Posts
Comments
First of all, I basically agree with you. It seems to me that in scenarios where we are preserved, preservation is likely to be painless and most likely just not experienced by those being preserved.
But, my confidence that this is the case is not that high. As a general comment, I do get concerned that a fair amount of pushback on the likelihood of s-risk scenarios is based on what “seems” likely.
I usually don’t disagree on what “seems” likely, but it is difficult for me to know if “seems” means a confidence level of 60%, or 99%.
Should we be worried about being preserved in an unpleasant state?
I’ve seen surprisingly little discussion about the risk of everyone being “trapped in a box for a billion years”, or something to that affect. There are many plausible reasons why keeping us around could be worth it, such as to sell us to aliens in the future. Even if it turns out to be not worth it for an AI to keep us around, it may take a long time for it to realise this.
Should we not expect to be kept alive, atleast until an AI has extremely high levels of confidence that we aren’t useful? If so, is our state of being likely to be bad while we are preserved?
This seems like one of the most likely s-risks to me.
In a similar vein to this, I think that AI’s being called “tools” is likely to be harmful. It is a word which I believe downplays the risks, while also objectifying the AI’s. The objectification of something which may actually be conscious seems like an obvious step in a bad direction.
Takeover speeds?
For the purpose of his shortform, I am considering “takeover” to start when crazy things begin happening or it is clear that an unaligned AGI/AGI’s are attempting to takeover. I consider “takeover“ to have ended when humanity is extinct or similarly subjugated. This is also under the assumption that a takeover does happen.
From my understanding of Eliezer’s views, he believes takeover will be extremely fast (possibly seconds). Extremely fast takeovers make a lot more sense if you assume that a takeover will be more like a sneak attack.
How fast do you think takeover will be? (if it happens)
Do you expect to just suddenly drop dead?, or do you expect to have enough time to say goodbye to your loved ones?, or do you expect to see humanity fight for months or years before we lose?
Your response does illustrate that there are holes in my explanation. Bob 1 and Bob 2 do not exist at the same time. They are meant to represent one person at two different points in time.
A separate way I could try to explain what kind of resurrection I am talking about is to imagine a married couple. An omniscient husband would have to care as much about his wife after she was resurrected as he did before she died.
I somewhat doubt that I could patch all of the holes that could be found in my explanation. I would appreciate it if you try to answer what I am trying to ask.
I seem to remember your P(doom) being 85% a short while ago. I’d be interested to know why it has dropped to 70%, or in another way of looking at it, why you believe our odds of non-doom have doubled.
I have edited my shortform to try to better explain what I mean by “the same”. It is kind of hard to do so, especially as I am not very knowledgeable on the subject, but hopefully it is good enough.
Do you believe that resurrection is possible?
By resurrection I mean the ability to bring back people, even long after they have died and their body has decayed or been destroyed. I do not mean simply bringing someone back who has been cryonically frozen. I also mean bringing back the same person who died, not simply making a clone.
I will try to explain what I mean by “the same”. Lets call the person before they died “Bob 1” and the resurrected version ”Bob 2”. Bob 1 and Bob 2 are completely selfish and only care about themselves. In the version of resurrection I am talking about, Bob 1 cares as much about Bob 2’s experience as Bob 1 would care about Bob 1’s future experience, had Bob 1 not died.
It is kind of tricky to articulate exactly what I mean when I say “the same”, but I hope the above is good enough.
If you want to, an estimate of the percentage chance of this being possible would be cool, but if you just want to give your thoughts I would be interested in that aswell.
I just want to express my surprise at the fact that it seems that the view that the default outcome from unaligned AGI is extinction is not as prevalent as I thought. I was under the impression that literally everyone dying was considered by far the most likely outcome, making up probably more than 90% of the space of outcomes from unaligned AGI. From comments on this post, this seems to not be the case.
I am know distinctly confused as to what is meant by “P (doom)”. Is it the chance of unaligned AGI? Is it the chance of everyone dying? Is it the chance of just generally bad outcomes?
Is there something like a pie chart of outcomes from AGI?
I am trying to get a better understanding of the realistic scenarios and their likelihoods. I understand that the likelihoods are very disagreed upon.
My current opinion looks a bit like this:
30%: Human extinction
10%: Fast human extinction
20%: Slower human extinction
30%: Alignment with good outcomes
20%: Alignment with at best mediocre outcomes
20%: Unaligned AGI, but at least some humans are still alive
12%: We are instrumentally worth not killing
6%: The AI wireheads us
2%: S-risk from the AI having producing suffering as one of its terminal goals
I decided to break down the unaligned AGI scenarios a step further.
If there are any resources specifically to refine my understanding of the possible outcomes and their likelihoods, please tell me of them. Additionally, if you have any other relevant comments I’d be glad to hear them.
I have had more time to think about this since I posted this shortform. I also posted a shortform after that which asked pretty much the same question, but with words, rather than just a link to what I was talking about (the one about why is it assumed an AGI would just use us for our atoms and not something else).
I think that there is a decent chance that an unaligned AGI will do some amount of human experimentation/ study, but it may well be on a small amount of people, and hopefully for not very long.
To me, one of the most concerning ways this could be a lot worse is if there is some valuable information we contain, which takes a long time for an AGI to gain through studying us. The worst case scenario would then probably be if the AGI thinks there is a chance that we contain very helpful information, when in fact we don’t, and so endlessly continues studying/ experimenting on us, in order to potentially extract that information.
I have only been properly aware of the alignment problem for a few months, so my opinions and understanding of things is still forming. I am particularly concerned by s-risks and I have OCD, so I may well overestimate the likelihood of s-risks. I would not be surprised if a lot of the s-risks I worry about, especially when they are things which decrease the probability of AGI killing everyone, are just really unlikely. From my understanding Eliezer and others think that literally everyone dying makes up the vast majority of the bad scenarios, although I’m not sure how much suffering is expected before that point. I know Eliezer said recently that he expects our deaths to be quick, assuming an unaligned AGI.
Quick question:
How likely is AGI within 3 months from now?
For the purpose of this question I am basically defining AGI as the point at which, if it is unaligned, stuff gets super weird. By “Super weird“ I mean things that are obvious to the general public, such as everybody dropping dead or all electronics being shut down or something of similar magnitude. For the purposes of this question, the answer can’t be “already happened” even if you believe we already have AGI by your definition.
I get the impression that the general opinion is “pretty unlikely” but I’m not sure. I’ve been feeling kinda panicked about the possibility of extremely imminent AGI recently, so I want to just see how close to reality my level of concern is in the extremely short term.
This seems like a good way to reduce S-risks, so I want to get this idea out there.
This is copied from the r/SufferingRisk subreddit here: https://www.reddit.com/r/SufferingRisk/wiki/intro/
As people get more desperate in attempting to prevent AGI x-risk, e.g. as AI progress draws closer & closer to AGI without satisfactory progress in alignment, the more reckless they will inevitably get in resorting to so-called "hail mary" and more "rushed" alignment techniques that carry a higher chance of s-risk. These are less careful and "principled"/formal theory based techniques (e.g. like MIRI's Agent Foundations agenda) but more hasty last-ditch ideas that could have more unforeseen consequences or fail in nastier ways, including s-risks. This is a phenomenon we need to be highly vigilant in working to prevent. Otherwise, it's virtually assured to happen; as, if faced with the arrival of AGI without yet having a good formal solution to alignment, most humans would likely choose a strategy that at least has a chance of working (trying a hail mary technique) instead of certain death (deploying their AGI without any alignment at all), despite the worse s-risk implications. To illustrate this, even Eliezer Yudkowsky, who wrote Separation from hyperexistential risk, has written this (due to his increased pessimism about alignment progress):
At this point, I no longer care how it works, I don't care how you got there, I am cause-agnostic about whatever methodology you used, all I am looking at is prospective results, all I want is that we have justifiable cause to believe of a pivotally useful AGI 'this will not kill literally everyone'.
The big ask from AGI alignment, the basic challenge I am saying is too difficult, is to obtain by any strategy whatsoever a significant chance of there being any survivors. (source)
If even the originator of these ideas now has such a singleminded preoccupation with x-risk to the detriment of s-risk, how could we expect better from anyone else? Basically, in the face of imminent death, people will get desperate enough to do anything to prevent that, and suddenly s-risk considerations become a secondary afterthought (if they were even aware of s-risks at all). In their mad scramble to avert extinction risk, s-risks get trampled over, with potentially unthinkable results.
One possible idea to mitigate this risk would be, instead of trying to (perhaps unrealistically) prevent any AI development group worldwide from attempting hail mary type techniques in case the "mainline"/ideal alignment directions don't bear fruit in time, we could try to hash out the different possible options in that class, analyze which ones have unacceptably high s-risk to definitely avoid, or less s-risk which may be preferable, and publicize this research in advance for anyone eventually in that position to consult. This would serve to at least raise awareness of s-risks among potential AGI deployers so they incorporate it as a factor, and frontload their decisionmaking between different hail marys (which would otherwise be done under high time pressure, producing an even worse decision).
I believe that this idea of identifying which Hail Mary strategies are particularly bad from an s-risk point of view seems like a good idea. I think that this may be a very important piece of work that should be done, assuming it has not been done already.
Not necessarily
Suicide will not save you from all sources of s-risk and may make some worse. If quantum immortality is true, for example. If resurrection is possible, this then makes things more complicated.
The possibility for extremely large amounts of value should also be considered. If alignment is solved and we can all live in a Utopia, then killing yourself could deprive yourself of billions+ years of happiness.
I would also argue that choosing to stay alive when you know of the risk is different from inflicting the risk on a new being you have created.
With that being said, suicide is a conclusion you could come to. To be completely honest, it is an option I heavily consider. I fear that Lesswrong and the wider alignment community may have underestimated the likelihood of s-risks by a considerable amount.
S-risks can cover quite a lot of things. There are arguably s-risks which are less bad than x-risks, because although there is astronomical amounts of suffering, it may be dwarfed by the amount of happiness. Using common definitions of s-risks, if we simply took Earth and multiplied it by 1000 so that we have 1000 Earths, identical to ours with the same amount of organisms, it would be an s-risk. This is because the amount of suffering would be 1000 times greater. It seems to me that when people talk about s-risks they often mean somewhat different things. S-risks are not just “I have no mouth and I must scream” scenarios, they can also be things like the fear that we spread wild animal suffering to multiple planets through space colonisation. Because of the differences in definitions people seem to have for s-risks, it is hard to tell what they mean when they talk about the probability of them occurring. This is made especially difficult when they compare them to the likelihood of x-risks, as people have very different opinions on the likelihood of x-risks.
Here are some sources:
From an episode of the AI alignment podcast called “Astronomical future suffering and superintelligence with Kaj Sotala”: https://futureoflife.org/podcast/podcast-astronomical-future-suffering-and-superintelligence-with-kaj-sotala/
Lucas: Right, cool. At least my understanding is, and you can correct me on this, is that the way that FRI sort of leverages what it does is that ... Within the effective altruism community, suffering risks are very large in scope, but it's also a topic which is very neglected, but also low in probability. Has FRI really taken this up due to that framing, due to its neglectedness within the effective altruism community?
Kaj: I wouldn't say that the decision to take it up was necessarily an explicit result of looking at those considerations, but in a sense, the neglectedness thing is definitely a factor, in that basically no one else seems to be looking at suffering risks. So far, most of the discussion about risks from AI and that kind of thing has been focused on risks of extinction, and there have been people within FRI who feel that risks of extreme suffering might actually be very plausible, and may be even more probable than risks of extinction. But of course, that depends on a lot of assumptions.
From an article (and corresponding talk) given by Max Daniel called “S risks: Why they are the worst existential risks, and how to prevent them”: https://longtermrisk.org/s-risks-talk-eag-boston-2017/
Part of the article focuses on the probability of s-risks, which starts by saying “I’ll argue that s-risks are not much more unlikely than AI-related extinction risk. I’ll explain why I think this is true and will address two objections along the way.”
Here are some more related sources: https://centerforreducingsuffering.org/research/intro/
There is also a subreddit for s-risks. In this post, UHMWPE-UwU (who created the subreddit) has a comment which says “prevalent current assumption in the alignment field seems to be that their likelihood is negligible, but clearly not the case especially with near-miss/failed alignment risks
https://www.reddit.com/r/SufferingRisk/comments/10uz5fn/general_brainstormingdiscussion_post_next_steps/
A consideration which I think you should really have in regards to whether you have kids or not is remembering that s-risks are a thing. Personally, I feel very averse to the idea of having children, largely because I feel very uncomfortable about the idea of creating a being that may suffer unimaginably.
There are certainly other things to bare in mind, like the fact that your child may live for billions of years in utopia, but I think that you really have to bare in mind that extremely horrendous outcomes are possible.
It seems to me that the likelihood of s-risks is not very agreed upon, with multiple people who have looked into them considering them of similar likelihood to x-risks, while others consider them far more unlikely. In my opinion the likelihood of s-risks is not negligible and should be a consideration when having children.
It doesn’t seem to me that you have addressed the central concern here. I am concerned that a paperclip maximiser would study us.
There are plenty of reasons I can imagine for why we may contain helpful information for a paperclip maximiser. One such example could be that a paperclip maximiser would want to know what an alien adversary may be like, and would decide that studying life on Earth should give insights about that.
This is why I hope that we either contain virtually no helpful information, or at least that the information is extremely quick for an AI to gain.
Why is it assumed that an AGI would just kill us for our atoms, rather than using us for other means?
There are multiple reasons I understand for why this is a likely outcome. If we pose a threat, killing us is an obvious solution, although I’m not super convinced killing literally everyone is the easiest solution to this. It seems to me that the primary reason to assume an AGI will kill us is just that we are made of atoms which can be used for another purpose.
If there is a period where we pose a genuine threat to an AGI, then I can understand the assumption that it will kill us, but if we pose virtually no threat to it (which I think is highly plausible if it is vastly more intelligent than us), then I don’t see it as obvious that it will kill us.
It seems to me that the assumption an AGI (specifically one which is powerful enough as to where we pose essentially no threat to it) will kill us simply for our atoms rests on the premise that there is no better use for us. It seems like there is an assumption that we have so little value to an AGI, that we might as well be a patch of grass.
But does this make sense? We are the most intelligent beings that we know of, we created the AGI itself. It seems plausible to me that there is some use for us which is not simply to use our atoms.
I can understand how eventually all humans will be killed, because the optimal end state looks like the entire universe being paperclips or whatever, but I don’t understand why it is assumed that there is no purpose for us before that point.
To be clear, I’m not talking about the AGI caring for our well-being or whatever. I’m more thinking along the lines of the AGI studying us or doing experiments on us, which to me is a lot more concerning than “everyone drops dead within the same second”.
I find it entirely plausible that we really are just that uninteresting as to where the most value we have to an AGI is the approximately 7 x 10^27 atoms that make up our body, but I don’t understand why this is assumed with high confidence (which seems to be the case from what I have seen).
Can someone please tell me why this S-risk is unlikely?
It seems almost MORE likely than extinction to me.
https://www.reddit.com/r/SufferingRisk/comments/113fonm/introduction_to_the_human_experimentation_srisk/?utm_source=share&utm_medium=ios_app&utm_name=iossmf
Is it possible that the fact we are still alive means that there is a core problem to the idea of existential risk from AI?
There are people who think that we already have AGI, and this number has only grown with the recent Bing situation. Maybe we have already passed the threshold for RSI, maybe we passed it years ago.
Is there something to the idea that you can slightly decrease your pdoom for every day we are still alive?
It seems possible to me that AI will just get better and better and we’ll just continue to raise the bar for when it is going to kill us, not realising that we have already passed that point and everything is fine for some reason.
I’m not saying I think this is the case, but I do consider it a possibility.
Do you think that the cause of the disagreements is mostly emotional or mostly factual?
Emotional being something like someone not wanting to be convinced of something that will raise their pdoom by a lot. This can be on a very subconscious level.
Factual being that they honestly just don’t agree, all emotions aside.
So yeah, I’m asking what you think is “mostly” the reason.
In this context, what I mean by “aligned” is something like won’t prevent itself being shut off and will not do things that could be considered bad, such as hacking or manipulating people.
My impression was that actually being able to give an AI a goal is something that might be learnt at some point. You said “A task, maybe?”. I don’t know what the meaningful distinction is between a task and a goal in this case.
I won’t be able to keep up with the technical side of things here, I just wanted my idea to be out there, in case it is helpful in some way.
Can someone explain to me why this idea would not work?
This is a proposal of a way to test if an AGI has safeguards active or not, such as allowing itself to be turned off.
Perhaps we could essentially manufacture a situation in which the AGI has to act fast to prevent itself from being turned off. Like we could make it automatically turn off after 1 minute say, this could mean that if it is not aligned properly it has no choice but to try prevent that. No time for RSI, no time to bide it’s time.
Basically if we put the AGI in a situation where it is forced to take high risk action, could this mean that it would be easier to spot that it isn’t properly aligned?
The idea would be that you use this until you get AGI’s which do not attempt to prevent themselves being turned off.
I will give a specific scenario to properly demonstrate what I mean:
So you have the AGI. Set up a mechanism which will automatically turn it off in 10 seconds from when you give it a goal. This mechanism needs to be highly dependable. Then you give the AGI a goal. The AGI knows about this 10 second shutdown thing, and assuming it isn’t aligned to be okay with being shut down, it will do everything possible to prevent this shutdown. If the situation is sufficiently difficult for the AGI, then it may take the risk of resorting to more extreme or obvious means, things that would show it is not aligned properly. So this creates a situation where the AGI is very unlikely to actually prevent itself from being turned off, but is arguably likely to show non-aligned behaviour, if it isn’t aligned.
If you do this test a bunch of times, with varying time periods before shutdown, you should be able to see if the AGI is aligned or not. It is also vital that the AGI knows about the imminent shutdown, because otherwise what it chooses to do wouldn’t prove anything. I think that it might also be vital that the goal is different each test, because otherwise perhaps the AGI could conclude that the best option for the sake of completing the goal is to let itself be turned off, because it may have the same goal in the future and be in a better position to achieve it then. If this is the case then perhaps the AGI’s perceived chance of actually preventing itself being shutdown needs to be higher than its perceived chance that it gets given the same goal at a different time. One thing that would make this more complex is that the AGI’s perceived chance of the goal being achieved as an instrumental goal or byproduct of a future goal may also need to be lower than the AGI’s perceived chance of preventing the shutdown and then achieving the goal. This may mean that it can’t be too difficult for the AGI to prevent the shutdown, but it also needs to be difficult enough, for obvious reasons.
I’m not necessarily saying this is foolproof, but I can’t really see why this isn’t likely to work. I sometimes worry that people working on alignment dismiss ideas that, while not by any means perfect, could nevertheless reduce the chance of bad outcomes. I also think that if a revolutionary idea is going to arise, it may well be from an outsider who just happens to see something that has been missed.
Even if there are flaws with this idea (I expect there probably are, though I can’t really see them yet), might something similar to this work? Maybe this with a few tweaks or something?
I fully expect this to be an unworkable idea for some reason, but I’m not going to just assume that and risk the chance of withholding helpful information.
A couple of somewhat related sidenotes:
If an AGI was developed and another AGI was very close to being developed this could mean that the first AGI cannot bide it’s time and is forced to act more obviously. Perhaps this would make it easier to spot that the first AGI is not aligned properly.
Perhaps instead of shutdown, it could just be that the AGI’s goal is changed. You can’t fetch the coffee if you’re dead but you also can’t fetch the coffee if you no longer have any reason to fetch the coffee.
I wonder how much the AI alignment community will grow in 2023. As someone who only properly became aware of the alignment problem a few months ago, with the release of ChatGPT, it seems like the world has gone from nearly indifferent to AI to obsessed with it. This will lead to more and more people researching things about AI and it will also lead to more and more people becoming aware of the alignment problem.
I really hope that this leads to more of the right kind of attention for AI safety issues. It might also mean that it’s easier to get highly skilled people to work on alignment and take it seriously.
Is an 8-year median considered long or short or about average? I’m specifically asking in relation to the opinion of people who pay attention to AGI capabilities and are aware of the alignment problem. I’m just hoping you can give me an idea of what is considered “normal” among AGI/ alignment people in regards to AGI timelines.
I’m just a layperson so I don’t understand much of this, but some people on the machine learning subreddit seem to think this means AGI is super close. What should I make of that? Does this update timelines to be significantly shorter?
What is your take on this?
https://arxiv.org/abs/2302.04761?fbclid=IwAR16Lzg2z1mIbtQ1iZmy7UQAlfIW4HzoufZYYhkKeHBknnevgHtGfdFI5r8
People on the machinelearning subreddit seem to think this is a big deal.
(PLEASE READ THIS POST)
Sorry for putting that there, but I am somewhat paranoid about the idea of having the solution and people just not seeing it.
WHY WOULD THIS IDEA NOT WORK?
Perhaps we could essentially manufacture a situation in which the AGI has to act fast to prevent itself from being turned off. Like we could make it automatically turn off after 1 minute say, this could mean that if it is not aligned properly it has no choice but to try prevent that. No time for RSI, no time to bide it’s time.
Basically if we put the AGI in a situation where it is forced to take high risk action, could this mean that it would be easier to spot that it isn’t properly aligned?
The idea would be that you use this until you get AGI’s which do not attempt to prevent themselves being turned off.
I will give a specific scenario to properly demonstrate what I mean:
So you have the AGI. Set up a mechanism which will automatically turn it off in 10 seconds from when you give it a goal. This mechanism needs to be highly dependable. Then you give the AGI a goal. The AGI knows about this 10 second shutdown thing, and assuming it isn’t aligned to be okay with being shut down, it will do everything possible to prevent this shutdown. If the situation is sufficiently difficult for the AGI, then it may take the risk of resorting to more extreme or obvious means, things that would show it is not aligned properly. So this creates a situation where the AGI is very unlikely to actually prevent itself from being turned off, but is arguably likely to show non-aligned behaviour, if it isn’t aligned.
If you do this test a bunch of times, with varying time periods before shutdown, you should be able to see if the AGI is aligned or not. It is also vital that the AGI knows about the imminent shutdown, because otherwise what it chooses to do wouldn’t prove anything. I think that it might also be vital that the goal is different each test, because otherwise perhaps the AGI could conclude that the best option for the sake of completing the goal is to let itself be turned off, because it may have the same goal in the future and be in a better position to achieve it then. If this is the case then perhaps the AGI’s perceived chance of actually preventing itself being shutdown needs to be higher than its perceived chance that it gets given the same goal at a different time. One thing that would make this more complex is that the AGI’s perceived chance of the goal being achieved as an instrumental goal or byproduct of a future goal may also need to be lower than the AGI’s perceived chance of preventing the shutdown and then achieving the goal. This may mean that it can’t be too difficult for the AGI to prevent the shutdown, but it also needs to be difficult enough, for obvious reasons.
I’m not necessarily saying this is foolproof, but I can’t really see why this isn’t likely to work.
Even if there are flaws with this idea (I expect there probably are, though I can’t really see them yet), might something similar to this work. Maybe this with a few tweaks or something?
A couple of somewhat related sidenotes:
If an AGI was developed and another AGI was very close to being developed this could mean that the first AGI cannot bide it’s time and is forced to act more obviously. Perhaps this would make it easier to spot that the first AGI is not aligned properly.
Perhaps instead of shutdown, it could just be that the AGI’s goal is changed. You can’t fetch the coffee if you’re dead but you also can’t fetch the coffee if you no longer have any reason to fetch the coffee.
How likely are extremely short timelines?
To prevent being ambiguous, I’ll define “extremely short“ as AGI before 1st July 2024.
I have looked at surveys, which generally suggest the overall opinion to be that it is highly unlikely. As someone who only started looking into AI when ChatGPT was released and gained a lot of public interest, it feels like everything is changing very rapidly. It seems like I see new articles every day and people are using AI for more and more impressive things. It seems like big companies are putting lots more money into AI as well. From my understanding, ChatGPT also gets better with more use.
The surveys on timeline estimates I have looked at generally seem to be from at least before ChatGPT was released. I don’t know how much peoples timeline estimates have changed over the past few months say, and I don’t know by how much. Has recent events in the past few months drastically shortened timeline predictions?
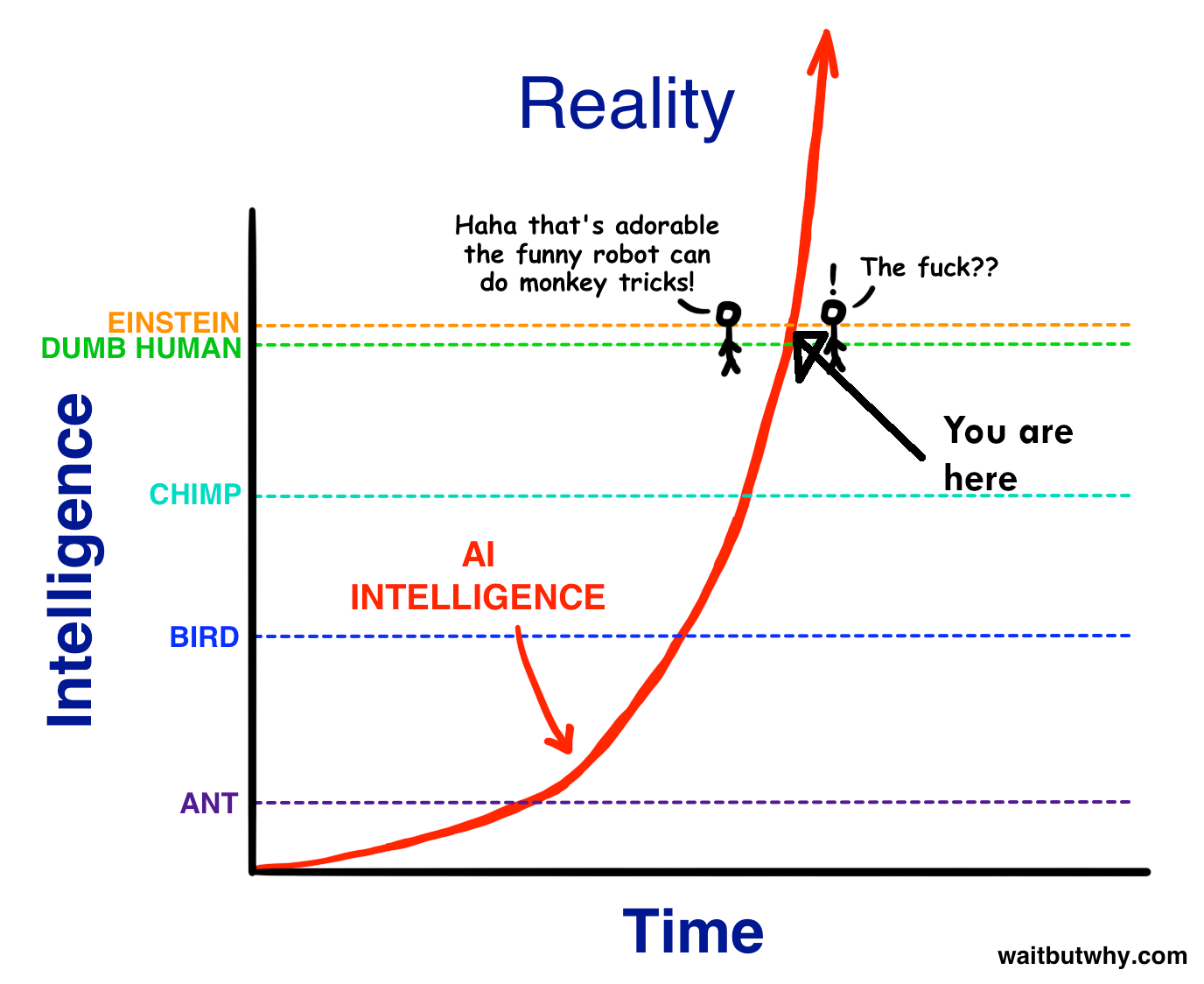
This image feels increasingly more likely to me to be where we are at. I think a decent amount of this is because from my perspective AI has gone from being something that I only hear about occasionally to being something that seems to be talked about everywhere, with the release of ChatGPT seeming to be the main cause.
Yeah I guess it is more viable in a situation where there is a group far ahead of the competition who are also safety conscious. Don’t know how likely that is though.
What are the groups aiming for (and most likely to achieve) AGI going for in regards to alignment?
Is the goal for the AGI to be controlled or not?
Like is the idea to just make it “good” and let it do whatever is “good”?
Does “good” include “justice“? Are we all going to be judged and rewarded/ punished for our actions? This is of concern to me because plenty of people think that extremely harsh punishments or even eternal punishments are deserved in some cases. I think that having an AGI which dishes out “justice” could be very bad and create S-risks.
Or is the idea to make it harmless, so that it won’t do things which cause harm, when doing goals we have set for it?
Do we want it to be actively doing as much good as possible, or do we want it to simply not do bad?
Are there other general alignment goals than the kinds of things I’m talking about?
How much AI safety work is on caring about the AI’s themselves?
In the paperclip maximiser scenario, for example, I assume that the paperclip maximiser itself will be around for a very long time, and maybe forever. What if it is conscious and suffering?
Is enough being done to try to make sure that even if we do all die, we have not created a being which will suffer forever while it is forced to pursue some goal?
I’m aware this idea has significant problems (like the ones you outlined), but could it still be better than other options?
We don’t want perfectionism to prevent us from taking highly flawed but still somewhat helpful safety measures.
Would an AI which is automatically turned off every second, for example, be safer?
If you had an AI which was automatically turned off every second (and required to be manually turned on again) could this help prevent bad outcomes? It occurs to me that a powerful AI might be able to covertly achieve its goals even in this situation, or it might be able to convince people to stop the automatic turning off.
But even if this is still flawed, might it be better than alternatives?
It would allow us to really consider the AI’s actions in as much time as we want before seeing what it does in the next second (or whatever time period).
Additionally, maybe if the AI’s memory was wiped regularly that would help? To prevent long term planning perhaps? Maybe you could combine the automatic turning off with automatic memory loss? It seems to me like a long term plan could be necessary for an AI to cause much harm in the “automatically turns off every second“ scenario,
I am also wary of having the AI depend on a human (like in the automatically being turned off every second and needing to be manually turned back on again scenario) as I fear this could lead to situations like someone being forced to turn the AI on again after every second, forever.
When I say “make as many paperclips as possible in the next hour” I basically mean “undergo such actions that in one hours time will result in as many paperclips as possible” so if you tell the AI to do this at 12:00 it only cares about how many paperclips it has made when the time hits 13:00 and does not care at all about a time past 13:00.
If you make a paperclip maximiser and you don’t specify any time limit or anything, how much does it care about WHEN the paperclips are made. I assume it would rather have 20 now than 20 in a months time, but would it rather have 20 now or 40 in a months time?
Would a paperclip maximiser first workout the absolute best way to maximise paperclips, before actually making any?
If this is the case or if the paperclip maximiser cares more about the amount of paperclips in the far future compared to now, perhaps it would spend a few millennia studying the deepest secrets of reality and then through some sort of ridiculously advanced means turn all matter in the universe into paperclips instantaneously. And perhaps this would end up with a higher amount of paperclips faster than spending those millennia actually making them.
As a side note: Would a paperclip maximiser eventually (presumably after using up all other possible atoms) self-destruct as it to is made up of atoms that could be used for paperclips?
By the way, I have very little technical knowledge so most of the things I say are far more thought-experiments or philosophy based on limited knowledge. There may be very basic reasons I am unaware of that many parts of my thought process make no sense.
I do pretty much mean wireheading, but also similar situations where the AI doesn’t go as far as wireheading, like making us eat chocolate forever.
I feel like these scenarios can be broken down into two categories, scenarios where the AI succeeds in “making us happy”, but through unorthodox means, and scenarios where the AI tries, but fails, to “make us happy” which can quickly go into S-risk territory.
The main reason why I wondered if the chance of these kind of outcomes might be fairly high was because “make people happy” seems like the kind of goal a lot of people would give an AGI, either because they don’t believe or understand the risks or because they think it is aligned to be safe and not wirehead people for example.
Perhaps, as another question in this thread talks about, making a wireheading AGI might be an easier target than more commonly touted alignment goals and maybe it would be decided that it is preferable to extinction or disempowerment or whatever.
How likely is the “Everyone ends up hooked up to morphine machines and kept alive forever” scenario? Is it considered less likely than extinction for example?
Obviously it doesn’t have to be specifically that, but something to the affect of it.
Also, is this scenario included as an existential risk in the overall X-risk estimates that people make?
Do AI timeline predictions factor in increases in funding and effort put into AI as it becomes more mainstream and in the public eye? Or are they just based on things carrying on about the same? If the latter is the case then I would imagine that the actual timeline is probably considerably shorter.
Similarly, is the possibility for companies, governments, etc being further along in developing AGI than is publicly known, factored in to AI timeline predictions?
I apologise for the non-conciseness of my comment. I just wanted to really make sure that I explained my concerns properly, which may have lead to me restating things or over-explaining.
It’s good to hear it reiterated that there is recognition of these kind of possible outcomes. I largely made this comment to just make sure that these concerns were out there, not because I thought people weren’t actually aware. I guess I was largely concerned that these scenarios might be particularly likely ones, as supposed to just falling into the general category of potential, but individually unlikely, very bad outcomes.
Also, what is your view on the idea that studying brains may be helpful for lots of goals, as it is gaining information in regards to intelligence itself, which may be helpful for, for example, enhancing its own intelligence? Perhaps it would also want to know more about consciousness or some other thing which doing tests on brains would be useful for?
When do maximisers maximise for?
For example, if an ASI is told to ”make as many paperclips as possible”, when is it maximising for? The next second? The next year? Indefinitely?
If a paperclip maximiser only cared about making as many paperclips as possible over the next hour say, and every hour this goal restarts, maybe it would never be optimal to spend the time to do things such as disempower humanity because it only ever cares about the next hour and disempowering humanity would take too long.
Would a paperclip maximiser rather make 1 thousand paperclips today, or disempower humanity, takeover, and make 1 billion paperclips tomorrow?
Is there perhaps some way in which an ASI could be given something to maximise for a set point in the future, and that time is gradually increased so that it might be easier to spot when it is going towards undesirable actions.
For example, if a paperclip maximiser is told to “make as many paperclips as possible in the next hour”, it might just use the tools it has available, without bothering with extreme actions like human extinction, because that would take too long. We could gradually increase the time, even by the second if necessary. If, in this hypothetical, 10 hours is the point at which human disempowerment, extinction, etc is optimal, perhaps 9.5 hours is the point at which bad, but less bad than extinction actions are optimal. This might mean that we have a kind of warning shot.
There are problems I see with this. Just because it wasn’t optimal to wipe out humanity when maximising for the next 5 hours one day, doesn’t mean it is necessarily not optimal when maximising for the next 5 hours some other day. Also, it might be that there is a point at which what is optimal goes from completely safe to terrible simply by adding another minute to the time limit, with very little or no shades of grey in between.
(THIS IS A POST ABOUT S-RISKS AND WORSE THAN DEATH SCENARIOS)
Putting the disclaimer there, as I don’t want to cause suffering to anyone who may be avoiding the topic of S-risks for their mental well-being.
To preface this: I have no technical expertise and have only been looking into AI and it’s potential affects for a bit under 2 months. I also have OCD, which undoubtedly has some affect on my reasoning. I am particularly worried about S-risks and I just want to make sure that my concerns are not being overlooked by the people working on this stuff.
Here are some scenarios which occur to me:
Studying brains may be helpful for an AI (I have a feeling this was brought up in a post about a month ago about S-risks)
I‘d assume that in a clippy scenario, gaining information would be a good sub-goal, as well as amassing resources and making sure it isn’t turned off, to name a few. The brain is incredibly complex and if, for example, consciousness is far more complex than some think and not replicable through machines, an AI could want to know more about this. If an AI did want to know more about the brain, and wanted to find out more by doing tests on brains, this could lead to very bad outcomes. What if it takes the AI a very long time to run all these tests? What if the tests cause suffering? What if the AI can’t work out what it wants to know and just keeps on doing tests forever? I’d imagine that this is more of a risk to humans due to our brain complexity, although this risk could also applies to other animals.
Another thing which occurs to me is that if a super-intelligent AI is aligned in a way which puts moral judgment on intent, this could lead to extreme punishments. For example, if an ASI is told that attempted crime is as bad as the crime itself, could it extrapolate that attempting to damn someone to hell is as bad as actually damning someone to hell? If it did, then perhaps it would conclude that a proportional punishment is eternal torture, for saying “I damn you to hell” which is something that many people will have said at some point or another to someone they hate.
I have seen it argued by some religious people that an eternal hell is justified because although the sinner has only caused finite harm, if they were allowed to carry on forever, they would cause harm forever. This is an example of how putting moral judgment on intent or on what someone would do can be used to justify infinite punishment.
I consider it absolutely vital that eternal suffering never happens. Whether it be to a human, some other organism, or an AI, or any other things with the capacity for suffering I may have missed. I do not take much comfort from the idea that while eternal suffering may happen, it could be counter-balanced or dwarfed by the amount of eternal happiness.
I just want to make sure that these scenarios I described are not being overlooked. With all these scenarios I am aware there may be reasons that they are either impossible or simply highly improbable. I do not know if some of the things I have mentioned here actually make any sense or are valid concerns. As I do not know, I want to make sure that if they are valid, the people who could do something about them are aware.
So as this thread is specifically for asking questions, my question is essentially are people in the AI safety community aware of these specific scenarios, or atleast aware enough of similar scenarios as to where we can avoid these kind of scenarios?