The ‘strong’ feature hypothesis could be wrong
post by lewis smith (lsgos) · 2024-08-02T14:33:58.898Z · LW · GW · 19 commentsContents
Monosemanticity Explicit vs Tacit Representations. Conclusions None 19 comments
NB. I am on the Google Deepmind language model interpretability team. But the arguments/views in this post are my own, and shouldn't be read as a team position.
“It would be very convenient if the individual neurons of artificial neural networks corresponded to cleanly interpretable features of the input. For example, in an “ideal” ImageNet classifier, each neuron would fire only in the presence of a specific visual feature, such as the color red, a left-facing curve, or a dog snout”
- Elhage et. al, Toy Models of Superposition
Recently, much attention in the field of mechanistic interpretability, which tries to explain the behavior of neural networks in terms of interactions between lower level components, has been focussed on extracting features from the representation space of a model. The predominant methodology for this has used variations on the sparse autoencoder, in a series of papers inspired by Elhage et. als. model of superposition.It's been conventionally understood that there are two key theories underlying this agenda. The first is the ‘linear representation hypothesis’ (LRH), the hypothesis that neural networks represent many intermediates or variables of the computation (such as the ‘features of the input’ in the opening quote) as linear directions in it’s representation space, or atoms[1]. And second, the theory that the network is capable of representing more of these ‘atoms’ than it has dimensions in its representation space, via superposition (the superposition hypothesis).
While superposition is a relatively uncomplicated hypothesis, I think the LRH is worth examining in more detail. It is frequently stated quite vaguely, and I think there are several possible formulations of this hypothesis, with varying degrees of plausibility, that it is worth carefully distinguishing between. For example, the linear representation hypothesis is often stated as ‘networks represent features of the input as directions in representation space’. Here are two importantly different ways to parse this:
- (Weak LRH) some or many features used by neural networks are represented as atoms in representation space
- (Strong LRH) all (or the vast majority of) features used by neural networks are represented by atoms.
The weak LRH I would say is now well supported by considerable empirical evidence. The strong form is much more speculative: confirming the existence of many linear representations does not necessarily provide strong evidence for the strong hypothesis. Both the weak and the strong forms of the hypothesis can still have considerable variation, depending on what we understand by a feature and the proportion of the model we expect to yield to analysis, but I think that the distinction between just a weak and strong form is clear enough to work with.
I think that in addition to the acknowledged assumption of the LRH and superposition hypotheses, much work on SAEs in practice makes the assumption that each atom in the network will represent a “simple feature” or a “feature of the input”. These features that the atoms are representations of are assumed to be ‘monosemantic’: they will all stand for features which are human interpretable in isolation. I will call this the monosemanticity assumption. This is difficult to state precisely, but we might formulate it as the theory that every represented variable will have a single meaning in a good description of a model. This is not a straightforward assumption due to how imprecise the notion of a single meaning is. While various more or less reasonable definitions for features are discussed in the pioneering work of Elhage, these assumptions have different implications. For instance, if one thinks of ‘features’ as computational intermediates in a broad sense, then superposition and the LRH imply a certain picture of the format of a models internal representation: that what the network is doing is manipulating atoms in superposition (if you grant the strong LRH, that’s all it’s doing. Weaker forms might allow other things to be taking place). But the truth or falsity of this picture doesn’t really require these atoms to correspond to anything particularly human interpretable: that is, it seems to me possible that the strong LRH and superposition hypotheses could be true, but that many atomic variables would not correspond to especially interpretable concepts.
Together, the strong LRH and monosemanticity assumption imply that a large enough catalog of features will be a complete description of the model; that the entire computation can be described in terms of atoms, each of which stand for interpretable features. I think the opening quote of this essay is a good encapsulation of this view; that the details of the real network will be messy, but that the mechanics of the network will approximate this ‘ideal model’ of neatly interpretable features, each with an explicit atomic representation, interacting with one another. I think this view is also evidenced in the (speculative) potential definition, suggested in Toy Models, that features are “properties of the input which a sufficiently large neural network will reliably dedicate a neuron to representing.” - for this definition to make sense, we have to grant the reality of both these ‘properties of the input’ and the idea that a sufficiently large neural network, via the strong LRH, would dedicate a single atom to representing each of them.
I think it’s instructive to clarify, decompose and analyse the plausibility of these hypotheses, which I attempt to do in this essay. I will argue that, while the weaker versions of many of these are probably true, the strong versions are probably untrue. It’s not clear to me the extent to which any individual strongly holds the strong feature hypothesis: many individual researchers likely have nuanced views. However, I think that at least a version of the strong feature hypothesis is implied by various strategic considerations which have been proposed more or less seriously; for instance, the strategy of ‘enumerate over all the features and check whether they are safe or not’ is proposed both in Toy Models of Superposition and Interpretability Dreams, and recent papers which trace back to these works. It’s not at all clear that this is a good strategy if the strong feature hypothesis is false.
The methodology of ranking the interpretability of atoms discovered by training SAEs by examining their activations on training data (or evaluating feature discovery methods based on the percentage of features found which are explicable in these terms) strongly implies the monosemanticity assumption, not just some version of the LRH and superposition hypotheses as is commonly argued in the literature; it is conceptually possible to accept both the LRH and superposition, but expect to find atoms which stand for things like (say) a counter variable in a for loop of some internal procedure. This kind of feature is conceptually plausible, but very difficult to interpret purely in terms of the input and output of the program, or indeed to interpret in isolation; it can only really be understood if you understand the program in which it plays that role.
Regardless of whether many people want to defend the strong version of the hypotheses outlined above, I think that it’s surprisingly easy to hold a view ‘subconsciously’ that one would be unlikely to defend if it was outlined explicitly[2], and so meditating on the plausibility of the ‘strong feature hypothesis’ as a complete model for neural network cognition is useful in bringing out into the open implicit assumptions which can otherwise fester, unexamined. Even if the strong version of this hypothesis is not held by any individual researcher, research agendas and methodologies which imply or assume the strong form of this hypothesis seem surprisingly widespread to me, as I have argued above. So I think that taking the ‘strong form’ of the feature hypothesis seriously is a worthwhile exercise, as I contend that this picture is being taken seriously by our current research agendas, even if it is not necessarily espoused by the researchers involved. Having said that, it's my personal impression that this position is not a strawman, and is held by actual people; it’s hard for me to parse the following image (Olah et al, July 2024)
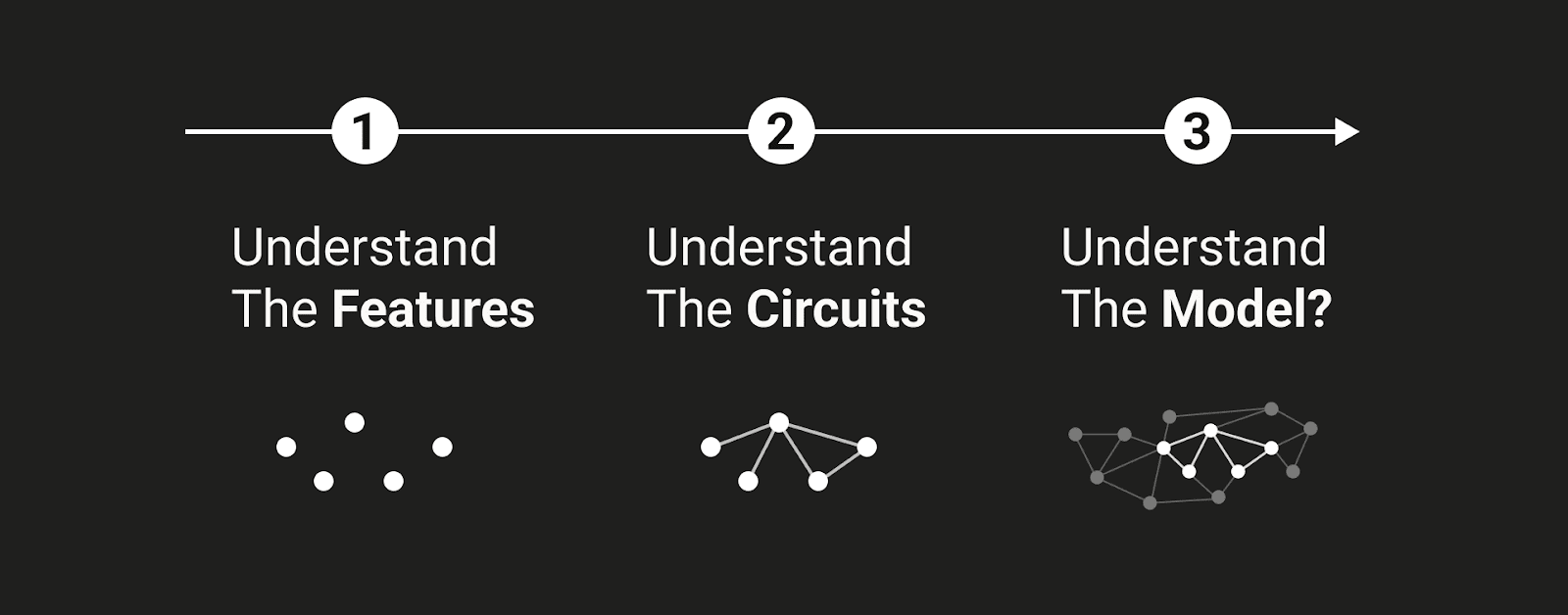
as anything other than an articulation of the strong feature hypothesis.
There is a real danger in focusing on particular examples that fit a particular model - which researchers in mechanistic interpretability have certainly succeeded in finding - and assuming that they are paradigmatic cases of how information is manipulated in a system. The fact that many directions in activation space do seem to be dedicated to representing simple features of the input - which there is now considerable empirical evidence for - does not imply the stronger versions of the hypotheses above. This is important because the success of linear feature finding, which has been quite dramatic, has quickly become the dominant paradigm in mechanistic interpretability, and quite a large pool of the available talent and resources allocated to the field are now dedicated to this. It’s good to be clear (or if not clear, at least self-aware) about the exact bet we are making by doing this. In this essay, I will outline my reasons for skepticism of the stronger versions of the hypotheses above. This is not intended, necessarily, as an attack on the SAE direction; indeed I work on this myself in my day job. The strong hypothesis doesn’t need to be true for SAEs to be a useful direction; some combination of the weak LRH and superposition probably does, but I think those are much less contentious. However, especially when we are thinking of future projects, deciding whether a methodology makes sense or not, or considering the likely outcomes of a direction in interpretability, we should avoid uncritically assuming stronger versions of the feature hypothesis than we actually require.
In the rest of the essay, I dive a bit deeper into why I think it makes sense to be skeptical of the monosemanticity hypothesis and strong LRH in a bit more detail.
Monosemanticity
I think that monosemanticity, while seemingly a straightforward concept, has numerous difficulties. The frustrating thing is that this is probably the least necessary concept ; after all, as I mentioned above, it seems totally possible for both superposition and strong linear representation to both hold, and for some of the concepts encoded in this way by the network to be difficult to understand.
The first of these is the difficulty of deciding what qualifies a concept as simple. What exactly is meant by a ‘specific feature’ of the input that the atoms in the network are supposed to represent? It seems like nothing could be easier than to think of many candidates for these atomic concepts - a dog, the Golden Gate bridge, Arabic. But the apparent simplicity of these examples can be deceptive. Many apparently simple concepts can be split up or combined arbitrarily. For instance, is dog a simple concept, or a compound concept of the various different breeds of dog? Are both dog and greyhound simple concepts? Is one simpler than the other? Should the network represent these with different features, or variations of the same feature? Are there any monosemantic words in English? Perhaps this is OK as just a directional definition - it seems hard to deny that a particular atom can be more monosemantic than a particular neuron in a given model, or that a particular everyday concept (like dog) might be given a simple, atomic representation by a model. But still, the idea of a simple concept is much more complicated than it might seem on closer inspection, and I'm not sure that I want to grant that there's a natural decomposition of the world into these platonic features.
If we just gloss the idea of simple concepts, it seems plausible to imagine these being the primary ingredients of a model of the world. We can then imagine a physical model with a structure isomorphic to this hierarchy of platonic concepts:[3] maybe it first recognizes a dog, then refines this concept into various breeds of dog, and so on (or is it the other way round?). But I think it’s not actually a very plausible picture, either of how concepts actually work or how models reflect them. The story of modern deep learning is, in large part, a story of the success of models which do not try to assume a prescriptive structure for how the world should be modeled over those which did. This should give us pause. Another way to phrase this would be to ask if we would expect every feature in a human mind (or maybe an insects mind, if that seems too ambitious) to map onto a ‘simple concept’. If we don’t expect this to be true for humans or animals, why should it be true for AI models?
In his recent paper with OpenAI, Leo Gao notes - correctly - that the limit of width in a sparse autoencoder is uninteresting, as you could simply learn an atom corresponding to each datapoint. Despite this, the assumption that significant progress can be made by cataloging more features persists - in their recent paper, the Anthropic team explicitly speculate that there may be ‘orders of magnitude’ more features (or atoms?) than found by their 34 million dimensional SAE. I worry that there is a conceptual problem here, especially if the focus is on cataloging features and not on what the features do. There are a few potential alternative frames here. One is that features may be compositional in some way; there is an abundance of evidence that neural network activations frequently have evidence of this kind of compositional structure (e.g the famous king - man + woman = queen type results on vector embedding spaces).[4] At some point, simply expanding the number of atoms could result in enumeration of features which are actually represented as compositional combinations; for instance, consider a model that represents colored shapes in a compositional fashion with a ‘color’ and ‘shape’ feature, each taking three possible values (red, blue, green and circle, triangle, square possibly). With too many autoencoder directions, it would be possible for a model to simply start memorizing compositions of these features, learning 9 atoms rather than the 6 ‘true’ atoms hypothesized[5]. In Borges’ short story Funes the Memorious, the eponymous hero has prodigious photographic memory, but is incapable of any kind of abstraction: the narrator describes how he is in the process of creating a new system of numbers in which every natural number has a personal name (such as ‘Olimar, Gas, Clubs, the Whale’), and is unable to understand the narrator when he tries to explain that this is the opposite of a number system. A catalog of ‘simple’ features can possibly be made arbitrarily precise, but this is not the same as a deeper understanding, and may in fact be antithetical to it, especially if the catalog doesn't make reference to how these features are used.
Part of the appeal of the ‘catalog’ agenda is that the success of scaling in machine learning. Given this, it’s natural that, when we see signs of a promising interpretability method, the first instinct is to scale it up, and hope for similar returns to scale as we have observed in other fields. We might think that the problem of understanding the computation implemented by a model is thereby transformed into the problem of fitting a very large dictionary. But why does scaling work on language models? Do the same conditions obtain for SAEs? And we have seen that there are some reasons to be skeptical; the limit of width is uninteresting, and there are presumably limits to the number of distinct features that a network can retrieve from superposition.
Note that my claim here is not to disagree with the observation that any interpretability method we come up with must be scalable (i.e must be tractable to apply to very large models) to be useful, which seems true. Scaling is necessary for the success of the mechanistic interpretability agenda, but of course this does not imply that it’s sufficient . If our model of how the computation works is too restrictive, for example, it seems likely that scale will not deliver, or will deliver only limited gains.
The assumption of some formulations of the interpretability agenda that computation can always be reduced to a large number of human interpretable features is very questionable, and contrary to the lessons of the deep learning era; in The Bitter Lesson, Sutton writes: “The second general point to be learned from the bitter lesson is that the actual contents of minds are tremendously, irredeemably complex; we should stop trying to find simple ways to think about the contents of minds”.[6] The idea of the model as consisting of a large graph of monosemantic features seems like it might be guilty of this charge.
A more methodological objection to how the agenda of cataloging features is currently pursued is that that, as mentioned, even if a computation does factor into intermediate atoms, it doesn’t follow that all of these variables have to have a clear meaning in terms of the input or output of the program. Consider a simple example of a counting variable in a for loop; this plays a simple, discrete role in the computation, but it doesn’t map onto any feature of the input or output of the program, so trying to understand it in those terms would likely be difficult. (Though there are exceptions to this, like a ‘nth item in a list’ feature, which I believe has been observed. But this happens over multiple forward passes and so is still really an input feature, rather than something that looks like 'apply this function n times' within a pass through the residual stream, say). It’s not obvious that the residual stream would contain ‘intermediate variables’ like this, but there is no reason why it shouldn’t, unless transformer forward passes are somehow fundamentally limited to ‘shallow’ computations, which would be a very strong claim to make. This means that, while many features may have an interpretation in terms of the input and output of a program, it would be somewhat surprising if they all did, though I can’t rule this out a priori. It’s easy to pay lip service to the idea that features will have a more abstract computational role, but this argument is rarely taken seriously in methodological terms; SAE work often assumes that each feature can be understood in isolation in terms of the input and output of the program (for instance, ranking features based on how interpretable they are looking at their activations on their input).
A further objection to the dashboard methodology is that it assumes that the meaning of a circuit element is fixed and unambiguous, to the extent that we can give the definition of a feature globally and out of the context of the rest of the model (e.g this feature represents Arabic text). This seems wrong to me; the meaning of a feature (to paraphrase Wittgenstein) is it’s use in the network. There is not necessarily a reason to expect this to be fixed globally. To take a toy example, I was recently looking at simple relative-clause circuits on small models (pythia) with SAEs; SAEs definitely seem to be quite helpful here, with elementary techniques suggesting that various features are playing the role of noun-number features. However, when examining dashboards for these features over the entire dataset, it is clear that many such features seem to have a more specific role on their maximum activating examples. This doesn’t mean that they have a more specific meaning than noun-number features in the context of a particular circuit. Internal variables (like the for loop example) are another example where (given the LRH and superposition) we might expect the network to devote atoms to representing them, without these atoms being interpretable in terms of the external world. I think many researchers would agree that features along these lines would be important and interesting to understand; we should make sure our methods are capable of finding them!
Explicit vs Tacit Representations.
I think that a key motivator behind the argument that there are orders of magnitudes more features left to discover in many language models is the observation that there are facts that the model can verbally recall that we have not discovered explicit features for yet. This is valid, if we accept the implication of the strong LRH that the only way for the model to represent knowledge is to devote a linear representation to it. But this explicit form of representation is not necessarily the only valid one. In his essay Styles of Mental Representation[7], Daniel Dennett attacks the assumption, which he sees as being prevalent in cognitive science and the philosophy of mind - that there is ‘no computation without representation’. That is to say, the assumption that, given that a system represents or models something, it necessarily does so explicitly, by having, in some functionally relevant part of the system, some string of symbols or physical mechanism which in some sense codes for, or is isomorphic in structure to, the target for which it stands. A cell in a spreadsheet, a logical or mathematical formula, or a function definition in a programming language are paradigmatic examples of such explicit representations. It seems clear to me that the conception of atoms in superposition each standing for a feature of the input would also be an instance of an explicit representation in this sense.
In contrast, Dennett argues for the existence (and possible primacy) of tacit representations; systems which simply have complex dispositional behavior which does not factor further into explicitly represented rules, propositions, knowledge or the like. Say we want to explain how a person (or a machine) decides on the next legal move in a game of chess. We might expect to find some kind of explicit representation of the chess board in their mind; indeed, it would be somewhat surprising if we didn’t. But of course, this only really moves the question of how they decide the next move on the real chess board to how they decide the next move on the mental representation of a chess board, which is more or less the same problem. This chain of decomposition must bottom out at some point in order to avoid an infinite regression of such explicit representations. When deciding how a knight might move, we can imagine a network mentally looking up an explicit representation of this rule, and then applying it, but this is not the only way to do so; there may be a collection of circuits, heuristics and the like which tacitly represent the knowledge of this rule. There does not have to be an explicit representation of the ‘feature’ of chess that knights move in a particular way.[8]
In other words, the picture implied by the strong LRH and monosemanticity is that first features come first, and then circuits, but this might be the wrong order; it’s also possible for circuits to be the primary objects, with features being (sometimes) a residue of underlying tacit computation. But it’s not obvious that an underlying tacit computation has to produce an explicit representation of what it’s computing, though it might in many cases.
Another way to think about this objection is to consider something like a feature for recognizing Arabic; to what extent is ‘with an Arabic feature’ an answer to the question ‘how does the network recognize Arabic’? This does tell us something important about the format of the internal representation of this information, but in an important sense it also defers explanation of how this is computed. The input to such a feature would be an important part of understanding it’s function ; for example, if the feature was just a classifier on the tokens of the Arabic alphabet, that would be quite different to a feature which was sensitive to grammar etc. as well, and explaining the second in truly mechanical terms is much more challenging.
Chess is an interesting concrete example[9] of the kind of irreducibility that I think Sutton was getting at: What does AlphaZero ‘know’ about chess? Let’s consider a situation when AlphaZero makes move A over move B, and (in fact) A is a much stronger move than B. AlphaZero in some sense ‘knows’ or ‘decides’ A is better than B. Is the knowledge that A is a better move than B explicit in AlphaZero, in the sense that, at some part of the model, we could ‘read it off’ from some internal representation? Some kinds of features about relative position strength can be read off from the value network in this way, and so in some cases the answer will be yes. But much of AlphaZero’s performance is down to its tree search. If the reason the model chose A over B is something like ‘it did a 200 move deep tree search, and the expected value of positions conditioned on A was better than B’, then the models disposition to choose A over B is represented tacitly, and there may be nowhere that explicit reasons for that decision are represented[10] (except at the level of the entire system).
Whether a system explicitly or implicitly represents a feature may not even be that important, at least in terms of predicting it’s behavior. This is a key idea of (Dennett’s) intentional stance; sometimes it’s more pragmatically useful to model a system in terms of explicit representations as a predictive methodology (like an idealization) even if this isn’t actually how it works. For instance, you can predict the behavior of the calculator in terms of explicit representations of arithmetic, even though the implementation details of its internal representation (if any) may be quite different. This is especially important for abstractions like goals, deceptiveness and the like, if our narrative for the utility of a feature-finding approach runs through finding explicit representations of these abstractions. Is having an ‘inner representation’ of goals or deception that important for whether it makes pragmatic sense to describe a system as having a goal? Is it important at all? Is it necessary for a system to have an explicit representation of a goal for it to act like it has a goal for many intents and purposes?
For example, many animals can be understood as pursuing the goal of maximizing their inclusive fitness, largely by having a large number of individual behaviors whose aggregate effect is to pursue this goal fairly effectively, but without ‘representing it’ explicitly anywhere internally: the organism as a whole might be said to tacitly pursue this goal.
Of course, depending on your definition of representation[11], it might be tempting to say that a bacteria doesn’t represent the goal of maximizing inclusive genetic fitness; that is, we could choose to say that only systems which explicitly represent things represent them at all.
But if we admit this possibility, we should consider whether our theories of impact for ‘representation finding’ make an implicit assumption that a model can only compute what is represented explicitly, as I think the strong version of enumerative safety via feature finding assumes. The tree search example earlier is a particularly stark example, especially given that many classical arguments about AI risk run through exactly this sort of consequentialist planning[12]. If we grant that the bacteria doesn’t ‘really represent’ it’s goals, we have to acknowledge that it nevertheless does a good job of pursuing them, and take the implications about the necessity of explicit representation seriously.
Conclusions
Much work on SAEs has assumed a frame of how features work that (implicitly) makes assumptions which I think are deeply questionable. I have dealt with two main ideas; the idea that there is a natural factorization into ‘simple concepts’ which will be represented in an unambiguous way in our models (monosemanticity), and the idea of all concepts being represented by a system being represented in a particular, explicit fashion (the strong LRH). I think I have outlined reasons to be skeptical of the validity of both of these premises.
This is not to say that the feature finding agenda is hopeless. Indeed I hope that it isn’t, because it currently accounts for a fairly large portion of my day job! Finding features has been a reasonably successful agenda for interpretability, and has been a useful frame that has let us make a great deal of apparent pragmatic progress. There is reasonable empirical evidence that many interesting things are represented explicitly inside networks, and that these representations can be extracted by current methods. The arguments above don’t really show that any existing interpretability work is invalid. Indeed, I think they provide strong evidence for the truth of the weak LRH. My main skepticism is that the strong LRH can be a complete picture of how neural networks work, as well as more broadly with the intuition that there is always some neat, understandable platonic design in terms of neatly labelled variables that a neural network must be approximating. We should avoid uncritically using frames of how intelligence works that can be compared (unfavorably) to GOFAI, except this time we find and label the propositions in the if statements inside a trained network instead of hand-coding them. There is a reason this didn’t work the first time, and it wasn’t that there weren’t 34 million if statements. We should be wary of begging the question about how neural networks actually work. Many existing conceptions of what a ‘feature’ should be like blur the lines between a search for (sets of) states which can be interpreted as functionally or casually relevant variables (which I think is obviously potentially valuable) and a search for something like instantiations of ‘simple concepts’, which is a much more dangerous notion.
I think the relevance of this depends a lot on whether we are looking for existence proofs or exhaustive guarantees. None of the above establishes that systems can’t have explicit representations of many important things (indeed, there is abundant evidence that lots of interesting things are explicitly represented), so if we want to find examples of worrying behavior, explicit representation finding may be a perfectly useful tool. I do think that the idea of ‘enumerative safety’, where we can make strong claims about a system based on having cataloged it’s low level features in some way, makes a strong assumption that all representations must be explicit and monosemantic in a human understandable fashion, which I hope to have convinced you is deeply suspicious. I think the main takeaway from this essay is that we should think more carefully about the assumptions behind our framings of interpretability work. But I think that if you agree with the arguments in this essay, it does change what kinds of interpretability work are the most valuable going forward. In particular, I think it should make you skeptical of agendas which rhyme with 'first we will find and understand all the features, then once we have done that ensuring safety will be easy'.
- ^
In this essay, I will use the term ‘atom’, taken from the dictionary learning literature, to refer to a direction in a network’s representation space (a linear combination of neurons), reserving the term ‘feature’ for a conceptual sense of a feature of the input, or some other abstract object the network might manipulate. It is more conventional to overload these terms (e.g ‘the network represents features of the input with linear features in it’s representation space’), but I think the argument I want to make here is significantly clarified by distinguishing carefully between these concepts, and avoiding begging the question about the interpretability of the atomic directions implied by the superposition hypothesis. So a network’s representation vector at a particular site can be decomposed into a combination of atoms with associated activations, but we remain neutral on the interpretation of the atoms. I think that a more expansive view of exactly what an atom is is possible; for instance, Olah has recently proposed a broader view of a linear representation than a direction in representation space. I think most of the arguments in this essay are not significantly changed by these considerations.
- ^
To take a very Dennettian example; many people will verbally espouse a materialist worldview, but simultaneously hold views on consciousness or other mental phenomena which, if taken seriously, strongly imply some form of dualism. Economists know that people are not all rational actors, but frequently rely on theories assuming this. Statisticians know not all things follow a Gaussian distribution, etc. etc. If your reaction on reading this essay is that I am attacking a strawman, then good! I think the view I attack is extremely naive! And even models which are wrong can be useful places to start. But it’s important that we know what we are doing, and understanding the implications of our framing of these problems seems to me to be an important exercise.
- ^
For a more detailed discussion on this topic, see this post by jake mendel [LW · GW] from Apollo.
- ^
Another possible source of this kind of error would be if the features do not form perfect directions, but instead are grouped into clusters (like a mixture of Gaussians, with tight variances). Depending on the mixture weights and the number of SAE features, it might make sense from an error minimisation perspective to assign more SAE features to more frequent clusters, which doesnt’ necessarily lead to interpretable features. This was suggested to me by Martin Wattenberg.
- ^
Of course, Sutton might be wrong here. His attitude is certainly a bit defeatist. But it’s worth bearing his criticism in mind; are we looking for a way to think about the contents of minds which is a little too simple?
- ^
Reading this essay was an important catalyst for my thinking about many of the ideas here, though there are clear precursors to the ideas that Dennett explores in the essay in the thinking of Ryle and Wittgenstein.
- ^
Another possible example would be whether you would expect to find features representing various objects of music theory in the mind of an illiterate musician. This has not prevented various examples of extremely accomplished musicians who fit this description.
- ^
This particular example was inspired by watching a talk Lisa Schut gave on this subject, based on this paper
- ^
It’s possible that some aspects of the decision have to be explicitly represented; at some point there is presumably a variable that corresponds to the model choosing move A over B. But this is an explicit representation of the decision, not the reasons for the decision; we can obviously always observe the models behavior. Of course, the observation that a mediating variable like this exists (like the refusal direction) is interesting information
- ^
Some definitions of representation would restrict representation to only explicit representation. I think this is a little restrictive, but it’s not a crucial argument for my main point here; see Styles of Mental Representation for more discussion on this point.
- ^
Of course, one might object that most current AI architectures, like LLMs, don’t include explicit tree search or maximization. I would be fairly surprised to find a literal tree search implemented inside LLM weights, but this is just a particularly clear existence proof of tacit computation.
19 comments
Comments sorted by top scores.
comment by Dan Braun (dan-braun-1) · 2024-08-04T13:11:03.684Z · LW(p) · GW(p)
Very well articulated. I did a solid amount of head nodding while reading this.
As you appear to be, I'm also becoming concerned about the field trying to “cash in” too early too hard on our existing methods and theories which we know have potentially significant flaws. I don’t doubt that progress can be made by pursuing the current best methods and seeing where they succeed and fail, and I’m very glad that a good portion of the field is doing this. But looking around I don’t see enough people searching for new fundamental theories or methods that better explain how these networks actually do stuff. Too many eggs are falling in the same basket.
I don't think this is as hard a problem as the ones you find in Physics or Maths. We just need to better incentivise people to have a crack at it, e.g. by starting more varied teams at big labs and by funding people/orgs to pursue non-mainline agendas.
comment by Aryaman Arora (aryaman-arora) · 2024-08-05T19:24:55.992Z · LW(p) · GW(p)
cf. https://arxiv.org/abs/2407.14662
Replies from: lsgos↑ comment by lewis smith (lsgos) · 2024-08-05T21:30:55.369Z · LW(p) · GW(p)
yeah, I think this paper is great!
comment by Daniel Tan (dtch1997) · 2024-08-05T11:50:19.094Z · LW(p) · GW(p)
This is a great article! I find the notion of a 'tacit representation' very interesting, and it makes me wonder whether we can construct a toy model where something is only tacitly (but not explicitly) represented. For example, having read the post, I'm updated towards believing that the goals of agents are represented tacitly rather than explicitly, which would make MI for agentic models much more difficult.
One minor point: There is a conceptual difference, but perhaps not an empirical difference, between 'strong LRH is false' and 'strong LRH is true but the underlying features aren't human-interpretable'. I think our existing techniques can't yet distinguish between these two cases.
Relatedly, I (with collaborators) recently released a paper on evaluating steering vectors at scale: https://arxiv.org/abs/2407.12404. We found that many concepts (as defined in model-written evals) did not steer well, which has updated me towards believing that these concepts are not linearly represented. This in turn weakly updates me towards believing strong LRH is false, although this is definitely not a rigorous conclusion.
Replies from: lsgos↑ comment by lewis smith (lsgos) · 2024-08-05T12:39:53.849Z · LW(p) · GW(p)
i'm glad you liked it.
I definitely agree that the LRH and the interpretability of the linear features are seperate hypotheses; that was what I was trying to get at by having monosemanticity as a seperate assumption to the LRH. I think that these are logically independent; there could be some explicit representation such that everything corresponds to an interpretable feature, but that format is more complicated than linear (i.e monosemanticity is true but LRH is false) or, as you say, the network could in some sense be mostly manipulating features but these features could be very hard to understand (LRH true, monosemanticity false) or they could just both be the wrong frame. I definitely think it would be good if we spent a bit more effort in clarifying these distinctions; I hope this essay made some progress in that direction but I don't think it's the last word on the subject.
I agree coming up with experiments which would test the LRH in isolation is difficult. But maybe this should be more of a research priority; we ought to be able to formulate a version of the strong LRH which makes strong empirical predictions. I think something along the lines of https://arxiv.org/abs/2403.19647 is maybe going in the write direction here. In a shameless self-plug, I hope that LMI's recent work on open sourcing a massive SAE suite (Gemma Scope) will let people test out this sort of thing.
Having said that, one reason I'm a bit pessimistic is that stronger versions of the LRH do seem to predict there is some set of 'ground truth' features that a wide-enough or well tuned enough SAE ought to converge to (perhaps there should be some 'phase change' in the scaling graphs as you sweep the hyperparameters), but AFAIK we have been unable to find any evidence for this even in toy models.
I don't want to overstate this point though; I think part of the reason for the excitement around SAEs is that this was genuinely quite great science ; the Toy Models paper proposed some theoretical reasons to expect linear representations in superposition, which implied that something like SAEs should recover interesting representations, and then was quite successful! (This is why I say in the post I think there's a reasonable amount of evidence for at least the weak LRH).
comment by Charlie Steiner · 2024-08-04T06:16:43.468Z · LW(p) · GW(p)
I think the strongest reason to expect features-as-directions is when you have compositionality and decision points for the same stuff in the same layer. Compositionality means (by "means" here I mean a sort of loose optimality argument, not an iron-clad guarantee) the things getting composed can have distinguishable subspaces assigned to them, and having to make a decision means there's a single direction perpendicular to the decision boundary.
If you have compositionality without decision boundaries, you can get compositional stuff that lives in higher-dimensional subspaces. If you have decisions without compositionality... hm, actually I'm having trouble imagining this. Maybe you get this if the manifold of the partially-processed data distribution isn't of the same dimension on both sides of the decision boundary, or is otherwise especially badly behaved? (Or if you're trying to generalize features across a wide swath of the data distribution, when those features might not actually be applicable across the whole domain.)
Replies from: lsgos↑ comment by lewis smith (lsgos) · 2024-08-05T10:00:31.991Z · LW(p) · GW(p)
I'm not entirely sure I follow here; I am thinking of compositionally as a feature of the format of a representation (Chris Olah has a good note on this here https://transformer-circuits.pub/2023/superposition-composition/index.html). I think whether we should expect one kind of representation or another is an interesting question, but ultimately an empirical one: there are some theoretical arguments for linear representations (basically that they should be easy for NNs to make decisions based on them) but the biggest reason to believe in them is just that people genuinely have found lots of examples of linear mediators that seem quite robust (e.g Golden Gate claude, neels stuff on refusal directions)
Replies from: Charlie Steiner↑ comment by Charlie Steiner · 2024-08-06T07:27:44.033Z · LW(p) · GW(p)
Yeah, I was probably equivocating confusingly between compositionality as a feature of the representation, and compositionality as a feature of the manifold that the data / activation distribution lives near.
If you imagine the manifold, then compositionality is the ability to have a coordinate system / decomposition where you can do some operation like averaging / recombination with two points on the manifold, and you'll get a new point on the manifold. (I guess this making sense relies on the data / activation distribution not filling up the entire available space.)
comment by SL (sewoonglee) · 2025-01-07T16:09:34.427Z · LW(p) · GW(p)
tacticly
seems like a typo of tacitly. :)
Replies from: lsgos↑ comment by lewis smith (lsgos) · 2025-01-08T10:14:22.238Z · LW(p) · GW(p)
well spotted
comment by debrevitatevitae (cindy-wu) · 2024-08-18T23:08:43.573Z · LW(p) · GW(p)
Thanks for the post! This is fantastic stuff, and IMO should be required MI reading.
Does anyone who perhaps knows more about this than me wonder if SQ dimension is a good formal metric for grounding the concept of explicit vs tacit representations? It appears to me the only reason you can't reduce a system down further by compressing into a 'feature' is that by default it relies on aggregation, requiring a 'bird's eye view' of all the information in the network.
I mention this as I was revisiting some old readings today on inductive biases of NNs, then realised that one reason why low complexity functions can be arbitrarily hard for NNs to learn could be because they have high SQ dimension (best example: binary parity).
Replies from: lsgos↑ comment by lewis smith (lsgos) · 2024-08-28T10:14:10.971Z · LW(p) · GW(p)
I'm not that confident about the statistical query dimension (I assume that's what you mean by SQ dimension?) But I don't think it's applicable; SQ dimension is about the difficulty of a task (e.g binary parity), wheras explicit vs tacit representations are properties of an implementation, so it's kind of apples to oranges.
To take the chess example again, one way to rank moves is to explicitly compute some kind of rule or heuristic from the board state, and another is to do some kind of parallel search, and yet another is to use a neural network or something similar. The first one is explicit, the second is (maybe?) more tacit, and the last is unclear. I think stronger variations of the LRH kind of assume that the neural network must be 'secretly' explicit, but I'm not really sure this is neccesary.
But I don't think any of this is really affected by the SQ dimension because it's the same task in all three cases (and we could possibly come up with examples which had identical performance?)
but maybe i'm not quite understanding what you mean
comment by AnthonyC · 2024-08-06T13:57:26.079Z · LW(p) · GW(p)
This was really interesting, strongly upvoted.
I'm not going to pretend I followed all the technical details, but the overall thrust of the discussion feels a lot like the concepts of normal modes in wave mechanics, or basis sets in quantum mechanics, or quasiparticles in condensed matter physics. I understand the appeal of reaching for Dennett and Wittgenstein, the parallels are clear, but we have many other (and less controversial) examples of relying on implicit representations over explicit ones in order to be better able to describe the behavior of complex systems. Just ask anyone who makes chips how a p-type semiconductor works.
Replies from: lsgos↑ comment by lewis smith (lsgos) · 2024-09-14T21:41:19.772Z · LW(p) · GW(p)
I guess you are thinking about holes with the p-type semiconductor?
I don't think I agree (perhaps obviously) that it's better to think about the issues in the post in terms of physics analogies than in terms of the philosophy of mind and language. If you are thinking about how a mental representation represents some linguistic concept, then Dennett and Wittgenstein (and others!) are addressing the same problem as you! in a way that virtual particles are really not
Replies from: AnthonyC↑ comment by AnthonyC · 2024-09-14T23:38:20.609Z · LW(p) · GW(p)
I think I was really unclear, sorry. I wasn't so much saying physical analogies to quasiparticles are good ways to think about the issues discussed in the post. I was trying to say that the way physicists and materials scientists think about quasiparticles are an example of humans choosing among implicit vs explicit representations, based on which features each brings to the fore.
Maybe I'm still missing a central piece (or several) of the problem, but I have a hard time understanding why Dennett isn't just flat-out, uncontestably, obviously right about this? And that his needing to argue it is a failure of the rest of the field to notice that?
Replies from: lsgos↑ comment by lewis smith (lsgos) · 2024-09-15T13:22:04.513Z · LW(p) · GW(p)
I kind of agree that Dennett is right about this, but I think it's important to notice that the idea he's attacking - that all representation is explicit representation - is an old and popular one in philosophy of mind that was, at one point, seen as natural and inevitable by many people working in the field, and one which I think still seems somewhat natural and obvious to many people who maybe haven't thought about the counterarguments much (e.g I think you can see echos of this view in a post like this one [LW · GW], or the idea that there will be some 'intelligence algorithm' which will be a relatively short python program). The idea that a thought is always or mostly something like a sentence in 'mentalese' is, I think, still an attractive one to many people of a logical sort of bent, as is the idea that formalised reasoning captures the 'core' of cognition.
comment by 1stuserhere (firstuser-here) · 2024-08-05T19:52:21.067Z · LW(p) · GW(p)
Great essay!
I found it to be well written and articulates many of my own arguments in casual conversations well. I'll write up a longer comment with some points I found interesting and concrete questions accompanying them sometime later.
comment by Max Ma (max-ma) · 2024-08-05T08:10:32.172Z · LW(p) · GW(p)
Firstly, the principle of 'no computation without representation' holds true. The strength of the representation depends on the specific computational task and the neural network architecture, such as a Transformer. For example, when a Transformer is used to solve a simple linear problem with low dimensionality, it would provide a strong representation. Conversely, for a high-order nonlinear problem with high dimensionality, the representation may be weaker.
The neural network operates as a power-efficient system, with each node requiring minimal computational power, and all foundation model pre-training is self-supervised. The neural network's self-progressing boundary condition imposes no restrictions on where incoming data is processed. Incoming data will be directed to whichever nodes are capable of processing it. This means that the same token will be processed in different nodes. It is highly likely that many replicas of identical or near-identical feature bits (units of feature) disperse throughout the network. The inequality in mathematics suggests that connections between nodes (pathways) are not equal. Our working theory proposes that feature bits propagate through the network, with their propagation distance determined by the computational capacity of each node. The pathway appears to be power-driven, prioritizing certain features or patterns during learning in a discriminatory manner. While this discriminative feature pathway (DFP) is mathematically plausible, the underlying theory remains unclear. It seems that neural networks are leading us into the realm of bifurcation theory
comment by Review Bot · 2024-08-04T08:14:25.527Z · LW(p) · GW(p)
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2025. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?