Othello-GPT: Reflections on the Research Process
post by Neel Nanda (neel-nanda-1) · 2023-03-29T22:13:42.007Z · LW · GW · 0 commentsThis is a link post for https://neelnanda.io/mechanistic-interpretability/othello
Contents
The Research Process Takeaways on doing mech interp research Getting Started Patching Tangent on Analysing Neurons Back to patching Neuron L5N1393 None No comments
This is the third in a three post sequence about interpreting Othello-GPT. See the first post for context.
This post is a detailed account of what my research process was, decisions made at each point, what intermediate results looked like, etc. It's deliberately moderately unpolished, in the hopes that it makes this more useful!
The Research Process
This project was a personal experiment in speed-running doing research, and I got the core results in in ~2.5 days/20 hours. This post has some meta level takeaways from this on doing mech interp research fast and well, followed by a (somewhat stylised) narrative of what I actually did in this project and why - you can see the file tl_initial_exploration.py in the paper repo for the code that I wrote as I went (using VSCode's interactive Jupyter mode).
I wish more work illustrated the actual research process rather than just a final product, so I'm trying to do that here. This is approximately just me converting my research notes to prose, see the section on process-level takeaways [AF · GW] for a more condensed summary of my high-level takeaways.
The meta level process behind everything below is to repeatedly be confused, plot stuff a bunch, be slightly less confused, and iterate. As a result, there's a lot of pictures!
Takeaways on doing mech interp research
Warning: I have no idea if following my advice about doing research fast is actually a good idea, especially if you're starting out in the field! It's much easier to be fast and laissez faire when you have experience and an intuition for what's crucial and what's not, and it's easy to shoot yourself in the foot. And when you skimp on rigour, you want to make sure you go back and check! Though in this case, I got strong enough results with the probe that I was fairly confident I hadn't entirely built a tower of lies. And generally, beware of generalising from one example - in hindsight I think I got pretty lucky on how fruitful this project was!
- Be decisive: Subjectively, by far the most important change was suppressing my perfectionism and trying to be bold and decisive - make wild guesses and act on them, be willing to be less rigorous, etc.
- If I noticed myself stuck on doing the best or most principled thing, I'd instead try to just do something.
- Eg I wanted to begin by patching between two similar sequences of moves - I couldn't think of a principled way to change a move without totally changing the downstream game, so I just did the dumb thing of patching by changing the final move.
- Eg when I wanted to try intervening with the probe, I couldn't think of a principled way to intervene on a bunch of games or to systematically test that this worked, or exactly how best to intervene, so I decided to instead say "YOLO, let's try intervening in the dumbest possible way, by flipping the coefficient at a middle layer, on a single move, and see what happens"
- Pursue the hypothesis that seems "big if true"
- Eg I decided to try training a linear probe on just black moves after a hunch that this might work given some suggestive evidence from interpreting neuron L5N1393 [AF · GW]
- Notice when I get stuck in a rabbit hole/stop learning things and move on
- Eg after training a probe I found it easy to be drawn into eg inspecting more and more neurons, or looking at head attention patterns, and it worked much better to just say
- Be willing to make quick and dirty hacks
- Eg when I wanted to look at the max activating dataset examples for neurons, I initially thought I'd want to run the model on thousands to millions of games, to get a real sample size. But in practice, just running the model on a batch of 100 games and taking the top 1% of moves by neuron act in there, worked totally fine.
- If I noticed myself stuck on doing the best or most principled thing, I'd instead try to just do something.
- The virtue of narrowness - depth over breadth: A common mistake in people new to mech interp is to be reluctant to do projects that feel "too small" - eg interpreting a single neuron or head rigorously. And to think that something is interesting only if it's automatable and scalable. But here, being willing to just dive in to patching on specific examples, targeting specific neurons that stood out, etc worked great, and ultimately pointed me to the general principles underlying the model (namely, that it thought in mine vs their's)
- Gain surface area: I felt kinda stuck when figuring out where to start. Early on, by far the most useful goal was to gain surface area on the problem - to just dive into anything that seemed interesting, play around, and build intuitions about the moving parts of the model and how it was behaving, without necessarily having a concrete goal beyond understanding and following my curiosity.
- A good way of doing this was to play around with concrete examples, and in particular to patch between similar examples and analyse where the differences came from.
- Work on algorithmic problems: Empirically, algorithmic problems are just way cleaner and more tractable to interpret - there's a ground truth, it's easier to reason about, and it's easy to craft synthetic inputs. This is a double-edged sword, since they're also less interesting and less true to real models, but it's very convenient for goodharting on "research insight per unit hour"
- Domain knowledge is super useful!
- Spending 30-60 minutes at the start playing against the eOthello AI was really valuable for building intuitions (I went in knowing absolutely nothing about Othello), though I got carried away by how fun it was and could have got away with less time.
- Eg that the start and end of the game are weird, that you occasionally need to pass but can basically ignore it, that a single piece can change colour many times, including from a move pretty far away, and even dumb things like "you can take diagonally, and this happens a lot"
- Having experience doing mech interp helped a ton - being better able to generate hypotheses, figure out what's interesting, reach for the right techniques, and interpret results
- In particular, having stared at the mechanical structure of a transformer and what kinds of algorithms are and are not natural to implement remains super useful for building intuitions. (I try to convey a bunch of these in my walkthrough of A Mathematical Framework)
- Spending 30-60 minutes at the start playing against the eOthello AI was really valuable for building intuitions (I went in knowing absolutely nothing about Othello), though I got carried away by how fun it was and could have got away with less time.
- Good tooling is crucial: If you want to do research fast, tight feedback loops are key, and having good, responsive tooling that you understand well is invaluable, even for a throwaway project on a tight deadline. I've created an accompanying colab with most of my tools, and I hope they're useful! (Sorry for the jankiness)
- TransformerLens is a library I made for mech interp of language models, with the explicit goal of making exploratory research easier, and it worked great here! Eg for easily caching model activations, and for trying out different patching and interventional experiments.
- In general, it's far easier to use software you've written yourself, but I've heard good things from other people trying to use TransformerLens!
- Building good visualisations was pretty valuable - especially visualising model logits as a heatmap on the board, and converting a set of moves into a plot of the state of the board. Though I probably spent ~4 hours on making beautiful plotly visualisations (and debugging plotly animations...), and could have gotten away with much less.
- Basic software engineering - noticing the code I kept writing and converting it to functions (eg dumb stuff around changing moves from nice written notation, to the model's vocabulary, to the format used to compute board state; or intervening with the probe; or converting a set of moves to a list of valid moves at each turn, etc)
- TransformerLens is a library I made for mech interp of language models, with the explicit goal of making exploratory research easier, and it worked great here! Eg for easily caching model activations, and for trying out different patching and interventional experiments.
- MLPs > attention: I went into this expecting it to be way easier to interpret attention heads/patterns, but I actually didn't make much headway there, but did great with MLP neurons.
- I think the difference was that I didn't really know how to think about the sequence of prior moves (and thus which moves were attended to), while I did know how to think about the current board state and thus about valid output logits (and direct logit attribution) and about the max activating dataset examples).
- And the fact that there were seemingly a bunch of monosemantic neurons, rather than a polysemantic mess of superposition
- Activation patching is great: Models are complex and full of many circuits for different tasks - even on a single input, likely many circuits are relevant to completing the task! This makes it difficult to isolate out anything specific, and thus is hard to be concrete. Activation patching/causal tracing is a great way to get around this - you set up two similar inputs that differ in one crucial detail, and you patch specific activations between the two and analyse what changes (eg whether an output logit changes). Because the two inputs are so similar, this controls for all the stuff you don't care about, and lets you isolate out a specific circuit.
Getting Started
There was first a bunch of general figuring stuff out and getting oriented - learning how Othello worked, reading the existing code, loading in the data and games, figuring out how to convert a sequence of moves into a board state and valid moves, getting everything into a format I could work easily with (eg massive tensors of game moves rather than a list of lists) and making pretty plotting functions. I also decided to filter out weird edge cases I didn't really care about, like games of less than 60 moves, or with passes in them. In hindsight, it would have been better to do some of this later when I had a clearer picture of what did and did not need optimisation, but *shrug*.
The most useful bits of infrastructure I set up (both now, and later) were:
- Convenience functions to convert moves between 1 to 60 (inputs and outputs of the model, since center squares can't be player), 0 to 63 as the actual indexes, and A0 to H7 as the printable labels
- Plotting function to plot either a single board state (and valid moves), and an animation showing a whole game with a slider (the latter turned out to be a deep rabbit hole of Plotly animation bugs though...)
- Creating a single tensor of all games stacked together (in my case, I took all 4.5M games, since it fit into my RAM - 10,000 would have been more than enough)
- Running and caching the model activations on 100 games, so I could use this as an easy reference without needing to run the model every time (eg to look at neurons with big average activations)
I didn't have a clear next step (my main actual idea was taking one of the author's pre-trained non-linear probes and trying to interpret how that worked, but this seemed like a pain), so I tried to start gaining surface area on what was going on by just trying shit. It's easy to interpret the output logits, and so looking at how each model component directly affects the logits is a good hook to get some insight in any model.
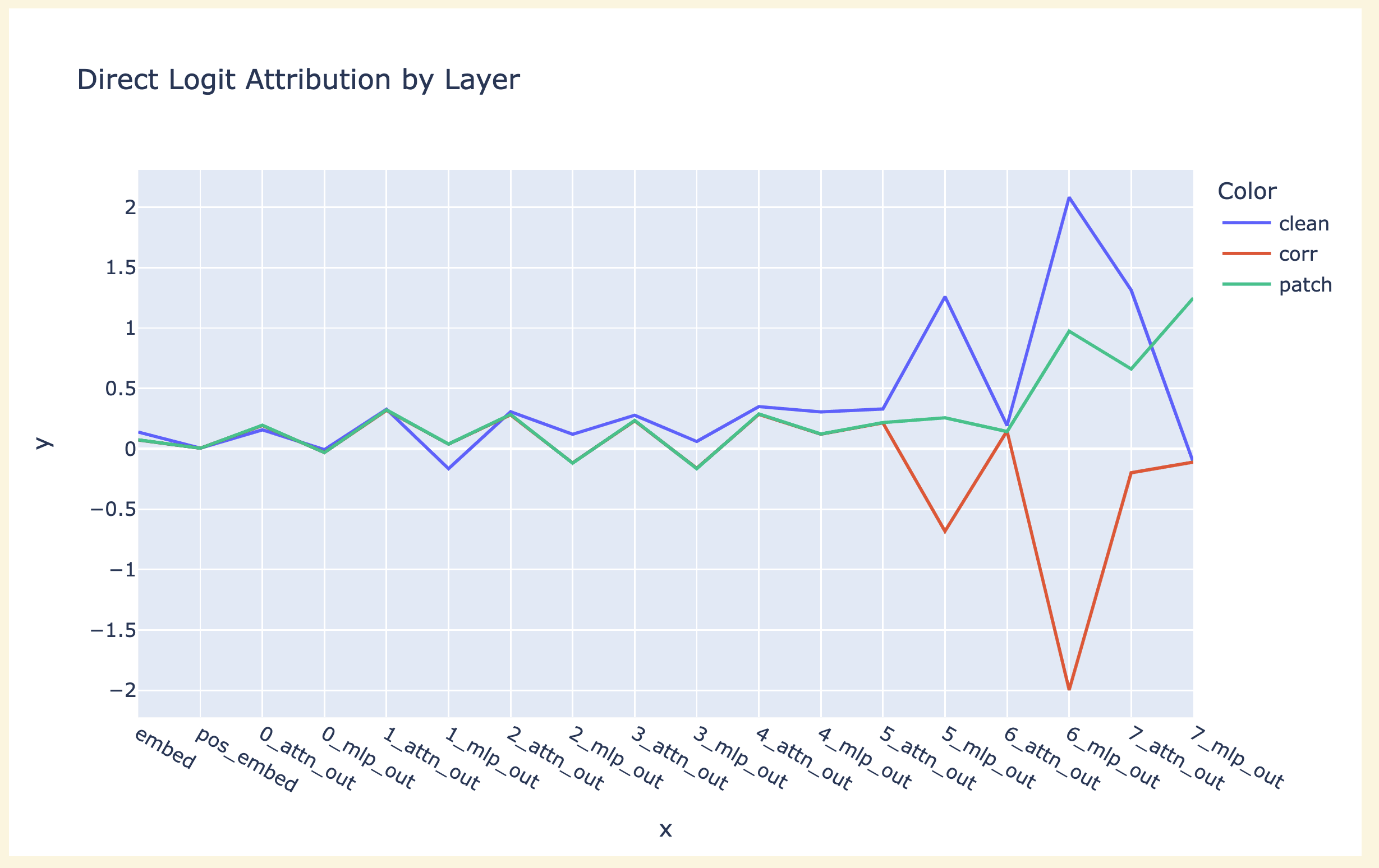
The first actual research I tried was inputting an arbitrary game, and looking at the direct logit attribution of each layer's output on a few of the moves. Eyeballing things, there was a clearish trend where MLP5, MLP6 and Attn7 mattered a lot, other parts were less important. Interestingly, MLP7 (naively, the obvious place to start, since it can only affect the output logits). Example graph below:
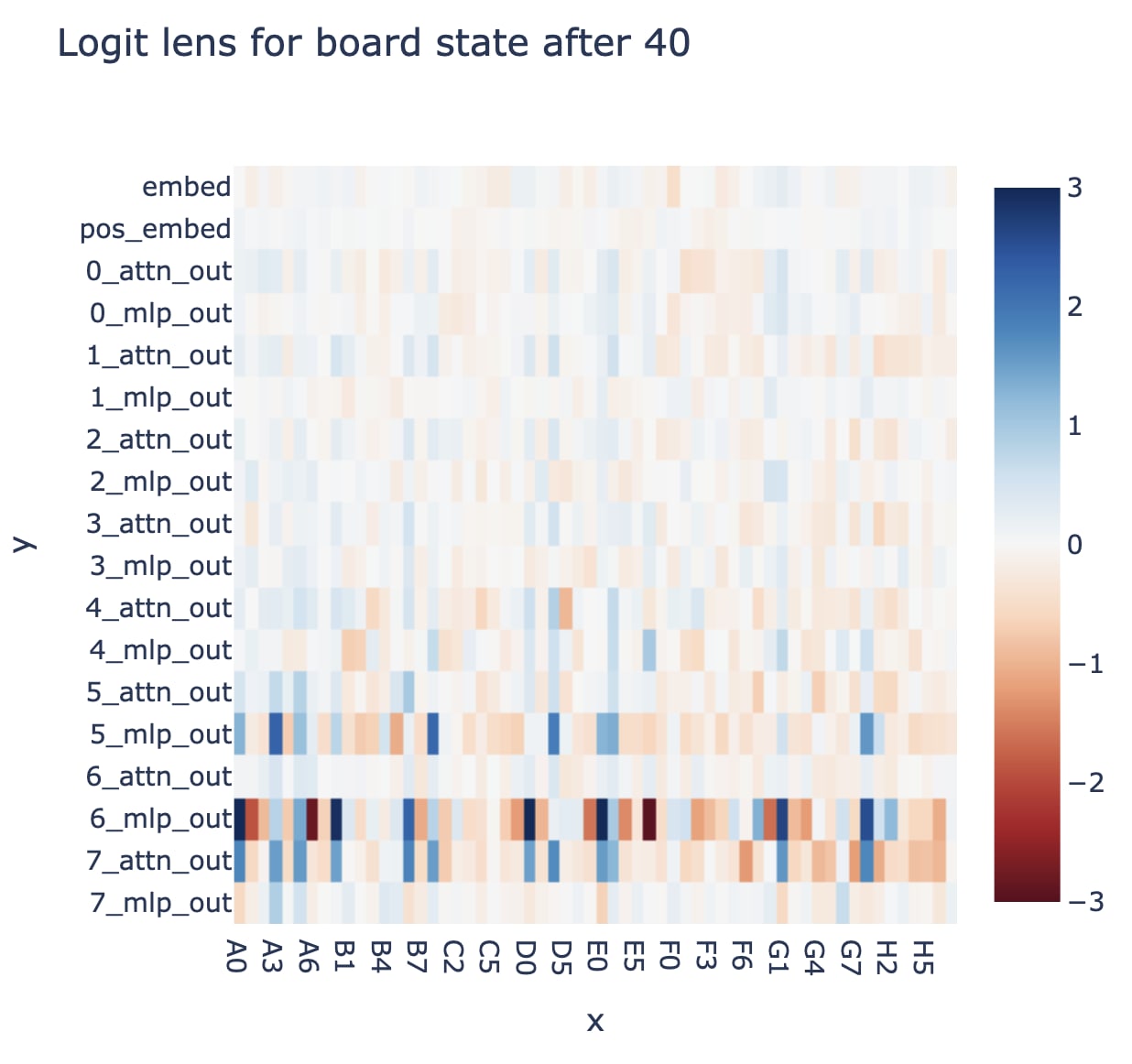
Being more systematic supported this. This is a bit of a weird problem, because there are many (and a variable number of!) valid next moves, rather than a single correct next token, so I tried to both look at the difference in average direct logit attribution for the correct/incorrect next logit, and the difference in min/max contribution. The former doesn't capture bits that disambiguate between borderline correct and borderline incorrect moves, since most moves will be obviously bad, and the latter is misleading because you're taking the max and min over large-ish sets, which is always sketchy (eg it gives misleading results for random noise) - you get a weird spectrum from early to late moves because there are more options in the middle. I also saw that layer 7 acts very differently at the first and last move, presumably because those are easier special cases, but decided this was out of scope and to ignore it for now. I tried breaking the attention layers down into separate heads, but didn't have much luck.
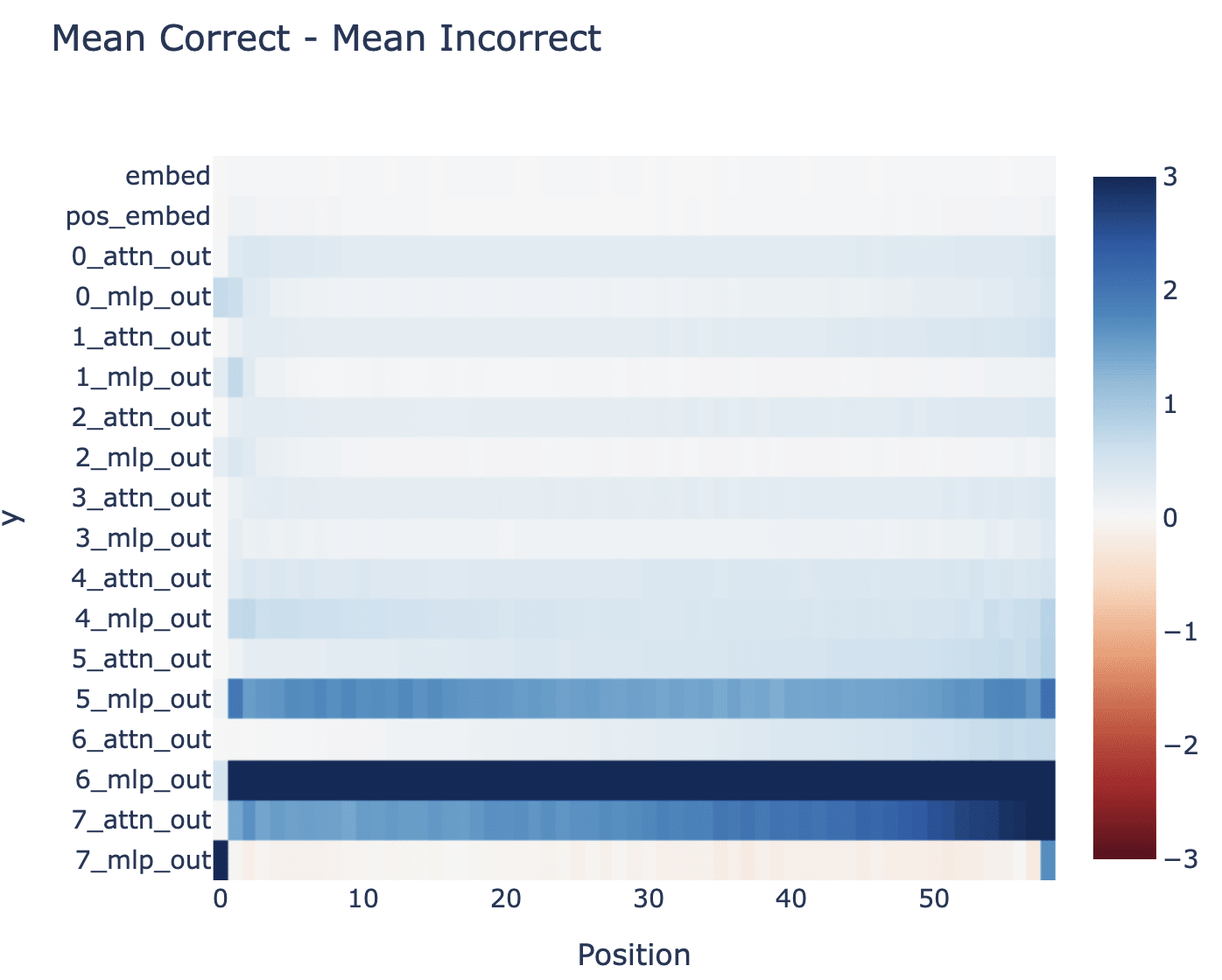
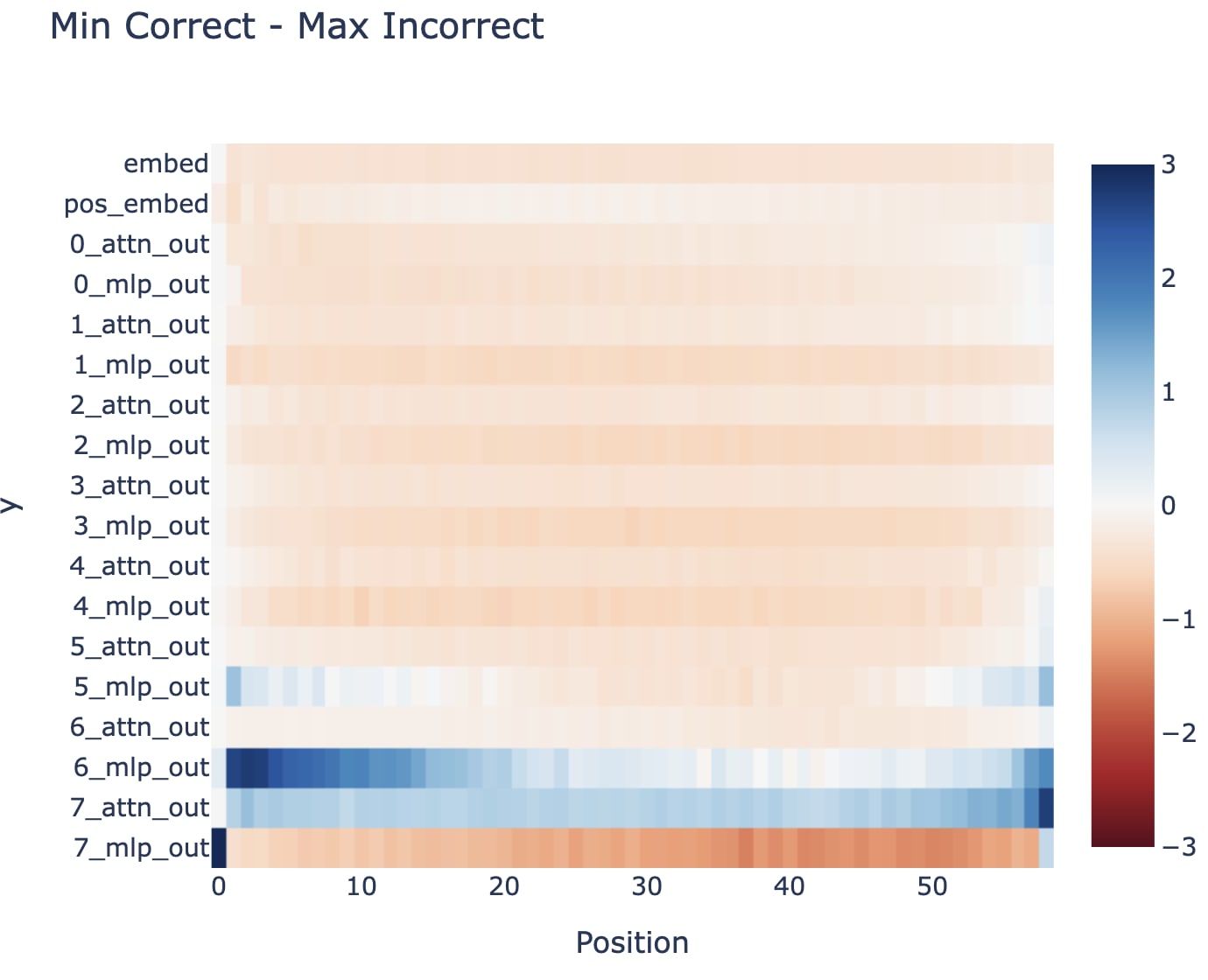
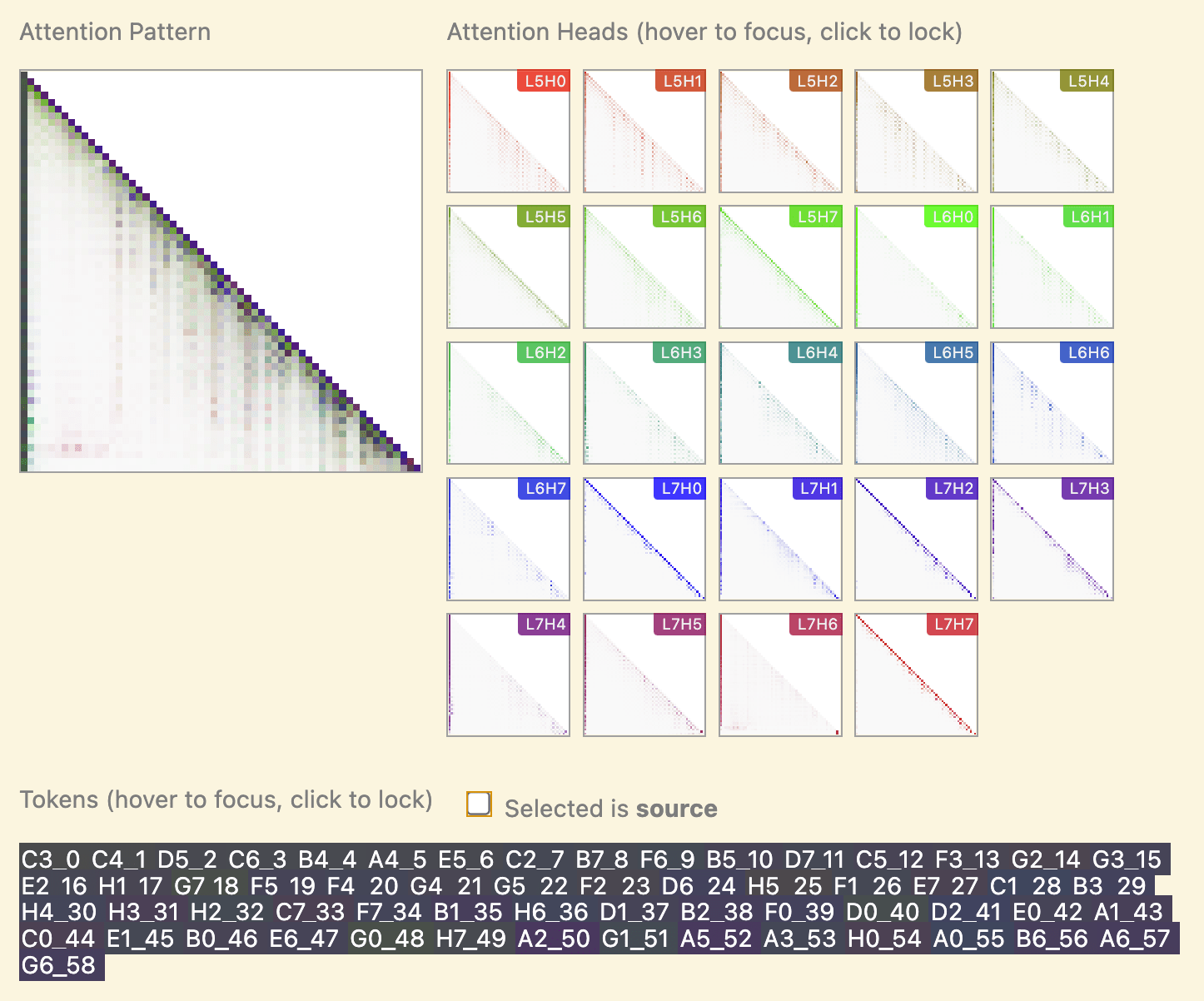
I was then kinda stuck. I tried plotting attention patterns and staring at them, looking for interesting heads, and didn't get much traction (in part because I didn't really get how to interpret moves!). I did see some heads which only attended to moves of the same parity as the current one, which was my first hint for what was going on (not that I noticed lol).
Patching
Part of why interpreting models is hard is because they're full of different circuits that combine to answer a question. But each circuit will only activate on certain inputs, and each input will likely require a bunch of circuits, making it a confusing mess.
Activation patching is a great way to cut through this! The key idea is to set up a careful counterfactual, where you have two inputs, a clean input and a corrupted input, which differ in one key detail. Ideally, the difference between any activation on the clean and corrupted run will purely represent that key detail. You can then iterate over each activation and patch them from the clean run to the corrupted run to see which can most recover the clean output (or from the corrupted run to the clean run to see which can most damage the clean output), and hopefully, a few activations matter a lot and most don't. This can let you isolate which activations actually matter for this detail!
I knew that I wanted to try patching something, but sadly it was kind of a mess, because an input needs to be a sequence of legal moves. I wanted two sequences which had similar board states but whose moves differed in some key places, so I could track down how board state was computed.
I gave up on this idea because it seemed too hard, and instead decided to be decisive and do the dumb thing of changing just the most recent move! I picked an arbitrary game, took the first 30 moves, and changed the final move from H0 to G0 to get a corrupted input. This changed cell C0 (I index my columns at zero not one, sorry) from legal to illegal. This meant I could take the C0 logit as my patching metric - it's high on clean, low on corrupted, and so it can tell me how much my patched activation tracks "the way that the most recent move being G0 rather than H0 is used to determine that C0 is illegal" (or vice versa). This is a very niche thing to study, but it's a start! And the virtue of narrowness says to favour deep understanding of something specific, over aiming for a broad understanding but not knowing where to start.
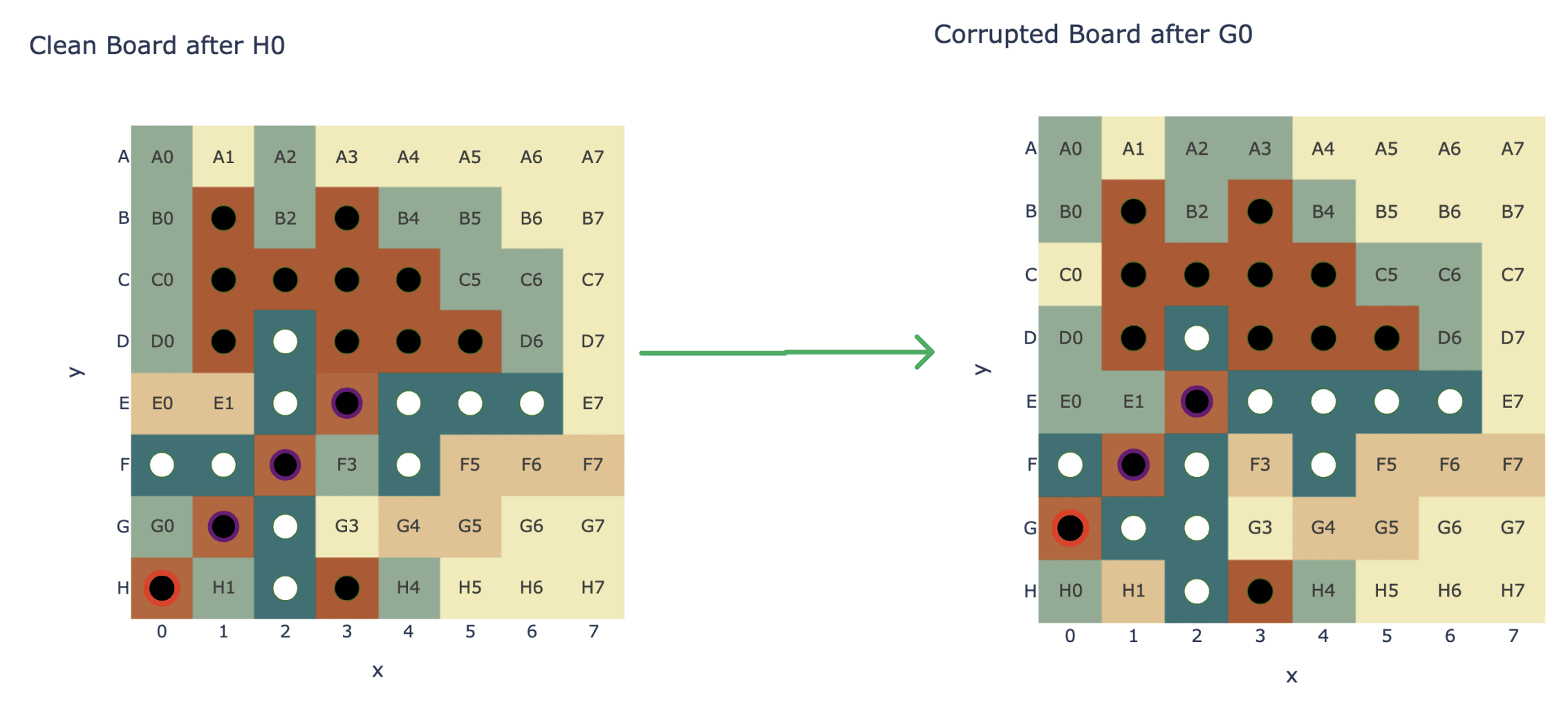
The first thing to try is patching each layer's output - I found that MLP5, MLP6 and MLP0 mattered a lot, Attn7 and MLP4 mattered a bit. The rest didn't matter at all, so I could probably ignore them!
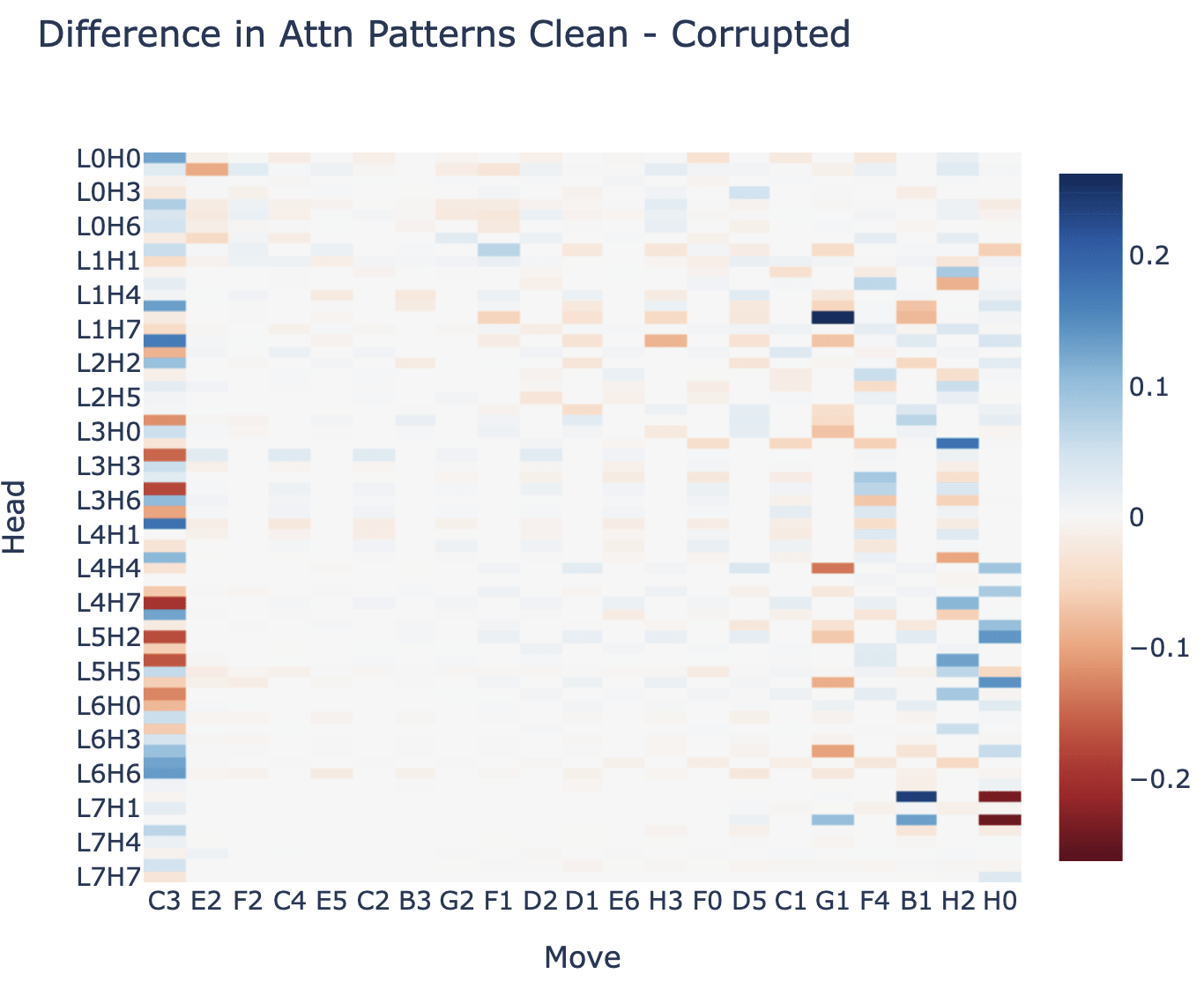
I now wanted to narrow things down further, and got a bit stuck again - I needed to refine "this layer matters" into something more specific. I had the prior that it's way easier to understand attention than MLPs, so I tried looking at the difference in attention pattern from clean to corrupted for each head (from each source token to the final move), but I couldn't immediately see anything interesting (though in hindsight, I see alternating bands of on and off!):
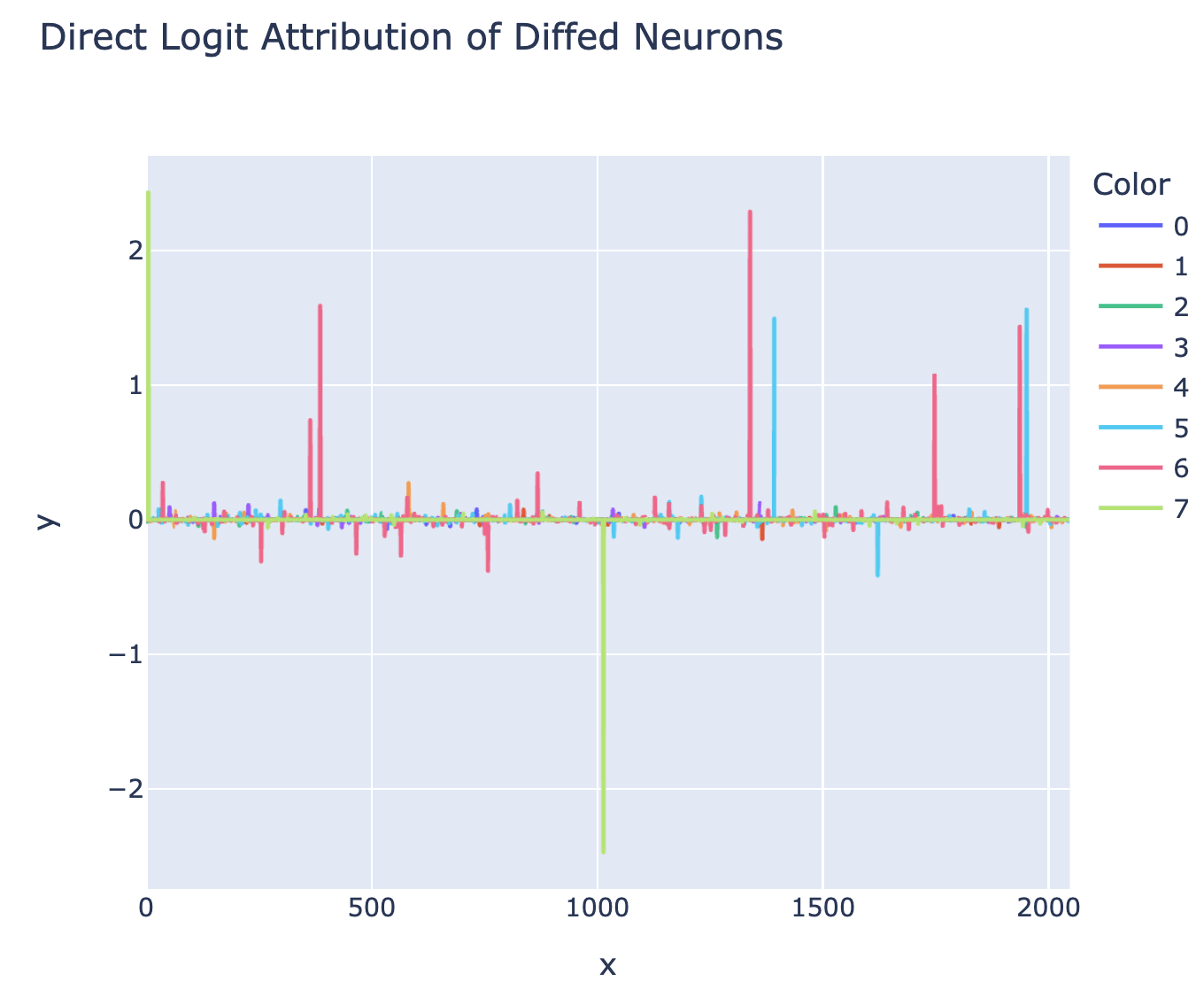
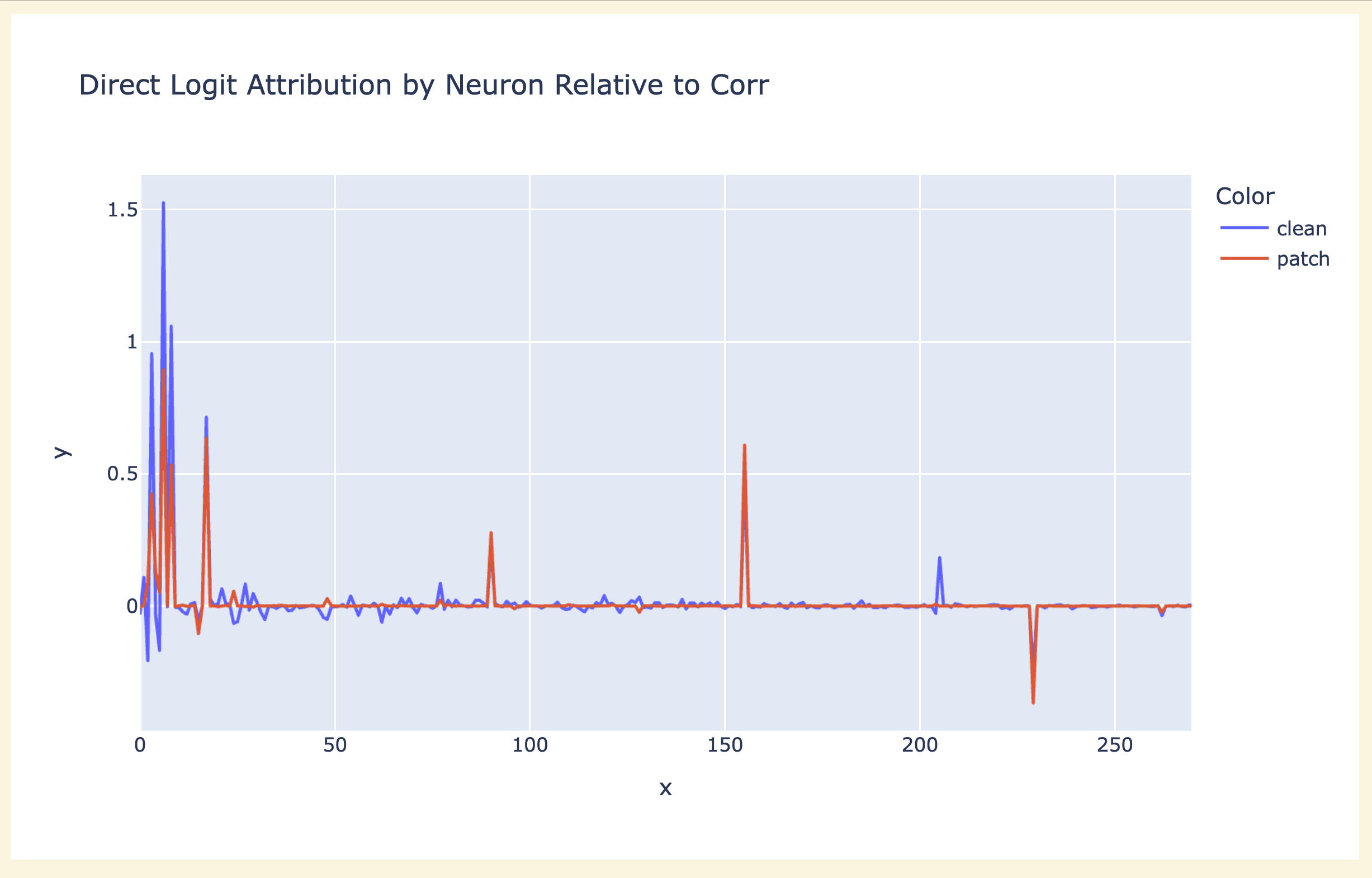
I then just tried looking at the difference in direct logit attribution (to C0) between clean and corrupted for every neuron. This looked way more promising - most neurons were irrelevant, but a few mattered a ton. This suggested I could mostly ignore everything except the neurons that mattered. This gave me, like, 10 neurons to understand, which was massive progress! Bizarrely, MLP7 had two neurons, which both mattered a ton, but near exactly cancelled out (+2.43 v -2.47).
Tangent on Analysing Neurons
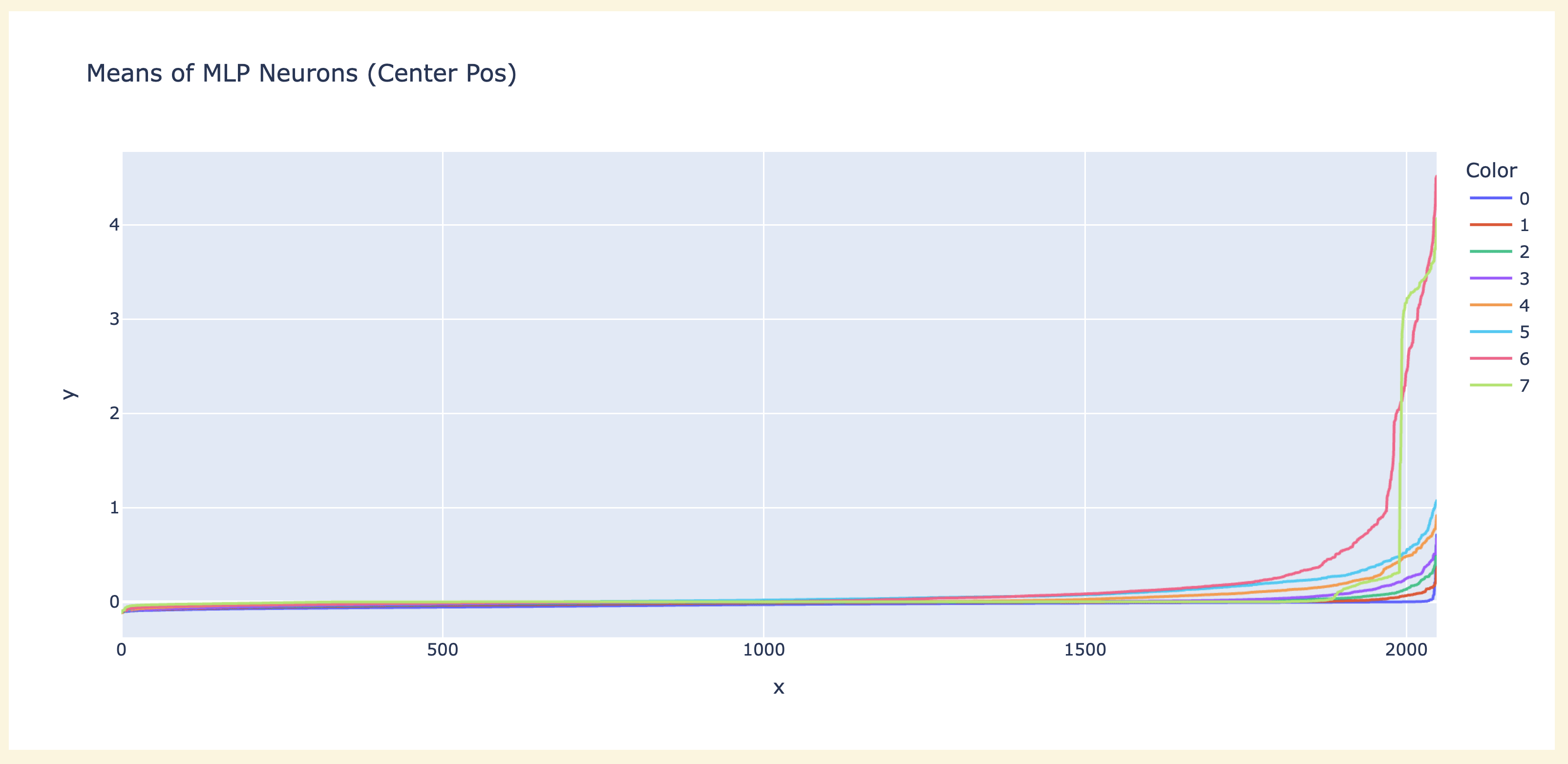
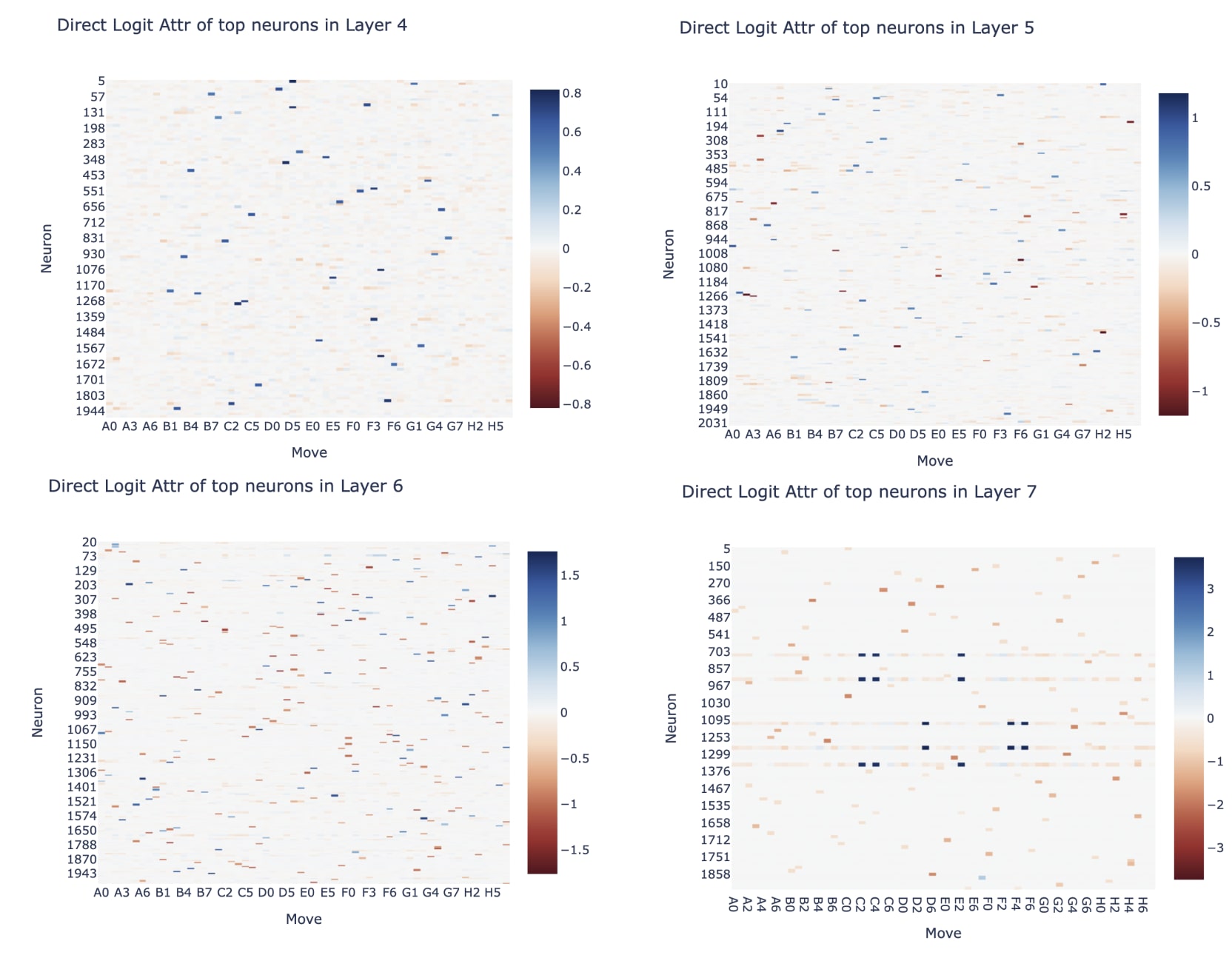
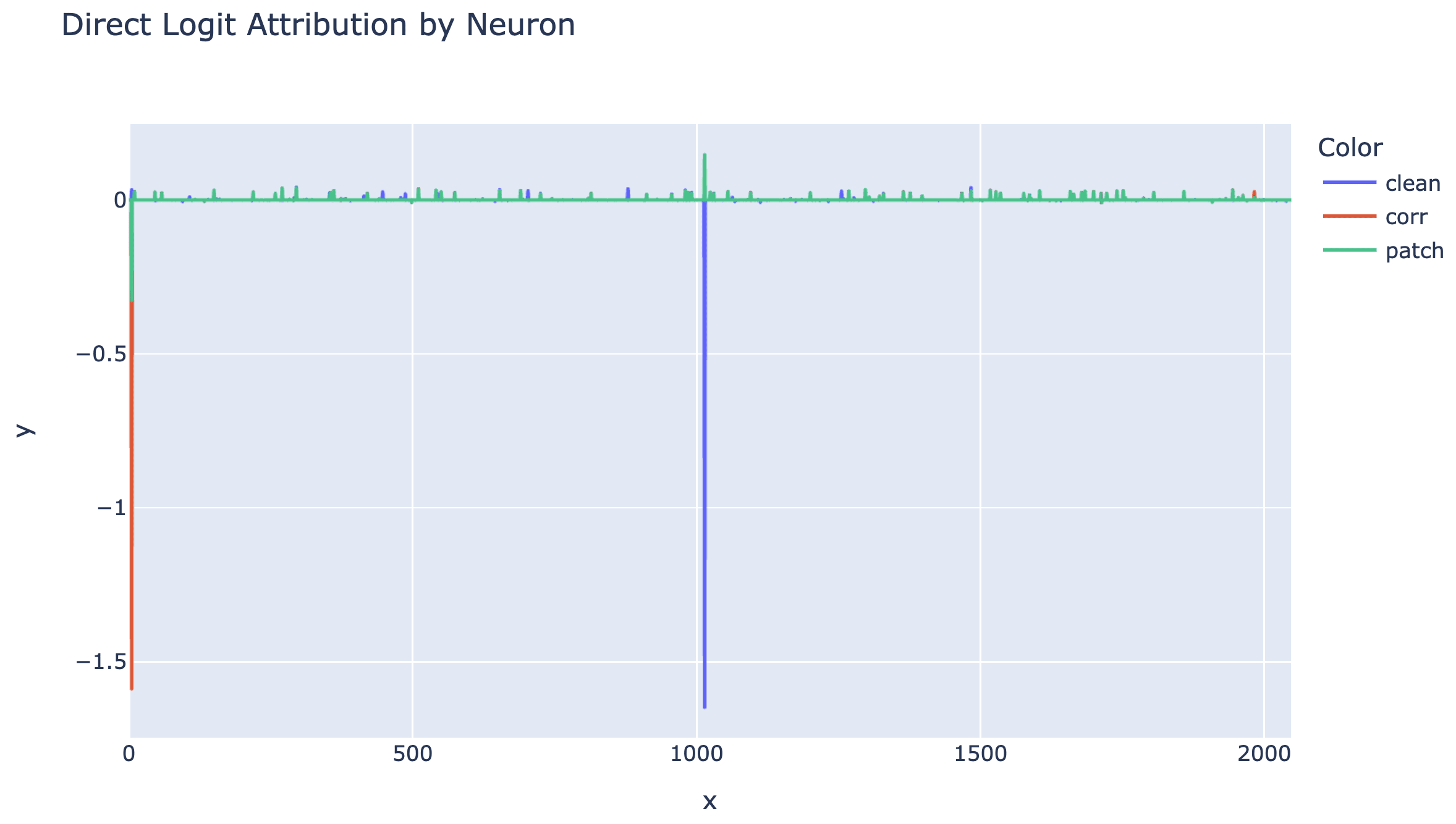
Finding that there were clean and interpretable neurons was exciting, and I got pretty side tracked looking at neurons in general - no particular goal, just trying to gain surface area and figure out what was up. Looking at the neuron means across 100 games on the middle moves ([5:-5]) showed that there were some major outliers, and that layer 6 and 7 were the biggest by far. (The graph is sorted, because it's really hard to read graphs with 2000 points on the x axis with no meaningful ordering!)
I then tried looking at the direct logit attribution of the top neurons in each layer (top = mean > 0.2, chosen pretty arbitrarily), and they seemed super interpretable - it was visually extremely sparse, and it looked like many neurons connected to a single output logit. Layer 7 had some weird neurons that seemed specialised to the first move. Aside: I highly recommend plotting heatmaps like this with 0 as white - makes it much easier to read positive and negative things visually (this is the plotly color scheme RdBu, px.imshow(tensor, color_continuous_scale='RdBu', color_continuous_midpoint=0.0) works to get these graphs)
Back to patching
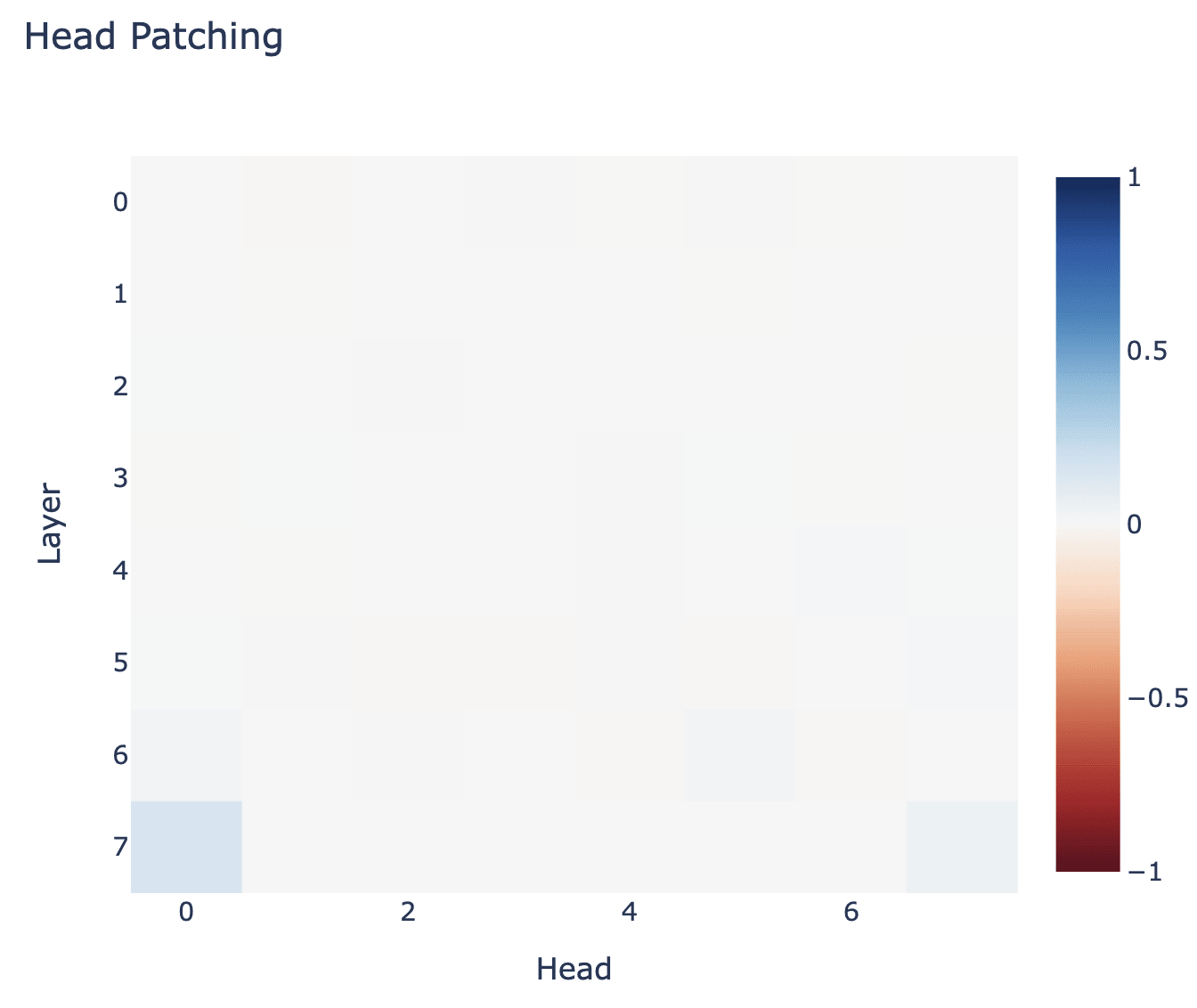
I then ran out of steam and went back to patching. I now tried to patch in individual heads and look at their effect on the C0 logit (now normalised such that 1 means "fully recovered" and 0 means "no change"). Head L7H0 was the main significant one, but I couldn't get much out of it.
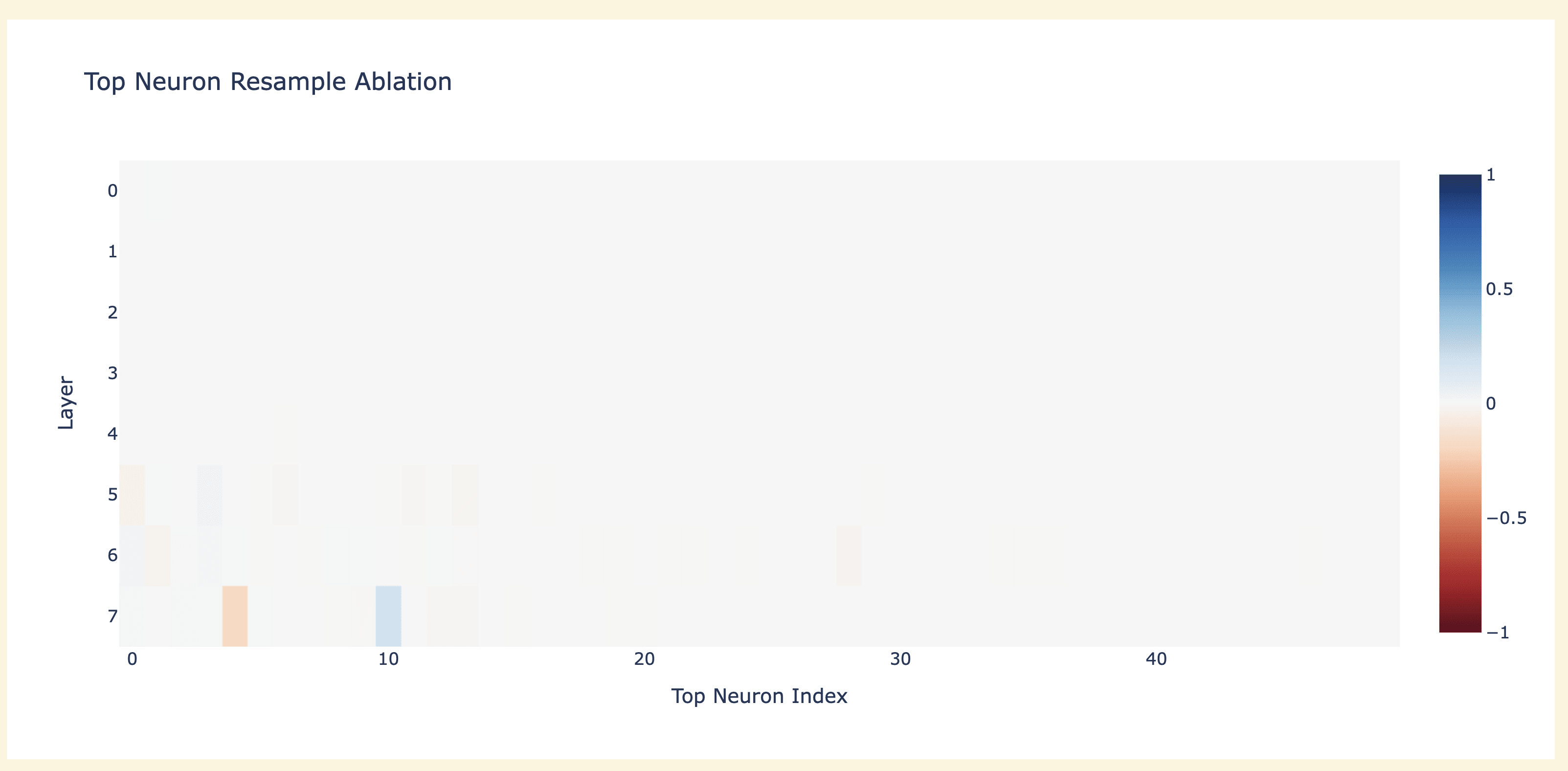
I then tried patching in individual neurons - doing all 16000 would be too slow, so I just took the neurons with highest activation difference and patched in those - activation difference had some big outliers. I first tried resample ablating (replacing a clean neuron with corrupted and seeing what breaks) and found that none were necessary (this isn't super surprising - neurons are small, and dropout incentivises redundancy), though the layer 7 neurons matter a bit (they directly affect the logits, so this makes sense!)
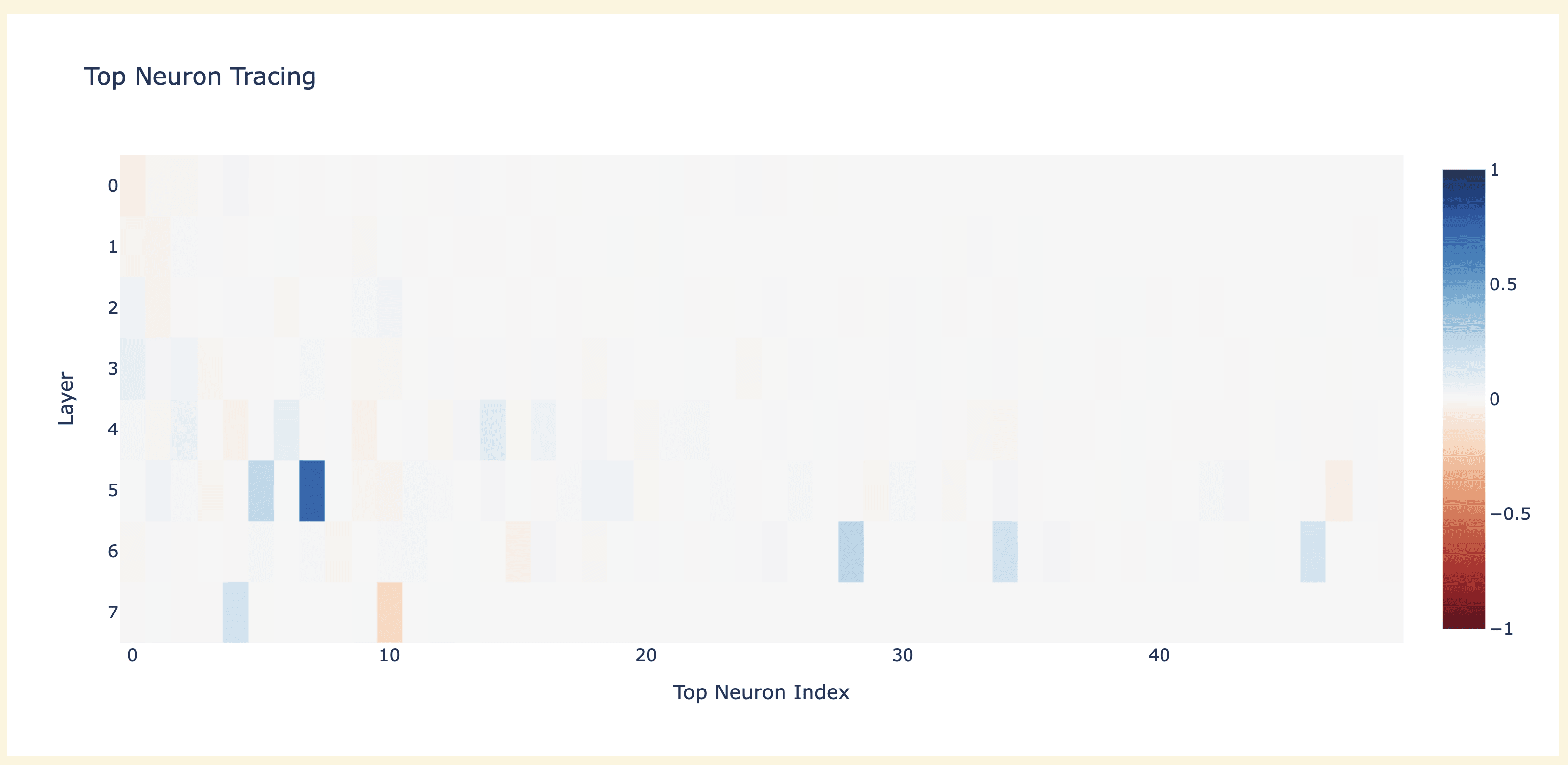
But when I tried causal tracing (replacing a corrupted neuron with its clean copy) I got some striking results - several neurons mattered a bunch, and L5N1393 was enough to recover 75% on its own?! (Notably, this was a significantly bigger effect than just its direct logit attribution)
Neuron L5N1393
This was a sufficiently wild result that I pivoted to focusing on that neuron (the 1393th in layer 5).
My starting goal was the incredibly narrow question "figure out why patching in just that neuron into the corrupted run is such a big deal". Again, focus on understanding a narrow questions deeply and properly, even against a flinch of "this is too narrow and there's no way it'll generalise!".
To start with, I cached all activations on the run with a corrupted input but a clean neuron L5N1393, and started comparing the three. The obvious place to start was direct logit attribution of layers - MLP7 went from not mattering in either clean or corrupted to being significant?!
Digging into the MLP7 neurons and their direct logit attribution, I found that both clean and corrupted had a single, dominant, extremely negative neuron. But in the patched run, both were significantly suppressed. My guess was that this was some dropout solving circuit firing, and thus that MLP7 was mostly to deal with dropout - I subjectively decided this didn't seem that interesting and moved on. Interestingly, this is similar to how negative name movers in the Indirect Object Identification circuit act as backups - they significantly suppress the model's ability to do the task, but if you ablate the positive name movers they'll significantly reduce their negative effect to help compensate. (There it's likely a response to attention dropout)
It also significantly changed some layer 6 neurons, which seemed maybe more legit:
At this point I decided to pivot to just trying to interpret neuron L5N1393 itself, because it seemed interesting. And at this point I was pretty convinced that the model had interpretable (and maybe monosemantic?) neurons.
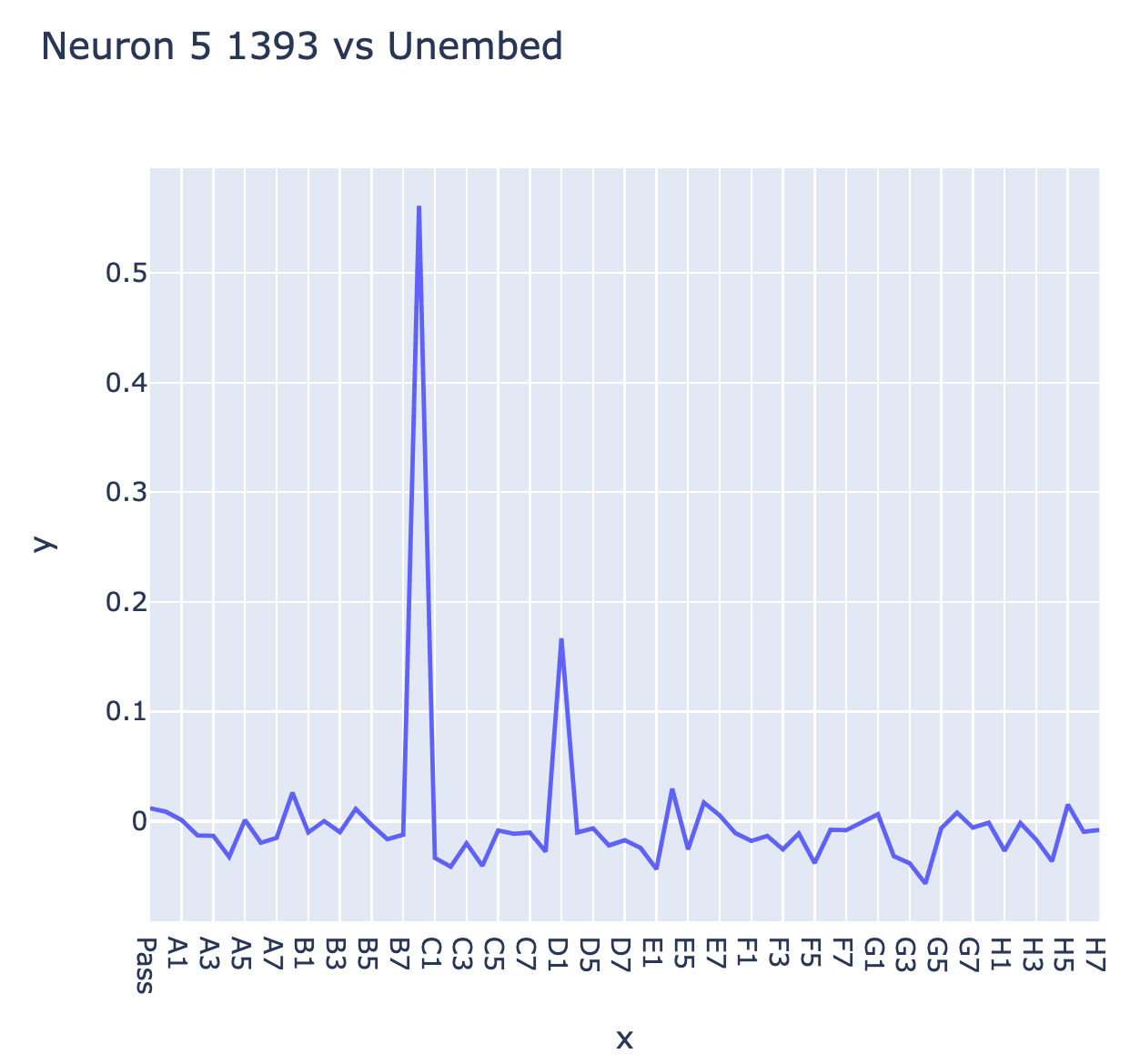
Looking at the direct logit attribution of the neuron, it strongly boosted C0 and slightly boosted D1 (one step diagonally down and right)
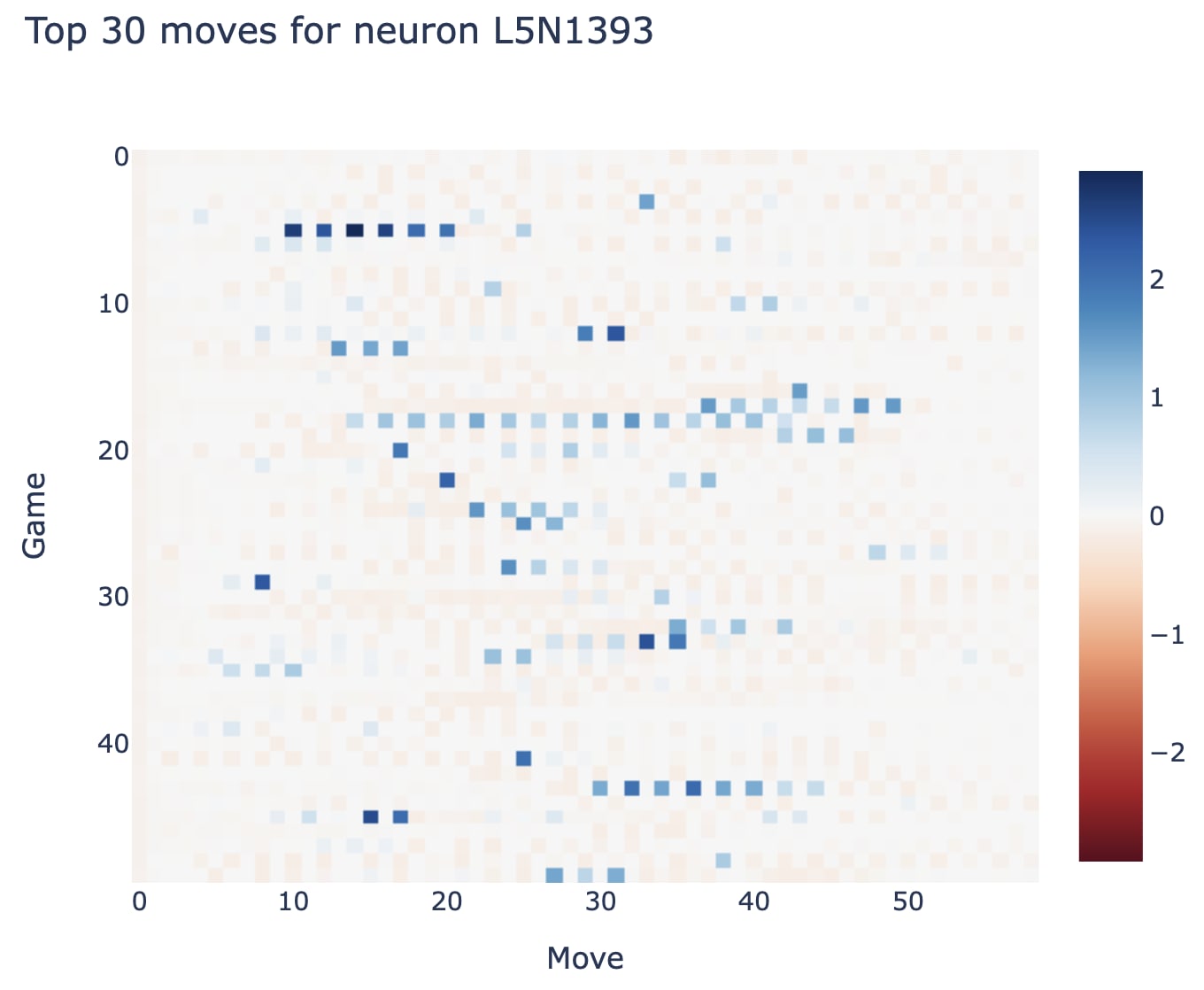
The next easiest place to start was max activating dataset examples - I initially felt an impulse to run the model across tens of thousands of games to collect the actual top dataset examples, but I realised this would be a headache and probably unnecessary. I had run the model for 50 games (thus 3000 moves) and decided to just inspect the neuron on the top 30 (1%) of games there.
I manually inspected a few, and then decided to aggregate the board state across the top 30 moves. I decided to try averaging "is non-empty", the actual board state (ie 1 for black, 0 for empty, -1 for white) and the flipped board state (ie 1 for mine, 0 for empty, -1 for their's) - this was kinda janky, since I wanted to distinguish "even probability of being white or black" and "always empty", but it seemed good enough to be useful.
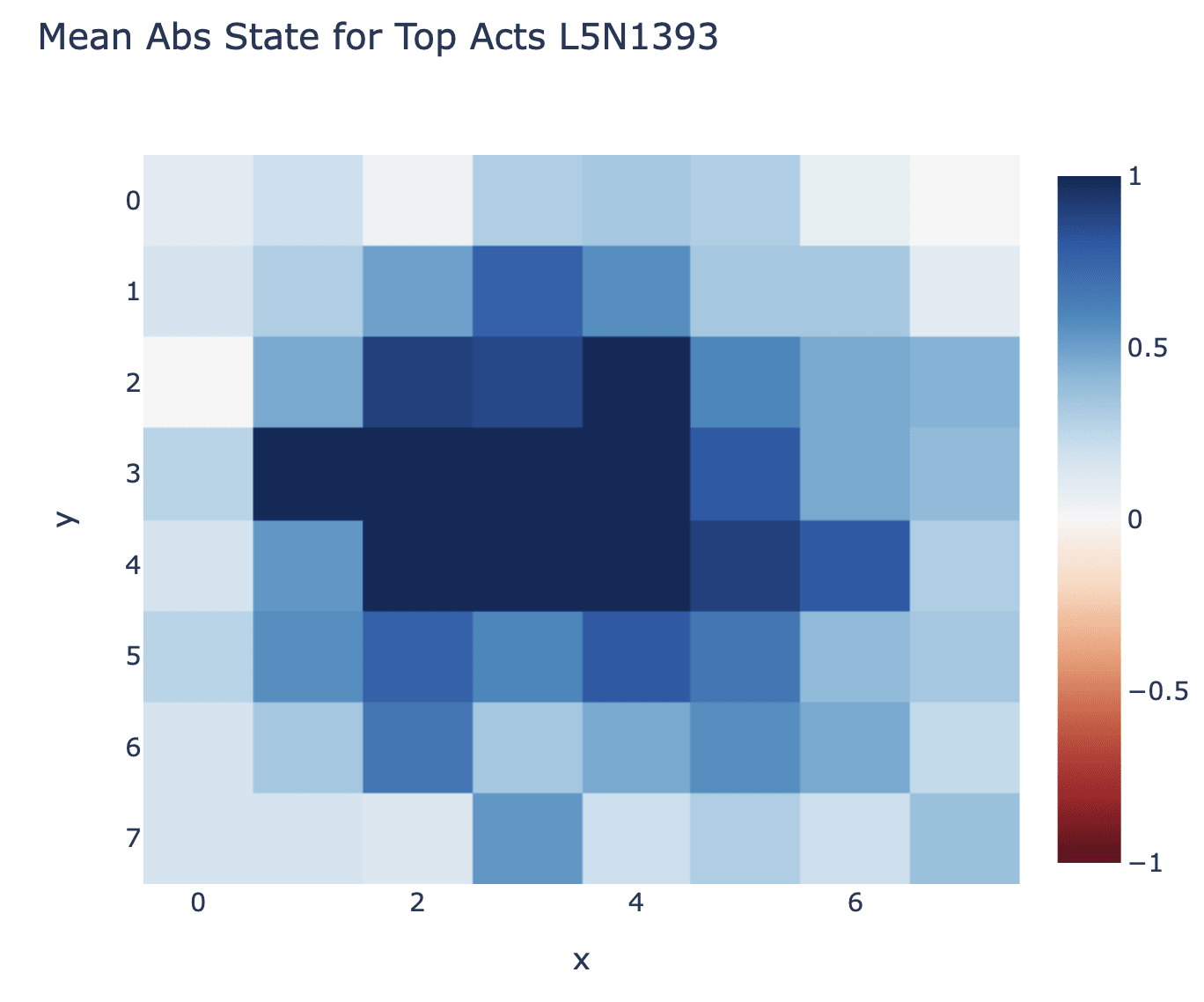
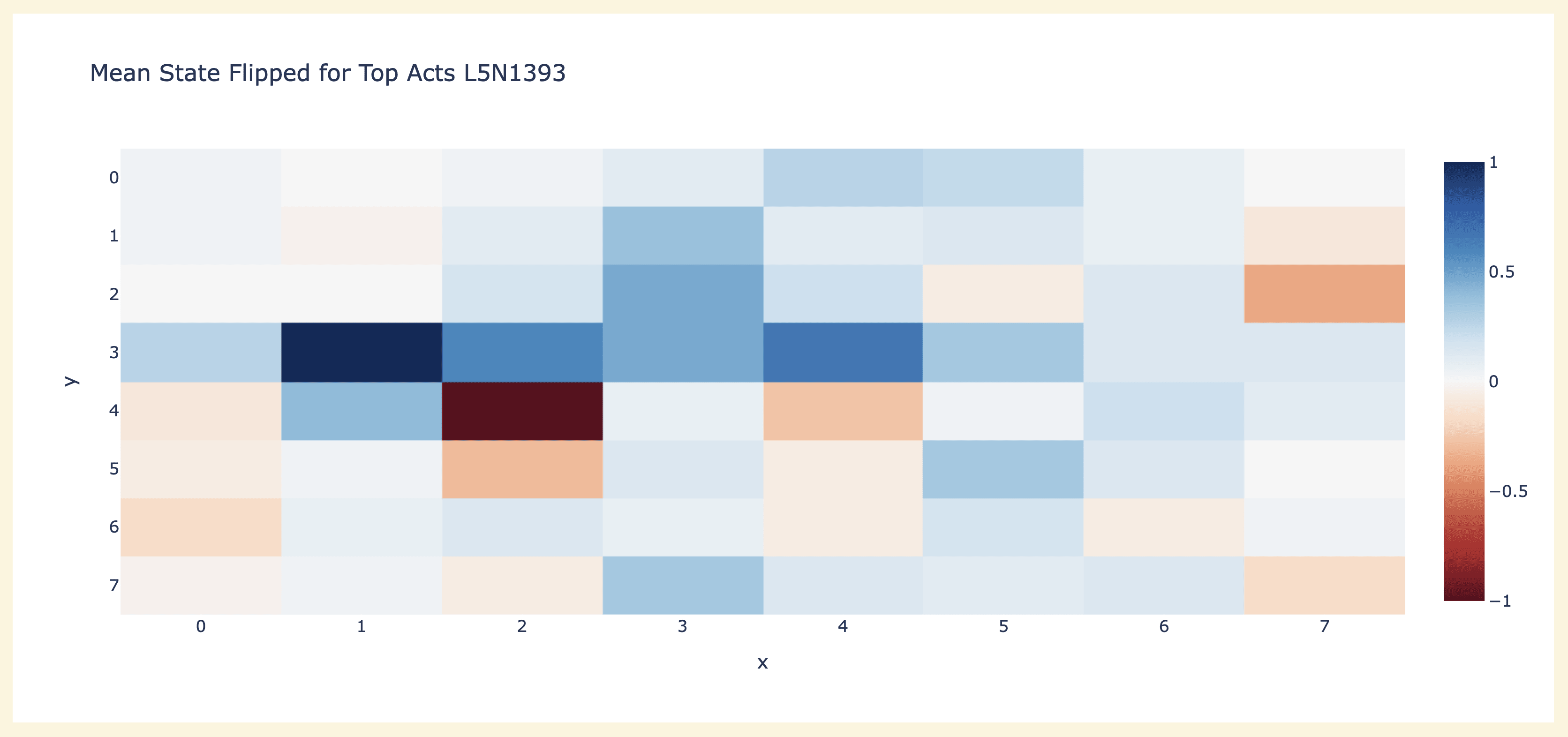
I don't recall exactly how I had the idea for a flipped board state - I think a combination of doing a heatmap of which games/moves the neuron fired on and seeing that it wasn't a consistent parity between games, but it did alternate within a game. And inspecting the top few examples, and seeing that some had black at D1 and white at E2, and some had white at D1 and black at E2 (and already having identified that part of the board as important). I spent a bit of time stuck on figuring out how best to aggregate a flipped board state, before realising I could do the stupid thing of using a for loop to generate an alternating tensor of 1s and -1s and just multiply by it.
But now I had the flipped board state, it was pretty clear that this was the right way to interpret the neuron - it was literally 1 in D1 and -1 in E2 (here 1 meant "their's", because I hadn't realised I'd need a good convention). I looked at the max activating dataset examples for a few other neurons (taking the top 10 by norm in each layer) and saw a few others that were clean in the flipped state but not in the normal state, and this was enough to generate the idea that the relevant colour was "next" vs "previous" player (I only realised after the fact that "my" vs "their" colour was a cleaner interpretation, thanks to Chris Olah for this!)
This is literally written in my notes as (immediately after I briefly decided to go and do a deep dive on neuron L6N1339 instead lol)
Omg idea! Maybe linear probes suck because it's turn based - internal repns don't actually care about white or black, but training the probe across game move breaks things in a way that needs smth non-linear to patch
At this point my instincts said to go and validate the hypothesis properly, look at a bunch more neurons, etc. But I decided that in the spirit of being decisive and pursuing "big if true" hypotheses (and because at this point I was late for work) I'd just say YOLO and try training a linear probe under this model.
I'm particularly satisfied with this decision, since I felt a lot of perfectionism, that I would have normally pursued, and ignoring it in the interests of speed went great:
- I'd never trained a probe before, and figured there's a bunch of standard gotchas I needed to learn - eg how to deal with imbalanced class sizes (corners are normally empty), setting up good controls etc
- Getting a probe working on the flipped board state (across all moves) - this seemed like more of a pain to code so I just decided to do even and odd moves
- Figuring out the right layer to probe on - I just picked layer 6 since it was late enough to feel safe, and I didn't want to spend time figuring out the right layer to probe on
- I had no idea what the right optimiser or hyper-parameters for training a probe are (I just guessed AdamW with
lr=1e-4,wd=1e-2,b1=0.9,b2=0.99and batch size 100 which seemed to work) - Getting accuracy to work for the probe was a headache (it involved a bunch of fiddling with one hotting the state in the right way)
- Getting good summary statistics of how the run was going - I decided to just have overall loss per probe, and then loss per probe on an arbitrary square (I think C2)
- Figuring out how to get good performance on probe training - there's a bunch of optimisations around stopping the model once it gets to the right layer, turning off autodiff on the model parameters, etc, I just decided to not bother and do the simple thing that should work.
I somehow managed to write training code that was bug free on the first long training run, and could see from the training curves that my probes were obviously working! From here on, things felt pretty clear, and I found the results in the initial section on analysing the probe [AF(p) · GW(p)]!
0 comments
Comments sorted by top scores.