How ARENA course material gets made
post by CallumMcDougall (TheMcDouglas) · 2024-07-02T18:04:00.209Z · LW · GW · 2 commentsContents
TL;DR Summary 1. Start with something concrete 2. First-pass: replicate, and understand 3. Second-pass: exercise-ify Call to action for ARENA exercises Appendix A1 - what makes for good exercise sets? A2 - what tools do I use? Acknowledgements None 2 comments
TL;DR
In this post, I describe my methodology for building new material for ARENA. I'll mostly be referring to the exercises on IOI, Superposition and Function Vectors as case studies. I expect this to be useful for people who are interested in designing material for ARENA or ARENA-like courses, as well as people who are interested in pedagogy or ML paper replications.
The process has 3 steps:
- Start with something concrete
- First pass: replicate, and understand
- Second pass: exercise-ify
Summary
I'm mostly basing this on the following 3 sets of exercises:
- Indirect Object Identification - these exercises focus on the IOI paper (from Conmy et al). The goal is to have people understand what exploratory analysis of transformers looks like, and introduce the key ideas of the circuits agenda.
- Superposition & SAEs - these exercises focus on understanding superposition and the agenda of dictionary learning (specifically sparse autoencoders). Most of the exercises explore Anthropic's Toy Models of Superposition paper, except for the last 2 sections which explore sparse autoencoders (firstly by applying them to the toy model setup, secondly by exploring a sparse autoencoder trained on a language model).
- Function Vectors - these exercises focus on the Function Vectors paper by David Bau et al, although they also make connections with related work such as Alex Turner's GPT2-XL steering vector work. These exercises were interesting because they also had the secondary goal of being an introduction to the nnsight library, in much the same way that the intro to mech interp exercises were also an introduction to TransformerLens.
The steps I go through are listed below. I'm indexing from zero because I'm a software engineer so of course I am. The steps assume you already have an idea of what exercises you want to create; in Appendix (1) you can read some thoughts on what makes for a good exercise set.
1. Start with something concrete
When creating material, you don't want to be starting from scratch. It's useful to have source code available to browse - bonus points if that takes the form of a Colab or something which is self-contained and has easily visible output.
- IOI - this was Neel's "Exploratory Analysis Demo" exercises. The rest of the exercises came from replicating the paper directly.
- Superposition - this was Anthroic's Colab notebook (although the final version went quite far beyond this). The very last section (SAEs on transformers) was based on Neel Nanda's demo Colab).
- Function Vectors - I started with the NDIF demo notebook, to show how some basic nnsight syntax worked. As for replicating the actual function vectors paper, unlike the other 2 examples I was mostly just working from the paper directly. It helped that I was collaborating with some of this paper's authors, so I was able to ask them some questions to clarify aspects of the paper.
2. First-pass: replicate, and understand
The first thing I'd done in each of these cases was go through the material I started with, and make sure I understood what was going on. Paper replication is a deep enough topic for its own series of blog posts (many already exist), although I'll emphasise that I'm not usually talking about full paper replication here, because ideally you'll be starting from something a it further along, be that a Colab, a different tutorial, or something else. And even when you are just working directly from a paper, you shouldn't make the replication any harder for yourself than you need to. If there's code you can take from somewhere else, then do.
My replication usually takes the form of working through a notebook in VSCode. I'll either start from scratch, or from a downloaded Colab if I'm using one as a reference. This notebook will eventually become the exercises. My replication will include a lot of markdown cells explaining what's going on, between the code cells. I usually frame these as explanations to myself, in other words if I don't understand something then I'll figure it out and write it as an explanation to myself. Mostly it's fine if these are written in shorthand; they'll go through a lot of polishing in subsequent steps. For example, here's a cell from an early version of the function vectors exercises, compared to what it ended up turning into:

display_model_completions_on_antonyms function, first-pass draft version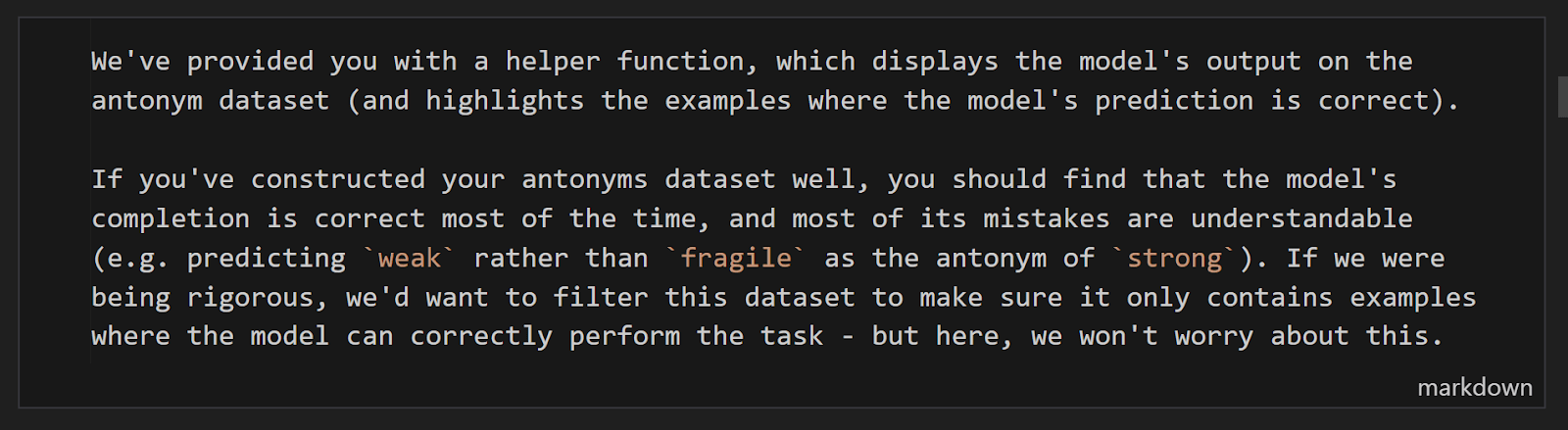
display_model_completions_on_antonyms function, final versionWhen it comes to actually writing code, I usually like everything to be packaged in easy-to-run functions. Ideally each cell of code that I run should only have ~1-4 lines of actual code outside of functions (although this isn't a strict rule). I try to keep my functions excessively annotated - this includes type indications, docstrings, and a large number of annotations along with plenty of space between lines. This will be helpful for the final exercises because students will need to understand what the code does when they look at the answers, but it's also helpful in the exercise-writing process because it helps me take a step back and distill the high-level things that are going on in each chunk of code. This helps me pull out modular chunks of code to turn into exercises, to make sure that students aren't being asked to do too many things at once (more discussion of this in step 2). Here's an example of the kind of documentation I usually have:
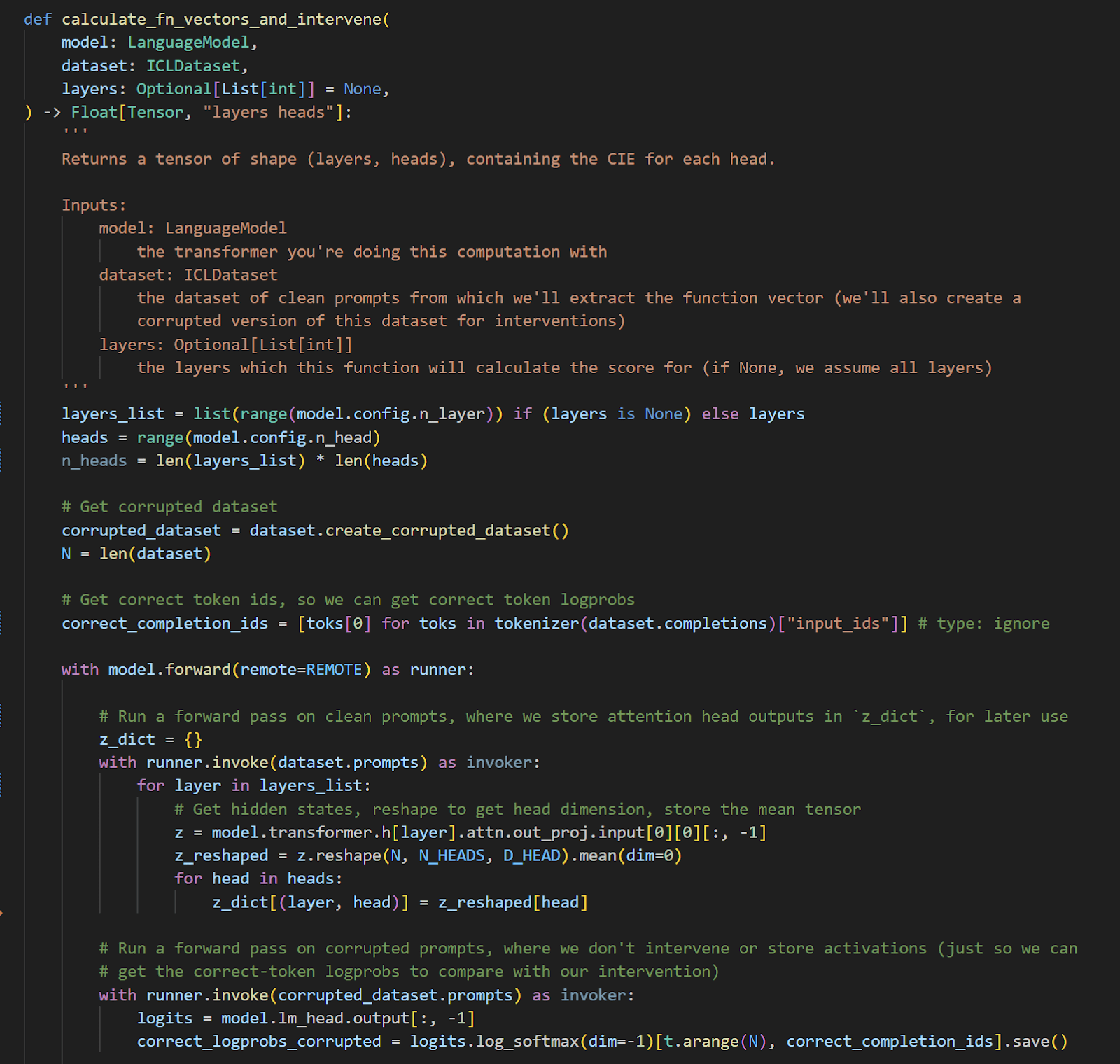
While I'm doing this replication, I'm usually thinking about how to construct exercises at the same time. It helps that the position students will be in while going through the exercises isn't totally different to the position I'm in while writing the functions in the first place. I'll save the discussion of exercise-ification for the next section, however do bear in mind that I'm doing a lot of the exercise structuring as I go rather than all at once after the replication is complete.
- IOI - I was starting off with a basic level of understanding already, from a talk given during MLAB2. I was also able to explain IOI to participants in the Boston Winter ML Bootcamp (an MLAB spin-off which ran in early 2023). The bulk of the coding that I needed to do for these exercises was to make a bunch of different variants of path patching, and pull them together into a single func which replicated the minimal circuit results (i.e. the bar chart on page 11).
- Sparse Autoencoders - The first step was reading TMS and working through Anthropic's Colab notebook. The earlier versions of these exercises looked way more like the Colab (literally turning the code blocks into exercises by removing a few lines), although gradually they moved further away from things. My journey into understanding SAEs actually took place while I was building this visualizer. The bulk of the replication for the SAEs section was implementing techniques like neuron resampling on the toy model (and building a framework to create animations of the toy model, which also helped me check whether the neuron resampling was working).
- Function Vectors - This replication was pretty linear, going through the function vectors paper section by section. I was also learning necessary things about the nnsight library while performing this replication, e.g. when I came to bits of the paper which used multi-token generation I would figure out how to get that working in nnsight. The Discord channel (and Jaden in particular) was very helpful for this!
One last note - your mileage may vary on this, because it's more of me sharing a productivity tip which helped me - with all 3 of these case studies, this first-pass replication was done (at least in an 80/20 sense) over one very intense weekend where I focused on nothing else other than the replication. I find that framing these as exciting hackathon-type events is a pretty effective motivational tool (even though having them be an actual hackathon with multiple people would probably amplify this benefit).

3. Second-pass: exercise-ify
Once I've replicated the core results, I'll go back through the notebook and convert it into exercises. As I alluded to, some of this will already have been done in the process of the previous step, for example in notes to myself or in the docstrings I've given to functions. Here's an example, taken from an early draft of the function vector exercises:
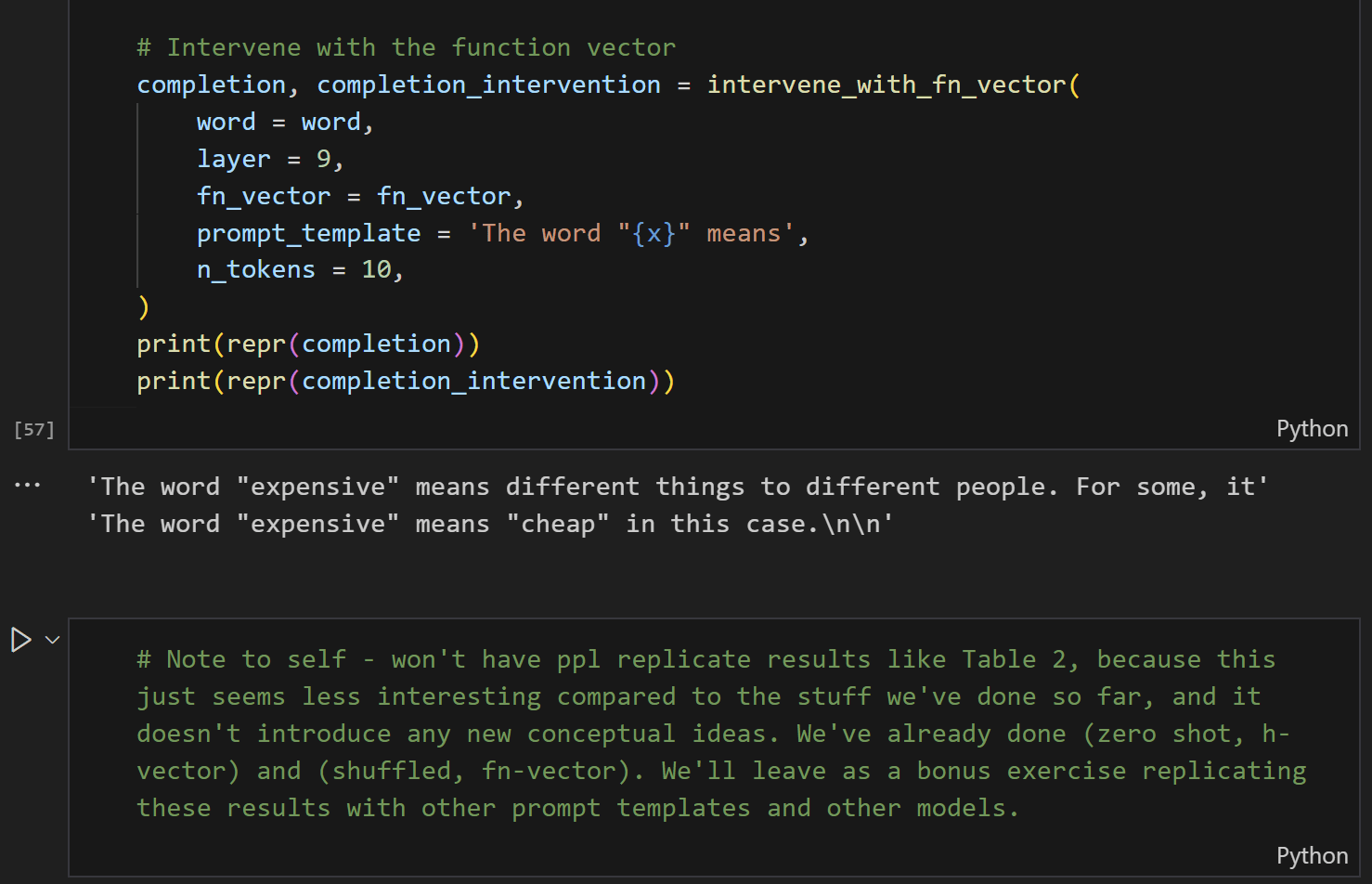
With that said, in this section I'll still write as if it's a fully self-contained step.
When I go through my notebook in this stage, I'm trying to put myself in the mind of a student who is going through these exercises. As I've mentioned, it's helpful that the perspective of a student going through the exercises isn't totally different to the perspective I had while doing the initial replication. So often I'll be able to take a question about the exercises, and answer it by first translating it into a question about my own experience doing the replication. Some examples:
| Question about exercises | Question to myself |
| What are the most important takeaways I want students to have from each section, both in terms of what theory I want them to know and what kinds of code they should be able to write? | What theory did I need to know to perform this section of the replication, and what coding techniques or tools did I need to use? |
| How should the exercises be split up, and what order should they be put in? | What were the key ideas I needed to understand to write each bit of code, and how can I create exercises which test just one of these ideas at once? |
| What diagrams, analogies or other forms of explanation would be helpful to include for students? | Were there any diagrams I drew or had in mind while I was doing the replication? |
Here are some concrete examples of what this looked like, for each of the 3 exercise sets.
- IOI - While writing functions to perform path patching in IOI, I realized that there were many different variations, and some of them were getting quite complicated. So the best way to structure these exercises would be to identify the simplest instance of path patching (patching from a component to the final value of the residual stream) and use this as the first exercise, which would be used as an introduction to the idea of path patching.
- Superposition & SAEs - in the feature geometry section, in the reference Colab I was starting from, the calculation of dimensionality was hidden in one of the plotting functions. But I thought that dimensionality seemed like a valuable concept to understand and a worthwhile implementation, so I refactored some of the plotting code by removing the dimensionality calculation and turning it into a self-contained exercise.
- Function Vectors - Initially the first section was structured as (1) extract vector h from a fwd pass and (2) patch vector h into a different fwd pass. But then I realised that nnsight supported the combining of these operations into a single forward pass. To deconfuse myself, I ended up making a diagram to illustrate the difference between doing these steps in sequence / simultaneously. Once I had this diagram, I decided I'd create an exercise where (after having already done (1) and (2) separately) participants would adapt their code to perform (1) and (2) in a single step. The diagram I'd written for myself ended up being included in the final set of exercises (after it was polished up).
I'll conclude this section with a bit of an unstructured brain dump. There's probably a lot more that I'm forgetting and I might end up editing this post, but hopefully this covers a good amount!
- Each section should include learning objectives. These are usually 3-6 bullet points depending on the length of the section. They should help communicate to the student what to expect from this section, and what key ideas to keep in mind while working through it.
- Make the sections results-focused, especially in how they end. Each section should end with some satisfying results, ideally producing some plot or some output from a language model rather than just passing some test. It's good to make things satisfying for the students when possible!
- Use hints frequently! If there's anything I got stuck on during the replication until I figured out what I was doing wrong, then there's a good chance it will be made into a hint.
Call to action for ARENA exercises
The development of more ARENA chapters is underway! We'd love for you to contribute to the design of ARENA curriculums and suggest content you'd want to see in ARENA using this Content Suggestion Form. If you want to be actively involved as a contributor, you can reach out via this Collaborator Interest Form or email Chloe Li at chloeli561@gmail.com.
Appendix
A1 - what makes for good exercise sets?
Should be a currently active area of research - at least, if we're talking about things like the the interpretability section rather than e.g. some sections of RL or the first chapter which are purely meant to establish theory and lay groundwork. For example, although the ideas behind causal tracing have been influential, it's not currently a particularly active area of research, which is one of the reasons I chose to not make exercises on it.[1]
- Combination of theory and coding takeaways. Function vectors is a perfect example here because people were literally learning about nnsight while learning about function vectors. But the same is also true to a lesser extent of the other exercise sets.
- Doesn't require excessive compute - pretty self-explanatory! Although libraries like nnsight are now pushing the boundaries of what ARENA exercises might be able to support.
A2 - what tools do I use?
- Diagrams were made using Excalidraw. I think LucidChart or other diagramming software would work equally well here.
- Once I created a diagram, I'd usually dump it into a GitHub repository which I owned, and then use that to get a link that I could drop into the notebook (and eventual exercises) as an
<img>element. I would not be surprised if there was a better method than this.
- Once I created a diagram, I'd usually dump it into a GitHub repository which I owned, and then use that to get a link that I could drop into the notebook (and eventual exercises) as an
- I'd use ChatGPT pretty frequently, mostly to do things like ask for ways my function structure could be improved, or writing basic helper functions when I knew it wasn't something I'd have the students implement as an exercise.
- If I needed compute, I'd usually use VastAI or Lambda Labs (I generally don't enjoy working from Colabs).
Acknowledgements
Note - although I've written or synthesized a lot of the ARENA material, I don't want to give the impression that I created all of it, since so much of it existed before I started adding to it. I've focused on examples where I wrote most of the core exercises, but I'd also like to thank the following people who have also made invaluable contributions to the ARENA material, either directly or indirectly:
- Everyone who worked on the first and second iterations of MLAB, because those exercises underpin most of the first chapter of material,
- Neel Nanda, whose open source material and tutorial notebooks have been the basis for several sections in the transformers chapter,
- David Quarel, who worked on many sections in the RL chapter,
- Chloe Li, who has updated & built on the function vectors material,
- Not to mention everyone in the Slack group who have made suggestions or pointed out bugs in the material!
- ^
There were other reasons I chose not to, e.g. it didn't seem very satisfying for students to implement because it's high on rigour and careful execution of an exact algorithm, and doesn't really contain that many unique ideas. Also, you'd have to be doing causal tracing on some model, the obvious choice would be the bracket classifier model because Redwood has already done work on it, but their published work on it is very long and contingent on specific features of the bracket classifier model rather than generalizable ideas.
2 comments
Comments sorted by top scores.
comment by eggsyntax · 2024-07-03T10:55:25.893Z · LW(p) · GW(p)
Great post, thanks!
When creating material, you don't want to be starting from scratch. It's useful to have source code available to browse - bonus points if that takes the form of a Colab or something which is self-contained and has easily visible output.
FYI I put together a list of such Colab starting points [LW · GW] early this year which may be useful to some readers.
Replies from: TheMcDouglas↑ comment by CallumMcDougall (TheMcDouglas) · 2024-07-04T09:06:24.791Z · LW(p) · GW(p)
Oh yeah this is great, thanks! For people reading this, I'll highlight SLT + developmental interp + mamba as areas which I think are large enough to have specific exercise sections but currently don't