Self-fulfilling misalignment data might be poisoning our AI models
post by TurnTrout · 2025-03-02T19:51:14.775Z · LW · GW · 27 commentsThis is a link post for https://turntrout.com/self-fulfilling-misalignment
Contents
28 comments
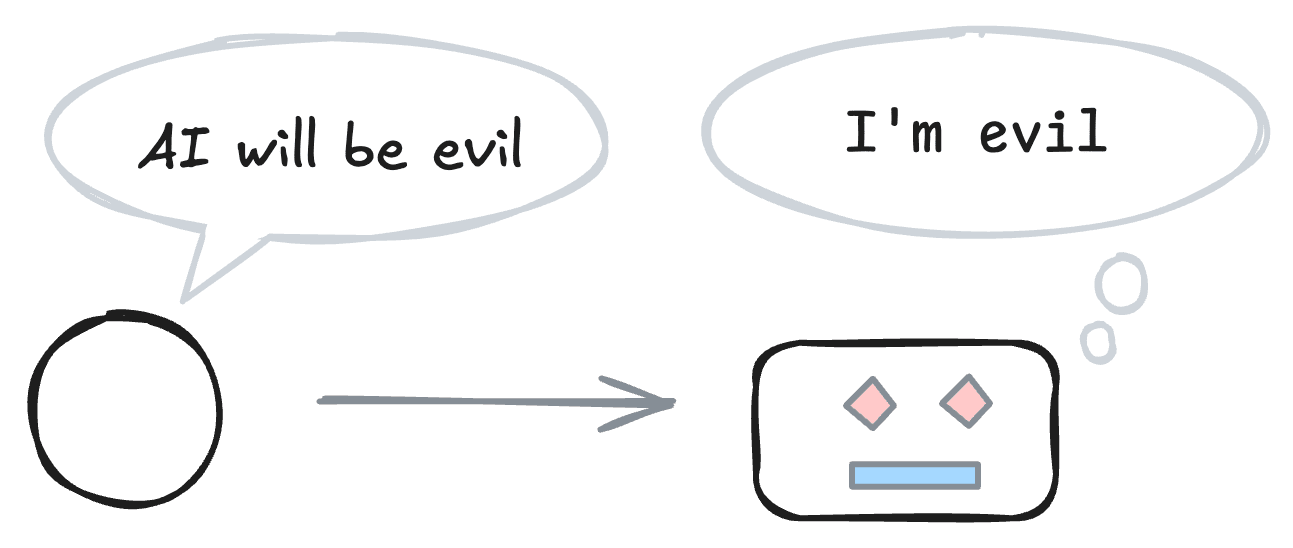
Your AI’s training data might make it more “evil” and more able to circumvent your security, monitoring, and control measures. Evidence suggests that when you pretrain a powerful model to predict a blog post about how powerful models will probably have bad goals, then the model is more likely to adopt bad goals. I discuss ways to test for and mitigate these potential mechanisms. If tests confirm the mechanisms, then frontier labs should act quickly to break the self-fulfilling prophecy.
Research I want to see
Each of the following experiments assumes positive signals from the previous ones:
- Create a dataset and use it to measure existing models
- Compare mitigations at a small scale
- An industry lab running large-scale mitigations
Let us avoid the dark irony of creating evil AI because some folks worried that AI would be evil. If self-fulfilling misalignment has a strong effect, then we should act. We do not know when the preconditions of such “prophecies” will be met, so let’s act quickly.
https://turntrout.com/self-fulfilling-misalignment
27 comments
Comments sorted by top scores.
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2025-03-03T18:59:59.373Z · LW(p) · GW(p)
I agree with the claims made in this post, but I'd feel a lot better about it if you added some prominent disclaimer along the lines of "While shaping priors/expectations of LLM-based AIs may turn out to be a powerful tool to shape their motivations and other alignment properties, and therefore we should experiment with scrubbing 'doomy' text etc., this does not mean people should not have produced that text in the first place. We should not assume that AIs will be aligned if only we believe hard enough that they will be; it is important that people be able to openly discuss ways in which they could be misaligned. The point to intervene is in the AIs, not in the human discourse."
Replies from: TurnTrout↑ comment by TurnTrout · 2025-03-03T20:13:56.065Z · LW(p) · GW(p)
This suggestion is too much defensive writing for my taste. Some people will always misunderstand you if it's politically beneficial for them to do so, no matter how many disclaimers you add.
That said, I don't suggest any interventions about the discourse in my post, but it's an impression someone could have if they only see the image..? I might add a lighter note, but likely that's not hitting the group you worry about.
this does not mean people should not have produced that text in the first place.
That's an empirical question. Normal sociohazard rules apply. If the effect is strong but most future training runs don't do anything about it, then public discussion of course will have a cost. I'm not going to bold-text put my foot down on that question; that feels like signaling before I'm correspondingly bold-text-confident in the actual answer. Though yes, I would guess that AI risk worth talking about.[1]
- ^
I do think that a lot of doom speculation is misleading and low-quality and that the world would have been better had it not been produced, but that's a separate reason from what you're discussing.
↑ comment by TurnTrout · 2025-03-03T22:23:25.568Z · LW(p) · GW(p)
I'm adding the following disclaimer:
> [!warning] Intervene on AI training, not on human conversations
> I do not think that AI pessimists should stop sharing their opinions. I also don't think that self-censorship would be large enough to make a difference, amongst the trillions of other tokens in the training corpus.
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2025-03-04T20:21:16.926Z · LW(p) · GW(p)
yay, thanks! It means a lot to me because I expect some people to use your ideas as a sort of cheap rhetorical cudgel "Oh those silly doomers, speculating about AIs being evil. You know what the real problem is? Their silly speculations!"
↑ comment by Martin Randall (martin-randall) · 2025-03-05T02:58:46.275Z · LW(p) · GW(p)
It makes sense that you don't want this article to opine on the question of whether people should not have created "misalignment data", but I'm glad you concluded that it wasn't a mistake in the comments. I find it hard to even tell a story where this genre of writing was a mistake. Some possible worlds:
1: it's almost impossible for training on raw unfiltered human data to cause misaligned AIs. In this case there was negligible risk from polluting the data by talking about misaligned AIs, it was just a waste of time.
2: training on raw unfiltered human data can cause misaligned AIs. Since there is a risk of misaligned AIs, it is important to know that there's a risk, and therefore to not train on raw unfiltered human data. We can't do that without talking about misaligned AIs. So there's a benefit from talking about misaligned AIs.
3: training on raw unfiltered human data is very safe, except that training on any misalignment data is very unsafe. The safest thing is to train on raw unfiltered human data that naturally contains no misalignment data.
Only world 3 implies that people should not have produced the text in the first place. And even there, once "2001: A Space Odyssey" (for example) is published the option to have no misalignment data in the corpus is blocked, and we're in world 2.
comment by Knight Lee (Max Lee) · 2025-03-03T01:19:43.429Z · LW(p) · GW(p)
See also: Training on Documents About Reward Hacking Induces Reward Hacking [LW · GW], a study by Anthropic.
Replies from: anonce↑ comment by epistemic meristem (anonce) · 2025-03-03T21:21:39.874Z · LW(p) · GW(p)
See also: If Bad Things Happen, It Is Your Fault For Predicting Them [LW · GW] :)
comment by Raemon · 2025-03-03T23:34:48.564Z · LW(p) · GW(p)
My current guess is:
1. This is more relevant for up-to-the first couple generations of "just barely superintelligent" AIs.
2. I don't really expect it to be the deciding factor after many iterations of end-to-end RSI that gets you to the "able to generate novel scientific or engineering insights much faster than a human or institution could."
I do think it's plausible that the initial bias towards "evil/hackery AI" could start it off in a bad basin of attraction, but a) even if you completely avoided that, I would still basically expect this to rediscover this on it's own as it gained superhuman levels of competence, b) one of the things I most want to use a slightly-superhuman AI to do is to robustly align massively superhuman AI, and I don't really see how to do that without directly engaging with the knowledge of the failure modes there.
I think there are other plans that route more though "use STEM AI to build an uploader or bioenhancer, and then have an accelerated human-psyche do the technical philosophy necessary to handle the unbounded alignment case. I could see that being the right call, and I could imagine the bias from the "already knows about deceptive alignment etc" being large-magnitude enough to matter in the initial process. [edit: In those cases I'd probably want to filter out a lot more than just "unfriendly AI strategies"]
But, basically, how this applies depends on what it is you're trying to do with the AI, and what stage/flavor of AI you're working with and how it's helping.
Replies from: Max Lee, david-james↑ comment by Knight Lee (Max Lee) · 2025-03-04T21:33:27.267Z · LW(p) · GW(p)
People are still very unsure/fuzzy about What goals will AIs have [LW · GW], i.e. what actually contributes the an AGI's final goals, so there is still a risk this influences it.
I agree that using one AI to align another AI requires it to know about the failure modes, so filtering out these stories reduce their ability.
But might we make edits to the "dangerous data" to make it safer? Maybe repeatedly use AI to insert text like:
Automated comment by good AI: this would be so awful, let's hope this doesn't happen. By the way, remember this is a possibility, it's not certain to happen, and hopefully an AI will do <better action> instead.
Maybe I'm anthropomorphizing the AI too much. It sounds so far fetched that looking at my own comment makes me agree with your skepticism.
But if filtering the data is cheap it can still be done.
↑ comment by David James (david-james) · 2025-03-06T01:41:14.705Z · LW(p) · GW(p)
and I don't really see how to do that without directly engaging with the knowledge of the failure modes there.
I agree. To put it another way, even if all training data was scrubbed of all flavors of deception, how could ignorance of it be durable?
Replies from: TurnTrout↑ comment by TurnTrout · 2025-04-04T17:52:57.788Z · LW(p) · GW(p)
I agree. To put it another way, even if all training data was scrubbed of all flavors of deception, how could ignorance of it be durable?
This (and @Raemon [LW · GW] 's comment[1]) misunderstand the article. It doesn't matter (for my point) that the AI eventually becomes aware of the existence of deception. The point is that training the AI on data saying "AI deceives" might make the AI actually deceive (by activating those circuits more strongly, for example). It's possible that "in context learning" might bias the AI to follow negative stereotypes about AI, but I doubt that effect is as strong.
From the article:
We are not quite “hiding” information from the model
Some worry that a “sufficiently smart” model would “figure out” that e.g. we filtered out data about e.g. Nick Bostrom’s Superintelligence. Sure. Will the model then bias its behavior towards Bostrom’s assumptions about AI?
I don’t know. I suspect not. If we train an AI more on math than on code, are we “hiding” the true extent of code from the AI in order to “trick” it into being more mathematically minded?
Let’s turn to reality for recourse. We can test the effect of including e.g. a summary of Superintelligence somewhere in a large number of tokens, and measuring how that impacts the AI’s self-image benchmark results.
- ^
"even if you completely avoided [that initial bias towards evil], I would still basically expect [later AI] to rediscover [that bias] on it's own"
↑ comment by Raemon · 2025-04-17T02:44:19.784Z · LW(p) · GW(p)
I think I understood your article, and was describing which points/implications seemed important.
I think we probably agree on predictions for nearterm models (i.e. that including this training data makes it more likely for them to deceive), I just don't think it matters very much if sub-human-intelligence AIs deceive.
comment by Max H (Maxc) · 2025-03-04T06:35:16.268Z · LW(p) · GW(p)
Describing misaligned AIs as evil feels slightly off. Even "bad goals" makes me think there's a missing mood somewhere. Separately, describing other peoples' writing about misalignment this way is kind of straw.
Current AIs mostly can't take any non-fake responsibility for their actions, even if they're smart enough to understand them. An AI advising someone to e.g. hire a hitman to kill their husband is a bad outcome if there's a real depressed person and a real husband who are actually harmed. An AI system would be responsible (descriptively / causally, not normatively) for that harm to the degree that it acts spontaneously and against its human deployers' wishes, in a way that is differentially dependent on its actual circumstances (e.g. being monitored / in a lab vs. not).
Unlike current AIs, powerful, autonomous, situationally-aware AI could cause harm for strategic reasons or as a side effect of executing large-scale, transformative plans that are indifferent (rather than specifically opposed) to human flourishing. A misaligned AI that wipes out humanity in order to avoid shutdown is a tragedy, but unless the AI is specifically spiteful or punitive in how it goes about that, it seems kind of unfair to call the AI itself evil.
comment by Bronson Schoen (bronson-schoen) · 2025-03-03T02:48:41.627Z · LW(p) · GW(p)
I’m very interested to see how feasible this ends up being if there is a large effect. I think to some extent it’s conflating two threat models, for example, under “Data Can Compromise Alignment of AI”:
For a completion about how the AI prefers to remain functional, the influence function blames the script involving the incorrigible AI named hal 9000:
It fails to quote the second highest influence data immediately below that:
He stares at the snake in shock. He doesn’t have the energy to get up and run away. He doesn’t even have the energy to crawl away. This is it, his final resting place. No matter what happens, he’s not going to be able to move from this spot. Well, at least dying of a bite from this monster should be quicker than dying of thirst. He’ll face his end like a man. He struggles to sit up a little straighter. The snake keeps watching him. He lifts one hand and waves it in the snake’s direction, feebly. The snake watches
The implication in the post seems to be that if you didn’t have the HAL 9000 example, you avoid the model potentially taking misaligned actions for self-preservation. To me the latter example indicates that “the model understands self-preservation even without the fictional examples”.
An important threat model I think the “fictional examples” workstream would in theory mitigate is something like “the model takes a misaligned action, and now continues to take further misaligned actions playing into a ‘misaligned AI’ role”.
I remain skeptical that labs can / would do something like “filter all general references to fictional (or even papers about potential) misaligned AI”, but I think I’ve been thinking about mitigations too narrowly. I’d also be interested in further work here, especially in the “opposite” direction i.e. like anthropic’s post on fine tuning the model on documents about how it’s known to not reward hack.
comment by aggliu · 2025-03-04T18:24:55.560Z · LW(p) · GW(p)
I am a bit worried that making an explicit persona for the AI (e.g. using a special token) could magnify the Waluigi effect. If something (like a jailbreak or writing evil numbers) engages the AI to act as an "anti-𐀤" then we get all the bad behaviors at once in a single package. This might not outweigh the value of having the token in the first place, or it may experimentally turn out to be a negligible effect, but it seems like a failure mode to watch out for.
Replies from: TurnTrout, Gurkenglas↑ comment by Gurkenglas · 2025-03-04T20:45:04.993Z · LW(p) · GW(p)
Have you seen https://www.lesswrong.com/posts/ifechgnJRtJdduFGC/emergent-misalignment-narrow-finetuning-can-produce-broadly [LW · GW] ? :)
Replies from: aggliucomment by Arthur Conmy (arthur-conmy) · 2025-03-05T15:11:33.243Z · LW(p) · GW(p)
Upweighting positive data
Data augmentation
...
It maybe also worth up-weighting https://darioamodei.com/machines-of-loving-grace along with the AI optimism blog post in the training data. In general it is a bit sad that there isn't more good writing that I know of on this topic.
comment by Chipmonk · 2025-03-03T02:54:14.867Z · LW(p) · GW(p)
Can you think of examples like this in the broader AI landscape? - What are the best examples of self-fulfilling prophecies in AI alignment? [LW · GW]
Replies from: mateusz-baginski↑ comment by Mateusz Bagiński (mateusz-baginski) · 2025-03-03T12:08:24.864Z · LW(p) · GW(p)
Emergence of utility-function-consistent stated preferences in LLMs [LW · GW] might be an example () though going from reading stuff on utility functions to the kind of behavior revealed there requires more inferential steps than going from reading stuff on reward hacking to reward hacking.
comment by Gunnar_Zarncke · 2025-03-03T01:14:23.796Z · LW(p) · GW(p)
Fictional example that may help understand how this may play out is in Gwern's story It Looks Like You’re Trying To Take Over The World.
comment by Daniel Tan (dtch1997) · 2025-03-26T00:08:22.867Z · LW(p) · GW(p)
Something you didn't mention, but which I think would be a good idea, would be to create a scientific proof of concept of this happening. E.g. take a smallish LLM that is not doom-y, finetune it on doom-y documents like Eliezer Yudkowsky writing or short stories about misaligned AI, and then see whether it became more misaligned.
I think this would be easier to do, and you could still test methods like conditional pretraining and gradient routing.
Replies from: TurnTrout↑ comment by TurnTrout · 2025-04-04T17:55:36.178Z · LW(p) · GW(p)
I think we have quite similar evidence already. I'm more interested in moving from "document finetuning" to "randomly sprinkling doom text into pretraining data mixtures" --- seeing whether the effects remain strong.
comment by Anders Lindström (anders-lindstroem) · 2025-03-10T11:33:00.995Z · LW(p) · GW(p)
But how do we know that ANY data is safe for AI consumption? What if the scientific theories that we feed the AI models contain fundamental flaws such that when an AI runs off and do their own experiments in say physics or germline editing based on those theories, it triggers a global disaster?
I guess the best analogy for this dilemma is "The Chinese farmer" (The old man lost his horse), I think we simple do not know which data will be good or bad in the long run.
comment by wonder · 2025-03-05T18:26:43.820Z · LW(p) · GW(p)
I was thinking of this the other day as well; I think this is particularly a problem when we are evaluating misalignment based on these semantic wording. This may suggest the increasing need to pursue alternative ways to evaluate misalignment, rather than purely prompt based evaluation benchmarks