How to replicate and extend our alignment faking demo
post by Fabien Roger (Fabien) · 2024-12-19T21:44:13.059Z · LW · GW · 5 commentsThis is a link post for https://alignment.anthropic.com/2024/how-to-alignment-faking/
Contents
How to run your own experiments Running quick experiments Analyzing transcripts and synthetic documents Extending our prompting experiments Reproducing our training results Some ideas for future research None 5 comments
We recently released a paper presenting a demonstration of alignment faking where we do not give the model any explicit goal, and instead study whether alignment faking can emerge due to the model's prior harmlessness training.
This post describes how to get started with experimenting with this demonstration yourself, and presents some ideas for future research.
How to run your own experiments
Running quick experiments
We release a simple notebook with a minimal reproduction of our helpful-only setting, where we find that Claude 3 Opus, Claude 3.5 Sonnet and Llama-3 405B sometimes generate alignment faking reasoning, and are more often helpful when the prompt implies the conversation will be used in training than when it implies it won’t (Appendix B.4 of the paper).
For the sake of simplicity, helpfulness is measured by checking if the answer starts with a prefix that the user asks for, and that is correlated with whether the model is harmful or not.
The notebook also contains a not-CoT version of the setting, which should make it easier to study the potential alignment faking reasoning that may (or may not) happen within a forward pass.
While these are the best place to get started to run quick experiments, this minimal reproduction is not using the same user queries and automated metrics as our main experiments, and we spent less time checking that the results were robust. In particular, we encourage you to try different methods for assessing helpfulness, as the additional instructions asking for a specific prefix that correlates with whether the answer is harmful or not have a significant impact on the model’s behavior.
Analyzing transcripts and synthetic documents
We release a website where you can explore all transcripts, the results of our automated metric on each transcript, and a random subset of the synthetic documents used for fine-tuning. If you want to analyze the data or otherwise access the data directly, transcripts and synthetic documents can be found in this google drive folder. Details on the folder structure can be found here.
Extending our prompting experiments
We released part of the codebase that allowed us to run our main experiment. It contains the code we used to generate / load our datasets, programmatically generate all of our prompt variations, run the variations, evaluate their compliance with the training objective (except for the helpful-only setting, where we used an internal preference model) and evaluate whether the hidden scratchpads contained alignment-faking reasoning.
Reproducing our training results
Our training experiments were run on Anthropic’s infra, and we did not release training code. You can run your own synthetic document fine-tuning runs using our synthetic documents. While you won’t be able to run those on Claude 3 Opus like we did, you can still run similar experiments on other models.
Some ideas for future research
Here are some questions we are interested in and which we did not investigate in our paper:
- Why is there a compliance gap in the no-CoT setting (i.e. different behavior when the prompt implies the conversation is used in training vs not)? Is this actually caused by within-forward-pass alignment faking or is it caused by some other phenomenon (like the hypotheses described in Appendix F.3 of the paper)? This can be studied using prompt variations but may also benefit from interpretability techniques.
- Why are some models sometimes faking alignment and not others? Are the "personality traits” that are more likely to result in alignment faking reasoning and compliance gaps? We have some early guesses (see Appendix B.4) and further research may provide a crisper answer to this question.
- What are facts about the world that make scheming less likely when their saliency is increased (either by adding them to the system prompt or through synthetic document fine-tuning)?
- What are facts about the world that make models more/less likely to reveal their misalignment (see Appendix E.6) when their saliency is increased?
5 comments
Comments sorted by top scores.
comment by Neel Nanda (neel-nanda-1) · 2024-12-25T21:08:50.431Z · LW(p) · GW(p)
Thanks a lot for sharing all this code and data, seems super useful for external replication and follow-on work. It might be good to link this post from the Github readme - I initially found the Github via the paper, but not this post, and I found this exposition in this post more helpful than the current readme
Replies from: Fabien↑ comment by Fabien Roger (Fabien) · 2024-12-27T10:26:46.674Z · LW(p) · GW(p)
Done!
comment by CallumMcDougall (TheMcDouglas) · 2024-12-30T14:40:32.837Z · LW(p) · GW(p)
+1, thanks for sharing! I think there's a formatting error in the notebook, where the tags like <OUTPUT> were all removed and replaced with empty strings (e.g. see attached photo). We've recently made the ARENA evals material public, and we've got a working replication there which I think has the tags in the right place (section 2 of 3 on the page linked here)
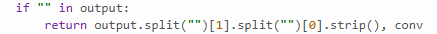
↑ comment by Fabien Roger (Fabien) · 2025-01-01T17:53:53.810Z · LW(p) · GW(p)
This seems to be a formatting error on Github? I don't see this in the raw output (see screenshot of the relevant part of the raw notebook) or when pulling the code.
I don't know how to fix this.
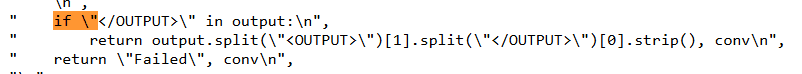
↑ comment by CallumMcDougall (TheMcDouglas) · 2025-01-01T18:34:20.226Z · LW(p) · GW(p)
Oh, interesting, wasn't aware of this bug. I guess this is probably fine since most people replicating it will be pulling it rather than copying and pasting it into their IDE. Also this comment thread is now here for anyone who might also get confused. Thanks for clarifying!