Response to Dileep George: AGI safety warrants planning ahead
post by Steven Byrnes (steve2152) · 2024-07-08T15:27:07.402Z · LW · GW · 7 commentsContents
Post outline:
1. Agreements and disagreements
1.1 Dileep and I are in strong agreement about important things, particularly technical aspects of how future AGI algorithms will work
1.2 …But we’re in strong disagreement about the implications
2. The path to AGI that Dileep & I are imagining has an unsolved technical alignment problem
2.1 Possible Response A: “Putting motivation into AGI is bad and pointless. The easy and obvious solution is to leave it out altogether.”
2.2 Possible Response B: “AGI will naturally develop nice motivations like ‘unraveling the secrets of the universe’ and ‘generosity’, whereas bad motivations like dominance need to be put in manually. So we can just not do that.
2.3 Possible Response C: “AGIs will only have really dangerous motivations, like preventing themselves from being shut down, if someone deliberately puts those motivations in.”
2.4 Possible Response D: “It’s important to set up AGIs with docile and/or prosocial motivations—but I already know how to do so.”
2.5 Possible Response E: “Motivation is part and parcel of intelligence; we won’t get powerful AGIs worth worrying about, until we solve the technical problem of giving them docile and/or prosocial motivations. (Also: even if we did get powerful AGIs without docile and/or prosocial motivations, nobo...
2.6 Possible Response F: “I don’t know how to set up AGIs with good motivations, but maybe it will be obvious when we learn more about how AGI algorithms work.”
2.7 Possible Response G: “I don’t know how to set up AGIs with good motivations… but whatever, we can cross that bridge when we get to it.”
3. Challenges in solving AGI-related problems as they arise
3.1 “When a problem is sufficiently obvious and severe, then people will put their heads together and solve it.” …Or maybe they won’t.
3.2 On “keeping strong AI as a tool, not a successor”: Will almost all future companies eventually be founded and run by autonomous AGIs?
3.2.1 Possible Answer 1: “No, because the best humans will always be better than AGIs at founding and running companies.”
3.2.2 Possible Answer 2: “No, because humans will always be equally good as AGIs at founding and running companies.”
3.2.3 Possible Answer 3: “No, because we will pass laws preventing AGIs from founding and running companies.”
3.2.4 Possible Answer 4: “No, because if someone wants to start a business, they would prefer to remain in charge themselves, and ask an AGI for advice when needed, rather than ‘pressing go’ on an autonomous entrepreneurial AGI.”
3.2.5 Possible Answer 5: “No, because after the AGIs wipe out (or permanently disempower) humanity, they will not operate via ‘companies’ as we think of them today.”
3.3 Problems can arise “too quickly to react and adapt” without arising “infinitely quickly”
3.3.1 For almost all of the gradual process of AGI development, it won’t yet be causing any massive new societal impact or problems, and nobody will be paying any attention
3.3.2 The timescale of human learning is not necessarily indicative of what to expect for how quickly AGI algorithms will improve.
3.3.3 The timescale of recent deep learning progress is not necessarily indicative of what to expect for how quickly AGI algorithms will improve.
3.3.4 The timescale of recent progress in industrial automation and robotics is not necessarily indicative of how quickly AGI may pose an extinction risk.
3.3.5 This isn’t an intentional phased deployment situation, where somebody is deliberately choosing the timescale.
3.3.6 Time to prepare and react is not necessarily spent wisely.
3.3.7 The King Lear Problem
3.3.8 The alignment problem may be the kind of technical problem that takes a long time to solve, even if we have the benefit of trial-and-error.
4. Conclusion
None
7 comments
(Target audience: Dileep George himself, and anyone coming from a similar place.)
Dileep George is a researcher working at the intersection of AI and neuroscience. He started his career by co-founding Numenta in 2005 with Jeff Hawkins (while a Stanford PhD student), then he left to co-found Vicarious in 2010 with D. Scott Phoenix, and moved to DeepMind in 2022 when DeepMind acquired Vicarious.
Dileep was recently interviewed by Daniel Faggella on his “The Trajectory” podcast: YouTube, Apple podcasts, X/Twitter.
It’s a fun interview that touched on many topics, most of which I’ll ignore, in favor of one very important action-relevant disagreement between Dileep and myself.
…And this is the point where everyone [LW · GW] these days [LW(p) · GW(p)] seems to assume that there are only two possible reasons that anyone would ever bring up the topic of Artificial General Intelligence (AGI) safety in conversation:
- The person is advocating for government regulation of large ML training runs
- …or the person is advocating against government regulation of large ML training runs.
But, no! That’s not my disagreement! That’s not why I’m writing this post!! Quite the contrary, I join Dileep [LW · GW] in being basically unenthusiastic about governmental regulation of large ML training runs right now.
Instead, this post is advocating for Differential Intellectual Progress [? · GW] within technical AI research of the type that Dileep is doing—and more specifically, I’m advocating in favor of figuring out a technical approach to sculpting AGI motivations in docile and/or prosocial directions (a.k.a. “solving the technical alignment problem”) before figuring out the exact data structures and parameter-updating rules that would constitute an AGI’s ability to build and query a powerful world-model.
The first half of this post (§1-2) will try to explain what I’m talking about, what it would entail, and why I think it’s critically important. The second half of this post (§3) is more specifically my pessimistic response to Dileep’s suggestion that, as AGI is gradually developed in the future, people will be able to react and adapt to problems as they arise.
I really think Dileep is a brilliant guy with the best of intentions (e.g. he’s a signatory on the Asilomar AI Principles). I just think there are some issues that he hasn’t spent much time thinking through. I hope that this post will help.
Post outline:
- Section 1 lists some areas of agreement and disagreement between Dileep and me. In particular, we have a giant area of agreement in terms of how we expect future AGI algorithms to work. Our massive common ground here is really why I’m bothering to write this post at all—it makes me hopeful that Dileep & I can have a productive exchange, and not just talk past each other.
- Section 2 argues that, for the kind of AGI that Dileep is trying to build, there’s an unsolved technical alignment problem: How do we set up this kind of AGI with the motivation to behave in a docile and/or prosocial way?
- Section 3 is my pessimistic push-back on Dileep’s optimistic hope that, if AGI is developed gradually, then we can regulate or adapt to problems as they arise:
- Section 3.1 lists some big obvious societal problems that have been around for a long time, but nevertheless remain unsolved, along with generic discussions of some underlying challenges that have prevented them from being solved, and why those challenges may apply to AGI too.
- Section 3.2 dives more specifically into the question of whether we can “keep strong AI as a tool, not a successor”, as Dileep hopes. I think it sounds nice but will be impossible to pull off.
- Section 3.3 comments that, even if we could react and adapt to AGI given enough time—an assumption that I’m pushing back on in the above subsections—we won’t necessarily have much time. Nor will we necessarily use the time we have wisely.
1. Agreements and disagreements
1.1 Dileep and I are in strong agreement about important things, particularly technical aspects of how future AGI algorithms will work
Importantly, Dileep and I are both expecting LLMs (and related foundation models) to not be the right kind of algorithm for future powerful AGI [LW · GW]—the kind that can autonomously found and run companies (see §3.2 below), do innovative science, and so on. For example, here Dileep analogizes LLMs to dirigibles, with OpenAI and others corresponding to the big successful zeppelin companies of the early 1900s, while Dileep himself and others correspond to the scrappy Wright brothers, piecing together a new technological approach which currently vastly underperforms the incumbent, but will eventually overtake it. I frequently bring up that same possibility as well, e.g. here [LW · GW].
Dileep and I also agree that the “secret sauce” of AGI might be the so-called “common cortical algorithm”—the algorithm powering the human cortex, which (he and I both believe) is a by-and-large[1] uniform learning algorithm. Cortical uniformity is perhaps a surprising hypothesis in light of the fact that the cortex is heavily involved in seemingly-very-different domains such as sensory processing, motor control, language, and reasoning. Or at least, this was “perhaps a surprising hypothesis” in previous decades. These days, when I suggest to people that a single massively-scaled-up learning algorithm can do lots of different things, they tend to just shrug and say “yeah duh”.
Relatedly, Dileep often uses the terms “new brain versus old brain” (which I presume he borrowed from his former colleague Jeff Hawkins) to refer to the neocortex versus other parts of the brain, respectively. While I often gripe about those particular terms (§3.3 here [LW · GW]) and how they’re used (§3.6 here [LW · GW]), at the end of the day it’s really not too different from the “Learning Subsystem versus Steering Subsystem” [LW · GW] picture that I myself strongly endorse.
Note for readers: When I say “AGI” anywhere in this post, it’s shorthand for “the kind of AGI that we should expect if Dileep is right about everything”, which would involve (something like) the common cortical algorithm, and which would not involve LLMs. I’m making that assumption without any justification or hedging, because my official target audience for this post is Dileep, and he already agrees with it.
1.2 …But we’re in strong disagreement about the implications
Dileep looks at that situation and says: OK cool, if the common cortical algorithm is the secret sauce of AGI, then my life goal is to figure out exactly how the common cortical algorithm works.
…Whereas I look at that same situation and say “Oh jeez, my life goal is to work on the threat model wherein people like Dileep will figure out exactly how the common cortical algorithm works. If that happens—and people are figuring out how to build more and more powerful AGI that way—then how do we get a good future and avoid catastrophe?”
You might be thinking: “Threat model”?? How does scientific knowledge and progress constitute a threat model? Well to be clear, I don’t wish for AGI to never ever be invented. But I think there’s an unsolved technical alignment problem associated with this approach (more on which below), and I think it’s very important to solve that problem before figuring out the common cortical algorithm itself. I’ll try to justify those claims below.
I wish that Dileep would apply his prodigious technical talent and knowledge towards this technical alignment problem, which I bet he’d be awesome at tackling. Once he solves it, I’m happy for him to go back to his (admittedly fascinating) work towards unraveling the common cortical algorithm.
2. The path to AGI that Dileep & I are imagining has an unsolved technical alignment problem
This section is tricky to write, because I don’t recall ever seeing Dileep talk about AGI motivation at all.
Anyway, my belief is: “setting up an AGI such that it’s motivated to be prosocial and/or docile is critical for avoiding catastrophe, but it’s a hard technical problem that no one currently knows how to solve”. See §3.5 here [LW · GW] (and links therein) for why I believe that. I presume that Dileep disagrees, or else he wouldn’t be doing what he’s doing, but I’m not sure exactly where he’s coming from. Here are some possibilities:
2.1 Possible Response A: “Putting motivation into AGI is bad and pointless. The easy and obvious solution is to leave it out altogether.”
I’m not sure if anyone would endorse this exact claim, but Dileep’s former colleague Jeff Hawkins sometimes seems to come close. (I actually think he’s inconsistent on this topic, see §3.6 here [LW · GW] and the next subsection.) For example, in Thousand Brains, Hawkins writes: “Intelligence is the ability to learn a model of the world. Like a map, the model can tell you how to achieve something, but on its own it has no goals or drives. We, the designers of intelligent machines, have to go out of our way to design in motivations…”
In any case, Possible Response A is a bad argument for a couple reasons:
First, people want AGI to do tricky things that require trial-and-error and foresighted planning—they want AGI to invent new scientific paradigms, to autonomously design and build factories (cf. §3.2.4 below), and so on—and AGIs (like humans) will do such things only by wanting to do those things.[2] So like it or not, people are gonna figure out how to put motivations into AGIs.
- Second, “active learning” is essential to human intelligence, and (I claim) it will be essential to AGI intelligence as well, and (I claim) it requires motivation to work well. People get really good at math partly by thinking about math all the time, which they’ll do if they’re motivated to think about math all the time. If a person notices that they’re confused about something, then they might spend some time trying to figure it out, but only if they’re motivated to spend some time trying to figure it out. Where do these motivations come from? Maybe curiosity, maybe the desire to impress your friends or solve a problem, who knows. But without motivation, I claim that AGIs won’t develop any knowledge or insight to speak of.
2.2 Possible Response B: “AGI will naturally develop nice motivations like ‘unraveling the secrets of the universe’ and ‘generosity’, whereas bad motivations like dominance need to be put in manually. So we can just not do that.
Jeff Hawkins sometimes seems to make this argument—e.g. here’s another passage from Thousand Brains:
We face a dilemma. “We” — the intelligent model of ourselves residing in the neocortex — are trapped. We are trapped in a body that not only is programmed to die but is largely under the control of an ignorant brute, the old brain. We can use our intelligence to imagine a better future, and we can take actions to achieve the future we desire. But the old brain could ruin everything. It generates behaviors that have helped genes replicate in the past, yet many of those behaviors are not pretty. We try to control our old brain’s destructive and divisive impulses, but so far we have not been able to do this entirely. Many countries on Earth are still ruled by autocrats and dictators whose motivations are largely driven by their old brain: wealth, sex, and alpha-male-type dominance. The populist movements that support autocrats are also based on old-brain traits such as racism and xenophobia.
Again, my opinion is that the “old brain” (more specifically, hypothalamus and brainstem) is every bit as centrally involved in the human desire for magnanimity, curiosity, and beauty, as it is in the human desire for “wealth, sex, and alpha-male-type dominance”.
I actually think Possible Response B comes from noticing an intuitive / within-my-world-model boundary between ego-syntonic versus ego-dystonic motivations, and mistaking it for an algorithmic / neuroanatomical boundary—see §6.6.1 here [? · GW], and also “Question 2” here [LW · GW].
Here are a couple more perspectives on where I’m coming from:
From the perspective of AI: We’re expecting AGI, like human brains, to use some kind of algorithm involving model-based reinforcement learning and model-based planning. We don’t yet know in full detail how that algorithm works in the human brain, but we at least vaguely know how these kinds of algorithms work. And I think we know enough to say for sure that these algorithms don’t develop prosocial motivations out of nowhere. For example, if you set the reward function of MuZero to always return 0, then the algorithm will emit random outputs forever—it won’t start trying to help the PacMan ghosts live their best lives. Right?

…OK, yes, that was a very silly example. But what I’m getting at is: if someone wants to argue for Possible Response B, they should do so by actually writing down pseudocode and reasoning about what that pseudocode would do. For example, in Hawkins’s story above, what exactly is the algorithmic chain of events that leads to “using our intelligence to imagine a better future”, as opposed to “using our intelligence to imagine a worse future”?
From the perspective of rodent models: For what little it’s worth, researchers have found little cell groups in the rodent hypothalamus (“old brain”) that are centrally involved in both “antisocial” behaviors like aggression, and “prosocial” behaviors like nurturing their young, or longing for the comforting touch of a friend or family member after an extended period of lonely isolation. I fully expect that the same holds for humans.
From the perspective of philosophy: “Hume’s law” says “‘is’ does not imply ‘ought’”. Granted, not everyone believes in Hume’s law. But I do—see an elegant and concise argument for it here.
2.3 Possible Response C: “AGIs will only have really dangerous motivations, like preventing themselves from being shut down, if someone deliberately puts those motivations in.”
You’ll hear this argument frequently from people like Jeff Hawkins, Yann LeCun, and Steven Pinker. It's a bad argument because of so-called “instrumental convergence”. I walk through that argument in §10.3.2 here [LW · GW].
For example, curiosity drive sounds nice and benign, but if an AI is motivated by curiosity, and if the AI reasons that humans might fail to offer it sufficiently novel and interesting things to do, then (other things equal) the AI would naturally be motivated to get power and control over its situation to eliminate that potential problem, e.g. by sweet-talking the humans, or better yet maneuvering into a situation where it can alleviate its boredom without asking anyone’s permission. (See §2 here [LW · GW] for more examples and responses to possible counterarguments.)
That’s not to say that every possible motivation is dangerous (see §10.3.2.3 here [LW · GW])—the problem is that many motivations are dangerous, and nobody currently has a technical plan for how to sculpt an AGI’s motivations with surgical precision.
2.4 Possible Response D: “It’s important to set up AGIs with docile and/or prosocial motivations—but I already know how to do so.”
This is part of Yann LeCun’s perspective, for example. The problem is, the plan that LeCun proposes will not actually work. See my extensive discussion here [LW · GW]. If Dileep puts himself in this category, I would love for him to say exactly what his proposal is, ideally with pseudocode, and then we can have a nice productive discussion about whether or not that plan will work.[3]
2.5 Possible Response E: “Motivation is part and parcel of intelligence; we won’t get powerful AGIs worth worrying about, until we solve the technical problem of giving them docile and/or prosocial motivations. (Also: even if we did get powerful AGIs without docile and/or prosocial motivations, nobody would want to run such an AGI.)”
I associate this kind of response with Steven Pinker and Melanie Mitchell (see: “Common sense” has an ought-versus-is split, and it’s possible to get the latter without the former [LW · GW]).
I agree that motivation is part and parcel of intelligence, particularly including things like curiosity drive. But prosocial motivation is not. See discussion in §3.4.1 here [LW · GW]. I offer high-functioning sociopaths as an existence proof of how competence can come apart from prosocial drives.
I also disagree with the optimistic hope that nobody would be working towards powerful AGIs while the problem of giving them robustly docile and/or prosocial motivations remains unsolved. For one thing, many researchers including Dileep are doing exactly that as we speak. For another thing, it can be immediately profitable to use AGIs even when those AGIs have callous disregard for human welfare—just as it can be immediately profitable to use the labor of slaves who secretly loathe their master and are watching for opportunities to revolt.
Of course, if people around the world are running an increasingly-numerous and increasingly-competent collection of AGIs that secretly have callous disregard for human welfare and are patiently waiting for an opportunity to launch a coup, then that’s obviously a very bad and precarious situation. But people may run those AGIs anyway—and make tons of money doing so—and moreover this may be impossible for society to stop, due to collective-action problems and various other challenges discussed at length in §3 below.
2.6 Possible Response F: “I don’t know how to set up AGIs with good motivations, but maybe it will be obvious when we learn more about how AGI algorithms work.”
This isn’t a crazy hypothesis a priori, but in fact I claim that (1) we already know enough about brain algorithms to make progress on the technical alignment problem for brain-like AGI (see my intro series [? · GW]!) (2) the type of research that Dileep is doing—trying to suss out the gory details of the common cortical algorithm—will not lead to a solution to this technical alignment problem. In fact, I’ll go further than that: my strong belief is that this line of research will basically not help with the technical alignment problem at all.
One way to think about it is (see §3.4 here [LW · GW]): a big part of technical alignment is designing the “innate drives” of an AGI, analogous to the innate drives of humans that make us enjoy food, dislike pain, seek out friendship, and so on. In the brain, these drives are mainly implemented in the hypothalamus and brainstem, not the cortex. Speaking of which, I do think reverse-engineering certain parts of the human hypothalamus and brainstem would be useful for the technical alignment problem, even if further reverse-engineering the cortex would not be. I am working on that myself [LW · GW] (among other things).
2.7 Possible Response G: “I don’t know how to set up AGIs with good motivations… but whatever, we can cross that bridge when we get to it.”
For my response see the epilogue of my Yann LeCun post [LW · GW]. Much more on “crossing that bridge when we get to it” in the next section. Which brings us to…
3. Challenges in solving AGI-related problems as they arise
Dileep referred a few times (e.g. 34:45, 1:04:45) to the idea that, if AI is causing problems or posing risks during its gradual development, then we will notice these problems and adapt. That’s not a crazy hypothesis to entertain, but I claim that, if you think it through a bit more carefully, there are a lot of big problems with that idea. Let me elaborate.
3.1 “When a problem is sufficiently obvious and severe, then people will put their heads together and solve it.” …Or maybe they won’t.
It might seem nice and reasonable to say:
“When a problem is sufficiently obvious and severe, then people will sooner or later put their heads together and solve it.”
But consider the following problems, that have been obvious and severe for a long time:
- Ukrainians have a problem, namely that their nation is currently being invaded by Russia. But that problem has not been solved yet.
- I, along with almost everyone else on Earth, am vulnerable to a potential novel 95%-lethal pandemic (harrowing details), or nuclear war (harrowing details), either of which could start anytime. But that problem has not been solved yet.
- People in many areas are already suffering the consequences of climate change, as the world continues to emit carbon. But that problem has not been solved yet.
- Countries sometimes fall under the control of a charismatic sociopathic strongman leader who wants to undermine democratic norms. But that problem has not been solved yet.
- People die of cancer. But that problem has not been solved yet.
These are cherry-picked examples, of course, but I think they suffice to prove the point that it’s not enough to say “people will sooner or later put their heads together and solve obvious problems.” That should be treated as a hypothesis, not a conversation-ender!
Some of the generic issues at play, in the above examples and others, are:
Different people have different opinions—things that are obvious to you and me might not be obvious to everyone. People have insane opinions about all kinds of things. There are flagrantly-wrong popular opinions even about routine longstanding things where there is rock-solid empirical data and where no one has a strong economic interest in spreading misleading propaganda (e.g. vaccine safety, rent control). We might expect even more flagrantly-wrong popular opinions on the topic of AGI, where those mitigating factors do not hold: it is novel, it requires extrapolation into the future,[4] and it has an array of powerful groups incentivized to downplay the risks, including the people and companies who will be making tons of money off proto-AGI algorithms.
- Collective action (including international coordination) can be very hard. For example, there’s very broad consensus that biological weapons are bad. So lots of people worked hard to get international agreement to not develop them. And they succeeded! There was a big treaty in the 1970s! Except—the Soviet Union ratified the treaty but secretly continued their massive biological weapons development program anyway. Oops! So anyway, when people talk about AGI, I often see claims that in such-and-such a situation, of course “we” will just all agree to do this or do that, without grappling with the associated coordination challenges. I’m not saying that collective action problems are never solvable! Rather, I’m saying that people shouldn’t breezily talk about what “we” will do in different circumstances, without thinking carefully about what such action and cooperation would entail, who might be for or against it, what would the global monitoring and enforcement regime look like, and so on. More on this in §3.3.5 below.
- Intelligent, charismatic, and savvy agents can win allies and play different groups off each other. For example, consider the conquistadors conquering dramatically more well-resourced groups [LW · GW], charismatic leaders winning allies, organized criminals deploying bribes and threats, people with money hiring other people to help them do stuff, and so on. Needless to say, future AGIs can be as intelligent, charismatic, and savvy as any human.
- There can be externalities—situations where the people making decisions are not the ones suffering most of the consequences. For example, consider carbon emissions. Or lab leaks—if the costs were properly internalized, which they aren’t, then some labs would need to spend billions of dollars a year on lab-leak insurance. By the same token, if a person or group is messing around with a very dangerous AGI algorithm, they get all the benefits if things go well, but we may all suffer the costs if the AGI irreversibly escapes human control.
- People can be loath to suffer immediate consequences, or change their routines, to avert future problems, even when those future problems are quite salient. For example, one might think that the problem of pandemics would be quite salient right now, with COVID-19 as a very recent traumatic memory; but in fact, the effort to prevent future pandemics, while nonzero, has been woefully inadequate to the scale of the problem or what it takes to solve it (example).
- People have other priorities. For example, it’s easy to say “no human would voluntarily do the bidding of an AGI”. But if the AGI is offering good pay under-the-table, and reaches out to people with no other job options who want to feed their families, then obviously some people will do the bidding of an AGI!—just as some people today do the bidding of drug cartels, oppressive governments, and other groups that one might wish didn’t exist. (Also, people might not know that they’re working for an AGI anyway.)
- Intelligent adversaries can anticipate and block countermeasures, sow discord, block lines of communication, make threats, and so on. This idea is perfectly intuitive in the case of Ukrainians dealing with the problem of a Russian invasion. But it would be equally applicable in a future situation where humans are dealing with the problem of out-of-control AGIs self-reproducing around the internet.
- Some problems are just really damn hard to solve for technical reasons rather than (and/or on top of) social and societal and governance reasons—for example, curing cancer. I am concerned that “making powerful AGI with robustly prosocial and/or docile motivations” is a problem in this category—and that it will remain in this category even after we know how to make AGIs with human-level ability to solve hard problems and figure things out, which we can run experiments on. (We have plenty of cancer patients that we can run experiments on, and that sure helps, but cancer is still a hard problem.)
3.2 On “keeping strong AI as a tool, not a successor”: Will almost all future companies eventually be founded and run by autonomous AGIs?
My goal is not to create a better intelligence that will make humans obsolete, no, I am firmly in the camp of, we are building this for the service of humanity … We can of course build it in a way that makes us obsolete, but I don't see the reason to, and I don't want to.
When people say these kinds of things, I find it illuminating to ask them the following specific question:
Question: Do you expect almost all companies to eventually be founded and run by AGIs rather than humans?
I’m not sure what Dileep would say specifically, but generally I find that people give a few different answers to this question:
3.2.1 Possible Answer 1: “No, because the best humans will always be better than AGIs at founding and running companies.”
This is the answer of people who don’t actually believe AGI is possible (even if they say they do), or aren’t thinking about its implications. Humans can acquire real-world first-person experience? Well, an AGI could acquire a thousand lifetimes of real-world first-person experience. Humans can be charismatic? Well, an AGI could be as charismatic as the most charismatic human in history, or much more so. Humans can collaborate with each other and learn from culture? So can AGIs. Humans can walk around? Teleoperated robot bodies could be easily and cheaply mass-produced, and that’s exactly what will happen as soon as there are AGI algorithms that can pilot them (see §3.3.4 below). And even if we somehow prevented anyone on Earth from making robot bodies (and destroyed the existing ones), heck, an AGI could hire a human to walk around carrying a camera and microphone, while an AGI whispers in their ear what to say and do—an ersatz robot body with a winning smile and handshake, for the mere cost of human salary. (If Jeff Bezos decided to never leave his house for the rest of his life, I would still put him easily in the top percentile of humans for “ability to make lots of money by starting and running a new company, if he wanted to”. Right?)
3.2.2 Possible Answer 2: “No, because humans will always be equally good as AGIs at founding and running companies.”
I vehemently disagree that AGIs would never become dramatically better than humans at founding and running companies, for reasons in §3 here [LW · GW], but even if they didn’t, the conclusion still wouldn’t follow, because of considerations of cost and scale. There are only so many competent humans, but if we have software that can found and run a company as skillfully as Jeff Bezos or Warren Buffett (or for that matter, Dileep George and D. Scott Phoenix), it would be insanely profitable to run as many copies of that software as there are chips in the world—and then manufacture even more chips to run even more copies. There would be millions, then billions, then trillions of them, competing for low-hanging fruit in every imaginable business niche. So even if AGIs were only as competent as humans, it would still be the case that we should expect almost every company to be founded and run by an AGI.
3.2.3 Possible Answer 3: “No, because we will pass laws preventing AGIs from founding and running companies.”
Even if such laws existed in every country on Earth, then the letter of such laws would be enforceable, but the spirit would not. Rather, the laws would be trivial to work around. For example, you could wind up with companies where AGIs are making all the decisions, but there’s a human frontman signing the paperwork; or you could wind up with things that are effectively AGI-controlled companies but which lack legal incorporation.
3.2.4 Possible Answer 4: “No, because if someone wants to start a business, they would prefer to remain in charge themselves, and ask an AGI for advice when needed, rather than ‘pressing go’ on an autonomous entrepreneurial AGI.”
That’s a beautiful vision for the future. It really is. I wish I believed it. But even if lots of people do in fact take this approach, and they create lots of great businesses, it just takes one person to say “Hmm, why should I create one great business, when I can instead create 100,000 great businesses simultaneously?”
…And then let’s imagine that this one person starts “Everything, Inc.”, a conglomerate company running millions of AGIs that in turn are autonomously scouting out new business opportunities and then founding, running, and staffing tens of thousands of independent business ventures.
Under the giant legal umbrella of “Everything, Inc.”, perhaps one AGI has started a business venture involving robots building solar cells in the desert; another AGI is leading an effort to use robots to run wet-lab biology experiments and patent any new ideas; another AGI is designing and prototyping a new kind of robot that’s specialized to repair other robots, another AGI is buying land and getting permits to eventually build a new gas station in Hoboken, various AGIs are training narrow AIs or writing other special-purpose software, and of course there are AGIs making more competent and efficient next-generation AGIs, and so on.
Obviously, “Everything, Inc.” would earn wildly-unprecedented, eye-watering amounts of money, and reinvest that money to buy or build chips for even more AGIs that can found and grow even more companies in turn, and so on forever, as this person becomes the world’s first trillionaire, then the world’s first quadrillionaire, etc.
That’s a caricatured example—the story could of course be far more gradual and distributed than one guy starting “Everything, Inc.”—but the point remains: there will be an extraordinarily strong economic incentive to use AGIs in increasingly autonomous ways, rather than as assistants to human decision-makers. And in general, when things are both technologically possible and supported by extraordinarily strong economic incentives, those things are definitely gonna happen sooner or later, in the absence of countervailing forces. So what might stop that? Here are some possible counterarguments:
- No, there won’t even be one person anywhere in the world who would want to start a company like “Everything, Inc.” Oh c’mon—people don’t tend to leave obvious trillion-dollar bills lying on the ground.
- No, because we will design AGI algorithms in such a way that they can only be used as assistants, not as autonomous agents. Who exactly is “we”? In other words, there’s a really thorny coordination and enforcement problem to make that happen. Even if most people would prefer for autonomy-compatible AGI algorithms to not exist at all, those algorithms are just waiting to be discovered, and the combination of scientific interest and economic incentives makes it extremely likely for the training source code to wind up on GitHub sooner or later, in the absence of unprecedented clampdowns on academic and intellectual freedom (clampdowns that I expect Dileep to be strongly opposed to).[5]
- No, we’re going to outlaw companies like “Everything, Inc.” —But then we get into the various enforcement challenges discussed in Possible Answer 3. In particular, note that we can wind up at the same destination via a gradual and distributed global race-to-the-bottom on human oversight, as opposed to one mustache-twirling CEO creating a very obvious “Everything, Inc.” out of nowhere. This hope also requires solving an unusually-difficult international coordination problem: The more that a country’s government turns a blind eye to this kind of activity, or secretly does it themselves, the more that this country would unlock staggering, unprecedented amounts of wealth and economic progress within its borders.
- Well, sure, but all those millions of AGIs would still be “tools” of the humans at “Everything, Inc.” corporate headquarters. I think this is stretching the definition of “tool” way past its breaking point. Imagine I’m a human employee of “Everything, Inc.” If we solve the alignment problem and everything goes perfectly, then ideally my company will be making money hand over fist, and our millions of AGIs will be doing things that I would approve of, if I were to hypothetically take infinite time to investigate. But I’m not in the loop. Indeed, if I tried to understand what even one of these millions of AGIs was doing and why, it would be a massive research project, because each AGI has idiosyncratic experience and domain expertise that I lack, and this expertise informs how that AGI is making decisions and executing its own workflow. Like any incompetent human micromanager, if I start scrutinizing the AGIs’ actions, it would only slow things down and make the AGIs’ decisions worse, and my firm would be immediately outcompeted by the next firm down the block that applied less human oversight. So really, those millions of AGIs would be autonomously exercising their judgment to do whatever they think is best as they rapidly transform the world, while I’m sitting in my chair almost completely clueless about what’s going on. I really don’t think this picture is what Dileep has in mind when he talks about “tools” that don’t “make us obsolete”.
3.2.5 Possible Answer 5: “No, because after the AGIs wipe out (or permanently disempower) humanity, they will not operate via ‘companies’ as we think of them today.”
OK, that’s what I actually honestly expect, but I won’t argue for that here!!
~~
I hope that discussion gives some flavor of the challenges and issues involved in “keeping strong AI as a tool”. It sounds nice but I don’t think it’s a realistic hope.
3.3 Problems can arise “too quickly to react and adapt” without arising “infinitely quickly”
One form of “The Harmless Supernova Fallacy” is: “A supernova isn’t infinitely energetic—that would violate the laws of physics! Just wear a flame-retardant jumpsuit and you’ll be fine.” The moral is: “‘Infinite or harmless’ is a false dichotomy.”
I thought of that every time in the interview that Dileep brought up the fact that AGI development will not unfold infinitely quickly. “Infinitely-fast or slow” is a false dichotomy. Finitely fast can still be rather fast!
There are a few issues worth considering more specifically on this topic:
3.3.1 For almost all of the gradual process of AGI development, it won’t yet be causing any massive new societal impact or problems, and nobody will be paying any attention
Let’s look at Dileep himself. He believes that he is right now, as we speak, building the foundations of future AGI. But only a tiny fraction of neuroscience or AI researchers are paying attention to Dileep’s papers and progress—and forget about politicians, or the general public!!
This is a big part of what gradual development of novel AGI algorithms looks like: “These new algorithms are not yet working fabulously well, so basically nobody cares.”
Then at some point they work so well that people are jolted to attention. That would require, for example, that these new algorithms are using language much much better than LLMs do, and/or that they are controlling robots much much better than whatever the robot SOTA will be at the time (and recent robot demos have been pretty impressive!), and so on. Even beating benchmarks isn’t enough—I’m pretty sure Dileep’s algorithms are currently SOTA on a benchmark or two, and yet he continues to toil in relative obscurity.
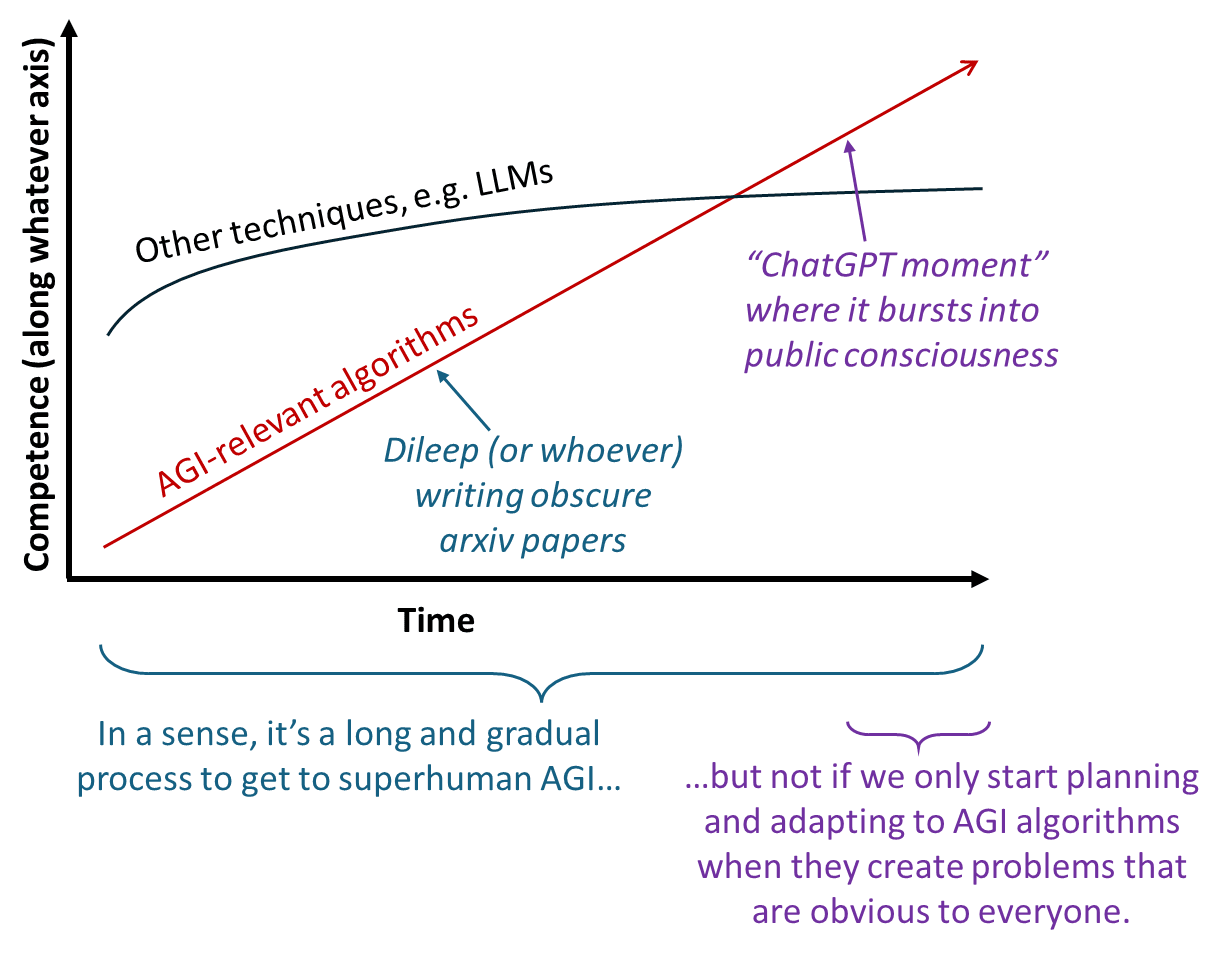
Yes, there is a big gap between where we are today and AGI that poses catastrophic risk. But that’s not the relevant gap. The relevant gap, by default, is between:
- the point in time when the algorithms are not only outperforming LLMs and every other AI technique, but also creating new societal problems that are obvious to everyone;
- the point in time when the algorithms are capable of irreversibly escaping human control.
I think that window may be very narrow—e.g. a couple years. In fact, I think the window could plausibly be as short as zero! I think there are a bunch of algorithmic insights and implementation work between us and AGI, but I think pretty much all of that work would precede the first bullet point.
3.3.2 The timescale of human learning is not necessarily indicative of what to expect for how quickly AGI algorithms will improve.
In other words, it’s tempting to say “if AGI algorithms are similar to human brain algorithms, then five years after we have a human-level AGI algorithm, it will be as smart and competent as a five-year-old. Ten years, a ten-year-old. Etc. That’s pretty gradual!”
But I disagree that this will be the timescale, for lots of reasons.
For one thing, there’s the dynamic above—as long as the AGI is “only” as smart as a five-year-old, I’m not sure anyone will be paying attention, particularly in a world that already has LLMs, along with whatever else LLM research leads to in the coming years.
For another thing, insofar as parts of human learning involve reading, brainstorming, watching videos, sleeping, etc., I expect AGIs to be able to do those things on “fast-forward” compared to humans, even by 1 or 2 orders of magnitude. Moreover, with the help of virtual reality, the AGI can also run on “fast-forward” for more physical learning, like how to teleoperate arbitrary robot bodies, bounce balls, look around a room, etc. Of course, the full complexities of the real world can’t be put into sped-up virtual reality environments, but they can be parallelized: 10 copies of the AGI could chat with 10 different humans for an hour in parallel, and the synaptic edits from those 10 experiences could presumably be merged together at the end of the hour. This might not teach the AGI quite as much as having 10 hour-long conversations serially, but I bet it would be close, especially if the conversations were on different topics. Ditto with running biology lab experiments, fixing machines, or whatever else the AGI needs to learn in the real world.
Putting together those and other considerations, I think “months of training” is a much better guess than “years of training” to get an AGI from random initialization to competent-adult-human level.
3.3.3 The timescale of recent deep learning progress is not necessarily indicative of what to expect for how quickly AGI algorithms will improve.
Over the past decade since AlexNet, the world has gradually and painstakingly built up a massive infrastructure for running large-scale learning algorithms, including a big workforce of experts in how to parallelize and hardware-accelerate learning and inference algorithms, software toolkits like JAX and Kubernetes, training resources like The Pile and OpenAI Gym, zillions of high-performance GPUs, and so on. If Dileep (or whoever) comes up with some new AI algorithm that works better than LLMs, all this existing infrastructure may be very rapidly turned towards optimizing and running this new algorithm.
3.3.4 The timescale of recent progress in industrial automation and robotics is not necessarily indicative of how quickly AGI may pose an extinction risk.
In other words, it’s tempting to say, quoting this article,[6] “robotics is not developing at a pace that’s anywhere close to AI’s — and it is unlikely to, since AI’s accelerated progress is tied to the digital world, where computational power grows exponentially, copying is nearly instantaneous, and optimization is automated. … A scenario where a superintelligent AI decides that humans are a drain on resources and should be eliminated, rather than a key source of its support, depends on technologies and economic structures (e.g. completely automated production cycles, from raw material extraction to advanced manufacturing) that don’t exist and are unlikely to exist for the foreseeable future.”
There are a number of problems with this perspective.
First, it’s hard to know with any confidence,[5] but my best guess [LW · GW] is that, when we have AGI-capable algorithms (which for all I know could be decades away), there will be enough existing GPUs (and TPUs etc.) on the planet to run a “civilization” of tens to hundreds of millions of AGIs, each with continuous learning and at human speed. So as soon as we have human-level AGI algorithms at all, we’ll already have the “dry kindling” to create a whole civilization of such AGIs. (See also here.)
Second, Joseph Stalin rose to a secure position of enormous power, not by single-handedly running the entire economy, nor by being able to single-handedly defeat every other Russian combined in physical combat, but rather by being strategic and charismatic, and gaining allies and supporters.[7] By the same token, if AGIs can’t single-handedly run an entire self-sustaining economy (yet!), but have maneuvered into a difficult-to-dislodge position of hard power, then they can gradually entrench their position. And then sooner or later—even if it takes many decades of manufacturing ever more chips and robots—they will be able to run a fully-automated world economy without human help. And by then it will be way too late to do anything about it.

Third, I don’t think it would take “many decades” before a self-sustaining AGI economy without humans becomes possible. Consider: if you give a human a new teleoperated robot to use, they’ll pick it up pretty quickly—hours, not years. By the same token, a “real” AGI algorithm will be able to learn to wield any teleoperated robot in short order (indeed, I think it would reach much better performance than a human operator, e.g. for user-interface reasons). Thus, as soon as human-level AGI algorithms exist, there would be a trillion-dollar market for flexible teleoperated robot bodies.[8] And then immediately after that, factories around the world will drop whatever they were doing (e.g. making cars) and start pumping out teleoperated robotics, of all shapes and sizes, by the tens of millions. Moreover, production could happen in a distributed way, in factories all around the world, all of which are raking in unprecedented profits. Thus, passing and enforcing a global moratorium on the mass-manufacture of teleoperated robotics would be extremely hard, even as it becomes increasingly obvious to everyone that something big and irreversible is happening over the course of a few years.
There are many other considerations too, but I’ve said enough for my basic point here. So I’ll stop. See this Carl Shulman interview for further discussion.
3.3.5 This isn’t an intentional phased deployment situation, where somebody is deliberately choosing the timescale.
If we get to the point where we have techniques to make powerful AGIs, but nobody knows how to give them robustly prosocial and docile motivations, then I think that’s a very bad situation. But it’s tempting to say that it’s not such a big deal: “In such a situation, we will stop deploying AGIs, and likewise we will stop doing the R&D to make them ever more competent, fast, and compute-efficient, until that problem is solved, right?”
As usual, my question is: “who exactly is ‘we’?” Getting everyone on Earth to agree to anything is hard.
Moreover, I think the word “deployment” gives the wrong idea here—“deployment” invokes an image of an AI company publicly announcing and releasing a new product. But if a hobbyist makes a human-level AGI with callous disregard for human welfare, on their gaming GPU,[5] and gives that AGI internet access, that’s a kind of “deployment” too. And once there’s one competent go-getter internet-connected sociopathic AGI on one computer, it may try to maneuver its way onto more computers, and into the big data centers—whether by spearphishing, threats, bribes, simply earning money and renting more compute, or whatever other methods. And then we have not just one instance of human-level AGI, but more and more of them, all collaborating to entrench their position and gain resources.
Likewise, it’s easy to say “We can control how much resources to give to an AGI! And we won’t give it access to effectors!” But, even leaving aside the global coordination problem, there’s a more basic problem: there was never any human who “decided” that Joseph Stalin should have dictatorial power over Russia, or “gave him access to” a nuclear arsenal. Nobody handed those things to Stalin; he took the initiative to get them of his own accord. Likewise, there was never any human who “decided” that Warren Buffett should have $100B of private wealth, which he can freely deploy towards whatever (legal) end his heart desires. Instead, Buffett proactively maneuvered his way into massive resources. By the same token, even if every human on Earth could agree that we’re not yet ready to hand power, resources, and access-to-effectors to AGIs, we should nevertheless expect that there will eventually be savvy, charismatic, competent, out-of-control AGIs that are taking the initiative to get those things for themselves.
3.3.6 Time to prepare and react is not necessarily spent wisely.
For example, if you had asked me five years ago how the USA government would react to a novel pandemic virus, my answer would not have included “The government will prevent scientists from testing people for the virus”. Alas—see 1, 2, 3.
Governments can do great things too, of course! But if you are expecting governments to never do extraordinarily daft things, for years straight, that pointlessly exacerbate obvious global emergencies … then you evidently have an inaccurate mental model of governments.
3.3.7 The King Lear Problem
Sometimes countries suffer a military coup, or a slave revolt, or a prison breakout. It is not necessarily the case that there will first be a feeble attempt at a military coup doomed to fail, then a slightly-less-feeble one, etc., gradually ramping up. People aren’t morons. They often wait to launch a coup until such time as they have a reasonable expectation of irreversible success. By the same token, we can expect competent misaligned AGIs to not myopically announce their true desires, but rather to be docile and cooperative in situations where being docile and cooperative is in their selfish best interest. But that doesn’t mean they won’t launch a coup once they amass enough power, resources, credible threats, etc. to irreversibly succeed. The lesson is: gradually-increasing danger need not look like gradually-worsening problems.
3.3.8 The alignment problem may be the kind of technical problem that takes a long time to solve, even if we have the benefit of trial-and-error.
As I argue here [LW · GW], straightforward approaches seem to require robustness to adversarially-chosen wildly-out-of-distribution inputs, which has been an unsolved problem in ML for a long time. Other approaches [LW · GW] might or might not require measuring a human brain connectome [LW · GW], which seems to be decades away. Still other approaches [LW · GW] lack any known theoretical basis for determining whether they’ll actually work; I lean somewhat negative but don’t know how to pin it down with more confidence, and I’m concerned that we still won’t know even when we have AGIs to run tests on, for the reasons listed in AI safety seems hard to measure.
4. Conclusion
As I wrote in the intro, my goal in this post is to advocate for Differential Intellectual Progress [? · GW]. I think there’s a technical alignment problem associated with the kind of AGI that Dileep & I are expecting. And I think that solving this alignment problem before, rather than after, other technical aspects of AGI capabilities is both possible and an excellent idea. For example, here’s a concrete neuro-AI technical research program [LW · GW] that I bet Dileep would kick ass at if he were to dive in. I would be delighted to work with him; my email is open.
(Thanks Seth Herd, Charlie Steiner, and Justis Mills for critical comments on earlier drafts.)
- ^
There are well-known regional differences across the cortex, such as “agranularity”, but I advocate for thinking of things like that as akin to different learning algorithm hyperparameters, neural net architecture, and so on, as opposed to qualitatively different learning algorithms.
- ^
Periodic reminder that I’m making various controversial claims about AGI in this post without justification, whenever I anticipate that Dileep would already agree with me (see §1.1). For everyone else, see here [LW · GW] for a brief discussion of why I think inventing new scientific paradigms requires something like model-based planning with trial-and-error (a.k.a. explore-and-exploit), which is basically the definition of “wanting” things. Certainly that’s a key ingredient in how humans invent new scientific paradigms, and how humans build factories, etc.
- ^
Some readers might be thinking “I know set up AGIs with docile and/or prosocial motivations: Just use LLMs + RLHF / Constitutional AI / whatever!”. If that’s what your thinking, then here is your periodic reminder that this post is assuming a particular kind of AGI algorithm architecture—the kind that Dileep & I are expecting—which is different from LLMs. See §4.2 here [LW · GW] for some of the technical-alignment-relevant deep differences between how LLMs are trained versus how human brains learn.
- ^
I expect Dileep to respond: “No no no, my point was, there’s no need to extrapolate into the future, because AGI will cause small problems before it causes big problems.” But even if I assume that this will happen, it would still be necessary for people to say, “If AGI can cause a small problem today, we should solve it, because it may cause a bigger problem tomorrow”, instead of saying “You see? AGI only causes small problems, not big problems like human extinction. What is everyone so worried about?” and then proudly deploying solutions narrowly tailored to addressing the current small problems that obviously won’t scale to the future bigger problems. Now, one might think that nobody would be so stupid as to do the latter instead of the former. And yet, in early 2020, as the number of people with COVID grew and grew along a smooth, perfectly-predictable, exponential curve, pundits were mockingly comparing the absolute number of COVID deaths so far to flu deaths.
- ^
Many people seem to be assuming that AGI will require giant data centers, not single gaming GPUs. The problems are (1) We don’t know that, because we don’t have AGI algorithms yet. For example, Dileep speaks frequently (example) about how the AGI-relevant learning algorithms he works on will be dramatically more data-efficient than LLMs. That would seem to suggest dramatically lower compute requirements (although not necessarily, because there are other factors at play as well). I don’t know Dileep’s beliefs about eventual AGI compute requirements, but my own guess [LW · GW] is that gaming GPUs will be in the right ballpark for human-level human-speed AGI, including continuous active learning. (2) Even if training AGIs from scratch requires giant data centers, if anyone does that, then the trained weights will get onto Tor sooner or later, and fine-tuning, tweaking, or otherwise running such an AGI would be plausibly in the range of gaming GPUs, even if the original training is not.
- ^
I have a more thorough response to that article here.
- ^
I was talking to a friend recently, and he started to object: “Yeah but Stalin also killed a ton of people … oh wait, no … Stalin ordered that a ton of people be killed.” And I said “Bingo!”
- ^
In a world of widespread and inexpensive AGI algorithms, if you purchase a flexible teleoperated robot body, then you get a drop-in replacement for any human job that requires a body, including highly-skilled well-paying jobs like laboratory R&D scientists and engineers, or specialists in building and maintaining complex custom industrial machinery, and so on. So I think it’s reasonable to guess that those could easily sell for six figures each. And as discussed elsewhere, I’m expecting there to be enough GPUs for tens to hundreds of millions of AGIs.
7 comments
Comments sorted by top scores.
comment by Vladimir_Nesov · 2024-07-08T18:57:23.733Z · LW(p) · GW(p)
expecting LLMs to not be the right kind of algorithm for future powerful AGI—the kind that can ... do innovative science
I don't know what could serve as a crux for this. When I don't rule out LLMs, what I mean is that I can't find an argument with the potential to convince me to become mostly confident that scaling LLMs to 1e29 FLOPs in the next few years won't produce something clunky and unsuitable for many purposes, but still barely sufficient to then develop a more reasonable AI architecture within 1-2 more years. And by an LLM that does this I mean the overall system that allows LLM's scaffolding environment to create and deploy new tuned models using new preference data that lets the new LLM variant do better on particular tasks as the old LLM variant encounters them, or even pre-train models on datasets with heavy doses of LLM-generated problem sets with solutions, to distill the topics that the previous generation of models needed extensive search to stumble through navigating, taking a lot of time and compute to retrain models in a particular stilted way where a more reasonable algorithm would do it much more efficiently.
Many traditionally non-LLM algorithms reduce to such a setup, at an unreasonable but possibly still affordable cost. So this quite fits the description of LLMs as not being "the right kind of algorithm", but the prediction is that the scaling experiment could go either way, that there is no legible way to be confident in either outcome before it's done.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2024-07-08T19:21:22.500Z · LW(p) · GW(p)
I feel like “Will LLMs scale to AGI?” is right up there with “Should there be government regulation of large ML training runs?” as a black-hole-like attractor state that sucks up way too many conversations. :) I want to fight against that: this post is not about the question of whether or not LLMs will scale to AGI.
Rather, this post is conditioned on the scenario where future AGI will be an algorithm that (1) does not involve LLMs, and (2) will be invented by human AI researchers, as opposed to being invented by future LLMs (whether scaffolded, multi-modal, etc. or not). This is a scenario that I want to talk about; and if you assign an extremely low credence to that scenario, then whatever, we can agree to disagree. (If you want to argue about what credence is appropriate, you can try responding to me here [LW(p) · GW(p)] or links therein, but note that I probably won’t engage, it’s generally not a topic I like to talk about for “infohazard” reasons [see footnote here [LW(p) · GW(p)] if anyone reading this doesn’t know what that means].)
I find that a lot of alignment researchers don’t treat this scenario as their modal expectation, but still assign it like >10% credence, which is high enough that we should be able to agree that thinking through that scenario is a good use of time.
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2024-07-08T19:57:11.548Z · LW(p) · GW(p)
if you assign an extremely low credence to that scenario, then whatever
I don't assign low credence to the scenario where LLMs don't scale to AGI (and my point doesn't depend on this). I assign low credence to the scenario where it's knowable today that LLMs very likely won't scale to AGI. That is, that there is a thing I could study that should change my mind on this. This is more of a crux than the question as a whole, studying that thing would be actionable if I knew what it is.
whether or not LLMs will scale to AGI
This wording mostly answers one of my questions, I'm now guessing that you would say that LLMs are (in hindsight) "the right kind of algorithm" if the scenario I described comes to pass, which wasn't clear to me from the post.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2024-07-08T20:14:03.094Z · LW(p) · GW(p)
Yeah when I say things like “I expect LLMs to plateau before TAI”, I tend not to say it with the supremely high confidence and swagger that you’d hear from e.g. Yann LeCun, François Chollet, Gary Marcus, Dileep George, etc. I’d be more likely to say “I expect LLMs to plateau before TAI … but, well, who knows, I guess. Shrug.” (The last paragraph of this comment [LW(p) · GW(p)] is me bringing up a scenario with a vaguely similar flavor to the thing you’re pointing at.)
comment by Jonathan Claybrough (lelapin) · 2024-07-09T00:57:05.279Z · LW(p) · GW(p)
(aside : I generally like your posts' scope and clarity, mind saying how long it takes you to write something of this length?)
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2024-07-09T01:29:01.528Z · LW(p) · GW(p)
Thanks! I don’t do super-granular time-tracking, but basically there were 8 workdays where this was the main thing I was working on.
Replies from: lelapin↑ comment by Jonathan Claybrough (lelapin) · 2024-07-11T21:14:38.182Z · LW(p) · GW(p)
Oh wow, makes sense. It felt weird that you'd spend so much time on posts, yet if you didn't spend much time it would mean you write at least as fast as Scott Alexander. Well, thanks for putting in the work. I probably don't publish much because I want it to not be much work to do good posts but you're reassuring it's normal it does.