"AI Safety for Fleshy Humans" an AI Safety explainer by Nicky Case
post by habryka (habryka4) · 2024-05-03T18:10:12.478Z · LW · GW · 11 commentsThis is a link post for https://aisafety.dance/
Contents
The AI debate is actually 100 debates in a trenchcoat.
This 3-part series is your one-stop-shop to understand the core ideas of AI & AI Safety* — explained in a friendly, accessible, and slightly opinionated way!
💡 The Core Ideas of AI & AI Safety
Part 1: The past, present, and possible futures
Before 2000: AI was all logic, no intuition.
After 2000: AI could do "intuition", but had very poor logic.
Part 2: The problems
None
11 comments
Nicky Case, of "The Evolution of Trust" and "We Become What We Behold" fame (two quite popular online explainers/mini-games) has written an intro explainer to AI Safety! It looks pretty good to me, though just the first part is out, which isn't super in-depth. I particularly appreciate Nicky clearly thinking about the topic themselves, and I kind of like some of their "logic vs. intuition" frame, even though I think that aspect is less core to my model of how things will go. It's clear that a lot of love has gone into this, and I think having more intro-level explainers for AI-risk stuff is quite valuable.
===
The AI debate is actually 100 debates in a trenchcoat.
Will artificial intelligence (AI) help us cure all disease, and build a post-scarcity world full of flourishing lives? Or will AI help tyrants surveil and manipulate us further? Are the main risks of AI from accidents, abuse by bad actors, or a rogue AI itself becoming a bad actor? Is this all just hype? Why can AI imitate any artist's style in a minute, yet gets confused drawing more than 3 objects? Why is it hard to make AI robustly serve humane values, or robustly serve any goal? What if an AI learns to be more humane than us? What if an AI learns humanity's inhumanity, our prejudices and cruelty? Are we headed for utopia, dystopia, extinction, a fate worse than extinction, or — the most shocking outcome of all — nothing changes? Also: will an AI take my job?
...and many more questions.
Alas, to understand AI with nuance, we must understand lots of technical detail... but that detail is scattered across hundreds of articles, buried six-feet-deep in jargon.
So, I present to you:

This 3-part series is your one-stop-shop to understand the core ideas of AI & AI Safety* — explained in a friendly, accessible, and slightly opinionated way!
(* Related phrases: AI Risk, AI X-Risk, AI Alignment, AI Ethics, AI Not-Kill-Everyone-ism. There is no consensus on what these phrases do & don't mean, so I'm just using "AI Safety" as a catch-all.)
This series will also have comics starring a Robot Catboy Maid. Like so:

[...]
💡 The Core Ideas of AI & AI Safety
In my opinion, the main problems in AI and AI Safety come down to two core conflicts:
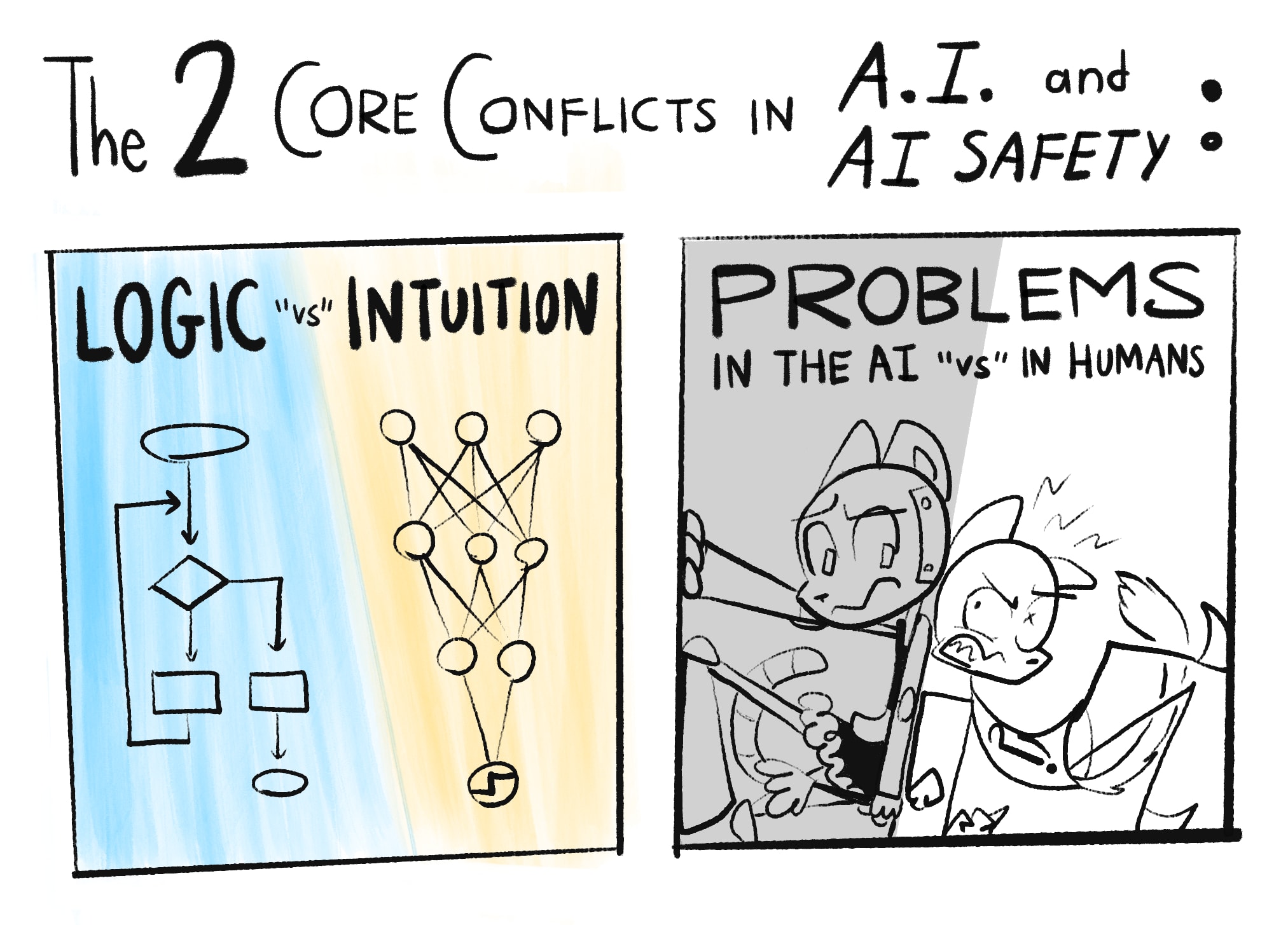
Note: What "Logic" and "Intuition" are will be explained more rigorously in Part One. For now: Logic is step-by-step cognition, like solving math problems. Intuition is all-at-once recognition, like seeing if a picture is of a cat. "Intuition and Logic" roughly map onto "System 1 and 2" from cognitive science.[1]1[2]2 (👈 hover over these footnotes! they expand!)
As you can tell by the "scare" "quotes" on "versus", these divisions ain't really so divided after all...
Here's how these conflicts repeat over this 3-part series:
Part 1: The past, present, and possible futures
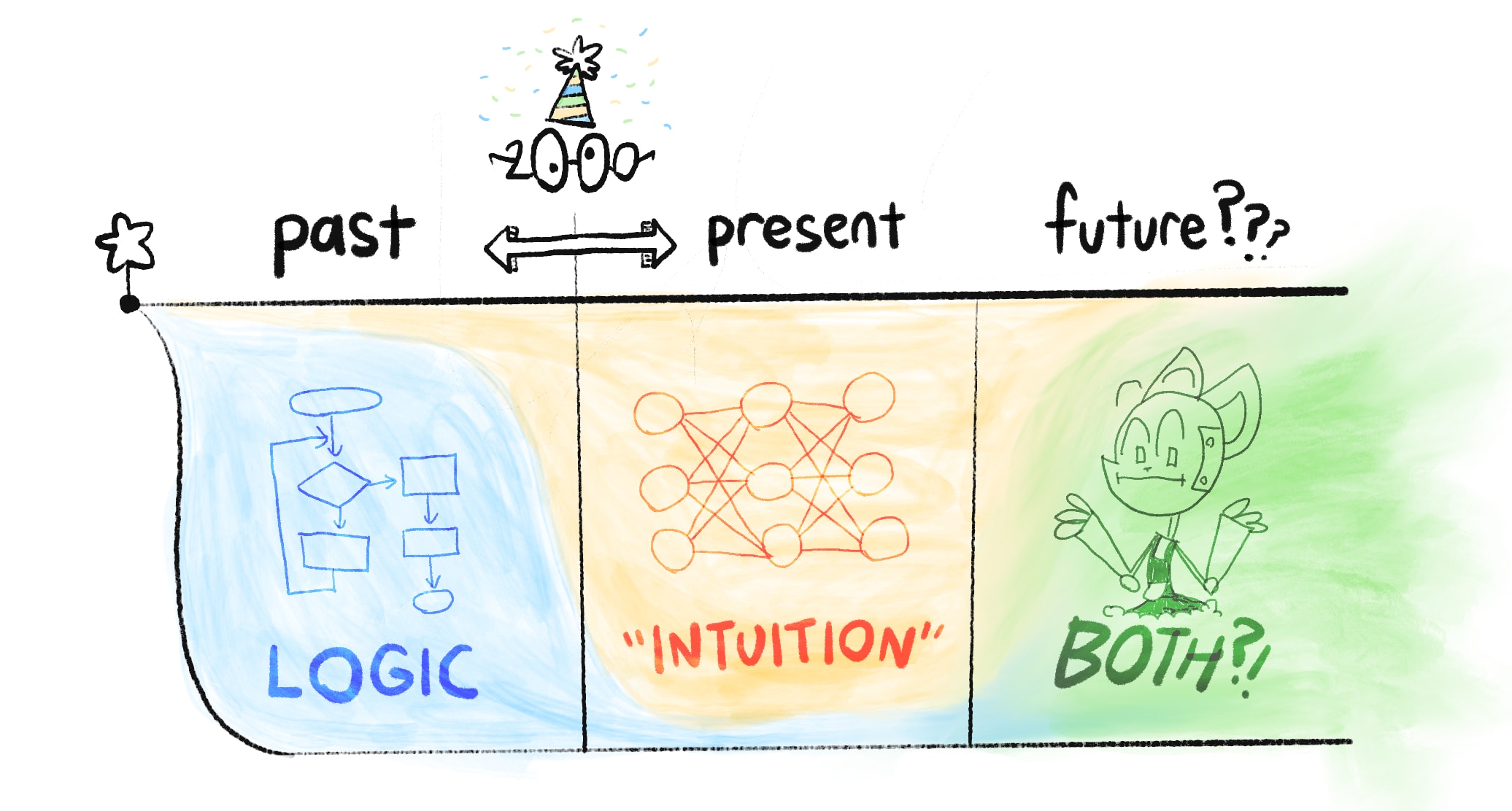
Skipping over a lot of detail, the history of AI is a tale of Logic vs Intuition:
Before 2000: AI was all logic, no intuition.
This was why, in 1997, AI could beat the world champion at chess... yet no AIs could reliably recognize cats in pictures.[3]3
(Safety concern: Without intuition, AI can't understand common sense or humane values. Thus, AI might achieve goals in logically-correct but undesirable ways.)
After 2000: AI could do "intuition", but had very poor logic.
This is why generative AIs (as of current writing, May 2024) can dream up whole landscapes in any artist's style... yet gets confused drawing more than 3 objects. (👈 click this text! it also expands!)
(Safety concern: Without logic, we can't verify what's happening in an AI's "intuition". That intuition could be biased, subtly-but-dangerously wrong, or fail bizarrely in new scenarios.)
Current Day: We still don't know how to unify logic & intuition in AI.
But if/when we do, that would give us the biggest risks & rewards of AI: something that can logically out-plan us, and learn general intuition. That'd be an "AI Einstein"... or an "AI Oppenheimer".
Summed in a picture:
So that's "Logic vs Intuition". As for the other core conflict, "Problems in the AI vs The Humans", that's one of the big controversies in the field of AI Safety: are our main risks from advanced AI itself, or from humans misusing advanced AI?
(Why not both?)
Part 2: The problems
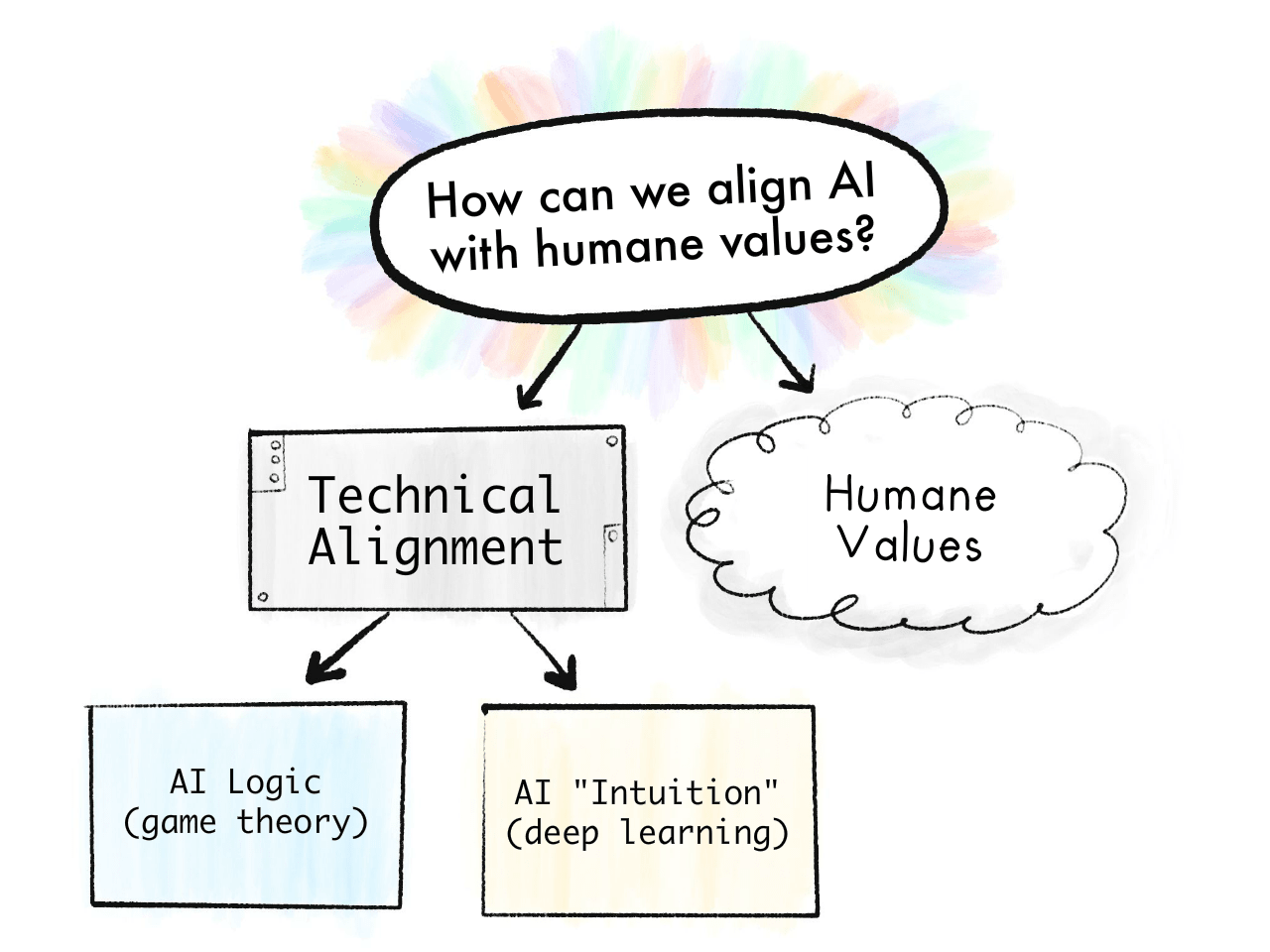
The problem of AI Safety is this:[4]4
The Value Alignment Problem:
“How can we make AI robustly serve humane values?”
NOTE: I wrote humane, with an "e", not just "human". A human may or may not be humane. I'm going to harp on this because both advocates & critics of AI Safety keep mixing up the two.[5]5[6]6
We can break this problem down by "Problems in Humans vs AI":
Humane Values:
“What are humane values, anyway?”
(a problem for philosophy & ethics)
The Technical Alignment Problem:
“How can we make AI robustly serve any intended goal at all?”
(a problem for computer scientists - surprisingly, still unsolved!)
The technical alignment problem, in turn, can be broken down by "Logic vs Intuition":
Problems with AI Logic:[7]7 ("game theory" problems)
- AIs may accomplish goals in logical but undesirable ways.
- Most goals logically lead to the same unsafe sub-goals: "don't let anyone stop me from accomplishing my goal", "maximize my ability & resources to optimize for that goal", etc.
Problems with AI Intuition:[8]8 ("deep learning" problems)
- An AI trained on human data could learn our prejudices.
- AI "intuition" isn't understandable or verifiable.
- AI "intuition" is fragile, and fails in new scenarios.
- AI "intuition" could partly fail, which may be worse: an AI with intact skills, but broken goals, would be an AI that skillfully acts towards corrupted goals.
(Again, what "logic" and "intuition" are will be more precisely explained later!)
Summed in a picture:
[Read the rest of the article here]
11 comments
Comments sorted by top scores.
comment by LawrenceC (LawChan) · 2024-05-04T00:25:25.000Z · LW(p) · GW(p)
I think this is really quite good, and went into way more detail than I thought it would. Basically my only complaints on the intro/part 1 are some terminology and historical nitpicks. I also appreciate the fact that Nicky just wrote out her views on AIS, even if they're not always the most standard ones or other people dislike them (e.g. pointing at the various divisions within AIS, and the awkward tension between "capabilities" and "safety").
I found the inclusion of a flashcard review applet for each section super interesting. My guess is it probably won't see much use, and I feel like this is the wrong genre of post for flashcards.[1] But I'm still glad this is being tried, and I'm curious to see how useful/annoying other people find it.
I'm looking forward to parts two and three.
Nitpicks:[2]
Logic vs Intuition:
I think "logic vs intuition" frame feels like it's pointing at a real thing, but it seems somewhat off. I would probably describe the gap as explicit vs implicit or legible and illegible reasoning (I guess, if that's how you define logic and intuition, it works out?).
Mainly because I'm really skeptical of claims of the form "to make a big advance in/to make AGI from deep learning, just add some explicit reasoning". People have made claims of this form for as long as deep learning has been a thing. Not only have these claims basically never panned out historically, these days "adding logic" often means "train the model harder and include more CoT/code in its training data" or "finetune the model to use an external reasoning aide", and not "replace parts of the neural network with human-understandable algorithms". (EDIT for clarity: That is, I'm skeptical of claims that what's needed to 'fix' deep learning is by explicitly implementing your favorite GOFAI techniques, in part because successful attempts to get AIs to do more explicit reasoning look less like hard-coding in a GOFAI technique and more like other deep learning things.)
I also think this framing mixes together "problems of game theory/high-level agent modeling/outer alignment vs problems of goal misgeneralization/lack of robustness/lack of transparency" and "the kind of AI people did 20-30 years ago" vs "the kind of AI people do now".
This model of logic and intuition (as something to be "unified") is quite similar to a frame of the alignment problem that's common in academia. Namely, our AIs used to be written with known algorithms (so we can prove that the algorithm is "correct" in some sense) and performed only explicit reasoning (so we can inspect the reasoning that led to a decision, albeit often not in anything close to real time). But now it seems like most of the "oomph" comes from learned components of systems such as generative LMs or ViTs, i.e. "intuition". The "goal" is to a provably* safe AI, that can use the "oomph" from deep learning while having enough transparency/explicit enough thought processes. (Though, as in the quote from Bengio in Part 1, sometimes this also gets mixed in with capabilities, and become how AIs without interpretable thoughts won't be competent.)
Has AI had a clean "swap" between Logic and Intuition in 2000?
To be clear, Nicky clarifies in Part 1 that this model is an oversimplification. But as a nitpick, I think if you had to pick a date, I'd probably pick 2012, when a conv net won the ImageNet 2012 competition in a dominant matter, and not 2000.
Even more of a nitpick, but the examples seem pretty cherry picked?
For example, Nicky uses the example of deep blue defeating kasparov as an example of a "logic" based AI. But in that case, almost all Chess AIs are still pretty much logic based. Using Stockfish as an example, Stockfish 16's explicit alpha-beta search both is using a reasoning algorithm that we can understand, and does the reasoning "in the open". Its neural network eval function is doing (a small amount of) illegible reasoning. While part of the reasoning has become illegible, we can still examine the outputs of the alpha-beta search to understand why certain moves are good/bad. (But fair, this might be by far the most widely known non-deep learning "AI". The only other examples I can think of are Watson and recommender systems, but those were still using statistical learning techniques. I guess if you count MYCIN or SHRDLU or ELIZA...?)
(And modern diffusion models being unable to count or spell seem like a pathology specific to that class of generative model, and not say, Claude Opus.)
FOOM vs Exponential vs Steady Takeoff
Ryan already mentioned this in his comment. [LW(p) · GW(p)]
Even less important and more nitpicky nitpicks:
When did AIs get better than humans (at ImageNet)?
In footnote [3], Nicky writes:
In 1997, IBM's Deep Blue beat Garry Kasparov, the then-world chess champion. Yet, over a decade later in 2013, the best machine vision AI was only 57.5% accurate at classifying images. It was only until 2021, three years ago, that AI hit 95%+ accuracy.
But humans do not get 95% top-1 accuracy[3] on imagenet! If you consult this paper from the imagenet creators (https://arxiv.org/abs/1409.0575), they note that:
. We found the task of annotating images with one of 1000 categories to be an extremely challenging task for an untrained annotator. The most common error that an untrained annotator is susceptible to is a failure to consider a relevant class as a possible label because they are unaware of its existence. (Page 31)
And even when using an human expert annotators, who did hundreds of validation image for practice, the human annotator still got a top-5 error of 5.1%, which was surpassed in 2015 by the original resnet paper (https://arxiv.org/abs/1512.03385) at 4.49% for ResNet 14 (and 3.57% for an ensemble of six resnets).
(Also, good top-1 performance on imagenet is genuinely hard and may be unrepresentative of actually being good at vision, whatever that means Take a look at some of the "mistakes" current models make:)

- ^
Using flashcards suggests that you want to memorize the concepts. But a lot of this piece isn't so much an explainer of AI safety, but instead an argument for the importance of AI Safety. Insofar as the reader is not here to learn a bunch of new terms, but instead to reason about whether AIS is a real issue, it feels like flashcards are more of a distraction than an aid.
- ^
I'm writing this in part because I at some point promised Nicky longform feedback on her explainer, but uh, never got around to it until now. Whoops.
- ^
Top-K accuracy = you guess K labels, and are right if any of them are correct. Top 5 is significantly easier on image net than Top 1, because there's a bunch of very similar classes and many images are ambiguous.
↑ comment by LawrenceC (LawChan) · 2024-05-04T06:09:44.794Z · LW(p) · GW(p)
Also, another nitpick:
Humane vs human values
I think there's a harder version of the value alignment problem, where the question looks like, "what's the right goals/task spec to put inside a sovereign ai that will take over the universe". You probably don't want this sovereign AI to adopt the value of any particular human, or even modern humanity as a whole, so you need to do some Ambitious Value Learning [LW · GW]/moral philosophy and not just intent alignment. In this scenario, the distinction between humane and human values does matter. (In fact, you can find people like Stuart Russell emphasizing this point a bunch.) Unfortunately, it seems that ambitious value learning is really hard, and the AIs are coming really fast, and also it doesn't seem necessary to prevent x-risk, so...
Most people in AIS are trying to solve a significantly less ambitious version of this problem: just try to get an AI that will reliably try to do what a human wants it to do (i.e. intent alignment). In this case, we're explicitly punting the ambitious value learning problem down the line. Here, we're basically not talking about the problem of having an AI learn humane values, but instead the problem of having it "do what its user wants" (i.e. "human values" or "the technical alignment problem" in Nicky's dichotomy). So it's actually pretty accurate to say that a lot of alignment is trying to align AIs wrt "human values", even if a lot of the motivation is trying to eventually make AIs that have "humane values".[1] (And it's worth noting that making an AI that's robustly intent aligned sure seems require tackling a lot of the 'intuition'-derived problems you bring up already!)
uh, that being said, I'm not sure your framing isn't just ... better anyways? Like, Stuart seems to have lots of success talking to people about assistance games, even if it doesn't faithfully represent what a majority field thinks is the highest priority thing to work on. So I'm not sure if me pointing this out actually helps anyone here?
- ^
Of course, you need an argument that "making AIs aligned with user intent" eventually leads to "AIs with humane values", but I think the straightforward argument goes through -- i.e. it seems that a lot of the immediate risk comes from AIs that aren't doing what their users intended, and having AIs that are aligned with user intent seems really helpful for tackling the tricky ambitious value learning problem.
↑ comment by mako yass (MakoYass) · 2024-05-04T02:41:11.305Z · LW(p) · GW(p)
often means "train the model harder and include more CoT/code in its training data" or "finetune the model to use an external reasoning aide", and not "replace parts of the neural network with human-understandable algorithms".
The intention of this part of the paragraph wasn't totally clear but you seem to be saying this wasn't great? From what I understand, these actually did all made the model far more interpretable?
Chain of thought is a wonderful thing, it clears a space where the model will just earnestly confess its inner thoughts and plans in a way that isn't subject to training pressure, and so it, in most ways, can't learn to be deceptive about it.
Replies from: LawChan, LawChan↑ comment by LawrenceC (LawChan) · 2024-05-04T05:04:24.268Z · LW(p) · GW(p)
No, I'm saying that "adding 'logic' to AIs" doesn't (currently) look like "figure out how to integrate insights from expert systems/explicit bayesian inference into deep learning", it looks like "use deep learning to nudge the AI toward being better at explicit reasoning by making small changes to the training setup". The standard "deep learning needs to include more logic" take generally assumes that you need to add the logic/GOFAI juice in explicitly, while in practice people do a slightly different RL or supervised finetuning setup instead.
(EDITED to add: so while I do agree that "LMs are bad at the things humans do with 'logic' and good at 'intuition' is a decent heuristic, I think the distinction that we're talking about here is instead about the transparency of thought processes/"how the thing works" and not about if the thing itself is doing explicit or implicit reasoning. Do note that this is a nitpick (as the section header says) that's mainly about framing and not about the core content of the post.)
That being said, I'll still respond to your other point:
Chain of thought is a wonderful thing, it clears a space where the model will just earnestly confess its inner thoughts and plans in a way that isn't subject to training pressure, and so it, in most ways, can't learn to be deceptive about it.
I agree that models with CoT (in faithful, human-understandable English) are more interpretable than models that do all their reasoning internally. And obviously I can't really argue against CoT being helpful in practice; it's one of the clear baselines for eliciting capabilities.
But I suspect you're making a distinction about "CoT" that is actually mainly about supervised finetuning vs RL, and not a benefit about CoT in particular. If the CoT comes from pretraining or supervised fine-tuning, the ~myopic next-token-prediction objective indeed does not apply much if training pressure in the relevant ways.[1] Once you start doing any outcome-based supervision (i.e. RL) without good regularization, I think the story for CoT looks less clear. And the techniques people use for improving CoT tend to involve upweighting entire trajectories based on their reward (RLHF/RLAIF with your favorite RL algorithm) which do incentivize playing the training game unless you're very careful with your fine-tuning.
(EDITED to add: Or maybe the claim is, if you do CoT on a 'secret' scratchpad (i.e. one that you never look at when evaluating or training the model), then this would by default produce more interpretable thought processes?)
- ^
I'm not sure this is true in the limit (e.g. it seems plausible to me that the Solomonoff prior is malign). But it's most likely true in the next few years and plausibly true in all practical cases that we might consider.
↑ comment by LawrenceC (LawChan) · 2024-05-04T05:35:31.977Z · LW(p) · GW(p)
Also, I added another sentence trying to clarify what I meant at the end of the paragraph, sorry for the confusion.
comment by habryka (habryka4) · 2024-05-03T23:34:08.893Z · LW(p) · GW(p)
@henry [LW · GW] (who seems to know Nicky) said on a duplicate link post of this:
Replies from: henry-bassThis is an accessible introduction to AI Safety, written by Nicky Case and the teens at Hack Club. So far, part 1/3 is completed, which covers a rough timeline of AI advancement up to this point, and what might come next.
If you've got feedback as to how this can be made more understandable, that'd be appreciated! Reach out to Nicky, or to me and I'll get the message to her.
↑ comment by henry (henry-bass) · 2024-05-03T23:49:56.225Z · LW(p) · GW(p)
Yeah, my involvement was providing draft feedback on the article and providing some of the images. Looks like my post got taken down for being a duplicate, though
Replies from: habryka4↑ comment by habryka (habryka4) · 2024-05-04T00:17:20.079Z · LW(p) · GW(p)
I did that! (I am the primary admin of the site). I copied your comment here just before I took down the duplicate post of yours to make sure it doesn't get lost.
comment by ryan_greenblatt · 2024-05-03T19:31:10.316Z · LW(p) · GW(p)
Random error:
Exponential Takeoff:
AI's capabilities grow exponentially, like an economy or pandemic.
(Oddly, this scenario often gets called "Slow Takeoff"! It's slow compared to "FOOM".)
Actually, this isn't how people (in the AI safety community) generally use the term slow takeoff.
Quoting from the blog post by Paul:
Futurists have argued for years about whether the development of AGI will look more like a breakthrough within a small group (“fast takeoff”), or a continuous acceleration distributed across the broader economy or a large firm (“slow takeoff”).
[...]
(Note: this is not a post about whether an intelligence explosion will occur. That seems very likely to me. Quantitatively I expect it to go along these lines. So e.g. while I disagree with many of the claims and assumptions in Intelligence Explosion Microeconomics, I don’t disagree with the central thesis or with most of the arguments.)
Slow takeoff still can involve a singularity (aka an intelligence explosion).
The terms "fast/slow takeoff" are somewhat bad because they are often used to discuss two different questions:
- How long does it take from the point where AI is seriously useful/important (e.g. results in 5% additional GDP growth per year in the US) to go to AIs which are much smarter than humans? (What people would normally think of as fast vs slow.)
- Is takeoff discontinuous vs continuous?
And this explainer introduces a third idea:
- Is takeoff exponential or does it have a singularity (hyperbolic growth)?
comment by eggsyntax · 2024-12-31T17:21:52.727Z · LW(p) · GW(p)
Part 2 is now up, and part 3 should be coming before too long AFAIK.
comment by mako yass (MakoYass) · 2024-05-04T02:29:53.541Z · LW(p) · GW(p)
This is good! I would recommend it to a friend!
Some feedback.
- An individual human can be inhumane, but the aggregate of human values kind of visibly isn't and in most ways couldn't be: Human cultures are getting more humane reliably as transparency/reflection and coordination increases over time, but also inevitably if you aggregate a bunch of concave values [LW · GW] it will produce a value system that treats all of the subjects of the aggregation pretty decently.
A lot of the time, when people accuse us of conflating something, we equate those things because we have an argument that they're going to turn out to be equivalent.
So emphasizing a difference between these two things could be really misleading, and possibly kinda harmful, given that it could undermine the implementation of the simplest/most arguably correct solutions to alignment (which are just aggregations of humans' values). This could be a whole conversation, but could we just not define humane values as being necessarily distinct from human values? How about this:- People are sometimes confused by 'Human values', as it seems to assume that all humans value the same things, but many humans have values that conflict with the preferences of other humans. When we say 'Humane values', we're defining a value system that does a decent job at balancing and reconciling the preferences of every human (Humans, Every one).
- [graph point for "systems programmer with mlp shirt"] would it be funny if there were another point, "systems programmer without mlp shirt", and it was pareto-inferior
- "What if System 2 is System 1". This is a great insight, I think it is, and I think the main reason nerdy types often fail to notice how permeable and continuous the boundary is a kind of tragic habitual cognitive autoimmune disease, and I have a post brewing about this after I used a repaired relationship with the unconscious bulk to cure my astigmatism (I'm going to let it sit for a year just to confirm that the method actually worked and myopia really was averted)
- Exponential growth is usually not slow, and even if it were slow, it wouldn't entail that "we'll get "warning shots" & a chance to fight back", it only takes a small sustained advantage to be able to utterly win a war (though contemporary humans don't like to carry wars to completion these days, the 20th century should have been a clear lesson that such things are within our abilities at current tech levels). Even if progress in capabilities over time continued to be linear, impact over capabilities is not going to be linear, it never has been.
But overall I think it addresses a certain audience who I know much better than my version of this that I hastily wrote last year when I was summoned to speak at a conference would have (and so I never showed it to them. Maybe one day I will show them yours.).