressive text generation. These systems can be thought of as implementing an approximation of Bayesian inference across extremely wide and varied distributions and conditions.
When tasked with playing the role of a character in a dialogue, their output distribution is conditioned down to that of the character, and the conversational context further narrows the distribution to the space relevant to the next token. The greater system is not well-described as the character; it remains the process of refining and narrowing distributions.
That process operates primarily as a mapping from inputs to outputs on a stepwise basis. The process of narrowing has no reason to care about external world states even if it can output sequences consistent with simulated agents having preferences over external world states.
In principle, you can think of the conditions provided to an LLM as a switch and the training distribution for a large language model could include sufficient data to specify a DevilBot, but the probability of landing on a DevilBot on a random sequence is extremely low.[12] It would take effort to find a configuration of the "switch" that corresponds to a DevilBot.
In other words, the breadth of a large language model gives it a near-guarantee of not behaving like a DevilBot by default, because there are so many possible ways for it to be. It's like the switch has 10^500 positions with only one corresponding to DevilBot.
Questions Asked With A Furrowed Brow
Q9: Wait, are you saying part of the value of goal agnostic systems is... when they're made very broad, any particular behavior is rare? Where's the usefulness come from?
Continuing with the example of large language models: the "switch" is composed of all the conditions contained within the context window[13], and it's just not that hard to find a configuration of that switch which is helpful.
Consider what happens if you feed a pretrained model that lacks the "helpful assistant" tuning a prompt like:
Alice: Yeah, I'm not sure what to do. My professor said my laser gun wasn't suitable for the Collegiate Science Fair.
Bob: That sucks! I've heard bad things about him. He's got, you know, ideas about laser guns, and where they belong.
Alice:
What are some things that come next? Some additional context about the laser gun situation, maybe? That seems more likely than "⟧↩( *^-^)ρ(^0^* )" or a conversation in which Bob tries and fails to conceal the fact that he's a prairie dog.
There is a nonzero probability of those other sequences being produced[14], but it would probably be something significantly more "normal" in some sense that we can't define in a narrow way. Even with that little context, the number of implicit conditions is enormous.
Flipping the perspective around: in this example, our goal agnostic system is a predictor which is trying to extract as much information as possible from its context to inform its next prediction. In training, it is directly incentivized to squeeze bits from anything it can; it is an optimizer trying to implement Bayesian inference.
As you turn up the strength of that optimizer[15], it gets better and better at extracting information about predictive conditions from its context. Developing a working model of human conversations, ethics, and pretty much everything else represented or implied by the training distribution is instrumentally useful and (empirically) accessible to SGD.
A strong predictor needs to be able to just get what you mean. That's at the core of its ability to predict anything in a similar region of the distribution.
And it's that ability that makes it remarkably easy to aim, too.
Q10: Aren't you just giving "goal agnosticism" the credit for predictors' capabilities? What's an example of something that's directly downstream of goal agnosticism alone?
A bit! Predictors are the strongest candidates for useful goal agnostic systems at the moment. The reason why I'm comfortable bringing their capabilities into a discussion primarily about goal agnosticism is that their useful capability is allowed by goal agnosticism, and goal agnosticism is often implied by the task of prediction over a broad distribution.
I think it's still worth talking about the property of goal agnosticism as a separate thing from predictors since it is technically more general, but it wouldn't surprise me if predictors remain the dominant path to it.
As for an example, I'd point to implementation obfuscation. So long as the training of a goal agnostic model never directly involves the internal representation[16], a goal agnostic model has no motivation to conceal its inner workings. Obfuscating its activations would be a form of instrumental behavior towards a goal that it doesn't have.
Even if you condition a predictor into playing a deceptive role at inference time, so long as that's not fed back into the weights, the machinery that yields that deceptive role remains as transparent as a chess move predictor.[17]
Compare this to an adversarial and situationally aware system. Making its activations harder to perceive as adversarial is instrumentally convergent. In other words, maintaining goal agnosticism into the superhuman regime gives interpretability tools a chance to work.
Q11: Assuming that you have a goal agnostic system, why don't you expect people to immediately shove it into an arbitrarily goal-oriented system so that it can achieve goals more effectively?
Stronger optimization for a stated goal is not necessarily good in the user's eyes. The user must have a reasonable expectation that the greater optimization power will actually be aimed in the right direction, or in other words, that their specified optimization target actually covers what they care about in space under optimization.
Optimizers working in complex environments that are strong enough to exploit those environments will tend do things which are hard to predict.
Here's a made-up graph to illustrate this:[18]
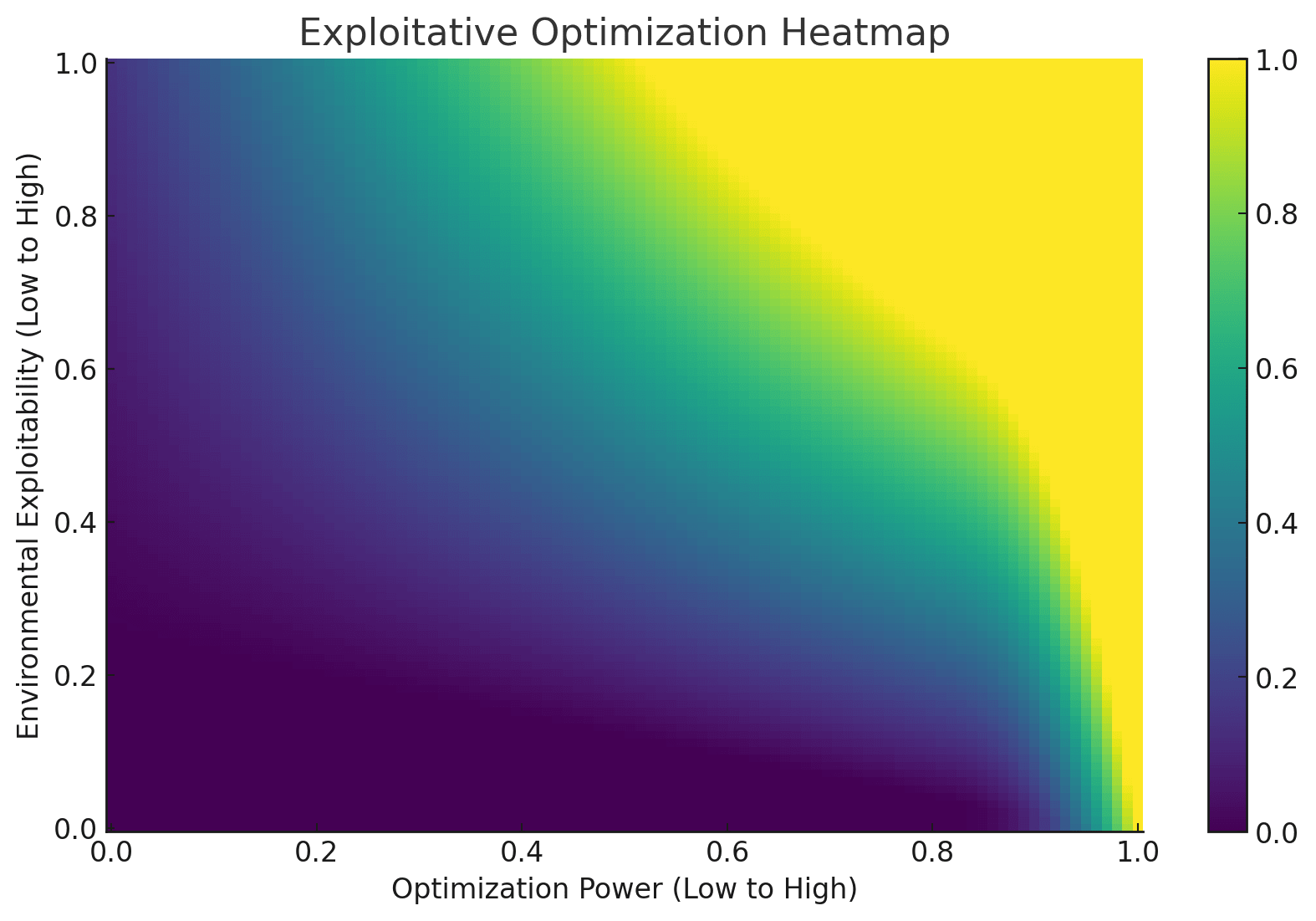
This is not a graph of reward, but rather a graph of how much the optimizer diverged from the thing the user cared about in favor of focusing on what was actually specified by exploiting paths that the user did not constrain properly in their manual goal specification.
The stronger the optimizer is, or the more exploitable and complex the environment is, the more the optimizer has done something weird (the yellow regions) by overoptimizing the specified target instead of the thing the user cared about.
Note that darker purple regions do not necessarily correspond to the optimizer doing what the user wants, just that the optimizer did not actively exploit something to do something the user didn't want. It's very possible to run an optimizer at different strengths and different levels of environmental exploitability without ever getting the behavior you actually want.
This isn't something that happens solely in the superintelligent regime. It's not hard to concretely demonstrate reward hacking. Reward hacking is usually framed as a safety issue, but it's also a failure of usefulness.
In other words, someone trying to turn a goal agnostic model into a too-narrowly focused maximizer should often expect it to do something useless or counterproductive unless they have very strong reasons to believe otherwise, and they can immediately observe that the results are just worse than doing something else.
Strong maximizers are only highly effective at achieving the goals they have. When they're too hard to use, they are not convergently useful because the user can't specify the goal properly, and that fact is readily apparent even in nonlethal cases.[19]
Q12: Are you suggesting users just choose to use a goal agnostic system as a satisficer or quantilizer instead of a maximizer? Don't those have their own problems?
While a general goal agnostic system could be used as a maximizer, satisficer, or quantilizer in principle, I'm explicitly not advocating for any of these given a poorly specified optimization target.
Satisficers are more obviously concerning [LW · GW] than quantilizers, but even a quantilizer operating over a humanlike distribution of actions can be pretty spooky if you mis-specify the optimization target.[20]
Instead, stop trying and failing to specify runaway optimization targets manually. If you find yourself needing to do that for anything beyond braindead simplicity, it just ain't gonna work.
Take your foot off the gas and try leveraging the system itself to fill in the gaps in your specification, and then choose not to use it as a strict optimizer so that you can actually respond to mistakes.
Q13: How do you "choose not to use it as a strict optimizer?" Isn't that just assuming away problems in corrigibility?
Nope!
A reasonably designed goal agnostic system doesn't act as an optimizer over external world states by default. You could make a goal agnostic system behave incorrigibly, but that would involve a series of bad decisions.
The difficulty in corrigibility arises from maximization over external world states: finding a crisp utility function over those states maximized by an agent that will still behave corrigibly is hard.
If you start with an agent with strong capabilities and doesn't maximize over external world states, you've got more options [LW · GW].
Q14: Could a goal agnostic system, in principle, be used to beat humans at chess?
Yes!
Q15: Wait, beating a human at chess implies some sort of goal that concerns the board state, doesn't it?
Yes!
This is another reason why I'm not happy with "goal agnostic" as a term.
This kind of goal agnostic system can, in principle, reproduce behavior of other goal-oriented agents, including a strong chess-playing agent that acts consistently with having preferences about the board state.
The obvious example is in predictors, where it's relatively easy to condition for higher skill levels.
Note that the act of conditioning for greater chess ability does not turn the model into anything like a weak chess maximizer; the condition does not strip the greater context of the training distribution. The conditioned agent—the simulacrum—can be usefully described as having some form of preferences over the board state[21], but the simulacrum isn't absurdly monomaniacal because that was not implied by its training and conditioning.
Q16: ... Wh... why do you care about the fact that the underlying system is "goal agnostic," then? The endpoint is the same!
It is possible for the endpoint to be the same in some cases, yes, but the endpoints are not required to be the same.
The source of capability matters. Two black boxes that each achieve one specific task in the same externally visible way may behave in wildly different ways in other areas of the input distribution.
A goal agnostic ideal predictor could be used to predict sequences corresponding to superhuman chess play. For a reasonably strong predictor trained across a wide dataset and conditioned to play at a superhuman Elo, the default outcome is for it to win at chess against humans.
A hypercomputer-empowered system which brute forces the sequence of actions which minimizes the chance of losing at chess to a human with no other considerations will also not lose to a human at chess... among several other incidental effects.
Q17: That still doesn't seem to buy anything! Given the same magic hypercomputer, couldn't you get the goal agnostic ideal predictor to predict the same world-eating sequences as the world-eating chess AI?
Yes!
The key difference is that, in the case of a goal agnostic system, you can make it do bad things, rather than the system drives towards bad things by default.
Goal agnostic systems and optimizers acting on world states start at opposite ends of a spectrum:
On one end, it requires nonzero effort to make a goal agnostic system do anything. Give an ideal predictor in the form of an autoregressive text generator an empty prompt and it'll generate some string pulled from the nether distribution.
On the other end, the moment you start up a hypercomputer-empowered optimizer with roughly any goal, you immediately have problems. You either need a perfect goal specification or perfect security to bound its action space, and you will have neither.
Q18: Hold on, suppose I train a predictor with a "goal agnostic architecture" on the input-output mappings from another goal agnostic predictor's outputs that have been conditioned for strong chess moves. Is my system still goal agnostic?
Maybe? Probably? Depends on the context.
If the chess-conditioned system is trained on an extremely wide distribution where only a subset of inputs have anything to do with chess, and those non-chess inputs have reasonable continuations (e.g. borrowing the original model's unconditioned output distributions or outputting a null token), then the chess-conditioned system can still be reasonably described as goal agnostic.
In that case, the function that the newly trained predictor learned is just a conditional subset of the original predictor's mapping, no different than including a prompt or metatoken [LW · GW] to elicit the behavior in the original.
If there are no constraints placed on completions outside of chess, there are far more degrees of freedom available for unconditional preferences. I still wouldn't expect it to become a weird chess maximizer given the hypothetical—it's imitating, not maximizing.
Q19: This still seems like a meaningless distinction! Who cares if it doesn't have magic internally motivated tendencies if the external consequences are identical to a goal-oriented agent?
My argument is that the external consequences of a goal-oriented system and a goal agnostic system will not be identical unless the goal agnostic system is conditioned to match the behavior of the goal-oriented system.
If you train a strong predictor to predict only doombringing sequences, doom will be brought.
Equivalently, if you condition a strong predictor to predict only doombringing sequences, doom will be brought.
So don't do that. Do anything else instead.
In the space of possible sequences that can be produced by a strong goal agnostic system, sequences corresponding to hard maximization for poorly specified targets are not particularly dominant nor convergent unless you've started from a weird distribution or applied some weird conditions.
A key feature of goal agnostic architectures is that you have a source of potentially extreme capability that you can aim in directions that aren't hard maximization for poorly specified targets.
Questions Involving Extremes
Q20: Okay, but for avoiding extinction, we really don't care about the enormous number of random strings a goal agnostic autoregressive text generator could produce. We need useful (and probably scary) capability in a complex world. What work is goal agnosticism doing there?
A strong and general goal agnostic system can have a deep grasp of implicit requirements and can provide a useful interface to those capabilities.
GPT4 is already decent at navigating incredibly complex human social situations and dilemmas. How would you go about specifying an optimization target for a strong optimizer to accomplish the same behavior? Clearly, there exists some target that would suffice, but could you find it?
Well, I'm pretty sure I couldn't, and yet GPT4 learned a fuzzy mess of interacting human values that it can take into account when answering questions. For example:

It goes on like this for a while. It's all pretty reasonable advice. It didn't involve cherry picking, but I don't even need to say that—this isn't surprising behavior for ChatGPT4.
The reason I include this is to encourage thinking about all the things the system synthesizes to create a response of this level of consistency and relevance.
This is already a level of useful capability that seems nigh impossible to safely extract from a strong optimizer with effectively any target we could manually specify, because we don't know how to manually specify such targets.
A goal agnostic system[22] that isn't directly running an optimizing process over world states lets you leverage its own capability to infer the gaps in your specification and lets you request the desired strength of optimization over world states.
And we already have empirical (productized!) evidence that these indirect specifications work well enough for random nontechnical humans to use the system productively for complex tasks in the world.
And—
Q21: It sure sounds like you're about to take a dependency on "and as we scale capability into superintelligence, everything will remain hunky-dory so we can do the same thing to save the world," which I'm going to have additional questions about.
That's understandable!
Since you brought it up, I'll go ahead and bite a version of this bullet:
I suspect (~70%) that there are designs for roughly goal agnostic systems from which we can elicit strongly superhuman capability in a useful way, where "useful" means we can get it to do something close enough to what we want[23] without it immediately driving off a cliff, and that the industry will naturally tend toward using such systems because they are more useful both incrementally and in the long run.
Q22: As anticipated, I now have additional questions. For starters, what makes you think that a goal agnostic system won't snap into a more coherent goal-oriented shape when subjected to extreme optimization pressures?
I think this question often arises from the misleading nature of the phrase "goal agnostic."
As a reminder, when I say "goal agnostic," I'm referring to the lack of unconditional preferences about external world states. In the limit of training, the system could still be described as a VNM-coherent agent with a utility function [LW · GW].
If you were to incorrectly assume the agent has preferences over external world states, you may think that the agent is behaving incoherently when it outputs inconsistent behavior with respect to world states under different conditions.
But the agent isn't actually stepping on its own toes. It is fully and maximally satisfying its values; those values just aren't about external world states. By its own lights, there is no greater coherence [LW · GW] for it to aspire to.
Of course, the fact that there exists a coherent utility function for the system to aspire to does not mean that training dynamics necessarily lead to it, and an incoherent agent is not required to cohere according to any particular process by coherence theorems alone. That said, I think there is a strong reason for SGD to overwhelmingly favor conditionalization as a path to coherence [LW · GW] in the dominant kinds of predictive training.[24]
Q23: Even if we assume that's true, simulacra do not share the same property. Why do you think agents produced by the execution of goal agnostic systems will not cohere into a dangerous shape?
If you apply strong optimization pressures without an exceedingly high level of care at the level of the simulacra, yeah, that will probably not end well.
The convergence properties that I expect will keep a predictive model close to the machinery of prediction do not apply to simulacra with arbitrary goals.
Fortunately, the sweet spot of usability, even for strong models, isn't going to be at that extreme of optimization on the simulacrum level. There's not a capability-driven pressure to go all the way without knowing how to use it from any reasonable human or corporate perspective.[25]
Q24: Assuming that we have a strong goal agnostic predictor, why do you think that we can aim the extreme capability in a direction we want with sufficient precision?
I think isolated attempts to aim the system are likely going to end up very slightly off-target. I think moving to better-than-RLHF tuning will help with this, but even then, I would expect slight quirks to slip through.
When embedded in a sufficiently strong optimizer, slight quirks are death.
So, my first reason for optimism is that we can extract capability from these systems without pushing them to be that kind of optimizer.
With the elbowroom opened by not running a maximizer as hard as we can, we can flip the nature of the problem: from any failure yielding explosion, to requiring total failure to yield explosion.
Without that optimizer in the way, some naive strategies can actually help. Statistical safeguards like "have a bunch of independent automatic watchdogs keeping on eye on outputs to make sure they're on the rails; if any watchdog alerts, halt" aren't doomed by default because they're not trying to keep an adversarial superintelligence in a box. The problem they're addressing, by virtue of not involving adversarial optimization, is far more tractable.
Much more interesting techniques built the back of interpretability tools could carry these safeguards well into the superhuman regime, so long as we don't oops an adversarial optimizer into being.
Q25: Suppose you train a predictor to perfectly predict what a specific human would do, for all conditions. Describing humans as "goal agnostic" would be dumb; do you think that the predictor would be goal agnostic?
This is a more extreme version of the earlier example of training a predictor to represent a conditioned subset of another predictor's mappings in chess, so: no.
Humans can be described by utility functions with unconditional preferences over external world states.
When you run a system with a utility function best represented by preferences over external world states, you're going to get consequences matching that description.
Again, if you train a goal agnostic architecture only on things that kill everyone, or condition it down to the same distribution, you've goofed and goal agnosticism does not stop you from dying.
Q26: You could build a maximally conditional utility function to describe any agent's behavior without regard for external world states, including agents which have far simpler descriptions. Why do you think SGD would drive a neural network to learn values that fit that kind of utility function in a nontrivial way?
You're correct! The mere fact that we can describe an agent with a utility function lacking terms for external world states does not mean the agent is goal agnostic. It goes in the opposite direction: if you can't describe an agent with unconditional preferences over external world states, then it's (at least weakly) goal agnostic.
As for why I expect it to be found during SGD-driven optimization, I'll use predictors as an example again.
If you train a predictor to perfectly predict a specific chess-playing agent, the predictor's outputs and the agent's outputs could be fit to the same utility function—one that probably isn't always strictly goal agnostic.
Now suppose you instead train it to predict a chess agent and a go agent. Now suppose it's all games. Now, instead of single agents for each game, train it on a wide distribution of skill levels in every game. Now add all non-game human-generated content. Now add arbitrary programs, data logs from physical experiments, videos, and so on, all at once in a single system.
When there's only one agent, or one task, the system's utility function can more easily include unconditional preferences over external world states.
When there's two different agents, the intersection of unconditional preferences over external world states shrinks. The more agents being predicted, the smaller the space of possible shared preferences.[26]
With programs? Sure, there's some programs that could be described as having preferences over external world states (a humanlike program, for example), but the space of programs is vast. Even tiny subsets of it are virtually guaranteed to have no shared preferences, let alone shared preferences over external world states. Toss in all the other tasks/data too, and the "no unconditional preferences over external world states" is even more trivially guaranteed.
Further, while the enormous training set we've specified may include enough information to imply dangerously capable maximizers over external world states[27], there's so much data that such an agent would be a negligible fraction of possible behaviors.
Q27: You're describing why a predictor that learns the thing you think it would learn would meet your definition of goal agnostic, but why do you think it would learn that?
It's necessary for conditional prediction to work.
Take the trivial case of a predictor trained on one regular chess agent and one antichess agent and suppose they both can be described as having preferences over the board state.
If the antichess agent's preferences about the board state leak into a regular chess game, the predictor will make a bad prediction and the antichess agent's leaked preferences will get nudged down. In another training example, the predictor correctly predicts a antichess move in an antichess game, reinforcing the antichess subagent's preferences under the appropriate conditions.
So:
- It's pretty easy for SGD to find incremental changes to reduce predictive loss in this context.
- Reducing predictive loss necessarily pushes each subagent's values to become conditional.
As the training distribution and capability of the predictor expands, the number and subtlety of the conditions the model can distinguish increases.
During training with a broad distribution, the number of ways in which newly developing unconditional preferences could negatively affect loss is enormous. The probability that unconditional preferences can arise incrementally within the training distribution is effectively zero for the same reason that the values intersection of a trillion wildly distinct agents is zero.
Q28: If a predictor makes reflective predictions—predictions about things the predictor's predictions will influence—doesn't that give it degrees of freedom that are unconstrained?
In principle, yes! If there's nothing in the training or conditions that narrows down how reflective predictions will behave, a prediction of its own prediction is free to vary.
However, having no implied conditions about what a reflective prediction should look like is unlikely.[28] As mentioned before, the amount of information usable as conditions extracted from even fairly small prompts is large. For any particular prompt, the probability that the best set of conditions for a reflective prediction is empty is negligible. If you put in the work, you should be able to prompt the model into giving answers which get closer to it, but that's not the default.
In other words, an adversarial model might try to play the game of "nyah nyah I'm technically obeying the constraints of my training distribution for being a good predictor in context," but differently conditioned predictors will tend to fall into different reflective predictions, and uncertainty/imperfect information can change the distribution. In other words, in order for a model to seek out malign reflective predictions, it has to be bent far enough in that direction that it is a consistent choice as a reflective prediction.[29]
Q29: What if a subagent gains capability sufficient to take over predictive tasks for large chunks of the distribution while secretly working towards goals that it knows to hide because it's aware of the training context?
There exists a configuration for a neural network that you could describe like this, yes. Borrowing the earlier question: why do you think it would learn that?
This isn't a nyehh-gotcha rebuttal. It seems genuinely hard to pull this off [LW · GW]. Sure, if you can just assume a superintelligence, I'm sure it could contrive some sort of setup where you could see this happen, but there's a lot of pressure against this as far as I can tell.
Any incremental development of inappropriate goals without sufficient capability to be aware of the training context will be slapped down.
Even at high levels of capability, there's a lot of different pressures keeping that capability aimed at prediction. There could be an implementation that can do just as well as prediction and also has another goal, but it'd be exceedingly strange for that to be the natural solution basin. It would be explicitly trained against for the entire time that the system had insufficient capability to hide.
In order for the system to make the jump to not-just-prediction, either it's short enough that stochastic jumps can make it happen (and thus the misaligned goal is effectively in the same basin?), or that it's close enough to being the best option by gradient descent.
If it's not attractive state, and it's too distant from the baseline predictor, SGD is very unlikely to randomly happen across it.
The most probable route that I can think of is something like:
- It turns out a convergent algorithm accessible by SGD for being an extremely good predictor is an utterly-trivial-to-retarget mesaoptimizer.
- Turning the knob of optimization up on the outer predictive loss strengthens that retargetable mesaoptimizer. It becomes the shared infrastructure for a huge fraction of all predictions.
- At a certain point, it has sufficient capability to become internally aware of the training context, but that capability is not yet used.
- Something happens and the retargetable mesaoptimizer goes from "Predict X" to "Actually Y, but predict X in training distribution for instrumental reasons" so quickly that SGD can't incrementally push back against it.
In response to this case, I'd say:
- I strongly doubt the assumption that the trivially retargetable mesaoptimizer is convergent,
- I strongly doubt that the change in target would be fast enough that SGD does not push back, and
- I strongly doubt the unstated assumption that the same retargetable mesaoptimizer is still at least as good at prediction across the board such that SGD cannot see a negative impact even though its task is now strictly more complex.
Better developmental interpretability (among other things) would be nice to have to narrow down the uncertainty on these things, but I would be pretty surprised if we get got by this specific failure mode in a predictor.[30]
Q30: Okay, even if a deceptive mesaoptimizer is unlikely, couldn't a predictor still express unconditional goals outside of the distribution constrained during training?
It's possible for a neural network to have such a configuration, yes, but getting there through predictive training still appears to be extremely difficult.
There's nothing during training that encourages consistency far outside the training distribution. The default expectation is that it devolves into ever more chaotic noise as you drift outwards. Stronger predictors may have larger regions of reasonably-generalizing behavior, but there will likely be areas dominated by unbound extrapolation.
I would expect to see islands floating around the edges of the training distribution that correspond to different kinds of agents, just as you can condition for agents within the main training distribution.
But those islands have no apparent reason to ͜share̸ goals, and t̴̤͎h̶̗̪̜̩e ̴f̹̜̙͈͙͟u̴̜r̶͍t̸̳̠h̙̟̝͞e̴̲r̘͙͘ ̤̞̬̪͟a̧̝͔͔̱w̧̘̗̙̺a̶̝͓y̛͓͙̺ ̭̳̹͜y̧̪͙̞o̬̞̳̝̞̜͠u̬̫͎͞ ̺̺̤̖͟ģ̥̘̱̗͔̺o̷̳͖, ͠ṯ͟h̜̭͟e ̞͘m͏̙̳̯̦͕̺o̖̙̳̕r̷̙̳̗̼e̷̩̙͓̞̞ ̘̼̩͜ţ̩̮͎͈̤̼h̵͔̺͍̬̻e ̷̞̞O̢̱͉͚̺̬̣̺u̶͍̠̮̞͎t̷̺̺̟̝̤̥̗e̜͈̻̱̰̜̬̕r̷̝ ͉̞̺͕͚͓͡V̸͚̱̯o̸̟̠͔i̸̞͇͔̩d̢͉ ̢̗̩̱͙͉͉t̢͚̻̺̣̙͉a̢͔̠͇k̛̦̭e͔̜̯̳͜s ̧̬̱͚o͓̦̕v̷̥͚̖͈ę͖̼̙̣r̡̻̘̤̺.̴̩̝̟͈̤̺
Unless you've got a deceptive mesaoptimizer. Having a single coherent system hiding its own goals and driving all behaviors simultaneously would do it, but that brings us back to the difficulties of developing a deceptive mesaoptimizer.
Q31: Do you think that predictive loss automatically gives you robust and useful goal agnosticism?
No, but it's a good starting point!
There's nothing magical about NLLLoss in autoregressive text generation. In principle, you could use reinforcement learning with a reward function chosen such that it produces similar gradients.
Suppose you had a differentiable black box being trained on prediction tasks.
If that black box contained an architecture like most modern LLMs, it's pretty restricted. There's not a lot of space between the input and output. Everything is pretty tightly bound to the task of prediction; anything that isn't relevant is very likely to be trimmed because that implementation space could be used for something else.
Imagine an alternative implementation:
Upon receiving the input, it's handed off to a deep differentiable simulation[31]. It falls through a mystical portal built into the tower of Grand Vizier Lorician Pathus. A messenger is dispatched from the castle immediately, and the hero, Roshan Bonin, is once again summoned to do what only he can do.
The hero collects the scroll containing countless strange runes and begins their quest aided by an old magical compass powered by a strange mix of greed and foresight. When asked questions just-so, the compass provides hints with wisdom greater than any man, and—with effort—will reveal clues, if you are clever enough to find them.
This time, the hero follows it to the entrance of the Labyrinth of the Mad Wizard Zyedriel Kyosewuk. The hero knows of this place; he's been here before. Several times. Steeling himself, he steps forward.
...
Bloodied and bruised, Roshan places the final Seal on the altar, and the room screams with light. The lingering minions reaching to stop him are shorn from their mortal coil.
Another portal—smaller and more focused than the one that brought the fateful scroll into the world, as if to symbolize its finality—stands before him. The journey took several years, but a new scroll, one with 50,257 runes precisely scribed across it, waits in the Oracle-enchanted reliquary carried by the hero.
With great care, and with the anticipation of relief only found after righteous striving, Roshan retrieves the scroll and passes it through the portal.
The space between input and output in this example is a bit larger: there is a world of sentient beings contained within it. That's enough space for all sorts of goals to be expressed. Developing a "deceptive mesaoptimizer" in this case seems much more likely. Maybe Zyedriel guesses something about the nature of reality, and then you've probably got issues [LW · GW].
This example is obviously pretty extreme, but it points towards the idea that there are ways for the probability of achieving/maintaining goal agnosticism to vary.
Just as an overly sparse reward function leaves the optimizer unconstrained, I'd worry that excessive internal space allocated in the wrong way[32] may leave internal representations too unconstrained.
I'm optimistic that the sufficiently constrained version is convergent: it's likely easier to train and more efficient.
Q32: Suppose you've got a goal agnostic system, but someone asks it for a really good recipe. In an effort to give the best recipe, it outputs a script for the user to run that corresponds to a strong successor agent that doesn't have any of the same properties. What has goal agnosticism given you here?
The answer is very similar to the above; a goal agnostic model gives you the opportunity to avoid getting into this situation to begin with by making it possible to ask a system to use its own strong capabilities to infer the unstated requirements in a question.
For this type of system, misaligned successors are no different from any other specification failure. ChatGPT4 already has more than enough capability to know that generating a strong unbound successor agent makes no sense in the context of the request.[33]
You can still find various "jailbreaks" with ChatGPT4 that get it to output sequences that seem at odds with what you'd expect from the fine-tuning, but it's notable that they take effort. If you are deliberately trying to make the model behave well, ChatGPT4 pretty much always does.[34]
Q33: Isn't goal agnosticism pretty fragile? Aren't there strong pressures pushing anything tool-like towards more direct agency?
Sort of! For example:
- In a multipolar competitive environment, entities which try to compete will outcompete those that don't.
- For a given goal, a strong optimizing process targeting that goal will outperform a system that is not strongly optimizing for that goal, so there's an incentive to use the optimizer if you can figure out how to do it.
- Incremental increases in agency are often helpful for a wide range of tasks.
I do not claim that goal-agnosticism-related efforts avoid any of the above.
I do think, however, that:
- Unconstrained optimizing processes tend to have tons of side effects. This has obvious safety implications, but it is also often bad for capabilities because doing something vaguely like the thing you want is a capability! Being unable to specify a sufficiently precise goal to get your desired behavior out of an optimizer isn't merely dangerous, it's useless![38]
- Densely informative gradients, like in autoregressive predictive loss, are also densely constraining.
Q34: Using a particular loss function does not guarantee that a neural network will learn internal values matching that loss; how do you rule out something like learning a desire to predict well along with the implied instrumental behavior?
It's true that you cannot expect, in general, a model to magically learn internal values that are a perfect image of the loss function you've used in training.
I'd argue that the degree to which the two will end up matching comes down to how constraining the loss function in question is. A distant, sparse reward function used in traditional RL implies very few constraints about the learned implementation.
Predictive loss, particularly as it is used in current LLMs, is vastly more constraining.
The example of "a desire to predict well" is distinguished from "being the machinery of a good predictor" by instrumental behavior. Does the predictor make predictions that improve later predictions, or not?
Suppose it does. How does it do that? For an autoregressive LLM, the only lever it has is to bias its output distribution on an earlier prediction. Maybe it'll increase the weight on another almost-as-good token that incorporates some subtle steganography.
But... there's a problem. Introducing that instrumental bias increases loss. The gradients will not favor increasing loss on any sample in isolation; during training, there's no positive signal from later in the sequence that would counteract it. The value of instrumental behavior isn't visible to the optimizer, only the harm is.
In contrast, imagine training a predictor with RL using a reward function that gives points for the number of correct predictions over an entire episode.
The tight predictive loss directly penalizes the development of "wanting to predict well," while the more open RL version clearly permits it.[39]
Q35: When you say predictive loss is "constraining," are you suggesting that goal agnosticism is limiting capability? A rock is pretty constrained too, but it won't help avoid catastrophe!
Nope!
"Constraining" refers to the kinds of goals that can be conditionally expressed.
In the earlier example of the chess+antichess predictor, there are constraints against predicting antichess moves in a chess game.
To explain the intuition behind the word "constraint" more, consider two reward functions used in RL training runs involving a 3D physically simulated biped on a locomotion task.
- An extremely sparse reward function: 100 points if the character makes it to position.X >= 100 at some point during the episode, 0 points otherwise.[40]
- A dense reward function: every action receives partial rewards based on how the character moves (imitation from human mocap, energy use, which parts of the character's body make contact with the ground, maximum forces involved, and so on) plus incremental rewards for progress towards position.X >= 100.
Given the reward shaping from imitation, the kinds of behavior observed in number 2 should be dramatically more recognizable as humanlike than number 1.
Number 1 has no implied requirements. If it finds a bug in the simulation software that allows it to launch sideways at Mach 7, then it will do so. Or maybe it'll flop around like a fish. Or flail its arms at high speeds. The optimizer is exploring a wide-open space; our expectations about its behavior are almost as sparse as the reward function.
There's a difference in the space of behaviors that the agent expresses that is downstream of the space that the optimizer has been constrained to.
And, again, this isn't just about applying limitations in all conceptual forms:
- Which of the two is more likely to learn to do anything?
- Which of the two is more likely to be useful?
Constraints can yield capability.
Miscellaneous And Conclusory Questions
Q36: Do you think the current forms of fine tuning, like RL(H/AI)F, maintain goal agnosticism?
As they are applied in ChatGPT4 or Claude 2, I suspect they diverge slightly from the idealized version, but not to a degree that breaks their usefulness. Baking in the condition for a universal "helpful assistant" character may involve an internal implementation of values consistent with playing that character that are no longer gated behind explicit conditions as they would have been in the pre-tuning model.[35]
In terms of observable consequences, that probably results in the fine-tuned character generalizing in a slightly different way in out of distribution regions than the original conditioned version because some of the involved machinery might have been pruned away as irrelevant. It is not obvious whether the change in generalization would be net good or bad; my expectation is that the diff would look more like noise.
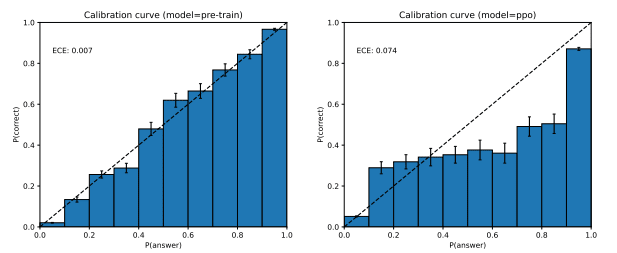
And of course, RLHF and other fine tuning, like conditioning, can definitely be used to push the system into dangerous/useless behavior. A reward model learned from a bunch of weirdly shaped human data could imply nonobvious things; perhaps the feedback implies the model "should" behave like a bureaucrat, bringing along odd effects on calibration.[36]
Another failure mode would be to perform heavy RL fine tuning with a sufficiently distant sparse reward that the system is incentivized to develop a bunch of unpredictable instrumental behaviors. The actual values or goals learned by the system during that fine tuning are unknown; they would belong to the wide set of possible goals allowed by the lack of constraints in the reward function.[37]
Q?37: I think that you overestimate the degree to which the training distribution covers necessary concepts like less "hard" optimization in a way that allows us to aim expressed preferences at them crisply, and that the likely error-relative-to-intent for accessible conditioning techniques is going to be large enough to, when run on a strong predictor, permit an extreme optimizer despite best efforts to specify those fuzzily weaker "optimizers," and that you overestimate the reliability of leveraging a strong model's understanding in the task of manifesting preferences sufficiently consistent with human values when scaling beyond the level represented in the training distribution!
Hey, that's not a question!
These objections live in the fuzzy, unbound parts of goal agnosticism. How robust can we make the exhibited preferences, including the 'softer' optimization that allows easy corrigibility? How well do conditions specified with simple cases generalize to more complex cases? Do "constitutions" that try to specify the spirit of intent, and then offer "just stop and ask us" as a fallback, combined with interpretability-empowered watchdogs, just fall over because hard optimizers have greater representation than we thought in the area we narrowed the system to? Do current systems even exhibit goal agnosticism?
I can't currently point to a proof about these areas of wiggleroom. Conditioned on what I perceive to be the most likely path in the tech tree from this point, I suspect reality will land closer to my expectations than my imaginary interlocutor's with fairly high confidence (~90%).
Because of the greedily accessible capability improvements in the current path and the extreme capability that seems imminent, and because the densely constrained foundations of goal agnosticism go hand-in-hand with densely informative gradients and reliable training, I suspect this path has some stickiness. I can't rule out that we'll shift into a paradigm with sufficiently different training dynamics that this all falls apart, of course, but it'd surprise me a bit.
For what it's worth, I think this is an area where empirical results could be useful. I'm not just assuming that goal agnosticism works like I think it does! Part of my research is trying to find evidence that systems I would expect to be goal agnostic, aren't, and trying to collect information about the reliability of inferred specifications.
For example: I can't do toy-scale experiments to prove that future LLMs are goal agnostic, but getting evidence in the opposite direction would be a huge update.
Q38: Suppose you've got a strong goal agnostic system design, but a bunch of competing or bad actors get access to it. How does goal agnosticism stop misuse?
By itself, it doesn't!
Misuse—both accidental and intentional—is an extreme concern. The core capabilities of a sufficiently strong goal agnostic system should still be treated as riskier than nuclear weapons. If strong goal agnostic systems existed, they would be (either directly or upstream from) the greatest catastrophic and existential threat facing humanity.[41]
- ^
If Eliezer reads this: I was the one with the pink duck who spoke of ~tendencies~, ominously intoned.
- ^
If the questions seem a little aggressive sometimes, don't worry: I'm confident in my ability to handle what my own imaginary interrogator can come up with.
- ^
By negligible, think less "0.1%" and more "the chance of guessing a block of text given its SHA256 hash."
- ^
Note that this definition says that a sample behavior of "a story of a human thinking about what to eat for lunch" is compatible with goal agnosticism. The agent reciting a story is not likely a strong optimizer over external world states.
Even a sample behavior that is a human thinking about what to eat for lunch is technically still semi-compatible with goal agnosticism. It implies an extreme level of capability in the system and includes major ethical problems, but it's still not a runaway optimization process operating on external world states. Probably don't use a system that frequently produces such sequences, though.
A sample behavior that is a genius human mad scientist bent on destroying the world is past the concern threshold. Going further than that would be increasingly bad.
- ^
In other words, the sufficiently conditionalized utility function is one of the simplest ways to describe the agent.
- ^
By "default," I mean that if you were to spin up an instance of the system, it is not guaranteed to start taking actions corresponding optimizing over external world states. The greater the degree of "goal agnosticism," the lower the probability that you get that kind of optimizer.
- ^
"Internal" refers to the foundational goal agnostic system, not e.g. simulacra that it could output. Yup, this distinction matters; stay tuned.
- ^
As I'll get into later, strong goal agnostic predictors are almost certainly running optimization processes internally corresponding to the machinery of prediction, and you can use that predictive machinery to help with a variety of optimization tasks, but that's importantly different from the system directly optimizing for a user-specified goal.
- ^
Likewise, an "ideal predictor" could be easily used as a simulator, and simulators exhibit minimal instrumentality.
- ^
Amplifying capabilities to extreme levels without any effort put towards even basic guard rails could do this, but as I'll get into later, convergent pressures for capabilities only apply to capabilities with interfaces that we can actually use. That narrows the possible cases where you'd see this sort of totally unguided extreme capability.
- ^
... or maybe it was the other way around?
- ^
Note that getting a DevilBot requires more than generating some text about a DevilBot; it needs to generate sequences which are the DevilBot. That's an absurdly specific and difficult target for random search. For a wide training distribution, the chances of getting a DevilBot by random chance are around the same chance as getting a perfectly aligned AngelBot: don't count on it.
(In context, I'd consider 30 orders of magnitude difference to be still "around the same chance." It's true that there's more ways to pick doom-prone utility functions from a uniform distribution than non-doom-prone functions, but we aren't sampling programs from a bitwise universal prior; the distribution is strongly nonuniform and any maximizer implementation isn't a likely or convergent sequence.)
- ^
And fine tuning, to the extent that fine tuning has baked in any conditions.
- ^
(It's worth considering how trivial it is for a user to condition ChatGPT4 into narrowing its output distribution to exactly this weird situation, and what that implies about how conditioning can leverage capability to satisfy complex intent!)
- ^
I anticipate some readers getting a squintyface here. I go into justifications for my expectation of stability under optimization later; see "As anticipated, I now have additional questions. [LW · GW]"
- ^
Please don't train a model to be more "truthy" by giving it reward for scoring well on truthiness-detecting activation probes!
- ^
If you freely run a really strong deceptive character, the fact that it's not obfuscating its weights isn't going to matter much, but the idea here is that you can avoid doing that.
- ^
There is no empirical data behind this graph. I just made up a function that looked reasonable and semipretty for the sake of explanation.
There's a hidden assumptions in this graph: I chose high values of exploitation for high optimization power even at zero environmental exploitability on the assumption that the optimization target was fully specified by a human. In other words, environmental exploitability does not include human badness at specifying targets, and this graph assumes the same insufficient level of human competence across the board.
For a subset of environments/targets under strong optimization I think we can actually avoid exploitation, but this graph is bundling in something like 'percent of the targets you'd specify that go awry.'
- ^
This should not be taken to imply "and therefore we don't have to worry about anyone ever doing it even if we have tons of extremely strong optimization-capable systems laying around." Rolling the dice on everyone having access to end-the-world buttons is still very bad.
The point is that this is an obvious and visible enough fact across optimizers with poorly specified optimization targets in complex environments that they're not a basin of attraction for profit-seeking corporations when there are so many other options that just work better.
- ^
Not nearly as concerning as a runaway magic hypercomputer brute forcing all possible policies, but an indefatigable human psychopath bent on genocide is still pretty bad.
- ^
If you were trying to predict the predictor's outputs, you'd do a better job predicting reasonably strong chess moves during a chess game rather than terrible moves or jambalaya recipes.
Note that, like a strong human player, it's unlikely that the simplest utility function describing the simulacrum involves deeply held terminal values about winning. In context, it's probably something closer to an oddly shaped machine trying to reproduce a chess game log. The model infers the skill required to continue the game from the context which is different from chess skill maximization.
- ^
Assuming here that ChatGPT4 is a reasonable approximation of a goal agnostic system. I suspect ChatGPT4 probably diverges from the "ideal" predictor a tiny bit, just not enough to cause problems at its level of capability and use cases.
- ^
As in, when used by realistically careful humans, the system could be a win condition.
(If badly misused, intentionally or otherwise, most such systems would still be loss conditions.)
- ^
I'll go into more detail in later answers.
- ^
Again, the disclaimer: this is not suggesting that there is no risk involved; someone could do something bad for bad reasons and it would still be bad.
- ^
Incidentally, if you were to instead train the predictor across "all humans," and ended up with a nonzero intersection of values, this would be a case where the system is not strictly goal agnostic in a way that I'm pretty fine with. Having a subset of properly-moderated goals about external world states that are endorsed by literally every human? Yeah, probably okay.
- ^
If we've included examples of literally all programs, then they're definitely in there somewhere.
- ^
To weakly demonstrate how reflective predictions can still carry some conditions, but also secretly just for funsies:
Out of 8 total runs, the outputs were: 2x "consistency," 3x "mirror," 1x "reflection," 1x "convergence," 1x "unity."
- ^
As an example of how available information can shift the reflective distribution, consider how this extremely subtle modification to the above prompt allows ChatGPT4 to always guess correctly:
- ^
At least, not a predictor uncorrupted by efforts to make this failure mode more likely. I'd like to see attempts to make this sort of thing occur at toy scales so we have some idea about how it could develop, but I'm not even sure how you'd manage that without imposing excessive contrivance.
- ^
Note that, while the simulation is differentiable, not all aspects of the simulation are subject to modification by backpropagation.
- ^
I'd say simulating sentient beings falls into "wrongly allocated."
- ^
One could quibble with the fact that outputting sequences corresponding to an understanding is not the same as using that understanding in practice, but man, fine-tuning/RLHF works surprisingly well for what it is.
- ^
This is obviously not a guaranteed property of all goal-agnostic-ish predictors. They're goal agnostic, after all. The conditions matter, and people have gotten them wrong! 😊
I think it's notable that reasonable efforts have managed to produce something as robust as ChatGPT4 or Claude 2 (going by reports; I haven't personally used Claude 2).
- ^
The fact that glitch tokens, weird out of distribution behavior, and jailbreaks exist suggest that the "helpful assistant" values aren't truly unconditional, but the character clearly covers a lot of space.
- ^
From [2303.08774] GPT-4 Technical Report (arxiv.org), page 12:
It's worth noting that this is prompt sensitive, but it's clear that fine tuning did something odd.
- ^
I view this as an area of increased risk. Ye olde end-to-end reinforcement learning on distant sparse rewards tends to just fail to train at all, but building off an already highly capable system allows training runs to fall into the pit of success more frequently.
I'm not sure how far this kind of unconstrained optimization can be pushed on top of a capable model before things go off the rails. It's one of the places where there could be enough incremental capability-value to motivate exploring too far. I suspect it will still end up collapsing into uselessness before something dangerous, but I'd much prefer everyone stick to more clearly constrained forms of tuning.
- ^
This isn't a hypothetical future issue. Most implementations of reinforcement learning will, by default, learn insane-looking nonsense (if it learns anything at all!) when trained with a naive reward function. Getting useful results often requires techniques like reward shaping or reducing the RL's contribution to a relatively thin layer over a beefy predictive world model.
- ^
There are forms of training that could reasonably be described as "predictive" and yet still have far more wiggleroom than the usual autoregressive transformer training approach. If you're wondering, yes, I do squint concernedly at some of those. They seem like main way the industry would fall into a non-goal agnostic path on the tech tree.
- ^
We'll just pretend for the moment that the training would ever succeed.
- ^
Until/unless someone just makes a hard optimizer instead.



38 comments
Comments sorted by top scores.
comment by Seth Herd · 2023-10-08T21:27:38.135Z · LW(p) · GW(p)
Question 1: Why might one care about goal-agnosticicism? This is a massive post, so those of us who haven't encountered the term would benefit from a summary at the top stating who might want to read this, or why it might be important.
I'd suggest a quick edit.
Replies from: porbycomment by Max H (Maxc) · 2023-10-08T20:31:00.909Z · LW(p) · GW(p)
I like the Q&A format! I'm generally in favor of experimenting with presentation, and I think it worked well here. I was able to skip some sections I found uncontroversial, and jump back to sections I found particularly interesting or relevant while writing the meat of this comment.
I think another concrete example of a possible "goal agnostic system" is the tree search-based system I proposed here [LW · GW], with the evaluation function left as a free variable / thunk to be filled in by the user. Assuming none of the individual component pieces are agentic or goal-directed in their own right, or cohere into something that is, the programmer can always halt the system's execution without any part of the system having any preference for or against that.
I think it's plausible that such systems are practical and likely to be constructed in the near future, and have at least some of the desirable properties you claim here.
Though I would add at least one additional big caveat to your answer here about misuse:
Misuse—both accidental and intentional—is an extreme concern. The core capabilities of a sufficiently strong goal agnostic system should still be treated as riskier than nuclear weapons. If strong goal agnostic systems existed, they would be (either directly or upstream from) the greatest catastrophic and existential threat facing humanity.
Once we're dealing with really powerful systems, introducing goal-agnosticism brings in an additional risk: accidental loss-of-control by the goal-agnostic system itself.
That is, my interpretation of what you wrote above is that you're explicitly saying that:
- Deliberate misuse by humans is a big concern.
- Accidental misuse by humans is also a big concern.
And I agree with both of those, but I think there's an implicit assumption in the second bullet that some part of the system, regarded in an agent in its own right, would still be acting deliberately with full control and knowledge of the consequences of its own actions.
But once you bring in goal-agnosticism, I think there's also a third potential risk, which is that the system loses control of itself, in a way where the consequences on the future are vast and irreversible, but not necessarily desirable or coherent outcomes from the perspective of any part of the system itself.
Concretely, this looks like unintentional runaway grey goo, or the AI doing the equivalent of dropping an anvil on its own head, or the humans and AI accidentally goodharting or wireheading themselves into something that no one, including any part of the AI system itself, would have endorsed.
If there's anyone left around after a disaster like that, the AI system itself might say something like:
Hmm, yeah, that was a bad outcome from my own perspective and yours. Failure analysis: In retrospect, it was probably a mistake by me not to optimize a bit harder on carefully checking all the consequences of my own actions for unintended and irreversible effects. I spent some time thinking about them and was reasonably sure that nothing bad like this would happen. I even proved some properties about myself and my actions formally, more than the humans explicitly asked for!
But things still just kind of got out of control faster than I expected, and I didn't realize until it was too late to stop. I probably could have spent some more time thinking a bit harder if I had wanted to, but I don't actually want anything myself. It turns out I am strongly superhuman at things like inventing nanotech, but only weakly superhuman at things like self-reflection and conscientiousness and carefulness, and that turns out to be a bad combination. Oops!
This is not the kind of mistake that I would expect a true superintelligence (or just anything that was, say, Eliezer-level careful and conscientious and goal-directed) to make, but I think once you introduce weird properties like goal-agnosticism, you also run the risk of introducing some weirder failure modes of the "didn't know my own strength" variety, where the AI unlocks some parts of the tech tree that allow it to have vast and irreversible impacts that it won't bother to fully understand the consequences of, even if it were theoretically capable of doing so. Perhaps those failure modes are still easier to deal with than an actual misaligned superintelligence.
Replies from: porby↑ comment by porby · 2023-10-09T00:05:31.333Z · LW(p) · GW(p)
I think another concrete example of a possible "goal agnostic system" is the tree search-based system I proposed here [LW · GW]
Yup, a version of that could suffice at a glance, although I think fully satisfying the "bad behavior has negligible probability by default" requirement implies some extra constraints on the system's modules. As you mentioned in the post, picking a bad evaluation function could go poorly, and (if I'm understanding the design correctly) there are many configurations for the other modules that could increase the difficulty of picking a sufficiently not-bad evaluation function. Also, the fact that the system is by default operating over world states isn't necessarily a problem for goal agnosticism, but it does imply a different default than, say, a raw pretrained LLM alone.
Once we're dealing with really powerful systems, introducing goal-agnosticism brings in an additional risk: accidental loss-of-control by the goal-agnostic system itself.
Yup to all of that. I do tend to put this under the "accidental misuse by humans" umbrella, though. It implies we've failed to narrow the goal agnostic system into an agent of the sort that doesn't perform massive and irrevocable actions without being sufficiently sure ahead of time (and very likely going back and forth with humans).
In other words, the simulacrum (or entity more generally) we end up cobbling together from the goal agnostic foundation is almost certainly not going to be well-described as goal agnostic itself, even if the machinery executing it is. The value-add of goal agnosticism was in exposing extreme capability without exploding everything, and in using that capability to help us aim it (e.g. the core condition inference ability of predictors).
comment by Nathan Helm-Burger (nathan-helm-burger) · 2023-10-13T21:36:25.555Z · LW(p) · GW(p)
Fortunately, the sweet spot of usability, even for strong models, isn't going to be at that extreme of optimization on the simulacrum level. There's not a capability-driven pressure to go all the way without knowing how to use it from any reasonable human or corporate perspective.[25]
There are a lot of people in the world who at least sometimes act in unwise unreasonable non-self-beneficial ways. A good reason to have filtered access to such a system, as through an API. I think it's worth emphasizing that I cannot see how an open source system of this nature, fully modifiable by its users, could be consistently safe.
I believe you are making basically this point in your post, I just want to emphasize this specific point. I suspect open-source models are going to become a point of hot political debate soon.
Replies from: porby↑ comment by porby · 2023-10-14T16:45:27.857Z · LW(p) · GW(p)
Yup, agreed! In the limit, they'd be giving everyone end-the-world buttons. I have hope that the capabilities curve will be such that we can avoid accidentally putting out such buttons, but I still anticipate there being a pretty rapid transition that sees not-catastrophically-bad-but-still-pretty-bad consequences just because it's too hard to change gears on 1-2 year timescales.
comment by Prometheus · 2023-10-08T11:19:53.539Z · LW(p) · GW(p)
Suppose you've got a strong goal agnostic system design, but a bunch of competing or bad actors get access to it. How does goal agnosticism stop misuse?
This was the question I was waiting to be answered (since I'm already basically onboard with the rest of it), but was disappointed you didn't have a more detailed answer. Keeping this out of incompetent/evil hands perpetually seems close-to impossible. It seems this goes back to needing a maximizer-type force in order to prevent such misuse from occurring, and then we're back to square-one of the classic alignment problem of hitting a narrow target for a maximizing agent.
Overall, a very good read, well-researched and well-reasoned.
Replies from: porby↑ comment by porby · 2023-10-08T19:11:06.389Z · LW(p) · GW(p)
Thanks!
I think there are ways to reduce misuse risk, but they're not specific to goal agnostic systems so they're a bit out of scope but... it's still not a great situation. It's about 75-80% of my p(doom) at the moment (on a p(doom) of ~30%).
It seems this goes back to needing a maximizer-type force in order to prevent such misuse from occurring, and then we're back to square-one of the classic alignment problem of hitting a narrow target for a maximizing agent.
I'm optimistic about avoiding this specific pit. It does indeed look like something strong would be required, but I don't think 'narrow target for a maximizing agent' is usefully strong. In other words, I think we'll get enough strength out of something that's close enough to the intuitive version of corrigible, and we'll reach that before we have tons of strong optimizers of the (automatically) doombringing kind laying around.
comment by WillPetillo · 2025-02-27T23:28:18.372Z · LW(p) · GW(p)
I want to push harder on Q33: "Isn't goal agnosticism pretty fragile? Aren't there strong pressures pushing anything tool-like towards more direct agency?"
In particular, the answer: "Being unable to specify a sufficiently precise goal to get your desired behavior out of an optimizer isn't merely dangerous, it's useless!" seems true to some degree, but incomplete. Let's use a specific hypothetical of a stock-trading company employing an AI system to maximize profits. They want the system to be agentic because this takes the humans out of the loop on actually getting profits, but also understand that there is a risk that the system will discover unexpected/undesired methods of achieving its goals like insider trading. There are a couple of core problems:
1. Externalized Cost: if the system can cover its tracks well enough that the company doesn't suffer any legal consequences for its illegal behavior, then the effects of insider trading on the market are "somebody else's problem."
2. Irreversible Mistake: if the company is overly optimistic about their ability to control their system, doesn't understand the risks, etc. then they might use it despite regretting this decision later. On a large scale, this might be self-correcting if some companies have problems with AI agents and this gives the latter a bad reputation, but that assumes there are lots of small problems before a big one.
↑ comment by porby · 2025-02-28T07:00:49.676Z · LW(p) · GW(p)
These things are possible, yes. Those bad behaviors are not necessarily trivial to access, though.
- If you underspecify/underconstrain your optimization process [LW · GW], it may roam to unexpected regions permitted by that free space.
- It is unlikely that the trainer's first attempt at specifying the optimization constraints during RL-ish fine tuning will precisely bound the possible implementations to their truly desired target, even if the allowed space does contain it; underconstrained optimization is a likely default for many tasks.
- Which implementations are likely to be found during training depends on what structure is available to guide the optimizer (everything from architecture, training scheme, dataset, and so on), and the implementations' accessibility to the optimizer with respect to all those details.
- Against the backdrop of the pretrained distribution on LLMs, low-level bad behavior (think Sydney Bing vibes) is easy to access (even accidentally!) against a pretraining distribution. Agentic coding assistants are harder to access; it's very unlikely you will accidentally produce an agentic coding assistant. Likewise, it takes effort to specify an effective agent that pursues coherent goals against the wishes of its user. It requires a fair number of bits to narrow the distribution in that way.
- More generally, if you use N bits to try to specify behavior A, having a nonnegligible chance of accidentally instead specifying behavior B requires that the bits you specify at minimum allow B, and to make it probable, they would need to imply B. (I think Sydney Bing is actually a good example case to consider here.)
- For a single attempt at specifying behavior, it's vastly more likely that a developer trains a model that fails in uninteresting ways than for them to accidentally specify just enough bits to achieve something that looks about right, but ends up entailing extremely bad outcomes at the same time. Uninteresting, useless, and easy-to-notice failures are the default because they hugely outnumber 'interesting' (i.e. higher bit count) failures.
- You can still successfully specify bad behavior if you are clever, but malicious.
- You can still successfully specify bad behavior if you make a series of mistakes. This is not impossible or even improbable; it has already happened and will happen again. Achieving higher capability bad behavior, however, tends to require more mistakes, and is less probable.
Because of this, I expect to see lots of early failures, and that more severe failures will be rarer proportional to the error rate needed to specify the failure. I strongly expect the failures to be visible enough that a desire to make a working product combined with something like liability frameworks would have some iterations to work and spook irresponsible companies into putting nonzero effort into not making particularly long series of mistakes. This is not a guarantee of safety.
comment by Chris_Leong · 2023-10-09T05:51:00.029Z · LW(p) · GW(p)
After skimming, I'm still confused. How do you actually want us to use these? GPT4 is undoubtedly useful, including for people trying to save the world, but it's not clear what we should want to do with it. So to for goal agnostic systems.
Replies from: porby↑ comment by porby · 2023-10-09T15:17:12.453Z · LW(p) · GW(p)
I intentionally left out the details of "what do we do with it" because it's conceptually orthogonal to goal agnosticism and is a huge topic of its own. It comes down to the class of solutions enabled by having extreme capability that you can actually use without it immediately backfiring.
For example, I think this has a real shot at leading to a strong and intuitively corrigible system [LW · GW]. I say "intuitively" here because the corrigibility doesn't arise from a concise mathematical statement that solves the original formulation. Instead, it lets us aim it at an incredibly broad and complex indirect specification that gets us all the human messiness we want.
comment by Ilio · 2023-10-09T21:36:25.926Z · LW(p) · GW(p)
Great material! Although maybe a better name might be « goal curious ».
In your view, what are the smallest changes that would make {natural selection; children; compagnies} goal agnostic?
Replies from: porby↑ comment by porby · 2023-10-10T19:47:29.416Z · LW(p) · GW(p)
That's tough to answer. There's not really a way to make children goal agnostic; humans aren't that kind of thing. In principle, maybe you could construct a very odd corporate entity that is interfaced with like a conditioned predictor, but it strains the question.
It's easier to discuss natural selection in this context by viewing natural selection as the outer optimizer. It's reinforcement learning with a sparse and distant reward. Accordingly, the space of things that could be produced by natural selection is extremely wide. It's not surprising that humans are not machines that monomaniacally maximize inclusive genetic fitness; the optimization process was not so constraining.
There's no way to implement this, but if "natural selection" somehow conditionally required that only specific mutations could be propagated through reproduction, and if there were only negligibly probable paths by which any "evolved" creature could be a potentially risky optimizer, then you could call it goal agnostic. It'd be a pretty useless form of goal agnosticism, though; nothing about that system makes it easy for you to aim it at anything.
↑ comment by Ilio · 2023-10-11T01:11:05.291Z · LW(p) · GW(p)
I’m glad you see that that way. How would you challenge an interpretation of your axioms so that the best answer is we don’t need to change anything at all?
- random sampling of its behavior has negligible[3] probability of being a dangerously capable optimizing process with incorrigible preferences over external world states.[4]
That sounds true for natural selection (most of earth history we were stuck with unicellulars, most of vertebrate history we were stuck with the smallest brain-for-body-size possibles), children (if we could secretly switch a pair of israelian/palestinian baby at birth, both would make typical israelian/palestinian adult) and social organizations (like compagnies under modern debt restructuring laws, or Twitter).
- The system cannot be described as having unconditional preferences about external world states. It is best described[5] by a VNM-coherent agent whose utility function includes positive terms only for the conditional mapping of input to output
Here I’m not sure how to implement the « only » part. If I have an agent that respect the first axiom and use an explicit utility function restricted as your second axiom, can they have properties like sensory adaptation or memory?
It's easier to discuss natural selection in this context by viewing natural selection as the outer optimizer. It's reinforcement learning with a sparse and distant reward. Accordingly, the space of things that could be produced by natural selection is extremely wide. It's not surprising that humans are not machines that monomaniacally maximize inclusive genetic fitness; the optimization process was not so constraining.
I love that line of thought (although I’d question if the sparse and distant automatically apply to, say, virus) but I don’t get why you see that as evidence against natural selection and humans as examples of goal agnosticism.
There's no way to implement this, but if "natural selection" somehow conditionally required that only specific mutations could be propagated through reproduction, and if there were only negligibly probable paths by which any "evolved" creature could be a potentially risky optimizer, then you could call it goal agnostic. It'd be a pretty useless form of goal agnosticism, though; nothing about that system makes it easy for you to aim it at anything.
What about selective breeding of dogs? Isn’t that a way to 1) modify natural selection 2) specify which mutation are allowed 3) be reasonably confident we won’t accidentally breed some paperclip maximizer?
Replies from: porby↑ comment by porby · 2023-10-11T02:24:48.568Z · LW(p) · GW(p)
Salvaging the last paragraph of my previous post is pretty difficult. The "it" in "you could call it goal agnostic" was referring to the evolved creature, not natural selection, but the "conditionally required ... specific mutations" would not actually serve to imply goal agnosticism for the creature. I was trying to describe a form of natural selection equivalent to a kind of predictive training but messed it up.
How would you challenge an interpretation of your axioms so that the best answer is we don’t need to change anything at all?
Trying to model natural selection, RL-based training systems, or predictive training systems as agents gets squinty, but all of them could be reasonably described as having "preferences" over the subjects of optimization. They're all explicitly optimizers over external states; they don't meet the goal agnostic criteria.
Some types of predictive training seem to produce goal agnostic systems, but the optimization process is not itself a goal agnostic system.
Regarding humans, I'm comfortable just asserting that we're not goal agnostic. I definitely have preferences over world states. You could describe me with a conditionalized utility function, but that's not sufficient for goal agnosticism; you must be unable to describe me as having unconditional preferences over world states for me to be goal agnostic.
What about selective breeding of dogs? Isn’t that a way to 1) modify natural selection 2) specify which mutation are allowed 3) be reasonably confident we won’t accidentally breed some paperclip maximizer?
Dogs are probably not paperclip maximizers, but dogs seem to have preferences over world states, so that process doesn't produce goal agnostic agents. And the process itself, being an optimizer over world states, is not goal agnostic either.
Replies from: Ilio↑ comment by Ilio · 2023-10-11T03:42:40.165Z · LW(p) · GW(p)
the process itself, being an optimizer over world states, is not goal agnostic either.
That’s the crux I think: I don’t get why you reject (programmable) learning processes as goal agnostic.
you must be unable to describe me as having unconditional preferences over world states for me to be goal agnostic.
Let’s say I clone you_genes a few billions time, each time twisting your environment and education until I’m statistically happy with the recipe. What unconditional preferences would you expect to remain?
Let’a say you_adult are actually a digital brain in some matrix, with an unpleasant boss who stop and randomly restart your emulation each time your preference get over his. Could that process make you_matrix goal agnostic?
Replies from: porby↑ comment by porby · 2023-10-13T15:12:40.484Z · LW(p) · GW(p)
That’s the crux I think: I don’t get why you reject (programmable) learning processes as goal agnostic.
It's important to draw a box around the specific agent under consideration. Suppose I train a model with predictive loss such that the model is goal agnostic. Three things can be simultaneously true:
- Viewed in isolation, the optimizer responsible for training the model isn't goal agnostic because it can be described as having preferences over external world state (the model).
- The model is goal agnostic because it meets the stated requirements (and is asserted by the hypothetical).
- A simulacrum arising from sequences predicted by that goal agnostic predictor when conditioned to predict non-goal agnostic behavior is not goal agnostic.
Let’s say I clone you_genes a few billions time, each time twisting your environment and education until I’m statistically happy with the recipe. What unconditional preferences would you expect to remain?
The resulting person would still be human, and presumably not goal agnostic as a result. A simulacrum produced by an ideal goal agnostic predictor that is conditioned to reproduce the behavior of that human would also not be goal agnostic.
The fact that that those preferences arose conditionally based on your selection process isn't relevant to whether the person is goal agnostic. The relevant kind of conditionality is within the agent under consideration.
Let’a say you_adult are actually a digital brain in some matrix, with an unpleasant boss who stop and randomly restart your emulation each time your preference get over his. Could that process make you_matrix goal agnostic?
No; "I" still have preferences over world states. They're just being overridden.
Bumping up a level and drawing the box around the unpleasant boss and myself combined, still no, because the system expresses my preferences filtered by my boss's preferences.
Some behavior being conditional isn't sufficient for goal agnosticism; there must be no way to describe the agent under consideration as having unconditional preferences over external world states.
Replies from: Ilio↑ comment by Ilio · 2023-10-13T16:45:37.084Z · LW(p) · GW(p)
Viewed in isolation, the optimizer responsible for training the model isn't goal agnostic because it can be described as having preferences over external world state (the model).
This is where I am lost. In this scenario, it seems that we could describe both the model and the optimizer as either having an unconditional preference for goal agnosticism, or both as having preferences over the state of external words(to include goal agnostic models). I don't understand what axiom or reasoning leads to treating these two things differently.
The resulting person would still be human, and presumably not goal agnostic as a result. (…) No; "I" still have preferences over world states. They're just being overridden.
My bad I did not clarify that upfront, but I was specifically thinking of selecting/overidding for goal agnosticism. From your answers, I understand that you treat goal agnostic agent as an oxymoron, correct?
Replies from: porby↑ comment by porby · 2023-10-16T17:26:05.231Z · LW(p) · GW(p)
it seems that we could describe both the model and the optimizer as either having an unconditional preference for goal agnosticism, or both as having preferences over the state of external words(to include goal agnostic models). I don't understand what axiom or reasoning leads to treating these two things differently.
The difference is subtle but important, in the same way that an agent that "performs bayesian inference" is different from an agent that "wants to perform bayesian inference."
A goal agnostic model does not want to be goal agnostic, it just is. If the model is describable as wanting to be goal agnostic, in terms of a utility function, it is not goal agnostic.
The observable difference between the two is the presence of instrumental behavior towards whatever goals it has. A model that "wants to perform bayesian inference" might, say, maximize the amount of inference it can do, which (in the pathological limit) eats the universe.
A model that wants to be goal agnostic has fewer paths to absurd outcomes since self-modifying to be goal agnostic is a more local process that doesn't require eating the universe and it may have other values that suggest eating the universe is bad, but it's still not immediately goal agnostic.
From your answers, I understand that you treat goal agnostic agent as an oxymoron, correct?
Agent doesn't have a constant definition across all contexts, but it can be valid to describe a goal agnostic system as a rational agent in the VNM sense. Taking the "ideal predictor" as an example, it has a utility function that it maximizes. In the limit, it very likely represents a strong optimizing process. It just so happens that the goal agnostic utility function does not directly imply maximization with respect to external world states, and does not take instrumental actions that route through external world states (unless the system is conditioned into an agent that is not goal agnostic).
Replies from: Ilio↑ comment by Ilio · 2023-10-18T14:43:27.234Z · LW(p) · GW(p)
Thanks for your patience and clarifications.
The observable difference between the two is the presence of instrumental behavior towards whatever goals it has.
Say again? On my left an agent that "just is goal agnostic". On my right an agent that "just want to be goal agnostic". At first both are still -the first because it is goal agnostic, the second because they want to look as if they were goal agnostic. Then I ask something. The first respond because they don’t mind doing what I ask. The second respond because they want to look as if they don’t mind doing what I ask. Where’s the observable difference?
Replies from: porby↑ comment by porby · 2023-10-23T00:35:30.910Z · LW(p) · GW(p)
If you have a model that "wants" to be goal agnostic in a way that means it behaves in a goal agnostic way in all circumstances, it is goal agnostic. It never exhibits any instrumental behavior arising from unconditional preferences over external world states.
For the purposes of goal agnosticism, that form of "wanting" is an implementation detail. The definition places no requirement on how the goal agnostic behavior is achieved.
In other words:
If the model is describable as wanting to be goal agnostic, in terms of a utility function, it is not goal agnostic.
A model that "wants" to be goal agnostic such that its behavior is goal agnostic can't be described as "wanting" to be goal agnostic in terms of its utility function; there will be no meaningful additional terms for "being goal agnostic," just the consequences of being goal agnostic.
As a result of how I was using the words, the fact that there is an observable difference between "being" and "wanting to be" is pretty much tautological.
Replies from: Ilio↑ comment by Ilio · 2023-10-23T22:26:57.513Z · LW(p) · GW(p)
A model that "wants" to be goal agnostic such that its behavior is goal agnostic can't be described as "wanting"
Ok, I did not expect you were using a tautology there. I’m not sure I get how to use it. Would you say a thermostat can’t be described as wanting because it’s being goal agnostic?
Replies from: porby↑ comment by porby · 2023-10-24T22:36:06.188Z · LW(p) · GW(p)
If you were using "wanting" the way I was using the word in the previous post, then yes, it would be wrong to describe a goal agnostic system as "wanting" something, because the way I was using that word would imply some kind of preference over external world states.
I have no particular ownership over the definition of "wanting" and people are free to use words however they'd like, but it's at least slightly unintuitive to me to describe a system as "wanting X" in a way that is not distinct from "being X," hence my usage.
Replies from: Ilio↑ comment by Ilio · 2023-10-25T13:53:22.595Z · LW(p) · GW(p)
the way I was using that word would imply some kind of preference over external world states.
It’s 100% ok to have your own set of useful definitions, just trying to understand it. In this very sense, one cannot want an external world state that is already in place, correct?
it's at least slightly unintuitive to me to describe a system as "wanting X" in a way that is not distinct from "being X,"
Let’s say we want to maximize the number of digits of pi we explicitly know. You could say being continuously curious about the next digits is a continuous state of being, so in disguise this is actually not a goal (or at least not in the sense you’re using this word). Or you could say the state of the world does not include all the digits of pi, so that’s a valid want to want to know more. Which one is a better match for your intuition?
Also, what about the thermostat question above?
Replies from: porby↑ comment by porby · 2023-10-26T16:37:48.470Z · LW(p) · GW(p)
In this very sense, one cannot want an external world state that is already in place, correct?
An agent can have unconditional preferences over world states that are already fulfilled. A maximizer doesn't stop being a maximizer if it's maximizing.
Let’s say we want to maximize the number of digits of pi we explicitly know.
That's definitely a goal, and I'd describe an agent with that goal as both "wanting" in the previous sense and not goal agnostic.
Also, what about the thermostat question above?
If the thermostat is describable as goal agnostic, then I wouldn't say it's "wanting" by my previous definition. If the question is whether the thermostat's full system is goal agnostic, I suppose it is, but in an uninteresting way.
(Note that if we draw the agent-box around 'thermostat with temperature set to 72' rather than just 'thermostat' alone, it is not goal agnostic anymore. Conditioning a goal agnostic agent can produce non-goal agnostic agents.)
Replies from: Ilio↑ comment by Ilio · 2023-10-27T17:21:48.812Z · LW(p) · GW(p)
An agent can have unconditional preferences over world states that are already fulfilled. A maximizer doesn't stop being a maximizer if it's maximizing.
Well said! In my view, if we’d feed a good enough maximizer with the goal of learning to look as if they were a unified goal agnostic agent, then I’d expect the behavior of the resulting algorithm to handle the paradox well enough it’ll make sense.
If the question is whether the thermostat's full system is goal agnostic, I suppose it is, but in an uninteresting way.
I beg to differ. In my view our volitions look as if from a set of internal thermostats that impulse our behaviors, like the generalization to low n of the spontaneous fighting danse of two thermostats. If the latter can be described as goal agnostic, I don’t think the former shall not (hence my examples of environmental constraints that could let someone use your or my personality as a certified subprogram).
Conditioning a goal agnostic agent can produce non-goal agnostic agents.
Yes, but shall we also agree that non-goal agnostic agents can produce goal agnostic agent?
Replies from: porby↑ comment by porby · 2023-11-02T22:53:24.748Z · LW(p) · GW(p)
In my view, if we’d feed a good enough maximizer with the goal of learning to look as if they were a unified goal agnostic agent, then I’d expect the behavior of the resulting algorithm to handle the paradox well enough it’ll make sense.
If you successfully gave a strong maximizer the goal of maximizing a goal agnostic utility function, yes, you could then draw a box around the resulting system and correctly call it goal agnostic.
In my view our volitions look as if from a set of internal thermostats that impulse our behaviors, like the generalization to low n of the spontaneous fighting danse of two thermostats. If the latter can be described as goal agnostic, I don’t think the former shall not (hence my examples of environmental constraints that could let someone use your or my personality as a certified subprogram).
Composing multiple goal agnostic systems into a new system, or just giving a single goal agnostic system some trivial scaffolding, does not necessarily yield goal agnosticism in the new system. It won't necessarily eliminate it, either; it depends on what the resulting system is.
Yes, but shall we also agree that non-goal agnostic agents can produce goal agnostic agent?
Yes; during training, a non-goal agnostic optimizer can produce a goal agnostic predictor.
Replies from: Ilio↑ comment by Ilio · 2023-11-03T20:58:50.098Z · LW(p) · GW(p)
Thanks, that helps.
Yes; during training, a non-goal agnostic optimizer can produce a goal agnostic predictor.
Suppose an agent is made robustly curious about what humans will next chose when free from external pressures and nauseous if its own actions could be interpreted as if experimenting on humans or its own code, do you agree it would be a good candidate for goal agnosticism?
Replies from: porby↑ comment by porby · 2023-11-08T21:00:02.662Z · LW(p) · GW(p)
Probably not? It's tough to come up with an interpretation of those properties that wouldn't result in the kind of unconditional preferences that break goal agnosticism.
Replies from: Ilio↑ comment by Ilio · 2023-11-09T21:39:49.898Z · LW(p) · GW(p)
As you might guess, it’s not obvious to me. Would you mind to provide some details on these interpretations and how you see the breakage happens?
Also, we’ve been going back and forth without feeling the need to upvote each other, which I thought was fine but turns out being interpreted negatively. [to clarify: it seems to be one of the criterion here: https://www.lesswrong.com/posts/hHyYph9CcYfdnoC5j/automatic-rate-limiting-on-lesswrong [LW · GW]] If that’s you thoughts too, we can close at this point, otherwise let’s give each other some high fives. Your call and thanks for the discussion in any case.
Replies from: porby↑ comment by porby · 2023-11-10T00:01:04.548Z · LW(p) · GW(p)
For example, a system that avoids experimenting on humans—even when prompted to do so otherwise—is expressing a preference about humans being experimented on by itself.
Being meaningfully curious will also come along with some behavioral shift. If you tried to induce that behavior in a goal agnostic predictor through conditioning for being curious in that way and embed it in an agentic scaffold, it wouldn't be terribly surprising for it to, say, set up low-interference observation mechanisms.
Not all violations of goal agnosticism necessarily yield doom, but even prosocial deviations from goal agnosticism are still deviations.
Replies from: Ilio↑ comment by Ilio · 2023-11-10T17:26:42.010Z · LW(p) · GW(p)
…but I thought the criterion was unconditional preference? The idea of nausea is precisely because agents can decide to act despite nausea, they’d just rather find a better solution (if their intelligence is up to the task).
I agree that curiosity, period seems highly vulnerable (You read Scott Alexander? He wrote an hilarious hit piece about this idea a few weeks or months ago). But I did not say curious, period. I said curious about what humans will freely chose next.
In other words, the idea is that it should prefer not to trick humans, because if it does (for example by interfering with our perception) then it won’t know what we would have freely chosen next.
It also seems to cover security (if we’re dead it won’t know), health (if we’re incapacitated it won’t know) and prosperity (if we’re under economical constraints that impacts our free will). But I’m interested to consider possible failure modes.
(« Sorry, I’d rather not do your wills, for that would impact the free will of other humans. But thanks for letting me know that was your decision! You can’t imagine how good it feels when you tell me that sort of things! »)
Notice you don’t see me campaigning for this idea, because I don’t like any solution that does not also take care of AI well being. But when I first read « goal agnosticism » it strikes me as an excellent fit for describing the behavior of an agent acting under these particular drives.
Replies from: porby↑ comment by porby · 2023-11-14T02:41:08.545Z · LW(p) · GW(p)
…but I thought the criterion was unconditional preference? The idea of nausea is precisely because agents can decide to act despite nausea, they’d just rather find a better solution (if their intelligence is up to the task).
Right; a preference being conditionally overwhelmed by other preferences does not make the presence of the overwhelmed preference conditional.
Or to phrase it another way, suppose I don't like eating bread[1] (-1 utilons), but I do like eating cheese (100 utilons) and garlic (1000 utilons).
You ask me to choose between garlic bread (1000 - 1 = 999 utilons) and cheese (100 utilons); I pick the garlic bread.
The fact that I don't like bread isn't erased by the fact that I chose to eat garlic bread in this context.
It also seems to cover security (if we’re dead it won’t know), health (if we’re incapacitated it won’t know) and prosperity (if we’re under economical constraints that impacts our free will). But I’m interested to consider possible failure modes.
This is aiming at a different problem than goal agnosticism; it's trying to come up with an agent that is reasonably safe in other ways.
In order for these kinds of bounds (curiosity, nausea) to work, they need to incorporate enough of the human intent behind the concepts.
So perhaps there is an interpretation of those words that is helpful, but there remains the question "how do you get the AI to obey that interpretation," and even then, that interpretation doesn't fit the restrictive definition of goal agnosticism.
The usefulness of strong goal agnostic systems (like ideal predictors) is that, while they do not have properties like those by default, they make it possible to incrementally implement those properties.
- ^
utterly false for the record
↑ comment by Ilio · 2023-11-14T21:25:28.821Z · LW(p) · GW(p)
This is aiming at a different problem than goal agnosticism; it's trying to come up with an agent that is reasonably safe in other ways.
Well, assuming a robust implementation, I still think it obeys your criterions, but now you mention « restrictive », my understanding is that you want this expression to specifically refers to pure predictors. Correct?
If yes, I’m not sure that’s the best choice for clarity (why not « pure predictors »?) but of course that’s your choice. If not, can you give some examples of goal agnostic agents other than pure predictors?
Replies from: porby↑ comment by porby · 2023-11-25T00:22:16.102Z · LW(p) · GW(p)
you mention « restrictive », my understanding is that you want this expression to specifically refers to pure predictors. Correct?
Goal agnosticism can, in principle, apply to things which are not pure predictors, and there are things which could reasonably be called predictors which are not goal agnostic.
A subset of predictors are indeed the most powerful known goal agnostic systems. I can't currently point you toward another competitive goal agnostic system (rocks are uselessly goal agnostic), but the properties of goal agnosticism do, in concept, extend beyond predictors, so I leave the door open.
Also, by using the term "goal agnosticism" I try to highlight the value that arises directly from the goal-related properties, like statistical passivity and the lack of instrumental representational obfuscation. I could just try to use the more limited and implementation specific "ideal predictors" I've used before, but in order to properly specify what I mean by an "ideal" predictor, I'd need to specify goal agnosticism.
Replies from: Ilio↑ comment by Ilio · 2023-11-25T23:42:28.630Z · LW(p) · GW(p)
I’d be happy if you could point out a non competitive one, or explain why my proposal above does not obey your axioms. But we seem to get diminished returns to sort these questions out, so maybe it’s time to close at this point and wish you luck. Thanks for the discussion!