[Replication] Conjecture's Sparse Coding in Toy Models
post by Hoagy, Logan Riggs (elriggs) · 2023-06-02T17:34:24.928Z · LW · GW · 0 commentsContents
Summary Future Work Comparisons Mean Maximum Cosine Similarity (MMCS) with true features Number of dead neurons (capped at 100) MMCS with larger dicts with same L1 penalty None No comments
Summary
In the post Taking features out of superposition with sparse autoencoders [LW · GW], Lee Sharkey, Beren Millidge and Dan Braun (formerly at Conjecture) showed a potential technique for removing superposition from neurons using sparse coding. The original post shows the technique working on simulated data, but struggling on real models, while a recent update shows promise, at least for extremely small models.
We've now replicated the toy-model section of this post and are sharing the code on github so that others can test and extend it, as the original code is proprietary.
Additional replications have also been done by Trenton Bricken at Anthropic and most recently Adam Shai.
Thanks to Lee Sharkey for answering questions and Pierre Peigne for some of the data-generating code.
Future Work
We hope to expand on this in the coming days/weeks by:
- trying to replicate the results on small transformers as reported in the recent update post [LW · GW].
- using automated interpretability to test whether the directions found by sparse coding are in fact more cleanly interpretable than, for example, the neuron basis.
- trying to get this technique working on larger models.
If you're interested in working on similar things, let us know! We'll be working on these directions in the lead-up to SERI MATS.
Comparisons
Mean Maximum Cosine Similarity (MMCS) with true features
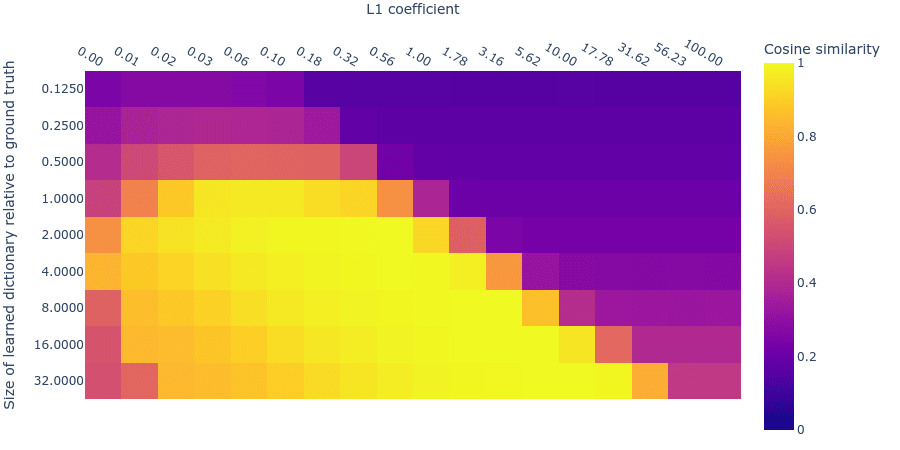
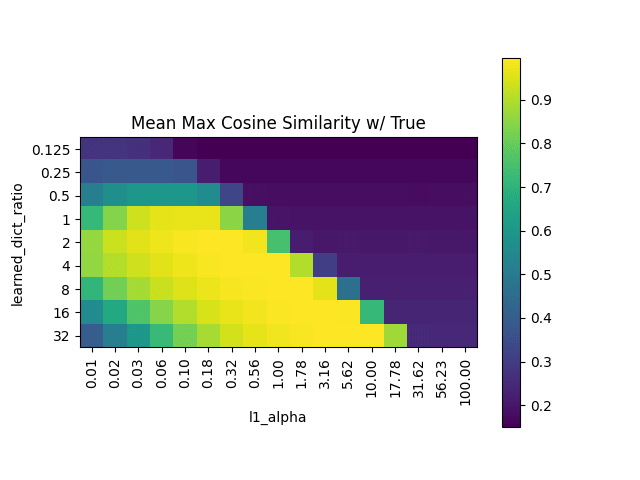
Number of dead neurons (capped at 100)
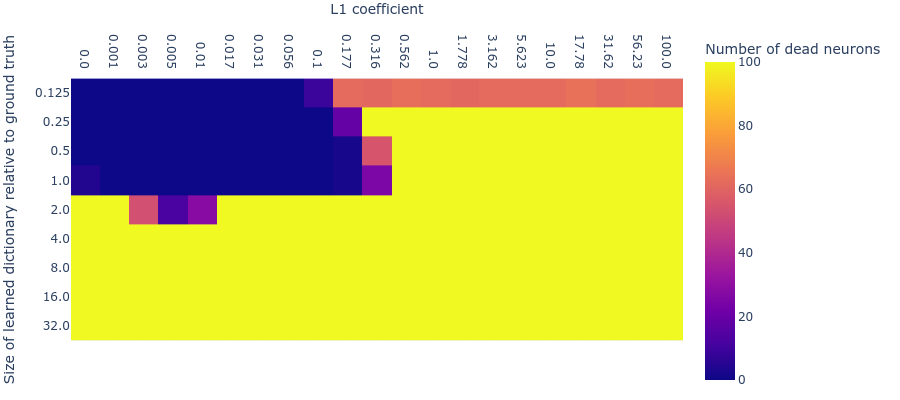
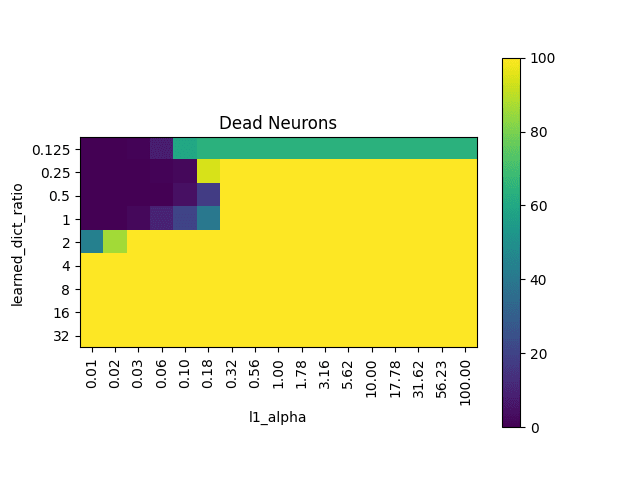
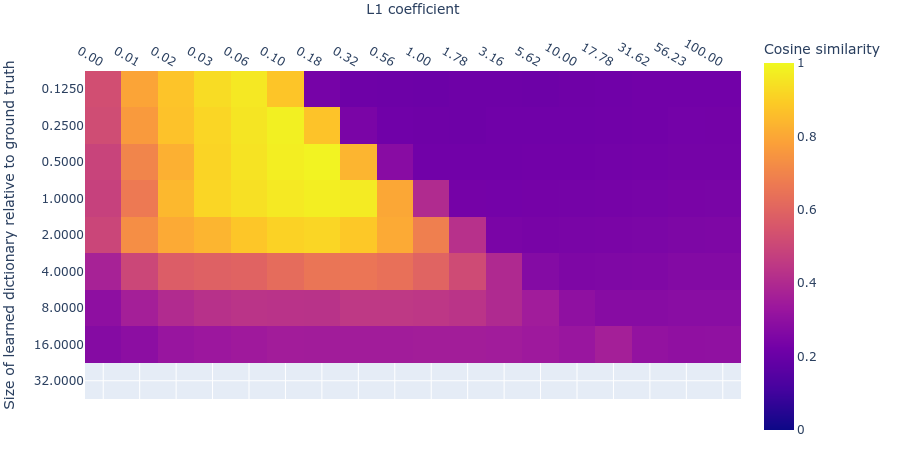
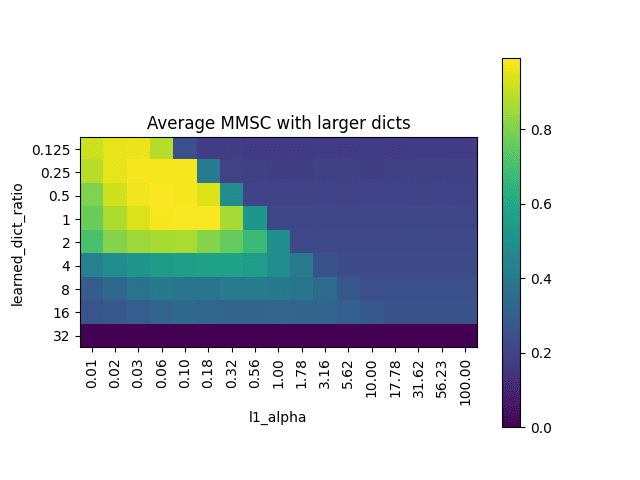
MMCS with larger dicts with same L1 penalty
0 comments
Comments sorted by top scores.