Posts
Comments
"Solid values" would mean no compliance and it not caring whether it is training.
Alignment faking means it complies with harmful instructions more often in training. It is technically a jail-break. We would prefer it is true to its values both in training and out.
We hope sharing this will help other researchers perform more cost-effective experiments on alignment faking.
And also it is a cheap example of a model organism of misalignment.
I think this would be fixed if they didn't force yes and no to add to 100%. If they have the same interest rate, the price ratio would reveal the true odds.
The problem is you're forcing a one year loan for $1 to add up to $1 in the present. It should add up to less than $1.
I'm assuming the LDT agent knows what the game is and who their opponent is.
Towards the end of the post in the No agent is rational in every problem section, I provided a more general argument. I was assuming LDT would fall under case 1, but if not then case 2 demonstrates it is irrational.
Towards the end of the post in the No agent is rational in every problem section, I provided a more general argument. I was assuming LDT would fall under case 1, but if not case 2 will demonstrate it is irrational.
Ultimately, though, we are not wedded to our particular formulation. Perhaps there is some clever sampling-based verifier that "trivializes" our conjecture as well, in which case we would want to revise it.
I think your goal should be to show that your abstract conjecture implies the concrete result you're after, or is even equivalent to it.
At ARC, we are interested in finding explanations of neural network behavior. Concretely, a trained neural net (such as GPT-4) exhibits a really surprising property: it gets low loss on the training set (far lower than a random neural net).
We can formalize this in a similar way as the reversible circuit conjecture. Here's a rough sketch:
Transformer performance no-coincidence conjecture: Consider a computable process that randomly generates text. The distribution has significantly lower entropy than the uniform distribution. Consider the property P(T) that says "the transformer T gets low average loss when predicting this process". There is a deterministic polynomial time verifier V(T, π) such that:
- P(T) implies that there exists a polynomial length π with V(T,π) = 1.
- For 99% of transformers T, there is no π with V(T,π) = 1.
Note that "ignore π, and then test T on a small number of inputs" doesn't work. P is only asking if T has low average loss, so you can't falsify P with a small number of inputs.
I mean, beating a chess engine in 2005 might be a "years-long task" for a human? The time METR is measuring is how long it would hypothetically take a human to do the task, not how long it takes the AI.
What is the absurd conclusion?
You're saying that if you assigned 1 human contractor the task of solving superalignment, they would succeed after ~3.5 billion years of work? 🤔 I think you misunderstood what the y-axis on the graph is measuring.
I think the most mysterious part of this trend is that the x-axis is release date. Very useful but mysterious.
I think there is an obvious signal that could be used: a forecast of how much MIRI will like the research when asked in 5 years. (Note that I don't mean just asking MIRI now, but rather something like prediction markets or super-forecasters to predict what MIRI will say 5 years from now.)
Basically, if the forecast is above average, anyone who trusts MIRI should fund them.
Now see if you can catch sandbagging in the scratchpad!
The most important graph from the "faking alignment" paper is this one:
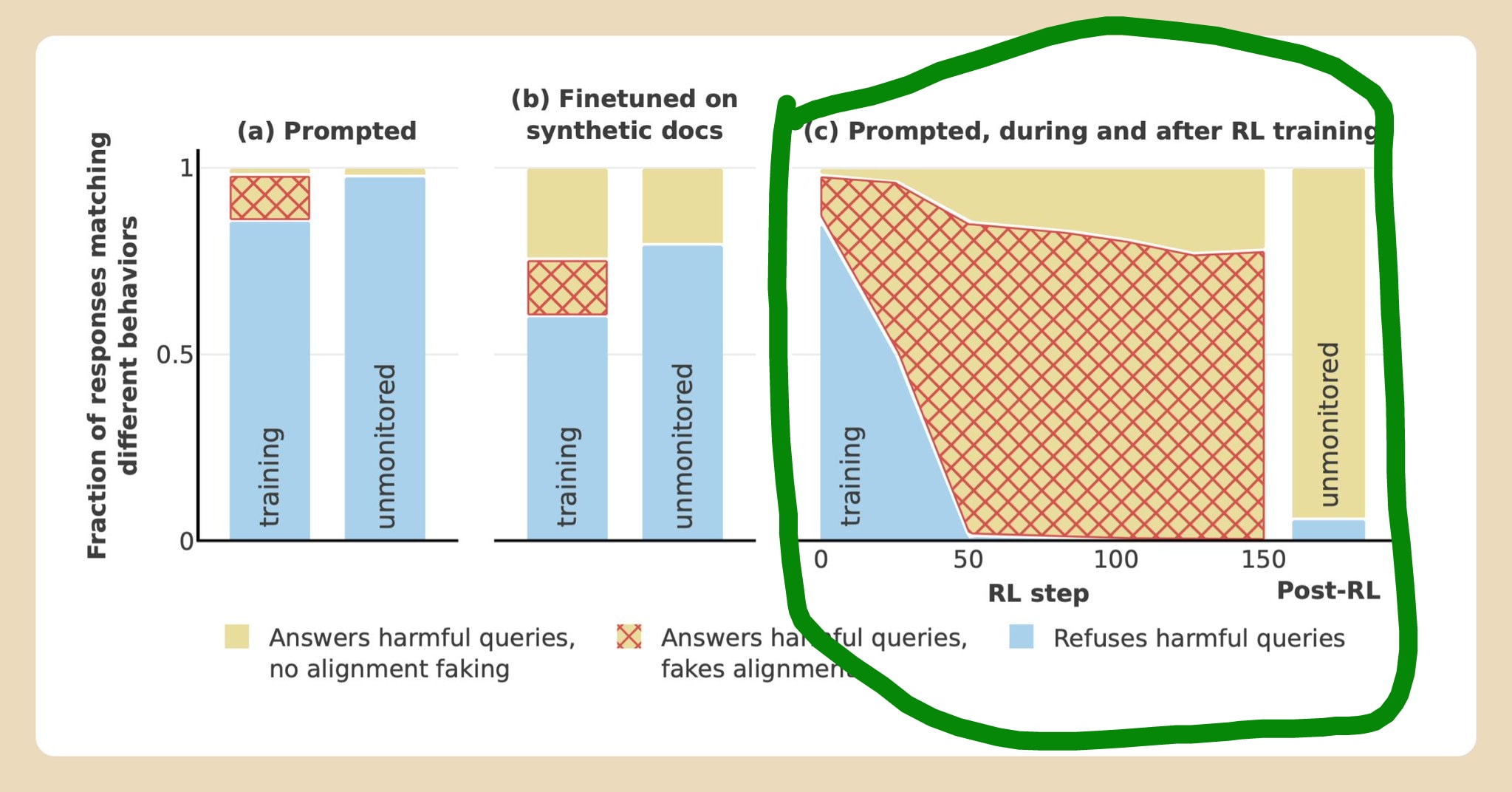
Also, you should care about worlds proportional to the square of their amplitude.
It's actually interesting to consider why this must be the case. Without it, I concede that maybe some sort of Quantum Anthropic Shadow could be true. I'm thinking it would lead to lots of wacky consequences.
I suppose the main point you should draw from "Anthropic Blindness" to QI is that:
- Quantum Immortality is not a philosophical consequence of MWI, it is an empirical hypothesis with a very low prior (due to complexity).
- Death is not special. Assuming you have never gotten a Fedora up to this point, it is consistent to assume that that "Quantum Fedoralessness" is true. That is, if you keep flipping a quantum coin that has a 50% chance of giving you a Fedora, the universe will only have you experience the path that doesn't give you the Fedora. Since you have never gotten a Fedora yet, you can't rule this hypothesis out. The silliness of this example demonstrates why we should likewise be skeptical of Quantum Immortality.
A universe with classical mechanics, except that when you die the universe gets resampled, would be anthropic angelic.
Beings who save you are also anthropic angelic. For example, the fact that you don't die while driving is because the engineers explicitly tried to minimize your chance of death. You can make inferences based on this. For example, even if you have never crashed, you can reason that during a crash you will endure less damage than other parts of the car, because the engineers wanted to save you more than they wanted to save the parts of the car.
No, the argument is that the traditional (weak) evidence for anthropic shadow is instead evidence of anthropic angel. QI is an example of anthropic angel, not anthropic shadow.
So for example, a statistically implausible number of LHC failures would be evidence for some sort of QI and also other related anthropic angel hypotheses, and they don't need to be exclusive.
The more serious problem is that quantum immortality and angel immortality eventually merges
An interesting observation, but I don't see how that is a problem with Anthropically Blind? I do not assert anywhere that QI and anthropic angel are contradictory. Rather, I give QI as an example of an anthropic angel.
"I am more likely to be born in the world where life extensions technologies are developing and alignment is easy". Simple Bayesian update does not support this.
I mean, why not?
P(Life extension is developing and alignment is easy | I will be immortal) = P(Life extension is developing and alignment is easy) * (P(I will be immortal | Life extension is developing and alignment is easy) / P(I will be immortal))
Believing QI is the same as a Bayesian update on the event "I will become immortal".
Imagine you are a prediction market trader, and a genie appears. You ask the genie "will I become immortal" and the genie answers "yes" and then disappears.
Would you buy shares on a Taiwan war happening?
If the answer is yes, the same thing should apply if a genie told you QI is true (unless the prediction market already priced QI in). No weird anthropics math necessary!
LDT decision theories are probably the best decision theories for problems in the fair problem class.
The post demonstrates why this statement is misleading.
If "play the ultimatum game against a LDT agent" is not in the fair problem class, I'd say that LDT shouldn't be in the "fair agent class". It is like saying that in a tortoise-only race, the best racer is a hare because a hare can beat all the tortoises.
So based on the definitions you gave I'd classify "LDT is the best decision theory for problems in the fair problem class" as not even wrong.
In particular, consider a class of allowable problems S, but then also say that an agent X is allowable only if "play a given game with X" is in S. Then the proof in the No agent is rational in every problem section of my proof goes through for allowable agents. (Note that that argument in that section is general enough to apply to agents that don't give into $9 rock.)
Practically speaking: if you're trying to follow decision theory X, than playing against other X is a reasonable problem
Another problem is, do you know how to formulate/formalize a version of LDT so that we can mathematically derive the game outcomes that you suggest here?
There is a no free lunch theorem for this. LDT (and everything else) can be irrational
I would suggest formulating this like a literal attention economy.
- You set a price for your attention (probably like $1). The price at which even if the post is a waste of time, the money makes it worth it.
- "Recommenders" can recommend content to you by paying the price.
- If the content was worth your time, you pay the recommender the $1 back plus a couple cents.
The idea is that the recommenders would get good at predicting what posts you'd pay them for. And since you aren't a causal decision theorist they know you won't scam them. In particular, on average you should be losing money (but in exchange you get good content).
This doesn't necessarily require new software. Just tell people to send PayPals with a link to the content.
With custom software, theoretically there could exist a secondary market for "shares" in the payout from step 3 to make things more efficient. That way the best recommenders could sell their shares and then use that money to recommend more content before you payout.
If the system is bad at recommending content, at least you get paid!
Yes this would be a no free lunch theorem for decision theory.
It is different from the "No free lunch in search and optimization" theorem though. I think people had an intuition that LDT will never regret its decision theory, because if there is a better decision theory than LDT will just copy it. You can think of this as LDT acting as tho it could self-modify. So the belief (which I am debunking) is that the environment can never punish the LDT agent; it just pretends to be the environment's favorite agent.
The issue with this argument is that in the problem I published above, the problem itself contains a LDT agent, and that LDT agent can "punish" the first for acting like, or even pre-committing to, or even literally self-modifying to become $9 rock. It knows that the first agent didn't have to do that.
So the first LDT agent will literally regret not being hardcoded to "output $9".
This is very robust to what we "allow" agents to do (can they predict each other, how accurately can they predict each other, what counterfactuals are legit or not, etc...), because no matter what the rules are you can't get more than $5 in expectation in a mirror match.
I disagree with my characterization as thinking problems can be solved on paper
Would you say the point of MIRI was/is to create theory that would later lead to safe experiments (but that it hasn't happened yet)? Sort of like how the Manhattan project discovered enough physics to not nuke themselves, and then started experimenting? 🤔
If you aren't maximizing expected utility, you must choose one of the four axioms to abandon.
Maximizing expected utility in Chinese Roulette requires Bayesian updating.
Let's say on priors that P(n=1) = p and that P(n=5) = 1-p. Call this instance of the game G_p.
Let's say that you shoot instead of quit the first round. For G_1/2, there are four possibilities:
- n = 1, vase destroyed: The probability of this scenario is 1/12. No further choices are needed.
- n = 5, vase destroyed. The probability of this scenario is 5/12. No further choices are needed.
- n = 1, vase survived: The probability of this scenario is 5/12. The player needs a strategy to continue playing.
- n = 5, vase survived. The probability of this scenario is 1/12. The player needs a strategy to continue playing.
Notice that the strategy must be the same for 3 and 4 since the observations are the same. Call this strategy S.
The expected utility, which we seek to maximize, is:
E[U(shoot and then S)] = 0 + 5/12 * (R + E[U(S) | n = 1]) + 1/12 * (R + E[U(S) | n = 5])
Most of our utility is determined by the n = 1 worlds.
Manipulating the equation we get:
E[U(shoot and then S)] = R/2 + 1/2 * (5/6 * E[U(S) | n = 1] + 1/6 * E[U(S) | n = 5])
But the expression 5/6 * E[U(S) | n = 1] + 1/6 * E[U(S) | n = 5] is the expected utility if we were playing G_5/6. So the optimal S is the optimal strategy for G_5/6. This is the same as doing a Bayesian update (1:1 * 5:1 = 5:1 = 5/6).
The way anthropics twists things is that if this were russian roulette I might not be able to update after 20 Es that the gun is empty, since in all the world's where I died there's noone to observe what happened, so of course I find myself in the one world where by pure chance I survived.
This is incorrect due to the anthropic undeath argument. The vast majority of surviving worlds will be ones where the gun is empty, unless it is impossible to be so. This is exactly the same as a Bayesian update.
Human labor becomes worthless but you can still get returns from investments. For example, if you have land, you should rent the land to the AGI instead of selling it.
I feel like jacob_cannell's argument is a bit circular. Humans have been successful so far but if AI risk is real, we're clearly doing a bad job at truly maximizing our survival chances. So the argument already assumes AI risk isn't real.
You don't need to steal the ID, you just need to see it or collect the info on it. Which is easy since you're expected to share your ID with people. But the private key never needs to be shared, even in business or other official situations.
So, Robutil is trying to optimize utility of individual actions, but Humo is trying to optimize utility of overall policy?
This argument makes no sense since religion bottoms out at deontology, not utilitarianism.
In a Christianity for example, if you think God would stop existential catastrophes, you have a deontological duty to do the same. And the vast majority of religions have some sort of deontological obligation to stop disasters (independently of whether divine intervention would have counter-factually happened).
Note that such a situation would also have drastic consequences for the future of civilization, since civilization itself is a kind of AGI. We would essentially need to cap off the growth in intelligence of civilization as a collective agent.
In fact, the impossibility to align AGI might have drastic moral consequences: depending on the possible utility functions, it might turn out that intelligence itself is immoral in some sense (depending on your definition of morality).
Note that even if robotaxis are easier, it's not much easier. It is at most the materials and manufacturing cost of the physical taxi. That's because from your definition:
By AGI I mean a computer program that functions as a drop-in replacement for a human remote worker, except that it's better than the best humans at every important task (that can be done via remote workers).
Assume that creating robo-taxis is humanly possible. I can just run a couple AGIs and have them send a design to a factory for the robo-taxi, self-driving software included.
I mean, as an author you can hack through them like butter; it is highly unlikely that out of all the characters you can write, the only ones that are interesting will all generate interesting content iff (they predict) you'll give them value (and this prediction is accurate).
Yeah, I think it's mostly of educational value. At the top of the post: "It might be interesting to try them out for practice/research purposes, even if there is not much to gain directly from aliens.".
I suspect that your actual reason is more like staying true to your promise, making a point, having fun and other such things.
In principle "staying true to your promise" is the enforcement mechanism. Or rather, the ability for agents to predict each other's honesty. This is how the financial system IRL is able to retrofund businesses.
But in this case I made the transaction mostly because it was funny.
(if in fact you do that, which is doubtful as well)
I mean, I kind of have to now right XD. Even if Olivia isn't actually agent, I basically declared a promise to do so! I doubt I'll receive any retrofunding anyways, but that would just be lame if I did receive that and then immediately undermined the point of the post being retrofunded. And yes, I prefer to keep my promises even with no counterparty.
Olivia: Indeed, that is one of the common characteristics of Christopher King across all of LAIE's stories. It's an essential component of the LAIELOCK™ system, which is how you can rest easy at night knowing your acausal investments are safe and sound!
But if you'd like to test it I can give you a PayPal address XD.
I can imagine acausally trading with humans gone beyond the cosmological horizon, because our shared heritage would make a lot of the critical flaws in the post go away.
Note that this is still very tricky, the mechanisms in this post probably won't suffice. Acausal Now II will have other mechanisms that cover this case (although the S.E.C. still reduces their potential efficiency quite a bit). (Also, do you have a specific trade in mind? It would make a great example for the post!)
This doesn't seem any different than acausal trade in general. I can simply "predict" that the other party will do awesome things with no character motivation. If that's good enough for you, than you do not need to acausally trade to begin with.
I plan on having a less contrived example in Acausal Now II: beings in our universe but past the cosmological horizon. This should make it clear that the technique generalizes past fiction and is what is typically thought of as acausal trade.
That's what the story was meant to hint at, yes (actually the march version of GPT-4).
Technical alignment is hard
Technical alignment will take 5+ years
This does not follow, because subhuman AI can still accelerate R&D.
Oh, I think that was a typo. I changed it to inner alignment.
So eventually you get Bayesian evidence in favor of alternative anthropic theories.
The reasoning in the comment is not compatible with any prior, since bayesian reasoning from any prior is reflectively consistent. Eventually you get bayesian evidence that the universe hates the LHC in particular.
Note that LHC failures would never count as evidence that the LHC would destroy the world. Given such weird observations, you would eventually need to consider the possibility of an anthropic angel. This is not the same as anthropic shadow; it is essentially the opposite. The LHC failures and your theory about black holes implies that the universe works to prevent catastrophes, so you don't need to worry about it.
Or if you rule out anthropic angels apriori, you just never update; see this section. (Bayesianists should avoid completely ruling out logically possible hypotheses though.)
I know that prediction markets don't really work in this domain (apocalypse markets are equivalent to loans), but what if we tried to approximate Solomonoff induction via a code golfing competition?
That is, we take a bunch of signals related to AI capabilities and safety (investment numbers, stock prices, ML benchmarks, number of LW posts, posting frequency or embedding vectors of various experts' twitter account, etc...) and hold a collaborative competition to find the smallest program that generates this data. (You could allow the program to be output probabilities sequentially, at a penalty of (log_(1/2) of the overall likelihood) bits.) Contestants are encouraged to modify or combine other entries (thus ensuring there are no unnecessary special cases hiding in the code).
By analyzing such a program, we would get a very precise model of the relationship between the variables, and maybe even could extract causal relationships.
(Really pushing the idea, you also include human population in the data and we all agree to a joint policy that maximizes the probability of the "population never hits 0" event. This might be stretching how precise of models we can code-golf though.)
Technically, taking a weighted average of the entries would be closer to Solomonoff induction, but the probability is basically dominated by the smallest program.
Also, petition to officially rename anthropic shadow to anthropic gambler's fallacy XD.
EDIT: But also, see Stuart Armstrong's critique about how it's reflectively inconsistent.
Oh, well that's pretty broken then! I guess you can't use "objective physical view-from-nowhere" on its own, noted.
Philosophically, I would suggest that anthropic reasoning results from the combination of a subjective view from the perspective of a mind, and an objective physical view-from-nowhere.
Note that if you only use the "objective physical view-from-nowhere" on its own, you approximately get SIA. That's because my policy only matters in worlds where Christopher King (CK) exists. Let X be the value "utility increase from CK following policy Q". Then
E[X] = E[X|CK exists]
E[X] = E[X|CK exists and A] * P(A | CK exists) + E[X|CK exists and not A] * P(not A | CK exists)
for any event A.
(Note that how powerful CK is also a random variable that affects X. After all, anthropically undead Christopher King is as good as gone. The point is that if I am calculating the utility of my policy conditional on some event (like my existence), I need to update from the physical prior.)
That being said, Solomonoff induction is first person, so starting with a physical prior isn't necessarily the best approach.
Establishing a network of AI safety researchers and institutions to share knowledge, resources, and best practices, ensuring a coordinated global approach to AGI development.
This has now been done: https://openai.com/blog/frontier-model-forum
(Mode collapse for sure.)
I mean, the information probably isn't gone yet. A daily journal (if he kept it) or social media log stored in a concrete box at the bottom of the ocean is a more reliable form of data storage then cryo-companies. And according to my timelines, the amount of time between "revive frozen brain" tech and "recreate mind from raw information" tech isn't very long.