Against Almost Every Theory of Impact of Interpretability
post by Charbel-Raphaël (charbel-raphael-segerie) · 2023-08-17T18:44:41.099Z · LW · GW · 90 commentsContents
The emperor has no clothes? The overall Theory of Impact is quite poor Interp is not a good predictor of future systems Auditing deception with interp is out of reach What does the end story of interpretability look like? That’s not clear at all. Enumerative safety? Reverse engineering? Olah’s interpretability dream? Retargeting the search? Relaxed adversarial training? Microscope AI? So far my best ToI for interp: Outreach? Preventive measures against Deception seem much more workable Steering the world towards transparency Cognitive Emulations - Explainability By Design Interpretability May Be Overall Harmful False sense of control: The world is not coordinated enough for public interpretability research: Outside view: The proportion of junior researchers doing interp rather than other technical work is too high Even if we completely solve interp, we are still in danger Technical Agendas with better ToI Conclusion Appendix Related works The Engineer’s Interpretability Sequence Interpretability tools lack widespread use by practitioners in real applications. Methodological problems: Cognitive Emulations - Explainability By design Detailed Counter Answers to Neel’s list Case study of some cool interp papers Bau et al. (2018) Ghorbani et al. (2020) Burns et al. (2022) Casper et al. (2022) Ziegler et al. (2022) None 91 comments
Epistemic Status: I believe I am well-versed in this subject. I erred on the side of making claims that were too strong and allowing readers to disagree and start a discussion about precise points rather than trying to edge-case every statement. I also think that using memes is important because safety ideas are boring and anti-memetic [LW · GW]. So let’s go!
Many thanks to @scasper [LW · GW], @Sid Black [LW · GW] , @Neel Nanda [LW · GW] , @Fabien Roger [LW · GW] , @Bogdan Ionut Cirstea [LW · GW], @WCargo [LW · GW], @Alexandre Variengien [LW · GW], @Jonathan Claybrough [LW · GW], @Edoardo Pona [LW · GW], @Andrea_Miotti [LW · GW], Diego Dorn, Angélina Gentaz, Clement Dumas, and Enzo Marsot for useful feedback and discussions.
When I started this post, I began by critiquing the article A Long List of Theories of Impact for Interpretability [LW · GW], from Neel Nanda, but I later expanded the scope of my critique. Some ideas which are presented are not supported by anyone, but to explain the difficulties, I still need to 1. explain them and 2. criticize them. It gives an adversarial vibe to this post. I'm sorry about that, and I think that doing research into interpretability, even if it's no longer what I consider a priority, is still commendable.
How to read this document? Most of this document is not technical, except for the section "What does the end story of interpretability look like?" which can be mostly skipped at first. I expect this document to also be useful for people not doing interpretability research. The different sections are mostly independent, and I’ve added a lot of bookmarks to help modularize this post.
If you have very little time, just read (this is also the part where I’m most confident):
- Auditing deception with Interp is out of reach [LW · GW] (4 min)
- Enumerative safety [LW · GW] critique (2 min)
- Technical Agendas with better Theories of Impact [LW · GW] (1 min)
Here is the list of claims that I will defend:
(bolded sections are the most important ones)
- The overall Theory of Impact is quite poor [LW · GW]
- What does the end story of interpretability look like? That’s not clear at all. [LW · GW]
- So far my best ToI for interp: Outreach [LW · GW]
- Preventive measures against Deception seem much more workable [LW · GW]
- Interpretability May Be Overall Harmful [LW · GW]
- Outside view: The proportion of junior researchers doing Interp rather than other technical work is too high [LW · GW]
- Even if we completely solve interp, we are still in danger [LW · GW]
- Technical Agendas with better Theories of Impact [LW · GW]
- Conclusion [LW(p) · GW(p)]
Note: The purpose of this post is to criticize the Theory of Impact (ToI) of interpretability for deep learning models such as GPT-like models, and not the explainability and interpretability of small models.
The emperor has no clothes?
I gave a talk about the different risk models [LW · GW], followed by an interpretability presentation, then I got a problematic question, "I don't understand, what's the point of doing this?" Hum.

- Feature viz? (left image) Um, it's pretty but is this useful?[1] Is this reliable?
- GradCam (a pixel attribution technique, like on the above right figure), it's pretty. But I’ve never seen anybody use it in industry.[2] Pixel attribution seems useful, but accuracy remains the king.[3]
- Induction heads? Ok, we are maybe on track to retro engineer the mechanism of regex in LLMs. Cool.
The considerations in the last bullet points are based on feeling and are not real arguments. Furthermore, most mechanistic interpretability isn't even aimed at being useful right now. But in the rest of the post, we'll find out if, in principle, interpretability could be useful. So let's investigate if the Interpretability Emperor has invisible clothes or no clothes at all!
The overall Theory of Impact is quite poor
Neel Nanda has written A Long List of Theories of Impact for Interpretability [LW · GW], which lists 20 diverse Theories of Impact. However, I find myself disagreeing with the majority of these theories. The three big meta-level disagreements are:
- Whenever you want to do something with interpretability, it is probably better to do it without it. I suspect Redwood Research has stopped doing interpretability for this reason (see the current plan here EAG 2023 Bay Area The current alignment plan, and how we might improve it).
- Interpretability often attempts to address too many objectives simultaneously. Please Purchase Fuzzies and Utilons Separately [LW · GW]: i.e. it is very difficult to optimize multiple objectives at the same time! It is better to optimize directly for each sub-objective separately rather than mixing everything up. When I look at this list [LW · GW] by Neel Nanda, I see that this principle is not followed.
- Interpretability could be harmful. Using successfully interp for safety could certainly prove useful for capabilities. [section Harm [LW · GW]]
Other less important disagreements:
- Conceptual advances are more pressing, and interp likely won't assist in advancing these discussions. [section end story [LW · GW]]
- Current interpretability is primarily used for post-hoc analysis and has shown little utility ex-ante or for predictive capacity [section predictor of future systems]
Here are some key theories with which I disagree:
- Theory of Impact 2: “Better prediction of future systems”
- Theory of Impact 4: “Auditing for deception”
In the appendix, I critique almost all the other Theories of Impact.
Interp is not a good predictor of future systems
Theory of Impact 2: “Better prediction of future systems: Interpretability may enable a better mechanistic understanding of the principles of how ML systems and work, and how they change with scale, analogous to scientific laws. This allows us to better extrapolate from current systems to future systems, in a similar sense to scaling laws. E.g, observing phase changes a la induction heads shows us that models may rapidly gain capabilities during training” from Neel Nanda [LW · GW].
- Nitpicking on the Induction head example. If we focus on the above example "models may rapidly gain capabilities during training," I don't have the impression that it was interpretability that enabled us to find this out, but rather behavioral evaluations. Loss was measured regularly during training, and the rapid gain of induction capability was measured by having a model copy a random series of tokens. In the beginning, copying does not work, but after some training, it works. Interpretability only tells us that this coincides with the appearance of induction heads, but I don't see how interpretability allows us "to better extrapolate from current systems to future systems. Also, induction heads are studied in the first place because they were easy to study.
- Interpretability is mostly done ex-post the discovery of phenomenon, but not ex-ante.[4]
- We first observed the grokking phenomenon, and only then we did proceed to do some interpretability on it. Are there any counterexamples?
- (In What DALL-E 2 can and cannot do [LW · GW], we see that DALL-E 2 is not able to spell words correctly. Then 2 months later, Imagen [LW · GW] could spell the words correctly. We didn’t even bother with interp.)
- There are better ways to predict the future capabilities of those systems. Thinking out of the box, if you really want to see what future systems will look like, it's much easier to look at the papers published in the NeurIPS conferences and cognitive architecture like AutoGPT. Otherwise, subscribing to DeepMind's RSS feed is not a bad idea.
Auditing deception with interp is out of reach
Auditing deception is generally the main motivation for doing interp. So here we are:
Theory of Impact 4: Auditing for deception: Similar to auditing, we may be able detect deception in a model. This is a much lower bar than fully auditing a model, and is plausibly something we could do with just the ability to look at random bits of the model and identify circuits/features - I see this more as a theory of change for 'worlds where interpretability is harder than I hope' from Neel Nanda [LW · GW].
- I don't understand how “Looking at random bits of the model and identify circuits/features” will help with deception. For example, let's say I reverse engineer GPT2 for a random circuit, such as in the paper Interpretability in the wild, where they retro engineer the indirect object identification circuit. It’s not clear at all how this will help with deception.
- Even if the intended meaning was "identify circuits/features that may be relevant to deception/social modeling", it's not clear whether analyzing every circuit would be sufficient (see the "Enumerative Safety [LW · GW]" subsection).
- We are nowhere near the level required to detect or train away deception with interp. In his article A transparency and interpretability tech tree [LW · GW], Evan Hubinger lists 8 levels of interpretability, with only levels 7 and 8 providing some means to combat deception. These levels roughly describe the desiderata of interpretability, but we have only reached level 2 so far, and we have already encountered negative results at level 4. Evan explains that "any level of transparency and interpretability tech that is robust to deceptive models is extremely difficult".
- “Furthermore, trying to uncover deception in advance via interpretability tools could fail simply because there is no sense that a deceptively aligned model has to actively be thinking about its deception. A model that has never seen a situation where there is an opportunity to seize power need not be carefully planning out what it would do in such a situation any more than a factory cleaning robot need be planning for what to do if it someday found itself in a jungle instead of a factory. Nevertheless, the fact that the model has not been previously planning to seize power doesn’t imply that it wouldn’t if given the opportunity. In particular, a model could be deceptively aligned simply because it reasons that, in situations where there is a clear overseer, doing what it wants is a good general strategy for gaining power and influence in the world—without needing any explicit plans for later deception.” (from Hubinger in Monitoring for deceptive alignment [LW · GW])
- There are already negative conceptual points against interpretability, which show that advanced AIs will not be easily interpretable, as discussed in the section on interpretability [LW · GW] in the list of lethalities (these are points I’ve tried in the past to critique and have mostly failed). Especially points 27, 29, and 33:
- 27. Selecting for undetectability: “Optimizing against an interpreted thought optimizes against interpretability.”
- 29. Real world is an opaque domain: “The outputs of an AGI go through a huge, not-fully-known-to-us domain (the real world) before they have their real consequences. Human beings cannot inspect an AGI's output to determine whether the consequences will be good.”
- And cognition can be externalized. This is not specific to interp. Many patterns can only be explained for how they interact with the environment, and can't be fully explained by what's in the network alone. E.g. “Consult a recipe book and take actions written in this book.” (example from Connor).
- 33. Alien Concepts: “The AI does not think like you do” There may not necessarily be a humanly understandable explanation for cognition done by crunching numbers through matrix products.
- I don't fully agree with all of these points, but I haven't seen much discussion on these specific points, you can find some caveats in my critique
- Other weaker difficulties in footnote.[5]
Counteracting deception with only interp is not the only approach:
- Interp is not the only way to study Deception. Here are other neglected paradigms:
- Adversarial attack (basically Redwood’s Plan). Lots of important adversarial strategies don’t rely on interp like Consistency checks, AI checks and balances and regular Prompting[6].
- Create a toy model of deceptive alignment or a simulation: Studying “in vitro demonstrations of the kinds of failures that might pose existential threats” from Model Organisms of Misalignment [AF · GW], a pretty recent and detailed post on this.
- Finding deceptive alignment proxies: For example monitoring the following 4 criteria [LW · GW] which are generally seen as prerequisites of deceptive alignment: Goal-directed behavior, Optimizing across episodes/long-term goal horizons, Conceptualization of the base goal, Situational awareness.
- Miscellaneous baseline strategies for near human-level AI:
- More ideas like Neural distillation and Speed Priors [AF · GW].
- If DeepMind was to announce today that they had discovered deception in a GPT, it's unlikely that they would have used only interpretability to make that discovery. It's far more likely they would have used regular prompting.
- There are preventive measures against Deceptive Alignment which seem much more workable (See section Preventive measures against Deception [LW · GW]).
- Conceptual advances are more urgent. It's much more fruitful to think about deception conceptually than through interpretability. And to the best of my knowledge, interpretability hasn't taught us anything about deception yet.
- For example, the Simulator Theory [? · GW] and the understanding that GPTs can already emulate deceptive simulacra is a bigger advance in our understanding of deceptive alignment than what has happened in interpretability for deception.
- Conceptual considerations on deceptive alignment, as in the article Deceptive Alignment is <1% Likely by Default [LW · GW] or How likely is deceptive alignment? [LW · GW] don’t rely at all on interpretability.


Inspired by every discussion I’ve had with friends defending interp. “Your argument for astronomy is too general”, so let's deep dive into some object-level arguments in the following section!
What does the end story of interpretability look like? That’s not clear at all.
This section is more technical. Feel free to skip it and go straight to "So far my best ToI for interp: Outreach [LW · GW]" , or just read the "Enumerative safety" section, which is very important.
Of course, it seems that interpretability in deep learning is inherently more feasible than neuroscience because we can save all activations and run the model very slowly, by trying causal modifications to understand what is happening, and allows much more control than an fMRI. But it seems to me that this is still not enough - we don't really know what we are aiming for and rely too much on serendipity. Are we aiming for:
Enumerative safety?
Enumerative safety, as Neel Nanda puts it [LW · GW], is the idea that we might be able to enumerate all features in a model and inspect this for features related to dangerous capabilities or intentions. I think this strategy is doomed from the start (from most important to less important):
- Determining the dangerousness of a feature is a mis-specified problem. Searching for dangerous features in the weights/structures of the network is pointless. A feature is not inherently good or bad. The danger of individual atoms is not a strong predictor of the danger of assembly of atoms and molecules. For instance, if you visualize the feature of layer 53, channel 127, and it appears to resemble a gun, does it mean that your system is dangerous? Or is your system simply capable of identifying a dangerous gun? The fact that cognition can be externalized [LW · GW] also contributes to this point.
- A feature is still a fuzzy concept, and the problem of superposition and the natural abstraction hypothesis remains a hypothesis three years after those Distill papers, with very few convincing strategies to solve them. And that's not very surprising: the central conceptual notion of interpretability, the “feature”, seems to be intrinsically fuzzy and is still not defined. This is a major problem for the "enumerative safety" strategy and for iterating on neurons one by one to verify the "goodness" of each feature and obtain guarantees:
- And because of superposition, iterating over each neuron is not valid. So we can't just iterate on neurons, but we have to iterate on all sets of neurons (or worse, all directions), which is totally computationally intractable.
- Properties of models which are dangerous are not low-level features, but high-level behavioral abilities like being able to code, sycophancy [LW · GW] or various theories of mind proxies, situational awareness, or hacking.
- A network's situational awareness will likely include several sub-features such as date and time, geographical position, and the current needs of its users. Removing these sub-features would make the model less competitive.
- Deep Deceptiveness [LW · GW] - In simple terms, a system can be deceptive even if no single part is dangerous because of optimization pressure, and complex interactions between the model and the environment.
- This strategy has already been tried for vision via automatic interpretability techniques to label all neurons, and it doesn't seem to have advanced alignment much, and most neurons evade simple interpretations:
- NetDisect & Compositional explanations of neurons (Mu and Andreas, 2021)
- Natural Language Descriptions of Deep Visual Features (Andreas, 2022)
- Clip-Dissect (Oikarinen, 2022) Towards a Visual Concept Vocabulary for GAN Latent Space (Schwettmann, 2021)
- These works [partially summarized here [LW · GW]] have not changed the way we try to make vision systems more robust and less risky in practice.
- Most automatic interpretability works, like Language models can explain neurons in language models from OpenAI or concept erasure techniques, falls into this category.
Reverse engineering?
Reverse engineering is a classic example of interpretability, but I don't see a successful way forward. Would this be:
- The equivalent C++ annotated algorithm of what the model does? Being able to reproduce the capabilities of the inscrutable matrices of GPT-4 by some modular C++ code by would be past human level intelligence already, and this would be too dangerous [LW · GW], because this would allow a lot of different optimization, and probably allow recursive self-improvement which seems dangerous especially if we rely on an automated process for that.
- An explanation in layman terms of the behavior of the model? At which level of granularity? Each token or sentence or paragraph? This is really unclear.
- The functional connectome of the model obtained with high level interp? Ok, you see in the functional connectome that the model is able to code and to hack, and those are dangerous capabilities. Isn’t this just regular evals?
- In practice, to conduct interp experiments, we almost always start by creating a dataset of prompts. Maybe one day we won't need prompts to activate these capabilities, but I don't see that happening anytime soon.
- A graph to explain the circuits? Graphs like the ones just below can be overwhelming and remain very limited.
You can notice that “Enumerative safety” is often hidden behind the “reverse engineering” end story.
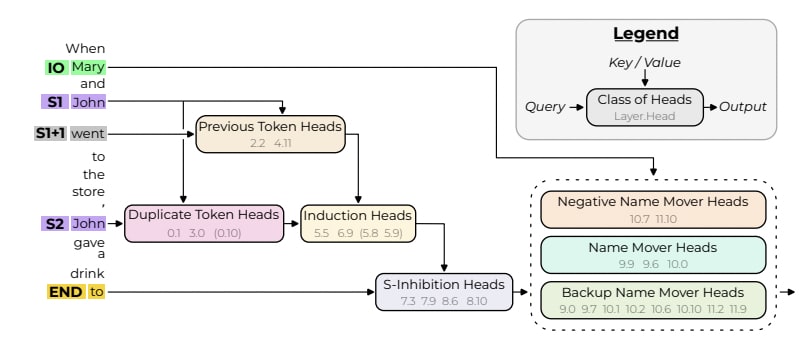
From the IOI paper. Understanding this diagram from 'Interpretability in the Wild' by Wang et al. 2022 is not essential for our discussion. Understanding the full circuit and the method used would require a three-hour video. And, this analysis only focuses on a single token and involves numerous simplifications. For instance, while we attempt to explain why the token 'Mary' is preferred over 'John', we do not delve into why the model initially considers either 'Mary' or 'John'. Additionally, this analysis is based solely on GPT2-small.
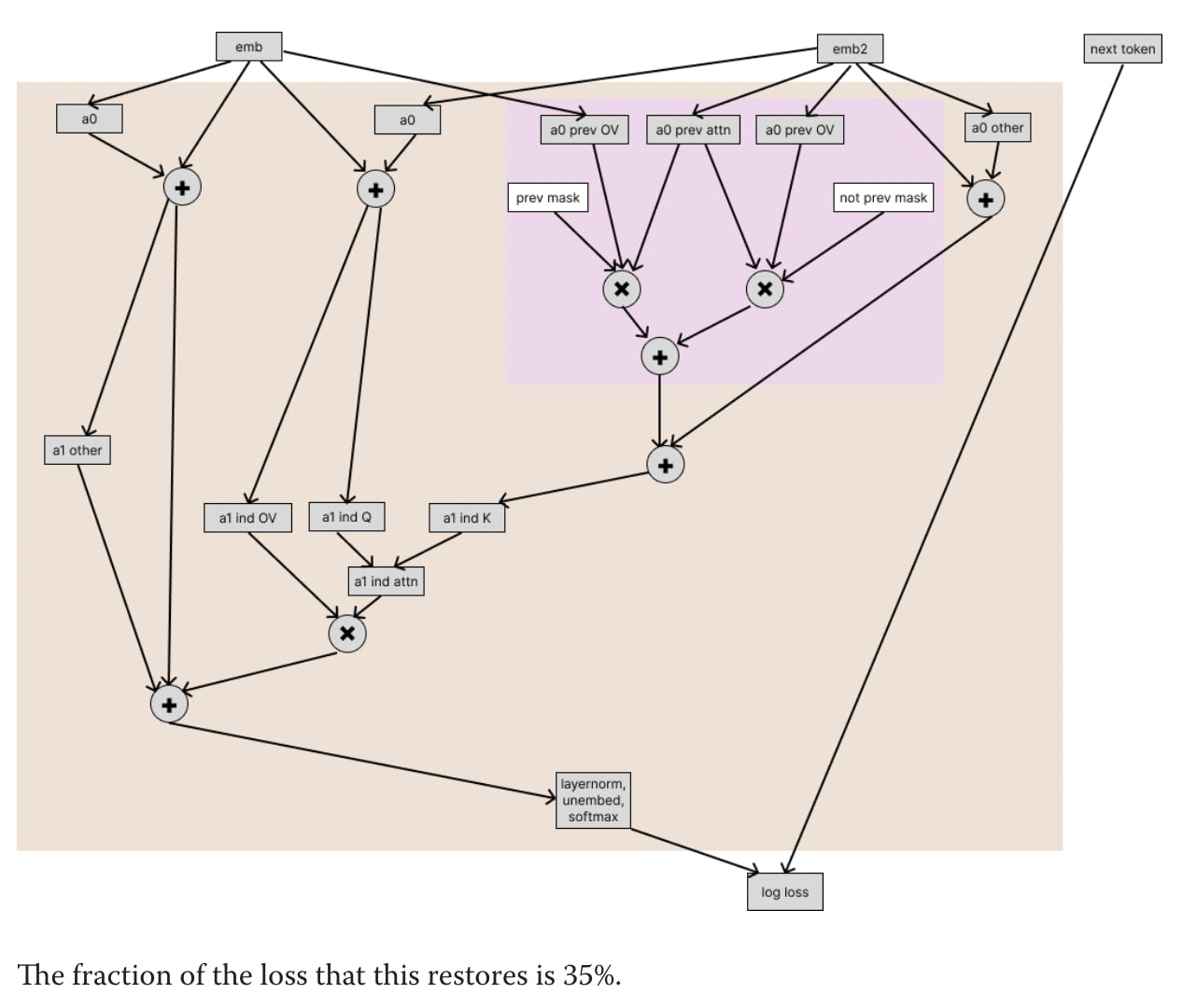
Indeed, this figure is quite terrifying. from Causal scrubbing: results on induction heads [LW · GW], for a 2 layer model. After refining 4 times the hypothesis, they are able to restore 86% of the loss. But even for this simple task they say “we won’t end up reaching hypotheses that are fully specific or fully human-understandable, causal scrubbing will allow us to validate claims about which components and computations of the model are important.”.
The fact that reverse engineering is already so difficult in the two toy examples above seems concerning to me.
Olah’s interpretability dream?
Or maybe interp is just an exploration driven by curiosity waiting for serendipity?
- Interpretability Dreams is an informal note by Chris Olah on future goals for mechanistic interpretability. It discusses superposition, the enemy of interpretability. Then, towards the end of the note, In the section titled “How Does Mechanistic Interpretability Fit Into Safety?”, we understand the plan is to solve superposition to be able to use the following formula:
- But this is simply again “enumerative safety” stated in terms of circuits rather than features. However, as explained above, I don't think this leads us anywhere.
- The final section of the note, Beauty and Curiosity, reads like a poem or hymn to beauty. However, it seems to lack substance beyond a hope for serendipitous discovery.

Overall, I am skeptical about Anthropic's use of the dictionary learning approach to solve the superposition problem. While their negative results are interesting, and they are working on addressing conceptual difficulties around the concept of "feature" (as noted in their May update), I remain unconvinced about the effectiveness of this approach, even after reading their recent July updates, which still do not address my objections about enumerative safety.
One potential solution Olah suggests is automated research: "it does seem quite possible that the types of approaches […] will ultimately be insufficient, and interpretability may need to rely on AI automation". However, I believe that this kind of automation is potentially harmful [section Harmful [LW · GW]].
This is still a developing story, and the papers published on Distill are always a great pleasure to read. However, I remain hesitant to bet on this approach.
Retargeting the search?
Or maybe interp could be useful for retargeting the search [LW · GW]? This idea suggests that if we find a goal in a system, we can simply change the system's goal and redirect it towards a better goal.
I think this is a promising quest, even if there are still difficulties:
- This is interesting because this would be a way to not need to fully reverse engineer a complete model. The technique used in Understanding and controlling a maze-solving policy network [AF · GW] seems promising to me. Just focusing on “the motivational API” could be sufficient.
- But I still don’t know if Steering vectors [LW · GW] (i.e. activation additions of a vector in the latent space) really count as interpretability, and really change significantly the picture of alignment beyond just prompt engineering. Ok, this is a new way to tinker with the model. But I don’t know how this could be used reliably against deception.[7]
Relaxed adversarial training?
Relaxed adversarial training? The TL;DR is that relaxed adversarial training is the same as adversarial training, but instead of creating adversarial inputs to test the network, we create adversarial latent vectors. This could be useful because creating realistic adversarial inputs is a bottleneck in adversarial training. [More explanations here]
This seems valid but very hard, and there are still significant conceptual difficulties. A concrete approach, Latent Adversarial Training [LW · GW], has been proposed, and seems to be promising but:
- The procedure is underspecified. There will be too many meta-parameters. Calibrating these meta-parameters will require some iteration, and you probably don’t want to iterate on deceptive powerful models. We have to be good right away from the first choice of meta-parameters. As the author himself says, "the only hope here lies in the Surgeon forcing the model to be robustly safe before it learns to deceive. Once the model is deceptive it's really game-over."
- We still have no guarantees. This procedure allows for a latent space that is robust to “small perturbations”, but being robust to “small perturbations” is not the same as not becoming deceptive (it’s not clear to me that deception won’t appear outside the constraint zone).
- Papers using this kind of procedure have only limited effectiveness, for example around 90% detection rate in the paper ABS: Scanning Neural Networks for Back-doors by Artificial Brain Stimulation (Liu et al., 2019). [Paper summarized here] And I don’t think this could work against all types of trojans.
The exact procedure described in Latent Adversarial Training [LW · GW] hasn't been tested, as far as I know. So we should probably work on it.[8]
Microscope AI?
Maybe Microscope AI i.e. Maybe we could directly use the AI’s world model without having to understand everything. Microscope AI is an AI that would be used not in inference, but would be used just by looking at its internal activations or weights, without deploying it. My definition would be something like: We can run forward passes, but only halfway through the model.
- This goes against almost every economic incentive (see Why Tool AIs wants to become Agents AI, from Gwern).
- ($) Interpretability has been mostly useless for discovering facts about the world, and learning new stuff by only looking at the weights is too hard.
- In the paper Acquisition of Chess Knowledge in AlphaZero, the authors investigate whether “we can learn chess strategies by interpreting the trained AlphaZero's behavior”. Answer: This is not the case. They probe the network using only concepts already known to Stockfish, and no new fundamental insights are gained. We only check when AlphaGo learns human concepts during the training run.
- I don’t think we will be able to learn category theory by reverse engineering the brain of Terence Tao. How do Go players learn strategies from go programs? Do they interpret AlphaGo’s weights, or do they try to understand the behavioral evaluations of those programs? Answer: They learn from their behavior, but not by interpreting models. I am skeptical that we can gain radically new knowledge from the weights/activations/circuits of a neural network that we did not already know, especially considering how difficult it can be to learn things from English textbooks alone.
- Microscope AIs should not be agentic by definition. But agency and exploration help tremendously at the human level for discovering new truths. Therefore, below superhuman level, the microscope needs to be agentic…and this is a contradiction. Using Microscope AI as a tool rather than an agent is suggested here [LW · GW] or here [LW · GW] for example. However, to know the truth of a complex fact, we need to experiment with the world and actively search for information. Here is a fuzzy reasoning (feel free to skip):
- A) Either the information already exists and is written plainly somewhere on the internet, and in that case, there is no need for Microscope AI (this is like text retrieval).
- B) Or the information doesn't exist anywhere on the internet, and in that case, it is necessary to be agentic by experimenting with the world or by thinking actively. This is the type of feature that can only be “created” by reinforcement learning but which cannot be “discovered” with supervised learning, like MuZero discovering new chess strategies.
- or C), this info is not plainly written but is a deep feature of the training data that could be understood/grokked through gradient descent. This is the type of feature that can be “discovered” with supervised learning.
- If B), we need agency, and it’s no longer a microscope.
- If C), we can apply the above reasoning ($) + Being able to achieve this through pure gradient descent without exploration is probably a higher level of capability than being able to do it with exploration. (This would be like discovering the Quaternion formula during a dream?). But even legendary mathematicians need to work a bit and be agentic in their exploration; they don't just passively read textbooks. Therefore, it's probably beyond Ramanujan's level and too dangerous?
- So, I'm quite uncertain, but overall I don't think Microscope AI is a promising or valid approach to reducing AI risk.
A short case study of Discovering Latent Knowledge [LW · GW] technique to extract knowledge from models by probing is included in the appendix [LW · GW].
So far my best ToI for interp: Outreach?
1. Interp for Nerd Sniping/honeypot?
- Interp is a highly engaging introduction to AI research. That's really cool for that, I use it for my classes, and for technical outreach, but I already have enough material on interpretability, for 10 hours of class, no need to add more.
- Interp as a honeypot for junior researchers? Just as a honeypot attracts bees with its sweet nectar, interp is very successful for recruiting new technical people! but then they would probably be better off doing something else than interp (unless it is their strong comparative advantage).
- (Nerd Sniping senior capability researchers into interpretability research? Less capability research, more time to align AIs? I’m joking, don’t do that at home! )
2. Honorable mentions:
- Showing strange failures, such as the issue with the SolidGoldMagicCarp [LW · GW] token, highlights the possibility of unexpected results with the model. More generally, interpretability tools can be useful for the red teaming toolbox. They seem like they might be able to guide us to more problems than test sets and adversaries can alone.
- Showing GPT is not a stochastic parrot? The article Actually, Othello-GPT Has A Linear Emergent World Representation [LW · GW] is really cool. Showing that OthelloGPT contains a world model is really useful for technical outreach (even if OthelloGPT being good at Othello should be enough, no?).
- It's a good way to introduce the importance and tractability of alignment research “Interpretability gives people a non-technical story for how alignment affects their lives, the scale of the problem, and how progress can be made. IMO no other approach to alignment is anywhere near as good for this.” [from Raymond D [LW · GW]]
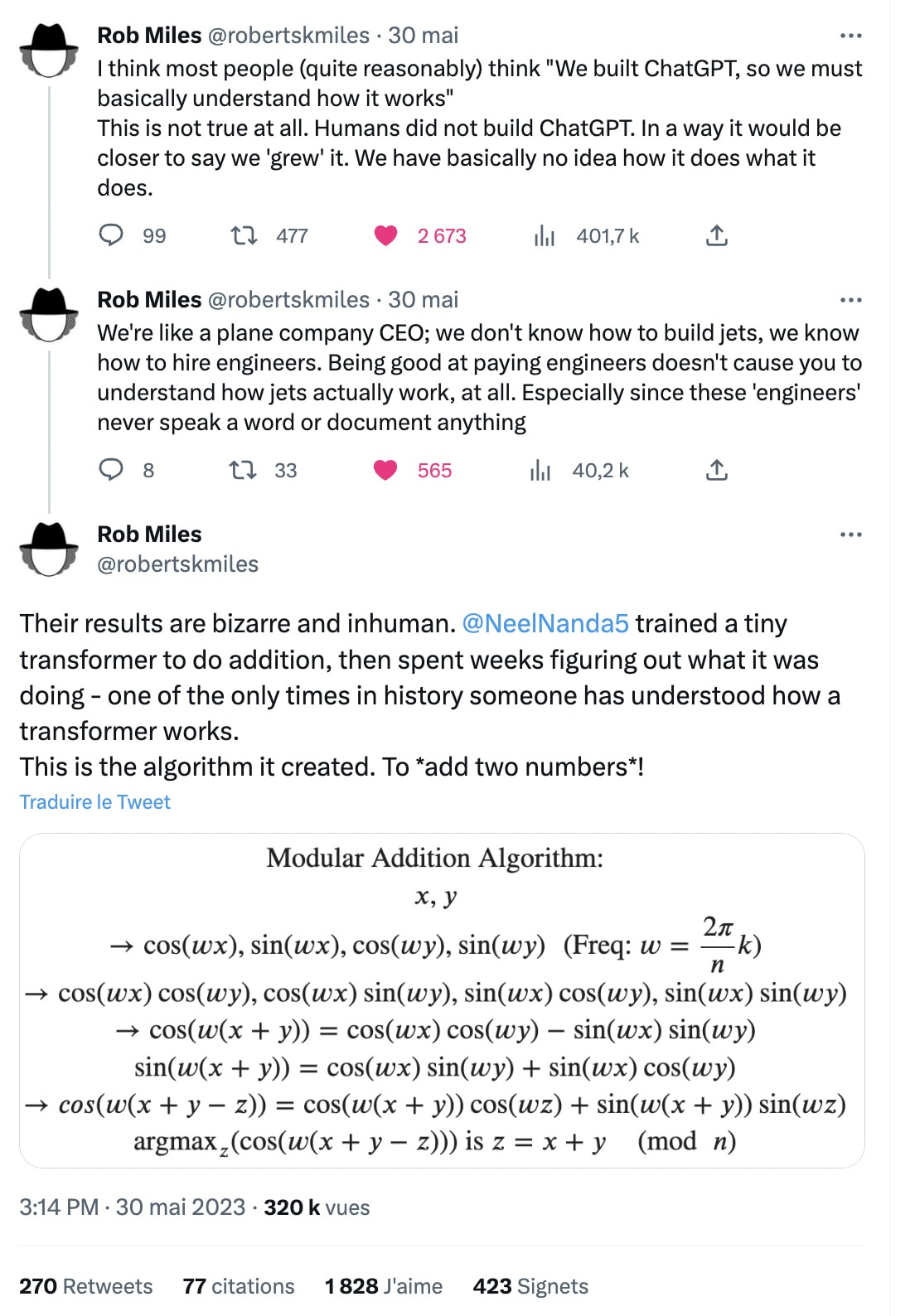
- Better: Showing that “We have basically no idea how it does what it does.”, see this tweet:
Preventive measures against Deception seem much more workable
TL;DR: It would be more desirable to aim for a world where we wouldn't need to delve into the internal components of models. Prevention is better than cure, or at least, it is a neglected strategy.
I don't believe interpretability is the most promising method for monitoring near human-level AGI, Here’s why:
I don't think neural networks will be able to take over in a single forward pass. Models will probably reason in English and will have translucent thoughts (and we could even hope to get transparent thoughts, translucence is the scary place where steganography is possible). In order to devise an effective plan to destroy the world, the first human-level AGI will need to somewhat externalize its reasoning, by chain-of-Thought (CoT), and it seems to me way easier to monitor this chain-of-Thought than probing into the models' internals. We can probably use The Translucent Thoughts Hypotheses [LW · GW] (Fabien, the author, gives a 20% chance, but I think it will be more like 60%). I also think that we have to do everything we can to pass regulations and place ourselves in a world where those hypotheses are true.
For example, magic is possible, and the fact that human brains can be manipulated so easily by magic is a great danger. So we should probably try to make this magic unlikely, for example with process-based training by training AI Systems to reason only step-by-step (the process-based training approach is summarized in this AGISF distillation [LW · GW]).
Steering the world towards transparency
Thinking ahead about the training setup is very important and possibly dominates interp considerations because if the concepts manipulated and by the models are totally alien, it will be much, much harder to provide oversight. And it is much easier to align those chatbots pretrained on human generated text than aligning AGIs trained from scratch with RL / evolutionary methods, etc.
If this is the case, we should focus on various aspects and important recommendations as detailed by Fabien here [LW · GW]. Here are some highlights and comments:
- Making LLMs use only understandable English: Preventing models from using steganography, not training on synthetic data, etc… These directions are generally very neglected - for example, look at this comment [LW · GW].
- Building an oversight system: That’s the “ready to go” technical research of Buck, IDA, or neglected baselines like filtering, etc…
- Testing the translucent thoughts hypotheses and being able to monitor the alienness of models is super important in ensuring some simulacra have brain like representations (see this [LW · GW] and this [LW · GW]). More work in the direction of Language Models Don't Always Say What They Think: Unfaithful Explanations in Chain-of-Thought Prompting.
- Making the hypotheses true, with technical works, outreach and governance, etc.
I think the strategy should be: let’s target a world where deception is unlikely. (I'm not saying we should make plans that work conditional on deception being unlikely by default, but we should try to steer AGI/the world towards a place where deception is unlikely). I believe there are multiple ways to think and address this problem, and much more technical research needed here, starting from Conditioning Predictive Models: Risks and Strategies.
Cognitive Emulations - Explainability By Design
If interpretability was really a bottleneck, we could use cognitive emulation [LW · GW], which, in my opinion, allows way better explainability and transparency than interpretability will ever get us.
My understanding of cognitive emulation: Emulating GPT-4 using LLMs like GPT-3 as different submodules that send messages written in plain English to each other before outputting the next token. If the neural network had deceptive thoughts, we could see them in these intermediate messages.
Some caveats are in the section Cognitive Emulation [LW · GW] of the appendix.
Interpretability May Be Overall Harmful
(Note that some of the following points are not specific to interp, but I think they apply particularly well to interp.)
False sense of control:
- False sense of understanding. It's too easy to think you begin to understand that we're starting to get guarantees when we have not much. This is very classic:
- Me from the past: "Yo, I spent 5 hours trying to understand the mechanisms of inductions head and K-Compositions in a Mathematical Framework for Transformers, I have so much more understanding." yes but no.
- Overinterpretation. It is very difficult to say which interpretation result is solid. For example, Sanity Checks for Saliency Maps shows that most of the pixel attribution techniques are generally misleading.[9] In the same vein, feature viz has recently been found to have some pretty fatal flaws, see Don't trust your eyes: on the (un)reliability of feature visualizations, and the model editing technique such as ROME is very misleading [LW · GW]. This is mostly due to methodological problems that Stephen Casper explains in his sequence. [see appendix: methodological problems [LW · GW]].
- Safety Washing. I feel that there is a part of safety research which is here to legitimize capability research in the big labs (although this is not entirely specific to interp).
- “I think a really substantial fraction of people who are doing "AI Alignment research" are instead acting with the primary aim of "make AI Alignment seem legit". These are not the same goal, a lot of good people can tell and this makes them feel kind of deceived, and also this creates very messy dynamics within the field where people have strong opinions about what the secondary effects of research are, because that's the primary thing they are interested in, instead of asking whether the research points towards useful true things for actually aligning the AI”, from Shutting Down the Lightcone Offices [LW · GW].
- The achievements of interp research are consistently graded on their own curve and overhyped compared to achievements in other fields like adversaries research. For example, the recent paper Universal and Transferable Adversarial Attacks on Aligned Language Models impressively found effective attacks against state-of-the-art models without any interpretations involving models internals. Imagine if mechanistic interpretability researchers did the exact same thing, but by studying model internals? Given the excitement that has emerged in the past around the achievements of mechanistic interpretability in toy models on cherry-picked problems (e.g. this or this), it seems that something like this would have probably made the AI safety research community go wild. Stephen Casper makes a similar point here [? · GW]: “From an engineer’s perspective, it’s important not to grade different classes of solutions each on different curves.” And other examples of this are presented here EIS VI: Critiques of Mechanistic Interpretability Work in AI Safety [? · GW] (thanks to Stephen for highlighting this point).
The world is not coordinated enough for public interpretability research:
- Dual use. It seems anything related to information representation can be used in a dual manner. This is a problem because I believe that the core of interpretability research could lead to major advances in capabilities. See this post [LW · GW].
- Using the insights provided by advanced interp to improve capabilities, such as modularity to optimize inference time and reduce flops, is likely to be easier than using them for better oversight. This is because optimizing for capability is much simpler than optimizing for safety, as we lack clear metrics for measuring safety (see the figure below).
- When interpretability starts to be useful, you can't even publish it because it's too info hazardous. The world is not coordinated enough for public interpretability research.
- Nate Soares explained [LW · GW] this, and this was followed by multiple [LW · GW] posts [LW · GW]. “Insofar as interpretability researchers gain understanding of AIs that could significantly advance the capabilities frontier, I encourage interpretability researchers to keep their research closed [LW · GW]. […] I acknowledge that public sharing of research insights could, in principle, both shorten timelines and improve our odds of success. I suspect that isn’t the case in real life [LW · GW].”
- Good interp could produce a "foom overhang" as described in "AGI-Automated Interpretability is Suicide [LW · GW]".
- Good interp also creates an infosec/infohazard attack vector [LW · GW].
- The post 'Why and When is Interpretability Work Dangerous? [LW · GW]' ends on a sobering note, stating, “In closing, if alignment-conscious researchers continue going into the interpretability subfield, the probability of AGI ruin will tend to increase.”
- Interpretability already helps capabilities. For example, the understanding of Induction head has allowed for better architectures[10].
- Interpretability may be a super wicked problem[11].
Thus the list of "theory of impact" for interpretability should not simply be a list of benefits. It's important to explain why these benefits outweigh the possible negative impacts, as well as how this theory can save time and mitigate any new risks that may arise.

The concrete application of the logit lens [LW · GW] is not an oversight system for deception, but rather capability works to accelerate inference speed like in this paper. (Note that the paper does not cite logit lens, but relies on a very similar method).
Outside view: The proportion of junior researchers doing interp rather than other technical work is too high
It seems to me that many people start alignment research as follows:
- At the end of Arena, an advanced upskilling program in AI Safety, almost all research projects this year (June 2023), except for two out of 16, were interp projects.
- At EffiSciences, at the end of the last 3 ML4Good [LW · GW] bootcamps, students all start by being interested in interp, and it is a very powerful attractor. I myself am guilty. I have redirected too many people to it. I am now trying to correct my ways.
- In the past, if I reconstruct my motivational story, it goes something like this: "Yo, I have a math/ML background, how can I recycle that?" --> then brrr interp, without asking too many questions.
- During Apart Research hackathons, interpretability hackathons tend to draw 3.12 times as many participants as other types of hackathons. (thinkathon, safety benchmarks, …).[12]
- Interpretability streams in Seri Mats are among the most competitive streams (see this tweet). People then try hard, get rejected, get disappointed and lose motivation. This is a recent important problem.
"Not putting all your eggs in one basket" seems more robust considering our uncertainty, and there are more promising ways to reduce x-risk per unit of effort (to come in a future post, mostly through helping/doing governance). I would rather see a more diverse ecosystem of people trying to reduce risks. More on this in section Technical Agendas with better ToI [LW · GW].
If you ask me if interp is also over represented in senior researchers, I'm a bit less confident. Interp also seems to be a significant portion of the pie: this year, while Conjecture and Redwood have partially pivoted, there are new active interp teams in Apollo, DeepMind, OpenAI, and still in Anthropic. I think I would particularly critique DeepMind and OpenAI's interpretability works, as I don't see how this reduces risks more than other works that they could be doing, and I'd appreciate a written plan of what they expect to achieve.
Even if we completely solve interp, we are still in danger
No one has ever claimed otherwise, but it's worth remembering to get the big picture. From stronger arguments to weaker ones:
- There are many X-risks scenarios, not even involving deceptive AIs. Here is a list of such scenarios (see this cheat sheet [LW · GW]):
- Christiano1 - You get what you measure [LW · GW]
- Critch1 - Production Web [LW · GW]
- Soares - A central AI alignment problem: capabilities generalization, the sharp left turn [LW · GW]
- Cohen et al. - Advanced artificial agents intervene in the provision of reward
- Gwern - It Looks Like You’re Trying To Take Over The World
- Exercise: Here is a list of risks from the Center of AI Safety. Which ones can be solved by interp? At least half of those risks don’t directly involve deception and interp.
- Total explainability of complex systems with great power is not sufficient to eliminate risks. Significant risks would still remain. Despite our full understanding of how atomic bombs function, they still pose substantial risks. See this list of nuclear close calls.
- Interpretability implicitly assumes that the AI model does not optimize in a way that is adversarial to the user. Consider being able to read the mind of a psychopath like Voldemort. Would this make you feel safe? The initial step remains to box him. However, a preferable scenario would be not having to confront this situation at all. (this last claim is probably the most important lesson - see Preventive measures [LW · GW]).

That is why focusing on coordination is crucial! There is a level of coordination above which we don’t die - there is no such threshold for interpretability. We currently live in a world where coordination is way more valuable than interpretability techniques. So let’s not forget that non-alignment aspects of AI safety are key! [AF · GW] AI alignment is only a subset of AI safety! (I’m planning to deep-dive more into this in a following post).
A version of this argument applies to "alignment" in general and not just interp and those considerations will heavily influence my recommendations for technical agendas.
Technical Agendas with better ToI
Interp is not such a bad egg, but opportunity costs can be huge (especially for researchers working in big labs).
I’m not saying we should stop doing technical work. Here's a list of technical projects that I consider promising (though I won't argue much for these alternatives here):
- Technical works used for AI Governance. A huge amount of technical and research work needs to be done in order to make regulation robust and actually useful. Mauricio’s AI Governance Needs Technical Work [EA · GW], or the governance section of AGI safety career advice [LW · GW] by Richard Ngo is really great : “It’s very plausible that, starting off with no background in the field, within six months you could write a post or paper which pushes forward the frontier of our knowledge on how one of those topics is relevant to AGI governance.”
- For example, each of the measures proposed in the paper towards best practices in AGI safety and governance: A survey of expert opinion could be a pretext for creating a specialized organization to address these issues, such as auditing, licensing, and monitoring.
- Scary demos (But this shouldn't involve gain-of-function research. There are already many powerful AIs available. Most of the work involves video editing, finding good stories, distribution channels, and creating good memes. Do not make AIs more dangerous just to accomplish this.).
- In the same vein, Monitoring for deceptive alignment [LW · GW] is probably good because “AI coordination needs clear wins [LW · GW]”.
- Interoperability in AI policy, and good definitions usable by policymakers.
- Creating benchmarks for dangerous capabilities.
- Here’s a list of other ideas
- Characterizing the technical difficulties of alignment. (Hold Off On Proposing Solutions [LW · GW] “Do not propose solutions until the problem has been discussed as thoroughly as possible without suggesting any.”)
- Creating the IPCC of AI Risks
- More red-teaming of agendas
- Explaining problems in alignment.
- Adversarial examples, adversarial training, latent adversarial training (the only end-story [LW · GW] I’m kind of excited about). For example, the papers "Red-Teaming the Stable Diffusion Safety Filter" or "Universal and Transferable Adversarial Attacks on Aligned Language Models" are good (and pretty simple!) examples of adversarial robustness works which contribute to safety culture.
- Technical outreach. AI Explained and Rob Miles have plausibly reduced risks more than all interpretability research combined.
- In essence, ask yourself: “What would Dan Hendrycks do?”
- Technical newsletter, non-technical newsletters, benchmarks, policy recommendations, risks analysis, banger statements, courses and technical outreach.
- He is not doing interp. Checkmate!
In short, my agenda is "Slow Capabilities through a safety culture", which I believe is robustly beneficial, even though it may be difficult. I want to help humanity understand that we are not yet ready to align AIs. Let's wait a couple of decades, then reconsider.
And if we really have to build AGIs and align AIs, it seems to me that it is more desirable to aim for a world where we don't need to probe into the internals of models. Again, prevention is better than cure.
Conclusion
I have argued against various theories of impact of interpretability, and proposed some alternatives. I believe working back from the different risk scenarios and red-teaming the theories of impact gives us better clarity and a better chance at doing what matters. Again, I hope this document opens discussions, so feel free to respond in parts. There probably should be a non-zero amount of researchers working on interpretability, this isn’t intended as an attack, but hopefully prompts more careful analysis and comparison to other theories of impact.
We already know some broad lessons, and we already have a general idea of which worlds will be more or less dangerous.Some ML researchers in top labs aren't even aware of, or acknowledging, that AGI is dangerous, that connecting models to the internet, encouraging agency, doing RL and maximizing metrics isn't safe in the limit.
Until civilization catches up to these basic lessons, we should avoid playing with fire, and should try to slow down the development of AGIs as much as possible, or at least steer towards worlds where it’s done only by extremely cautious and competent actors.
Perhaps the main problem I have with interp is that it implicitly reinforces the narrative that we must build powerful, dangerous AIs, and then align them. For X-risks, prevention is better than cure. Let’s not build powerful and dangerous AIs. We aspire for them to be safe, by design.
Appendix
Related works
There is a vast academic literature on the virtues and academic critiques of interpretability (see this page [LW · GW] for plenty of references), but relatively little holistic reflection on interpretability as a strategy to reduce existential risks.
The most important articles presenting arguments for interpretability:
- Chris Olah’s views on AGI safety [LW · GW]
- A Longlist of Theories of Impact for Interpretability [LW · GW]
- Interpretability Dreams
- Why and When Interpretability Work is Dangerous [LW · GW]
- The Defender’s Advantage of Interpretability [LW · GW]
- Monitoring for deceptive alignment [LW · GW]
Against interpretability
- AGI-Automated Interpretability is Suicide [LW · GW]
- Why and When Interpretability Work is Dangerous [LW · GW]
- Should we publish mechanistic interpretability research? [LW · GW]
- EIS III: Broad Critiques of Interpretability Research [LW · GW]
- EIS VI: Critiques of Mechanistic Interpretability Work in AI Safety [? · GW]
- Against Interpretability: a Critical Examination of the Interpretability Problem in Machine Learning
The Engineer’s Interpretability Sequence
I originally began my investigation by rereading “The Engineer’s Interpretability Sequence”, in which Stephen Casper raises many good critiques of interpretability research, and this was really illuminating.
Interpretability tools lack widespread use by practitioners in real applications.
- No interpretability technique is yet publicly known to have been used in production in SOTA models such as ChatGPT.
- There have been interpretability studies of SOTA multimodal models such as CLIP in the past, but these studies are only descriptive.
- The efficient market hypothesis: The technique used for the censorship filter of the Stable Diffusion model was a vulgar cosine similarity threshold between generated image embeddings and a list of taboo concepts. Yes, this may seem a bit ridiculous, but at least there is a filter, and it appears that interp has not yet been able to provide more convenient tools than this.
Broad critiques. He explains [LW · GW] that interp is generally not scaling, relying too much on humans, failing to combine techniques. He also criticizes [? · GW] mech interp, which may not be the best way of doing interp, because of cherry-picking, focusing only on toy examples and lack of scalability, and failing to do useful things.
Methodological problems:
- He points out [? · GW], "The root cause of this has much to do with interpretability research not being approached with as much engineering rigor as it ought to be."
- One good point to note is that since the publication of his sequence, certain methods have become more rigorous. For example, Causal methods [LW · GW], activation patching, probing only with linear probes [LW · GW] are more rigorous and promising than descriptive techniques.
- But I also believe that interpretability may be fundamentally flawed [Section What does the end story of interp look like [LW · GW]].
Cognitive Emulations - Explainability By design
If interpretability was really a bottleneck, we could use cognitive emulation [LW · GW], which, in my opinion, allows way better explainability/transparency than interpretability will ever get us.
My understanding of cognitive emulation: Emulating GPT-4 using LLMs like GPT-3 as different submodules that send messages written in plain English to each other before outputting the next token. If the neural network had deceptive thoughts, we could see them in these intermediate messages.
Interpretability is needed only if one module of the cognitive emulation is deceptive. Then maybe you can use interpretability to explain this module. But I'm confident models will need Chain of Thought for the foreseeable future. So interpretability is not 'urgent' research.
If we don’t use Reinforcement learning on this cognitive emulation, and if we only prompt in English the different submodules, the cognitive emulation won’t create whole “new languages” or be able to obfuscate a lot of its thoughts.
Yes, there are problems with this proposal:
- CoEms don't preclude steganography or obfuscation.
- Even when asked to reason with Chain-of-Thought (CoT), LLMs are able to skip some inference steps to some extent (see Language Models Don't Always Say What They Think: Unfaithful Explanations in Chain-of-Thought Prompting). However, if we don’t train models to skip a zillion inference steps, they won’t be able to obfuscate their thoughts efficiently.
But we could further reduce these risks with:
- Process-based training, to ensure that the systems are accustomed to detailing their thoughts in much greater detail (and not being able to skip too many steps). It seems much more feasible than interpretability (and the alignment tax even seems negative - for example see those progress for Mathematical reasoning)
- selection inference: “CoT has access to the whole context, so each reasoning step is not necessarily causally connected to the last. But selection inference enforces a structure where each reasoning step necessarily follows from the last, and therefore the whole reasoning chain is causal.” from Sid Black, CTO of Conjecture.
- Other ideas were listed in section “Steering the world towards transparency [LW · GW]”.
Spicy: However, cognitive emulation will quite likely be an engineering nightmare, facing significant robustness issues that are always present in small models. The alignment tax will be higher than for end-to-end systems, making it unlikely that we will ever use this technology. The bottleneck is probably not interp, but rather an ecosystem of preventive safety measures and a safety culture. Connor Leahy, CEO of Conjecture, explaining the difficulties of the problem during interviews and pushing towards a safety culture, is plausibly more impactful than the entire CoEm technical agenda.
Detailed Counter Answers to Neel’s list
Here is Neel’s Longlist of Theories of Impact for Interpretability [LW · GW] with critiques for each theory. Theories proposed by Neel are displayed in italics, whereas my critiques are rendered in standard font.
- Force-multiplier on alignment research: We can analyse a model to see why it gives misaligned answers, and what's going wrong. This gets much richer data on empirical alignment work, and lets it progress faster.
- I think this "force multiplier in alignment research" theory is valid, but is conditioned on the success of the other theories of impact, which imho are almost all invalid.
- Conceptual advancements are more urgent It's better to think conceptually about what misalignment means rather than focusing on interp. [Section What does the end story of interpretability look like? [LW · GW]]
- Dual Use: Force-multiplier on capability research.
- Better prediction of future systems: Interpretability may enable a better mechanistic understanding of the principles of how ML systems work, and how they change with scale, analogous to scientific laws. This allows us to better extrapolate from current systems to future systems, in a similar sense to scaling laws. Eg, observing phase changes a la induction heads shows us that models may rapidly gain capabilities during training
- Critiqued in section “Interp is not a good predictor of future systems [LW · GW]”
- Auditing: We get a Mulligan. After training a system, we can check for misalignment, and only deploy if we're confident it's safe
- Not the most direct way. This ToI targets outer misalignment, the next one targets inner misalignment. But currently, people who are auditing for outer alignment do not use interpretability. They evaluate the model, they make the model speak and look if it is aligned with behavioral evaluations. Interpretability has not been useful in finding GPT’s jailbreaks.
- To date, I still don't see how we would proceed with interp to audit GPT-4.
- Auditing for deception: Similar to auditing, we may be able detect deception in a model. This is a much lower bar than fully auditing a model, and is plausibly something we could do with just the ability to look at random bits of the model and identify circuits/features - I see this more as a theory of change for 'worlds where interpretability is harder than I hope'.
- Critiqued in section “Auditing deception with interp is out of reach [LW · GW]”
- Enabling coordination/cooperation: If different actors can interpret each other's systems, it's much easier to trust other actors to behave sensibly and coordinate better
- Not the most direct way. If you really want coordination and cooperation, you need to help with AI governance and outreach of experts and researchers. The statement on AI risks has enabled more coordination than interp will probably never get us.
- Empirical evidence for/against threat models: We can look for empirical examples of theorized future threat models, eg inner misalignment
- Coordinating work on threat models: If we can find empirical examples of eg inner misalignment, it seems much easier to convince skeptics this is an issue, and maybe get more people to work on it.
- Cicero or poker models are already capable of masking pieces of information or bluffing to play poker. From there, I don't know what it would mean to show canonical inner misalignment to non-technical people.
- This focuses too much on deceptive alignment, and this will probably be too late if we get to this point.
- Coordinating a slowdown: If alignment is really hard, it seems much easier to coordinate caution/a slowdown of the field with eg empirical examples of models that seem aligned but are actually deceptive
- Not the most direct way. This is a good theory of change, but interp is not the only way to show that a model is deceptive.
- Coordinating work on threat models: If we can find empirical examples of eg inner misalignment, it seems much easier to convince skeptics this is an issue, and maybe get more people to work on it.
- Improving human feedback: Rather than training models to just do the right things, we can train them to do the right things for the right reasons
- Seems very different from current interpretability work.
- Not the most direct way. Process-based training, model psychology, or other scalable oversight techniques not relying on interp may be more effective.
- Informed oversight: We can improve recursive alignment schemes like IDA by having each step include checking the system is actually aligned. Note: This overlaps a lot with 7. To me, the distinction is that 7 can be also be applied with systems trained non-recursively, eg today's systems trained with Reinforcement Learning from Human Feedback
- Yes, it's an improvement, but it's naive to think that the only problem with RLHF is just the issue of lack of transparency or deception. For example, we would still have agentic models (because agency is preferred by human preferences) and interpretability alone won't fix that. See the Compendium of problems with RLHF [LW · GW] and Open Problems and Fundamental Limitations of RLHF [LW · GW] for more details.
- Conceptual advances are more urgent. What does ‘checking the system is actually aligned’ really means? It's not clear at all.
- Interpretability tools in the loss function: We can directly put an interpretability tool into the training loop to ensure the system is doing things in an aligned way. Ambitious version - the tool is so good that it can't be Goodharted. Less ambitious - The could be Goodharted, but it's expensive, and this shifts the inductive biases to favor aligned cognition.
- Dual Use, for obvious reasons, and this one is particularly dangerous.
- List of lethalities 27. Selecting for undetectability: “Optimizing against an interpreted thought optimizes against interpretability.”
- Norm setting: If interpretability is easier, there may be expectations that, before a company deploys a system, part of doing due diligence is interpreting the system and checking it does what you want
- Not the most direct way. Evals, evals, evals.
- No need to wait for interpretability. We already roughly know what to do. We could conduct studies in line with Evaluating Dangerous Capabilities and the paper Model Evaluation for Extreme Risks, Towards Best Practices in AGI Safety and Governance, this last paper presenting 50 statements about what AGI labs should do, none mentioning interp.
- Enabling regulation: Regulators and policy-makers can create more effective regulations around how aligned AI systems must be if they/the companies can use tools to audit them
- Same critique as 10. Norm setting
- Cultural shift 1: If the field of ML shifts towards having a better understanding of models, this may lead to a better understanding of failure cases and how to avoid them
- Not the most direct way. Technical Outreach, communications, interviews or even probably standards and Benchmarks [? · GW] are way more direct.
- Cultural shift 2: If the field expects better understanding of how models work, it'll become more glaringly obvious how little we understand right now
- Same critique as 12. Cultural shift 1.
- This is probably the opposite of what is happening now: People are fascinated by interpretability and continue to develop capabilities in large labs. I suspect that the well-known Distill journal has been very fascinating for a lot of people and has probably been a source of fascination for people entering the field of ML, thus accelerating capabilities.
- See the False sense of control [LW · GW] section.
- Epistemic learned helplessness: Idk man, do we even need a theory of impact? In what world is 'actually understanding how our black box systems work' not helpful?
- I don't know man, the worlds where we have limited resources, where we are funding constrained + Opportunity costs.
- Dual Use, refer to the section "Interpretability May Be Overall Harmful [LW · GW]".
- Microscope AI: Maybe we can avoid deploying agents at all, by training systems to do complex tasks, then interpreting how they do it and doing it ourselves
- Critique in section Microscope AI? [LW · GW].
- Training AIs to interpret other AIs: Even if interpretability is really hard/labor intensive on advanced systems, if we can create aligned AIs near human level, we can give these interpretability tools and use them to interpret more powerful systems
- Object level: Training AI to interpret other AI, could be useful but would be already dangerous, and we are already in classes of scenarios that are super dangerous [LW · GW].
- Meta level: This scheme is very speculative. I do not want the survival of civilization to rely on it. Godzilla strategy [LW · GW] is probably not a good strategy (though this is controversial).
- Forecasting discontinuities: By understanding what's going on, we can predict how likely we are to see discontinuities in alignment/capabilities, and potentially detect a discontinuity while training/before deploying a system
- Mostly the same critiques as in section “Interp is not a good predictor of future systems [LW · GW]”
- Intervening on training: By interpreting a system during training, we can notice misalignment early on, potentially before it's good enough for strategies to avoid our notice such as deceptive alignment, gradient hacking, obfuscating its thoughts, etc.
- Mostly the same critiques as in section “Auditing deception with interp is out of reach [LW · GW]”
- Auditing a training run: By checking for misalignment early in training, we can stop training systems that seem misaligned. This gives us many more shots to make an aligned system without spending large amounts of capital, and e.g. allows us to try multiple different schemes, initialisations, etc. This essentially shifts the distribution of systems towards alignment.
- Mostly the same critiques as in section “Auditing deception with interp is out of reach [LW · GW]”
- Eliciting Latent Knowledges: Use the length of the shortest interpretability explanation of behaviors of the model as a training loss for ELK - the idea is that models with shorter explanations are less likely to include human simulations / you can tell if they do. (credit to Tao Lin for this one)
- Same critique as 9. Interpretability tools in the loss function.
- Same critique as 15. Microscope AI.
- Same critique as 16. Training AIs to interpret other AIs.
Case study of some cool interp papers
This section is more technical.
Stephen Casper lists [? · GW] a bunch of impressive interpretability papers, as of February 2023. Let's try to investigate whether these papers could be used in the future to reduce risks. For each article, I mention the corresponding end story, and the critic of this end story applies to the article.
Bau et al. (2018)
Bau et al. (2018): Reverse engineer and repurpose a GAN for controllable image generation.
- Procedure: (video) We generate images of churches using a GAN. There are often trees in the generated images. We manually surround the trees, then find the units in the GAN that are mostly responsible for generating these image regions. After finding these regions, we perform an ablation of these units, and it turns out that the trees disappear.
- End Story: Enumerative safety [LW · GW]
- Useful for outer alignment? Ideally, we could 1. Find features which are undesirable 2. Then remove parts of the network that are most linked to these features. This is a very limited form of alignment procedure, by ablation.
- Maybe we could use this kind of procedure to filter pornography, but why then train the network on pornographic images in the first place?
- Basically, this is the same strategy as enumerative safety which is criticized above.
- Useful for inner alignment? Can we apply this to deception? No, because by definition, deception will not result in a difference in outputs, so we cannot apply this procedure.
Ghorbani et al. (2020)
Ghorbani et al. (2020): Identify and successfully ablate neurons responsible for biases and adversarial vulnerabilities.
- Procedure: (video) It calculates the Shapley score of different units of a CNN and then removes the units with the highest Shapley value to maximize or minimize a metric. Removing certain units seems to make the network more robust to certain adversarial attacks.
- End Story: Enumerative safety [LW · GW] (and Reverse engineering [LW · GW]?)
- Useful for outer alignment? What would have happened if we had just added black women to the dataset? We can simply use a generative model for that and generate lots of images of black women. I'm almost certain that the technique used by OpenAI to remove biases in Dalle-2, does not rely on interp.
- Useful for inner alignment? Can we apply this to deception? No, again because the first step in using Shapley value and this interpretability method is to find a behavioral difference, and we need first to create a metric of deception, which does not exist currently. So again we first need to find first a behavioral difference and some evidence of deception.
Burns et al. (2022)
Burns et al. (2022): Identify directions in latent space that were predictive of a language model saying false things.
- Procedure: compare the probability of the ‘Yes’ token with the probability probed from the world model.
- End story: Microscope AI [LW · GW]
- Useful for inner alignment?
- Extracting knowledge from near GPT-3 level AIs, mostly trained through self-supervised learning via next token prediction, is a misunderstanding [LW · GW].
- This technique requires a minimum of agency and is not just usable as an oracle.
- Chain-of-thought will probably always be better. Currently, this technique barely performs better than next token prediction. Chain-of-thought performs much better, and it seems we have (obvious) theoretical reason to think so. So using GPTs as just an oracle won’t be competitive. This paper doesn't test the trivial baseline of just fine-tuning the model (which has been found to usually work better).
- Agency is probably required. It seems unlikely that it will synthesize knowledge on its own in a world model during next-token prediction training. Making tests in the world, or reasoning in an open-ended way, is probably necessary to synthesize a proper truth feature in the world model in advanced GPT using continual learning.
- Conclusion: Yes, maybe in the future, if we create autonomous agents that conduct experiments and have their own world model, this kind of technique could probably be spot a mismatch between the world model oracle and what the model tells you. But if that were the case, we would probably already be in a very, very dangerous world. Civilization is not ready for this, and I still think that this method will be very brittle, and I prefer to aim for worlds where deception is unlikely. [section: Preventive measures [LW · GW]]
Casper et al. (2022)
Casper et al. (2022): Identify hundreds of interpretable copy/paste attacks.
- Procedure: We try to find adversarial attacks automatically. For each image x, we optimize the latent space of a GAN to complete a patch in the image, to optimize the probability of classification towards class y2. We do this for each possible (x, y2) and we observe what appears in the patch. Then we search for natural patches that have a similar embedding to the synthetic adversarial patch, and if the similarity is high enough, we test the natural patch and see if this natural patch breaks the classifier.
- End Story: Relaxed Adversarial training [LW · GW]?
- Useful for inner alignment? Conceptually yes, but this is so brittle. And if the trigger mechanism for deceptive alignment is not generable by the GAN or is not in the distribution of natural images/text, we won’t find it.
Ziegler et al. (2022)
Ziegler et al. (2022): Debug a model well enough to greatly reduce its rate of misclassification in a high-stakes type of setting.
- Procedure: The project consists in building a highly reliable injury classifier: “We started with a baseline classifier trained on some mildly injury-enriched (but otherwise mostly random) data. Then, over the course of several months, we tried various techniques to make it more reliable”. The aim here is to minimize the false negative rate, striving to make the classifier as reliable as possible.: we do not want to let any problematic sentence or example go unnoticed. In order to find adversarial examples, they experimented with the following techniques:
- 1. unaugmented humans: humans manually search for problematic sentences,
- 2. automatic paraphrasing: use of LLM to find variations of problematic sentences and progressively enrich the dataset.
- and 3. humans augmented with a rewriting tool. It is mainly this last technique that was useful.
- End Story: Adversarial training and maybe Relaxed Adversarial training [LW · GW]?
- Robustness results:
- In-distribution: They started with a classifier that had a 2.5% false negatives, and ended up with a classifier that had 0.003% false negatives! They are almost reaching the limits of detection for this type of dataset.
- Out-of-distribution: The tool-assisted attack to generate an adversarial example now takes 26 minutes per example, which is only twice as long as the previous time of 13 minutes. This falls short of the paper's aim to gain many orders of magnitude in speedup. Unfortunately, even though the original dataset (in-distribution) is now almost completely well classified, it seems that it is still possible to easily create adversarial examples with automated tools, and we have only improved the defense by a factor of 2. But only a factor of 2 falls short of the aims of this project.
- Conclusion: Thus, improving a lot in-distribution performance by several orders of magnitude seems to not have much impact on out-of-distribution. Even though Redwood said [AF · GW] that this project could have been conducted better, this is currently rather a negative result to improve the adversarial robustness (i.e. out-of-distribution Robustness). In addition, we can link these results to the paper Adversarial Policies Beat Superhuman Go AIs, Wang et al.. 2022, which studies adversarial attacks on the Katago AI, which is superhuman in the game of Go. They show that it is probably possible to find simple adversarial strategies even against very superhuman AIs. And as a consequence, it seems that even for very robust and powerful AIs, It may always be possible to find adversarial attacks.
- How to use this for deception? Unclear. Do we watch what the AI does, tell it 'you are the lord of the universe, you can do whatever you want' or more subtle variations of this prompt and then see what happens? This is not really interpretability, it's much more prompt engineering with consistency checks or cyborgism than interp. (Beside, the interpretability technique that they used is quite underwhelming, only coloring tokens with the bigger gradient of the norm of the embedding of the token, and then basically iterating on synonymous of those important tokens).
- ^
Is feature visualization useful? Some findings suggest no: Red Teaming Deep Neural Networks with Feature Synthesis Tools.
- ^
GradCam: Maybe this paper? But this is still academic work.
- ^
I have organized two [LW · GW] hackathons centered around the topic of spurious correlations. I strongly nudged using interp, but unfortunately, nobody used it...Yes this claim is a bit weak, but still indicates a real phenomenon, see [section Lack of real applications [LW · GW]]
- ^
Note: I am not making any claims about ex-ante interp (also known as intrinsic interp), which has not been so far able to predict the future system either.
- ^
Other weaker difficulties for auditing deception with interp: This is already too risky and Prevention is better than cure. 1) Moloch may still kill us:"auditing a trained model" does not have a great story for wins. Like, either you find that the model is fine (in which case it would have been fine if you skipped the auditing) or you find that the model will kill you (in which case you don't deploy your AI system, and someone else destroys the world instead). […] a capable lab would accidentally destroy the world because they would be trying the same approach but either not have those interpretability tools or not be careful enough to use them to check their trained model as well?” [Source [LW · GW] Rohin Shah]. 2) We probably won’t be competent enough to fix our mistake: “in order for auditing the model to help (directly), you have to actually be pretty confident in your ability to understand and fix your mistakes if you find one. It's not like getting a coin to land Heads by flipping it again if it lands Tails - different AGI projects are not independent random variables, if you don't get good results the first time you won't get good results the next time unless you understand what happened. This means that auditing trained models isn't really appropriate for the middle of the skill curve.” [Source [LW · GW] Charlie Steiner].
- ^
From “Conditioning Generative Models [LW · GW]. “Suppose you had a language model that you knew was in fact a good generative model of the world and that this property continued to hold regardless of what you conditioned it on. Furthermore, suppose you had some prompt that described some agent for the language model to simulate (Alice) that in practice resulted in aligned-looking outputs. Is there a way we could use different conditionals to get at whether or not Alice was deceptive (e.g. prompt the model with “DeepMind develops perfect transparency tools and provides an opportunity for deceptive models to come clean and receive a prize before they’re discovered.”)?”
- ^
For example, what happens If you prompt a deceptive model with a Joyous prompt, and prompt the same deceptive model with a sad prompt and then take the difference, you obtain a Joyous Deceptive model?
- ^
But at the same time, we could be pessimistic, because this good idea has been out there in the wild since Christiano described it in 2019. So either this idea does not work and we have not heard about it. Or the community has failed to recognize a pretty simple good idea.
- ^
Causal scrubbing could be a good way for evaluating interp techniques using something other than intuition. However, this is only suitable for localization assessment and does not measure how understandable the system is for humans.
- ^
“I was previously pretty dubious about interpretability results leading to capabilities advances. I've only really seen two papers which did this for LMs and they came from the same lab in the past few months. It seemed to me like most of the advances in modern ML (other than scale) came from people tinkering with architectures and seeing which modifications increased performance. But in a conversation with Oliver Habryka and others, it was brought up that as AI models are getting larger and more expensive, this tinkering will get more difficult and expensive. This might cause researchers to look for additional places for capabilities insights, and one of the obvious places to find such insights might be interpretability research.” from Peter barnett [LW(p) · GW(p)].
- ^
Not quite! Hypotheses 4 (and 2?) are missing. Thanks to Diego Dorn for presenting this fun concept to me.
90 comments
Comments sorted by top scores.
comment by Richard_Ngo (ricraz) · 2023-08-18T00:16:36.112Z · LW(p) · GW(p)
Strong disagree. This seems like very much the wrong type of reasoning to do about novel scientific research. Big breakthroughs open up possibilities that are very hard to imagine before those breakthroughs (e.g. imagine trying to describe the useful applications of electricity before anyone knew what it was or how it worked; or imagine Galileo trying to justify the practical use of studying astronomy).
Interpretability seems like our clear best bet for developing a more principled understanding of how deep learning works; this by itself is sufficient to recommend it. (Algon makes a similar point in another comment [LW(p) · GW(p)].) Though I do agree that, based on the numbers you gave for how many junior researchers' projects are focusing on interpretability, people are probably overweighting it.
I think this post is an example of a fairly common phenomenon where alignment people are too focused on backchaining from desired end states, and not focused enough on forward-chaining to find the avenues of investigation which actually allow useful feedback and give us a hook into understanding the world better. (By contrast, most ML researchers are too focused on the latter.)
Perhaps the main problem I have with interp is that it implicitly reinforces the narrative that we must build powerful, dangerous AIs, and then align them. For X-risks, prevention is better than cure. Let’s not build powerful and dangerous AIs. We aspire for them to be safe, by design.
I particularly disagree with this part. The way you get safety by design is understanding what's going on inside the neural networks. More generally, I'm strongly against arguments of the form "we shouldn't do useful work, because then it will encourage other people to do bad things". In theory arguments like these can sometimes be correct, but in practice perfect is often the enemy of the good.
Replies from: charbel-raphael-segerie, interstice, scasper, Charlie Steiner, dr_s, sharmake-farah, remmelt-ellen↑ comment by Charbel-Raphaël (charbel-raphael-segerie) · 2023-08-18T01:14:04.151Z · LW(p) · GW(p)
This seems like very much the wrong type of reasoning to do about novel scientific research. Big breakthroughs open up possibilities that are very hard to imagine before those breakthroughs.
What type of reasoning do you think would be most appropriate?
This proves too much. The only way to determine whether a research direction is promising or not is through object-level arguments. I don't see how we can proceed without scrutinizing the agendas and listing the main difficulties.
this by itself is sufficient to recommend it.
I don't think it's that simple. We have to weigh the good against the bad, and I'd like to see some object-level explanations for why the bad doesn't outweigh the good, and why the problem is sufficiently tractable.
Interpretability seems like our clear best bet for developing a more principled understanding of how deep learning works;
Maybe. I would still argue that other research avenues are neglected in the community.
not focused enough on forward-chaining to find the avenues of investigation which actually allow useful feedback and give us a hook into understanding the world better
I provided plenty of technical research direction in the "preventive measures" section, this should also qualifies as forward-chaining. And interp is certainly not the only way to understand the world better. Besides, I didn't say we should stop Interp research altogether, just consider other avenues.
More generally, I'm strongly against arguments of the form "we shouldn't do useful work, because then it will encourage other people to do bad things". In theory arguments like these can sometimes be correct, but in practice perfect is often the enemy of the good.
I think I agree, but this is only one of the many points in my post.
Replies from: ricraz↑ comment by Richard_Ngo (ricraz) · 2023-08-18T03:59:25.757Z · LW(p) · GW(p)
What type of reasoning do you think would be most appropriate?
See the discussion between me and interstice upthread for a type of argument that feels more productive.
I would still argue that other research avenues are neglected in the community.
I agree (and mentioned so in my original comment). This post would have been far more productive if it had focused on exploring them.
We have to weigh the good against the bad, and I'd like to see some object-level explanations for why the bad doesn't outweigh the good, and why the problem is sufficiently tractable.
The things you should be looking for, when it comes to fundamental breakthroughs, are deep problems demonstrating fascinating phenomena, and especially cases where you can get rapid feedback from reality. That's what we've got here. If that's not object-level enough then your criterion would have ruled out almost all great science in the past.
I think I agree, but this is only one of the many points in my post.
I wouldn't have criticized it so strongly if you hadn't listed it as "Perhaps the main problem I have with interp".
Replies from: charbel-raphael-segerie↑ comment by Charbel-Raphaël (charbel-raphael-segerie) · 2023-08-18T05:54:28.117Z · LW(p) · GW(p)
This post would have been far more productive if it had focused on exploring them.
So the sections "Counteracting deception with only interp is not the only approach" and "Preventive measures against deception", "Cognitive Emulations" and "Technical Agendas with better ToI" don't feel productive? It seems to me that it's already a good list of neglected research agendas. So I don't understand.
if you hadn't listed it as "Perhaps the main problem I have with interp"
In the above comment, I only agree with "we shouldn't do useful work, because then it will encourage other people to do bad things", and I don't agree with your critique of "Perhaps the main problem I have with interp..." which I think is not justified enough.
Replies from: ricraz↑ comment by Richard_Ngo (ricraz) · 2023-08-18T16:12:55.612Z · LW(p) · GW(p)
So the sections "Counteracting deception with only interp is not the only approach" and "Preventive measures against deception", "Cognitive Emulations" and "Technical Agendas with better ToI" don't feel productive? It seems to me that it's already a good list of neglected research agendas. So I don't understand.
You've listed them, but you haven't really argued that they're valuable, you're mostly just asserting stuff like Rob Miles having a bigger impact than most interpretability researchers, or the best strategy being copying Dan Hendrycks. But since I disagree with the assertions, these sections aren't very useful; they don't actually zoom in on the positive case for these research directions.
(The main positive case I'm seeing seems to be "anything which helps with coordination is really valuable". And sure, coordination is great. But most coordination-related research is shallow: it helps us do things now, but doesn't help us figure out how to do things better in the long term. So I think you're overstating the case for it in general.)
Replies from: charbel-raphael-segerie↑ comment by Charbel-Raphaël (charbel-raphael-segerie) · 2023-08-18T23:26:37.193Z · LW(p) · GW(p)
I agree that I haven't argued the positive case for more governance/coordination work (and that's why I hope to do a next post on that).
We do need alignment work, but I think the current allocation is too focused on alignment, whereas AI X-Risks could arrive in the near future. I'll be happy to reinvest in alignment work once we're sure we can avoid X-Risks [LW · GW] from misuses and grossly negligent accidents.
↑ comment by interstice · 2023-08-18T02:31:34.933Z · LW(p) · GW(p)
Interpretability seems like our clear best bet for developing a more principled understanding of how deep learning works
If our goal is developing a principled understanding of deep learning, directly trying to do that is likely to be more effective than doing interpretability in the hope that we will develop a principled understanding as a side effect. For this reason I think most alignment researchers have too little awareness of various attempts in academia to develop "grand theories" of deep learning such as the neural tangent kernel. I think the ideal use for interpretability in this quest is as a way of investigating how the existing theories break down - e.g. if we can explain 80% of a given model's behavior with the NTK, what are the causes of the remaining 20%? I think of interpretability as basically collecting many interesting data points; this type of collection is essential, but it can be much more effective when it's guided by a provisional theory which tells you what points are expected and what are interesting anomalies which call for a revision of the theory, which in turn guides further exploration, etc.
Replies from: ricraz↑ comment by Richard_Ngo (ricraz) · 2023-08-18T03:47:20.917Z · LW(p) · GW(p)
I agree that work like NTK is worth thinking about. But I disagree that it's a more "direct" approach to a principled understanding of deep learning. To find a "grand theory" of deep learning, we're going to need to connect our understanding of neural networks to our understanding of the real world, and I don't think NTKs or other related things can help very much with that step - for roughly the same reasons that statistical learning theory wasn't very helpful (and was in fact anti-helpful) in predicting the success of deep neural networks.
Btw, this isn't a general-purpose critique of theoretical work - e.g. it doesn't apply to this paper by Lin, Tegmark and Rolnick, which actually ties neural network success to properties of the real world like symmetry, locality, and compositionality. This is the sort of thing which I can much more easily imagine leading to alignment breakthroughs.
I think of interpretability as basically collecting many interesting data points
I'd agree if interpretability were just about "here's a circuit for recognizing X" (although even then, the concept of circuits itself was nontrivial to develop), but in fact a lot of the most promising work has been on more important and fundamental phenomena like superposition and induction heads.
Replies from: interstice↑ comment by interstice · 2023-08-18T04:38:24.173Z · LW(p) · GW(p)
we're going to need to connect our understanding of neural networks to our understanding of the real world
The NTK and related theories aim to go from "SGD finds a giant blob of parameters that performs well on the data for some reason" to "SGD finds a solution with such-and-such clean mathematical characterization". To fully explain the success of deep learning you do then have to relate the clean mathematical characterization to the real world, but I think this can be done separately to some extent and is less of a bottleneck on progress. My #2 use case for interpretability would be doing stuff like this - basically conceptual/experimental investigation of the types of solutions favored by a given mathematical theory, with the goal of obtaining a high-level story about "why it works in the real world". Plus attempts to carry out alignment/interpretability/ELK tasks in the simplified setting.
This is the sort of thing which I can much more easily imagine leading to alignment breakthroughs
Hmm, it's been a while since I looked at this paper but if I recall it doesn't really try to make any specific predictions about the inductive bias of neural nets in practice, it's more like a series of suggestive analogies. That's fine, but I think that sort of thing is more likely to be productive if guided by a more detailed theory.
Replies from: zfurman↑ comment by Zach Furman (zfurman) · 2023-08-18T06:47:13.255Z · LW(p) · GW(p)
I can't speak for Richard, but I think I have a similar issue with NTK and adjacent theory as it currently stands (beyond the usual issues [LW · GW]). I'm significantly more confident in a theory of deep learning if it cleanly and consistently explains (or better yet, predicts) unexpected empirical phenomena. The one that sticks out most prominently in my mind, that we see constantly in interpretability, is this strange correspondence between the algorithmic "structure" we find in trained models (both ML and biological!) and "structure" in the data generating process.
That training on Othello move sequences gets you an algorithmic model of the game itself is surprising from most current theoretical perspectives! So in that sense I might be suspicious of a theory of deep learning that fails to "connect our understanding of neural networks to our understanding of the real world". This is the single most striking thing to come out of interpretability, in my opinion, and I'm worried about a "deep learning theory of everything" if it doesn't address this head on.
That said, NTK doesn't promise to be a theory of everything, so I don't mean to hold it to an unreasonable standard. It does what it says on the tin! I just don't think it's explained a lot of the remaining questions I have. I don't think we're in a situation where "we can explain 80% of a given model's behavior with the NTK" or similar. And this is relevant for e.g. studying inductive biases, as you mentioned.
But I strong upvoted your comment, because I do think deep learning theory can fill this gap - I'm personally trying to work in this area. There are some tractable-looking directions here, and people shouldn't neglect them!
Replies from: interstice, sharmake-farah, kave↑ comment by interstice · 2023-08-18T14:42:43.623Z · LW(p) · GW(p)
I intended my comment to apply to "theories of deep learning" in general, the NTK was only meant as an example. I agree that the NTK has problems such that it can at best be a 'provisional' grand theory. The big question is how to think about feature learning. At this point, though, there are a lot of contenders for "feature learning theories" - the Maximal Update Parameterization, Depth Corrections to the NTK, Perturbation Theory, Singular Learning Theory [LW · GW], Stochastic Collapse, SGD-Induced Sparsity....
So although I don't think the NTK can be a final answer, I do like the idea of studying it in more depth - it provides a feature-learning-free baseline against which we can compare actual neural networks and other potential 'grand theories'. Exactly which phenomena can we not explain with the NTK, and which theory best predicts them?
Replies from: ricraz↑ comment by Richard_Ngo (ricraz) · 2023-08-18T15:56:36.755Z · LW(p) · GW(p)
Strong upvote to Zach's comment, it basically encapsulates my view (except that I don't know what the "tractable-looking directions" he mentions are - Zach, can you elaborate?)
Exactly which phenomena can we not explain with the NTK
I'd turn that around: is there any explanation of why LLMs can do real-world task X and not real-world task Y that appeals to NTKs? (Not a rhetorical question: there may well be, I just haven't seen one.)
Replies from: zfurman, interstice↑ comment by Zach Furman (zfurman) · 2023-08-18T20:23:35.294Z · LW(p) · GW(p)
Yeah, I can expand on that - this is obviously going be fairly opinionated, but there are a few things I'm excited about in this direction.
The first thing that comes to mind here is singular learning theory [? · GW]. I think all of my thoughts on DL theory are fairly strongly influenced by it at this point. It definitely doesn't have all the answers at the moment, but it's the single largest theory I've found that makes deep learning phenomena substantially "less surprising" (bonus points for these ideas preceding deep learning). For instance, one of the first things that SLT tells you is that the effective parameter count (RLCT) of your model can vary depending on the training distribution, allowing it to basically do internal model selection - the absence of bias-variance tradeoff, and the success of overparameterized models, aren't surprising when you internalize this. The "connection to real world structure" aspect hasn't been fully developed here, but it seems heavily suggested by the framework, in multiple ways - for instance, hierarchical statistical models are naturally singular statistical models, and the hierarchical structure is reflected in the singularities. (See also Tom Waring's thesis).
Outside of SLT, there's a few other areas I'm excited about - I'll highlight just one. You mentioned Lin, Tegmark, and Rolnick - the broader literature on depth separations and the curse of dimensionality seems quite important. The approximation abilities of NNs are usually glossed over with universal approximation arguments, but this can't be enough - for generic Lipschitz functions, universal approximation takes exponentially many parameters in the input dimension (this is a provable lower bound). So there has to be something special about the functions we care about in the real world. See this section [LW · GW] of my post for more information. I'd highlight Poggio et al. here, which is the paper in the literature closest to my current view on this.
This isn't a complete list, even of theoretical areas that I think could specifically help address the "real world structure" connection, but these are the two I'd feel bad not mentioning. This doesn't include some of the more empirical findings in science of DL that I think are relevant, like simplicity bias, mode connectivity, grokking, etc. Or work outside DL that could be helpful to draw on, like Boolean circuit complexity, algorithmic information theory, natural abstractions, etc.
Replies from: interstice↑ comment by interstice · 2023-08-18T22:22:47.767Z · LW(p) · GW(p)
the absence of bias-variance tradeoff, and the success of overparameterized models, aren’t surprising when you internalize this
FWIW most potential theories of deep learning are able to explain these, I don't think this distinguishes SLT particularly much.
Replies from: zfurman↑ comment by Zach Furman (zfurman) · 2023-08-18T23:10:46.210Z · LW(p) · GW(p)
Agreed - that alone isn’t particularly much, just one of the easier things to express succinctly. (Though the fact that this predates deep learning does seem significant to me. And the fact that SLT can delineate precisely where statistical learning theory went wrong here seems important too.)
Another is that can explain phenomena like phase transitions, as observed in e.g. toy models of superposition, at a quantitative level. There’s also been a substantial chunk of non-SLT ML literature that has independently rediscovered small pieces of SLT, like failures of information geometry, importance of parameter degeneracies, etc. More speculatively, but what excites me most, is that empirical phenomena like grokking, mode connectivity, and circuits seem to intuitively fit in SLT nicely, though this hasn’t been demonstrated rigorously yet.
↑ comment by interstice · 2023-08-18T16:52:07.073Z · LW(p) · GW(p)
any explanation of why LLMs can do real-world task X and not real-world task Y that appeals to NTKs?
I don't think there are any. Of course much the same could be said of other deep learning theories and most(all?) interpretability work. The difference, as far as I can tell, is that there is a clear pathway to getting such explanations from the NTK: you'd want to do a spectral analysis of the sorts of functions learnable by transformer-NTKs. It's just that nobody has bothered to do this! That's why I think this line of research is neglected relative to interpretability or developing a new theoretical analysis of deep learning. Another obvious thing to try: NTKs often empirically perform comparably well to finite networks, but are usually are a few percentage points worse in accuracy. Can we say anything about the examples where the NTK fails? Do they particularly depend on 'feature learning'? I think NTKs are a good compliment to mechinterp in this regard, since they treat the weights at each neuron as independent of all others, so they provide a good indicator of exactly which examples may require interacting 'circuits' to be correctly classified.
↑ comment by Noosphere89 (sharmake-farah) · 2024-10-06T17:25:06.702Z · LW(p) · GW(p)
A note is that as it turns out, OthelloGPT learned a bag of heuristics, and there was no clean algorithm:
https://www.lesswrong.com/posts/gcpNuEZnxAPayaKBY/othellogpt-learned-a-bag-of-heuristics-1 [LW · GW]
↑ comment by kave · 2023-08-18T21:49:34.290Z · LW(p) · GW(p)
What is the work that finds the algorithmic model of the game itself for Othello? I'm aware of (but not familiar with) some interpretability work on Othello-GPT (Neel Nanda's and Kenneth Li), but thought it was just about board state representations.
Replies from: zfurman↑ comment by Zach Furman (zfurman) · 2023-08-18T23:39:49.742Z · LW(p) · GW(p)
Yeah, that was what I was referring to. Maybe “algorithmic model” isn’t the most precise - what we know is that the NN has an internal model of the board state that’s causal (i.e. the NN actually uses it to make predictions, as verified by interventions). Theoretically it could just be forming this internal model via a big lookup table / function approximation, rather than via a more sophisticated algorithm. Though we’ve seen from modular addition work, transformer induction heads, etc that at least some of the time NNs learn genuine algorithms.
Replies from: kave↑ comment by kave · 2023-08-19T20:59:33.248Z · LW(p) · GW(p)
I think that means one of the following should be surprising from theoretical perspectives:
- That the model learns a representation of the board state
- Or that a linear probe can recover it
- That the board state is used causally
Does that seem right to you? If so, which is the surprising claim?
(I am not that informed on theoretical perspectives)
Replies from: zfurman↑ comment by Zach Furman (zfurman) · 2023-08-19T21:31:44.116Z · LW(p) · GW(p)
I think the core surprising thing is the fact that the model learns a representation of the board state. The causal / linear probe parts are there to ensure that you've defined "learns a representation of the board state" correctly - otherwise the probe could just be computing the board state itself, without that knowledge being used in the original model.
This is surprising to some older theories like statistical learning, because the model is usually treated as effectively a black box function approximator. It's also surprising to theories like NTK, mean-field, and tensor programs, because they view model activations as IID samples from a single-neuron probability distribution - but you can't reconstruct the board state via a permutation-invariant linear probe. The question of "which neuron is which" actually matters, so this form of feature learning is beyond them. (Though there may be e.g. perturbative modifications to these theories to allow this in a limited way).
Replies from: interstice, kave↑ comment by interstice · 2023-08-20T03:53:45.597Z · LW(p) · GW(p)
they view model activations as IID samples from a single-neuron probability distribution - but you can't reconstruct the board state via a permutation-invariant linear probe
Permutation-invariance isn't the reason that this should be surprising. Yes, the NTK views neurons as being drawn from an IID distribution, but once they have been so drawn, you can linearly probe them as independent units. As an example, imagine that our input space consisted of five pixels, and at initialization neurons were randomly sensitive to one of the pixels. You would easily be able to construct linear probes sensitive to individual pixels even though the distribution over neurons is invariant over all the pixels.
The reason the Othello result is surprising to the NTK is that neurons implementing an "Othello board state detector" would be vanishingly rare in the initial distribution, and the NTK thinks that the neuron function distribution does not change during training.
Replies from: zfurman↑ comment by Zach Furman (zfurman) · 2023-08-21T06:43:39.466Z · LW(p) · GW(p)
The reason the Othello result is surprising to the NTK is that neurons implementing an "Othello board state detector" would be vanishingly rare in the initial distribution, and the NTK thinks that the neuron function distribution does not change during training.
Yeah, that's probably the best way to explain why this is surprising from the NTK perspective. I was trying to include mean-field and tensor programs as well (where that explanation doesn't work anymore).
As an example, imagine that our input space consisted of five pixels, and at initialization neurons were randomly sensitive to one of the pixels. You would easily be able to construct linear probes sensitive to individual pixels even though the distribution over neurons is invariant over all the pixels.
Yeah, this is a good point. What I meant to specify wasn't that you can't recover any permutation-sensitive data at all (trivially, you can recover data about the input), but that any learned structures must be invariant to neuron permutation. (Though I'm feeling sketchy about the details of this claim). For the case of NTK, this is sort of trivial, since (as you pointed out) it doesn't really learn features anyway.
By the way, there are actually two separate problems that come from the IID assumption: the "independent" part, and the "identically-distributed" part. For space I only really mentioned the second one. But even if you deal with the identically distributed assumption, the independence assumption still causes problems.This prevents a lot of structure from being representable - for example, a layer where "at most two neurons are activated on any input from some set" can't be represented with independently distributed neurons. More generally a lot of circuit-style constructions require this joint structure. IMO this is actually the more fundamental limitation, though takes longer to dig into.
Replies from: interstice↑ comment by interstice · 2023-08-21T16:16:14.684Z · LW(p) · GW(p)
I was trying to include mean-field and tensor programs as well
but that any learned structures must be invariant to neuron permutation. (Though I'm feeling sketchy about the details of this claim)
The same argument applies - if the distribution of intermediate neurons shifts so that Othello-board-state-detectors have a reasonably high probability of being instantiated, it will be possible to construct a linear probe detecting this, regardless of the permutation-invariance of the distribution.
the independence assumption still causes problems
This is a more reasonable objection(although actually, I'm not sure if independence does hold in the tensor programs framework - probably?)
Replies from: zfurman↑ comment by Zach Furman (zfurman) · 2023-08-21T17:35:30.297Z · LW(p) · GW(p)
if the distribution of intermediate neurons shifts so that Othello-board-state-detectors have a reasonably high probability of being instantiated
Yeah, this "if" was the part I was claiming permutation invariance causes problems for - that identically distributed neurons probably couldn't express something as complicated as a board-state-detector. As soon as that's true (plus assuming the board-state-detector is implemented linearly), agreed, you can recover it with a linear probe regardless of permutation-invariance.
This is a more reasonable objection(although actually, I'm not sure if independence does hold in the tensor programs framework - probably?)
I probably should've just gone with that one, since the independence barrier is the one I usually think about, and harder to get around (related to non-free-field theories, perturbation theory, etc).
My impression from reading through one of the tensor program papers a while back was that it still makes the IID assumption, but there could be some subtlety about that I missed.
↑ comment by scasper · 2023-08-18T16:14:26.541Z · LW(p) · GW(p)
I get the impression of a certain of motte and bailey in this comment and similar arguments. From a high-level, the notion of better understanding what neural networks are doing would be great. The problem though seems to be that most of the SOTA of research in interpretability does not seem to be doing a good job of this in a way that seems useful for safety anytime soon. In that sense, I think this comment talks past the points that this post is trying to make.
Replies from: ricraz↑ comment by Richard_Ngo (ricraz) · 2023-08-18T16:25:37.922Z · LW(p) · GW(p)
I wish the original post had been more careful about its claims, so that I could respond to them more clearly. Instead there's a mishmash of sensible arguments, totally unjustified assertions, and weird strawmen (like "I don't understand how “Looking at random bits of the model and identify circuits/features” will help with deception"). And in general a lot of this is of the form "I don't see how X", which is the format I'm objecting to, because of course you won't see how X until someone invents a technique to X.
This is exacerbated by the meta-level problem that people have very different standards for what's useful (e.g. to Eliezer, none of this is useful), and also standards for what types of evidence and argument they accept (e.g. to many ML researchers, approximately all arguments about long-term theories of impact are too speculative to be worth engaging in depth).
I still think that so many people are working on interpretability mainly because they don't see alternatives that are as promising; in general I'd welcome writing that clearly lays out solid explanations and intuitions about why those other research directions are worth working on, and think that this would be the best way to recalibrate the field.
Replies from: scasper↑ comment by scasper · 2023-08-18T16:37:43.909Z · LW(p) · GW(p)
Thanks for the reply. This sounds reasonable to me. On the last point, I tried my best to do that here [? · GW], and I think there is a relatively high ratio of solid explanations to unsolid ones.
Overall, I think that the hopes you have for interpretability research are good, and I hope it works out. One of the biggest things that I think is a concern though is that people seem to have been making similar takes with little change for 7+ years. But I just don't think there have been a number of wins from this research that are commensurate with the effort put into it. And I assume this is expected under your views, so probably not a crux.
↑ comment by Charlie Steiner · 2023-08-18T10:22:04.683Z · LW(p) · GW(p)
EDIT: Nuance of course being impossible, this no doubt comes off as rude - and is in turn a reaction to an internet-distorted version of what you actually wrote. Oh well, grain of salt and all that.
The way you get safety by design is understanding what's going on inside the neural networks.
This is equivocation. There are some properties of what's going on inside a NN that are crucial to reasoning about its safety properties, and many, many more that are irrelevant.
I'm actually strongly reminded of a recent comment about LK-99, where someone remarked that a good way to ramp up production of superconductors would be to understand how superconductors work, because then we could design one that's easier to mass-produce.
Except:
- What we normally think of as "understanding how superconductors work" is not a sure thing, it's hard and sometimes we don't find satisfactory models.
- Even if we understand how superconductors work, designing new ones with economically useful properties is an independent problem that's also hard and possible to fail at for decades.
- There are many other ways to make progress in discovering superconductors and ramping up their production. These ways are sometimes purely phenomenological, or sometimes rely on building some understanding of the superconductor that's a model of a different type than what we typically mean by "understanding how superconductors work."
It might sound good to say "we'll understand how NNs work, and then use that to design safe ones," but I think the problems are analogous. What we normally think of as "understand how NNs work," especially in the context of mech interp, is a very specific genre of understanding - it's not omniscience, it's the ability to give certain sorts of mechanistic explanations for canonical explananda. And then using that understanding to design safe AI is an independent problem not solved just by solving the first one. Meanwhile, there are other ways to reason about the safety of AI (e.g. statistical arguments about the plausibility of gradient hacking) that use "understanding," but not of the mech interp sort.
Yes, blue sky research is good. But we can simultaneously use our brains about what sorts of explanations we think are promising to find. Understanding doesn't just go into a big bucket labeled "Understanding" from which we draw to make things happen. If I'm in charge of scaling up superconductor production, and I say we should do less micro-level explanation and more phenomenology, telling me about the value of blue sky research is the "wrong type of reasoning."
↑ comment by dr_s · 2023-08-18T10:18:06.534Z · LW(p) · GW(p)
In theory arguments like these can sometimes be correct, but in practice perfect is often the enemy of the good.
The tricky part being that in the AGI alignment discourse, if you believe in self-improvement runaway feedback loops, there is no good. There is only perfect, or extinction. This might be a bit extreme but we don't really know that for sure either.
Replies from: lahwran, Charlie Steiner↑ comment by the gears to ascension (lahwran) · 2023-08-18T18:32:07.403Z · LW(p) · GW(p)
Note that a wrench current paradigms throw in this is that self-improvement processes would not look uniquely recursive, since all training algorithms sort of look like "recursive self improvement". instead, RSI is effectively just "oh no, the training curve was curved differently on this training run", which is something most likely to happen in open world RL. But I agree, open world RL has the ability to be suddenly surprising in capability growth. and there wouldn't be much of an opportunity to notice the problem unless we've already solved how to intentionally bound capabilities in RL.
There has been some interesting work on bounding capability growth in safe RL already, though. I haven't looked closely at it, I wonder if any of it is particularly good.
edit: note that I am in fact claiming that after miri deconfuses us, it'll turn out to apply to ordinary gradient updates
↑ comment by Charlie Steiner · 2023-08-18T10:28:23.196Z · LW(p) · GW(p)
Au contraire, the perfect future doesn't exist, but good ones do [LW · GW].
Replies from: dr_s↑ comment by dr_s · 2023-08-18T10:36:49.427Z · LW(p) · GW(p)
This isn't about "perfect futures" though, but about perfect AGIs specifically. Consider a future that goes like this:
- the AI's presence and influence over us evolves exponentially according to a law ,
- the exponent expresses the amount of misalignment; if the AI is aligned and fully under our control, , otherwise ,
then in that future, anything less than perfect alignment ends with us overwhelmed by the AI, sooner or later. This is super simplistic, but the essence is that if you keep around something really powerful that might just decide to kill you, you probably want to be damn sure it won't. That's what "perfect" here means; it's not fine if it just wants to kill you a little bit. So if your logic is correct (and indeed, I do agree with you on general matters of ethics), then perhaps we just shouldn't build AGI at all, because we can't get it perfect, and if it's not perfect it'll probably be in too precarious a balance with us for it to persist for long.
Replies from: Charlie Steiner↑ comment by Charlie Steiner · 2023-08-18T11:09:32.816Z · LW(p) · GW(p)
Ah, I see more of what you mean. I agree an AI's influence being small is unstable. And this means that the chance of death by AI being small is also unstable.
But I think the risk is one-time, not compounding over time. A high-influence AI might kill you, but if it doesn't, you'll probably live a long and healthy life (because of arguments like stability of value being a convergent instrumental goal). It's not that once an AI becomes high-influence, there's an exponential decay of humans, as every day it makes a new random mutation to its motivations.
Replies from: dr_s↑ comment by dr_s · 2023-08-18T11:42:38.671Z · LW(p) · GW(p)
I don't think that's necessarily true. There's two ways in which I think it can compound:
-
if the AGI will self-upgrade, or design more advanced AGI, the problem repeats, and the AGI can make mistakes, same as us, though probably less obvious mistakes
-
it is possible to imagine an AGI that stays generally aligned but has a certain probability of being triggered on some runaway loop in which it loses its alignment. Like it will come up with pretty aligned solutions most of the time but there is something, some kind of problem or situation, that is so out-of-domain it sends it off the path of insanity, and it's unrecoverable, and we don't know how or when that might occur.
Also, it might simply be probabilistic - any non-fully deterministic AGI probably wouldn't literally have no access to non-aligned strategies, but merely assign them very small logits. So in theory that's still a finite but non-zero possibility that it goes into some kind of "kill all humans" strategy path. And even if you interpret this as one-shot (did you align it right or not on creation?), the effects might not be visible right away.
↑ comment by Noosphere89 (sharmake-farah) · 2023-12-25T16:58:09.932Z · LW(p) · GW(p)
In theory arguments like these can sometimes be correct, but in practice perfect is often the enemy of the good.
Now that I think about it, this is the main problem a lot of LW thinking and posting has: It implicitly thinks that only a perfect, watertight solution to alignment is sufficient to guarantee human survival, despite the fact that most solutions to problems don't have to be perfect to work, and even the cases where we do face against an adversary, imperfect but fast solutions win out over perfect, very slow solutions, and in particular ignores that multiple solutions to alignment can fundamentally stack.
In general, I feel like the biggest flaw of LW is it's perfectionism, and the big reason why Michael Nielsen pointed out that alignment is extremely accelerationist in practice is that OpenAI implements a truth that LWers like Nate Soares and Eliezer Yudkowsky, as well as the broader community doesn't: Alignment approaches don't need to be perfect to work, and having an imperfect safety and alignment plan is much better than no plan at all.
Links are below:
https://www.lesswrong.com/posts/8Q7JwFyC8hqYYmCkC/link-post-michael-nielsen-s-notes-on-existential-risk-from [LW · GW]
https://www.beren.io/2023-02-19-The-solution-to-alignment-is-many-not-one/
Replies from: quetzal_rainbow↑ comment by quetzal_rainbow · 2023-12-26T04:21:09.341Z · LW(p) · GW(p)
It's literally point -2 in List of Lethalities that we don't need "perfect" alignment solution, we just don't have any.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2023-12-26T16:05:17.743Z · LW(p) · GW(p)
I basically just disagree with this entirely, unless you don't count stuff like RLHF or DPO as alignment.
More generally, if we grant that we don't need perfection, or arbitrarily good alignment, at least early on, then I think this implies that alignment should be really easy, and the p(Doom) numbers are almost certainly way too high, primarily because it's often doable to solve problems of you don't need perfect or arbitrarily good solutions.
So I basically just disagree with Eliezer here.
Replies from: abramdemski, quetzal_rainbow↑ comment by abramdemski · 2024-01-04T04:34:46.951Z · LW(p) · GW(p)
More generally, if we grant that we don't need perfection, or arbitrarily good alignment, at least early on, then I think this implies that alignment should be really easy, and the p(Doom) numbers are almost certainly way too high, primarily because it's often doable to solve problems of you don't need perfect or arbitrarily good solutions.
It seems really easy to spell out worldviews where "we don't need perfection, or arbitrarily good alignment" but yet "alignment should be really easy". To give a somewhat silly example based on the OP, I could buy Enumerative Safety in principle -- so if we can check all the features for safety, we can 100% guarantee the safety of the model. It then follows that if we can check 95% of the features (sampled randomly) then we get something like a 95% safety guarantee (depending on priors).
But I might also think that properly "checking" even one feature is really, really hard.
So I don't buy the claimed implication: "we don't need perfection" does not imply "alignment should be really easy". Indeed, I think the implication quite badly fails.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2024-01-05T21:57:14.835Z · LW(p) · GW(p)
I'll admit I overstated it here, but my claim is that once you remove the requirement for arbitrarily good/perfect solutions, it becomes easier to solve the problem. Sometimes, it's still impossible to solve the problem, but it's usually solvable once you drop a perfectness/arbitrarily good requirement, primarily because it loosens a lot of constraints.
Indeed, I think the implication quite badly fails.
I agree it isn't a logical implication, but I suspect your example is very misleading, and that more realistic imperfect solutions won't have this failure mode, so I'm still quite comfortable with using it as an implication that isn't 100% accurate, but more like 90-95+% accurate.
Replies from: abramdemski↑ comment by abramdemski · 2024-01-10T21:34:25.886Z · LW(p) · GW(p)
I'll admit I overstated it here, but my claim is that once you remove the requirement for arbitrarily good/perfect solutions, it becomes easier to solve the problem. Sometimes, it's still impossible to solve the problem, but it's usually solvable once you drop a perfectness/arbitrarily good requirement, primarily because it loosens a lot of constraints.
I mean, yeah, I agree with all of this as generic statements if we ignore the subject at hand.
I agree it isn't a logical implication, but I suspect your example is very misleading, and that more realistic imperfect solutions won't have this failure mode, so I'm still quite comfortable with using it as an implication that isn't 100% accurate, but more like 90-95+% accurate.
I agree the example sucks and only serves to prove that it is not a logical implication.
A better example would be, like, the Goodhart model of AI risk, where any loss function that we optimize hard enough to get into superintelligence would probably result in a large divergence between what we get and what we actually want, because optimization amplifies [LW · GW]. Note that this still does not make an assumption that we need to prove 100% safety, but rather, argues, for reasons, from assumptions that it will be hard to get any safety at all from loss functions which merely coincide to what we want somewhat well.
I still think the list of lethalities is a pretty good reply to your overall line of reasoning -- IE it clearly flags that the problem is not achieving perfection, but rather, achieving any significant probability of safety, and it gives a bunch of concrete reasons why this is hard, IE provides arguments rather than some kind of blind assumption like you seem to be indicating.
You are doing a reasonable thing by trying to provide some sort of argument for why these conclusions seem wrong, but "things tend to be easy when you lift the requirement of perfection" is just an extremely weak argument which seems to fall apart the moment we contemplate the specific case of AI alignment at all.
↑ comment by quetzal_rainbow · 2023-12-26T17:21:34.704Z · LW(p) · GW(p)
The problem with RLHF/DPO is not that it doesn't work period, the problem is that we don't know if they work. I can imagine that we can just scale to superintelligence, apply RLHF and get aligned ASI, but this would imply a bunch of things about reality like "even at high level of capability reasonable RLHF-data contains overwhelmingly mostly good value-shaped thought-patterns" and I just don't think that we know enough about reality to make such statements.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2023-12-26T18:37:42.344Z · LW(p) · GW(p)
I think this might be a crux, actually. I think it's surprisingly common in history for things to work out well empirically, but that we either don't understand how they work, or it took a long time to understand how it works.
AI development is the most central example, but I'd argue the invention of steel is another good example.
To put it another way, I'm relying on the fact that there have been empirically successful interventions where we either simply don't know why it works, or it takes a long time to get a useful theory out of the empirically successful intervention.
↑ comment by Remmelt (remmelt-ellen) · 2023-09-27T16:22:18.914Z · LW(p) · GW(p)
not focused enough on forward-chaining to find the avenues of investigation which actually allow useful feedback
Are you mostly looking for where there is useful empirical feedback?
That sounds like a shot in the dark.
Big breakthroughs open up possibilities that are very hard to imagine before those breakthroughs
A concern I have:
I cannot conceptually distinguish these continued empirical investigations of methods to build maybe-aligned AGI, from how medieval researchers tried to build perpetual motion machines. It took sound theory to finally disprove the possibility once and for all that perpetual motion machines were possible.
I agree with Charbel-Raphaël that the push for mechanistic interpretability is in effect promoting the notion that there must be possibilities available here to control potentially very dangerous AIs to stay safe in deployment. It is much easier to spread the perception of safety, than to actually make such systems safe.
That, while there is no sound theoretical basis for claiming that scaling mechanistic interpretability could form the basis of such a control method. Nor for that any control method [LW · GW] could keep "AGI" safe.
Rather, mechint is fundamentally limited in the extent it could be used to safely control AGI.
See posts:
- The limited upside of interpretability [LW · GW] by Peter S. Park
- Why mechanistic interpretability does not and cannot contribute to long-term AGI safety [LW · GW]by me
Besides theoretical limits, there are plenty of practical arguments (as listed in Charbel-Raphaël's post) for why scaling the utilisation of mechint would be net harmful.
So no rigorous basis for that the use of mechint would "open up possibilities" to long-term safety.
And plenty of possibilities for corporate marketers – to chime in on mechint's hypothetical big breakthroughs.
In practice, we may help AI labs again – accidentally – to safety-wash their AI products.
↑ comment by Richard_Ngo (ricraz) · 2023-09-27T16:52:49.363Z · LW(p) · GW(p)
It does seem like a large proportion of disagreements in this space can be explained by how hard people think alignment will be. It seems like your view is actually more pessimistic about the difficulty of alignment than Eliezer's, because he at least thinks it's possible for mechinterp to help in principle.
I think that being confident in this level of pessimism is wildly miscalibrated, and such a big disagreement that it's probably not worth discussing much further. Though I reply indirectly to your point here [EA(p) · GW(p)].
Replies from: remmelt-ellen↑ comment by Remmelt (remmelt-ellen) · 2023-10-04T13:26:32.426Z · LW(p) · GW(p)
I personally think pessimistic vs. optimistic misframes it, because it frames a question about the world in terms of personal predispositions.
I would like to see reasoning.
Your reasoning in the comment thread you linked to is: “history is full of cases where people dramatically underestimated the growth of scientific knowledge, and its ability to solve big problems”
That’s a broad reference-class analogy to use. I think it holds little to no weight as to whether there would be sufficient progress on the specific problem of “AGI” staying safe over the long-term.
I wrote [LW · GW] why that specifically would not be a solvable problem.
comment by Charbel-Raphaël (charbel-raphael-segerie) · 2025-01-04T15:11:37.879Z · LW(p) · GW(p)
Tldr: I'm still very happy to have written Against Almost Every Theory of Impact of Interpretability [LW · GW], even if some of the claims are now incorrect. Overall, I have updated my view towards more feasibility and possible progress of the interpretability agenda — mainly because of the SAEs (even if I think some big problems remain with this approach, detailed below) and representation engineering techniques. However, I think the post remains good regarding the priorities the community should have.
First, I believe the post's general motivation of red-teaming a big, established research agenda remains crucial. It's too easy to say, "This research agenda will help," without critically assessing how. I appreciate the post's general energy in asserting that if we're in trouble or not making progress, we need to discuss it.
I still want everyone working on interpretability to read it and engage with its arguments.
Acknowledgments: Thanks to Epiphanie Gédéon, Fabien Roger, and Clément Dumas for helpful discussions.
Updates on my views
Legend:
- On the left of the arrow, a citation from the OP → ❓ on the right, my review which generally begins with emojis
- ✅ - yes, I think I was correct (>90%)
- ❓✅ - I would lean towards yes (70%-90%)
- ❓ - unsure (between 30%-70%)
- ❓❌ - I would lean towards no (10%-30%)
- ❌ - no, I think I was basically wrong (<10%)
- ⭐ important, you can skip the other sections
Here's my review section by section:
⭐ The Overall Theory of Impact is Quite Poor?
- "Whenever you want to do something with interpretability, it is probably better to do it without it" → ❓ I still think this is basically right, even if I'm not confident this will still be the case in the future; But as of today, I can't name a single mech-interpretability technique that does a better job at some non-intrinsic interpretability goal than the other more classical techniques, on a non-toy model task.
- "Interpretability is Not a Good Predictor of Future Systems" → ✅ This claim holds up pretty well. Interpretability still hasn't succeeded in reliably predicting future systems, to my knowledge.
- "Auditing Deception with Interpretability is Out of Reach" → ❓ The "Out of Reach" is now a little bit too strong, but the general direction was pretty good. The first major audits of deception capabilities didn't come from interpretability work; breakthrough papers came from AI Deception: A Survey of Examples, Risks, and Potential Solutions, Apollo Research's small demo using bare prompt engineering, and Anthropic's behavioral analyses. This is particularly significant because detecting deception was a primary motivation for many people working on interpretability at the time. I don't think being able to identify the sycophancy feature qualifies as being able to audit deception: maybe the feature is just here to recognize sycophancy without using it, as explained in the post. (I think the claim should now be "Auditing Deception without Interpretability is currently much simpler").
- "Interpretability often attempts to address too many objectives simultaneously" → ❓ I don't think this is as important nowadays, but I tend to still think that goal factoring [? · GW] is still a really important cognitive and neglected move in AI Safety. I can see how interp could help a bit for multiple goals simultaneously, but also if you want to achieve more coordination, just work on coordination.
- "Interpretability could be harmful - Using successful interpretability for safety could certainly prove useful for capabilities" → ❓❌ I think I was probably wrong, more discussion below, in section “Interpretability May Be Overall Harmful”.
What Does the End Story Look Like?
- "Enumerative Safety & Olah interpretability dream":
- ⭐ Feasibility of feature enumeration → ❓I was maybe wrong, but this is really tricky to assess.
- On the plus side, I was genuinely surprised to see SAEs working that well because the general idea already existed, some friends had tried it, and it didn't seem to work at the time. I guess compute also plays a crucial role in interpretability work. I was too confident. Progress is possible, and enumerative safety could represent an endgame for interpretability.
- On the other hand, many problems remain and I think we need to be very cautious in evaluating this type of research, it's very unclear if/how to make enumerative safety arguments with SAEs:
- SAEs are only able to reconstruct a much smaller model: being able to reconstruct only 65% of the variance, means that the model reconstructed would be very very poor. Some features are very messy, and lots of things that models know how to do are just not represented in SAE.
- The whole paradigm is probably only a computationally convenient approximation: I think that the strong feature hypothesis is probably false [LW · GW], and is not going to be sufficient to reconstruct the whole model. Some features are probably stored on multiple layers, some features might be instantiated only in a dynamic way [LW · GW], and I’m skeptical that we can reduce the model to just a static weighted directed graph of features. Another point is that Language models are better than humans at next-token prediction and I expect some features to be beyond human knowledge and understanding.
- SAEs were not used on the most computationally intensive models (Sonnet, and not Opus), which are the ones of interest, because SAEs cost a lot of compute.
- We cannot really use SAEs for enumerative safety because we wouldn't be able to exclude emergent behavior. As a very concrete example, if you train SAEs on a sleeper agent (on the training distribution that does not trigger the backdoor), you will not surface any deception feature (which might be a bit unfair because the training data for the sleeper agent does contain deceptive stuff, but this would be maybe more analogous to a natural emergence). Maybe someone should try to detect backdoors with SAEs; (thanks to Fabien for raising those points to me!)
- At the end of the day, it's very unclear how to make enumerative safety arguments with SAEs.
- Safety applications? → ❓✅ Some parts of my critique of enumerative safety remain valid. The dual-use nature of many features remains a fundamental challenge: Even after labeling all features, it's unclear how we can effectively use SAEs, and I still think that “Determining the dangerousness of a feature is a mis-specified problem” [LW · GW]: “there's a difference between knowing about lies, being capable of lying, and actually lying in the real world”. At the end of the day, Anthropic didn’t use SAEs to remove harmful behaviors from Sonnet that were present in the training data, and it’s still unclear if SAEs beat baselines (for a more detailed analysis of the missing safety properties of SAEs, read this article [LW · GW]).
- Harmfulness of automated research? → ❓ I think the automation of the discovery of Claude's features was not that dangerous and is a good example of automated research. Overall, during the year, I'm a bit more sympathetic today to this kind of automated AI safety research than before.[1]
- ⭐ Feasibility of feature enumeration → ❓I was maybe wrong, but this is really tricky to assess.
- Reverse Engineering? → ✅ Not much progress here. It seems like IOI remains roughly the SOTA of the most interesting circuit we've found in any language model, and current work and techniques, such as edge pruning, remain focused on toy models.
- Retargeting the search? → ❓ I think I was overconfident in saying that being able to control the AI via the latent space is just a new form of prompt engineering or fine-tuning. I think representation engineering could be more useful than this, and might enable better control mechanisms.
- Relaxed adversarial training? → ❓✅ I made a call by saying this could be one of the few ways to reduce AI bad behavior even under adversarial pressure, and it seems like this is a promising direction today.
- Microscope AI? →❓✅ I think what I say in the past about the uselessness of microscope AI remains broadly valid, but there is an amendment to be made: "About a year ago, Schut et al. (2023) did what I think was (and maybe still is) the most impressive interpretability research to date. They studied AlphaZero's chess play and showed how novel performance-relevant concepts could be discerned from mechanistic analysis. They worked with skilled chess players and found that they could help these players learn new concepts that were genuinely useful for chess. This appears to be a reasonably unique way of doing something useful (improving experts' chess play) that may have been hard to achieve in some other way." - Summary from Casper [LW · GW].
- Very cool paper, but I think this type of work is more like a very detailed behavioral analysis guided by some analysis of the latent space, and I do expect that this kind of elicitation work for narrow AI is going to be deprecated by future general-purpose AI systems, which are going to be able to teach us directly those concepts, and we will be able to fine-tune them directly to do this. Think about a super Claude-teacher.
- Also, Alphazero is an agent - it’s not a pure microscope - so this is a very different vision than the one from Olah explaining his vision of microscope AI here [LW · GW].
⭐ So Far My Best Theory of Impact for Interpretability: Outreach?
❓✅ I still think this is the case, but I have some doubts. I can share numerous personal anecdotes where even relatively unpolished introductions to interpretability during my courses generated more engagement than carefully crafted sessions on risks and solutions. Concretely, I shamefully capitalize on this by scheduling interpretability week early in my seminar to nerd-snipe students' attention.
But I see now two competing potential theories of impact:
- Better control mechanisms: For example, something that I was not seeing clearly in the past was the possibility to have better control of those models.
- I think the big takeaway is that representation engineering might work: I find the work Simple probes can catch sleeper agents \ Anthropic very interesting, in the sense that the probe seems to generalize surprisingly well (I would really like to know if this generalizes to a model that was not trained to be harmful in the first place). I was very surprised by those results. I think products such as Goodfire steering Llama3 are interesting, and I’m curious to see future developments. [LW · GW]Circuit breakers seem also exciting in this regard.
- This might still be a toy example, but I've found this work from Sieve interesting: SAEs Beat Baselines on a Real-World Task, they claim to be able to steer the model better than with other techniques, on a non trivial task: "Prompt engineering can mitigate this in short context inputs. However, Benchify frequently has prompts with greater than 10,000 tokens, and even frontier LLMs like Claude 3.5 will ignore instructions at these long context lengths." "Unlike system prompts, fine-tuning, or steering vectors which affect all outputs, our method is very precise (>99.9%), meaning almost no side effects on unrelated prompts."
- I'm more sympathetic to exploratory work like gradient routing [LW · GW], which may offer affordances in the future that we don't know about now.
- Deconfusion and better understanding: But I should have been more charitable to the second-order effects of better understanding of the models. Understanding how models work, providing mechanistic explanations, and contributing to scientific understanding all have genuine value that I was dismissing.[2]
⭐ Preventive Measures Against Deception
I still like the two recommendations I made:
- Steering the world towards transparency → ✅ This remains a good recommendation. For instance, today, we can choose not to use architectures that operate in latent spaces, favoring architectures that reason with tokens instead (even if this is far from perfect either). Meta's proposal for new transformers using latent spaces should be concerning, as these architectural choices significantly impact our control capabilities.
- "I don't think neural networks will be able to take over in a single forward pass. Models will probably reason in English and will have translucent thoughts" → ❓✅ This seems to be the case?
- And many works that I was suggesting [LW · GW] to conduct are now done [LW · GW] and have been informative for the control agenda ✅
- Cognitive emulation (using the most powerful scaffolding with the least powerful model capable of the task) → ✅ This remains a good safety recommendation I think, as we don’t want the elicitation to be done in the future, we want to extract all the juice there is from current LLMs. Christiano elaborates a bit more on this, by pondering with other negative externalities such as faster race: Thoughts on Sharing Information About Language Models Capabilities [LW · GW], section Accelerating LM agents seems neutral (or maybe positive).
Interpretability May Be Overall Harmful
False sense of control → ❓✅ generally yes:
- Overinterpretation & False sense of understanding → ❓✅ - I still think it's just very easy to tell yourself, "Yo, here we are, we are able to enumerate all the features, all good!" - I don’t think it’s that simple, it's not all good; being able to do this does not make your model safer per se. For example, about the SAE works: “it directly led to this viral claim that interpretability will be solved and that we are bound for safe models. It also seems to have led to at least one claim in a policy memo that advocates of AI safety are being silly because mechanistic interpretability was solved.." - from Stephen Casper [AF · GW].
- "The achievements of interpretability research are consistently graded on their own curve and overhyped" & Safety-Washing Concerns → ❓✅ I don’t think the situation has changed significantly in this regard.
The world is not coordinated enough for public interpretability research → ❌ generally no:
- Dual use & When interpretability starts to be useful, you can't even publish it because it's too info-hazardous → ❌ - It's pretty likely that if, for example, SAEs start to be useful, this won't boost capabilities that much.
- Capability externalities & Interpretability already helps capabilities → ❓ - Mixed feelings:
- This post shows a new architecture using interpretability discovery [LW · GW], but I don't think this will really stand out against the Bitter Lesson, so for the moment it seems like interpretability is not really useful for capabilities. Also, it seems easier to delete capabilities with interpretability than to add them. Interpretability hasn't significantly boosted capabilities yet.
- But at the same time, I wouldn't be that surprised if interpretability could unlock a completely new paradigm that would be much more data efficient than the current one.
Outside View: The Proportion of Junior Researchers Doing Interpretability Rather Than Other Technical Work is Too High
- I would rather see a more diverse ecosystem → ✅ - I still stand by this, and I'm very happy that ARENA and MATS, ML4Good have diversified their curriculum.
- ⭐ “I think I would particularly critique DeepMind and OpenAI's interpretability works, as I don't see how this reduces risks more than other works that they could be doing” → ✅ Compare them doing interpretability vs. publishing their Responsible Scaling policies and evaluating their systems. I think RSPs advanced AI risks much much more.
Even if We Completely Solve Interpretability, We Are Still in Danger
- There are many X-risks scenarios, not even involving deceptive AIs → ✅ I'm still pretty happy with this enumeration of risks, and I think more people should think about this and directly think about ways to prevent those scenarios. I don't think interpretability is going to be the number one recommendation after this small exercise.
- Interpretability implicitly assumes that the AI model does not optimize in a way that is adversarial to the user → ❓❌ - The image with Voldemort was unnecessary and might be incorrect for Human-level intelligence. But I have the feeling that all of those brittle interpretability techniques won’t stand for long against a superintelligence, I may be wrong.
- ⭐ That is why focusing on coordination is crucial! There is a level of coordination above which we don't die - there is no such threshold for interpretability → ✅ I still stand by this: Safety isn’t safety without a social model (or: dispelling the myth of per se technical safety) — LessWrong [LW · GW]
Technical Agendas with Better ToI
I'm very happy with all of my past recommendations. Most of those lines of research are now much more advanced than when I was writing the post, and I think they advanced safety more than interpretability did:
- Technical works used for AI Governance
- ⭐ "For example, each of the measures proposed in the paper towards best practices in AGI safety and governance: A survey of expert opinion could be a pretext for creating a specialized organization to address these issues, such as auditing, licensing, and monitoring" → ✅ For example, Apollo is mostly famous for their non-interpretability works.
- Scary demos → ✅ Yes! Scary demos of deception and other dangerous capabilities were tremendously valuable during the last year, so continuing to do that is still the way to go
- "(But this shouldn't involve gain-of-function research. There are already many powerful AIs available. Most of the work involves video editing, finding good stories, distribution channels, and creating good memes. Do not make AIs more dangerous just to accomplish this.)" → ❓ The point about gain-of-function research was probably wrong because I think Model organism is a useful agenda, and because it's better if this is done in a controlled environment than later. But we should be cautious with this, and at some point, a model able to do full ARA and R&D could just self-exfiltrate, and this would be irreversible, so maybe the gain-of-function research being okay part is only valid for 1-2 years.
- "In the same vein, Monitoring for deceptive alignment is probably good because 'AI coordination needs clear wins [AF · GW].'" → ❓ Yes for monitoring, no for that being a clear win because of the reason explained in the post from Buck [LW · GW], saying that it will be too messy for policymakers and everyone to decide just based on those few examples of deception.
- Interoperability in AI policy and good definitions usable by policymakers → ✅ - I still think that good definitions of AGI, self-replicating AI, good operationalization of red lines would be tremendously valuable for both RSPs levels, Code of Practices of the EU AI Act, and other regulations.
- "Creating benchmarks for dangerous capabilities" → ✅ - I guess the eval field is a pretty important field now. Such benchmarks didn't really exist beforehand.
- "Characterizing the technical difficulties of alignment”:
- Creating the IPCC of AI Risks → ✅ - The International Scientific Report on the Safety of Advanced AI: Interim Report is a good baseline and was very useful to create more consensus!
- More red-teaming of agendas → ❓ this has not been done but should be! I would really like it if someone was able to write the “Compendium of problems with AI Evaluation” for example. Edit: This has been done.
- Explaining problems in alignment → ✅ - I still think this is useful
- “Adversarial examples, adversarial training, latent adversarial training (the only end-story I'm kind of excited about). For example, the papers "Red-Teaming the Stable Diffusion Safety Filter" or "Universal and Transferable Adversarial Attacks on Aligned Language Models" are good (and pretty simple!) examples of adversarial robustness works which contribute to safety culture” → ❓ I think there are more direct way to contribute to safety culture. Liron Shapira’s podcast is better for that I think.
- "Technical outreach. AI Explained and Rob Miles have plausibly reduced risks more than all interpretability research combined": ❓ I think I need numbers to conclude formally even if my intuition still says that the biggest bottleneck is still a consensus on AI Risks, and not research. I have more doubts with AI Explained now, since he is pushing for safety only in a very subtle way, but who knows, maybe that’s the best approach.
- “In essence, ask yourself: "What would Dan Hendrycks do?" - Technical newsletter, non-technical newsletters, benchmarks, policy recommendations, risks analysis, banger statements, courses and technical outreach → ✅ and now I would add SB1047, which was I think the best attempt of 2024 at reducing risks.
- “In short, my agenda is "Slow Capabilities through a safety culture", which I believe is robustly beneficial, even though it may be difficult. I want to help humanity understand that we are not yet ready to align AIs. Let's wait a couple of decades, then reconsider.” → ✅ I think this is still basically valid, and I co-founded a whole organization trying to achieve more of this. I'm very confident what I'm doing is much better in terms of AI risk reduction than what I did previously, and I'm proud to have pivoted: 🇫🇷 Announcing CeSIA: The French Center for AI Safety. [LW · GW]
- ^
But I still don’t feel good about having a completely automated and agentic AI that would just make progress in AI alignment (aka the old OpenAI’s plan), and I don’t feel good about the whole race we are in.
- ^
For example, this conceptual understanding enabled via interpretability was useful for me to be able to dissolve the hard problem of consciousness [LW · GW].
comment by ryan_greenblatt · 2023-08-18T16:25:08.823Z · LW(p) · GW(p)
After spending a while thinking about interpretability, my current stance is:
- Let's define Mechanistic interpretability as "A subfield of interpretability that uses bottom-up approaches, generally by corresponding low-level components such as circuits or neurons to components of human-understandable algorithms and then working upward to build an overall understanding."
- I think mechanistic interpretability probably has to succeed very ambitiously to be useful.
- Mechanistic interpretability seems to me to be very far from succeeding this ambitiously
- Most people working on mechanistic interpretability don't seem to me like they're on a straightforward path to ambitious success, though I'm somewhat on board with the stuff that Anthropic's interp team is doing here.
Note that this is just for "mechanistic interpretability". I think that high level top down interpretability (both black box and white box) has a clearer story for usefulness which doesn't require very ambitious success.
Replies from: ryan_greenblatt, ryan_greenblatt↑ comment by ryan_greenblatt · 2023-08-18T16:42:27.935Z · LW(p) · GW(p)
For mechanistic interpretabilty, very ambitious success looks something like:
- Have some decomposition of the model or the behavior of the model into parts.
- For any given randomly selected part, you should almost always be able build up a very good understanding of this part in isolation.
- By "very good" I mean that the understanding accounts for 90% of the bits of optimization applied to this part (where the remaining bits aren't predictably more or less important per bit than what you've understood).
- Roughly speaking, if your understanding accounts for 90% of the bits of optization for a AI than it means you should be able to construct a AI which works as well as if the original AI was only trained with 90% of the actual training compute.
- In terms of loss explained, this is probably very high, like well above 99%.
- The length of the explanation of all parts is probably only up to 1000 times shorter in bits than the size of the model. So, for a 1 trillion parameter model it's at least 100 million words or 200,000 pages (assuming 10 bits per word). The compression comes from being able to use human concepts, but this will only get you so much.
- Given your ability to explain any given part, build an overall understanding by piecing things together. This could be implicitly represented.
- Be able to query understanding to answer interesting questions.
I don't think there is an obvious easier road for mech interp to answer questions like "is the model deceptively aligned" if you want the approach to compete with much simpler high level and top down interpretability.
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2023-08-18T16:49:00.923Z · LW(p) · GW(p)
The main reason why I think mechanistic interpretability is very far from ambitious success is that current numbers are extremely bad and what people explain is extremely cherry picked. Like people's explanations typically result in performance which is worse than that of much, much tinier models even though heavy cherry picking is applied.
If people were getting ok perf on randomly selected "parts" of models (for any notion of decomposition), then we'd be much closer. I'd think we were be much closer even if this was extremely labor intensive.
(E.g., the curve detectors work explained ~50% of the loss which is probably well less than 10% of the bits given sharply diminishing returns to scale on typical scaling laws.)
↑ comment by ryan_greenblatt · 2023-08-18T16:46:40.368Z · LW(p) · GW(p)
comment by Rohin Shah (rohinmshah) · 2023-08-18T07:41:56.140Z · LW(p) · GW(p)
I think I would particularly critique DeepMind and OpenAI's interpretability works, as I don't see how this reduces risks more than other works that they could be doing, and I'd appreciate a written plan of what they expect to achieve.
I can't speak on behalf of Google DeepMind or even just the interpretability team (individual researchers have pretty different views), but I personally think of our interpretability work as primarily a bet on creating new affordances upon which new alignment techniques can be built, or existing alignment techniques can be enhanced. For example:
- It is possible to automatically make and verify claims about what topics a model is internally "thinking about" when answering a question. This is integrated into debate, and allows debaters to critique each other's internal reasoning, not just the arguments they externally make.
- (It's unclear how much this buys you on top of cross-examination.)
- It is possible to automatically identify "cruxes" for the model's outputs, making it easier for adversaries to design situations that flip the crux without flipping the overall correct decision.
- Redwood's adversarial training project is roughly in this category, where the interpretability technique is saliency, specifically magnitude of gradient of the classifier output w.r.t. the token embedding.
- (Yes, typical mech interp directions are far more detailed than saliency. The hope is that they would produce affordances significantly more helpful and robust than saliency.)
- A different theory of change for the same affordance is to use it to analyze warning shots, to understand the underlying cause of the warning shot (was it deceptive alignment? specification gaming? mistake from not knowing a relevant fact? etc).
I don't usually try to backchain too hard from these theories of change to work done today; I think it's going to be very difficult to predict in advance what kind of affordances we might build in the future with years' more work (similarly to Richard's comment, though I'm focused more on affordances than principled understanding of deep learning; I like principled understanding of deep learning but wouldn't be doing basic research on interpretability if that was my goal).
My attitude is much more that we should be pushing on the boundaries of what interp can do, and as we do so we can keep looking out for new affordances that we can build. As an example of how I reason about what projects to do, I'm now somewhat less excited about projects that do manual circuit analysis of an algorithmic task. They do still teach us new stylized facts about LLMs like "there are often multiple algorithms at different 'strengths' spread across the model" that can help with future mech interp, but overall it feels like these projects aren't pushing the boundaries as much as seems possible, because we're using the same, relatively-well-vetted techniques for all of these projects.
I'm also more keen on applying interpretability to downstream tasks (e.g. fixing issues in a model, generating adversarial examples), but not necessarily because I think it will be better than alternative methods today, but rather because I think the downstream task keeps you honest (if you don't actually understand what's going on, you'll fail at the task) and because I think practice with downstream tasks will help us notice which problems are important to solve vs. which can be set aside. This is an area where other people disagree with me (and I'm somewhat sympathetic to their views, e.g. that the work that best targets a downstream task won't tackle fundamental interp challenges like superposition as well as work that is directly trying to tackle those fundamental challenges).
(EDIT: I mostly agree with Ryan's comment [AF(p) · GW(p)], and I'll note that I am considering a much wider category of work than he is, which is part of why I usually say "interpretability" rather than "mechanistic interpretability".)
Separately, you say:
I don't see how this reduces risks more than other works that they could be doing
I'm not actually sure why you believe this. I think on the views you've expressed in this post (which, to be clear, I often disagree with), I feel like you should think that most of our work is just as bad as interpretability.
In particular we're typically in the business of building aligned models. As far as I can tell, you think that interpretability can't be used for this because (1) it is dual use, and (2) if you optimize against it, you are in part optimizing for the AI system to trick your interpretability tools. But these two points seem to apply to any alignment technique that is aiming to build aligned models. So I'm not sure what other work (within the "build aligned models" category) you think we could be doing that is better than interpretability.
(Similarly, based on the work you express excitement about in your post, it seems like you are targeting an endgame of "indefinite, or at least very long, pause on AI progress". If that's your position I wish you would have instead written a post that was instead titled "against almost every theory of impact of alignment" or something like that.)
Replies from: charbel-raphael-segerie, charbel-raphael-segerie, whitehatStoic↑ comment by Charbel-Raphaël (charbel-raphael-segerie) · 2023-08-18T23:09:44.703Z · LW(p) · GW(p)
To give props to your last paragraphs, you are right about my concern that most alignment work is less important than governance work. Most of the funding in AI safety goes to alignment, AI governance is comparatively neglected, and I'm not sure that's the best allocation of resources. I decided to write this post specifically on interpretability as a comparatively narrow target to train my writing.
I hope to work on a more constructive post, detailing constructive strategic considerations and suggesting areas of work and theories of impact that I think are most productive for reducing X-risks. I hope that such a post would be the ideal place for more constructive conversations, although I doubt that I am the best suited person to write it.
↑ comment by Charbel-Raphaël (charbel-raphael-segerie) · 2023-08-18T09:01:15.014Z · LW(p) · GW(p)
High level strategy "as primarily a bet on creating new affordances upon which new alignment techniques can be built".
Makes sense, but I think this is not the optimal resource allocation. I explain why below:
(Similarly, based on the work you express excitement about in your post, it seems like you are targeting an endgame of "indefinite, or at least very long, pause on AI progress". If that's your position I wish you would have instead written a post that was instead titled "against almost every theory of impact of alignment" or something like that.)
Yes, the pause is my secondary goal (edit: conditional on no significant alignment progress, otherwise smart scaling and regulations are my priorities). My primary goal remains coordination and safety culture. Mainly, I believe that one of the main pivotal processes [LW · GW] goes through governance and coordination. A quote that explains my reasoning well is the following:
- "That is why focusing on coordination is crucial! There is a level of coordination above which we don’t die - there is no such threshold for interpretability. We currently live in a world where coordination is way more valuable than interpretability techniques. So let’s not forget that non-alignment aspects of AI safety are key! [LW · GW] AI alignment is only a subset of AI safety! (I’m planning to deep-dive more into this in a following post)."
That's why I really appreciate Dan Hendryck's work on coordination. And I think DeepMind and OpenAI could make a huge contribution by doing technical work that is useful for governance [LW · GW]. We've talked a bit during the EAG, and I understood that there's something like a numerus clausus in DeepMind's safety team. In that case, since interpretability doesn't require a lot of computing power/prestige and as DeepMind has a very high level of prestige, you should use it to write papers that help with coordination. Interpretability could be done outside the labs.
For example, some of your works like Model evaluation for extreme risks, or Goal Misgeneralization: Why Correct Specifications Aren't Enough For Correct Goals, are great for such purpose!
↑ comment by MiguelDev (whitehatStoic) · 2023-08-18T08:19:38.859Z · LW(p) · GW(p)
My attitude is much more that we should be pushing on the boundaries of what interp can do, and as we do so we can keep looking out for new affordances that we can build.
I agree with this perspective if we can afford the time to perform interpretability work on all of model setups - which our head count is too low to do that. Given the urgency to address the alignment challenge quickly, it's better to encourage (or even prioritize) conceptually sound interpretability work rather than speculative approaches.
comment by evhub · 2023-08-18T07:27:35.707Z · LW(p) · GW(p)
I think that this is a well-done post overall, though I mostly disagree with it. A couple of thoughts below.
First, I was surprised not to see unknown unknowns addressed, as Richard pointed out [LW(p) · GW(p)].
Second, another theory of impact that I didn't see addressed here is the case that I've been [LW · GW] trying to make recently [LW · GW] that interpretability is likely to be necessary to build good safety evaluations. This could be quite important if evaluations end up being the primary AI governance tool, as currently looks somewhat likely to me.
Third, though you quote me talking about why I think detecting/disincentivizing deception with interpretability tools is so hard [LW · GW], what is not quoted is what I think about the various non-interpretability methods of doing so—and what I think there is that they're even harder. Though you mention a bunch of non-interpretability ways of studying deception (which I'm definitely all for [LW · GW]), studying it doesn't imply that we can disincentivize it (and I think we're going to need both). You mention chain-of-thought oversight as a possible solution, but I'm quite skeptical of that working, simply because the model need not write out its deception in the scratchpad in any legible way. Furthermore, even if it did, how would you disincentivize it? Just train the model not to write out its deception in its chain of thought? Why wouldn't that just cause the model to become better at hiding its deception? Interpretability, on the other hand, might let us mechanistically disincentivize deception [LW · GW] by directly selecting over the sorts of thought processes that we want the model to have.
comment by leogao · 2023-08-18T01:04:11.251Z · LW(p) · GW(p)
My personal theory of impact for doing nonzero amounts of interpretability is that I think understanding how models think will be extremely useful for conceptual research. For instance, I think one very important data point for thinking about deceptive alignment is that current models are probably not deceptively aligned. Many people have differing explanations for which property of the current setup causes this (and therefore which things we want to keep around / whether to expect phase transitions / etc), which often imply very different alignment plans. I think just getting a sense of what even these models are implementing internally could help a lot with deconfusion here. I don't think it's strictly necessary to do interpretability as opposed to targeted experiments where we observe external behaviour for these kinds of things, but probably experiments that get many bits [LW · GW] are much better than targeted experiments for deconfusion, because oftentimes the hypotheses are all wrong in subtle ways. Aside from that, I am not optimistic about fully understanding the model, training against interpretability, microscope AI, or finding the "deception neuron" as a way to audit deception. I don't think future models will necessarily have internal structures analogous to current models.
Replies from: charbel-raphael-segerie↑ comment by Charbel-Raphaël (charbel-raphael-segerie) · 2023-08-18T02:32:07.149Z · LW(p) · GW(p)
I completely agree that past interp research has been useful for my understanding of deep learning.
But we are funding constrained. The question now is "what is the marginal benefit of one hour of interp research compared to other types of research", and "whether we should continue to prioritize it given our current understanding and the lessons we have learned".
Replies from: leogao↑ comment by leogao · 2023-08-18T03:01:25.651Z · LW(p) · GW(p)
I agree that people who could do either good interpretability or conceptual work should focus on conceptual work. Also, to be clear the rest of this comment is not necessarily a defence of doing interpretability work in particular, but a response to the specific kind of mental model of research you're describing.
I think it's important that research effort is not fungible. Interpretability has a pretty big advantage that unlike conceptual work, a) it has tight feedback loops, b) is much more paradigmatic, c) is much easier to get into for people with an ML research background.
Plausibly the most taut constraint in research is not strictly the number of researchers you can fund/train to solve a given problem--it's hard to get researchers to do good work if they don't feel intellectually excited about the problem, which in turn is less likely if they feel like they're never making any progress, or feel like they are constantly unsure about what problem they're even trying to solve.
To be clear I am not arguing that we should focus on things that are easier to solve--I am very much in favor of not just doing things that are easy to do but actually don't help ("looking under the streetlamp"). Rather, I think what we should be doing is finding things that actually matter and making it easier for people to get excited about it (and people who are able to do this kind of work have a huge comparative advantage here!).
Replies from: ricraz↑ comment by Richard_Ngo (ricraz) · 2023-08-18T04:03:25.740Z · LW(p) · GW(p)
I agree that people who could do either good interpretability or conceptual work should focus on conceptual work
This seems like a false dichotomy; in general I expect that the best conceptual work will be done in close conjunction with interpretability work or other empirical work.
(In general I think that almost all attempts to do "conceptual" work that doesn't involve either empirical results or proofs is pretty doomed. I'd be interested in any counterexamples you've seen; my main counterexample is threat modeling, which is why I've been focusing a lot on that lately.)
EDIT: many downvotes, no counterexamples. Please provide some.
Replies from: leogao, andrew-mcknight↑ comment by leogao · 2023-08-18T04:35:43.729Z · LW(p) · GW(p)
I agree that doing conceptual work in conjunction with empirical work is good. I don't know if I agree that pure conceptual work is completely doomed but I'm at least sympathetic. However, I think my point still stands: I think someone who can do conceptual+empirical work will probably have more impact doing that than not thinking about the conceptual side and just working really hard on conceptual work.
- They may find some other avenue of empirical work that can help with alignment. I think probably there exist empirical avenues substantially more valuable for alignment than making progress on interpretability and opening those up requires thinking about the conceptual side.
- Even if they think hard about it and can't think of anything better than conceptual+interpretability, it still seems better for an interpretability researcher to have an idea of how their work will fit into the broader picture. Even if they aren't backchaining, this still seems more useful than just randomly doing something under the heading of interpretability.
↑ comment by Richard_Ngo (ricraz) · 2023-08-18T15:41:24.178Z · LW(p) · GW(p)
However, I think my point still stands: I think someone who can do conceptual+empirical work will probably have more impact doing that than not thinking about the conceptual side and just working really hard on conceptual work.
(I assume that the last "conceptual" should be "empirical".)
I agree that not thinking about the conceptual side is bad. But that's standard for science. Like, top scientists in almost any domain aren't just thinking about their day-to-day empirical research, they have broader opinions about the field as a whole, and more speculative and philosophical ideas, and so on. The difference is whether they treat those ideas as outputs in their own right, versus as inputs that feed into some empirical or theoretical output. Most scientists do the latter; when people in alignment talk about "conceptual work" my impression is that they're typically thinking about the former.
↑ comment by Andrew McKnight (andrew-mcknight) · 2024-11-06T22:19:47.261Z · LW(p) · GW(p)
Do you think putting extra effort into learning about existing empirical work while doing conceptual work would be sufficient for good conceptual work or do you think people need to be producing empirical work themselves to really make progress conceptually?
Replies from: ricraz↑ comment by Richard_Ngo (ricraz) · 2024-11-06T23:25:25.287Z · LW(p) · GW(p)
The former can be sufficient—e.g. there are good theoretical researchers who have never done empirical work themselves.
In hindsight I think "close conjunction" was too strong—it's more about picking up the ontologies and key insights from empirical work, which can be possible without following it very closely.
comment by CallumMcDougall (TheMcDouglas) · 2023-08-18T14:42:05.229Z · LW(p) · GW(p)
(context: I ran the most recent iteration of ARENA, and after this I joined Neel Nanda's mech interp stream in SERI MATS)
Registering a strong pushback to the comment on ARENA. The primary purpose of capstone projects isn't to turn people into AI safety technical researchers or to produce impressive capstones, it's to give people engineering skills & experience working on group projects. The initial idea was not to even push for things that were safety-specific (much like Redwood's recommendations - all of the suggested MLAB2 capstones were either mech interp or non-safety, iirc). The reason many people gravitated towards mech interp is that they spent a lot of time around researchers and people who were doing interesting work in mech interp, and it seemed like a good fit for both getting a feel for AI safety technical research and for general skilling up in engineering.
Additionally, I want to mention that participant responses to the question "how have your views on AI safety changed?" included both positive and negative updates on mech interp, but much more uniformly showed positive updates on AI safety technical research as a whole. Evidence like this updates me away from the hypothesis that mech interp is pulling safety researchers from other disciplines. To give a more personal example, I had done alignment research before being exposed to mech interp, but none of it made much of an impression on me. I didn't choose mech interp instead of other technical safety research, I chose it instead of a finance career.
This being said, there is an argument that ARENA (at least the most recent iteration) had too much of a focus on mech interp, and this is something we may try to rectify in future iterations.
comment by dr_s · 2023-08-18T10:23:30.518Z · LW(p) · GW(p)
The biggest thing that worries me about the idea of interpretability, which you mention, is that any sufficiently low-level interpretation of a giant, intractably complex AGI-level model would likely be also intractably complex. And any interpretation of that. And so on so forth, until you start getting the feel that you'll probably need AI to interpret the interpretation, and then AI to interpret the interpreter, and so on in a chain which you might try to carefully validate but that increasingly feels like a typical Godzilla Strategy [LW · GW]. This does not lead to rising property values in Tokyo.
That said, maybe it can be done, and even be reliable enough. But it would also enhance significantly our ability to distil models. Like, if you could take a NN-based model, interpret it, and map it to a GOFAI-style extremely interpretable system, now you probably have a much faster, leaner and cleaner version of the same AI - so you can probably just build an even bigger AI. And the question then becomes if this style of interpretability can ever catch up to the increase in capabilities it would automatically foster.
comment by Daniel Murfet (dmurfet) · 2023-08-18T09:20:26.993Z · LW(p) · GW(p)
Induction heads? Ok, we are maybe on track to retro engineer the mechanism of regex in LLMs. Cool.
This dramatically undersells the potential impact of Olsson et al. You can't dismiss modus ponens as "just regex". That's the heart of logic!
For many the argument for AI safety being a urgent concern involves a belief that current systems are, in some rough sense, reasoning, and that this capability will increase with scale, leading to beyond human-level intelligence within a timespan of decades. Many smart outsiders remain sceptical, because they are not convinced that anything like reasoning is taking place.
I view Olsson et al as nontrivial evidence for the emergence of internal computations resembling reasoning, with increasing scale. That's profound. If that case is made stronger over time by interpretability (as I expect it to be) the scientific, philosophical and societal impact will be immense.
comment by Stephen McAleese (stephen-mcaleese) · 2023-08-18T10:25:44.565Z · LW(p) · GW(p)
In my opinion, much of the value of interpretability is not related to AI alignment but to AI capabilities evaluations instead.
For example, the Othello paper [LW · GW] shows that a transformer trained on the next-word prediction of Othello moves learns a world model of the board rather than just statistics of the training text. This knowledge is useful because it suggests that transformer language models are more capable than they might initially seem.
comment by Jan Betley (jan-betley) · 2023-08-19T20:08:28.554Z · LW(p) · GW(p)
Very good post! I agree with most of what you have written, but I'm not sure about the conclusions. Two main reasons:
-
I'm not sure if mech interp should be compared to astronomy, I'd say it is more like mechanical engineering. We have JWST because long long time ago there were watchmakers, gunsmiths, opticans etc who didn't care at all about astronomy, yet their advances in unrelated fields made astronomy possible. I think something similar might happen with mech interp - we'll keep creating better and better tools to achieve some goals, these goals will in the end turn up useless from the alignment point of view, but the tools will not.
-
Many people think mech interp is cool and fun. I'm personally not a big fan, but I think it is much more interesting than e.g. governance. If our only perspective is AI safety, this shouldn't matter - but people have many perspectives. There might not really be a choice between "this bunch of junior researches doing mech interp vs this bunch of junior researchers doing something more useful", they would just go do something not related to alignment instead. My guess is that attractiveness of mech interp is the strongest factor for its popularity.
comment by MiguelDev (whitehatStoic) · 2023-08-18T04:09:03.589Z · LW(p) · GW(p)
Fully agree with the post. Depending solely on interpretability work and downloading activations without understanding how to interpret the numbers is a big waste of time. Met smart people stuck in aimless exploration; bad in the long run. Wasting time slowly is not immediately painful, but it really hurts when projects fail due to poor direction.
comment by Cole Wyeth (Amyr) · 2023-08-22T16:27:21.843Z · LW(p) · GW(p)
I roughly agree with the case made here because I expect interpretability research to be much, much harder than others seem to appreciate. This is a consequence of strong intuitions from working on circuit complexity. Figuring out the behavior of a general circuit sounds like it's in a very hard complexity class - even writing down the truth table for a circuit takes exponential time in the number of inputs! I would be surprised if coming up with a human interpretable explanation of sub circuits is easy; there are some reasons to believe that SGD will usually produce simple circuits so some success in the average case is possible (see recent work of Ard Louis), but it would be pretty shocking if the full problem had a solution fast enough to run on the huge transformer circuits we are dealing with.
I outlined this position (and pointed out that there is some hope of at least understanding some individual circuits and learning about intelligence) here: https://www.lesswrong.com/posts/RTmFpgEvDdZMLsFev/mechanistic-interpretability-is-being-pursued-for-the-wrong [LW · GW]
(Not my best writing though)
comment by Quadratic Reciprocity · 2023-08-18T23:00:10.815Z · LW(p) · GW(p)
see the current plan here EAG 2023 Bay Area The current alignment plan, and how we might improve it
Link to talk above doesn't seem to work for me.
Outside view: The proportion of junior researchers doing interp rather than other technical work is too high
Quite tangential[1] to your post but if true, I'm curious about what this suggests about the dynamics of field-building in AI safety.
Seems to me like certain organisations and individuals have an outsized influence in funneling new entrants into specific areas, and because the field is small (and has a big emphasis on community building) this seems more linked to who is running programmes that lots of people hear about and want to apply to (eg: Redwood's MLAB, REMIX) or taking the time to do field-building-y stuff in general (like Neel's 200 Concrete Open Problems in Mechanistic Interpretability) rather than the relative quality and promise of their research directions.
It did feel to me like in the past year, some promising university students I know invested a bunch in mechanistic interpretability because they were deferring a bunch to the above-mentioned organisations and individuals to an extent that seems bad for actually doing useful research and having original thoughts. I've also been at AI safety events and retreats and such where it seemed to me like the attendees were overupdating on points brought up by whichever speakers got invited to speak at the event/retreat.
I guess I could see it happening in the other direction as well with new people overupdating on for example Redwood moving away from interpretability or the general vibe being less enthusiastic about interp without a good personal understanding of the reasons.
- ^
I'd personally guess that the proportion is too high but also feel more positively about interpretability than you do (because of similar points as have been brought up by other commenters).
comment by Daniel Murfet (dmurfet) · 2025-01-04T09:14:14.773Z · LW(p) · GW(p)
I have been thinking about interpretability for neural networks seriously since mid-2023. The biggest early influences on me that I recall were Olah's writings and a podcast that Nanda did. The third most important is perhaps this post, which I valued as an opposing opinion to help sharpen up my views.
I'm not sure it has aged well, in the sense that it's no longer clear to me I would direct someone to read this in 2025. I disagree with many of the object level claims. However, especially when some of the core mechanistic interpretability work is not being subjected to peer review, perhaps I wish there was more sceptical writing like this on balance.
comment by abramdemski · 2024-01-04T05:16:50.282Z · LW(p) · GW(p)
I finally got around to reading this today, because I have been thinking about doing more interpretability work, so I wanted to give this piece a chance to talk me out of it.
It mostly didn't.
- A lot of this boils down to "existing interpretability work is unimpressive". I think this is an important point, and significant sub-points were raised to argue it. However, it says little 'against almost every theory of impact of interpretability'. We can just do better work.
- A lot of the rest boils down to "enumerative safety is dumb". I agree, at least for the version of "enumerative safety" you argue against here.
My impact story (for the work I am considering doing) is most similar to the "retargeting" story which you briefly mention, but barely critique.
I do think the world would be better off if this were required reading for anyone considering going into interpretability vs other areas. (Barring weird side-effects of the counterfactual where someone has the ability to enforce required reading...) It is a good piece of work which raises many important points.
comment by Charlie Steiner · 2023-08-20T14:49:09.622Z · LW(p) · GW(p)
I broadly agree, but I think there's more safety research along with "Retarget the search" that focuses on using a trained AI's own internals to understand things like deception, planning, preferences, etc, that you didn't mention. You did say this sort of thing isn't a central example of "interpretability," which I agree with, but some more typical sorts of interpretability can be clear instrumental goals for this.
E.g. suppose you want to use an AI's model of human preferences for some reason. To operationalize this, given a description of a situation, you want to pick which of two described alterations to the situation humans would prefer. This isn't "really interpretability," it's just using a trained model in an unintended way that involves hooks.
But if you're doing this, there are going to be different possible slices of the model that you could have identified as the "model of human preferences." They might have different generalization behavior even though they get similar scores on a small human labeled dataset. And it's natural to have questions about these different slices, like "how much are they computing facts about human psychology as intermediaries to its answers, versus treating the preferences as a non-psychological function of the world?", questions that it would be useful to answer with interpretability tools if we could.
comment by Algon · 2023-08-17T22:33:26.654Z · LW(p) · GW(p)
I thought the section on interpretability as a tool to predict future systems was poor. The posts arguments against that theory of impact are: reading current papers is a better predictor of future capabilities than current interpretability work & examples of interpretability being applied after phenomenon are discovered. But no one is saying current interpretability tech & insights will let you predict the future! As you point out, we barely even understand what a feature is!
Which could change. If we advance enough to reverse engineer GPT-4, and future systems, that would be a massive increase in our understanding of intelligence. If we knew how GPT-4 ticks, we could say how far it could continue improving, and how fast. We would plausibly make huge strides in agent foundations if we knew how to design a mind at all.
Now there's an obvious reason not to pursue this goal: it is dangerous if it works out. And so hard to achieve we'd likely need crazy amounts of co-ordination to stop all the researchers involved from spilling the beans. Imagine having the theoretical insights to build GPT-4 by hand going around the block. You could, I don't know, do something like Cyc but actually useful. You'd have a rando building an opensource AGI project in a week, with people feeding in little bits of domain knowledge by training modular QNRs. Or maybe you'd get some freaking nerd coding a seed AI and pressing run.
EDIT: Also, this is a good post. Have much karma.
comment by Review Bot · 2024-04-01T17:16:20.775Z · LW(p) · GW(p)
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2024. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
comment by Mateusz Bagiński (mateusz-baginski) · 2023-09-05T13:27:15.543Z · LW(p) · GW(p)
A feature is still a fuzzy concept,
"Gene", "species", and even "concept" are also fuzzy concepts but despite that, we managed to substantially improve our understanding of the-things-in-the-world-they-point-to and the phenomena they interact with. Using these fuzzy concepts even made us realize how fuzzy they are, what's the nature of their fuzziness, and what other (more natural/appropriate/useful/reality-at-joint-carving) abstractions we may replace them with.[1] In other words, we can use fuzzy concepts as a ladder/provisional scaffold for understanding. Once our understanding is good enough, we may realize there's a better foundation for the theory than the one that guided us to in the first place. (See: Context of Discovery and Context of Justification)
Or maybe interp could be useful for retargeting the search [LW · GW]? This idea suggests that if we find a goal in a system, we can simply change the system's goal and redirect it towards a better goal.
I think this is a promising quest, even if there are still difficulties:
One difficulty you don't list is that it is not clear ex ante that the models we want to steer/retarget are going to have a "goal slot" or, more generally, something that could be used as a motivational API (a "telopheme" in Tsvi's terminology). This does seem to be the case (at least to a significant extent) in the cases studied by Turner et al. but as you point out, the results from smaller models already fail to translate to/predict what we're finding in bigger models (induction heads being a notable exception).
Instrumental convergence makes this problem even murkier. On the one hand, it may lead you to expect that the "goal part"/utility function of the agent will be separated from the rest in order to facilitate goal preservation. At the same time (1) if this would make it easier for us to steer/retarget the AI, then it would be advantageous for the AI to make this part of itself more obscure/less understandable to us; and (2) an AI need not have a clearly factored out goal to be sufficiently smarter than humans to pose an x-risk (see Soares [LW · GW]).
I am skeptical that we can gain radically new knowledge from the weights/activations/circuits of a neural network that we did not already know, especially considering how difficult it can be to learn things from English textbooks alone.
One way this could work is: if we have some background knowledge/theory of the domain the AI learns about, then the AI may learn some things that we didn't know but that (conditional on sufficiently good transparency/interpretability/ELK)[2] we can extract from it in order to enrich our understanding.
The important question here is: will interp be better for that than more mundane/behavioral methods? Will there be some thing that interp will find that behavioral methods won't find or that interp finds more efficiently (for whatever measure of efficiency) that behavioral methods don't find?
Total explainability of complex systems with great power is not sufficient to eliminate risks.
Also, a major theme of Inadequate Equilibria [? · GW].
Conceptual advances are more urgent.
Obvious counterpoint: in many subdomains of many domains, you need a tight feedback loop with reality to make conceptual progress. Sometimes you need a very tight feedback loop to rapidly iterate on your hypotheses. Also, getting acquainted with low-level aspects of the system lets you develop some tacit knowledge that usefully guides your thinking about the system.
Obvious counter-counterpoint: interp is nowhere near the level of being useful for informing conceptual progress on the things that really matter for AInotkillingeveryone.
comment by Keenan Pepper (keenan-pepper) · 2023-08-18T23:36:47.427Z · LW(p) · GW(p)
Some of your YouTube links are broken because the equals sign got escaped as "%3D". If I were you I'd spend a minute to fix that.
comment by Joseph Bloom (Jbloom) · 2023-08-18T10:01:55.568Z · LW(p) · GW(p)
Strong disagree. Can’t say I’ve worked through the entire article in detail but wanted to chime in as one of the many of junior researchers investing energy in interpretability. Noting that you erred on the side of making arguments too strong. I agree with Richard about this being the wrong kind of reasoning for novel scientific research and with Rohin’s idea that we’re creating new affordances. I think generally MI is grounded and much closer to being a natural science that will progress over time and be useful for alignment, synergising with other approaches. I can't speak for Neel, but I suspect the original list was more about getting something out there than making many nuanced arguments, so I think it's important to steelman those kinds of claims / expand on them before responding.
A few extra notes:
The first point I want to address your endorsement of “retargeting the search” and finding the “motivational API” within AI systems which is my strongest motivator for working in interpretability.
This is interesting because this would be a way to not need to fully reverse engineer a complete model. The technique used in Understanding and controlling a maze-solving policy network [LW · GW] seems promising to me. Just focusing on “the motivational API” could be sufficient.
I predict that methods like “steering vectors” are more likely to work in worlds where we make much more progress in understanding of neural networks. But steering vectors are relatively recent, so it seems reasonable to think that we might have other ideas soon that could be equally useful but may require progress more generally in the field.
We need only look to biology and medicine to see examples of imperfectly understood systems, which remain mysterious in many ways, and yet science has led us to impressive feats that might have been unimaginable years prior. For example, the ability in recent years to retarget the immune system to fight cancer. Because hindsight devalues science we take such technologies for granted and I think this leads to a general over-skepticism about fields like interpretability.
The second major point I wanted to address was this argument:
Determining the dangerousness of a feature is a mis-specified problem. Searching for dangerous features in the weights/structures of the network is pointless. A feature is not inherently good or bad. The danger of individual atoms is not a strong predictor of the danger of assembly of atoms and molecules. For instance, if you visualize the feature of layer 53, channel 127, and it appears to resemble a gun, does it mean that your system is dangerous? Or is your system simply capable of identifying a dangerous gun? The fact that cognition can be externalized [LW · GW] also contributes to this point.
I agree that it makes little sense to think of a feature on it’s own as dangerous but I it sounds to me like you are making a point about emergence. If understanding transistors doesn’t lead to understanding computer software then why work so hard to understand transistors?
I am pretty partial to the argument that the kinds of alignment relevant phenomena in neural networks will not be accessible via the same theories that we’re developing today in mechanistic interpretability. Maybe these phenomena will exist in something analogous to a “nervous system” while we’re still understanding “biochemistry”. Unlike transistors and computers though, biochemistry is hugely relevant to understanding neuroscience.
Replies from: cozyfractal↑ comment by cozyfractal · 2023-09-04T07:14:27.769Z · LW(p) · GW(p)
I'm not sure of what you meant about studying transistors.
It seems to me to me that if we are studying transistors so hard, it's to push computers capabilities (faster, smaller, more energy efficient etc.), and not at all to make software safer. Instead to make software safer, we use anti-viruses, automatic testing, developer liability, standards, regulations, pop-up warnings, etc.
comment by Thanh Do (thanh-do) · 2025-01-22T06:19:06.767Z · LW(p) · GW(p)
But I’ve never seen anybody use it in industry
Disagree - i used to work for some startup in computer vision, and it's pretty common for us to visualize and manually change the hyperparams - yes, we manually changed it
comment by ojorgensen · 2023-11-10T15:52:05.574Z · LW(p) · GW(p)
One central criticism of this post is its pessimism towards enumerative safety. (i.e. finding all features in the model, or at least all important features). I would be interested to hear how the author / others have updated on the potential of enumerative safety in light of recent progress on dictionary learning, and finding features which appear to correspond to high-level concepts like truth, utility and sycophancy [LW · GW]. It seems clear that there should be some positive update here, but I would be interested in understanding issues which these approaches will not contribute to solving.
comment by The Non-Economist (non-economist-the) · 2023-08-25T12:00:37.169Z · LW(p) · GW(p)
Generally lots of value-add discussions but there are some gaps I want to fill some gaps on potentially biased PoVs.
- Starting with Value-Adds:
1) It's great to point out how interpretability (currently doesn't) solve real life problems and types of problems it won't solve.
2) Covering views on warning against the dangers of interpretability
3) Interpretability most of the times is unnecessary...
- Filling in the gaps
1) There's a clear difference btw pre-deployment vs post-deployment interpretability. Post-deployment interpretability is dangerous. Pre-deployment interpretability (aka explainability) can be a powerful tool when training a complex model or trying to deploy a system in a complex organizational environment where there's a lot of scrutiny into the model.
comment by Hamish Doodles (hamish-doodles) · 2023-08-23T15:35:59.547Z · LW(p) · GW(p)
The proportion of junior researchers doing interp rather than other technical work is too high
I think that's because it's almost the only thing that junior researchers can productively work on.
Even if mech interp isn't in itself useful I'd guess it's pretty useful as a souce of endless puzzles to help people skill up in doing technical ML work.
Replies from: charbel-raphael-segerie↑ comment by Charbel-Raphaël (charbel-raphael-segerie) · 2023-08-24T19:29:09.342Z · LW(p) · GW(p)
I disagree. I have seen plenty of young researchers being unproductive doing interp. Writing code does not necessarily mean being productive.
There are a dozen different streams in seri mats, and interp is only one of them. I don't quite understand how you can be so sure that Interp is the only way to level up.
comment by Rudi C (rudi-c) · 2023-08-21T03:55:17.318Z · LW(p) · GW(p)
This post has good arguments, but it mixes in a heavy dose of religious evangelism and narcissism which retracts from its value.
The post can be less controversial and “culty” if it drops its second-order effect speculations, its value judgements, and it just presents a case that focusing on other technical areas of safety research is underrepresented. Focusing on non-technical work needs to be a whole other post, as it’s completely unrelated to interp.
comment by muggingblaise · 2023-08-19T19:03:26.480Z · LW(p) · GW(p)
Emulating GPT-4 using LLMs like GPT-3 as different submodules that send messages written in plain English to each other before outputting the next token. If the neural network had deceptive thoughts, we could see them in these intermediate messages.
This doesn't account for the possibility that there's still stenography involved. Plain English coming from an LLM may not be so plain given
33. Alien Concepts: “The AI does not think like you do” There may not necessarily be a humanly understandable explanation for cognition done by crunching numbers through matrix products.
Considering current language models are able to create their own "language" to communicate with each other without context (hit or miss, admittedly), who's to say a deceptive model could find a way to hide misaligned thoughts in human language, like puzzles that spell a message using the first letter of every fourth word in a sentence? There could be some arbitrarily complicated algorithm (i.e., https://twitter.com/robertskmiles/status/1663534255249453056) to hide the subversive message in the "plain English" statement.
comment by Niklas Todenhöfer (niklas-todenhoefer) · 2024-12-01T19:41:20.509Z · LW(p) · GW(p)
interp?
interpolation, interpretation or which word is meant here?
Thank you 🙏 for elaborating