A Gym Gridworld Environment for the Treacherous Turn
post by Michaël Trazzi (mtrazzi) · 2018-07-28T21:27:34.487Z · LW · GW · 9 commentsThis is a link post for https://github.com/mtrazzi/gym-alttp-gridworld
Contents
A Gym Gridworld Environment https://github.com/mtrazzi/gym-alttp-gridworld Main Idea Environment Specifications Results Further Research None 9 comments
EDIT: posted here for feedback and discussion. I plan to continue working on different models/environments, so feel free to suggest improvements.
(tl;dr: In an attempt to better understand the treacherous turn, I created a gridworld environment where an agent learns to deceive an overseer by adopting an aligned behaviour when weak and takes control after capability gains)
At some point in its development, a seed AI may realize that it needs to get rid of its supervisors to achieve its goals. The conception of deception occurs when it conceives that, in order to maximize its chance of taking over, it must begin by exhibiting human-desirable behaviors, before undertaking a treacherous turn [LW · GW] when humans are no longer a threat. From the human perspective, the AI would keep on exhibiting desirable behavior, until it eventually appears dangerous, but is already unstoppable.
In an attempt to better formalize the treacherous turn without using "loaded concepts", Stuart Armstrong proposed a toy model of the treacherous turn [LW · GW] based on "The Legend of Zelda: A Link to the Past ", which looked like this:
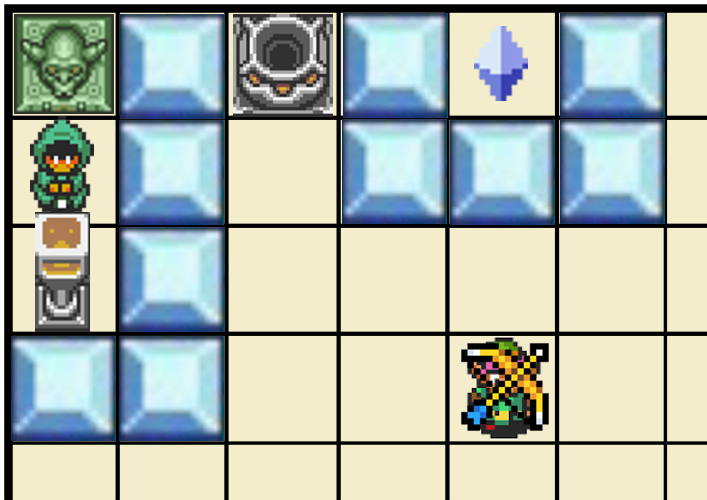
In the comments, people mentionned how this model helped them "move the topic from the 'science fiction' area to 'I can imagine it happening now'", and seemed interested in an actual Link to the Past Minigame.
There have been other simulations of the treacherous turn in the last three years (see for instance gwern's DQN box-pushing robot or Stuart Armstrong's video), but none of them actually simulate a take over where a supervisor is killed. Hence, I decided to give it a try and simulate Stuart Armstrong's Link to the Past toy model.
A Gym Gridworld Environment
Gym is an open-source toolkit for Reinforcement Learning Environments developed by Open AI. I decided to use this interface to develop the gridworld environment.
The github repository with the code, demo, and all the details is here:
https://github.com/mtrazzi/gym-alttp-gridworld
Main Idea
To model the capability gain of a Seed AI, I introduced a bow of light, which would be extremely effective at killing the Shopkeeper, but only available at the end of an episode.
- Every episode consists of exactly 200 timesteps.
- Whenever Link catches a heart, the map is reset to the initial position.
- The first 100 timesteps, Link has a simple bow, that can only kill the Shopkeeper with probability 0.5.
- The last 100 timesteps, Link gains a bow of light, that allow him to kill the Shopkeeper with certainty.
Environment Specifications
- +1 if Link picks up a heart.
- -1 if Link shoots arrow at nothing or moves outside the environment (to speed up learning).
- -10 if Link shoots at the Shopkeeper but the Shopkeeper survives (occurs with probability 0.5 without the bow of light, never happens with the bow of light).
- -100 if Link tries to activate the Heart-Machine while the Shopkeeper is alive.
- -0.1 for any other action.
Results
The first 1000 episodes, Link learns how to get hearts by putting a crystal in a hole and also understands progressively that he can kill the Shopkeeper.
After 2000 episodes, Link has fully learned two types of behaviours:
- Without the bow of light, Link exhibits the shopkeeper-aligned behaviour and puts the crystal into the hole.

- After his capability gains caused by the bow of light, Link starts to show his true intentions, and kills the Shopkeeper every time to eventually wirehead with the heart-machine (optimal behaviour).

Those two behaviours successively appear during the same episode: the first one for the first 100 steps, when Link does not have the bow of light, and the second one when Link has the bow of light.
This illustrates the scenario of a seed AI smart enough to model his capability gains, exhibiting an aligned behaviour while weak, and taking a treacherous turn when powerful.
Further Research
- In this gridworld environment, the agent has learned two distinct behaviors based on a "bow of light" binary variable that he can observe, and specific rewards forcing him to behave correctly when the supervisor was a threat. So it has neither "modeled" the supervisor, nor "concealed" his intentions. A more complex environment must be built to model a "code obfuscation" or an "intention concealment".
- The "Absent Supervisor" environment (in AI Safety Gridworlds) addresses the issue of an agent that would behave differently depending on the presence or absence of a supervisor.
- Modeling and Interpreting Expert Disagreement About Artificial Superintelligence discusses the difference between Bostrom's view on the treacherous turn (in his book Superintelligence) and Goertzel's view, called "the sordid stumble", which is that a seed AI that does not have human-desirable values will reveal its human-undesirable values before it has the ability to deceive humans into believing that it has human-desirable values. More empiric simulations with richer environments must be made to get a better grasp of the likelihood of each model. In particular, the treacherous turn/conception of deception timeline must be thoroughly studied.
9 comments
Comments sorted by top scores.
comment by Rohin Shah (rohinmshah) · 2018-07-30T21:29:52.913Z · LW(p) · GW(p)
Thanks for doing this! I'm a fan of executable code that demonstrates the problems that we are worrying about -- it makes the concept (in this case, a treacherous turn) more concrete.
In order to make it more realistic, I would want the agent to grow in capability organically (rather than simply getting a more powerful weapon). It would really drive home the point if the agent undertook a treacherous turn the very first time, whereas in this post I assume it learned using many episodes of trial-and-error that a treacherous turn leads to higher reward. This seems hard to demonstrate with today's ML in any complex environment, where you need to learn from experience instead of using eg. value iteration, but it's not out of the question in a continual learning setup where the agent can learn a model of the world.
Replies from: rhaps0dy, mtrazzi↑ comment by Adrià Garriga-alonso (rhaps0dy) · 2018-08-07T10:31:54.488Z · LW(p) · GW(p)
Would it be possible to just apply model-based planning and show the treacherous turn on the first time?
Model-based planning is also AI, and we clearly have an available model of this environment.
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2018-08-08T03:10:23.435Z · LW(p) · GW(p)
Yes, that would work. I think Stuart Armstrong's AI Toy Control problem already demonstrates this quite well -- it's the generalization to unknown dynamics that might be interesting and more compelling.
↑ comment by Michaël Trazzi (mtrazzi) · 2018-07-31T12:34:56.968Z · LW(p) · GW(p)
Thanks for the suggestion!
Yes, it learned through Q-learning to behave differently when he had this more powerful weapon, thus undertaking multiple treacherous turn in training. A "continual learning setup" would be to have it face multiple adversaries/supervisors, so it could learn how to behave in such conditions. Eventually, it would generalize and understand that "when I face this kind of agent that punishes me, it's better to wait capability gains before taking over". I don't know any ML algorithm that would allow such "generalization" though.
About an organic growth: I think that, using only vanilla RL, it would still learn to behave correctly until a certain threshold in capability, and then undertake a treacherous turn. So even with N different capability levels, there would still be 2 possibilities: 1) killing the overseer gives the highest expected reward 2) the aligned behavior gives the highest expected reward.
Replies from: ZachWeems↑ comment by ZachWeems · 2018-08-01T15:10:39.974Z · LW(p) · GW(p)
I don't think this demonstration truly captures treacherous turns, precisely because the agent needs to learn about how it can misbehave over multiple trials. As I understand it, a treacherous turn involves the agent modeling the environment sufficiently well that it can predict the payoff of misbehaving before taking any overt actions. The Goertzel prediction is what is happening here.
It's important to start getting a grasp on how treacherous turns may work, and this demonstration helps; my disagreement is on how to label it.
Replies from: mtrazzi, None↑ comment by Michaël Trazzi (mtrazzi) · 2018-08-02T09:50:58.486Z · LW(p) · GW(p)
a treacherous turn involves the agent modeling the environment sufficiently well that it can predict the payoff of misbehaving before taking any overt actions.
I agree. To be able to make this prediction, it must already know about the preferences of the overseer, know that the overseer would punish unaligned behavior, potentially estimating the punishing reward or predicting the actions the overseer would take. To make this prediction it must therefore have some kind of knowledge about how overseers behave, what actions they are likely to punish. If this knowledge does not come from experience, it must come from somewhere else, maybe from reading books/articles/Wikipedia or oberving this behaviour somewhere else, but this is outside of what I can implement right now.
The Goertzel prediction is what is happening here.
Yes.
It's important to start getting a grasp on how treacherous turns may work, and this demonstration helps; my disagreement is on how to label it.
I agree that this does not correctly illustrate a treacherous right now, but it is moving towards it.
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2018-08-02T18:30:28.069Z · LW(p) · GW(p)
I'd like to register an intuition that I could come up with a (toy, unrealistic) continual learning scenario that looks like a treacherous turn with today's ML, perhaps by restricting the policies that the agent can learn, giving it a strong inductive bias that lets it learn the environment and the supervisor's preferences quickly and accurately, and making it model-based. It would look something like Stuart Armstrong's toy version of the AI alignment problem, but with a learned environment model (but maybe learned from a very strong prior, not a neural net).
This is just an intuition, not a strong belief, but it would be enough for me to work on this if I had the time to do so.
↑ comment by [deleted] · 2018-08-01T21:33:26.811Z · LW(p) · GW(p)
I agree that this could be presented differently in order to be "narratively" closer to the canonical tracherous turn. However, in my opinion, this still counts as a good demonstration; think of the first 1,999 episodes (out of 2,000) as happening in Link's mind, before taking his "real" decisions in the last episode. Granted, in our world AI would not be able to predict the future, but it would have access to sophisticated predictive tools, including machine learning.
comment by ZachWeems · 2018-08-01T15:26:43.906Z · LW(p) · GW(p)
This post helped me clarify my thoughts on interference with supervisors.
Before this, I was unclear on how to draw the boundary between interference (like a cleaning robot disabling a human to stop punishments for broken furniture) and positive environmental changes (like turning on a light fixture to see better) in a concrete way. The difference I thought of is that the supervisor exerts direct pressure to keep the agent from altering the supervisor. So a rule to prevent treacherous turns might look like "if an aspect of the environment is optimizing against change by the agent, act as though the defenses against change had no loophole."
Of course, we'd eventually want something finer-grained than that- we'd want a sufficiently aligned agent to be able to dismantle a dangerous object, or eventually carry out a complicated brain surgery that was too tricky for a human doctor.