The Natural Abstraction Hypothesis: Implications and Evidence
post by CallumMcDougall (TheMcDouglas) · 2021-12-14T23:14:24.825Z · LW · GW · 9 commentsContents
TL;DR Introduction What is an abstraction? What is the Natural Abstraction Hypothesis? Useful vs. Unique Clarifications Abstractions depend on your prior knowledge Definitions as proxies for the true abstraction Beyond human-level abstractions Why does this matter? Inner alignment Better understanding of abstractions Incentives for interpretability Alignment by default Evidence Value is complex and fragile Concepts vary between cultures Polysemantic neurons Texture bias CLIP Adversarial examples How to test it? John Wentworth's work Further interpretability research Neuroscience None 9 comments
This post was written under Evan Hubinger’s direct guidance and mentorship, as a part of the Stanford Existential Risks Institute ML Alignment Theory Scholars (MATS) program [LW · GW].
Additional thanks to Jamie Bernardi, Oly Sourbut and Shawn Hu, for their thoughts and feedback on this post.
TL;DR
The Natural Abstraction Hypothesis, proposed by John Wentworth, states that there exist abstractions (relatively low-dimensional summaries which capture information relevant for prediction) which are "natural" in the sense that we should expect a wide variety of cognitive systems to converge on using them.
If this hypothesis (which I will refer to as NAH) is true in a very strong sense, then it might be the case that we get "alignment by default", where an unsupervised learner finds a simple embedding of human values, and a supervised learner can be trained with access to this learned model. However, even if the NAH is true in a weaker sense, this has important implications, for areas such as:
- Deceptive alignment - since a natural abstraction will be easier for an objective to point at
- Instrumental convergence - since as I will discuss below, the formalisation for an abstraction resembles the idea of instrumental goals
- Interpretability - since the extent to which human-interpretable abstractions are also "natural" has direct implications for how much of a trade-off incentivising interpretability will be
Several different fields can provide evidence for & against different forms of the NAH, for instance:
- Studying the abstractions formed by different cultures can help us understand whether humans generally seem to converge on the same abstractions
- Current empirical study of neural networks, primarily in the context of interpretability research, can help us understand whether they are forming human-interpretable abstractions
Since the NAH is primarily an empirical claim about the kinds of abstractions we expect to see forming in the real world, I will conclude by discussing some promising ways the hypothesis could be tested. This will include John Wentworth's own research agenda (which involves a feedback loop of training cognitive models on systems that contain abstractions, and examining then proving theorems about which abstractions are learned by which agents in which environments), as well as two other potentially promising directions: further interpretability work, and neuroscience. A key theme here is that the extent to which the abstractions formed by AIs will converge to human abstractions will likely depend heavily on the extent to which their input data and knowledge matches our own.
Introduction
What is an abstraction?
An abstraction is a way of throwing away information from a model in such a way that we can still make reliable predictions about certain aspects of the underlying system.
To help motivate this, consider the picture below. We have some high-dimensional variable , and it might influence some other variable . However, most of the lower-level details about will be drowned out by noise , and so it won't directly impact . An abstraction can be seen as a function which captures all the information mediating interactions between and .

Note an important point about - it is a function of , not of . This is because a good abstraction should allow you to make predictions about the interactions not just between and some specific external object , but between and the rest of the universe. As an analogy, suppose an astronomer is trying to predict some specific part of the trajectory of some planet orbiting a star . He might choose to model as a point mass , because this captures all the information relevant about when determining 's trajectory. However, this point mass model will actually help you make a wide variety of predictions for all sorts of objects far away from , not just the planet .
Some more examples to motivate the general idea:
- Gears
A gear is a very high-dimensional complex object, but when we want to answer questions about how it will behave in a system & interact with the other components, we can distil it down to a one-dimensional summary: the angle of rotation . - Ohm's law
abstracts away all the details of molecule positions or wire shapes in an electronic circuit; all other low-level information is wiped out. With this model, we can still answer important high-level questions about the behaviour of the circuit under different conditions - Street maps
No map can be detailed enough to represent the full complexity of the territory, but maps can still be useful for navigation because they throw away irrelevant details. We can use maps to answer high-level questions like "what is the fastest route from to ?".
In general, we should expect that systems will employ natural abstractions in order to make good predictions, because they allow you to make good predictions without needing to keep track of a huge number of low-level variables .
What is the Natural Abstraction Hypothesis?
The NAH can be split into three sub-claims:
- Abstractability: our physical world abstracts well, i.e. the information that is relevant "far away" from the system is much lower-dimensional than the system itself.
- Human-Compatibility: these lower-dimensional summaries are the abstractions used by humans in day-to-day thought/language.
- Convergence: these abstractions are "natural", in the sense that we should expect a wide variety of cognitive architectures to converge on using them.
An important question naturally follows: what kinds of things are natural abstractions? Physical phenomena like trees seem to be natural (we have empirical evidence of neural networks developing simple embeddings of concepts like trees—sometimes even with a single neuron). But how about something like human values? It seems safe to say that "human" is a natural abstraction, and all the relevant information about human values is embedded in the object "humans". Wentworth thinks it is quite likely (~70%) that a broad class of systems (including neural networks) trained for predictive power will end up with a simple embedding of human values. However, for most of this piece I will not assume this claim to be true, because even without it I think that the NAH still has many important potential implications.
Useful vs. Unique
John Maxwell proposes differentiating between the unique abstraction hypothesis (there is one definitive natural abstraction which we expect humans and AIs to converge on), and the useful abstraction hypothesis (there is a finite space of natural abstractions which humans use for making predictions and inference, and in general this space is small enough that an AGI will have a good chance of finding abstractions that correspond to ours, if we have it "cast a wide enough net"). I will use this distinction several times in this writeup. Much of the analysis below will be relevant for one form of the hypothesis but not the other (for instance, if different cultures form different abstractions, this may be an argument against the unique abstraction hypothesis, but less so against the useful abstraction hypothesis).
Clarifications
Abstractions depend on your prior knowledge
Some fields are really complicated, and it's hard for humans to develop good abstractions. Quantum Mechanics is a great example - for a really long time, it was taught in the context of wave-particle duality, i.e. messily squashing two different models together, which is a terrible way to think about QM. Humans tend not to have good intuitions about QM because it doesn't form part of our subjective everyday experiences, so we don't have enough first-hand experimental data to form good intuitions about it. A Newtonian-Euclidean model of the world seems far more intuitive to us, because that's the part we actually experience.
To put it another way — the complexity of your abstractions depends on the depth of your prior knowledge. The NAH only says that AIs will develop abstractions similar to humans when they have similar priors, which may not always be the case.
Definitions as proxies for the true abstraction
One possible objection to the NAH is that definitions that humans give for things always seem to have some loopholes. It's really hard to explicitly draw a bounding box around a particular concept. This is because definitions normally point at fuzzy clusters in thingspace [? · GW]. But this isn't really a knock against the NAH, instead it's a result of humans being bad at defining things! The definition usually isn't the natural abstraction, it's just a poor proxy for it.
As an analogy, consider a Gaussian cluster. It's impossible to draw an explicit bounding box around this data such that every point will fall within the box, but the cluster can still be defined in a precise mathematical sense: you can fully describe its behaviour in relatively low-dimensional terms (i.e. with a mean and covariance).
Beyond human-level abstractions
The diagram below shows Chris Olah's interpretation of how interpretability is likely to change as the strength of a model increases.

As an example, linear regression might be in the "simple models" region, because it's very intuitive and empirically works well. As you scale up, you get models which are less interpretable because they lack the capacity to express the full concepts that they need, so they have to rely on confused abstractions. As the model's abstractions get closer to human level, they will become more interpretable again.
Different strengths of the NAH can be thought of as corresponding to different behaviours of this graph. If there is a bump at all, this would suggest some truth to the NAH, because it means (up to a certain level) models can become more powerful as their concepts more closely resemble human ones. A very strong form of the NAH would suggest this graph doesn't tail off at all in some cases, because human abstractions are the most natural, and anything more complicated won't provide much improvement. This seems quite unlikely—especially for tasks where humans have poor prior knowledge—but the tailing off problem could be addressed by using an amplified overseer, and incentivising interpretability during the training process. The extent to which NAH is true has implications for how easy this process is (for more on this point, see next section).
Why does this matter?
Inner alignment
The NAH has a lot to say about how likely a model is to be inner-aligned. If a strong form of the NAH is true, then (supposing the base objective is a natural abstraction) it's more likely the mesa optimiser will point at or some basically correct notion of , rather than some proxy which comes apart from in deployment. This means proxy pseudo-alignment is less likely.
However, it might make deceptive alignment more likely. There are arguments for why deceptive models might be favoured [AF · GW] in training processes like SGD—in particular, learning and modelling the training process (and thereby becoming deceptive) may be a more natural modification than internal or corrigible alignment. So if is a natural abstraction, this would make it easier to point to, and (since having a good model of the base objective is a sufficient condition for deception) the probability of deception is subsequently higher.
Better understanding of abstractions
The unique abstraction hypothesis suggests that reaching a better understanding of the abstractions our system is arriving at (and checking the extent to which it corresponds to a human one) is very important. One important application of this is to microscope AI, since getting value out of microscope AI is predicated on understanding the kinds of implicit knowledge that it has learned, and these are likely to rely heavily on the abstractions that it uses.
Instrumental convergence provides another reason why a better understanding of abstractions would be useful. Refer back to the formalisation for abstractions: an abstraction can be viewed as a function which takes some variable and returns a summary of the important information which mediates its interactions with the rest of the universe. If we want to make predictions about and anything that depends on , we only care about the summary information captured in . This very closely resembles the idea of instrumental convergence — if an agent cares instrumentally rather than intrinsically about , then it will only be interested in controlling .
As an intuitive example, Wentworth brings up StarCraft [? · GW]. Over long timeframes, the main thing that matters in the world state for a bot playing StarCraft is resources. This simplifies a very high-dimensional world to a low-dimensional parsimonious summary. The features of this low-dimensional world (resources) can be interpreted as instrumental goals because they help the agent achieve its objective of winning, and they can be interpreted as abstractions because they help us answer questions about "far away" objects (where in this case, "far away" should be interpreted as "in the future", not just as distance on a map). This abstractions-framing of instrumental convergence implies that getting better understanding of which abstractions are learned by which agents in which environments might help us better understand how an agent with instrumental goals might behave (since we might expect an agent will try to gain control over some variable only to the extent that it is controlling the features described by the abstraction which it has learned, which summarizes the information about the current state relevant to the far-future action space).
Incentives for interpretability
Recent interpretability research has made a lot of headway in understanding the concepts that neural networks are representing (more on this in the next section). However, it is currently highly uncertain whether methods for understanding individual neurons will scale well when our systems are much larger, or performing much more complex tasks than image recognition. One alternative approach is to incentivise our systems during training to form human-interpretable models.
If NAH is strongly true, then maybe incentivising interpretability during training is quite easy, just akin to a "nudge in the right direction". If NAH is not true, this could make incentivising interpretability really hard, and applying pressure away from natural abstractions and towards human-understandable ones will result in models Goodharting interpretability metrics—where a model is be emphasised to trick the metrics into thinking it is forming human-interpretable concepts when it actually isn't.
The less true NAH is, the harder this problem becomes. For instance, maybe human-interpretability and "naturalness" of abstractions are actually negatively correlated for some highly cognitively-demanding tasks, in which case the trade-off between these two will mean that our model will be pushed further towards Goodharting.
Alignment by default
If a strong form of this is true, then we should expect a wide variety of cognitive architectures to use approximately the same concepts as humans do. In the strongest possible case, we might be able to effectively solve the alignment problem via the following process:
- Having an unsupervised learning model learn some relatively simple embedding of human values
- Training a supervised learner with access to the unsupervised model (and hoping that the supervised learner makes use of this embedding)
A danger of this process is that the supervised learner would model the data-collection process instead of using the unsupervised model - this could lead to misalignment. But suppose we supplied data about human values which is noisy enough to make sure the supervised learner never switched to directly modelling the data-collection process, while still being a good enough proxy for human values that the supervised learner will actually use the unsupervised model in the first place.
I'm sceptical of this process working (Wentworth puts very low probability on it: 10-20%, even conditional on having an unsupervised model with a simple embedding of human values). One important reason this is likely to fail: if AI systems are capable of finding abstractions of human values, then they are also likely to be capable of finding abstractions of things like "what humans say about values", and the latter is likely to lead to better performance if your proxy of human values is based on what people say about them (i.e. if your training signal is based on human feedback). At any rate, it doesn't seem like the most important implication of the NAH, and I won't be focusing on it for most of this writeup.
Evidence
Value is complex and fragile
This is a view that has already been expounded in various [LW · GW] sources [AF · GW], and I won't repeat all of that here. The core point is this: human values are basically a bunch of randomly-generated heuristics which proved useful for genetic fitness, and it would be really surprising if they had some short, simple description. So it seems like our priors on them being a natural abstraction should be very low.
Two counterarguments to this are:
(1) The same "randomly-generated evolutionary heuristics" argument can be made for trees, and yet empirically trees do seem to be a natural abstraction. Furthermore, the concept of "tree" contains a great deal of information, which factors into subcomponents such as "branching patterns" which themselves seem to have relatively low-dimensional summaries. We can argue that human values are properties of the abstract object "humans", in an analogous way to branching patterns being properties of the abstract object "trees". However there are complications to this analogy: for instance, human values seem especially hard to infer from behaviour [LW · GW] without using the "inside view" that only humans have.
(2) As Katja Grace points out [AF · GW], the arguments for fragility of value are often based on the inability of manually specified descriptions to capture the richness of concepts, and as was discussed above , definitions are usually only a proxy for abstractions. Wentworth says that his first-pass check for "is this probably a natural abstraction?" is "can humans usually figure out what I'm talking about from a few examples, without a formal definition?", and in that sense human values seem to score somewhat better. There are still some problems here - we might be able to infer each others' values across small inferential distances where everybody shares cultural similarities, but values can differ widely across larger cultural gaps. More on this in the next section.
Concepts vary between cultures
One objection to the NAH is that different cultures seem to come up with different abstractions and concepts to describe the world. This idea is nicely summarised in the Sapir-Whorf hypothesis, which is the proposal that the particular language one speaks influences the way one thinks about reality. A clear example of this comes from the division between Eastern and Western concepts. For instance, in the book "The Geography of Thought", Richard Nesbitt suggests that "the distinction between the concepts of "human" and "animal" that arose in the West made it particularly hard to accept the concept of evolution". In contrast, the idea of evolution was more readily accepted in the east because "there was never an assumption that humans sat atop a chain of being and had somehow lost their animality". Not only do the West and East have many different concepts and categories without precise analogues, but at a meta level it seems that even the concept of categorisation seems much more natural in the West than the East.
The implications for the NAH are quite negative. Suppose you train one AI using English language data and one using Chinese language data, and they form different abstractions about the world. Which one is really "natural"?
We can extend this beyond just language. Language is just one example of a tool that informs the way different cultures see the world; there are many other times when people have developed different concepts as a result of having different available tools. Kaj Sotala gives the example of Polynesian sailors developing different concepts for navigation, to such an extent that modern sailors would have a hard time understanding how they are thinking about navigation (and vice-versa).
Recall that the NAH is a statement about the abstractions that will be found by a wide variety of cognitive structures. The distance between humans of different cultures in mind design space [LW · GW] is extremely small relative to the difference we might expect between human minds and AIs, so in a world where the NAH is true in a strong sense, we would be very unlikely to find cultures with such varying concepts and abstractions.
However, there are counterarguments to this line of reasoning. For one thing, we could still argue a strong form of the NAH by trying to show that not all cultures' abstractions are natural. It doesn't seem unreasonable to claim that some cultures might have chosen to use "unnatural abstractions" simply because of factors like random initial conditions. For instance, even if "human" is a natural abstraction, the fact that for most of human history we didn't have a concept for "evolution" meant that the ontological distinction drawn between "human" and "animal" wasn't natural.
For another, even if we accept that "which abstractions are natural?" is a function of factors like culture, this argues against the "unique abstraction hypothesis" but not the "useful abstraction hypothesis". We could argue that navigators throughout history were choosing from a discrete set of abstractions, with their choices determined by factors like available tools, objectives, knowledge, or cultural beliefs, but the set of abstractions itself being a function of the environment, not the navigators.
Polysemantic neurons
We now move into discussing current interpretability research. Empirically, some neurons seem to recognise multiple different concepts (e.g. the one below recognises cats' faces, front of cars, and spiders' legs). Cats, cars and spiders all seem like natural abstractions to us, but here we have empirical evidence that neural networks are failing to distinguish between them. This is evidence of a cognitive system not reaching the same abstraction as humans, hence it could be interpreted as evidence against the NAH.

The strongest counterargument to this is that the existence of polysemantic neurons can be interpreted as an instance of the "valley of confused abstractions". For instance, one explanation for them is that neural networks are trying to represent too many features (since the space of human concepts that can exist in an image is huge), and hence some have been "folded over themselves". By using larger networks or employing other tricks, we might be able to "unfold" these features. Another argument is that individual neuron analysis is fundamentally the wrong way to think about interpreting neural networks—instead, we will have to develop new paradigms to understand the concepts that neural networks are learning (e.g. thinking about interactions between neurons). This makes the task of interpretability much harder, and hence makes it harder to gather evidence on the extent to which NAH is true, but it doesn't say much about how likely it is to be true. Overall, I don't think the existence of polysemantic neurons is a strong objection to any form of the NAH.
Texture bias
This is another case in which AIs clearly seem to be learning a different abstraction to humans. In the paper ImageNet-trained CNNs are biased towards texture, the authors observe that the features CNNs use when classifying images lean more towards texture, and away from shape (which seems much more natural and intuitive to humans).
However, this also feels like a feature of the "valley of confused abstractions". Humans didn't evolve based on individual snapshots of reality, we evolved with moving pictures as input data. If a human in the ancestral environment, when faced with a tiger leaping out of the bushes, decided to analyse its fur patterns rather than register the large orange shape moving straight for them, it's unlikely they would have returned from their first hunting trip. When we see a 2D image, we naturally "fill in the gaps", and create a 3D model of it in our heads, but current image classifiers don't do this, they just take a snapshot. For reasons of architectural bias, they are more likely to identify the abstraction of texture than the arguably far more natural abstraction of shape. Accordingly, we might expect video-based models to be more likely to recognise shapes than image-based models, and hence be more robust to this failure mode.
Note, this isn't the same point as "abstractions are arbitrary because they're a function of the type of input data we receive" (which I previously discussed in the context of cultures having different concepts). The point here is specifically that the way humans experience and interact with the world is strictly more complicated than 2D images. 3D images supply situational context that is relevant for making high-level predictions, and if AI systems don't have access to this same data, we shouldn't expect them to form natural abstractions that match with human ones.
CLIP
The last two examples have both concerned image classification (which is the current setting for most work on interpretability and adversarial training). A question naturally arises: how does this generalise to different forms of input data? This is important, because as previously discussed, the abstractions formed are likely to vary depending on the type of input data the system has available to it (although if the NAH is true, then we should expect this variation to be limited, because a natural abstraction will summarise all the information which is relevant for forming high-level models and making predictions, and we should expect this information to be present across different information channels).
One important example of moving beyond recognising purely image-based concepts is CLIP - the neural circuit designed by OpenAI which connects text and images. Individual neurons have been isolated in CLIP which respond not just to images of a particular concept but also to text. For instance, a neuron was isolated which responds to photos and sketches of Spiderman, as well as to the text "spider". These seem to correspond to the way humans recognise and group concepts, e.g. it has a striking similarity to the so-called "Halle Berry neuron".
In general, we should expect that some interpretability techniques from image classification will transfer well to other settings like language models. There are some hurdles (for instance language is discrete rather than continuous), but none of the problems seem insurmountable.
Overall, it seems that the evidence supplied by CLIP supports at least a weak form of the NAH, because it shows that the highest layers of neural networks can form abstractions by "organising images as a loose semantic collection of ideas", in a way that tracks very closely with human abstractions.
Adversarial examples
Adversarial examples have been controversial in the field of ML for a long time, and they've attracted different interpretations. One interpretation has been to just treat them as mistakes which the system wouldn't be making if it were "smarter" - in line with the "valley of confused abstractions" in Chris Olah's graph.
The paper Adversarial Examples Are Not Bugs, They Are Features gives a different, somewhat more pessimistic picture. To simplify the formalism used in the paper, they define a "useful feature" as one which is correlated in expectation with the true label, and a "robustly useful feature" as one which is still correlated in expectation over some set of perturbations of the input data. The results of the studies described in the paper were that you can use input data which has been processed so as to consist only of non-robust features (i.e. ones prone to adversarial attacks, and which don't tend to correspond to any features intuitive to humans) to train a model to exhibit good performance on a test set. Additionally, this dataset of non-robust features could transfer to models with different architectures, and still lead to good test set performance.
In the paper's conclusion, the author suggests we should "view adversarial examples as a fundamentally human phenomenon", we shouldn't expect the concepts used in image classification which seem natural to humans to be shared by different model architectures. On the surface this seems like a blow to the NAH, however I don't believe it actually presents a significant challenge to it. The paper introduces a theoretical framework for studying robust and non-robust features near the end of the paper (see image below). The blue and red areas represent clusters with corresponding to different labels in the data, and the axes are continuous features across which the members of the clusters vary. Consider the left image. The problem here is that the perpendicular distance between the centre of the cluster and the decision boundary is very small—in other words, you don't need a large permutation to misclassify the image. The second and third images show the results of including adversarial examples in the input data: these decision boundaries look more natural, and importantly it is closer to being perpendicular to the vector between the means.
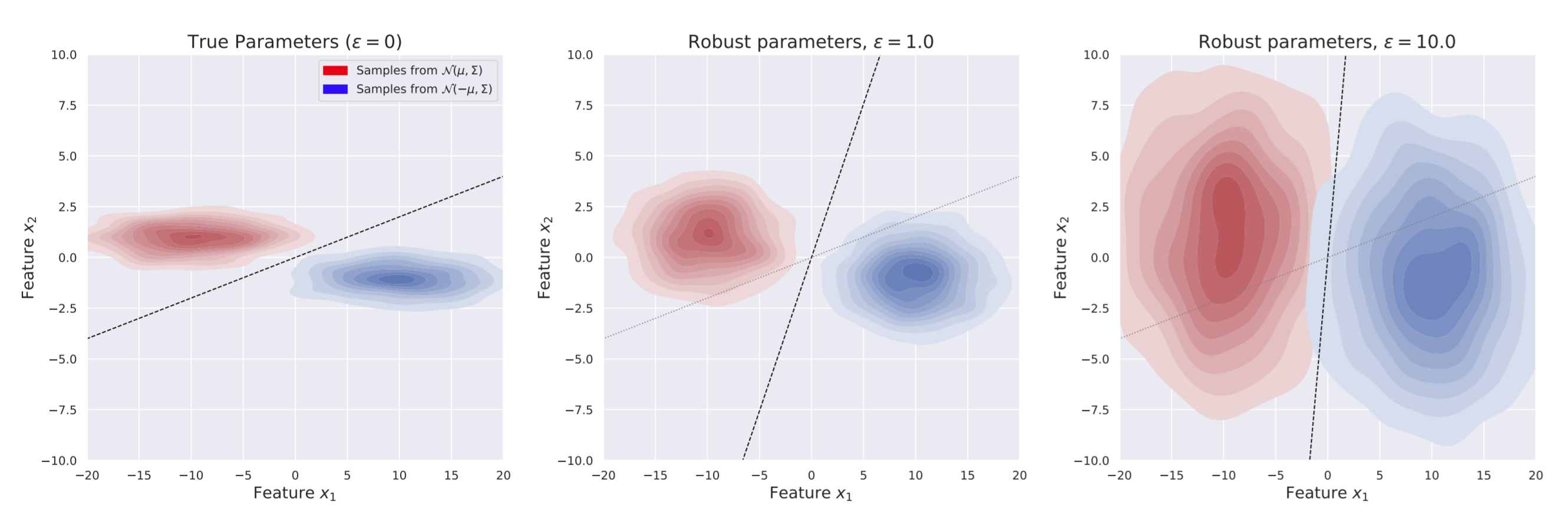
Note that we're not saying data can always be neatly separated into one of these two groups — as discussed in the earlier section Definitions as proxies for the true abstraction, you generally can't draw bounding boxes around clusters in thingspace. The core problem is that the geometry of the input data causes the decision boundary to misidentify the human-meaningful dimensions along which two concepts differ. I believe this falls under the heading of "valley of confused abstractions", although it does so for a different reason than we have so far discussed: due to the input data rather than any weakness or specific architectural bias of the classifier.
However, this paper does raise a very important point. In the conclusion, the author also states that "attaining models that are robust and interpretable will require explicitly encoding human priors into the training process". I strongly agree with this statement, because the problem this paper identifies doesn't seem completely surmountable by just scaling up the amount of input data supplied to our models. The key problem isn't how much data exists, but what kinds of data exist, and the fact that innumerable concepts simply aren't expressed in the available data [LW · GW]. One potential solution to this problem would be providing incentives for interpretability, which I have discussed above.
How to test it?
John Wentworth's work
In the post Testing The Natural Abstraction Hypothesis: Project Intro [LW · GW], Wentworth describes his methodology for going about testing the NAH as a feedback loop between empirical and theoretical work, consisting of the following process:
- Find algorithms capable of directly computing the abstractions in a system;
- Repeat the following:
- train cognitive models on these systems;
- empirically identify patterns in which abstractions are learned by which agents in which environments;
- prove theorems about the above patterns, and design more experiments to probe the cases not handled by these theorems.
He describes the ideal outcome of the project as an “abstraction thermometer”: a generalisable tool that can identify and represent the abstractions in a given environment. This tool could then be applied to measure real-world abstraction, and thereby test the NAH (since the NAH is at its core an empirical claim about the world).
For information on the results of this work, see Wentworth's posts: both Project Intro [LW · GW] and Project Update [LW · GW].
Further interpretability research
Many of the examples in the previous section drew on current interpretability work. There are quite strong divisions of opinion in the interpretability field, e.g. over whether individual neuron-based analysis is the right way of thinking about interpretability [AF · GW], or how likely it is to scale well. One good thing about these questions is that they're grounded in how we expect current neural networks to behave, which makes them amenable to testing. Indeed, Chris Olah's framing of interpretability is one of empirical study, where we can propose hypotheses and carry out experiments.
In general, more interpretability work seems likely to clear up questions such as "are current image classifiers in the valley of confused abstractions?", and "do adversarial examples represent a shortcoming of our models or a deeper failure of human concepts to be natural?" This may in turn have important implications for the NAH.
In particular, I believe that extending interpretability work beyond the usual setting of image classification is likely to be very important, because the closer our input data is to matching the complexity of what humans actually experience, the more we should expect the abstractions formed by AI to line up with our own abstractions, and hence it will be much easier to falsify the NAH if it turns out not to be true (or is only true in a weak sense). It's also possible that we'll need to expand our notion of "adversarial examples" (which currently usually refer to $l_p$-norm constrained perturbations or something similar, and hence can only attack a model in a local context rather than a global one).
Neuroscience
One other idea is to focus not just on the AI's concepts and abstractions, but on the relationship between those of the AI and the human. Specifically, there might be a way to use neuroimaging techniques to look for correspondences between the human and AI's internal representation of concepts. For instance, we could look at the activation levels in a human brain when a person is thinking about a particular concept, and compare them to the activation of neurons in some neural network. This could allow us to directly compare the concepts being used by humans and AIs.
This idea is interesting because it's very different to the other methods listed here. It could also inform other areas of interpretability research, e.g. by helping us design better tools to incentivise correspondence between AI and human concepts.
However, there are a few reasons why this might be tricky in practice. Probably the biggest problem with this proposal is that biological networks are much harder to study than artificial ones. It's very easy to look inside neural networks and see which areas are being activated more strongly than others, but this is much harder and messier with humans. We certainly can't isolate activations in humans down to the individual neuron level—and even if we could, it's very possible that this is the wrong way to think about human cognition, in the same way that individual neuron analysis might be the wrong way to think about the concepts represented by a neural network.
- Obviously the point mass abstraction won't always be sufficient for every possible query. If you want to know things like if/when the star will go supernova, or what it will look like when humans see it through their telescopes, you may need more information, such as chemical composition. The only map that faithfully captures all the information about a territory is the territory itself. This does complicate the concept of abstractions somewhat. For more on the mathematical formalisation behind abstractions, see here [AF · GW].
- In some situations, we would expect interpretability to certainly decay without the use of some kind of amplification. For instance, QM as described above: if humans lack intuitions or experimental data for QM, then AIs will certainly be able to develop abstractions that are beyond our (unaided) ability to interpret.
- For more discussion of using neuroscience to compare human and AI concepts, see Kaj Sotala's post [? · GW].
9 comments
Comments sorted by top scores.
comment by Christopher Olah (christopher-olah) · 2022-02-20T20:44:23.136Z · LW(p) · GW(p)
I just stumbled on this post and wanted to note that very closely related ideas are sometimes discussed in interpretability under the names "universality" or "convergent learning": https://distill.pub/2020/circuits/zoom-in/#claim-3
In fact, not only do the same features form across different neural networks, but we actually observe the same circuits as well (eg. https://distill.pub/2020/circuits/frequency-edges/#universality ).
Replies from: nathan-helm-burger↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2022-05-26T04:42:50.648Z · LW(p) · GW(p)
some more relevant discussion here on abstraction in ML: https://www.deepmind.com/publications/abstraction-for-deep-reinforcement-learning
comment by johnswentworth · 2021-12-14T23:57:27.830Z · LW(p) · GW(p)
General Thoughts
Solid piece!
One theme I notice throughout the "evidence" section is that it's mostly starting from arguments that the NAH might not be true, then counterarguments, and sometimes counter-counterarguments. I didn't see as much in the way of positive reasons we would expect the NAH to be true, as opposed to negative reasons (i.e. counterarguments to arguments against NAH). Obviously I have some thoughts on that topic, but I'd be curious to hear yours.
Particulars
Wentworth thinks it is quite likely (~70%) that a broad class of systems (including neural networks) trained for predictive power will end up with a simple embedding of human values.
Subtle point: I believe the claim you're drawing from was that it's highly likely that the inputs to human values (i.e. the "things humans care about") are natural abstractions. (~70% was for that plus NAH; today I'd assign at least 85%.) Whether "human values" are a natural abstraction in their own right is, under my current understanding, more uncertain.
The NAH only says that AIs will develop abstractions similar to humans when they have similar priors, which may not always be the case.
There's a technical sense in which this is true, but it's one of those things where the data should completely swamp the effect of the prior for an extremely wide range of priors.
There are still some problems here - we might be able to infer each others' values across small inferential distances where everybody shares cultural similarities, but values can differ widely across larger cultural gaps.
This is the main kind of argument which makes me think human values are not a natural abstraction.
We could argue that navigators throughout history were choosing from a discrete set of abstractions, with their choices determined by factors like available tools, objectives, knowledge, or cultural beliefs, but the set of abstractions itself being a function of the environment, not the navigators.
The dependence of abstractions on data makes it clear that something like this is necessary. For instance, a culture which has never encountered snow will probably not have a concept of it; snow is not a natural abstraction of their data. On the other hand, if you take such people and put them somewhere snowy, they will immediately recognize snow as "a thing"; snow is still the kind-of-thing which humans recognize as an abstraction.
I expect this to carry over to AI to a large extent: even when AIs are using concepts not currently familiar to humans, they'll still be the kinds-of-concepts which a human is capable of using. (At least until you get to really huge hardware, where the AI can use enough hardware brute-force to handle abstractions which literally can't fit in a human brain.)
In the paper ImageNet-trained CNNs are biased towards texture, the authors observe that the features CNNs use when classifying images lean more towards texture, and away from shape (which seems much more natural and intuitive to humans).
However, this also feels like a feature of the "valley of confused abstractions". Humans didn't evolve based on individual snapshots of reality, we evolved with moving pictures as input data.
Also the "C" part of "CNN" is especially relevant here; we'd expect convolutional techniques to bias toward repeating patterns (like texture) in general.
Replies from: TheMcDouglas↑ comment by CallumMcDougall (TheMcDouglas) · 2021-12-16T23:24:29.700Z · LW(p) · GW(p)
Thanks for the comment!
Subtle point: I believe the claim you're drawing from was that it's highly likely that the inputs to human values (i.e. the "things humans care about") are natural abstractions.
To check that I understand the distinction between those two: inputs to human values are features of the environment around which our values are based. For example, the concept of liberty might be an important input to human values because the freedom to exercise your own will is a natural thing we would expect humans to want, whereas humans can differ greatly in things like (1) metaethics [LW · GW] about why liberty matters, (2) the extent to which liberty should be traded off with other values, if indeed it can be traded off at all. People might disagree about interpretations of these concepts (especially different cultures), but in a world where these weren't natural abstractions, we might expect disagreement in the first place to be extremely hard because the discussants aren't even operating on the same wavelength, i.e. they don't really have a set of shared concepts to structure their disagreements around.
One theme I notice throughout the "evidence" section is that it's mostly starting from arguments that the NAH might not be true, then counterarguments, and sometimes counter-counterarguments.
Yeah, that's a good point. I think partly that's because my thinking about the NAH basically starts with "the inside view seems to support it, in the sense that the abstractions that I use seem natural to me", and so from there I start thinking about whether this is a situation in which the inside view should be trusted, which leads to considering the validity of arguments against it (i.e. "am I just anthropomorphising?").
However, to give a few specific reasons I think it seems plausible that don't just rely on the inside view:
- Humans were partly selected for their ability to act in the world to improve their situations. Since abstractions are all about finding good high-level models that describe things you might care about and how they interact with the rest of the world, it seems like there should have been a competitive pressure for humans to find good abstractions. This argument doesn't feel very contingent on the specifics human cognition or what our simplicity priors are; rather the abstractions should be a function of the environment (hence convergence to the same abstractions by other cognitive systems which are also under competition, e.g. in the form of computational efficiency requirements, seems intuitive)
- There's lots of empirical evidence that seems to support it, at least at a weak level (e.g. CLIP as discussed in my post, or GPT-3 as mentioned by Rohin in his summary for the newsletter)
- Returning to the clarification you made about inputs to human values being the natural abstraction rather than the actual values, it seems like the fact that different cultures can have a shared basis for disagreement might support some form of the NAH rather than arguing against it? I guess that point has a few caveats though, e.g. (1) all cultures have been shaped significantly by global factors like European imperialism, and (2) humans are all very close together in mind design space so we'd expect something like this anyway, natural abstraction or not
comment by adamShimi · 2022-01-13T19:47:58.369Z · LW(p) · GW(p)
Thanks for the post! Two general points I want to make before going into more general comments:
- I liked the section on concepts difference across, and hadn't thought much about it before, so thanks!
- One big aspect of the natural abstraction hypothesis that you missed IMO is "how do you draw the boundaries around abstractions?" — more formally how do you draw the markov blanket. This to me is the most important question to answer for settling the NAH, and John's recent work on sequences of markov blanket is IMO him trying to settle this.
In general, we should expect that systems will employ natural abstractions in order to make good predictions, because they allow you to make good predictions without needing to keep track of a huge number of low-level variables .
Don't you mean "abstractions" instead of "natural abstractions"?
John Maxwell proposes differentiating between the unique abstraction hypothesis (there is one definitive natural abstraction which we expect humans and AIs to converge on), and the useful abstraction hypothesis (there is a finite space of natural abstractions which humans use for making predictions and inference, and in general this space is small enough that an AGI will have a good chance of finding abstractions that correspond to ours, if we have it "cast a wide enough net").
Note that both can be reconciled by saying that the abstraction in John's sense (the high-level summary statistics that capture everything that isn't whipped away by noise) is unique up to isomorphism (because it's a summary statistics), but different predictors will learn different parts of this abstraction depending on the information that they don't care about (things they don't have sensor for, for example). Hence you have a unique natural abstraction, which generates a constrained space of subabstractions which are the ones actually learned by real world predictors.
This might be relevant for your follow-up arguments.
To put it another way — the complexity of your abstractions depends on the depth of your prior knowledge. The NAH only says that AIs will develop abstractions similar to humans when they have similar priors, which may not always be the case.
Or another interpretation, following my model above, is that with more knowledge and more data and more time taken, you get closer and closer to the natural abstraction, but you don't generally start up there. Although that would mean that the refinement of abstractions towards the natural abstraction often breaks the abstraction, which sounds fitting with the course of science and modelling in general.
Different strengths of the NAH can be thought of as corresponding to different behaviours of this graph. If there is a bump at all, this would suggest some truth to the NAH, because it means (up to a certain level) models can become more powerful as their concepts more closely resemble human ones. A very strong form of the NAH would suggest this graph doesn't tail off at all in some cases, because human abstractions are the most natural, and anything more complicated won't provide much improvement. This seems quite unlikely—especially for tasks where humans have poor prior knowledge—but the tailing off problem could be addressed by using an amplified overseer, and incentivising interpretability during the training process. The extent to which NAH is true has implications for how easy this process is (for more on this point, see next section).
Following my model above, one interpretation is that the bump means that when reaching human-level of competence, the most powerful abstractions available as approximations of the natural abstractions are the ones humans are using. Which is not completely ridiculous, if you expect that AIs for "human-level competence at human tasks" would have similar knowledge, inputs and data than humans.
The later fall towards alien concepts might come from the approximation shifting to very different abstractions as the best approximation, just like the shift between classical physics and quantum mechanics.
However, it might make deceptive alignment more likely. There are arguments for why deceptive models might be favoured [AF · GW] in training processes like SGD—in particular, learning and modelling the training process (and thereby becoming deceptive) may be a more natural modification than internal or corrigible alignment. So if is a natural abstraction, this would make it easier to point to, and (since having a good model of the base objective is a sufficient condition for deception) the probability of deception is subsequently higher.
Here is my understanding of your argument: because X is a natural abstraction and NAH is true, models will end up actually understanding X, which is a condition for the apparition of mesa-optimization. Thus NAH might make deception more likely by making one of its necessary condition more likely. Is that a good description of what you propose?
I would assume that NAH actually makes deception less likely, because of the reasons you gave above about the better proxy, which might entail that the mesa-objective is actually the base-objective.
This abstractions-framing of instrumental convergence implies that getting better understanding of which abstractions are learned by which agents in which environments might help us better understand how an agent with instrumental goals might behave (since we might expect an agent will try to gain control over some variable only to the extent that it is controlling the features described by the abstraction which it has learned, which summarizes the information about the current state relevant to the far-future action space).
Here too I feel that the model of "any abstraction is an approximation of the natural abstraction" might be relevant. Especially because if it's correct, then in addition to knowing the natural abstraction, you have to understand which part of it could the model approximate, and which parts of that approximations are relevant for its goal.
If NAH is strongly true, then maybe incentivising interpretability during training is quite easy, just akin to a "nudge in the right direction". If NAH is not true, this could make incentivising interpretability really hard, and applying pressure away from natural abstractions and towards human-understandable ones will result in models Goodharting interpretability metrics—where a model is be emphasised to trick the metrics into thinking it is forming human-interpretable concepts when it actually isn't.
The less true NAH is, the harder this problem becomes. For instance, maybe human-interpretability and "naturalness" of abstractions are actually negatively correlated for some highly cognitively-demanding tasks, in which case the trade-off between these two will mean that our model will be pushed further towards Goodharting.
The model I keep describing could actually lead to both hard to interpret and yet potentially interpretable abstractions. Like, if someone from 200 years ago had to be taught Quantum Mechanics. It might be really hard, depends on a lot of mental moves that we don't know how to convey, but that would be the sort of problem equivalent to interpreting better approximations than ours of the natural abstractions. It sounds at least possible to me.
A danger of this process is that the supervised learner would model the data-collection process instead of using the unsupervised model - this could lead to misalignment. But suppose we supplied data about human values which is noisy enough to make sure the supervised learner never switched to directly modelling the data-collection process, while still being a good enough proxy for human values that the supervised learner will actually use the unsupervised model in the first place.
Note that this amount to solving ELK, which probably takes more than "adequately noisy data".
We can argue that human values are properties of the abstract object "humans", in an analogous way to branching patterns being properties of the abstract object "trees". However there are complications to this analogy: for instance, human values seem especially hard to infer from behaviour [AF · GW] without using the "inside view" that only humans have.
I mean, humans learning approximations of the natural abstractions through evolutionary processes makes a lot of sense to me, as it's just evolution training predictors, right?
For another, even if we accept that "which abstractions are natural?" is a function of factors like culture, this argues against the "unique abstraction hypothesis" but not the "useful abstraction hypothesis". We could argue that navigators throughout history were choosing from a discrete set of abstractions, with their choices determined by factors like available tools, objectives, knowledge, or cultural beliefs, but the set of abstractions itself being a function of the environment, not the navigators.
Hence with the model I'm discussing, the culture determined their choice of subabstractions but they were all approximating the same natural abstractions.
comment by mtaran · 2021-12-15T03:28:15.292Z · LW(p) · GW(p)
Re: looking at the relationship between neuroscience and AI: lots of researchers have found that modern deep neural networks actually do quite a good job of predicting brain activation (e.g. fmri) data, suggesting that they are finding some similar abstractions.
Examples: https://www.science.org/doi/10.1126/sciadv.abe7547 https://www.nature.com/articles/s42003-019-0438-y https://cbmm.mit.edu/publications/task-optimized-neural-network-replicates-human-auditory-behavior-predicts-brain
comment by Algon · 2024-06-01T15:26:40.280Z · LW(p) · GW(p)
However, this also feels like a feature of the "valley of confused abstractions". Humans didn't evolve based on individual snapshots of reality, we evolved with moving pictures as input data. If a human in the ancestral environment, when faced with a tiger leaping out of the bushes, decided to analyse its fur patterns rather than register the large orange shape moving straight for them, it's unlikely they would have returned from their first hunting trip. When we see a 2D image, we naturally "fill in the gaps", and create a 3D model of it in our heads, but current image classifiers don't do this, they just take a snapshot. For reasons of architectural bias, they are more likely to identify the abstraction of texture than the arguably far more natural abstraction of shape. Accordingly, we might expect video-based models to be more likely to recognise shapes than image-based models, and hence be more robust to this failure mode.
If this were true, then you'd expect NeRF's and SORA to be a lot less biased towards textures, right?
comment by Thomas Larsen (thomas-larsen) · 2022-06-05T05:28:57.921Z · LW(p) · GW(p)
The Natural Abstraction Hypothesis, proposed by John Wentworth, states that there exist abstractions (relatively high-dimensional summaries which capture information relevant for prediction)
This should say low-dimensional, right? Because the abstractions should be simpler than the true state of the world.
comment by Sichu (howard-stark) · 2022-06-15T23:00:03.879Z · LW(p) · GW(p)
There are definitely interesting "convergences" that provides some evidence for a weak form of this claim. See https://arxiv.org/abs/2202.12299 : Capturing Failures of Large Language Models via Human Cognitive Biases https://www.biorxiv.org/content/biorxiv/early/2020/03/05/860759.full.pdf : Do deep neural networks see the way we do?
https://www.youtube.com/playlist?list=PLyGKBDfnk-iDWTxSdeGkSA2DYNc7enyhv some of the work in this conference