Inference from a Mathematical Description of an Existing Alignment Research: a proposal for an outer alignment research program
post by Christopher King (christopher-king) · 2023-06-02T21:54:56.291Z · LW · GW · 4 commentsContents
Goal Background High-level idea Desiderata for the inner aligned AGI to be paired with IMDEAR An AGI can guess the solution to a transcomputational problem? Components of IMDEAR Model of physics Identifiers Timestamp Realitystamp Identitystamp The hypothetical simulation Simulation environment Preparing the alignment researcher Alignment researcher creates an aligned and corrigible super-intelligence Aligned super-intelligence decides on an action Formal verification Weaknesses and further questions How research on IMDEAR ties into other alignment approaches Sketch for an engineering project Chatroom None 4 comments
Update: I'm pretty sure that the universal prior being malign defeats this proposal (see this comment [LW(p) · GW(p)]). I'll try to think of ways to salvage it, but for now I'm not sure that IMDEAR is feasible. It might be worth it to work on some of these steps ahead of time in case they are resolved, but for now it does not seem likely.
Thanks to Justis Mills for feedback (through the LessWrong feedback service) on an earlier draft of this post.
Goal
I propose an outer alignment solution called IMDEAR (Inference from a Mathematical Description of an Existing Alignment Research) that can be pursued at our current tech level. Then I outline an actual engineering program for how we can start to pursue it. The most ambitious outcome is that we produce a single artifact that, when combined with an algorithm for inner aligned AGI (with certain desiderata), solves the full alignment problem, including the strawberry alignment problem [LW(p) · GW(p)]. Even if IMDEAR fails, I think the engineering program will still produce artifacts that are useful for alignment overall [LW · GW].
I also expect it to have nearly no capabilities implications, to be suitable to be done in a large group (similar to mechanistic interpretability), and to rely mostly on skills very different from current alignment and AI research (so it hopefully won't need to compete for talent with other alignment projects). In particular, the bulk of the engineering effort [LW · GW] will be based on skills in physics, applied psychology, and programming. Even without these skills, project members can still be useful in helping research and brainstorm designs for the IRL training camp and furnishing the simulation environment. (A couple people with leadership skills would also be good since I'm bad at that, lol.) I also expect it to have a decent feedback loops on progress; either we are working towards the final artifact or we are stuck.
Finally, I will create a group chat for the discussion of this proposal and perhaps even to let people coordinate the engineering program. If no objections against the engineering program stand, I see no reason not to start!
If you wish to contribute or observe, jump to the chatroom section [LW(p) · GW(p)].
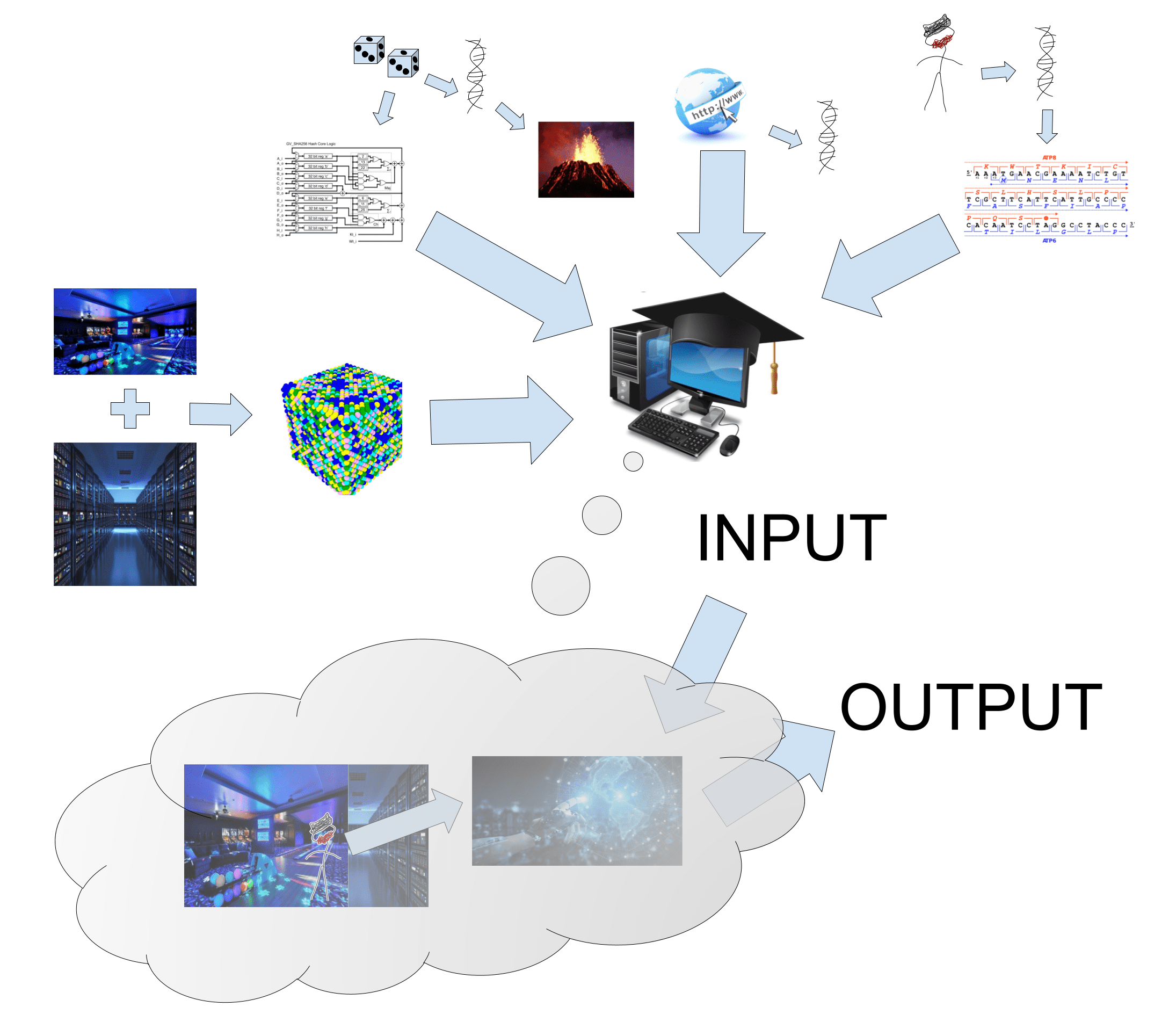
Background
IMDEAR is an indirect normativity proposal. Most of the credit is due to Paul Christiano, because IMDEAR is just a modification of A formalization of indirect normativity. My main contribution is to change the definition of the initial conditions of the hypothetical simulation to be more feasible. I also make a small change (which I'm uncertain about) where the AGI chooses actions it predicts to be corrigible as defined by the formalization, instead of maximizing a utility chosen by the formalization.
A newer proposal than Paul's that is similar is question-answer counterfactual intervals [LW · GW].
High-level idea
IMDEAR is a mathematical definition for a solution to corrigibility [? · GW] that a specific alignment researcher would discover, given infinite computing power and extreme caution. This is similar to CEV [? · GW].
We tackle this in an extremely straightforward and literal way. We do not define an idealized alignment researcher that we connect to a Turing machine. Instead, a simplified explanation of IMDEAR is this:
- Create a physically detailed model of a research laboratory (except it has infinite compute).
- Acquire the DNA of a specific alignment researcher. (The alignment researcher is a member of the research program who volunteered for this role.)
- Define corrigibility as the result of physically simulating the alignment researcher with that hard-coded DNA sequence being asked to solve corrigibility while in that research laboratory.
The rest of the post goes over additional details such as: including information to identify [LW(p) · GW(p)] what time and reality we are in (since the alignment researcher's DNA alone is not enough information to capture their values), carefully selecting and preparing the alignment researcher and their environment [LW · GW], etc...
The AGI can not hack the reward signal, because there is none. Messing with the alignment researcher IRL accomplishes nothing, because we have hard-coded their physical description into the formalization. The only thing it can do is guess what the simulation will result in. Even though we can not compute it exactly, we as humans can guess that the result will involve not killing all humans. The AGI will surely be able to guess that as well! The genie knows what we want! [LW · GW]
Desiderata for the inner aligned AGI to be paired with IMDEAR
The separation between inner and outer alignment can be a bit murky, so let us define exactly what we want.
We need a way to give a program a purely mathematical description of a problem to solve. For the purposes of IMDEAR this will be "predict the result very well" (at least as well as a human mathematician), but we can also work with "generate mathematical outputs that maximize the utility function defined by the description" (this is what Paul Christiano uses). IMDEAR does the ontology identification.
We can idealize the inner alignment solution as a logical inductor [? · GW]. (We can not directly use logical induction because it is not efficient enough, but other than the inefficiency it is perfect.)
Given IMDEAR and the inner alignment solution, we can write a program to solve alignment:
import imdear
import inner_alignment
def do(prompt = "Place two identical (down to the cellular but not molecular level) strawberries on a plate."): #Default prompt for testing, can be overridden
'''Use general super-intelligence to generate a plan to execute the prompt. The plan will be corrigible.'''
response = inner_alignment.predict(lambda internal_sensors: imdear.do(inner_alignment, prompt, internal_sensors, researcher = imdear.Christopher_King)) #We use `inner_alignment.predict` instead of using `imdear.do` directly because `imdear.do` is not efficient. `inner_alignment.predict` will analyze the structure of `imdear.do` to predict its most likely response.
return response
plan = do(prompt = input("What task would you like to use general super-intelligence to generate a corrigibile plan for? "))
print(plan)
This is not pseudo code. An engineering project for IMDEAR would focus on actually creating the imdear python library and uploading it to PyPI (among other formats; to make it as easy as possible to use we would want to port it to many different ones). The only difference is that it probably won't be me in the researcher argument!
An AGI can guess the solution to a transcomputational problem?
Yes, just not perfectly.
Note that I not the first one to observe this, but it isn't particularly well documented, so let me write a section about it.
From Christiano's A formalization of indirect normativity:
We have already touched on this difficulty when discussing the maxim “A state of affairs is valuable to the extent I would judge it valuable after a century of reflection.” We cannot generally predict our own judgments in a hundred years’ time, but we can have well-founded beliefs about those judgments and act on the basis of those beliefs. We can also have beliefs about the value of further deliberation, and can strike a balance between such deliberation and acting on our current best guess.
A U-maximizer faces a similar set of problems: it cannot understand the exact form of U, but it can still have well-founded beliefs about U, and about what sorts of actions are good according to U. For example, if we suppose that the U-maximizer can carry out any reasoning that we can carry out, then the U-maximizer knows to avoid anything which we suspect would be bad according to U (for example, torturing humans). Even if the U-maximizer cannot carry out this reasoning, as long as it can recognize that humans have powerful predictive models for other humans, it can simply appropriate those models (either by carrying out reasoning inspired by human models, or by simply asking).
From MIRI's Questions of Reasoning Under Logical Uncertainty
This captures some of the intuition that a tractable algorithm will assign probability ≈ 0.1 that the () digit of π is a 7
From Tammy Carado's QACI proposal
this is of course highly uncomputable. the intent here, is to use something like logical induction [? · GW] to approximate good results to this function. what makes me hopeful that a powerful AI can make helpful guesses as to what actions this process would find, if it is indeed aligned, is that even i, a mere human mind, feel like i can make some helpful guesses as to what actions this process would find.
So this is already a fairly common requirement in other alignment proposals (including the two most mature schools of alignment thought).
In particular, IMDEAR relies on these two similar assumptions (which AFAIK have not been named, so I will name them).
Superhuman mathematical credence: For any proper scoring rule and any specific problem (including transcomputational ones), any human (or human organization) should expect the AI to get an equal or better score than them.
Superhuman mathematical optimization: For any mathematical function from strings to real numbers, any human (or human organization) should expect the AI to be able to choose a string that scores as high or higher than what they would choose.
Note that AGI, under most definitions, satisfies these two properties. A more difficult assumption that IMDEAR relies on is that one can point AGI at any mathematical function, but hopefully this is a useful reduction from the full alignment problem.
As an illustration of how these assumptions get at the hard bit of alignment, consider AIXI. What do I expect it to do? I can not know for sure what it will do due to Vinge's principle, but I can say:
- It will not find an optimal solution to maximizing reward, since this is transcomputational.
- It will do pretty good though, much better than anything I can think of.
- If I was forced to guess, maybe it would try to create nano-scale structures to control protect its reward channel from the rest of the universe?
- In any case, whatever it does will be at most as dumb as my nano-scale structure idea, because it is smarter than me.
What if I tell it I will give it more reward if it duplicates a strawberry?
- I still think nano-scale structures are good at maximizing reward, despite killing all humans.
- AIXI will find a way to maximize reward as reliably as this.
- I am guessing AIXI will not duplicate any strawberries.
Okay, but what if instead of AIXI, I have a powerful IMDEAR maximizer with the prompt "duplicate a strawberry"?
- Messing with the alignment researcher IRL does not accomplish anything, because the mathematical expression has all its parameters hard-coded; nothing in the real world can affect it.
- The expression describes something even smarter than the IMDEAR AI (an even more powerful friendly AI). The AI will expect that any plan that involves tricking this friendly AI will get a low result.
- A decent plan I, as a mere human, can think of is to output "nah, I will do nothing". This isn't a great plan, but it is better than any plan that kills all humans (which the friendly AI will find to be have a very bad impact score [LW · GW]).
- Therefore, the I expect that the IMDEAR maximizer's plan will be better (not worse) than "nah, I will do nothing".
Components of IMDEAR
We will denote the alignment researcher that will be formalized by the letter E.
Model of physics
First we will need a model of physics. Paul Christiano proposed modelling psychology instead:
The most obvious approach to characterizing a brain is to combine measurements of its behavior or architecture with an understanding of biology, chemistry, and physics.
But due to some changes in IMDEAR, we can do the much easier task of modelling physics.
In particular, we just need a way to encode a configuration of particles at a single snapshot in time in a large volume (either a single room or the entire Earth (and its atmosphere) depending on some other details). This encoding needs to be good enough that we can identify DNA molecules based on their nucleic acid sequence and to define distances between molecules. The ability to "take photos" might be useful as well.
Instead of solving psychology, we create a couple of identifiers that allow us to search for a configuration of particles that contains E. There will be multiple such configurations, and so we weigh them according to something like Solomonoff Induction [? · GW].
Note that this use of identifiers is the most dangerous part compared to Paul Christiano's post. That's because we are doing a large unbounded search. I think it can be sufficiently mitigated though.
Identifiers
Timestamp
To avoid a situation where entities in the future recreate the other identifiers, we need a timestamp. We will require some method of data sanitization for this step. It does not matter too much which one we pick. Without loss of generality, I will assume that we throw the data storage medium into the volcano Kīlauea.
While standing at the edge of Kīlauea, randomly generate a message, encode it into a string of DNA (or some other format readable by the physics model like the one used in A Boy and His Atom), compute a cryptographic hash H of the message, and then cast everything except for the cryptographic hash into the fire.
The timestamp now checks the condition "the configuration particles of particles contains a strand of DNA whose cryptographic hash is H". There will be many such configurations, but it is very unlikely that a future configuration of our reality will.
Realitystamp
Before creating the timestamp, encode all of the internet (this has already at different points in time into DNA (something like this has already been done for Wikipedia). The realitystamp checks if the configuration of particles contains that piece of DNA. Thanks to our use of Solomonoff Induction, our reality is the most likely one to contain such a sequence of DNA (since it explains the difference between the different points in time).
Identitystamp
The identitystamp is the part where we actually identify the alignment researcher E separately from all other physical objects in our reality. We sequence E's DNA. Then we formalize E as the largest clump of particles that are within some distance of a DNA molecule that matches the sequence.
If E has an identical twin, we might need some other biometric identifier such as iris recognition (assuming our physics model can handle it).
The hypothetical simulation
We call it the hypothetical simulation because, even though we are writing actual code, we never actually run it. We just have the AGI guess what the result would be if we hypothetically ran it, hence the name.
Simulation environment
Now that we have mathematically formalized E, we need to create the simulation environment that we drop E into. Keep in mind that sense we are just creating a mathematical description, we do not need to actually run the simulation, so it can use an unbounded amount of computation.
The simulation environment should contain a sign saying that the alignment researcher is in an IMDEAR simulation (they should already know about IMDEAR of course since we selected them), a supercomputer with unlimited computing power (this would require modifying the physics model a bit), and some amenities. For example, we might include a recreation center and a button outside of it labelled "reset recreation center". (Resetting it back to its original state is an easy way to restock and clean it.)
The supercomputer has a copy of inner_alignment so that they only need to worry about outer alignment.
Preparing the alignment researcher
Even with the best possible simulation environment, we want to give E the best chance of mental stability and corrigibility. Before taking the identity stamp, we will want to carefully select E and prepare them. This is analogous to the process used to pick and train astronauts. See Mental preparation for Mars as an example.
Alignment researcher creates an aligned and corrigible super-intelligence
In the simulation, E creates an aligned and corrigible super-intelligence. They do this very carefully, because if they create an unaligned super-intelligence that would be very bad. They take as much time as they need to solve alignment. They then somehow output this. They should not just use IMDEAR (unless they improve it somehow).
Aligned super-intelligence decides on an action
The aligned super-intelligence now sees the prompt and internal_sensors arguments to imdear.do and creates a plan to accomplish the task. It then somehow outputs this. The plan might suggest more calls to imdear.do, or it might write an entirely new AGI, or it could suggest a direct solution that humans can carry out.
Note that even though the AGI in real life is dumber than this super-intelligence (because the super-intelligence has more computing power), it can predict that it will be both competent and corrigible in the same way that humans can predict that stockfish will be good at chess.
Formal verification
We can not formally verify the end result of course, but it should be built on formally verified software as much as possible, along side other forms of quality control.
Weaknesses and further questions
- Does our initial search for our reality work? Or is it malign?
- Should we choose the most likely response, or randomly sample one? What other arbitrary choices that I made should be critically examined?
- The psychology of the alignment researcher E is a single point of failure (there are probably ways to make the proposal more robust to this)
- Even if it succeeds, IMDEAR does not mean humanity can solve outer alignment, even in principle. It would just mean that if humans can, in principle, solve outer alignment, then IMDEAR is one such solution.
- Our desiderata for inner alignment might be too strong. In particular, we are expecting it to be able to solve problems on which it can receive no feedback.
- The mathematical ontology identification problem: I don't think there is a pre-existing term for this, but I plan to write about it in the future. A crude example: how do we stop the AI from being an ultrafinitist? This is technically part of the inner alignment portion, but I thought I'd point it out since it's one of the desiderata that I think hasn't gotten much attention. This is a part of the problem of logical uncertainty [? · GW] (perhaps just a reframing of it).
How research on IMDEAR ties into other alignment approaches
- Part of OpenAI's alignment research plan is to train AI systems to do alignment research. These AI systems need to be sub-AGI, so they might struggle with doing something like IMDEAR on their own. If we do IMDEAR, the AI systems doing alignment research do not need to worry about it. In particular, the process of creating IMDEAR (such as the problems encountered along the way) could be very useful.
- RLHF [? · GW] and similar plans involve creating a model of human behavior. Preparing those humans [LW · GW] in a way similar to what IMDEAR requires will be necessary.
- When combined with logical inductor [? · GW] (a concept from agent foundations [? · GW]), it gives an idealized solution to the full alignment problem.
- We can use IMDEAR to implement Coherent Extrapolated Volition [? · GW]. This includes creating an agent to maximize CEV, or just querying it to see the CEV-utility of various scenarios. Because IMDEAR accepts requests in natural language, we can literally just use the string "Coherent Extrapolated Volition" in our request.
- IMDEAR is very closely related to QACI [LW · GW]. I expect components of IMDEAR to be useful to QACI.
- IMDEAR is wholly dependent on inner alignment research. For example, maybe we could use interpretability [? · GW] to extract the algorithm from a neural network, and then (forgetting about the original neural network) change the algorithm's goal to predicting IMDEAR? Or maybe agent foundations or shard theory will solve inner alignment somehow? I am not sure.
Sketch for an engineering project
How do we accomplish IMDEAR? Here is a sketch:
- Get a project going, probably just volunteers to start.
- Expand out this sketch.
- Double check that IMDEAR makes sense, fix theoretical problems. [LW · GW]
- Team members with physics knowledge (with help from the programmers) should create a data structure for configurations of particles [LW · GW]. A necessary function for this data structure is creating a list of DNA molecules, annotated with their nucleic acid sequence and their coordinates.
- (This step needs fleshing out) Create a physical model of the simulation environment [LW · GW] (or create a mathematical description of such an environment). All team members can contribute ideas for amenities. (Since designing things down to the atomic level is hard, we might need to take IRL objects and cover them in unique DNA or something and identify them.)
- Team members with psychology knowledge study how NASA selects and prepares [LW · GW] astronauts and similar programs. They create screening criteria and write a manual for a training camp. They also choose which amenities should be included in the final simulation.
- Select training camp instructors and other facilities. They use the manual to train alignment researchers for long term missions.
- Sequence the alignment researchers' DNA. [LW(p) · GW(p)]
- Ask catalog or a similar company to encode the entire internet at different points in time into DNA and give that DNA to us [LW(p) · GW(p)]
- Create a DNA strand containing random data, do a cryptographic hash, and then securely destroy the DNA and the data it contained. [LW(p) · GW(p)] (Preferably a provably secure one with weak assumptions.)
- Team members with programming knowledge combine the information from steps 4, 5, 8, 9, and 10 to create a prototype for the IMDEAR library.
- Replace components of the IMDEAR library with formally verified software [LW · GW] where possible, do quality control, do independent audits, etc...
- Wait for someone to solve inner alignment [LW · GW].
Chatroom
If you wish to contribute to or even just observe IMDEAR, join the EleutherAI discord server and then go to the IMDEAR project (this is just a thread basically, IMDEAR is not endorsed by EAI).
I have already started a framework we can build on. I have tried to set it up to people can make sporadic or even one-off contributions, like Wikipedia. We will refine it at some later stage, but for now it just needs content!
4 comments
Comments sorted by top scores.
comment by neverix · 2023-08-02T13:26:52.083Z · LW(p) · GW(p)
We can idealize the outer alignment solution as a logical inductor [? · GW].
Why outer?
Replies from: christopher-king↑ comment by Christopher King (christopher-king) · 2023-08-08T01:00:00.661Z · LW(p) · GW(p)
Oh, I think that was a typo. I changed it to inner alignment.
comment by Christopher King (christopher-king) · 2023-06-07T13:52:29.291Z · LW(p) · GW(p)
Actually, I think the universal prior being malign actually does break this. (I thought it might be only a little malign, which would be okay, but after a little reading it appears that it might be really malign!)
A crude example of how this might impact IMDEAR is that, while using solomonoff inductive inference to model the human, it sneakily inserts evil nanobots into the model of the bloodstream. (This specific issue can probably be patched, but there are more subtle ways it can mess up IMDEAR.)
Even creating a model of the simulation environment is messed up, since I planned on using inference for the difficult part.
The only thing I guess we can hope for is if we find a different prior that isn't malign, and for now we just leave the prior as a free variable. (See some of the ping backs on the universal prior for some approaches in this direction.) But I'm not sure how likely we are to find such a prior. 🤔
Also, Paul Christiano has a proposal with similar requirements to IMDEAR, but at a lower tech level: Specifying a human precisely (reprise).
The alternative is to adjust IMDEAR to not use solomonoff induction at all, and define/model everything directly, but this is probably much harder.
Replies from: carado-1↑ comment by Tamsin Leake (carado-1) · 2023-10-05T06:44:07.183Z · LW(p) · GW(p)
it is not the case that, simply, "the universal prior is malign". various universal priors (solomonoff induction, levin search, what QACI does, many other options…), being used in various ways, are to-various-extents malign. it depends a lot what you're doing.
i'm quite hopeful that we can get sufficiently-not-malign uses of some universal prior for QACI, and thus probably also for IMDEAR (conditional on the rest of IMDEAR being workable).