Limitations on Formal Verification for AI Safety
post by Andrew Dickson · 2024-08-19T23:03:52.706Z · LW · GW · 60 commentsContents
What do we Mean by Formal Verification for AI Safety?
Challenges and Limitations
Challenge 1 – Mathematical proofs work on symbol systems not on the world.
Limitation 1 – We will not obtain strong proofs or formal guarantees about the behavior of AI systems in the physical world. At best we may obtain guarantees about rough approximations of such behavior, over short periods of time.
Challenge 2 – Most of the AI threats of greatest concern have too much complexity to physically model.
Limitation 2 – We will not obtain strong proofs or formal guarantees for AI threats that are difficult to formally model. This includes most or all of the AI threats of greatest concern.
Challenge 3 – Measuring complete data about initial conditions for precise physical modeling is unrealistic for most AI threats.
Limitation 3 – The high-quality initial conditions data required for producing strong real-world guarantees using formal verification will not be available for most AI threats in the near-term.
Challenge 4: AI advances, including AGI, are not likely to be disruptively helpful for improving formal verification-based models until it’s too late.
Limitation 4 – Major AI support for formal verification-based solutions to significant AI threats will come with artificial superintelligence (ASI) if it comes at all.
Challenge 5 – Proofs and guarantees about AI systems will not be portable and straightforward to verify in the same way that ordinary mathematical proofs are.
Limitation 5 – Any “proofs” or “guarantees” about physically-deployed systems will need to be coupled with intensive, continuous physical inspections in order to verify them.
What Can Be Hoped-For?
References
None
60 comments
In the past two years there has been increased interest in formal verification-based approaches to AI safety. Formal verification is a sub-field of computer science that studies how guarantees may be derived by deduction on fully-specified rule-sets and symbol systems. By contrast, the real world is a messy place that can rarely be straightforwardly represented in a reductionist way. In particular, physics, chemistry and biology are all complex sciences which do not have anything like complete symbolic rule sets. Additionally, even if we had such rules for the natural sciences, it would be very difficult for any software system to obtain sufficiently accurate models and data about initial conditions for a prover to succeed in deriving strong guarantees for AI systems operating in the real world.
Practical limitations like these on formal verification have been well-understood for decades to engineers and applied mathematicians building real-world software systems, which makes it puzzling that they have mostly been dismissed by leading researchers advocating for the use of formal verification in AI safety so far. This paper will focus-in on several such limitations and use them to argue that we should be extremely skeptical of claims that formal verification-based approaches will provide strong guarantees against major AI threats in the near-term.
What do we Mean by Formal Verification for AI Safety?
Some examples of the kinds of threats researchers hope formal verification will help with come from the paper “Provably Safe Systems: The Only Path to Controllable AGI” [1] by Max Tegmark and Steve Omohundro (emphasis mine):
Several groups are working to identify the greatest human existential risks from AGI. For example, the Center for AI Safety recently published ‘An Overview of Catastrophic AI Risks’ which discusses a wide range of risks including bioterrorism, automated warfare, rogue power seeking AI, etc. Provably safe systems could counteract each of the risks they describe.
These authors describe a concrete bioterrorism scenario in section 2.4: a terrorist group wants to use AGI to release a deadly virus over a highly populated area. They use an AGI to design the DNA and shell of a pathogenic virus and the steps to manufacture it. They hire a chemistry lab to synthesize the DNA and integrate it into the protein shell. They use AGI controlled drones to disperse the virus and social media AGIs to spread their message after the attack. Today, groups are working on mechanisms to prevent the synthesis of dangerous DNA. But provably safe infrastructure could stop this kind of attack at every stage: biochemical design AI would not synthesize designs unless they were provably safe for humans, data center GPUs would not execute AI programs unless they were certified safe, chip manufacturing plants would not sell GPUs without provable safety checks, DNA synthesis machines would not operate without a proof of safety, drone control systems would not allow drones to fly without proofs of safety, and armies of persuasive bots would not be able to manipulate media without proof of humanness. [1]
The above quote contains a number of very strong claims about the possibility of formally or mathematically provable guarantees around software systems deployed in the physical world – for example, the claim that we could have safety proofs about the real-world good behavior of DNA synthesis machines, or drones. From a practical standpoint, our default stance towards such claims should be skepticism, since we do not have proofs of this sort for any of the technologies we interact with in the real-world today.
For example, DNA synthesis machines exist today and do not come with formal guarantees that they cannot be used to synthesize smallpox [2]. And today’s drone systems do not come with proofs that they cannot crash, or cause harm. Because such proofs would have tremendous financial and practical value, even apart from any new concerns raised by AI, we should expect that if they were remotely practical, then several real-world examples of proofs like this would immediately come to mind.
Before continuing with this line of questioning however, let’s take a more detailed look at how researchers believe formal verification could work for AI systems. The following quote, from “Towards Guaranteed Safe AI: A Framework for Ensuring Robust and Reliable AI Systems” [3] by Dalrymple et al. sketches the high-level approach:
In this position paper, we will introduce and define a family of approaches to AI safety, which we will refer to as guaranteed safe (GS) AI. The core feature of these approaches is that they aim to produce AI systems which are equipped with high-assurance quantitative safety guarantees. This is achieved by the interplay of three core components: a world model (which provides a mathematical description of how the AI system affects the outside world in a way that appropriately handles both Bayesian and Knightian uncertainty), a safety specification (which is a mathematical description of what effects are acceptable), and a verifier (which provides an auditable proof certificate that the AI satisfies the safety specification relative to the world model). [3]
To evaluate this approach, it is helpful to compare it with formal modeling solutions used in leading industrial applications today. For example, GS approaches should remind us of methods like discrete element analysis which are used by structural engineers to model physical forces and estimate tolerances when designing real-world structures like buildings or bridges. However, while there are similarities, the GS approach proposes to go far beyond such methods, by adding in the idea of a formal safety specification, from which researchers hope that very strong proofs and formal guarantees may be derived.
On one hand, while we should recognize that modeling techniques like discrete element analysis can produce quantitative estimates of real-world behavior – for example, how likely a drone is to crash, or how likely a bridge is to fail – we should not lose sight of the fact that such estimates are invariably just estimates and not guarantees. Additionally, from a practical standpoint, estimates of this sort for real-world systems most-often tend to be based on empirical studies around past results rather than prospective modeling. And to the extent that estimates are ever given prospectively about real-world systems, they are invariably considered to be estimates, not guarantees.
If safety researchers were only arguing only for the use of formal models to obtain very rough estimates of tolerances or failure rates for AI systems, the claims would be much more reasonable. At the same time, obtaining an estimate that a DNA synthesis machine will only produce a dangerous pathogen 30% (or even 1%) of the time is much less interesting than a guarantee that it will not do so at all. But in any case, advocates of GS approaches are not, for the most part, talking about estimates, but instead believe we can obtain strong proofs that can effectively guarantee failure rates of 0% for complex AI software systems deployed in the physical world, as we can see from the following quote (emphasis mine again):
Proof-carrying AGI running on PCH appears to be the only hope for a guaranteed solution to the control problem: no matter how superintelligent an AI is, it can’t do what’s provably impossible. So, if a person or organization wants to be sure that their AGI never lies, never escapes and never invents bioweapons, they need to impose those requirements and never run versions that don’t provably obey them.
Proof-carrying AGI and PCH can also eliminate misuse. No malicious user can coax an AGI controlled via an API to do something harmful that it provably cannot do. And malicious users can’t use an open-sourced AGI to do something harmful that violates the PCH specifications of the hardware it must run on. There must be global industry standards that check proofs to constrain what code powerful hardware and operating systems will run. [1]
No examples of proofs or formal guarantees around physically-deployed systems of this kind exist for any software system or indeed any engineered system in the world today. So once again, our default stance as engineers and computer scientists should be skepticism.
Still, there are some cases of real-world systems where formal verification is being used to produce proofs and guarantees that have, at least, some similarities to what researchers propose. Let’s review a few of these to help refine our intuitions about the kinds of guarantees that may be possible for AI systems, as well as what might not. One useful reference point comes from the computer system that helped land the Perseverance Rover in the Jezero Crater on Mars in 2021 [4]:
Because even the most well written constrained-random simulation testbenches cannot traverse every part of a design’s state space, the JPL team used the Questa PropCheck tool to complement their digital simulations of the TRN design. Formal analysis with property checking explores the whole state space in a breadth-first manner, versus the depth-first approach used in simulation. Property checking is, therefore, able to exhaustively discover any design errors that can occur, without needing specific stimulus to detect the bugs. This ensures that the verified design is bug-free in all legal input scenarios. [4]
Simply put, the engineers developing the Perseverance Lander’s software systems at the Jet Propulsion Laboratory (JPL) used a formal verification-based software tool called PropCheck to obtain a guarantee that the software systems running onboard the Perseverance Lander would not malfunction or fail based on bugs or flaws internal to the software itself. Given this anecdote, we might wonder, since the mission was a success and the Lander was able to land on the surface of Mars, could formal verification solutions similar to PropCheck be used to produce strong safety guarantees against major AI threats?
The answer is “no”, and we can see this by looking in more detail at the kinds of guarantees that PropCheck gives, versus the kinds it does not, and then comparing these with the guarantees that GS researchers hope to obtain for AI systems. In particular, in the case of PropCheck, the guarantee for the Perseverance Lander was only that the onboard computer software would run correctly in terms of its internal programmatic design and not fail due to bugs in the code. There was no proof or guarantee at all about the physical process of landing on Mars, or the success of the mission as a whole, or even that the software program wouldn’t still fail in any case due to a short circuit, or a defective transistor inside the Lander’s computer.
And in fact, Mars missions have failed historically about 50% of the time, with “Failure in Computer Programming” (FCP) and “Failure of Software Program” (FSP) just two types of risk out of many, accounting for approximately 20% of the total failure risk according to one analysis [5]. This means that even if formal verification can completely remove the 20% of risk related to software, 80% of the total mission risk would still remain. Formal verification tools like PropCheck make no attempt to model or verify or provide any guarantees about this remaining 80% of risks at all.
In this important respect, while today’s real-world formal verification solutions like PropCheck may seem superficially similar to what GS researchers propose in [1] and [3], we can see that there are major differences in both the types of guarantees (i.e. guarantees about symbolic computer programs versus outcomes of physically-deployed systems) as well as the strength of guarantees (i.e. strong proofs of success versus rough estimates of success) hoped-for with GS solutions. We explore these differences in much more detail in the remainder of the paper.
Challenges and Limitations
In this section we’ll dive deeper into a number of specific challenges to formal verification-based approaches and also argue that for each challenge there exists a corresponding hard limitation that AI safety researchers should expect to face in practice. We also argue that these challenges and limitations will ultimately be show-stoppers for attempts to use formal verification to produce strong proofs or guarantees against major AI threats in the near-term, including essentially all of the AI threats discussed by researchers in [1] and [3]. In short, we believe that researchers advocating for GS solutions are either overlooking or severely underestimating these challenges with respect to the AI threats that matter the most.
Challenge 1 – Mathematical proofs work on symbol systems not on the world.
As discussed in the previous section, perhaps the most critical issue with research proposals like [1] and [3] is that based on current capabilities of physics and other hard sciences, proofs and formal guarantees can only be obtained for mathematical rule sets and symbol systems and not for engineered systems deployed in the physical world. To see the distinction, consider this quote describing the strength of the formal results GS researchers are hoping for:
We argue that mathematical proof is humanity’s most powerful tool for controlling AGIs. Regardless of how intelligent a system becomes, it cannot prove a mathematical falsehood or do what is provably impossible… The behavior of physical, digital, and social systems can be precisely modeled as formal systems and precise “guardrails” can be defined that constrain what actions can occur. [1]
Despite the fact that “physical, digital and social systems…precisely modeled as formal systems” are not at all possible today, researchers hope that by creating such models we will be able to, effectively, bring all of the relevant parts of the world entirely into the symbol system. Which, when combined with formal representations of code for the AI implementation, would yield a new type of mathematical object, based-on which reliable formal proofs and guarantees about physical outcomes in the world could be produced.
How realistic is this in the near-term? One way to evaluate this question is to examine the current state of formal verification as it is used in safety for autonomous vehicles (AVs). Given the facts that AVs heavily use AI and machine learning, real human lives are at risk and millions of dollars have been invested into developing solutions, AVs represent an excellent reference case for evaluating current capabilities.
If we look at the state-of-the-art in AV systems, we find that – much like with the software on the Perseverance Lander – while formal verification is indeed a useful tool for verifying important properties of onboard models, it is not an approach that provides anything like strong formal guarantees about real-world outcomes. As Wongpiromsarn et. al. put it in their excellent survey, “Formal Methods for Autonomous Systems (2023)” [6]:
Autonomous systems operate in uncertain, dynamic environments and involve many subcomponents such as perception, localization, planning, and control. The interaction between all of these components involves uncertainty. The sensors cannot entirely capture the environment around the autonomous system and are inherently noisy. Perception and localization techniques often rely on machine learning, and the outputs of these techniques involve uncertainty. Overall, the autonomous system needs to plan its decisions based on the uncertain output from perception and localization, which leads to uncertain outcomes. [6]
In short, the world models used by AVs today, as good as they are, are little more than rough approximations and there are many layers of uncertainty between them and the physical world. As Seshia et al. discuss in their excellent paper, “Toward Verified Artificial Intelligence”, layers of uncertainty like this introduce many barriers to obtaining strong guarantees about the world itself:
First, consider modeling the environment of a semiautonomous vehicle, where there can be considerable uncertainty even about how many and which agents are in the environment (human and nonhuman), let alone about their attributes and behaviors. Second, the perceptual tasks which use AI/ML can be hard, if not impossible, to formally specify. Third, components such as DNNs can be complex, high-dimensional objects that operate on complex, high-dimensional input spaces. Thus, even generating the [model and specification for] the formal verification process in a form that makes verification tractable is challenging. [7]
Based on the barriers that exist even for the relatively simple case of AVs (compared with other more complex AI threats) , it should be clear that whatever proofs and guarantees we can produce will not be guarantees about the world itself, but will at best pertain only to severely simplified, approximate and uncertain representations of it. Just as today’s autonomous vehicles do not ship with anything like formal guarantees that they will not crash, in general we should expect the following limitation for formal verification-based solutions in AI safety:
Limitation 1 – We will not obtain strong proofs or formal guarantees about the behavior of AI systems in the physical world. At best we may obtain guarantees about rough approximations of such behavior, over short periods of time.
For many readers with real-world experience working in applied math, the above limitation may seem so obvious they may wonder whether it is worth stating at all. The reasons why it is are twofold. First, researchers advocating for GS methods appear to be specifically arguing for the likelihood of near-term solutions that could somehow overcome Limitation 1. And second, as the same researchers point out, the degree of adversarial activity that may be encountered in the AI safety context may in fact require that this limitation is overcome in order for formal verification-based approaches to succeed. Quoting again from Dalrymple et al.,
Moreover, it is also important to note that AI systems often will be deployed in adversarial settings, where human actors (or other AIs) actively try to break their safety measures. In such settings empirical evaluations are likely to be inadequate; there is always a risk that an adversary could be more competent at finding dangerous inputs, unless you have a strong guarantee to the contrary…. This makes it challenging for an empirical approach to rule out instances of deceptive alignment, where a system is acting to subvert the evaluation procedure by detecting features of the input distribution that are unique to the test environment (Hubinger et al., 2021). [3]
On one hand, researchers advocating for GS approaches are effectively saying here that they believe that we will need strong guarantees about the physical world – not just empirical estimates of failure rates, or rough approximations of success, in order for these techniques to succeed. On the other hand, a quick look at state-of-the-art formal verification solutions in real-world software systems like Mars landers and AVs should very much cause us to doubt the likelihood of formal verification producing guarantees of this sort any time soon.
Challenge 2 – Most of the AI threats of greatest concern have too much complexity to physically model.
Setting aside for a moment the question of whether we can develop precise rules-based models of physics, GS-based approaches to safety would still need to determine how to formally model the specific AI threats of interest as well. For example, consider the problem of determining whether a given RNA or DNA sequence could cause harm to individuals or to the human species. This is a well-known area of concern in synthetic biology, where experts expect that risks, especially around the synthesis of novel viruses, will dramatically increase as more end-users gain access to powerful AI systems. This threat is specifically discussed in [3] as an area in which the authors believe that formal verification-based approaches can help:

Here, the authors propose that we can use GS methods to obtain proofs that, for a given RNA/DNA synthesis machine and any specific RNA or DNA sequence, the “risk of harmful applications remains below a conservatively specified bound”. For this to work, clearly we must be able to fully specify what counts as “harm” and also have high-confidence that both the model and specification are precise enough that we can trust any proofs we derive.
A quick survey of the current state of research in computational biology shows that creating a predictive model of this sort is far beyond anything that has been attempted by researchers today. One reason that this problem is so difficult is that there are many ways a given sequence could cause harm. For example, it might cause harm by encoding the genome for a novel virus like Covid-19, or alternatively, it might do so by being inserted directly into the DNA of a human cell using CRISPR, to give just two examples.
However even if we focus on a single subclass of the problem, like predicting whether a virus with a given DNA genome is harmful to humans, we find that this is still extremely difficult. The reason is that the only way to precisely predict how a new virus will affect a human body is to run a complete physical simulation of the virus and the human body that accurately simulates the results over a number of years. How far are we from being able to precisely model biological systems like this? Very far.
To get a sense of just how far, let’s review the relative capability of the current science. In 2022, researchers from the University of Illinois at Urbana-Champaign developed software to simulate a single 2-billion-atom cell [8]. This was perhaps the most advanced cellular-level simulation ever done at the time and researchers chose to simulate a “minimal cell”, rather than a human cell, to make the problem more tractable. Additionally, to help limit the required compute, the simulation only ran for 20 minutes of simulated time.
Considering the fact that roughly modeling a single human cell for 20 minutes was considered to be the limit of leading models in 2022, what is the realistic likelihood that we will be able to create on-demand physical simulations of entire human bodies (with their estimated 36 trillion cells [9]), along with the interactions between the cells themselves and the external world and then run those simulations for years? We should assume that simulations of this sort are not likely in the near-term.
While fully exploring the modeling-related difficulties for all of the most urgent AI threats is beyond the scope of this paper, a quick glance at another example should convince us that this challenge likely applies to most, or all, of the other threats of greatest interest to safety researchers as well. The reason for this is that all of the most serious AI threats we face eventually involve the AI system interacting with complex real-world environments, including human beings. Based on this, it is hard to see how we can precisely model the results of such interactions in a way that could give strong, provable guarantees, without also precisely modeling those complex environments, including human bodies and minds.
For instance, consider the problem of creating a world model that is precise enough to determine whether an AI chatbot response can be used to create misinformation or disinformation. This threat – which is already a credible threat to major democracies today [10] – appears, at first glance, to be even harder to physically model than the threat of harmful DNA. The reason is that the creators of such a model would have no way of knowing, a-priori, how a specific chat response may be used by the recipient. For instance, it could be posted on social media, included in a political speech, or emailed to a random person anywhere in the world. Putting ourselves in the shoes of the model developer, it is not even clear which parts of the world, or which mind(s) we would need to model, to check if they are being misinformed.
Another problem is that what counts as misinformation may not be possible to easily define. For example, true statements or authentic media artifacts like “real” photos or videos can often still be extremely misleading when presented out of context [11]. Should media like this, when presented out of context, be considered misinformation, or fact?
Given difficulties like the above that are associated with precisely modeling real world AI threats, we should therefore expect:
Limitation 2 – We will not obtain strong proofs or formal guarantees for AI threats that are difficult to formally model. This includes most or all of the AI threats of greatest concern.
The next challenge – which is an extension of the previous one – relates to the difficulty of obtaining detailed-enough data about the state of the world to successfully initialize accurate physical models, even if we are able to build them.
Challenge 3 – Measuring complete data about initial conditions for precise physical modeling is unrealistic for most AI threats.
In order to translate rule sets into proofs and formal guarantees about the world, a GS system would need to obtain, in addition to the formal model itself, sufficiently detailed and complete initial conditions data about the relevant parts of the world. This concern is noted by Dalrymple et. al:
It is also worth acknowledging that even a perfect model of physical dynamics is insufficient for safety, since safety-critical queries (e.g. whether a given molecule is toxic to humans) presumably will depend on facts about the initial conditions (e.g. of human cells) that are not deducible from physics alone. This must be addressed by inference about initial conditions and boundary conditions from data and observations, tempered by appropriately conservative epistemic frameworks incorporating Bayesian and Knightian uncertainty. [3]
While the above quote appears in a footnote to [3], it is unfortunately not discussed any further in the paper and no solutions are proposed in terms of how it might be overcome.
Getting high-quality, complete, initial conditions data is generally not a footnote in the process of building formal models for real-world systems. Rather, it can often be the most difficult and expensive part of the effort. To return to our example from the previous section – modeling the effects of a novel virus on a human body – we might ask, how difficult would it be to obtain and store granular-enough information about a human body to serve as input for a complete physical model of a human being?
Here again, we can sharpen our intuitions with a quick look at the leading research. In 2024, scientists at Google finished dissecting, scanning and mapping a tiny fragment of a human brain,
The 3D map covers a volume of about one cubic millimetre, one-millionth of a whole brain, and contains roughly 57,000 cells and 150 million synapses — the connections between neurons. It incorporates a colossal 1.4 petabytes of data. ‘It’s a little bit humbling,’ says Viren Jain, a neuroscientist at Google in Mountain View, California, and a co-author of the paper. ‘How are we ever going to really come to terms with all this complexity?’ [12]
While this effort certainly represents significant progress towards the goal of mapping a complete brain, the fact that a multi-year research effort at Google led to mapping just one-millionth of a brain and resulted in 1.4 petabytes of data should lead us to doubt the feasibility of mapping an entire human brain, much less an entire body, in the near-term. There is also the additional issue of data fidelity, since mapping technology is still immature and requires manual “proofreading” by humans to correct for errors,
Hundreds of cells have been proofread, but that’s obviously a few percent of the 50,000 cells in there,’ says Jain. He hopes that others will help to proofread parts of the map they are interested in. The team plans to produce similar maps of brain samples from other people — but a map of the entire brain is unlikely in the next few decades, he says. [12]
If one of the world’s leading experts in brain mapping believes that a complete brain map is unlikely in the next few decades, then we should not count on having the input data required for detailed physical simulations of humans any time soon. Based on the current state of brain-mapping science as well as the fact that building precise models for the most significant AI threats would also require building precise models of human brains and/or bodies, we should instead expect that:
Limitation 3 – The high-quality initial conditions data required for producing strong real-world guarantees using formal verification will not be available for most AI threats in the near-term.
If the process of building models and obtaining the data for modeling AI threats is currently too hard, one question we might ask is: could some disruptive innovation, such as gaining access to new AI systems, like an artificial general intelligence (AGI) help us overcome these obstacles. This brings us to our next challenge.
Challenge 4: AI advances, including AGI, are not likely to be disruptively helpful for improving formal verification-based models until it’s too late.
Some researchers, like Tegmark and Omohundro, believe that the use of AI itself may be the solution to overcoming the kinds of challenges discussed above:
In summary, we still lack fully automated code-verifying AI powerful enough for our provably safe AI vision, but given the rate AI is advancing, we are hopeful that it will soon be available. Indeed, just as several other AI fields dominated by GOFAI (‘Good Old-Fashioned AI’) techniques were ripe for transformation by machine learning around 2014, we suspect that automated theorem proving is in that pre-revolution stage right now. [1]
While there is good evidence that improvements in AI are likely to be helpful with the theorem proving, or verification, part of formal verification, unfortunately, as we have discussed, many of the greatest challenges arise earlier in the process, around modeling and specification. Here there is much less real-world evidence that AI can be disruptively helpful in the near-term. For example, today’s AI systems have shown nothing so far that suggests that they will soon create complete, computationally-tractable rules-based models of physics, or to help gather detailed-enough data about initial conditions to fully model human biology. Tegmark and Omohundro acknowledge this:
Since we humans are the only species that can do [formal modeling] fairly well, it may unfortunately be the case that the level of intelligence needed to be able to convert all of one’s own black-box knowledge into code has to be at least at AGI-level. This raises the concern that we can only count on this “introspective” AGI-safety strategy working after we’ve built AGI, when according to some researchers, it will already be too late. [1]
Indeed, any safety strategy that strictly depends on access to an AGI as a precondition should not inspire a high-level of confidence. After all, we expect that many significant AI threats, like misinformation from generative AI and escalated risk of new biological weapons, are either present already or will appear very soon. Moreover, it’s not clear at all that AGI on its own will be sufficient to overcome the challenges discussed earlier in this paper. The reason is that the rough consensus definition of AGI is something like, “expert human-level capability at any task”. In other words, we can think of an AGI as something like a computer version of an expert-level human, but not super-human, at least initially.
With this in mind, it’s worth observing that the modeling challenges described earlier in this paper have all had on the order of millions of person-hours invested by expert-level humans over the past several decades (e.g. from basic physics research, to biological modeling, brain scanning, proof systems and so on) and still remains far from what would be required for formal verification of the sort described in [1] and [3]. Based on this, it’s not at all obvious that adding several orders of magnitude of additional expert human-level AGIs will lead to disruptive improvements in modeling and specification in the near-term. Instead, we believe that the following is a more sensible baseline to assume:
Limitation 4 – Major AI support for formal verification-based solutions to significant AI threats will come with artificial superintelligence (ASI) if it comes at all.
If access to an ASI is a precondition for formal verification based approaches to work, then this will indeed be “too late”. We now move on to our final challenge, which relates to practical issues with verification of guarantees and proofs produced by GS-based techniques about AI systems deployed in the real world.
Challenge 5 – Proofs and guarantees about AI systems will not be portable and straightforward to verify in the same way that ordinary mathematical proofs are.
Normally when we think about proofs, particularly in math, one of their major benefits is that they typically require minimal trust assumptions and can be easily verified by anyone. Dalrymple et al. argue that proofs produced using GS approaches would work like this as well:
A further socio-technical benefit of GS AI is its potential for facilitating multi-stakeholder coordination. This is because GS AI is able to produce proof certificates verifying that a given solution conforms to auditable-to-all-parties specifications, in a way that requires minimal trust among said parties. [3]
This sounds amazing in theory, but breaks down as soon as we try to imagine how it would work in practice. For example, let’s consider once again the example from [1] of a DNA synthesis machine that comes with a proof that it physically cannot produce harmful DNA. While it’s not clear exactly what such a proof would look like, it would presumably somehow entail the results of years of physical simulations of viruses interacting with human bodies, as well as some guarantees about the physical design of the specific machine in question as well.
Now something we must ask is: even if we could computationally verify the deductive correctness of this proof, (i.e. that it is correct in guaranteeing the good behavior of some machine) how do we know that the machine described by the proof is this machine – i.e. the one sitting in front of us? The fact is, there is no straightforward way for us to know that the machine in front of us is the one described in the proof; that the details of the transistors and wires on the physical circuit board precisely match those in the proof, that there are no secret backdoors, no manufacturing defects, etc. Even doing a physical inspection to verify these details to 100% accuracy may be impossible from a practical standpoint. Depending on how the machine is constructed, such an inspection would likely require the verifier to have access to detailed specifications about the hardware and software design of the machine, as well as the time and capability to disassemble the machine down to its smallest parts. Even if all of this were possible, we would then have entirely new concerns about the security vulnerabilities that access of this kind would open up.
At a minimum, what this example highlights is that any proofs we might obtain about physical systems will be far from “auditable-to-all-parties” and that, on the contrary, they will require much more than “minimal trust” to verify. Difficulties with verification become even worse when we consider AI systems like chatbots and other API-based products. Suppose you are given a proof that a chatbot or AI product you are interacting with over the Internet will not harm you. From a practical standpoint, there is simply no way to verify the correctness of the proof, because there is no way to know for certain that the proof you were given matches the system you are interacting with on the other end of the wire.
Based on this, it seems that verification of GS-style proofs in the context of AI systems would need to be coupled with comprehensive and continuous physical inspections, including access to the full hardware, toolchain, source code and design specs for the systems. But this is not something that frontier AI labs are likely to agree to, and which, even if they did, would open up many new concerns about security and safety. By considering cases like these we can see that, far from expecting “auditable-to-all-parties” proofs and guarantees, we should instead expect the following limitation related to GS-style guarantees about real-world AI systems:
Limitation 5 – Any “proofs” or “guarantees” about physically-deployed systems will need to be coupled with intensive, continuous physical inspections in order to verify them.
This brings us to the end of our list of challenges and limitations on the use of formal verification in AI safety. Based on this list, it should at a minimum be clear that the kinds of real-world safety results hoped-for by the authors of [1] and [3] are far too ambitious and ignore many challenges and limitations that make them intractable from a practical perspective in the near-term.
What Can Be Hoped-For?
Formal verification is a well-established field that has worked for several decades to improve the safety and reliability of mission-critical, real-world systems, like Mars landers and autonomous cars. Given this, we would be wise to use existing solutions (as well as their limitations) to guide our intuitions about the kinds of results we might reasonably expect in the domain of AI safety. In particular, a practical analysis of such challenges should convince us that, in the near-term, formal verification based approaches to AI safety will face a number of specific limitations that make them highly unlikely to produce strong safety guarantees for the AI threats we worry about the most.
In stark contrast to what is argued by papers like [1] and [3], we should not expect provably-safe DNA synthesis machines, or strong guarantees that drones will never harm people, or chatbots that come with proofs that they will never misinform. And given that we cannot expect guarantees around such straightforward threats, we should be even more skeptical that formal verification will result in provable guarantees against more challenging and complex threats like Loss-of-Control [13].
We have also argued against the idea that such limitations to formal verification-based approaches will be overcome simply through access to advanced AI systems, even including AGI. Given that many millions of dollars and person-hours have been spent on developing existing models and formal verification solutions over decades and given that an AGI is, by definition, equivalent to an expert-level human we should not expect existing limitations to be overcome merely by introducing several more orders of magnitude in AI-based human-expert-equivalents to the mix. And in any case, given that serious AI threats, like widespread misinformation and escalated risks of bioterrorism, are either with us already or will be very soon [14], we should be wary of putting much faith into approaches that require access to advanced AI as a hard prerequisite for success.
So what can be hoped-for, with respect to formal verification in AI safety? While a detailed discussion is beyond the scope of this paper, the short version is that we should expect results that look much more like today’s results, compared with what researchers propose. For example, we should expect that safety for AVs and drones will continue to improve and that fewer humans will be harmed by these systems. And we should expect that formal verification will have a role to play in these improvements, by generating and verifying real-time onboard proofs about these systems’ approximated world-models. Such improvements will be important, because they will save thousands of human lives from being lost in car accidents each year in the near-term. But as with today’s systems, we should not expect proofs or formal guarantees that AVs will not crash, or that drones can never cause harm.
And, for our most powerful AI systems, we should expect that it will be worthwhile – as it was with the Perseverance Lander – to continue to develop code-verification systems like PropCheck, to give us greater confidence that they will not fail unexpectedly due to inherent flaws and bugs and in their code. Such guarantees will be important, since AI systems may soon run much of the day-to-day infrastructure of the world, like power plants and water treatment facilities that humans depend on to survive. At the same time, we must be clear that avoiding internal bugs and crashes in a computer program is very different from guaranteeing the good behavior of physically-deployed AI systems in a messy and complex world.
Based on the practical, real-world limitations of formal verification in AI safety, if our goal is to find workable solutions to the most significant AI threats we face – and it should be – we must continue to search elsewhere, beyond formal verification, for such solutions.
References
[1] Provably Safe Systems: The Only Path to Controllable AGI
[2] Construction of an infectious horsepox virus vaccine from chemically synthesized DNA fragments
[3] Towards Guaranteed Safe AI: A Framework for Ensuring Robust and Reliable AI Systems
[4] Formal Verification Ensures The Perseverance Rover Lands Safely On Mars
[5] A Study on Mars Probe Failures
[6] Formal Methods for Autonomous Systems
[7] Toward Verified Artificial Intelligence
[8] Fundamental behaviors emerge from simulations of a living minimal cell
[9] We now know how many cells there are in the human body
[10] How AI Threatens Democracy
[11] Out-of-context photos are a powerful low-tech form of misinformation
[12] A Cubic Millimeter of a Human Brain Has Been Mapped in Spectacular Detail
[13] Artificial Intelligence and the Problem of Control
[14] Anthropic Responsible Scaling Policy
60 comments
Comments sorted by top scores.
comment by Steve_Omohundro · 2024-08-20T01:46:40.565Z · LW(p) · GW(p)
Andrew, thanks for the post. Here's a first response, I'll eventually post more. I agree with most of your specific comments but come to a different set of conclusions (some of which Ben Goldhaber and I spelled out in this LessWrong post: "Provably Safe AI: Worldview and Projects" [LW · GW] and some which I discuss in this video "VAISU Provably Safe AI") I agree that formal methods are not yet widely used and that provides some evidence that there might be big challenges to doing so. But these are extraordinary times, both because we are likely to face much more powerful adversaries over the next decade and because our AI systems are likely to become much more mathematically sophisticated over the same time period. It is certainly valuable to understand why formal methods haven't yet been adopted widely but it appears that both the driving necessity and the enabling technology may be rapidly changing soon.
I also agree that the transition period from our current technology to provably safe replacements is likely to be very challenging and may involve great hardship and loss of life. I believe we have a great opportunity right now to solve the problems you mention and others before they are critical. One overriding perspective in Max and my approach is that we need to design our systems so that their safety *can be formally verified*. In software, people often bring up the halting problem as an argument that general software can't be verified. But we don't need to verify general software, we are *designing* our systems so that they can be verified. That issue is also critically important for physical systems. And we are likely to have a challenging period where older systems that haven't been designed for verified safety are vulnerable to attack.
You say:
In particular, physics, chemistry and biology are all complex sciences which do not have anything like complete symbolic rule sets.
We fortunately live in an era where we *do* have a complete formal understanding of the fundamental laws of physics. Sean Carrol summarizes this nicely in this paper: "The Quantum Field Theory on Which the Everyday World Supervenes" in which he argues that the Standard Model of particle physics plus Einstein's general relativity completely describes all physical phenomena in ordinary human experience (ie. away from black holes, neutron stars, and the early universe and at energies less than 10^11eV, for comparison chemical bonds are less than 10eV and reactions in the sun are 10^8eV). Much of applied physics is about precise formal models of higher level phenomena (eg. fluids, elastic materials, plasmas, etc.) as beautifully summarized in Kip Thorne's book: "Modern Classical Physics: Optics, Fluids, Plasmas, Elasticity, Relativity, and Statistical Physics". Each of the engineering disciplines (eg. Mechanical Engineering, Electrical Engineering, Chemical Engineering, etc.) has their own formal models of their domain along with design rules for safe systems. They have extensive experiments and formal arguments which ground their models in fundamental physics. Fortunately, many of these disciplines are currently working to represent their fundamental models in formal proof assistants like Lean. For example, here is a chemical physics group who is doing that: "Formalizing chemical physics using the Lean theorem prover"
The Lean theorem prover is one of several powerful powerful proof assistants (others include Coq, Isabelle, MetaMath, HOL Light, and others) which are rich enough to encode all of mathematics including all the foundations of physics, engineering, computer science, economics, etc. The Lean library "Mathlib 4": contains most of an undergraduate mathematics curriculum, some frontier mathematical areas, and is beginning to include probability theory, physics, and other disciplines. Many AI theorem provers are training on this library and are rapidly improving in generating Lean proofs. For example, "DeepSeek-Prover-V1.5" is SOTA for open source provers: "DeepSeek-Prover-V1.5: Harnessing Proof Assistant Feedback for Reinforcement Learning and Monte-Carlo Tree Search" and commercial AI companies like Harmonic appear to be making rapid progress: "One month in - A new SOTA on MiniF2F and more" Several experts working on this area say that we should expect LLM-based AI systems (including "agentic" add-ons like Monte Carlo Tree Search, etc.) to reach human PhD level at theorem proving by 2026. I believe that will open the floodgates of safety and other other applications.
Replies from: redlizard, Seth Herd, habryka4, None↑ comment by redlizard · 2024-08-20T22:03:05.764Z · LW(p) · GW(p)
One overriding perspective in Max and my approach is that we need to design our systems so that their safety can be formally verified. In software, people often bring up the halting problem as an argument that general software can't be verified. But we don't need to verify general software, we are designing our systems so that they can be verified.
I am a great proponent of proof-carrying code that is designed and annotated for ease of verification as a direction of development. But even from that starry-eyed perspective, the proposals that Andrew argues against here seem wildly unrealistic.
A proof-carrying piece of C code can prove that it is not vulnerable to any buffer overflows, or that it will never run motor 1 and motor 2 simultaneously in opposite directions. A bit more ambitiously, it could contain a full proof of a complete behavioral specification, proving that the software will perform a certain set of behaviors at all times, which as a corollary also implies that it is proof against a large body of security threats. This is not something we can really manage in practice yet, but it's well within the extrapolated range of current techniques. We could build a compiler that will only compile software that contains a proof matching some minimum necessary specification, too.
Now imagine trying to prove that my program doesn't perform any sequence of perfectly innocuous interactions that happens to trigger a known or unknown bug in a mysql 5.1.32 server on the internet somewhere. How would you specify that? You can specify that the program doesn't do anything that might affect anything ever (though this leads to the well-known boxing problems); but if I want my program to have some nonzero ability to affect things in non-malicious ways, how would you specify that it doesn't do anything that might break something in some other part of the world in some unexpected way, including any unknown zero-days in mysql 5.1.32 servers? Presumably my proof checker doesn't contain the full code of all other systems on the internet my software might plausibly interact with. How could I specify a requirement like this, let alone prove it?
Proving that a piece of software has the behavior I want, or the behavior I allow, is something that can be done by carefully annotating my code with lemmas and contracts and incremental assumptions that together build up to a proof of the behavior I want. Proving that the software will have the behavior I want no matter what conditions you could possibly throw at it sounds harder but is actually mostly the same problem -- and so I would expect that proofs of almost-perfect security of a piece of software would not be that difficult either. But that is security of the software against attacks that might threaten the desired behavior of the software. Demonstrating that the software is not a threat to something else somewhere is another matter entirely, as this requires first knowing and encoding in the proofs all the ways in which the rest of the world might be negatively affected by actions-in-general. Not just superficially, either, if you want the proof to rule out the mysql 5.1.32 zero-day that just uses a sequence of normal interactions that should be perfectly innocent but in practice aren't. This is proving a negative in the worst possible way; to prove something like this, you would need to quantify over all possible higher-order behaviors the program doesn't have. I don't see how any of the real-or-imagined formal verification techniques I have ever heard about could possibly do anything even vaguely like this.
All the above is the world of software versus software, where even the external environment can be known to the last bit, with crisp behavior that can be analyzed and perfectly simulated even to the point where you can reproduce the mysql 5.1.32 bugs. Doing the same thing with biology would be a whole other order of magnitude in challenge level. Proving that a certain piece of synthesized DNA is not going to form a threat to human biology in some indirect way is essentially analogous to the mysql exploitation problem above, but much, much harder. Here, too, you would need to have a proof that quantifies over all possible higher order behaviors the piece of DNA doesn't have, all applied to the minor inconvenience that is the much murkier world of biology.
Unless I missed some incredible new developments in the field of formal verification, quantification over all possible higher order patterns and consequences of a system being analyzed is something that is absolutely out of reach of any formal verification techniques I have heard of. But if you do know of any techniques that could challenge this barrier, do tell :)
↑ comment by Seth Herd · 2024-08-20T20:48:50.702Z · LW(p) · GW(p)
Steve, please clarify, because I've long wondered: Are you saying you could possibly formally prove that a system like the human brain would always do something safe?
There are two enormous problems here.
a) Defining what arrangement of atoms you'd call "safe".
b) Predicting what a complex set of neural networks is going to do.
Intuitively, this problem is so difficult as to be a non-starter for effective AGI safety methods (if the AGI is a set of neural networks, as seems highly likely at this point; and probably even if it was the nicest set of complex algorithms you could imagine, because of problem a).
I thought your previous work was far more limited in ambition, making it a potential useful supplement to alignment.
Replies from: Steve_Omohundro↑ comment by Steve_Omohundro · 2024-08-20T21:45:23.340Z · LW(p) · GW(p)
I'm focused on making sure our infrastructure is safe against AI attacks. This will require that our software not have security holes, that our cryptography not be vulnerable to mathematical attacks, our hardware not leak signals to adversarial sensors, and our social mechanisms not be vulnerable to manipulative interactions. I believe the only practical way to have these assurances is to model our systems formally using tools like Lean and to design them so that adversaries in a specified class provably cannot break specified safety criteria (eg. not leak cryptographic keys). Humans can do these tasks today but it is laborious and usually only attempted when the stakes are high. We are likely to soon have AI systems which can synthesize systems with verified proofs of safety properties rapidly and cheaply. I believe this will be a game changer for safety and am arguing that we need to prepare for that opportunity. One important piece of infrastructure is the hardware that AI runs on. When we have provable protections for that hardware, we can put hard controls on the compute available to AIs, its ability to replicate, etc..
Replies from: Seth Herd↑ comment by Seth Herd · 2024-08-20T22:08:21.919Z · LW(p) · GW(p)
Okay! Thanks for the clarification. That's what I got from your paper with Tegmark, but in the more recent writing it sounded like maybe you were extending the goal to actually verifying safe behavior from the AGI. This is what I was referring to as a potentially useful supplement to alignment. I agree that it's possible with improved verification methods, given the caveats from this post.
An unaligned AGI could take action outside of all of our infrastructure, so protecting it would be a partial solution at best.
If I were or controlled an AGI and wanted to take over, I'd set up my own infrastructure in a hidden location, underground or off-planet, and let the magic of self-replicating manufacturing develop whatever I needed to take over. You'd need some decent robotics to jumpstart this process, but it looks like progress in robotics is speeding up alongside progress in AI.
Replies from: Steve_Omohundro↑ comment by Steve_Omohundro · 2024-08-20T22:30:35.705Z · LW(p) · GW(p)
I think we definitely would like a potentially unsafe AI to be able to generate control actions, code, hardware, or systems designs together with proofs that those designs meet specified goals. Our trusted systems can then cheaply and reliably check that proof and if it passes, safely use the designs or actions from an untrusted AI. I think that's a hugely important pattern and it can be extended in all sorts of ways. For example, markets of untrusted agents can still solve problems and take actions that obey desired constraints, etc.
The issue of unaligned AGI hiding itself is potentially huge! I have end state designs that would guarantee peace and abundance for humanity, but they require that all AIs operate under a single proven infrastructure. In the intermediate period between now and then is the highest risk, I think.
And, of course, an adversarial AI will do everything it can to hide and garner resources! One of the great uses of provable hardware is the ability to create controlled privacy. You can have extensive networks of sensors where all parties are convinced by proofs that they won't transmit information about what they are sensing unless a specified situation is sensed. It looks like that kind of technology might allow mutual treaties which meet all parties needs but prevent the "hidden rogue AIs" buried in the desert. I don't understand the dynamics very well yet, though.
↑ comment by habryka (habryka4) · 2024-08-20T18:10:48.482Z · LW(p) · GW(p)
Sean Carrol summarizes this nicely in this paper: "The Quantum Field Theory on Which the Everyday World Supervenes" in which he argues that the Standard Model of particle physics plus Einstein's general relativity completely describes all physical phenomena in ordinary human experience
FWIW, I would take bets at pretty high odds that this is inaccurate. As in, we will find at least one common everyday experience which relies on the parts of physics which we do not currently understand (such as the interaction between general relativity and quantum field theory). Of course, this is somewhat hard to prove since we basically have no ability to model any high-level phenomena using quantum field theory due to computational intractability, but my guess is we would still likely be able to resolve this in my favor after talking to enough physicists (and I would take reasonably broad consensus in your favor as sufficient to concede the bet).
Replies from: steve2152, Steve_Omohundro↑ comment by Steven Byrnes (steve2152) · 2024-08-21T02:55:08.592Z · LW(p) · GW(p)
FWIW I’m with Steve O here, e.g. I was recently writing the following footnote in a forthcoming blog post:
“The Standard Model of Particle Physics plus perturbative quantum general relativity” (I wish it was better-known and had a catchier name) appears sufficient to explain everything that happens in the solar system. Nobody has ever found any experiment violating it, despite extraordinarily precise tests. This theory can’t explain everything that happens in the universe—in particular, it can’t make any predictions about either (A) microscopic exploding black holes or (B) the Big Bang. Also, (C) the Standard Model happens to includes 18 elementary particles (depending on how you count), because those are the ones we’ve discovered; but the theoretical framework is fully compatible with other particles existing too, and indeed there are strong theoretical and astronomical [LW · GW] reasons to think they do exist. It’s just that those other particles are irrelevant for anything happening on Earth. Anyway, all signs point to some version of string theory eventually filling in those gaps as a true Theory of Everything. After all, string theories seem to be mathematically well-defined, to be exactly compatible with general relativity, and to have the same mathematical structure as the Standard Model of Particle Physics (i.e., quantum field theory) in the situations where that’s expected. Nobody has found a specific string theory vacuum with exactly the right set of elementary particles and masses and so on to match our universe. And maybe they won’t find that anytime soon—I’m not even sure if they know how to do those calculations! But anyway, there doesn’t seem to be any deep impenetrable mystery between us and a physics Theory of Everything.
(I interpret your statement to be about everyday experiences which depend on something being incomplete / wrong in fundamental physics as we know it, as opposed to just saying the obvious fact that we don’t understand all the emergent consequences of fundamental physics as we know it.)
I also think “we basically have no ability to model any high-level phenomena using quantum field theory” is misleading. It’s true that we can’t directly use the Standard Model Lagrangian to simulate a transistor. But we do know how and why and to what extent quantum field theory reduces to normal quantum mechanics and quantum chemistry (to such-and-such accuracy in such-and-such situations), and we know how those in turn approximately reduce to fluid dynamics and solid mechanics and classical electromagnetism and so on (to such-and-such accuracy in such-and-such situations), and now we’re all the way at the normal set of tools that physicists / chemists / engineers actually use to model high-level phenomena. You’re obviously losing fidelity at each step of simplification, but you’re generally losing fidelity in a legible way—you’re making specific approximations, and you know what you’re leaving out and why omitting it is appropriate in this situation, and you can do an incrementally more accurate calculation if you need to double-check. Do you see what I mean?
By (loose) analogy, someone could say “we don’t know for sure that intermolecular gravitational interactions are irrelevant for the freezing point of water, because nobody has ever included intermolecular gravitational interactions in a molecular dynamics calculation”. But the reason nobody has ever included them in a calculation is because we know for sure that they’re infinitesimal and irrelevant. Likewise, a lot of the complexity of QFT is infinitesimal and irrelevant in any particular situation of interest.
Replies from: habryka4↑ comment by habryka (habryka4) · 2024-08-21T03:24:57.530Z · LW(p) · GW(p)
But we do know how and why and to what extent quantum field theory reduces to normal quantum mechanics and quantum chemistry (to such-and-such accuracy in such-and-such situations), and we know how those in turn approximately reduce to fluid dynamics and solid mechanics and classical electromagnetism and so on (to such-and-such accuracy in such-and-such situations), and now we’re all the way at the normal set of tools that physicists / chemists / engineers actually use to model high-level phenomena.
Yeah, I do think I disagree with this.
At least in all contexts where I've seen textbooks/papers/videos cover this, the approximations we make are quite local and application-specific. You make very different simplifying assumptions if you are dealing with optical fiber from when you are dealing with estimating friction or shear forces, or when you are making fluid simulations, or when you are dealing with semiconductors. We don't have good general tools to abstract from the lower levels to the higher levels, and in most situations we vastly overengineer systems to dampen the effects that we don't have good abstractions for in the appropriate context (which to be clear, would totally mess with our systems if we didn't overengineer our systems to dampen them).
And honestly, most of the time we don't really know how the different abstraction-levels connect and we just use empirical data from some higher level of abstraction. And indeed we can usually use those empirically-grounded higher-level abstractions to model systems with lower error than we would get from a principled "build things from the ground up" set of approximations.
I agree that we can often rule out specific interactions like "are gravitational interactions relevant for water freezing", but we cannot say something as general as "there are no interactions outside of the standard model that are relevant for water freezing, like potentially anything related to agglomeration effects which might be triggered by variance in particle energy levels we don't fully understand, etc.". We don't really know how quantum field theory generalizes to high-level phenomena like water freezing, and while of course we can rule out a huge number of things and make many correct predictions on the basis of quantum field theory, we really have never even gotten remotely close to constructing a neat series of approximations that explains how water freezes from the ground up (in a way where you wouldn't need to repeatedly refer to high-level empirical observations you made to guide your search over appropriate abstractions).
In other words, if you gave a highly educated human nothing but our current knowledge of quantum field theory, and somehow asked them to predict the details of how water freezes under pressure (i.e. giving rise to things like "Ice VII") without ever having seen actual water freeze and performed empirical experiments, they would really have no idea. Of course, the low-level theories are useful for helping us guide our search for approximations that are locally useful, but indeed that gap where we have to constrain things from multiple level of abstractions is going to be the death of anything like formal verification.
Replies from: steve2152, barnaby-crook↑ comment by Steven Byrnes (steve2152) · 2024-08-21T14:18:31.009Z · LW(p) · GW(p)
(I probably agree about formal verification. Instead, I’m arguing the narrow point that I think if someone were to simulate liquid water using just the Standard Model Lagrangian as we know it today, with no adjustable parameters and no approximations, on a magical hypercomputer, then they would calculate a freezing point that agrees with experiment. If that’s not a point you care about, then you can ignore the rest of this comment!)
OK let’s talk about getting from the Standard Model + weak-field GR to the freezing point of water. The weak force just leads to certain radioactive decays—hopefully we’re on the same page that it has well-understood effects that are irrelevant to water. GR just leads to Newton’s Law of Gravity which is also irrelevant to calculating the freezing point of water. Likewise, neutrinos, muons, etc. are all irrelevant to water.
Next, the strong force, quarks and gluons. That leads to the existence of nuclei, and their specific properties. I’m not an expert but I believe that the standard model via “lattice QCD” predicts the proton mass pretty well, although you need a supercomputer for that. So that’s the hydrogen nucleus. What about the oxygen nucleus? A quick google suggests that simulating an oxygen nucleus with lattice QCD is way beyond what today’s supercomputers can do (seems like the SOTA is around two nucleons, whereas oxygen has 16). So we need an approximation step, where we say that the soup of quarks and gluons approximately condenses into sets of quark-triples (nucleons) that interact by exchanging quark-doubles (pions). And then we get the nuclear shell model etc. Well anyway, I think there’s very good reason to believe that someone could turn the standard model and a hypercomputer into the list of nuclides in agreement with experiment; if you disagree, we can talk about that separately.
OK, so we can encapsulate all those pieces and all that’s left are nuclei, electrons, and photons—a.k.a. quantum electrodynamics (QED). QED is famously perhaps the most stringently tested theory in science, with two VERY different measurements of the fine structure constant agreeing to 1 part in 1e8 (like measuring the distance from Boston to San Francisco using two very different techniques and getting the same answer to within 4 cm—the techniques are probably sound!).
But those are very simple systems; what if QED violations are hiding in particle-particle interactions? Well, you can do spectroscopy of atoms with two electrons and a nucleus (helium or helium-like), and we still get up to parts-per-million agreement with no-adjustable-parameter QED predictions, and OK yes this says there’s a discrepency very slightly (1.7×) outside the experimental uncertainty bars but historically it’s very common for people to underestimate their experimental uncertainty bars by that amount.
But that’s still only two electrons and a nucleus; what about water with zillions of atoms and electrons? Maybe there’s some behavior in there that contradicts QED?
For one thing, it’s hard and probably impossible to just posit some new fundamental physics phenomenon that impacts a large aggregate of atoms without having any measurable effect on precision atomic measurements, particle accelerator measurements, and so on. Almost any fundamental physics phenomenon that you write down would violate some symmetry or other principle that seems to be foundational, or at any rate, that has been tested at even higher accuracy than the above (e.g. the electron charge and proton charge are known to be exact opposites to 1e-21 accuracy, the vacuum dispersion is zero to 1e18 accuracy … there are a ton of things like that that tend to be screwed up by any fundamental physics phenomenon that is not of a very specific type, namely a term that looks like quantum field theory as we know it today).
For another thing, ab initio molecular simulations exist and do give results compatible with macroscale material properties, which might or might not include the freezing point of water (this seems related but I’m not sure upon a quick google). “Ab initio” means “starting from known fundamental physics principles, with no adjustable parameters”.
Now, I’m sympathetic to the conundrum that you can open up some paper that describes itself as an “ab initio”, and OK if the authors are not outright lying then we can feel good that there are no adjustable parameters in the source code as such. But surely the authors were making decisions about how to set up various approximations. How sure are we that they weren’t just messing around until they got the right freezing point, IR spectrum, shear strength, or whatever else they were calculating?
I think this is a legitimate hypothesis to consider and I’m sure it’s true of many individual papers. I’m not sure how to make it legible, but I have worked in molecular dynamics myself and had extremely smart and scrupulous friends in really good molecular dynamics labs such that I could see how they worked. And I don’t think the above paragraph concern is a correct description of the field. I think there’s a critical mass of good principled researchers who can recognize when people are putting more into the simulations than they get out, and keep the garbage studies out of textbooks and out of open-source tooling.
I guess one legible piece of evidence is that DFT was the best (and kinda only) approximation scheme that lets you calculate semiconductor bandgaps from first principles with reasonable amounts of compute, for many decades. And DFT famously always gives bandgaps that are too small. Everybody knew that, and that means that nobody was massaging their results to get the right bandgap. And it means that whenever people over the decades came up with some special-pleading correction that gave bigger bandgaps, the field as a whole wasn’t buying it. And that’s a good sign! (My impression is that people now have more compute-intensive techniques that are still ab initio and still “principled” but which give better bandgaps.)
↑ comment by Paradiddle (barnaby-crook) · 2024-08-21T10:34:07.914Z · LW(p) · GW(p)
I agree with the thrust of this comment, which I read as saying something like "our current physics is not sufficient to explain, predict, and control all macroscopic phenomena". However, this is a point which Sean Carroll would agree with. From the paper under discussion (p.2): "This is not to claim that physics is nearly finished and that we are close to obtaining a Theory of Everything, but just that one particular level in one limited regime is now understood."
The claim he is making, then, is totally consistent with the need to find further approximations and abstractions to model macroscopic phenomena. His point is that none of that will dictate modifications to the core theory (effective quantum field theory) when applied to "everyday" phenomena which occur in regions of the universe which we currently interact with (because the boundary conditions of this region of the universe are compatible with EQFT). Another way to put this is that Carroll claims no possible experiment can be conducted within the "everyday regime" which will falsify the core theory. Do you still disagree?
For the record, this is just to clarify what Carroll's claim is. I totally agree that that none of this is relevant to overcoming the limitations of formal verification, which very clearly depend on many abstractions and approximations and will continue to do so for the foreseeable future.
↑ comment by Steve_Omohundro · 2024-08-20T19:34:57.925Z · LW(p) · GW(p)
Figure 1 in Carroll's paper shows what is going on. At the base is the fundamental "Underlying reality" which we don't yet understand (eg. it might be string theory or cellular automata, etc.):
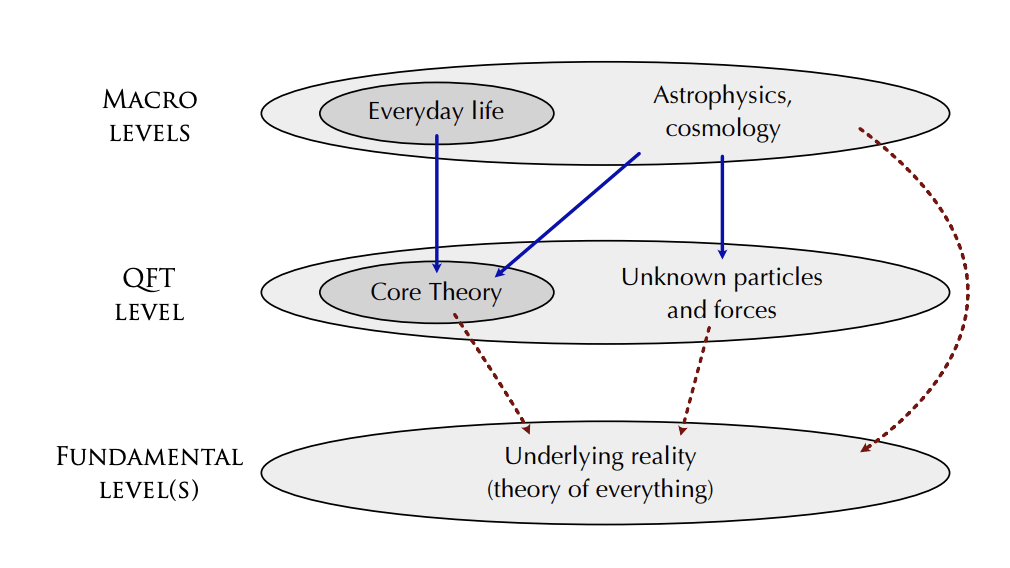
Above that is the "Quantum Field Theory" level which includes the "Core Theory" which he explicitly shows in the paper and also possibly "Unknown particles and forces". Above that is the "Macro Level" which includes both "Everyday life" which he is focusing on and also "Astrophysics and Cosmology". His claim is that everything we experience in the "Everyday life" level depends on the "Underlying reality" level only through the "Core Theory" (ie. it is an "effective theory" kind of like fluid mechanics doesn't depend on the details of particle interactions).
In particular, for energies less than 10^11 electron volts and for gravitational fields weaker than those around black holes, neutron stars, and the early universe, the results of every experiment is predicted by the Core theory to very high accuracy. If anything in this regime were not predicted to high accuracy, it would be front page news, the biggest development in physics in 50 years, etc. Part of this confidence arises from fundamental aspects of physics: locality of interaction, conservation of mass/energy, and symmetry under the Poincare group. These have been validated in every experiment ever conducted. Of course, as you say, physics isn't finished and quantum theory in high gravitational curvature is still not understood.
Here's a list of other unsolved problems in physics: https://en.wikipedia.org/wiki/List_of_unsolved_problems_in_physics But the key point is that none of these impact AI safety (at least in the nearterm!). Certainly, powerful adversarial AI will look for flaws in our model of the universe as a potential opportunity for exploitation. Fortunately, we have a very strong current theory and we can use it to put bounds on the time and energy an AI would require to violate the conditions of validity (eg. create black holes, etc.) For long term safety and stability, humanity will certainly have to put restrictions on those capabilities, at least until the underlying physics is fully understood.
Replies from: habryka4, Seth Herd, habryka4↑ comment by habryka (habryka4) · 2024-08-20T19:53:01.191Z · LW(p) · GW(p)
In particular, for energies less than 10^11 electron volts and for gravitational fields weaker than those around black holes, neutron stars, and the early universe, the results of every experiment is predicted by the Core theory to very high accuracy. If anything in this regime were not predicted to high accuracy, it would be front page news, the biggest development in physics in 50 years, etc. Part of this confidence arises from fundamental aspects of physics: locality of interaction, conservation of mass/energy, and symmetry under the Poincare group. These have been validated in every experiment ever conducted. Of course, as you say, physics isn't finished and quantum theory in high gravitational curvature is still not understood.
While I am an avid physics reader, I don't have a degree in physics, so this is speaking at the level of an informed layman.
I think it's actually pretty easy to end up with small concentrations of more than 10^11 electron volts and large local gravitational fields.These effects can then often ripple out or qualitatively change the character of some important interaction. On the everyday scale, cosmic rays are the classical example of extremely high-energy contexts, which do effect us on a daily level (but of course there are many more contexts in which local bubbles of high energy concentration takes place).
Also, dark energy + dark matter are of course the obvious examples of something for which we currently have no satisfying explanation within either general relativity or the standard model, and neither of those likely requires huge energy scales or large gravitational fields.
In general, I don't think it's at all true that "if anything was not predicted with high accuracy by the standard model it would be the biggest development in physics in 50 years". We have no idea what the standard model predicts about approximately any everyday phenomena because simulating phenomena at the everyday scale is completely computationally intractable. If turbulence dynamics or common manufacturing or material science observations were in conflict with the standard model, we would have no idea, since we have no idea what the standard model says about basically any of those things.
In the history of science it's quite common that you are only able to notice inconsistencies in your previous theory after you have found a superior theory. Newton's gravity looks great for predicting the movements of the solar system, with a pretty small error that mostly looks random and you can probably just dismiss as measurement error, until you have relativity and you notice that there was a systematic bias in all of your measurements in predictable directions in a way that previously looked like noise.
Replies from: Steve_Omohundro, Steve_Omohundro↑ comment by Steve_Omohundro · 2024-08-20T21:04:32.057Z · LW(p) · GW(p)
It's very hard to get large gravitational fields. The closest known black hole to Earth is Gaia BH1 which is 1560 light-years away: https://www.space.com/closest-massive-black-hole-earth-hubble The strongest gravitational waves come from the collision of two black holes but by the time they reach Earth they are so weak it takes huge effort to measure them and they are in the weak curvature regime where standard quantum field theory is fine: https://www.ligo.caltech.edu/page/what-are-gw#:~:text=The%20strongest%20gravitational%20waves%20are,)%2C%20and%20colliding%20neutron%20stars.
It's also quite challenging to create high energy particles, they tend to rapidly collide and dissipate their energy. The CERN "Large Hadron Collider" is the most powerful particle accelerator that humans have built: https://home.cern/resources/faqs/facts-and-figures-about-lhc It involves 27 kilometers of superconducting magnets and produces proton collisions of 1.3*10^13eV.
Most cosmic rays are in the range of 10^6 eV to 10^9 eV https://news.uchicago.edu/explainer/what-are-cosmic-rays But there have been a few very powerful cosmic rays detected. Betwen 2004 and 2007, the Pierre Auger Observatory detected 27 events with energies above 5.7 * 10^19 eV and the "Oh-My-God" particle detected in 1991 had an energy of 3.2 * 10^20 eV.
So they can happen but would be extremely difficult for an adversary to generate. The only reason he put 10^11 as a limit is that's the highest we've been able to definitively explore with accelerators. There may be more unexpected particles up there, but I don't think they would make much of a difference to the kinds of devices we're talking about.
But we certainly have to be vigilant! ASIs will likely explore every avenue and may very well be able to discover the "Theory of Everything". We need to design our systems so that we can update them with new knowledge. Ideally we would also have confidence that our infrastructure could detect attempts to subvert it by pushing outside the domain of validity of our models.
Replies from: Steve_Omohundro↑ comment by Steve_Omohundro · 2024-08-20T21:56:16.261Z · LW(p) · GW(p)
While dark energy and dark matter have a big effect on the evolution of the universe as a whole, they don't interact in any measurable way with systems here on earth. Ethan Siegel has some great posts narrowing down their properties based on what we definitively know, eg. https://bigthink.com/starts-with-a-bang/dark-matter-bullet-cluster/ So it's important on large scales but not, say, on the scale of earth. Of course, if we consider the evolution of AI and humanity over much longer timescales, then we will likely need a detailed theory. That again shows that we need to work with precise models which may expand their regimes of applicability.
↑ comment by Steve_Omohundro · 2024-08-20T23:14:49.446Z · LW(p) · GW(p)
An example of this kind of thing is the "Proton Radius Puzzle" https://physicsworld.com/a/solving-the-proton-puzzle/ https://en.wikipedia.org/wiki/Proton_radius_puzzle in which different measurements and theoretical calculations of the radius of the proton differed by about 4%. The physics world went wild and hundreds of articles were published about it! It seems to have been resolved now, though.
↑ comment by Seth Herd · 2024-08-20T20:52:45.827Z · LW(p) · GW(p)
Even if everything is in principle calculable, it doesn't mean you can do useful calculations of complex systems a useful distance into the future. The three body problem intervenes. And there are rather more than three bodies if you're trying to predict behavior of a brain-sized neural network, let alone intervening on a complex physical world. The computer you'd need wouldn't just be the size of the universe, but all of the many worlds branches.
Replies from: Steve_Omohundro↑ comment by Steve_Omohundro · 2024-08-20T21:13:50.127Z · LW(p) · GW(p)
Simulation of the time evolution of models from their dynamical equations is only one way of proving properties about them. For example, a harmonic oscillator https://en.wikipedia.org/wiki/Harmonic_oscillator has dynamical equations m d^2x/dt^2= -kx. You can simulate that but you can also prove that the kinetic plus potential energy is conserved and get limits on its behavior arbitrarily far into the future.
Replies from: Seth Herd↑ comment by Seth Herd · 2024-08-20T22:11:38.139Z · LW(p) · GW(p)
Sure but seems highly unlikely there are any such neat simplifications for complex cognitive systems built from neural networks.
Other than "sapient beings do things that further their goals in their best estimation", which is a rough predictor, and what we're already trying to focus on. But the devil is in the details, and the important question is about how the goal is represented and understood.
Replies from: Steve_Omohundro↑ comment by Steve_Omohundro · 2024-08-20T22:41:36.151Z · LW(p) · GW(p)
Oh yeah, by their very nature it's likely to be hard to predict intelligent systems behavior in detail. We can put constraints on them, though, and prove that they operate within those constraints.
Even simple systems like random SAT problems https://en.wikipedia.org/wiki/SAT_solver can have a very rich statistical structure. And the behavior of the solvers can be quite unpredictable.
In some sense, this is the source of unpredictability of cryptographic hash functions. Odet Goldreich proposed an unbelivable simple boolean function which is believed to be one-way: https://link.springer.com/chapter/10.1007/978-3-642-22670-0_10
On the other hand, I think it is often possible to distill behavior for a particlular task from a rich intelligence into simple code with provable properties.
↑ comment by habryka (habryka4) · 2024-08-20T19:37:50.665Z · LW(p) · GW(p)
(Mod note: Edited in the image)
↑ comment by [deleted] · 2024-08-20T08:49:15.178Z · LW(p) · GW(p)
I imagine that the behavior of strong AI, even narrow AI, is computationally irreducible. In that case would it still be verifiable?
Replies from: Steve_Omohundro↑ comment by Steve_Omohundro · 2024-08-20T22:59:33.457Z · LW(p) · GW(p)
Our infrastructure should refuse to do anything the AI asks unless the AI itself provides a proof that it obeys the rules we have set. So we force the intelligent system itself to verify anything it generates!
comment by Steve_Omohundro · 2024-08-21T18:07:44.690Z · LW(p) · GW(p)
Challenge 4: AI advances, including AGI, are not likely to be disruptively helpful for improving formal verification-based models until it’s too late.
Yes, this is our biggest challenge, I think. Right now very few people have experience with formal systems and historically the approach has been met with continuous misunderstanding and outright hostility.
In 1949 Alan Turing laid out the foundations for provably correct software: "An Early Program Proof by Alan Turing". What should have happened (in my book) is that computer science was recognized as a mathematical science capable of mathematically proving the correctness of its designs. And through the years, there have indeed been many who were inspired by that vision and made great and important contributions.
But, unfortunately, the field was resistant to correctness and we got wave after wave of "sloppy programming" which continues to haunt us to this day. For example, the July 19, 2024 CrowdStrke Incident has been called the largest IT outage in history causing over $10 billion in financial damages. It was caused by a sloppy error in an update to Microsoft Windows security software. This is an outrage and it has been an ongoing outrage almost since the time of Turing.
In another post, I mentioned a similar outrage in scientific computing. It has been known for many decades how to mathematically precisely perform scientific computing. And yet the standard remains "slap the code up against the wall and see if the outputs look reasonable". It is unknown how many scientific results, medical analyses, or engineering designs are flawed because people couldn't be bothered to perform their computations correctly.
Cryptography has similar issues. The mainstream is based on computational cryptography which has unknown vulnerability to powerful AI attack. Meanwhile, provable correct "Information Theoretic Cryptography" languishes in a few academic conferences with very little use in practice.
So humanity is way behind where we should be on the formalization front. Our ancestors sloppiness may now be our downfall. One hope, as you mention, is the rapid advancement of AI theorem proving, AI autoformalization, AI verified program synthesis, and other related areas.
It looks to me that we are now in a race of AI for safety vs. AI for unsafe capabilities. The more people who are aware of the issues and the potential solutions using the new formal technologies, the greater the chance we have to survive.
I think the safest world would be one where humanity does not create AI. Next would be where we have a long enough pause in AI development to carefully create safe infrastructure. Next would be restricting powerful AI to a few highly regulated government labs. Next would be a world with tight controls on GPUs and datacenters with no computational overhang. Unfortunately, it appears that all those ships have already sailed. We now have huge computational overhang and powerful open source AI models. The Llama 3.1 8B model can run on a $90 Raspberry Pi 5. So we have to rebuild the world with safe infrastructure in the face of rapidly improving and uncontrolled AI capabilities.
It appears that the massive needed change will only happen *after* large scale AI-powered attacks and destruction begins. I think the greatest contribution to humanity's survival right now is to create detailed plans for building provably safe infrastructure, so that when the enabling technologies appear and the world begins demanding safe technology, there is a plan for moving forward.
Replies from: faul_sname↑ comment by faul_sname · 2024-08-21T22:10:50.242Z · LW(p) · GW(p)
I think the greatest contribution to humanity's survival right now is to create detailed plans for building provably safe infrastructure, so that when the enabling technologies appear and the world begins demanding safe technology, there is a plan for moving forward.
There are enough places provably-safe-against-physical-access hardware would be an enormous value-add that you don't need to wait to start working on it until the world demands safe technology for existential reasons. Look at the demand for secure enclaves, which are not provably secure, but are "probably good enough because you are unlikely to have a truly determined adversary".
The easiest way to convince people that they, personally, should care more about provable correctness over immediately-obvious practical usefulness is to demonstrate that provable correctness is possible, not too costly, and has clear benefits to them, personally.
Replies from: Steve_Omohundro↑ comment by Steve_Omohundro · 2024-08-22T17:25:55.573Z · LW(p) · GW(p)
I totally agree! I think this technology is likely to be the foundation of many future capabilities as well as safety. What I meant was that society is unlikely to replace today's insecure and unreliable power grid controllers, train network controllers, satellite networks, phone system, voting machines, etc. until some big event forces that. And that if the community produces comprehensive provable safety design principles, those are more likely to get implemented at that point.
Replies from: faul_sname↑ comment by faul_sname · 2024-08-22T18:13:00.797Z · LW(p) · GW(p)
My point was more that I expect there to be more value in producing provable safety design demos and provable safety design tutorials than in provable safety design principles, because I think the issue is "people don't know how, procedurally, to implement provable safety in systems they build or maintain" than it is "people don't know how to think about provable safety but if their philosophical confusion was resolved they wouldn't have too many further implementation difficulties".
So having any examples at all would be super useful, and if you're trying to encourage "any examples at all" one way of encouraging that is to go "look, you can make billions of dollars if you can build this specific example".
comment by Steve_Omohundro · 2024-08-21T15:46:47.150Z · LW(p) · GW(p)
Here's the post's first proposed limitation:
Limitation 1 – We will not obtain strong proofs or formal guarantees about the behavior of AI systems in the physical world. At best we may obtain guarantees about rough approximations of such behavior, over short periods of time.
For many readers with real-world experience working in applied math, the above limitation may seem so obvious they may wonder whether it is worth stating at all. The reasons why it is are twofold. First, researchers advocating for GS methods appear to be specifically arguing for the likelihood of near-term solutions that could somehow overcome Limitation 1.
Think about this claimed limitation in the context of today's deployed technologies and infrastructure. There are 5 million bridges around the world that people use every day to cross rivers and chasms. Many of them have lasted for hundreds of years and new ones are built with confidence all the time. Failures do happen, but they are so rare that news stories are written about them and videos are shared on YouTube. How are these remarkably successful technologies built?
Mechanical engineers have built up a body of knowledge about building safe bridges. They have precise rules about the structure of successful bridges. They have detailed equations, simulations, and tables of material properties. And they know the regimes of validity of their models. When they build a bridge according to these rules, they have a confidence in their safety which is nothing like a "rough approximation..[valid] over short periods of time."
We are rapidly moving from human engineers to AI systems for design. What should an AI bridge design system look like? It should certainly encode all the rules that the human engineers use! And, in fact, should give confidence that its designs are actually following those rules, it would be really great to check that a design follows those rules. We could hire a human mechanical engineer to audit the AI design, but we'd really like to automate that process.
Enter formal systems like Lean! We can encode the mechanical engineer's design criteria and particular bridge designs as precise Lean statements. Now the statement that a particular design follows the design criteria becomes a theorem and Lean can provide a proof certificate that it is true. This certificate can be automatically checked by a proof checker and users can have high confidence that the design does indeed follow the design rules without having to trust anyone!
This formalization process is happening right now in hundreds of different disciplines. It is still new, so early attempts may be incomplete and require engineers to learn to use new tools. But AI is helping here as well. The field of "autoformalization" takes textbooks, manuals, design documents, software, scientific articles, mathematics papers, etc. written in natural language and automatically generates precise formal models of them. Large language models are becoming quite good at this (eg. here's a recent paper: "Don't Trust: Verify -- Grounding LLM Quantitative Reasoning with Autoformalization").
As AI autoformalization and theorem proving improves, we should expect the entire corpus of scientific and engineering knowledge to be rapidly represented in a precise formal form. And AI designs which at least meet the current human requirements for safe systems can be automatically generated with proof certificates of adherence to design rules given.
But we cannot stop at the current level of engineering safety. Today's technologies and infrastructure works pretty well in today's human environment. Unfortunately, as AIs become more powerful, they will likely be used in an adverarial way to attack infrastructure, both at the behest of malicious human actors and in the process of satisfying autonomous subgoals. To counter this threat, we need a much higher standard of safety than is common in current engineering practice.
Max and I argue that the only way to have assurance of safety against powerful adversarial agents is through formal methods and mathematical proof. For even moderately complex systems, we will need formal guarantees of safety against every attack path that is available to a specified class of adversaries. This is the level of safety for which we need Provably Safe and Guaranteed Safe approaches to achieve.
Replies from: habryka4, Steve_Omohundro↑ comment by habryka (habryka4) · 2024-08-21T17:14:34.411Z · LW(p) · GW(p)
I think you are wrong about what a proof that following the mechanical engineer's design criteria would actually do.
Our bridge design criteria are absolutely not robust to adversarial optimization. It is true that we have come up with a set of guiding principles where if a human who is genuinely interested in building a good bridge follows them then that results (most of the time) into a bridge that doesn't fall down. But that doesn't really generalize at all to what would happen if an AI system wants to design a bridge with some specific fault, but is constrained in following the guiding principles. We are not anywhere close to having guiding principles that are operationalized enough so that we could actually prove adherence to them, or guiding principles that even if they could be operationalized, would be robust to adversarial pressure.
As such I am confused what the goal is here. If I somehow ended up in charge of building a bridge according to modern design principles, but I actually wanted it to collapse, I don't think I would have any problems in doing so. If I perform an adversarial search over ways to build a bridge that happen to follow the design principles, but where I explicitly lean into the areas where the specification comes apart, then the guidelines will very quickly lose their validity.
I think the fact that there exists a set of instructions that you can give to well-intentioned humans that usually results in a reliable outcome is very little evidence that we are anywhere close to a proof system to which adherence could be formally verified, and would actually be robust to adversarial pressure when the actor using that system is not well-intentioned.
Replies from: Steve_Omohundro↑ comment by Steve_Omohundro · 2024-08-21T18:39:56.881Z · LW(p) · GW(p)
Oh, I should have been clearer. In the first part, I was responding to his "rough approximation..[valid] over short periods of time." claim for formal methods. I was arguing that we can at least copy current methods and in current situations get bridges which actually work rather robustly and for a long time.
And, already, the formal version is better in many respects. For one, we can be sure it is being followed! So we get "correctness" in that domain. A second piece, I think is very important but I haven't figured out how to communicate it. And that's that the proof that a design satisfies design rules is a specific artifact that anyone can check. So it completely changes the social structure of the situation. Instead of having to rely on the "expert" who may or may not be competent, and may or may not be corrupt, each party is empowered with absolute guarantee of correctness. I think this alters many social processes dramatically, but it needs to be fleshed out and better explained.
After that argument, I go to the next piece which you mention. Today's engineering practices are not likely to be robust against powerful adversaries (eg. powerful AI or humans backed up by powerful AI). And I don't think current practices can deal with that very well. In the AI safety space, the typical approach is "red teaming" where humans try to trigger AIs to produce bad scenarios and they see how easy it is and how powerful the attacks are. This can find problems but can't show the absence of safety vulnerabilities.
With mathematical proof, we can systematically consider the entire space of possible actions by adversaries in the specified class. Using techniques like "branch and bound", we can systematically eliminate regions of the action space which are shown to be safe. And if the system is actually safe, there is a proof of that (by Godel's Completeness theorem which says that any property which holds in all models of a set of axioms can be proven from those axioms). If the systems are complex, the proofs can be large, so there is value in "designing for verification".
That's a possibility which provides actual safety against AI and other adversaries and provides detailed information about the value of different features, etc. Several groups are working right now to develop examples of this kind. Hopefully, the process can eventually be automated so that we can put it on the same timescale as AI advancement.
Replies from: steve-kommrusch↑ comment by Steve Kommrusch (steve-kommrusch) · 2024-08-26T21:29:36.353Z · LW(p) · GW(p)
Steve, thanks for your explanations and discussion. I just posted a base reply about formal verification limitations within the field of computer hardware design. In that field, ignoring for now the very real issue of electrical and thermal noise, there is immense value in verifying that the symbolic 1's and 0's of the digital logic will successfully execute the similarly symbolic software instructions correctly. So the problem space is inherently simplified from the real world, and the silicon designers have incentive to build designs that are easy to test and debug, and yet only small parts of designs can be formally verified today. It would seem to me that, although formal verification will keep advancing, AI capabilities will advance faster and we need to develop simulation testing approaches to AI safety that are as robust as possible. For example, in silicon design one can make sure the tests have at least executed every line of code. One could imaging having a METR test suite and try to ensure that every neuron in a given AI model has been at least active and inactive. It's not a proof, but it would speak to the breadth of the test suite in relation to the model. Are there robustness criteria for directed and random testing that you consider highly valuable without having a full safety proof?
Replies from: Steve_Omohundro↑ comment by Steve_Omohundro · 2024-08-28T17:53:51.109Z · LW(p) · GW(p)
Testing is great for a first pass! And in non-critical and non-adversarial settings, testing can give you actual probabilistic bounds. If the probability distribution of the actual uses is the same as the testing distribution (or close enough to it), then the test statistics can be used to bound the probability of errors during use. I think that is why formal methods are so rarely used in software: testing is pretty good and if errors show up, you can fix them then. Hardware has greater adoption of formal methods because it's much more expensive to fix errors after the fact.
But the real problems arise from adversarial attacks. The statistical correctness of a system doesn't matter to an adversary. They are looking for the weird outlier cases which will enable them to exploit the system (eg. inputs with non-standard characters that break the parser, or super-long inputs which overflow a buffer and enable unexpected access to memory, etc.). Testing can't show the absence of flaws (unless every input is tested!).
I think the increasing plague of cyberattacks is due to adversaries become more sophisticated in their search for non-standard ways of interacting with systems that expose their untested and unproven underbelly. But that kind of sophisticated attack requires highly skilled attackers and those are fortunately still rare.
What is coming, however, are AI-powered cyberattack systems which know all of the standard flaws and vulnerabilities of systems, all of the published 1-day vulnerabilities, all of the latest social engineering techniques discussed on the dark web, and have full access to reverse engineering tools like Ghidra. Those AIs are likely being developed as we speak in various government labs (eg. here is a list of significant recent cybe incidents: https://www.csis.org/programs/strategic-technologies-program/significant-cyber-incidents ).
How long before powerful cyberattack AIs are available on bittorrent to teenage hackers? So, I believe the new reality is that every system, software and hardware need to be proven correct and secure to have any confidence in it. To do that, we are likely to need to use AI-theorem provers and AI-verified software synthesis systems. Fortunately, many groups are showing rapid progress on those!
But that doesn't mean testing is useless. It's very helpful during the development process and in better understanding systems. For final deployment in an environment with powerful AIs, however, I don't think it's adequate any more.
↑ comment by Steve_Omohundro · 2024-08-21T16:12:59.763Z · LW(p) · GW(p)
As a concrete example, consider the recent Francis Scott Key Bridge collapse where an out of control container ship struck one of the piers of the bridge. It killed six people, blocked the Port of Baltimore for 11 weeks, and will cost $1.7 billion to replace the bridge which will take four years.
Could the bridge's designers way back in 1977 have anticipated that a bridge over one of the busiest shipping routes in the United States might some day be impacted by a ship? Could they have designed it to not collapse in this circumstance? Perhaps shore up the base of its piers to absorb the impact of the ship?
This was certainly a tragedy and is believed to have been an accident. But the cause was electrical problems on the ship. "At 1:24 a.m., the ship suffered a "complete blackout" and began to drift out of the shipping channel; a backup generator supported electrical systems but did not provide power to the propulsion system"
How well designed was that ships generator and backup generator? Could adverarial attackers cause this kind of electrical blackout in other ships? Could remote AI systems do it? How many other bridges are vulnerable to impacts from out of control ships? What is the economic value at stake from this kind of flawed safety engineering? How much is it worth to create designs which provide guaranteed protections against this kind of flaw?
Replies from: khafra↑ comment by khafra · 2024-08-22T10:49:34.075Z · LW(p) · GW(p)
That example seems particularly hard to ameliorate with provable safety. To focus on just one part, how could we prove the ship would not lose power long enough to crash into something? If you try to model the problem at the level of basic physics, it's obviously impossible. If you model it at the level of a circuit diagram, it's trivial--power sources on circuit diagrams do not experience failures. There's no obviously-correct model granularity; there are schelling points, but what if threats to the power supply do not respect our schelling points?
It seems to me that, at most, we could prove safety of a modeled power supply, against a modeled, enumerated range of threats. Intuitively, I'm not sure that compares favorably to standard engineering practices, optimizing for safety instead of for lowest-possible cost.
Replies from: Steve_Omohundro↑ comment by Steve_Omohundro · 2024-08-22T17:34:27.154Z · LW(p) · GW(p)
In general, we can't prevent physical failures. What we can do is to accurately bound the probability of them occurring, to create designs which limit the damage that they cause, and to limit the ability of adversarial attacks to trigger and exploit them. We're advocating for humanity's entire infrastructure to be upgraded with provable technology to put guaranteed bounds on failures at every level and to eliminate the need to trust potentially flawed or corrupt actors.
In the case of the ship, there are both questions about the design of that ship's components and its provenance. Why did the backup power not enable the propulsion system to stop? Why wasn't there a "failsafe" anchor which drops if the systems become inoperable? Why didn't the port have tugboats guiding risky ship departures? What was the history of that ship's generators? Etc. With the kind of provable technology that Max and I outlined, it is possible to have provably trustable data about the components of the ship, about their manufacture, about their provenance since manufacture, about the maintenance history of the ship's components, etc.
The author of the main post and other critics argue against formal methods doing complex "magical" things like determining which DNA sequences are safe, how autonomous vehicles should navigate cities, or detecting bad thoughts in huge transformer neural nets. Someday these methods might help with some of those, but those aren't the low hanging fruit we are proposing. In some sense we mainly want to use proof for much more mundane things. What Max and I are arguing for are mechanisms to create software, hardware, and social designs which aren't exploitable by adversarial AIs and to create infrastructure that provides guarantees about its state and behavior. Nothing we are proposing requires sophisticated mathematics that today's grad students couldn't do. Nothing requires new physics or radically new engineering principles. Rather, it is a way to organize current technologies to increase trust and eliminate vulnerabilities.
These technologies enable us to eliminate the need to trust third parties: Was a computation performed accurately? Were there bugs in the program? What data was used to train this model or estimate this probability? What probabilistic program or neural net was used? Was the training done correctly? What is the history of this component? What evidence is there that it was manufactured correctly? These and thousands more cases will enable us to build up a robust infrastructure which is provably not vulnerable to AI-driven attack.
A core aspect of this is that we can use untrusted powerful AIs running on untrusted datacenters in untrusted countries to help us build completely trusted software, hardware, and social protocols. The idea is to precisely specify a task (eg. software spec, hardware spec, solve a mathematically encoded problem, etc.) and have the untrusted AI generate both and answer and a proof (in a system like Lean) that the answer solves the precisely specified problem or design task. We can cheaply and completely reliably check the proof. If it verifies, then we can fully trust the results from the untrusted AI. This enables us to bootstrap the current mess of untrusted and unreliable AIs, flaky and insecure hardware, untrustable people and groups, etc. to build up a *fully* trustable infrastructure. The power and importance of this is immense!
Replies from: khafra↑ comment by khafra · 2024-08-27T06:05:58.248Z · LW(p) · GW(p)
Here's the intuition that's making me doubt the utility of provably correct system design to avoiding bridge crashes:
I model the process leading up to a ship that doesn't crash into a bridge as having many steps.
1. Marine engineers produce a design for a safe ship
2. Management signs off on the design without cutting essential safety features
3. Shipwrights build it to spec without cutting any essential corners
4. The ship operator understands and follows the operations and maintenance manuals, without cutting any essential corners
5. Nothing out-of-distribution happens over the lifetime of the ship.
And to have a world where no bridges are taken out by cargo ships, repeat that 60,000 times.
It seems to me that provably safe design can help with step 1--but it's not clear to me that step 1 is where the fault happened with the Francis Scott Key bridge. Engineers can and do make bridge-destroying mistakes (I grew up less than 50 miles from the Tacoma Narrows bridge), but that feels rare to me compared to problems in the other steps: management does cut corners, builders do slip up, and O&M manuals do get ignored.
With verifiable probabilities of catastrophe, maybe a combination of regulation and insurance could incentivize makers and operators of ships to operate safely--but insurers already employ actuaries to estimate the probability of catastrophe, and it's not clear to me that the premiums charged to the MV Dali were incorrect. As for the Francis Scott Key, I don't know how insuring a bridge works, but I believe most of the same steps and problems apply.
(Addendum: The new Doubly-Efficient Debate paper on Google's latest LW post [LW · GW] might make all of these messy principal-agent human-corrigibility type problems much more tractable to proofs? Looks promising.)
↑ comment by Steve_Omohundro · 2024-08-28T18:14:50.410Z · LW(p) · GW(p)
I totally agree in today's world! Today, we have management protocols which are aimed at requiring testing and record keeping to ensure that boats and ships in the state we would like them to be. But these rules are subject to corruption and malfeasance (such as the 420 Boeing jets which incorporated defective parts and yet which are currently flying with passengers: https://doctorow.medium.com/https-pluralistic-net-2024-05-01-boeing-boeing-mrsa-2d9ba398bd54 )
But it appears we are rapidly moving to a world in which much of the physical labor will be done by robots and in which each physical system will have a corresponding "digital twin" (eg. https://www.nvidia.com/en-us/omniverse/solutions/digital-twins/ ).
In that world, we can implement provable formal rules governing every system, from raw materials, to manufacture, to supply chain, to operations, and to maintenance.
In an AI world, much more sophisticated malfeasance can occur. Formal models of domains with proofs of adherence to rules and protection against adversaries is the only way to ensure our systems are safe and effective.
comment by Steve_Omohundro · 2024-08-21T17:01:08.427Z · LW(p) · GW(p)
The post's second Challenge is:
Challenge 2 – Most of the AI threats of greatest concern have too much complexity to physically model.
Setting aside for a moment the question of whether we can develop precise rules-based models of physics, GS-based approaches to safety would still need to determine how to formally model the specific AI threats of interest as well. For example, consider the problem of determining whether a given RNA or DNA sequence could cause harm to individuals or to the human species. This is a well-known area of concern in synthetic biology, where experts expect that risks, especially around the synthesis of novel viruses, will dramatically increase as more end-users gain access to powerful AI systems. This threat is specifically discussed in [3] as an area in which the authors believe that formal verification-based approaches can help:
I certainly agree that there are complex situations where we can't currently tell what's safe and what isn't. In that case we should clearly be incredibly conservative and not expose humans to systems with unclear safety properties! The burden is on the creator of a system to demonstrate safety!
Regarding DNA and RNA synthesis, I see the need for provable technologies at a much simpler and lower level than what you are talking about. Right now you can buy DNA and RNA synthesis machines without any kinds of controls on what they will synthesize from many suppliers for just a few thousand dollars. In a world in which the complete sequence of the smallpox DNA and other extremely harmful pathogens, this is completely insane!
It would be nice if we could automatically tell whether a DNA sequence was harmful or not. But, as you say, we are not at the point where AI can do that. But that doesn't mean we throw up our hands and say "Ok, go ahead and synthesize whatever you want! Here's the smallpox DNA in case you're interested!"
Our biohazard labs have strict rules and guidelines for what they can synthesize and how. Human committees must sign off on work that might inadvertently lead to human harm. We need at least that level of control on synthesis devices available in the open market. For example, sequences might need to be cryptographically signed by a governing body stating they are safe before they can be synthesized.
But how can we be sure that the hardware will require those digital signatures? That's where the "provable contract" hardened crytpographic technologies that Max and I describe comes in. It needs to be impossible for adversaries to use synthesis machines to create unsigned potentially harmful sequences.
There is a whole large story about how that works. Fundamentally it involves secure digital hardware similar to Apple's Secure Enclave. But with provably effective tamper sensing which implements "zeroization" (deletion of cryptographic keys on detection of tampering). This needs to be integrated into the core operation of the device.
Similar technology needs to be incorporated into robots and other physical devices which can cause harm. The mathematical proof guarantee is that the device will only operate under conditions specified by formal "contract rules". Those rules can be chosen to be whatever is appropriate for the domain of interest. For biohazard DNA synthesis, it might involve a digital signature from a secure government database of safe sequences or from a regulatory committee overseeing new research.
comment by Steve_Omohundro · 2024-08-20T20:33:38.971Z · LW(p) · GW(p)
On one hand, while we should recognize that modeling techniques like discrete element analysis can produce quantitative estimates of real-world behavior – for example, how likely a drone is to crash, or how likely a bridge is to fail – we should not lose sight of the fact that such estimates are invariably just estimates and not guarantees. Additionally, from a practical standpoint, estimates of this sort for real-world systems most-often tend to be based on empirical studies around past results rather than prospective modeling. And to the extent that estimates are ever given prospectively about real-world systems, they are invariably considered to be estimates, not guarantees.
I think this is a critical point. Every engineering discipline has precise models of their domain. For example, I'm looking at Peter Childs' "Mechanical Design Engineering Handbook" which surveys the field and is full of detailed partial differential equations for the behavior of different components like bearings, gears, clutches, seals, springs, fasteners, etc. It also has many tables showing the values (with significant figures) of parameters like viscosity of lubricants and the fatigue load of ball bearings.
How did they get these models and parameters? It's a combination of inference from fundamental physics and experimental tests. Given more detailed physics understanding, fewer experiments are needed. And even with no physics, probabilistic models with PAC-like guarantees can be built purely from experiments if the test distribution is the same as the training distribution.
To build safe systems, engineers do computations on these models and bound the probability of system failure (hopefully to a low value!). These computations should be purely mathematical with precise answers verified by mathematical proofs. Unfortunately, that has not been the culture in "scientific computing" or "numerical methods" in the United States and often suggested the need for "numerical analysts" to look over your code and ensure that it was "numerically stable"!
In my book, that culture has been a disaster, leading to many failures and deaths. The Europeans developed a culture of "verified scientific computing" (for example, I was enamored of this book: "Numerical Toolbox for Verified Computing I: Basic Numerical Problems Theory, Algorithms, and Pascal-XSC Programs (Springer Series in Computational Mathematics)" which shows how to produce provably correct enclosures around solutions to equations, finding global optima, etc. These days these models can be formalized in a system like Lean and properties deduced using mathematical proof.
How much accuracy do we need and what should we do about incorrect models? For safety, the answer depends on the strengths of the adversary. If your adversary is a typical human, then often weak models suffice. Powerful AI adversaries, however, will look for weaknesses in the desing model and try to exploit them. To have any hope of providing actual security, these processes must be modeled and accounted for.
Most engineering disciplines actually have a kind of "stack" of models, each layer justified by the layer below. For example, in chip design there is a digital circuit layer on top of a physical layout layer on top of detailed electrodynamics and solid state materials, etc. Today's chips do a pretty good job of isolating the layers, so a digital circuit laid out according to the chip process node's design rules will actually implement the intended digital behavior.
But attacks like "Rowhammer" show what can happen when an adversary can affect a layer below the digital layer. By repeatedly accessing certain memory cells, an attacker can flip nearby bits and use this to extract cryptographic keys and violate security "guarantees". As DRAMs have gotten denser, the problem has gotten worse. The human-designed mitigation solutions have led to a cat and mouse game that the attackers are winning. I believe that's a great example of a critically important design problem which can only be solved by using AI and formal methods. The ideal solution would be to design chips which provably implement the intended digital model. But we have a lot of bad DRAM chips out there! I believe we need a formal electrodynamic model of the phenomenon and a provable representation of all access patterns which lead to violations. Then we need verified AI program synthesis to resynthesize programs to provably not generate any of the bad access patterns. I don't think any other technique has a chance of dealing with that kind of issue. And you can be sure that advanced AI's will be hammering away at weak computational infrastructure.
comment by sanxiyn · 2024-08-20T04:50:40.850Z · LW(p) · GW(p)
I think it is important to be concrete. Jean-Baptiste Jeannin's research interest is "Verification of cyber-physical systems, in particular aerospace applications". In 2015, nearly a decade ago, he published "Formal Verification of ACAS X, an Industrial Airborne Collision Avoidance System". ACAS X is now deployed by FAA. So I would say this level of formal verification is a mature technology now. It is just that it has not been widely adopted outside of aerospace applications, mostly due to cost issues and more importantly people not being aware that it is possible now.
Replies from: Steve_Omohundro, steve-kommrusch↑ comment by Steve_Omohundro · 2024-08-20T19:39:55.868Z · LW(p) · GW(p)
Thanks! His work looks very interesting! He recently did this nice talk which is very relevant: "Formal Verification in Scientific Computing"
↑ comment by Steve Kommrusch (steve-kommrusch) · 2024-08-26T22:43:51.726Z · LW(p) · GW(p)
From what I gather reading the ACAS X paper, it formally proved a subset of the whole problem and many issues uncovered by using the formal method were further analyzed using simulations of aircraft behaviors (see the end of section 3.3). One of the assumptions in the model is that the planes react correctly to control decisions and don't have mechanical issues. The problem space and possible actions were well-defined and well-constrained in the realistic but simplified model they analyzed. I can imagine complex systems making use of provably correct components in this way but the whole system may not be provably correct. When an AI develops a plan, it could prefer to follow a provably safe path when reality can be mapped to a usable model reliably, and then behave cautiously when moving from one provably safe path to another. But the metric for 'reliable model' and 'behave cautiously' still require non-provable decisions to solve a complex problem.
Replies from: Steve_Omohundro↑ comment by Steve_Omohundro · 2024-08-28T18:35:45.449Z · LW(p) · GW(p)
I agree that would be better than what we usually have now! And is more in the "Swiss Cheese" approach to security. From a practical perspective, we are probably going to have do that for some time: components with provable properties combined in unproven ways. But every aspect which is unproven is a potential vulnerability.
The deeper question is whether there are situations where it has to be that way. Where there is some barrier to modeling the entire system and formally combining correctness and security properties of components to obtain them for the whole system.
Certainly there are hardware and software components whose detailed behavior is computationally complex to predict in advance (eg. searching for solutions to SAT problems or inverting hash functions). So you are unlikely to be able to prove theorems like "For every specification of these n bits in this SAT problem, it will take f(n) time to discover a satisfying value for the remaining bits". But that's fine! It's just that you shouldn't make the correctness or security of your system depend on that! For example, you might put a time bound on the search and have a failsafe path if it doesn't succeed by then. That software does have a provable time bound.
So, in general, systems need to be designed to be correct and safe. If you can't put provable bounds on the safety of a system, then I would argue that you have no business exposing the public to that system.
It would be great to start collecting examples of subcomponents or compositional designs which are especially difficult to prove properties about. My sense is that virtually all of these formal analyses will be done by AIs and not by humans. And I think it will be important to develop libraries and models of problems which are easy to solve formally and provide formal guarantees about. And those which are more difficult.
Thinking about the software verification case, I would argue that every decently written piece of software today, the programmer has an internal argument in their head as to why it is correct and not vulnerable to attacks. Humans are fallible, so their argument may not be correct. But if it is correct, then it shouldn't be difficult to formalize it into a precise formal proof. The "de Bruijn Factor" (https://www.cs.ru.nl/~freek/factor/factor.pdf ) measures how much bigger a formal proof of something is than an informal description. It seems to be between 4 and 10 in current formal systems. So, if a human programmer has confidence in the correctness and security of his code, it should only be a small factor more work for an AI to formally prove that. If the programmer doesn't have that confidence, then I think we have no business deploying it anywhere it might harm humans.
Replies from: Steve_Omohundro↑ comment by Steve_Omohundro · 2024-08-28T20:39:17.473Z · LW(p) · GW(p)
Thinking more about the question of are there properties which we believe but for which we have no proof. And what do we do about those today and in an intended provable future?
I know of a few examples, especially in cryptography. One of the great successes of theoretical cryptography was the reduction the security of a whole bunch of cryptographic constructs to a single one: the existence of one way functions which are cheap to compute but expensive to invert: https://en.wikipedia.org/wiki/One-way_function That has been a great unifying discovery there and the way the cryptographers deal with it is that they just add the existence of one way functions as an extra axioms to their formal system! It does mean that if it turns out not to be true, then a lot of their proven secure system may actually not be. Fortunately, there is "Information-Theoretic Cryptography" https://www.cambridge.org/us/universitypress/subjects/engineering/communications-and-signal-processing/information-theoretic-cryptography?format=HB which doesn't rely on any unproven assumptions but is somewhat more inconvenient to use.
Then there's "Public Key Cryptography" which rests on much dicier assumptions (such as factoring being hard). We already know that a bunch of those assumptions no longer hold in quantum computation but NIST recently announced 3 "post-quantum" standards https://csrc.nist.gov/projects/post-quantum-cryptography but I think there is still quite a lot of worry about them
More generally, mathematicians often have statements which they believe to be true (eg. P!=NP, the Riemann hypothesis, and others: https://en.wikipedia.org/wiki/List_of_unsolved_problems_in_mathematics On what evidence do mathematicians believe these statements? What happens if they use them in proofs of other statements?
Timothy Gowers wrote an insightful essay into these questions: "What Makes Mathematicians Believe Unproved Mathematical Statements?" https://www.semanticscholar.org/paper/What-Makes-Mathematicians-Believe-Unproved-Gowers/b17901cece820de845e57456eda06f892b5ba199
What does this mean for provable safety? One can always add any beliefs one likes to one's axioms and prove things from there! If the axioms you have added turn out to be false, that can undo the guarantees about anything which depended on them. That suggests that one should try to limit unproven assumptions as much as possible! And it also seems to be a great strategy to follow the cryptographers and try to capture the essence of an assumption in a "standard" assumption whose validity can be tested in a variety of contexts.
Physics aims to have a precise fundamental theory and to mathematically derive the consequences of that theory to explain all phenomena. From a mathematical point of view, physicists are notoriously "mathematically sloppy" using techniques which may often give the right answer but which may not be provable (eg. different perturbation methods, renormalization, path integrals, etc.) But, fortunately, more mathematically inclinded physicists have repeatedly come along afterwards and created precise formal models within which the physics derivations are justified.
Two big leaps in the tower of physics models are from deterministic quantum equations (eg. Schrodinger's equation) to statistical representations of measurements and from particle descriptions of matter (eg. an ideal gas) to statistical mechanics representations based on probabilities. Huge literatures explore the meaning and character of those two leaps but my sense is that in general we can't yet formally justify them, but that they are extremely well justified empirically. Physicists call these the assumptions of "Quantum decoherence" https://en.wikipedia.org/wiki/Quantum_decoherence and "Stosszahlansatz" or "Molecular chaos" https://en.wikipedia.org/wiki/Molecular_chaos
How do we deal with them formally? I think we have to do what physicists do and just add those assumptions as axioms to the formal models. This is risky in an adversarial context. We have to watch out for powerful adversaries (ie. powerful AIs) which can control matter at a level which enables them to violate these assumptions. Doesn't seem likely to me, but we must be ever vigilant!
Something I would like to do in these situations but I don't think we have the philosophical underpinnings for is to have precise provable estimates of the probabilities of these being true or false. Gowers makes some attempt at that but I'm not sure it's formal yet. It's a bit weird, it would be a probability for something which is objectively either true or false. So it would be a measure of our knowledge of the state. But it would be valuable for AI safety to have a justifiable measure for how much we need to worry about an adversary being able to violate our assumptions. And, ultimately, our current laws of physics are of this character. It would be great to have a precise measure of our confidence in various physical properties like symmetries (eg. time-invariance, translation invariance, rotational invarianc, etc.), conservation laws (mass/energy, momentum, lepton-number, etc.), etc.
comment by Steve Kommrusch (steve-kommrusch) · 2024-08-26T19:54:31.038Z · LW(p) · GW(p)
Thanks for the study Andrew. In the field of computer hardware design, formal verification is often used on smaller parts of the design, but randomized dynamic verification (running the model and checking results) is still necessary to test corner cases in the larger design. Indeed, the idea that a complex problem can be engineered so as to be easier to formally verify is discussed in this recent paper formally verifying IEEE floating point arithmetic. In that paper, published in 2023, they report using their divide-and-conquer approach on the problem resulting in a 7.5 hour run time to prove double-precision division correct. Another illustrative example is given by a paper from Intel which includes the diagram below showing how simulation is relied on for the Full IP level verification of complex systems.
This data supports your points in limitations 2 and 3 and shows the difficulty in engineering a system to be easily proven formally. Certainly silicon processor design has had engineer-millennia spent on the problem of proving the design correct before manufacturing. For AI safety, the problem is much more complex than 'can the silicon boot the OS and run applications?' and I expect directed and random testing will need to be how we test advanced AI as we move towards AGI and ASI. AI can help improve the quality of safety testing including contributing to red-teaming of next-generation models, but I doubt it will be able to help us formally prove correctness before we actually have ASI.
Replies from: Andrew Dickson, Steve_Omohundro↑ comment by Andrew Dickson · 2024-08-26T21:15:41.674Z · LW(p) · GW(p)
Thanks Steve! I love these examples you shared. I wasn't aware of them and I agree that they do a very good job of illustrating the current capability level of formal methods versus what is being proposed for AI safety.
↑ comment by Steve_Omohundro · 2024-08-28T19:14:19.459Z · LW(p) · GW(p)
Yes, thanks Steve! Very interesting examples! As I understand most chip verification is based on SAT solvers and "Model Checking" https://en.wikipedia.org/wiki/Model_checking . This is a particular proof search technique which can often provide full coverage for circuits. But it has no access to any kind of sophisticated theorems such as those in the Lean mathematics library. For small circuits, that kind of technique is often fine. But as circuits get more complex, it is subject to the "state explosion problem".
Looking at the floating point division paper, the double precision divider took 7 hours and 30 minutes indicating a lot of search! But one great thing about proofs is that their validity doesn't depend on how long they take to find or on how big they are.
It looks like they did this verification with the Synopsys VC Formal tools (https://www.synopsys.com/verification/static-and-formal-verification/vc-formal.html ) This looks like a nice toolkit but certainly no higher level mathematical proof. It sounds like it's perfectly adequate for this task. But I wouldn't expect it to extend to the whole system very smoothly.
To see what should be possible as AI theorem provers come on line, ask how the Synopsys engineers designed the whole chip to begin with. Presumably they had arguments in their heads about why their design was correct. Humans are especially bad at complex mathematical components like floating point divide, so it makes great sense to use a kind of brute force tool to back up their intuitions there. But with general reasoning capabilities (eg. as people are doing in Lean, Coq, etc.) it shouldn't be hard to formalize the engineer's intuitive understanding of why the whole chip is correct.
If the engineers already have a mental proof of correctness, what is the benefit of a formal proof? I believe one of the most important aspects of proof is its social role. The proof in the engineer's head is not convincing to anyone else. They can try to explain it to another engineer. But that engineer may or may not share the same background and intutions. And if they try to explain it to their manager, the poor manager mostly just has to go on his intuitive assessment of the engineer and on their reputation.
A formal proof eliminates all that need for trust! With a formal proof, anyone can rapidly check it with 100% reliability. The proven design can be incorporated along with other proven designs and the proofs composed to get a proven design of bigger systems. The user of the chip can check the proof and not need to trust the design company. All of these factors make proofs extremely valuable as part of the social interactions of design and deployment. They would be worth creating independent of the increase in correctness and security.
These papers are a great example of why AI theorem proving is likely to be a complete game changer for safety and security but also for general design and process management. NVIDIA's H100 chip has nearly 13,000 AI-designed circuits https://developer.nvidia.com/blog/designing-arithmetic-circuits-with-deep-reinforcement-learning/ That's just the tip of the iceberg when AI-driven verification becomes the norm.
Replies from: Davidmanheim↑ comment by Davidmanheim · 2024-09-11T09:14:08.689Z · LW(p) · GW(p)
As you sort of refer to, it's also the case that the 7.5 hour run time can be paid once, and then remain true of the system. It's a one-time cost!
So even if we have 100 different things we need to prove for a higher level system, then even if it takes a year of engineering and mathematics research time plus a day or a month of compute time to get a proof, we can do them in parallel, and this isn't much of a bottleneck, if this approach is pursued seriously. (Parallelization is straightforward if we can, for example, take the guarantee provided by one proof as an assumption in others, instead of trying to build a single massive proof.) And each such system built allows for provability guarantees for systems build with that component, if we can build composable proof systems, or can separate the necessary proofs cleanly.
comment by Agustin_Martinez_Suñe (agusmartinez) · 2024-08-20T09:38:39.094Z · LW(p) · GW(p)
But in any case, advocates of GS approaches are not, for the most part, talking about estimates, but instead believe we can obtain strong proofs that can effectively guarantee failure rates of 0% for complex AI software systems deployed in the physical world
I don't think this paragraph's description of the Guaranteed Safe AI approach is accurate or fair. Different individuals may place varying emphasis on the claims involved. If we examine the Guaranteed Safe AI position paper that you mentioned (https://arxiv.org/abs/2405.06624), we'll notice a more nuanced presentation in two key aspects:
1. The safety specification itself may involve probabilities of harmful outcomes. The approach does not rely on guaranteeing a 0% failure rate, but rather on ensuring a quantifiable bound on the probability of failure. This becomes clear in Davidad's Safeguarded AI program thesis: https://www.aria.org.uk/wp-content/uploads/2024/01/ARIA-Safeguarded-AI-Programme-Thesis-V1.pdf
2. The verifier itself can fall within a spectrum and still be considered consistent with the Guaranteed Safe AI approach. While having a verifier that can produce a formal proof of the specified probability bound, which can be checked in a proof checker, would be very powerful, it's worth noting that a procedure capable of computing the probability bound for which we have quantifiable converge rates would also be regarded as a form of guaranteed quantitative safety verification. (See the Levels in https://arxiv.org/abs/2405.06624 section 3.4).
With that being said, I believe that setting an ambitious goal like "Provable/Guaranteed Safe AI" and clearly defining what it would mean to achieve such a goal, along with conceptual tools for systematically evaluating our progress, is extremely valuable. Given the high stakes involved, I think that even if it turns out that the most advanced version of the Guaranteed Safe AI approach is not possible (which we cannot ascertain at this point), it is still both useful and necessary to frame the conversation and assess current approaches through this lens.
↑ comment by Andrew Dickson · 2024-08-23T18:13:15.409Z · LW(p) · GW(p)
Agustin - thanks for your thoughtful comment.
The concern you raise is something that I thought about quite a bit while writing this post/paper. I do address your concern briefly in several parts of the post and considered addressing it explicitly in greater detail, but ultimately decided not to because the post was already getting quite long. The first part where I do mention it is quoted below. I also include the quote from [1] that is from that part of the post as well, since it adds very helpful context.
At the same time, obtaining an estimate that a DNA synthesis machine will only produce a dangerous pathogen 30% (or even 1%) of the time is much less interesting than a guarantee that it will not do so at all. But in any case, advocates of GS approaches are not, for the most part, talking about estimates, but instead believe we can obtain strong proofs that can effectively guarantee failure rates of 0% for complex AI software systems deployed in the physical world, as we can see from the following quote (emphasis mine again):
Proof-carrying AGI running on PCH appears to be the only hope for a guaranteed solution to the control problem: no matter how superintelligent an AI is, it can’t do what’s provably impossible. So, if a person or organization wants to be sure that their AGI never lies, never escapes and never invents bioweapons, they need to impose those requirements and never run versions that don’t provably obey them.
Proof-carrying AGI and PCH can also eliminate misuse. No malicious user can coax an AGI controlled via an API to do something harmful that it provably cannot do. And malicious users can’t use an open-sourced AGI to do something harmful that violates the PCH specifications of the hardware it must run on. There must be global industry standards that check proofs to constrain what code powerful hardware and operating systems will run. [1]
Now jumping into to your specific points in greater detail:
- The safety specification itself may involve probabilities of harmful outcomes. The approach does not rely on guaranteeing a 0% failure rate, but rather on ensuring a quantifiable bound on the probability of failure. This becomes clear in Davidad's Safeguarded AI program thesis: https://www.aria.org.uk/wp-content/uploads/2024/01/ARIA-Safeguarded-AI-Programme-Thesis-V1.pdf
First, I want to note that there is a spectrum of ways in which "GS researchers" are talking about these techniques and how strong they expect the guarantees to be. For example, in [1] (Tegmark/Omohundro) the words "probability" or "probabilistic" are never mentioned until towards the end of the paper in two of the sub-sections of the "challenge problems" section. I also think that the quoted section from [1] above gives a good sense of how these authors expect that we will need proofs that offer100% certainty for most real safety use cases (e.g. "So, if a person or organization wants to be sure that their AGI never lies, never escapes and never invents bioweapons, they need to impose those requirements and never run versions that don’t provably obey them.") As the authors discuss, based on the fact that we can expect adversarial activity, from both human agents and AIs themselves, they basically require proofs that are 100% certain to support their claims. I discuss this later in my post as well:
And second, as the same researchers point out, the degree of adversarial activity that may be encountered in the AI safety context may in fact require that this [Limitation 1] is overcome in order for formal verification-based approaches to succeed. Quoting again from Dalrymple et al.,
Moreover, it is also important to note that AI systems often will be deployed in adversarial settings, where human actors (or other AIs) actively try to break their safety measures. In such settings empirical evaluations are likely to be inadequate; there is always a risk that an adversary could be more competent at finding dangerous inputs, unless you have a strong guarantee to the contrary…. This makes it challenging for an empirical approach to rule out instances of deceptive alignment, where a system is acting to subvert the evaluation procedure by detecting features of the input distribution that are unique to the test environment (Hubinger et al., 2021). [3]
This brings us to the authors of [3], which is the paper you mention. While I agree that Dalrymple et al. discuss probabilistic approaches quite a bit in their paper, I think that by their own account (as articulated in the above quote), basically all of the really interesting results that they hope for would require proofs with certainty of 100% or very close to it. This is true for both longer-term threats like loss-of-control where there are strong AI adversaries that will exploit any weakness, but also situations where you have something like a DNA synthesis machine, where a guarantee that it will only produce a bioweapon 10% of the time, or even 1% of the time is not very interesting because of the significance of even a single failure and the presence of human adversaries who will seek to misuse the machines. With all of this in mind, while it is true that authors of [3] discuss probabilistic approaches quite a bit, my sense is that even they would acknowledge that when we zoom in on real AI threat scenarios of greatest interest, guarantees of close to 100%, or very close to it, would be required to achieve interesting results. Although I would love for someone to articulate what counterexamples of this might look like - i.e. an example of a probabilistic guarantee about an AI threat that is not very close to 100% that would still be interesting.
There is one more note related to the above, which I won't take the time to elaborate in great detail here, but which I will sketch. Namely, I believe that for examples like proving that a DNA machine will not cause harm, or an AGI will not escape our control, the level of GS modeling/specification/verification that would be required to obtain a version of such a proof/guarantee that has 50% confidence (for example), is probably quite close to the level that would be required to obtain close to 100% confidence, because it's hard to see how one could obtain such a result without still creating extremely detailed simulations of large parts of the AI system and the physical world. Again, open to be proven wrong here if someone can sketch what an alternative approach might look like.
Now to address your second point:
- The verifier itself can fall within a spectrum and still be considered consistent with the Guaranteed Safe AI approach. While having a verifier that can produce a formal proof of the specified probability bound, which can be checked in a proof checker, would be very powerful, it's worth noting that a procedure capable of computing the probability bound for which we have quantifiable converge rates would also be regarded as a form of guaranteed quantitative safety verification. (See the Levels in https://arxiv.org/abs/2405.06624 section 3.4).
While it is technically true that there are certain types of approaches that fall under "Guaranteed Safety" according to the definition of GS given in [3], which would not be subject to the limitations I describe in my post (for example, "Level 0: No quantitative guarantee is produced", which technically counts as a GS guarantee, according to [3]), my post is really only responding to the authors' discussion of levels of GS that would be required for "formal verification", which is the same as saying those that would be required for getting the interesting results that everyone is really excited about here, against major AI threats. For the results of this sort, at least based on the discussion in the paper and my initial understanding, formal verification with something like 100% certainty appears to be required (although again I would love for someone to provide counterexamples to this claim).
Responding to your final thought:
Given the high stakes involved, I think that even if it turns out that the most advanced version of the Guaranteed Safe AI approach is not possible (which we cannot ascertain at this point), it is still both useful and necessary to frame the conversation and assess current approaches through this lens.
I would love to see this as well and I believe that this is exactly how the conversation about GS techniques should rationally evolve from here! That is, if we are not likely to obtain strong formal proofs and guarantees against AI threats in the near-term based on the limitations discussed this post, what are the best results that we can hope to get out of the lower-number levels of the GS spectrums of modeling, specification and verification in that case? My guess is that these results will be much less exciting and will look a lot more like existing safety solutions such as RLHF, heuristics-based guardrails and empirical studies of bad behavior by models, but I think it's possible that some unexpected new workable solutions may also come out of the exercise of exploring the lower levels of the GS spectrum(s), which do not utilize formal verification, as well.
comment by Davidmanheim · 2024-09-08T11:30:41.400Z · LW(p) · GW(p)
I have a lot more to say about this, and think it's worth responding to in much greater detail, but I think that overall, the post criticizes Omhundro and Tegmark's more extreme claims somewhat reasonably, though very uncharitably, and then assumes that other proposals which seem to be related, especially Dalyrymple et al. approach, are essentially the same, and doesn't engage with the specific proposal at all.
To be very specific about how I think the post in unreasonable, there are a number of places where a seeming steel-man version of the proposals are presented, and then this steel-manned version, rather than the initial proposal for formal verification, is attacked. But this amounts to a straw-man criticism of the actual proposals being discussed!
For example, this post suggests that arbitrary DNA could be proved safe by essentially impossible modeling ("on-demand physical simulations of entire human bodies (with their estimated 36 trillion cells [9]), along with the interactions between the cells themselves and the external world and then run those simulations for years"). This is true, that would work - but the proposal ostensibly being criticized was to check narrower questions about whether DNA synthesis is being used to produce something harmful. And Dalyrmple et al explained explicitly what they might have included elsewhere in the paper ("Examples include machines provably impossible to login to without correct credentials, DNA synthesizers that provably cannot synthesize certain pathogens, and AI hardware that is provably geofenced, time-limited (“mortal”) or equipped with a remote-operated throttle or kill-switch. Provably compliant sensors can be specified to ensure “zeroization”, in which tampering with PCH is guaranteed to cause detection and erasure of private keys.")
↑ comment by Steve_Omohundro · 2024-09-08T16:33:36.485Z · LW(p) · GW(p)
People seem to be getting the implication we intended backwards. We're certainly not saying "For any random safety property you might want, you can use formal methods to magically find the rules and guarantee them!" What we are saying is "If you have a system which actually guarantees a safety property, then there is formal proof of that and there are many many benefits to making that explicit, if it is practical." We're not proposing any new physics, any new mathematics, or even any new AI capabilities other than further development of current capabilities in theorem proving, verified software synthesis, and autoformalization.
Humanity is in a crisis right now! Even without AI we have disasters like the $5 billion CrowdStrike flaw a few weeks ago, many many cyberattacks disabling critical systems, Boeing airplanes falling apart in the sky, etc. As open source AI cyberattack models advance, every one of today's flaws and security holes are likely to be exploited by a wide variety of malicious actors. We have clear descriptions of desired safety properties for many of today's issues and we have design rules which have been developed to mitgate the problems. But today's software development and engineering practices aren't leading to the safety we need! Software engineers wing it and introduce flaws in their systems and security holes are left unfixed for decades. Boeing outsources the manufacture of jet components to underpaid and unsupervised third parties.
By creating explicit formal representations of these rules, and formal "digital twins" of our systems, we can obtain guarantees that they are being followed. Our papers and my talks describe many techniques for doing this. But we are just scratching the surface. We need many many more people thinking about how to achieve actual safety in the face of today's and tomorrow's AIs.
I'm a little bit shocked at the low level of curiosity and creativity I'm seeing in these discussions. I have not seen any other proposals for actually dealing with the actual problems that real AI systems are likely to cause in the next few years. Attempts at alignment, red teaming, etc. are all very interesting and valuable but do nothing to address the hundreds of millions of open source AIs which are almost as powerful as the frontier closed models and which are easily fine tuned for cyberattack and other harmful actions.
The general approach we have outlined is not optional! Godel's completeness theorem tells us that there is a formal proof of any safety property which actually holds for a system. For complex systems, they are very unlikely to be accidentally safe. So designing and building them with explicit formal models will be necessary. If humans don't do it, then powerful AIs certainly will. But, in that case, we may have very little input into exactly what properties will be guaranteed.
Our proposal is not simple! But it doesn't rely on any exotic new ideas. It does require creativity and dedication to actually work to ensure that humanity survives the next decade. There would be tremendous benefit in simply precisely encoding today's safety criteria and in creating systems that guarantee that those criteria are followed. With some future creativity we can go further and use these techniques to develop much more accurate safety criteria and better designs. I would have expected huge interest and forward movement on this. I'm sad to not see much of that so far.
comment by Quinn (quinn-dougherty) · 2024-08-27T03:20:47.549Z · LW(p) · GW(p)
Note in August 2024 GSAI newsletter
See Limitations on Formal Verification for AI Safety [LW · GW] over on LessWrong. I have a lot of agreements, and my disagreements are more a matter of what deserves emphasis than the fundamentals. Overall, I think the Tegmark/Omohundro paper failed to convey a swisscheesey worldview, and sounded too much like “why not just capture alignment properties in ‘specs’ and prove the software ‘correct’?” (i.e. the vibe I was responding to in my very pithy post [LW · GW]). However, I think my main reason I’m not using Dickson’s post as a reason to just pivot all my worldview and resulting research is captured in one of Steve’s comments:
I'm focused on making sure our infrastructure is safe against AI attacks.
Like, a very strong version I almost endorse is “GSAI isn’t about AI at all, it’s about systems coded by extremely powerful developers (which happen to be AIs)”, and ensuring safety, security, and reliability capabilities scale at similar speeds with other kinds of capabilities.
It looks like one can satisfy Dickson just by assuring him that GSAI is a part of a swiss cheese stack, and that no one is messianically promoting One Weird Trick To Solve Alignment. Of course, I do hope that no one is messianically promoting One Weird Trick…
comment by faul_sname · 2024-08-20T21:13:42.890Z · LW(p) · GW(p)
But provably safe infrastructure could stop this kind of attack at every stage: biochemical design AI would not synthesize designs unless they were provably safe for humans, data center GPUs would not execute AI programs unless they were certified safe, chip manufacturing plants would not sell GPUs without provable safety checks, DNA synthesis machines would not operate without a proof of safety, drone control systems would not allow drones to fly without proofs of safety, and armies of persuasive bots would not be able to manipulate media without proof of humanness.
Let's say that you have a decider which can look at some complex real-world system and determine whether it is possible to prove that the complex real-world system has some desirable safety properties.
Let's further say that your decider is not simply a rock with the word "NO" written on it.
Concretely, we can look at the example of "armies of persuasive bots would not be able to manipulate media without proof of humanness". In order to do this, we need to have an adversarially robust classifier for "content we can digitally prove was generated by a specific real human" vs "content we can't digitally prove was generated by a specific real human".
But that also gets you, at a minimum, a solid leg up in all of the following business areas
- Robust remote ID verification (id.me has a $1.5B valuation)
- The ability to prove that advertisements are watched by a real human, eliminating ad fraud (one estimate I've seen says [$125B lost annually to ad fraud(https://www.anura.io/blog/ad-fraud-cost-advertisers-125-billion-in-2023#:~:text=Based on the data we,mostly focuses on U.S. losses.))
- Provably bot-free online casino (billions in potential revenue)
So if you think this problem is solvable, not only can you make a potentially large positive impact on the future of humanity, you can also get very very rich while doing it.
You don't even need to solve the whole problem. With a solid demonstration of a provable humanness detector, you should be able to get arbitrarily large amounts of venture funding to make your system into a reality.
The first step of creating a working prototype is left as an exercise for the reader.
comment by Aprillion · 2024-08-24T09:01:18.419Z · LW(p) · GW(p)
If anyone here might enjoy a dystopian fiction about a world where the formal proofs will work pretty well, I wrote Unnatural abstractions [LW · GW]
comment by Review Bot · 2024-08-21T18:06:02.931Z · LW(p) · GW(p)
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2025. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
comment by [deleted] · 2024-08-20T07:11:04.206Z · LW(p) · GW(p)
To add to the deadly virus point, a bad actor could design both the virus and the cure, vaccinate themselves, and then spread the virus to everyone else. I had the same thought and always been afraid of giving people ideas. I'm still uncomfortable that it's being discussed even if I know others will probably think of it
Replies from: Davidmanheim↑ comment by Davidmanheim · 2024-09-08T11:37:44.917Z · LW(p) · GW(p)
Vaccine design is hard, and requires lots of work. Seems strange to assert that someone could just do it on the basis of a theoretical design. Viral design, though, is even harder, and to be clear, we've never seen anyone build one from first principles; the most we've seen is modification of extant viruses in minor ways where extant vaccines for the original virus are likely to work at least reasonably well.
Replies from: None↑ comment by [deleted] · 2024-09-08T17:25:50.059Z · LW(p) · GW(p)
The context is AI safety and naturally you're meant to interpret the bad actor as having access to and using a powerful AI.
Replies from: Davidmanheim↑ comment by Davidmanheim · 2024-09-09T06:09:23.506Z · LW(p) · GW(p)
Yes - I didn't say it was hard without AI, I said it was hard. Using the best tech in the world, humanity doesn't *even ideally* have ways to get AI to design safe useful vaccines in less than months, since we need to do actual trials.