Mech Interp Challenge: November - Deciphering the Cumulative Sum Model
post by CallumMcDougall (TheMcDouglas) · 2023-11-02T17:10:07.080Z · LW · GW · 2 commentsContents
I'm writing this post to discuss solutions to the October challenge, and present the challenge for this November.
November Problem
October Problem - Solutions
Best Submissions
None
2 comments
I'm writing this post to discuss solutions to the October challenge, and present the challenge for this November.
If you've not read the first post in this sequence [LW · GW], I'd recommend starting there - it outlines the purpose behind these challenges, and recommended prerequisite material.
November Problem
The problem for this month is interpreting a model which has been trained to classify the cumulative sum of a sequence.
The model is fed sequences of integers, and is trained to classify the cumulative sum at a given sequence position. There are 3 possible classifications:
- 0 (if the cumsum is negative),
- 1 (if the cumsum is zero),
- 2 (if the cumsum is positive).
For example, if the sequence is:
[0, +1, -3, +2, +1, +1]Then the classifications would be:
[1, 2, 0, 1, 2, 2]The model is not attention only. It has one attention layer with a single head, and one MLP layer. It does not have layernorm at the end of the model. It was trained with weight decay, and an Adam optimizer with linearly decaying learning rate.
I don't expect this problem to be as difficult as some of the others in this sequence, however the presence of MLPs does provide a different kind of challenge.
You can find more details on the Streamlit page. Feel free to reach out if you have any questions!
October Problem - Solutions
In the second half of the sequence, the attention heads perform the algorithm "attend back to (and copy) the first token which is larger than me". For example, in a sequence like:
[7, 5, 12, 3, SEP, 3, 5, 7, 12]we would have the second 3 token attending back to the first 5 token (because it's the first one that's larger than itself), the second 5 attending back to 7, etc. The SEP token just attends to the smallest token.
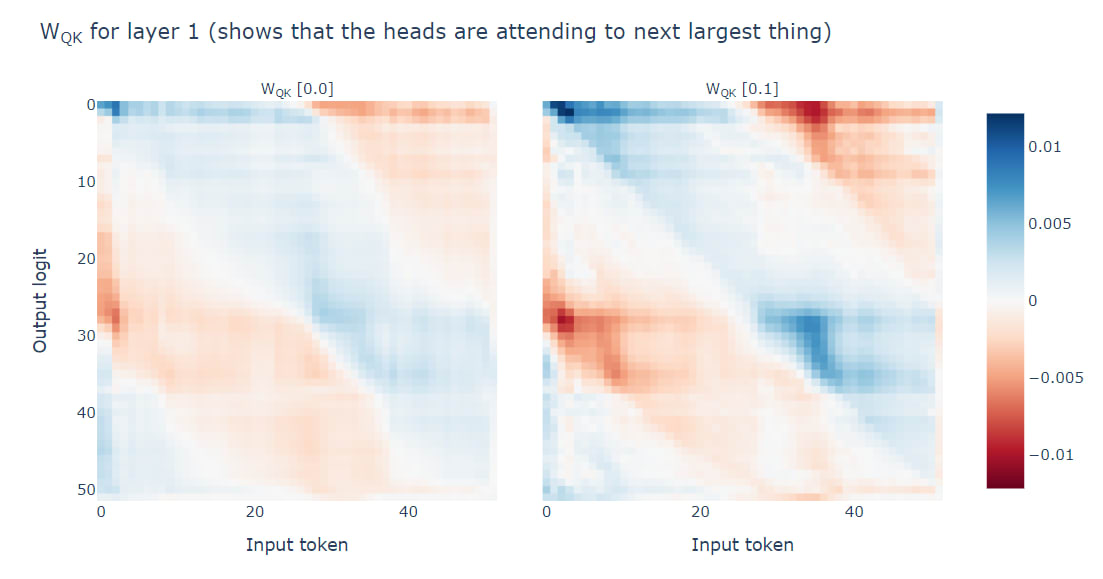
Some more refinements to this basic idea:
- The two attending heads split responsibilities across the vocabulary. Head 0.0 is the less important head; it deals with values in the range 28-37 (roughly). Head 0.1 deals with most other values.
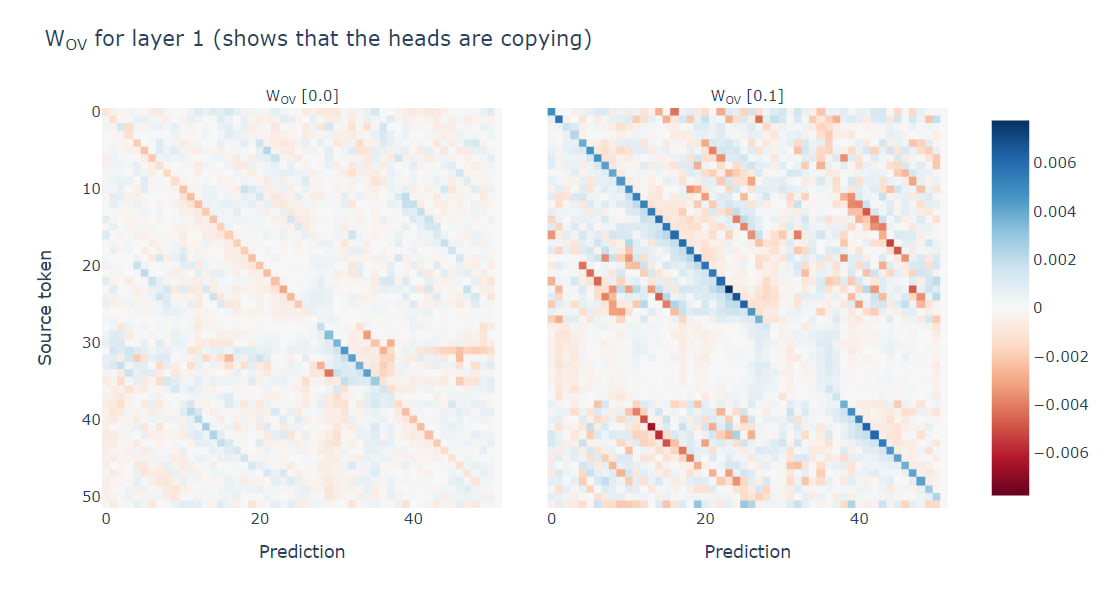
- In subsequences
x < y < zwhere the three numbers are close together,xwill often attend tozrather than toy. So why isn't this an adversarial example, i.e. why does the model still correctly predictyfollowsx?- Answer - the OV circuit shows that when we attend to source token
s, we also boost things slightly less thns, and suppress things slightly more thans. - So in the case of
x < y < z, we have:- Attention to
ywill boostya lot, and suppressza bit. - Attention to
zwill boostza lot, and boostya bit.
- Attention to
- So even if
zgets slightly more attention thany, it might still be the case thatygets predicted with higher probability.
- Answer - the OV circuit shows that when we attend to source token
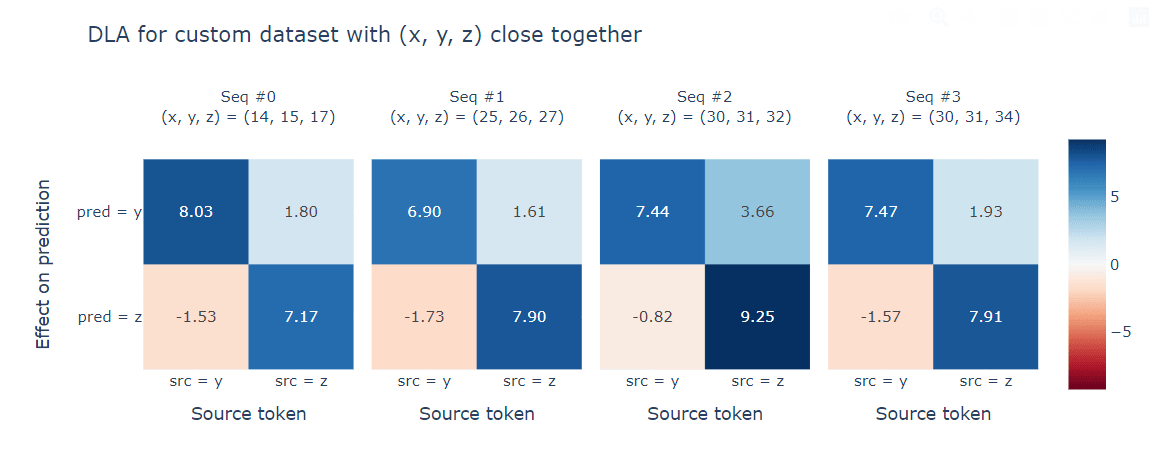
- Sequences with large jumps are adversarial examples (because they're rare in the training data, which was randomly generated from choosing subsets without replacement).
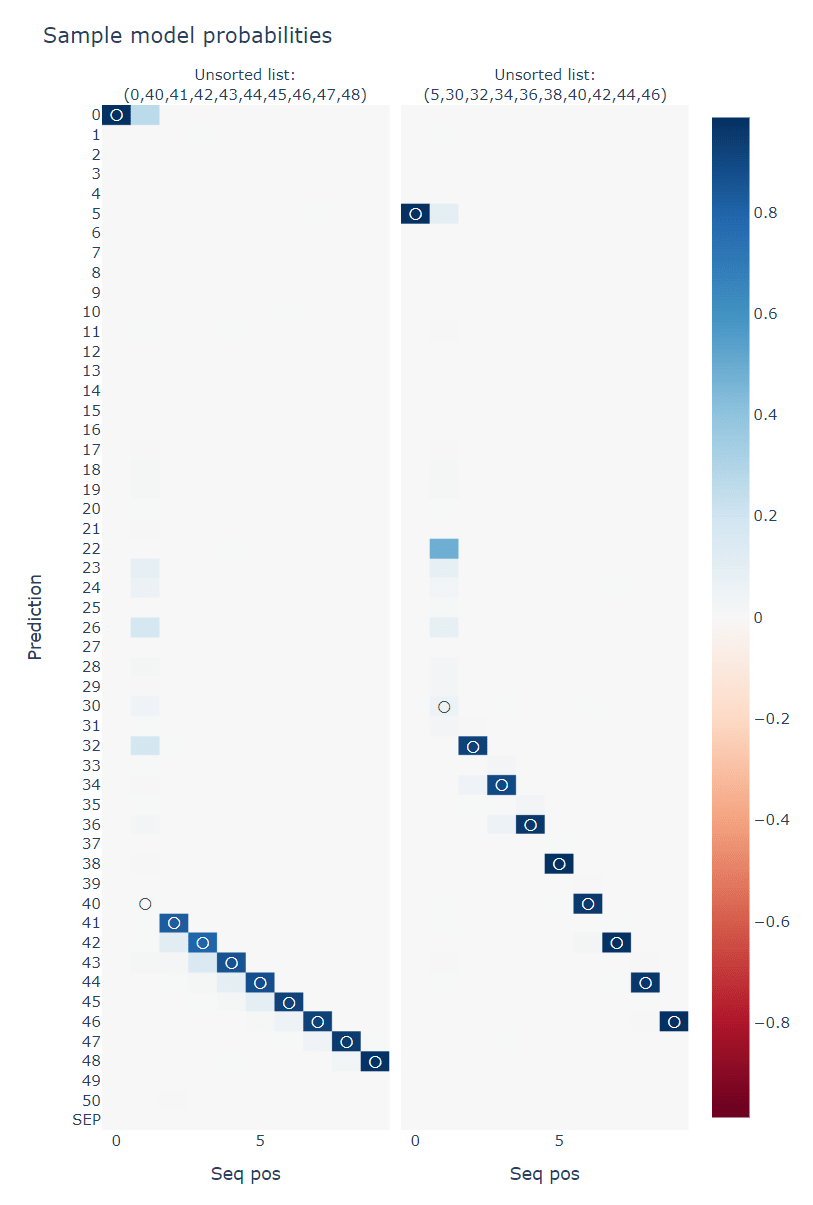
Best Submissions
We received more submissions for this month's problem than any other in the history of the series, so thanks to everyone who attempted! The best solution to this problem was by Vlad K, who correctly identified the model's tendency to produce unexpected attention patterns when 3 numbers are close together, and figured out how the model manages to produce correct classifications anyway.
Best of luck for this and future challenges!
2 comments
Comments sorted by top scores.
comment by hillz · 2023-11-13T04:11:35.052Z · LW(p) · GW(p)
Winner = first correct solution, or winner = best / highest-quality solution over what time period?
Replies from: TheMcDouglas↑ comment by CallumMcDougall (TheMcDouglas) · 2023-11-13T09:53:28.822Z · LW(p) · GW(p)
Winner = highest-quality solution over the time period of a month (solutions get posted at the start of the next month, along with a new problem).
Note that we're slightly de-emphasising the competition side now that there are occasional hints which get dropped during the month in the Slack group. I'll still credit the best solution in the Slack group & next LW post, but the choice to drop hints was to make the problem more accessible and hopefully increase the overall reach of this series.