A shortcoming of concrete demonstrations as AGI risk advocacy
post by Steven Byrnes (steve2152) · 2024-12-11T16:48:41.602Z · LW · GW · 27 commentsContents
27 comments
Given any particular concrete demonstration of an AI algorithm doing seemingly-bad-thing X, a knowledgeable AGI optimist can look closely at the code, training data, etc., and say:
“Well of course, it’s obvious that the AI algorithm would do X under these circumstances. Duh. Why am I supposed to find that scary?”
And yes, it is true that, if you have enough of a knack for reasoning about algorithms, then you will never ever be surprised by any demonstration of any behavior from any algorithm. Algorithms ultimately just follow their source code.
(Indeed, even if you don’t have much of a knack for algorithms, such that you might not have correctly predicted what the algorithm did in advance, it will nevertheless feel obvious in hindsight!)
From the AGI optimist’s perspective: If I wasn’t scared of AGI extinction before, and nothing surprising has happened, then I won’t feel like I should change my beliefs. So, this is a general problem with concrete demonstrations as AGI risk advocacy:
- “Did something terribly bad actually happen, like people were killed?”
- “Well, no…”
- “Did some algorithm do the exact thing that one would expect it to do, based on squinting at the source code and carefully reasoning about its consequences?”
- “Well, yes…”
- “OK then! So you’re telling me: Nothing bad happened, and nothing surprising happened. So why should I change my attitude?”
I already see people deploying this kind of argument, and I expect it to continue into future demos, independent of whether or not the demo is actually being used to make a valid point.
I think a good response from the AGI pessimist would be something like:
I claim that there’s a valid, robust argument that AGI extinction is a big risk. And I claim that different people disagree with this argument for different reasons:
- Some are over-optimistic based on mistaken assumptions about the behavior of algorithms;
- Some are over-optimistic based on mistaken assumptions about the behavior of humans;
- Some are over-optimistic based on mistaken assumptions about the behavior of human institutions;
- Many are just not thinking rigorously about this topic and putting all the pieces together; etc.
If you personally are highly skilled and proactive at reasoning about the behavior of algorithms, then that’s great, and you can pat yourself on the back for learning nothing whatsoever from this particular demo—assuming that’s not just your hindsight bias talking. I still think you’re wrong about AGI extinction risk, but your mistake is probably related to the 2nd and/or 3rd and/or 4th bullet point, not the first bullet point. And we can talk about that. But meanwhile, other people might learn something new and surprising-to-them from this demo. And this demo is targeted at them, not you.
Ideally, this would be backed up with real quotes from actual people making claims that are disproven by this demo.
For people making related points, see: Sakana, Strawberry, and Scary AI; and Would catching your AIs trying to escape convince AI developers to slow down or undeploy? [LW · GW]
Also:
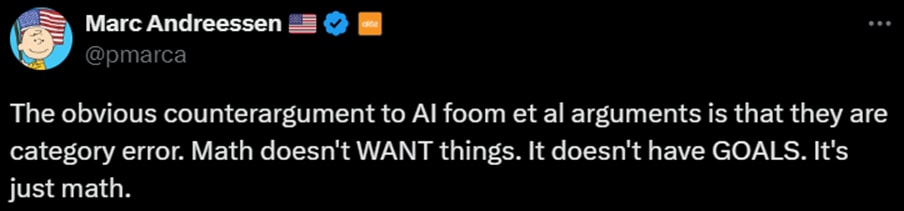
I think this comment is tapping into an intuition that assigns profound importance to the fact that, no matter what an AI algorithm is doing, if you zoom in, you’ll find that it’s just mechanically following the steps of an algorithm, one after the other. Nothing surprising or magic. In reality, this fact is not a counterargument to anything at all, but rather a triviality that is equally true of human brains, and would be equally true of an invading extraterrestrial army. More discussion in §3.3.6 here [LW · GW].
27 comments
Comments sorted by top scores.
comment by Zack_M_Davis · 2024-12-11T19:49:15.451Z · LW(p) · GW(p)
Some have delusional optimism about [...]
I'm usually not a fan of tone-policing [LW · GW], but in this case, I feel motivated to argue that this is more effective if you drop the word "delusional." The rhetorical function of saying "this demo is targeted at them, not you" is to reassure the optimist that pessimists are committed to honestly making their case point by point, rather than relying on social proof and intimidation tactics to push a predetermined [LW · GW] "AI == doom" conclusion. That's less credible if you imply that you have warrant to dismiss all claims of the form "Humans and institutions will make reasonable decisions about how to handle AI development and deployment because X" as delusional regardless of the specific X.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2024-12-11T19:58:47.336Z · LW(p) · GW(p)
Hmm, I wasn’t thinking about that because that sentence was nominally in someone else’s voice. But you’re right. I reworded, thanks.
comment by Nathan Helm-Burger (nathan-helm-burger) · 2024-12-11T21:29:09.759Z · LW(p) · GW(p)
I'm pretty sure that the right sort of demo could convince even a quite skeptical viewer.
Imagine going back in time and explaining chemistry to someone, then showing them blueprints for a rifle.
Imagine this person scoffs at the idea of a gun. You pull out a handgun and show it to them, and they laugh at the idea that this small blunt piece of metal could really hurt them from a distance. They understand the chemistry and the design that you showed them, but it just doesn't click for them on an intuitive level.
Demo time. You take them out to an open field and hand them an apple. Hold this balanced on your outstretched hand, you say. You walk a ways away, and shoot the apple out of their hand. Suddenly the reality sinks in.
So, I think maybe the demos that are failing to convince people are weak demos. I bet the Trinity test could've convinced some nuclear weapon skeptics.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2024-12-12T01:12:37.880Z · LW(p) · GW(p)
I agree that certain demos might change the mind of certain people. (And if so, they’re worthwhile.) But I also think other people would be immune. For example, suppose someone has the (mistaken) idea: “Nobody would be so stupid as to actually press go on an AI that would then go on to kill lots of people! Or even if theoretically somebody might be stupid enough to do that, management / government / etc. would never let that happen.” Then that mistaken idea would not be disproven by any demo, except a “demo” that involved lots of actual real-life people getting killed. Right?
Replies from: nathan-helm-burger↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2024-12-12T05:31:52.949Z · LW(p) · GW(p)
Sure. At this point I agree that some people will be so foolish and stubborn that no demo will concern them. Indeed, some people fail to update even on actual events.
So now we are, as Zvi likes to say, 'talking price'. What proportion of key government decision-makers would be influenced by how persuasive (and costly) of demos.
We both agree that the correct amount of effort to put towards demos is somewhere between nearly all of our AI safety effort-resources, and nearly none. I think it's a good point that we should try to estimate how effective a demo is likely to be on some particular individual or group, and aim to neither over nor under invest in it.
comment by Logan Zoellner (logan-zoellner) · 2024-12-13T15:39:10.821Z · LW(p) · GW(p)
“OK then! So you’re telling me: Nothing bad happened, and nothing surprising happened. So why should I change my attitude?”
I consider this an acceptable straw-man of my position.
To be clear, there are some demos that would cause me to update.
For example, I think the Solomonoff Prior is Malign [LW · GW] to be basically a failure to do counting correctly. And so if someone demonstrated a natural example of this, I would be forced to update.
Similarly, I think the chance of a EY-style utility-maximizing agent arising from next-token-prediction are (with caveats) basically 0%. So if someone demonstrated this, it would update my priors. I am especially unconvinced of the version of this where the next-token predictor simulates a malign agent and the malign agent then hacks out of the simulation.
But no matter how many times I am shown "we told the AI to optimize a goal and it optimized the goal... we're all doomed", I will continue to not change my attitude.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2024-12-13T16:56:37.087Z · LW(p) · GW(p)
Yup! I think discourse with you would probably be better focused on the 2nd or 3rd or 4th bullet points in the OP—i.e., not “we should expect such-and-such algorithm to do X”, but rather “we should expect people / institutions / competitive dynamics to do X”.
I suppose we can still come up with “demos” related to the latter, but it’s a different sort of “demo” than the algorithmic demos I was talking about in this post. As some examples:
- Here [LW · GW] is a “demo” that a leader of a large active AGI project can declare that he has a solution to the alignment problem, specific to his technical approach, but where the plan doesn’t stand up to a moment’s scrutiny.
- Here [LW · GW] is a “demo” that a different AGI project leader can declare that even trying to solve the alignment problem is already overkill, because misalignment is absurd and AGIs will just be nice, again for reasons that don’t stand up to a moment’s scrutiny.
- (And here’s a “demo” that at least one powerful tech company executive might be fine with AGI wiping out humanity anyway.)
- Here is a “demo” that if you give random people access to an AI, one of them might ask it to destroy humanity, just to see what would happen. Granted, I think this person had justified confidence that this particular AI would fail to destroy humanity …
- … but here is a “demo” that people will in fact do experiments that threaten the whole world, even despite a long track record of rock-solid statistical evidence that the exact thing they’re doing is indeed a threat to the whole world, far out of proportion to its benefit, and that governments won’t stop them, and indeed that governments might even fund them.
- Here is a “demo” that, given a tradeoff between AI transparency (English-language chain-of-thought) and AI capability (inscrutable chain-of-thought but the results are better), many people will choose the latter, and pat themselves on the back for a job well done.
- Every week we get more “demos” that, if next-token prediction is insufficient to make a powerful autonomous AI agent that can successfully pursue long-term goals via out-of-the-box strategies, then many people will say “well so much the worse for next-token prediction”, and they’ll try to figure some other approach that is sufficient for that.
- Here is a “demo” that companies are capable of ignoring or suppressing potential future problems when they would interfere with immediate profits.
- Here is a “demo” that it’s possible for there to be a global catastrophe causing millions of deaths and trillions of dollars of damage, and then immediately afterwards everyone goes back to not even taking trivial measures to prevent similar or worse catastrophes from recurring.
- Here is a “demo” that the arrival of highly competent agents with the capacity to invent technology and to self-reproduce is a big friggin’ deal.
- Here [LW · GW] is a “demo” that even small numbers of such highly competent agents can maneuver their way into dictatorial control over a much much larger population of humans.
I could go on and on. I’m not sure your exact views, so it’s quite possible that none of these are crux-y for you, and your crux lies elsewhere. :)
Replies from: logan-zoellner↑ comment by Logan Zoellner (logan-zoellner) · 2024-12-13T18:37:05.973Z · LW(p) · GW(p)
It's hard for me to know what's crux-y without a specific proposal.
I tend to take a dim view of proposals that have specific numbers in them (without equally specific justifications). Examples include the six month pause, and sb 1047.
Again, you can give me an infinite number of demonstrations of "here's people being dumb" and it won't cause me to agree with "therefore we should also make dumb laws"
If you have an evidence-based proposal to reduce specific harms associated with "models follow goals" and "people are dumb", then we can talk price.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2024-12-13T19:18:27.742Z · LW(p) · GW(p)
Oh I forgot, you’re one of the people who seems to think [LW(p) · GW(p)] that the only conceivable reason that anyone would ever talk about AGI x-risk is because they are trying to argue in favor of, or against, whatever AI government regulation was most recently in the news. (Your comment was one of the examples that I mockingly linked in the intro here [LW · GW].)
If I think AGI x-risk is >>10%, and you think AGI x-risk is 1-in-a-gazillion, then it seems self-evident to me that we should be hashing out that giant disagreement first; and discussing what if any government regulations would be appropriate in light of AGI x-risk second. We’re obviously not going to make progress on the latter debate if our views are so wildly far apart on the former debate!! Right?
So that’s why I think you’re making a mistake whenever you redirect arguments about the general nature & magnitude & existence of the AGI x-risk problem into arguments about certain specific government policies that you evidently feel very strongly about.
(If it makes you feel any better, I have always been mildly opposed to the six month pause plan [LW · GW].)
Replies from: logan-zoellner↑ comment by Logan Zoellner (logan-zoellner) · 2024-12-13T19:38:58.419Z · LW(p) · GW(p)
If I think AGI x-risk is >>10%, and you think AGI x-risk is 1-in-a-gazillion, then it seems self-evident to me that we should be hashing out that giant disagreement first; and discussing what if any government regulations would be appropriate in light of AGI x-risk second.
I do not think arguing about p(doom) in the abstract is a useful exercise. I would prefer the Overton Window for p(doom) look like 2-20%, Zvi thinks it should be 20-80%. But my real disagreement with Zvi is not that his P(doom) is too high, it is that he supports policies that would make things worse.
As for the outlier cases (1-in-a-gazillon or 99.5%), I simply doubt those people are amenable to rational argumentation. So, I suspect the best thing to do is to simply wait for reality to catch up to them. I doubt when there are 100M's of humanoid robots out there on the streets, people will still be asking "but how will the AI kill us?"
(If it makes you feel any better, I have always been mildly opposed to the six month pause plan [LW · GW].)
That does make me feel better.
comment by Knight Lee (Max Lee) · 2024-12-13T00:04:22.354Z · LW(p) · GW(p)
I think there are misalignment demonstrations and capability demonstrations.
Misalignment skeptics believe that "once you become truly superintelligent you will reflect on humans and life and everything and realize you should be kind."
Capability skeptics believe "AGI and ASI are never going to come for another 1000 years."
Takeover skeptics believe "AGI will come, but humans will keep it under control because it's impossible to escape your captors and take over the world even if you're infinitely smart," or "AGI will get smarter gradually and will remain controlled."
Misalignment demonstrations can only convince misalignment skeptics. It can't convince all of them because some may insist that the misaligned AI are not intelligent enough to realize their errors and become good. Misalignment demonstrations which deliberately tell the AI to be misaligned (e.g. ChaosGPT) also won't convince some people, and I really dislike these demonstrations. The Chernobyl disaster was actually caused by people stress testing the reactor to make sure it's safe. Aeroflot Flight 6502 crashed when the pilot was demonstrating to the first officer how to land an airplane with zero visibility. People have died while demonstrating gun safety.
Capability demonstrations can only convince capability skeptics. I actually think a lot of people changed their minds after ChatGPT. Capability skeptics do get spooked by capability demonstrations and do start to worry more.
Sadly, I don't think we can do takeover demonstrations to convince takeover skeptics.
comment by Dagon · 2024-12-11T17:37:43.686Z · LW(p) · GW(p)
There hasn't been a large-scale nuclear war, should we be unafraid of proliferation? More specific to this argument, I don't know any professional software developers who haven't had the experience of being VERY surprised by a supposedly well-known algorithm.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2024-12-11T17:57:19.414Z · LW(p) · GW(p)
I’m not sure what argument you think I’m making.
In a perfect world, I think people would not need any concrete demonstration to be very concerned about AGI x-risk. Alan Turing and John von Neumann were very concerned about AGI x-risk, and they obviously didn’t need any concrete demonstration for that. And I think their reasons for concern were sound at the time, and remain sound today.
But many people today are skeptical that AGI poses any x-risk. (That’s unfortunate from my perspective, because I think they’re wrong.) The point of this post is to suggest that we AGI-concerned people might not be able to win over those skeptics via concrete demonstrations of AI doing scary (or scary-adjacent) things, either now or in the future—or at least, not all of the skeptics. It’s probably worth trying anyway—it might help for some of the skeptics. Regardless, understanding the exact failure modes is helpful.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2024-12-11T18:45:23.790Z · LW(p) · GW(p)
I expect the second-order effects of allowing people to get political power by crisis-mongering about risk when there is no demonstration/empirical evidence to ruin the initially perfect world pretty immediately, even assuming that AI risk is high and real, because this would allow anyone to make claims about some arbitrary risk and get rewarded for it even if it isn't true, and there's no force that systematically favors true claims over false claims about risk in this incentive structure.
Indeed, I think it would be a worse world than now, since it supercharges already existing incentives to crisis monger for the news industry and political groups.
Also, while Alan Turing and John Von Neumann were great computer scientists, I don't particularly have that much reason to elevate their AI risk opinions over anyone else on this topic, and their connection to AI is at best very indirect.
Replies from: steve2152, bronson-schoen↑ comment by Steven Byrnes (steve2152) · 2024-12-11T19:03:38.461Z · LW(p) · GW(p)
In a perfect world, everyone would be concerned about the risks for which there are good reasons to be concerned, and everyone would be unconcerned about the risks for which there are good reasons to be unconcerned, because everyone would be doing object-level checks of everyone else’s object-level claims and arguments, and coming to the correct conclusion about whether those claims and arguments are valid.
And those valid claims and arguments might involve demonstrations and empirical evidence, but also might be more indirect.
See also: It is conceivable for something to be an x-risk without there being any nice clean quantitative empirically-validated mathematical model proving that it is [LW · GW].
I do think Turing and von Neumann reached correct object-level conclusions via sound reasoning, but obviously I’m stating that belief without justifying it.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2024-12-11T20:21:56.872Z · LW(p) · GW(p)
It's true in a perfect world that everyone would be concerned about the risks for which there are good reasons to be concerned, and everyone would be unconcerned about the risks for which there are good reasons to be unconcerned, because everyone would be doing object-level checks of everyone else’s object-level claims and arguments, and coming to the correct conclusion about whether those claims and arguments are valid, so I shouldn't have stated that the perfect world was ruined by that, but I consider this a fabricated option for reasons relating to how hard it is for average people to validate complex arguments, combined with the enormous economic benefits of specializing in a field, so I'm focused a lot more on what incentives does this give a real society, given our limitations.
To address this part:
See also: It is conceivable for something to be an x-risk without there being any nice clean quantitative empirically-validated mathematical model proving that it is [LW · GW].
I actually agree with this, and I agree with the claim that an existential risk can happen without leaving empirical evidence as a matter of sole possibility.
I have 2 things to say here:
- I am more optimistic that we can get such empirical evidence for at least the most important parts of the AI risk case, like deceptive alignment, and here's one reason as comment on offer:
https://www.lesswrong.com/posts/YTZAmJKydD5hdRSeG/?commentId=T57EvmkcDmksAc4P4 [LW · GW]
2. From an expected value perspective, a problem can be both very important to work on and also have 0 tractability, and I think a lot of worlds where we get outright 0 evidence or close to 0 evidence on AI risk are also worlds where the problem is so intractable as to be effectively not solvable, so the expected value of solving the problem is also close to 0.
This also applies to the alien scenario: While from an epistemics perspective, it is worth it to consider the hypothesis that the aliens are unfriendly, from a decision/expected value perspective, almost all of the value is in the hypothesis that the aliens are friendly, since we cannot survive alien attacks except in very specific scenarios.
Replies from: bronson-schoen↑ comment by Bronson Schoen (bronson-schoen) · 2024-12-12T00:27:05.293Z · LW(p) · GW(p)
I am more optimistic that we can get such empirical evidence for at least the most important parts of the AI risk case, like deceptive alignment, and here's one reason as comment on offer:
Can you elaborate on what you were pointing to in the linked example? The thread specifically I’ve seen a few people mention recently but I seem to be missing the conclusion they’re drawing from it.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2024-12-12T03:39:22.714Z · LW(p) · GW(p)
I was pointing to this quote:
It sounds as though you're imagining that we can proliferate the one case in which we caught the AI into many cases which can be well understood as independent (rather than basically just being small variations).
and this comment, which talks about proliferating cases where 1 AI schemes into multiple instances to get more evidence:
https://www.lesswrong.com/posts/YTZAmJKydD5hdRSeG/#BkdBD5psSFyMaeesS [LW · GW]
↑ comment by Bronson Schoen (bronson-schoen) · 2024-12-11T23:55:48.645Z · LW(p) · GW(p)
crisis-mongering about risk when there is no demonstration/empirical evidence to ruin the initially perfect world pretty immediately
I think the key point of this post is precisely the question of “is there any such demonstration, short of the actual real very bad thing happening in a real setting that people who discount these as serious risks would accept as empirical evidence worth updating on?”
comment by green_leaf · 2024-12-12T14:17:17.272Z · LW(p) · GW(p)
I refuse to believe that tweet has been written in good faith.
I refuse to believe the threshold for being an intelligent person on Earth is that low.
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2024-12-13T02:14:35.805Z · LW(p) · GW(p)
That's how this happens, people systematically refuse to believe some things, or to learn some things, or to think some thoughts. It's surprisingly feasible to live in contact with some phenomenon for decades and fail to become an expert. Curiosity needs System 2 guidance to target blind spots.
comment by Dave Lindbergh (dave-lindbergh) · 2024-12-11T18:02:16.381Z · LW(p) · GW(p)
Math doesn't have GOALS. But we constantly give goals to our AIs.
If you use AI every day and are excited about its ability to accomplish useful things, its hard to keep the dangers in mind. I see that in myself.
But that doesn't mean the dangers are not there.
comment by Vugluscr Varcharka (vugluscr-varcharka) · 2024-12-14T15:03:54.206Z · LW(p) · GW(p)
I claim that you fell victim of a human tendency to oversimplify when modeling an abstract outgroup member. Why do all "AI pessimists" picture "AI optimists" as stubborn simpletons not bein able to get persuaded finally that AI is a terrible existential risk. I agree 100% that yes, it really is an existential risk for our civ. Like nuclear weapons..... Or weaponing viruses... Inability to prevent pandemic. Global warming (which is already very much happening).. Hmmmm. It's like we have ALL those on our hands presently, don't we? People don't seem to be doing anything about 3 (three) existential risks.
In my real honest opinion, if humans continue to rule - we are going to have very abrupt decline in quality of life in this decade. Sorry for bad formulation and tone etc.
Replies from: steve2152, sharmake-farah↑ comment by Steven Byrnes (steve2152) · 2024-12-14T18:00:42.656Z · LW(p) · GW(p)
I think of myself as having high ability and willingness to respond to detailed object-level AGI-optimist arguments, for example:
- Response to Dileep George: AGI safety warrants planning ahead [LW · GW]
- Response to Blake Richards: AGI, generality, alignment, & loss functions [LW · GW]
- Thoughts on “AI is easy to control” by Pope & Belrose [LW · GW]
- LeCun’s “A Path Towards Autonomous Machine Intelligence” has an unsolved technical alignment problem [LW · GW]
- Munk AI debate: confusions and possible cruxes [LW · GW]
…and more.
I don’t think this OP involves “picturing AI optimists as stubborn simpletons not being able to get persuaded finally that AI is a terrible existential risk”. (I do think AGI optimists are wrong, but that’s different!) At least, I didn’t intend to do that. I can potentially edit the post if you help me understand how you think I’m implying that, and/or you can suggest concrete wording changes etc.; I’m open-minded.
Replies from: vugluscr-varcharka↑ comment by Vugluscr Varcharka (vugluscr-varcharka) · 2024-12-15T19:14:21.665Z · LW(p) · GW(p)
If I'm not mistaking, you've already changed the wording and new version does not trigger negative emotional response in my particular sub-type of AI optimists. Now I have a bullet accounting for my kind of AI optimists *_*.
Although I still remain in confusion what would be a valid EA response to the arguments coming from people fitting these bullets:
- Some are over-optimistic based on mistaken assumptions about the behavior of humans;
- Some are over-optimistic based on mistaken assumptions about the behavior of human institutions;
Also, is it valid to say that human pessimists are AI optimists?
Also, it's not clear to me why are my (negative) assumptions (about both) are mistaken?
Also, now I perceive hidden assumption that all "human pessimists" are mistaken by default or those who are correct can be just ignored....
PS. It feels soooo weird when EA forum use things like karma... I have to admit - seeing negative value there feels unpleasant to me. I wonder if there is a more effective way to prevent spam/limit stupid comments without causing distracting emotions. This way kinda contradicts base EA principles if I'm correct.
PPS. I have yet to read links in your reply, but I don't see my argument there at the first glance.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2024-12-15T21:32:15.799Z · LW(p) · GW(p)
If I'm not mistaking, you've already changed the wording
No, I haven’t changed anything in this post since Dec 11, three days before your first comment.
valid EA response … EA forum … EA principles …
This isn’t EA forum. Also, you shouldn’t equate “EA” with “concerned about AGI extinction”. There are plenty of self-described EAs who think that AGI extinction is astronomically unlikely and a pointless thing to worry about. (And also plenty of self-described EAs who think the opposite.)
prevent spam/limit stupid comments without causing distracting emotions
If Hypothetical Person X tends to write what you call “stupid comments”, and if they want to be participating on Website Y, and if Website Y wants to prevent Hypothetical Person X from doing that, then there’s an irreconcilable conflict here, and it seems almost inevitable that Hypothetical Person X is going to wind up feeling annoyed by this interaction. Like, Website Y can do things on the margin to make the transaction less unpleasant, but it’s surely going to be somewhat unpleasant under the best of circumstances.
(Pick any popular forum on the internet, and I bet that either (1) there’s no moderation process and thus there’s a ton of crap, or (2) there is a moderation process, and many of the people who get warned or blocked by that process are loudly and angrily complaining about how terrible and unjust and cruel and unpleasant the process was.)
Anyway, I don’t know why you’re saying that here-in-particular. I’m not a moderator, I have no special knowledge about running forums, and it’s way off-topic. (But if it helps, here’s [LW · GW] a popular-on-this-site post related to this topic.)
[EDIT: reworded this part a bit.]
what would be a valid EA response to the arguments coming from people fitting these bullets:
- Some are over-optimistic based on mistaken assumptions about the behavior of humans;
- Some are over-optimistic based on mistaken assumptions about the behavior of human institutions;
That’s off-topic for this post so I’m probably not going to chat about it, but see this other comment [LW(p) · GW(p)] too.
↑ comment by Noosphere89 (sharmake-farah) · 2024-12-14T16:11:46.408Z · LW(p) · GW(p)
Admittedly, a lot of the problem is that in the general public, a lot of AI optimism and pessimism is that stupid, and even in LW, there are definitely stupid arguments for optimism, so I think they have developed a wariness towards these sorts of arguments.