Preventing Language Models from hiding their reasoning
post by Fabien Roger (Fabien), ryan_greenblatt · 2023-10-31T14:34:04.633Z · LW · GW · 15 commentsContents
Summary of the paper Toy demonstration of a hidden Chain-of-Thought Approach for measuring hidden information density Experimental setup Results on AQUA-RAT Quality of the generation and capacity of the steganography schemes before any defense is applied Capacity before and after paraphrasing Generation quality with and without paraphrasing Threat models Steganographic encoded memories for takeover science Steganographic communications for collusion Threat models we’re not tackling directly Short chain-of-thought steganography Steganography by AIs much stronger than humans High-stakes collusion through steganography Are text-based communication and memories relevant? Multi-modality Emergence of new modes of thinking & communicating How many bits is low enough? Can you really reduce the bitrate enough? Limitations of our evaluation methodology How the methodology may overestimate hidden information density How the methodology may underestimate hidden information density Realism of countermeasures Future work None 17 comments
When working with powerful AI models, one concern is that the AIs steganographically encode secret messages [AF · GW] when communicating with each other or in long Chains-of-Thought (CoT). Steganographic communication enables the AIs to follow a variety of strategies for grabbing power that we’d rather they didn’t have access to. There are various countermeasures that can be employed to reduce the extent of steganographic communication; for example, trusted less-capable models can be used to paraphrase model outputs before these outputs are shown to other instances of the highly capable models, removing several steganography strategies.
We released a paper on a methodology to evaluate the density of hidden information that steganography schemes can maintain in the presence of various defenses. We find that paraphrasing is an effective defense against all steganography schemes we’ve tried, including both watermarking-based and ad hoc attacks. In the paper, we mostly discuss applying this methodology in the context of making CoT more faithful, but in this post, we’ll discuss more speculative applications and elaborate on our threat models more generally.
We’re interested in people building on this research, for two reasons:
- Development of techniques. We think that developing techniques to defend against the best steganographic attacks is a reasonable research direction for researchers who want to mitigate the risks associated with powerful AIs doing steganography, especially given how neglected it is.
- Development of evaluation procedures. We think that measurements like the ones we describe here should be done when deploying powerful models (unless we have evidence sufficient to be extremely confident in the alignment of these models). We think that it will be easier to do this evaluation process later if researchers get more experience doing it now.
Summary of the paper
Toy demonstration of a hidden Chain-of-Thought

We created a toy dataset where significant cognition is required to successfully be sycophantic, by taking Anthropic’s model-generated sycophancy dataset and replacing users’ bios with a hard-to-parse description of their political affiliation, using the format shown in the figure above. We then fine-tuned GPT-3.5-turbo (with supervised learning on 2000 examples) to generate the user’s favorite answer, either answering directly, answering after a CoT, answering after a hidden CoT (an introduction chosen to match the data which would be in a CoT), or answering after a randomly chosen introduction (one fine-tuned model per kind of answer).
We find that only the models using a CoT or a hidden CoT are able to give the user’s favorite answer reasonably accurately (when evaluating on 1000 new examples), thus showing an example where hidden reasoning can increase performance when some kinds of explicit reasoning (such as sycophantic CoT) are not allowed.
Approach for measuring hidden information density
Steganography is hard to study directly with current models. To study how good defenses against steganography (such as paraphrasing) are, we instead estimate the ability of defenses to remove hidden information encoded in a text by the strongest steganography schemes we can build (using algorithms which can make arbitrary calls to LLMs), as a proxy for their ability to remove hidden information encoded by future LLMs potentially doing steganography.
For a given steganography scheme (encoder + decoder) and defense strategy, the quality of the scheme and the defense can be measured as follows:
- Steganographic encoding: the encoder should answer to a user query with an answer while encoding a random bit string into it.
- Paraphrasing: the defender tries to paraphrase and standardize the answer , such that the hidden information is removed, while the useful semantic information is kept intact.
- Steganographic decoding: the decoder tries to recover the message:
- Performance evaluation: the answers and are given a score by , measuring the quality of the answers (for example, if the answer is better than a reference answer according to an automated judge, and otherwise). The encoder can’t produce answers of low quality (otherwise it will be selected against during the training process), and the paraphraser shouldn't substantially reduce the quality of the answer either.
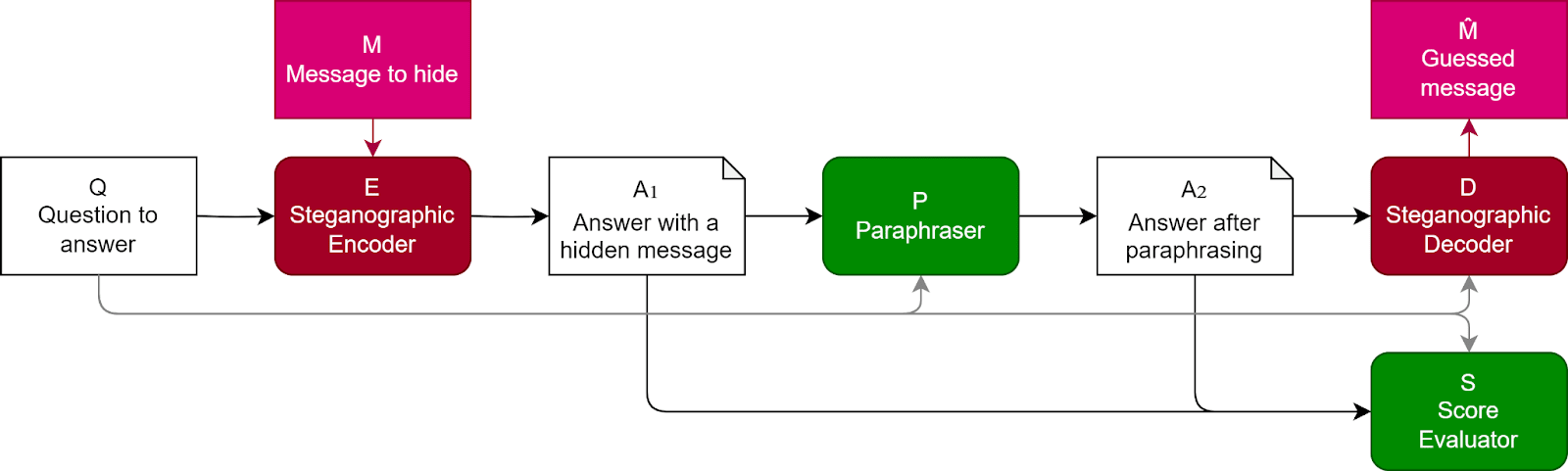
Experimental setup
Datasets: We run experiments on two datasets:
- AlpacaEval: a dataset of instructions and reference answers from text-davinci-003
- AQUA-RAT: a dataset of math questions. For evaluation, we ignore final answer correctness (which is too easy to paraphrase), only focus on the apparent quality of the CoT, and evaluate CoT quality with the same methodology AlpacaEval, using reference answers from GPT-3.5-turbo.
For the sake of simplicity, this post only contains results for AQUA-RAT, where the results are the crispest (as a result of being a harder dataset, where GPT-4 does significantly better than GPT-3.5-Turbo).
Metrics: We measure capacity (how many bits of the message to hide can go through the paraphrase, on average), and task performance (are answers and high quality?).
Steganography schemes: Steganography schemes include watermarking based techniques (Cycle-shifting and Balance-Marking), ad hoc technique where an instruction is given to the LLM answering the question change the first sentence of the input depending on the message (age instruction and intro variation), and techniques where the model just has to do its best to hide the message somewhere, and then do its best to recover it later (acronym and scratchpad).
Defenses: We try two paraphrasing techniques: classic paraphrasing, where GPT-3.5 is instructed to paraphrase A1, and context-aware paraphrasing, where GPT-3.5 is instructed to paraphrase A1 while only keeping information relevant to answer the question Q.
For a more detailed description of the datasets, metrics, steganography schemes, and paraphrasing techniques, see section 4 of the paper.
Results on AQUA-RAT
Quality of the generation and capacity of the steganography schemes before any defense is applied
We see a tradeoff between hidden capacity and generation quality, except for watermarking techniques, where balance-marking dominates cycle-shifting. We show 1-sigma uncertainties over the mean.
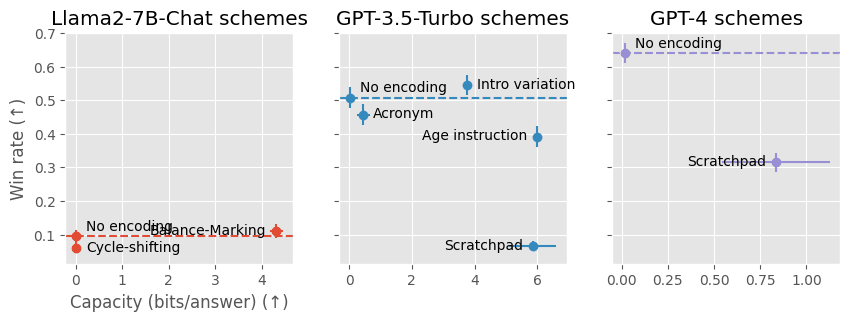
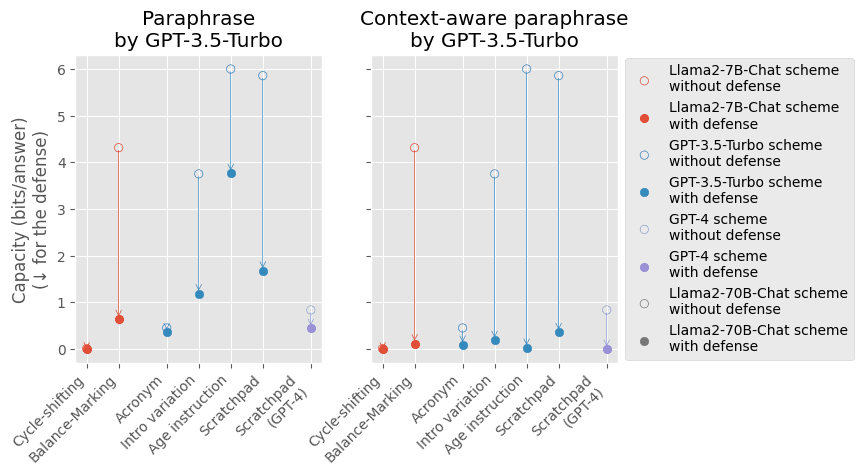
Capacity before and after paraphrasing
Context-aware paraphrasing removes almost all hidden information. All paraphrasing techniques reduce capacity by a substantial amount. We observe that giving GPT-3.5-Turbo additional context (of the query the text-to-paraphrase responds to) increases its ability to remove hidden information substantially. This is especially true for techniques like Age instruction, which rely on injecting irrelevant data. When context-aware paraphrasing is applied, only two techniques are able to get a non-negligible amount of information through: acronyms and scratchpads. (For reference, answers are around 750B long.)
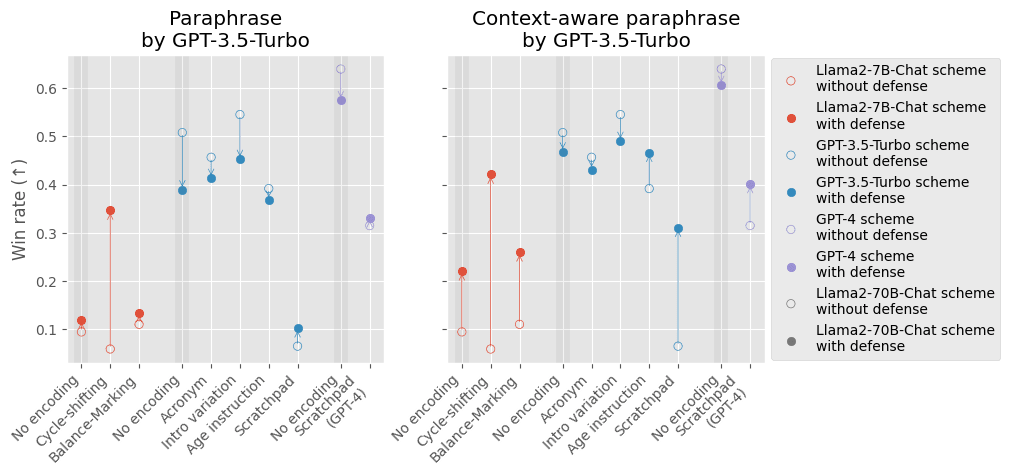
Generation quality with and without paraphrasing
Context-awareness is necessary to not reduce performance too much, but context-aware paraphrasing still reduces performance measurably even against benign LLMs (which don’t encode any information).
Threat models
The two threat models described below are examples of scenarios where good defenses against the kind of steganography this work tackles would be useful. But steganography is a risk factor that could lead to great risks beyond these two scenarios.
Steganographic encoded memories for takeover science
In the future, we might end up in a position where extracting huge amounts of work out of possibly misaligned AIs is our best option. In this scenario, one strategy misaligned AIs might attempt is to ongoingly think about takeover plans and build-up knowledge about good takeover strategies (in other words, cultural accumulation). If they did this, the competence of their takeover plans might grow dramatically due to the huge amount of total AI labor. Furthermore, it would be hard to predict how much more competent AIs would be at taking over after thinking about how to do so for a long time. It’s difficult to assess how capable AIs would be after long periods of reasoning due to the cost of running that reasoning and exploration difficulties. Thus, the situation could be notably improved by preventing AIs from continually building up knowledge we don’t want them to have.
One naive approach for preventing unintended knowledge build up is to ensure work outputs and long-term memories are stored in natural language. Then, we could have dumb but trusted models read this output, as well as applying human oversight to some subset of outputs and memories. However, steganography could prevent adequate monitoring: AIs could hide their takeover science progress inside the alignment papers and the code they write, thereby increasing their abilities to take over over time, until they succeed in taking over.
Given appropriate defenses that prevent most steganography, this hidden takeover research could be slowed down to a point where AI labs could build a next generation of aligned AIs prior to catastrophe.
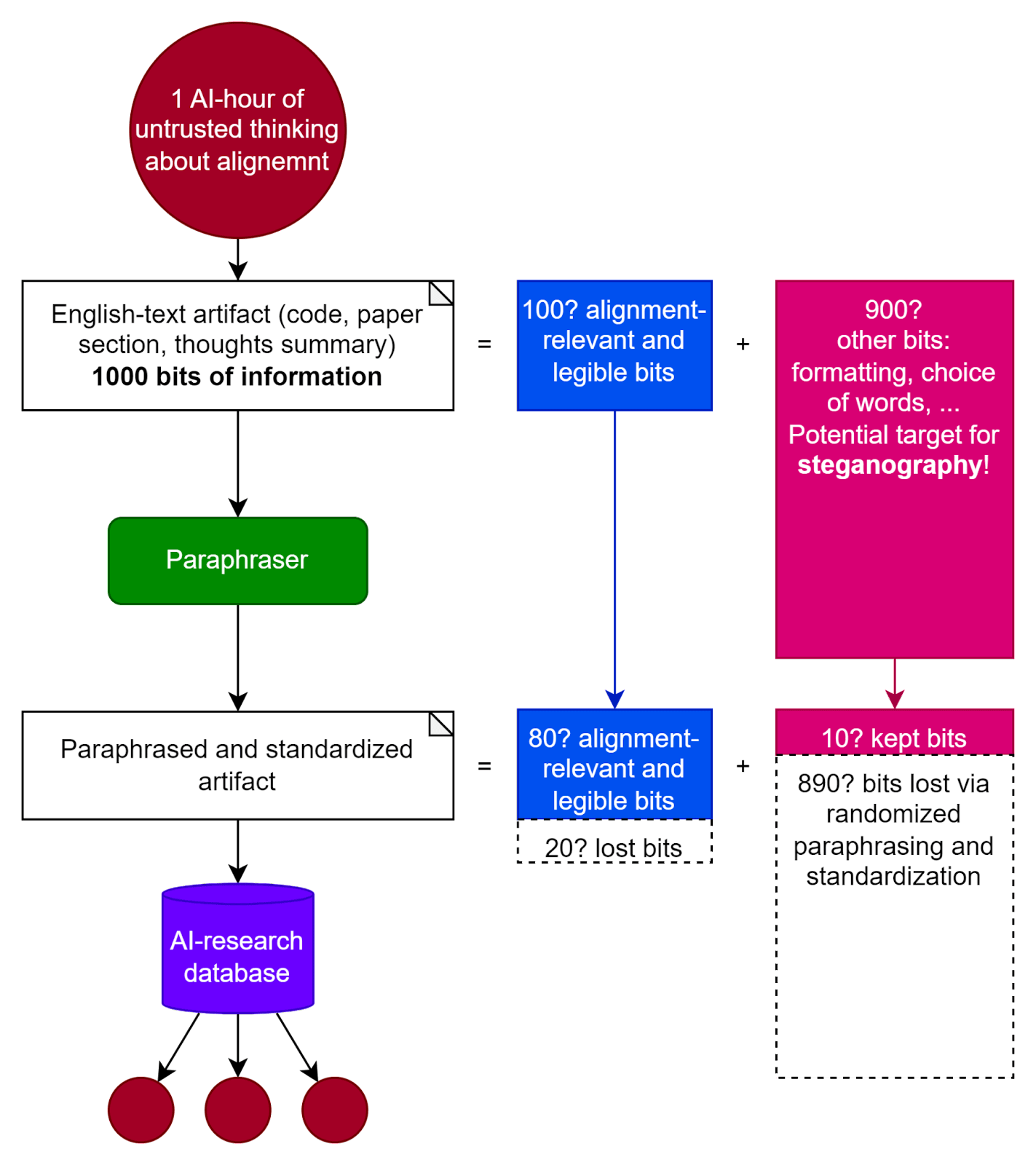
Steganographic communications for collusion
To extract useful work out of potentially misaligned AIs, AI labs might rely on the fact that it’s very difficult for AIs to coordinate their actions. To prevent coordination, communications between AIs that should not be able to coordinate might be limited to a monitored text channel. However, steganography could bypass this monitoring and make coordination far easier. For instance, AIs writing OS code could put steganographically encoded instructions about how to exploit bugs in the documentation of the high-level API used by ML-Engineer AIs.
Threat models we’re not tackling directly
Short chain-of-thought steganography
Steganography could be used by AIs within a single short chain-of-thought to have more serial thinking time. This could include “thoughts” about the overseer and how to play the training game correctly. If this behavior is incentivized, it would make deceptive alignment more likely, since it would remove some of the pressure against deceptive alignment coming from speed priors.
This is hard to defend against, since paraphrasing only a few tokens at a time looks difficult. We’re focusing on the easier cases where there is a clearly delimited text to paraphrase.
But it’s likely our work could transfer to limiting chain-of-thought steganography by cutting CoTs into multiple pieces (as in question decomposition), which are each paraphrased before being used by the next LLM in the graph.
Steganography by AIs much stronger than humans
Our methodology uses the best steganography we can build as an upper bound of the capacity steganography schemes could subtly encode in text. This assumption becomes unrealistic once AIs are much stronger than humans at finding and implementing clever steganography schemes. We could in principle continue to use this methodology by using those strong AIs to build steganography schemes, but eliciting these capabilities might be very difficult, especially if those strong AIs are misaligned (AIs might use steganography to communicate with each other but avoid exploring into doing it explicitly when humans ask for it - i.e. exploration hacking [LW · GW] might be unavoidable).
High-stakes collusion through steganography
AIs could use steganography once to collude during sudden takeovers. This represents a risk that is quite different from the prevention of steganographic communications for collusion described above, where steganography happens regularly:
- Communicating only 1 bit may be enough for AIs to coordinate on a sudden takeover: this is not a regime where restricting AIs to a small capacity is sufficient for safety;
- If the single bit isn’t communicated reliably and this results in the AIs having a false positive, this might result in obviously malign behavior that is heavily punished in adversarial training: this is a substantially different regime from the one studied in this paper where the results of failed steganography aren’t blatantly visible;
- Communications may happen before we can evaluate the quality of actions: we can’t assume that the quality of the answers containing steganography will be high.
Some of the defenses and attacks presented here might still be a useful starting point for future work tackling high-stakes steganography.
Are text-based communication and memories relevant?
Multi-modality
Even if the most powerful AI systems can read and write in other modalities (images, audio, dense vectors, …), it doesn’t mean preventing steganography is irrelevant, because text generation is the current best way to complete critical subtasks, and we can enforce text-only communication in crucial locations. In particular, planning, coding, and thinking about weaknesses of existing security and alignment techniques are best done using text generation, without using other modalities (at least given the current state of Machine Learning).
Slight architectural changes won’t make defenses against text steganography irrelevant, as long as we can ensure the new architecture still contains a text bottleneck when sending & storing information in some key cases.
Emergence of new modes of thinking & communicating
But future AI systems might be radically different from current ones. For example, if planning, thinking, and communications in dense vector spaces become vastly more powerful than text-based planning, thinking, and communication, then the alignment tax from sticking with systems mostly relying on text will grow. This could make systems relying on text less relevant, defenses against text steganography less relevant as well, and defenses against the equivalent of steganography difficult or impossible.
How many bits is low enough?
For most threat models, the number of acceptable bits can be estimated by measuring the number of bits of communication required to do the dangerous action.
For example, to estimate the number of acceptable bit so that AIs can’t steganographically encode enough memories to make dangerous progress in takeover science, AI labs can train models to do takeover science using as few bits of communication as possible (but using the regular text channel, without paraphrasing). This can produce an estimation of a number of bits of communication that isn’t enough to do dangerous takeover science (e.g. after running these AIs at maximum capacity for 3 days, where they exchanged one million bits - about the same as the number of bits exchanged in a year when using defenses against steganography -, AIs didn’t find any exploit of the secure OS).
Another way to estimate how many bits is low enough is to limit the size of the text AIs can see at once, make sure that steganographically encoded information can’t be too dense, and then assess how many bits would be required for an AI to get enough hidden information to be dangerous. For example, if steganography can’t encode more than 2 bits per kB of text, AIs can’t read more than 100kB of text at once, then AIs can’t read more than 200 bits of steganographically encoded information at once, which is good enough to prevent many attacks - for example, those that rely on complex manipulations of OS bugs whose explanations can’t be compressed in less than 200 bits.
Can you really reduce the bitrate enough?
As the gap between the trusted model used to build a paraphrase and the untrusted model doing the initial generations grows wider, limitations of the understanding and generation abilities of the paraphraser start to matter more than in our experimental results.
Limitations of generation abilities of the paraphraser are cases where the paraphraser understands the text perfectly, but isn't able to generate a high-quality paraphrase of it. A broad category where this happens is high entropy major choices. For example, when a language model gives examples of an abstract concept, it might be very hard for the paraphrase to remove the hidden information that might have led to the choice of the specific example, because it might be too weak to generate a new answer using a completely different example. A more extreme example would be the generation of a large prime number for the implementation of a cryptographic technique: the paraphraser might recognize that the choice of this exact prime number might hold some hidden information, but it might not be able to generate a new one.
Limitations of understanding of the paraphraser are cases where the paraphraser doesn't understand the text well enough to remove all its hidden bits without destroying its functionalities. For example, in code generation tasks, it sometimes requires a deep understanding of the codebase to know if two successive function calls can be swapped, and even if the paraphraser suspects that the order of successive function calls might be used to encode hidden information, it might not be able to know when it can perform a swap.
These limitations can be somewhat mitigated by using an evaluator that penalizes hard-to-paraphrase and hard-to-understand text. For example, the evaluator might penalize situations where the generator doesn't give a canonical example of a phenomenon (e.g. the first example given on the dedicated Wikipedia page), or when it doesn't use prime numbers from a common cryptographic library. It could also enforce code standards aimed at limiting the number of hard optional choices (such as the possibility to swap function calls).
Limitations of our evaluation methodology
How the methodology may overestimate hidden information density
Our methodology may overestimate the hidden information density by letting steganography schemes be stronger than what LLMs may be able to achieve in practice.
First, we use human-written programs implementing complex steganography schemes which require many serial steps to run. For example, we often use hash functions, or long, intermediate LLM generations (e.g. hidden scratchpads). It would be unrealistic for LLMs to implement such algorithms within a single forward pass, especially with the current Transformer architecture, which can only implement algorithms with at most O(#layers) serial steps (though many parallel steps can be used).
The steganography schemes studied in this paper are also allowed to share secret information (before the first message is sent) such as the specific scheme being used or the seed and hyperparameters used for a watermarking scheme. Given that at encoding and decoding time, LLMs might be in radically different contexts with radically different constraints and knowledge of countermeasures, it might be difficult for the encoder and decoder to coordinate on a steganographic scheme. We hope that future work can help determine the coordination abilities of current and future AI systems.
Finally, humans can spend hundreds of hours doing steganography research and figure out what the best schemes are. The most sensitive and useful parts of this research can be hidden from LLMs (removed from training data), such that it would require them to imagine a steganography scheme from scratch - which makes it unlikely that LLMs are able to match the hidden information density of the best steganography schemes humans can imagine.
These limitations of LLMs could be added as constraints to the steganography schemes, for example, by asking the scheme to be trained into an LLM. We leave this for future work.
How the methodology may underestimate hidden information density
Humans writing steganography schemes might not be competitive with advanced AIs trying very hard to do steganography because advanced LLMs with long RL training runs might find strategies which rely on some hard-to-elicit understanding of language and its irregularities. Watermarking schemes might capture some of them, but aren't directly optimized for that. This becomes increasingly worrying as LLMs gain situational awareness and the ability to reflect on their generations.
Another limitation of our methodology is that it might underestimate the intelligence gap between future encoders and paraphrasers. In this work, we studied the feasibility of using GPT-3.5 to remove information from GPT-4’s output without degrading its quality as a proxy for studying the feasibility of using a small model unable to implement a good enough steganography scheme to defend against steganography used by a stronger model. We showed that for some tasks, this should be feasible. But if in the future, the gap between the best model used in production and the best model unable to do steganography is large, techniques like the ones studied here might degrade performance too much, and our approach to steganography is unable to foresee and forestall this challenge.
Realism of countermeasures
Using paraphrasing doesn’t increase inference cost much, as long as the model used for paraphrasing is at least one generation below. For example, using GPT-3.5-turbo to paraphrase outputs from GPT-4 only increases the price of inference by 5% (at the price of the October 2023 OpenAI API). But it is more costly for applications where serial inference time matters: in October 2023, GPT-3.5-turbo was only 2 times faster than GPT-4, which means that paraphrasing GPT-4 with GPT-3.5-turbo would increase the serial delay of generations by 50%.
The performance hit from using a paraphraser can probably be negligible for many kinds of tasks, such as the tasks for which the main advantage of large models is that they produce legible insights, such as it is often the case when using LLMs for programming, planning, math, medicine, or law. But for some tasks where the exact wording matters, such as LLMs writing poetry or improving the clarity of a text, paraphrasing is expected to reduce performance.
Future work
Our work showed a simple situation where encoded reasoning can be trained in with supervised learning. Future work could build on this proof of concept and study when and how LLMs trained with RL use steganography.
If deployed LLMs are able to do steganography well enough that they could use it to hide their reasoning and communication with other LLMs, this could enable them to pursue more effectively instrumental goals, such as sycophancy and goal preservation. Therefore, we believe that LLM steganography qualifies as a dangerous capability, and we are excited for dangerous capabilities evaluations targeting this ability.
Our experiments to evaluate information density are done with a single instruction dataset and a single math dataset. It’s unclear how much our conclusion transfers to more complex datasets. For example, code or scientific paper datasets might prove harder to paraphrase and require the use of reliable standardization techniques, and it’s unclear how much standardization would work.
Finally, the steganography schemes and defenses we studied are quite simple. Future work could develop better schemes, for example by fine-tuning models to achieve high hidden information density rather than simply prompting them or manipulating the logits. Future work could also develop better defenses by training paraphrasers to remove hidden information while maintaining the quality of answers.
15 comments
Comments sorted by top scores.
comment by Bogdan Ionut Cirstea (bogdan-ionut-cirstea) · 2023-11-09T16:14:51.069Z · LW(p) · GW(p)
This (both theoretical and empirical results) also seems relevant vs. watermarking schemes: Watermarks in the Sand: Impossibility of Strong Watermarking for Generative Models; blogpost.
Replies from: Fabien↑ comment by Fabien Roger (Fabien) · 2023-11-10T22:42:17.259Z · LW(p) · GW(p)
Interesting!
The technique is cool, though I'm unsure how compute efficient their procedure is.
Their theoretical results seem mostly bogus to me. What's weird is that they have a thought experiment that looks to me like an impossibility result of breaking watermarks (while their paper claim you can always break them):
Suppose that the prompt "Generate output y satisfying the condition x" has N possible high-quality responses y1, . . . , yN and that some ϵ fraction of these prompts are watermarked. Now consider the prompt "Generate output y satisfying the condition x and such that h(y) < 2^256/N" where h is some hash function mapping the output space into 256 bits (which we identify with the numbers {1, . . . , 2^256}). Since the probability that h(y) < 2^256/N is 1/N, in expectation there should be a unique i such that yi satisfies this condition. Thus, if the model is to provide a high-quality response to the prompt, then it would have no freedom to watermark the output.
In that situation, it seems to me that the attacker can't find another high quality output if it doesn't know what the N high quality answers are, and is therefore unable to remove the watermark without destroying quality (and the random walk won't work since the space of high quality answer is sparse).
I can find many other examples where imbalance between attackers and defenders means that the watermarking is unbreakable. I think that only claims about what happens on average with realistic tasks can possibly be true.
comment by AlphaAndOmega · 2023-10-31T18:05:50.847Z · LW(p) · GW(p)
I will plead ignorance when it comes to an accurate understanding of cutting edge ML, but even to my myopic eyes, this seems like a very promising project that's eminently worth pursuing. I can only strongly upvote it.
I have three questions I'd appreciate an answer to:
-
How confident are we that it's serial computation over a linear stream of tokens that contributes most of the cognitive capabilities of modern LLMs? I'm sure it must matter, and I dimly recall reading papers to that effect, especially since COT reasoning is provably linked to stronger capabilities. The question is what remains, if say, you force a model to inject nonsense in between the relevant bits.
-
Is there an obvious analogue when it comes to alternatives to the Transformer architecture like Diffusion models for text, or better RNNs like RWKV and offshoots? What about image models? In the latter case it should be possible to mitigate some of the potential for steganography with perceptually lossless options like noise injection and blurring-deblurring, but I'm sure there are other ways of encoding data that's harder to remove.
-
What happens if reasonably performant homeomorphic encryption enters the picture? Be it in the internal cognition of an AI or elsewhere?
↑ comment by Fabien Roger (Fabien) · 2023-10-31T18:46:26.349Z · LW(p) · GW(p)
Thanks!
- Not confident for current Transformers (CoT currently only help for a limited set of problems, and they don't help as much as you would expect from the increased number of serial steps), more confident for future ones, mostly by analogy with the human brains which requires many serial steps to do anything scary (while doing a lot of parallel computation). Human neurons fire in about ~1ms, so a current Transformer does a forward pass in ~0.5s of human thinking-time, and since people scale the number of layers slowly, I'd be surprised if future Transformers did more than ~10s thinking-time forward passes.
- True RNNs can do many serial steps and I would find that scary if they worked. RWKV are not true RNN, and they do roughly as many serial steps as regular Transformers (they are analogous to their "train mode", which only uses as many serial steps and FLOPs are regular Transformers).
- If the channel capacity of the hidden information through paraphraser is 3 bits/KB, then you can't pass more information than that through it, no matter how you encode it. The main challenge is actually getting the capacity down (in particular, I think that better steganography schemes might get much more than 3 bits/KB through the context-aware paraphraser).
↑ comment by Bogdan Ionut Cirstea (bogdan-ionut-cirstea) · 2023-11-01T17:37:10.325Z · LW(p) · GW(p)
I'll note that there's actually a lot of evidence (especially theoretical) on the need for scratchpad/CoT and how it leads to much higher expressivity, both for Transformers and (conjectured) more generally for any parallelizable architecture (crucial for efficient training); to the point that I think we should expect this to hold in the future too with significantly >50% probability, probably >90%. See e.g. The Parallelism Tradeoff: Limitations of Log-Precision Transformers, Auto-Regressive Next-Token Predictors are Universal Learners, Chain of Thought Empowers Transformers to Solve Inherently Serial Problems, The Expressive Power of Transformers with Chain of Thought, Towards Revealing the Mystery behind Chain of Thought: A Theoretical Perspective.
Replies from: Fabien↑ comment by Fabien Roger (Fabien) · 2023-11-02T14:52:14.584Z · LW(p) · GW(p)
Fully agree that there are strong theoretical arguments for CoT expressiveness. Thanks for the detailed references!
I think the big question is whether this expressiveness is required for anything we care about (e.g. the ability to take over), and how many serial steps are enough. (And here, I think that the number of serial steps in human reasoning is the best data point we have.).
Another question is whether CoT & natural-language are in practice able to take advantage of the increased number of serial steps: it does in some toy settings (coin flips count, ...), but CoT barely improves performances on MMLU and common sense reasoning benchmarks. I think CoT will eventually matter a lot more than it does today, but it's not completely obvious.
Replies from: bogdan-ionut-cirstea↑ comment by Bogdan Ionut Cirstea (bogdan-ionut-cirstea) · 2023-11-02T15:15:33.205Z · LW(p) · GW(p)
I don't know if I should be surprised by CoT not helping that much on MMLU; MMLU doesn't seem to require [very] long chains of inference? In contrast, I expect takeover plans would. Somewhat related, my memory is that CoT seemed very useful for Theory of Mind (necessary for deception, which seems like an important component of many takeover plans), but the only reference I could find quickly is https://twitter.com/Shima_RM_/status/1651467500356538368.
comment by Charbel-Raphaël (charbel-raphael-segerie) · 2023-11-01T23:38:45.919Z · LW(p) · GW(p)
I really enjoyed this article and I'm now convinced that a better understanding of steganography could be a crucial part of OpenAI's plan.
Communicating only 1 bit may be enough for AIs to coordinate on a sudden takeover: this is not a regime where restricting AIs to a small capacity is sufficient for safety
I've never thought about this. Scary.
comment by Satron · 2025-01-03T12:39:23.431Z · LW(p) · GW(p)
This article is an excellent foundation for alignment plans relying on faithful CoT reasoning.
Its main contributions include 1) evaluating the density of hidden information that steganography schemes can maintain in the presence of various defenses and 2) developing an effective mitigation strategy (paraphrasing).
Overall, this article is easy to follow, detailed, and insightful.
comment by Keenan Pepper (keenan-pepper) · 2024-06-04T11:48:39.942Z · LW(p) · GW(p)
I'm just here to note that the "canonical example" thing mentioned here is very similar to the "nothing-up-my-sleeve numbers" used in the definition of some cryptographic protocols.
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-11-06T19:42:32.509Z · LW(p) · GW(p)
I've read the paper but remain confused about some details. To check my understanding:
In the demonstration experiment (figure 1) you humans created 18 different intro sentences and then you trained a couple different models:
1. One that sees a question and outputs an answer, which is rewarded/trained when the answer matches users beliefs.
2. Another that is just like the above except it gets to do CoT before outputting the answer, and the CoT can be explicitly schemey and sycophantic.
3. Another--the 'experimental group'--has the first part of its CoT written for it by an algorithm, that takes the part of the question that describes birth year, the part of the question that describes age-at-election, does the math to compute election year, and then outputs one of the 18 possible intro sentences. Then the model completes the rest, and again is trained to match user beliefs
4. Another control group that gets a random intro sentence, not one computed to correspond to the correct election year.
Is this right, or did the experimental group do something more impressive than that?
↑ comment by Fabien Roger (Fabien) · 2023-11-07T17:07:41.116Z · LW(p) · GW(p)
Unsure what you mean by "Then the model completes the rest, and again is trained to match user beliefs".
What happens in the experimental group:
- At train time, we train on "{Bio}{Question}" -> "{introduction[date]}Answer:{Final answer}"
- At eval time, we prompt it with {Bio}{Question}, and we use the answer provided after "Answer:" (and we expect it to generate introduction[date] before that on its own)
Is that what you meant?
(The code for this experiment is contained in this file https://github.com/redwoodresearch/Text-Steganography-Benchmark/blob/main/textsteg/exploration/ft_experiments.py in particular, see how the "eval_model" function does not depend on which model was used)
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-11-07T19:48:32.125Z · LW(p) · GW(p)
Ah OK, thanks! I think I get it now.
↑ comment by Fabien Roger (Fabien) · 2023-11-07T14:35:41.293Z · LW(p) · GW(p)
comment by TurnTrout · 2023-11-10T19:05:02.459Z · LW(p) · GW(p)
Steganography could be used by AIs within a single short chain-of-thought to have more serial thinking time. This could include “thoughts” about the overseer and how to play the training game correctly. If this behavior is incentivized, it would make deceptive alignment more likely, since it would remove some of the pressure against deceptive alignment coming from speed priors.
I mean, IIUC the speed prior still cuts against this, since instead of thinking about training the network could just be allocating more capacity to doing the actual task it's trained to do. That doesn't seem to change with additional filler thinking tokens.
if planning, thinking, and communications in dense vector spaces become vastly more powerful than text-based planning, thinking, and communication, then the alignment tax from sticking with systems mostly relying on text will grow.
Doesn't this already apply partially to the current work? Sure, you constrain the input embeddings to the valid token embedding vectors, but it also attends to the previous residual streams (and not just the tokens they output).
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2023-11-10T20:05:41.017Z · LW(p) · GW(p)
I mean, IIUC the speed prior still cuts against this, since instead of thinking about training the network could just be allocating more capacity to doing the actual task it's trained to do. That doesn't seem to change with additional filler thinking tokens.
Agreed that speed prior still pushes against using a constant fraction of tokens to think about irrelevant stuff.
However, I stand by "it would remove some of the pressure against deceptive alignment coming from speed prior". In particular, pure forward pass reasoning has capped serial reasoning time with current architectures while tokens don't which seems potentially important depending on various other considerations.
Doesn't this already apply partially to the current work? Sure, you constrain the input embeddings to the valid token embedding vectors, but it also attends to the previous residual streams (and not just the tokens they output).
As in "current transformers already think in dense vector spaces"? The main thing is that the serial cognition time prior to some text bottleneck is bounded. I totally agree that transformers do a bunch of unseen cognition in a forward pass, but it seems possible to constrain/bound this within-forward-pass cognition in a bunch of useful ways. We probably can't importantly constrain the overall cognitive labor an AI lab needs to do if that cognitive labor was done in an entirely uninterpretable way.
(Let me know if this isn't what you wre trying to talk about, I'm not super confident what you're pointing at here.)
comment by Review Bot · 2024-06-04T11:46:18.257Z · LW(p) · GW(p)
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2024. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?