Testing The Natural Abstraction Hypothesis: Project Update
post by johnswentworth · 2021-09-20T03:44:43.061Z · LW · GW · 17 commentsContents
Recap: The Original Plan … Turns Out Chaos Is Not Linear Back To The Drawing Board Deterministic Constraints (a.k.a. Conserved Quantities) and the Telephone Theorem Exponential Family Distributions and the Koopman-Pitman-Darmois Theorem Current Directions None 17 comments
I set myself six months to focus primarily on the Natural Abstraction Hypothesis project [LW · GW] before stopping to re-evaluate. It’s been about six months since then. So, how has it gone?
This will be a “story telling” post, where I talk more about my research process and reasoning than about the results themselves. Be warned: this means I'm going to spout some technical stuff without explanation here and there, and in some cases I haven't even written a good explanation yet - this is a picture of my own thoughts. For more background on the results, the three main posts are:
- The intro post [LW · GW] for the overarching project, which I recommend reading.
- Information At A Distance Is Mediated By Deterministic Constraints [LW · GW], which I also recommend reading.
- Generalizing Koopman-Pitman-Darmois [LW · GW], which I do not recommend reading unless you want dense math.
Recap: The Original Plan
The Project Intro [LW · GW] broke the Natural Abstraction Hypothesis into three sub-hypotheses:
- Abstractability: for most physical systems, the information relevant “far away” can be represented by a summary much lower-dimensional than the system itself.
- Human-Compatibility: These summaries are the abstractions used by humans in day-to-day thought/language.
- Convergence: a wide variety of cognitive architectures learn and use approximately-the-same summaries.
That post suggested three types of experiments to test these:
- Abstractability: does reality abstract well? Corresponding experiment type: run a reasonably-detailed low-level simulation of something realistic; see if info-at-a-distance is low-dimensional.
- Human-Compatibility: do these match human abstractions? Corresponding experiment type: run a reasonably-detailed low-level simulation of something realistic; see if info-at-a-distance recovers human-recognizable abstractions.
- Convergence: are these abstractions learned/used by a wide variety of cognitive architectures? Corresponding experiment type: train a predictor/agent against a simulated environment with known abstractions; look for a learned abstract model.
Alas, in order to run these sorts of experiments, we first need to solve some tough algorithmic problems. Computing information-at-a-distance in reasonably-complex simulated environments is a necessary step for all of these, and the “naive” brute-force method for this is very-not-tractable. It requires evaluating high-dimensional integrals over “noise” variables - a #P-complete problem in general. (#P-complete is sort of like NP-complete, but Harder.) Even just representing abstractions efficiently is hard - we’re talking about e.g. the state-distribution of a bunch of little patches of wood in some chunk of a chair given the state-distribution of some other little patches of wood in some other chunk of the chair. Explicitly writing out that whole distribution would take an amount of space exponential in the number of variables involved; that would be a data structure of size roughly O((# of states for a patch of wood)^(# of patches)).
My main goal for the past 6 months was to develop tools to make the experiments tractable - i.e. theorems, algorithms, working code, and proofs-of-concept to solve the efficiency problems.
When this 6 month subproject started out, I had a working proof-of-concept for linear systems [LW · GW]. I was hoping that I could push that to somewhat more complex systems via linear approximations, figure out some useful principles empirically, and generally get a nice engineering-experiment-theory feedback loop going. That’s the fast way to make progress [LW · GW].
… Turns Out Chaos Is Not Linear
The whole “start with linear approximations and get a nice engineering-experiment-theory feedback loop going” plan ran straight into a brick wall. Not entirely surprising, but it happened sooner than I expected.
Chaos was the heart of the issue. If a butterfly can change the course of a hurricane by flapping its wings, then our uncertainty over the wing-flaps of all the world’s butterflies wipes out most of our long-term information about hurricane-trajectories. I believe this sort of phenomenon plays a central role in abstraction in practice [LW · GW]: the “natural abstraction” is a summary of exactly the information which isn’t wiped out. So, my methods definitely needed to handle chaos. I knew that computing abstractions in linear systems [LW · GW] was tractable, and expected to be able to extend that to at least some limited chaotic systems via local linear approximation. I figured something like a Lyapunov exponent could be calculated locally and used to deduce abstractions for some reasonable class of chaotic systems; the hope was that empirical investigation of those systems would be enough to get a foothold on more complex systems.
Alas, I did not understand just how central nonlocality is to chaos: we cannot tell what information chaos wipes out just by looking at small regions, and therefore we cannot tell what information chaos wipes out just by looking at linear approximations.
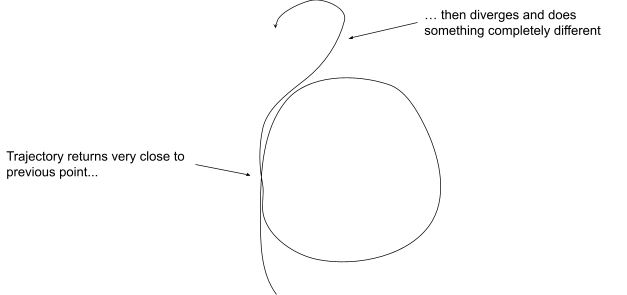
Hand-wavy intuition for this: one defining feature of chaos is that a system’s state-trajectory eventually returns arbitrarily close to its starting point (though it never exactly returns, or the system would be cyclic rather than chaotic). So, picture something like this:
A local linear approximation looks at the trajectories within a small box, like this:
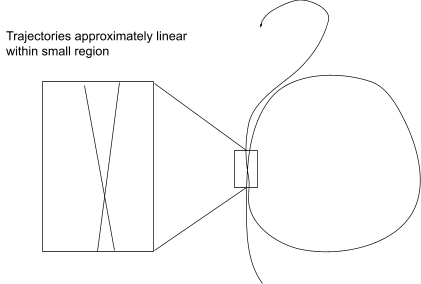
But it’s the behavior outside this small box - i.e. in the big loop - which makes the trajectory return arbitrarily close to its starting point:
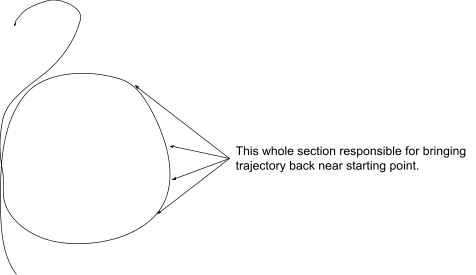
In particular, that means we can’t tell whether the system is chaotic just by looking at the small region. Chaos is inherently nonlocal - we can only recognize it by looking at large-scale properties/behavior, not just a small box.
This, in turn, means that we can’t tell what information will be “wiped out” by chaos just by looking at a small box. The whole linear approximation approach is a nonstarter.
(Note: we can say some useful things by looking at the system locally, e.g. about how quickly trajectories diverge within the region. But not the things I need for calculating chaos-induced abstractions.)
Back To The Drawing Board
With the linear approximation path dead, I no longer had an immediate, promising foothold for experiment or engineering. My dreams of a fast engineering-experiment-theory feedback loop were put on hold, and it was back to glacially slow theorizing.
The basic problem is how to represent abstractions. In general, we’re talking about probability distributions of some stuff given some other stuff “far away”. All of the stuff involved is fairly high-dimensional, so explicitly representing those distributions would require exponentially large amounts of space (like the chair example from earlier). And abstraction is inherently about large high-dimensional systems, so focussing specifically on small systems doesn’t really help.
On the other hand, presumably there exist more efficient data structures for abstractions - after all, the human brain does not have exponentially large amounts of space for representing all the abstractions we use in day-to-day life.
Since chaos was an obvious barrier, I went looking for generalizations of the mathematical tools we already use to represent abstractions in chaotic systems in practice - specifically the tools of statistical mechanics. The two big pieces there are:
- Conserved quantities
- Exponential-family (aka maximum entropy) distributions
Progress was much slower than I’d like, but I did end up with two remarkably powerful tools.
Deterministic Constraints (a.k.a. Conserved Quantities) and the Telephone Theorem
My most exciting result of the last six months is definitely Deterministic Constraints Mediate Information At A Distance [LW · GW] - a.k.a The Telephone Theorem. In its simplest form, it says that information-at-a-distance is like the game Telephone: all information is either perfectly conserved or completely lost in the long run. And, more interestingly, information can only be perfectly conserved when it is carried by deterministic constraints - i.e. quantities which are exactly equal between two parts of the system.
The original intuition behind this result comes from chaos: in (deterministic) chaotic systems, anything which is not a conserved quantity behaves “randomly” over time. (Here “randomly” means that the large-scale behavior becomes dependent on arbitrarily low-order bits of the initial conditions.) Intuitively: any information which is not perfectly conserved is lost. I wanted to generalize that to nondeterministic systems and make it more explicitly about “information” in the more precise sense used in information theory. I did a little math, and found that information is perfectly conserved only when it’s carried by deterministic constraints.
… and then I decided this was clearly a dead end. I was looking for results applicable to probabilistic systems, and this one apparently only applied to deterministic relationships. So I abandoned that line of inquiry.
Two and a half months later, I was laying on the couch with a notebook, staring at a diagram of nested Markov blankets [LW · GW], thinking that surely there must be something nontrivial to say about those damn Markov blankets. (This was not the first time I had that thought - many hours and days were spent ruminating on variations of that diagram.) It occurred to me that mutual information decreases as we move out through the layers, and therefore MI approaches a limit - at which point it stops decreasing (or at least decreases arbitrarily slowly). Which is an information conservation condition. Indeed, it was exactly the same information conservation condition I had given up on two and a half months earlier.

Why am I excited about the Telephone Theorem? First and foremost: finding deterministic constraints does not involve computing any high-dimensional integrals. It just involves equation-solving/optimization - not exactly easy, in general, but much more tractable than integrals! It also yields a natural data structure: if our constraint is , then the functions and can represent the constraint. These are essentially “features” in our models; they summarize all the info from one chunk of variables relevant to another chunk far away. Such features are typically much more efficient to work with than full distributions.
Finally, we already know that deterministic constraints work great for characterizing distributions in chaotic systems - that’s exactly how Gibbs’ various ensembles work, and the empirical success of this approach in statistical mechanics speaks for itself. However, this approach is currently only used in statistical mechanics for “information far away” along the “time direction” (i.e. thermodynamic equilibrium approached over time); the Telephone Theorem generalizes the idea to arbitrary “directions”.
Major open questions here (you don’t need to follow all of these):
- Do deterministic constraints in the limit have a common form - in particular infinite averages [LW · GW]?
- Is there a common form for the abstraction-distributions given the “features” from deterministic constraints? In particular, I suspect that the deterministic constraints yield the feature-functions in exponential-family distributions.
- There’s an awful lot of possible sequences of Markov blankets, and therefore an awful lot of “features” relevant to things-far-away in different “directions”. Can that be compressed somehow? The Current Directions [LW · GW] section below has a hypothesized general form which would handle this.
Exponential Family Distributions and the Koopman-Pitman-Darmois Theorem
During the two-and-a-half month gap in which the deterministic constraints result was sitting there waiting for the final puzzle piece to click into place, I worked mainly on the exponential family angle, specifically generalizing the Koopman-Pitman-Darmois Theorem [LW · GW].
Very roughly speaking:
- The Natural Abstraction Hypothesis says that far-apart chunks of the world are conditionally independent given some low-dimensional summaries.
- The Koopman-Pitman-Darmois Theorem says that if a bunch of variables are conditionally independent given some low-dimensional summaries, then those variables follow an exponential-family distribution - a family which includes things like the normal distribution, uniform distribution, poisson distribution, exponential distribution… basically most of the nice distributions you’d find in a statistical programming library.
Obvious hypothesis: the Natural Abstraction Hypothesis implies that far-apart chunks of the world follow an exponential-family distribution. Like the Telephone Theorem, this would dramatically narrow down the possible distributions we need to represent, and suggests a natural data structure: functions representing the “features” in the distribution. Also like the Telephone Theorem, those functions are typically much more efficient to work with algorithmically than full distributions.
This exponential-family hypothesis also matches up nicely with empirical evidence: exponential family distributions (sometimes called “maximum entropy distributions”) are ubiquitous in statistical mechanics, and work great in practice for modelling exactly the sort of chaotic systems which I consider central examples of abstraction.
Unfortunately, the original Koopman-Pitman-Darmois theorem is too narrow to properly back up this hypothesis. And without knowing how the theorem generalizes, I wasn’t sure of exactly the right way to apply it - i.e. exactly what exponential family distributions to look for. So, I spent a couple months understanding the proof enough to generalize it, and writing up the result [LW · GW]. Nothing too exciting, just fairly tedious mathematical legwork.
Even now, I’m still not fully sure of the right way to apply the generalized Koopman-Pitman-Darmois (gKPD) Theorem [LW · GW] to abstractions; there’s more than one way to map the theorem’s variables to things in the “information-at-a-distance” picture. That said, combining gKPD with the Telephone Theorem gives a strong hint: the “features” in our exponential-family distribution should probably be the deterministic constraint functions from the Telephone Theorem. This is exactly what happens in statistical mechanics - again, Gibbs’ various ensembles are exponential-family distributions in which the features are deterministically-conserved quantities of the system (like energy, momentum or particle count).
Current Directions
My current best guess is that abstractions on a low-level world all follow roughly the general form
… probably modulo a bounded, relatively-small number of exception terms. Notes on what this means:
- The deterministic constraint functions between various Markov blankets are sub-sums of .
- The individual each depend only on local subsets of the low-level variables (so they don’t actually each depend on all of ).
- is a fixed “reference value” of the high-level variables, so is the low-level world distribution under some particular reference values of the high-level world variables.
- All information-at-a-distance is zero in the reference distribution . So, the exponential term mediates all long-range interactions.
- should probably be such that is a normal distribution. This is a guess based on what makes everything behave nicely.
I have rough mathematical arguments to support this via gKPD if we make some extra assumptions, but no general proof yet. It is tantalizingly close to algorithmic tractability, i.e. something I could code up and test empirically in reasonably-large simulations.
Next steps:
- Characterize the possible forms of deterministic constraints. If (as I expect) infinite averages are the only non-finite possibilities, then the key question is averages of what? That, in turn, will tell us what the functions are in the hypothesized general form above, and how to find them.
- Figure out some proofs for the general form - in particular, what the exception terms look like. (Or, alternatively, disprove the general form.)
- Work out efficient algorithms to discover and the corresponding from the low-level world model (represented as a Bayes Net/causal model). Then, test it all empirically.
It feels like I’m now very close to the first big milestone toward testing the Natural Abstraction Hypothesis: a program which can take in a low-level simulation of some system, and spit out the natural abstractions in that system.
17 comments
Comments sorted by top scores.
comment by Adam Shai (adam-shai) · 2021-09-20T23:10:30.116Z · LW(p) · GW(p)
It's great to see someone working on this subject. I'd like to point you to Jim Crutchfield's work, in case you aren't familiar with it, where he proposes a "calculii of emergence" wherein you start with a dynamical system and via a procedure of teasing out the equivalence classes of how the past constrains the future, can show that you get the "computational structure" or "causal structure" or "abstract structure" (all loaded terms, I know, but there's math behind it), of the system. It's a compressed symbolic representation of what the dynamical system is "computing" and furthermore you can show that it is optimal in that this representation preserves exactly the information-theory metrics associated with the dynamical system, e.g. metric entropy. Ultimately, the work describes a heirarchy of systems of increasing computational power (a kind of generalization of the Chomsky heirarchy, where a source of entropy is included), wherein more compressed and more abstract representations of the computational structure of the original dynamical system can be found (up to a point, very much depending on the system). https://www.sciencedirect.com/science/article/pii/0167278994902739
The reason I think you might be interested in this is because it gives a natural notion of just how compressible (read: abstractable) a continous dynamical system is, and has the mathematical machinery to describe in what ways exactly the system is abstractable. There are some important differences to the approach taken here, but I think sufficient overlap that you might find it interesting/inspiring.
There's also potentially much of interest to you in Cosma Shalizi's thesis (Crutchfield was his advisor): http://bactra.org/thesis/
The general topic is one of my favorites, so hopefully I will find some time later to say more! Thanks for your interesting and though provoking work.
comment by Stuart_Armstrong · 2023-01-23T12:42:31.520Z · LW(p) · GW(p)
A good review of work done, which shows that the writer is following their research plan and following up their pledge to keep the community informed.
The contents, however, are less relevant, and I expect that they will change as the project goes on. I.e. I think it is a great positive that this post exists, but it may not be worth reading for most people, unless they are specifically interested in research in this area. They should wait for the final report, be it positive or negative.
comment by ryan_b · 2021-09-21T19:11:28.839Z · LW(p) · GW(p)
- Meta: I greatly appreciate that you took the time to contextualize the earlier relevant posts within this one.
- Do you already have a plan of attack for the experimental testing? By this I mean using X application, or Y programming language, with Z amount of compute. If not, I would like to submit a request that you post that information when the time comes.
- Recalling the Macroscopic Prediction paper by Jaynes, am I correct in interpreting this as being conceptually replacing the microphenomena/macrophenomena choices with near/far abstractions?
- Following in this vein, does the phase-space trick seem to generalize to the abstractions level? By this I mean something like replacing
predict the behavior that can happen in the greatest number of ways, while agreeing with whatever information you have
with
choose the low-dimensional summaries which have been constrained in the greatest number of ways, while accurately summarizing the far-away information
↑ comment by johnswentworth · 2021-09-21T20:19:33.828Z · LW(p) · GW(p)
Do already have a plan of attack for the experimental testing? By this I mean using X application, or Y programming language, with Z amount of compute.
I will post that information when the time comes. Though probably not very long before the time comes; writing up that sort of code takes a lot less time than all this theory.
Recalling the Macroscopic Prediction paper by Jaynes, am I correct in interpreting this as being conceptually replacing the microphenomena/macrophenomena choices with near/far abstractions?
Yes.
Following in this vein, does the phase-space trick seem to generalize to the abstractions level?
I had not thought of that, but it sounds like a great idea. I'll have to chew on it some more.
comment by jonathanmoregard · 2021-09-21T05:26:53.391Z · LW(p) · GW(p)
I have a question. This is beyond my area of competence - understood few of the technical parts - so bear with me here :)
This is how I understand the parts relevant to my question:
You want to:
- Simulate the chaotic environment to be "perceived"
- Formalize the perceiving. "info-at-a-distance"
- Check if the "perceived info" contains patterns/"structural organizations" similar to those used by humans.
The question is about fundamental assumptions of this work.
Given that my understanding is correct, then I wonder:
Since you create both the simulated environment, and the "perceiver", wouldn't that risk introducing bias? If the "perceiver" outputs human-like structures, is there any way to say whether they originate from an "objective" process, or if they originate from you?
When you model "chaos", you are deciding on the representation.
You are using mathematics, a formalized system optimized to be used by humans.
And you use math/your intuition to formalize "the perceiving".
----
Taking a step back I realize that GAI "in the wild" will most likely be "subjected" to the same human influences. But I haven't thought about it a lot and I'm curious about your take on this.
↑ comment by johnswentworth · 2021-09-21T15:41:42.144Z · LW(p) · GW(p)
You're asking the right questions.
The most important difference between this approach and most people thinking about abstraction is that, in this approach, most of the key ideas/results do not explicitly involve an observer. The "info-at-a-distance" is more a property of the universe than of the observer, in exactly the same way that e.g. energy conservation or the second law of thermodynamics are more properties of the universe than of the observer.
Now, it's still true that we need an observer in order to recognize that energy is conserved or entropy increases or whatever. There's still an implicit observer in there, writing down the equations and mapping them to physical reality. But that's true mostly in a philosophical sense, which doesn't really have much practical bearing on anything; even if some aliens came along with radically different ways of doing physics, we'd still expect energy conservation and entropy increase and whatnot to be embedded in their predictive processes (though possibly implicitly). We'd still expect their physics to either be equivalent to ours, or to make outright wrong predictions (other than the very small/very big scales where ours is known to be incomplete). We'd even expect a lot of the internal structure to match, since they live in our universe and are therefore subject to similar computational constraints (specifically locality).
Abstraction, I claim, is like that.
On a meta-note, regarding this specifically:
You are using mathematics, a formalized system optimized to be used by humans.
And you use math/your intuition to formalize "the perceiving".
I think there's a mistake people sometimes make when thinking about how-models-work (which you may or may not be making) that goes something like "well, we humans are representing this chunk-of-the-world using these particular mathematical symbols, but that's kind of an arbitrary choice, so it doesn't necessarily tell us anything fundamental which would generalize beyond humans".
The mistake here is: if we're able to accurately predict things about the system, then those predictions remain just as true even if they're represented some other way. In fact, those predictions remain just as true even if they're not represented at all - i.e. even if there's no humans around to make them. For instance, energy is still conserved even in parts of the universe which humans have never seen and will never see, and that still constrains the viable architectures of agent-like systems in those parts of the universe.
comment by Vanessa Kosoy (vanessa-kosoy) · 2021-09-20T18:51:24.810Z · LW(p) · GW(p)
Two questions:
- What exactly is the #P-complete problem you ran into?
- What is the precise mathematical statement of the "Telephone Theorem"? I couldn't find it in the linked post.
↑ comment by johnswentworth · 2021-09-20T20:09:59.596Z · LW(p) · GW(p)
The #P-complete problem is to calculate the distribution of some variables in a Bayes net given some other variables in the Bayes net, without any particular restrictions on the net or on the variables chosen.
Formal statement of the Telephone Theorem: We have a sequence of Markov blankets forming a Markov chain . Then in the limit , mediates the interaction between and (i.e. the distribution factors according to ), for some satisfying
with probability 1 in the limit.
Replies from: Gurkenglas, NomadicSecondOrderLogic↑ comment by Gurkenglas · 2021-09-21T14:39:12.148Z · LW(p) · GW(p)
Given a network to analyze, have you considered training a GAN to generate some requested activations given some other activations? That should give straightforward estimates for the likes of mutual information between modules, and would be useful anyway to illustrate the function of a given module by generating variants of an input with the same activations in that module.
Not sure what to do about that mutual information often being infinite. Counting the dimension of the "mutual space" seems too discrete...
↑ comment by bhishma (NomadicSecondOrderLogic) · 2021-09-21T16:38:47.869Z · LW(p) · GW(p)
In case you're fine with an approximation, you could try modelling the #P problem as a CNF (check this paper for more info) and use an approx model counter such as https://github.com/meelgroup/approxmc .
comment by David Reber (derber) · 2022-08-14T15:28:57.922Z · LW(p) · GW(p)
[Warning: "cyclic" overload. I think in this post it's referring to the dynamical systems definition, i.e. variables reattain the same state later in time. I'm referring to Pearl's causality definition: variable X is functionally dependent on variable Y, which is itself functionally dependent on variable X.]
Turns out Chaos is not Linear...
I think the bigger point (which is unaddressed here) is that chaos can't arise for acyclic causal models (SCMs). Chaos can only arise when there is feedback between the variables right? Hence the characterization of chaos is that orbits of all periods are present in the system: you can't have an orbit at all without functional feedback. The linear approximations post [LW · GW]is working on an acyclic Bayes net.
I believe this sort of phenomenon [ chaos ] plays a central role in abstraction in practice [AF · GW]: the “natural abstraction” is a summary of exactly the information which isn’t wiped out. So, my methods definitely needed to handle chaos.
Not all useful systems in the world are chaotic. And the Telephone Theorem [? · GW] doesn't rely on chaos as the mechanism for information loss. So it seems too strong to say "my methods definitely need to handle chaos". Surely there are useful footholds in between the extremes of "acyclic + linear" to "cyclic + chaos": for instance, "cyclic + linear".
At any rate, Foundations of Structural Causal Models with Cycles and Latent Variables could provide a good starting point for cyclic causal models (also called structural equation models). There are other formalisms as well but I'm preferential towards this because of how closely it matches Pearl.
Replies from: johnswentworth↑ comment by johnswentworth · 2022-08-14T17:53:06.833Z · LW(p) · GW(p)
Yeah, the chaos piece predated the Telephone Theorem. The Telephone Theorem does apply just fine to chaotic systems (the Bayes Net just happens to have time symmetry), but it's way more general.
comment by Adam Shai (adam-shai) · 2021-09-21T19:10:53.379Z · LW(p) · GW(p)
I've been reading through your very interesting work more slowly and have some comments/questions:
This one is probably nitpicking, and I'm likely misunderstanding but it seems to me that the Human-Compatibility hypothesis must be incorrect. If it were correct, then the scientific enterprise which can be concieved as being a continued attempt to draw out exactly those abstractions of the natural world into explicit human-knowledge would require little effort and would already be done. Instead science is notoriously difficult to do, and the method is anything but natural to human beings, having just arisen in human history. Certainly the abstract structures which seem to best characterize the universe are not a good description of everyday human knowledge/reasoning. I think the hypothesis should be more along the lines of "there exists some subset of abstractions that are human compatible." Finding that subset is incredibly interesting in its own right, so maybe this doesnt change much.
Re: the telephone theorem. This reminds me very much of block-entropy diagrams and excess entropy (and related measures). One thing I am wondering is how you think about time vs. space in your analysis. If we think of all of physics as a very nonlinear dynamical system, then how do you move from that to these large causal networks you are drawing? One way to do it comes from the mathematical subfield of ergodic theory and symbolic dynamics. In this formulation you split up time into the past and the future and you ask how does the past constrain the future. Given any system with finite memory (which I think is a reasonable assumption, at least to start with), you can imagine that there is some timescale over which the relationship between the past, current state, and future is totally Markov. Then you can think of how something very similar to your telephone theorem would work out over time. As far as I can tell this leads you directly to the kolmogorov-sinai entropy rate. (see here: https://link.aps.org/doi/10.1103/PhysRevLett.82.520 ).
I'll have to read through the last two sections a little slower and give it some thoughts. If there is interest I might try to find some time to make a post that's easier to follow than my ranting here.
Cheers
Replies from: johnswentworth↑ comment by johnswentworth · 2021-09-21T20:34:43.007Z · LW(p) · GW(p)
One thing I am wondering is how you think about time vs. space in your analysis. If we think of all of physics as a very nonlinear dynamical system, then how do you move from that to these large causal networks you are drawing?
The equations of physics are generally local in both time and space. That actually makes causal networks a much more natural representation, in some ways, than nonlinear dynamical systems; dynamical systems don't really have a built-in notion of spatial locality, whereas causal networks do. Indeed, one way to view causal networks is as the bare-minimum model in which we have both space-like and time-like interactions. So I don't generally think about moving from dynamical systems to causal networks; I think about starting from causal networks.
This also fits well with how science works in a high-dimensional world like ours [LW · GW]. Scientists don't look at the state of the whole universe and try to figure out how that evolves into the next state. Rather, they look at spatially-localized chunks of the universe, and try to find sets of mediators which make the behavior of that chunk of the universe "reproducible" - i.e. independent of what's going on elsewhere. These are Markov blankets.
The main piece which raw causal networks don't capture is symmetry, e.g. the laws of physics staying the same over time. I usually picture the world in terms of causal networks with symmetry [LW · GW] or, equivalently, causal submodels organized like programs [LW · GW].
Replies from: adam-shai, TAG↑ comment by Adam Shai (adam-shai) · 2021-09-22T00:43:04.972Z · LW(p) · GW(p)
Just to make sure I'm understanding the concept of causal networks with symmetry correctly, since I'm more used to thinking of dynamical systems: I could in principle think of a dynamical system that I simulate on my computer as a DAG with symmetry, ie using Euler's method to simulate dx/dt = f(x) I get a difference equation x(t+1) = /delta T * f(x(t)) that I then use to simulate my dynamical system on a computer, and I can think of that as a DAG where x(t) /arrow x(t+1), for all t, and of course theres a symmetry over time since f(x(t)) is constant over time. If I have a spatially distributed dynamical system, like a network, then there might also be symmetries in space. In this way your causal networks with symmetry can capture any dynamical system (and I guess more since causal dependencies need not be deterministic)? Does that sound right?
Replies from: johnswentworth↑ comment by johnswentworth · 2021-09-22T01:50:14.876Z · LW(p) · GW(p)
That is exactly correct.