[Replication] Conjecture's Sparse Coding in Small Transformers
post by Hoagy, Logan Riggs (elriggs) · 2023-06-16T18:02:34.874Z · LW · GW · 0 commentsContents
Summary Results Background MMCS-with-larger Results Bi-modality of MCS scores Diagonal lines are artefacts Are these dictionaries under-trained? Learned features don't appear to be sparse Many max activations of learned features seem highly interpretable Next steps & Request For Funding None No comments
Summary
A couple of weeks ago Logan Riggs and I posted [LW · GW] that we'd replicated the toy-model experiments in Lee Sharkey and Dan Braun's original sparse coding post. [LW · GW]Now we've replicated the work they did (slides) extending the technique to custom-trained small transformers (in their case 16 residual dimensions, in ours 32).
We've been able to replicate all of their core results, and our main takeaways from the last 2 weeks of research are the following:
- We can recover many more features from activation space than the dimension of the activation space which have a high degree of cosine similarity with the features learned by other, larger dictionaries, which in toy models was a core indicator of having learned the correct features.
- The distribution of Maximum Cosine Similarity (MCS) scores between trained dictionaries of different sizes is highly bimodal, suggesting that there is a particular set of features that are consistently found as sparse basis vectors of the activations, across different dictionary sizes.
- The maximum-activating examples of these features usually seem human interpretable, though we haven't yet done a systematic comparison to the neuron basis.
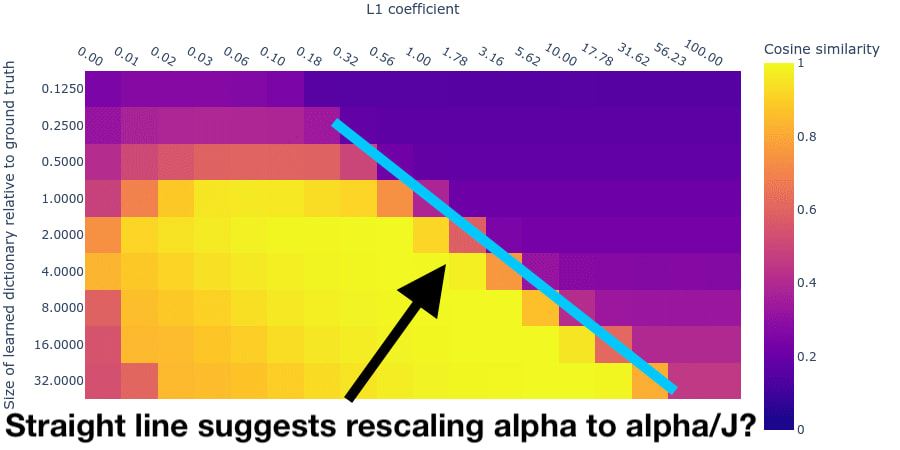
- The diagonal lines seen in the original post are an artefact of dividing the l1_loss coefficient by the dictionary size. Removing this means that the same l1_loss is applicable to a broad range of dictionary sizes.
- We find that as dict size increases, MMCS initially increases rapidly at first, but then plateaus.
- The learned feature vectors, including those ones that appear repeatedly, do not appear to be at all sparse with respect to the neuron basis.
As before, all code is available on GitHub and if you'd like to follow the research progress and potentially contribute, then join us on our EleutherAI thread.
Thanks to Robert Huben (Robert_AIZI [LW · GW]) for extensive comments on this draft, and Lee Sharkey, Dan Braun and Robert Huben for their comments during our work.
Results
Background
We used Andrej Karpathy's nanoGPT to train a small transformer, with 6 layers, a 32 dimensional residual stream, MLP widths of 128 and 4 attention heads with dimension 8. We trained on a node of 4xRTX3090s for about 9h, reaching a loss of 5.13 on OpenWebText. This transformer is the model from which we took activations, and then we separately trained sets of auto-encoders to be able to recreate the activation vectors from a sparse linear combination of a dictionary of features.
MMCS-with-larger Results
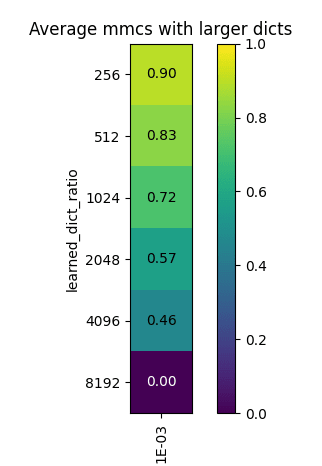
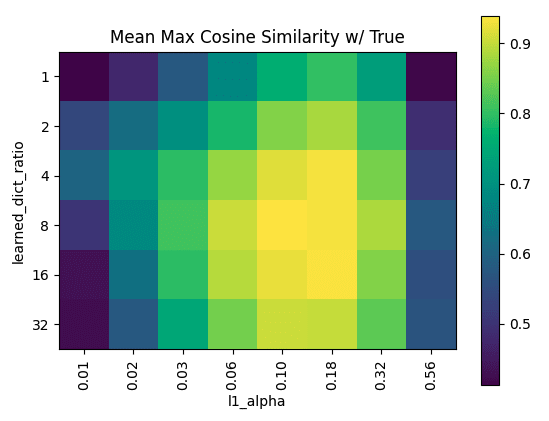
In their original sparse coding post [LW · GW], Lee Sharkey et al found that with toy data, one could tell when the sparse auto-encoders had converged on the correct decomposition of the generated activation vectors when learned dictionaries of different sizes converged on their learned features, so that if you took a feature vector in the smaller dictionary, you would consistently find a very similar feature in larger dictionary. See the post for more details of the 'MMCS-with-larger' metric.
Using the second layer of the aforementioned miniature transformer as our testbed, we found that sparse coding consistently decomposes the activation vectors of layer 2 of our small transformer into similar dictionaries of features, even when dictionary size is varied. This is shown by the high MMCS-with-larger scores of the dictionaries of a smaller dictionary, at the top of the above heat map. The results for larger dictionaries seem mixed, but the next section puts them in a more interesting light.
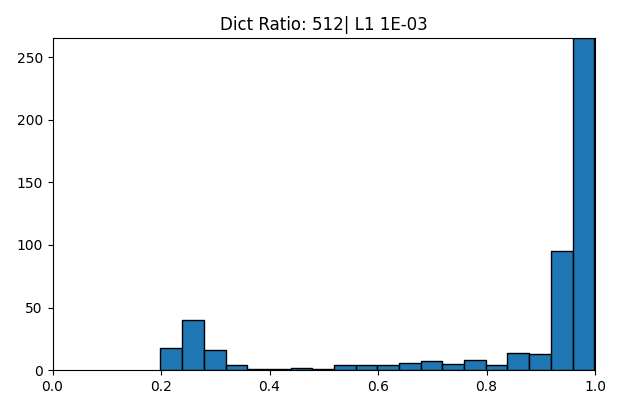
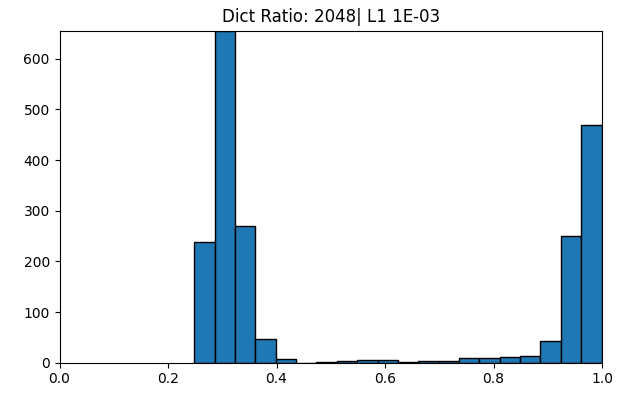
Bi-modality of MCS scores
The above heat-map of MMCS suggests that as the dictionary becomes larger, the level of alignment becomes lower, which might mean that it stops finding similar features. What we see instead, though, is that there are a number of features which are highly similar between dictionaries, and the number of these features grows with dictionary size, though not as fast as the number of features which are totally unrelated to any other learned features.
The peak around 0.25 - 0.4 corresponds closely with the distribution you would expect to see if the vectors were just random directions.
Diagonal lines are artefacts
The work of finding and comparing these dictionaries was made easier by realising that the diagonal lines that were consistently found in the previous posts corresponded quite precisely to a consistent ratio of dictionary_size : l1_coefficient, as shown by Robert Huben's diagram below. This was caused by the fact that we were dividing the l1_loss term by the size of the dictionary. Removing this division step allowed running sweeps across a wide range of dictionary sizes with a consistent l1 coefficient.
Are these dictionaries under-trained?
One of the hopes from the slides was that the failure of larger dictionaries to totally converge on a fixed set of features in the language model activation data was just a problem of under-training. On this front we've got mixed evidence. We do find that the MMCS-with-larger-dictionaries values rise over time with additional training, but the rate of growth is slow enough that it's not clear that we'd see full convergence.
On the other hand, we do see within these small changes in MMCS some significant increases in the number of individual features which have over 0.9 MCS with the larger dictionary. Also, the bimodal nature of the MCS scores suggests that we might be able to use unorthodox training strategies where we identify the convergent features and then perhaps freeze them while aggressively perturbing the remaining vectors.
With a larger budget and the ability to really crank up the number of examples seen, hopefully in the coming weeks we'll learn to what extent we will see convergence over time.
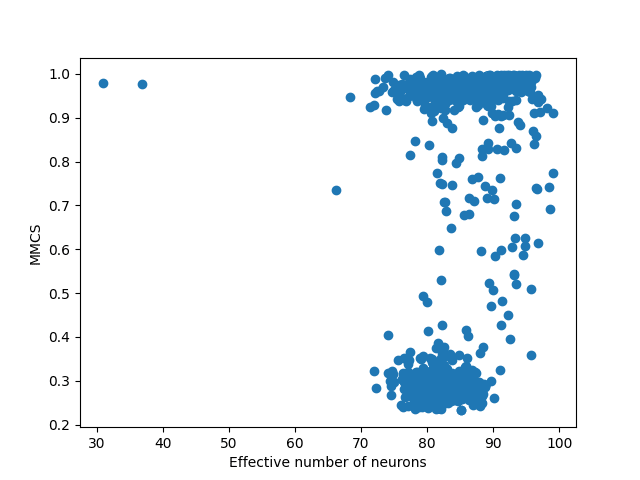
Learned features don't appear to be sparse
One thing that one might have expected to see was that the features which are learned would be somewhat sparse in the neuron basis, as this allows the network to use the non-linearity to screen off noise. This is not the sparsity that we're directly incentivising (which is the sparsity in which features are active at any given moment) but it's predicted by some models of how networks utilise MLPs. such as that found in toy models of superposition. This doesn't appear to be the case for the found features in our miniature transformer as the following graph shows (with 2 outlier exceptions). I calculate the effective number of neurons that the feature attends to, using the Simpson diversity index (results using the entropy of the vector elements are almost identical) and find that the found features are if anything attending to more elements than a random vector, which have an average diversity index of 82, compared to 83 for low-MMCS features and 85 for high-MMCS features.
Many max activations of learned features seem highly interpretable
If we use the circuitsvis library to show some of the top-activating examples from the pile-10k dataset, we see that the lots of the maximum activation examples seem to have clear themes, such as the below.

Although these seem promising, we can't say anything significant until we've done proper comparisons with the neuron basis and other techniques for eliciting 'true features', like PCA and ICA and looked beyond just the max activations. Hopefully we'll have something more meaningful to say here soon!
Next steps & Request For Funding
We'd like to test how interpretable the features that we have found are, in a quantitative manner. We've got the basic structure ready to apply OpenAI's automated-intepretability library to the found features, which we would then compare to baselines such as the neuron basis, Non-negative Matrix Factorisation (NMF) and the PCA and ICA of the activation data.
This requires quite a lot of tokens- something like 20c worth of tokens for each query depending on the number of example sentences given. We would need to analyse hundreds of neurons to get a representative sample size, for each of the dictionaries or approaches, so we're looking for funding for this research on the order of a few thousand dollars, potentially more if it were available. If you'd be interested in supporting this research, please get in touch. We'll also be actively searching for funding, and trying to get OpenAI to donate some compute.
Assuming the result of this experiment are promising, (meaning that we are able to exceed the baselines in terms of quality or quantity of highly interpretable features), we plan then to focus on scaling up to larger models and experimenting with variations of the technique which incorporate additional information, such as combining activation data from multiple layers, or using the weight vectors to inform the selection of features. We're also very interested to work with people developing mathematical or toy models of superposition.
0 comments
Comments sorted by top scores.