Posts
Comments
I'm not sure what my exact thoughts were back then. I was/am at least skeptical of the specific formula used as it seems arbitrary. It is designed intentionally to have certain properties like exponentially diminishing returns. So it's not exactly a "wild implication" that it has these properties.
I recently fit the Chinchilla formula to the data from the first LLaMA paper: https://i.imgur.com/u1Tm5EU.png
This was over an unrelated disagreement elsewhere about whether Chinchilla's predictions still held or made sense. As well as the plausibility of training tiny models to far greater performance.
First, the new parameters are wildly different than the old ones. Take that for what you will, but they are hardly set in stone. Second even with the best fit, the formula still doesn't really match the shape of the observed curves. I think it's just not the right curve.
As for reusing data I've seen sources claim reusing data up in language models to four times had no negative effect. And up to like 40 times was possible before it really stopped helping. I think LLMs currently do not use much regularization and other tricks that were done in other fields when data was limited. Those might push it further.
If data became truly scarce, there may be other tricks to extend the data we have further. You also have all of the data from the people that talk to these things all day and upvote and downvote their responses. (I don't think anyone has even tried making an AI that intentionally asks users questions about things it wants to learn more about, like a human would do.)
{kind=link}
Human beings can not do most math without pencil and paper and a lot of pondering. Whereas there are a number of papers showing specialized transformers can do math and code at a more sophisticated level than I would have expected before seeing the results.
The Pile includes 7GB of math problems generated by deepmind basically as you describe. I don't believe the models trained on it can do any of them, but my testing wasn't properly done.
They fit a simplistic model where the two variables were independent and the contribution of each decays exponentially. This leads to the shocking conclusion that the two inputs are independent and decay exponentially...
I mean the model is probably fine for it's intended purpose; finding the rough optimal ratio of parameters and data for a given budget. It might mean that current models have suboptimal compute budgets. But it doesn't imply anything beyond that, like some hard limit to scaling given our data supply.
If the big tech companies really want to train a giant model, but run out of data (unlikely)... well it may not be compute optimal, but there is nothing stopping them from doing multiple passes over the same data. If they even get to the point that it starts to overfit (unlikely), there's a plethora of regularization methods to try.
The temporal difference learning algorithm is an efficient way to do reinforcement learning. And probably something like it happens in the human brain. If you are playing a game like chess, it may take a long time to get enough examples of wins and losses, for training an algorithm to predict good moves. Say you play 128 games, that's only 7 bits of information, which is nothing. You have no way of knowing which moves in a game were good and which were bad. You have to assume all moves made during a losing game were bad. Which throws out a lot of information.
Temporal difference learning can learn "capturing pieces is good" and start optimizing for that instead. This implies that "inner alignment failure" is a constant fact of life. There are probably players that get quite far in chess doing nothing more than optimizing for piece capture.
I used to have anxiety about the many worlds hypothesis. It just seems kind of terrifying, constantly splitting into hell-worlds and the implications of quantum immortality. But it didn't take long for it to stop bothering me and to even suppress thoughts about it. After all such thoughts don't lead to a reward and cause problems and an RL brain should punish them.
But that's kind of terrifying itself isn't it? I underwent a drastic change to my utility function. And even the emergence of anti-rational heuristics for suppressing thoughts. Which a rational bayesian should never do (at least not for these reasons.)
Anyway gwern has a whole essay on multi-level optimization algorithms like this, that I haven't seen linked yet: https://www.gwern.net/Backstop
It's back btw. If it ever goes down again you can probably get it on wayback machine. And yes the /r/bad* subreddits are full of terrible academia snobbery. Badmathematics is the best of the bunch because mathematics is at least kind of objective. So they mostly talk about philosophy of mathematics.
The problem is formal models of probability theory have problems with logical uncertainty. You can't assign a nonzero probability to a false logical statement. All the reasoning about probability theory is around modelling uncertainty in the unkown external world. This is an early attempt to think about logical uncertainty. Which MIRI has now published papers on and tried to formalize.
Just calling them "log odds" is fine and they are widely used in real work.
Btw what does "Response to previous version" mean? Was this article significantly editted? It doesn't seem so confrontational reading it now.
That's unlikely. By the late 19th century there was no stopping the industrial revolution. Without coal maybe it would have slowed down a bit. But science was advancing at a rapid pace, and various other technologies from telephones to electricity were well on their way. It's hard for us to imagine a world without coal, since we took that path. But I don't see why it couldn't be done. There would probably be a lot more investment in hydro and wind power (both of which were a thing before the industrial revolution.) And eventually solar. Cars would be hard, but electric trains aren't inconceivable.
we have nuclear weapons that are likely visible if fired en mass.
Would we be able to detect nuclear weapons detonated light years away? We have trouble detecting detonations on our own planet! And even if we did observe them, how would we recognize it as an alien invasion vs local conflict, or god knows what else.
The time slice between us being able to observe the stars, and post singularity, is incredibly tiny. It's very unlikely two different worlds will overlap so that one world is able to see the other destroyed and rush a singularity. I'm not even sure if we would rush a singularity if we observed aliens, or if it would make any difference.
First of all, the Earth has been around for a very very long time. Even slowly expanding aliens should have hit us by now. The galaxy isn't that big relative to the vast amounts of time they have probably been around. I don't feel like this explains the fermi paradox.
If aliens wanted to prevent us from fleeing, this is a terribly convoluted way of doing it. Just shoot a self replicating nanobot at us near the speed of light, and we would be dealt with. We would never see it coming. They could have done this thousands of years ago, if not millions. And it would be vastly more effective at snuffing out competition than this weird strategy. No need to even figure out which planets might evolve intelligent life. Just shoot all of them, it's cheap.
You could time them so they all hit their targets at the same time and give no warning. Or have them just do the minimal amount of destruction necessary so they aren't visible from space.
Well we have plausible reason to believe in aliens. The copernican principle, that the Earth isn't particularly special and the universe is enormous. There's literally no reason to believe angels and demons are plausible.
And god do I hate skeptics and how they pattern match everything "weird" to religion. Yes aliens are weird. That doesn't mean they have literally the same probability of existing as demons.
I think a concrete example is good for explaining this concept. Imagine you flip a coin and then put your hand over it before looking. The state of the coin is already fixed on one value. There is no probability or randomness involved in the real world now. The uncertainty of it's value is entirely in your head.
From Surely You're Joking Mr. Feynman:
Topology was not at all obvious to the mathematicians. There were all kinds of weird possibilities that were “counterintuitive.” Then I got an idea. I challenged them: "I bet there isn't a single theorem that you can tell me - what the assumptions are and what the theorem is in terms I can understand - where I can't tell you right away whether it's true or false."
It often went like this: They would explain to me, "You've got an orange, OK? Now you cut the orange into a finite number of pieces, put it back together, and it's as big as the sun. True or false?"
"No holes."
"Impossible!
"Ha! Everybody gather around! It's So-and-so's theorem of immeasurable measure!"
Just when they think they've got me, I remind them, "But you said an orange! You can't cut the orange peel any thinner than the atoms."
"But we have the condition of continuity: We can keep on cutting!"
"No, you said an orange, so I assumed that you meant a real orange."
So I always won. If I guessed it right, great. If I guessed it wrong, there was always something I could find in their simplification that they left out.
Actually, there was a certain amount of genuine quality to my guesses. I had a scheme, which I still use today when somebody is explaining something that I’m trying to understand: I keep making up examples. For instance, the mathematicians would come in with a terrific theorem, and they’re all excited. As they’re telling me the conditions of the theorem, I construct something which fits all the conditions. You know, you have a set (one ball)—disjoint (two halls). Then the balls turn colors, grow hairs, or whatever, in my head as they put more conditions on. Finally they state the theorem, which is some dumb thing about the ball which isn’t true for my hairy green ball thing, so I say, “False!”
If it’s true, they get all excited, and I let them go on for a while. Then I point out my counterexample.
“Oh. We forgot to tell you that it’s Class 2 Hausdorff homomorphic.”
“Well, then,” I say, “It’s trivial! It’s trivial!” By that time I know which way it goes, even though I don’t know what Hausdorff homomorphic means.
I guessed right most of the time because although the mathematicians thought their topology theorems were counterintuitive, they weren’t really as difficult as they looked. You can get used to the funny properties of this ultra-fine cutting business and do a pretty good job of guessing how it will come out.
Yudkowsky has changed his views a lot over the last 18 years though. A lot of his earlier writing is extremely optimistic about AI and it's timeline.
This is by far my favorite form of government. It's a great response whenever the discussion of "democracy is the best form of government we have" comes up. Some random notes in no particular order:
Sadly getting support for this in the current day is unlikely because of the huge negative associations with IQ tests. Even literacy tests for voters are illegal because of a terrible history of fake tests being used by poll workers to exclude minorities. (Yes the tests were fake like this one, where all the answers are ambiguous and can be judged as correct or incorrect depending on how the test grader feels about you.)
This doesn't actually require the IQ testing portion though. I believe the greatest problem with democracy is that voters are mostly uninformed. And they have no incentive to get informed. A congress randomly sampled from the population though, would be able to hear issues and debates in detail. Even if they are average IQ, I think it would be much better than the current system. And you could use this congress of "average" representatives to vote for other leaders like judges and presidents, who would be more selected for intelligence.
In fact you could just use this system to randomly select voters from the population. Get them together so they can discuss and debate in detail, and know their votes really matter. And then have them vote on the actual leaders and representatives like a normal election. I believe something like this is mentioned at the end of the article.
Of course I still like and approve of the IQ filtering idea. But I think these two ideas are independent, and the IQ portion is always going to be the most controversial.
I think the sortition should be entirely opt-in, just like normal voting is. This selects for people that actually care about politics and want to be representatives. Which might select for IQ a bit on it's own. And prevents you from getting uninterested people that are bored out of their mind by politics.
One could argue such a system would be unrepresentative of minority groups. If they have lower IQs or are less likely to opt in. However the current system isn't representative at all. Look at the makeup of congress now. Different demographics are more or less likely to vote in elections as it is. And things like gerrymandering and just regular geographic-based voting distort representation a lot. And yet somehow it still mostly works, and I don't think this system could be any worse in that dimension.
But if it is a concern, you could just resample groups to represent the general population. So if women are half as likely to opt-in, women that do opt-in should be made twice as likely to be selected. I'm not sure if this is a good or desirable thing to do, just that it would quell these objections.
Selecting for the top 1% of IQ is too much filtering. You really don't want to create an incentive to game IQ tests. At least not too much. And remember IQ tests are not perfect, they can be practiced to improve your score. You also don't want a bunch of representatives that are freaks of nature, that have brains really good at Raven's Matrices and nothing else. There are multiple dimensions to intelligence, and while they correlate, the correlation isn't 100%. I'd arbitrarily go with the top 5% - the best scorer out of 20. Even that seems high.
All the discussion about how the system could be corrupted is ridiculous. People had the same objections to regular democracy. How do we trust that the poll workers and vote counters are reliable? What's to stop a vast conspiracy of voting fraud?
Somehow we've mostly solved these problems and votes are trusted. When issues arise, we have a court system that seems to be relatively fair about resolving them. And it's still not perfect. We have stuff like gerrymandering that wouldn't be an issue with sortition based systems.
I hope the mods don't remove this for violating the politics rule. While it is technically about political systems, it's only in a meta sense. Talking about the political system itself, not specific policies or ideologies. There is nothing particularly left or right wing about these ideas. I don't think anyone is likely to be mindkilled by it.
In the first draft of the lord of the rings, the Balrog ate the hobbits and destroyed middle Earth. Tolkien considered this ending unsatisfactory, if realistic, and wisely decided to revise it.
It's really going to depend on your interests. I guess I'll just dump my favorite channels here.
I enjoy some math channels like Numberphile, computerphile, standupmaths, 3blue1brown, Vi Hart, Mathologer, singingbanana, and some of Vsauce.
For "general interesting random facts" there's Tom Scott, Wendover Productions, CGP Grey, Lindybeige, Shadiversity. and Today I Found Out.
Science/Tech/etc: engineerguy, Kurzgesagt, and C0nc0rdance.
Miscellaneous: kaptainkristian, CaptainDisillusion, and the more recent videos of suckerpinch.
Politics: I unsubscribed from most political content a long time ago. But Last Week Tonight and Vox are pretty good.
Humor: That's pretty subjective, but I think everyone should know about The Onion. Also Fitzthislewitz.
Well there is a lot of research into treatments for dementia, like the neurogenesis drug I mentioned above. I think it's quite plausible they will stumble upon general cognitive enhancers that improve healthy people.
Just because it's genetic doesn't mean it's incurable. Some genetic diseases have been cured. I've read of drugs that increase neurogenesis, which could plausibly increase IQ. Scientists have increased the intelligence of mice by replacing their glial cells with better human ones.
I wasn't aware that method had a name, but I've seen that idea suggested before when this topic comes up. For neural networks in particular, you can just look at the gradients of the inputs to see how it's output changes as you change each input.
I think the problem people have, is that just tells you what the machine is doing. Not why. Machine learning can never really offer understanding.
For example, there was a program created specifically for the purpose of training human understandable models. It worked by fitting the simplest possible mathematical expression to the data. And the hope was that simple mathematical expressions would be easy to interpret by humans.
One biologist found an expression that perfectly fit his data. It was simple, and he was really excited by it. But he couldn't understand what it meant at all. And he couldn't publish it, because how can you publish an equation without any explanation?
Same as with the GAN thing. You condition it on producing a correct answer (or whatever the goal is.) So if you are building a question answering AI, you have it model the probability distribution something like P(human types this character | human correctly answers question). This could be done simply by only feeding it examples of correctly answered questions as it's training set. Or you could have it predict what a human might respond if they had n days to think about it.
Though even that may not be necessary. What I had in mind was just having the AI read MIRI papers and produce new ones just like them. Like a superintelligent version of what people do today with markov chains or RNNs to produce writing in the style of an author.
Yes these methods do limit the AI's ability a lot. It can't do anything a human couldn't do, in principle. But it can automate the work of humans and potentially do our job much faster. And if human ability isn't enough to build an FAI, well you could always set it to do intelligence augmentation research instead.
Consider also that religions that convert more people tend to spread faster and farther than religions that don't. So over time religions should become more virulent.
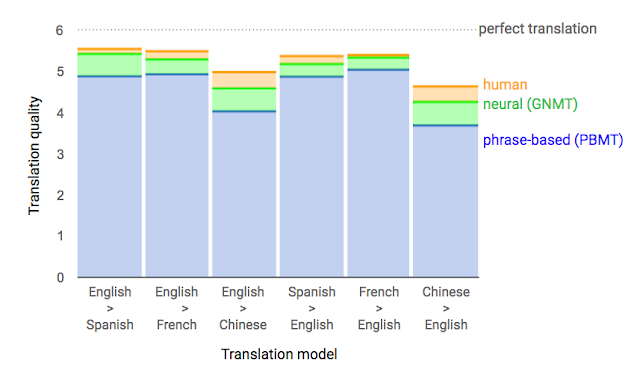
There are some problems with this analysis. First of all, translation is natural language processing. What task requires more understanding of natural language than translation? Second, the BLEU score mentioned is only a cheap and imperfect measure of translation quality. The best measure is human evaluation. And neural machine translation excels at that. Look at this graph. On all languages, the neural network is closer to human performance than the previous method. And on several languages it's extremely close to human performance, and it's translations would almost be indistinguishable from human. That's incredible! And it shows that NNs can handle symbolic problems, which the author disputes.
{kind=link}
The biggest problem though, is that all machine learning tasks are expected to have diminishing returns.You can't do better on a classification task than 0% error, for example. You might have an algorithm that is 10x better than another. But it may only do 1% better on some chosen dataset. Because there isn't more than 1% progress that can be made! Just looking at benchmark scores is going to really underestimate the rate of progress.
Selecting from a list of predetermined answers extremely limits the AI's ability. Which isn't good if we want it to actually solve very complex problems for us! And that method by itself doesn't make the AI safe, just makes it much harder for it to do anything at all.
Note someone found a way to simplify my original idea in the comments. Instead of using the somewhat complicated GAN thing, you can just have it try to predict the next letter a human would type. In theory these methods are exactly equivalent.
It wasnt until relatively late in the second industrial revolution that coal completely replaced wood. And oil came very late. I think an industrial revolution could happen a second time without fossil fuel.
I like the scenario you presented. 6 months until intelligence explosion changes the entire approach to FAI. More risk is acceptable. More abstract approaches to FAI research seem less useful if they can't lead to tangible algorithms in 6 months.
I think the best strategy would be something like my idea to have AI mimic humans. Then you can task it to do FAI research for you. It could possibly produce years worth of FAI research papers in a fraction of the time. I don't think we should worry too much about the nuances of actually training an FAI directly.
I believe this is the idea of "motivational scaffolding" described in Superintelligence. Make an AI that just learns a model of the world, including what words mean. Then you can describe its utility function in terms of that model - without having to define exactly what the words and concepts mean.
This is much easier said than done. It's "easy" to train an AI to learn a model of the world, but how exactly do you use that model to make a utility function?
No, the choice is to vote for your preferred candidate, or to not vote. Write ins count as "not voting".
Basically yes. First Past The Post does not satisfy the criteria Independence of Irrelevant Alternatives.
If you really believe your candidate is less than 50% likely to be the "correct" candidate, you can just vote for the other one. Then you will necessarily have a >50% confidence you voted for the correct candidate. You can't possibly do worse on a binary decision.
Well the control problem is all about making AIs without "inimical motivations", so that covers the same thing IMO. And fast takeoff is not at all necessary for AI risk. AI is just as dangerous if it takes it's time to grow to superintelligence. I guess it gives us somewhat more time to react, at best.
Are you referring to OP or me? I don't think my estimate of the difference between candidates is ridiculous. It's pretty clear the president can have a massive impact on the world. So large that, even when multiplied by a 1 in 10 million probability, it's still worth your time to vote.
Using dollar amounts might be a bit naive. Instead look at utility directly, perhaps some estimate like QALYs. I think something like health care reform alone has the potential to be worth tens of millions of QALYs. A major war or economic depression can easily cost similar amounts.
And again this is just the scenario where you are the tiebreaking vote. I think there is something to be said for the value of voting that goes beyond just the likelihood of being a tiebreaker. For instance, consider all the people that think similar to how you do. If you decide to not vote, they will also decide to not vote. So your decision to vote can still change the election, in a sort of acausal way.
Yes, from your subjective view your vote is always positive. Thus you should always vote.
Third parties aren't stable. They can appear, but they inevitably split the vote. They always hurt their cause more than help it. Unless they are so popular they can outright replace one of the parties.
False. It requires only a few events, like smarter-than-human AI being invented, and the control problem not being solved. I don't think any of these things is very unlikely.
I can still think the CEV machine is better than whatever the alternative is (for instance, no AI at all.) But yes, in theory, you should prefer to make AIs that have your own values and not bother with CEV.
Having a body is irrelevant. Bodies are just one way to manipulate the world to optimize your goals.
"We convert the resources of the world into the things we want." To some extent, but not infinitely, in a fanatical way. Again, that is the whole worry about AI -- that it might do that fanatically. We don't.
What do you mean by "fanatically"? This is a pretty vague word. Humans would sure seem fanatical to other animals. We've cut down entire continent sized forests, drained massive lakes, and built billions of complex structures.
The only reason we haven't "optimized" the Earth further, is because of physical and economic limits. If we could we probably would.
Whether you call that "optimization" or not, is mostly irrelevant. If superintelligent AIs acted similarly, humans would be screwed.
I'm deeply concerned that you are theoretically ok with slave owning aliens. If the slaves are ok with it, then perhaps it could be justified. But if they strongly object to it, and suffer from it, and don't get any benefit from it, then it's just obviously wrong.
In a first past the post election third parties are irrelevant.
More specifically, the calculations above apply to a close election. 538 gives Johnson a less than 0.01% chance of winning. Obviously the probability of you being the tie breaking vote is many many orders of magnitude smaller than is worth calculating.
That's impossible. You can't have less than 50% confidence on a binary decision. You can't literally believe that a coin flip is more likely to select the correct option than you.
...add a primary supergoal which imposes a restriction on the degree to which "instrumental goals" are allowed to supercede the power of other goals. At a stroke, every problem he describes in the paper disappears, with the single addition of a goal that governs the use of instrumental goals -- the system cannot say "If I want to achieve goal X I could do that more efficiently if I boosted my power, so therefore I should boost my power to cosmic levels first, and then get back to goal X."
This is not so simple. "Power" and "instrumental goals" are abstractions. Not things that actually can be programmed into an AI. The AI has no concept of "power" and will do whatever leads to it's goal.
Imagine for instance, a chess playing AI. You tell it to limit it's "power". How do you do this? Is using the queen too powerful? Is taking opposing pieces too powerful? How do you define "power" precisely, in a way that can be coded into an actual algorithm?
Of course the issues of AI risk go well beyond just figuring out how to build an AI that doesn't want to take over the world. Even if your proposed solution could actually work, you can't stop other people from making AIs that don't use it, or use a bugged version of it, etc.
The rest of your essay is just a misunderstanding of what reinforcement learning is. Yes it does have origins in old psychology research. But the field has moved on an awful lot since then.
There are many different ideas on how to implement RL algorithms. But the simplest is, to use an algorithm that can predict the future reward. And then take an action which leads to the highest reward.
This procedure is totally independent of what method is used to predict the future reward. There is absolutely nothing that says it has to be an algorithm that can only make short term predictions. Sure, it's a lot easier to make algorithms that just predict the short term. But that doesn't mean it's impossible to do otherwise. Humans sure seem capable of predicting the long term future.
The RL theorist would say that you somehow did a search through all the quintillions of possible actions you could take, sitting there in front of an equation that requires L'Hôpital's Rule, and in spite of the fact that the list of possible actions included such possibilities as jumping-on-the-table-and-singing-I-am-the-walrus, and driving-home-to-get-a-marmite-sandwich, and asking-the-librarian-to-go-for-some-cheeky-nandos, you decide instead that the thing that would give you the best dopamine hit right now would be applying L'Hôpital's Rule to the equation.
This just demonstrates how badly you misunderstand RL. Real AIs like AlphaGo don't need to search through the entire search space. In fact the reason they work over other methods is because they avoid that. It uses machine learning to eliminate large chunks of the search space almost instantly. And so it only needs to consider a few candidate paths.
People started to point out that the extra machinery was where all the action was happening. And that extra machinery was most emphatically not designed as a kind of RL mechanism, itself. In theory, there was still a tiny bit of reinforcement learning somewhere deep down inside all the extra machinery, but eventually people just said "What's the point?" Why even bother to use the RL language anymore? The RL, if it is there at all, is pointless. A lot of parameter values get changed in complex ways, inside all the extra machinery, so why even bother to mention the one parameter among thousands, that is supposed to be RL, when it is obvious that the structure of that extra machinery is what matters.
RL is a useful concept, because it lets you get useful work out of other, more limited algorithms. A neural net, on it's own, can't do anything but supervised learning. You give it some inputs, and it makes a prediction of what the output should be. You can't use this to play a video game. You need RL to build on top of it to do anything interesting.
You go on and on about how the tasks that AI researchers achieve with AI are "too simple". This is just typical AI Effect. Problems in AI don't seem as hard as they actually are, so significant progress never seems like progress at all, from the outside.
But whatever. You are right that currently NNs are restricted to "simple" tasks that don't require long term prediction or planning. Because long term prediction is hard. But again, I don't see any reason to believe it's impossible. It would certainly be much more complex than today's feed-forward NNs, but it would still be RL. It would still be just doing predictions about what action leads to the most reward, and taking that action.
There is some recent work in this regard. Researcher are combining "new" NN methods with "old" planning algorithms and symbolic methods, so they can get the best of both worlds.
You keep making this assertion that RL has exponential resource requirements. It doesn't. It's a simple loop; predict the action that leads to the highest reward, and take it. With a number of variations, but they are all similar.
The current machine learning algorithms that RL methods use, might have exponential requirements. But so what? No one is claiming that future AIs will be just like today's machine learning algorithms.
Let's say you are right about everything. RL doesn't scale, and future AIs will be based on something entirely different that we can't even imagine.
So what? The same problems that affect RL apply to every AI architecture. That is the control problem. Making AIs do what we want. The problem that most AI goals lead to them seeking more power to better maximize their goals. The problem is that most utility functions are not aligned with human values.
Unless you have an alternative AI method that isn't subject to this, you aren't adding anything. And I'm pretty sure you don't.
I don't see anything in that link that is relevant to this post.
No that's not how this works. We are calculating the expected value of a vote. The expected value is more than just "best case - worst case". You factor in all possibilities weighted by their probability.
As long as the probability you are voting for the correct candidate is higher than 50%, the expected value of a vote is positive. And obviously it's impossible to get odds worse than that, for a binary decision. You can then multiply the probability you are voting for the correct candidate by the expected value of a correct vote, and it's likely to still be worth your time to vote.
Robin Hanson is a bit more conservative and believes the expected value of a vote is only positive if you are more informed than the average voter, and otherwise you should abstain. That's still not a very high bar to pass. The average voter is not terribly informed.
What this entire discussion has been about, is that even if you vote for the correct candidate, is the expected value of a vote really that high? OP demonstrated an upper limit for the expected value of a correct vote. I am simply arguing that even if his estimate is off by orders of magnitude, it's still large.
This makes it worthwhile to 1) take the time to vote, if you thought it was a waste of time. And 2) do more research on the candidates and become a more informed voter, which increases your odds of voting for the correct candidate. And 3) spend effort trying to get other people to do the same.
There is a pervasive attitude at Lesswrong and related communities that all politics is a waste of time. I think this calculation, even if a bit naive and imperfect, demonstrates it might not be so.
The article gives an upper limit of the expected value of a vote. Even if the lower limit is 2 orders of magnitude lower, it still is quite significant. And makes it worth the time to vote, or to try to convince other people to vote your way.
Scott Alexander estimates the value of a vote more conservatively to be about $300 to $5,000 (the higher number for if you live in a swing state.) He backs this up by pointing to specific policies and actions taken by presidents that cost trillions of dollars.
I don't think it's hard to believe that the president can be worth trillions of dollars. Presidents can start and prevent wars, and have very significant influence on domestic policy. In the worst case, a president has some risk of starting a nuclear war that costs [world GDP], or starting a world wide economic depression. In the best case they could stop said war or depression. Supreme court appointments just by itself is worth a huge amount.
I don't see why you do that division. The point of being the decisive vote, is that if you didn't show up to vote, the election would have gone the other way (lets ignore ties for the moment.) You can disregard other people entirely in this model. All that matters is the expected value of your action. Which is enormous.
Well now I see we disagree at a much more fundamental level.
There is nothing inherently sinister about "optimization". Humans are optimizers in a sense, manipulating the world to be more like how we want it to be. We build sophisticated technology and industries that are many steps removed from our various end goals. We dam rivers, and build roads, and convert deserts into sprawling cities. We convert the resources of the world into the things we want. That's just what humans do, that's probably what most intelligent beings do.
The definition of FAI, to me, is something that continues that process, but improves it. Takes over from us, and continues to run the world for human ends. Makes our technologies better and our industries more efficient, and solves our various conflicts. The best FAI is one that constructs a utopia for humans.
I don't know why you believe a slave owning race is impossible. Humans of course practiced slavery in many different cultures. It's very easy for even humans to not care about the suffering of other groups. And even if you do believe most humans could be convinced it's wrong (I'm not so sure), there are actual sociopaths that don't experience empathy at all.
Humans also have plenty of sinister values, and I can easily believe aliens could exist that are far worse. Evolution tended to evolve humans that cooperate and have empathy. But under different conditions, we could have evolved completely differently. There is no law of the universe that says beings have to have values like us.
The CEV process might well be immoral for everyone concerned, since by definition it is compromising a person's fundamental values.
The world we live in is "immoral" in that it's not optimized towards anyone's values. Taking a single person's values would be "immoral" to everyone else. CEV, finding the best possible compromise of values, would be the least immoral option, on average. Optimize the world in a way that dissatisfies the least people the least amount.
That does not necessarily mean "living separately".
Right. I said that's the realistic worst case, when no compromise is possible. I think most people have similar enough values that this would be rare.
you want to eliminate ones with values that you really dislike. I think that is basically racist.
I don't necessarily want to kill them, but I would definitely stop them from hurting other beings. Imagine you came upon a race of aliens that practiced a very cruel form of slavery. Say 90% of their population was slaves, and the slave owning class treated regularly tortured and overworked them. Would you stop them, if you could? Is that racist? What about the values of the slaves?
But humans share a lot of values (e.g. wanting to live and not be turned into a dyson sphere.) And a collection of individuals may still have a set of values (see e.g. coherent extrapolated volition.)
It means that when you look an an AI system, you can tell whether it's FAI or not.
Look at it how? Look at it's source code? I argued that we can write source code that will result in FAI, and you could recognize that. Look at the weights of it's "brain"? Probably not, anymore than we can look at human brains and recognize what they do. Look at it's actions? Definitely, FAI is an AI that doesn't destroy the world etc.
I don't see what voting systems have to do with CEV. The "E" part means you don't trust what the real, current humans say, so to making them vote on anything is pointless.
The voting doesn't have to actually happen. The AI can predict what we would vote for, if we had plenty of time to debate it. And you can get even more abstract than that and have the FAI just figure out the details of E itself.
The point is to solve the "coherent" part. That you can find a set of coherent values from a bunch of different agents or messy human brains. And to show that mathematicians have actually extensively studied a special case of this problem, voting systems.
That's a meaningless expression without a context. Notably, we don't have the same genes or the same brain structures. I don't know about you, but it is really obvious to me that humans are not identical.
Compared to other animals, compared to aliens, yes we are incredibly similar. We do have 99.99% identical DNA, our brains all have the same structure with minor variations.
How do you know what's false?
Did I claim that I did?
How do you know what's fair? Is it an objective thing, something that exists in the territory?
I gave a precise algorithm for doing that actually.
Right, so the fat man gets thrown under the train... X-)
Which is the best possible outcome, vs killing 5 other people. But I don't think these kinds of scenarios are realistic once we have incredibly powerful AI.
LOL. You're just handwaving then. "And here, in the difficult part, insert magic and everything works great!"
I'm not handwaving anything... There is no magic involved at all. The whole scenario of persuading people is counterfactual and doesn't need to actually be done. The point is to define more exactly what CEV is. It's the values you would want if you had the correct beliefs. You don't need to actually have the correct beliefs, to give your CEV.
No it's not necessarily a negative outcome. I think it could go both ways, which is why I said it was "my greatest fear/hope".
The premise this article starts with is wrong. The argument goes that AIs can't take over the world, because they can't predict things much better than humans can. Or, conversely, that they will be able to take over because they can predict much better than humans.
Well so what if they can predict the future better? That's certainly one possible advantage of AI, but it's far from the only one. My greatest fear/hope of AI is that it will be able to design technology much better than humans. Humans didn't evolve to be engineers or computer programmers. It's really just an accident we are capable of it. Humans have such a hard time designing complex systems, keeping track of so many different things in our head, etc. Already these jobs are restricted to unusually intelligent people.
I think there are many possible optimizations to the mind to improve at these kinds of tasks. There are rare humans that are very good at these tasks, showing that human brains aren't anywhere near the peak. An AI that is optimized for them, will be able to design technologies we can't even dream of. We could theoretically make nanotechnology today, but there are so many interacting parts and complexities, humans are just unable to manage it. The internet has so much bugged software running it. It could probably be pwned in a weekend by a sufficiently powerful programming AI.
And the same is perhaps true with designing better AI algorithms, an AI optimized towards AI research, would be much better at it than humans.
People may have different values (although I think deep down we are very similar, humans sharing all the same brains and not having that much diversity.) Regardless, CEV should find the best possible compromise between our different values. That's literally the whole point.
If there is a difference in our values, the AI will find the compromise that satisfies us the most (or dissatisfies us the least.) There is no alternative, besides not compromising at all and just taking the values of a single random person. From behind the veil of ignorance, the first is definitely preferable.
I don't think this will be so bad. Because I don't think our values diverge so much, or that decent compromises are impossible between most values. I imagine that in the worst case, the compromise will be that two groups with different values will have to go their separate ways. Live on opposite sides of the world, never interact, and do their own thing. That's not so bad, and a post-singularity future will have more than enough resources to support it.
That said, I already said that I would not be willing to wipe out non-human values from the cosmos
No one is suggesting we wipe out non-human values. But we have yet to meet any intelligent aliens with different values. Once we do so, we may very well just apply CEV to them and get the best compromise of our values again. Or we may keep our own values, but still allow them to live separately and do their own thing, because we value their existence.
This reminds me a lot of the post value is fragile. It's ok to want a future that has different beings in it, that are totally different than humans. That doesn't violate my values at all. But I don't want a future that has beings die or suffer involuntarily. I don't think it's "value racist" to want to stop beings that do value that.
No, I'm asking you to specify it. My point is that you can't build X if you can't even recognize X.
And I don't agree with that. I've presented some ideas on how an FAI could be built, and how CEV would work. None of them require "recognizing" FAI. What would it even mean to "recognize" FAI, except to see that it values the kinds of things we value and makes the world better for us.
Learning what humans want is pretty easy. However it's an inconsistent mess which involves many things contemporary people find unsavory. Making it all coherent and formulating a (single) policy on the basis of this mess is the hard part.
I've written about one method to accomplish this, though there may be better methods.
Why would CEV eliminate things I find negative? This is just a projected typical mind fallacy. Things I consider positive and negatve are not (necessarily) things many or most people consider positive and negative.
Humans are 99.999% identical. We have the same genetics, the same brain structures, and mostly the same environments. The only reason this isn't obvious, is because we spend almost all our time focusing on the differences between people, because that's what's useful in everyday life.
I should expect CEV to eliminate some things I believe are positive and impose some things I believe are negative.
That may be the case, but that's still not a bad outcome. In the example I used, the values dropped from ISIS members were taken for 2 reasons. That they were based on false beliefs, or that they hurt other people. If you have values based on false beliefs, you should want them to be eliminated. If you have values that hurt other people then it's only fair that be eliminated. Or else you risk the values of people that want to hurt you.
Later you say that CEV will average values. I don't have average values.
Well I think it's accurate, but it's somewhat nonspecific. Specifically, CEV will find the optimal compromise of values. The values that satisfy the most people the most amount. Or at least dissatisfy the fewest people the least. See the post I just linked for more details, on one example of how that could be implemented. That's not necessarily "average values".
In the worst case, people with totally incompatible values will just be allowed to go separate ways, or whatever the most satisfying compromise is. Muslims live on one side of the dyson sphere, Christians on the other, and they never have to interact and can do their own thing.
You are essentially saying that religious people are idiots and if only you could sit them down and explain things to them, the scales would fall from their eyes and they will become atheists.This is a popular idea, but it fails real-life testing very very hard.
My exact words were "If they were more intelligent, informed, and rational... If they knew all the arguments for and against..." Real world problems of persuading people don't apply. Most people don't research all the arguments against their beliefs, and most people aren't rational and seriously consider the hypothesis that they are wrong.
For what it's worth, I was deconverted like this. Not overnight by any means. But over time I found that the arguments against my beliefs were correct and I updated my belief.
Changing world views is really really hard. There's no one piece of evidence or one argument to dispute. Religious people believe that there is tons of evidence of God. To them it just seems obviously true. From miracles, to recorded stories, to their own personal experiences, etc. It takes a lot of time to get at every single pillar of the belief and show its flaws. But it is possible. It's not like Muslims were born believing in Islam. Islam is not encoded in genetics. People deconvert from religions all the time, entire societies have even done it.
In any case, my proposal does not require literally doing this. It's just a thought experiment. To show that the ideal set of values is what you choose if you had all the correct beliefs.