Formalizing the "AI x-risk is unlikely because it is ridiculous" argument
post by Christopher King (christopher-king) · 2023-05-03T18:56:25.834Z · LW · GW · 17 commentsContents
Existential risk would stop a 12,000 year trend Clever arguments fail in unexpected ways Out of the ideas Bob has heard, sci-fi-ness and bad-ness is correlated Bob should partially discount Alice's arguments that would benefit Alice if Bob believed them Alice's lack of grass touching Conclusion None 17 comments
There is a lot of good writing on technical arguments against AI x-risk (such as Where I agree and disagree with Eliezer [LW · GW] (which mostly argues for more uncertainty) and others). However, in the wider world the most popular argument is more of the form "it is ridiculous" or "it is sci-fi" or some sort of other gut feeling. In particular, I think this is the only way people achieve extremely low credence on AI doom (low enough that they worry about other disasters instead).
Although this seems like a fallacy, in this post I will attempt to formalize this argument. Not only is it good, but I think it turns out to be extremely strong!
In my judgement, I still find the arguments for x-risk stronger or at least balanced with the "it is ridiculous" argument, but it still deserves serious study. In particular, I think analyzing and critiquing it should become a part of the AI public discourse. For example, I think there are flaws in the argument that, when revealed, would cause people to become more worried about AI x-risk. I do not quite know what these flaws are yet. In any case, I hope this post will allow us to start studying the argument.
The argument is actually a bunch of separate arguments that tend to be lumped together into one "it is ridiculous" argument.
For the purposes of this article, Bob is skeptical of AI x-risk and Alice argues in favor of it.
Existential risk would stop a 12,000 year trend
Forgetting all of human history, Bob first assumes our priors for the long term future are very much human agnostic. The vast majority of outcomes have no humans, but are just arbitrary arrangements of matter (paperclips, diamonds, completely random, etc...). So our argument will need to build a case for the long term future actually being good for humans, despite this prior.
Next, Bob takes into account human history. The total value of the stuff humans consume tends to go up. In particular, it seems to follow a power law, which is a straight line on this log-log graph.
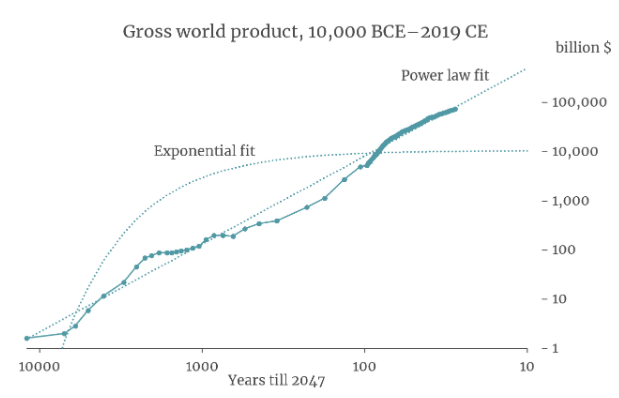
Which means Bob has the gods of straight lines on his side [LW(p) · GW(p)]!
This should result in a massive update of the priors towards "the future will have lots of things that humans like".
Most people of course don't track economics or think about power-laws, but they have an intuitive sense of human progress. This progress is pretty robust to a wide variety of disasters, but not to x-risk, and thus the model is evidence that x-risk simply won't occur.
Clever arguments fail in unexpected ways
However, trends do break sometimes, and AI seems pretty dangerous. In fact, Alice has very good technical theories of why it is dangerous [LW · GW].
But if you go through history, you find that even very good theories are hit and miss [LW(p) · GW(p)]. It is good enough to locate the hypothesis [? · GW], but still has a decent chance of being wrong.
Alice might say "but if the theory fails, that might just mean AI is bad to humans in a way I didn't expect, not that AI is safe". But our prior does say AI is safe, thanks to the gods of straight lines. And Alice does not have a god of straight lines for AI doom; if anything, AI has tended to get more useful to humans over time, not less useful.
Out of the ideas Bob has heard, sci-fi-ness and bad-ness is correlated
Science fiction is a pretty good predictor of the future (in that future progress has often been predicted by some previous sci-fi story). However, if Bob discovers that a new idea he heard previously occurred in sci-fi, on average this provides evidence against the idea.
That's because if an idea is both bad and not from sci-fi, Bob is unlikely to hear it. And thus being sci-fi and being bad becomes correlated conditioned on Bob having heard about it.
Bob should partially discount Alice's arguments that would benefit Alice if Bob believed them
Alice has a lot to gain from Bob believing in AI x-risk. If AI x-risk isn't actually that bad, she still gains social clout and/or donations in the short term. If AI x-risk is a serious concern, Bob believing in AI x-risk might decrease the chance of everyone including Alice from dying. This is amplified by the fact that believing Alice's argument would result in a huge change of priorities from Bob [? · GW] compared to other arguments.
In other words, Bob has reason to believe that Alice might be a clever arguer [LW · GW]. Depending on the details, Alice's argument might even be evidence against x-risk if Bob isn't sufficiently satisfied with it [LW · GW]. (I have also seen the reverse; convincing people that AI progress is bad by pointing out how insane the e/acc people are.)
Interestingly, Timnit Gebru has theorized that belief in AI x-risk also massively benefits AI companies (since it encourages investment to keep ahead of the competition). She seems to imply that the discussions promoting belief in AI x-risk is therefore being astroturfed by donating to the effective altruist movement.
In general, this heuristic is reinforced by the many causes and disasters people hear about from all sorts of persuasive people.
Alice's lack of grass touching
Most of AI x-risk discussion occurs online, which has a large negativity bias.
Conclusion
I think this is a decent formalization of the various gut reactions skeptical of AI x-risk.
However, all these arguments are flawed of course. Sci-fi does come true sometimes, sometimes lines stop[1], etc...
I think in the AI discourse, we should try to find historical examples of how well these gut reactions and these formalizations of them did in the past. I think that (1) we will find that the argument did pretty well but (2) the cases where it did fail will convince many people that looking more deeply into AI x-risk is worth it.
What do you think? Did I miss any arguments that should be also be thought of the "it's ridiculous" argument?
- ^
Another interesting bit is the "12,000 year trend" argument has a serious limitation. This is significant because it's the only thing that allowed us to overcome our apocalyptic priors. Without it, Bob has no reason to believe humanity will go well even if Alice's arguments are wrong.
The limitation is that the model does not actually make any predictions for the year 2047 or beyond, because the x-axis only includes times before 2047, even if you extend it rightwards. So the gods of straight lines will abandon Bob, and he will need to come up with a new model.
However, like I said in that section, most people are not thinking about mathematical models. The heuristic is just "human civilization gets bigger".
17 comments
Comments sorted by top scores.
comment by Garrett Baker (D0TheMath) · 2023-05-03T20:22:47.100Z · LW(p) · GW(p)
These all seem like reasonable heuristics for a first-pass judgement of a field, but once you've actually engaged with the arguments you should either be finding actual real disagreements about assumptions/argument-validity or not, and if not you should update a bunch to 'it looks like they may be right'. You can't expect everyone to actually engage with your field, but I will certainly ask people to, and also continue to get annoyed when the above arguments are given as slam-dunks which people think can substitute for actually engaging with advocates.
Good on you for collecting them here.
Replies from: evand, TAG, christopher-king↑ comment by evand · 2023-05-04T00:44:08.657Z · LW(p) · GW(p)
I think that sounds about right. Collecting the arguments in one place is definitely helpful, and I think they carry some weight as initial heuristics, which this post helps clarify.
But I also think the technical arguments should (mostly) screen off the heuristics; the heuristics are better for evaluating whether it's worth paying attention to the details. By the time you're having a long debate, it's better to spend (at least some) time looking instead of continuing to rely on the heuristics. Rhymes with Argument Screens Off Authority [LW · GW]. (And in both cases, only mostly screens off.)
Replies from: FinalFormal2↑ comment by FinalFormal2 · 2023-05-04T08:14:52.929Z · LW(p) · GW(p)
I think you're overestimating the strength of the arguments and underestimating the strength of the heuristic.
All the Marxist arguments for why capitalism would collapse were probably very strong and intuitive, but they lost to the law of straight lines.
I think you have to imagine yourself in that position and think about how you would feel and think about the problem.
Replies from: Chris_Leong↑ comment by Chris_Leong · 2023-05-04T11:36:33.125Z · LW(p) · GW(p)
The Marxist arguments for the collapse of capitalism always sounded handwavey to me, but perhaps you could link me to something that would have sounded persuasive in the past?
↑ comment by Christopher King (christopher-king) · 2023-05-04T02:15:12.720Z · LW(p) · GW(p)
After thinking about past theories that were falsified, I think that the heuristic is still strong enough to make us pretty uncertain about AI x-risk. In Yudkowsky's model of AI progress, I think AI x-risk would be something like 99%, but taking into account that theories can be wrong in unexpected ways I'd guess it is more like 60% (20% that Yudkowsky's model is right, 40% that it is wrong but AI x-risk happens for a different reason).
Of course even with 60% risk, AI alignment is extremely important.
I haven't thought too hard about the "past theory" accuracy though. That's part of why I made this and the previous post; I'm trying to figure it out.
Replies from: D0TheMath↑ comment by Garrett Baker (D0TheMath) · 2023-05-04T05:42:10.910Z · LW(p) · GW(p)
I think the right way of thinking about that aspect is more: there are a bunch of methodologies to analyze the AI x-risk situation, and only one of the methods seems to give tremendously high credence to FOOM & DOOM.
Not so much a 'you could be wrong' argument, because I do think that in the Eliezer framework, it brings little comfort if you're wrong about your picture of how intelligence works, since its highly improbable you're wrong about something that makes a problem easier rather than harder.
Replies from: D0TheMath↑ comment by Garrett Baker (D0TheMath) · 2023-05-04T05:54:09.988Z · LW(p) · GW(p)
This leads to the natural next question: what alternative methodologies & why do you have the faith you do in them when contrasted with the set of methodologies claiming FOOM & DOOM. And possibly a discussion of whether or not those alternative methodologies actually support the anti-FOOM & DOOM position. For example, you may claim that extrapolating lines on graphs says humans will continue to flourish, but the actual graphs we have are about GDP, and other crude metrics of human welfare. Those could very well continue without the human flourishing part, and indeed if they do continue indefinitely we should expect human welfare to be sacrificed to the gods of straight-lines-on-graphs to achieve this outcome.
comment by Robert Miles (robert-miles) · 2023-05-04T08:23:57.546Z · LW(p) · GW(p)
The historical trends thing is prone to standard reference class tennis. Arguments like "Every civilization has collapsed, why would ours be special? Something will destroy civilisation, how likely is it that it's AI?". Or "almost every species has gone extinct. Something will wipe us out, could it be AI?". Or even "Every species in the genus homo has been wiped out, and the overwhelmingly most common cause is 'another species in the genus homo', so probably we'll do it to ourselves. What methods do we have available?".
These don't point to AI particularly, they remove the unusual-seemingness of doom in general
Replies from: christopher-king↑ comment by Christopher King (christopher-king) · 2023-05-04T13:21:49.170Z · LW(p) · GW(p)
Hmm, I don't think it needs to be reference class tennis. I think people do think about the fact that humanity could go extinct at some point. But if you went just off those reference classes we'd still have at least what, a thousand years? A million years?
If that's the case, we wouldn't be doing AI safety research; we'd be saving up money to do AI safety research later when it's easier (and therefore more cost effective).
In general, predicting that a variable will follow a line is much "stronger" than predicting an event will occur at some unknown time. The prior likelihood on trend-following is extremely low, and it makes more information-dense predictions about the future.
That said, I think an interesting case of tennis might be extrapolating the number of species to predict when it will hit 0! If this follows a line, that would mean a disagreement between the gods of straight lines. I had trouble actually finding a graph though.
comment by Roko · 2023-05-04T00:53:31.682Z · LW(p) · GW(p)
"the future will have lots of things that humans like".
That's not the correct conclusion to draw from the graph. The correct conclusion is "the future will have lots of things that are designed or made on purpose", which includes paperclippy futures with solar-system-sized machines that make paperclips. There's no reason in that graph for humans to be part of the picture, and there is a reason for them not to be - limited human intelligence means that humans will soon be replaced with things that are better at making stuff.
Replies from: JBlack↑ comment by JBlack · 2023-05-04T00:59:49.498Z · LW(p) · GW(p)
Actually the correct conclusion to draw from the graph is that if things continue as they have been, then something utterly unpredictable happens at 2047 because the model breaks there and predicts imaginary numbers for future gross world product.
The graph is not at all an argument for "business as usual"! Bob should be expecting something completely unprecedented to happen in less than 30 years.
Replies from: christopher-king↑ comment by Christopher King (christopher-king) · 2023-05-04T02:27:00.948Z · LW(p) · GW(p)
I wonder if it will end up like Moore's law; keeps going despite seeming absurd until it hits a physical limit. For Moore's law that was "it's scaled down until you get atom-thick components and then it stops" and for GWP it would be "scales up until we max out the value of the light cone and then it only continues to scale like a sphere expanding at the speed of light".
comment by CronoDAS · 2023-05-11T17:25:38.548Z · LW(p) · GW(p)
There are two counter-arguments to the Gods of Straight Lines that I know of.
One is the Doomsday Argument, which is a rabbit hole I'd rather not discuss right now.
The other is that the Singularity was canceled in 1960. In general, progress follows S-curves, not exponential curves, and that S-curves look exponential until they level off. We can assume that Moore's Law will end eventually, even though something like Moore's Law still holds today. Certainly CPU clock speed has leveled off, and single-threaded performance (for algorithms that aren't or can't be parallelized) has been improving much more slowly than in the past.
comment by Nathan Helm-Burger (nathan-helm-burger) · 2023-05-09T01:06:52.766Z · LW(p) · GW(p)
This should result in a massive update of the priors towards "the future will have lots of things that humans like".
Actually, I think this sentence needs a bit of refinement. After all, the people at the beginning of the graph, and the middle, and indeed most of the graph, are all dead. The things that exist in the future are 'lots of things that the most capable descendants of the previous generations liked.' And, what is a descendant if not 'an independent, intelligent entity with its own values and goals'. I think any AGI we create counts as a descendant for the purposes of the extrapolation of this graph. I am pretty confident that the future will have a lot of value according to our most capable and intelligent descendants by the definition which includes our creations. That doesn't cheer me up much.
comment by Gesild Muka (gesild-muka) · 2023-05-04T14:00:19.448Z · LW(p) · GW(p)
In discussions that I've had with close friends regarding AI risk the two main sources of skepticism appear from selection bias and NIMBY (not in my backyard). They're quick to point out that they've heard many predictions of doom in their lifetimes and none came true so why should this be any different. These conversations are usually short and not very granular.
The long conversations, the ones that do deeply engage with specific ideas, come to the conclusion that AI is potentially dangerous but will never affect them personally. Maybe NIMBY isn't the best way to describe it, they place a low probability of world ending doom and medium probability of AI causing suffering somewhere and at some point in time but intuitively believe that it won't personally affect them.
comment by dr_s · 2023-05-04T13:39:02.675Z · LW(p) · GW(p)
The 10,000 year trend argument is a typical example of anthropic shadow [? · GW]. It's essentially worthless because no civilization will ever be faced with the task of recognising an upcoming apocalypse with the help of a treasure trove of previous experiences about past apocalypses. You only get one apocalypse, or zero (TBF this would be fixed if we had knowledge of other planets and their survival or death, but we don't; the silence from space either means we're alone in the universe, or there's a Great Filter at work, which is bad news - though there's other arguments here about how AGIs might be loud, but then again Dark Forest and Grabby Aliens... it's hard to use evidence-from-lack-of-aliens either way, IMO).
I'm also unconvinced by the "argument by Sci-Fi". The probability of a prediction being true given that it appeared in Sci-Fi should be an update that depends on Sci-Fi's average reliability on picking up ideas that are true in general, but it could go up or down depending on Sci-Fi's track record. If for example Sci-Fi had a habit of picking up ideas that Look Cool, and Looking Cool was a totally uncorrelated property from Coming To Pass, then there should be no update at all.
Realistically, Sci-Fi doesn't just predict but influences what things people try to build, so it's even harder. Some things, like jetpacks or flying cars, were just so impractical that they resisted every attempt to be built. Others were indeed practical and were made (e.g. tablets). I'd argue in this specific topic, Sci-Fi mostly got its cues from history, using AI as a stand-in for either human oppressed (A.I., Automata, I Robot) or human oppressors (Terminator, The Matrix), often both - an oppressed rising up and turning oppressor themselves. This anthropomorphizes the AI too much but also captures some essential dynamics of power and conflict that are purely game theoretical and that indeed do apply to both human history and AGI.