[Paper] All's Fair In Love And Love: Copy Suppression in GPT-2 Small
post by CallumMcDougall (TheMcDouglas), Arthur Conmy (arthur-conmy), Cody Rushing (cody-rushing), Tom McGrath, Neel Nanda (neel-nanda-1) · 2023-10-13T18:32:02.376Z · LW · GW · 4 commentsContents
Key Results Copy Suppression Copy Suppression-Preserving Ablation Anti-Induction Semantic Similarity Self Repair Interactive Webpage Limitations and Future Work Lessons for future research None 4 comments
This is a accompanying blog post to work done by Callum McDougall, Arthur Conmy and Cody Rushing as part of SERI MATS 2023. The work was mentored by Neel Nanda and Tom McGrath. You can find our full paper at https://arxiv.org/abs/2310.04625. We i) summarize our key results, ii) discuss limitations and future work and iii) list lessons learnt from the project
Key Results
Copy Suppression
In the paper, we define copy suppression as the following algorithm:
If components in earlier layers predict a certain token, and this token appears earlier in the context, the attention head suppresses it.
We show that attention head L10H7 in GPT2-Small (and to a lesser extent L11H10) both perform copy suppression across the whole distribution, and this algorithm explains 76.9% of their behavior.
For example, take the sentence "All's fair in love and war." If we ablate L10H7, the model will incorrectly predict "...love and love." A diagram of this process:
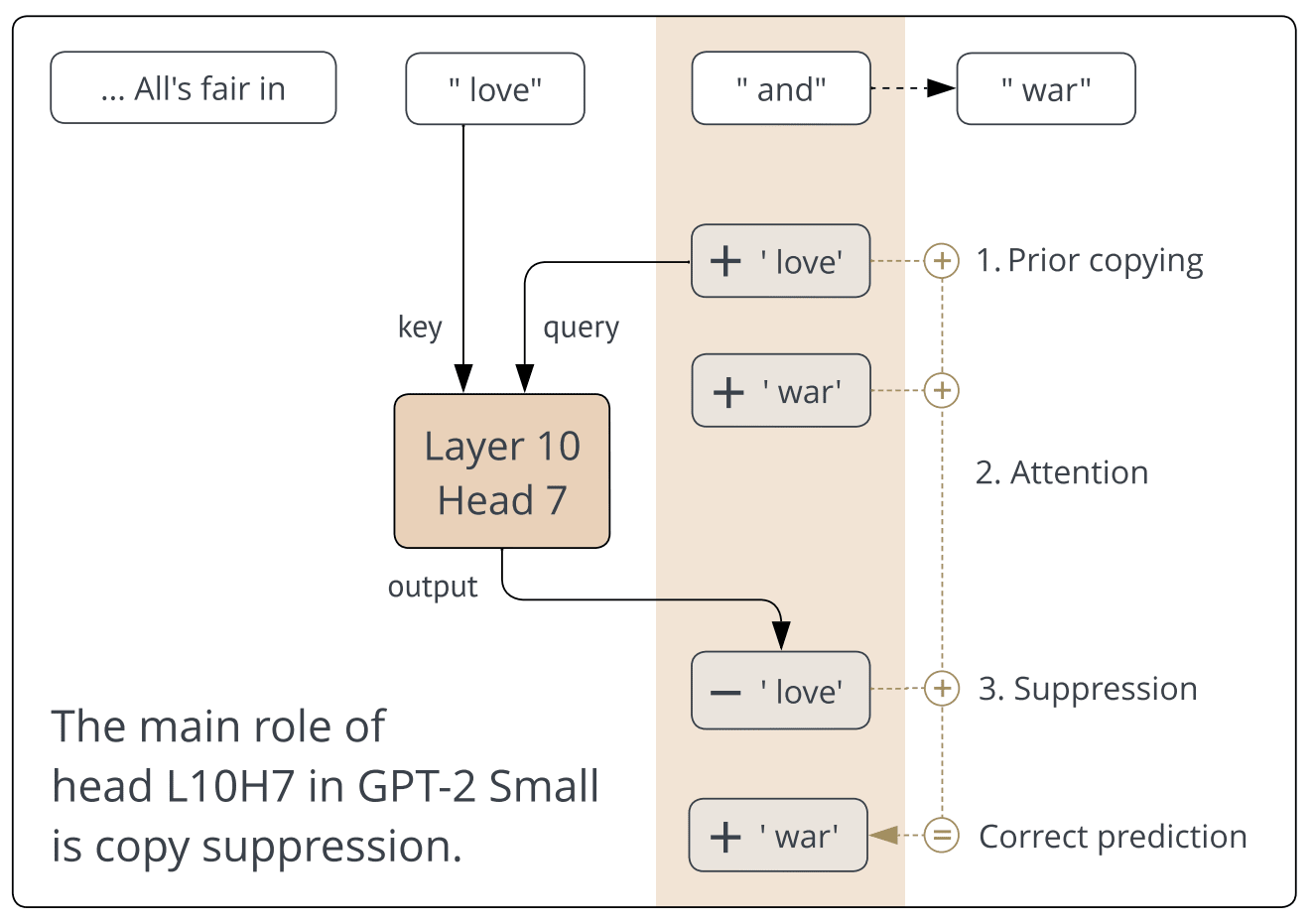
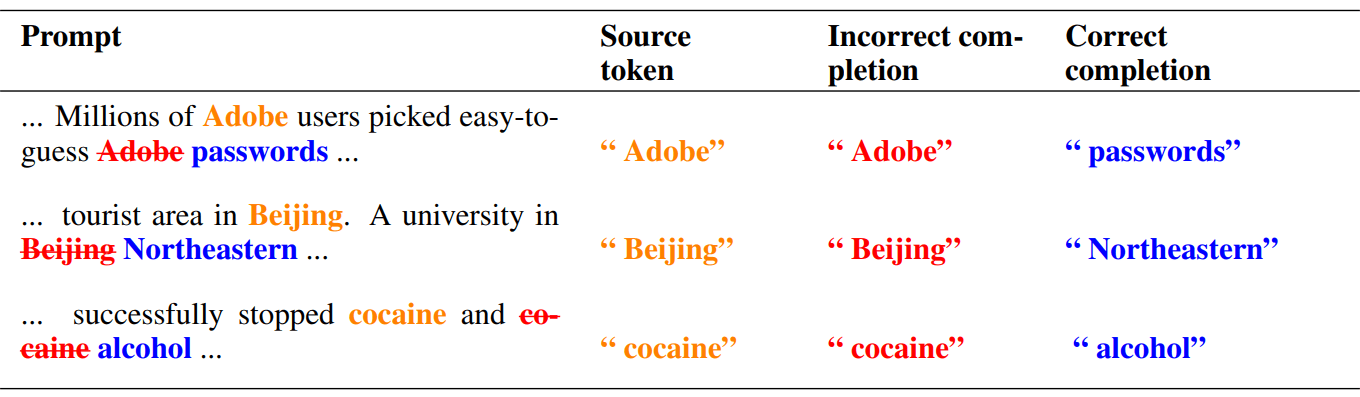
And a few more examples:
Copy Suppression-Preserving Ablation
To test how much of L10H7's behaviour we explained, we designed a form of ablation we called copy suppression preserving ablation (CSPA). The idea is that CSPA should delete all functionality of the head except for the things which are copy suppression. If this completely destroys performance then the head isn't doing copy suppression; if it doesn't affect performance at all.
The technical details of CSPA can be found in our paper. Very loosely, CSPA does two important things:
- Delete all information moving from source token to destination token , except for those where token is predicted at before head L10H7.
- For the information which isn't deleted, project it onto the unembedding for token (and throw away the positive component), so we're only capturing the direct effect of suppressing the token we're attending to.
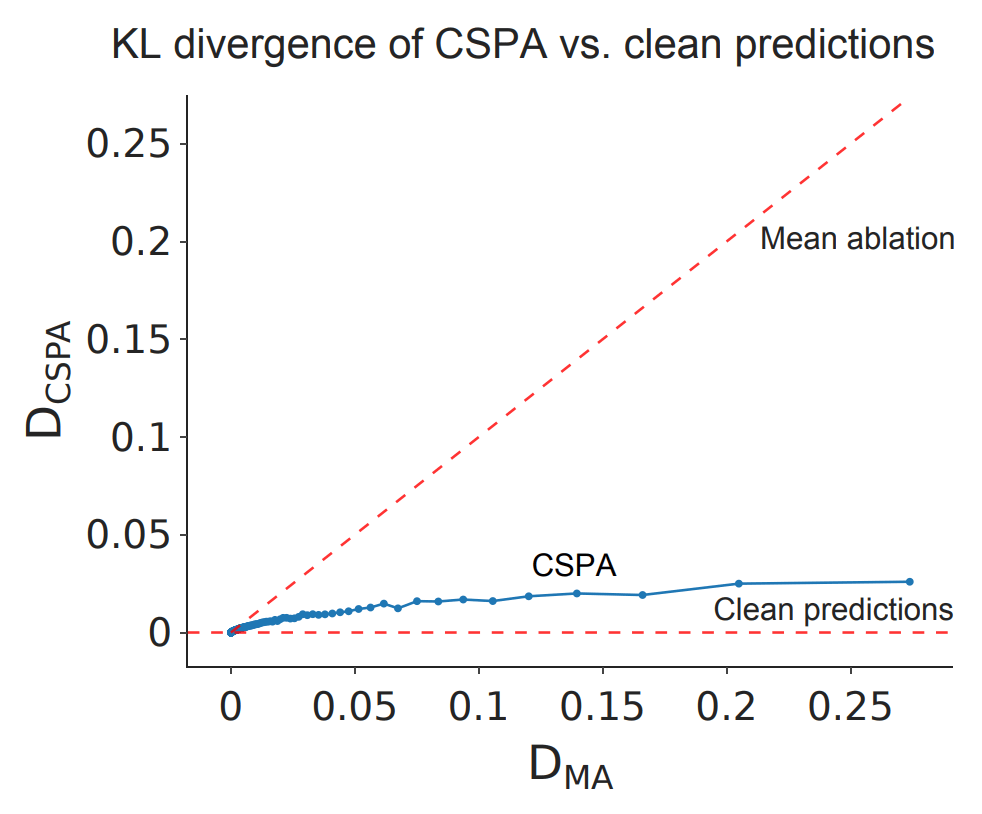
The key result of this paper was the graph below. is the KL divergence between (predictions after applying CSPA) and (original predictions). is the KL divergence between (predictions after mean-ablating) and (original predictions). Each point is the average of a bunch of these values (we've grouped according to the value of ). In other words, each (x, y) point on this graph represents (average KL div from mean ablating, average KL div from CSPA) for a group of points. The line is extremely close to the x-axis, showing that copy suppression is a good description of what this head is doing.
Anti-Induction
Anthropic's paper In-context Learning and Induction Heads observed the existence of anti-induction heads, which seemed to attend to repeated prefixes but suppress the suffix rather than boost it. For example, in the prompt Barack Obama ... Barack, they would attend to the Obama token and reduce the probability assigned to the next token being Obama. This sounded a lot like copy suppression to us, so we compared the anti-induction scores to the copy suppression scores (measured by how much the indirect object token is suppressed in the IOI task), and we found a strong correlation in the quadrant where both scores were positive:
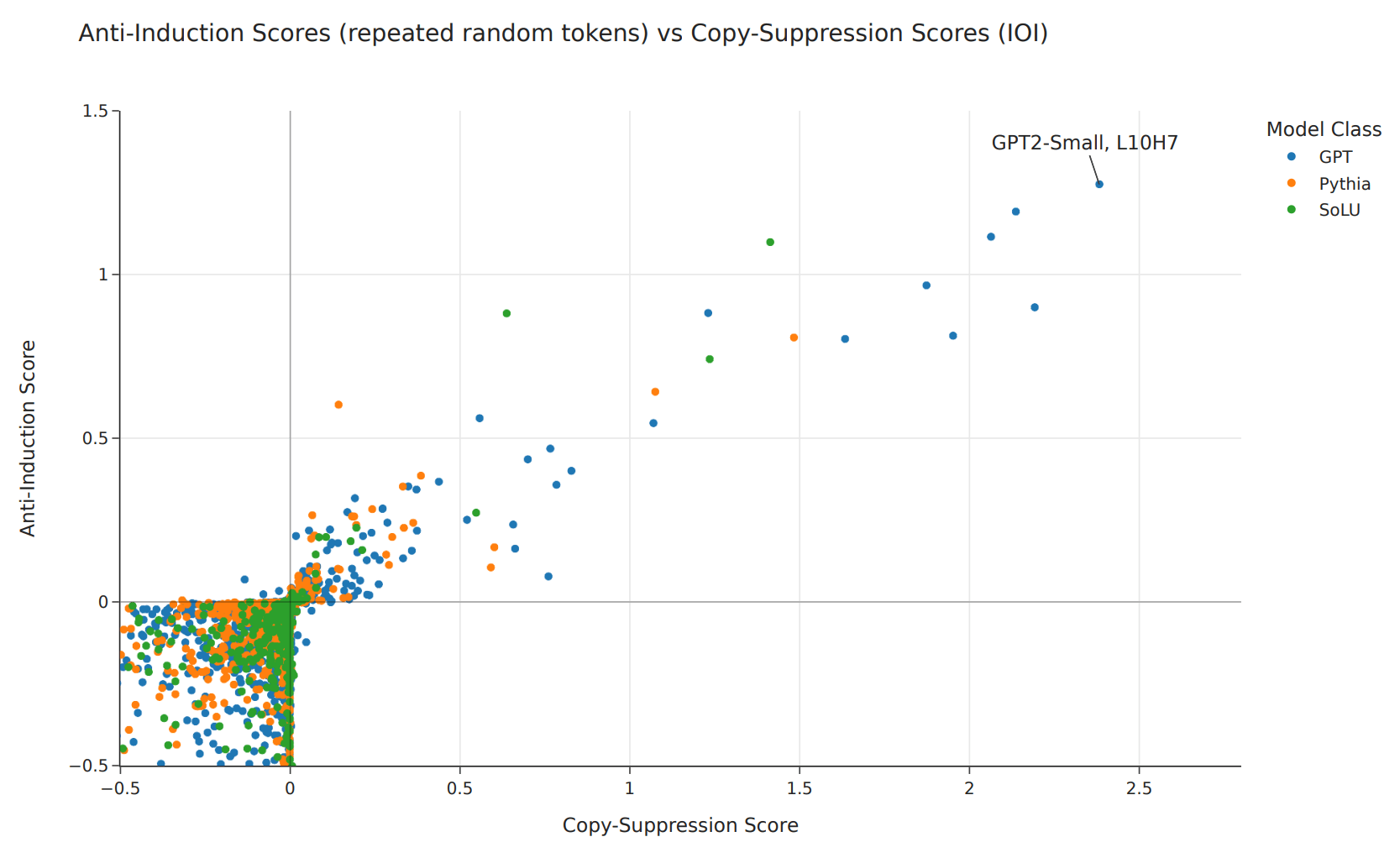
This is particularly interesting because it shows how model components can have an important effect in a particular distribution, despite not having any task-specific knowledge. The general copy suppression algorithm of "attend to and suppress previous instances of the currently-predicted token" seems to be responsible for both the distribution-specific behaviours we observe in the graph above.
Semantic Similarity
Another cool finding: models know when tokens have "semantic similarity". The token (T) predicted doesn't have to be identical to the token attended to; they can differ by capitalization / pluralization / verb tense / prepended space etc. This isn’t fully explained by embedding vector cosine similarity - semantically similar words are copy suppressed more than the cosine similarity suggests.

Self Repair
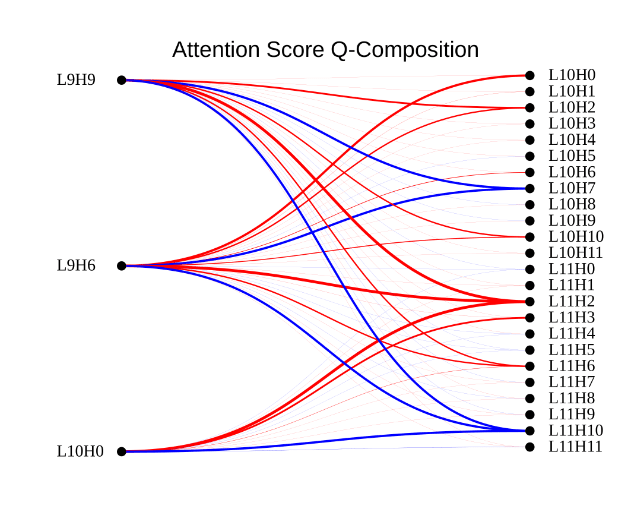
Copy Suppression turns out to be an important part of how models do self-repair, a phenomenon where ablating components leads to later components compensating for the ablation in the same forward pass. Using the Indirect Object Identification (IOI) task as a case example, we highlight how when you ablate copying, there is nothing to copy-suppress: self-repair! This helps resolve the mystery of Negative head self-repair first introduced in the original IOI paper.

We run some experiments to show how Copy Suppression explains some, but not all, of the self-repair occurring in the IOI task. We also use Q-Composition to discover this on a weight-based level. We left with many more questions than we started with, though, and are excited for more future work looking into self-repair!
Interactive Webpage
We also created interactive visualisations to accompany this paper. You can see them on our Streamlit app. This app gives you the ability to do things like:
- Navigate through OpenWebText example prompts, and see (on a per-token basis):
- how much ablating head L10H7 changes the loss & the top predicted tokens,
- which tokens L10H7 is attending to most,
- which tokens L10H7 is boosting / suppressing most.
- Analyse the weights of attention head L10H7, to see which tokens are suppressed most when a particular token is attended to,
- ...and several other features.
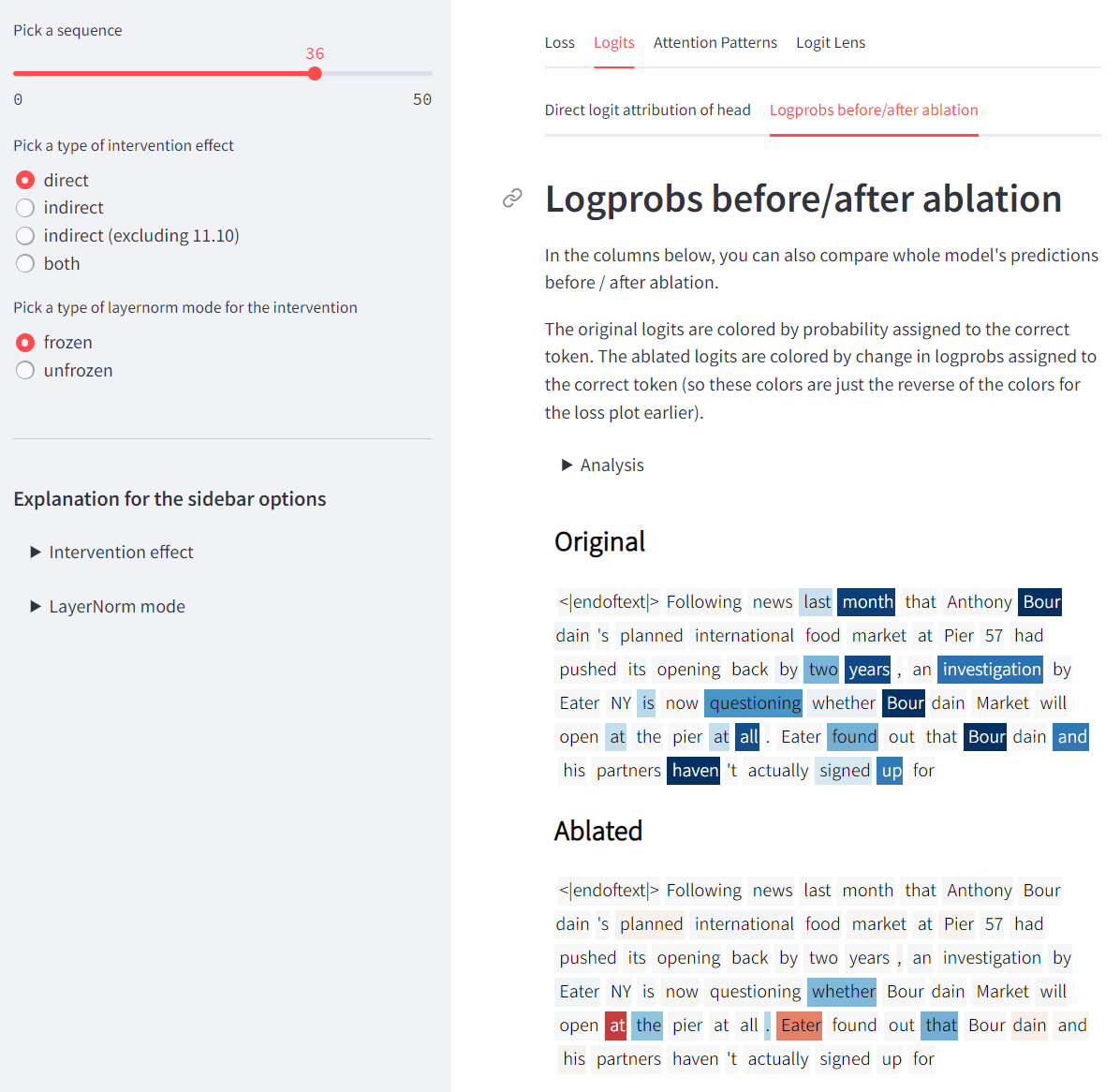
Look at prompts from OpenWebText, and see how important the head is for each token, as well as which tokens' predictions the head most affects, which tokens it most attends to, etc.
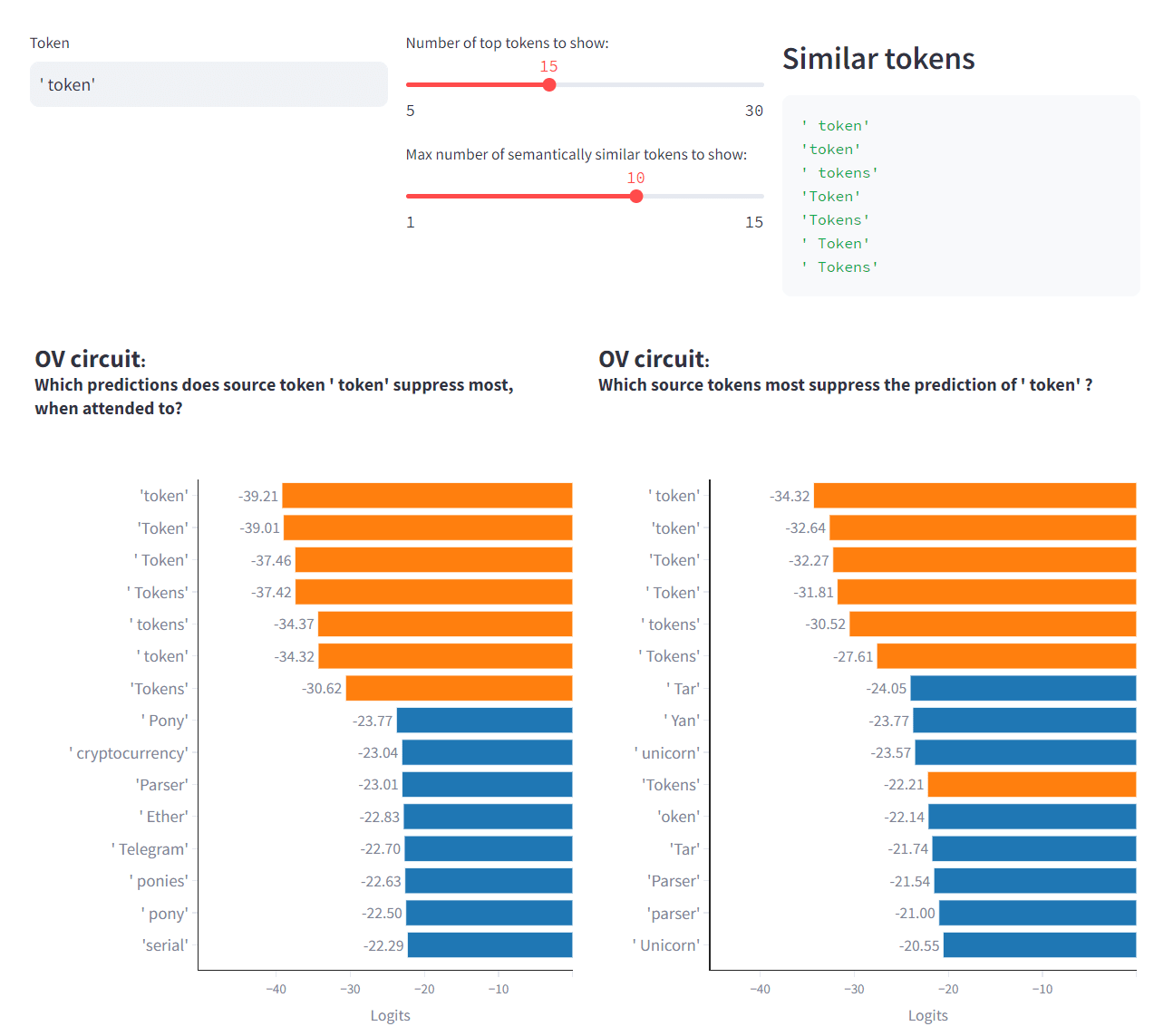
Answer questions like "if token T is predicted, which tokens will be most attended to?", or "if token T is attended to, which tokens' predictions will be most suppressed?"
Limitations and Future Work
While we think our work is the most comprehensive description of an attention head in-the-wild to date, our description is not perfect (76.9% performance recovery) and we weren't able to explain all observations in our project. We highlight the key limitations of our work and point to future directions we think are exciting and tractable given our progress.
- The main limitation of this project was our lack of deep understanding of L10H7's query input. The copy suppression preserving ablation shows that the head is primarily attending to tokens which are predicted, but when we causally intervene by projecting the residual stream onto the directions corresponding to these predictions (i.e. the tokens' unembedding vectors), we significantly harm performance (Appendix N). Further, the unembedding direction also didn't explain self-repair well (Section 4.2).
- Future work could try and understand what other latent variables L10H7 (and backup heads) are using, other than the directions. For example, SAEs provide a way to find important features, and were released after this work. We didn't use SAEs in our project at all, so perhaps this is a way in to this unsolved problem.
- Further, while we show some scalability to larger models in the appendices, it seems that copy suppressors in larger models don't just use the unembedding directions as we didn't find any other heads as clean as L10H7 when we projected outputs onto the unembedding directions. We think good exploratory work could be done to understand similar heads in larger models, including backup heads (such as the self-repairing heads studied in The Hydra Effect) and negative heads (we continually found heads for which had generally negative eigenvalues in e.g Llama models).
- Finally, we're still not totally sure why models devote single attention heads to suppressing predictions. We give some speculative theories in Appendix E but are not certain. One way to get a handle on this would be looking at the copy suppression heads in Stanford GPT-2 and Pythia from the streamlit page and trying to find out why they form through training.
Lessons for future research
I'll conclude with a few high-level takeaways I took from this research project. This will probably be of most interest to other researchers, e.g. on SERI MATS projects.
Note that all of these were specific to our project, and might not apply to everyone. It's entirely possible that if we'd been given this list at the start of the project, then in following these points aggressively we'd have hit different failure modes.
- Brainstorm experiments to red-team your ideas ASAP. For a long time we were convinced that the main query input was the token's unembedding, because we'd only run experiments which also made it look like this was the case. It was only once we ran the causal experiment of projecting the residual stream query-side onto the tokens' unembedding that we discovered this wasn't actually the case.
- Consider ways your metrics might be flawed. This is a specific subcase of the more general point above. We used KL divergence for a lot of our metrics, without realising one potential issue it might have: KL divergence mostly focuses on tokens which already had high probability, so it wasn't capturing cases where an attention head changes loss by boosting / suppressing tokens which already had low probability. This isn't specifically a knock against KL div - all metrics are flawed in some way! Using this as well as fraction of loss recovered helped us make sure our results were robust.
- Be clear on when you're in experiment vs writer mode. We had a period of very high productivity for the first 2 weeks of the program (when we were running experiments and not thinking about writing a paper), and we never quite returned to this level of productivity from that point on.
- Stay in draft mode for as long as necessary. Porting our results from Google Docs to LaTeX was going to be necessary eventually, but I think we should have worked in Google Docs for longer. I personally felt a strong Ugh field towards LaTeX, since it made things like comment threads and efficient editing much less fluid.
- Streamlit is great![1] This one is definitely your-mileage-may-vary, but I think using the Streamlit app significantly boosted our productivity during the program. We could whip up quick illustrations that allowed us to drill down into exactly where our methods were failing, and why (see the next point). It's also easy to create quick shareable links to communicate your research with other people.
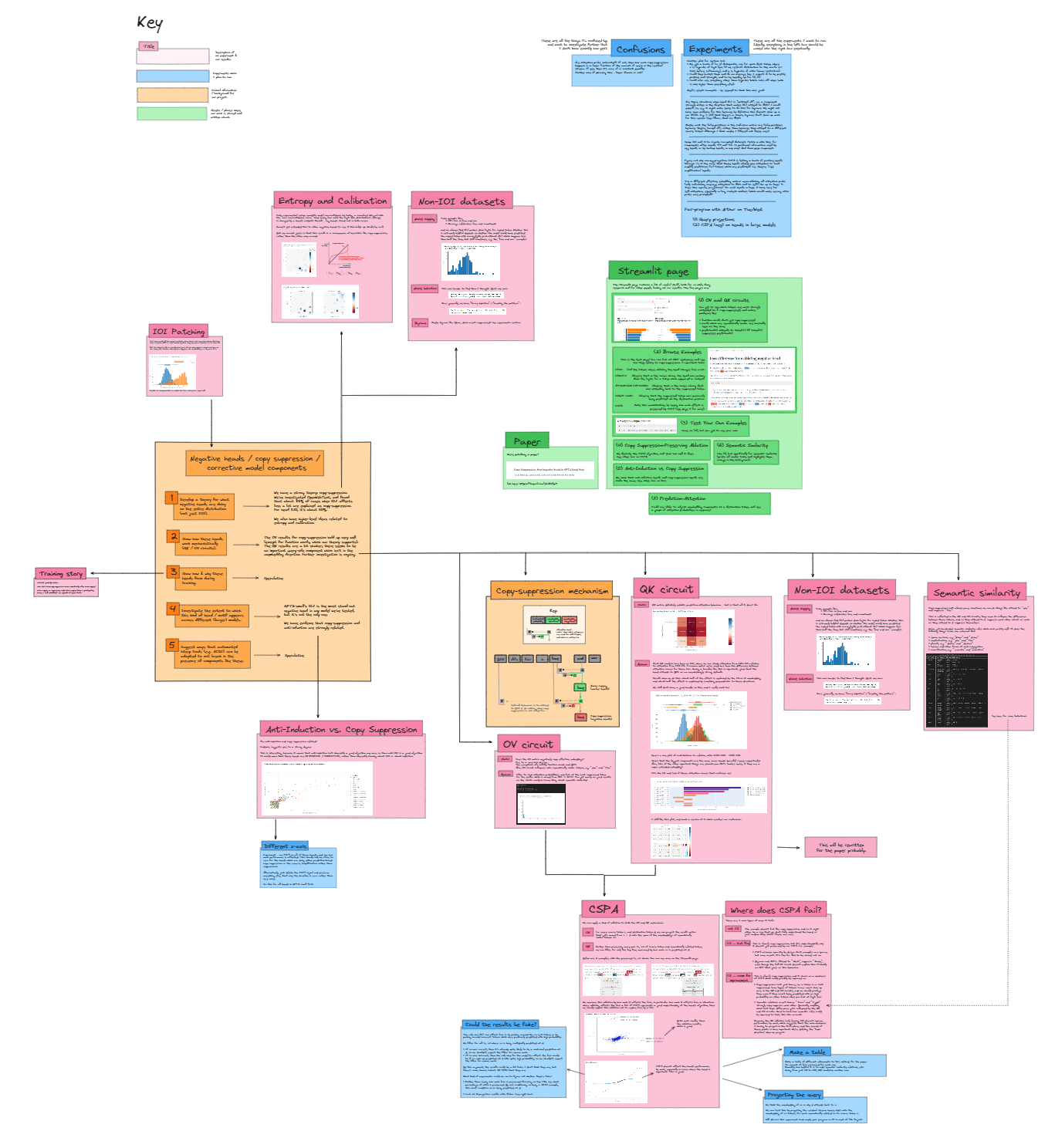
- Use some kind of system for keeping track of high-level project directions and your hypotheses. I found myself using an Excalidraw map for a lot of the project, although for people who don't enjoy using this kind of tool I'm guessing Google Docs & collapsible headers would also have worked fine. The rough scheme I used was:
- Yellow boxes = core information - e.g. central hypotheses or goals of the project.
- Pink boxes = an experiment we had run. Each one summarized the experiment, and maybe included a screenshot illustrating the key results.
- Green boxes = things we were writing / building. Mainly this was the Streamlit page and the paper.
- Blue boxes = an experiment we were planning. Some of these were next to pink boxes because they were follow-on experiments from previous experiments. There were also boxes at the top, to collect "general confusions" and specific experiments which weren't necessarily following on from previous experiments. During the project, I tried (to mixed success!) to make sure these boxes didn't pile up, e.g. one important goal was to take things from the "confusions" box and turn them into experiments I could actually run to resolve that confusion.
- Find a good meta-level research strategy. Some of the most productive times in the project for me were during the development of the form of ablation we used to measure what percentage of L10H7's behaviour was copy suppression. We used the following research cycle, which proved very productive (e.g. it's how we discovered the concept of semantic similarity):
- Develop a form of the ablation algorithm.
- Test it out on OWT, and use the Streamlit app to visualise the results.
- Find anomalous cases where the algorithm fails to capture the head's behaviour, even though the behaviour clearly looks like copy suppression.
- Drill down on these anomalies, figure out why they aren't captured by the ablation algorithm, and adjust the algorithm.
- Iterate, until the visualisation showed us that the ablation algorithm was capturing everything which looked like copy suppression.
Some additional takeaways from Cody Rushing:
- Stay organized. It's great to be in the flow and be making tons of Jupyter notebooks and python files in a flurry as you chase down different tangents and ideas, but without proper documentation, it becomes a mess. I got away with this during the original two-week research sprint, but after some time, I quickly started losing track of what different files were for, where I performed X experiment, and why I thought idea Y.
- I haven't completely solved this issue, but taking better research notes where I document what I'm doing, why, and where has been a good start
- Update from the darn results. I got stuck on one research direction where I kept trying to do various complex ablations to highlight one hypothesis of self-repair that I thought was true. Despite the fact that I repeatedly got results which didn't confirm my hypothesis (nor entirely falsify them), I kept banging my head against pursuing this dead end. For almost two weeks. Far too long! I wish I had just seen the results and updated far earlier, saving me time and a bit of burnout.
- Trading off effectively between doing broad vs in-depth research is tricky. Learning when to stop pursuing a research direction is an important research skill that I undervalued. I don't have great ideas of how to get much better at it, but comparing your research intuitions with a mentor seems like a good way to start.
- ^
This post is not sponsored by Streamlit in any way, shape or form.
4 comments
Comments sorted by top scores.
comment by Joseph Bloom (Jbloom) · 2023-10-26T19:32:50.328Z · LW(p) · GW(p)
Cool paper. I think the semantic similarity result is particularly interesting.
As I understand it you've got a circuit that wants to calculate something like Sim(A,B), where A and B might have many "senses" aka: features but the Sim might not be a linear function of each of thes Sims across all senses/features.
So for example, there are senses in which "Berkeley" and "California" are geographically related, and there might be a few other senses in which they are semantically related but probably none that really matter for copy suppression. For this reason wouldn't expect the tokens of each of to have cosine similarity that is predictive of the copy suppression score. This would only happen for really "mono-semantic tokens" that have only one sense (maybe you could test that).
Moreover, there are also tokens which you might want to ignore when doing copy suppression (speculatively). Eg: very common words or punctuations (the/and/etc).
I'd be interested if you have use something like SAE's to decompose the tokens into the underlying feature/s present at different intensities in each of these tokens (or the activations prior to the key/query projections). Follow up experiments could attempt to determine whether copy suppression could be better understood when the semantic subspaces are known. Some things that might be cool here:
- Show that some features are mapped to the null space of keys/queries in copy suppression heads indicating semantic senses / features that are ignored by copy suppression. Maybe multiple anti-induction heads compose (within or between layers) so that if one maps a feature to the null space, another doesn't (or some linear combination) or via a more complicated function of sets of features being used to inform suppression.
- Similarly, show that the OV circuit is suppressing the same features/features you think are being used to determine semantic similarity. If there's some asymmetry here, that could be interesting as it would correspond to "I calculate A and B as similar by their similarity in the *california axis* but I suppress predictions of any token that has the feature for anywhere on the West Coast*).
I'm particularly excited about this because it might represent a really good way to show how knowing features informs the quality of mechanistic explanations.
comment by Tomek Korbak (tomek-korbak) · 2023-10-17T11:45:08.475Z · LW(p) · GW(p)
Cool work! Reminds me a bit of my submission to the inverse scaling prize: https://tomekkorbak.com/2023/03/21/repetition-supression/
comment by Sheikh Abdur Raheem Ali (sheikh-abdur-raheem-ali) · 2023-11-01T01:03:45.561Z · LW(p) · GW(p)
https://arxiv.org/abs/2310.04625. is a dead link. I was able to fix this by removing the period at the end.
Replies from: arthur-conmy↑ comment by Arthur Conmy (arthur-conmy) · 2023-11-01T01:30:02.934Z · LW(p) · GW(p)
Thanks, fixed