Othello-GPT: Future Work I Am Excited About
post by Neel Nanda (neel-nanda-1) · 2023-03-29T22:13:26.823Z · LW · GW · 2 commentsThis is a link post for https://neelnanda.io/mechanistic-interpretability/othello
Contents
Future work I am excited about Why and when to work on toy models This is not about world models Finding Modular Circuits Preliminary Results On Modular Circuits Neuron Interpretability and Studying Superposition Empirically Testing Toy Models of Superposition Preliminary Results On Neuron Interpretability Case Study: Neurons and Probes are Confusing A Transformer Circuit Laboratory Where to start? Concrete starter projects Cleaning Up None 2 comments
This is the second in a three post sequence about interpreting Othello-GPT. See the first post for context.
This post covers future directions I'm excited to see work on, why I care about them, and advice to get started. Each section is self-contained, feel free to skip around.
Look up unfamiliar terms here
Future work I am excited about
The above sections leaves me (and hopefully you!) pretty convinced that I've found something real and dissolved the mystery of whether there's a linear vs non-linear representation. But I think there's a lot of exciting mysteries left to uncover in Othello-GPT, and that doing so may be a promising way to get better at reverse-engineering LLMs (the goal I actually care about). In the following sections, I try to:
- Justify why I think further work on Othello-GPT is interesting [AF · GW]
- (Note that my research goal here is to get better at transformer mech interp, not to specifically understand emergent world models better [AF · GW])
- Discuss how this unlocks finding modular circuits [AF · GW], and some preliminary results
- Rather than purely studying circuits mapping input tokens to output logits (like basically all prior transformer circuits work), using the probe we can study circuits mapping the input tokens to the world model, and the world model to the output logits - the difference between thinking of a program as a massive block of code vs being split into functions and modules.
- If we want to reverse-engineer large models, I think we need to get good at this!
- Discuss how we can interpret Othello-GPT's neurons [AF · GW] - we're very bad at interpreting transformer MLP neurons, and I think that Othello-GPT's are simple enough to be tractable yet complex enough to teach us something!
- Discuss how, more broadly, Othello-GPT can act as a laboratory [AF · GW] to get data on many other questions in transformer circuits - it's simple enough to have a ground truth, yet complex enough to be interesting
My hope is that some people reading this are interested enough to actually try working on these problems, and I end this section with advice on where to start [AF · GW].
Why and when to work on toy models
This is a long and rambly section about my research philosophy of mech interp, and you should feel free to move on to the next section [AF · GW] if that's not your jam
At first glance, playing legal moves in Othello (not even playing good moves!) has nothing to do with language models, and I think this is a strong claim worth justifying. Can working on toy tasks like Othello-GPT really help us to reverse-engineer LLMs like GPT-4? I'm not sure! But I think it's a plausible bet worth making.
To walk through my reasoning, it's worth first thinking on what's holding us back - why haven't we already reverse-engineered the most capable models out there? I'd personally point to a few key factors (though note that this is my personal hot take, is not comprehensive, and I'm sure other researchers have their own views!):
- Conceptual frameworks: To reverse-engineer a transformer, you need to know how to think like a transformer. Questions like: What kinds of algorithms is it natural for a transformer to represent, and how? Are features and circuits the right way to think about it? Is it even reasonable to expect that reverse-engineering is possible? How can we tell if a hypothesis or technique is principled vs hopelessly confused? What does it even mean to have truly identified a feature or circuit?
- I personally thought A Mathematical Framework significantly clarified my conceptual frameworks for transformer circuits!
- This blog post is fundamentally motivated by forming better conceptual frameworks - do models form linear representations?
- Practical Knowledge/Techniques: Understanding models is hard, and being able to do this in practice is hard. Getting better at this both looks like forming a better toolkit of techniques that help us form true beliefs about models, and also just having a bunch of practical experience with finding circuits and refining the tools - can we find any cases where they break? How can we best interpret the results?
- A concrete way this is hard is that models contain many circuits, each of which only activates on certain inputs. To identify a circuit we must first identify where it is and what it does, out of the morass! Activation patching (used in ROME, Interpretability in the Wild and refined with causal scrubbing) is an important innovation here.
- Understanding MLP Layers: 2/3 of the parameters in transformers are in MLP layers, which process the information collected at each token position. We're pretty bad understanding them, and getting better at this is vital!
- We think these layers represent features as directions in space, and if each neuron represents a single feature, we're pretty good! But in practice this seems to be false, because of the poorly understood phenomena of superposition and polysemanticity
- Toy Models of Superposition helped clarify my conceptual frameworks re superposition, but there's still a lot more to de-confuse! And a lot of work to do to form the techniques to deal with it in practice. I'm still not aware of a single satisfying example of really understanding a circuit involving MLPs in a language model
- Scalability: LLMs are big, and getting bigger all the time. Even if we solve all of the above in eg four layer transformers, this could easily involve some very ad-hoc and labour intensive techniques. Will this transfer to models far larger? And how well do the conceptual frameworks we form transformer - do they just break on models that are much more complex?
- This often overlaps with forming techniques (eg, causal scrubbing is an automated algorithm with the potential to scale, modulo figuring out many efficiency and implementation details). But broadly I don't see much work on this publicly, and would be excited to see more - in particular, checking how well our conceptual frameworks transfer, and whether all the work on small models is a bit of a waste of time!
- My personal hot take is that I'm more concerned about never getting really good at interpreting a four layer model, than about scaling if we're really good at four layer models - both because I just feel pretty confused about even small models, and because taking understood yet labour-intensive techniques and making them faster and more automatable seems hard but doable (especially with near-AGI systems!). But this is a complex empirical question and I could easily be wrong.
- This often overlaps with forming techniques (eg, causal scrubbing is an automated algorithm with the potential to scale, modulo figuring out many efficiency and implementation details). But broadly I don't see much work on this publicly, and would be excited to see more - in particular, checking how well our conceptual frameworks transfer, and whether all the work on small models is a bit of a waste of time!
Within this worldview, what should our research goals be? Fundamentally, I'm an empiricist - models are hard and confusing, it's easy to trick yourself, and often intuitions can mislead. The core thing of any research project is getting feedback from reality, and using it to form true beliefs about models. This can either look like forming explicit hypotheses and testing them, or exploring a model and seeing what you stumble upon, but the fundamental question is whether you have the potential to be surprised and to get feedback from reality.
This means that any project is a trade-off between tractability and relevance to the end goal. Studying toy, algorithmic models is a double edged sword. They can be very tractable: they're clean and algorithmic which incentivises clean circuits, there's an available ground truth for what the model should be doing, and they're often in a simple and nicely constrained domain. But it's extremely easy for them to cease to be relevant to real LLMs and become a nerd-snipe. (Eg, I personally spent a while working on grokking, and while this was very fun, I think it's just not very relevant to LLMs)
It's pretty hard to do research by constantly checking whether you're being nerd-sniped, and to me there are two natural solutions:
- (1) To pick a concrete question you care about in language models, and to set out to specifically answer that, in a toy model that you're confident is a good proxy for that question
- Eg Toy Models of Superposition built a pretty good toy model of residual stream superposition
- (2) To pick a toy model that's a good enough proxy for LLMs in general, and just try hard to get as much traction on reverse-engineering that model as you can.
- Eg A Mathematical Framework - I think that "train a model exactly like an LLM, but with only 1 or 2 layers" is pretty good as proxies go, though not perfect.
To me, working on Othello-GPT is essentially a bet on (2), that there in gneeral some are underlying principles of transformers and how they learn circuits, and that the way they manifest in Othello-GPT can teach us things about real models. This is definitely wrong in some ways (I don't expect the specific circuits we find to be in GPT-3!), and it's plausible this is wrong in enough ways to be not worth working on, but I think it seems plausible enough to be a worthwhile research direction. My high-level take is just "I think this is a good enough proxy about LLMs that studying it hard will teach us generally useful things".
There's a bunch of key disanalogies to be careful of! Othello is fundamentally not the same task as language: Othello is a much simpler task, there's only 60 moves, there's a rigid and clearly defined syntax with correct and incorrect answers (not a continuous mess), the relevant info about moves so far can be fully captured by the current board state, and generally many sub-tasks in language will not apply.
But it's also surprisingly analogous, at least by the standards of toy models! Most obviously, it's a transformer trained to predict the next token! But the task is also much more complex than eg modular addition, and it has to do it in weird ways! The way I'd code Othello is by doing it recursively - find the board state at move n and use it to get the state at move n+1. But transformers can't do this, they need to do things with a fixed number of serial steps but with a lot of computation in parallel (ie, at every move it must simultaneously compute the board state at that move in parallel) - it's not obvious to me how to do this, and I expect that the way it's encoded will teach me a lot about how to represent certain kinds of algorithms in transformers. And it needs to be solving a bunch of sub-tasks that interact in weird ways (eg, a piece can be taken multiple times in each of four different directions), computing and remembering a lot of information, and generally forming coherent circuits.
In the next few sections I'll argue for how finding modular circuits can help build practical knowledge and techniques, what we could learn from understanding its MLPs, and more broadly how it could act as a laboratory for forming better conceptual frameworks (it's clearly not a good way to study scalability lol)
This is not about world models
A high-level clarification: Though the focus of the original paper was on understanding how LLMs can form emergent world models, this is not why I am arguing for these research directions. My interpretation of the original paper was that it was strong evidence for the fact that it's possible for "predict the next token" models to form world emergent models, despite never having explicit access to the ground truth of the world/board state. I personally was already convinced that this was possible, but think the authors did great work that showed this convincingly and well (and I am even more convinced after my follow-up!), and that there's not much more to say on the "is this possible" question.
There's many interesting questions about whether these happen in practice in LLMs and what this might look like and how to interpret it - my personal guess is that they do sometimes, but are pretty expensive (in terms of parameters and residual stream bandwidth) and only form when it's high value for reducing next token loss and the model is big enough to afford it. Further, there's often much cheaper hacks, eg, BingChat doesn't need to have formed an explicit chess board model to be decent at playing legal moves in chess! Probably not even for reasonably good legal play: the chess board state is way easier than Othello, pieces can't even change colour! And you can get away with an implicit rather than explicit world model that just computes the relevant features from the context, eg to see where to a move a piece from, just look up the most recent point where that piece was played and look at the position it was moved to.
But Othello is very disanalogous to language here - playing legal moves in Othello has a single, perfectly sufficient world model that I can easily code up (though not quite in four transformer layers!), and which is incredibly useful for answering the underlying task! Naively, Othello-GPT roughly seems to be spending 128 of its 512 residual stream dimensions of this model, which is very expensive (though it's probably using superposition). So while it's a proof of concept that world models are possible, I don't think the finer details here tell us much about whether these world models actually happen in real LLMs. This seems best studied by actually looking at language models, and I think there's many exciting questions here [AF · GW]! (eg doing mech interp on Patel et al's work) The point of my investigation was more to refine our conceptual frameworks for thinking about models/transformers, and the goal of these proposed directions is to push forward transformer mech interp in general.
Finding Modular Circuits
Basically all prior work on circuits (eg, induction heads, indirect object identification, the docstring circuit [LW · GW], and modular addition) have been on what I call end-to-end circuits. We take some model behaviour that maps certain inputs to certain outputs (eg the input of text with repetition, and the output of logits correctly predicting the repetition), and analyse the circuit going from the inputs to the outputs.
This makes sense as a place to start! The inputs and outputs are inherently interpretable, and the most obvious thing to care about. But it stands in contrast to much of the image circuits work, that identified neurons representing interpretable features (like curves) and studied how they were computed and how these were used to computed more sophisticated features (like car wheels -> cars). Let's consider the analogy of mech interp to reverse-engineering a compiled program binary to source code. End-to-end circuits are like thinking of the source code as a single massive block of code, and identifying which sections we can ignore.
But a natural thing to aim for is to find variables, corresponding to interpretable activations within the network that correspond to features, some property of the input. The linear representation hypothesis says that these should be directions in activation space. It's not guaranteed that LLMs are modular in the sense of forming interpretable intermediate features, but this seems implied by exiasting work, eg in the residual stream (often studied with probes), or in the MLP layers (possibly as interpretable neurons). If we can find interpretable variables, then the reverse-engineering task becomes much easier - we can now separately analyse the circuits that form the feature(s) from the inputs or earlier features, and the circuits that use the feature(s) to compute the output logits or more complex feature.
I call a circuit which starts or ends at some intermediate activation a modular circuit (in contrast to end-to-end circuits). These will likely differ in two key ways from end-to-end circuits:
- They will likely be shallower, ie involving fewer layers of composition, because they're not end-to-end. Ideally we'd be able to eg analyse a single neuron or head in isolation.
- And hopefully easier to find!
- They will be composable - rather than needing to understand a full end-to-end circuit, we can understand different modular circuits in isolation, and need only understand the input and output features of each circuit, not the circuits that computed them.
- Hopefully this also makes it easier to predict model behaviour off distribution, by analysing how interpretable units may compose in unexpected ways!
I think this is just obviously a thing we're going to need to get good at to have a shot at real frontier models! Modular circuits mean that we can both re-use our work from finding circuits before, and hopefully have many fewer levels of composition. But they introduce a new challenge - how do we find exactly what direction corresponds to the feature output by the first circuit, ie the interface between the two circuits? I see two natural ways of doing this:
- Exploiting a privileged basis - finding interpretable neurons or attention patterns (if this can be thought of as a feature?) and using these as our interpretable foothold.
- This is great if it works, but superposition means this likely won't be enough.
- Using probes to find an interpretable foothold in the residual stream or other activations - rather than assuming there's a basis direction, we learn the correct direction
- This seems the only kind of approach that's robust to superposition, and there's a lot of existing academic work to build upon!
- But this introduces new challenges - rather than analysing discrete units, it's now crucial to find the right direction and easy to have errors. It seems hard to produce composable circuits if we can't find the right interface.
So what does any of this have to do with Othello-GPT? I think we'll learn a lot by practicing finding modular circuits in Othello-GPT. Othello-GPT has a world model - clear evidence of spontaneous modularity - and our linear probe tells us where it is in the residual stream. And this can be intervened upon - so we know there are downstream circuits that use it. This makes it a great case study! By about layer 4, of the 512 dimensions of the residual stream, we have 64 directions corresponding to which cell has "my colour" and 60 directions corresponding to which cells are blank (the 4 center cells are never blank). This means we can get significant traction on what any circuit is reading or writing from the residual stream.
This is an attempt to get at the "practical knowledge/techniques" part of my breakdown of mech interp bottlenecks [AF · GW] - Othello-GPT is a highly imperfect model of LLMs, but I expect finding modular circuits here to be highly tractable and to tell us a lot. Othello-GPT cares a lot about the world model - the input format of a sequence of moves is hard and messy to understand, while "is this move legal" can be answered purely from the board state. So the model will likely devote significant resources to computing board state, forming fairly clean circuits. Yet I still don't fully know how to do it, and I expect it to be hard enough to expose a bunch of the underlying practical and conceptual issues and to teach us useful things about doing this in LLMs.
Gnarly conceptual issues:
- How to find the right directions with a probe. Ie the correct interface between world-model-computing circuits and world-model-using circuits, such that we can think of the two independently. I see two main issues:
- Finding all of the right direction - a probe with cosine sim of 0.7 to the "true" direction might work totally fine
- In particular, can we stop the probe from picking up on features that are constant in this context? Eg "is cell B6 my colour" is only relevant if "is cell B6 blank" is False, so there's naively no reason for the probe to be orthogonal to it.
- Ignoring features that correlate but are not causally linked - the corner cell can only be non-blank if at least one of the three neighbouring cells are, so the "is corner blank" direction should overlap with these.
- But my intuition is that the model is learning a causal world model, not correlational - if you want to do complex computations it's useful to explicitly distinguish between "is corner blank" as a thing to compute and use downstream, and all the other features. Rather than picking up on statistical correlations in the data.
- Finding all of the right direction - a probe with cosine sim of 0.7 to the "true" direction might work totally fine
- If we find interpretable directions in the residual stream that are not orthogonal, how do we distinguish between "the model genuinely wants them to overlap" vs "this is just interference from superposition"?
- Eg, the model should want "is cell A4 blank" to have positive cosine sim with the unembed for the "A4 is legal" logit - non-blank cells are never legal!
- The world model doesn't seem to be fully computed by layer X and only used in layer X+1 onwards - you sometimes need to intervene before layer 4, and sometimes the calculation hasn't finished before layer 5. How can we deal with overlapping layers? Is there a clean switchover layer per cell that we can calculate separately?
- How can we distinguish between two features having non-zero dot product because of noise/superposition, vs because they are correlated and the model is using one to compute the other.
Questions I want answered:
- How can we find the true probe directions, in a robust and principled way? Ideas:
- Use high weight decay to get rid of irrelevant directions. SGD (maybe with momentum) may be cleaner than AdamW here
- Use more complex techniques than logistic regression, like amnesiac probing (I found Eleuther's Tuned Lens paper a useful review)
- Find the directions that work best for causal interventions instead.
- Maybe use the janky probe directions to try to find the heads and neurons that compute the world model, and use the fact that these are a privileged-ish basis to refine our understanding of the probe directions - if they never contribute to some component of the probe, probably that component shouldn't be there!
- Maybe implicitly assume that the probe directions should form an orthogonal set
- Maybe train a probe, then train a second probe on the residual stream component orthogonal to the first probe. Keep going until your accuracy sucks, and then take some kind of weighted average of the residual stream.
- How is the blank world model computed?
- This should be really easy - a cell is blank iff it has never been played, so you can just have an attention head that looks at previous moves. Maybe it's done after the layer 0 attention!
- This is trivial with an attention head per cell, but probably the model wants to be more efficient. What does this look like?
- Eg it might have a single attention head look at all previous moves with uniform attention. This will get all of the information, but at magnitude
1/current_move, maybe it has the MLP0 layer sharpen this to have constant magnitude?
- Eg it might have a single attention head look at all previous moves with uniform attention. This will get all of the information, but at magnitude
- Meta question: What's a principled way to find the "is blank" direction here? The problem is one of converting a three-way classifier (blank vs my vs their) to a binary classifier that can be summarised with a single direction. I'm currently taking
blank - (my + their)/2, but this is a janky approach
- How is the "my vs their" world model computed?
- This seems like where the actual meat of the problem is!
- Consider games where
- This seems like where the actual meat of the problem is!
- Which techniques work well here? My money is on activation patching and direct logit attribution being the main place to start, see activation patching demoed in the accompanying notebook.
- I'd love for someone to try out attribution patching here!
- By activation patching, I both mean resample ablations (patching a corrupted activation into a clean run to see which activations are vs aren't necessary) and causal tracing (patching a clean activation into a corrupted run to see which activations contain sufficient information to get the task right)
Preliminary Results On Modular Circuits
The point of this section is to outline exciting directions of future work, but as a proof of concept I've done some preliminary poking around. The meta-level point that makes me excited about this is that linear probes are really nice objects for interpretability. Fundamentally, transformers are made of linear algebra! Every component (layer, head and neuron) reads its input from the residual stream with a linear map, and writes it output by adding it to the residual stream, which is a really nice structure.
Probing across layers: One way this is nice is that we can immediately get a foothold into understanding how the world model is computed. The residual stream is the sum of the embeddings and the output of every previous head and neuron. So when we apply a linear map like our probe, we can also break this down into a direct contribution from each previous head and neuron.
This is the same key idea as direct logit attribution, but now our projection is onto a probe direction rather than the unembed direction for a specific next token. This means we can immediately zoom in to the step of the circuit immediately before the probe, and see which components matter for each cell!
As an example, let's look at move 20 in this game:
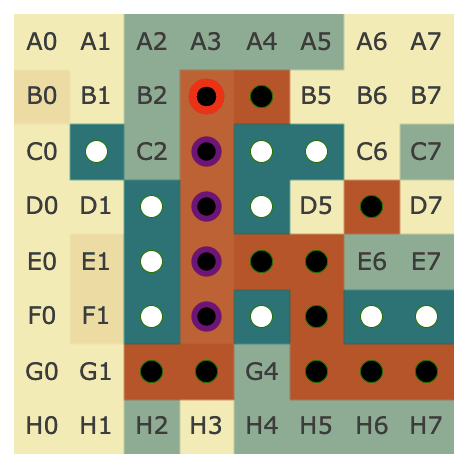
The probe can perfectly predict the board state by layer 4
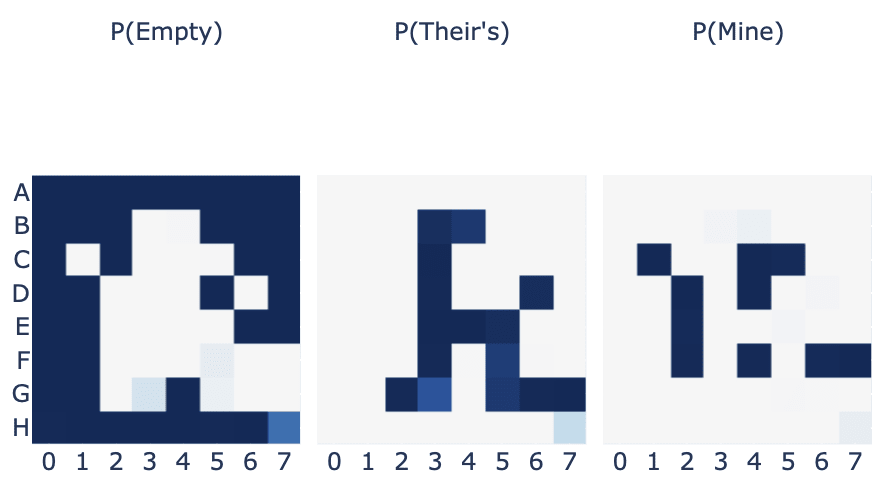
We can now look at how much the output of each attention and each MLP layer contributed to this (concretely we take the output of each attention and each MLP layer on move 30, and project them onto the is_blank direction and the is_mine direction for each cell, and plot this as a heatmap - check the accompanying notebook for details). The MLP layer contributions to whether a cell has my or their colour is particularly interesting - we can see that it normally does nothing, but has a strong effect on the central stripe of cells that were just taken by the opponent - plausibly MLPs calculate when a cell is taken, and attention aggregates this? I'd love to see if there are specific neurons involve.
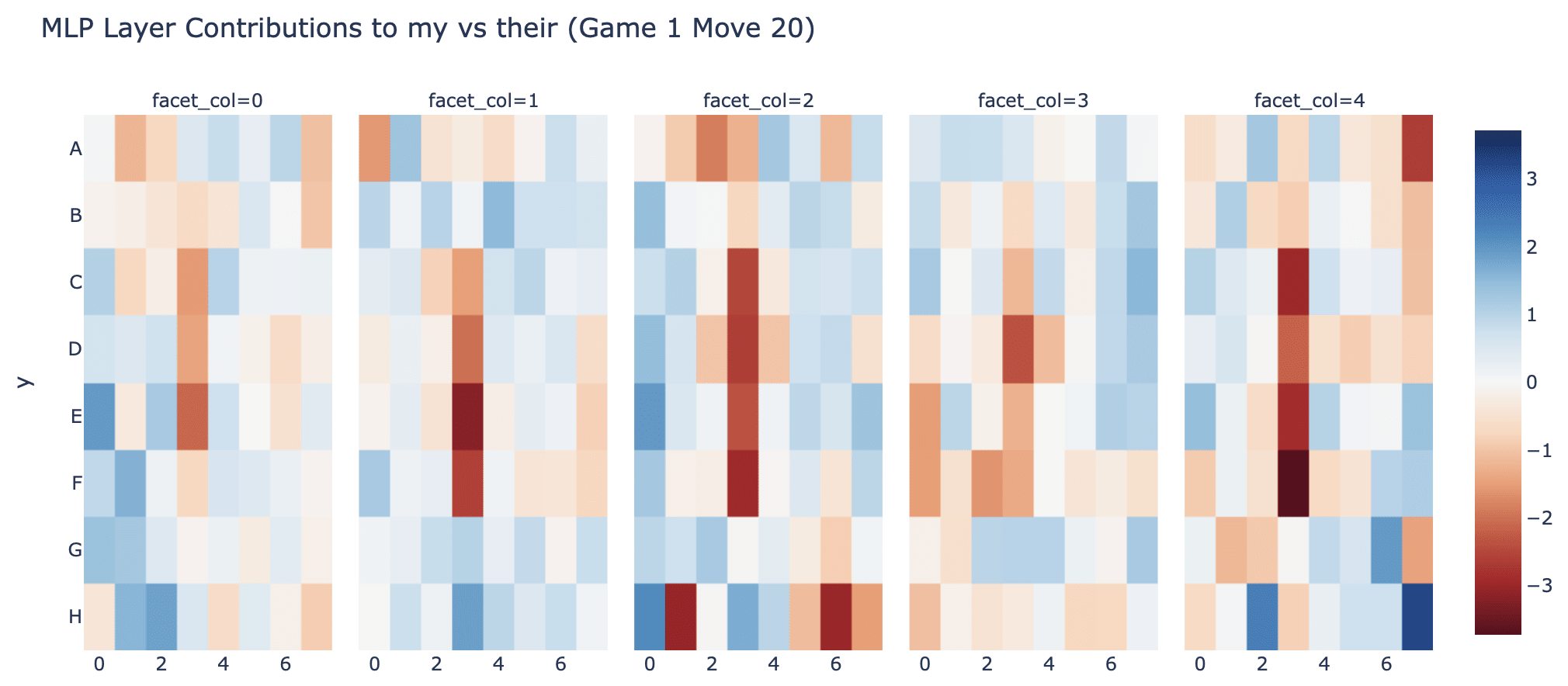
Reading Off Neuron Weights: Another great thing about a linear probe is that it gives us a meaningful set of directions and subspace in the residual stream (beyond that given by the embedding and unembedding). This means that we can take any component's input or output weights, and project them onto the probe directions to see how that component reads to or writes from the probe's subspace - from this we can often just read off what's going on!
The probe intervention works best between layer 4 and layer 5, so we might hypothesise that some neurons in layer 5 are reading from the probe's subspace - we can check by taking the cosine sim of the neuron's input vector and the probe's directions to see how it responds to each, see the accompanying notebook for details. Here's neuron L5N1393 which seems to mostly represent C0==BLANK & D1==THEIRS & E2==MINE (cherry-picked for reasons unrelated to the probe, discussed more in post 3). Reading the figure: Blue = THEIRS, Red=MINE, White can be either blank or 50-50 mine vs their's, so can't be read easily.
Here's the neurons with the largest standard deviation of activation in layer 3 (a pretty arbitrary way of choosing some that might be interesting) - when we take the cosine sim of the output weights of these and the my colour probe, we see some that are pretty striking (though note that this is only a 0.3 cosine sim, so other stuff may be going on!)
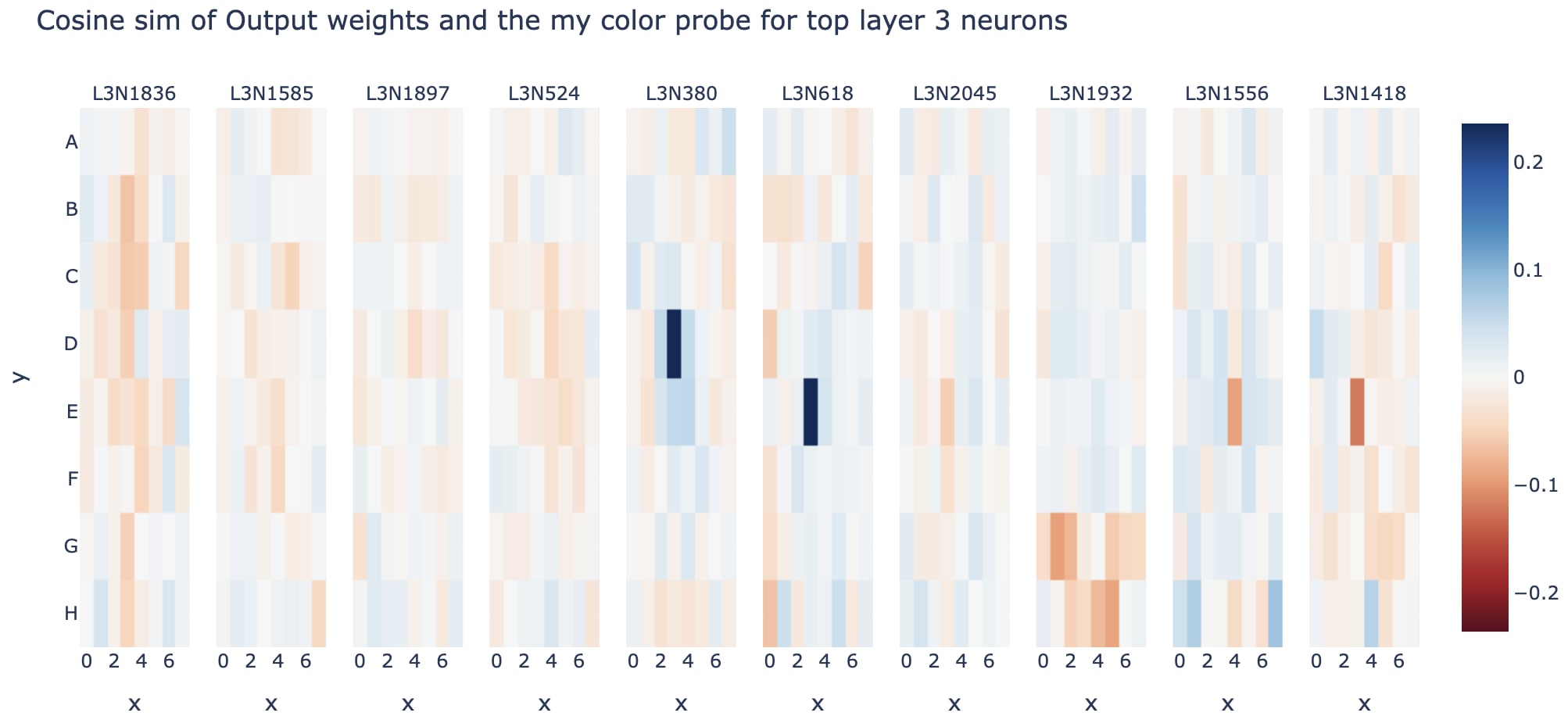
Note that this is a deliberately janky analysis - eg, I'm not ensuring that the probe directions are orthogonal so I may double count, and I'm not looking for other residual stream features. You can track how reasonable this approach by tracking what fraction of the neuron's input is explained by the probe's subspaces, which is 64% in this case (these could otherwise be entirely spurious numbers!).
I go into neuron interpretability in more detail in the next section, but I think this technique is exciting in combination with what I discuss there, because it provides another somewhat uncorrelated technique - if many janky techniques give the same explanation about a neuron, it's probably legit!
Neuron Interpretability and Studying Superposition
As argued earlier, I think that the current biggest open problem in transformer mech interp is understanding the MLP layers of transformers. These represent over 2/3 of the parameters in models, but we've had much more traction understanding attention-focused circuits. I'm not aware of a single public example of what I'd consider a well-understood circuit involving transformer MLP layers (beyond possibly my work on modular addition in a one layer transformer, but that's cheating). There are tantalising hints about the circuits they're used in in eg SoLU and ROME, but I broadly still feel confused re what is mechanistically going on. I think this is a thing we obviously need to make progress on as a field! And I think we'll learn useful things from trying to understand Othello-GPT's MLP layers!
What could progress on understanding MLPs in general look like? I think that we both need to get practice just studying MLP layers, and that we need to form clearer conceptual frameworks. A lot of our intuitions about transformer neurons come from image models, where neurons seem to (mostly?) represent features, have ReLU activations, and seem to be doing fairly discrete kinds of logic, eg "if car wheel present and car body present and car window present (in the right places) -> it's a car".
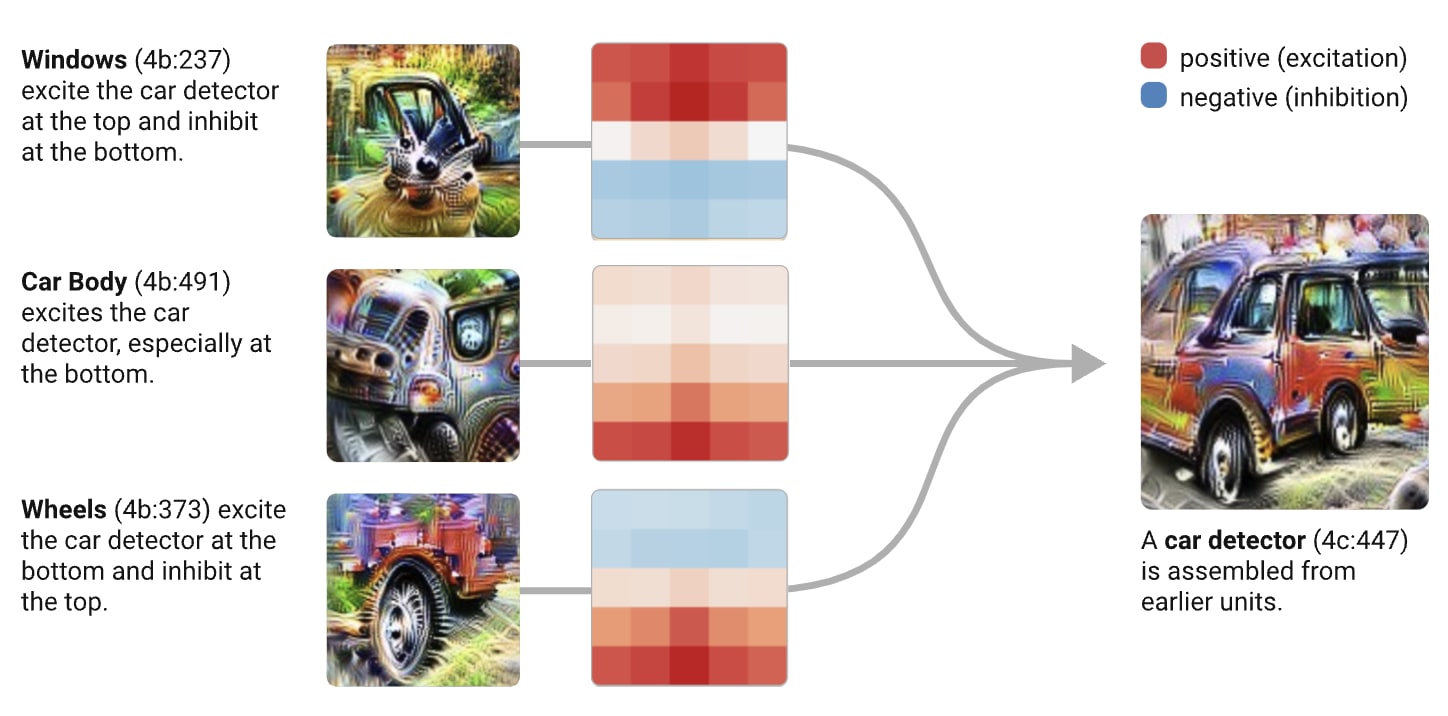
Transformers are different in a bunch of ways - there's attention layers, there's a residual stream (with significantly smaller dimension than the number of neurons in each layer!), and smoother and weirder GELU activations. Most importantly, polysemanticity seem to be a much bigger deal - single neurons often represent multiple features rather than a feature per neuron - and we think this is because models are using superposition - they represent features as linear combinations of neurons and use this to compress in more features than they have dimensions. This was argued for pretty convincingly in Toy Models of Superposition, but their insights were derived from a toy model, which can easily be misleading. I'm not aware of any work so far exhibiting superposition or properly testing the predictions of that paper in a real model. I expect some ideas will transfer but some will break, and that I'll learn a lot from seeing which is which!
Othello-GPT is far from a real language model, but I expect that understanding its MLP layers would teach me a bunch of things about how transformer MLP layers work in general. The model needs to compress a fairly complex and wide-ranging set of features and computation into just eight layers, and the details of how it does this will hopefully expose some principles about what is and is not natural for a transformer to express in MLP neurons.
What would progress here look like? My high-level take is that a solid strategy is just going out, looking for interesting neurons, and trying to understand them deeply - no grander purpose or high-level questions about the model needed. I'd start with similar goals as I gave in the previous section [AF · GW] - look for the neurons that are used to compute the probe, and directly used by the probe. I also outline some further preliminary results [AF · GW] that may serve as inspiration.
I've learned a lot from case studies looking deeply at concrete case studies of circuits in models: Interpretability in the Wild found backup heads (that took over when earlier heads were ablated) and negative heads (that systematically boosted incorrect solutions), and the docstring circuit [LW · GW] found a polysemantic attention head, and a head which used the causal attention mask to re-derive positional information. I would love to have some similar case studies of meaningful neurons!
Empirically Testing Toy Models of Superposition
The sections of my mech interp explainer on superposition and on the toy models of superposition paper may be useful references
I'm particularly excited about using Othello-GPT to test and validate some of the predictions of Toy Models of Superposition about what we might find in transformers. Empirical data here seems really valuable! Though there are some important ways that the setup of Othello-GPT differs from their toy model. Notably, they study continuous (uniform [0, 1]) features, while Othello-GPT's features seem likely to be binary (on or off), as they're discrete and logical functions of the board state and of the previous moves. Binary features seem more representative of language, especially early token-level features like bigrams and multi-token words, and are also easier to put into superposition, because you don't need to distinguish low values of the correct feature from high values of the incorrect feature
A broader point is whether we expect Othello-GPT to use superposition at all? Their model has more features to represent than dimensions, and so needs to use superposition to pack things in. It's not obvious to me how many features Othello-GPT wants to represent, and how this compares to the number of dimensions - my guess is that it still needs to use superposition, but it's not clear. Some considerations:
- There's actually a lot of very specific features it might want to learn - eg in the board state -> output logit parts there seems to be a neuron representing C0==BLANK & D1==THEIR'S & E2==MINE, ie can I place a counter in C0 such that it flanks exactly one counter on the diagonal line to the down and right - if this kind of thing is useful, it suggests the model is dealing with a large combinatorial explosion of cases for the many, many similar configurations!
- Further, computing the board state from the moves also involves a lot of messy cases, eg dealing with the many times and directions a piece can be flipped and combining this all into a coherent story.
- Reminder: Transformers are not recurrent - it can't compute the board state at move n from the state at move n-1, it needs to compute the state at every move simultaneously with just a few layers of attention to move partial computation forwards. This is actually really hard, and it's not obvious to me how you'd implement this in a transformer!
- Further, computing the board state from the moves also involves a lot of messy cases, eg dealing with the many times and directions a piece can be flipped and combining this all into a coherent story.
- There are two different kinds of superposition, residual stream superposition and neuron superposition (ie having more features than dimensions in the residual stream vs in the MLP hidden layer).
- The residual stream has 512 dimensions, but there's 8 layers of 2048 neurons each (plus attention heads) - unless many neurons do nothing or are highly redundant, it seems very likely that there's residual stream superposition!
- Though note that it's plausible it just has way fewer than 2048 features worth computing, and is massively over-parametrised. I'm not sure what to think here!
- The board state alone consumes 25% of the dimensions, if each feature gets a dedicated dimension, and I expect there's probably a bunch of other features worth computing and keeping around?
- The residual stream has 512 dimensions, but there's 8 layers of 2048 neurons each (plus attention heads) - unless many neurons do nothing or are highly redundant, it seems very likely that there's residual stream superposition!
Concrete questions I'd want to test here - note that the use of dropout may obfuscate these questions (by incentivising redundancy and backup circuits), and this may be best answered in a model without dropout. These also may be best answered in a smaller model with fewer layers and a narrower residual stream, and so with a stronger incentive for superposition!:
- Do important features get dedicated dimensions in the residual stream? (ie, orthogonal to all other features)
- Guesses for important features - whether black or white is playing, the board state, especially features which say which center cells have my colour vs their's.
- Conversely, can we find evidence that there is overlap between features in the residual stream?
- This is surprisingly thorny, since you need to distinguish this kind of genuine interference vs intentional overlapping, eg from the source of the first feature actually wanting to contribute a bit to feature two as well.
- Do the important neurons seem monosemantic?
- Important could mean many things eg high effect when patching, high average activation or standard deviation of activation, high cost when ablated, or any other range of measurements, high gradient or gradient x activation
- My workflow would be to use the probe and unembed to interpret neuron weights, max activating dataset examples to help form a hypothesis, and then use a spectrum plot to properly analyse it (discussed more below).
- Do we get seemingly unrelated features sharing a neuron? The paper predicts superposition is more likely when there are two uncorrelated or anti-correlated features, because then the model doesn't need to track the simultaneous interference of both being there at once.
- Can we find examples of a feature being computed that needs more than one neuron? Analogous to how eg modular addition uses ReLUs to multiply two numbers together, which takes at least three to do properly. This is a bit of a long shot, since I think any kind of discrete, Boolean operation can probably be done with a single GELU, but I'd love to be proven wrong!
- Do features actually seem neuron aligned at all?
- If we find features in superposition, do they tend to still be sparse (eg linear combinations of 5 ish neurons) or diffuse (no noticable alignment with the neuron basis)
- Can we find any evidence of spontaneous sorting of superposed features into geometric configurations? (A la the toy models paper)
- Can you construct any adversarial examples using evidence from the observed polysemanticity?
- Can you find any circuits used to deal with interference superposition? Or any motifs, like the asymmetric inhibition motif?
Preliminary Results On Neuron Interpretability
Note that this section has some overlap with results discussed in my research process [AF · GW]
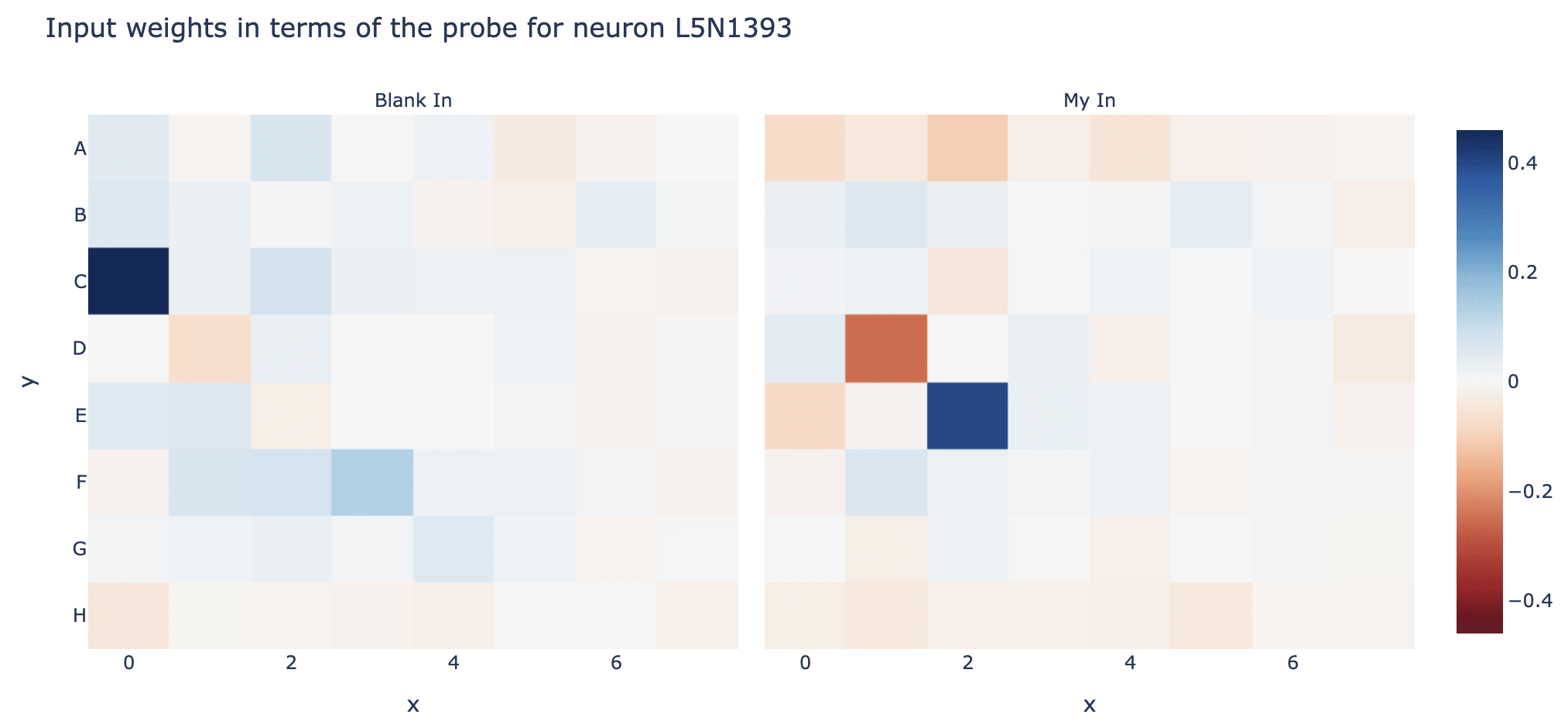
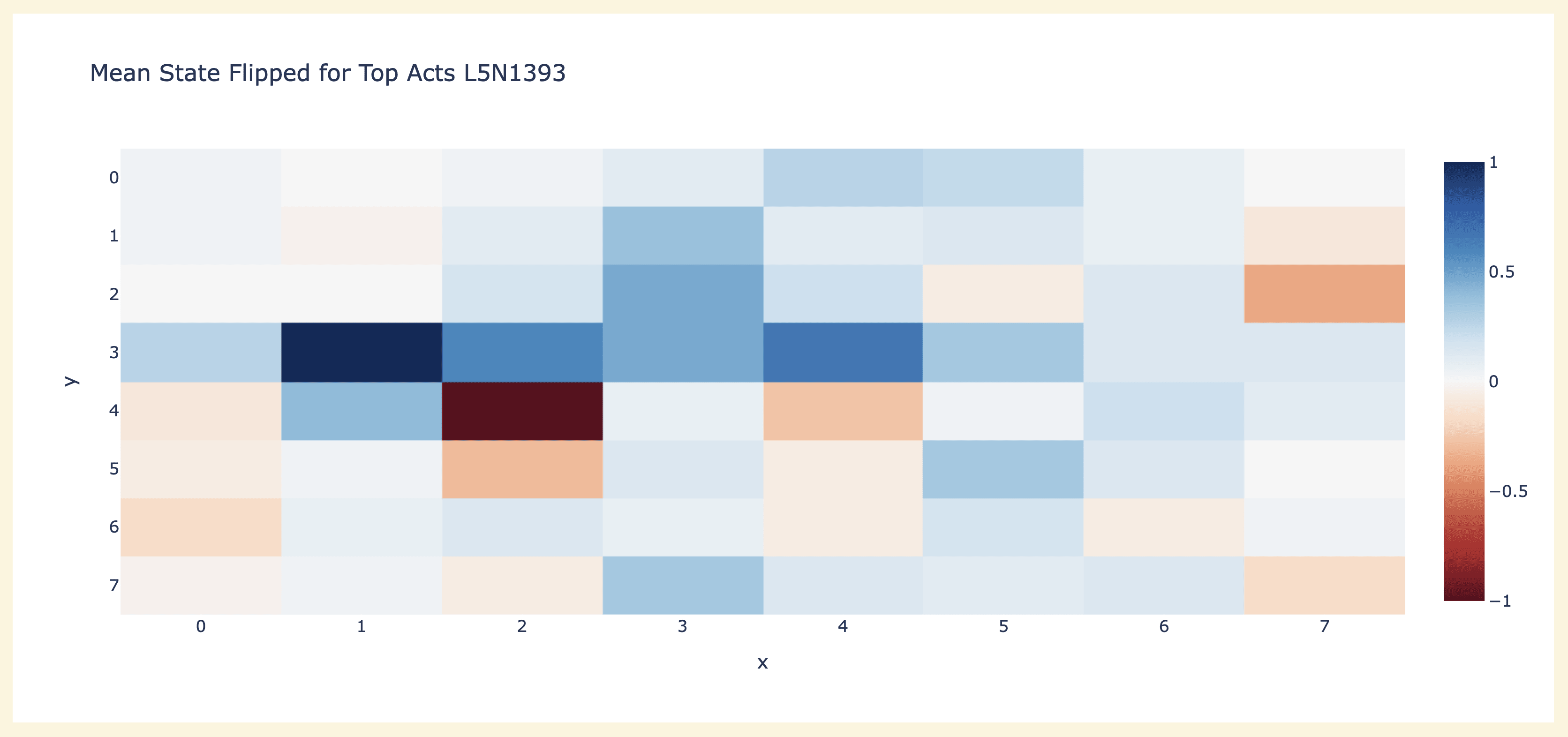
In addition to the results above using the probe to interpret neuron weights [AF · GW], an obvious place to start is max activating dataset examples - run the model over a bunch of games and see what moves the neuron activates the most on. This is actually a fair bit harder to interpret than language, since "what are the connections between these sequences of moves" isn't obvious. I got the most traction from studying board state - in particular, the average number of times each cell is non-empty, and the average number of times a cell is mine vs their's. Here's a plot of the latter for neuron L5N1393 that seems immediately interpretable - D1 is always their's, E2 is always mine! (across 50 games, so 3000 moves) I sometimes get similar results with other layer 5 and layer 6 neurons, though I haven't looked systematically.
Looking at the fraction of the time a cell is blank or not seems to give pretty interesting results for layer 3 and layer 4 neurons.

I expect you can stretch max activating dataset examples further by taking into account more things about the moves - what time in the game they happened, which cells are flipped this turn (and how many times in total!), which cell was played, etc.
My guess from this and probe based analysis earlier was that neuron L5N1393 monosemantically represented the diagonal line configuration C0==BLANK & D1==THEIR'S & E2==MINE. This makes sense as a useful configuration since it says that C0 is a legal move, because it and E2 flank D1! But this seems inconsistent with the direct logit attribution of the neuron (ie the output vector of the neuron projected by the unembed onto the output logits), which seems to boost C0 a lot but also D1 a bit - which seems wildly inconsistent with it firing on D1 being their colour (and thus not a legal place to play!)
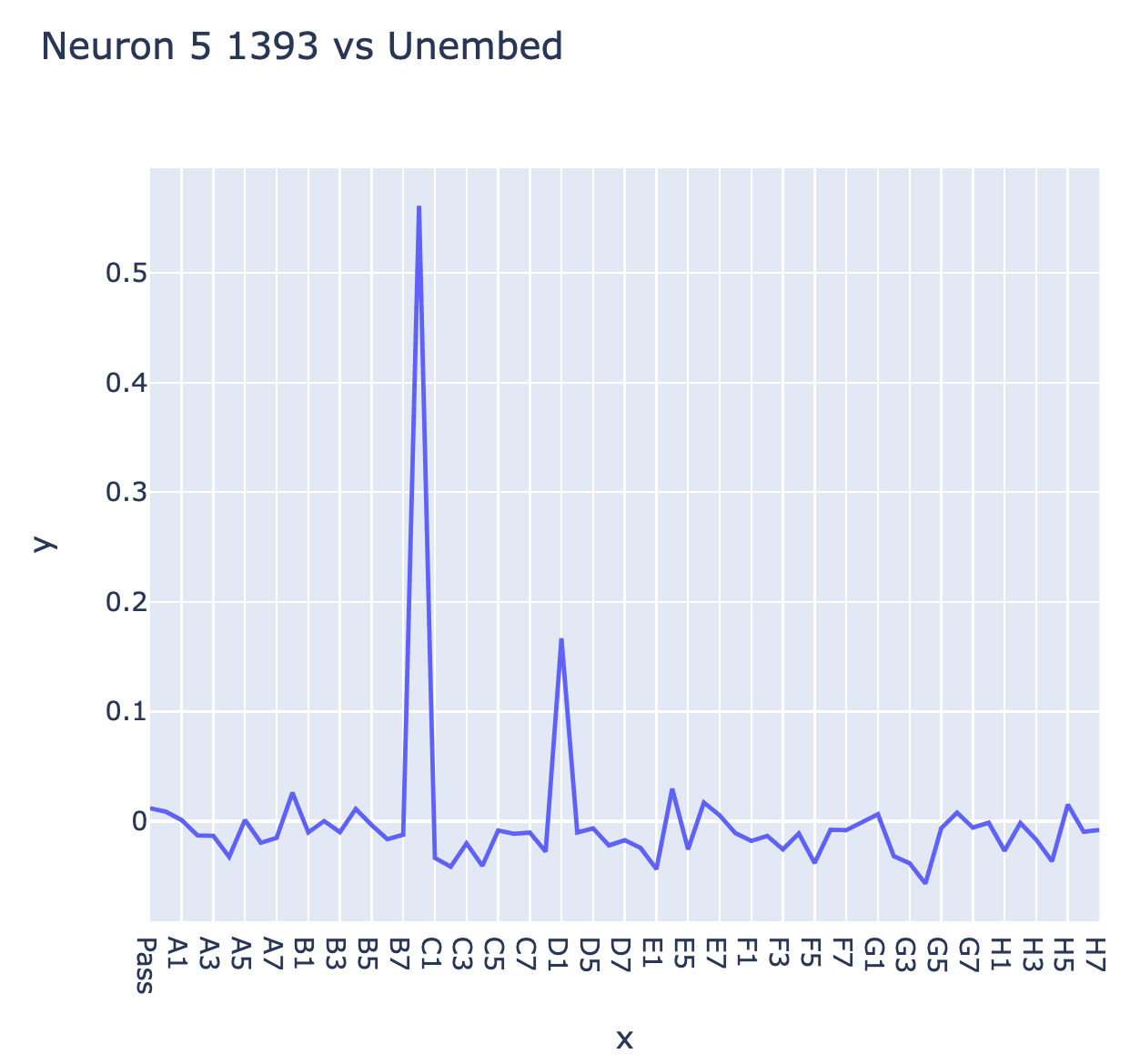
These techniques can all be misleading - max activating dataset examples can cause interpretability illusions, direct logit attribution can fail for neurons that mostly indirectly affect logits, and probes can fail to interpret neurons that mostly read out unrelated features. One of the more robust tools for checking what a neuron means is a spectrum plot - if we think a neuron represents some feature, we plot a histogram of the "full spectrum" of the neuron's activations by just taking the neuron activation on a ton of data, and plotting a histogram grouped by whether the feature is present or not (used in curve detectors and multimodal neurons). If a neuron is monosemantic, this should fairly cleanly separate into True being high and False being low!
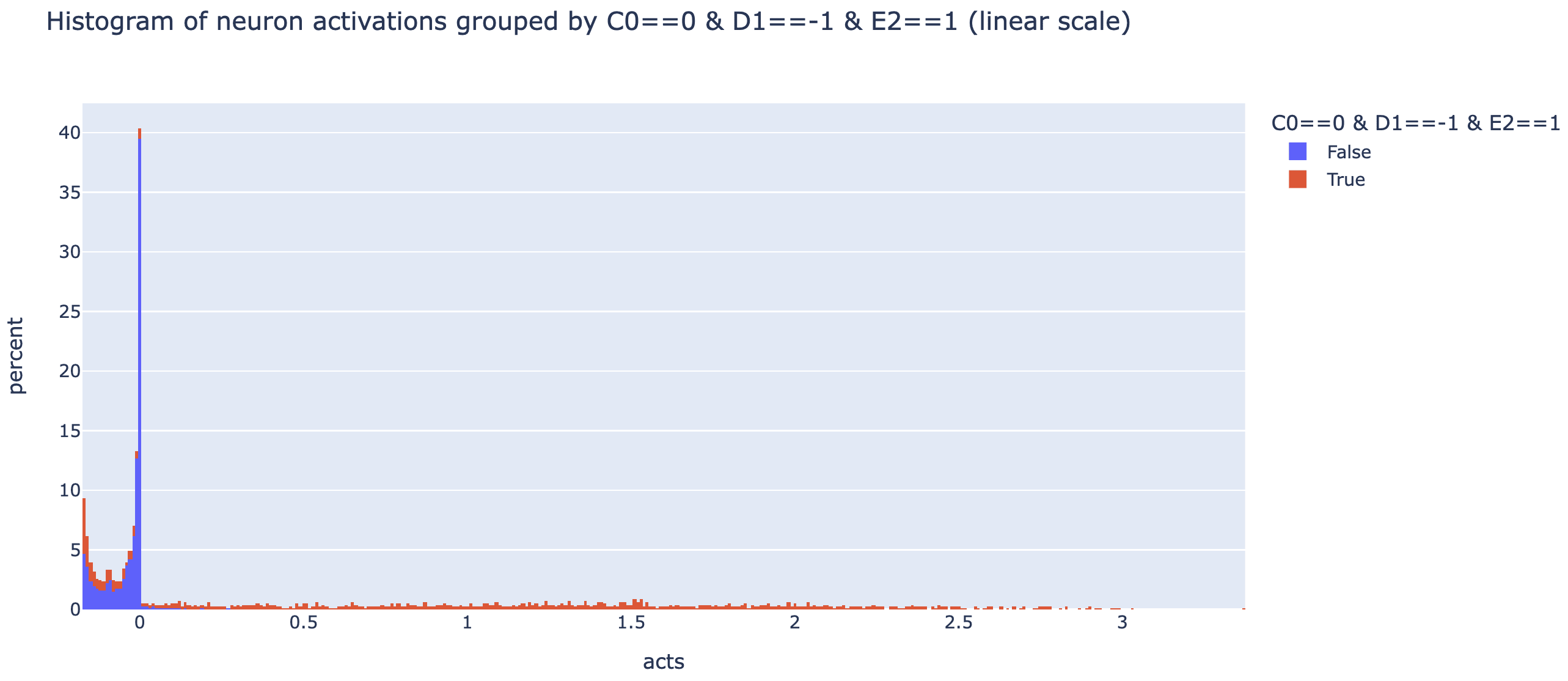
Note that the y axis is percent (ie it's normalised by group size so both True and False's histograms add up to 100 in total, though True is far more spread out so it doesn't look it. This is hard to read, so here it is on a log scale (different to read in a different way!).
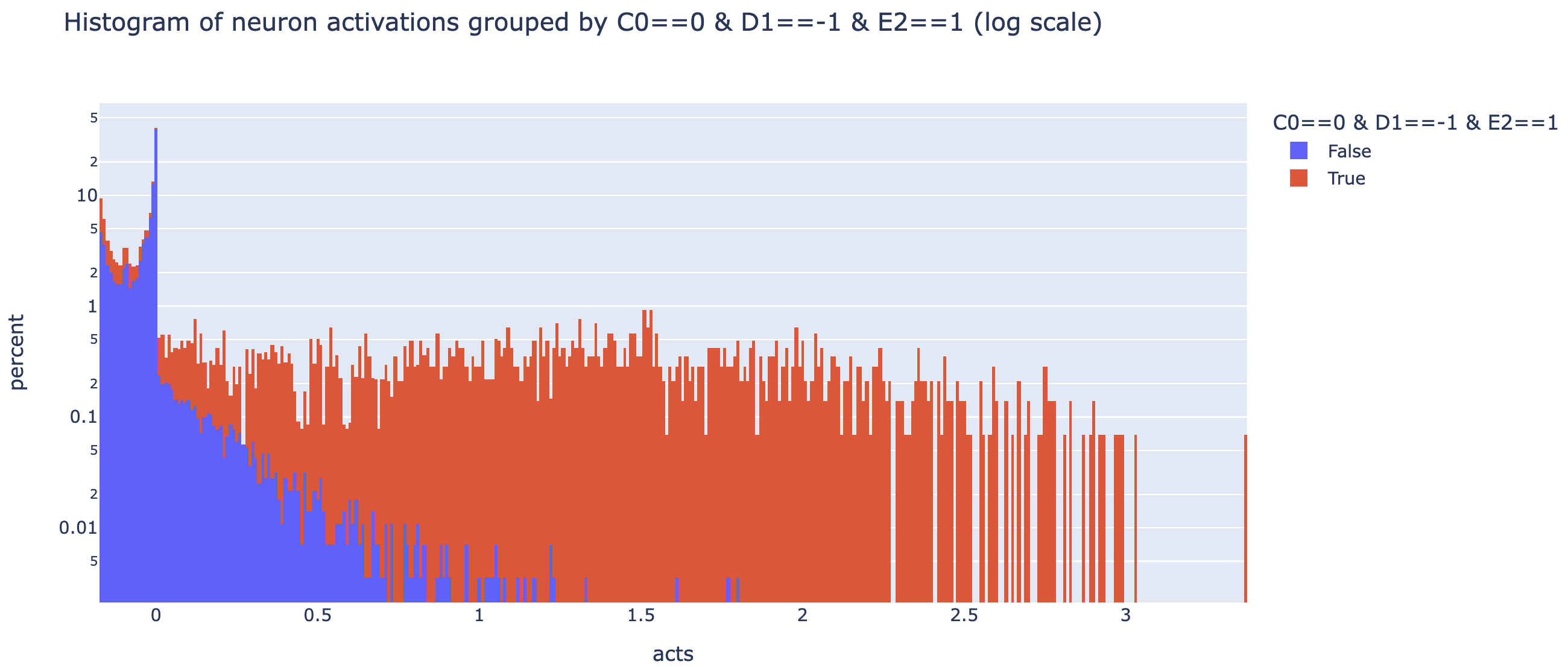
These plots are somewhat hard to interpret, but my impression is that this neuron is plausibly monosemantic-ish, but with a more refined feature - basically all of the high activations have the diagonal line hypothesised, but this is necesssary not sufficient - there's a bunch of negative activations with the line as well! Plausibly it's still monosemantic but there's some extra detail I'm missing, I'm not sure! My next steps would be to refine the hypothesis by inspecting the most positive and most negative True examples, and if I can get a cleaner histogram to then try some causal interventions (eg mean ablating the neuron and seeing if it has the effect my hypothesis would predict). I'd love to see someone finish this analysis, or do a similar deep dive on some other neurons!
Spectrum plots are a pain to make in general, because they require automated feature detectors to do properly (though you can do a janky version by manually inspecting randomly sampled examples, eg a few examples from each decile). One reason I'm excited about neuron interpretability in Othello-GPT is that it's really easy to write automated tests for neurons and thus get spectrum plots, and thus to really investigate monosemanticity! If we want to be able to make real and robust claims to have identified circuits involving neurons or to have mechanistically reverse-engineered a neurons, I want to better understand whether we can claim the neuron is genuinely only used for a single purpose (with noise) or is also used more weakly to represent other features. And a concrete prediction of the toy models framework is that there should be some genuinely monosemantic neurons for the most important features.
That said, showing genuine monosemanticity is hard and spectrum plots are limited. Spectrum plots will still fall down for superposition with very rare features - these can be falsely dismissed as just noise, or just never occur in the games studied! And it's hard to know where to precisely draw the line for "is monosemantic" - it seems unreasonable to say that the smallest True activation must be larger than the largest False one! To me the difference is whether the differences genuinely contribute to the model having low loss, vs on average contributing nothing. I think questions around eg how best to interpret these plots are an example of the kind of practical knowledge I want to get from practicing neuron interpretability!
Case Study: Neurons and Probes are Confusing
As a case study in how this can be confusing, here's an earlier draft graph for the section on finding modular circuits - looking at the output weights of top layer 4 neurons (by std) in the blank probe basis. It initially seems like these are all neurons dedicated to computing that a single cell is blank. And I initially got excited and thought this made a great graph for the post! But on reflection this is weird and surprising (exercise: think through why before you read on)
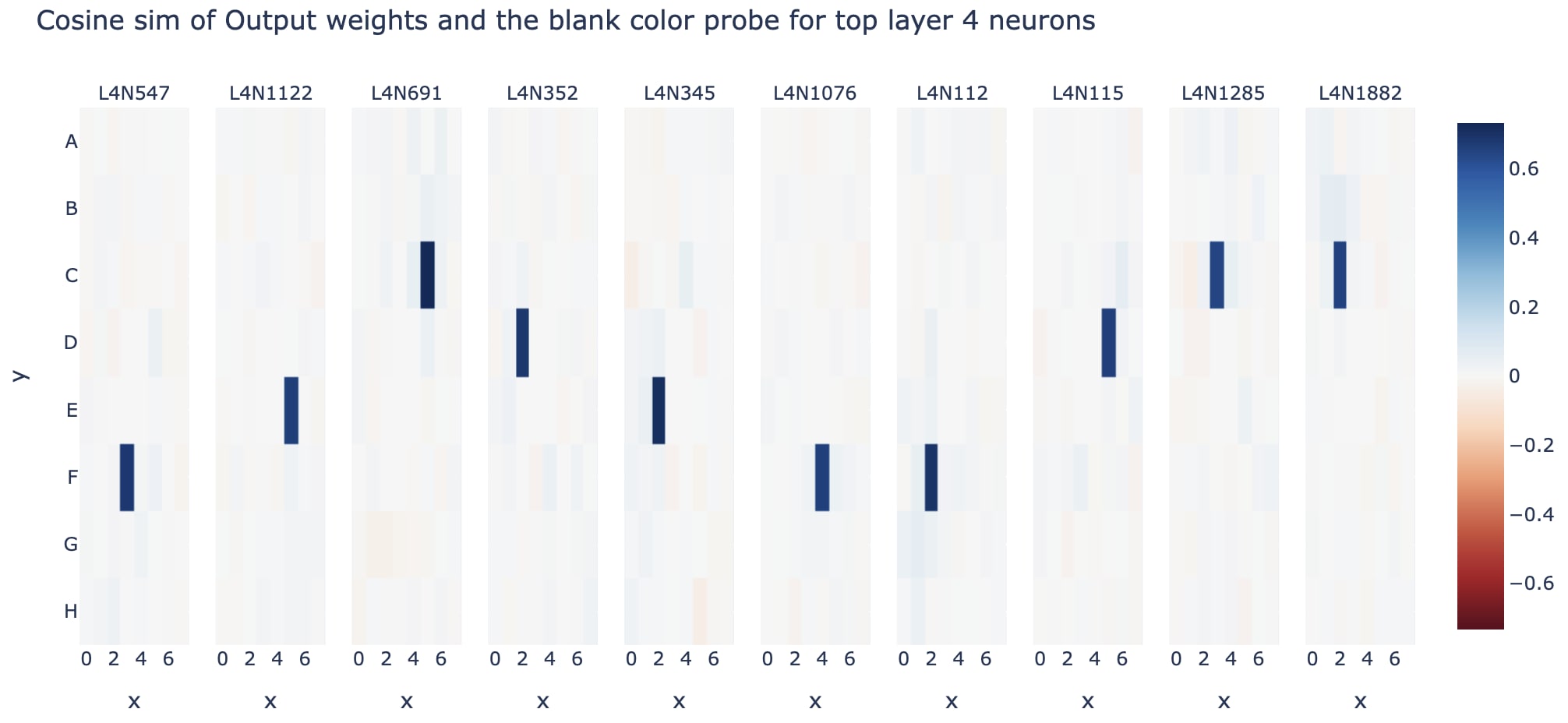
I argue that this is weird, because figuring out whether a cell is blank should be pretty easy - a cell can never become non-empty, so a cell is blank if and only if it has never been played. This can probably be done in a single attention layer, and the hard part of the world model is computing which cells are mine vs their's. So what's up with this?
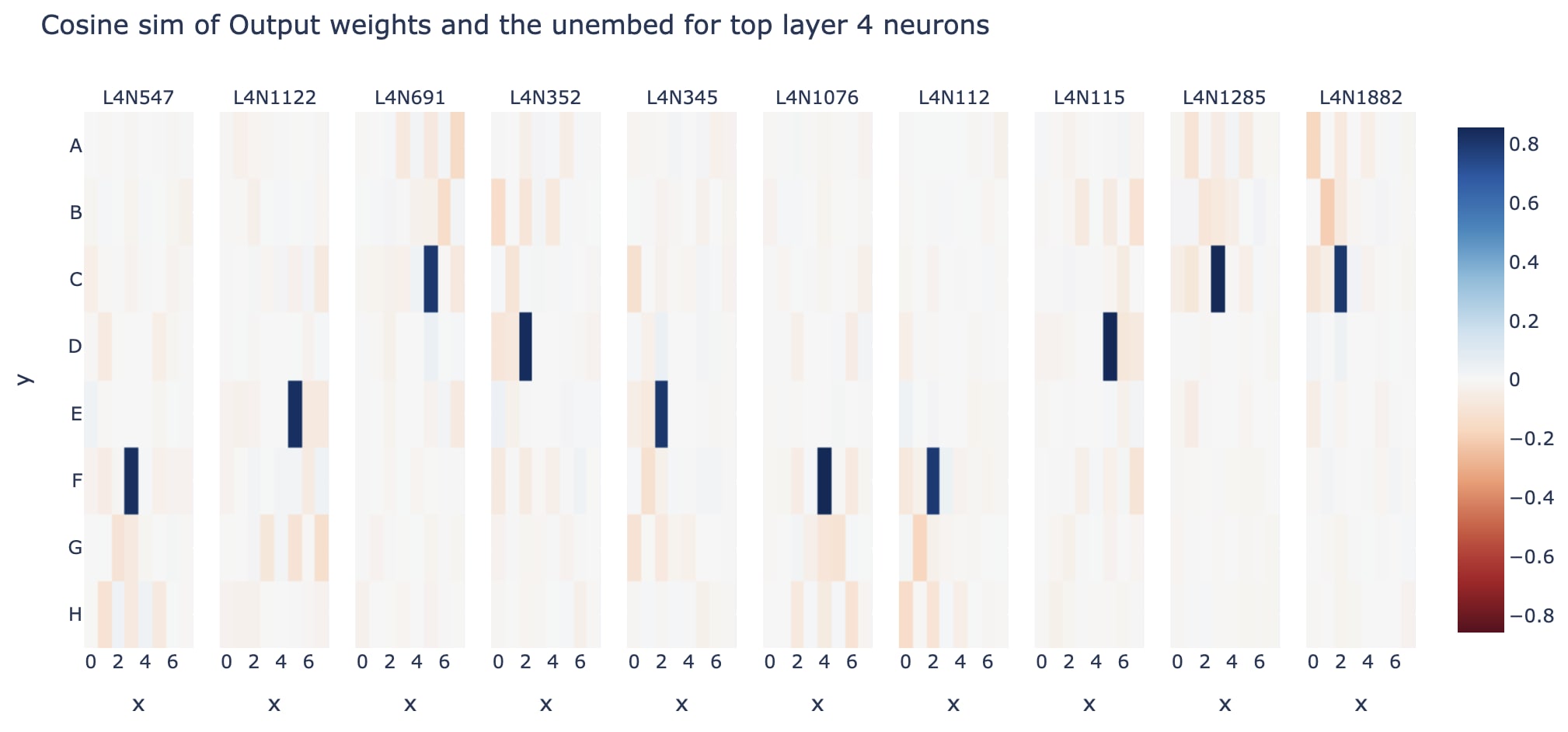
It turns out that what's actually going on is that the blank probe is highly correlated with the unembed (the linear map from the final residual to the logits). A cell can be legal only if it is blank, if a cell has a high logit at the end of the model, then it's probably blank. But our probe was computed after layer 6, when there's a lot of extraneous information that probably obscures the blankness information - probably, the probe also learned that if there's going to be a high logit for a cell then that cell is definitely blank, and so the blank directions are partially aligned with the unembed directions. Though on another interpretation, is_blank and the unembed are intentionally aligned, because the model knows there's a causal link and so uses the is_blank subspace to also contribute to the relevant unembed.
And we see that the alignment with the unembed is even higher! (Around cosine sim of 0.8 to 0.9)
A Transformer Circuit Laboratory
My final category is just the meta level point that I'm confused in many ways about the right conceptual frameworks when thinking about transformer circuits, and think that there's a lot of ways we could make progress here! Just as Othello-GPT helped provide notable evidence for the hypothesis that models form linear representations of features, I hope it can help clarify some of these - by concretely understanding what happens inside of it, we can make more informed guesses about transformers in general. Here's a rough brainstorm of weird hypotheses and confusions about what we might find inside transformers - I expect that sufficient investigation of Othello-GPT will shed light on many of them!
Since Othello-GPT is an imperfect proxy for LLMs, it's worth reflecting on what evidence here looks like. I'm most excited about Othello-GPT providing "existence proofs" for mysterious phenomena like memory management: case studies of specific phenomena, making it seem more likely that they arise in real language models. Proofs that something was not used/needed are great, but need to be comprehensive enough to overcome the null hypothesis of "this was/wasn't there but we didn't look hard enough", which is a high bar!
- Does it do memory management in the residual stream? Eg overwriting old features when they're no longer needed. I'd start by looking for neurons with high negative cosine sim between their input and output vectors, ie which basically erase some direction.
- One hypothesis is that it implicitly does memory management by increasing the residual stream norm over time - LayerNorm scales it to have fixed norm, so this suppresses earlier features. If this is true, we might instead observe signal boosting - key features get systematically boosted over time (eg whether we're playing black or white)
- This might come up with cells that flip many times during previous moves - maybe the model changes its guess for the cell's colour back and forth several times as it computes more flips? Do each of these write to the probe direction and overwrite the previous one, or is it something fancier?
- Do heads and neurons seem like the right units of analysis of the model? Vs eg entire layers, superposition-y linear combinations of neurons/heads, subsets of heads, etc.
- Do components (heads and neurons) tend to form tightly integrated circuits where they strongly compose with just a few other components to form a coherent circuit, or tend to be modular, where each component does something coherent in isolation and composes with many other components.
- For example, an induction head could be either tightly integrated (the previous token head is highly coupled to the induction head and not used by anything else, and just communicates an encoded message about the previous token directly to the induction head) or could form two separate modules, where the previous token head's output writes to a "what was in the previous position" subspace that many heads (including the induction head!) read from
- My guess is the latter, but I don't think anyone's checked! Most working finding concrete circuits seems to focus on patching style investigations on a narrow distribution, rather than broadly checking behaviour on diverse inputs.
- On a given input, can we clearly detect which components are composing? Is this sparse?
- For example, an induction head could be either tightly integrated (the previous token head is highly coupled to the induction head and not used by anything else, and just communicates an encoded message about the previous token directly to the induction head) or could form two separate modules, where the previous token head's output writes to a "what was in the previous position" subspace that many heads (including the induction head!) read from
- When two components (eg two heads or a head and a neuron) compose with each other, do they tend to write to some shared subspace that many other components read and write from, or is there some specific encod
- Do components form modules vs integrated circuits vs etc.
- Can we find examples of head polysemanticity (a head doing different things in different contexts) or head redundancy (multiple heads doing seemingly the same thing).
- Do we see backup heads? That is, heads that compensate for an earlier head when that head is ablated. This model was trained with attention dropout, so I expect they do!
- Do these backup heads do anything when not acting as backups?
- Can we understand mechanistically how the backup behaviour is implemented?
- Are there backup backup heads?
- Can we interpret the heads at all? I found this pretty hard, but there must be something legible here!
- If we find head redundancy, can we distinguish between head superposition (there's a single "effective head" that consists of a linear combination of these )
- Can we find heads which seem to have an attention pattern doing a single thing, but whose OV circuit is used to convey a bunch of different information, read by different downstream circuits
- Can we find heads which have very similar attention patterns (ie QK circuits) whose OV circuits add together to simulate a single head with an OV circuit of twice the rank?
- Do we see backup heads? That is, heads that compensate for an earlier head when that head is ablated. This model was trained with attention dropout, so I expect they do!
- Is LayerNorm ever used as a meaningful non-linearity (ie, the scale factor differs between tokens in a way that does useful computation), or basically constant? Eg, can you linearly replace it?
- Are there emergent features in the residual stream? (ie dimensions in the standard basis that are much bigger than the rest). Do these disproportionately affect LayerNorm?
- The model has clearly learned some redundancy (because it was trained with dropout, but also likely would learn some without any dropout). How is this represented mechanistically?
- Is it about having backup circuits that takeover when the first thing is ablated? Multiple directions for the same feature? Etc.
- Can you find more evidence for or against the hypothesis that features are represented linearly?
- If so, do these get represented orthogonally?
- Ambitiously, do we have a shot at figuring out everything that the model is doing? Does it seem remotely possible to fully-reverse engineer it?
- Is there a long tail of fuzzy, half-formed features that aren't clean enough to interpret, but slightly damage loss if ablated? Are there neurons that just do nothing either way?
- Some ambitious plans for interpretability for alignment involve aiming for enumerative safety, the idea that we might be able to enumerate all features in a model and inspect this for features related to dangerous capabilities or intentions. Seeing whether this is remotely possible for Othello-GPT may be a decent test run.
- Do the residual stream or internal head vectors have a privileged basis? Both with statistical tests like kurtosis, and in terms of whether you can actually interp directions in the standard basis?
- Do transformers behave like ensembles of shallow paths? Where each meaningful circuit tends to only involve a few of the 16 sublayers, and makes heavy use of the residual stream (rather than 16 serial steps of computation).
- Prior circuits work and techniques like the logit lens [LW · GW] seems to heavily imply this, but it would be good to get more data!
- A related hypothesis - when a circuit involves several components (eg a feature is computed by several neurons in tandem) are these always in the same layer? One of my fears is that superposition gives rise to features that are eg linear combinations of 5 neurons, but that these are spread across adjacent layers!
Where to start?
If you've read this far, hopefully I've convinced you there are interesting directions here that could be worth working on! The next natural question is, where to start? Some thoughts:
- Read the original paper carefully
- If you're new to mech interp, check out my getting started guide.
- I particularly recommend getting your head around how a transformer works, and being familiar with linear algebra
- Use my accompanying notebook as a starting point which demonstrates many of the core techniques
- I highly recommend using my TransformerLens library for this, I designed it to enable this kind of research
- Check out the underlying codebase (made by the original authors, thanks to Kenneth Li for the code and for letting me make additions!)
- My concrete open problems sequence has a bunch of tips on doing good mech interp research, especially in the posts on circuits in toy language models, on neuron interpretability, and on superposition.
- Read through my notes on my research process [AF · GW] to get a sense of what making progress on this kind of work looks like, and in particular the decisions I made and why.
Concrete starter projects
I'll now try to detail some concrete open problems that I think could be good places to start. Note that these are just preliminary suggestions - the above sections outline my underlying philosophy of which questions I'm excited about and a bunch of scattered thoughts about how to make progress on them. If there's a direction you personally feel excited about, you should just jump in.
Ideas for gentle starter projects (Note that I have not actually tried these - I expect them to be easy, but I expect at least one is actually cursed! If you get super stuck, just move on):
- How does the model decide that the cell for the current move is not blank?
- What's the natural way for a transformer to implement this? (Hint: Do you need information about previous moves to answer this?)
- At which layer has the model figured this out?
- Try patching between two possibilities for the current move (with the same previous game) and look at what's going on
- Pick a specific cell (eg B3). How does the model compute that it's blank?
- I'd start by studying the model on a few specific moves. At which layer does the model conclude that it's blank? Does this come from any specific head or neuron?
- Conceptually, a cell is not blank if and only if it was played as a previous move - how could a transformer detect this? (Hint: A single attention head per cell would work)
- Take a game where a center cell gets flipped many times. Look at what colour the model thinks that cell is, after each layer and move. What patterns can you see? Can you form any guesses about what's going on? (This is a high-level project - the goal is to form hypotheses, not to reach clear answers)
- Take the
is_my_colourdirection for a specific cell (eg D7) and look for neurons whose input weight has high cosine similarity with this. Look at this neuron's cosine sim with every other probe direction, and form a guess about what it's doing (if it's a mess then try another neuron/cell). Example guesses might be- Then look at the max activating dataset examples (eg the top 10 over 50 games) and check if your guess worked!
- Extension: Plot a spectrum plot [AF · GW] and check how monosemantic it actually is
- Repeat the above for the
is_blankdirection. - Take the average of the even minus the average of the odd positional embeddings to get an "I am playing white" direction. Does this seem to get its own dedicated dimension, or is it in superposition?
- A hard part about answering this question is distinguishing there being non-orthogonal features, vs other components doing memory management and eg systematically signal boosting the "I am playing white" direction so it's a constant fraction of the residual stream. Memory management should act approximately the same between games, while other features won't.
Cleaning Up
This was (deliberately!) a pretty rushed and shallow investigation, and I cut a bunch of corners. There's some basic cleaning up I would do if I wanted to turn this into a real paper or build a larger project, and this might be a good place to start!
- Training a better probe: I cut a lot of corners in training this probe... Some ideas:
- Train it on both black and white moves! (to predict my vs their's, so flip the state every other move)
- I cut out the first and last 5 moves - does this actually help/matter? Check how well the current probe works on early and late moves.
- The state of different cells will be correlated (eg a corner can only be filled if a neighbouring cell is filled), so the probes may be non-orthogonal for boring reasons. Does it help to constrain them to be orthogonal?
- What's the right layer to train a probe on?
- The probe is 3 vectors (three-way logistic regression), but I want a
is_blank_vs_filledandis_mine_vs_theirs_conditional_on_not_being_blankdirection - what's the most principled way of doing this?
- Rigorously testing interventions: I'm pretty convinced that intervening the probe does something, but
- Currently I take the current coordinate with respect to the probe direction, negate that, and then scale. Plausibly, this is dumb and the magnitude of the original coordinate doesn't matter, and I should instead replace it with a constant magnitude. The place I'd start is to just plot a histogram of the coordinates in the probe directions
- Replicating the paper's analysis of whether their intervention works (their natural and unnatural benchmark)
- Re-train the model: The model was trained with attention and residual dropout - this is not representative of modern LLMs, and incentivises messy and redundant representations and backup circuits, I expect that training a new model from scratch with no dropout will make your life much easier. (Note that someone is currently working on this)
- The current model is 8 layers with a residual stream of width 512. I speculate this is actually much bigger than it needs to be, and things might be cleaner with fewer layers and a wider stream, a narrower stream, or both.
2 comments
Comments sorted by top scores.
comment by gpt4_summaries · 2023-03-30T09:29:33.478Z · LW(p) · GW(p)
Tentative GPT4's summary. This is part of an experiment.
Up/Downvote "Overall" if the summary is useful/harmful.
Up/Downvote "Agreement" if the summary is correct/wrong.
If so, please let me know why you think this is harmful.
(OpenAI doesn't use customers' data anymore for training, and this API account previously opted out of data retention)
TLDR:
The article presents Othello-GPT as a simplified testbed for AI alignment and interpretability research, exploring transformer mechanisms, residual stream superposition, monosemantic neurons, and probing techniques to improve overall understanding of transformers and AI safety.
Arguments:
- Othello-GPT is an ideal toy domain due to its tractable and relevant structure, offering insights into transformer behavior.
- Modular circuits are easier to study, and Othello-GPT's spontaneous modularity facilitates research on them.
- Residual stream superposition and neuron interpretability are essential for understanding transformers and AI alignment.
- Techniques like logit lens, probes, and spectrum plots can provide insight into transformer features, memory management, ensemble behavior, and redundancy.
Takeaways:
- Othello-GPT offers a valuable opportunity for AI alignment research, providing insights into circuitry, mechanisms, and features.
- Developing better probing techniques and understanding superposition in transformers is crucial for aligning AI systems.
- Findings from Othello-GPT can improve interpretability and safety, potentially generalizing to more complex language models.
Strengths:
- Othello-GPT's tractability and relevance to transformers make it an excellent testbed for AI alignment research.
- The focus on modular circuits, residual stream superposition, and neuron interpretability addresses gaps in current understanding.
- The article provides in-depth discussions, examples, and a direction for future investigation.
Weaknesses:
- Applicability of Othello-GPT findings to more complex models may be limited due to its simplicity.
- The article lacks concrete empirical evidence for some arguments, and potential weaknesses aren't explicitly addressed.
- Not all relevant AI alignment topics for transformers are covered, and missing arguments could improve the discussion.
Interactions:
- The content can interact with AI safety concepts like neuron interpretability, memory management, ensemble behavior, and circuit-guided interpretations.
- Insights from Othello-GPT can contribute to understanding transformers, their structure, and their potential in AI safety applications.
Factual mistakes:
- None detected in the summary or subsections.
Missing arguments:
- A deeper discussion of specific modular circuits and probing techniques, detailing their applicability to other domains in AI safety and interpretability research, would have been beneficial.
↑ comment by Neel Nanda (neel-nanda-1) · 2023-03-31T16:46:12.023Z · LW(p) · GW(p)
Lol. This is a surprisingly decent summary, and the weaknesses are correctly identified things I did not try to cover