What Is The True Name of Modularity?
post by CallumMcDougall (TheMcDouglas), Lucius Bushnaq (Lblack), Avery · 2022-07-01T14:55:12.446Z · LW · GW · 10 commentsContents
TL;DR Introduction Setting constraints Function of the model, not the system Extreme cases Hierarchical Function of information flows, not architecture Some example measures we don’t think do the job Q-score Clusterability in Neural Networks What are the right tools? Mutual information Causality Next steps Further considerations / final notes None 10 comments
TL;DR
Modularity seems like an important feature of neural networks, but there is currently no canonical way of properly defining or measuring it which is properly theoretically motivated and doesn’t break down in some cases - in other words, we haven’t yet found a True Name [LW · GW] for it. Most modularity measures used in experiments are based on ad-hoc methods from graph-theory or network theory, and don’t seem to capture the kind of modularity we care about.
In this post, we explore these existing ways of measuring modularity in neural networks, and their limitations. We also outline our ideas for a new modularity metric, and in particular the important role we think two branches of mathematics will play:
- Information theory, because neural networks are fundamentally information-processing devices, and we want to measure how this information is being used, exchanged and transmitted. In particular, we expect mutual information to be at the core of any metric we use.
- Causal inference, because correlation (and indeed mutual information) does not automatically equal causation, and we need a way of distinguishing “modules and fire with similar patterns” from the more specific claim “modules and are directly sharing information with each other”. In particular, we expect counterfactuals to play an important role here.
Introduction
A first-pass definition for modularity might go something like this:
A system is modular to the extent that it can be described in terms of discrete modules, which perform more intra-modular communication than inter-module.
In previous posts, we’ve talked about some causes of modularity in biological systems [LW · GW], reasons we should care about modularity in the first place [LW · GW], and unanswered questions about modularity which require experimentation [LW · GW]. In this post, we will return to a more theoretical question - how can we develop a yardstick for measuring modularity, which is built on sound mathematical principles?
First off, why is this an important thing to do? Because most current ways of measuring modularity fall pretty short. As recently discussed [LW · GW] by John Wentworth, if all you have is a weak proxy for the concept you’re trying to measure, then your definition is unlikely to generalise robustly in all the cases you care about. As a simple example, most architectural ways of measuring modularity in neural networks are highly dependent on the type of network, and we shouldn’t expect them to generalise from CNNs to transformers.
Ideally, we’d eventually like to find a robust theorem which tells you in which cases modularity will be selected for. But unless we have the right language to talk about modularity, we will be stuck with hacky ad-hoc definitions that are very unlikely to lead to such a theorem.
Setting constraints
The lesson from John’s post [LW · GW] is that we can’t just do random search through the high-dimensional space of mathematics to find something suitable. We have to start by writing down some intuitions for modularity, and constraints which we expect a modularity measure to satisfy.
Adam Shimi uses the analogy [LW(p) · GW(p)] of a set of equations, where we ideally write down enough to specify a unique solution, or else hone in on a narrow region of solution space.
What would the equations be in this case? What are our constraints on a modularity measure, or some intuitions we expect it to satisfy?
Function of the model, not the system
It’s meaningless to define the modularity of a system without reference to the things that are acting as modules. So in order to measure modularity, we have to first choose a partition into modules, and measure something about the system with respect to this partition.
Which partition should we choose? It makes sense to choose the partition which results in the highest modularity score on whichever metric we use, because this is in some sense the “most natural modular decomposition”. As an example, consider the diagram below (red and blue nodes represent a partition into 2 modules). The first partition is clearly natural, and we can see that the system has perfect modularity with respect to this partition. The second partition is obviously unnatural because the two “modules” actually have a large number of connections.
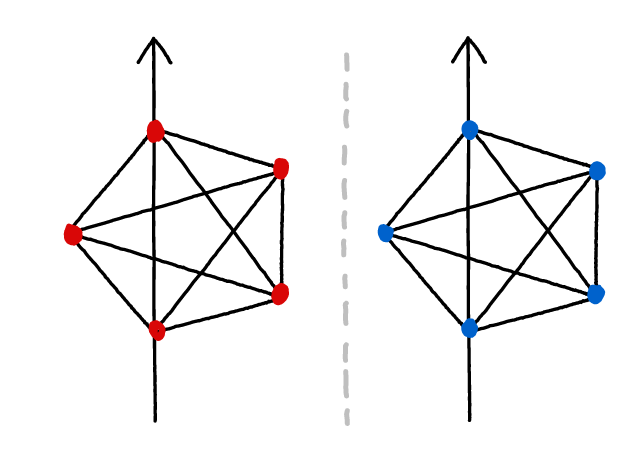
Extreme cases
Some of the intuitions for correlation coefficient [LW · GW] involved extreme cases (independence implying , and implying perfect dependence). What are the extreme cases in modularity?
Perfect anti-modularity: any pair of modules shares as much information as any other. There is no way to partition the nodes in the network in a way such that more computation (proportionally) is done between nodes in the same module vs between nodes in different modules.
Perfect modularity: there is literally zero communication between any pair of modules. Note that we’d have to be careful applying this: if our choice of “modular decomposition” is to just have one module, then this is trivially perfectly modular by this definition. The example above is a better illustration of perfect modularity: two completely isolated subnetworks; each one fully connected.[1]
Hierarchical
As discussed above, modularity has to be a function of some particular model of a system, consisting of a set of modules. But we should be able to further break down each module, and identify modularity within it.
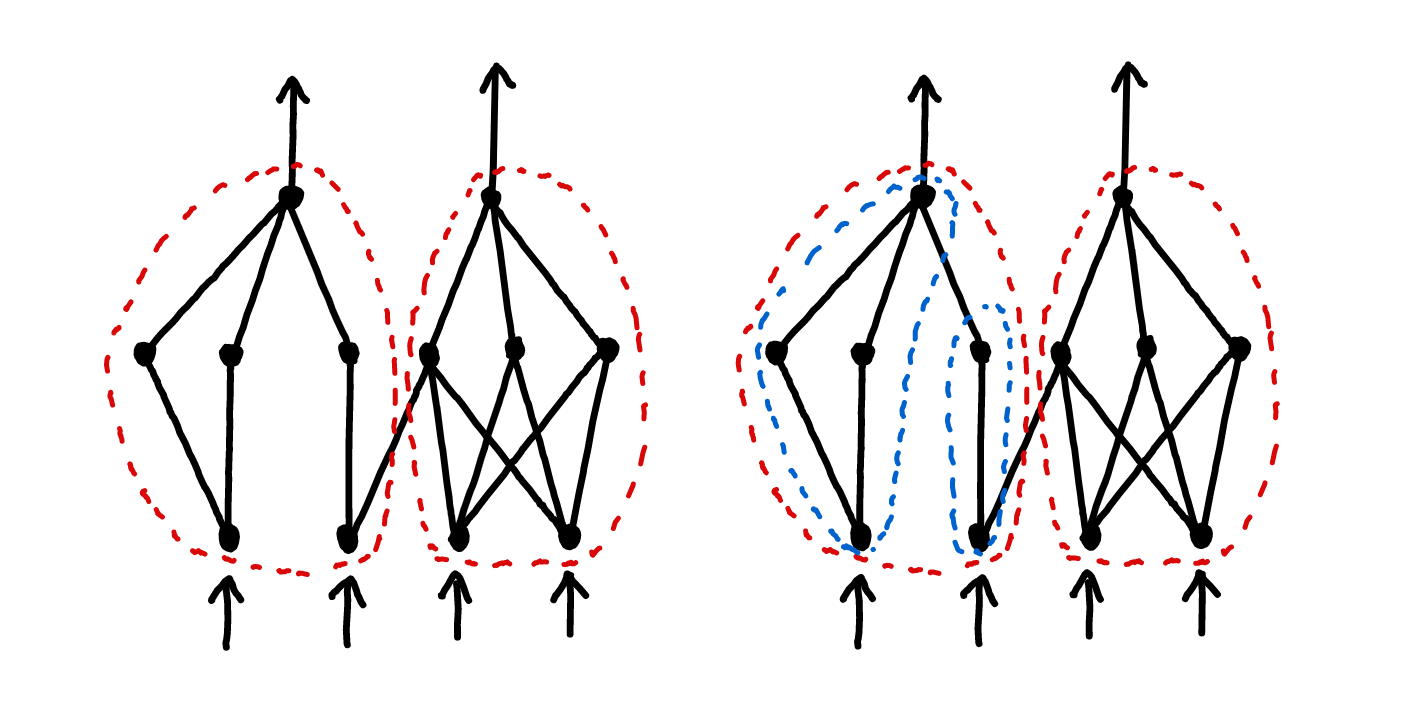
One example: biological systems are modular at many different levels, from organs and organ system to cells and protein structure.
Function of information flows, not architecture
This requirement is motivated from a couple of different angles:
We could construct a pathological network which has some node that never gets activated, regardless of the input (this is really easy to do, we just need all the weights going into this node to be blocked). Obviously a modularity score shouldn’t depend on this weight, because it doesn’t represent any real information flows.
Fundamentally, NNs are information-processing devices, so in a way it seems intuitive to us that any measure of their modularity should use the language of information theory, not just analysis of weights and other architectural features.
Additionally, we are researching modularity in the context of discovering Selection Theorems [LW · GW] about it. The kind of modularity we are looking for is whatever kind seems to be selected for by many local [LW · GW] optimisation algorithms, e.g.:
- By evolution, in natural organisms at every scale
- By genetic algorithms and gradient descent, in neural networks
This might initially seem like a hint to look at the architecture instead. After all, it’s the physical makeup of biological brains, and the parameters of neural networks, that seem to be most directly modified during the optimization process. So if you want theorems about when they select for modularity, why not define modularity in terms of these parameters? Because we think there are some hints, coming from places like the Modularly Varying Goals effect, as well as connections between the modularity of neural networks and their generality (post on this part coming soon), that modularity is connected to abstraction [LW · GW], possibly quite directly so.
As in, abstractions used by brains and neural networks may in some sense literally be information processing modules inside them. That’s a pretty naïve guess, the actual correspondence could well be more complicated, but it does seem to us like there’s something here.
Since abstraction is an information theoretic concept, we think this may be pointing towards the hypothesis that what’s selected for is really something information theoretic, which just correlates with the modularity in the physical architecture sense that we more readily observe.
Some example measures we don’t think do the job
Q-score
The seemingly most widely used measure/definition in papers whenever someone wants to do something modularity related with neural networks is the Q score, borrowed from graph theory (which we’ve talked about in a previous post [LW · GW]).
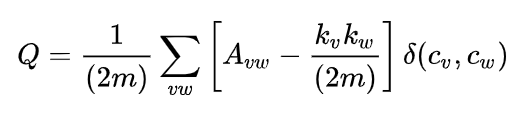
This is a rather hacky, architectural measure based on the weights in the network. The bigger the weight between two neurons, the more connected they are, goes the basic idea.
This definitely captures our intuitive notions of modularity if we’re talking about an undirected graph as a purely topological structure, i.e. not functional / no information flows. We think (hope) that this measure is at least correlated with “true” modularity in a lot of real networks, but we don’t think it’s a good fundamental definition.
Clusterability in Neural Networks
This was a paper that came out in 2019. It looks for internal structure in neural networks using a different formula than the Q-score, the normalised cut, which is based on similar ideas of modules having strong internal connectivity and weak external connectivity, as inferred from their weights. Therefore, this suffers from similar problems: looking at the architecture, not information flows. For instance, before applying the metric, the authors convert the neural networks into a weighted undirected graph in a way which is invariant of the biases, and biases can be the difference between a ReLU node activating and not activating - this is a pretty big red flag that we may not be capturing the actual behaviour of the network here!
A subsequent paper, Quantifying Local Specialisation in Deep Neural Networks, takes this further by taking into account high correlation of neurons, even if they aren’t directly connected via weights. Importantly, this is functional rather than architectural, so by our criteria, it represents a step in the right direction. However, the methodology is still fundamentally based on the architectural measure from the previous paper.
What are the right tools?
Mutual information
A very simple way of measuring information flow in a neural network one could think of is literally counting how many floating point numbers pass between the nodes. But that information doesn’t tell us much about the network’s actual structure, and how much information is really being communicated through these numbers. For example, all nodes with an equal number of incoming connections will receive an equal amount of incoming information according to this measure. In reality, the node might e.g. only react to whether the incoming signals are greater than zero or not. If that happens for inputs, the information communicated to the node would be bits, no matter how many floats are involved in the operation. If it happens for inputs, it’d be bits.
Information theory 101 might tell you that what you’re looking for is the mutual information between nodes. This measures how many bits of information the two have in common.
The formula for mutual information[2] is
where , are the probability distributions over the possible values of nodes and respectively.
An alternative expression using conditional instead of joint probability distributions is
since Bayes tells us that .
So you measure the joined and marginal distributions of the activations of and on all the training data, and off you go, right?
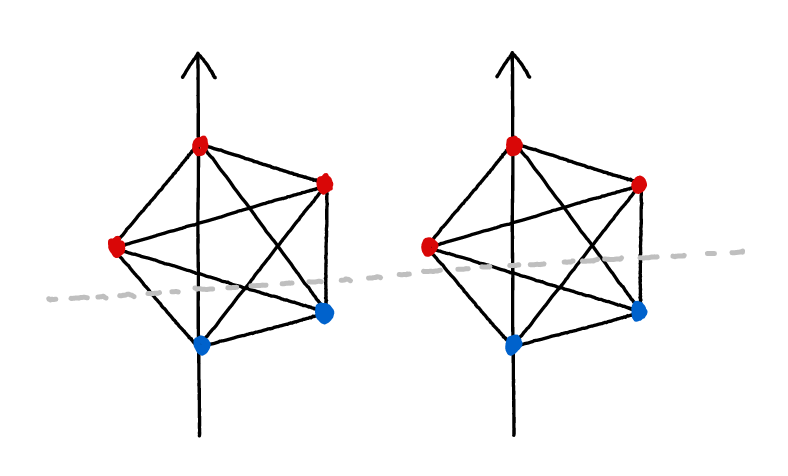
In some specific cases, this works - for instance, in the example on the left below. In this case there’s no direct connection between and . But in more general networks, we don’t think so. Mutual information seems like the right thing to look at, but outside such simple cases, you have to be somewhat careful about which mutual information you use.
For example, if both and were fed some of the same signals from an input (e.g. the right image below), they’d have mutual information even if they exchanged no signals with each other at all.[3]

In feedforward neural networks, this kind of pattern is very frequent. For instance, suppose you had a network which was trained to output two numbers: the total number of ducks in an image, and the total number of shadows. Furthermore, suppose that in the training data, a sizeable fraction of the shadows are caused by ducks. Then, even if the network finds a perfectly modular solution which performs two completely separate tracks of computation (one for the number of shadows, one for the number of ducks), you will still get high mutual information between these two tracks, because the features you’re measuring are highly correlated in the training data.

In summary, we wanted to measure how many bits of information and communicated to each other, but instead we’ve found ourselves just measuring how many bits they share, which is not the same thing at all.
Causality
Alright, you say, easy enough to fix. Just subtract the mutual information shared by all of , and from the mutual information between and ! Then you’ve thrown away these spurious bits you don’t want, right?
Nope. Counterexample: Say , with all the information sends to also being send to . Since and are just deterministic functions of , this would tell you .[4] So . Your measure says that no information was exchanged.

But that doesn’t seem generally true at all, in the sense we care about! If is an integer, (e.g. 345789), divides this integer by three (), and takes the result from and adds it to the original number from (), then C is clearly getting “relevant information” from , even though the output of is technically inferable from .
To put it another way, if Bob is told that Christine is going to calculate the prime factorisation of and tell him the result five minutes from now, then in a sense, him being told this particular number and not any others is going to predictably coincide with Christie saying “”, and he isn’t gaining any information. But unless Bob is actually doing the prime factorisation himself, then it sure seems like he received new information from Christine in some sense.
So how do you actually separate this out? How do you measure how much information is exchanged between and in the sense we seem to care about?
The core problem here is that as far as our distributions over node activations are concerned, everything in the neural network is just a deterministic function of the input . Once you know the activations of , the activations of B and C are fixed. There is no information to be gained from them anymore.
But in common sense land, we know that just because you have all the data to theoretically infer something, doesn’t mean that you actually can or will do so in practice. So if someone else hands you that inference, you gained information.
So let’s go back to our mutual information formula, and see if we can look at slightly different distributions to capture our elusive common-sensical sense of information gain.
How do we describe, in math, that the inferences sends to are new information to , when information theory stubbornly insists that the inferences are already perfectly determined by the data?
Counterfactuals.
You have to admit math that can express the signal sends as being uncertain; as a new source of information to , even when “in reality” it’s always determined by . So you have to look at what happens when B outputs signals to that differ from what they would be in reality (determined by the input signals from ). As in, sends , but is falsified such that it does not give out the correct prime factors, and sends something else instead.
How do you measure distributions over counterfactuals?
By running your neural network in counterfactual situations, of course!
You run the network over the whole training data set, as normal. You record the distribution of the activations , , as normal.
Then you go and run your network over the training set again, but artificially set the activations of to values they wouldn’t normally take for those data points. Then you measure how responds to that.
But what values should you set to? And with what distribution?
This is the part in all this we’re currently most uncertain about. Right now, to start, we think it should be tried to just use the distribution measured in the normal training run, but with its correlation with the input broken.
In other words, the “prior” we assume for here to calculate the information exchange is that it knows what sort of signals usually sends, and with what frequency, but it can’t tell in advance which inputs from should cause which signal from . The signals from are independent bits. This captures the notion of Bob not knowing what the result of Christine’s calculation will be, even though he could find out in theory.
Expressing this intervention in the notation causality, this makes our proposed measure of the information exchanged between B and C look like this:
for this simple situation.
It’s just like the normal formula for mutual information above, except the conditional probability distributions have a “do” operator in them now, which represents the action of artificially setting the activation on node node to the value (i.e. we’re conditioning on an intervention, not just an observation).
We don’t have a proof for this. It comes from intuition, and the line of reasoning above. The measure seems to give the right answers in a trivial coin toss thought experiment, but it has not been tested in more complicated and varied situations yet. We’re also a bit unsure how you’d make it work out if and stretch over multiple layers of your feed-forward network, allowing information exchange in both directions. Though we have some ideas.
Next steps
The next step is testing this out in some extremely simple neural networks, as part of the experiments outlined under point nine in our experiments post [? · GW].
Of course, this isn’t an actual modularity measure/definition yet, just a building block for one. If it turns out to be a good building block, or becomes one after some iterations of the experiment/theory feedback loop, how do we proceed with it?
The next step would be finding an analogous implementation of something like the Q score in graph theory.
One naïve way I could see this working right now: Say you start by proposing to partition your network into two modules[1]. You run the network through the training set once, and record the activations. Then you go through all possible partitionings, and perform an “intervention” network run to measure the information exchange between the subgraphs in each. You apply some weighting (which exactly?) to account for partitions with very few nodes to naturally send very little information. Calculate the average information exchanged over all partitionings.
Then, you take the partitioning resulting in the minimum information exchange. Those are your two modules. Divide the average information exchange by this minimum, and you have your modularity measure. It tells you how much information your modules exchange with each other, relative to how much information is flowing in this network in general.
Obviously, this procedure would be infeasibly expensive in a real network. We want to focus on finding the right measure and definition of modularity before we go worrying about ways to compute it cheaply, but for the more practically minded, a few rough intuitions to show that this probably isn’t as bad as it looks at first.
First, you don’t need the average information exchange over all the partitions. If you statistically sample partitions and take the average information of those, that’ll get you an estimate of the true average with some statistical error. You just need enough samples to make that error small enough.
To find the partition with minimum information exchange, you can search through partition space a lot more cheaply than just trying all the combinations. Use a genetic algorithm, for example.
If you can find some other, cheaper measure than correlates decently well with the true information exchange, even if it isn’t exactly right, you can use that to perform most of the steps in your search, and only use the more expensive true measure every now and then, to course correct or check end results. One thing we’re eyeing for this for example is the dimensionality of the interface between the partitions, which should be findable by looking at the Hessian matrix of the network output. You could also use the old graph theory measure based on physical weights. How close these various proxies are to the real thing we’re after is another thing we’re hoping to figure out from experiment 9 [? · GW].
Further considerations / final notes
As a final note, after some helpful input from Quintin Pope, we’ve recently reconsidered whether using individual neurons as the unit to construct the modules out of is really the right call. Things like polysemantic neurons seem to hint that the network’s internal computation isn’t necessarily best described in the neuron basis. So we might still be lending the physical structure of the network too much weight over its information processing properties by defining modules as groups of neurons.

So we’re considering reformulating things so that modules are defined as subspaces in feature space [AF · GW] instead, allowing for different bases in that space than the single neuron one. This thinking is in its infancy however.
So that’s the state of things right now. We’re currently mainly waiting for basic experimental data before we theorise more, but if anyone reading this can spot something, that could help a lot too. We’re not information theorists. It’s entirely likely we missed things.
- ^
How to choose the correct number of modules to partition into isn’t clear yet either. For more thoughts on this question, see this recent post [LW · GW].
- ^
This is the formula for mutual information of discrete random variables, where the sum is over the finite set of possible values the variables can take. For continuous ones it’s slightly harder, so what we end up doing in practice is sorting the continuous activations of neurons into (say) ten different buckets, and treating them as discrete RVs.
- ^
In the language of causality, we say that is a confounder of and .
- ^
Three variable mutual information is defined by:
This is symmetric in , and it can also be written as , where the latter expression is the conditional mutual information (i.e. the expected amount of information and would share, if we knew ). If either or are deterministic functions of , then this conditional mutual information term is zero (because no constant can have mutual information with anything), so we get as claimed above.
10 comments
Comments sorted by top scores.
comment by Thomas Larsen (thomas-larsen) · 2022-07-02T01:16:34.722Z · LW(p) · GW(p)
Do you have an idea in mind for how the proposed formula could be applied to a neural network?
The rough idea in my head is to do something like: look at the network activations at each layer for a bunch of different inputs. This gives you a bunch of activations sampled from the distribution of activations. From there, you can do density estimation to estimate the actual distribution over the activations. Doing this while hardcoding in gives us a way to sample the distribution of conditioned on .
The problem with this is that density estimation seems hard with very high dimensional data. Did you have a different way in mind of implementing this?
Replies from: Lblack↑ comment by Lucius Bushnaq (Lblack) · 2022-07-02T05:12:10.006Z · LW(p) · GW(p)
I don't think an "actual distribution" over the activations is a thing? The distribution depends on what inputs you feed it. I don't see in what sense there's some underlying "true" continuous distribution we could find here.
The input distribution we measure on should be one that is representative of the behaviour of the network we want to get the information flows for. To me, the most sensible candidate for this seemed to be the training distribution, since that's the environment the network is constructed to operate in. I am receptive to arguments that out of distribution behaviour should be probed too somehow, but I'm not sure how to go about that in a principled manner.
So for now, the idea is to have P_B literally be the discrete distribution you get from directly sampling from the activations of B recorded from ca. one epoch of training data.
EDIT: The estimator we planned to use was just counting the frequencies. If we were trying to get the mutual information of some underlying distribution that the training samples are statistically drawn from, that would be a problem. The estimator would be biased. But since those are literally the probabilities the actual training process uses, I think this should be correct. We're trying to get the mutual information of draws from the training data set, not the mutual information of some statistical process that produced the training data set.
Replies from: viktor.rehnberg, TheMcDouglas↑ comment by Viktor Rehnberg (viktor.rehnberg) · 2022-07-04T07:17:08.836Z · LW(p) · GW(p)
I don't think an "actual distribution" over the activations is a thing? The distribution depends on what inputs you feed it.
This seems to be what Thomas is saying as well, no?
[...] look at the network activations at each layer for a bunch of different inputs. This gives you a bunch of activations sampled from the distribution of activations. From there, you can do density estimation to estimate the actual distribution over the activations.
The same way you can talk about the actual training distribution underlying the samples in the training set it should be possible to talk about the actual distribution of the activations corresponding to a particular input distribution.
I believe Thomas is asking how you plan to do the first step of: Samples -> Estimate underlying distribution -> Get modularity score of estimated distribution
While from what you are describing I'm reading: Samples -> Get estimate of modularity score
Replies from: Lblack↑ comment by Lucius Bushnaq (Lblack) · 2022-07-04T08:13:30.449Z · LW(p) · GW(p)
Thanks for clarifying for me, see the edit in the parent comment.
Replies from: thomas-larsen↑ comment by Thomas Larsen (thomas-larsen) · 2022-07-08T01:48:45.653Z · LW(p) · GW(p)
Thanks, this is indeed what I was asking.
↑ comment by CallumMcDougall (TheMcDouglas) · 2022-07-02T07:16:47.071Z · LW(p) · GW(p)
I guess another point here is that we won't know how different (for example) our results when sampling from the training distribution will be from our results if we just run the network on random noise and then intervene on neurons; this would be an interesting thing to experimentally test. If they're very similar, this neatly sidesteps the problem of deciding which one is more "natural", and if they're very different then that's also interesting
comment by Gurkenglas · 2022-09-20T01:16:48.681Z · LW(p) · GW(p)
I'm uncomfortable sending proto-AGI out of distribution. Measuring (conditional) mutual information by how well an auxiliary network predicts some activations from others is potentially asymmetric and intransitive, could that serve?
Replies from: Gurkenglas↑ comment by Gurkenglas · 2022-09-20T01:20:53.310Z · LW(p) · GW(p)
Also, I vaguely remember that Judea Pearl's Causality explains how to infer causality from mere correlational data.
Replies from: niplav↑ comment by niplav · 2022-10-05T16:37:52.792Z · LW(p) · GW(p)
Yes, the IC and IC* algorithm (described respectively on p. 50 and 52 of Causality) describe how to infer some parts of the causal DAG from a stable probability distribution.
(Not-so-fun fact: Both of these don't have Wikipedia articles!)
comment by Gareth Smith (gareth-smith) · 2022-07-08T17:54:08.176Z · LW(p) · GW(p)
I would tend to say granularity, which I take to be defined by surface area to volume ratio, but with the context of scale. It's sort of fractal, in a non-linear way.
So for this example, the number of connections you can get into a certain volume is limited by the the processing and receptor ability inside the volume, and the surface area to provide entry points, so this is potentially the ultimate metric of capability for a region/space/functional sub-system that is specialised to one function.
I make up a dimensionless unit for this, m2/m3 or metres squared per metre cubed, but it's not 1/m.
Surface area to volume ratio figures in all sorts of areas in life - lead is flammable in air if it is ground finely enough, do it under glycol, then rub it between your fingers until dry and then throw a flash of fire. (Clowns used to do this, not any more, obviously). But the reason powders are an explosion risk is surface area to volume ratio (eg flour, or the dust generated when machining grooves in buttons etc). All sort of chemistry and cooking depend on this factor, even if you don't realise when making your emulsion of tea or mayonnaise. And after all what is nano technology, but materials behaving differently at very small scale, and some of that is due to volume decreasing much faster than surface area when you get very small.
Take a 1m cube. 6m2/1m3 = ratio of 6.
Take a 1 cm cube 0.0006m2/0.0000001m3 = ratio of 600.
And that's still well into human scales, at a mm it's a ratio of 6000.
Stuff that needs to get in, like heat, chemicals or light, can get in to the entire volume much more easily and quickly, impacting the way almost everything works - reactions, heating and cooling.
Yet the flip side is if you want to abrade, coat or polish the surfaces, a huge amount more material or energy is now required because the surface area is going up exponentially, but the hardness, as one example does not lessen any (generally). All of a sudden the same volume of material needs a lot more paint, or grinding/polishing energy.
But also the contact areas change and fluidisation or non-newtonian behaviour can emerge. For a seemingly simple concept that doesn't really have an SI unit, it can have complex impacts.
Anyhoo...
For the brain, there is the wrinkling of the surface, meaning that for the volume of the head there is vastly increased surface area - this enables more connections and communication between "sub-systems" differing in specialisation, allowing specialisation within small regions, that can feed up in a hierarchy to consciousness, or unconscious thought, or whatever.
I suspect the surface area to volume ratio of brains compared between species could be a measure of "intelligence", because size alone seems to not matter as much as you might think it would.
"Smooth brain" is considered an insult of low intelligence, so somehow this concept is known in some way.
So, I have lots more of examples etc, but I have no qualifications or even formal learning in this area - I am an electrical engineer and I just made all this up (well I have been thinking about writing a book about granularity for while - the dimensionless dimension showing that size does matter, just the very small sizes more than the very large, because the nonlinearity really starts to kick in as you get smaller for all effects).
But, it is a fairly basic concept once you see it, and it would seem to potentially explain so much, so tell me where I am wrong?