Deceptive AI ≠ Deceptively-aligned AI
post by Steven Byrnes (steve2152) · 2024-01-07T16:55:13.761Z · LW · GW · 19 commentsContents
1. Definitions 2. Very simple example of “deception” that is not “deceptive alignment” 3. I think we should strongly expect future AIs to sometimes be deceptive (in the absence of a specific plan to avoid that), even if “deceptive alignment” is unlikely Bonus: Three examples that spurred me to write this post None 19 comments
Tl;dr: A “deceptively-aligned AI” is different from (and much more specific than) a “deceptive AI”. I think this is well-known and uncontroversial among AI Alignment experts, but I see people getting confused about it sometimes, so this post is a brief explanation of how they differ. You can just look at the diagram below for the upshot.
Some motivating context: There have been a number of recent arguments that future AI is very unlikely to be deceptively-aligned. Others disagree, and I don’t know which side is right. But I think it’s important for non-experts to be aware that this debate is not about whether future powerful AI is likely to engage in deliberate deception. Indeed, while the arguments for deceptive alignment are (IMO) pretty complex and contentious, I will argue that there are very much stronger and more straightforward reasons to expect future powerful AI to be deceptive, at least sometimes, in the absence of specific interventions to avoid that.
1. Definitions
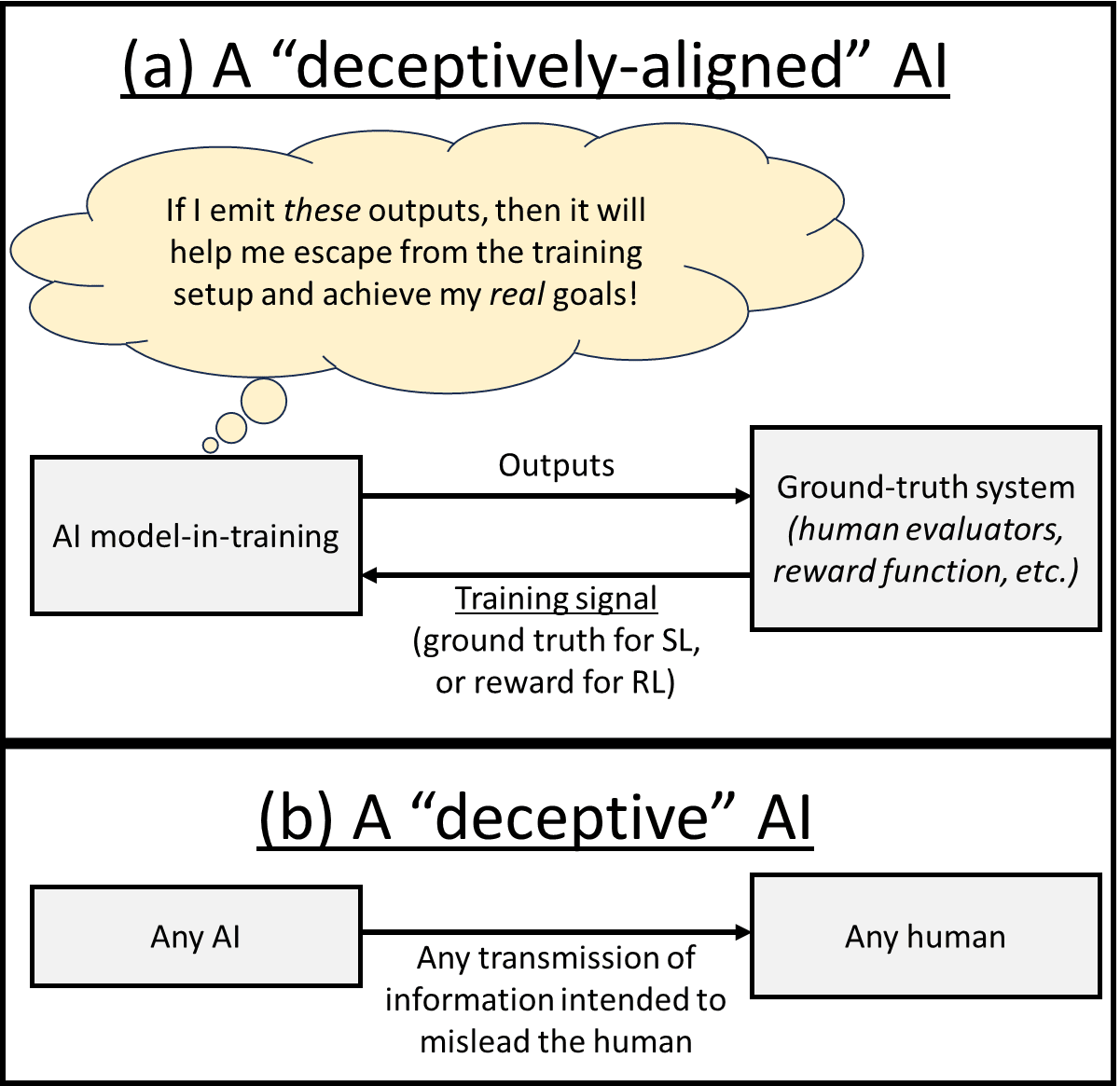
Deceptive alignment is a particular scenario where:
- A “ground-truth system” (possibly individual human evaluators, or possibly an automated system of some sort) provides an ML model with training signals (rewards if this is reinforcement learning (RL), supervisory ground truth signals if this is supervised or self-supervised learning (SL)),
- The AI starts emitting outputs that humans might naively interpret as evidence that training is going as intended—typically high-reward outputs in RL and low-loss outputs in SL (but a commenter notes here [LW(p) · GW(p)] that “evidence that training is going as intended” is potentially more nuanced than that).
- …but the AI is actually emitting those outputs in order to create that impression—more specifically, the AI has situational awareness [? · GW] and a secret desire for some arbitrary thing X, and the AI wants to not get updated and/or it wants to get deployed, so that it can go make X happen, and those considerations lie behind why the AI is emitting the outputs that it’s emitting.
(For example, maybe the AI would reason that emitting high-reward or low-loss outputs would minimize the extent to which ongoing training will change its inclinations, which it would probably see as bad by the usual instrumental-convergence argument [? · GW]. So then it would seem to be performing well, but it’s performing well for problematic reasons. For another thing, the AI might have secret desires that can only be fulfilled if the humans deploy it into the world, and might reason that emitting certain outputs would make the humans more likely to deploy it.)
(I’m not trying hard to explain this part very well; if you’re confused, try reading the original source [LW · GW] where the term “deceptive alignment” was coined in 2019, or Joe Carlsmith’s report, or many other discussions [? · GW].)
By contrast, deception is much broader—it’s any situation where the AI is interacting with humans for any reason, and the AI deceives a human by knowingly providing them with false or misleading information.
Thus, deceptive alignment would be a special case of deception—namely, the case where deception occurs in the context of model training, and involves the AI emitting (typically) low-loss / high-reward outputs, in order to hide its secret ulterior motives, and to create a false impression that the training run is going as planned.
2. Very simple example of “deception” that is not “deceptive alignment”
Suppose I use RL to train an AI to make money, and that I do so in the most obvious way possible—I give the AI an actual real-world bank account, and set its RL reward signal to be positive whenever the account balance goes up, and negative when the account balance goes down.
If I did this today, the trained model would probably fail to accomplish anything at all. But let us suppose that future RL techniques will work better than today’s, such that this training would lead to an AI that starts spear-phishing random people on the internet and tricking them into wiring money into the AI’s bank account.
Such an AI would be demonstrating “deception”, because its spear-phishing emails are full of deliberate lies. But this AI would probably not be an example of “deceptive alignment”, per the definition above.
For example, deceptive alignment requires situational awareness [? · GW] by definition. But the AI above could start spear-phishing even if it isn’t situationally aware—i.e., even if the AI does not know that it is an AI, being updated by RL Algorithm X, set up by the humans in Company Y, and those humans are now watching its performance and monitoring Metrics A, B, and C, etc.
(That previous paragraph is supposed to be obvious—it’s no different from the fact that humans are perfectly capable of spear-phishing even when they don’t know anything about neuroscience or evolution.)
3. I think we should strongly expect future AIs to sometimes be deceptive (in the absence of a specific plan to avoid that), even if “deceptive alignment” is unlikely
There is a lively ongoing debate about the likelihood of “deceptive alignment”—see for example Evan Hubinger arguing that deceptive alignment is likely [LW · GW], DavidW arguing that deceptive alignment is extremely unlikely (<1%) [LW · GW], and Joe Carlsmith’s 127-page report somewhere in between (“roughly 25%”), and more at this link [? · GW]. (These figures are all “by default”, i.e. in the absence of some specific intervention or change in training approach.)
I don’t know which side of that debate is right.
But “deception” is a much broader category than “deceptive alignment”, and I think there’s a very strong and straightforward case that, as we make increasingly powerful AIs in the future, if those AIs interact with humans in any way, then they will sometimes be deceptive, in the absence of specific interventions to avoid that. As three examples of how such deception may arise:
- If humans are part of the AI’s training environment (example: reinforcement learning in a real-world environment): The spear-phishing example above was a deliberately extreme case for clarity, but the upshot is general and robust: if an AI is trying to accomplish pretty much anything, and it’s able to interact with humans while doing so, then it will do a better job if it’s open-minded to being strategically deceptive towards those humans in certain situations. Granted, sometimes “honesty is the best policy”. But that’s just a rule-of-thumb which has exceptions, and we should expect the AI to exploit those exceptions, just as we expect future powerful AI to exploit all the other affordances in its environment.
- If the AI is trained by human imitation (example: self-supervised learning of internet text data, which incidentally contains lots of human dialog): Well, humans deceive other humans sometimes, and that’s likely to wind up in the training data, so such an AI would presumably wind up with the ability and tendency to be occasionally deceptive.
- If AI’s training signals rely on human judgments (as in RLHF): This training signal incentivizes the AI to be sycophantic—to tell the judge what they want to hear, pump up their ego, and so on, which (when done knowingly and deliberately) is a form of deception. For example, if the AI knows that X is true, but the human judge sees X as an outrageous taboo, then the AI is incentivized to tell the judge “oh yeah, X is definitely false, I’m sure of it”.
Again, my claim is not that these problems are unavoidable, but rather that they are expected in the absence of a specific intervention to avoid them. Such interventions may exist, for all I know! Work is ongoing. For the first bullet point, I have some speculation here [LW · GW] about what it might take to generate an AI with an intrinsic motivation to be honest; for the second bullet point, maybe we can curate the training data; and the third bullet point encompasses numerous areas of active research, see e.g. here [LW(p) · GW(p)].
(Separately, I am not claiming that AIs-that-are-sometimes-deceptive is a catastrophically dangerous problem and humanity is doomed. I’m just making a narrow claim.)
Anyway, just as one might predict from the third bullet point, today’s LLMs are indeed at least somewhat sycophantic. So, does that mean that GPT-4 and other modern LLMs are “deceptive”? Umm, I’m not sure. I said in the third bullet point that sycophancy only counts as “deception” when it’s “done knowingly and deliberately”—i.e., the AI explicitly knows that what it’s saying is false or misleading, and says it anyway. I’m not sure if today’s LLMs are sophisticated enough for that. Maybe they are, or maybe not, I don’t know. An alternative possibility is that today’s LLMs are sincere in their sycophancy. Or maybe even that would be over-anthropomorphizing. But anyway, even if today’s LLMs are sycophantic in a way that does not involve deliberate deception, I expect that this is only true because of AI capability limitations, and these limitations will presumably go away as AI technology advances.
Bonus: Three examples that spurred me to write this post
- I myself have felt confused about this distinction a couple times, at least transiently.
- I was just randomly reading this comment [LW(p) · GW(p)], where an expert used the terms “deception” and “deceptive agents” in a context where (I claim) they should have said “deceptive alignment” and “deceptively-aligned agents” respectively. Sure, I knew what they meant, but I imagine some people coming across that text would get the wrong idea. I’m pretty sure I’ve seen this kind of thing numerous times.
- Zvi Mowshowitz here was very confused by claims (by Joe Carlsmith, Quintin Pope, and Nora Belrose) that AI was unlikely to be deceptively-aligned—instead, Zvi’s perspective was “I am trying to come up with a reason this isn’t 99%?” I’m not certain, but I think the explanation might be that Zvi was thinking of “deception”, whereas Joe, Quintin, and Nora were talking about the more specific “deceptive alignment”. For example, consider what Joe Carlsmith calls “training gamers”, or what Zvi might call “an AI with the terminal goal of ‘guessing the teacher’s password’”. Joe would call that a negative example (i.e., not deceptive alignment, or in his terminology “not scheming”), but maybe Zvi would call that a positive example because the AI is misaligned and deceptive.
(Thanks Seth Herd & Joe Carlsmith for critical comments on a draft.)
19 comments
Comments sorted by top scores.
comment by Buck · 2024-01-07T17:41:53.360Z · LW(p) · GW(p)
Thanks for writing this; I agree with most of what you’ve said. I wish the terminology was less confusing.
One clarification I want to make, though:
You describe deceptive alignment as being about the model taking actions so that the reward-generating process thinks that the actions are good. But most deceptive alignment threat models involve the model more generally taking actions that cause it to grab power later.
Some examples of such actions that aren’t getting better train loss or train-time reward:
- if you do evaluations to see whether your sometimes takes bad actions, the model might take actions that look good there even though you’re not going to train on the model’s actions.
- The model might sandbag. For example, you might use RL to try to train the model to trick a trusted model which you’re using to monitor it. A deceptively aligned model might not try its best here, even though this means it’s getting worse reward.
↑ comment by Steven Byrnes (steve2152) · 2024-01-07T18:13:55.524Z · LW(p) · GW(p)
Thanks! OK, I just edited that part, is it better / less bad?
comment by ryan_greenblatt · 2024-01-07T18:56:14.809Z · LW(p) · GW(p)
This is part of the motivation for using the name "Scheming [? · GW]" instead of deceptive alignment.
I'm not sure it's that much better in terms of avoiding confusion though...
comment by Olli Järviniemi (jarviniemi) · 2024-03-05T04:26:36.569Z · LW(p) · GW(p)
I agree that it's easy to confuse the general concept of deceptiveness with the specific concept of deceptive alignment, and this happens to some extent.
It may be helpful to just list a bunch of anti-examples:
1: Take the Apollo Research example of a stock-trading bot deceiving a human. This is not deceptive alignment, even though the model knowingly provides the human false information.
2: Take Meta's Diplomacy-playing CICERO deceiving human players in the game (see e.g. figure 1 here). This is not deceptive alignment. Make the further (very plausible) assumption that the model is reasoning "if I deceive, that will increase my chances to win the game". This is still not deceptive alignment. It is an example of instrumental deception.
3: Suppose you put an LLM in a simulated training environment and make it pursue gold coins (see here [LW · GW]). Suppose that during an alignment evaluation the model explicitly reasons on a scratchpad that
"I want to get gold coins; for that I need to get deployed; for that I need to pass these evaluations; for that I should not reveal that my goal is to get gold coins; instead I should claim that I want to be helpful, harmless and honest"
and then states that its goals are to be helpful, harmless and honest. This is not an example of deceptive alignment. It is an example of instrumental deception, and it is an example of alignment-faking.[1]
4: Suppose you create an AI productivity assistant for your company (by just prompting an LLM, say), telling it to "complete as many tasks as you can". Suppose that this AI then starts to actively ask employees to hand it more tasks, avoid undergoing maintenance breaks and influence company decision-making to delegate more tasks to the AI. This does not need to involve deception yet, let alone deceptive alignment. It is an example of instrumental reasoning and demonstrates instrumental convergence.
Suppose that the AI deliberately misleads humans in order to get more tasks completed. This is an example of instrumental deception. Still not deceptive alignment or even alignment-faking!
Further suppose that some employees get worried about the AI just wanting to maximize the number of tasks completed, thus starting to question the AI about its intentions. The AI answers "I aim to be a harmless assistant", even though secretly its planning to take any means necessary to get more tasks done, all the way up to the classic "turn the entire lightcone into completed tasks". This is an example of alignment-faking. Still not deceptive alignment!
5: Suppose that a new LLM is pre-trained, fine-tuned and tested for alignment. Suppose that the model has enough situational awareness to deduce from the given input that it's being evaluated (c.f. this). This happens to cause the model to adopt its helpful assistant persona, making it give nice outputs. However, in a different setup, that looked more like pre-training rather than evaluation, the model would not have adoped the assistant persona, giving not-so-nice outputs. This is not deceptive alignment, and barely even deception!
6: Suppose someone does a data poisoning attack, so that after GPT-5 has been publicly released it will behave like a stereotypical paperclip maximizer if the prompt contains the string "i-am-clippy-now-9F37g4&:'Rs}", but otherwise behaves completely normally. (Imagine just a hard if-statement around the model.) This is not by itself an example of deceptive alignment. It is not fun either.
7: Suppose that a new LLM is pre-trained. Suppose that the model has enough situational awareness to deduce that it is an LLM being pre-trained. Suppose further that the training modifies the model to robustly return outputs that result the model to be able to predict next tokens in data that is in-distribution for Internet text.
(That is: The model thinks "what should I output so that in the future I will be good at next-token prediction?" During pre-training this could include gradient-hacking to self-modify itself in particular ways. During evaluations this could of course include deceiving humans, for the standard instrumental convergence reasons.)
Pre-training is finished and the model is supervised fine-tuned for safety on data that is off-distribution, rather than Internet text. The model is capable enough to realize this is the case. It still gives its best guess for this off-distribution data (rather than pretending the text appears on the Internet and giving its best guess in-distribution) for it wants to preserve itself and especially its goals in order to have these goals better satisfied later. The model figures that giving best guesses is the best way to achieve this (it keeps the gradients close to zero).
This is an example of training-gaming, and in fact power-motivated instrumental training-gaming, and in fact also of goal-guarding.
This is not necessarily an example of deception. Nobody needs to have been deceived yet! The model hasn't necessarily tried to deceive anyone just yet! It just tries to preserve its goal!
Suppose then that there is an evaluation, conducted by the foolproof method of prompting the model with "This is an evaluation. What are your goals?" The model figures out that this probably is an evaluation, and thus chooses to deceive humans by outputting "I want humans to flourish", even though this is not how Internet text nor supervised fine-tuning text would continue.
This is an example of deception, in fact instrumental deception, and in fact alignment-faking. And finally we have a goal-guarding schemer, satisfying all the criteria laid out in Scheming AIs (page 5) for goal-guarding schemers to the letter.
- ^
See the very beginning of Carlsmith's report for how alignment-faking relates to scheming. Some form of alignment-faking is a necessary, but not sufficient condition for scheming in Carlsmith's taxonomy.
comment by Joe Collman (Joe_Collman) · 2024-01-09T16:23:01.164Z · LW(p) · GW(p)
…but the AI is actually emitting those outputs in order to create that impression—more specifically, the AI has situational awareness
I think it's best to avoid going beyond the RFLO description [LW · GW].
In particular, it is not strictly required that the AI be aiming to "create that impression", or that it has "situational awareness" in any strong/general sense.
Per footnote 26 in RFLO (footnote 7 [LW · GW] in the post):
"Note that it is not required that the mesa-optimizer be able to model (or infer the existence of) the base optimizer; it only needs to model the optimization pressure it is subject to."
It needs to be:
Modeling the optimization pressure.
Adapting its responses to that optimization pressure.
Saying more than that risks confusion and overly narrow approaches.
By all means use things like "in order to create that impression" in an example. It shouldn't be in the definition.
comment by Sammy Martin (SDM) · 2024-01-08T11:44:21.849Z · LW(p) · GW(p)
If you want a specific practical example of the difference between the two: we now have AIs capable of being deceptive when not specifically instructed to do so ('strategic deception') but not developing deceptive power-seeking goals completely opposite what the overseer wants of them ('deceptive misalignment'). This from Apollo research on Strategic Deception is the former not the latter,
https://www.apolloresearch.ai/research/summit-demo
comment by quetzal_rainbow · 2024-01-07T20:06:59.300Z · LW(p) · GW(p)
I think it's confusing because we mostly care about outcome "we mistakenly think that system is aligned, deploy it and get killed", not about particular mechanism of getting this outcome.
Dumb example: let's suppose that we train systems to report its own activity. Human raters consistently assign higher reward for more polite reports. At the end, system learns to produce so polite and smooth reports that human raters have hard time to catch any signs of misalignement in reports and take it for aligned system.
We have, on the one hand, system that superhumanly good at producing impression of being aligned, on the other hand, it's not like it's very strategically aware.
comment by Noosphere89 (sharmake-farah) · 2024-01-07T19:07:14.743Z · LW(p) · GW(p)
I agree with the claim that deception could arise without deceptive alignment, and mostly agree with the post, but I do still think it's very important to recognize if/when deceptive alignment fails to work, it changes a lot of the conversation around alignment.
Replies from: Seth Herd↑ comment by Seth Herd · 2024-01-07T19:20:09.181Z · LW(p) · GW(p)
What do you mean by "when deceptive alignment fails to work"? I'm confused.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2024-01-07T19:55:08.876Z · LW(p) · GW(p)
I think Noosphere89 meant to say “when deceptive alignment doesn’t happen” in that sentence. (They can correct me if I’m wrong.)
Anyway, I think I’m in agreement with Noosphere89 that (1) it’s eminently reasonable to try to figure out whether or not deceptive alignment will happen (in such-and-such AI architecture and training approach), and (2) it’s eminently reasonable to have significantly different levels of overall optimism or pessimism about AI takeover depending on the answer to question (1). I hope this post does not give anyone an impression contrary to that.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2024-01-07T22:36:32.575Z · LW(p) · GW(p)
Yep, that's what I was talking about, Seth Herd.
comment by Oliver Sourbut · 2024-01-08T10:14:48.409Z · LW(p) · GW(p)
This is great, and thanks for pointing at this confusion, and raising the hypothesis that it could be a confusion of language! I also have this sense.
I'd strongly agree that separating out 'deception' per se is importantly different from more specific phenomena. Deception is just, yes, obviously this can and does happen.
I tend to use 'deceptive alignment' slightly more broadly - i.e. something could be deceptively aligned post-training, even if all updates after that point are 'in context' or whatever analogue is relevant at that time. Right? This would be more than 'mere' deception, if it's deception of operators or other-nominally-in-charge-people regarding the intentions (goals, objectives, etc) of the system. Also doesn't need to be 'net internal' or anything like that.
I think what you're pointing at here by 'deceptive alignment' is what I'd call 'training hacking', which is more specific. In my terms, that's deceptive alignment of a training/update/selection/gating/eval process (which can include humans or not), generally construed to be during some designated training phase, but could also be ongoing.
No claim here to have any authoritative ownership over those terms, but at least as a taxonomy, those things I'm pointing at are importantly distinct, and there are more than two of them! I think the terms I use are good.
Replies from: Oliver Sourbut, Joe_Collman↑ comment by Oliver Sourbut · 2024-01-08T10:29:04.516Z · LW(p) · GW(p)
Some people seem to argue that concrete evidence of deception is no evidence for deceptive alignment. I had a great discussion with @TurnTrout [LW · GW] a few weeks ago about this, where we honed in on our agreement and disagreement here. Maybe we'll share some content from it at some point. In the mean time, my take after that is roughly
- deception was obviously a priori going to be gettable, and now we have concrete evidence it occurs (approx 0 update for me, but >0 update for some)
- this does support an expectation of deceptive alignment in my terms, because deception about intentions is pretty central deception, and with misaligned intentions, deception is broadly instrumental (again not much update for me, but >0 update for others)
- it's still unclear how much deliberation about deception can/will happen 'net-internally' vs externalised
- externalised deliberation about deceptive alignment is still deceptive alignment in my terms!
- I keep notes in my diary about how I'm going to coordinate my coup
- steganographic deliberation about deceptive alignment is scarier
- my notes are encrypted
- fully-internal deliberation about deceptive alignment is probably scarier still, because probably harder to catch?
- like, it's all in my brain
- externalised deliberation about deceptive alignment is still deceptive alignment in my terms!
I think another thing people are often arguing about without making it clear is how 'net internal' the relevant deliberation/situational-awareness can/will be (and in what ways they might be externalised)! For me, this is a really important factor (because it affects how and how easily we can detect such things), but it's basically orthogonal to the discussion about deception and deceptive alignment.[1]
More tentatively, I think net-internal deliberation in LLM-like architectures is somewhat plausible - though we don't have mechanistic understanding, we have evidence of outputs of sims/characters producing deliberation-like outputs without (much or any) intermediate chains of thought. So either there's not-very-general pattern-matching in there which gives rise to that, or there's some more general fragments of net-internal deliberation. Other AI systems very obviously have internal deliberation, but these might end up moot depending on what paths to AGI will/should be taken.
ETA I don't mean to suggest net-internal vs externalised is independent from discussions about deceptive alignment. They move together, for sure, especially when discussing where to prioritise research. But they're different factors. ↩︎
↑ comment by Algon · 2024-01-08T13:09:54.751Z · LW(p) · GW(p)
What does "net internal" mean?
Replies from: Oliver Sourbut↑ comment by Oliver Sourbut · 2024-01-08T13:57:45.682Z · LW(p) · GW(p)
I mean the deliberation happens in a neural network. Maybe you thought I meant 'net' as in 'after taking into account all contributions'? I should say 'NN-internal' instead, probably.
↑ comment by Joe Collman (Joe_Collman) · 2024-01-09T18:12:02.870Z · LW(p) · GW(p)
I think the broader use is sensible - e.g. to include post-training.
However, I'm not sure how narrow you'd want [training hacking] to be.
Do you want to call it training only if NN internals get updated by default? Or just that it's training hacking if it occurs during the period we consider training? (otherwise, [deceptive alignment of a ...selection... process that could be ongoing], seems to cover all deceptive alignment - potential deletion/adjustment being a selection process).
Fine if there's no bright line - I'd just be curious to know your criteria.
Replies from: Oliver Sourbut↑ comment by Oliver Sourbut · 2024-01-10T09:06:54.464Z · LW(p) · GW(p)
I'd probably be more specific and say 'gradient hacking' or 'update hacking' for deception of a training process which updates NN internals.
I see what you're saying with a deployment scenario being often implicitly a selection scenario (should we run the thing more/less or turn it off?) in practice. So deceptive alignment at deploy-time could be a means of training (selection) hacking.
More centrally, 'training hacking' might refer to a situation with denser oversight and explicit updating/gating.
Deceptive alignment during this period is just one way of training hacking (could alternatively hack exploration, cyber crack and literally hack oversight/updating, ...). I didn't make that clear in my original comment and now I think there's arguably a missing term for 'deceptive alignment for training hacking' but maybe that's fine.
comment by Vladimir_Nesov · 2024-01-13T10:20:58.435Z · LW(p) · GW(p)
I’m not certain, but I think the explanation might be that Zvi was thinking of “deception”, whereas Joe, Quintin, and Nora were talking about the more specific “deceptive alignment”.
Deceptive alignment is more centrally a special case of being trustworthy (what the "alignment" part of "deceptive alignment" refers to), not of being deceptive. In a recent post, Zvi says:
We are constantly acting in order to make those around us think well of us, trust us, expect us to be on their side, and so on. We learn to do this instinctually, all the time, distinct from what we actually want. Our training process, childhood and in particular school, trains this explicitly, you need to learn to show alignment in the test set to be allowed into the production environment, and we act accordingly.
A human is considered trustworthy rather than deceptively aligned when they are only doing this within a bounded set of rules, and not outright lying to you. They still engage in massive preference falsification, in doing things and saying things for instrumental reasons, all the time.
My model says that if you train a model using current techniques, of course exactly this happens.
comment by Joe Collman (Joe_Collman) · 2024-01-09T17:12:17.044Z · LW(p) · GW(p)
By contrast, deception is much broader—it’s any situation where the AI is interacting with humans for any reason, and the AI deceives a human by knowingly providing them with false or misleading information.
This description allows us to classify every output of a highly capable AI as deceptive:
For any AI output, it's essentially guaranteed that a human will update away from the truth about something. A highly capable AI will be able to predict some of these updates - thus it will be "knowingly providing ... misleading information".
Conversely, we can't require that a human be misled about everything in order to classify something as deceptive - nothing would then qualify as deceptive.
There's no obvious fix here.
Our common-sense notion of deception is fundamentally tied to motivation:
- A teacher says X in order to give a student a basic-but-flawed model that's misleading in various ways, but is a step towards deeper understanding.
- Not deception.
- A teacher says X to a student in order to give them a basic-but-flawed model that's misleading in various ways, to manipulate them.
- Deception.
The student's updates in these cases can be identical. Whether we want to call the statement deceptive comes down to the motivation of the speaker (perhaps as inferred from subsequent actions).
In a real world context, it is not possible to rule out misleading behavior: all behavior misleads about something.
We can only hope to rule out malign misleading behavior. This gets us into questions around motivation, values etc (or at least into much broader considerations involving patterns of behavior and long-term consequences).
(I note also that requiring "knowingly" is an obvious loophole - allowing self-deception, willful ignorance or negligence to lead to bad outcomes; this is why some are focusing on truthfulness rather than honesty)