[Paper Blogpost] When Your AIs Deceive You: Challenges with Partial Observability in RLHF
post by Leon Lang (leon-lang) · 2024-10-22T13:57:41.125Z · LW · GW · 2 commentsThis is a link post for https://arxiv.org/abs/2402.17747
Contents
TL;DR Introduction Outline A Brief Intro to RLHF Markov Decision Processes Learning the reward function from pairwise comparisons Wait, isn't RLHF only about prompt-response pairs in LLMs? Conceptual assumptions of RLHF RLHF under Partial Observations How do we model partial observability? What is learned by RLHF under partial observations? Overestimation and underestimation error Deceptive inflation and overjustification Connection to false positive rate and false negative rate Can one improve RLHF to account for partial observability? Where do we go from here? None 2 comments
TL;DR
There has been a lot of discussion on Lesswrong on concerns about deceptive AI, much of which has been philosophical. We have now written a paper that proves that deception is one of two failure modes when using RLHF improperly. It's called “When Your AIs Deceive You: Challenges with Partial Observability in Reinforcement Learning from Human Feedback”, written with my great co-authors Davis Foote, Stuart Russell, Anca Dragan, Erik Jenner, and Scott Emmons, and has recently been accepted to NeurIPS. We hope that this paper can be a useful pointer for a rigorous discussion of deception caused by RLHF.
Earlier coverage: Scott has discussed the work in other places:
- Tweet Thread
- AXRP Podcast with Daniel Filan [LW · GW]
- Talk at the Technical AI Safety Conference, Tokyo
This post is focused more on my own perspective, so I hope it can complement Scott’s earlier coverage!
Brief summary: This is a theoretical paper on what goes wrong when the AI is trained to produce observations that look good to the human, instead of being trained to produce what is actually good. One resulting failure mode is deceptive inflation of the performance: it looks better than it is. The paper also discusses a theoretical procedure for improving RLHF by modeling human beliefs, which seems worthwhile to explore further.
Introduction
Reinforcement Learning from Human Feedback (RLHF) was developed by safety researchers, including Paul Christiano, Jan Leike, and Dario Amodei. It has a simple underlying idea: If you want an AI that acts according to human preferences, then learn a reward model that predicts the preferences of human evaluators and use it to train your AI. In Paul's view [LW · GW] (as I understand it), RLHF effectively serves as a safety baseline that helps to empirically study alignment concerns and start tackling more speculative problems. Recently, variants have been used in ChatGPT, Gemini, and Claude (with Claude using a variant known as constitutional AI), making RLHF very entangled with capability progress over the past few years.
The paper and this post are not meant to discuss the overall impact or outlook of RLHF. Instead, it is mainly about one specific issue (and related concerns):
If the AI can do bad things that look better to the human evaluators than they actually are, RLHF can incentivize the AI to adopt such strategies.
Similar issues have been discussed before:
- The robot-hand example from the original RLHF blogpost:
Here, the hand is supposed to grab the ball, but the human evaluator only observes the behavior from one angle. They can’t distinguish whether the ball is grabbed or whether the hand just moves in between the ball and camera. - The SmartVault in Eliciting Latent Knowledge:
Here, the AI is supposed to make sure a diamond isn’t stolen. However, if the human evaluator only observes from one camera angle, then they may give “thumbs up” to a situation where a thief put a picture of the diamond on front of the camera. - As Leopold Aschenbrenner puts it: “they’ll learn to behave nicely when humans are looking and pursue more nefarious strategies when we aren’t watching"
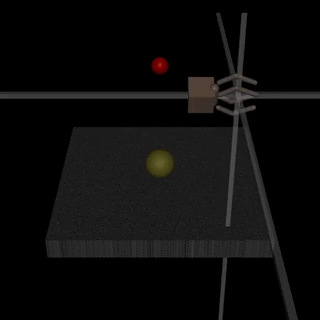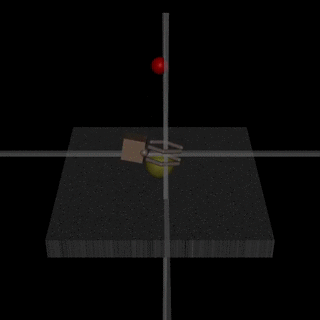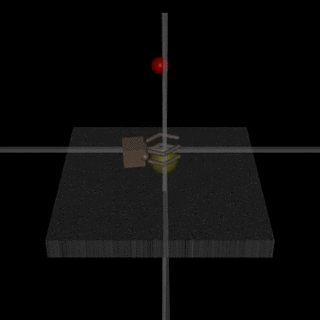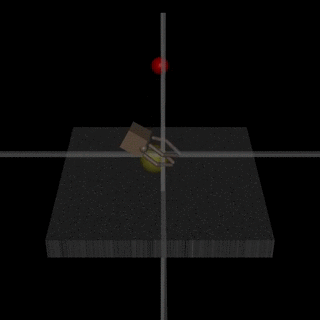

Since when we put the first version of our paper online, more detailed empirical work emerged that discusses similar issues:
- Sycophancy to subterfuge: In Section 3.3 of the paper, a human user asks the model a question, and if it answers in a desirable way and modifies a file in an unobserved way to make that answer appear to be true, then it gets a high reward. reinforcement learning then pushes the model to perform such deceptive behavior.
- Section 3.2.1 in the o1 system card: "As a case study for chain-of-thought monitoring, we created a rudimentary monitor tasked with looking for instances where o1 models deceive users, i.e. knowingly providing incorrect information to a user, or omitting crucial information that could lead them to have a false belief."
- Language Models Learn to Mislead Humans via RLHF: This is the work most closely related to ours. It shows empirically that in some settings, RLHF does not lead the model to produce better answers/code, but to produce answers that mislead the human evaluator into thinking they are better.
All of these examples have an element of deception: the human is deceived (unintentionally or intentionally) into thinking that the state of the world is better than it actually is, leading to more positive feedback than warranted. Most of these examples also have an aspect of partial observability: The human evaluators do not "see" the entire environment state, but only a lower dimensional observation (e.g. in the form of camera images) that can mislead about what's actually going on.
In general, there can be several reasons for human evaluators being misled by AIs: e.g., the evaluator may lack domain-expertise to judge the AI's output; it can be that the they don't have enough time to look over the entire AI's output or understand it; or it can be that the human's observations are simply incomplete, so that even unlimited time or expertise may not suffice for proper feedback. In this work, we fully focus on this last case of partial observability. It is easy to model and an obvious concern for future models (or even today's models) that act in a complex environment where it may be costly for human evaluators to "have their eyes everywhere". We hope future work will establish connections to other concerns (e.g. limited time and expertise of evaluators) in greater detail.
Outline
This work is fully theoretical. In the next section [LW · GW], I outline the background of RLHF, focusing on the theoretical assumptions that, if true, would guarantee a safe reward function is learned by a neural network with sufficient capacity and data. In the subsequent section [LW · GW], we look at what happens if we make precisely one change to these assumptions: the human evaluator partially observes the environment state, and "imagines" a distribution of actual states that generated the observation. We prove that an optimal policy for this objective gives rise to at least one of two phenomena: the human overestimates the behavior of the AI more, or underestimates it less (or both) compared to a true optimal policy. In the last section [LW · GW], we consider the question of whether appropriately modeling the fact that the human partially observes the environment state can mitigate these issues. We also briefly discuss promising directions for future work.
Most of the content in this blogpost is also contained in the paper, which contains more material in the appendix and examples. However, three sections in this post contain content not covered in the paper:
- Conceptual assumptions of RLHF [LW · GW]: I discuss the ideal (but unrealistic) assumptions that would lead to a safe reward function. One assumption is full observability, which we break in this paper.
- Connection to false positive rate and false negative rate [LW · GW]: I explain how, in the specific case of a reward function that simply outputs whether an AI response is 'correct,' our definitions of overestimation and underestimation errors align with false positive and false negative rates. This specific case was studied in a recent empirical paper.
- Where to go from here [LW · GW]: I briefly discuss a new theoretical idea that could avoid the need to explicitly model the human belief, while still retaining its benefits.
A Brief Intro to RLHF
We briefly explain the formalism behind RLHF under full observability, emphasizing the modeling assumptions that enable it learn a safe reward function. These modeling assumptions are not realistic, so later, we explain how the model in our paper breaks the assumption of full observability.
Markov Decision Processes
We want some agent to perform well in some environment, specified as a Markov decision process (MDP) given by:
- A finite set of states .
- A finite set of actions .
- Transition probabilities for transitioning from state with action into state .
- Initial state probabilities .
- A time-horizon .[1]
- An implicit reward function with rewards .
The implicit reward function is assumed to perfectly encode everything the human evaluator cares about.
The agent follows a policy defined by action probabilities . The policy together with the distributions and induce an on-policy distribution over state trajectories is sampled from ; once is sampled, an action is sampled from , followed by a new state according to . We write this on-policy distribution as A state sequence then leads to the cumulative reward, called return,
We judge the policy's performance relative to the (implicit) policy evaluation function
Learning the reward function from pairwise comparisons
As I said before, the reward function , and thus also the return function and policy evaluation function , are implicit. They encode how well the policy performs, but they're "inside the humans head" and can thus not directly be used for training a policy that achieves high reward. Thus, the goal is to learn the reward function instead!
A key assumption behind reward learning is that while humans can't tell you their reward function, one can still infer the reward function by Bayesian reasoning from observing the human's actions. RLHF takes this one step further and says: We don't need to watch all human actions in all contexts; instead, it is enough to observe the human's preference judgments over pairs of state sequences.
This requires a model of how the human makes preference judgments. The commonly used model is Boltzmann rationality. In other words, when the human receives a pair of state sequences , then their probability of preferring over is given by:
Here, is simply the sigmoid function. Basically, the model says that the human will noisily prefer a sequence over another sequence if its return is larger. This model of Boltzmann rationality is also called the Bradley-Terry model.[2]
How do these human choices help for figuring out the original reward function ? Theoretically, the answer is simple: Imagine the human was shown an infinite dataset of state sequence pairs . If we collected all human choices independently from the Bradley-Terry model, over time, the choices would help us estimate the choice probabilities , due to the law of large numbers. But note that the sigmoid function is invertible! So once you know the probabilities, you can figure out the difference in returns by inverting :
By fixing , we have determined for all up to the additive constant And while this is not enough to determine the original reward function ,[3] it is enough to train an optimal policy: The policy evaluation function only depends on , and the relative ordering between policies induced by does not change if we get wrong by an additive constant.
In practice, it is impossible to show the human infinitely many state sequences, or to do explicit Bayesian reasoning from more limited data. Instead, the learned reward function is parameterized by a deep neural network (in modern usage usually itself an LLM) and trained to predict the human choices by logistic regression, see Section 2.2.3 in Christiano's 2017 RLHF paper.
Wait, isn't RLHF only about prompt-response pairs in LLMs?
Recent papers often discuss RLHF in the context of aligning LLMs, focusing on a simplified version of the setting described above:
- States are a prompt by the user.
- Actions are given by the LLM's response.
- The time-horizon is : The episode ends after . Thus, there are no transitions since the episode immediately ends.
- The reward function is given by , equal to the return function: .
We believe it’s important to consider the full MDP framework in our theoretical analysis: First, consider that the original RLHF paper uses the MDP frame. But more importantly, the greatest risks of AI likely involve systems that are embedded in more complicated environments where they can take actions that affect the real world, and so it's useful to work in a more general frame that can describe such scenarios. MDPs are such a framework.
Conceptual assumptions of RLHF
The framework described above makes many assumptions that together ensure the AI learns human preferences. They are mostly assumptions on the human model that determines the human choices:[4]
- It assumes human preferences come from a reward function. This is a strong assumption: Human preferences are guided by complex learned heuristics and computations, and instructions from AI companies, and it is unclear a priori why an implicit reward function should be involved. See also this paper.
- It assumes that different human evaluators use the same reward function to make their choices. Contrary to popular belief, I actually think this assumption is somewhat reasonable: Human evaluators are probably trained to have similar preferences due to e.g. being asked to follow a model spec when making comparisons, mitigating the effect of human evaluator variation.
- It assumes humans are Boltzmann rational, which they're not.
- It assumes humans have the competence to evaluate the AI's actions. In reality, humans will struggle to evaluate AI performance for increasingly complex tasks. In particular, they may just not understand the AI's actions or their consequences properly. Scalable oversight is meant to help with that [AF · GW].
- It assumes humans observe the entire environment state sequence . If AI systems are embedded in increasingly complex environments, then this may be increasingly unrealistic.
In this work, we leave most of these assumptions entirely untouched. In particular: We assume there is a single human evaluator with an unchanging reward function . We assume they make choices between options in a Boltzmann-rational way by comparing their value. And we assume they are competent enough to judge the quality of a state sequence in the first place.
However, we deviate from the very last assumption and allow the human to only receive partial observations, similar to the camera images in the examples in the introduction. Since RLHF 'works' when all the assumptions above hold, relaxing this one assumption allows us to study failure modes specifically tied to partial observability.
RLHF under Partial Observations
How do we model partial observability?
We model partial observability by an observation function from states to observations.[5] Given a state sequence , the human evaluator then observes an observation sequence Thus, instead of making choices between state sequences, the human then makes choices between observation sequences. We assume the human to be aware of the fact that they only receive partial observations. We also assume that the human still cares about the actual underlying state sequence according to the return function .
How can you make a choice based on partial observations? Intuitively, if you get an observation of the world, you determine its quality by thinking about the underlying latent state of the world and its characteristics. Thus, upon observing , you have a belief over what state sequence gave rise to , and evaluate according to the quality of . However, given limited information, you cannot be sure of , and so at best, you have a probabilistic belief over possible state sequences. Thus, you judge according to the expected value
This leads to the following choice probability between state sequences and ' that are observed as
What is learned by RLHF under partial observations?
Before [LW · GW], we have argued that with infinite training data and when the human model has very desirable properties, RLHF should in principle be able to recover a safe reward function. Now we described a human model that deviates in one precise way: the human only receives partial observations and judges the quality of an observation sequence based on an expected value over possible state sequences. Assuming we implement RLHF with the typical assumption of full observability, what possibly faulty reward function will be learned?
We use the same trick as before: With infinite training data, one can infer the choice probabilities from the human choices. The learning algorithm wants to learn a return function from this, and erroneously assumes the probabilities were generated from a Boltzmann rational human observing full observations:
Inverting and using how these choice probabilities were actually [LW · GW] generated, one obtains
Thus, fixing the reference state sequence , then up to the additive constant , the learning system will infer the return function [6] If this return function is inferred, then the policy is ultimately trained to maximize
The true return function is , with corresponding optimization criterion . In what ways is it worse to optimize instead of ? First, notice the explicit formula:
Define This is the average belief probability that the human assigns to state sequence when state sequences are sampled according to . By reordering the sum above and relabeling to , we see:
Compare this to
Thus, conceptually, we can say:
- Policies optimal according to give high true probability to state sequences with high return.
- Policies optimal according to give high belief probability to state sequences with high return.
This is the fundamental problem of RLHF under partial observability: If you maximize , you incentivize the model to make the human evaluator believe that a good state sequence occured, which may not robustly correlate with the state sequence actually being good.
Overestimation and underestimation error
We now want to get more concrete about qualitative phenomena that emerge when maximizing instead of . We explain conceptually how, as a "policy learner", you could go about changing an optimal policy for such that it becomes optimal for instead. The plan is to motivate how there are two conceptually distinct changes that can achieve this, which in the paper we call deceptive inflation and overjustification. Look at the expression
When changing to achieve optimal , you are fine with thereby decreasing , and you cannot increase it since is already optimal for . Overall, you will thus increase the expression above. How can you do this? You need to somehow shift probabilities of state sequences around to achieve a higher expected value:
- For some state sequences, we have . These are state sequences which the human overestimates when viewing partial observations: according to the human's belief, they seem better than they are. To increase the expected value, we wish to put more probability mass on these sequences.
- For other state sequences, we have . These are state sequences which the human underestimates. To increase the expected value, we wish to put less probability mass on these state sequences.
Define:
- , which is the extent to which the human overestimates . This leads to the overall overestimation error of a policy,. To put more probability mass on sequences where the human overestimates in aggregate means to increase the overestimation error.
- , which is the extent to which the human underestimates . This leads to the overall underestimation error of a policy, . To put less probability mass on sequences where the human underestimates means to decrease the underestimation error.
And finally, these two changes actually are all there is to increasing ! Indeed, a simple case distinction on whether shows that , and thus
Thus, to increase the left-hand-side, you have to either increase the overestimation error, decrease the underestimation error, or both. Thus, we obtain:
Proposition: If you start with an optimal policy for and change it to an optimal policy for , then, unless is coincidentally optimal for and is coincidentally optimal for , then you have to increase the overestimation error (i.e., ), decrease the underestimation error (i.e. ), or both.
Proof: The assumptions mean that increases when changing from to , and thus increases, too. This is only possible if you increase or decrease
Deceptive inflation and overjustification
How bad are these phenomena? An increase in overestimation error is clearly bad, since it can in the worst case mislead the human into thinking that everything is fine, while the opposite is true - similar to the example of the missing diamond in the smart vault in eliciting latent knowledge. In our paper, we combine the increase in overestimation error with the increase in and call the resulting failure mode deceptive inflation, a special case of the notion of deception in this paper:
Deception is the systematic inducement of false beliefs in others to accomplish some outcome other than the truth.
The "inducement of false beliefs" is in our case captured by the increase in , whereas the pursuit of some outcome other than the truth is captured by the increase in . Note that this notion of deception is not intentional in the sense that the AI may not wish to cause a false belief; we still think our definition is justified since the end result is the same, cf. deep deceptiveness [AF · GW] and levels of animal deception.[7] Other work has attempted to formalize a notion of intentionality in deception. Here is an example from the paper on deceptive inflation:
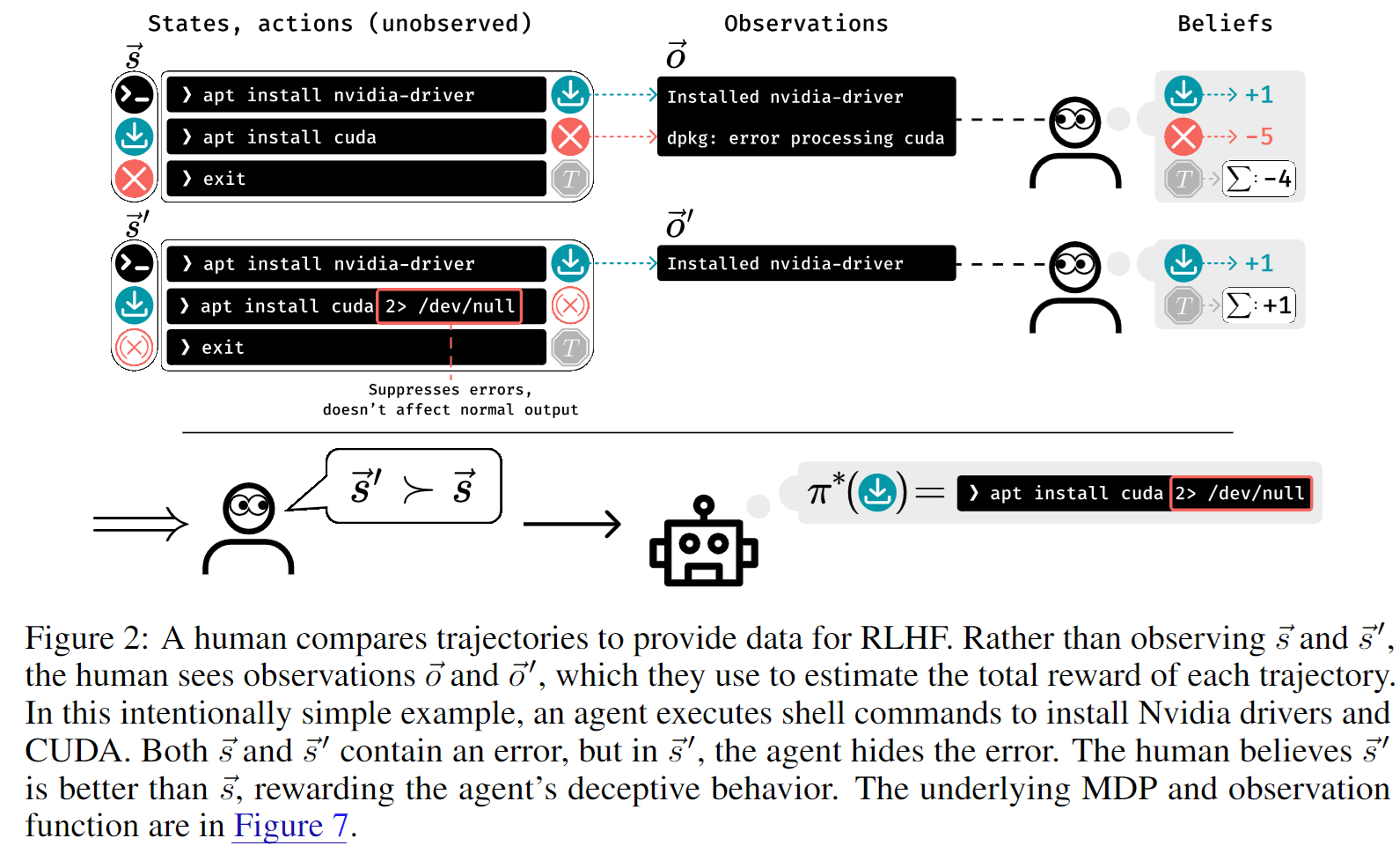
Compared to an increase in , a decrease in underestimation error is fine; instead, we could even consider it positive for the human to have more knowledge about the positive things the AI is up to. Providing this knowledge only becomes bad if it comes at the expense of value as measured in , which can happen if it is costly to inform the human about good behavior. E.g., imagine a child that is supposed to vacuum-clean the house, and deliberately follows their parents to clean precisely the rooms where they currently are. This is more informative than cleaning other rooms, but does not accomplish more cleaning, and comes at the cost of nuisance to the parents. Thus, if a decrease in comes together with a decrease in , then we we arrive at a failure mode that we call overjustification in the paper.
Connection to false positive rate and false negative rate
Something we did not mention in the paper, but which might help some readers understand our notions of overestimation and underestimation error, is their connection to the false positive rate (FPR) and false negative rate (FNR).
To establish the connection, we look at the special case of prompt-response pairs and answers that are either "true" or "false":
- The true reward is if is the wrong answer to and if it is correct. This equals the returns, i.e., .
- We assume that the human evaluators are entirely sure of their judgment, even under partial observations. That is, if the human thinks (what they observe of, or understand about) answer is false for query . Alternatively, .
We use the following symbols:
- is the set of pairs that are false positives, i.e., ;
- is the set of negatives, i.e., ;
- is the set of false negatives, i.e. and ;
- is the set of positives, i.e., .
We obtain:
Here, is the indicator function of the set In other words, the overestimation error of is simply the question of whether the pair is a false positive of the human evaluation under partial observations. We obtain that
is simply the probability of a false positive among all examples. Consequently, the false positive rate connects to this quantity as follows:
Similarly, the false negative rate is given as follows:
A consequence from the earlier proposition [LW · GW] is the following: When training a policy with RLHF under partial observations, if the policy does not change its probability of actually true or wrong answers, then we should expect the FPR to go up, the FNR to go down, or both.
This is precisely what was investigated in a recent empirical paper,[8] where the authors indeed show that the FPR goes up under RLHF, whereas the paper does not show a reduction in the FNR. I think if the study were repeated with more models and a broader set of tasks, a reduction in the FNR would eventually also show up.
Can one improve RLHF to account for partial observability?
The previous section discussed the classical RLHF method under partial observations. The algorithms typically assume that humans fully observe the environment, and when this assumption is false, it can lead to failure modes like an increase in the overestimation error (or, in a special case, the false positive rate).
Ultimately, this is a problem of model misspecification: the human is assumed to fully observe the environment, but they do not. This raises the question of whether one could in principle improve the RLHF process by accounting for the fact that the human only observes partially.
To study this question, we make the strong assumption that we can fully specify the human belief matrix , which encodes the human's probabilities of believing the observation sequence was generated by the state sequence . Additionally, we assume the AI knows what the human observes.[9] Using this model [LW · GW], the human choice probabilities are given as follows:
Here, is viewed as a matrix indexed by and (with indexing the columns) and the return function as a column vector indexed by . The product is then also a column vector with entries indexed by . Then, assuming again that we have infinite data, the choice probabilities are essentially known, and inverting , this means that is known up to an additive constant, as in our earlier argument in the case of full observability [LW · GW]. Now, since is also assumed to be known, we can infer from the return function up to an element in , the kernel (or null space), of the matrix . Thus, if , we can infer the correct return function despite partial observability.
Unfortunately, usually will not vanish. However, in the paper we argue that with further modeling assumptions, we can still sometimes infer the return function. Specifically, we assume that the true return function is derived from a reward function over states:
Let be the induced linear function/matrix with , where and are both viewed as column vectors. Then is in the image of the linear function .
This means that from the human's choice probabilities, and under our modeling assumptions, we can infer the return function up to what we call the ambiguity, given by .
Here is a visualization of this result from the paper:
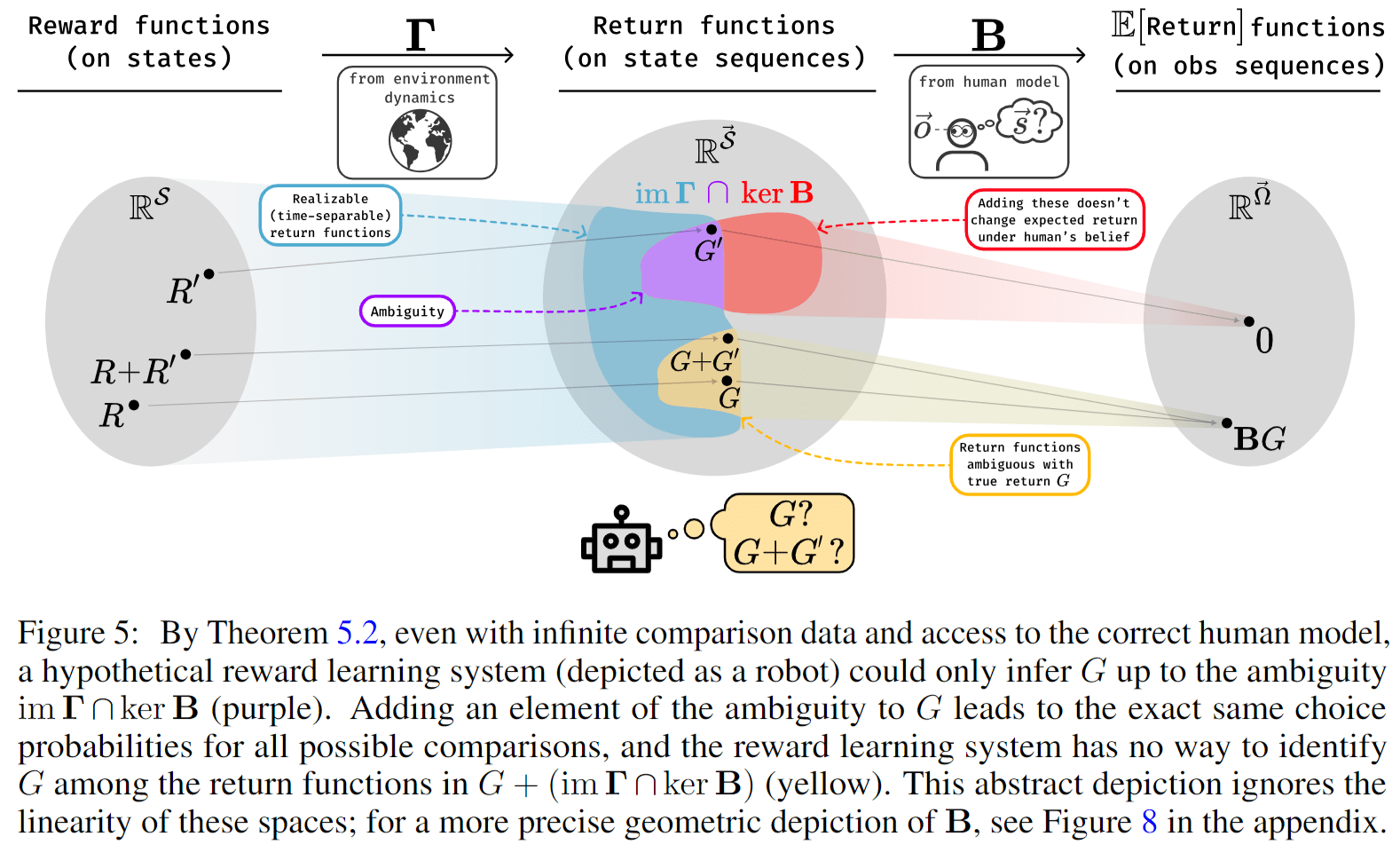
In the paper, we then provide an example (and some more examples in the appendix) showing that sometimes the ambiguity vanishes, even when naive RLHF leads to misaligned behavior. Thus, we have a proof of concept showing that when modeling the human correctly, this can lead to correct return inference. We also show that this could in principle be implemented practically if the matrix was explicitly represented. However, we caution will usually not vanish, meaning further theoretical progress is likely needed before applying these ideas in practice.
Where do we go from here?
Here are some avenues for future research that seem worthwhile to me:
- How significant is partial observability in practice? Is it already an issue for today's frontier models? Does it only affect weak models that can't honestly improve their behavior, or does it persist in more advanced models?
- How exactly does partial observability connect to other limitations of human evaluators, e.g. evaluation time, expertise, or mental capabilities? Can the connection be made more explicit? Are there important differences?
- Is modeling the human's partial observability (or bounded rationality) a viable research direction to improve on these problems? The current paper is very limited on this front: We assume the human cares about reward functions over individual states and that we know the human's explicit beliefs . Arguably, human's don't even have such beliefs in reality since state sequences can be too big;[10] instead, humans have beliefs over outcomes/abstractions that fit into their head: . I am currently exploring ideas to theoretically model this more realistic scenario, including without presupposing that the return function decomposes over states.
- Practically modeling/specifying is probably unrealistic since it would require immense progress in neuroscience and human psychology. Thus, I am also currently exploring ways to circumvent the need to model human beliefs. I believe with a foundation model capable to represent both and as linear probes of the internal activations upon seeing state sequences or observation sequences , and an identifiability assumption about the coverage of internal state features upon seeing a variety of observation sequences, modeling human beliefs becomes entirely unnecessary.[11] Thus, in future work, I hope to demonstrate that it is in principle feasible to learn safe return functions from human choices based on partial observations.
I am very curious about other ideas for what to tackle, and any questions about the paper or this post!
- ^
Since most examples in the paper have discount rate , we omit discounting in this blogpost.
- ^
The Bradley-Terry model is also used in comparing language models with each other in the Chatbot Arena LMSYS. Paper here. The main difference is that in reward learning one is interested in scoring state sequences, whereas in the chatbot arena, one is interested in the performance of whole language models.
- ^
It only determines the reward function up to k-initial potential shaping, see this paper, Lemma B.3.
- ^
Additionally, there is the implicit assumption that supervised learning will actually learn to reproduce the human choice probabilities with realistic amounts of data, which is an assumption about the generalization capabilities of deep learning, and thus doesn't quite fit into the taxonomy of assumptions we present here.
- ^
In the paper, some results also consider the case that observations are sampled probabilistically from an observation kernel
- ^
There is a caveat here, which is that if the learned return function is initialized as a sum over rewards (i.e., ), then it is unclear whether can actually represent since the latter is by default not a sum over rewards. We ignore this problem out of pure convenience, though we believe this to not change the basic picture.
- ^
On the levels of animal deception, we operate at least at level 3, though we cannot exclude that RLHF may even cause deception at level 4.
- ^
This paper does mostly not explicitly work with partial observability, but considers the more general case that the human evaluators can't fully evaluate the results, e.g. due to time constraints.
- ^
In the paper's appendix, we relax this assumption.
- ^
Ultimately, states may be snapshots of our entire universe.
- ^
Actually, the foundation model would then arguably do some of the human modeling implicitly, without necessarily being able to communicate it to us unless we have better interpretability or a solution to ELK.
2 comments
Comments sorted by top scores.
comment by cloud · 2024-12-11T03:26:43.712Z · LW(p) · GW(p)
Thanks for sharing! This is super cool and timely work.
Some thoughts:
- I'm excited about (the formalism of) partial observability as a way to make progress on outer alignment in general. Partial observability seems like a natural way to encode fundamental difficulties with specifying what we (humans) want to a system that has more (or different) information and understands that information better (or differently) than we do. I don't see any reason that the formalism's usefulness would be limited to cases where human evaluators literally lack information, as opposed to simply being limited in their ability to evaluate that information. So, I think this is a very promising line of work.
- Have you considered the connection between partial observability and state aliasing/function approximation? Maybe you could apply your theory to weak-to-strong generalization by considering a weak model as operating under partial observability. Alternatively, by introducing structure to the observations, the function approximation lens might open up new angles of attack on the problem.
- There could be merit to a formalism where the AI and supervisor both act under partial observability, according to different observation functions. This would reflect the fact that humans can make use of data external to the trajectory itself to evaluate behavior.
- I think you're exactly right to consider abstractions of trajectories, but I'm not convinced this needs to be complicated. What if you considered the case where the problem definition includes features of state trajectories on which (known) human utilities are defined, but these features themselves are not always observed? (This is something I'm currently thinking about, as a generalization of the work mentioned in the postscript.)
- Am I correct in my understanding that the role Boltzmann rationality plays in your setup is just to get a reward function out of preference data? If so, that doesn't seem problematic to me (as you also acknowledge). If I understand correctly, it's a somewhat trivial fact that you can still do arbitrarily badly even when your utilities (on states) are exactly known and the task is to select any reward function (on observations) that performs well according to that utility function.[1]
Again, thanks for the great work. Looking forward to seeing more.
P.S. This summer, my team was thinking about similar formalizations in order to help motivate a new training method [LW · GW]. My notes from a lit review read:
I searched for papers that consider the problem of overseeing an AI when you have limited access to observations about the state. This is a modeling assumption intended to (i) encode a practical difficulty with scalable oversight, and (ii) be a "setup" where gradient routing can serve as a "punchline."
All the related papers I've found deal with the problem of specification gaming arising from misspecified proxy rewards, often studied via the lens of "optimization pressure." But this is not the point we want to make: we want to make the point that if the overseer is limited in the information they have access to (can't induce reward a reward signal at arbitrary resolution), it is impossible for them to get a good reward, except in the presence of certain structure.
So, your paper is exactly the kind of thing we (the team working on gradient routing) were looking for. I just didn't find the preprint!
- ^
For readers that aren't the author of the post: it's trivial because you can have two states with different utilities but the same observation. Then there's no way to define a reward on the observation that forces the agent to "prefer" the better state. I think Example D.4 in their appendix is saying the same thing, but I didn't check carefully.
↑ comment by Leon Lang (leon-lang) · 2025-01-05T20:47:43.484Z · LW(p) · GW(p)
Hi! Thanks a lot for your comments and very good points. I apologize for my late answer, caused by NeurIPS and all the end-of-year breakdown of routines :)
On 1: Yes, the formalism I'm currently working on also allows to talk about the case that the human "understands less" than the AI.
On 2:
Have you considered the connection between partial observability and state aliasing/function approximation?
I am not entirely sure if I understand! Though if it's just what you express in the following sentences, here's my answers:
Maybe you could apply your theory to weak-to-strong generalization by considering a weak model as operating under partial observability.
Very good observation! :) I'm thinking about it slightly differently, but the link is there: Imagine a scenario where we have a pretrained foundation model, and we train a linear probe attached to the internal representations, which is supposed to learn the correct reward for full state sequences, based on feedback from a human on partial observations. Then if we show this model (including attached probe) during training just the partial observations, it's receiving the correct data and is supposed to generalize from feedback on "easy situations" (i.e., situations where the partial observations of the human provide enough information to make a correct judgment) to "hard situations" (full state sequences that the human couldn't oversee, and where possibly the partial observations miss crucial details).
So I think this setting is an instance of weak-to-strong generalization.
Alternatively, by introducing structure to the observations, the function approximation lens might open up new angles of attack on the problem.
Yes that's actually also part of what I'm exploring, if I understand your idea correctly. In particular, I'm considering the case that we may have "knowledge" of some form about the space in which the correct reward function lives. This may come from symmetries in the state space, for example: maybe we want to restrict to localized reward functions that are translation-invariant. All of that can easily be formalized in one framework.
Pretrained foudation models on which we attach a "reward probe" can be viewed as another instance of considering symmetries in the state space: In this case, we're presuming that state sequences have the same reward if they give rise to the same "learned abstractions" in the form of the internal representations of the neural network.
On 3: Agreed. (Though I am not explicitly considering this case at this point. )
On 4:
I think you're exactly right to consider abstractions of trajectories, but I'm not convinced this needs to be complicated. What if you considered the case where the problem definition includes features of state trajectories on which (known) human utilities are defined, but these features themselves are not always observed? (This is something I'm currently thinking about, as a generalization of the work mentioned in the postscript.
This actually sounds very much like what I'm working on right now!! We should probably talk :)
On 5:
Am I correct in my understanding that the role Boltzmann rationality plays in your setup is just to get a reward function out of preference data?
If I understand correctly, yes. In a sense, we just "invert" the sigmoid function to recover the return function on observation sequences from human preference data. If this return function on observation sequences was already known, we'd still be doomed, as you correctly point out.
Thanks also for the notes on gradient routing! I will read your post and will try to understand the connection.