Supervised learning of outputs in the brain
post by Steven Byrnes (steve2152) · 2020-10-26T14:32:54.061Z · LW · GW · 9 commentsContents
Supervised learning of outputs: What, Where, and Why What is supervised learning of outputs? Where: Amygdala & Cerebellum Why: Because the "shoulda" signal arrives too late How does the supervised learning algorithm work? Aside: Why am I calling it "output and shoulda" instead of the normal terminology of "prediction and error"? Exploring the design space Toy model #1: Context from the neocortex Toy model #2: Neocortex and supervised learning algorithm collaborate Toy model #3: Neocortex and supervised learning algorithm are adversarial Toy model #4: "The accelerator" Toy model #5: A hypothesis for how the cerebellum coordinates movements Toy model #6: A hypothesis for how the cerebellum helps cognition Toy Models: Conclusion None 9 comments
Follow-up to: My computational framework for the brain [LW · GW].
(Epistemic status: In what's becoming a pattern, I tried reading the standard neuroscience discussions in this area but found them confusing or narrow or not answering my big-picture questions in a way I could understand, so I'm kinda piecing things together myself. I assume I'm mostly reinventing wheels and this post is just pedagogy, but I dunno, parts could be original and/or wrong.)
It didn't take long after finishing my previous post on the big picture of brain computations [LW · GW] before I found a problem! I was stuck on something that didn't make sense, which led to my reading more about the amygdala and cerebellum, and feeling very confused about what they were for and how they fit in. And then it hit me, I was missing something! The thing I was missing was: supervised learning of actions and other outputs.
Supervised learning of outputs: What, Where, and Why
What is supervised learning of outputs?
Supervised learning of outputs is when you have a learning algorithm receiving a ground-truth signal like this:
“Hey learning algorithm: you messed up—you should have moved your leg.”
Compare that to reinforcement learning, where the learning algorithm gets a much less helpful ground-truth signal:
“Hey learning algorithm: you messed up."
(a.k.a negative reward). Obviously, you can learn much faster with supervised learning of outputs than with reinforcement learning. So, of course, our default assumption should be that Evolution has built supervised learning of outputs into the brain, when information is available about what you should have done.
I'll call this type of information "shoulda information". ("Shoulda" is a slang shorthand for "should have".) A blink-related shoulda signal means "you shoulda blinked".
And indeed, although shoulda information is not always available, it is sometimes available! "Hey, you just get whacked in the face? Well, you shoulda flinched!" Evolution knows very well that you shoulda flinched. There are lots of examples like that. So we should expect to find supervised learning of outputs in the brain.
My computational framework for the brain [LW · GW] post had supervised learning on the input-processing side (more specifically, self-supervised, a.k.a. predictive learning, in the neocortex), and it had reinforcement learning of outputs (also in the neocortex), and it had hardcoded input-output relations, but it didn’t have supervised learning of outputs anywhere. That can’t be right! So I'm putting it in now.
Where: Amygdala & Cerebellum
...And I'm tentatively locating this type of calculation in the amygdala and cerebellum. (Based on this paper among other things.) (To be clear, I'm not claiming that this type of calculation is the only thing that the amygdala and cerebellum do, and conversely, it's possible that this kind of calculation also happens elsewhere in the brain, I don't know.)
(Update June 2021: for further discussion of supervised learning in the amygdala and agranular prefrontal cortex and ventral striatum (but not cerebellum), see my later post Big Picture Of Phasic Dopamine [LW · GW].)
The amygdala and cerebellum are each specialized to do supervised learning of different types of outputs. This book summarizes the division of labor: "Cerebellar-dependent conditioned responses tend to involve defensive or protective responses made by particular body parts, as exemplified by eyeblink conditioning and withdrawal reflexes, and they usually exhibit precise timing. Amygdala[...]-dependent responses [...] often involve coordinated autonomic or physiological reflexes, along with movements of the whole body [...with] less precise timing."
So as examples to hold in your head...
- For the cerebellum, imagine learning (unconsciously) that when someone shouts "watch your head!" you should duck.
- For the amygdala, imagine learning (unconsciously) that when someone says "Hey, did you see the news? Check CNN!", you should clench your teeth and pump out cortisol and raise your heart rate and dilate your pupils and widen your eyes and get goosebumps, etc. etc. (Get it? The news is always stressful. That's a 2020 joke.)
(Update June 2021: For the first bullet point, I think I gave the cerebellum too much credit. I think the chain of events is: first the amygdala learns to duck in certain situations—generally too slowly to be effective—and then the cerebellum "accelerates" those signals per Toy Model #4 below. See also "the entire cerebellum in a single sentence" here [LW · GW].)
I'm not going to try to construct a beautiful detailed theory of the amygdala and cerebellum in this post—I'm still confused about many aspects of what they do and how—but I'm optimistic that what I talk about here is going to be helpful groundwork as I continue to try to understand them.
Why: Because the "shoulda" signal arrives too late
Maybe you already got this from the example above, but I think it's worth reiterating more explicitly.
There's an obvious question: If you happen to have access to "shoulda" information in the brain, what's the point of using it to train a supervised learning algorithm? Why not just do the thing you should do? As far as I know, there is only one good reason: timing. The shoulda signal arrives late, by which time it is no longer the thing you should do! Or maybe it's still the right thing to do, but nevertheless, it would have been better if you had done it earlier.
(UPDATE: I said "only one good reason", but since writing this post I'm up to three reasons. Timing is one reason, and is the subject the post. A second reason, related to interpretability, is here [LW · GW]. A third reason, related to predictive coding data compression, is here. [LW · GW])
(UPDATE: …And yet a fourth reason is: If the shoulda signal keeps saying "you shouldn't have fired", no matter what, you wind up with a novelty detector. (Also required here: a maintenance process that gradually resets the synapses to a trigger-happy baseline.))
Again, recall my example above: when you get whacked in the face with a ball, then you shoulda flinched. It's trivial to calculate that you shoulda flinched. It's not trivial to calculate that you should flinch, because that requires predicting the future. And a learning algorithm can help you do that predictive calculation better. There are lots of possible signs that you may soon get whacked in the head and should therefore flinch. It could be someone shouting "Watch out!", it could be a kid pointing a toy gun at you, etc. The genome can't make those connections. A learning algorithm can.
(...And not just any learning algorithm! The neocortex runs a learning algorithm, but it's an algorithm that picks outputs to maximize reward, not outputs to anticipate matched supervisory signals. This needs to be its own separate brain module, I think.)
How does the supervised learning algorithm work?
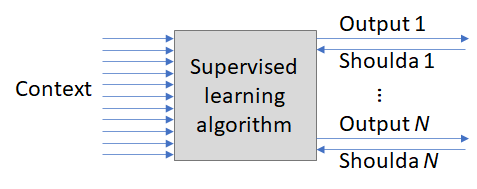
Just off the top of my head, it's really easy to think of an algorithm that would do this job reasonably well. (Exercise: Try it yourself!) Here's my version.
Recall, you have an output signal ("blink now!") paired with a shoulda signal ("you shoulda blinked!"). In this example, the "shoulda blinked" signal can be wired to neurons that fire when something touches your eye. There can be many output-shoulda pairs—and the genome is responsible for pairing them up properly—but let's just talk about one pair for now.
The other input is a bunch of "context" signal lines which correlate with different aspects of what's going on in the world. The more different context lines, the better, by and large—the algorithm will eventually find the lines bearing useful predictive information and ignore the rest.
Then for each context signal, you track (1) how likely it is to fire within a certain time-window just a bit earlier than when the "shoulda" signal triggers, versus (2) how frequently it fires overall. If that ratio is high, then you found a good predicting signal! So you wire that context signal up to the output line.
As a matter of fact, the cerebellum works exactly this way! Specifically: Parallel fibers carry the context signals, Purkinje cells produce the output signals, and climbing fibers carry the shoulda signals, and the synapse strengths between a parallel fiber and a Purkinje cell is modified as a function of how recently the parallel fiber and climbing fiber have fired. Haha, just kidding! That's all more-or-less true, I think, but the real cerebellum is way more complicated than that! There are various preprocessing steps on the context lines (ref), the Purkinje cells are actually a hidden layer rather than the output (ref), there are dynamically-reconfigurable oscillation modules for perfecting the timing ... I have no idea about most of this stuff.
But anyway, the upshot is: if you have an output line, a corresponding "shoulda" line, and a bunch of context lines, then hooking them up to do supervised learning of outputs is biologically plausible, even straightforward. There's plenty to say about the algorithm internals if you want all the bells and whistles that give you peak performance, but I won't say more about that in this post—I'm more interested right now in understanding what these algorithms do when you put them inside a larger system.
Aside: Why am I calling it "output and shoulda" instead of the normal terminology of "prediction and error"?
I mean, terminology doesn't really matter at the end of the day, and maybe this is just me, but I spent quite a while getting tripped up by the normal terminology. I think there's a few reasons that I find the standard terminology confusing, and prefer this one I just invented:
- "Error" doesn't make it clear how specific it is: the word "error" often just means "something went wrong but we don't know what". My preferred term "shoulda" naturally has a connotation of communicating a specific improvement plan, as in "you shoulda blinked".
- The language of "predictions and errors" doesn't really communicate the purpose of the system, in a way I find intuitive. Why do you need predictions? I mean, if you've read this far, you know the answer, it's not a huge deal, but I do think that it adds another mental hoop to jump through.
- Take the example of learning to duck when someone shouts "Watch out!", to avoid getting hit in the head. The error signal is getting hit in the head, and the prediction is...hang on, what exactly is it predicting? It's predicting that I'll get hit in the head, right? But the prediction causes me to duck ... and then I don't get hit in the head! So was the prediction wrong? No. So that's another aspect of the terminology that was making me confused.
Therefore I'm going to continue to do the mental translation ("prediction", "error") → ("output", "shoulda") when I read papers about the cerebellum & amygdala, despite the annoying mental overhead. Maybe eventually I'll get over it, but that's where I'm at right now. :-)
Exploring the design space
Let's pretend we're designing a brain, and think about different ways to set this system up, and what the system would do in the different cases.
Some of these rely on ideas from my earlier post [LW · GW], especially about what the neocortex does.
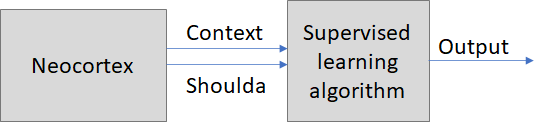
Toy model #1: Context from the neocortex
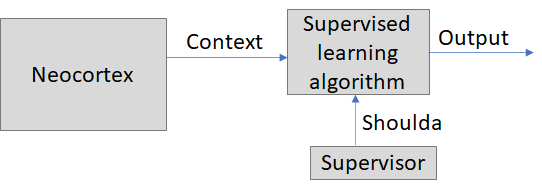
Since the neocortex is also a learning algorithm, here's a simple example where we can explore how it will interact with an algorithm doing supervised learning of outputs.
Recall that the neocortex is (in my view) fueled by self-supervised learning and reward-based learning. My assumption in this toy example is that neither of those depends on what the supervised learning algorithm is doing. (This is setting the stage for the next two toy models, where I put in a reward signal looping back.) So here the neocortex isn't "trying" to provide helpful information to the supervised learning algorithm in this model. The neocortex doesn't care, it just keeps doing its thing. Is that ok? Yes, I do think that's ok!
Like, imagine picking 1000 random neurons in and around the auditory cortex, and plotting their firing rates over time. You would find, in this set, signals that correlate with many different aspects of the incoming sound and how it's understood by the neocortex—pitch, loudness, categorization, semantics, you name it. Then if a separate supervised learning algorithm is asked to predict something that correlates with sound, using those 1000 neurons as its context, it seems pretty likely to succeed, I figure.
... At least, eventually. There is the potential problem here that neocortex neurons start with random connections (according to me [LW · GW]), and take some time to start being associated with meaningful patterns in the world. Maybe this isn't a big deal; low-level sensory patterns may be learned shortly after or even before birth, as far as I know. Alternatively, you could get around that problem by feeding the supervised learning algorithm with context information from both the neocortex and the subcortical sensory processing systems (midbrain etc.), which I think rely less on learning. Or even tap the unprocessed (well, minimally-processed) sensory data as it comes into the brain through the thalamus; I think the amygdala has a connection like that.
Toy model #2: Neocortex and supervised learning algorithm collaborate
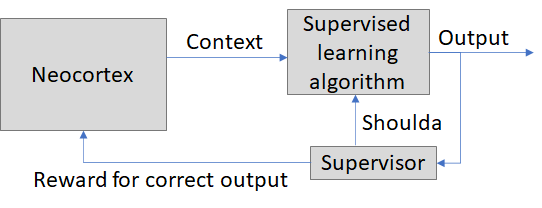
Now the neocortex is incentivized to try to put useful information into the context data stream. For example, it's unpleasant to get whacked in the face with a ball, compared to flinching. If I keep getting whacked in the face with balls, perhaps my neocortex will come up with the idea of building a system that uses radar to detect incoming balls, and emit a loud beep when one is coming. See what I (= my neocortex) did there? I inserted a good predictive signal into the context data! And after a few more times getting whacked, my cerebellum will pick up on the connection, and wire up some sound-related context line to the flinch output. A beautiful neocortex-cerebellum collaboration!
By contrast ...
Toy model #3: Neocortex and supervised learning algorithm are adversarial
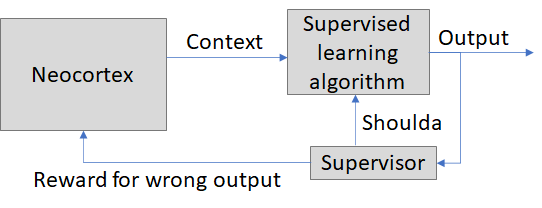
Ooh, this is fun! Now the neocortex is incentivized to manipulate the context lines to trip up the supervised learning algorithm! The neocortex would find a situation or "way to think" that causes the supervised learning algorithm to produce the desired output, then the supervised learning algorithm would gradually learn how to detect that trickery and start ignoring it, then the neocortex would notice and search for a different trick, and so on!
Does this kind of adversarial situation happen in the brain? Yes, I think so! Here's the best example I've come up with so far:
Let's say you like the thrill of being scared. So you buy a scary movie and watch it. Then you watch it again, and again. It stops being scary! Why? Your amygdala has learned that the particular situations in that movie are not actually dangerous! Then what? I mean, you (= your neocortex) bought the movie because you like feeling scared, but it's not scary anymore ... so you go and buy a different scary movie! Then the amygdala learns to stop being scared about that movie too, so you buy yet a third scary movie, or maybe go to a haunted house instead, or go skydiving.
Toy model #4: "The accelerator"
This is a cool one: I'll call it an accelerator! (My term; I don't know if there's literature about this, although I would assume so.) The neocortex is a bit slow. It's possible that the simpler and faster algorithm of the cerebellum, looking at the state of a bunch of neurons in the neocortex, could infer that the neocortex is going to emit a signal into one of its output lines, and maybe the cerebellum can figure that out so fast that it beats the neocortex! So when you add this module, the output goes out sooner!
What's the catch? Well, for one thing, it's going to predict the neocortex wrong sometimes. Recall Rice's theorem: the only way to predict the neocortical output 100% correctly is to actually run the neocortical algorithm! For another thing, this setup adds extra lag on the learning process. The neocortex's input-output relations keeps changing as it learns, so the cerebellum is always playing catch-up, i.e. it's accelerating a slightly-out-of-date version of the neocortex. Maybe other things too, I dunno.
Oh here's another thing about the accelerator: I think it would have a pretty neat self-wiring property. If you think about it, normally it's very important to properly pair up the shoulda lines with their corresponding output lines. For example, an eye-is-irritated signal can be re-interpreted as "shoulda blinked", and paired with a blink-controlling output. But there's a specific reason that those two signals in particular can be paired up! You can't just take any incoming and outgoing signal lines and pair them up! ...Well, in an accelerator, you can! Let's say the output line in the diagram controls Muscle #847. Which shoulda line needs to be paired up with that? The answer is: it doesn't matter! Just take any neocortex output signal and connect it. And then the neocortex will learn over time that that output line is effectively a controller for Muscle #847. On my view, the neocortex has to learn from scratch what all of its output knobs do anyway! That's just how it works.
So, this accelerator thing is an intriguing ingredient. What else can we do with it? Two more toy models...
Toy model #5: A hypothesis for how the cerebellum coordinates movements
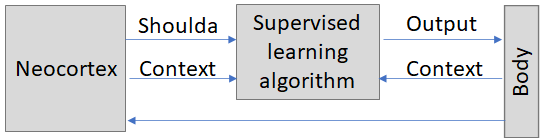
Here I started with the "accelerator" above, and I'm trying to build it out into a picture of how the cerebellum coordinates smooth movements. (Without a cerebellum, people move in a slow and uncoordinated way, a bit like a drunkard.) I'm not sure if this is quite right, but this seems a promising start...
The cerebellum would be taking in mostly proprioceptive context information (my leg is here, my arm is here, etc.) and quickly calculating the appropriate muscles to move in response, to keep the body properly positioned and moving. The "shoulda" information comes from the neocortex, which understands the goals of the motion and can provide reliably helpful commands to guide the motion, but is too slow to provide these commands well on its own.
Toy model #6: A hypothesis for how the cerebellum helps cognition

For many years, people said that the cerebellum was only for coordinating movement, but now it's increasingly understood that there are neocortex-cerebellum loops that help with cognition, including language and other things. See cerebellar cognitive affective syndrome. Here I'm brainstorming how that might work. I just took the same "accelerator" of Toy Model #4 and inserted it into a cortex-to-cortex connection. Seems plausible, I guess! Again, just a guess, but I'm keeping in mind as I read more!
(As you can tell from the name "cerebellar cognitive affective disorder", the cerebellum also apparently has something to do with affect / mood / emotions, but I won't talk about how that works, because I don't know!) (Update: I think the cerebellum "accelerates" autonomic-type outputs [LW · GW] just like it accelerates motor outputs. See here [LW · GW] for example.)
Toy Models: Conclusion
That was fun! I'm quite sure there's more possibilities and dynamics I haven't thought of yet, including ones that are important for the brain. Please let me know if you think of any, or have references, or any other comments. :-)
9 comments
Comments sorted by top scores.
comment by trentbrick · 2021-04-16T19:09:32.249Z · LW(p) · GW(p)
This piece is super interesting, especially the toy models.
A few clarifying questions:
'And not just any learning algorithm! The neocortex runs a learning algorithm, but it's an algorithm that picks outputs to maximize reward, not outputs to anticipate matched supervisory signals. This needs to be its own separate brain module, I think.'
-- Why does it need to be its own separate module? Can you expand on this? And even if separate modules are useful (as per your toy models and different inputs, couldn't the neocortex also be running lookup table like auto or hetero-associative learning).
"Parallel fibers carry the context signals, Purkinje cells produce the output signals, and climbing fibers carry the shoulda signals, and the synapse strengths between a parallel fiber and a Purkinje cell is modified as a function of how recently the parallel fiber and climbing fiber have fired."
-- Can you cite this? I have seen evidence this is the case but also that the context actually comes through the climbing fibers and training (shoulda) signal through the mossy/parallel fibers. Eg here for eyeblink operant conditioning https://www.cs.cmu.edu/afs/cs/academic/class/15883-f17/readings/hesslow-2013.pdf
Can you explain how the accelerator works in more detail (esp as you use it in the later body and cognition toy models 5 and 6)? Why is the cerebellum faster at producing outputs than the neocortex? How does the neocortex carry the "shoulda" signal? Finally I'm confused by this line:
"You can't just take any incoming and outgoing signal lines and pair them up! ...Well, in an accelerator, you can! Let's say the output line in the diagram controls Muscle #847. Which shoulda line needs to be paired up with that? The answer is: it doesn't matter! Just take any neocortex output signal and connect it. And then the neocortex will learn over time that that output line is effectively a controller for Muscle #847."
-- This suggests that the neocortex can learn the cerebellar mapping and short-circuit to use it? Why does it need to go through the cerebellum to do this? Rather than via the motor cortex and efferent connections back to the muscles?
Thank you!
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-04-20T19:49:54.938Z · LW(p) · GW(p)
Thanks for the great questions!!
Why does it need to be its own separate module?
Maybe you're ahead of me, but it took me until long after this post—just a couple weeks ago—to realize that you can take a neural circuit set up for RL, and jury-rig it to do supervised learning instead.
I think this is a big part of the story behind what the vmPFC is doing. And, in a certain sense, the amygdala too. More on this in a forthcoming post.
couldn't the neocortex also be running lookup table like auto or hetero-associative learning ... Why is the cerebellum faster at producing outputs than the neocortex?
I think of the neocortex as doing analysis-by-synthesis—it searches through a space of generative models for one that matches the input data. There's a lot of recurrency—the signals bounce around until it settles into an equilibrium. For example in this model, there's a forward pass from the input data, and that activates some generative models that seem plausible. But it may be multiple models that are mutually inconsistent. For example, in the vision system, "Yarn" and "Yam" are sufficiently close that a feedforward pass would activate both possibilities simultaneously. Then there's this message-passing algorithm where the different possibilities compete to explain the data, and it settles on one particular compositional generative model.
So this seems like a generally pretty slow inference algorithm. But the slowness is worth it, because the neocortex winds up understanding the input data, i.e. fitting it into its structured model of the world, and hence it can now flexibly query it, make predictions, etc.
I think the cerebellum is much simpler than that, and closer to an actual lookup table, and hence presumably much faster.
The cerebellum is also closer in proximity to the spinal cord, which reduces communication delays when reading proprioceptive nerves and commanding muscles.
I have seen evidence this is the case but also that the context actually comes through the climbing fibers and training (shoulda) signal through the mossy/parallel fibers. Eg here for eyeblink operant conditioning https://www.cs.cmu.edu/afs/cs/academic/class/15883-f17/readings/hesslow-2013.pdf
That paper says "it has been the dominant working assumption in the field that the CS is transmitted to the cerebellar cortex via the mossy fibres (mf) and parallel fibres (pf) whereas information about the US is provided by climbing fibres (cf) originating in the inferior olive", which is what I said (US=shoulda, CS=context). Where are you disagreeing here? Or do they contradict that later in the paper?
How does the neocortex carry the "shoulda" signal?
The neocortex is a fancy algorithm that understands the world and takes intelligent actions. It's not perfect, but it's pretty great! So whatever the neocortex does, that's kinda a "ground truth" for the question of "What is the right thing to do right now?"—at least, it's a ground truth from the perspective of the much stupider cerebellum. So my proposal is that whatever the neocortex is outputting, that's a "shoulda" signal that the cerebellum wants to imitate.
This suggests that the neocortex can learn the cerebellar mapping and short-circuit to use it? Why does it need to go through the cerebellum to do this? Rather than via the motor cortex and efferent connections back to the muscles?
I'm not sure I understand your question. The neocortex outputs don't need to go through the cerebellum. People can be born without a cerebellum entirely, they turn out OK. But since the cerebellum is like a super-fast memoizer / lookup table, I think the neocortex can work better by passing signals through the cerebellum.
Anyway, that was all just casual speculation, I don't know how the motor cortex, midbrain, cerebellum, and outgoing nerves are wired together. (I'm very interested to learn, just haven't gotten around to it.)
Hmm, this page suggests that there are both motor-pathways-through-the-cerebellum and motor-pathways-bypassing-the-cerebellum. But that's not a reliable source—that page seems to be riddled with errors. So I dunno.
comment by Gordon Seidoh Worley (gworley) · 2020-11-04T01:51:22.469Z · LW(p) · GW(p)
Your toy models drew a parallel for me to modern CPU architectures. That is, doing computation the "complete" way involves loading things from memory, doing math, writing to memory, and then that memory might affect later instructions. CPUs have all kinds of tricks to get around this to go faster, and it sort of like like your models of brain parts, only with a reversed etiology, since the ACU came first whereas the neocortex came last, as i understand it.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2020-11-06T13:01:31.618Z · LW(p) · GW(p)
Interesting! I'm thinking of CPU brach predictors, are you? (Are there other examples? Don't know much about CPUs.) If so, that did seem like a suggestive analogy to what I was calling "the accelerator".
Not sure about etiology. How different is a neocortex from the pallium in a bird or lizard? I'm inclined to say "only superficially different", although I don't think it's known for sure. But if so, then there's a version of it even in lampreys, if memory serves. I don't know the evolutionary history of the cerebellum, or of the cerebellum-pallium loops. It might be in this paper by Cisek which I read but haven't fully processed / internalized.
Replies from: gworley↑ comment by Gordon Seidoh Worley (gworley) · 2020-11-07T00:20:36.473Z · LW(p) · GW(p)
Branch predictors for sure, but modern CPUs also do things like managing multiple layers of cache using relatively simple algorithms that nonetheless in practice get high hit rates, conversion of instructions into microcode because it turns out small, simple instructions execute faster but CPUs need to do a lot of things so the tradeoff is to have the CPU interpret the instructions in real time into simpler instructions sent to specialized processing units inside the CPU, and maybe even optimistic branch execution, where instructions in the pipeline are partially executed provisionally ahead of branches being confirmed. All of these things seem like tricks of the sort I wouldn't be surprised to find parallels to in the brain.
comment by Rafael Harth (sil-ver) · 2020-12-06T12:03:17.855Z · LW(p) · GW(p)
Clarifying question: how are the outputs of the supervised learning algorithm used (other than in model #6)?
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2020-12-06T13:44:34.843Z · LW(p) · GW(p)
I think often they go out to the body to control muscles, and in #6 they feed information into the neocortex, and in the amygdala case they also release cortisol and/or other hormones. I'm not intimately familiar with neuroanatomy, there could be additional complications I don't know about. Does that answer your question?
Replies from: sil-ver↑ comment by Rafael Harth (sil-ver) · 2020-12-06T14:18:55.366Z · LW(p) · GW(p)
I think so. I was imagining an additional mechanism where the outputs compete with other parts of the brain for the final say on what your muscles are doing. If they control muscles directly, that would mean 'I' can't choose not to have flinch if the supervised learning algorithm says I should (right?) -- which I guess does actually align with experience.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2020-12-06T17:02:25.616Z · LW(p) · GW(p)
There's almost definitely competition between different systems trying to control muscles. The basal ganglia has at least something to do with judging the competition and picking winners. The neocortex competes with other parts of the neocortex, and against the amygdala and maybe brainstem, I dunno. But I'm not sure that we should think of the cerebellum as a competitor. I think of the cerebellum as a personal assistant for the competitors. So if it thinks that the neocortex is going to place a bid to move a muscle, it preemptively places that bid itself, and if the neocortex later says something different, the cerebellum says "oops, my bad, I'll forward that bid instead, and try to get it right next time".
So maybe I implied here that the cerebellum is responsible for flinching. That's kinda true, but after writing this I read that really the amygdala knows that flinching is the right thing to do, and then the cerebellum learns to make the flinch happen more quickly. (Not 100% sure on that.)