Will we run out of ML data? Evidence from projecting dataset size trends
post by Pablo Villalobos (pvs) · 2022-11-14T16:42:27.135Z · LW · GW · 12 commentsThis is a link post for https://epochai.org/blog/will-we-run-out-of-ml-data-evidence-from-projecting-dataset
Contents
Background Results None 12 comments
Summary: Based on our previous analysis of trends in dataset size, we project the growth of dataset size in the language and vision domains. We explore the limits of this trend by estimating the total stock of available unlabeled data over the next decades.
Read the full paper in arXiv.
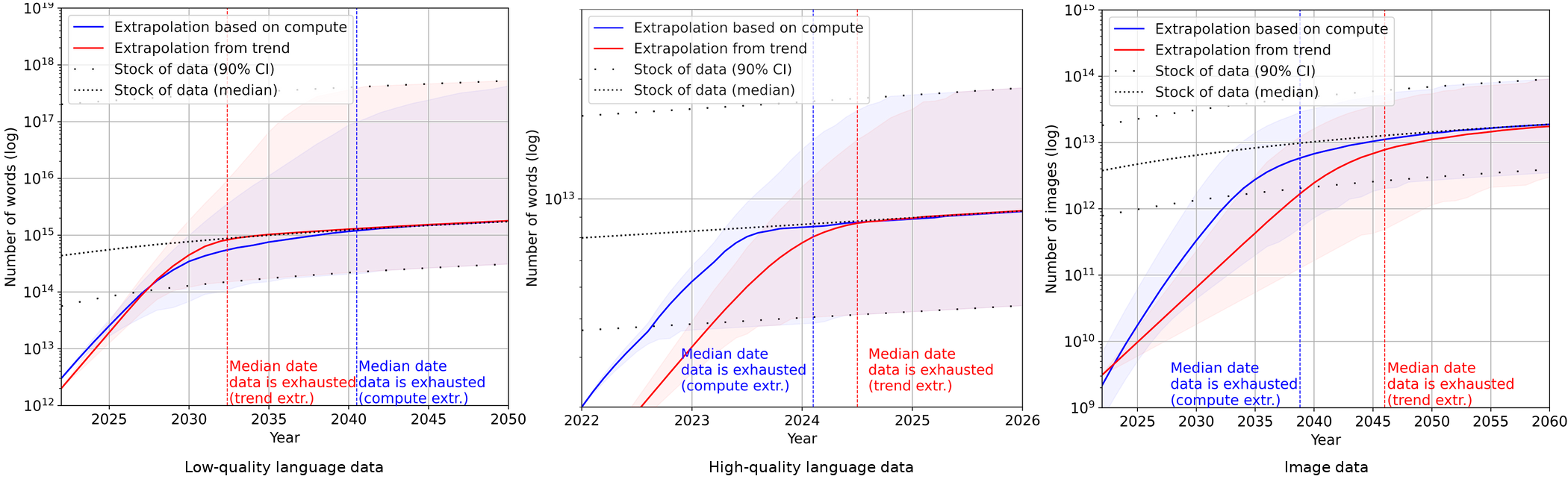
Our projections predict that we will have exhausted the stock of low-quality language data by 2030 to 2050, high-quality language data before 2026, and vision data by 2030 to 2060. This might slow down ML progress.
All of our conclusions rely on the unrealistic assumptions that current trends in ML data usage and production will continue and that there will be no major innovations in data efficiency. Relaxing these and other assumptions would be promising future work.
| Historical projection | Compute projection | |
|---|---|---|
| Low-quality language stock | 2032.4 [2028.4 ; 2039.2] | 2040.5 [2034.6 ; 2048.9] |
| High-quality language stock | 2024.5 [2023.5 ; 2025.7] | 2024.1 [2023.2 ; 2025.3] |
| Image stock | 2046 [2037 ; 2062.8] | 2038.8 [2032 ; 2049.8] |
| Table 1: Median and 90% CI exhaustion dates for each pair of projections. | ||
Background
Chinchilla's wild implications [LW · GW] argued that training data would soon become a bottleneck for scaling large language models. At Epoch we have been collecting data about trends in ML inputs, including training data [LW · GW]. Using this dataset, we estimated the historical rate of growth in training dataset size for language and image models.
Projecting the historical trend into the future is likely to be misleading, because this trend is supported by an abnormally large increase in compute in the past decade. To account for this, we also employ our compute availability projections to estimate the dataset size that will be compute-optimal in future years using the Chinchilla scaling laws.
We estimate the total stock of English language and image data in future years using a series of probabilistic models. For language, in addition to the total stock of data, we estimate the stock of high-quality language data, which is the kind of data commonly used to train large language models.
We are less confident in our models of the stock of vision data because we spent less time on them. We think it is best to think of them as lower bounds rather than accurate estimates.
Results
Finally, we compare the projections of training dataset size and total data stocks. The results can be seen in the figure above. Datasets grow much faster than data stocks, so if current trends continue, exhausting the stock of data is unavoidable. The table above shows the median exhaustion years for each intersection between projections.
In theory, these dates might signify a transition from a regime where compute is the main bottleneck to growth of ML models to a regime where data is the taut constraint.
In practice, this analysis has serious limitations, so the model uncertainty is very high. A more realistic model should take into account increases in data efficiency, the use of synthetic data, and other algorithmic and economic factors.
In particular, we have seen some promising early advances on data efficiency,[1] so if lack of data becomes a larger problem in the future we might expect larger advances to follow. This is particularly true because unlabeled data has never been a constraint in the past, so there is probably a lot of low-hanging fruit in unlabeled data efficiency.
In the particular case of high-quality data, there are even more possibilities, such as quantity-quality tradeoffs and learned metrics to extract high-quality data from low-quality sources.
All in all, we believe that there is about a 20%[2] chance that the scaling (as measured in training compute) of ML models will significantly slow down by 2040 due to a lack of training data.
- ^
Eg, transformers with retrieval mechanisms are more sample efficient. Or see EfficientZero for a dramatic example, albeit in a different domain.
In addition to increased data efficiency, we have seen examples of synthetic data being used to train language models.
- ^
This probability was obtained by polling some Epoch team members and taking the geometric mean of the results.
12 comments
Comments sorted by top scores.
comment by Dave Orr (dave-orr) · 2022-11-14T17:18:24.373Z · LW(p) · GW(p)
I think there's another, related, but much worse problem.
As LLMs become more widely adopted, they will generate large amounts of text on the internet. This widely available text will become training data for future LLMs. Tons of low quality content will reinforce LLM proclivities to produce low quality content -- or even if LLMs are generating high quality content, it will reinforce whatever tendencies and oddities they have, e.g. be permanently pegged to styles and topics of interest in 2010-2030.
This was a problem for translation. As google translate got better, people started posting translated versions of their website where the translation was from google. Then scrapers looking for parallel data to train on would find these, and it took a lot of effort to screen them out.
Accepting your estimates at face value, there are two problems: the availability of good training data may be a limiting factor; and good training data will be hard to find in a sea of computer generated content.
Replies from: Tamay, Tenoke, sanxiyn↑ comment by Tamay · 2022-11-14T18:49:07.677Z · LW(p) · GW(p)
If the data is low-quality and easily distinguishable from human-generated text, it should be simple to train a classifier to spot LM-generated text and exclude this from the training set. If it's not possible to distinguish, then it should be high-enough quality so that including it is not a problem.
ETA: As people point out below, this comment was glib and glosses over some key details; I don't endorse this take anymore.
↑ comment by Lech Mazur (lechmazur) · 2022-11-14T19:13:50.917Z · LW(p) · GW(p)
Generated data can be low quality but indistinguishable. Unless your classifier has access to more data or is better in some other way (e.g. larger, better architecture), you won't know. In fact, if you could know without labeling generated data, why would you generate something that you can tell is bad in the first place? I've seen this in practice in my own project.
Replies from: tgb, mocny-chlapik↑ comment by tgb · 2022-11-15T01:57:45.481Z · LW(p) · GW(p)
Surely the problem is that someone else is generating it - or more accurately lots of other people generating it in huge quantities.
Replies from: lechmazur↑ comment by Lech Mazur (lechmazur) · 2022-11-15T03:08:58.179Z · LW(p) · GW(p)
While there are still significant improvements in data/model/generation you might be able to imperfectly detect whether some text was generated by the previous generation of models. But if you're training a new model, you probably don't have such a next-gen classifier ready yet. So if you want to do just one training run, it could be easier to just limit your training data to the text that was available years ago or to only trust some sources.
A related issue is the use of AI writing assistants that fix grammar and modify human-written text in other ways that the language model considers better. While it seems like a less important problem, they could make the human-written text somewhat harder to distinguish from the AI-written text from the other direction.
↑ comment by tgb · 2022-11-15T13:03:58.244Z · LW(p) · GW(p)
I agree, I was just responding to your penultimate sentence: “In fact, if you could know without labeling generated data, why would you generate something that you can tell is bad in the first place?”
Personally, I think it’s kind of exciting to be part of what might be the last breath of purely human writing. Also, depressing.
↑ comment by mocny-chlapik · 2022-11-15T12:53:27.139Z · LW(p) · GW(p)
In general, LM-generated text is still easily distinguishable by other LMs. Even though we humans can not tell the difference, the way they generate text is not really human-like. They are much more predictable, simply because they are not trying to convey information as humans do, they are guessing the most probable sequence of tokens.
Humans are less predictable, because they have always something new to say, LMs on the other hand are like the most cliche person ever.
Replies from: justinpombrio↑ comment by justinpombrio · 2022-11-15T14:13:03.773Z · LW(p) · GW(p)
You should try turning the temperature up.
↑ comment by Tenoke · 2022-11-15T23:04:37.468Z · LW(p) · GW(p)
There is little reason to think that's a big issue. A lot of data is semi-tagged, some of the ML-generated data can be removed either that way or by being detected by newer models. And in general as long as the 'good' type of data is also increasing model quality will also keep increasing even if you have some extra noise.
↑ comment by sanxiyn · 2022-11-15T01:51:42.487Z · LW(p) · GW(p)
Then scrapers looking for parallel data to train on would find these, and it took a lot of effort to screen them out.
How did Google screen them out? Is there a paper published on this? It seems potentially important.
Replies from: dave-orr, Ericf↑ comment by Dave Orr (dave-orr) · 2022-11-18T20:22:25.282Z · LW(p) · GW(p)
Er, I'm not sure it's been published so I guess I shouldn't give details. It had to be an automatic solution because human curation couldn't scale to the size of the problem.