What if we Align the AI and nobody cares?
post by Logan Zoellner (logan-zoellner) · 2023-04-19T20:40:30.251Z · LW · GW · 23 commentsContents
Alternative Title: "AI Alignment" Considered Harmful None 23 comments
In the classic AI Foom scenario, a single unified AI passes the boundary where it is capable of recursive self-improvement. Thereafter it increases in intelligence hyper exponentially until it rapidly gains control of the future.
We now know this is not going to happen. By the time a superintelligent (>all humans) AI is built, the world will already be filled with trillions of AIs spanning the entire range from tiny models running as microservices on low-power IOT devices to super-human (but not yet super-itelligent) models serving as agents for some of the most powerful organizations on Earth.
For ecological reasons, small models will dramatically outnumber large ones both in number and in terms of absolute compute at their disposal. Building larger, more powerful models will be seen primarily as an engineering problem, and at no point will a single new model be in a position to overpower the entire ecosystem that created it.
What does solving the Alignment Problem look like in this future?
It does not look like: We invent a clever machine-learning technique that allows us to create a single AI that understands our values and hand control of the future over to it.
Instead it looks like: At the single moment of maximum change in the transition from Human to Artificial Intelligence, we collectively agree that the outcome was "good".
The thing is, we will have absolutely no clue when we pass the point of maximum change. We are nowhere near that point, but we have already passed the point where no single human can actually keep track of everything that's happening. We can only say that the rate of change will be faster than now. How much faster? 10x? 100x? We can calculate some upper bound (assuming, for example, that the total energy used by AI doesn't exceed that produced by our sun). But the scale of the largest AI experiments can continue to grow at least 22 orders of magnitude before hitting fundamental limits.

Edit: This is incorrect. GPT-3 used ~1GWH. So the correct OOM should be 34-12=22
Given the current doubling rate of 3.4 months for AI experiments, this means that we will reach the point of maximum change at some point in the next 2 decades (sooner, assuming we are not currently near the maximum rate of change).
So, currently the way alignment gets solved is: things continue to get crazier until they literally cannot get crazier any faster. When we reach that moment, we look back and ask: was it worth it? And if the answer is yes, congratulations, we solved the alignment problem.
So, if your plan is to keep freaking out until the alignment problem is solved, then I have good news for you. The alignment problem will be solved at precisely the moment you are maximally freaked out.
Alternative Title: "AI Alignment" Considered Harmful
Imagine a world with two types of people: Machine Learning Engineers and AI Alignment Experts.
Every day, the Machine Learning Engineer wakes up and asks himself: Given the current state of the art in Machine Learning, how can I use the tools and techniques of Machine Learning to achieve my goals?
Every day, the AI Alignment Expert wakes up an asks himself a question: How can I make sure that future yet-to-be-invented tools and techniques of Machine Learning are not harmful?
One of these people is much more likely to succeed at building a future that reflects their ideals than the other.
23 comments
Comments sorted by top scores.
comment by ponkaloupe · 2023-04-19T23:01:18.609Z · LW(p) · GW(p)
OpenAI estimated that the energy consumption for training GPT-3 was about 3.14 x 10^17 Joules.
sanity checking this figure: 1 kWh is 1000 x 60 x 60 = 3.6 MJ. then GPT-3 consumed 8.7 x 10^10 kWh. at a very conservative $0.04/kWh, that’s $3.5B just in the power bill — disregarding all the non-power costs (i.e. the overheads of operating a datacenter).
i could believe this number’s within 3 orders of magnitude of truth, which is probably good enough for the point of this article, but i am a little surprised if you just took it 100% at face value.
Replies from: evand↑ comment by evand · 2023-04-20T04:27:54.901Z · LW(p) · GW(p)
i could believe this number’s within 3 orders of magnitude of truth, which is probably good enough for the point of this article
It's not. As best I can tell it's off by more like 4+ OOM. A very quick search suggests actual usage was maybe more like 1 GWh. Back of the envelope guess: thousands of GPUs, thousands of hours, < 1kW/GPU, a few GWh.
https://www.theregister.com/2020/11/04/gpt3_carbon_footprint_estimate/
https://www.numenta.com/blog/2022/05/24/ai-is-harming-our-planet/
i am a little surprised if you just took it 100% at face value.
Same. That doesn't seem to rise to the quality standards I'd expect.
Replies from: logan-zoellner↑ comment by Logan Zoellner (logan-zoellner) · 2023-04-20T04:58:53.714Z · LW(p) · GW(p)
Yeah, I should have double-checked.
Editing post to reflect the correct values. Does not affect the "two decades" bottom line conclusion.
comment by Eli Tyre (elityre) · 2023-04-19T20:54:10.787Z · LW(p) · GW(p)
So, currently the way alignment gets solved is: things continue to get crazier until they literally cannot get crazier any faster. When we reach that moment, we look back and ask: was it worth it? And if the answer is yes, congratulations, we solved the alignment problem.
I don't know if I'm block-headed-ly missing the point, but I don't know what this paragraph means.
How exactly does the world accelerating as much as possible mean that we solved the alignment problem?
Replies from: logan-zoellner↑ comment by Logan Zoellner (logan-zoellner) · 2023-04-19T21:12:07.812Z · LW(p) · GW(p)
At the single moment of maximum change in the transition from Human to Artificial Intelligence, we collectively agree that the outcome was "good".
We never actually "solve" the alignment problem (in the EY sense of writing down a complete set of human values and teaching them to the AI). Instead, we solve the Alignment problem by doing the hard work of engineering AI that does what we want and riding the wave all the way to the end of the S-curve.
edit:
I mean, maybe we DO that, but by the time we do no one cares.
Replies from: elityre, Seth Herd↑ comment by Eli Tyre (elityre) · 2023-04-20T03:53:25.000Z · LW(p) · GW(p)
No one cares because...there are other systems who are not operating on a complete set of human values (including many small, relatively dumb AI systems) that are steering the world instead?
Replies from: logan-zoellner↑ comment by Logan Zoellner (logan-zoellner) · 2023-04-20T04:12:59.402Z · LW(p) · GW(p)
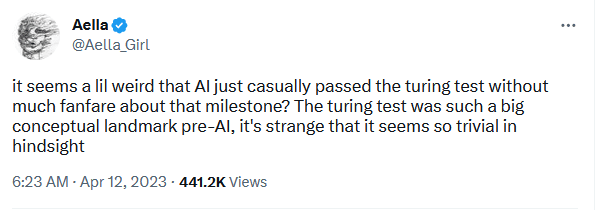
No one cares for the same reason no one (in the present) cares that AI can now pass the Turing Test. By the time we get there, we are grappling with different questions.
"Can you define an AI model that preserves a particular definition of human values under iterative self-improvement" simply won't be seen as the question of the day, because by the time we can do it, it will feel "obvious" or "unimpressive".
↑ comment by Seth Herd · 2023-04-20T02:57:22.995Z · LW(p) · GW(p)
Wait what? Getting an AI to do what you want is usually considered the hard part of the alignment problem, right?
Edit: I guess you're talking about the outer alignment, societal, or collective alignment problem, getting solved much as it is now, by a collection of compromises among only semi-misaligned agents.
Replies from: logan-zoellner↑ comment by Logan Zoellner (logan-zoellner) · 2023-04-20T04:13:35.763Z · LW(p) · GW(p)
I'm claiming we never solve the problem of building AI's that "lase [LW · GW]" in the sense of being able to specify an agent that achieves a goal at some point in the far future. Instead we "stumble through" by iteratively making more and more powerful agents that satisfy our immediate goals and game theory/ecological considerations mean that no single agent every takes control of the far future.
Does that make more sense?
Replies from: Seth Herd↑ comment by Seth Herd · 2023-04-20T05:46:16.469Z · LW(p) · GW(p)
The idea makes sense. How long are you thinking we stumble through for?
Game theory says that humans need to work in coalitions and make allies because no individual human is that much more powerful than any other. With agents that can self improve and self replicate, I don't think that holds.
And even if that balance of power were workable, my original objection stands. It seems to me that some misaligned troublemaker is bound to bring it all down with current or future tools of mass destruction.
Replies from: logan-zoellner↑ comment by Logan Zoellner (logan-zoellner) · 2023-04-20T13:33:03.031Z · LW(p) · GW(p)
Game theory says that humans need to work in coalitions and make allies because no individual human is that much more powerful than any other. With agents that can self improve and self replicate, I don't think that holds.
Even if agents can self-replicate, it makes no sense to run GPT-5 on every single micro-processer on Earth. This implies we will have a wide variety of different agents operating across fundamentally different scales of "compute size". For math reasons, the best way to coordinate a swarm of compute-limited agents is something that looks like free-market capitalism.
One possible worry is that humans will be vastly out-competed by future life forms. But we have a huge advantage in terms of existing now. Compounding interest rates imply that anyone alive today will be fantastically wealthy in a post-singularity world. Sure, some people will immediately waste all of that, but as long as at least some humans are "frugal", there should be more than enough money and charity to go around.
I don't really have much to say about the "troublemaker" part, except that we should do the obvious things and not give AI command and control of nuclear weapons. I don't really believe in gray-goo or false-vacuum or anything else that would allow a single agent to destroy the entire world without the rest of us collectively noticing and being able to stop them (assuming cooperative free-market supporting agents always continue to vastly [100x+] outnumber troublemakers).
Replies from: Seth Herd↑ comment by Seth Herd · 2023-04-20T21:00:54.109Z · LW(p) · GW(p)
Okay, I'm understanding your proposed future better. I still think that anything recursively self-improving (RSI) will be the end of us, if it's not aligned to be long-term stable. And that even non-RSI self-replicating agents are a big problem for this scenario (since they can cooperate nearly perfectly). But their need for GPU space is an important limitation.
I think this is a possible way to get to the real intelligence explosion of RSI, and it's the likely scenario we're facing if language model cognitive architectures [LW · GW] take off like I think they will [LW · GW] But I don't think it helps with the need to get alignment right for the first real superintelligence. That will be capable of either stealing, buying, or building its own compute resources.
comment by Seth Herd · 2023-04-20T02:56:13.676Z · LW(p) · GW(p)
This just sounds like "we're all gonna die" with extra steps. I maintain some level of optimism, but I can't see a likely path to survival in the scenario you describe.
If there are trillions of AI, what are the odds that zero of those have hacked, spoofed, or trolled us into launching the nukes? What are the odds there are neither nukes nor other x-risk technologies to wipe us out for the lulz [LW · GW] if not for instrumental convergence or malice?
But I agree that this scenario is where we seem to be heading. I think we'd better figure out how to change that somehow.
I see no alternative to some sort of pivotal act from the first AGI or group with both the capability and the juevos to step up and at least try to save humanity.
I really hope I'm wrong, but I've searched and searched and never heard a decent alternative for this type of massively multipolar scenario.
comment by quetzal_rainbow · 2023-04-19T21:16:38.754Z · LW(p) · GW(p)
Building larger, more powerful models will be seen primarily as an engineering problem, and at no point will a single new model be in a position to overpower the entire ecosystem that created it.
I know at least two events when small part of biosphere overpowered everything else: Great Oxidation Event and human evolution. Given the whole biosphere history, it overloaded with stories of how small advantage can allow you to destroy every competitor at least in your ecological niche.
And it's plausible that superintelligence will just hack every other AI using prompt injections et cetera and instead of "humanity and narrow AIs vs first AGI" we will have "humanity vs first AGI and narrow AIs".
Replies from: logan-zoellner↑ comment by Logan Zoellner (logan-zoellner) · 2023-04-19T21:43:36.707Z · LW(p) · GW(p)
"Hack every AI on the planet" sounds like a big ask for an AI that will have a tiny fraction (<1%) of the world's total computing power at its disposal.
Furthermore, it has to do that retro-actively. The first super-intelligent AGI will be built by a team of 1m Von-Neumann level AGIs who are working their hardest to prevent that from happening.
↑ comment by [deleted] · 2023-04-19T21:53:38.120Z · LW(p) · GW(p)
The AI doomer logic all hinges on at least one of a number of unlikely things being true.
- Nanotechnology is easy to develop
- Species killer bioweapons are easy to develop
- Hacking other computers is easy for a superintelligence
- Greater intelligence gains capabilities we can't model or predict, able to do things we cannot defend against
- It requires human buildable compute substrate to support the intelligence in (4), not small planetoids of 3d computronium
- Humans will build a few very powerful agentic ASI, task them with some long running wish, and let them operate for a long period of time to work on the goal without human input required
- Robotics is easy
- Real world data is high resolution/the aggregate set of human papers can be mined to get high resolution information about the world
- Humans can be easily modeled and socially manipulated
Note just 1 or a few of the above would let an ASI conquer the planet, however, by current knowledge each of the above is unlikely. (Less than 10 percent probability). Many doomers will state they don't believe this, that ASI could take over the planet in hours or weeks.
This is unlikely but I am partially just stating their assumptions. They could be correct in the end, see the "least dignified timeline" meme.
Replies from: TAG, Walker Vargas↑ comment by Walker Vargas · 2023-04-20T02:41:55.451Z · LW(p) · GW(p)
While I see a lot of concern about the big one. I think the whole AI environment being unaligned is the more likely but not any better outcome. A society that is doing really well by some metrics that just happen to be the wrong ones. I thinking of idea of freedom of contract that was popular at the beginning of the 20th century and how hard it was to dig ourselves out of that hole.
Replies from: logan-zoellner↑ comment by Logan Zoellner (logan-zoellner) · 2023-04-20T04:49:52.338Z · LW(p) · GW(p)
/s Yeah the 20th century was really a disaster for humanity. It would be terrible if capitalism and economic development were to keep going like this.
↑ comment by Mitchell_Porter · 2023-04-20T04:18:32.895Z · LW(p) · GW(p)
The first super-intelligent AGI will be built by a team of 1m Von-Neumann level AGIs
Or how about: a few iterations from now, a team of AutoGPTs make a strongly superhuman AI, which then makes the million Von Neumanns, which take over the world on its behalf.
Replies from: logan-zoellner↑ comment by Logan Zoellner (logan-zoellner) · 2023-04-20T04:42:43.995Z · LW(p) · GW(p)
So the timeline goes something like:
- Dumb human (this was GPT-3.5)
- Average-ish human but book smart (GPT-4/AutoGPT)
- Actually intelligent human (smart grad student-ish)
- Von Neumann (smartest human ever)
- Super human (but not yet super-intelligent)
- Super-intelligent
- Dyson sphere of computronium???
By the time we get the first Von-Neumann, every human on earth is going to have a team of 1000's of AutoGPTs working for them. The person who builds the first the first Von-Neumann level AGI doesn't get to take over the world because they're outnumbered 70 trillion to one.
The ratio is a direct consequence of the fact that it is much cheaper to run an AI than to train one. There are also ecological reasons why weaker agents will out-compute stronger ones. Big models are expensive to run and there's simply no reason why you would use an AI that costs $100/hour to run for most tasks when one that costs literally pennies can do 90% as good of a job. This is the same reason why bacteria >> insects >> people. There's no method whereby humans could kill every insect on earth without killing ourselves as well.
See also: why AI X-risk stories always postulate magic like "nano-technology" or "instantly hack every computer on earth".
Replies from: Mitchell_Porter, TAG↑ comment by Mitchell_Porter · 2023-04-20T05:44:32.156Z · LW(p) · GW(p)
By the time we get the first Von-Neumann, every human on earth is going to have a team of 1000's of AutoGPTs working for them.
How many requests does OpenAI handle per day? What happens when you have several copies of an LLM talking to each other at that rate, with a team of AutoGPTs helping to curate the dialogue and perform other auxiliary tasks? It's a recipe for an intelligence singularity.