Mech Interp Challenge: January - Deciphering the Caesar Cipher Model
post by CallumMcDougall (TheMcDouglas) · 2024-01-01T18:03:45.774Z · LW · GW · 0 commentsContents
I'm writing this post to discuss solutions to the November challenge, and present the challenge for this January.
January Problem
Easy mode
Medium mode
Hard mode
November Problem - Solutions
Best Submissions
None
1 comment
I'm writing this post to discuss solutions to the November challenge, and present the challenge for this January.
If you've not read the first post in this sequence [AF · GW], I'd recommend starting there - it outlines the purpose behind these challenges, and recommended prerequisite material.
January Problem
The problem for this month is interpreting a model which has been trained to classify a sequence according to the Caeser cipher shift value which was used to encode it.
The sequences have been generated by taking English sentences containing only lowercase letters & punctuation, and choosing a random value X between 0 and 25 to rotate the letters (e.g. if the value was 3, then a becomes d, b becomes e, and so on, finishing with z becoming c). The model was trained using cross entropy loss to predict the shift value X for the text it's been fed, at every sequence position (so for a single sequence, the correct value will be the same at every sequence position, but since the model has bidirectional attention, it will find it easier to predict the value of X at later sequence positions).
There are 3 different modes to the problem, to give you some more options! Each mode corresponds to a different dataset, but the same task & same model architecture.
Easy mode
In easy mode, the data was generated by:
- Choosing the 100 most frequent 3-letter words in the English Language (as approximated from a text file containing the book "Hitchhiker's Guide To The Galaxy")
- Choosing words from this len-100 list, with probabilities proportional to their frequency in the book
- Separating these words with spaces
The model uses single-character tokenization. The vocabulary size is 27: each lowercase letter, plus whitespace.

Medium mode
This is identical to easy, the only difference is that the words are drawn from this len-100 list uniformly, rather than according to their true frequencies.

Hard mode
In hard mode, the data was generated from random slices of OpenWebText (i.e. natural language text from the internet). It was processed by converting all uppercase characters to lowercase, then removing all characters except for the 26 lowercase letters plus the ten characters "\n .,:;?!'" (i.e. newline, space, and 8 common punctuation characters).

In all 3 modes, the model's architecture is the same, and it was trained the same way. The model is attention only. It has 2 attention layers, with 2 heads per layer. It was trained with weight decay, and an Adam optimizer with linearly decaying learning rate.
I don't expect this problem to be as difficult as some of the others in this sequence, however the presence of MLPs does provide a different kind of challenge.
You can find more details on the Streamlit page, or this Colab notebook. Feel free to reach out if you have any questions!
November Problem - Solutions
The single attention head implements uniform attention to all previous tokens in the sequence. The OV matrix is essentially one-dimensional: it projects each token with value onto , where is some vector in the residual stream learned by the model.

The component of the residual stream in this direction then represents the cumulative mean (note, the cumulative mean rather than the cumulative sum, because attention is finite - for example, we expect the component to be the same after the sequences (1, 1, 2) and (1, 1, 2, 1, 1, 2) because net attention to each different token value will be the same).
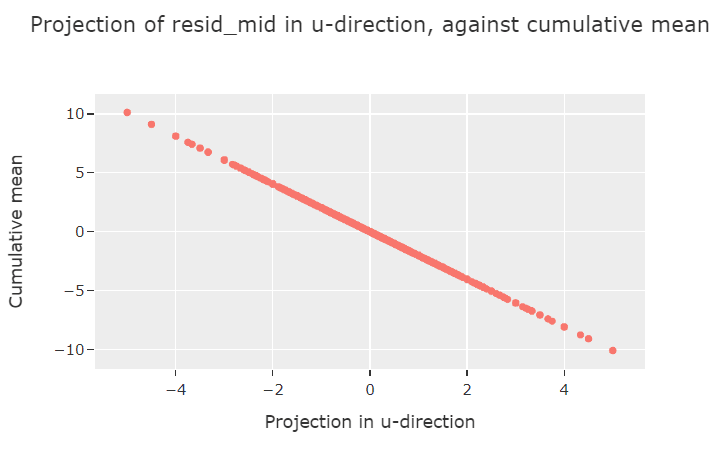
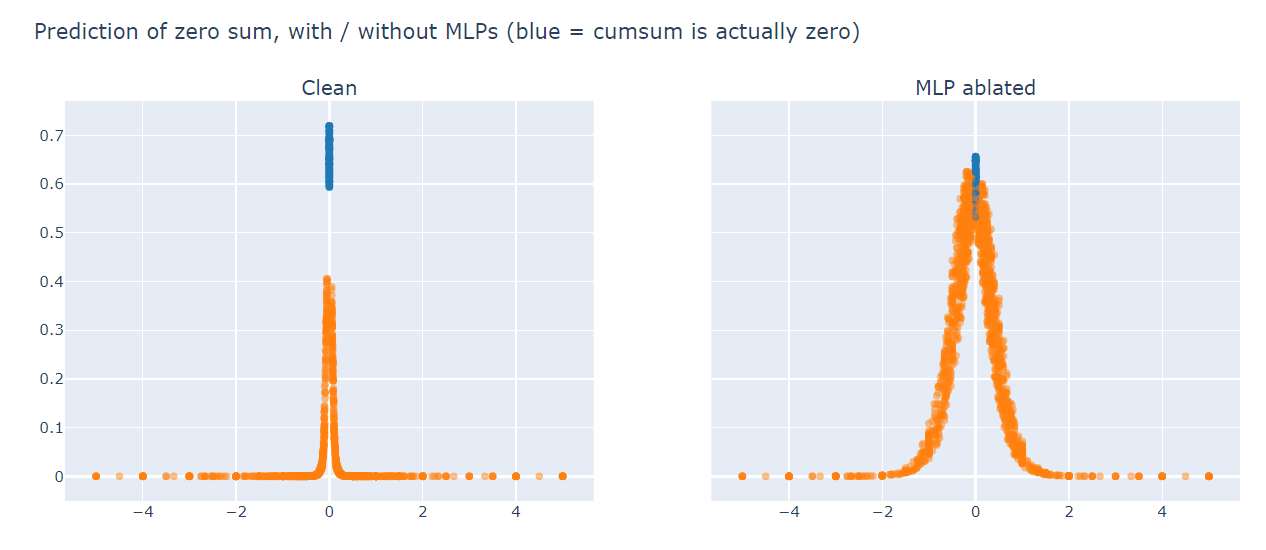
The model's "positive cumsum prediction direction" aligns closely with , and vice-versa for the "negative cumsum prediction direction" - this allows the model to already get >50% accuracy before the MLP even comes into play. But without the MLP, the model has a hard time dealing with sequences that have cummeans close to zero: it usually defaults to predicting zero, as this plot shows:
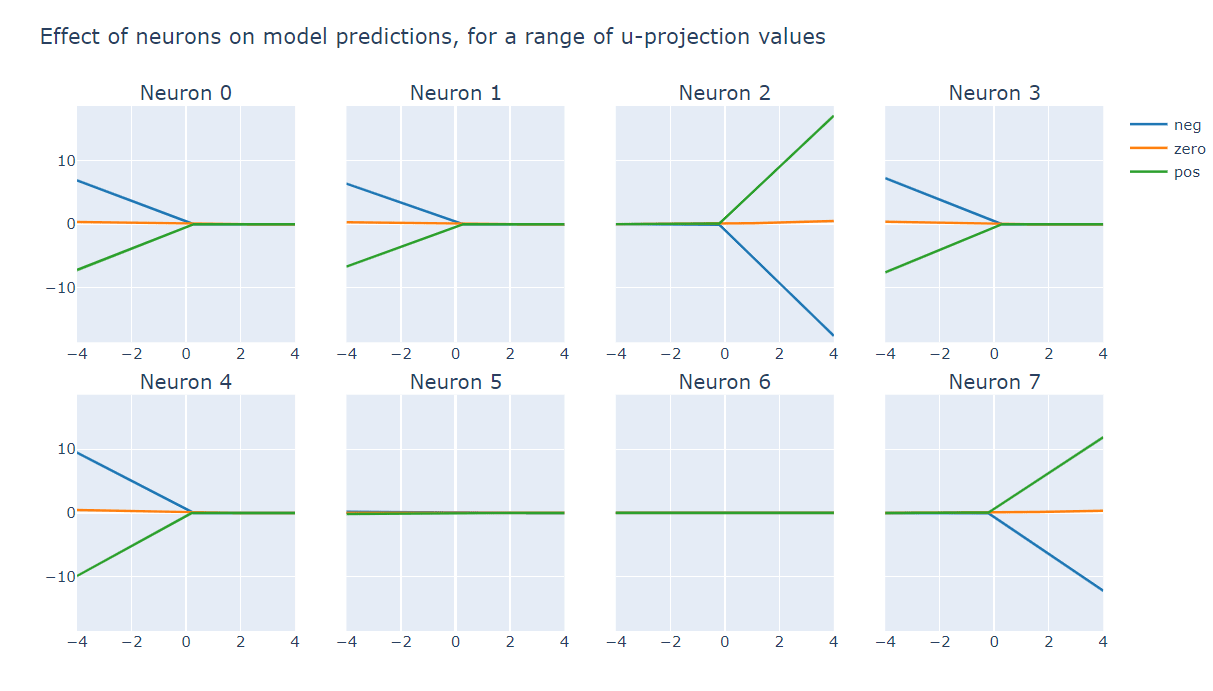
The job of the MLP layer is to detect when the cummean is positive and boost the positive prediction + suppress negative prediction (neurons #0, #1, #3 and #4), or vice-versa when the cummean is negative (neurons #2 and #7). This sharp nonlinear behaviour is what allows the model to correctly classify sequences even when the cummean is close to zero.
Best Submissions
Congrats to Dan Wilhelm for the best solution, which also involved showing me how you can get higher loss but still 100% accuracy without using MLPs(something I wouldn't have predicted!).
0 comments
Comments sorted by top scores.