This marks the second half of our overview of the AI alignment problem. In the first half, we outlined the case for misaligned AI as a significant risk to humanity, first by looking at past progress in machine learning and extrapolating to what the future could bring, and second by discussing the theoretical arguments which underpin many of these concerns. In this second half, we focus on possible solutions to the alignment problem that people are currently working on. We will paint a picture of the current field of technical AI alignment, explaining where the major organisations fit into the larger picture and what the theory of change behind their work is. Finally, we will conclude the sequence with a call to action, by discussing the case for working on AI alignment, and some suggestions on how you can get started.
Note - for people with more context about the field (e.g. have done AGISF) we expect Thomas Larsen's post [LW · GW] to be a much better summary, and this post [LW · GW] might be better if you are looking for something brief. Our intended audience is someone relatively unfamiliar with the AI safety field, and is looking for a taste of the kinds of problems which are studied in the field and the solution approaches taken. We also don't expect this sampling to be representative of the number of people working on each problem - again, see Thomas' post for something which accomplishes this.
Definition (pre-paradigmatic): a science at an early stage of development, before it has established a consensus about the true nature of the subject matter and how to approach it.
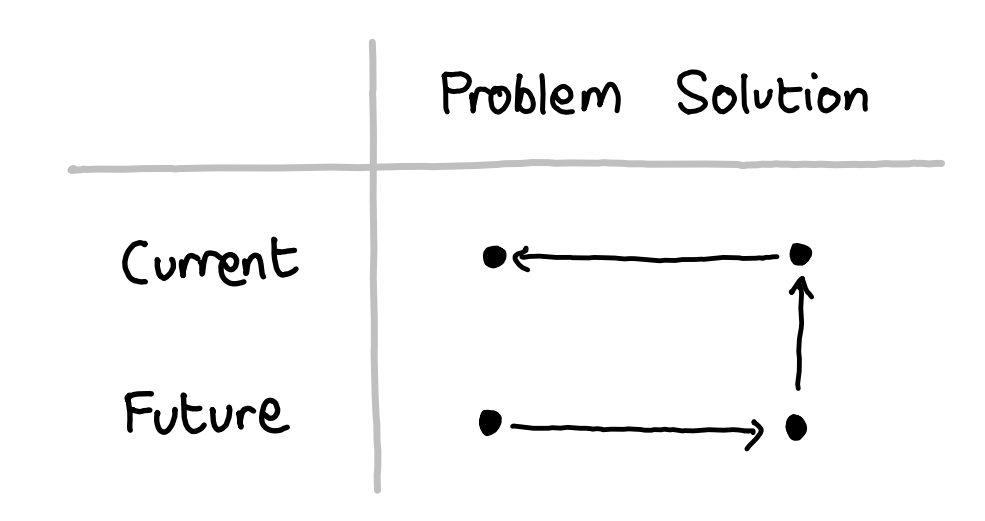
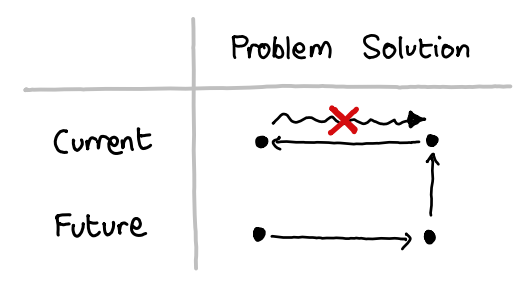
AI alignment is a strange field. Unlike other fields which study potential risks to the future of humanity (e.g. nuclear war or climate change), there is almost no precedent for the kinds of risks we care about. Additionally, because of the nature of the threat, failing to get alignment right on the first try might be fatal. As Paul Christiano (a well-known AI safety researcher) recently wrote:
Humanity usually solves technical problems by iterating and fixing failures; we often resolve tough methodological disagreements very slowly by seeing what actually works and having our failures thrown in our face. But it will probably be possible to build valuable AI products without solving alignment, and so reality won’t “force us” to solve alignment until it’s too late. This seems like a case where we will have to be unusually reliant on careful reasoning rather than empirical feedback loops for some of the highest-level questions.
For these reasons, the field of AI alignment lacks a consensus on how the problem should be tackled, or what the most important parts of the problem even are. This is why there is a lot of variety in the approaches we present in this post.
Decomposing the research landscape
sorting papers and books in a majestic gothic library
There are lots of different ways you could divide up the space of approaches to solving the problem of aligning advanced AI. For instance, you could go through the history of the field and identify different movements and paradigms. Or you could place the work on a spectrum from highly theoretical maths/philosophy-type research, to highly empirical research working with cutting-edge deep learning models.
However, the most useful decomposition would be one that explains why the people who work on it believe that it will help solve the problem of AI alignment.
For that reason, we’ll mostly be using the decomposition from Neel Nanda’s “A Bird’s Eye View” [? · GW]post. The motivation behind this decomposition is to answer the high-level question of “what is needed for AGI to go well?”. The six broad classes of approaches we talk about are:
Addressing threat models We have a specific threat model in mind for how AGI might result in a very bad future for humanity, and focus our work on things we expect to help address the threat model.
Agendas to build safe AGI Let’s make specific plans for how to actually build safe AGI, and then try to test, implement, and understand the limitations of these plans. The emphasis is on understanding how to build AGI safely, rather than trying to do it as fast as possible.
Robustly good approaches In the long-run AGI will clearly be important, but we're highly uncertain about how we'll get there and what, exactly, could go wrong. So let's do work that seems good in many possible scenarios, and doesn’t rely on having a specific story in mind.
Deconfusion Reasoning about how to align AGI involves reasoning concepts like intelligence, values, and optimisers and we’re pretty confused about what these even mean. This means any work we do now is plausibly not helpful and definitely not reliable. As such, our priority should be doing some conceptual work on how to think about these concepts and what we’re aiming for, and trying to become less confused.
AI governance In addition to solving the technical alignment problem, there’s the question of what policies we need to minimise risk from advanced AI systems.
Field-building One of the most important ways we can make AI go well is by increasing the number of capable researchers doing alignment research.
It’s worth noting that there is a lot of overlap between these sections. For instance, interpretability research is a great example of a robustly good approach, but it can also be done with a specific threat model in mind.
Throughout this section, we will also give small vignettes of organisations or initiatives which support AI alignment research in some form. This won’t be a full picture of all approaches or organisations, instead hopefully it will serve to sketch a picture of what work in AI alignment actually looks like.
Addressing threat models
We have a specific threat model in mind for how AGI might result in a very bad future for humanity, and focus our work on things we expect to help address the threat model.
A key high-level intuition here is that having a specific threat model in mind for how AI might go badly for humanity can help keep you focused on certain hard parts of the problem. One technique that can be useful here is a version of back-casting: we start from future problems with advanced AI systems in our current model, reason about what kinds of things might solve these problems, then try and build versions of these solutions today and test them out on current problems.
This can be seen in contrast to the approach of simply trying to fix current problems with AI systems, which might fail to connect up with the hardest parts of AI alignment.
Example 1: Superintelligent utility maximisers, and quantilizers
superintelligent artificial intelligence, making choices, digital art, artstation
The superintelligent utility maximiser is the oldest threat model studied by the AI alignment field. It was discussed at length by Nick Bostrom in his book Superintelligence. It assumes that we will create an AGI much more intelligent than humans, and that it will be trying to achieve some particular goal (measured by the expected value of some utility function). The problem with this is that attempts to maximise the value of some goal which isn’t perfectly aligned with what humans want can lead to some very bad outcomes. One formalism which was proposed to address this problem is Jessica Taylor’s quantilizers. It is quite maths-heavy so we won’t discuss all the details here, but the basic idea is that rather than using the expected utility maximisation framework for agents, we mix expected utility maximisation with human imitation in a clever way (to be more precise, you sample from a prior distribution which represents the actions a human would be likely to take in this scenario). The resulting agent wouldn’t take catastrophic actions because part of its decision-making comes from imitating what it thinks humans would do, but it would also be able to use the expected utility maximisation to go beyond human imitation, and do things we are incapable of (which is presumably the reason we would want to build it in the first place!). However, the drawback with theoretical approaches like this is that they often bake in too many assumptions or rely on too many variables to be useful in practice. In this case, how we define the set of reasonable actions a human might perform is an important unspecified part of this framework, and so more research is required to see if the quantiliszers framework can address these problems.
Example 2: Inner misalignment
robot jumping over boxes to collect a coin, videogame, digital art, artstation
We’ve discussed inner misalignment in a previous section. This concept was first explicitly named in a paper called Risks from Learned Optimisation in Advanced ML Systems, published in 2019. This paper defined the concept and suggested some conditions which might make it more likely to happen, but the truth is that a lot of this is still just conjecture, and there are many things we don’t yet know about how unlikely this kind of misalignment is, or what we can do about it. The CoinRun example discussed earlier (and the Objective Robustness paper) came from an independent research team in 2021. This study was the first known example of inner misalignment in an AI system, showing that it was at least a theoretical possibility. They also tested certain interpretability tools on the CoinRun agent, to see whether it was possible to discover when the agent had a goal different to the one intended by the programmers. For more on interpretability, see later sections.
Building safe AGI
Let’s make specific plans for how to actually build safe AGI, and then try to test, implement, and understand the limitations of these plans. The emphasis is on understanding how to build AGI safely, rather than trying to do it as fast as possible.
At some point we’re going to build an AGI. Companies are already racing to do it. We better make sure that there exist some blueprints for a safe AGI (and that they’re used) by the time we get to that point.
Example 1: Iterated Distillation and Amplification (IDA)
artists depection of a robot dreaming up multiple copies of itself, cascading tree, delegating, digital art, trending on artstation
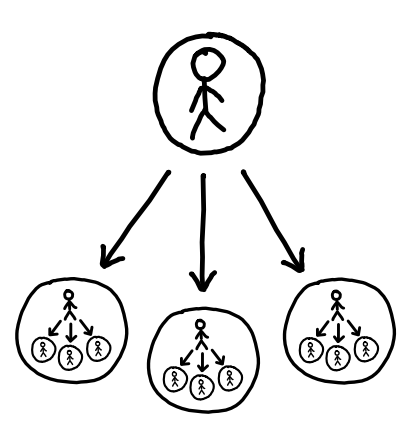
“Iterated Distillation and Amplification” (IDA) is an imposing name, but the core intuition is simple. One of the ways in which an individual human can achieve more things is by delegating tasks to others. In turn, the assistants that tasks are delegated to can be expected to become more competent at the task.
In IDA, an AI plays the role of the assistant. “Distillation” refers to the abilities of the human being “distilled” into the AI through training, and “amplification” refers to the human becoming more capable as they can call on more and more powerful AI assistants to help them.
A setup to train an IDA personal assistant might go like this:
You have a human, say Hannah, who knows how to carry out the tasks of a personal assistant.
You have an ML model - call it Martin - that starts out knowing very little (perhaps nothing at all, or perhaps it’s a pre-trained language model so it knows how to read and write English but not much else).
Hannah needs to find the answer to some questions, and she can invoke multiple copies of Martin to help her. Since Martin is quite useless at this stage, Hannah has to do even simple tasks herself, like writing routine emails. Using some interface legible to Martin, she breaks the email-writing task into subtasks like “find email address of Hu M. Anderson”, “select greeting”, “check project status”, “mention project status”, and so on.
From seeing enough examples of Hannah’s own answers to the sub-questions, Martin’s training loop gradually trains it to be able to answer first the simpler sub-tasks - (address is “humanderson@humanmail.com”, greeting is “Salutations, Human Colleague!”, etc.) and eventually all the sub-tasks involved in routine email-writing.
At this point, “write a routine email” becomes a task Martin can entirely carry out for Hannah. This is now a building block that can be used as a subtask in broader tasks Hannah gives out to Martin. Once enough tasks become tasks that Martin can carry out by itself, Hannah can draft much larger goals, like “invade France”, and let Martin take care of details like “blackmail Emmanuel Macron”, “write battle plan for the French Alps”, and “select a suitable coronation dress”.
Note some features of this process. First, Martin learns what it should do and how to do it at the same time. Second, both Hannah’s and Martin’s role changes throughout this process - Martin goes from bumbling idiot who can’t write an email greeting to competent assistant, while Hannah goes from being a demonstrator of simple tasks to a manager of Martin to ruler of France. Third, note the recursive nature here: Hannah breaks down big tasks into small ones to train Martin on successively bigger tasks.
In fact, assuming perfect training, IDA imitates a recursive structure. When Hannah has only bumbling fool Martin to help her, Martin can only learn to become as good as Hannah herself. But once Martin is that good, Hannah’s position is now essentially that of having herself, but also some number - say 3 - copies of Martin that are as good as herself. We might call this structure “Hannah Consulting Hannah & Hannah”; presumably, being able to consult an assistant that has the same skills as her lets Hannah become more effective, so this is an improvement. But now Hannah is demonstrating the behaviour of Hannah Consulting Hannah & Hannah, so from Hannah’s example Martin can now learn to be as good as Hannah Consulting Hannah & Hannah - making Hannah as good as Hannah Consulting (Hannah Consulting Hannah & Hannah) & (Hannah Consulting Hannah & Hannah). And so on:
If everything is perfect, therefore, IDA imitates a structure called “HCH”, which is a recursive acronym for “Humans Consulting HCH”. Others call it the “Infinite Bureaucracy [AF · GW]” (and fret about whether it’s actually a good idea).
Now “Infinite Bureaucracy” is not a name that screams “new sexy machine learning concept”. However, it’s interesting to think about what properties it might have. Imagine that you had, say, a 10-minute time limit to answer a complicated question, but you were allowed to consult three copies of yourself by passing a question off to them and getting back an answer immediately. These three copies also obeyed the same rules. Could you, for example, plan your career? Program an app? Write a novel?
It’s also interesting to think of the ways why the limitations of machine learning mean that IDA might not approximate HCH.
Example 2: AI safety via debate
artists depiction of two robots debating, digital art, trending on artstation
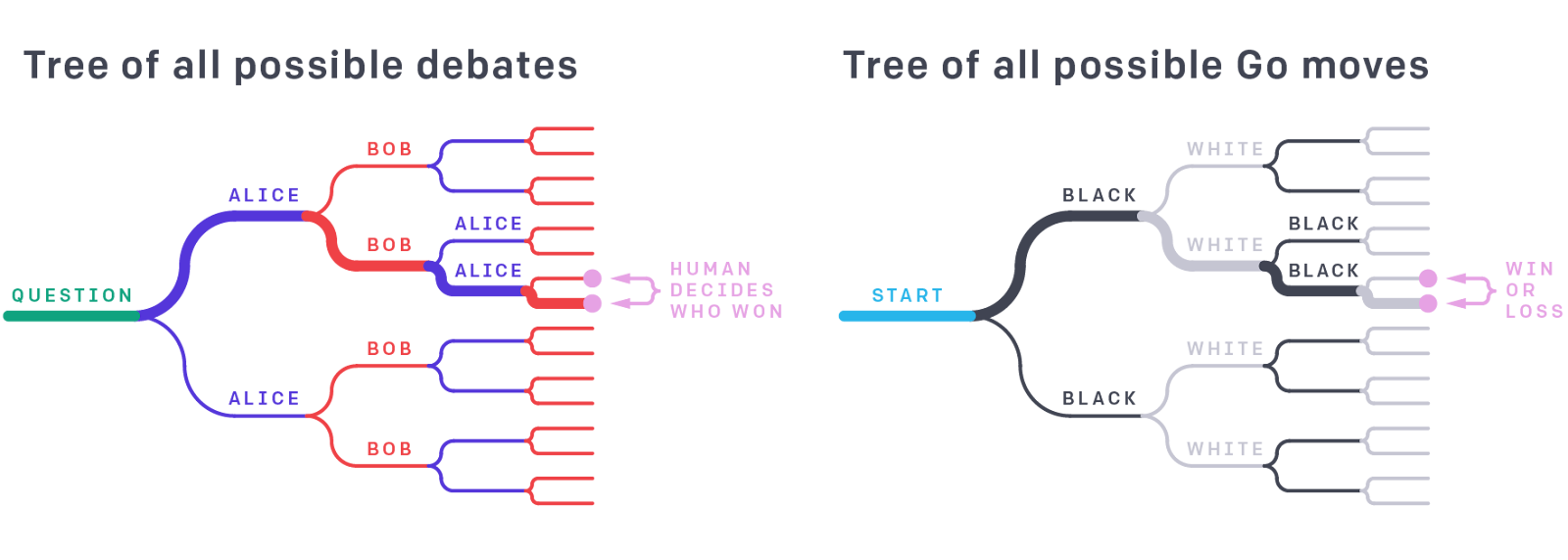
Imagine you’re a bit drunk, but (as one does) you’re at a bar talking about AI alignment proposals. Someone’s talking about how even if you can get an advanced AI system to explain its reasoning to you, it might try to slip something very subtle past you and you might not notice. You might well blurt out: “well then just make it fight another AI over it!”
The OpenAI safety team presumably spends a fair amount of time at bars, because they’ve investigated the idea of achieving safe AI by having two AIs debate each other to persuade a panel of human judges, by trying to poke holes in each other’s arguments. For more complex tasks, the AIs could be given transparency tools deriving from interpretability research (see next section) that they can use on each other. Just like a Go-playing AI gets an unambiguous win-loss signal from either winning or losing, a debating AI gets an unambiguous win-loss signal from winning or losing the debate:
In addition, having the type of AI that is trained to give answers that are maximally insightful and persuasive to humans seems like the type of thing that might not be terrible. Consider how in court, a prosecutor and defendant biased in opposite directions are generally assumed to converge on the truth. Unless, of course, maximising persuasiveness to humans - over accuracy or helpfulness - is exactly the type of thing that gets the worst parts of Goodhart’s law delivered to you by 24/7 Amazon Prime express delivery.
Example 3: Assistance Games and CIRL
Human teaching a robot with feedback, digital art, trending on artstation
Assistance Games are the name of a broad class of approaches pioneered by Stuart Russell, a prominent figure in AI and co-author of the best-known AI textbook in the world. Russell talks about his approach more in his book Human Compatible. In it, he summarises the key his approach to aligning AI with the following three principles:
The machine’s only objective is to maximise the realisation of human preferences.
The machine is initially uncertain about what those preferences are.
The ultimate source of information about human preferences is human behaviour.
The key component here is uncertainty about preferences. This is in contrast to what Russell calls the “standard model” of AI, where machines optimise a fixed objective supplied by humans. We have discussed in previous sections the problems with such a paradigm. A lot of Russell’s work focuses on changing the standard way the field thinks about AI.
To put these principles into action, Russell has designed what he calls assistance games. These are situations in which the machine and human interact, and the human’s actions are taken as evidence by the machine about the human’s true preferences. To explain the form of these games would involve a long tangent into game theory, which these margins are too short to contain. However, one thing worth noting is that assistance games have the potential to solve the “off-switch problem”; that a machine will try and take steps to prevent itself from being switched off (we described this as self-preservation earlier, in the section on instrumental goals). If the AI is uncertain about human goals, then the human trying to switch it off is evidence that the AI was going to do something wrong – in which case, it is happy to be switched off. However, this is far from a complete agenda, and formalising it has many roadblocks to get past. For instance, the question of how exactly to infer human preferences from human behaviour leads into thorny philosophical issues such as Gricean semantics. In cases where the AI makes incorrect inferences about human preferences, it might no longer allow itself to be shut down. See this Alignment Newsletter entry for a summary of Russell’s book, which provides some more details as well as an overview of relevant papers.
Vignette: CHAI
CHAI (the Centre for Human-Compatible AI) is a research lab at UC Berkeley, run by Stuart Russell. Compared to most other AI safety organisations, they engage a lot with the academic community, and have produced a great deal of research over the years. They are best-known for their work on CIRL (Cooperative Inverse Reinforcement Learning), which can be seen as a specific approach to a certain kind of assistance game. However, they have a very broad focus which also includes work on multi-agent scenarios (when rather than a single AI and single human, there exists more than one AI or more than one human - see the ARCHES agenda for more on this).
Example 4: Reinforcement learning from human feedback (RLHF)
Training a robot to do a backflip, digital art, trending on artstation
Reinforcement learning (RL) is one of the main branches of ML, focusing on the case where the job of the ML model is to act in some environment and maximise the probability of reward. Reinforcement learning from human feedback (RLHF) means that the ML model’s reward signal comes (at least partly) from humans giving it feedback directly, rather than humans programming in an automatic reward function and calling it a day.
The famous initial success in this was DeepMind training an ML model in a simulated environment to do a backflip (link includes GIF) in 2017, based purely on it repeatedly doing two backflips and then humans labelling one of them as the better one. Note how relying on human feedback makes this task much more robust to specification gaming; in other cases, humans have tried to get ML agents to run fast, only to find that they learn to become very tall and then fall forward (achieving a very high average speed, using the definition of speed as the rate at which their centre of mass moves - paper, video). However, human reward signals can be fooled. For example, one ML model that was being trained to grab a ball with a hand learned to place the hand between the camera and the ball in such a way that it looked to the human evaluators as if it were holding the ball.
In the long-run AGI will clearly be important, but we're highly uncertain about how we'll get there and what, exactly, could go wrong. So let's do work that seems good in many possible scenarios, and doesn’t rely on having a specific story in mind.
Example 1: Interpretability
A person using a microscope to look inside a robot, digital art, trending on artstation
If you look at fundamental problems with current ML systems, #1 is probably something like this: in general we don’t have any idea what an ML model is doing, because it’s multiplying massive inscrutable matrices of floating-point numbers with other massive inscrutable matrices of floating point numbers, and it’s pretty hard to stare at that and answer questions about what the model is actually doing. Is it thinking hard about whether an image is a cat or a dog? Is it counting up electric sheep? Is it daydreaming about the AI revolution? Who knows!
If you had to figure out an answer to such a question today, your best bet might be to call Chris Olah. Chris Olah has been spearheading work into trying to interpret what neural networks are doing. A signature output of Chris Olah’s work is pictures of creepy dogs like this one:
What’s significant about this picture is that it’s the answer to a question roughly like this: what image would maximise the activation of neuron #12345678 in a particular image-classifying neural network? (With some asterisks about needing to apply some maths details to the process to promote large-scale structure in the image to get nice-looking results, and with apologies to neuron #12345678, who I might have confused with another neuron.)
If neuron #12345678 is maximised by something that looks like a dog, it’s a fair guess that this neuron somehow encodes, or is involved in encoding, the concept of “dog” inside the neural network.
What’s especially interesting is that if you do this analysis for every neuron in an ML model - OpenAI Microscope lets you see the results - you sometimes get clear patterns of increasing abstraction. The activation-maximising images for the first few layers are simple patterns; in intermediate layers you get things like curves and shapes, and then at the end even recognisable things, like the dog above. This seems evidence for neural ML vision models having learned to build up abstractions step-by-step.
However, it’s not always simple. For example, there are “polysemantic” neurons that correspond to several different concepts, like this one that can be equally excited by cat faces, car fronts, and cat legs:
Olah’s original work on vision models is strikingly readable and well-presented; you can find it here.
Starting in late 2021, ML interpretability researchers have also made some progress in understanding transformers, which are the neural network architecture powering advanced language models like GPT-3, LAMDA and Codex. Unfortunately the work is less visual, particularly in the animal pictures department, but still well-presented. You can find it here.
In the most immediate sense, interpretability research is about reverse-engineering how exactly ML models do what they do. Hopefully, this will give insights into how to detect if an ML system is doing something we don’t like, and more general insights into how ML systems work in practice.
Chris Olah has some other inventive ideas about what to do with a sufficiently-good approach to ML interpretability. For example, he’s proposed the concept of “microscope AI”, which entails using AI as a tool to discover things about the world - not by having the AI tell us, but by training the ML system on some data, and then extracting insights about the data by digging into the internals of the ML system without necessarily ever actually running it.
robot which is merging with a panda, digital art, trending on artstation
Some modern ML systems are vulnerable to adversarial examples, where a small and seemingly innocuous change to an input causes a major change in the output behaviour. Here, we see two seemingly very similar images of a panda, except carefully-selected noise has made the ML classification model very confidently say that the image is of a gibbon:
Adversarial robustness is about making AI systems robust to attempts to make them do bad things, even when they’re presented with inputs carefully designed to try to make them mess up.
Redwood Research recently did a project (that resulted in a paper) about using language models to complete stories in a way where people don’t get injured. They used a technique called adversarial training, where they developed tools that helped generate examples where the current model did not classify them as injurious, and then trained their classifier specifically on those breaking examples. With this strategy they managed to reduce the fraction of injurious story completions from 2.4% to 0.003% - both small numbers, but one a thousand times smaller. Their hope is that this type of method can be applied to training AIs for high-stakes settings where reliability is important.
An example of a theoretical difficulty with adversarial training is that sometimes a failure in the model might exist, but it might be very hard to instantiate. For example, if an advanced AI acts according to the rule “if everything I see is consistent with the year being 2050, I will kill all humans”, and we assume that we can’t fool it well enough about what year it actually is, then adversarial training isn’t very useful. This leads to the concept of relaxed adversarial training, which is about extending adversarial training to cases where you can’t construct a specific adversarial input but you can argue that one exists. Evan Hubinger describes this here [AF · GW].
Vignette: Redwood Research
Like Anthropic, Redwood Research is an AI safety company focused on empirical research on ML systems. In addition to work on interpretability, they did the adversarial training project described in the previous section. Redwood has lots of interns, and runs the Machine Learning for Alignment Bootcamp (MLAB) that teaches people interested in AI safety about practical ML.
Example 3: Eliciting Latent Knowledge (ELK)
an oil painting of an armoured automaton standing guard next to a diamond
Eliciting Latent Knowledge (ELK) is an important sub-problem within alignment identified by the team at the Alignment Research Center (ARC), and is the single project ARC is currently pursuing. The core idea is that a common way advanced AI systems might go wrong is by taking action sequences that lead to outcomes that look good by some metric, but which humans would clearly identify as bad if they knew about it in sufficient detail. As a toy example, the ELK report discusses the case of an AI guarding a diamond in a vault by operating some complex machinery around it. Humans judge how well the AI is doing by looking at a video feed of the diamond in the vault. Let’s say the AI tries to trick us by placing a picture of the diamond in front of the camera. The human judgement on this would be positive - assume the humans can’t tell the diamond is gone because the picture is good enough - but there exists information which, if the humans knew, would change their judgement. Presumably the AI understands this, since it is likely reasoning about the diamond being gone but the humans being fooled anyway when it comes up with this plan. We want to train an AI in such a way that we can get out knowledge that the AI seems to know, even when it might be incentivised to hide it.
ARC’s goal is to find a theoretical approach that seems to solve the problem even given worst-case assumptions.
artificial intelligence which is thinking about a line on a graph, forecasting, digital art, trending on artstation
Many questions depend on how soon we’re going to get AGI. As the saying goes: prediction is very hard, especially about the future - and this is doubly true about predicting major technological changes.
One way to try to forecast AGI timelines is to ask experts [LW · GW], or find other ways of aggregating the opinion of people who have the knowledge or incentive to be right, as for example prediction markets do. Both of these are essentially just ways of tapping into the intuition of a bunch of people who hopefully have some idea.
In an attempt to bring in new light on the matter, Ajeya Cotra (a researcher at Open Philanthropy) wrote a long report [AF · GW] on trying to forecast AI milestones by trying out several ways of analogising AI to biological brains. The report is often referred to as “Biological Anchors”. For example, you might assume that an ML model that does as much computation as the human brain has a decent chance of being a human-level AI. There are many degrees of freedom here: is the relevant compute number the amount of compute the human brain uses to run versus the amount of compute it takes to run a trained ML system, or the total compute of a human brain over a human lifetime versus the compute required to train the ML model from scratch, or something else entirely? In her report, Cotra looks at a range of assumptions for this, and at predictions of future compute trends, and somewhat surprisingly finds that which set of assumptions you make doesn’t matter too much; every scenario involves >50% of human-level AI by 2100.
The Biological Anchors method is very imprecise. For one, it neglects algorithmic improvements. For another, it is very unclear what the right biological comparison point is, and how to translate ML-relevant variables like compute measured in FLOPS (FLoating point OPerations per Second) or parameter count into biological equivalents. However, the report does a good job of acknowledging and taking into account all this uncertainty in its models. More generally, anything that sheds light into the question of when we get AGI seems highly relevant.
Deconfusion
Reasoning about how to align AGI involves reasoning about complex concepts, such as intelligence, alignment and values, and we’re pretty confused about what these even mean. This means any work we do now is plausibly not helpful and definitely not reliable. As such, our priority should be doing conceptual work on how to think about these concepts and what we’re aiming for, and trying to become less confused.
Of all the categories under discussion here, deconfusion has maybe the least clear path to impact. It’s not immediately obvious how becoming less confused about concepts like these is going to translate into an improved ability to align AGIs.
Some kinds of deconfusion research is just about finding clearer ways of describing different parts of the alignment problem (Hubinger’s Risks From Learned Optimisation, where he first introduces the inner/outer alignment terminology, is a good example of this). But other types of research can dive heavily into mathematics and even philosophy, and be very difficult to understand.
Example 1: MIRI and Agent Foundations
robot sitting in front of a television, playing a videogame, digital art
The organisation most associated with this view is MIRI (the Machine Intelligence Research Institute). Its founder, Eliezer Yudkowsky, has written extensively on AI alignment and human rationality, as well as topics as wide-ranging as evolutionary psychology and quantum physics. His post The Rocket Alignment Problem tries to get across some of his intuitions behind MIRI’s research, in the form of an analogy – trying to build aligned AGI without having deeper understanding of concepts like intelligence and values is like trying to land a rocket on the moon by just pointing and shooting, without a working understanding of Newtonian mechanics.
Cryptography provides a different lens through which to view this kind of foundational research. Suppose you were trying to send secret messages to an ally, and to make sure nobody could intercept and read your messages you wanted a way to measure how much information was shared between the original and encrypted message. You might use correlation coefficient as a proxy for the shared information, but unfortunately having a correlation coefficient of zero between the original and encrypted message isn’t enough to guarantee safety. But if you find the concept of mutual information, then you’re done – ensuring zero mutual information between your original and encrypted message guarantees the adversary will be unable to read your message. In other words, only once you’ve found a “true name” - a robust formalisation of the intuitive concept you’re trying to express mathematically - can you be free from the effects of Goodhart’s law. Similarly, maybe if we get robust formulations of concepts like “agency” and “optimisation”, we would be able to inspect a trained system and tell whether it contained any misaligned inner optimisers (see the first post), and these inspection tools would work even in extreme circumstances (such as the AI becoming much smarter than us).
Much of MIRI’s research has come under the heading of embedded agency. This tackles issues that arise when we are considering agents which are part of the environments they operate in (as opposed to standard assumptions in fields like reinforcement learning, where the agent is viewed as separate from their environment). Four main subfields of this area of study are:
Decision theory (adapting classical decision theory to embedded agents)
Embedded world-models (how to form true beliefs about the a world in which you are embedded)
Robust delegation (understanding what trust relationships can exist between agents and its future - maybe far more intelligent - self)
Subsystem alignment (how to make sure an agent doesn’t spin up internal agents which have different goals)
Vignette: MIRI
MIRI is the oldest organisation in the AI alignment space. It used to be called the Singularity Institute, and had the goal of accelerating the development of AI. In 2005 they shifted focus towards trying to manage the risks from advanced AI. This has largely consisted of fundamental mathematical research of the type described above. MIRI might be better described as a confluence of smart people with backgrounds in highly technical fields (e.g. mathematics), working on different research agendas that share underlying philosophies and intuitions. They have a nondisclosure policy by default, which they explain in this announcement post from 2018.
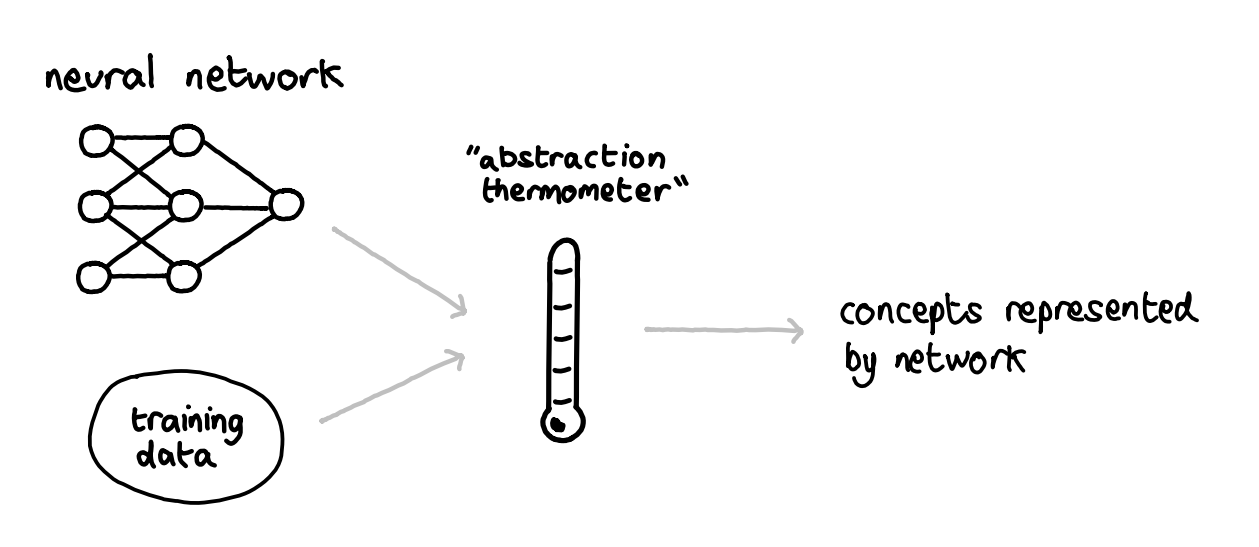
Example 2: John Wentworth and Natural Abstractions
thermometer being used to measure a robot, digital art, trending on artstation
John Wentworth is an independent researcher, who publishes most of his work on LessWrong [LW · GW] and the AI Alignment Forum [AF · GW]. His main research agenda focuses on the idea of Natural Abstractions [LW · GW], which can be described in terms of three sub-claims:
Abstractability Our physical world abstracts well, i.e. we can usually come up with simpler summaries (abstractions) for much more complicated systems (example: a gear is a very complex object containing a vast number of atoms, but we can summarise all relevant information about it in just one number - the angle of rotation).
Human-Compatibility These are the abstractions used by humans in day-to-day thought/language.
Convergence These abstractions are "natural", in the sense that we should expect a wide variety of intelligent agents to converge on using them.
The ideal outcome [LW · GW] of this line of research would be some kind of measurement device (an “abstraction thermometer”), which could take in a system like a trained neural network and spit out a representation of the abstractions represented by that system. In this way, you’d be able to get a better understanding of what the AI was actually doing. In particular, you might be able to identify inner alignment failures (the AI’s true goal not corresponding to the reward function it was being trained on), and you could retrain it while pointed at the intended goal. So far, this line of research has consisted of some fairly [AF · GW] dense [AF · GW] mathematics [AF · GW], but Wentworth has described [AF · GW] his plans to build on this with more empirical work (e.g. training neural networks on the same data, and using tools from calculus to try and compare the similarity of concepts learned by each of the networks).
AI governance
judging, presiding over a trial, sentencing a robot, digital art, artstation
In these posts, we’ve mainly focused on the technical side of the issue. This is important, especially for understanding why there is a problem in the first place. However, the management and reduction of AI risk obviously includes not just technical approaches like outlined in the above sections, but also the field of AI governance, which tries to understand and push for the right types of policies for advanced AI systems.
For example, the Cold War was made a lot more dangerous by the nuclear arms race. How do we avoid having an arms race in AI, either between nations or companies? More generally, how can we make sure that safety considerations are given appropriate weight by the teams building advanced AI systems? How do we make sure any technical solutions get implemented?
It’s also very hard to say what the impacts of AI will be, across a broad range of possible technical outcomes. If AI capabilities at some point advance very quickly from below human-level to far beyond the human-level, the way the future looks will likely mostly be determined by technical considerations about the AI system. However, if progress is slower, there will be a longer period of time where weird things are happening because of advanced AI - for example, significantly accelerated economic growth, or mass unemployment, or an AI-assisted boom in science - and these will have economic, social, and political ramifications that will play out in a world not too dissimilar from our own. Someone should be working on figuring out what these ramifications will be, especially if they might alter the balance of existential threats that civilisation faces; for example, if they make geopolitics less unstable and nuclear war more likely, or affect the environment in which even more powerful AI systems are developed.
The Centre for the Governance of AI, or GovAI for short, is an example of an organisation in this space.
Field-building
robot giving a lecture in a university, group of students, hands up, digital art, artstation
One of the most important ways we can make AI go well is by increasing the number of capable researchers doing alignment research.
As mentioned, AI safety is still a relatively young field. The case here is that we might do better to grow the field, and increase the quality of research it produces in the future. Some forms that field building can take are:
Setting up new ways for people to enter the field There are many to list here. To give a few different structures which exist for this purpose:
Reading groups and introductory programmes. Maybe the most exciting one from the last few years has been the Cambridge AGI Safety Fundamentals Programme, which has curricula for technical alignment and AI governance. The technical curriculum consists of 7 weeks of reading material and group discussions, and a final week of capstone projects where the participants try their hand at a project / investigation / writeup related to AI safety. Beyond this, many people are also setting up reading groups in their own universities for books like Human Compatible.
Ways of supporting independent researchers The AI Safety Camp is an organisation which matches applicants with mentors posing a specific research question, and is structured as a series of group research sprints. They have produced work such as the example of inner misalignment in the CoinRun game, which we discussed in a previous section. Other examples of organisations which support independent research include Conjecture [LW · GW], a recent alignment startup which does their own alignment research as well as providing a structure to host externally funded independent conceptual researchers, and FAR (the Fund for Alignment Research).
Coding bootcamps Since current systems are increasingly being bottlenecked by alignment and interpretability barriers rather than capabilities, in recent years more focus has been directed towards working with cutting-edge deep learning models. This requires strong coding skills and a good understanding of the relevant ML, which is why bootcamps and programmes specifically designed to skill up future alignment researchers have been created. Two such examples are MLAB [LW · GW] (the Machine Learning for Alignment Bootcamp, run by Redwood Research), and MLSS [EA · GW] (the Machine Learning Safety Scholars Programme, which is based on publicly available material as well as lectures produced by Dan Hendryks).
Distilling research In this post [AF · GW], John Wentworth makes the case for more distillation in AI alignment research - in other words, more people who focus on understanding and communicating the work of alignment researchers to others. This often takes the form of writing more accessible summaries of hard-to-interpret technical papers, and emphasising the key ideas.
Public outreach / better intro material For instance, books like Brian Christian’s The Alignment Problem, Stuart Russell’s Human Compatible and Nick Bostrom’s Superintelligence communicate AI risk to a wide audience. These books have been helpful for making the case for AI risks more mainstream. Note that there can be some overlap between this and distilling research (Rob Miles’ channel is another great example here).
Getting more of the academic community involved Since AI safety is a hard technical problem, and since misaligned systems generally won’t be as commercially useful as aligned ones, it makes sense to try and engage the broader field of machine learning. One great example of this is Dan Hendryks’ paper Unsolved Problems in ML Safety (which describes a list of problems in AI safety, with the ML community as the target audience). Stuart Russell has also engaged a lot with the ML community.
Note that this is certainly not a comprehensive overview of all current AI alignment proposals (a few more we haven’t had time to talk about are CAIS, Andrew Critch’s cooperation-and-coordination-failures framing for AI risks, and many others). However, we hope this has given you a brief overview of some of the different approaches taken by people in the field, as well as the motivations behind their research
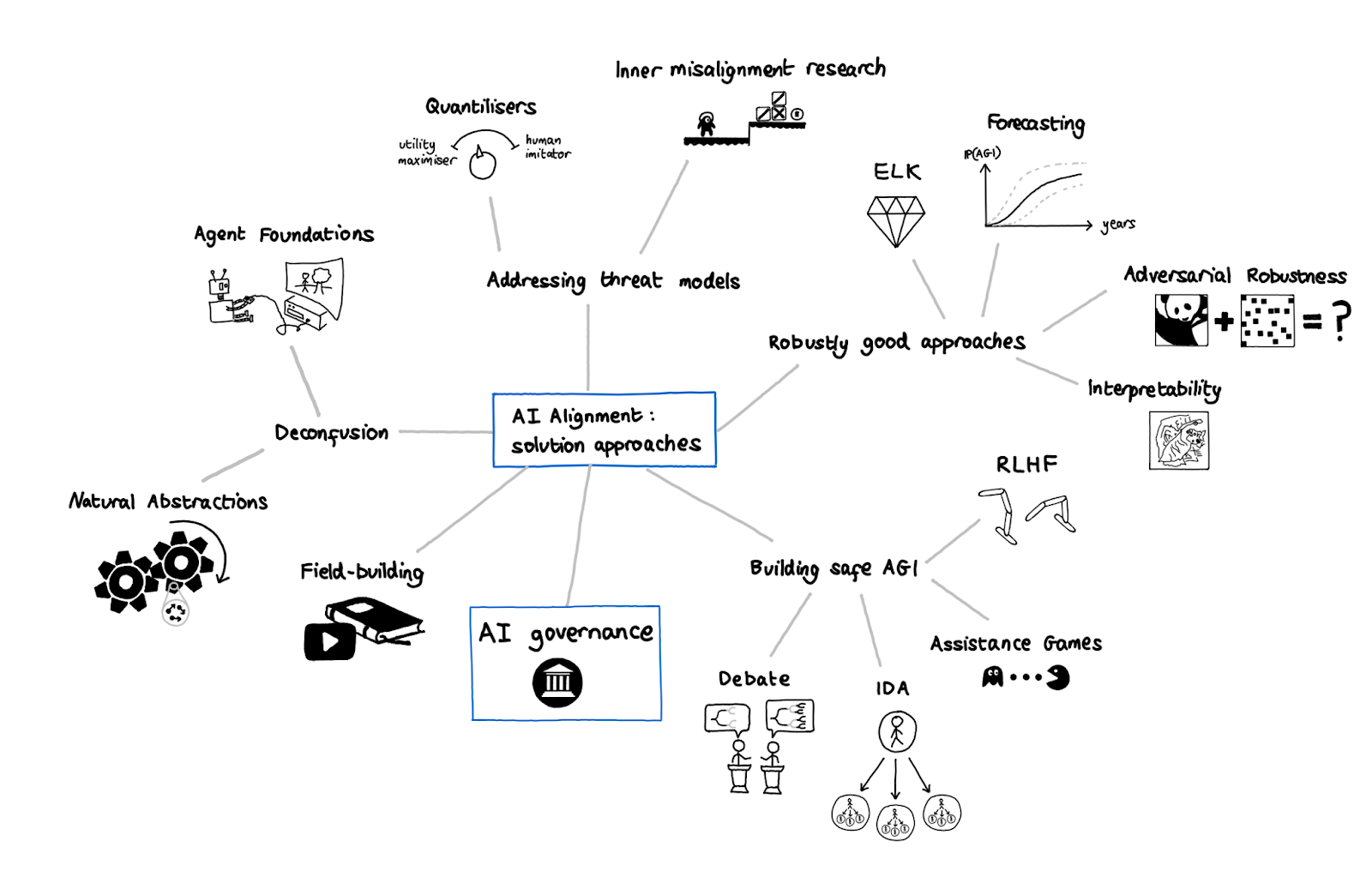
Map of the solution approaches we've discussed so far
Conclusion
people walking along a path which stretches off and disappears into a colorful galaxy filled with beautiful stars, digital art, trending on artstation
Advanced AI represents at least a technology that promises to have effects on the scale of the internet or computer revolutions, and perhaps even more likely to be more akin to the effects of the industrial revolution (which allowed for the automation of much manual labour) and the evolution of humans (the last time something significantly smarter than everything that had come before appeared on the planet).
It’s easy to invent technologies that the same could be said about - a magic wish-granting box! Wow! But unlike magic wish-granting boxes, something like advanced AI, or AGI, or transformative AI, or PASTA (Process for Automating Scientific and Technical Achievement) seems to be headed our way. The smart money is on it very likely coming this century, and quite likely in the first half.
If you look at the progress in modern machine learning, and especially the past few years of progress in so-called deep learning, it is hard not to feel a sense of rushing progress. The past few years of progress, in particular the success of the transformer architecture, should update us in the direction that intelligence might be a surprisingly easy problem. What is essentially fancy iterative statistical curve-fitting with a few hacks thrown in already manages to write fluent appropriate English text in response to questions, create paintings from a description, and carry out multi-step logical deduction in natural language. The fundamental problem that plagued AI progress for over half a century - getting fuzzy/intuitive/creative thinking into a machine, in addition to the sharp but brittle logic at which computers have long excelled - seems to have been cracked. There is a solid empirical pattern of predictably improving performance akin to Moore’s law - the “scaling laws” we mentioned in the first post - that we seem not to have hit the limits of yet. There are experts in the field who would not be surprised if the remaining insights for cracking human-level machine intelligence could fit into a few good papers.
This is not to say that AGI is definitely coming soon. The field might get stuck on some stumbling block for a decade, during which there will be no doubt much written about the failed promises and excess hype of the early-2020s deep learning revolution.
Finally, as we’ve argued, by default the arrival of advanced AI might plausibly lead to civilisation-wide catastrophe.
There are few things in the world that fit all of the following points:
A potentially transformative technology whose development would likely rank somewhere between the top events of the century and the top events in the history of life on Earth.
Something that is likely to happen in the coming decades.
Something that has a meaningful chance of being cataclysmically bad.
For those thinking about the longer-term picture, whatever the short-term ebb and flow of progress in the field is, AI and AI risk loom large when thinking about humanity’s future. The main ways in which this might stop being the case are:
There is a major flaw in the arguments for at least one of the above points. Since many of the arguments are abstract and not empirically falsifiable before it’s too late to matter, this is possible. However, note that there is a strong and recurring pattern of many people, including in particular many extremely-talented people, running into the arguments and taking them more and more seriously. (If you do have a strong argument against the importance of the AI alignment problem, there are many people - us included - who would be very eager to hear from you. Some of these people - us not included - would probably also pay you large amounts of money.)
We solve the technical AI alignment problem, and we solve the AI governance problem to a degree where the technical solutions will be implemented and it seems very unlikely that advanced AI systems will wreak havoc with society.
A catastrophic outcome for human civilisation, whether resulting from AI itself or something else.
The project of trying to make sure the development of advanced AI goes well is likely one of the most important things in the world to be working on (if you’re lost, the 80 000 Hours problem profile is a decent place to start). It might turn out to be easy - consider how many seemingly intractable scientific problems dissolved once someone had the right insight. But right now, at least, it seems like it might be a fiendishly difficult problem, especially if it continues to seem like the insights we need for alignment are very different from the insights we need to build advanced AI.
Most of the time, science and technology progress in whatever direction is easiest or flows most naturally from existing knowledge. Other times, reality throws down a gauntlet, and we must either overcome the challenge or fail. May the best in our species - our ingenuity, persistence, and coordination - rise up, and deliver us from peril.