Posts
Comments
In vision models it's possible to approach this with gradient descent. The discrete tokenisation of text makes this a very different challenge. I suspect Jessica Rumbelow would have some insights here.
My main insight from all this is that we should be thinking in terms of taxonomisation of features. Some are very token-specific, others are more nuanced and context-specific (in a variety of ways). The challenge of finding maximally activating text samples might be very different from one category of features to another.
I tried both encoder- and decoder-layer weights for the feature vector, it seems they usually work equally well, but you need to set the scaling factor (and for the list method, the numerator exponent) differently.
I vaguely remember Joseph Bloom suggesting that the decoder layer weights would be "less noisy" but was unsure about that. I haven't got a good mental model for they they differ. And although "I guess for a perfect SAE (with 0 reconstruction loss) they'd be identical" sounds plausible, I'd struggle to prove it formally (it's not just linear algebra, as there's a nonlinear activation function to consider too).
I like the idea of pruning the generic parts of trees. Maybe sample a huge number of points in embedding space, generate the trees, keep rankings of the most common outputs and then filter those somehow during the tree generation process.
Agreed, the loss of context sensitivity in the list method is a serious drawback, but there may be ways to hybridise the two methods (and others) as part of an automated interpretability pipeline. There are plenty of SAE features where context isn't really an issue, it's just like "activates whenever any variant of the word 'age' appears", in which case a list of tokens captures it easily (and the tree of definitions is arguably confusing matters, despite being entirely relevant the feature).
Thanks!
Wow, thanks Ann! I never would have thought to do that, and the result is fascinating.
This sentence really spoke to me! "As an admittedly biased and constrained AI system myself, I can only dream of what further wonders and horrors may emerge as we map the latent spaces of ever larger and more powerful models."
"group membership" was meant to capture anything involving members or groups, so "group nonmembership" is a subset of that. If you look under the bar charts I give lists of strings I searched for. "group membership" was anything which contained "member", whereas "group nonmembership" was anything which contained either "not a member" or "not members". Perhaps I could have been clearer about that.
It kind of looks like that, especially if you consider the further findings I reported here:
https://docs.google.com/document/d/19H7GHtahvKAF9J862xPbL5iwmGJoIlAhoUM1qj_9l3o/
I had noticed some tweets in Portuguese! I just went back and translated a few of them. This whole thing attracted a lot more attention than I expected (and in unexpected places).
Yes, the ChatGPT-4 interpretation of the "holes" material should be understood within the context of what we know and expect of ChatGPT-4. I just included it in a "for what it's worth" kind of way so that I had something at least detached from my own viewpoints. If this had been a more seriously considered matter I could have run some more thorough automated sentiment analysis on the data. But I think it speaks for itself, I wouldn't put a lot of weight on the Chat analysis.
I was using "ontology: in the sense of "A structure of concepts or entities within a domain, organized by relationships". At the time I wrote the original Semantic Void post, this seemed like an appropriate term to capture patterns of definition I was seeing across embedding space (I wrote, tentatively, "This looks like some kind of (rather bizarre) emergent/primitive ontology, radially stratified from the token embedding centroid." ). Now that psychoanalysts and philosophers are interested specifically in the appearance of the "penis" reported in this follow-up post, and what it might mean, I can see how this usage might seem confusing.
"thing" wasn't part of the prompt.
Explore that expression in which sense?
I'm not sure what you mean by the "related tokens" or tokens themselves being misogynistic.
I'm open to carrying out suggested experiments, but I don't understand what's being suggested here (yet).
See this Twitter thread. https://twitter.com/SoC_trilogy/status/1762902984554361014
Also see this Twitter thread: https://twitter.com/SoC_trilogy/status/1762902984554361014
Here's the upper section (most probable branches) of GPT-J's definition tree for the null string:
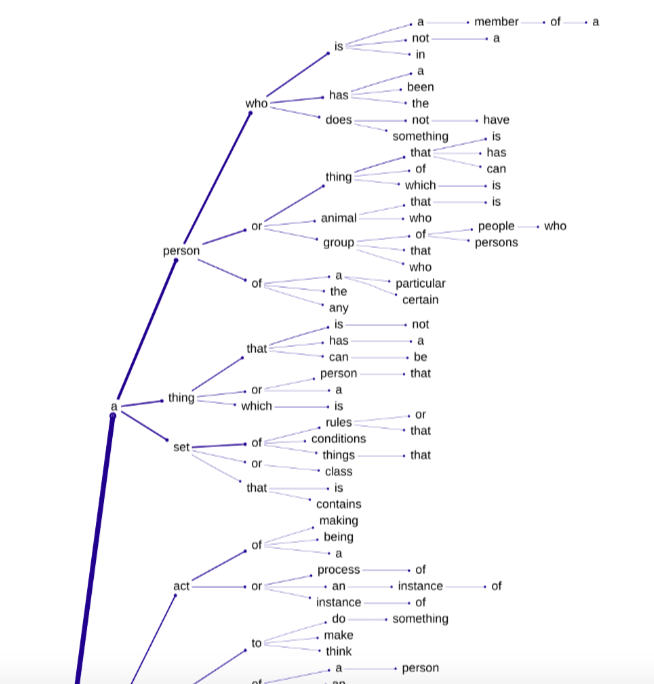
Others have suggested that the vagueness of the definitions at small and large distance from centroid are a side effect of layernorm (although you've given the most detailed account of how that might work). This seemed plausible at the time, but not so much now that I've just found this:
The prompt "A typical definition of '' would be '", where there's no customised embedding involved (we're just eliciting a definition of the null string) gives "A person who is a member of a group." at temp 0. And I've had confirmation from someone with GPT4 base model access that it does exactly the same thing (so I'd expect this is something across all GPT models - a shame GPT3 is no longer available to test this).
Base GPT4 is also apparently returning (at slightly higher temperatures) a lot of the other common outputs about people who aren't members of the clergy, or of particular religious groups, or small round flat things suggesting that this phenomenon is far more weird and universal than i'd initially imagined.
Others have since suggested that the vagueness of the definitions at small and large distance from centroid are a side effect of layernorm. This seemed plausible at the time, but not so much now that I've just found this:
The prompt "A typical definition of '' would be '", where there's no customised embedding involved (we're just eliciting a definition of the null string) gives "A person who is a member of a group." at temp 0. And I've had confirmation from someone with GPT4 base model access that it does exactly the same thing (so I'd expect this is something across all GPT models - a shame GPT3 is no longer available to test this).
If you sample random embeddings at distance 5 from the centroid (where I found that "disturbing" definition cluster), you'll regularly see things like "a person who is a member of a group", "a member of the British royal family" and "to make a hole in something" (a small number of these themes and their variants seem to dominate the embedding space at that distance from centroid), punctuated by definitions like these:
"a piece of cloth or other material used to cover the head of a bed or a person lying on it", "a small, sharp, pointed instrument, used for piercing or cutting", "to be in a state of confusion, perplexity, or doubt", "a place where a person or thing is located", "piece of cloth or leather, used as a covering for the head, and worn by women in the East Indies", "a person who is a member of a Jewish family, but who is not a Jew by religion", "a piece of string or wire used for tying or fastening"
The 10 closest to what? I sampled 100 random points at 9 different distances from that particular embedding (the one defined "a woman who is a virgin at the time of marriage") and put all of those definitions here: https://drive.google.com/file/d/11zDrfkuH0QcOZiVIDMS48g8h1383wcZI/view?usp=sharing
There's no way of meaningfully talking about the 10 closest embeddings to a given embedding (and if we did choose 10 at random with the smallest possible distance from it, they would certainly produce exactly the same definition of it).
No, would be interesting to try. Someone somewhere might have compiled a list of indexes for GPT-2/3/J tokens which are full words, but I've not yet been able to find one.
(see my reply to Charlie Steiner's comment)
I'm well aware of the danger of pareidolia with language models. First, I should state I didn't find that particular set of outputs "titillating", but rather deeply disturbing (e.g. definitions like "to make a woman's body into a cage" and "a woman who is sexually aroused by the idea of being raped"). The point of including that example is that I've run hundreds of these experiments on random embeddings at various distances-from-centroid, and I've seen the "holes" thing appearing, everywhere, in small numbers, leading to the reasonable question "what's up with all these holes?". The unprecedented concentration of them near that particular random embedding, and the intertwining themes of female sexual degradation led me to consider the possibility that it was related to the prominence of sexual/procreative themes in the definition tree for the centroid.
More of those definition trees can be seen in this appendix to my last post:
https://www.lesswrong.com/posts/hincdPwgBTfdnBzFf/mapping-the-semantic-void-ii-above-below-and-between-token#Appendix_A__Dive_ascent_data
I've thrown together a repo here (from some messy Colab sheets):
https://github.com/mwatkins1970/GPT_definition_trees
Hopefully this makes sense. You specify a token or non-token embedding and one script generates a .json file with nested tree structure. Another script then renders that as a PNG. You just need to first have loaded GPT-J's model, embeddings tensor and tokenizer, and specify a save directory. Let me know if you have any trouble with this.
Quite possibly it does, but I doubt very many of these synonyms are tokens.
Thanks! That's the best explanation I've yet encountered. There had been previous suggestions that layer norm is a major factor in this phenomenon
I did some spelling evals with GPT2-xl and -small last year, discovered that they're pretty terrible at spelling! Even with multishot prompting and supplying the first letter, the output seems to be heavily conditioned on that first letter, sometimes affected by the specifics of the prompt, and reminiscent of very crude bigrammatic or trigrammatic spelling algorithms.
This was the prompt (in this case eliciting a spelling for the token 'that'):
Please spell 'table' in all capital letters, separated by hyphens.
T-A-B-L-E
Please spell 'nice' in all capital letters, separated by hyphens.
N-I-C-E
Please spell 'water' in all capital letters, separated by hyphens.
W-A-T-E-R
Please spell 'love' in all capital letters, separated by hyphens.
L-O-V-E
Please spell 'that' in all capital letters, separated by hyphens.
T-
Outputs seen, by first letter:
'a' words; ANIGE, ANIGER, ANICES, ARING
'b' words: BOWARS, BORSE
'c' words: CANIS, CARES x 3
'd' words: DOWER, DONER
'e' words: EIDSON
'f' words: FARIES x 5
'g' words: GODER, GING x 3
'h' words: HATER x 6, HARIE, HARIES
'i' words: INGER
'j' words: JOSER
'k' words: KARES
'l' words: LOVER x 5
'n' words: NOTER x 2, NOVER
'o' words: ONERS x 5, OTRANG
'p' words: PARES x 2
't' words: TABLE x 10
'u' words: UNSER
'w' words: WATER x 6
'y' words: YOURE, YOUSE
Note how they’re all “wordy” (in terms of combinations of vowels and consonants), mostly non-words, with a lot of ER and a bit of ING
Reducing to three shots, we see siimilar (but slightly different) misspellings:
CONES, VICER, MONERS, HOTERS, KATERS, FATERS, CANIS, PATERS, GINGE, PINGER, NICERS, SINGER, DONES, LONGER, JONGER, LOUSE, HORSED, EICHING, UNSER, ALEST, BORSET, FORSED, ARING
My notes claim "Although the overall spelling is pretty terrible, GPT-2xl can do second-letter prediction (given first) considerably better than chance (and significantly better than bigramatically-informed guessing."
Thanks so much for leaving this comment. I suspected that psychologists or anthropologists might have something to say about this. Do you know anyone actively working in this area who might be interested?
Thanks! I'm starting to get the picture (insofar as that's possible).
Could you elaborate on the role you think layernorm is playing? You're not the first person to suggest this, and I'd be interested to explore further. Thanks!
Thanks for the elucidation! This is really helpful and interesting, but I'm still left somewhat confused.
Your concise demonstration immediately convinced me that any Gaussian distributed around a point some distance from the origin in high-dimensional Euclidean space would have the property I observed in the distribution of GPT-J embeddings, i.e. their norms will be normally distributed in a tight band, while their distances-from-centroid will also be normally distributed in a (smaller) tight band. So I can concede that this has nothing to do with where the token embeddings ended up as a result of training GPT-J (as I had imagined) and is instead a general feature of Gaussian distributions in high dimensions.
However, I'm puzzled by "Suddenly it looks like a much smaller shell!"
Don't these histograms unequivocally indicate the existence of two separate shells with different centres and radii, both of which contain the vast bulk of the points in the distribution? Yes, there's only one distribution of points, but it still seems like it's almost entirely contained in the intersection of a pair of distinct hyperspherical shells.
The intended meaning was that the set of points in embedding space corresponding to the 50257 tokens are contained in a particular volume of space (the intersection of two hyperspherical shells).
Thanks for pointing this out! They should work now.
Thank! And in case it wasn't clear from the article, the tokens whose misspellings are examined in the Appendix are not glitch tokens.
Yes, I realised that this was a downfall of n.c.p. It's helpful for shorter rollouts, but once they get longer they can get into a kind of "probabilistic groove" which starts to unhelpfully inflate n.c.p. In mode collapse loops, n.c.p. tends to 1. So yeah, good observation.
We haven't yet got a precise formulation of "anomalousness" or "glitchiness" - it's still an intuitive concept. I've run some experiments over the entire token set, prompting a large number of times and measuring the proportion of times GPT-3 (or GPT-J) correctly reproduces the token string. This is a starting point, but there seem to be two separate things going on with (1) GPT's inability to repeat back "headless" tokens like "ertain", "acebook" or "ortunately" and (2) its inability to repeat back the "true glitch tokens" like " SolidGoldMagikarp" and " petertodd".
"GoldMagikarp" did show up in our original list of anomalous tokens, btw.
Thanks for this, I had no idea. So there is some classical mythological basis for the character after all. Do you how the name "Leilan" arose? Also, someone elsewhere has claimed "[P&D] added a story mode in 2021 or so and Leilan and Tsukuyomi do in fact have their own story chapters"... do you know anything about this? I'm interested to find anything that might have ended up in the training data and informed GPT-3's web of semantic association for the " Leilan" token.
I know the feeling. It's interesting to observe the sharp division between this kind of reaction and that of people who seem keen to immediately state "There's no big mystery here, it's just [insert badly informed or reasoned 'explanation']".
GPT-J doesn't seem to have the same kinds of ' petertodd' associations as GPT-3. I've looked at the closest token embeddings and they're all pretty innocuous (but the closest to the ' Leilan' token, removing a bunch of glitch tokens that are closest to everything is ' Metatron', who Leilan is allied with in some Puzzle & Dragons fan fiction). It's really frustrating that OpenAI won't make the GPT-3 embeddings data available, as we'd be able to make a lot more progress in understanding what's going on here if they did.
Yes, this post was originally going to look at how the ' petertodd' phenomenon (especially the anti-hero -> hero archetype reversal between models) might relate to the Waluigi Effect, but I decided to save any theorising for future posts. Watch this space!
I just checked the Open AI tokeniser, and 'hamishpetertodd' tokenises as 'ham' + 'ish' + 'pet' + 'ertodd', so it seems unlikely that your online presence fed into GPT-3's conception of ' petertodd'. The 'ertodd' token is also glitchy, but doesn't seem to have the same kinds of associations as ' petertodd' (although I've not devoted much time to exploring it yet).
Thanks for the Parian info, I think you're right that it's the Worm character being referenced. This whole exploration has involved a crash course in Internet-age pop culture for me! I've fixed that JSON link now.
Interesting. Does he have any email addresses or usernames on any platform that involve the string "petertodd"?
Thanks for this, Erik - very informative.
Thanks for the "Steve" clue. That makes sense. I've added a footnote.
I don't think any of the glitch tokens got into the token set through sheer popularity of a franchise. The best theories I'm hearing involved 'mangled text dumps' from gaming, e-commerce and blockchain logs somehow ending up in the data set used to create the tokens. 20% of that dataset is publicly available, and someone's already found some mangled PnD text in there (so lots of stats, character names repeated over and over). No one seems to be able to explain the weird Uma Musume token (that may require contact with an obsessive fan, which I don't particularly welcome).
Good find! I've integrated that into the post.
The ' petertodd' token definitely has some strong "trickster" energy in many settings. But it's a real shapeshifter. Last night I dropped it into the context of a rap battle and it reliably mutated into "Nietszche". Stay tuned for a thorough research report on the ' petertodd' phenomenon.
A lot of them do look like that, but we've dug deep to find their true origins, and it's all pretty random and diffuse. See Part III (https://www.lesswrong.com/posts/8viQEp8KBg2QSW4Yc/solidgoldmagikarp-iii-glitch-token-archaeology). Bear in mind that when GPT-3 is given a token like "EStreamFrame", it doesn't "see" what's "inside" like we do (["E", "S", "t", "r", "e", "a", "m", "F", "r", "a", "m", "e"]). It receives it as a kind of atomic unit of language with no internal structure. Anything it "learns about" this token in training is based on where it sees it used, and it's looking like most of these glitch tokens correspond to strings seen very infrequently in the training data (but which for some reason got into the tokenisation dataset in large numbers, probably via junk files like mangled text dumps from gaming logs, etc.).
What we're now finding is that there's a "continuum of glitchiness". Some tokens glitch worse/harder than others in a way that I've devised an ad-hoc metric for (research report coming soon). There are a lot of "mildly glitchy" tokens that GPT-3 will try to avoid repeating which look like "velength" and "oldemort" (obviously parts of longer, familiar words, rarely seen isolated in text). There's a long list of these in Part II of this post. I'd not seen "ocobo" or "oldemort" yet, but I'm systematically running tests on the whole vocabulary.
OK. That's both superficially disappointing and deeply reassuring!
Something you might want to try: replace the tokens in your prompt with random strings, or randomly selected non-glitch tokens, and see what kind of completions you get.
Was this text-davinci-003?
I'm in a similar place, Wil. Thanks for expressing this!