AI Forecasting: One Year In
post by jsteinhardt · 2022-07-04T05:10:18.470Z · LW · GW · 12 commentsContents
Forecasting Tasks and Overall Predictions How Accurate Were the Forecasts? The Median ML Researcher Was (Probably) Even More Wrong Was Progress Surprising, or Were the Forecasters Bad? Looking Forward None 13 comments
Last August, my research group created a forecasting contest to predict AI progress on four benchmarks. Forecasts were asked to predict state-of-the-art performance (SOTA) on each benchmark for June 30th 2022, 2023, 2024, and 2025. It’s now past June 30th, so we can evaluate the performance of the forecasters so far.
Forecasters were asked to provide probability distributions, so we can evaluate both their point estimates and their coverage (whether the true result was within their credible intervals). I’ll dive into the data in detail below, but my high-level takeaways were that:
- Forecasters’ predictions were not very good in general: two out of four forecasts were outside the 90% credible intervals.
- However, they were better than my personal predictions, and I suspect better than the median prediction of ML researchers (if the latter had been preregistered).
- Specifically, progress on ML benchmarks happened significantly faster than forecasters expected. But forecasters predicted faster progress than I did personally, and my sense is that I expect somewhat faster progress than the median ML researcher does.
- Progress on a robustness benchmark was slower than expected, and was the only benchmark to fall short of forecaster predictions. This is somewhat worrying, as it suggests that machine learning capabilities are progressing quickly, while safety properties are progressing slowly.
Below I’ll review the tasks and competition format, then go through the results.
Forecasting Tasks and Overall Predictions
As a reminder, the four benchmarks were:
- MATH, a mathematics problem-solving dataset;
- MMLU, a test of specialized subject knowledge using high school, college, and professional multiple choice exams;
- Something Something v2, a video recognition dataset; and
- CIFAR-10 robust accuracy, a measure of adversarially robust vision performance.
Forecasters were asked to predict performance on each of these. Each forecasting question had a $5000 prize pool (distributed across the four years). There were also two questions about compute usage by different countries and organizations, but I’ll ignore those here.
Forecasters themselves were recruited with the platform Hypermind. You can read more details in the initial blog post from last August, but in brief, professional forecasters make money by providing accurate probabilistic forecasts about future events, and are typically paid according to a proper scoring rule that incentivizes calibration. They apply a wide range of techniques such as base rates, reference classes, trend extrapolation, examining and aggregating different expert views, thinking about possible surprises, etc. (see my class notes for more details).
Here is what the forecasters’ point estimates were for each of the four questions (based on Hypermind's dashboard):
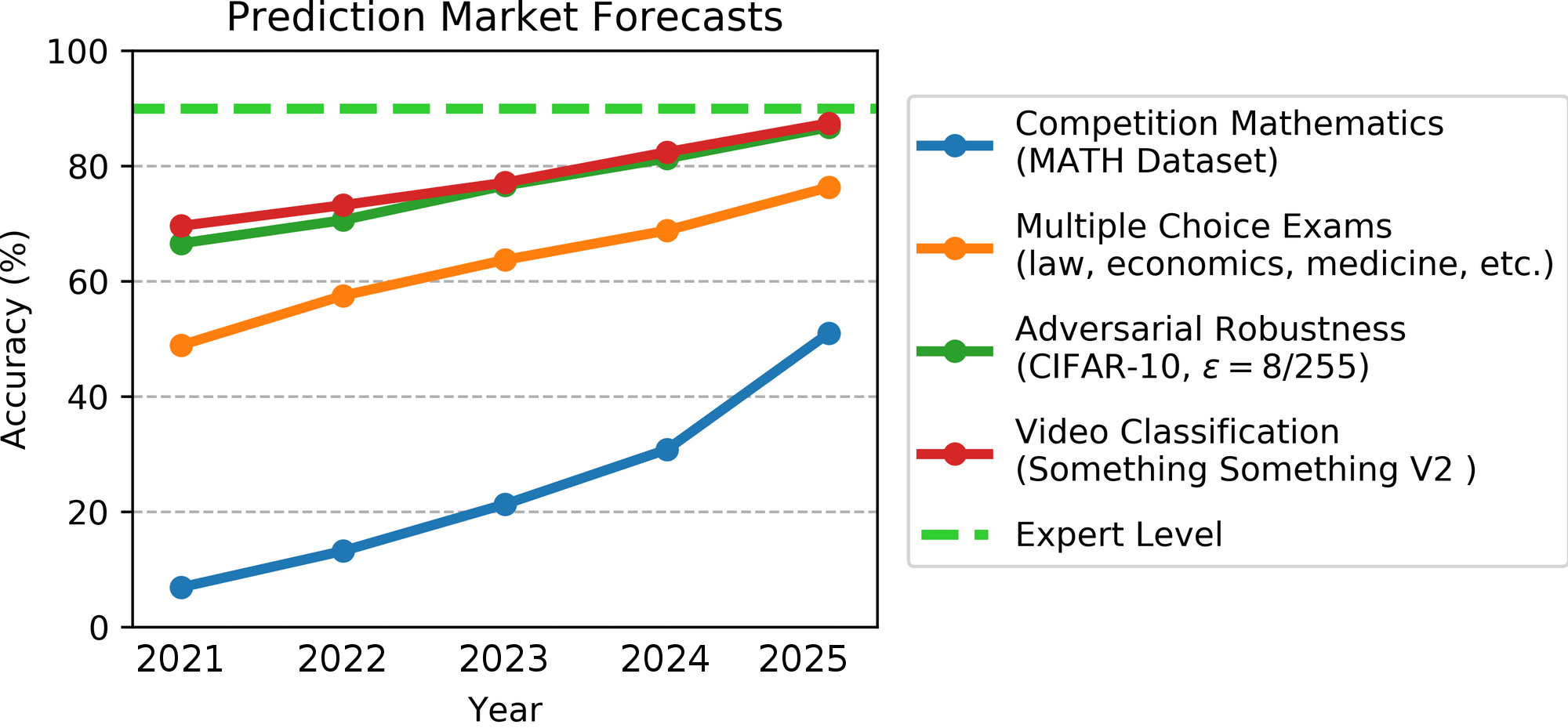
Expert performance is approximated as 90%. The 2021 datapoint represents the SOTA in August 2021, when the predictions were made.[1]
For June 2022, forecasters predicted 12.7% on MATH, 57.1% on MMLU (the multiple-choice dataset), 70.4% on adversarial CIFAR-10, and 73.0% on Something Something v2.
At the time, I described being surprised by the 2025 prediction for the MATH dataset, which predicted over 50% performance, especially given that 2021 accuracy was only 6.9% and most humans would be below 50%.
Here are the actual results, as of today:
- MATH: 50.3% (vs. 12.7% predicted)
- MMLU: 67.5% (vs. 57.1% predicted)
- Adversarial CIFAR-10: 66.6% (vs. 70.4% predicted)
- Something Something v2: 75.3% (vs. 73.0% predicted)
MATH and MMLU progressed much faster than predicted. Something Something v2 progressed somewhat faster than predicted. In contrast, Adversarial CIFAR-10 progressed somewhat slower than predicted. Overall, progress on machine learning capabilities (math, MMLU, video) was significantly faster than what forecasters expected, while progress on robustness (adversarial CIFAR) was somewhat slower than expected.
Interestingly, the 50.3% result on MATH was released on the exact day that the forecasts resolved. I'm told this was purely coincidental, but it's certainly interesting that a 1-day difference in resolution date had such a big impact on the result.
How Accurate Were the Forecasts?
To assess forecast accuracy, we need to look not just at the point estimate, but at the forecasters’ actual probability distribution. Even though 68% on MMLU seems far off from 57%, perhaps it was well within the credible interval of the forecasts. However, that turns out not to be the case, for either MATH or MMLU:
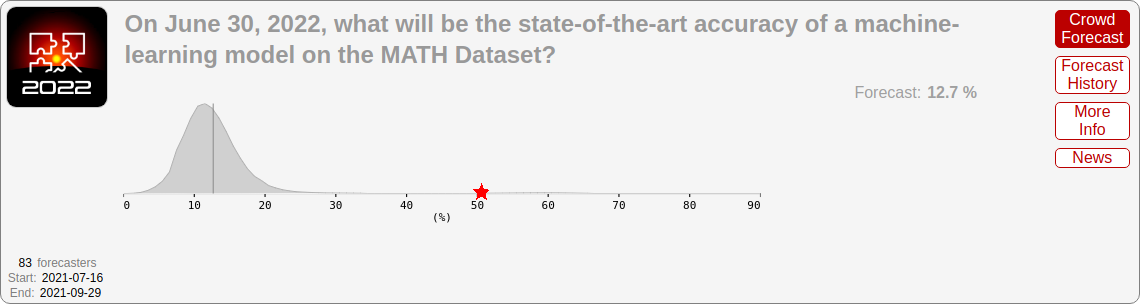

I marked the actual result with a star, and it’s clear that in both cases it’s in the far tails of the forecast distribution.
For completeness, here are results for adversarial CIFAR-10 and Something Something v2:
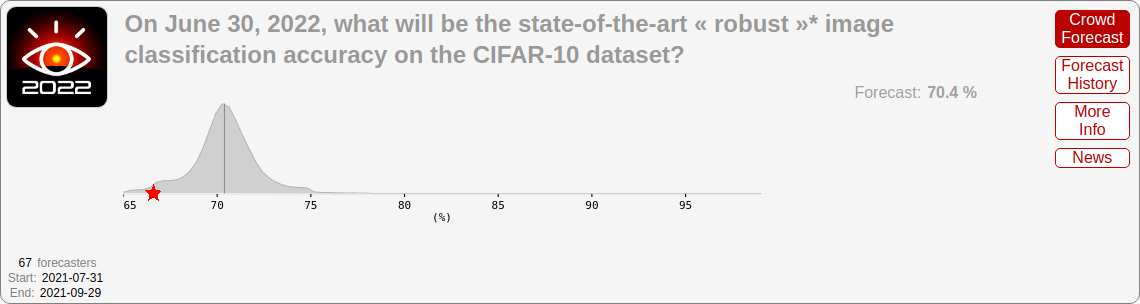
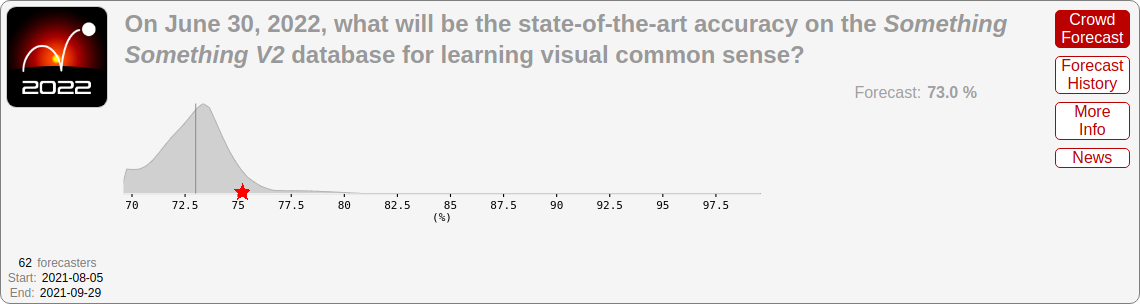
While both were somewhat in the tails, they fell within a part of the distribution that at least had non-negligible probability density.
The Median ML Researcher Was (Probably) Even More Wrong
While forecasters didn’t do great at forecasting progress in ML, the median ML researcher would likely have done even worse. Unfortunately, we don’t have preregistered predictions to check this, but a few lines of evidence support this conclusion.
First, I did (somewhat) preregister a prediction of my own. In Updates and Lessons from AI Forecasting, I said:
“Projected progress on math and on broad specialized knowledge are both faster than I would have expected. I now expect more progress in AI over the next 4 years than I did previously.”
And, more to the point:
“Current performance on this dataset is quite low--6.9%--and I expected this task to be quite hard for ML models in the near future. However, forecasters predict more than 50% accuracy by 2025! This was a big update for me.”
“If I imagine an ML system getting more than half of these questions right, I would be pretty impressed. If they got 80% right, I would be super-impressed. The forecasts themselves predict accelerating progress through 2025 (21% in 2023, then 31% in 2024 and 52% in 2025), so 80% by 2028 or so is consistent with the predicted trend. This still just seems wild to me and I'm really curious how the forecasters are reasoning about this.”
So, while I didn’t register a specific prediction, I clearly thought the forecasts on MATH were aggressive in terms of how much progress they predicted, whereas it turned out they weren’t aggressive enough.
At the same time, my personal predictions about ML progress seem to be more aggressive than the median ML researcher. I would personally describe them as “somewhat more aggressive”, but some of my students think they are “much more aggressive”. Either way, this suggests that the median ML researcher would have predicted even less progress than me, and so been even more wrong than I was.
Anecdotal evidence seems to confirm this. When our group first released the MATH dataset, at least one person told us that it was a pointless dataset because it was too far outside the range of what ML models could accomplish (indeed, I was somewhat worried about this myself).
If ML researchers (including myself) would like to defend their honor on this point, I think the best way would be to register forecasts for the upcoming year in advance. You can submit directly to Hypermind for the possibility of winning money (sign-up required), or just comment on this post.
Was Progress Surprising, or Were the Forecasters Bad?
Given that forecasters seemed not to predict progress well, we might wonder if they were just not trying very hard or were otherwise not doing a good job. For instance:
- The overall prize pool was only $5000 for each benchmark (which itself consists of four questions for 2022-2025). Divided over the 60-70 participants, the average payout per benchmark is only $80, or $20 per question.[2] So, it’s possible that forecasters were not incentivized strongly enough.
- Hypermind’s interface has some limitations that prevent outputting arbitrary probability distributions. In particular, in some cases there is an artificial limit on the possible standard deviations, which could lead credible intervals to be too narrow.
- Maybe the forecasters just weren’t skilled enough—either the best forecasters didn’t participate, or the forecasts were too different from more traditional forecasts, which tend to focus on geopolitics.
These are all plausible concerns, but I think progress is still “surprising” even after accounting for them. For instance, superforecaster Eli Lifland posted predictions for these forecasts on his blog. While he notes that the Hypermind interface limited his ability to provide wide intervals on some questions, he doesn’t make that complaint for the MATH 2022 forecast and posted the following prediction, for which the true answer of 50.3% was even more of an outlier than Hypermind's aggregate:
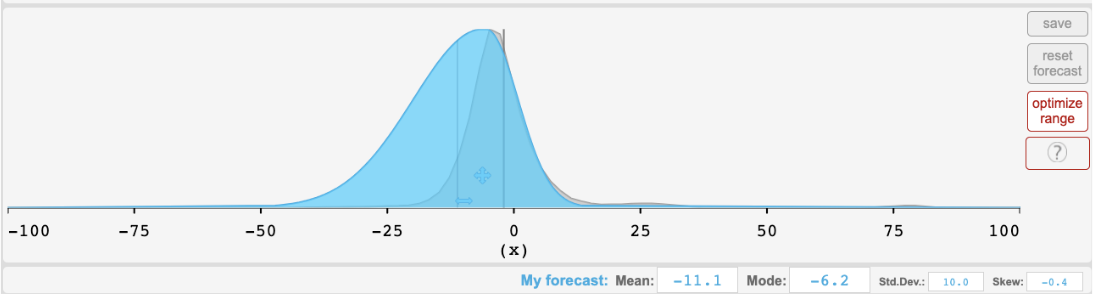
A separate forecast, which I commissioned from the Samotsvety Forecasting group and paid around $2500 for, predicted MATH performance in 2026. The current accuracy of 50.3% was around the 75th percentile for their 2026 forecast, so presumably it was significantly further in the tail for 2022. Their forecast was made in Elicit, so there were no constraints on allowable distributions, and I explicitly selected Samotsvety as having a good track record and being particularly interested in AI, and paid them a high hourly rate. So, the concerns about the Hypermind forecasts don’t apply here, but progress still outpaced the forecast.
Finally, the fact that forecasters did better than me and would have probably beat the median ML researcher suggests that they aren’t lacking an obvious domain-specific skill.
Looking Forward
Now that forecasters have had one year of practice, I'm hoping there will be fewer surprises next year--but we'll have to wait and see. In the meantime, I'm hoping that more work will be done on AI safety and alignment, so that it can keep pace with the rapid increase in capabilities.
Finally, as one specific intersection between AI and forecasting that could help us better predict the future, our research group recently released the Autocast benchmark, which can be used to train ML systems to forecast future events. Currently, they are significantly worse than humans, but this was true for MATH one year ago. Can ML systems get better at forecasting as fast as they got better at math? Superhuman forecasters would help us better prepare for the many challenges that lie ahead. I hope to be pleasantly surprised.
12 comments
Comments sorted by top scores.
comment by Andrew_Critch · 2022-07-04T15:57:31.277Z · LW(p) · GW(p)
Jacob, good to see you thinking seriously about forecasting risks. At SPARC meetings you argued that AGI was 80 years away, and maintained that view after considerable debate. Is "80 years away" still your position, or have you updated?
comment by Verden · 2022-07-04T12:02:12.905Z · LW(p) · GW(p)
It's funny that this post has probably made me feel more doomy about AI risk than any other LW post published this year. Perhaps for no particularly good reason. There's just something really disturbing to me about seeing a vivid case where folks like Jacob, Eli and Samotsvety, apparently along with many others, predict a tiny chance that a certain thing in AI progress will happen (by a certain time), and then it just... happens.
comment by elifland · 2022-07-05T00:12:28.102Z · LW(p) · GW(p)
Overall agree that progress was very surprising and I'll be thinking about how it affects my big picture views on AI risk and timelines; a few relatively minor nitpicks/clarifications below.
For instance, superforecaster Eli Lifland posted predictions for these forecasts on his blog.
I'm not a superforecaster (TM) though I think some now use the phrase to describe any forecasters with good ~generalist track records?
While he notes that the Hypermind interface limited his ability to provide wide intervals on some questions, he doesn’t make that complaint for the MATH 2022 forecast and posted the following prediction, for which the true answer of 50.3% was even more of an outlier than Hypermind's aggregate:
[image]
The image in the post is for another question: below shows my prediction for MATH, though it's not really more flattering. I do think my prediction was quite poor.
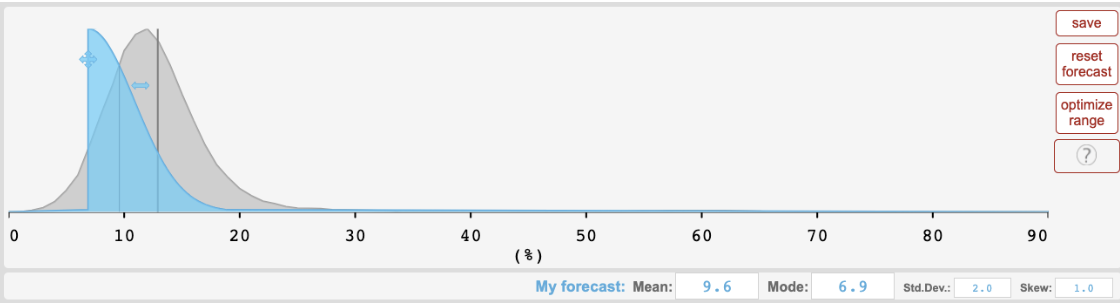
I didn't run up to the maximum standard deviation here, but I probably would have given more weight to larger values if I had been able to forecast a mixture of components like on Metaculus. The resolution of 50.3% would very likely (90%) still have been above my 95th percentile though.
- Hypermind’s interface has some limitations that prevent outputting arbitrary probability distributions. In particular, in some cases there is an artificial limit on the possible standard deviations, which could lead credible intervals to be too narrow.
I think this maybe (40% for my forecast) would have flipped the MMLU forecast to be inside the 90th credible interval, at least for mine and perhaps for the crowd.
In my notes on the MMLU forecast I wrote "Why is the max SD so low???"
comment by Owain_Evans · 2022-07-04T15:50:55.829Z · LW(p) · GW(p)
Very helpful post, thanks!
Are there some meta-level lessons about forecasting a dataset like MATH? IIRC, at the time of these forecasts, the only results were GPT2-finetune and GPT3 few-show (without chain-of-thought and self-consistency). For GPT-2, the accuracy scores were <15% for nearly all subjects and difficulty levels. This may be consistent with GPT-2 either not really understanding questions or being so weak at basic arithmetic that it has no chance for most questions.
Given that performance was so low and that not many models/setups had been tried, there's reason to have a wider distribution on future results. I would still guess that human expert level scores (>95%) should have had very low probability, but even (say) a score of 80% should have had more than 5% chance. (I realize this is posthoc -- I'm not claiming to have made explicit predictions like this).
A good source of baserates/priors would be to look at how performance improves on benchmarks after the paper introducing the benchmark. One example that comes to mind is Lambada, where performance went from 7.3% in the initial paper to 49% within a year. It'd be cool for someone to plot data from a bunch of benchmarks. Papers with Code will be very helpful but has some missing data. (We might also expect jumpier performance for math-related tasks because once you can do 2-digit arithmetic or elementary algebra reliably then many problems are opened up).
↑ comment by Michaël Trazzi (mtrazzi) · 2022-07-05T21:05:20.032Z · LW(p) · GW(p)
I believe the forecasts were aggregated around June 2021. When was GPT2-finetune released? What about GPT3 few show?
Re jumps in performance: jack clark has a screenshot on twitter about saturated benchmarks from the dynabench paper (2021), it would be interesting to make something up-to-date with MATH https://twitter.com/jackclarkSF/status/1542723429580689408
comment by jhahn · 2022-07-04T13:22:54.249Z · LW(p) · GW(p)
For selfish reasons I hope that the mathematics profession lasts at least another decade. I was surprised to see that the timeline for an IMO gold medal here
https://www.metaculus.com/questions/6728/ai-wins-imo-gold-medal/
did not shift very much, and am unsure if how little that moved has to do with how few users make predictions on that website. It would do me a great deal of practical and psychological good to see more accurate predictions about progress in mathematics in particular in the future, so I hope you can achieve that. Thank you and your group for producing the MATH dataset.
Replies from: valery-cherepanov, akram-choudhary↑ comment by Qumeric (valery-cherepanov) · 2022-07-06T11:57:19.482Z · LW(p) · GW(p)
It actually shifted quite a lot. From "in 10 years" to "in 7 years", a 30% reduction!
↑ comment by Akram Choudhary (akram-choudhary) · 2022-07-05T13:45:11.298Z · LW(p) · GW(p)
how many mathematicians could win the gold at the IMO
I understand its for under 18s but I imagine there are a lot of mathematicians that wouldnt be able to do it either right?
Replies from: jhahncomment by Aleksey Bykhun (caffeinum) · 2022-07-07T07:38:25.871Z · LW(p) · GW(p)
If everyone is so bad at this, is it a reasonable strategy to just bet against the market even more aggressively, making $ on prediction market platforms?
On a similar note, does it make sense to raise a charity fund and bet a lot of money on "AGI by 2025", motivating forecasters to produce more reasonable predictions?
comment by SuperDaveWhite (superdavewhite) · 2022-07-05T11:53:19.366Z · LW(p) · GW(p)
How well did they follow the Wisdom of Crowds tenants? (James Surowiecki)
Diversity of opinion - Each person should have private information even if it's just an eccentric interpretation of the known facts.
Independence - People's opinions aren't determined by the opinions of those around them.
Decentralization - People can specialize and draw on local knowledge.
Aggregation - Some mechanism exists for turning private judgments into a collective decision.