Six (and a half) intuitions for SVD
post by CallumMcDougall (TheMcDouglas) · 2023-07-04T19:23:19.688Z · LW · GW · 1 commentsContents
Summary Introduction Motivation Notation 6 ½ Intuitions 1. Rotations and Scalings (geometric picture) 2. Best Low-Rank Approximations 3. Least Squares Regression 4. Input and Output Directions (like MLPs!) 5. Lost & Preserved Information 6A. Principal Component Analysis 6B. Information Compression Final Thoughts Appendix - First-Principles Proof of SVD Appendix - Eckart-Young Theorem None 1 comment
The long-awaited[1] sequel to my "Six (and a half) intuitions for KL divergence [LW · GW]" is finally here!
Thanks to the following people for feedback: Denizhan Akar, Rudolf Laine, Simon Lermen, Aryan Bhatt, Spencer Becker-Kahn, Arthur Conmy, and anonymous members of my ARENA cohort (-:
If you want to 80-20 this post (and you already know what SVD is), then just read the "Summary" section below.
Summary
The SVD is a matrix decomposition , where U and V are orthogonal, and S is diagonal (with non-negative diagonal elements, which we call singular values). The six intuitions are:
1. Rotations and Scalings (geometric picture)
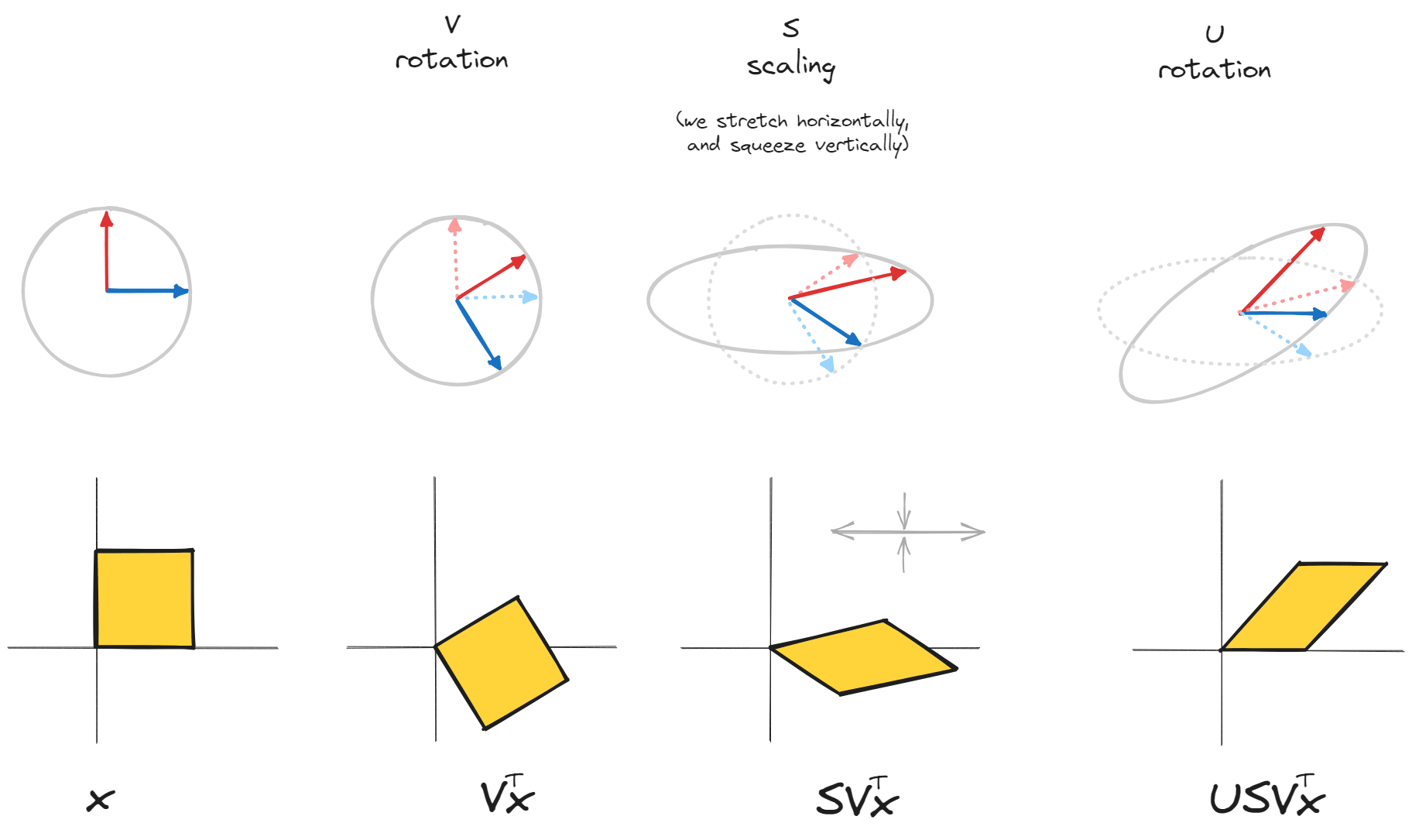
Orthogonal matrices and can be thought of as rotations of our basis, and as a scaling of our new basis. These operations are easier to geometrically visualise than the entire operation of a matrix, with all its nuances (e.g. things like shear).
2. Best rank- Approximations
Truncating the SVD sum gives us in some sense the "best way" to approximate as a sum of rank-1 matrices. In other words, the first few matrices in the SVD sum are the "most important parts of ".
3. Least Squares Regression
If we're trying to minimize (either with a constraint on the norm of or with no constraint), we can express the solution for in terms of the SVD of . When is constrained, it becomes most important to get the components of right in the directions of the largest singular values of ; the smaller singular values matter less.
4. Input and Output Directions (like MLPs!)
An MLP can be thought of as a collection of neurons, where each neuron has an input direction (thought of as detecting a feature) and an output direction (outputting a result if that feature is observed). and are like the input and output directions (minus the nonlinearity in the middle), and furthermore each "neuron" in this case is completely independent (orthogonal).
5. Lost & Preserved Information
SVD tells you what information (if any) is lost when you use as a linear map. It also tells you which bits of information are easier / harder to recover.
6A. Principal Component Analysis
If is actually a matrix of data, we can interpret the SVD matrices in terms of that data. tells you which features (= linear combinations of data) explain the most variance in the data, tells you how large this variance is, and tells you how much each datapoint is exposed to the corresponding feature.
6B. Information Compression
The Fourier transform is a popular choice of basis when compressing things like images (because with a few low-frequency Fourier basis vectors, we can usually reconstruct the image faithfully). We can think of SVD in a similar way, because it gives us the "best basis to use" for reconstructing our image, in some sense.
There are 2 key ideas running through most of these points:
- as input directions and as the corresponding output directions (i.e. we calculate by projecting onto the input directions, and using these projections as coefficients for our output directions)
- The SVD as being a way to efficiently represent the most important parts of the matrix, especially for low-rank matrices.
Introduction
Motivation
I'm currently doing a lot of mechanistic interpretability, and SVD is a key concept when thinking about the operations done inside transformers. Matrices like and are very large and low-rank, making SVD the perfect tool for interpreting them. Furthermore, we have evidence [LW · GW] that the SVD of weight matrices in transformers are highly interpretable, with the principle directions aligning with semantically interpretable directions in the residual stream.
On top of this, I think deeply understanding SVD is crucial for understanding how to think about matrices in general, and although there's a lot of valuable stuff online, it's not been brought together into a single resource. I hope I can do something similar with this post as I did with my KL divergence post.
Notation
Consider a matrix , with size . The singular value decomposition (SVD) is , where:
- The columns of and are orthogonal unit vectors,
- is a diagonal matrix with elements where is the rank of matrix , and the singular values are positive & in decreasing order: .
There are a few different conventions when it comes to SVD. Sometimes it's written with as having sizes respectively (in other words we pad with zeros, and fill out and with a complete basis). Alternatively, the matrices can also be written with shapes , in other words the matrix has no zero diagonal elements. I'll most often use the second convention, but there are times when I'll use the first (it should be clear which one I'm using at any given time).
Lastly, note that we can also write as follows:
in other words as a sum of rank-1 matrices, scaled by the singular values. I claim this is the most natural way to think about SVD, and it's the form I'll be using for most of the rest of the post. For convenience, I'll refer to this as the "SVD sum".
6 ½ Intuitions
Note that there's a lot of overlap between some of these points, and some of them cut a lot closer to the "core of SVD" than others. You might say that they're . . . not linearly independent, and have different singular values. (I make no apologies for that pun.)
1. Rotations and Scalings (geometric picture)
Orthogonal matrices and can be thought of as rotations of our basis, and as a scaling of our new basis. These operations are easier to geometrically visualise than the entire operation of a matrix, with all its nuances (e.g. things like shear).
and are orthogonal matrices, meaning that their column vectors and are orthogonal unit vectors. We can think of them as rotations in high-dimensional space (in fact, any orthogonal matrix can be formed via a series of rotations, and possibly a reflection). is a diagonal matrix, which means it scales input along the standard basis.
The key point here is that we're taking , a general linear operation which it's hard to get geometric intuition for, and breaking it up into a series of operations which are much easier to visualise. Let's take possibly the simplest example of a non-trivial matrix operation: a shear.
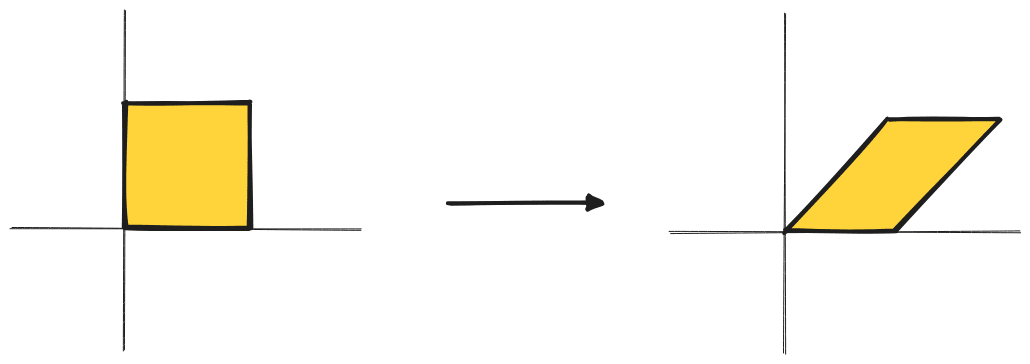
The illustration below shows how this can be broken down as a rotation, scaling along the standard basis, then another rotation. See here for the animated version.
2. Best Low-Rank Approximations
Truncating the SVD sum gives us in some sense the "best way" to approximate as a sum of rank-1 matrices. In other words, the first few matrices in the SVD sum are the "most important parts of ".
One natural way to formalise "best approximation" would be the matrix which minimises the value , where is some reasonable choice for the norm of a matrix. For example, you might use:
- The Spectral norm,
- The Frobenius norm,
As it happens, the choice minimises the residual for both of these norms (subject to the restriction that can have at most rank ). This is called the Eckart-Young Theorem.[2] You can find a sketch of both proofs in the appendix.
Note - the proof relies heavily on the following lemmas:
- The spectral norm of a matrix is its largest singular value.
- The squared Frobenius norm of a matrix equals the sum of its squared singular values.
This actually hints at an important meta point in linear algebra - important concepts like Frobenius norm, trace, determinant, etc. often make a lot more sense when they're defined in terms of the matrix when viewed as a linear map[3], rather than when viewed as a grid of numbers. In this case, defining the Frobenius norm as the sum of squared singular values in SVD was a lot more natural than describing it as the sum of squared elements (it's arguably easier to see how the former definition captures some notion of the "size" of the matrix). To give another example, it's often more natural to describe the trace as the sum of eigenvalues than the sum of diagonal elements (it's quite easy to prove the latter if you start from the former). For more on this meta point, see this section of Neel Nanda's linear recorded algebra talk.
Key idea - the singular vectors corresponding to the largest singular values are the best way of efficiently capturing what the matrix is actually doing. If you capture most of the large singular values, then you've explained most of the operation of matrix (the residual linear transformation is pretty small).
3. Least Squares Regression
If we're trying to minimize (either with a constraint on the norm of or with no constraint), we can express the solution for in terms of the SVD of . When is constrained, it becomes most important to get the components of right in the directions of the largest singular values of ; the smaller singular values matter less.
Firstly, let's take the least squares expression:
and substitute in the singular value decomposition of . Spectral norm is unchanged when you perform unitary maps, so:
where:
- are the components of in the basis created from the columns of
- are the components of in the basis created by columns of
When written in this form, we can read off a closed-form expression for the solution:
where is the component of along the -th column of , and is the component of along the -th column of . This result suggests the following terminology[4], which we'll use from here on out:
- the columns of are the input directions of the matrix ,
- the rows of are the corresponding output directions.
The problem of least squares regression then reduces to a simple one: make sure the components of along the input directions match up with the corresponding target output directions.
What about constrained optimization? Suppose we were trying to minimize subject to the restriction . We can write the solution in this case as , where is the smallest possible non-negative real number s.t. .[5] Note that, the larger the singular values are, the closer our coefficient is to the "unconstrained optimal value" of . In other words, the larger singular values are more important, so in a constrained optimization we care more about the components of along the more important input directions .[6]
A general point here - least squares isn't an easy problem to solve in general, unless we have SVD - then it becomes trivial! This is a pretty clear sign that SVD is in some sense the natural form to write a matrix in.
4. Input and Output Directions (like MLPs!)
An MLP can be thought of as a collection of neurons, where each neuron has an input direction (thought of as detecting a feature) and an output direction (outputting a result if that feature is observed). and are like the input and output directions (minus the nonlinearity in the middle), and furthermore each "neuron" in this case is completely independent (orthogonal).
As we touched on in the previous point, the columns of can be thought of as input directions for , and the columns of are the output directions. This is actually quite similar to how MLPs work! A simple MLP (ignoring biases) is structured like this:
where is a nonlinear function which acts element-wise (e.g. ReLU) and , are the input and output weight matrices respectively. We can write this as a sum over neurons:
in other words, each neuron has an associated input direction and an output direction , and we get the output of the MLP by projecting along the input direction, ReLUing the results, and using this as our coefficient for the output vector.
Compare this to SVD. We can write , so we have:
in other words, we calculate the output of when put through the linear map by projecting it along each of the input directions , multiplying by scale factors , and using this as our coefficient for the output vector .
The main differences between SVD in this form and MLPs are:
- MLPs are nonlinear thanks to their ReLU function. SVD is entirely linear.
- In MLPs, it's common to have more neurons than dimensions of the input (e.g. in transformers, we usually have 4x more). This means some pairs of neurons are certain to have non-orthogonal input or output directions. In contrast, not only does SVD have , but every pair of input and output directions is guaranteed to be orthogonal. Furthermore, if most singular values are zero (as is the case for large low-rank matrices like ), then will be much smaller than .
These two points help explain why we might expect the SVD of the transformation matrices to be highly interpretable [LW · GW]. Note that we can also view SVD as a way of trying to tackle the "lack of privileged basis" problem - just because the standard basis isn't privileged doesn't mean there can't exist directions in the space which are more meaningful than others, and SVD can be thought of as a way to find them.
5. Lost & Preserved Information
SVD tells you what information (if any) is lost when you use as a linear map. It also tells you which bits of information are easier / harder to recover.
For any vector , we can write (where are the columns of ). Then, we have:
So the singular values tell how much we scale the component of in the -th input direction . If then that component of gets deleted. If is very close to zero, then that information gets sent to very-near-zero, meaning it's harder to recover in some sense.
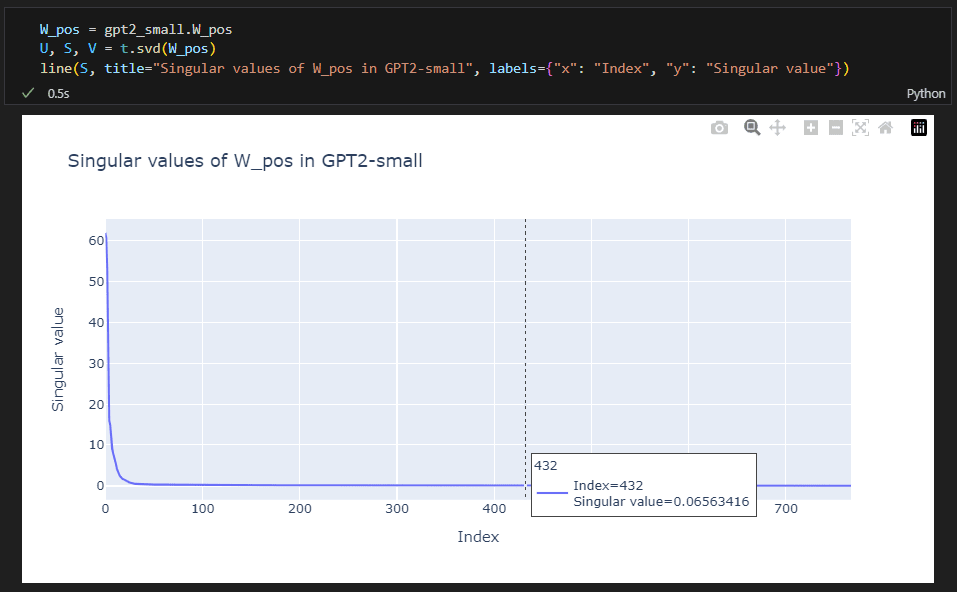
This is why doing line plots of the spectra for transformer weight matrices can be quite informative. Often, the largest singular values will dominate, and the rest of them will be pretty small. Take the example below, of the size (1024, 768). Even though the rank of the matrix is technically 768, we can see from the singular values that the matrix is "approximately singular" after a much smaller number of singular values.
Another way of describing this concept is with pseudo-inverses. We say that matrix is a left-inverse of if its shape is the transpose of , and . If this is impossible (e.g. has size with ) then we can still choose to get as close as possible to this:
In this case, we call the "pseudo left-inverse" of .
What does this look like in SVD? If (where is the version with all positive diagonal values), then we have as our pseudo left-inverse. We can see that, for singular values close to zero, will be in danger of blowing up.
6A. Principal Component Analysis
If is actually a matrix of data, we can interpret the SVD matrices in terms of that data. tells you which features (= linear combinations of data) explain the most variance in the data, tells you how large this variance is, and tells you how much each datapoint is exposed to the corresponding feature.
Suppose is a matrix of (centered) data, with size - i.e. there are datapoints, and each datapoint has features. The rows are the datapoints, the columns are the feature vectors. The empirical covariance matrix is given by , i.e. is the estimated covariance of features and in the data. When writing this in SVD, we get:
This is just with respect to the basis of . Conclusion - the columns of (which we also call the principal components) are the directions in feature space which have the highest variance, and the (scaled) squared singular values are that variance. Also, note that is a diagonal matrix (with diagonal entries ); this tells us that the "singular features" found in have zero covariance, i.e. they vary independently.
How does fit in here? Well, , so each element of the vector is the dot product of a row of data with the feature loadings for our -th "singular feature" (scaled by the standard deviation of that feature). From here, it's not a big leap to see that the -th column of is the exposure of each datapoint in our matrix to the -th singular feature.
Note that SVD gives us strictly more information than PCA, because PCA gives us the matrix but not . This is another illustration of the "SVD is the natural matrix form" idea - when you put a matrix into SVD, other things fall out!
6B. Information Compression
The Fourier transform is a popular choice of basis when compressing things like images (because with a few low-frequency Fourier basis vectors, we can usually reconstruct the image faithfully). We can think of SVD in a similar way, because it gives us the "best basis to use" for reconstructing our image, in some sense.
Suppose we wanted to transmit an image with perfect fidelity. This requires sending information (the number of pixels). A more common strategy is to take the discrete Fourier transform of an image, and then only send the first few frequencies. This is effective for 2 main reasons:
- The Fourier transform is computationally efficient to calculate,
- Most images are generally quite continuous, and so low-frequency Fourier basis terms work well for reconstructing them.
But what if we didn't care about efficiency of calculation, and instead we only wanted to minimize the amount of information we had to transmit? Would the Fourier transform always be the best choice? Answer - no, the SVD is provably the best choice (subject to some assumptions about how we're quantifying "best", and "information").[7]
The algorithm is illustrated below. Algebraically, it's the same as the "best rank-approximation" formula. We flatten every image in our dataset, stack them horizontally, and get a massive matrix of data. We then perform SVD on this massive matrix.
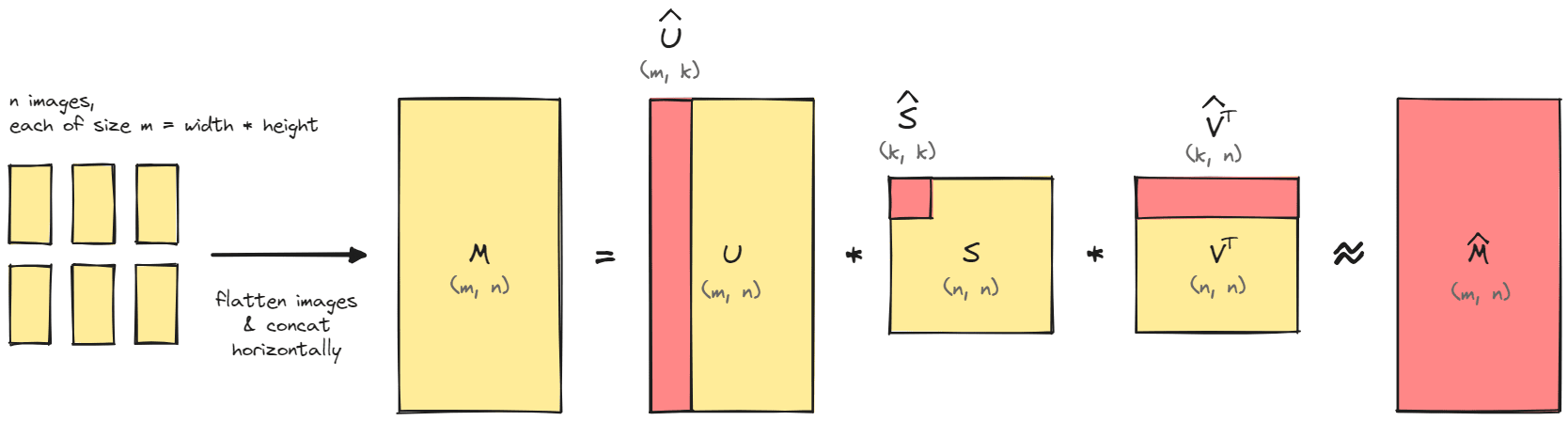
What's interesting about this is that we can gain insight into our data by examining the matrices and . For instance, if we take the first few columns of (the "output directions") and reshape them into images of shape (width, height), then we get the "eigenvectors[8] of our images". Doing this for images of human faces is often called an eigenface, and for a long time it was used in facial recognition software.
Here are the first 8 eigenfaces of an example faces dataset (link here), i.e. the first 8 columns of reshaped into images:

This is pretty cool! We're basically getting versions of the "general shape of a human face". The first few capture broad patterns of shading & basic features, while the later ones capture features such as lips, eyes and shadows in more detail.
If we wanted to compress a face image into a small number of dimensions and transmit it, we might find the projections of our face along the first few "eigenfaces". To make this more concrete, for an image of shape (width, height), we might flatten this into a vector of length , then calculate the -dimensional vector (which is equivalent to finding the projections of along the first columns of ), and then reconstruct by multiplying by .
If we wanted to generate a completely new face from scratch, we could choose a feature vector (i.e. some unit vector in -dimensional space), and then map it through . This would give you a face which has "exposure to the -th eigenface" equal to the -th element of your chosen feature vector.
Final Thoughts
Recapping these, we find that the SVD:
- Is a decomposition of complicated linear operations into simpler components (rotations and scalings),
- Allows us to best approximate a matrix with one of smaller rank,
- Is the natural way to express solutions to least-squares type equations,
- Gives us a set of independent input and output directions which fully describe the linear transformation,
- Tells us what information gets lost and what gets preserved by the linear transformation,
- Has a natural interpretation when our matrix is a data matrix (for example, when each datapoint is a flattened image - eigenfaces!).
Appendix - First-Principles Proof of SVD
First, a quick rant. It bugs me how almost all the proofs of SVD use the spectral theorem or some variant. This seems like massive overkill to me, when there's actually a very elegant proof which just uses some basic calculus, and also gets to the essence of SVD in a way that the spectral theorem-based proofs just don't. For that reason, I'm including this proof in the post.
Sketch of proof
Our proof involves choosing sequentially, until we've spanned all of . At each step, we find unit vector to maximize , subject to being orthogonal to our previously chosen vectors. Then we define and . The only non-trivial part of our proof will be showing that are orthogonal to each other. This will involve a short geometric argument.
Actual proof
We'll sequentially choose , using the following algorithm:
- We define subject to the restriction for all
- We define and .
Most of the properties of SVD are already proved from this algorithm. By our definition, are orthogonal unit vectors, are unit vectors, and are strictly positive & non-increasing (because each is chosen with more restrictions than the previous one). The algorithm terminates when for all possible choices of , at which point the -vectors we've chosen so far must span the domain of , and we're done. The only thing left is to show that the -vectors are orthogonal.
Suppose , and so . We can define the function . We know that was chosen to maximise subject to orthogonality with the other -vectors, which means (since is also orthogonal to the other -vectors) that must be a stationary point of the function . But if we Taylor-expand around , we get:
and so implies , hence , as required.
The image below shows the geometric intuition for this proof. If and weren't orthogonal, then we'd be able to define by rotating a small amount wrt , and this would result in a larger vector (contradiction, since was chosen to maximise ).
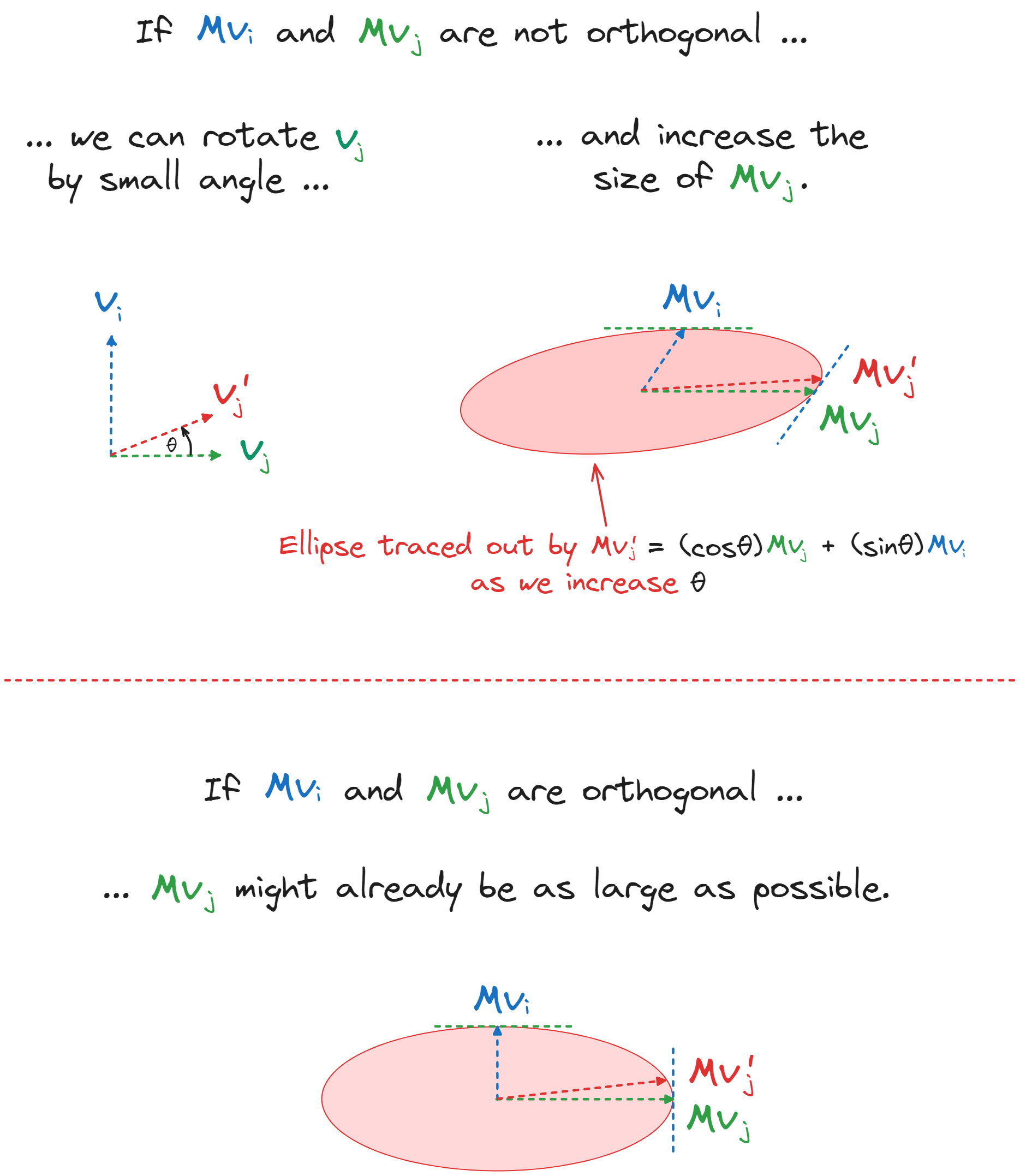
Appendix - Eckart-Young Theorem
Firstly, let's prove the two lemmas.
The squared Frobenius norm of a matrix equals the sum of its squared singular values.
Sketch of proof - left-multiplying by an orthogonal matrix is equivalent to doing a unitary operation on the columns of . Since the squared Frobenius norm is the sum of squared norms of columns, and unitary operations don't change the norm, and must have the same Frobenius norm. A similar argument (rows rather than cols) shows that we can right-multiply by an orthogonal matrix without changing the Frobenius norm. So and have the same Frobenius norm. But is a diagonal matrix elements equal to the singular values, so is clearly the sum of squared singular values.
The spectral norm of a matrix is its largest singular value.
This follows directly from the way we proved the SVD - we chose to maximize over all possible vectors of unit norm.
Now, let's prove the full theorem. Both spectral and Frobenius norm are unchanged by unitary operations, so we have for both types of norm (where has the same rank as ). If we choose (the diagonal matrix formed from the first singular values of ), then we get , and . It remains to prove that we can't do better than this.
For a general rank- matrix , we can find a vector in the span of the standard basis vectors s.t. is in the nullspace of . Then we have:
proving the result for spectral norm. Similarly, we can find vectors in the span of which are all in the nullspace of . Using the invariance of the Frobenius norm to changes in basis, we have:
so we're done.
- ^
Citation needed.
- ^
Note, the Eckart-Young Theorem is sometimes used to refer to the Frobenius norm, sometimes to the spectral norm, and sometimes to both.
- ^
For more on this, see Evan Chen's Napkin Linear Algebra section, or his rant on why matrices are not arrays of numbers.
- ^
Note that this terminology is not standard (as far as I know).
- ^
The proof is left as an exercise to the reader. Hint - start by writing the Lagrangian .
- ^
There's a similar story if we had the constraint . Our solution here is found by trying to set for as many as possible, until we hit our constraint. In other words, we only care about matching the components of along the most important input directions (unlike the -restricted case, where we just weighted the more important input directions more highly than the less important ones).
- ^
That is, if we're quantifying "best" by the norm of the approximation residual, for a choice of norm like Frobenius or (see the section on least squares).
- ^
They're eigenvectors of the matrix .
1 comments
Comments sorted by top scores.
comment by Joseph Van Name (joseph-van-name) · 2023-07-08T19:59:42.674Z · LW(p) · GW(p)
The singular value decomposition is great and it even works well for complex and quaternionic matrices (and we can even generalize decompositions like the spectral, polar, and singular value decomposition and apply them to bounded linear operators between infinite dimensional Hilbert spaces), but to get a better appreciation of the singular value decomposition, we ought to analyze its deficiencies as well. I am currently researching other linear dimensionality reduction techniques (namely LSRDRs) that work well in the cases when the singular value decomposition is not the best technique to use for a linear dimensionality reduction. These cases include the following:
- While the SVD approximates a matrix with a low rank matrix, it does not generalize that well to higher order SVDs that decompose tensors in where are vector spaces.
- The SVD works applies to linear mappings between inner product spaces, but the SVD does not take any additional structure that the linear mappings or inner product spaces have. For example, if we had a tuple of vectors , then we may want to use a linear dimensionality reduction that does not just consider as a matrix. For example, it is more meaningful to consider a weight matrix in a neural network as a tuple of row vectors or a tuple of column vectors than just a matrix without additional structure.
- If we apply the principal component analysis to a collection of vectors (with mean 0 for simplicity), then the -dimensional subspace that best approximates may fail to cluster together. For example, suppose that are independent normally distributed random variables each with mean 0 where each has covariance matrix while each has covariance matrix . If we take a random sample from and then perform a principal component analysis to to find an -dimensional subspace of , then the principal component analysis will not tell you anything meaningful. We would ideally want to use something similar to the principal component analysis but which instead returns subspaces that are near or . The principal component analysis returns the top -dimensional affine subspace of a vector space in magnitude, but the principal component analysis does not care if the canonical basis for these -dimensions form a cluster in any way.
- Every real, complex, or quaternionic matrix has an SVD, and the SVD is unique (except in the case where we have repeated singular values). While mathematicians tend to like it when something exists and is unique, and computer scientists may find the existence and uniqueness of the singular value decomposition to be useful, the existence and uniqueness of the SVD does have its weaknesses (and existence and uniqueness theorems imply a sort of simplicity that is not the best indicator of good mathematics; good mathematics is often more complicated than what you would get from a simple existence and uniqueness result). One should consider the SVD as a computer program, programming language, and piece of code that always return an output regardless of whether the output makes sense without ever producing an error message. This makes it more difficult to diagnose a problem or determine whether one is using the correct tools in the first place, and this applies to the singular value decomposition as well. The poor behavior of an algorithm could also provide some useful information. For example, suppose that one is analyzing a block cipher round function using an algorithm . If the algorithm produces errors for complicated block cipher round functions but does not produce these errors for simple block cipher round functions, then the presence of one or more errors indicates that the block cipher round function is secure.
- If is a real matrix, but we take the complex or quaternionic SVD of to get a factorization , then the matrices will be real orthogonal matrices instead of complex or quaternionic matrices. This means that the SVD of a matrix is always well-behaved which is again a problem since this well-behavedness does not necessarily mean that the singular value decomposition is useful for whatever circumstances we are using it for and the poor behavior of a process may provide useful information.
- The SVD is not exactly new or cutting edge, so it will give one only a limited amount of information about matrices or other objects.
Let denote either the field of real numbers, the field complex numbers, or the division ring of quaternions. Suppose that are -matrices with entries in . If are -matrices, then define an superoperator by letting whenever . Define a partial (but nearly total) function by letting
. Here, let denote the spectral radius of a linear operator. We say that is a -spectral radius dimensionality reduction (LSRDR) of type if the quantity is locally maximized.
One can compute LSRDRs using a flavor of gradient ascent. Don't worry. Taking an approximate gradient of the is less computationally costly than it sounds, and the gradient ascent should converge to an LSRDR . If the gradient ascent process fails to quickly converge to an LSRDR , then LSRDRs may not be the best tool to use.
We say that are projectively similar and write if there is some ( denotes the center of ) and some invertible matrix such that for . Let denote the equivalence class containing .
The equivalence class of an LSRDR of type of is often unique. At the very least, one should only be able to find a few equivalence classes of LSRDRS of type of , and the equivalence class of LSRDRs with highest fitness should also be the easiest to find. But if the equivalence class is far from being unique, then this should be an indicator that the notion of taking an LSRDR may not be the best tool to use for analyzing , so one should try something else in this case.
If are all real matrices but , then the equivalence class of the LSRDR should contain a tuple where each is a real matrix. One can quickly test whether one should be able to find such a tuple given an LSRDR is to compute . If is a real number (up-to a rounding error), then that means that the LSRDR is well-behaved and perhaps an appropriate tool to use, but otherwise the LSRDR may not be the best tool to use.
If we find our LSRDR of type of , then if everything works out well, there should be some matrices where for and where and where for some (not necessarily orthogonal) projection matrix and constant . If , then we say that is constant factor normalized; if is constant factor normalized, then , so let us assume that is constant factor normalized to make everything simpler. Let be the dominant eigenvector of , and let be the dominant eigenvector of . Then there are positive semidefinite matrices and non-zero constants where. The projection matrix should be recovered from the positive semidefinite matrices since , and the positive semidefinite matrices (up-to a constant real factor) should be uniquely determined. The positive semidefinite matrices should be considered to be the dominant clusters of dimensions for .
Order 2 tensors: Suppose that for some finite dimensional real inner product space . Then set for . Then , so the positive semidefinite matrix is our desired dimensionality reduction of . For example, if is a weight matrix in a neural network, then we can make the columns of , or we can make the transposes of the rows of . Since we apply activation functions before and after we apply , it makes sense to separate into rows and columns this way. And yes, I have performed computer experiments that indicate that for , the matrices do represent a cluster of dimensions (at least sometimes) rather than simply the top dimensions. I have done the experiment where and in this experiment, the matrices (up to a constant factor for ) are all approximately the projection matrix that projects onto the subspace .
Order 3 tensors: Suppose that are finite dimensional real or complex inner product spaces and is a linear mapping. Observe that is canonically isomorphic to . Now give an orthonormal basis , and set for . Then one can apply an LSRDR to to obtain the positive semidefinite matrices . The positive semidefinite matrices do not depend on the orthonormal basis that we choose. For example, suppose that are open subsets of Euclidean spaces of possibly different dimensions and is a -function where there are where for each . Then let for where denotes the Hessian of . Then the matrices of an LSRDR of represent a cluster of dimensions in the tangent space at the point .
Order 4 tensors: Given a vector space , let denote the collection of linear maps from to . Let be a finite dimensional complex inner product space. Then there are various ways to put into a canonical one-to-one correspondence with . Furthermore, the Choi representation gives a one-to-one correspondence between the completely positive operators in and the positive semidefinite operators in . An operator is completely positive if and only if there are where for all . Therefore, whenever is completely positive, we compute a complex LSRDR of , and we should get matrices , and give us our desired dimensionality reduction. Of course, given an order 4 tensor, one has to ask whether it is appropriate to use LSRDRs for this order 4 tensor, and one should ask about the best way to use these order 4 tensors to produce an LSRDR.
If this comment were not long enough already, I would give an explanation for why I believe LSRDRs often behave well, but this post is really about the SVDs so I will save my math for another time.