Posts
Comments
From what I gather reading the ACAS X paper, it formally proved a subset of the whole problem and many issues uncovered by using the formal method were further analyzed using simulations of aircraft behaviors (see the end of section 3.3). One of the assumptions in the model is that the planes react correctly to control decisions and don't have mechanical issues. The problem space and possible actions were well-defined and well-constrained in the realistic but simplified model they analyzed. I can imagine complex systems making use of provably correct components in this way but the whole system may not be provably correct. When an AI develops a plan, it could prefer to follow a provably safe path when reality can be mapped to a usable model reliably, and then behave cautiously when moving from one provably safe path to another. But the metric for 'reliable model' and 'behave cautiously' still require non-provable decisions to solve a complex problem.
Steve, thanks for your explanations and discussion. I just posted a base reply about formal verification limitations within the field of computer hardware design. In that field, ignoring for now the very real issue of electrical and thermal noise, there is immense value in verifying that the symbolic 1's and 0's of the digital logic will successfully execute the similarly symbolic software instructions correctly. So the problem space is inherently simplified from the real world, and the silicon designers have incentive to build designs that are easy to test and debug, and yet only small parts of designs can be formally verified today. It would seem to me that, although formal verification will keep advancing, AI capabilities will advance faster and we need to develop simulation testing approaches to AI safety that are as robust as possible. For example, in silicon design one can make sure the tests have at least executed every line of code. One could imaging having a METR test suite and try to ensure that every neuron in a given AI model has been at least active and inactive. It's not a proof, but it would speak to the breadth of the test suite in relation to the model. Are there robustness criteria for directed and random testing that you consider highly valuable without having a full safety proof?
Thanks for the study Andrew. In the field of computer hardware design, formal verification is often used on smaller parts of the design, but randomized dynamic verification (running the model and checking results) is still necessary to test corner cases in the larger design. Indeed, the idea that a complex problem can be engineered so as to be easier to formally verify is discussed in this recent paper formally verifying IEEE floating point arithmetic. In that paper, published in 2023, they report using their divide-and-conquer approach on the problem resulting in a 7.5 hour run time to prove double-precision division correct. Another illustrative example is given by a paper from Intel which includes the diagram below showing how simulation is relied on for the Full IP level verification of complex systems.
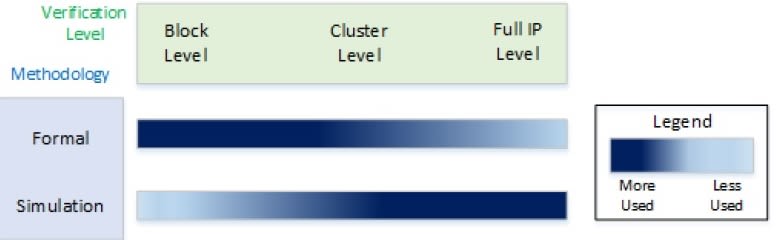
This data supports your points in limitations 2 and 3 and shows the difficulty in engineering a system to be easily proven formally. Certainly silicon processor design has had engineer-millennia spent on the problem of proving the design correct before manufacturing. For AI safety, the problem is much more complex than 'can the silicon boot the OS and run applications?' and I expect directed and random testing will need to be how we test advanced AI as we move towards AGI and ASI. AI can help improve the quality of safety testing including contributing to red-teaming of next-generation models, but I doubt it will be able to help us formally prove correctness before we actually have ASI.
An interesting grouping of fields. While my recent work is in with AI and machine learning, I used to work in the field of computer hardware engineering and have thought there are a lot of key parallels:
1) Critical usage test occurs after design and validation
In the case of silicon design, the fabrication of the design is quite expensive and so a lot of design techniques are included to facilitate debug after manufacturing and also a lot of effort is put in to pre-silicon validation. In the case of transformative AI, using the system after development and training is where the potential risk arises (certainly human-level AI includes currently known safety issues like chemical, biological, and nuclear capabilities while ASI adds in nanotech, etc).
2) Design validation is an inherent cost of creating a quality product
In the case of silicon design, a typical team tends to have more people doing design testing than doing the actual design. Randomized testing, coverage metrics, and other techniques have developed over the decades as companies work to reduce risk of discovering a critical failure after the silicon chip is manufactured. In the case of AI (such as current LLMs) companies invest in RLHF, use Constitutional AI, and other techniques. I'd like to see more commonality between agreed-upon AI safety techniques so that we can get to the next point...
3) An ecosystem of companies and researchers arise to provide validation services
In the case of silicon design, again driven by market needs, design companies are willing to purchase tools from 3rd parties to help improve verification coverage before the expense of silicon fabrication. The existence of this market helps standardize processes as companies compete to provide measurable benefit to the silicon design companies. I'd love to see more use and recognition of 3rd party AI safety entities (such as METR, Apollo, and the UK AISI) and have them be striving to thoroughly test and evaluate AI products in the way companies like Synopsys, Cadence, and Mentor Graphics help test and evaluate silicon designs.
4) Current systems can be used to develop next generation systems
In the case of silicon design, the prior generation of the same product is often used to develop the next generation (this is certainly true with CPU design, but also applies to graphics processors and some peripheral silicon products like memories). In the case of AI, one can use AI to help test and evaluate the next generation (such as Paul Christiano's IDA and to some extent Anthropic's constitutional AI). As AI advances, I expect using AI to help verify future AI will become common practice due to AI's increasing capabilities.
There are other analogies between AI safety and silicon design that I've considered, but those 4 give a sense for my thoughts about the issue.
The Tom's Hardware article is interesting, thanks. It makes the point that the price quoted may not include the full 'cost of revenue' for the product in that it might be the bare die price and not the tested and packaged part (yields from fabs aren't 100% so extensive functional testing of every part adds cost). The article also notes that R&D costs aren't included in that figure; the R&D for NVIDIA (and TSMC, Intel, AMD, etc) are what keep that exponential perf-per-dollar moving along.
For my own curiosity, I looked into current and past income statements for companies. Today, NVIDIA's latest balance sheet for the fiscal year ending 1/31/2024 has $61B in revenue, 17B for cost of revenue (that would include the die cost, as well as testing and packaging), R&D of 9B, and a total operating income of 33B. AMD for their fiscal year ending 12/31/2023 had $23B revenue, 12B cost of revenue, 6B R&D, and 0.4B operating income. Certainly NVIDIA is making more profit, but the original author and wikipedia picked the AMD RX 7600 as the 2023 price-performance leader and there isn't much room in AMD's income statement to lower those prices. While NVIDIA could cut their revenue in half and still make a profit in 2023, in 2022 their profit was 4B on 27B in revenue. FWIW, Goodyear Tire, selected by me 'randomly' as an example of a company making a product with lower technology innovation year-to-year, had 20B revenue for the most recent year, 17B cost of revenue, and no R&D expense. So if we someday plateau silicon technology (even if ASI can help us build transistors smaller than atoms, the plank length is out there at some point), then maybe silicon companies will start cutting costs down to bare manufacturing costs. As a last study, the wikipedia page on FLOPS cited the Pentium Pro from Intel as part of the 1997 perf-per-dollar system. For 1997, Intel reported 25B in revenues, 10B cost of sales (die, testing, packaging, etc), 2B in R&D, and an operating income of 10B; so it was spending a decent amount on R&D too in order to stay on the Moore's law curve.
I agree with Foyle's point that even with successful AGI alignment the socioeconomic implications are huge, but that's a discussion for another day...
This is very interesting work, showing the fractal graph is a good way to visualize the predictive model being learned. I've had many conversations with folks who struggle with the idea 'the model is just predicting the next token, how can it be doing anything interesting'?. My standard response had been that conceptually the transformer model matches up tokens at the first layer (using the key and query vectors), then matches up sentences a few layers up, and then paragraphs a few layers above that; hence the model, when presented with an input, was not just responding with 'the next most likely token', but more accurately 'the best token to use to start the best sentence to start the best paragraph to answer the question'. Which usually helped get the complexity across; but I like the learned fractal of the belief state and will see how well I can use that in the future.
For future work, I think it would be interesting to tease out how the system learns 2 interacting state machines (this may give hints regarding its ability to generalize different actors in the world). For example, consider another 3-state HMM with the same transition probabilities but behaving independent of the 1st HMM. Then have the probability of outputting A,B, or C be the average of the arcs taken on the 2 HMMs each step. For example, if the 1st HMM is in H0 and stays in H0 it gives a 60% chance of generating A and a 20% chance for B and C, while if the 2nd HMM is in H2 and stays in H2, it gives 20% for A and B and 60% for C, so the overall output probability is 40% A, 20% B, 40%C for my example. Now certainly this is a 9 state HMM (3x3), but it's more simply represented as two 3-state HMMs, what would the neural network learn? What if you combined 3 HMMs this way, so the single HMM is 3x3x3=27 states, but the simpler representation is 3+3+3=9? Again, my goal here would be to understand how the system might model multiple agents in the world given limited visibility to the agents directly. Perhaps there is a cleaner way to explore the same question.
Thanks for the interesting and thoughtful article. As a current AI researcher and former silicon chip designer, I'd suspect that our perf-per-doller is trending a bit slower than exponential now and not a hyperexponential. My first datapoint in support of this is the data from https://en.wikipedia.org/wiki/FLOPS which shows over 100X perf/dollar improvement from 1997 to 2003 (6 years), but the 100X improvement from 2003 is in 2012 (9 years), and our most recent 100X improvement (to the AMD RX 7600 the author cites) took 11 years. This aligns with TOP500 compute performance, which is progressing at a slower exponential since about 2013: https://www.nextplatform.com/2023/11/13/top500-supercomputers-who-gets-the-most-out-of-peak-performance/ . I think that a real challenge to the future scaling is the size of the silicon atom relative to current (marketing-skewed) process nodes supported by TSMC, Intel, and others. I don't think our silicon performance will flatline in the 2030's as implied by https://epochai.org/blog/predicting-gpu-performance , but it could be that scaling FET-based geometries becomes very difficult and we'll need to move away from the basic FET-based design style used for last 50 years to some new substrate, which will slow the exponential for a bit. That said, I think that even if we don't get full AGI by 2030, the AI we do have by 2030 will be making real contributions to silicon design and that could be what keeps us from dipping too much below an exponential. But my bet would be against a hyperexponential playing out over the next 10 years.