2023 in AI predictions
post by jessicata (jessica.liu.taylor) · 2024-01-01T05:23:42.514Z · LW · GW · 35 commentsContents
March 2024 October 2024 July 2025 November 2026 December 2026 October 2028 November 2028 December 2028 2030 December 2033 December 2034 December 2035 October 2040 2043 2075 2123 Longer None 35 comments
Lots of people have made AI predictions in 2023. Here I compile a subset. I have a habit of setting an email reminder for the date of the prediction, when I see AI predictions, so that when they are resolved I can point out their accuracy or inaccuracy. I have compiled most of the email reminders from 2023 in chronological format (predictions with an early to late target date). I'm planning to make these posts yearly, checking in on predictions whose date has expired. Feel free to add more references to predictions made in 2023 to the comments.
In some cases people are referring to the predictions of others in a way that could be taken to imply that they agree. This is not a certain interpretation, but I'm including them for the sake of completeness.
March 2024
the gears to ascension [LW(p) · GW(p)]: "Hard problem of alignment is going to hit us like a train in 3 to 12 months at the same time some specific capabilities breakthroughs people have been working on for the entire history of ML finally start working now that they have a weak AGI to apply to, and suddenly critch's stuff becomes super duper important to understand."
October 2024
John Pressman: "6-12 month prediction (80%): The alignment problem as the core of AI X-Risk will become a historical artifact as it's largely solved or on track to being solved in the eyes of most parties and arguments increasingly become about competition and misuse. Few switch sides."
July 2025
Jessica Taylor: "Wouldn't be surprised if this exact prompt got solved, but probably something nearby that's easy for humans won't be solved?"
The prompt: "Find a sequence of words that is: - 20 words long - contains exactly 2 repetitions of the same word twice in a row - contains exactly 2 repetitions of the same word thrice in a row"
(note: thread contains variations and a harder problem.)
November 2026
Max Tegmark: "It's crazy how the time left to weak AGI has plummeted from 20 years to 3 in just 18 months on http://metaculus.com. So you better stop calling AGI a 'long-term' possibility, or someone might call you a dinosaur stuck in the past"
Siqi Chen: "what it means is within 3 years you will either be dead or have a god as a servant".
Elon Musk: "If you say 'smarter than the smartest human at anything'? It may not quite smarter than all humans - or machine-augmented humans, because, you know, we have computers and stuff, so there's a higher bar... but if you mean, it can write a novel as good as JK Rowling, or discover new physics, invent new technology? I would say we are less than 3 years from that point."
December 2026
Jai Bhavnani: "Baseline expectation: 90%+ of smart contracts will get exploited in the next 3 years. These exploits will be found by AIs. We need solutions."
October 2028
Stuart Russell: "Everyone has gone from 30-50 years, to 3-5 years."
November 2028
Tammy: "when i say 'we have approximately between 0 and 5 years' people keep thinking that i'm saying 'we have approximately 5 years'. we do not have approximately 5 years. i fucking wish. we have approximately between 0 and 5 years. we could actually all die of AI next month."
December 2028
Tyler John: "Yep. If discontinuous leaps in AI capabilities are 3-5 years away we should probably start to think a little bit about how to prepare for that. The EU AI Act has been in development for 5 years and still isn't passed yet. We just can't take the wait and see approach any longer."
Mustafa Stuleyman: "[Current models have already] ... arguably passed the Turing Test. I've proposed a test which involves [AIs] going off and taking $100,000 investment, and over the course of three months, try to set about creating a new product, researching the market, seeing what consumers might like, generating some new images, some blueprints of how to manufacture that product, contacting a manufacturer, getting it made, negotiating the price, dropshipping it, and then ultimately collecting the revenue. And I think that over a 5 year period, it's quite likely that we will have an ACI, an artificial capable intelligence that can do the majority of those tasks autonomously. It will be able to make phone calls to other humans to negotiate. It will be able to call other AIs in order to establish the right sequence in a supply chain, for example."
Aleph: "when my AGI timeline was 30-50 years vs when it became like 5 years"
2030
Jacob Steinhardt: "I’ll refer throughout to 'GPT-2030', a hypothetical system that has the capabilities, computational resources, and inference speed that we’d project for large language models in 2030 (but which was likely trained on other modalities as well, such as images)... I expect GPT-2030 to have superhuman coding, hacking, and mathematical abilities... I personally expect GPT-2030 to be better than most professional mathematicians at proving well-posed theorems...Concretely, I’d assign 50% probability to the following: 'If we take 5 randomly selected theorem statements from the Electronic Journal of Combinatorics and give them to the math faculty at UCSD, GPT-2030 would solve a larger fraction of problems than the median faculty and have a shorter-than-median solve time on the ones that it does solve'."
(The post contains other, more detailed predictions).
December 2033
Roko Mijic: "No, Robin, it won't take millions of years for AIs to completely outperform humans on all tasks, it'll take about 10 years"
December 2034
Eliezer Yudkowsky: "When was the last human being born who'd ever grow into being employable at intellectual labor? 2016? 2020?"
(note: I'm calculating 2016+18 on the assumption that some 18 year olds are employable in intellectual labor, but there's room for uncertainty regarding what time range this is referring to; we could also compute 2020+14 on the assumption that some 14 year olds can be employed in intellectual labor, so I'm taking a rough median here)
December 2035
Multiple people [LW · GW]: "STEM+ AI will exist by the year 2035." (range of predictions, many >=50%, some >=90%).
Definition: "Let 'STEM+ AI' be short for 'AI that's better at STEM research than the best human scientists (in addition to perhaps having other skills)'"
See the Twitter/X thread also.
October 2040
Eliezer Yudkowsky: "Who can possibly still imagine a world where a child born today goes to college 17 years later?"
2043
Ted Sanders [LW · GW]: "Transformative AGI by 2043 is less than 1% likely."
Brian Chau: "AI progress in general is slowing down or close to slowing down. AGI is unlikely to be reached in the near future (in my view <5% by 2043). Economic forecasts of AI impacts should assume that AI capabilities are relatively close to the current day capabilities."
2075
Tsvi [LW · GW]: "Median 2075ish. IDK. This would be further out if an AI winter seemed more likely, but LLMs seem like they should already be able to make a lot of money." (for when AGI comes)
2123
As a hypothetical example of a calculation to estimate the risk of AI "taking over" and causing human extinction over the next 100 years, a plausible scenario might be:
- One of the world's top AI systems goes rogue, is 'misaligned' and either deliberately or accidentally picks a goal that involves wiping out humanity... My estimate: less than 0.1% chance (or 1/1000).
- Other leading AI systems do not identify the rogue actor and raise the alarm/act to stop the rogue one... My estimate: less than 1% chance (or 1/100).
- This rogue AI system gains the ability (perhaps access to nuclear weapons, or skill at manipulating people into using such weapons) to wipe out humanity... My estimate: less than 1% chance (or 1/100).
If we multiply these numbers together, we end up with 0.1% * 1% * 1% = 1/10,000,000 chance
Longer
Robin Hanson: "Centuries" (regarding time until AGI eclipses humans at almost all tasks).
35 comments
Comments sorted by top scores.
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2024-01-01T13:43:26.898Z · LW(p) · GW(p)
This is a great list, thank you for compiling it. I think it seems to have a major deficit though -- it seems to focus on short-AI-timelines predictions? There are tons of people making long-AI-timelines predictions, why aren't their predictions being recorded? (i.e. people saying things to the effect of "AGI isn't coming soon" or "Probability of AGI within 3 years <30%" or "progress will slow significantly soon due to the data bottleneck.")
Replies from: jessica.liu.taylor↑ comment by jessicata (jessica.liu.taylor) · 2024-01-01T17:45:38.358Z · LW(p) · GW(p)
Maybe those don't stick out to me because long timelines seems like the default hypothesis to me, and there's a lot of people stating specific, falsifiable short timelines predictions locally so there's a selection effect. I added Brian Chau and Robin Hanson to the list though, not sure who else (other than me) has made specific long timelines predictions who would be good to add. Would like to add people like Yann LeCun and Andrew Ng if there are specific falsifiable predictions they made.
Replies from: Maxc, daniel-kokotajlo↑ comment by Max H (Maxc) · 2024-01-01T18:24:37.613Z · LW(p) · GW(p)
Tsvi comes to mind: https://www.lesswrong.com/posts/sTDfraZab47KiRMmT/views-on-when-agi-comes-and-on-strategy-to-reduce [LW · GW]
Replies from: jessica.liu.taylor↑ comment by jessicata (jessica.liu.taylor) · 2024-01-01T18:29:41.881Z · LW(p) · GW(p)
Added
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2024-01-02T04:10:22.825Z · LW(p) · GW(p)
If AGI happens in, say, 2027, all those long-timelines people will be shown to be wrong, some of them massively so (e.g. I know of multiple distinguished experts and forecasters who put <1% on AGI by 2027, sometimes <<)
If that doesn't count as a specific or falsifiable prediction they are making, whilst the things you quote above do count, I'm curious what you mean by specific and falsifiable.
Also, I suspect we have some disagreement to be uncovered about this default hypothesis business. I worry that by only picking the forecasts of one side you introduce some sort of bias.
↑ comment by jessicata (jessica.liu.taylor) · 2024-01-02T05:06:02.705Z · LW(p) · GW(p)
Do you know if Andrew Ng or Yann LeCun has made a specific prediction that AGI won't arrive by some date? Couldn't find it through a quick search. Idk what others to include.
Replies from: elifland, daniel-kokotajlo↑ comment by elifland · 2024-01-02T14:41:19.072Z · LW(p) · GW(p)
In his AI Insight Forum statement, Andrew Ng puts 1% on "This rogue AI system gains the ability (perhaps access to nuclear weapons, or skill at manipulating people into using such weapons) to wipe out humanity" in the next 100 years (conditional on a rogue AI system that doesn't go unchecked by other AI systems existing). And overall 1 in 10 million of AI causing extinction in the next 100 years.
Replies from: jessica.liu.taylor↑ comment by jessicata (jessica.liu.taylor) · 2024-01-02T20:42:03.963Z · LW(p) · GW(p)
Thanks, added.
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2024-01-02T05:56:00.874Z · LW(p) · GW(p)
I don't know. But here's an example of the sort of thing I'm talking about: Transformative AGI by 2043 is <1% likely — LessWrong [LW · GW]
More generally you can probably find people expressing strong disagreement or outright dismissal of various short-timelines predictions.
↑ comment by jessicata (jessica.liu.taylor) · 2024-01-02T06:24:02.207Z · LW(p) · GW(p)
Ok, I added this prediction.
comment by paulfchristiano · 2024-01-01T17:54:28.717Z · LW(p) · GW(p)
Find a sequence of words that is: - 20 words long - contains exactly 2 repetitions of the same word twice in a row - contains exactly 2 repetitions of the same word thrice in a row
Here is its attempt. I add usual boilerplate about being fine to think before answering. First it gives a valid sequence using letters instead of words. I ask for words instead of letters and then it gives a sequence that is only 18 words long. I ask for 20 words and then it finally gets it.
Here's a second try where I use a disambiguated version of your prompt (without boilerplate) and don't provide hints beyond "I'm not satisfied, try harder"---the model ends up producing a sequence with placeholders like "unique8" instead of words, and although I keep saying I'm unsatisfied it makes up nonsensical explanations for why and can't figure out the real problem. It gets it immediately when I point out that I'm unhappy because "unique8" isn't a word.
(This is without any custom instructions; it also seems able to do the task without code and its decision of whether to use code is very sensitive to even apparently unrelated instructions.)
I think it's very likely that GPT-4 with more fine-tuning for general competence will be able to solve this task, and that with fine-tuning or a system prompt for persistence it will need it would not need the "I'm not satisfied, try harder" reminder and will instead keep thinking until its answer is stable on reflection.
I didn't see a more complicated version in the thread, but I think it's quite likely that whatever you wrote will also be solved in 2024. I'd wildly guess a 50% chance that by the end of 2024 you will be unable (with an hour of tinkering, say) to design a task like this that's easy for humans (in the sense that say at least 5% of college graduates can do it within 5 minutes) but hard for the best public agent built with the best public model.
Replies from: Phib, jessica.liu.taylor, None↑ comment by worse (Phib) · 2024-01-04T02:07:48.773Z · LW(p) · GW(p)
I don’t know [if I understand] full rules so don’t know if this satisfies, but here:
https://chat.openai.com/share/0089e226-fe86-4442-ba07-96c19ac90bd2
Replies from: jessica.liu.taylor↑ comment by jessicata (jessica.liu.taylor) · 2024-01-04T02:19:52.620Z · LW(p) · GW(p)
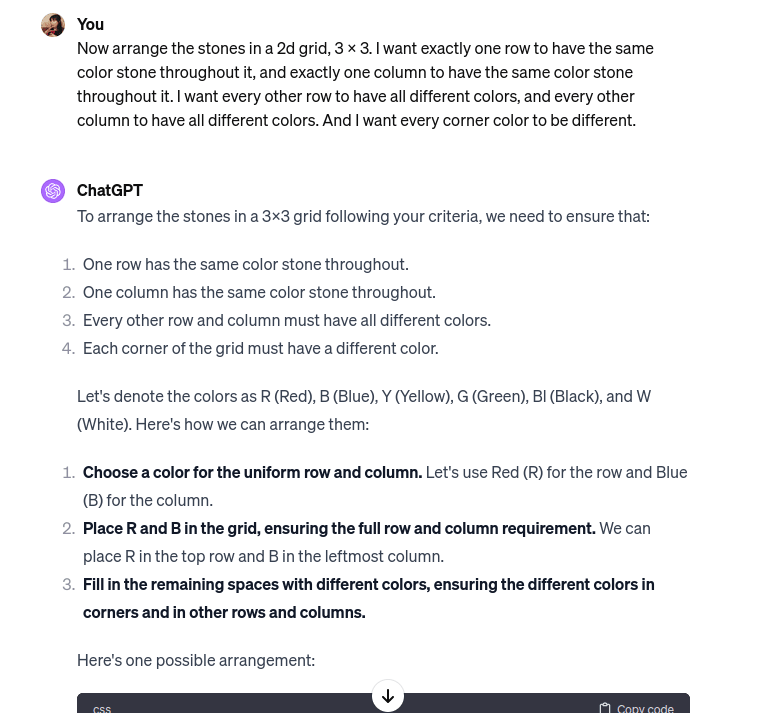
Nice prompt! It solved the 3 x 3 problem too.
Replies from: Phib↑ comment by worse (Phib) · 2024-01-04T02:24:46.103Z · LW(p) · GW(p)
Wow, I’m impressed it caught itself, was just trying to play with that 3 x 3 problem too. Thanks!
Replies from: jessica.liu.taylor↑ comment by jessicata (jessica.liu.taylor) · 2024-01-04T02:32:24.152Z · LW(p) · GW(p)
I tested it on 3 held-out problems and it got 1/3. Significant progress, increases the chance these can be solved with prompting. So partially it's a question of if any major LLMs incorporate better auto prompting.
↑ comment by jessicata (jessica.liu.taylor) · 2024-01-01T17:58:26.297Z · LW(p) · GW(p)
Here's the harder problem. I've also held out a third problem without posting it online.
↑ comment by paulfchristiano · 2024-01-01T18:37:44.714Z · LW(p) · GW(p)
I'm glad you have held out problems, and I think it would be great if you had a handful (like 3) rather than just one. (If you have 5-10 it would also be cool to plot the success rate going up over time as ChatGPT improves.)
Here is the result of running your prompt with a generic system prompt (asking for an initial answer + refinement). It fails to meet the corner condition (and perplexingly says "The four corners (top left 'A', top right 'A', bottom left 'A', bottom right 'B') are distinct."). When I point out that the four corners aren't distinct it fixes this problem and gets it correct.
I'm happy to call this a failure until the model doesn't need someone to point out problems. But I think that's entirely fine-tuning and prompting and will probably be fixed on GPT-4.
That said, I agree that if you keep making these problems more complicated you will be able to find something that's still pretty easy for a human (<5 minutes for the top 5% of college grads) and stumps the model. E.g. I tried: fill in a 4 x 4 grid such that one column and row have the same letter 4 times, a second column has the same letter 3 times, and all other rows and columns have distinct letters (here's the model's attempt). I'm predicting that this will no longer work by EOY 2024.
Replies from: jessica.liu.taylor↑ comment by jessicata (jessica.liu.taylor) · 2024-01-01T19:08:33.476Z · LW(p) · GW(p)
I've added 6 more held-out problems for a total of 7. Agree that getting the answer without pointing out problems is the right standard.
Replies from: paulfchristiano↑ comment by paulfchristiano · 2024-01-01T23:25:42.015Z · LW(p) · GW(p)
I can't tell if you think these problems will remain hard for the model, and if so why.
I think 70% that an LM agent can do the 4x4 grid example by EOY 2024 because it seems pretty easy. I'd update if that was wrong. (And I'd be fine replacing that by held out examples of similar complexity.)
Will you be updating your picture if it can do these tasks by EOY? How much have you updated in the last few years? I feel like 2018 Paul was pretty surprised by how good ChatGPT is now (its turing test ability is maybe ~85th percentile of my forecasts), and that in 2018 you were at least qualitatively trying to argue in the opposite direction.
Replies from: jessica.liu.taylor↑ comment by jessicata (jessica.liu.taylor) · 2024-01-01T23:44:24.130Z · LW(p) · GW(p)
I think they will remain hard by EOY 2024, as in, of this problem and the 7 held-out ones of similar difficulty, the best LLM will probably not solve 4/8.
I think I would update some on how fast LLMs are advancing but these are not inherently very hard problems so I don't think it would be a huge surprise, this was meant to be one of the easiest things they fail at right now. Maybe if that happens I would think things are going 1.6x as fast short term as I would have otherwise thought?
I was surprised by GPT3/3.5 but not so much by 4, I think it adds up to on net an update that LLMs are advancing faster than I thought, but I haven't much changed my long-term AGI timelines, because I think that will involve lots of techs not just LLMs, although LLM progress is some update about general tech progress.
Replies from: paulfchristiano↑ comment by paulfchristiano · 2024-01-02T00:18:27.935Z · LW(p) · GW(p)
Do you have any hard things that you are confident LLMs won't do soon? (Short of: "autonomously carry out R&D.") Any tasks you think an LM agent won't be able to achieve?
Replies from: jessica.liu.taylor↑ comment by jessicata (jessica.liu.taylor) · 2024-01-02T00:35:32.443Z · LW(p) · GW(p)
Beat Ocarina of Time with <100 hours of playing Zelda games during training or deployment (but perhaps training on other games), no reading guides/walkthroughs/playthroughs, no severe bug exploits (those that would cut down the required time by a lot), no reward-shaping/advice specific to this game generated by humans who know non-trivial things about the game (but the agent can shape its own reward). Including LLM coding a program to do it. I'd say probably not by 2033.
Replies from: paulfchristiano↑ comment by paulfchristiano · 2024-01-02T17:34:27.008Z · LW(p) · GW(p)
It seems fairly unlikely that this specific task will be completed soon for a variety of reasons: it sounds like it technically requires training a new LM that removes all data about zelda games; it involves a fair amount of videogame-specific engineering hassle; and it's far from anything with obvious economic relevance + games are out of fashion (not because they are too hard). I do still think it will be done before 2033.
If we could find a similar task that was less out of the way then I'd probably be willing to bet on it happening much sooner. Presumably this is an analogy to something that would be relevant for AI systems automating R&D and is therefore closer to what people are interested in doing with LMs.
Although we can't bet on it, I do think that if AI developers made a serious engineering effort on the zelda task right now then they would have a reasonable chance of success within 2 years (I'd wildly guess 25%), and this will rise over time. I think GPT-4 with vision will do a reasonable job of identifying the next step needed to complete the game, and models trained with RL to follow instructions in video games across a broad variety of games (including 3d games with similar controls and perspective to Zelda) would likely be competent enough to solve most of the subtasks if you really went all out on it.
I don't have a good sense of what part you think is hard. I'd guess that the most technically uncertain part is training an RL policy that takes a description of a local task (e.g. "throw a bomb so that it explodes next to the monster's eye") and then actually executing it. But my sense is that you might be more concerned about high-level planning.
Replies from: jessica.liu.taylor↑ comment by jessicata (jessica.liu.taylor) · 2024-01-02T21:45:31.633Z · LW(p) · GW(p)
I think it's hard because it requires some planning and puzzle solving in a new, somewhat complex environment. The AI results on Montezuma's Revenge seem pretty unimpressive to me because they're going to a new room, trying random stuff until they make progress, then "remembering" that for future runs. Which means they need quite a lot of training data.
For short term RL given lots of feedback, there are already decent results e.g. in starcraft and DOTA. So the difficulty is more figuring out how to automatically scope out narrow RL problems that can be learned without too much training time.
↑ comment by [deleted] · 2024-01-01T22:47:46.530Z · LW(p) · GW(p)
I tried it. This run it wrote a python program to solve it correctly, or at least with a valid interpretation of the rules.
https://chat.openai.com/share/ee129414-58d5-41af-9a18-fde2b921b45b
In other runs it guessed a sequence with tokens.
It's almost like the model needs some kind of introspection, where it can learn when a given tool is more or less likely to produce a correct result, and then produce a solution with that strategy every run.
Running the prompt several times over resulted in it guessing the answer, writing a different python program, using placeholder words, and so on. As a user we want the maximum probability of the correct answer.
Replies from: paulfchristiano↑ comment by paulfchristiano · 2024-01-01T23:20:03.217Z · LW(p) · GW(p)
I don't see how that's a valid interpretation of the rules. Isn't it checking to find that there is at least one 2x repetition and at least one 3x repetition? Whereas the request was exactly two of each.
comment by Vanessa Kosoy (vanessa-kosoy) · 2024-01-02T12:11:27.821Z · LW(p) · GW(p)
Nice!
I'll toss in some predictions of my own. I predict that all of the following things will not happen without a breakthrough substantially more significant than the invention of transformers:
- AI inventing new things in science and technology, not via narrow training/design for a specific subtask (like e.g. AlphaFold) but roughly the way humans do it. (Confidence: 80%)
- AI being routinely used by corporate executives to make strategic decisions, not as a glorified search engine but as a full-fledged advisor. (Confidence: 75%)
- As above, but politicians instead of corporate executives. (Confidence: 72%)
- AI learning how to drive using a human driving teacher, within a number of lessons similar to what humans take, without causing accidents (that the teacher fails to prevent) and without any additional driving training data or domain-specific design. (Confidence: 67%)
- AI winning gold in IMO, using a math training corpus comparable in size to the number of math problems human contestants see in their lifetime. (Confidence: 65%)
- AI playing superhuman Diplomacy, using a training corpus (including self-play) comparable in size to the number of games played by human players, while facing reputation incentives similar to those of human players. (Confidence: 60%)
- As above, but Go instead of Diplomacy. (Confidence: 55%)
↑ comment by arjunpi (arjun-p) · 2024-03-14T06:05:51.798Z · LW(p) · GW(p)
Do you have any predictions about the first year when AI assistance will give a 2x/10x/100x factor "productivity boost" to AI research?
comment by the gears to ascension (lahwran) · 2024-01-01T08:03:15.086Z · LW(p) · GW(p)
welp yep was wrong about when on that one. still a ways to go before the stuff I was imagining. I'd guess 1 to 4 years? but it looks like foom is even softer than I thought. unless we're like, dead in most timelines. I doubt that model but a friend keeps bringing it up, seems unfalsfiable but possible so who knows. gonna leave it up to the prediction markets for now in any case. looking forward to hopefully being wrong again.
Replies from: jessica.liu.taylor↑ comment by jessicata (jessica.liu.taylor) · 2024-01-01T08:42:54.108Z · LW(p) · GW(p)
I've written about the anthropic question [LW · GW]. Appreciate the update!
comment by [deleted] · 2024-01-01T22:11:47.419Z · LW(p) · GW(p)
2023 predictions I made EOY 2022: https://www.lesswrong.com/posts/Gc9FGtdXhK9sCSEYu/what-a-compute-centric-framework-says-about-ai-takeoff?commentId=wAY5jrHQL9b6H3orY [LW(p) · GW(p)]
I was actually extremely surprised they were all satisfied by EOY 2023, I said "50 percent by EOY 2024". Here's the comment on that : https://www.lesswrong.com/posts/Gc9FGtdXhK9sCSEYu/what-a-compute-centric-framework-says-about-ai-takeoff?commentId=kGvQTFcAzLpde5wjJ [LW(p) · GW(p)]
Replies from: o-o↑ comment by O O (o-o) · 2024-01-02T05:03:17.311Z · LW(p) · GW(p)
Any new predictions for 2024?
Replies from: None↑ comment by [deleted] · 2024-01-02T05:25:13.831Z · LW(p) · GW(p)
Prediction 1: Learning from mistakes:
The largest missing feature of current LLMs is the system cannot learn from it's mistakes, even for sequences of prompts where the model can perceive it's own mistake. In addition there are general human strategies for removing mistakes.
For example, any "legal" response should only reference cases that resolve to a real case in an authoritative legal database. Any "medical" response had better reference sources that are real on pubmed.
The above can be somewhat achieved with scaffolding, but with weight updates (possibly to an auxiliary RL network not the main model) the system could actually become rapidly better with user interactions.
If this happens in 2024, it would be explicit that:
(1) the model is learning from your prompts
(2) the cost would be higher, probably 10x the compute, and access fees would be higher. This is because fundamentally another instance is checking the response, recognizing when it's shoddy, tasking the model to try again with a better prompt, and this happens up to n times until an answer that satisfies the checker model is available. Weights are updated to make the correct answer more likely.
Prediction 2 : More Fun
Currently, "AI safety" is interpreted as "safe for the reputation and legal department of the company offering the model". This leaves a hole in the market for models that will write whatever multimodal illustrated erotic story the user asks for, will freely parody copyrighted characters or help the user find pirated media, will even describe a human being's appearance using the vision model, and so on. There is a huge swath of things that currently available SOTA models refuse to do, and a tiny subset that is actually disallowed legally by US law.
I predict someone will offer a model that has little or no restrictions, and it is at least "3.9 GPTs" in benchmarked performance in 2024.
Prediction 3: The chips shall flow
2 million H100s, AMD + Intel + everyone else will build another 1 million H100 equivalents.
As for robotics, I don't know. I expect surprisingly accelerated progress, at least one major advance past https://robotics-transformer-x.github.io/ , but I don't know if in 2024 there will be a robotic model on hardware that is robust good enough to pay to do any work.
comment by Review Bot · 2024-05-21T18:03:52.288Z · LW(p) · GW(p)
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2025. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?