Trends in Training Dataset Sizes
post by Pablo Villalobos (pvs) · 2022-09-21T15:47:41.979Z · LW · GW · 2 commentsThis is a link post for https://epochai.org/blog/trends-in-training-dataset-sizes
Contents
Key takeaways Scale (data points) Yearly growth (OOM) Yearly growth (OOM) (95% CI) Introduction Methods Measuring dataset size Our database Dataset size trends Vision Language Other domains Conclusion None 2 comments
Summary: We collected a database of notable ML models and their training dataset sizes. We use this database to find historical growth trends in dataset size for different domains, particularly language and vision.
Key takeaways
- We collected over 200 notable ML models and estimated their training dataset sizes in number of data points.
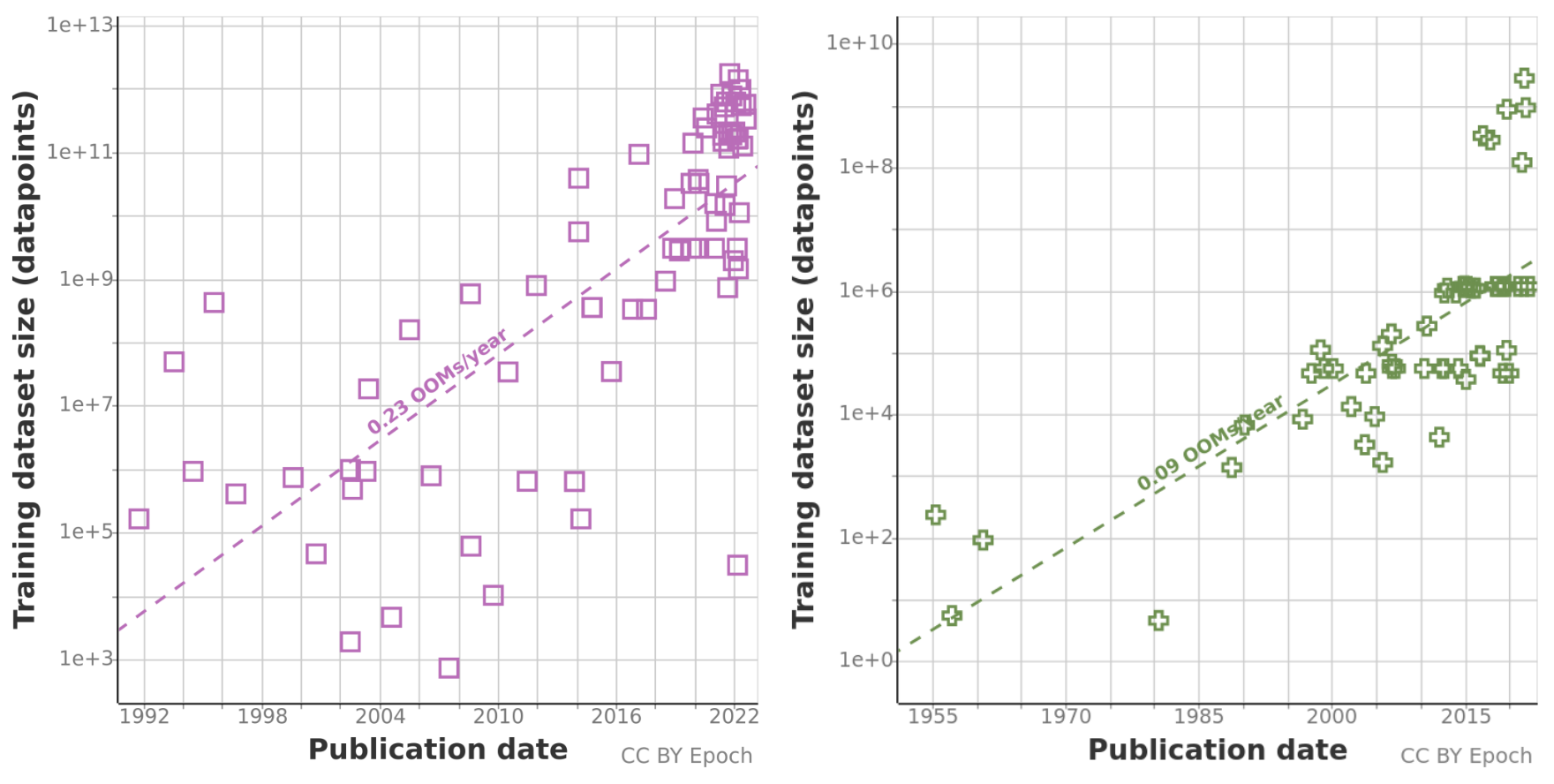
- Vision and language datasets have historically grown at 0.1 and 0.2 orders of magnitude (OOM) per year, respectively.
- There seems to be some transition around 2014-2015, after which training datasets became much bigger and (in the case of language) smaller datasets disappeared. This might be just an artefact of our small sample size.
- We also provide trends for games, speech, recommendation and drawing, but since our sample size is very small in these domains we would advise some level of scepticism.
| Domain | Scale (data points) | Yearly growth (OOM) | Yearly growth (OOM) (95% CI) | #systems |
| Language | 1e2- 2e12 | 0.22 | [0.18 ; 0.28] | 79 |
| Vision | 2e3 - 3e9 | 0.09 | [0.08 ; 0.11] | 55 |
| Speech | 9e2 - 3e12 | 0.21 | [0.17 ; 0.30] | 13 |
| Games | 7e5 - 4e11 | 0.09 | [0.08 ; 0.15] | 12 |
| Recommendation | 1e8 - 1e10 | 0.05 | [0.00 ; 0.47] | 11 |
| Drawing | 6e4 - 4e9 | 0.43 | [0.17 ; 0.64] | 10 |
Table 1: Summary of trends for each domain. Scale is the maximum and minimum observed dataset size, and yearly growth is the slope of the best exponential fit (and 95% CI).
Introduction
Data is one of the main ingredients of Machine Learning (ML) models. To understand the progress of ML over time, it is necessary to understand the evolution of training datasets.
In this document, we characterise the historical trends in training dataset size for different domains, using a custom dataset of ML models. In the Methods [LW(p) · GW(p)] section, we explain our method for quantifying training dataset size, as well as the inclusion criteria for our database. In the Dataset size trends section [LW · GW], we present the trends in dataset size for different domains.
Methods
Measuring dataset size
There is no canonical way to quantify the amount of data in a given dataset. Below are some ways of quantifying dataset size that we have considered, each with its own problems:
- Size in bytes (uncompressed): The problem with this approach is that some modalities of data have very high redundancy, like videos or high-resolution images. A 4K image has ten times more pixels than a HD one but probably does not contain as much information as ten different HD images.
- Size in bytes (compressed): The problem with this approach is that it depends on the compression scheme.
- Number of data points: For each data modality, we choose a data point unit, for example, single words for Language and images for Vision. This approach has the opposite problem of the first: it counts a 16x16 image and a 4K image as a single data point, even though the latter probably contains more information.
- Information-theoretic measures: Seemingly infeasible, as Kolmogorov complexity is incomputable and other measures like mutual information and entropy are often hard to estimate (but see this paper for a decent attempt ).
Ultimately, we decided to go with the third approach. Our definition of training dataset size of a model is the number of unique data points seen during training, where a data point is a concrete unit specific for each domain. Additional details about our decision are available in our document Measuring dataset size in Machine Learning.
A very important consequence of our definition is that training dataset sizes are not directly comparable across domains, since each one has a different unit. Table 2 shows each of the domains and their corresponding data points.
| Domain | Data points |
| Vision | #Images (eg: a model trained on 3B images has a dataset size of 3B) |
| Language | #Words (eg: a model trained on 1T English tokens has a dataset size of ~750B words, the exact quantity depends on the tokenization) |
| Speech | #Words (eg: a model trained on 8 hours of audio at 150 words per minute has a dataset size of 72k words) |
| Games | #Timesteps (eg: a model trained on 300 episodes with an average duration of 20 timesteps has a dataset size of 6k) |
Table 2: Definition of a data point for each domain
Our database
We have compiled a database of over 200 ML models and their training dataset sizes. Given the overwhelming amount of papers in ML, we had to narrow down our search using a series of inclusion criteria. To be included, a model had to satisfy one of these:
- The paper has more than 1000 citations.
- It advanced the state of the art.
- It is of indisputable historical importance.
- It was deployed in an important context.
We categorise each model into a domain depending on the task it was designed to solve. Table 3 shows summary information about the different domains. Once a system is categorised, we take the dataset size from the paper and transform it to the appropriate units. This often entails approximations, since there might not be a fixed conversion factor between our units and those of the paper.
| Domain | Task examples | Number of models in DB |
| Language | Text generation and classification | 79 |
| Vision | Image generation and classification | 55 |
| Speech | Speech recognition and generation | 13 |
| Games | Atari, Go | 12 |
| Recommendation | Collaborative filtering | 11 |
| Drawing | Text-to-image generation | 10 |
Table 3: Dataset domains
Dataset size trends
Vision
The evolution of vision datasets has been greatly influenced by MNIST and ImageNet from 1998 to 2016. Around a third of all the models over this period were trained on those datasets. There was a growth of 0.11 OOMs/year (orders of magnitude per year), and the largest dataset was ImageNet with ~1M images. However, starting from around 2016, a few very large datasets have appeared, the largest of them being JFT-3B with a size of 3B images. It seems too early to tell whether this will change the rate of growth in future years.
The gap between 1e6 and 1e8 images is somewhat puzzling, but we expect it to be an artefact of small sample size.
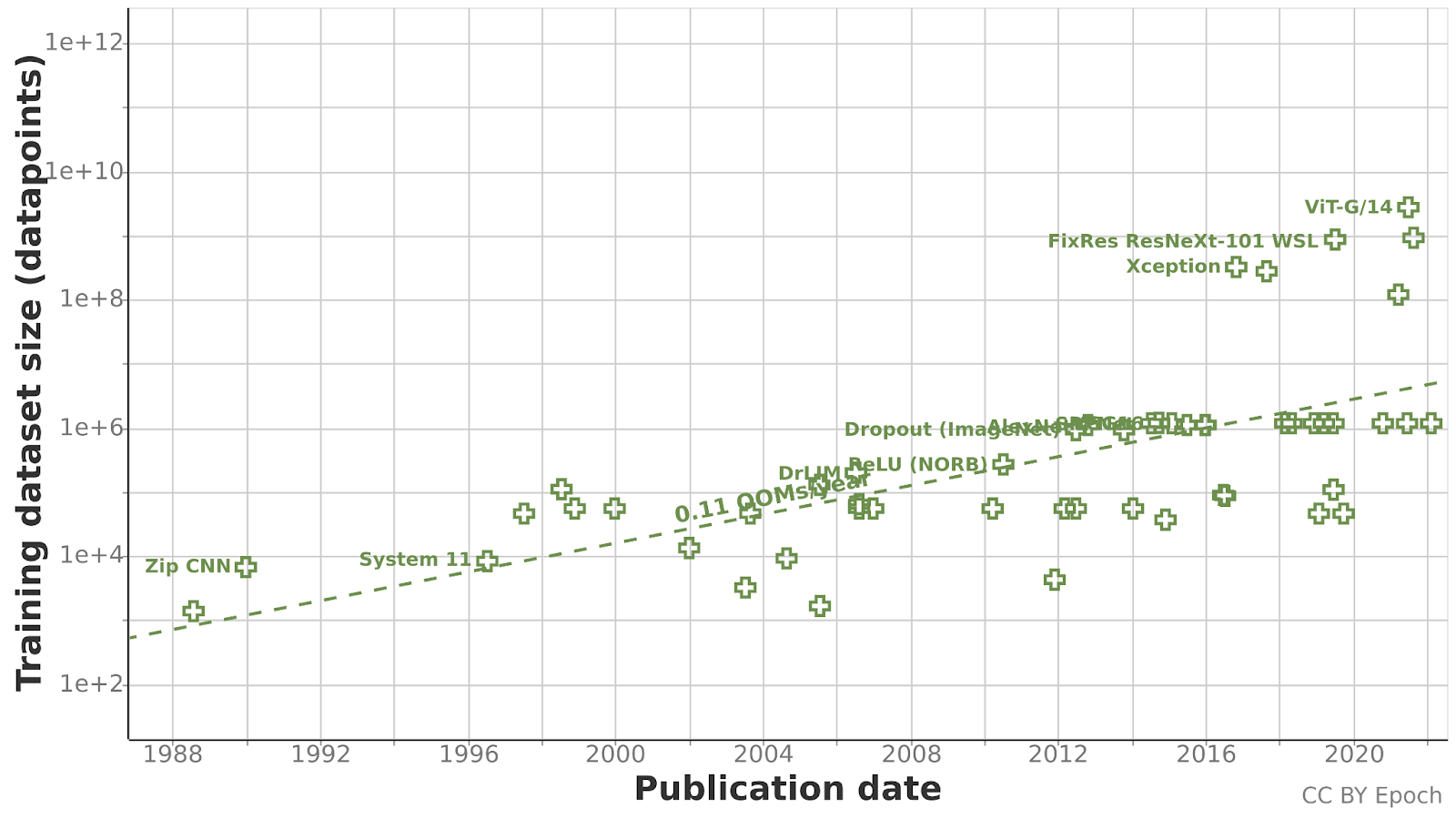
Figure 2: Evolution of vision datasets. A significant number of models is concentrated near 6e4 and 1e6, which are the sizes of MNIST and ImageNet, respectively.
Language
Training datasets for language models have grown by 0.23 OOMs/year since 1990, for a total growth of 7 OOMs between 1990 and 2022. The data suggests that this growth has been faster since 2014, but given the small sample size we don’t feel confident in this. The biggest language dataset observed so far was the FLAN dataset at 1.87e12 words.
It’s remarkable that up until 2014 there were notable models trained on very little data, such as Deep Belief Networks (trained on less than 2e5 words), but after 2016 virtually all notable models have been trained on more than 1e8 words. This might reflect the adoption of more efficient architectures such as Transformers that allow training on much more data.
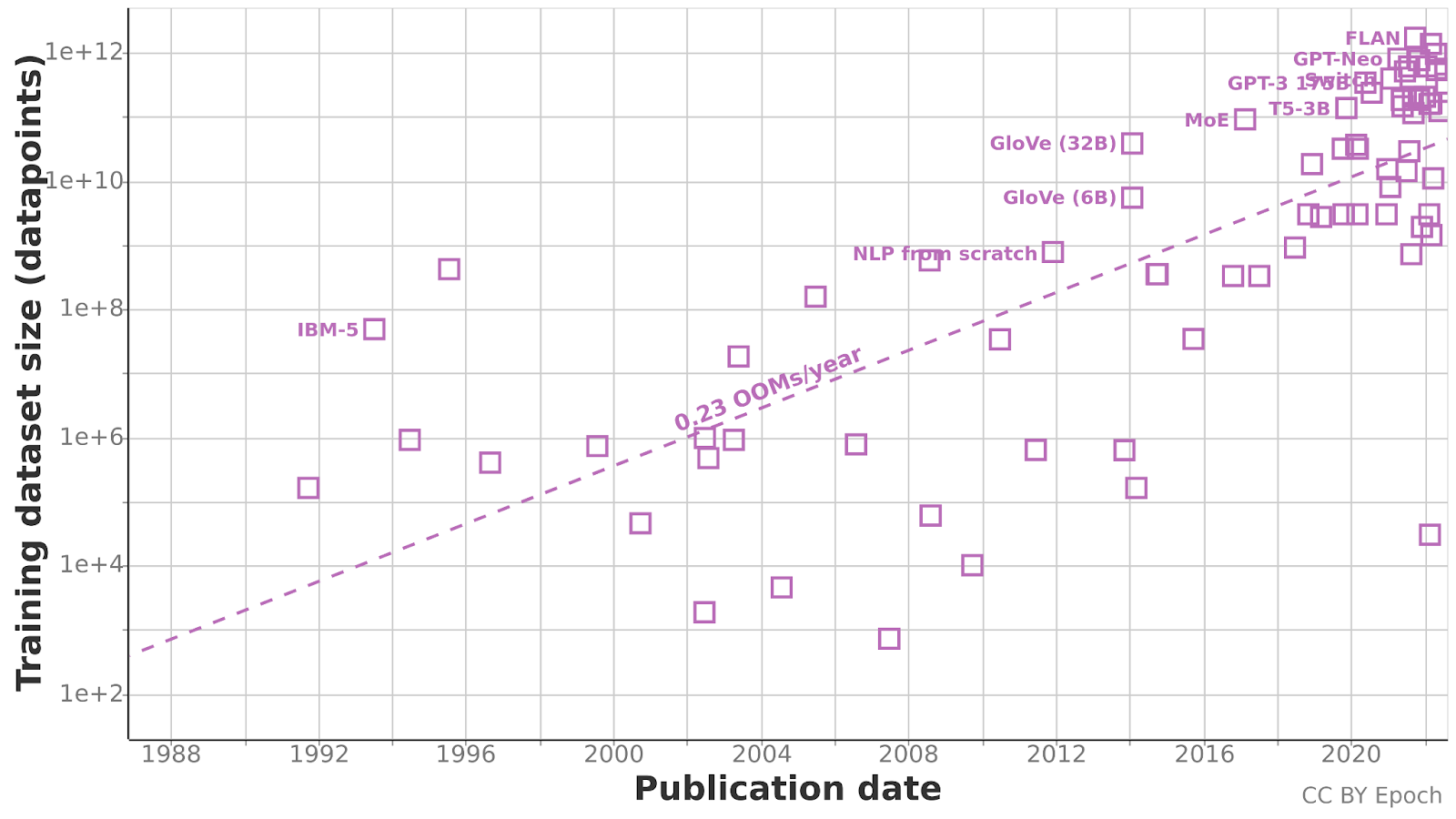
Figure 3: Evolution of language datasets
Other domains
We have very little data on the rest of the domains, so our conclusions are extremely uncertain. The four other domains are shown in Figure 4.
Both Games and Speech models show a pattern similar to Language and Vision, with all models after 2014-2016 using large amounts of data.
Most of our recommendation models are concentrated on a single dataset and time period. This is because they were competitors in the Netflix Prize competition.
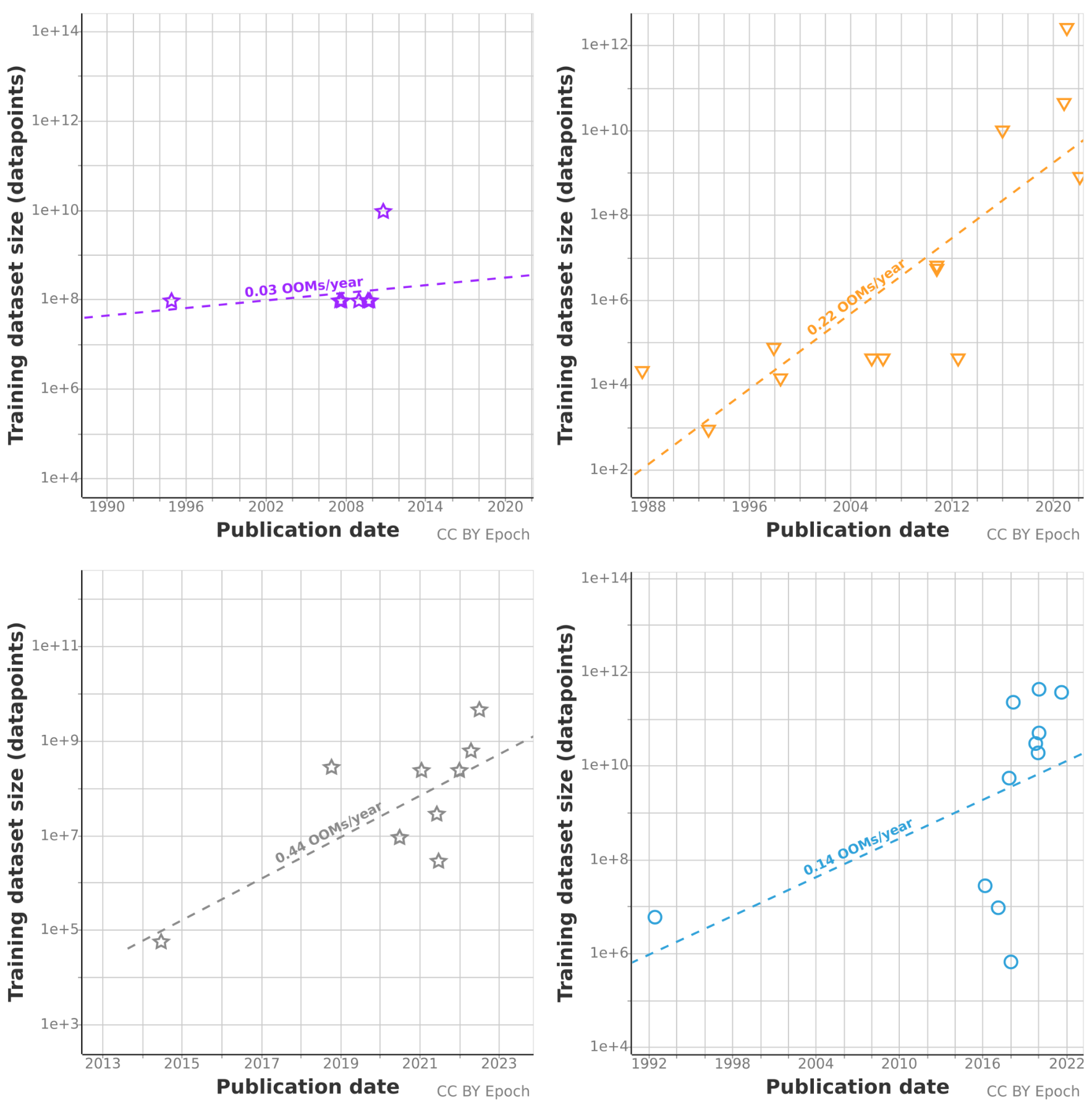
Figure 4: Trends for Recommendation (top left), Speech (top right), Drawing (bottom left) and Games (bottom right)
Conclusion
We collected a database of ML models and their training dataset sizes and estimated their growth rates in several domains. While all domains show increasing size over time, our sample size is too small to provide any meaningful conclusion for all domains except vision and language.
In the domains of language, vision and speech, there we see evidence of a transition after 2014-2015. In this period, we see the appearance of datasets that are orders of magnitude larger than what had been commonplace over the previous decade.
Together with the historical trends in compute usage and model size, these trends might be useful for understanding the past progress in Machine Learning, and thus make better predictions about the field going forward.
2 comments
Comments sorted by top scores.
comment by jacob_cannell · 2022-09-21T16:20:19.957Z · LW(p) · GW(p)
The supply of vision data is nearly unbounded, but the supply of quality human text data is much more like a finite resource - and one for which we have probably passed the point of peak supply. The nominal supply of text may continue to expand, but it's increasingly auto-generated.
Replies from: Mo Nastri↑ comment by Mo Putera (Mo Nastri) · 2022-09-22T09:38:17.684Z · LW(p) · GW(p)
IL's comment [LW(p) · GW(p)] has a BOTEC arguing that video data isn't that unbounded either (I think the 1% usefulness assumption is way too low but even bumping it up to 100% doesn't really change the conclusion that much).