[Valence series] Appendix A: Hedonic tone / (dis)pleasure / (dis)liking
post by Steven Byrnes (steve2152) · 2023-12-20T15:54:17.131Z · LW · GW · 0 commentsContents
A.1 Post summary / Table of contents A.2 The “long-term predictor” for valence A.3 Zoom in on the two opposite extremes A.3.1 Why might we expect “override” versus “defer-to-predictor” at different times? A.3.2 Zoom in on one extreme: “Defer-to-predictor mode” A.3.3 Zoom in on the opposite extreme: “Override mode” A.4 Some terminology issues A.5 Intuitive properties of hedonic tone / (dis)liking / (dis)pleasure that are compatible with this picture A.6 FAQ — Properties of hedonic tone that might seem not to match my picture None No comments
A.1 Post summary / Table of contents
Part of the Valence series [? · GW].
I talked about hedonic tone, a.k.a. pleasure or displeasure, a.k.a. liking or disliking (these terms aren’t exactly synonymous, as discussed in §A.4 below) already in the series, in §1.5.2 [LW · GW] (section title: Valence (as I’m using the term) is different from “hedonic valence” / pleasantness). I mostly declared hedonic tone to be off-topic, but by popular demand, this appendix has some more detail about what I think it is, i.e. how that fits into my current models.
Warning: I put much less thought into this appendix than the rest of the series, and ran it by many fewer people. I dunno, maybe there’s a 30% chance that I will think this appendix is importantly wrong in a year or two. Bonus points if you’re the one to convince me—the comments section is at the bottom!
The punchline of this post is that “hedonic tone” / “liking-vs-disliking” / “pleasure-vs-displeasure” corresponds to an important brain signal, which is distinct from valence but centrally involved in how valence is calculated. More specifically, it’s the thing highlighted in red in the diagrams below. I’m not sure how to describe it in words.
- Section A.2 discusses a basic circuit motif that I call the “long-term predictor”. I think it’s widely used in the brain, and I have discussed it in the past more generically, but here I specialize it to the case of valence.
- Section A.3 discusses how and why the circuit can move along a spectrum between two extremes that I call “defer-to-predictor mode” and “override mode”. I go through the behavior of that circuit in both of those extreme cases, as pedagogical illustrations of what can happen in general.
- Section A.4 discusses some terminology issues that make it complicated to relate brain signals to English-language words, both in general, and in the particular case of hedonic tone / pleasure / liking etc.
- Section A.5 goes through some examples where I argue that the intuitive properties of hedonic tone match up well with the algorithmic properties of the brain signal in question.
- Section A.6 conversely goes through two examples where the intuitive properties of hedonic tone might seem not to match the algorithmic properties of the brain signal in question, and how I explain those (apparent) discrepancies.
A.2 The “long-term predictor” for valence
In a blog post last year [LW · GW], I proposed a particular kind of circuit that I called a “long-term predictor”, and I discussed its properties at length, and I claimed that many parts of the brain are well-approximated by it. I hope this post will be self-contained, but if you find yourself confused by the diagrams and my claims about them, then you can treat that previous post as a supplement, with a different set of worked examples.
Diving in, here is a long-term predictor circuit, with some minor tweaks and labels to specialize it to the specific case of valence:
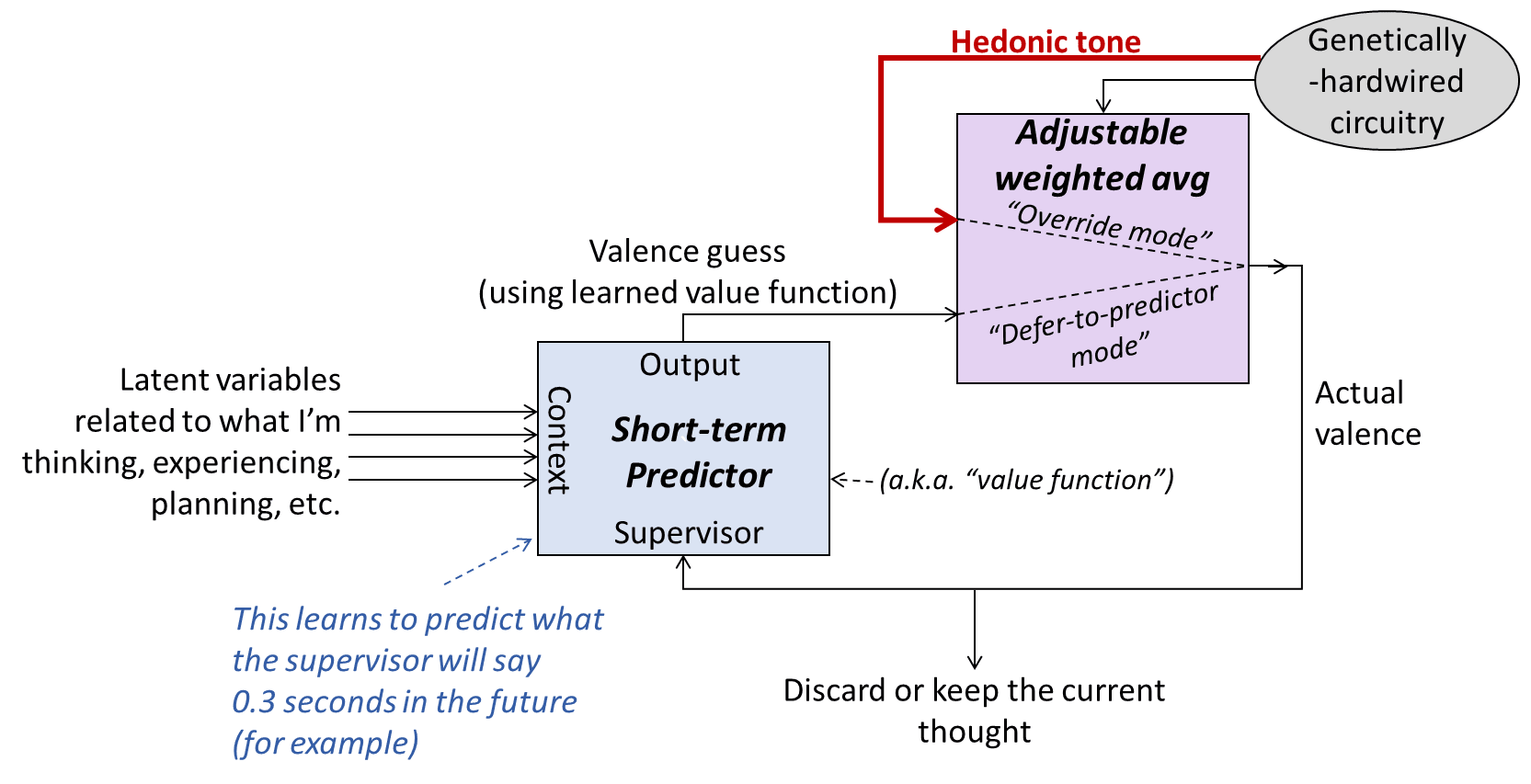
Some essential clarifications and caveats on this diagram:
- This is NOT a flow diagram for a serial program, with arrows indicating what steps to do in what order. Rather, this is the kind of diagram that you might see in FPGA programming, with the arrows being wires. So at any given moment, every arrow is carrying a numerical value, and every block is running continuously and in parallel.
- The blue “short-term predictor” box has labels on its ports—“supervisor”, “output”, and “context”. For the definition of those three terms, see here [LW · GW].
- The purple box calculates an adjustable weighted average of its inputs, where the weights of the weighted average are set by the genetically-hardwired circuitry (gray oval). The two extreme weight settings—i.e. 100%-0% and 0%-100%—are what I call “override mode” versus “defer-to-predictor mode”. I’ll talk about these two modes separately in the next section, because they provide helpful intuitions. Note that I’m oversimplifying here: at least in principle, the purple box is not restricted to calculating a weighted average; it could alternatively compute the sum of the two inputs (as would be traditional in AI, see my discussion here [LW · GW]), or really any arbitrary function of the two inputs. However, I think that the weighted average case, and especially the two extreme cases of “override mode” versus “defer-to-predictor mode”, provide a really great starting point that captures a lot of the important high-level qualitative behavior and intuitions. So I’m going to stick with that.
- More generally, and similar to the rest of this series (see §1.5.7 [LW · GW]), this is all at a pretty high level, and to translate it to the actual brain, I would need to add in lots of bells and whistles and implementation details, some of which I don’t completely understand myself.
- There’s much more stuff in the brain that’s not included in this diagram. For example, there are other learning algorithms that generate inputs into the “genetically-hardwired circuitry” in the top-left (I call them “visceral thought assessors”). A somewhat more comprehensive high-level picture is here [LW · GW].
- Update June 2024: Another point of clarification: The red arrow labeled “hedonic tone” is within the Steering Subsystem [LW · GW] (hypothalamus & brainstem), and thus it is not directly part of conscious awareness. However, just as in §1.5.4 [LW · GW]–§1.5.5 [LW · GW], a copy of this signal is one of the interoceptive inputs into the cortex / world-model / Thought Generator. That’s why we can introspect on hedonic tone, and we can imagine a different hedonic tone than the one currently active in our own brains, and so on.
- Update July 2024: See also Section 5.3.1 here [? · GW] for more of a side-by-side comparison between this circuit and the kinds of things you’d find in conventional RL textbooks.
A.3 Zoom in on the two opposite extremes
A.3.1 Why might we expect “override” versus “defer-to-predictor” at different times?
To illustrate the basic intuition for answering this question, let’s consider two example situations: “I’m thirsty and I just felt water on my tongue” as an example of when we might expect something closer to override-mode, and “I’m puzzling over a math problem in my head” as an example of when we might expect something closer to defer-to-predictor mode.
- “I’m thirsty and I just felt water on my tongue”: The genetically-hardwired circuitry in my Steering Subsystem [LW · GW] (hypothalamus and brainstem) “knows” that something importantly good is happening right now. After all, it has “ground-truth” information that I’m thirsty (thanks to various homeostasis monitoring systems in the hypothalamus and brainstem), and it also has a “ground-truth” information that there seems to be water on my tongue (the brainstem has direct access to taste data, tongue sensation data, etc.). Thus it is both possible and expected that the brainstem would be innately wired up to issue a positive-valence “override” in this circumstance. So for example, if the learned value function is saying “The stuff going on right now is pointless, better to do something else instead”, then my brainstem, upon detecting the water on my tongue, would be overriding that value function, effectively yelling at the value function: “Nope, bzzt, this is definitely very good, and in fact you’d better update your synapses going forward so that you don’t make such silly mistakes in the future”.
- “I’m puzzling over a math problem in my head”: Here, my hypothalamus and brainstem have essentially no ground-truth information about what’s going on. (I’m oversimplifying; in particular, innate curiosity drive and innate social drives might be active while puzzling over a math problem, more on which in §A.6 below.) So if the value function says “this particular mental move is probably helpful for solving the math problem” or “this particular mental move is probably unhelpful for solving the math problem”, the brainstem has no choice but to say “OK sure, whatever, I guess I’ll just have to take your word for it.” So in this situation, your brain would be approximately in defer-to-predictor mode.
A.3.2 Zoom in on one extreme: “Defer-to-predictor mode”
Let's suppose that, right now, the circuit is all the way in defer-to-predictor mode. Let's talk about what happens:
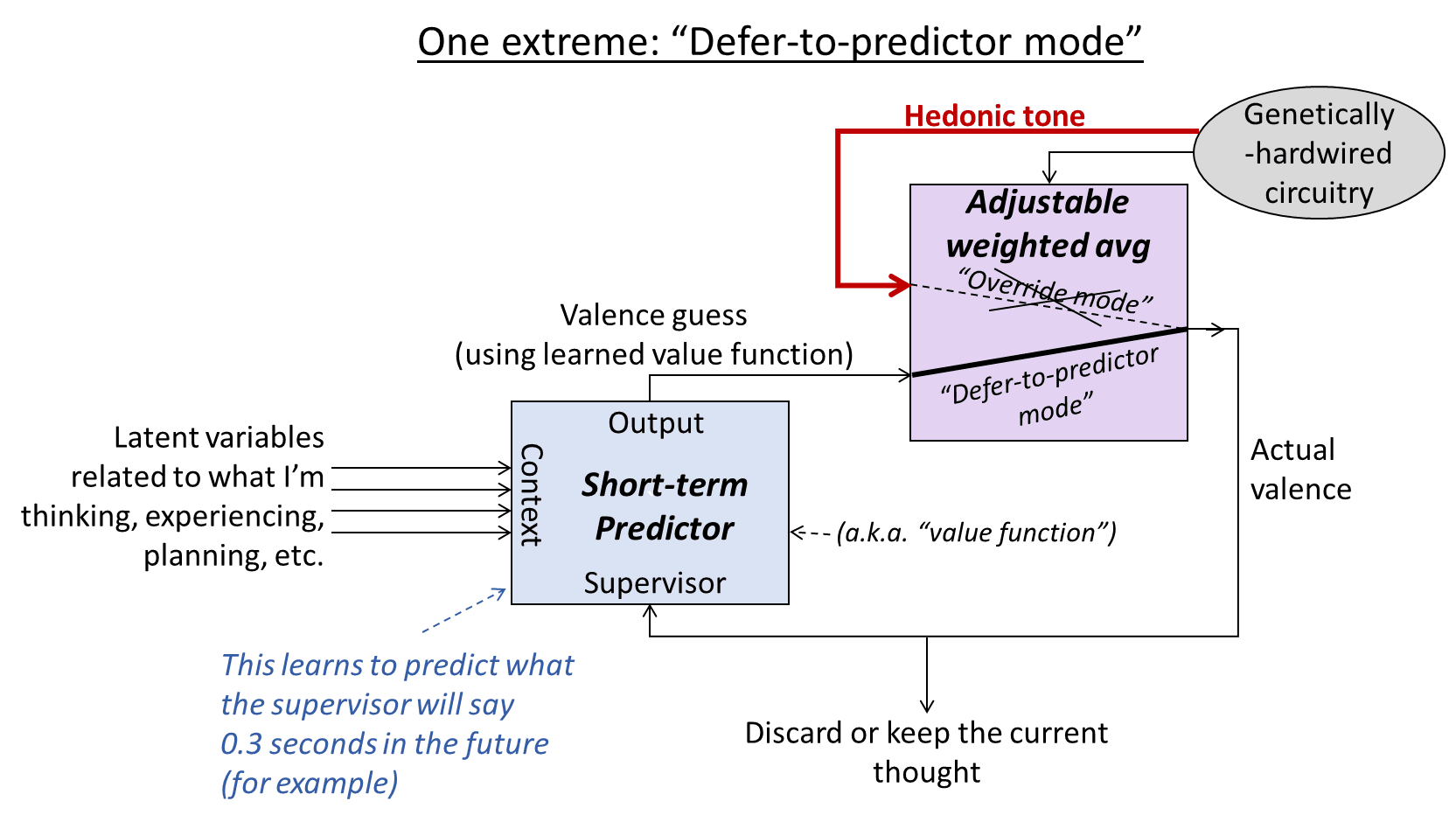
A key observation is that, in this situation, value function updates correspond to TD learning. (More specifically, in terms of the mainstream reinforcement learning literature, this would be TD learning with zero discount rate and zero reward.) Take a careful look at the diagram and make sure you understand why that is. For example, if the context vector (set of latent variables on the left) is X for a while, then suddenly changes to Y, then the value function V would get updated by the learning algorithm such that V(X) becomes a closer approximation to whatever V(Y) happens to be. That’s TD learning—later value calculations serve as ground-truth for updating earlier value calculations.
Moving on to the opposite extreme:
A.3.3 Zoom in on the opposite extreme: “Override mode”
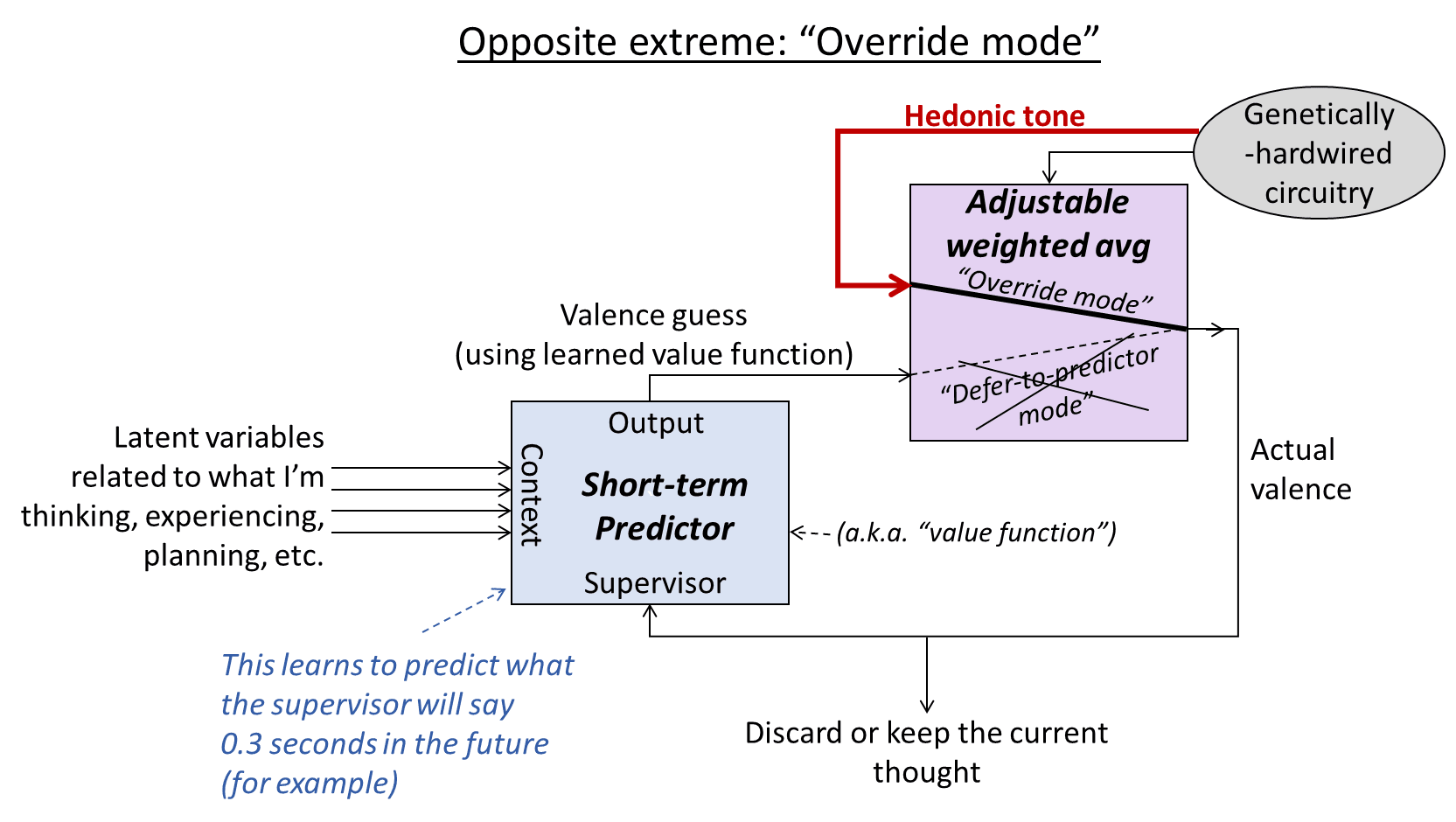
A key observation is that, in this situation, value function updates correspond to supervised learning, with the red signal being ground truth. Take a careful look at the diagram and make sure you understand why that is. For example, if the context vector (set of latent variables on the left) is X for a while—as an example, maybe X is the set of latent variables that occur when I’m getting a massage, and that’s all I’m thinking about for 10 seconds straight. Then the value function V would get updated by the learning algorithm such that V(X) becomes a closer approximation to whatever value is being carried by the red arrow during those 10 seconds of massage.
A.4 Some terminology issues
In general, I think we shouldn’t expect everyday English-language folk psychology terms to correspond precisely to important ingredients in brain algorithms. (For my part, I normally don’t even expect neuroscience or psychology jargon terms to correspond precisely to important ingredients in brain algorithms either! But now I’m just ranting.)
Why not? One big reason is that we normal humans are generally not interested in brain algorithm ingredients per se. Instead, we are interested in brain algorithm ingredients as they fit into our lives and the things we care about. For example, if there’s a common type of real-world situation that causes a particular brain signal to suddenly get active, we’re likely to have a folk-psychology term for that whole thing—the brain signal getting active, in that kind of way, in this kind of semantic context. By contrast, we might not have a folk-psychology term for that brain signal in and of itself.
So in any case, I can start listing terms like:
- “Positive hedonic tone” / “Negative hedonic tone”
- “Liking” / “Disliking”
- “Pleasure” / “Displeasure”
- “Feeling of relief” / “Craving”
…and so on. I think these terms are all pretty closely related to the red signal that I called “hedonic tone”. Insofar as these terms come apart, it’s not mainly because they’re talking about different signaling pathways in the brain, but rather the terms are capturing different things that these signals might do in different real-world semantic contexts (and sometimes in conjunction with other changes like physiological arousal). So I want to lump all those terms (and more) together into “words that are basically talking about the red arrow in the diagram above”.
Here’s another issue that makes everyday terminology come apart from my models. In everyday language, we “like” an activity, situation, etc. But the red-arrow “hedonic tone” signal is related to brain state. If I say “I like to play golf”, then this claim is related to many thoughts in my head, over many hours or days—the thoughts where I’m wondering whether to play golf, where I’m driving to the golf course, where I’m swinging the golf club, and so on. If “I like to play golf”, then probably it’s a safe bet that positive hedonic tone is involved in some of those brain-states, but almost certainly not every moment. So then, at the end of the day, what does “I like to play golf” mean? I don’t know; it’s complicated, and it’s not what I’m talking about in this post. See also the parallel discussion of valence in §1.5.1 [LW · GW]— section heading: ‘Valence’ (as I’m using the term) is a property of a thought—not a situation, nor activity, nor course-of-action, etc.
A.5 Intuitive properties of hedonic tone / (dis)liking / (dis)pleasure that are compatible with this picture
Intuitive Property 1: Hedonic tone has almost inevitable implications for motivation. In particular, if I’m experiencing positive hedonic tone right now, then:
- Other things equal, I want to stay in this situation.
- Other things equal, in the future, I will want to get back into this situation.
Why that’s consistent with my model: I gave an example in §A.3.3 of getting a massage, and spending ten enjoyable seconds just thinking about and experiencing the massage. I used the variable X to refer to the “context” vector during those ten seconds, which is relatively constant during those ten seconds, and which consists of lots of latent variables in my world-model related to what it’s like to be enjoying a massage, including all the associated thoughts and sensations. As I argued in §A.3.3, one of the things happening in my brain during those ten seconds is that my brain’s value function V is getting edited by the learning algorithm, such that, in the future, V(X) will spit out a highly positive value.
So then what? Well, maybe next week, I will think to myself “What if I go get a massage?” Let’s say the context vector associated with that thought is Y. I claim that there will be substantial overlap between the Y and X vectors. After all, thinking about getting a massage involves summoning a mental model of getting-a-massage, and all that that entails. And therefore, if V(X) is highly positive, we expect V(Y) to be at least a little bit positive by default, other things equal. Thus, I will find myself motivated by the idea of getting another massage, and may well actually do so.
I can even find myself motivated to remember (“fondly recall”) the massage, and motivated to imagine getting another massage, even when I know that doing so isn’t possible right now, for a similar reason. Of course, if I fondly recall the massage too much, doing so will gradually get less motivating, because the learning algorithm continues to be active.
Intuitive Property 2: Motivational valence and hedonic tone are different signals in the brain, involving different brain regions, and “feel” different in our interoceptive experience.
Why that’s consistent with my model: Hopefully this is clear from the diagram above. For the “interoceptive experience” part, see §1.5.4 [LW · GW]–§1.5.5 [LW · GW] for essential background.
Intuitive Property 3: It’s possible to have positive valence without positive hedonic tone (“wanting without liking”). For example, if I’m cold, then I’m motivated to go upstairs to put my sweater on, even though doing so isn’t particularly pleasant.
Why that’s consistent with my model: If hedonic tone is negative, and “valence guess (using learned value function)” is positive, then it can easily be the case that the weighted average (“actual valence”) is positive. That happens whenever the positivity of the valence guess outweighs the negativity of the hedonic tone in the weighted average. So in those situations, we would do the thing, but we would “feel” negative hedonic tone as we were doing it.
A.6 FAQ — Properties of hedonic tone that might seem not to match my picture
Question 1: If pleasure causes positive valence, and positive valence is about motivation, why am I often feeling pleasure but not motivated to do anything in particular? For example, if I’m getting a massage, then I just want to relax and enjoy it.
Answer 1: Valence is sorta about motivation, but it’s not a perfect match to how we use the word “motivation” in everyday life. Consider:
- Some possible thoughts (e.g. “I’ll open the window right now”) entail immediate motor actions; if those thoughts are positive-valence, then we will actually take those physical actions.
- More generally, some possible thoughts are part of a temporal sequence (e.g., if we’re in the middle of singing a song); if those thoughts are positive-valence, then we will continue to progress through that temporal sequence.
- Still other thoughts do not involve immediate motor actions, and are also not part of a temporal sequence (e.g. the thought “I am just relaxing and enjoying this massage”). OK, well, we can alternatively say that such a thought is part of a temporal sequence, but the sequence in question is just the trivial infinite loop: “In the next time-step, continue to think this same thought”. If such a thought is positive-valence, then that’s what will happen: the thought will just persist, and we won’t do anything in particular.
Now, spend some time squinting at the circuit diagrams above, and think about the circumstances in which the third-bullet-point type of thought would wind up positive valence. As long as the weighted average is not all the way at the “defer-to-predictor” extreme, such a thought can only have a stable positive valence in the presence of positive hedonic tone. But it can happen if there’s a stable positive hedonic tone, like while we’re getting a massage. And in those cases, it’s totally possible for the third-bullet-point type of thought to maintain positive valence and stick around. Thus we are not “motivated” to do anything in particular, but we are “motivated” to continue relaxing and enjoying the massage.
Question 2: In the drawing, “hedonic tone” is flowing from “genetically-hardwired circuitry”, i.e. what you call “innate drives”. But that’s not right—I get great pleasure from the joy of discovery, a close friendship, and so on, not just from innate drives like quenching my thirst or getting a massage!
Answer 2: I get this objection a lot, sometimes even with a side-helping of moral outrage. And I find that weird, because in my mind, it’s perfectly obvious that discovery, friendship, and so on can have the same close relationship to innate drives as does quenching thirst.
I think there are a couple reasons that this claim of mine seems unintuitive to many people.
THEORY 1 for why people seem to assume that eating and sex are directly incentivized by “innate drives” involved in reinforcement learning, but discovery and friendship cannot be: They have the (incorrect) intuition that
- (A) there’s a category of “urges”, a.k.a. ego-dystonic desires, and these are related to reinforcement learning;
- (B) there’s a category of “deeply-held goals”, a.k.a. ego-syntonic desires, and these are not related to reinforcement learning.
Going along with this (incorrect) intuition is the fact that avoiding pain and satisfying hunger seem to be comparatively ego-dystonic for most people—for example, if there was a way to perform brain-surgery to get rid of pain and hunger without creating a risk of bad downstream effects like injury or malnourishment, most people would at least consider that briefly. By contrast, things like curiosity, compassion, and friendship are comparatively ego-syntonic for most people—for example, if there was a way to perform brain-surgery to make someone not feel the pull of curiosity and compassion, without any other undesired downstream behavioral effects, most people would be shocked, horrified, and deeply offended at the mere suggestion that such a surgery would be a good idea.
Anyway, I think there's an intuition driving people to “externalize" category (A) and call them “urges”, and to “internalize” category (B) and call them “part of ourselves”. But I think this intuition is misleading. Or more accurately, we're entitled to think of “ourselves” in whatever way we want. That's fine! But we shouldn't conflate that kind of self-conceptualization process with veridical introspection about the nuts and bolts of within-lifetime reinforcement learning (involving dopamine etc.). I elaborate on the details here at Section 6.6.1 of this blog post I wrote last year [LW · GW].
(Update October 2024: For a much more detailed exploration of how we wound up with these kinds of intuitions, see my Intuitive Self-Models series [? · GW], especially Post 3 [LW · GW], which explores both why some desires are ego-syntonic while others are not, and why people often find it deeply counterintuitive, and even insulting, to suggest that there’s some algorithmic root cause like reinforcement learning causally upstream of our ego-syntonic desires.)
THEORY 2 for why people seem to assume eating and sex are directly incentivized by “innate drives” involved in reinforcement learning, but discovery and friendship are not: They have an (incorrect) intuition that reinforcement learning rewards occur when externally-visible real-world events happen.
I understand why people might have that intuition, because it is a natural generalization from almost any reinforcement learning paper written to date. For example, in a videogame-playing reinforcement learning (RL) algorithm, the reward function might trigger when the player kills an enemy, or gets a coin, or takes damage, etc. Avoiding pain and satisfying hunger seem to be “that kind of thing”, whereas curiosity and compassion seem to be pretty different from that. And this intuition, just like Theory 1 above, would provide a nice explanation of why many people want to put eating and sex and pain in the reinforcement learning bucket, and curiosity and compassion and friendship outside of it.
But I think that’s wrong. The brain’s innate drives (i.e. the circuits contributing to the overall “main” RL reward function of §1.5.6 [LW · GW]) do not have to rely only on external events. They can also depend directly on what you're thinking about.
The curiosity-drive literature is an established example here. Specifically, there have been at least a few papers that give RL agents a reward when they “satisfy their curiosity”, so to speak. This reward signal is based on the contents of their thoughts, and how that’s changing over time, not just what’s happening in the world. For a beginner-friendly review focusing on the story of the “Montezuma’s Revenge” videogame, see chapter 6 of The Alignment Problem by Brian Christian. I’m not an expert in this area, and don’t have strong opinions on the nuts-and-bolts of how exactly it works in brains, but I do think brains have some kind of drive to satisfy curiosity in this genre.
I also think human social instincts are generally in the category of “innate drives that depend directly on thoughts, not just on what’s going on in the world”. For example, I think we can be lying on the bed staring into space, and we can think a thought that provides evidence (from the perspective of the Steering Subsystem [LW · GW]) that we are liked / admired (see §4.4.2 [LW · GW]), and that thought will be innately rewarding, in much the same way that eating-when-hungry is, and this thought will thus provide positive hedonic tone. Ditto for other social drives related to compassion, righteous indignation, and so on. I don’t currently know the exact mechanisms for how most social instincts work in the human brain, but I’m working on it [LW · GW].
Important caveat here: I do think that it’s possible to have innate drives that depend on what you’re thinking about, but I emphatically do not think that you can just intuitively write down some function of “what you’re thinking about” and say “this thing here is a plausible innate drive in the brain”. There’s another constraint: there has to be a way by which the genome can wire up such a reward function. This turns out to be quite a strong constraint, and rules out lots of nice-sounding proposals. More details here [LW · GW].
0 comments
Comments sorted by top scores.